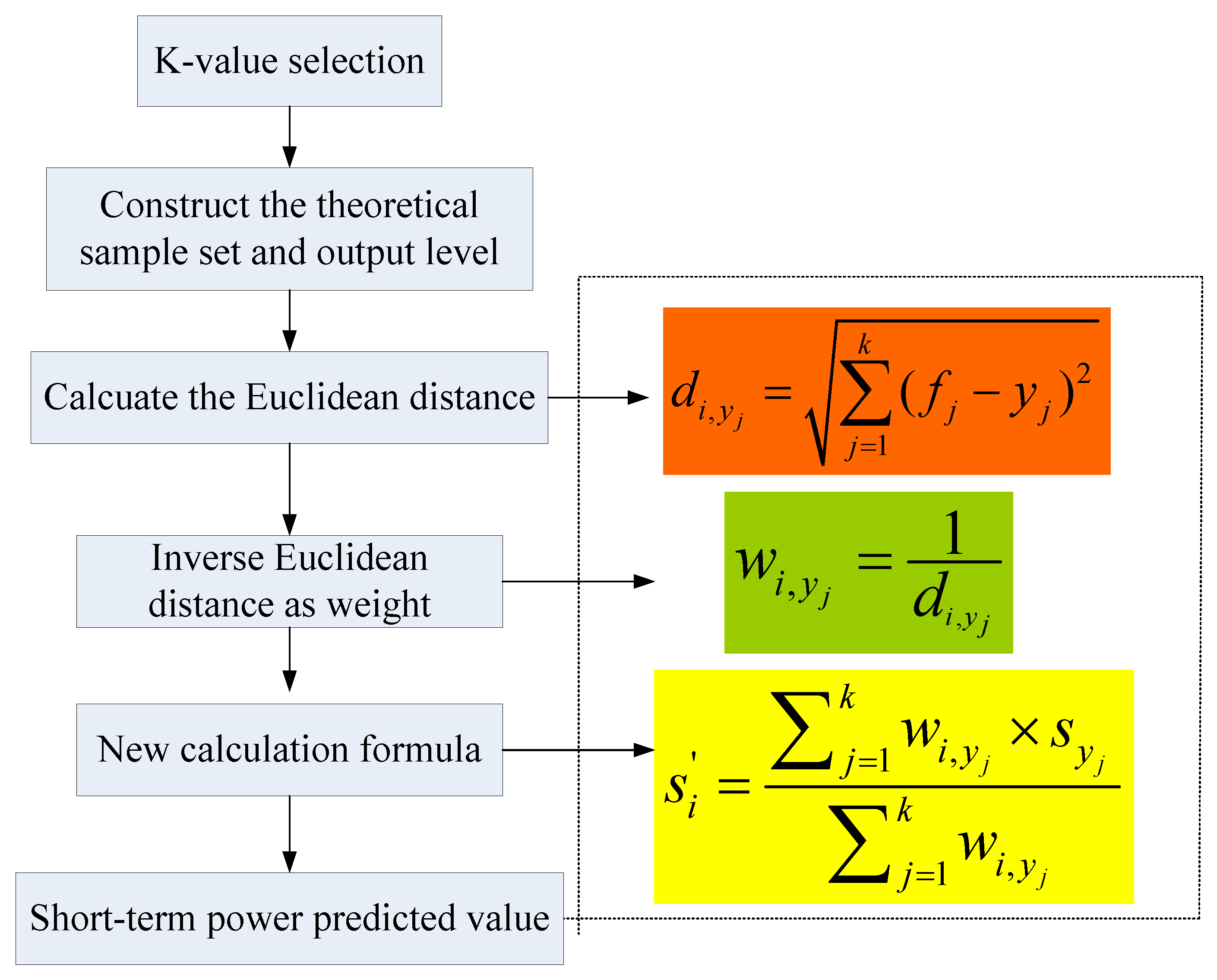
4.1. Forecasting Results and Analysis
The proposed W-K-NN model performed the forecasting processes and the associated results. The employed electricity load data were acquired from National Electricity Market (NEM, Australia), in total 1095 electricity load data, and data time period was from 8:00 on 1 January 2007 to 0:00 on 1 January 2008. In this paper, the collected data were based on an eight-hour scale (i.e., mean value of every eight hours), which often adopts the eight-hour work system (i.e., three shifts), as shown in
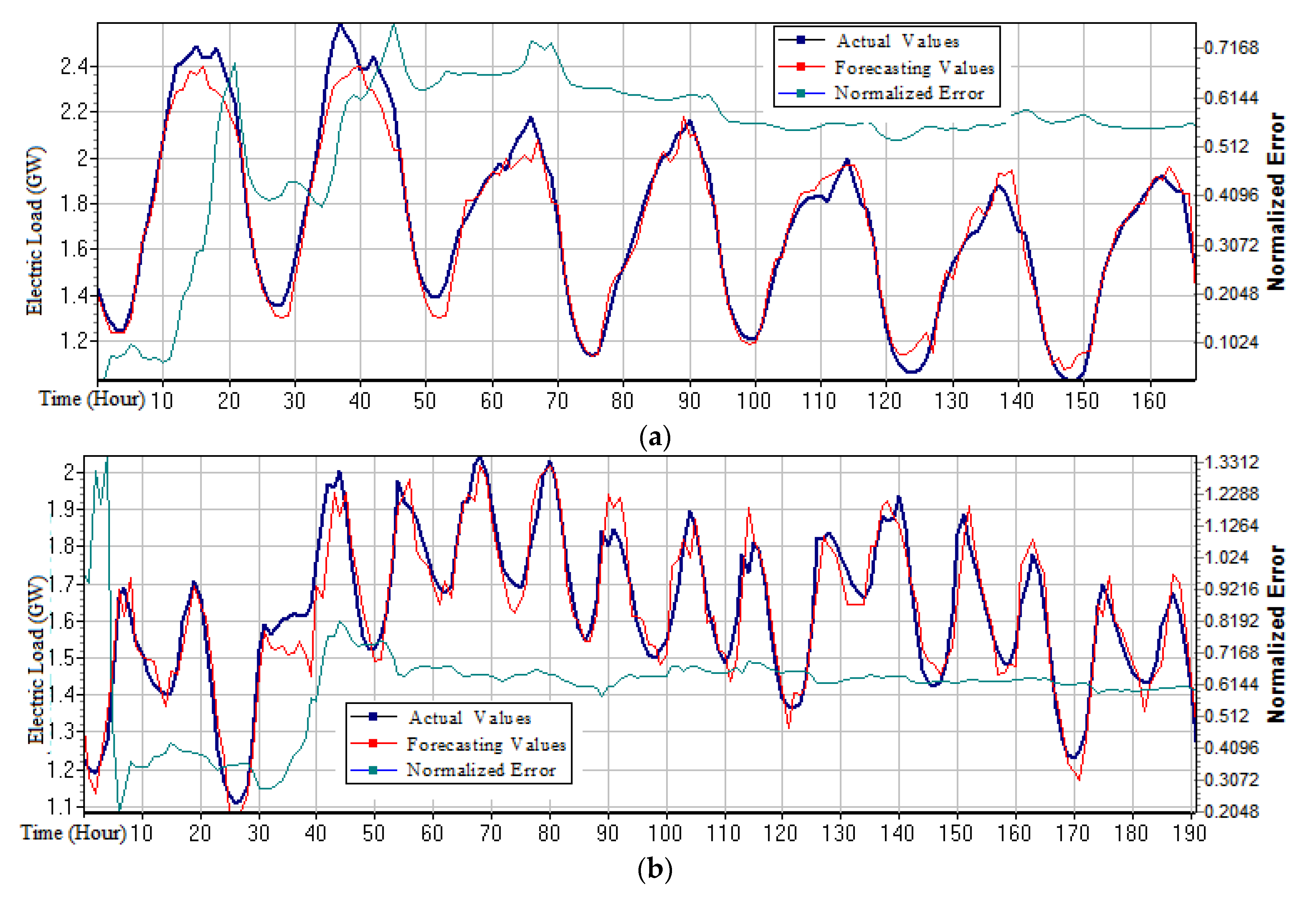
Table 3. The electricity load forecasting values of the third month (for the large sample) or of the fourth week (for the small sample) were obtained by the proposed W-K-NN model, the associated forecasting results are demonstrated in
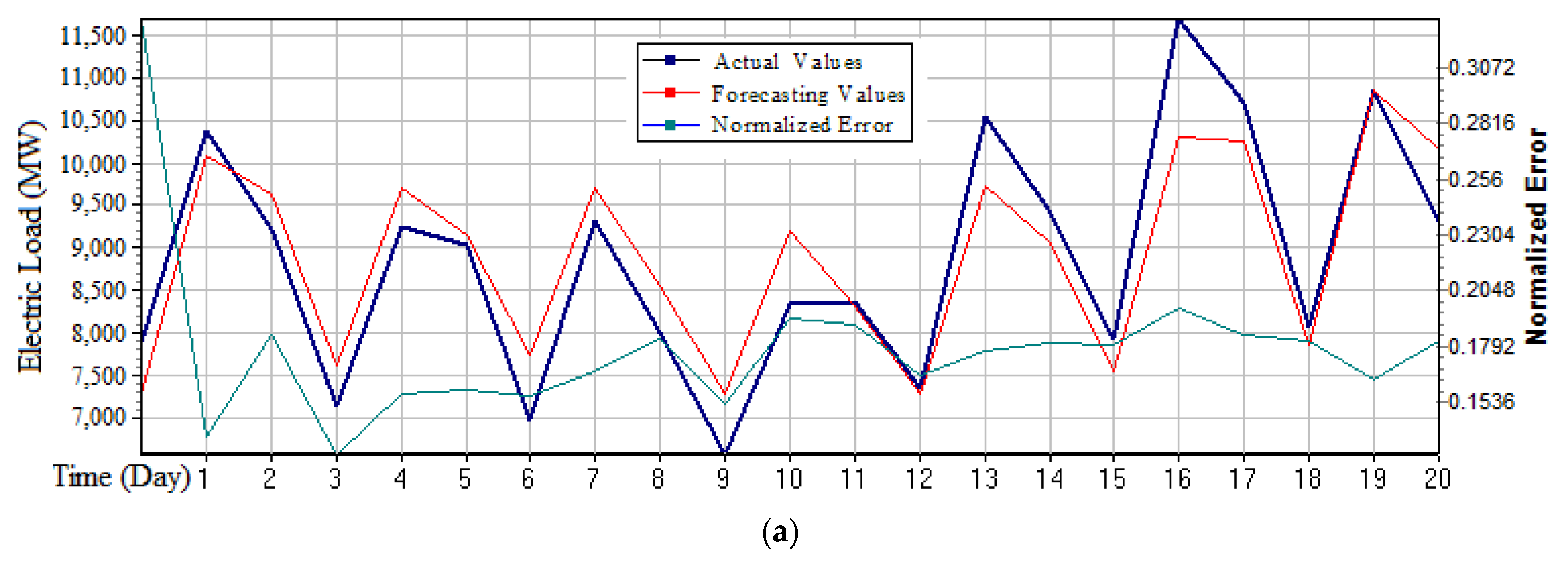
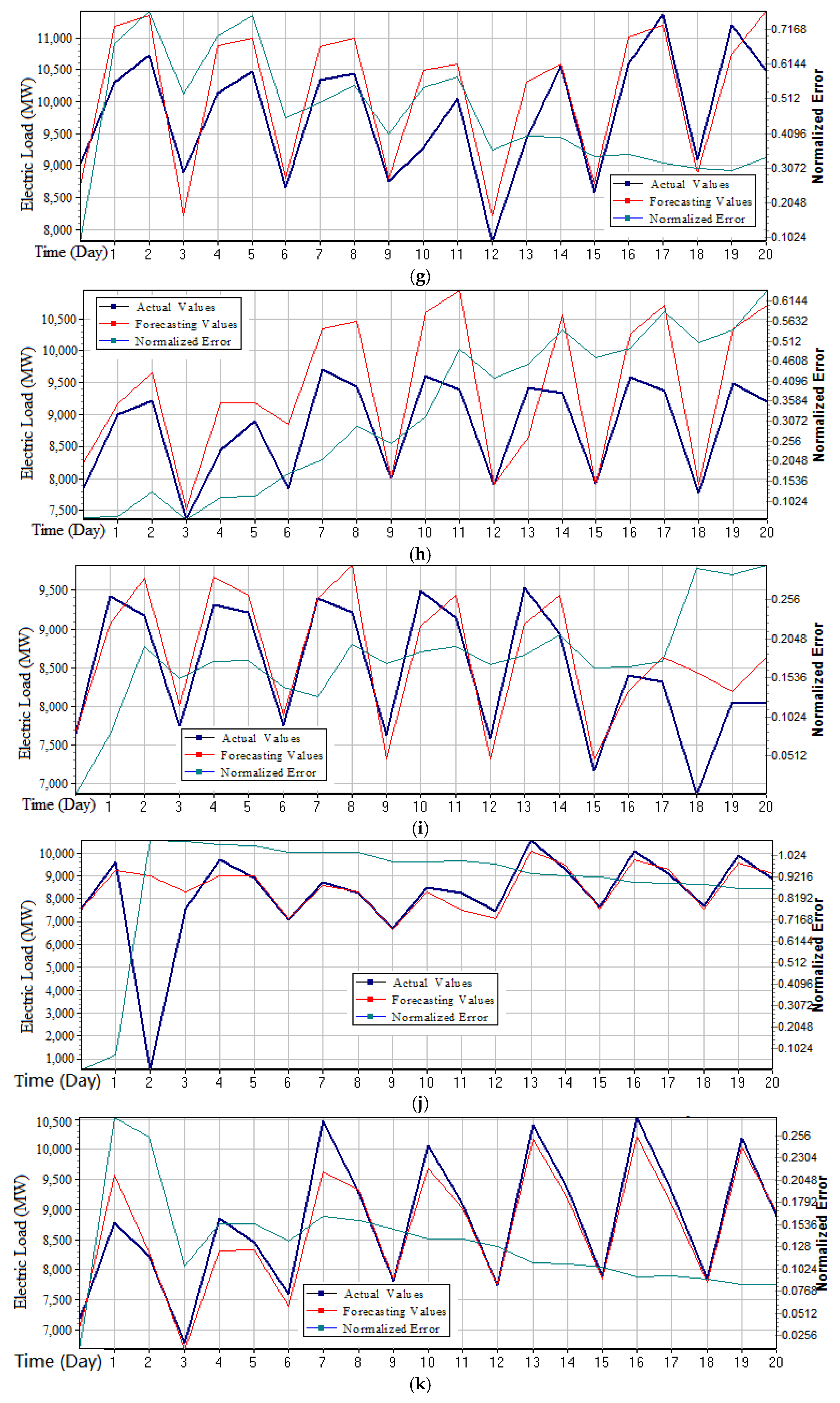
Figure 3 (large sample) and
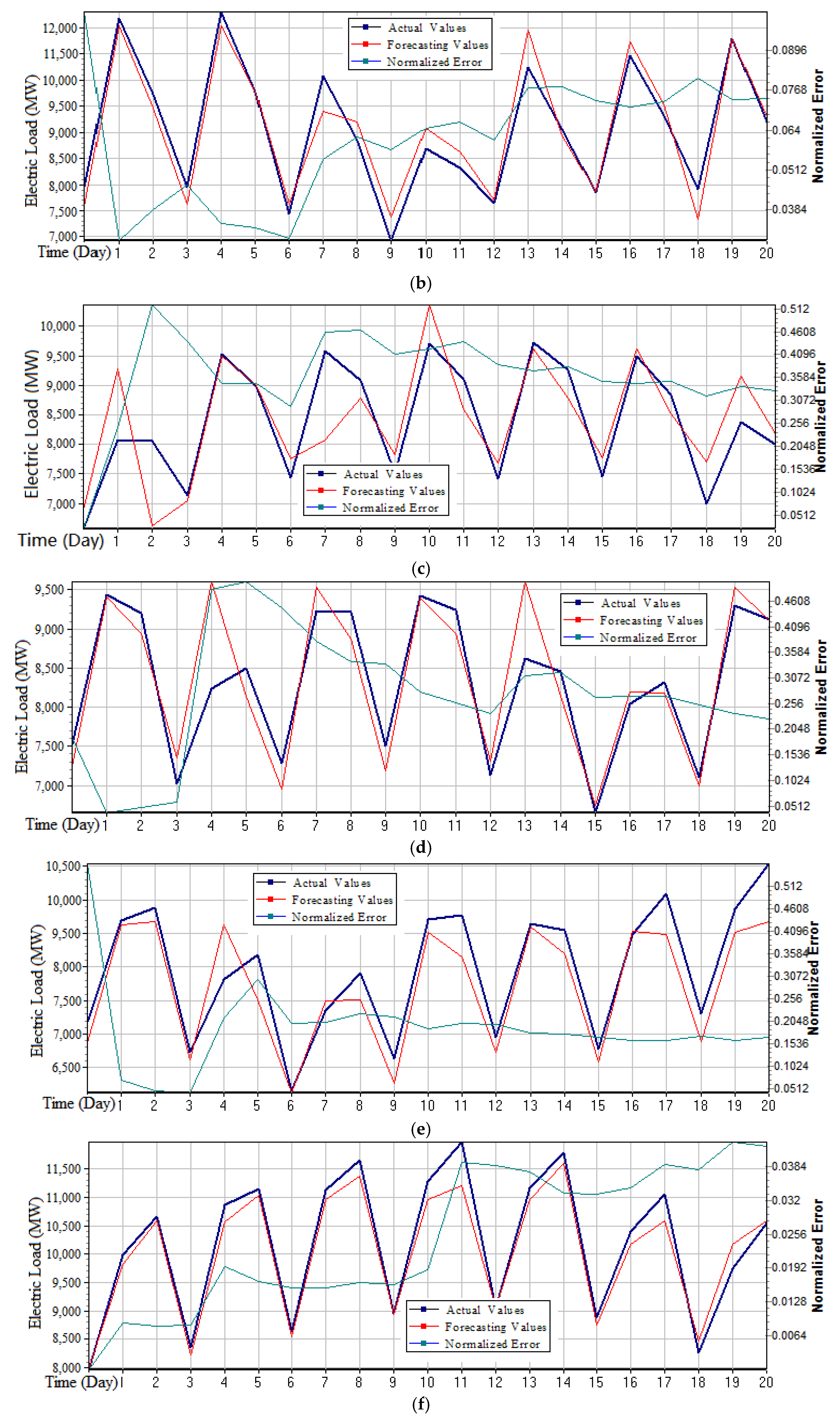
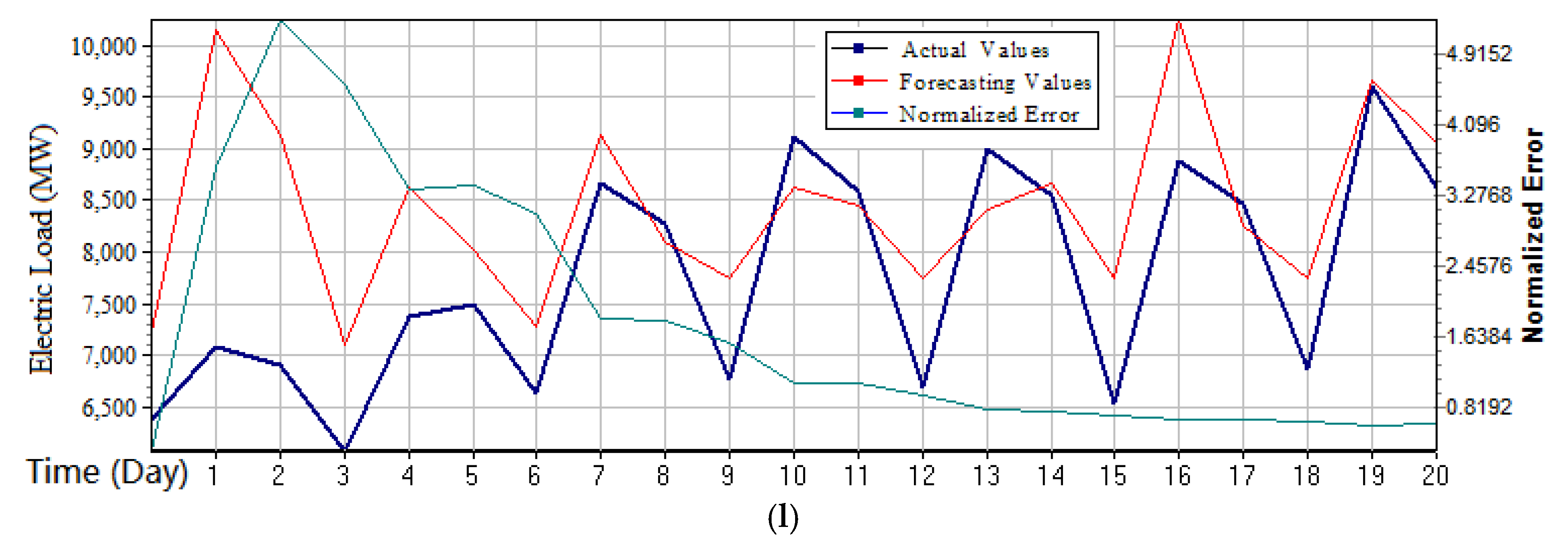
Figure 4 (small sample), respectively.
It can be learned from
Figure 3 that the forecasting curve changed periodically, due to the three-stage-division of the data in a day. The first stage was from 0:00 to 8:00 (i.e., the period is at night, also is the origin in the figures); the second stage was from 8:00 to 16:00 (i.e., that is the first half of a day, the first point in the figures); and, the third stage was from 16:00 to 0:00 (i.e., that is the next half of a day, the second point in the figures. The three stages form a cycle (i.e., one activity cycle); in addition, a work cycle contains a total of seven cycles. The specific characteristics of electricity used in a cycle could be illustrated as follows: (1) The night was from 0:00 to 8:00, the residents’ daily electricity and educational electricity were at their lowest valley; the industrial electricity consumption was also small, so the lowest value of electricity consumption would occur during this period. (2) Start working at 8:00 in the morning, so the electricity consumption would gradually increase, until reaching the peak. (3) After 16:00, according to the production capacity demand plans, industrial production work load was generally reduced, so the electricity consumption would gradually decline.
Based on above observations, the trend of the curve variation in
Figure 3 is in line with the actual electricity consumption. The third stage forecasting curve of each cycle in
Figure 3a deviates from the actual curve, it may be caused from: (1) increased demand at this stage; or (2) a sudden increase in the workload of industrial production. Therefore, it can be learned from
Figure 3 that the trend of the actual data and the forecasting data were generally consistent. Although there were certain errors, it was in line with the actual situation, and it indicates that the proposed W-K-NN model is suitable for short-term neighbor behavior detection, impact characterization, and could be weighted by the collected information, and, eventually, provide more effective and accurate forecasting results.
It can be learned from
Figure 4, that the forecasting data curve demonstrates a rising and downward trend of cyclical variation, and consists of the actual data change trend. Similar to the small sample, the day data was also divided into three stages: from 0:00 to 8:00 (the first stage), from 8:00 to 16:00 (the second stage); and from 16:00 to 0:00 (the third stage). According to the arrangement of one day’s workload, it can reflect the cyclical variations, which indicates that this model can effectively reveal the rules of electricity consumption activities in each divided time period, particularly in the lowest points (i.e., the valley period). It demonstrates that this model can detect the information of the demand turning point (i.e., the demand is greater than the production capacity of the enterprise in this moment). Therefore, at this moment (valley period), for the power sector, it needs to organize production to simultaneously take into account market’s needs and own resources, managers should use their relatively fixed production capacity to meet changing market needs, such as several units are used to complete the power generation task.
Based on above observations, it can be seen from the
Figure 4a,d that their fitting effects were good, while in
Figure 4b,c, the fitting process shows a certain deviation, especially when the demand was turning to decrease (i.e., the top point, or the peak point), the fitting performance was not good. It also demonstrates that this model found it difficult to detect the oversupply information from the market. It was also affected by uncertain factors such as vacation and work plan; however, the error was not large and was within the controllable range.
4.2. Forecasting Results Comparison
In order to demonstrate the superiority of the proposed model, the ARMA model and BPNN model were selected for comparison analysis. The comparison results for both small sample and large sample are shown in Tables 5 and 6, respectively.
The following brief the modeling processes for these two employed models.
ARMA model is one of the most common time series models, it is widely used in economic field forecasting. The ARMA model principle is to regard the data sequence formed by the forecasting index over time as a random sequence. The dependence of this random sequence reflects the continuity of the original data in time. On the one hand, the influencing factors are relatively fixed and are easily expressed and explained. On the other hand, it has its own regulations of change, and the inertia is easily described. Therefore, the ARMA model was used to compare with the proposed W-K-NN model. By using MATLAB software R2017a version, after multiple tests, the AR order was determined to be 3. The electricity load forecasting values of the third month (for the large sample) could be obtained by using the data of the first two months, or, of the fourth week (for the small sample) could be obtained by using the data of the first three weeks. Then, the forecasting accuracy indexes, the RMSE and the NMSE (Equations (2) and (3)), were employed to calculated the forecasting accuracy for each case.
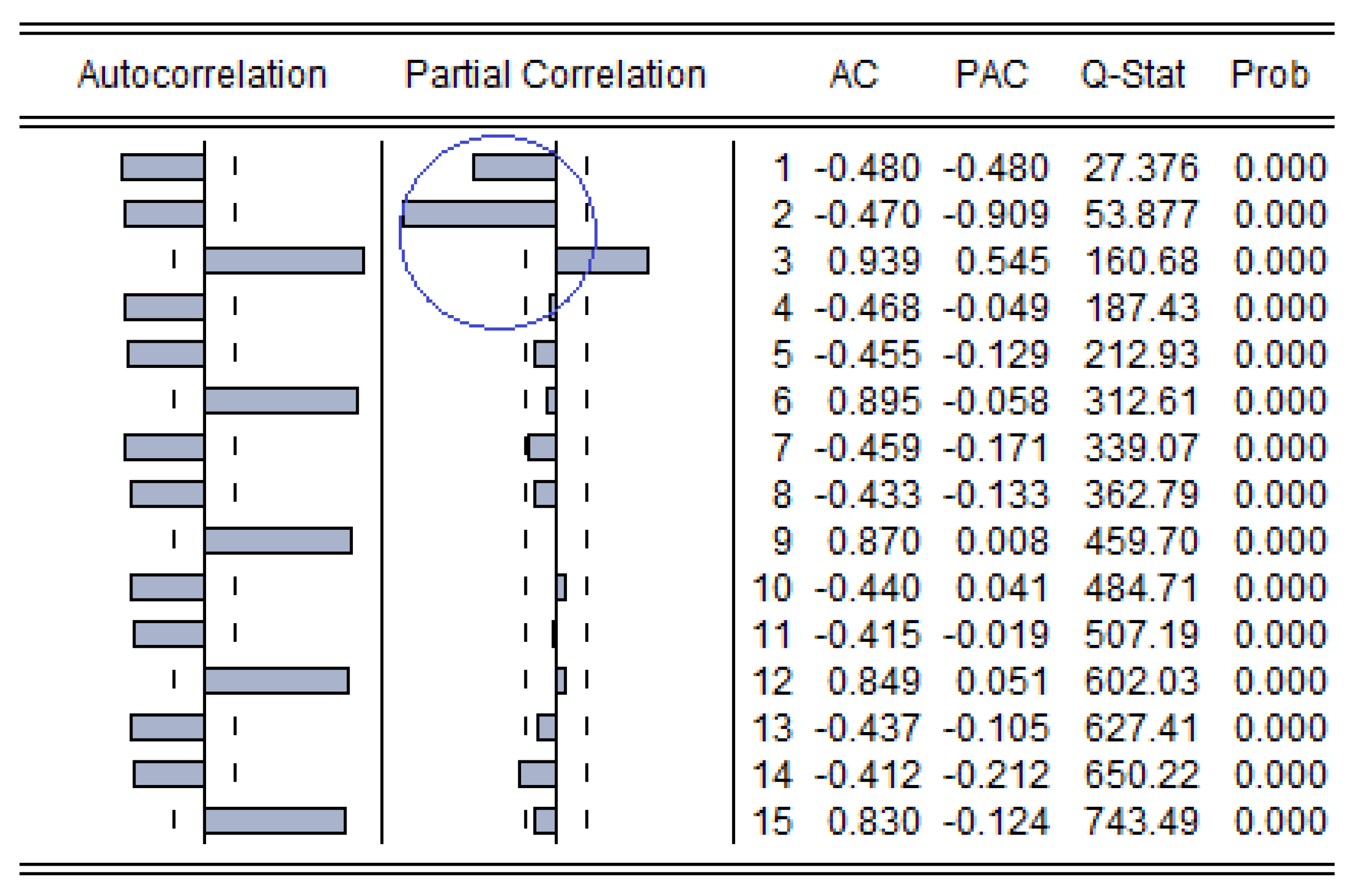
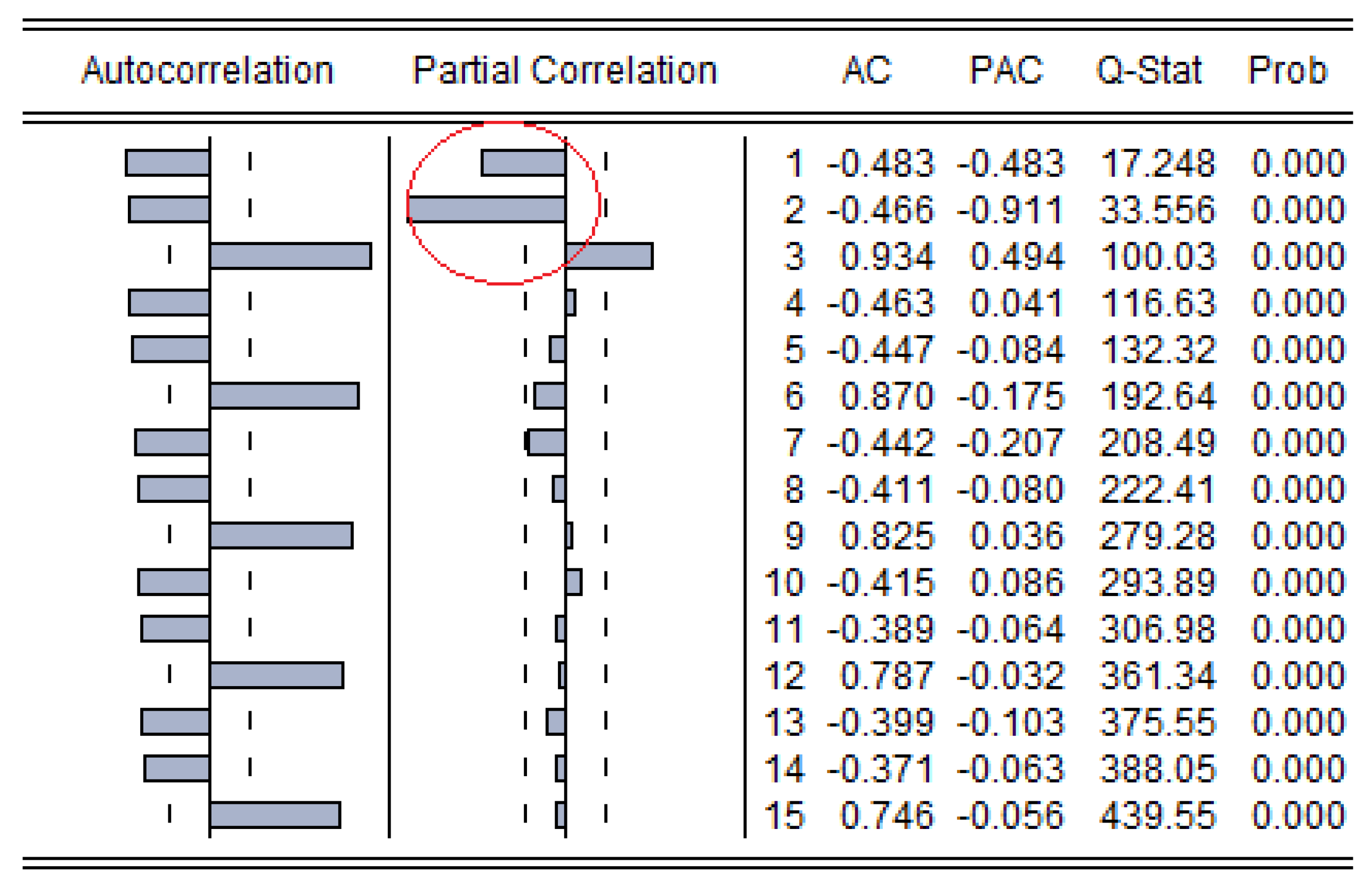
In general, for the stationary time series, the forecasting model could be determined from the auto-correlation function (ACF) and the partial auto-correlation function (PACF), the judgment criteria of the ARMA model are shown in
Table 4. The ACF and the PACF graphs for the small sample and the large sample are illustrated in
Figure 5 and
Figure 6, respectively. It can be easily found that, in both samples, the ACF was trailing and the PACF was truncated, and there was a large attenuation after the third order (
Figure 5 is outside the blue circle, while
Figure 6 is outside the red circle). Thus, the AR (3) model was selected.
In
Figure 5 and
Figure 6, the ACF was defined as the correlation between time series
and
, as shown in Equation (9),
The PACF was defined as the correlation between
,
, …, and
. Q-statistics was defined as Equation (10),
where
n is the number of the forecasting points;
m is the delay points.
Q-statistics would be approximated to Chi-square () distribution with m-degree of freedom; therefore, the decision rule is “Q-statistics is larger than ” or “p-value is smaller than significant level ()”.
As mentioned above, the characteristics of the National Electricity Market (NEM, Australia) data set obviously reveal that a day can be regarded as a physiological cycle (the so-called micro-production cycle), and it can be divided into three stages: (1) the first stage, from 0:00 to 8:00; (2) the second stage, from 8:00 to 16:00; and (3) the third stage, from 16:00 to 0:00. The electricity load forecasting values in the third stage can be found by using the electricity load data from the first two stages, it also reflects the applicability and rationality of this model.
The BPNN model, also known as the back propagation neural network, which is, through the training of the sample data, to continuously revise the network weights and thresholds to reduce the forecasting errors along the negative gradient direction, and eventually approximate the expected output. BPNN model has been widely applied in function approximation, data compression, and time series forecasting. In order to reveal the self-adaptability and sensitivity of electricity demanding behavior, the BP neural training toolbox of the MATLAB software, R2017a version, was implemented to forecast electricity load values by using the data of the first two months (for the large sample), or using the data of the first three weeks (for the small sample). In the BPNN modeling process, network layers were chosen as three, and intermediate neurons were selected as 10. The functions for hidden layer and output layer function were chosen as follows: Tansig (Tangent S type transfer function) and Logsig (Logarithmic sigmoid transfer function) were used as the implicit layer node transfer function, and Trainglx function was selected as the output layer node transfer function. Then, the forecasting accuracy indexes for each sample were calculated for comparison.
The proposed W-K-NN model not only has several theoretical advantages, such as less training parameters and good timeliness, but also had higher forecasting accuracy than ARMA and BPNN models, for both the small sample and large sample, as shown in
Table 5 and
Table 6, respectively. Thus, it is more suitable for solving the nonlinear problem with time-varying uncertainties in short-term load forecasting. The error values of RMSE and NMSE, obtained by the proposed W-K-NN model, in the small and large samples were both relatively small, and from
Figure 3 and
Figure 4, the stability of the proposed W-K-NN model had certain volatility. However, with the better performances of these two evaluation indexes, the proposed W-K-NN model could provide more accurate forecasting results. For ARMA model, its accuracy may be affected by different parameters, due to the assumptions of the ARMA model that even if all the errors are completely objective, the forecasting process will still be affected by some uncertainties. Thus, the forecasting errors were unable to be reduced. However, the stability of the forecasting errors of the ARMA model was better, which indicates that it has its own robustness and inherent regularity. For the BPNN model, not only were the forecasting errors large, but also the stability of the forecasting errors fluctuated largely. This may be caused by the lack of training set of the BPNN model. After the case comparison and empirical investigation, the specific reasons for the above situation were found as follows: (1) The summer vacation of Australian schools is often from the middle of November to the end of February; therefore, the electricity consumption demonstrates great differences and instabilities from December to January; (2) From the view point of the annual plan of industrial production, a large amount of industrial production is generally carried out at the beginning of the year. Principal marketing activities are carried out in the middle of the year, namely clearance of stock. Additionally, some output may be increased at the end of the year. Therefore, the differences of the electricity consumption are relatively large between the beginning and the end of a year, but the middle of the year is relatively stable.
Finally, verification of the significance of the accuracy improvement of the proposed W-K-NN model was also an important issue. The forecasting accuracy comparisons in both samples among ARMA, BPNN, and W-K-NN models were implemented by the Wilcoxon signed-rank test under 0.025 and 0.05 significant levels (one-tail), respectively [
29,
30]. The Wilcoxon signed-rank test is a famous statistical test tool. It is suitable for pair comparison to evaluate whether their performance is different. It often uses Student’s
t-test as the statistics, particularly for those cases that the associate population could not be guaranteed to satisfy the normally distributed [
31]. The Wilcoxon signed-rank test results for small and large samples are demonstrated in
Table 7 and
Table 8, respectively. Obviously, the proposed models all received significant forecasting results, compared with other alternative models, under two significant levels.
In order to compare the advantages of the proposed model, a similar model (namely recency effect model) from a published paper [
32] in GEFCom2012, was employed. The recency effect model was also used to extract similar features in time, the more prominent forecasting effect was reflected in summer and winter. According to [
32], in summer, the electricity load data from June 1 to June 17, 2007 (17 days in total) were employed as the training set to forecast the electricity load from June 18 to June 24 (total 7 days); in winter, the electricity load data from October 21 to November 13, 2007 (24 days in total) to forecast the electricity load from November 14 to November 21, 2007 (total eight days).
The forecasting results of the proposed model are demonstrated in
Figure 7. In which, it was found that the forecasting accuracy was superior at both the peak point and the valley period, particularly for the valley, its forecasting performances were very prominent.
Table 9 shows the forecasting errors in terms of RMSE, NMSE, MAE, and MAPE. It can be seen that it had the same advantages and effects as the recency effect model. It was more prominent in summer, which indicates that it was superior in capturing the laws of summer economic activities.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}