Solar-Powered Deep Learning-Based Recognition System of Daily Used Objects and Human Faces for Assistance of the Visually Impaired

 ,
,  ,
,  , and
, and
Abstract
:1. Introduction
2. Related Works
2.1. State of the Art on Innovative Assistive Technology Devices for Aiding VI People
2.2. Overview of Applications and Innovative Methods for Visual Recognition
3. System Overview
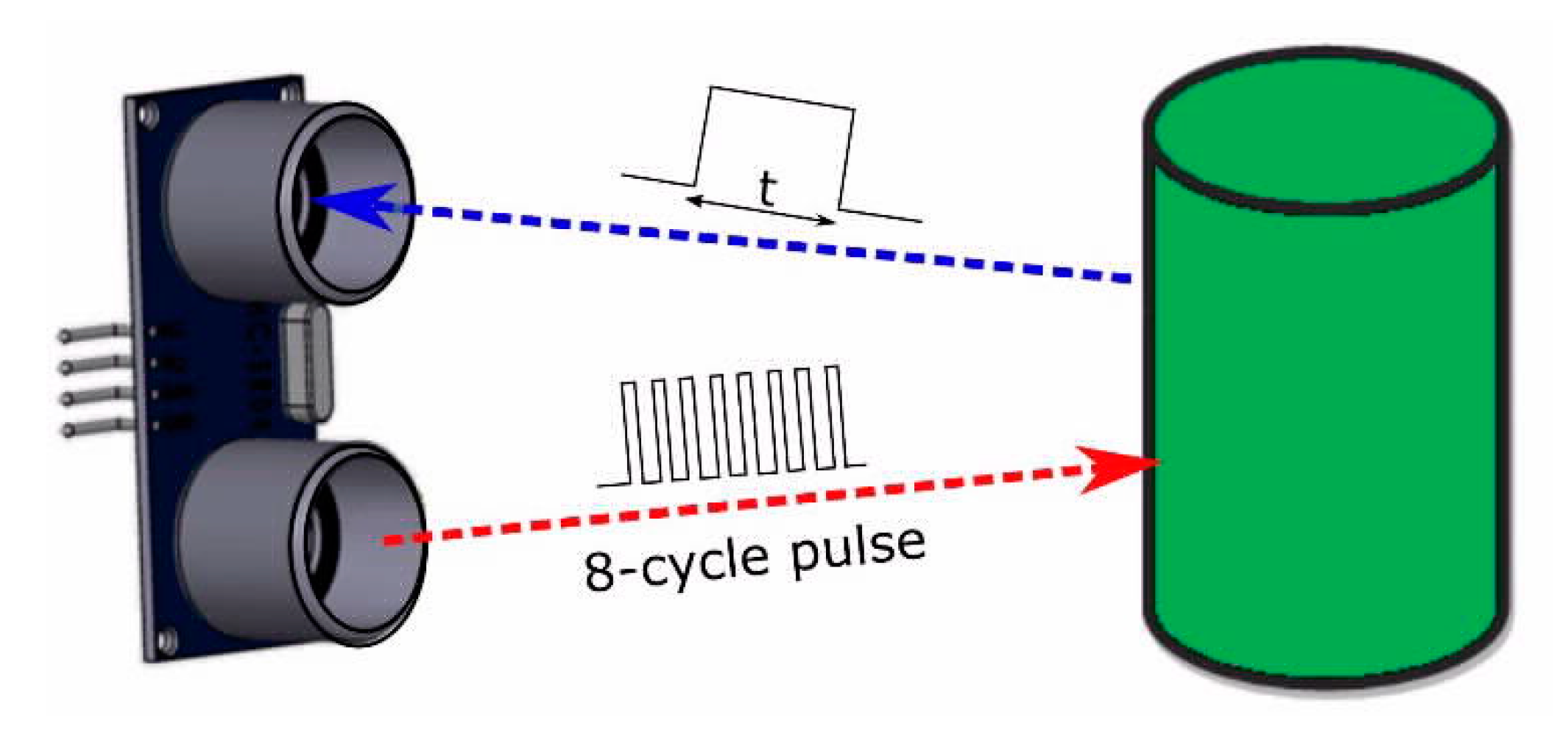
3.1. Hardware Section
Design of Solar Energy Harvesting System to Extend the AT Device Life-Time
3.2. Software Section
3.2.1. Object Recognition
3.2.2. Object Positioning
3.2.3. Implementation
4. Experimental Results
4.1. Training of the Designed Object Detection System
4.2. Object Recognition
4.3. Object Positioning
4.4. Performance Metrics
5. Results Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization. Fact Sheet on Blindness and Vision Impairment (October 2019). Available online: https://www.who.int/en/news-room/fact-sheets/detail/blindness-and-visual-impairment (accessed on 2 October 2020).
- Bourne, R.R.; Flaxman, S.R.; Braithwaite, T.; Cicinelli, M.V.; Das, A.; Jonas, J.B.; Keeffe, J.; Kempen, J.H.; Leasher, J.; Limburg, H.; et al. Magnitude, temporal trends, and projections of the global prevalence of blindness and distance and near vision impairment: A systematic review and meta-analysis. Lancet Glob. Health 2017, 5, 888–897. [Google Scholar] [CrossRef] [Green Version]
- Velazquez, R. Wearable Assistive Devices for the Blind. In Wearable and Autonomous Biomedical Devices and Systems for Smart Environment: Issues and Characterization; Lay-Ekuakille, A., Mukhopadhyay, S.C., Eds.; LNEE, 75; Springer: Berlin/Heidelberg, Germany, 2010; pp. 331–349. ISBN 978-3-642-15687-8. [Google Scholar]
- National Academies of Sciences, Engineering, and Medicine. Making Eye Health a Population Health Imperative: Vision for Tomorrow; The National Academies Press: Washington, DC, USA, 2016. [Google Scholar]
- Velazquez, R.; Fontaine, E.; Pissaloux, E. Coding the Environment in Tactile Maps for Real-Time Guidance of the Visually Impaired. In Proceedings of the IEEE International Symposium on MicroNanoMechanical and Human Science, Nagoya, Japan, 5–8 November 2006; pp. 1–6. [Google Scholar]
- Bologna, G.; Deville, B.; Diego-Gomez, J.; Pun, T. Toward Local and Global Perception Modules for Vision Substitution. Neurocomputing 2017, 74, 1182–1190. [Google Scholar] [CrossRef] [Green Version]
- Velazquez, R.; Pissaloux, E.; Rodrigo, P.; Carrasco, M.; Giannoccaro, N.I.; Lay-Ekuakille, A. An Outdoor Navigation System for Blind Pedestrians Using GPS and Tactile-Foot Feedback. Appl. Sci. 2018, 8, 578. [Google Scholar] [CrossRef] [Green Version]
- Real, S.; Araujo, A. Navigation Systems for the Blind and Visually Impaired: Past Work, Challenges, and Open Problems. Sensors 2019, 19, 3404. [Google Scholar] [CrossRef] [Green Version]
- Bhowmick, A.; Hazarika, S.M. An insight into assistive technology for the visually impairedand blind people: State-of-the-art and future trends. J. Multimodal User Interfaces 2017, 11, 1–24. [Google Scholar] [CrossRef]
- Velazquez, R.; Hernandez, H.; Preza, E. A Portable Piezoelectric Tactile Terminal for Braille Readers. Appl. Bionics Biomech. 2012, 9, 45–60. [Google Scholar] [CrossRef]
- Neto, R.; Fonseca, N. Camera Reading for Blind People. Procedia Technol. 2014, 16, 1200–1209. [Google Scholar] [CrossRef] [Green Version]
- Oproescu, M.; Iana, G.; Bizon, N.; Novac, O.C.; Novac, M.C. Software and Hardware Solutions for Using the Keyboards by Blind People. In Proceedings of the International Conference on Engineering of Modern Electric Systems, Oradea, Romania, 13–14 June 2019; pp. 25–28. [Google Scholar]
- Watanabe, T.; Kaga, H.; Shinkai, S. Comparison of Onscreen Text Entry Methods when Using a Screen Reader. IEICE Trans. Inf. Syst. 2018, 101, 455–461. [Google Scholar] [CrossRef] [Green Version]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Jmour, N.; Zayen, S.; Abdelkrim, A. Convolutional Neural Networks for Image Classification. In Proceedings of the International Conference on Advanced Systems and Electric Technologies, Hammamet, Tunisia, 22–25 March 2018; pp. 397–402. [Google Scholar]
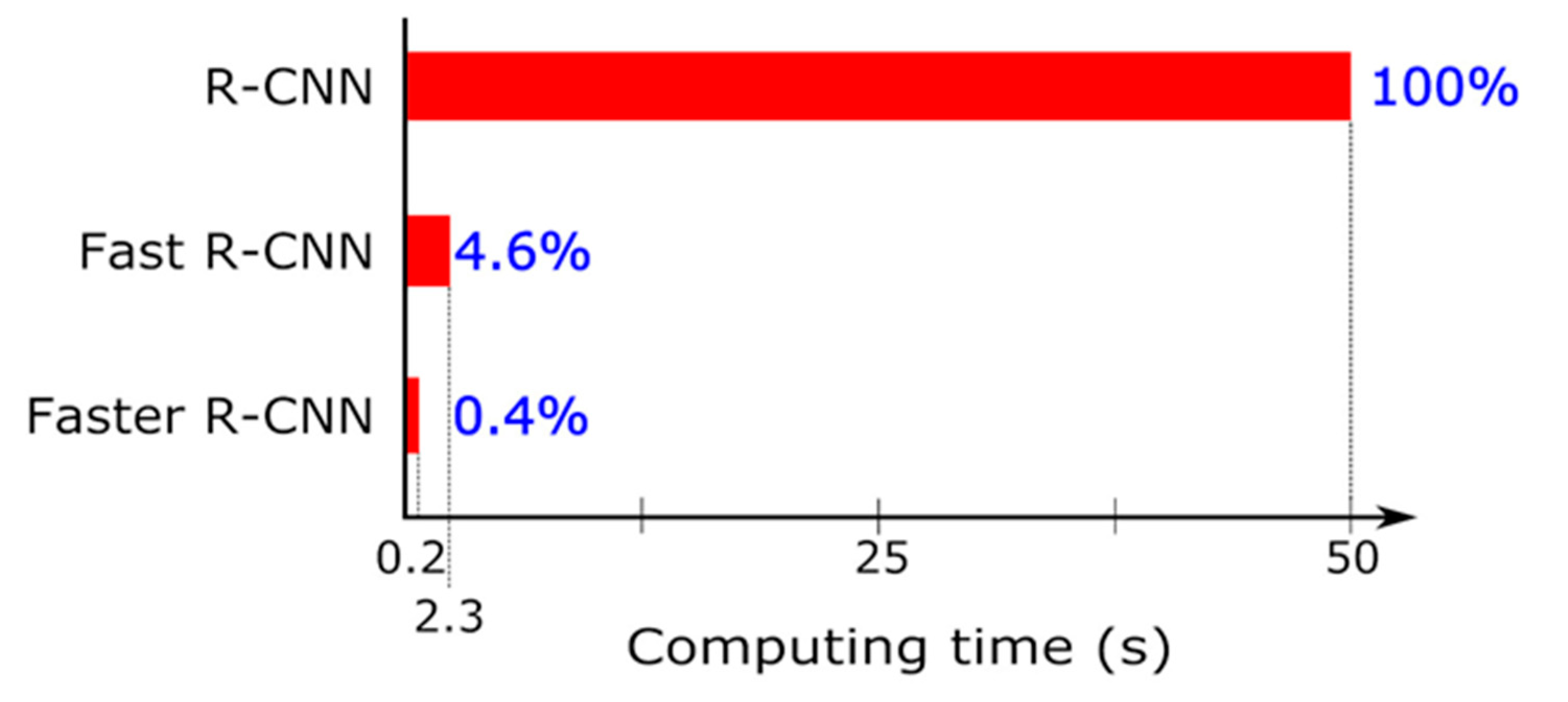
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Meshram, V.V.; Patil, K.; Meshram, V.A.; Shu, F.C. An Astute Assistive Device for Mobility and Object Recognition for Visually Impaired People. IEEE Trans. Hum.-Mach. Syst. 2019, 49, 449–460. [Google Scholar] [CrossRef]
- Krishnan, A.; Deepakraj, G.; Nishanth, N.; Anandkumar, K.M. Autonomous walking stick for the blind using echolocation and image processing. In Proceedings of the 2016 2nd International Conference on Contemporary Computing and Informatics (IC3I), Noida, India, 14–17 December 2016; pp. 13–16. [Google Scholar]
- Cardin, S.; Thalmann, D.; Vexo, F. A wearable system for mobility improvement of visually impaired people. Vis. Comput. 2007, 23, 109–118. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Yao, D.; Cao, H.; Shen, C. A Novel Approach to Wearable Image Recognition Systems to Aid Visually Impaired People. Appl. Sci. 2019, 9, 3350. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Zhang, X.; Munoz, J.P.; Xiao, J.; Rong, X.; Tian, Y. Assisting blind people to avoid obstacles: An wearable obstacle stereo feedback system based on 3D detection. In Proceedings of the 2015 IEEE International Conference on Robotics and Biomimetics (ROBIO), Zhuhai, China, 6–9 December 2015; pp. 2307–2311. [Google Scholar]
- Neto, L.B.; Grijalva, F.; Maike, V.R.M.L.; Martini, L.C.; Florencio, D.; Baranauskas, M.C.C.; Rocha, A.; Goldenstein, S. A Kinect-Based Wearable Face Recognition System to Aid Visually Impaired Users. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 52–64. [Google Scholar] [CrossRef]
- Katzschmann, R.K.; Araki, B.; Rus, D. Safe Local Navigation for Visually Impaired Users With a Time-of-Flight and Haptic Feedback Device. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 583–593. [Google Scholar] [CrossRef]
- Chen, T.; Ravindranath, L.; Deng, S.; Bahl, P.; Balakrishnan, H. Glimpse: Continuous, Real-Time Object Recognition on Mobile Devices. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, New York, NY, USA, 1–4 November 2015; pp. 155–168. [Google Scholar]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Jauregi, E.; Lazkano, E.; Sierra, B. Approaches to Door Identification for Robot Navigation. In Mobile Robots Navigation; Barrera, A., Ed.; InTech: London, UK, 2010; ISBN 978-953-307-076-6. [Google Scholar]
- Niu, L.; Qian, C.; Rizzo, J.-R.; Hudson, T.; Li, Z.; Enright, S.; Sperling, E.; Conti, K.; Wong, E.; Fang, Y. A Wearable Assistive Technology for the Visually Impaired with Door Knob Detection and Real-Time Feedback for Hand-to-Handle Manipulation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1500–1508. [Google Scholar]
- Panchal, A.; Varde, S.; Panse, M. Character Detection and Recognition System for Visually Impaired People. In Proceedings of the IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology, Bangalore, India, 20–21 May 2016; pp. 1492–1496. [Google Scholar]
- Jabnoun, H.; Benzarti, F.; Amiri, H. Object Recognition for Blind People based on Features Extraction. In Proceedings of the International Image Processing, Applications and Systems Conference, Sfax, Tunisia, 5–7 November 2014; pp. 1–6. [Google Scholar]
- Ciobanu, A.; Morar, A.; Moldoveanu, F.; Petrescu, L.; Ferche, O.; Moldoveanu, A. Real-Time Indoor Staircase Detection on Mobile Devices. In Proceedings of the International Conference on Control Systems and Computer Science, Bucharest, Romania, 29–31 May 2017; pp. 287–293. [Google Scholar]
- Nascimento, J.C.; Marques, J.S. Performance Evaluation of Object Detection Algorithms for Video Surveillance. IEEE Trans. Multimed. 2016, 8, 761–774. [Google Scholar] [CrossRef]
- Hernandez, A.C.; Gómez, C.; Crespo, J.; Barber, R. Object Detection Applied to Indoor Environments for Mobile Robot Navigation. Sensors 2016, 16, 1180. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Dong, M.; Wen, S.; Hu, X.; Zhou, P.; Zeng, Z. CLU-CNNs: Object Detection for Medical Images. Neurocomputing 2019, 350, 53–59. [Google Scholar] [CrossRef]
- Baeg, S.; Park, J.; Koh, J.; Park, K.; Baeg, M. An Object Recognition System for a Smart Home Environment on the Basis of Color and Texture Descriptors. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 901–906. [Google Scholar]
- Paletta, L.; Fritz, G.; Seifert, C.; Luley, P.; Almer, A. Visual Object Recognition for Mobile Tourist Information Systems. In Proceedings of the SPIE 5684, Multimedia on Mobile Devices, San Jose, CA, USA, 14 March 2005; pp. 190–197. [Google Scholar]
- Lu, S.; Wang, B.; Wang, H.; Chen, L.; Linjian, M.; Zhang, X. A real-time object detection algorithm for video. Comput. Electr. Eng. 2019, 77, 398–408. [Google Scholar] [CrossRef]
- Trabelsi, R.; Jabri, I.; Melgani, F.; Smach, F.; Conci, N.; Bouallegue, A. Indoor object recognition in RGBD images with complex-valued neural networks for visually-impaired people. Neurocomputing 2019, 330, 94–103. [Google Scholar] [CrossRef]
- Malūkas, U.; Maskeliūnas, R.; Damaševičius, R.; Woźniak, M. Real Time Path Finding for Assisted Living Using Deep Learning. J. Univers. Comput. Sci. 2017, 24, 475–486. [Google Scholar] [CrossRef]
- Jayakanth, K. Comparative Analysis of Texture Features and Deep Learning Method for Real-time Indoor Object Recognition. In Proceedings of the 2019 International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 17–19 July 2019; pp. 1676–1682. [Google Scholar]
- Jabnoun, H.; Benzarti, F.; Morain-Nicolier, F.; Amiri, H. Video-based assistive aid for blind people using object recognition in dissimilar frames. Int. J. Adv. Intell. Parad. 2019, 14, 122–139. [Google Scholar] [CrossRef]
- Kulikajevas, A.; Maskeliūnas, R.; Damaševičius, R.; Ho, E.S.L. 3D Object Reconstruction from Imperfect Depth Data Using Extended YOLOv3 Network. Sensors 2020, 20, 2025. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Cho, M.; Chung, T.; Lee, H.; Lee, S. N-RPN: Hard Example Learning for Region Proposal Networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3955–3959. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Proceedings of the Computer Vision—ECCV 2012, Florence, Italy, 7–13 October 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view RGB-D object dataset. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1817–1824. [Google Scholar]
- ImageNet. Available online: http://www.image-net.org/ (accessed on 2 October 2020).
- Bashiri, F.S.; LaRose, E.; Peissig, P.; Tafti, A.P. MCIndoor20000: A Fully-Labeled Image Dataset to Advance Indoor Objects Detection. Data Brief 2018, 17, 71–75. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Velazquez, R.; Varona, J.; Rodrigo, P.; Haro, E.; Acevedo, M. Design and Evaluation of an Eye Disease Simulator. IEEE Latin Am. Trans. 2015, 13, 2734–2741. [Google Scholar] [CrossRef]
- Meet Jetson, the Platform for AI at the Edge. Available online: https://developer.nvidia.com/embedded-computing (accessed on 2 October 2020).
- How to Configure Your NVIDIA Jetson Nano for Computer Vision and Deep Learning. Available online: https://www.pyimagesearch.com/2020/03/25/how-to-configure-your-nvidia-jetson-nano-for-computer-vision-and-deep-learning (accessed on 2 October 2020).
- NVIDIA Co. Jetson Partner Supported Cameras. 2020. Available online: https://developer.nvidia.com/embedded/jetson-partner-supported-cameras (accessed on 2 October 2020).
- NVIDIA Co. Jetson Partner Hardware Products. 2020. Available online: https://developer.nvidia.com/embedded/community/jetson-partner-products (accessed on 2 October 2020).
- NVIDIA Jetson Linux Developer Guide: Clock Frequency and Power Management. Available online: https://docs.nvidia.com/jetson/l4t/index.html#page/Tegra%2520Linux%2520Driver%2520Package%2520Development%2520Guide%2Fclock_power_setup.html%23 (accessed on 2 October 2020).
- Özdemir, A.T. An Analysis on Sensor Locations of the Human Body for Wearable Fall Detection Devices: Principles and Practice. Sensors 2016, 16, 1161. [Google Scholar] [CrossRef]
- This Powerful Wearable Is a Life-Changer for the Blind. Available online: https://blogs.nvidia.com/blog/2016/10/27/wearable-device-for-blind-visually-impaired/ (accessed on 2 October 2020).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; LNCS, 8693; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. ISBN 978-3-319-10601-4. [Google Scholar]
- Getting Started with Jetson Nano Developer Kit. Available online: https://developer.nvidia.com/embedded/learn/get-started-jetson-nano-devkit (accessed on 2 October 2020).
- Installing TensorFlow For Jetson Platform. Available online: https://docs.nvidia.com/deeplearning/frameworks/install-tf-jetson-platform/index.htm (accessed on 2 October 2020).
- Alvarez-Pato, V.M.; Sanchez, C.N.; Dominguez-Soberanes, J.; Mendoza-Perez, D.E.; Velazquez, R. A Multisensor Data Fusion Approach for Predicting Consumer Acceptance of Food Products. Foods 2020, 9, 774. [Google Scholar] [CrossRef]
- TensorFlow 1 Detection Model Zoo. Collection of Pre-trained Detection Models. Available online: https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md (accessed on 2 October 2020).
- Pissaloux, E.; Velazquez, R. Mobility of Visually Impaired People: Fundamentals and ICT Assistive Technologies, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Pissaloux, E.; Maybank, S.; Velazquez, R. On Image Matching and Feature Tracking for Embedded Systems: A State of the Art. In Advances in Heuristic Signal Processing and Applications; Chatterjee, A., Nobahari, H., Siarry, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 357–380. ISBN 978-3-642-37879-9. [Google Scholar]
- Visconti, P.; de Fazio, R.; Costantini, P.; Miccoli, S.; Cafagna, D. Innovative complete solution for health safety of children unintentionally forgotten in a car: A smart Arduino-based system with user app for remote control. IET Sci. Meas. Technol. 2020, 14, 665–675. [Google Scholar] [CrossRef]
- Visconti, P.; de Fazio, R.; Costantini, P.; Miccoli, S.; Cafagna, D. Arduino-based solution for in-car-abandoned infants’ controlling remotely managed by smartphone application. J. Commun. Softw. Syst. 2019, 15, 89–100. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; LNCS 9905; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Xue, Y.; Li, Y. A fast detection method via region-based fully convolutional neural networks for shield tunnel lining defects. Comput. -Aided Civ. Infrastruct. Eng. 2018, 33, 638–654. [Google Scholar] [CrossRef]
- Wang, H.; Yu, Y.; Cai, Y.; Chen, X.; Chen, L.; Liu, Q. A comparative study of state-of-the-art deep learning algorithms for vehicle detection. IEEE Intell. Transp. Syst. Mag. 2019, 11, 82–95. [Google Scholar] [CrossRef]
- Intellica Co. A Comparative Study of Custom Object Detection Algorithms. 2019. Available online: https://medium.com/@Intellica.AI/a-comparative-study-of-custom-object-detection-algorithms-9e7ddf6e765e (accessed on 2 October 2020).

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technology | Application |
|---|---|
| Visual recognition system | Object recognition, Face Recognition, Navigation, Positioning, Access control, Text recognition |
| Radio-frequency identification (RFID) technology | Object recognition, Positioning, Access Control |
| Global Positioning System (GPS) Navigation system | Navigation, Positioning |
| Ultrasound detection system | Navigation, Access control, Obstacle detection |
| Laser Imaging Detection and Ranging (LIDAR)/Optical Time-of-Flight distance sensors | Navigation, Obstacles detection |
| Vibrotactile Interfaces | User interface |
| Audio Interfaces | User interface |
| Algorithm | Architecture | Mean Average Precision [%] | Mean Computing Time [ms] | Dataset |
|---|---|---|---|---|
| Hernández [34] | SVM | 78.34 | n.a. | NYU Depth Dataset V2 [46] |
| Lu [38] | Fast YOLO | 88.45 | 22 | Custom |
| Trabelsi [39] | ML-CVNN | 87.2 | n.a. | RGBD [47] |
| Malūkas [40] | FCN-VGG16 | 96.1 | 105 | ImageNet [48] |
| Jayakanth [41] | CNN + SVM | 100 | 451 | MCindoor20000 [49] |
| Redmon [50] | YOLOv3 | 57.9 | 51 | COCO |
| Ren [45] | Faster R-CNN | 73.2 | 198 | COCO |
| Frozen Inference Graph Model (COCO Dataset) | Custom Objects | ||||
|---|---|---|---|---|---|
| apple | carrot | giraffe | person | suitcase | doorknob |
| backpack | cat | hair brush | pizza | surfboard | power outlet |
| banana | cell phone | hair drier | plate | teddy bear | switch |
| baseball bat | chair | handbag | potted plant | tennis racket | white cane |
| baseball glove | clock | hat | refrigerator | tie | human subject 1 |
| bear | couch | horse | remote | toaster | human subject 2 |
| bed | cow | hot dog | sandwich | toilet | human subject 3 |
| bench | cup | keyboard | scissors | toothbrush | human subject 4 |
| bicycle | desk | kite | sheep | traffic light | human subject 5 |
| bird | dining table | knife | shoe | train | human subject 6 |
| blender | dog | laptop | sink | truck | human subject 7 |
| boat | donut | microwave | skateboard | TV | human subject 8 |
| book | door | mirror | skis | umbrella | |
| bottle | elephant | motorcycle | snowboard | vase | |
| bowl | eye glasses | mouse | spoon | window | |
| broccoli | fire hydrant | orange | sports ball | wine glass | |
| bus | fork | oven | stop sign | zebra | |
| cake | Frisbee | parking meter | street sign | suitcase | |
| car | |||||
| Training Parameter | Value | Description |
|---|---|---|
| Total trained classes | 103 | The total number of objects (91 of the COCO dataset plus 12 custom). |
| Dimensions (pixels) | 1024 × 768 | Resolution of the images used for the training phase. |
| Batch size (images) | 12 | The number of samples processed before the model is updated. |
| Optimizer | Adaptive Moment Estimation (Adam) | Optimizers are methods used to configure the attributes of the neural network, such as weights and learning rate in order to reduce the losses. |
| Learning rate (first 60 k mini-batches) | 0.0002 | The learning rate is a hyper parameter that controls the model’s response face to the estimated error each time that the model weights are updated. |
| Learning rate (60 k–120 k mini-batches) | 0.00002 | |
| Weight decay | 0.0005 | Weight decay allows the neural network to decrease its complexity and to reduce the training time without penalizing the detector’s accuracy. |
| Intersection over Union (IoU) | 0.55 | IoU is an evaluation metric used to measure the accuracy of an object detector on a particular dataset. |
| Dropout | FALSE | Dropout is a regularization method that approximates training a large number of neural networks with different architectures in parallel. |
| Shuffle | TRUE | Shuffle is used to mix up the custom dataset, so it prevents the neural network from memorizing it. |
| Max detections per class | 100 | It is the maximum number of detection of one object (class) in one frame. |
| Max total detections | 300 | The maximum detections, of any class, allowed in one frame. |
| Solution | mAP [%] | Mean Computing Time [ms] | Complexity | Cost |
|---|---|---|---|---|
| L.B. Neto [24] | 94 | 2.4 | High | High |
| S. Lu [38] | 88 | 22 | High | High |
| U. Malūkas [40] | 96 | 105 | High | High |
| K. Jayakanth [41] | 100 | 451 | Medium-High | High |
| Our system | 86 | 215 | Low | Low |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calabrese, B.; Velázquez, R.; Del-Valle-Soto, C.; de Fazio, R.; Giannoccaro, N.I.; Visconti, P. Solar-Powered Deep Learning-Based Recognition System of Daily Used Objects and Human Faces for Assistance of the Visually Impaired. Energies 2020, 13, 6104. https://doi.org/10.3390/en13226104
Calabrese B, Velázquez R, Del-Valle-Soto C, de Fazio R, Giannoccaro NI, Visconti P. Solar-Powered Deep Learning-Based Recognition System of Daily Used Objects and Human Faces for Assistance of the Visually Impaired. Energies. 2020; 13(22):6104. https://doi.org/10.3390/en13226104
Chicago/Turabian StyleCalabrese, Bernardo, Ramiro Velázquez, Carolina Del-Valle-Soto, Roberto de Fazio, Nicola Ivan Giannoccaro, and Paolo Visconti. 2020. "Solar-Powered Deep Learning-Based Recognition System of Daily Used Objects and Human Faces for Assistance of the Visually Impaired" Energies 13, no. 22: 6104. https://doi.org/10.3390/en13226104