
Analysis of Business Customers’ Energy Consumption Data Registered by Trading Companies in Poland

 , , and
, , and
Abstract
:1. Introduction
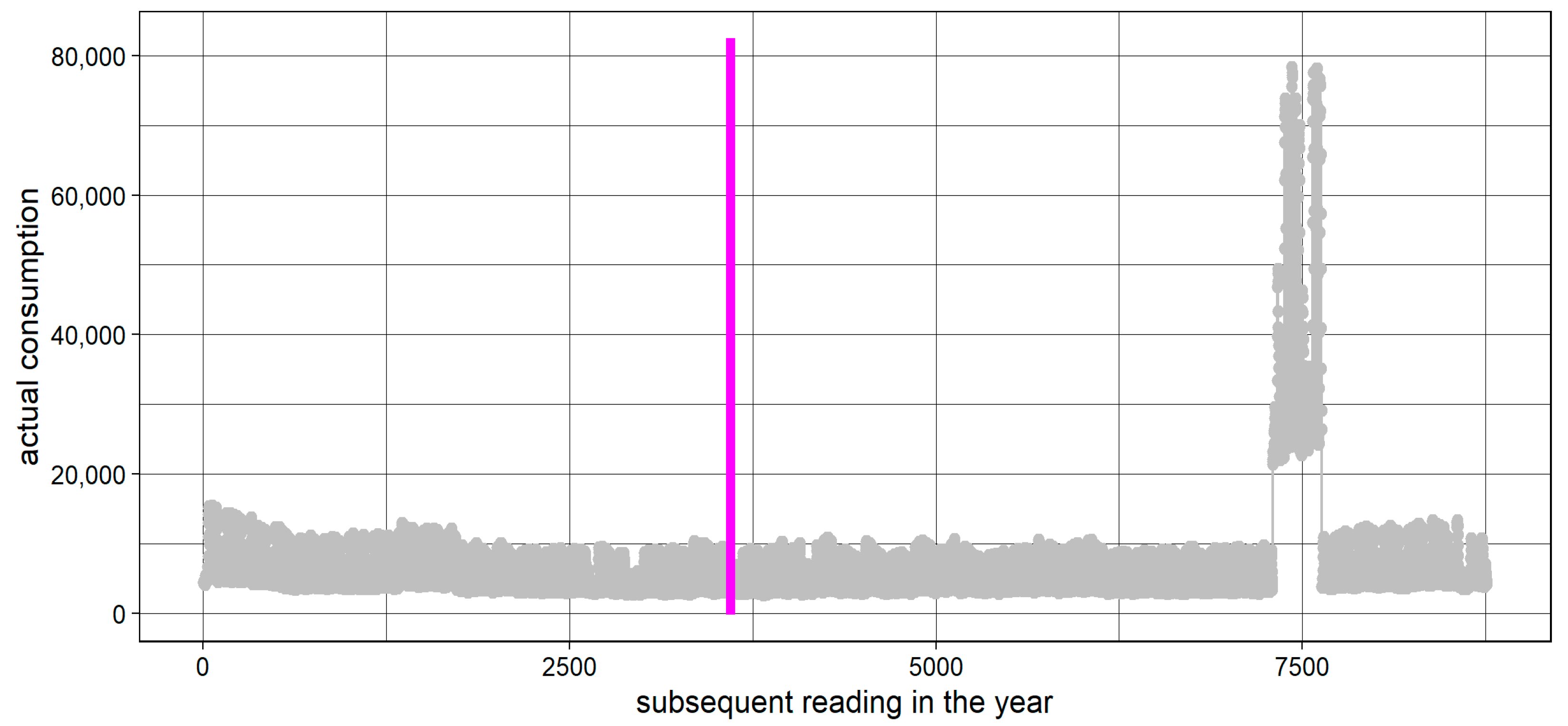
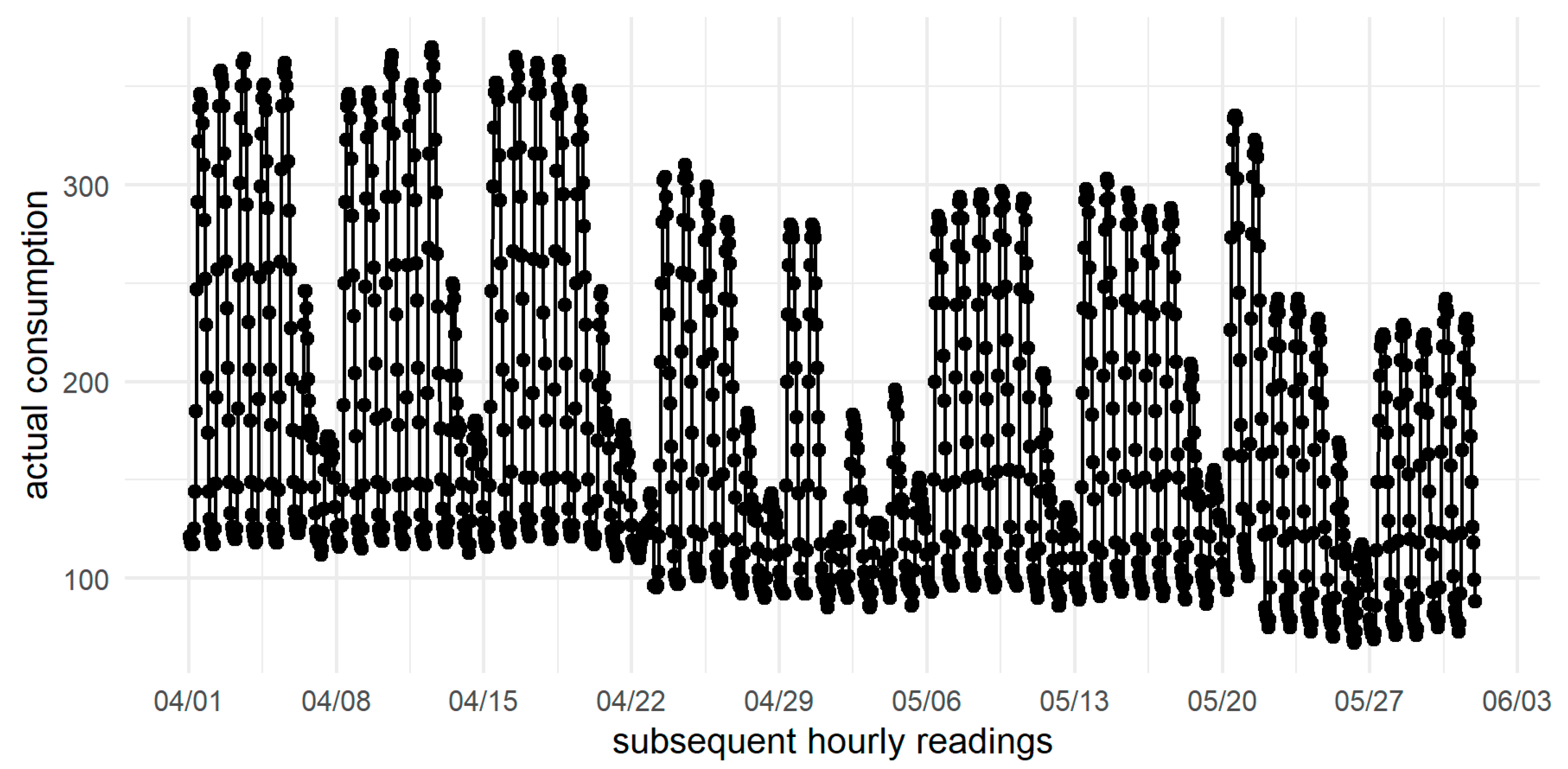
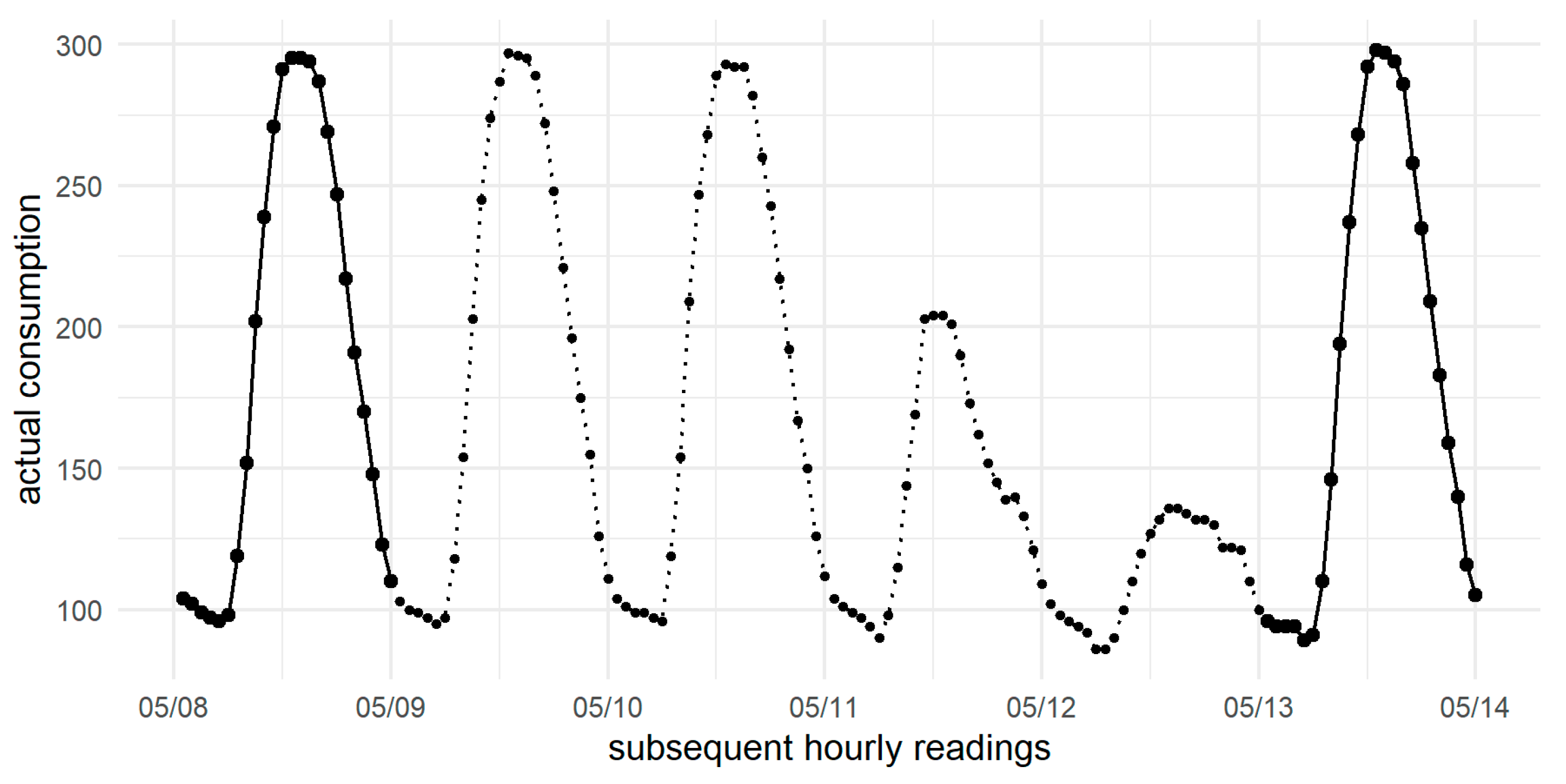
2. Data
- the length of a single sequence of missing data (gaps) not longer than 48 h in one sequence,
- no more than 576 h with missing data during the year,
- no more than 20% of profile consumption (these are values estimated based on profiles prepared by trading companies in the event that the energy consumption readings occur in periods longer than every hour, e.g., once a day or once a week).
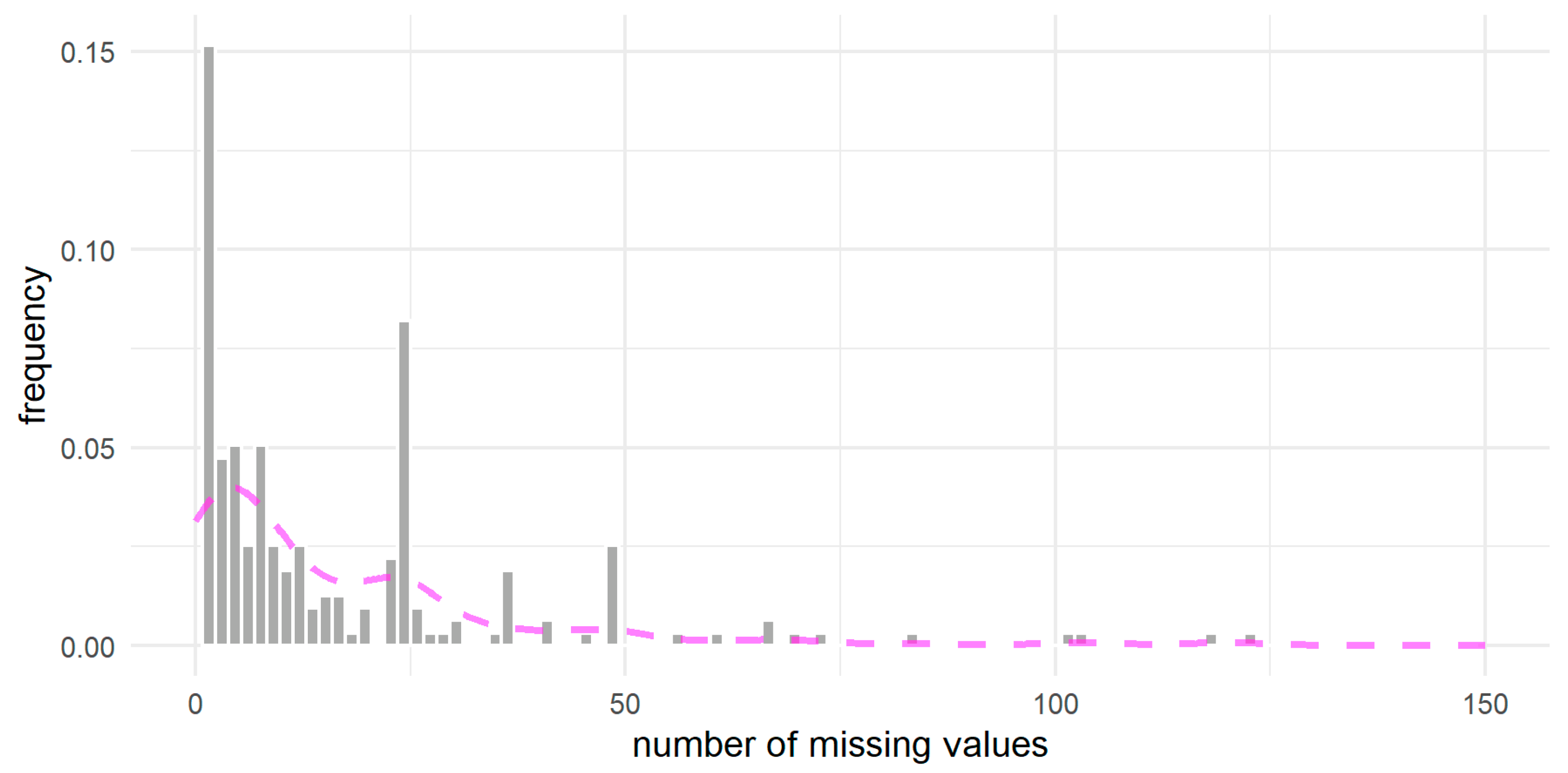
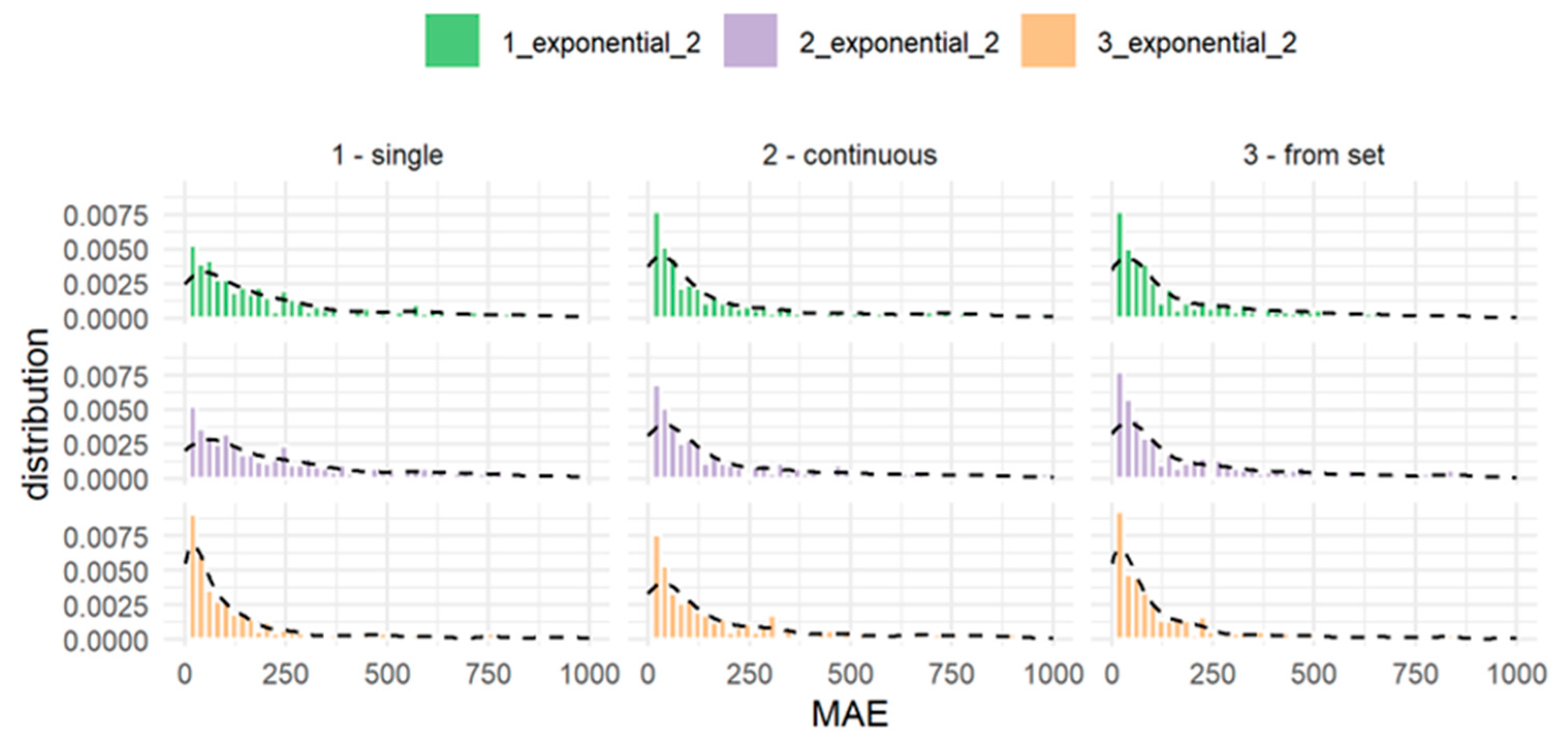
Missing Values Analysis
- most, because there were as many as 19 cases, of the missing data concerned 3:00 a.m. on 27 November 2019—the time change point (it is worth noting that on this day, the day has 25 h). However, in the second point of the time change on 31 March 2019 at 2 o’clock, no data appeared in the 14 PPE. The problems with the missing values at the time of the time change affected 29 different PPEs, but in only four cases, they occurred simultaneously in the same PPE;
- on 26 January 2019 from 1:00 to 24:00, no data appeared in 15 PPEs;
- when examining the distribution of missing values in the indicated set of 210 PPEs, it was found that out of 8760 measurement items—in 6371 (72.7%), there were no missing values in any PPE.
- MCAR—missing completely at random—the process of the occurrence of missing data is considered to be completely random (there is no specific mechanism for creating missing values)
- MAR—missing at random—in the process of data occurrence, it is possible to link the occurrence of data with observable variables (there are other variables that affect the existence of missing values, and the probability of their occurrence is independent of the value itself)
- MNAR—missing not at random—in this process, missing data is related to unobservable variables (the probability of a missing value is related to the missing value itself).
- Random generator—single points—set (1—single). For each of the selected PPEs, 58 locations of missing data were randomly selected. The determined number of missing data was because, for 95% of PPEs with missing data, the number of missing data was not greater than 58 (see Table 1).
- Random generator—continuous data gap—set (2—continuous). For each of the selected PPEs, one gap with a length of 48 was created randomly, i.e., the longest observed missing data (see Table 1).
- Generator based on set 210—set (3—from the set). For each of the selected PPEs with complete data, one PPE was selected at random from a set of 210 imputation candidates. Missing data were inserted in the selected PPE with complete data in the places of their occurrence in the randomly selected PPE from the set of 210.
3. Methods
- One-dimensional algorithms that work with one-dimensional inputs but do not typically use time series characteristics (e.g., mean, mode, median, random sample).
- Univariate time series algorithms that can work with one-dimensional inputs but use time series characteristics. These are algorithms such as last observation carried forward, next observation carried forward, arithmetic smoothing and linear interpolation, and more advanced methods based on structured time series models that deal with seasonality.
- Multivariate algorithms on lagged data, which generally cannot be used for univariate series, but it is possible to add time information as covariates, which allows the use of multivariate imputation algorithms. This can usually be done by using lags (which take the value of another variable from the preceding period) and ‘leads’ (which take the value of another variable in the next period).
3.1. Method 1—Calendar Method and 2k Weighted Moving Average Method
3.2. Method 2—Imputation Using Seasonally Splitted Missing Value Imputation
3.3. Method 3—Imputation Using Seasonally Decomposed Missing Value Imputation
3.4. Comparison of Selected Imputation Methods
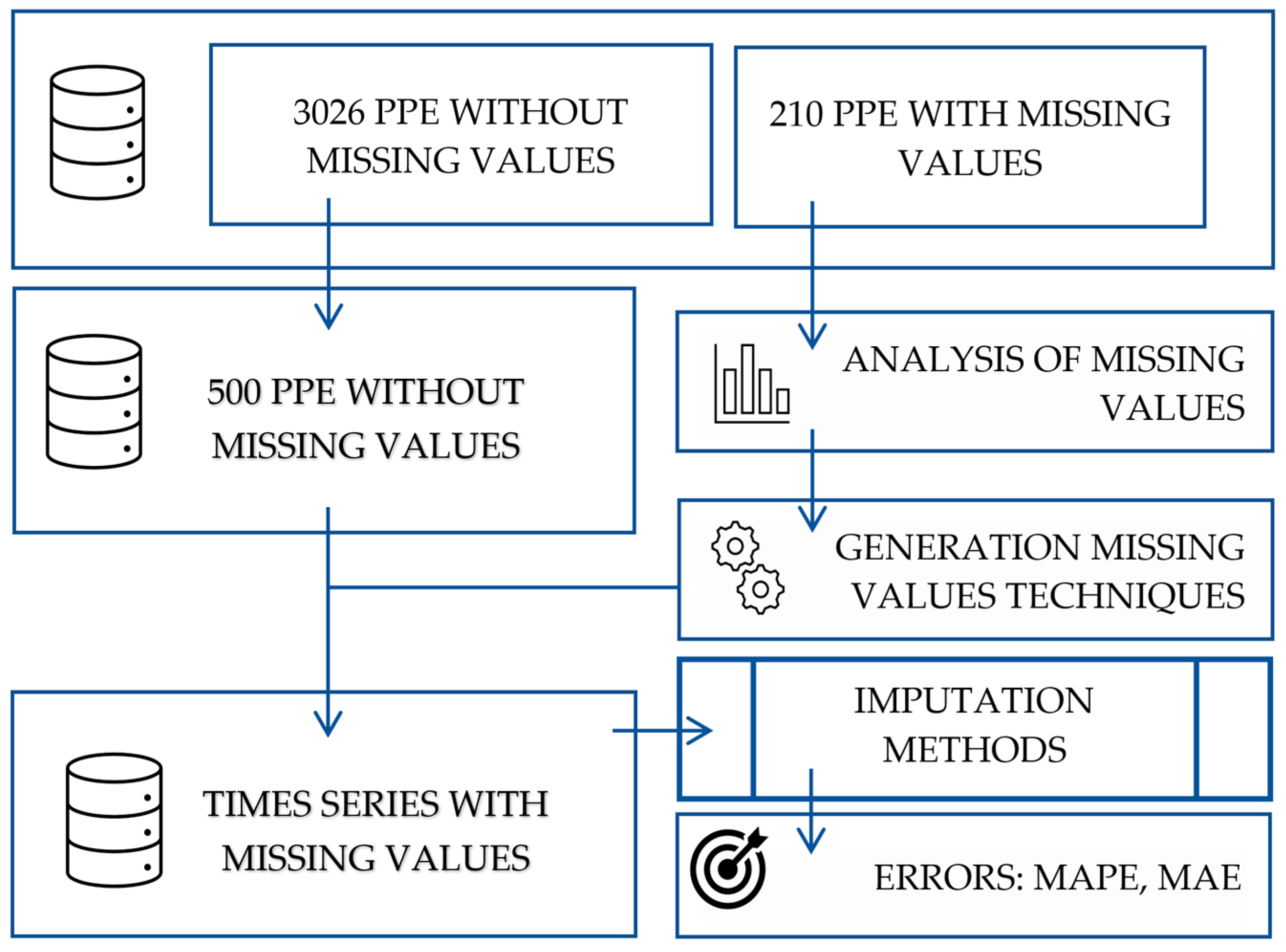
- Step 1. Select from database PPE with missing data.
- Step 2. Perform an analysis of missing data. Determine the number and distribution of missing values.
- Step 3. Prepare techniques for generating missing data adequate to the results of the analysis.
- Step 4. Select a random PPE group from the PPE database without missing data.
- Step 5. Generate missing data according to the generation techniques prepared in step 3.
- Step 6. Apply the selected imputation methods on the series from step 4.
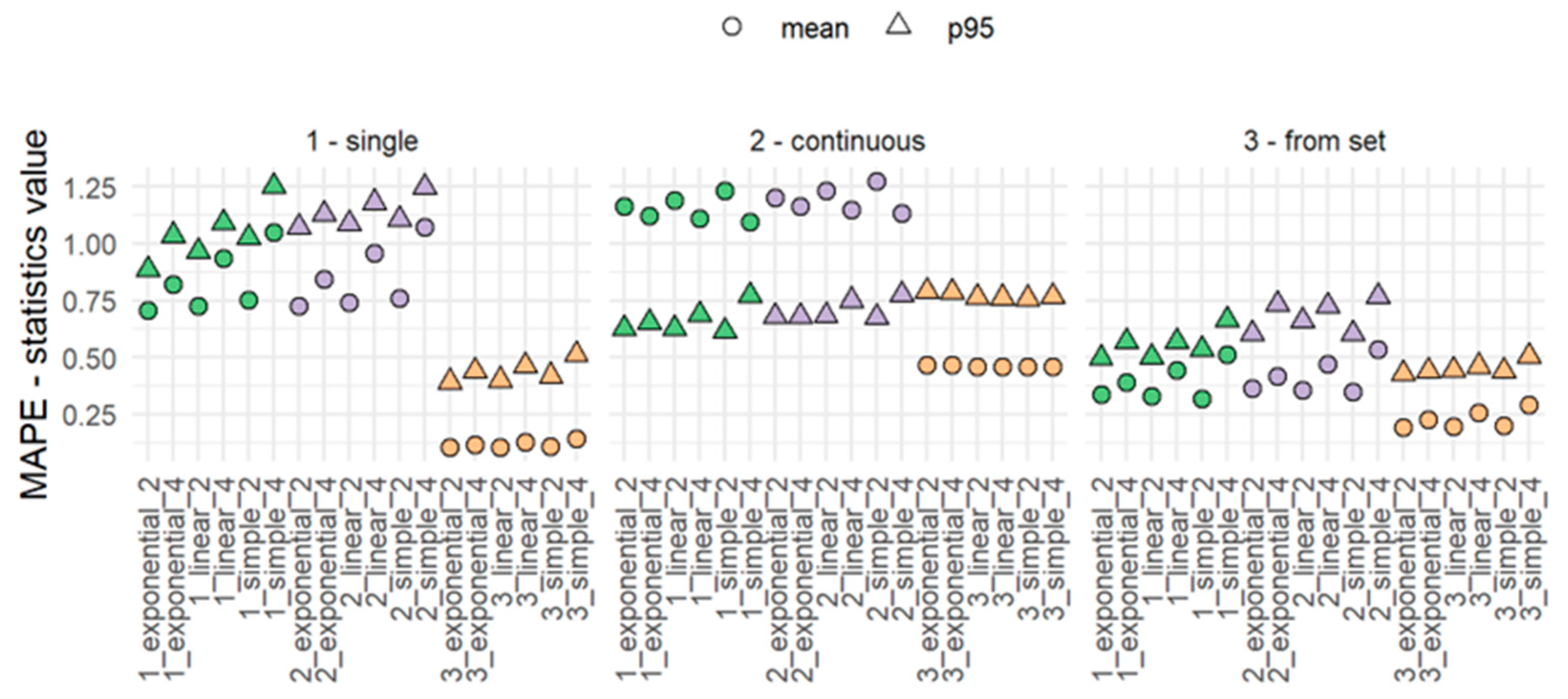
- Step 7. Determine the accuracy of imputation methods based on MAE and MAPE errors.
- Step 8. Select the data imputation method.
- —a set of indexes of readings for which data has been imputed, with no values for which ,
- —number of inserted missing values with no values for which ,
- —value of actual consumption for the generated missing data,
- —imputed consumption value.
- —a set of indexes of readings for which data has been imputed,
- —the number of inserted missing values,
- —value of actual consumption for the generated missing data,
- —imputed consumption value.
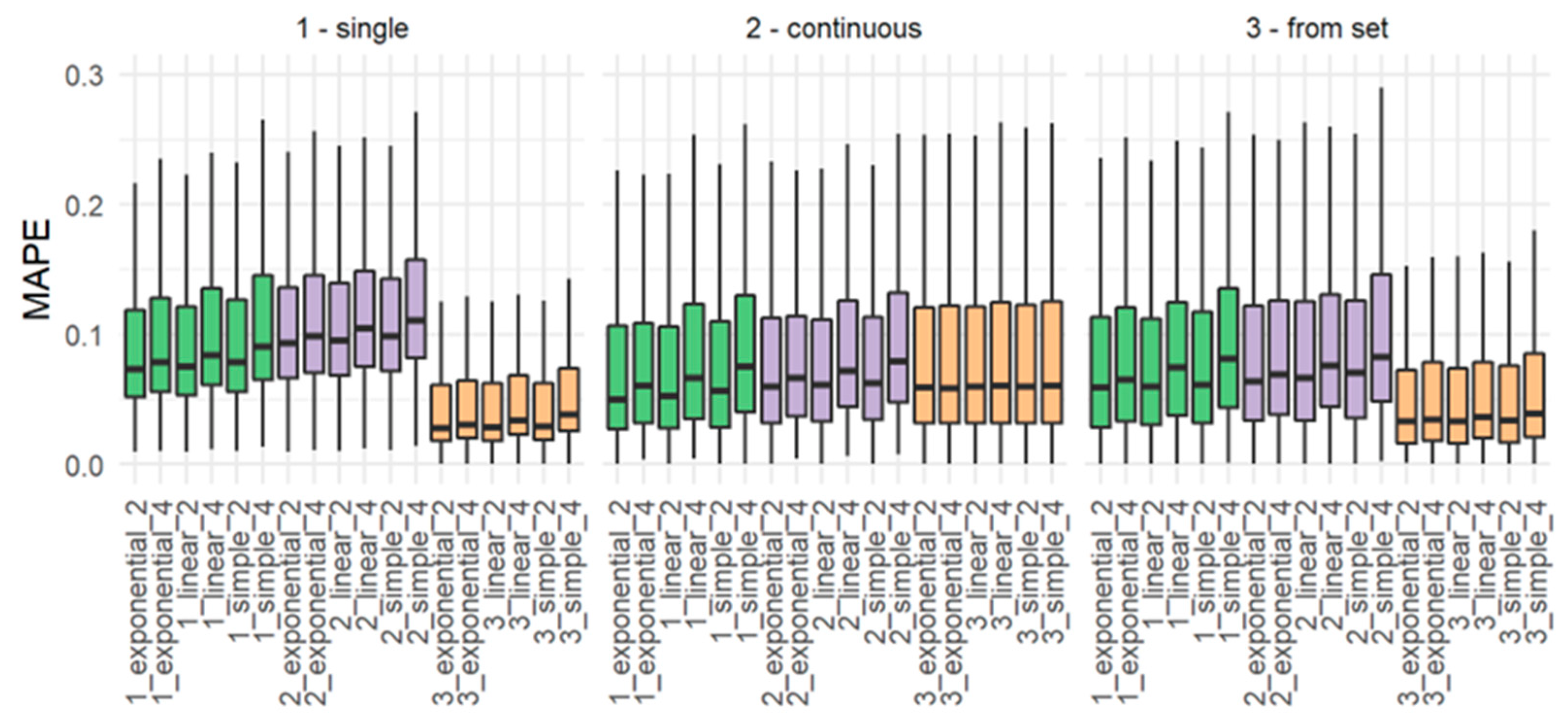
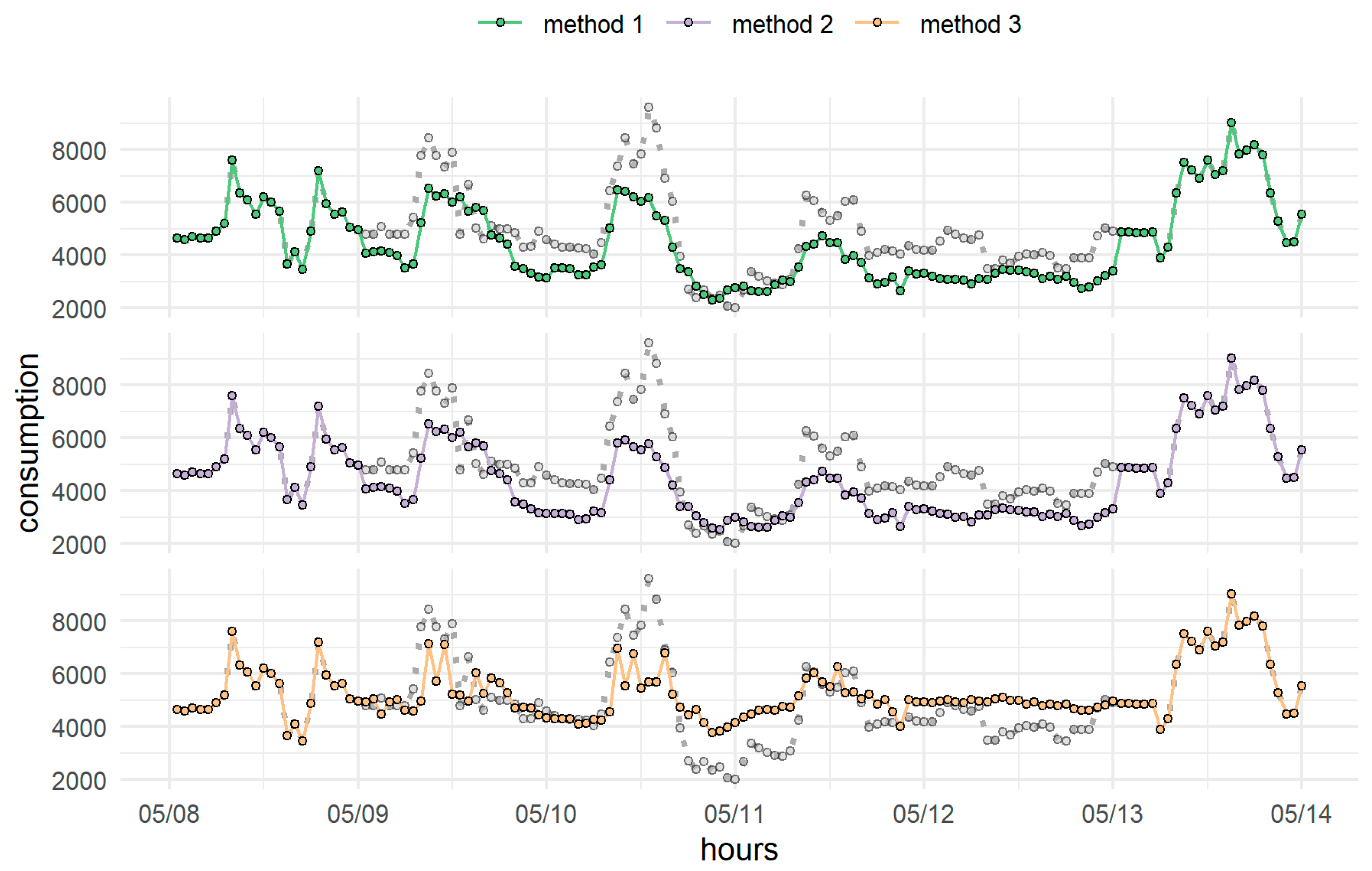
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, X.; He, Z.; Chen, Y.; Lu, Y.; Wang, J. Missing traffic data imputation and pattern discovery with a Bayesian augmented tensor factorization model. Transp. Res. Part C 2019, 104, 66–77. [Google Scholar] [CrossRef]
- Choi, Y.-Y.; Shon, H.; Byon, Y.-J.; Kim, D.-K.; Kang, S. Enhanced application of principal component analysis in machine learning for imputation missing traffic data. Appl. Sci. 2019, 9, 2149. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Li, M.; Lin, X.; He, F.; Wang, Y. A spatiotemporal approach for traffic data imputation with complicated missing patterns. Transp. Res. Part C 2020, 119, 102730. [Google Scholar] [CrossRef]
- Yang, B.; Kang, Y.; Yuan, Y.; Huang, X.; Li, H. ST-LBAGAN: Spatio-temporal learnable bidirectional attention generative adversarial networks for missing traffic data imputation. Knowl. -Based Syst. 2021, 215, 106705. [Google Scholar] [CrossRef]
- Demirhan, H.; Renwick, Z. Missing value imputation for short to mid-term horizontal solar irradiance data. Appl. Energy 2018, 225, 98–1012. [Google Scholar] [CrossRef]
- Junger, W.L.; Ponce de Leon, A. Imputation of missing data in time series for air pollutants. Atmos. Environ. 2015, 102, 96–104. [Google Scholar] [CrossRef]
- Kim, T.; Ko, W.; Kim, J. Analysis and impact evaluation of missing data imputation in day-ahead PV generation forecasting. Appl. Sci. 2019, 9, 204. [Google Scholar] [CrossRef] [Green Version]
- Martinez-Luengo, M.; Shafiee, M.; Kolios, A. Data management for structural integrity assessment of offshore wind turbine support structures: Data cleansing and missing data imputation. Ocean Eng 2019, 173, 867–883. [Google Scholar] [CrossRef]
- Altukhova, O. Choice of method imputation missing values for obstetrics clinical data. Procedia Comput. Sci. 2020, 176, 976–984. [Google Scholar] [CrossRef]
- Armitage, E.G.; Godzien, J.; Alonso-Herranz, V.; Lopez-Gonzalvez, A.; Barbas, C. Missing value imputation strategies for metabolomics data. Electrophoresis 2015, 36, 3050–3060. [Google Scholar] [CrossRef]
- Choudhury, S.J.; Pal, N.R. Imputation of missing data with neural networks for classification. Knowl. -Based Syst. 2019, 182, 104838. [Google Scholar] [CrossRef]
- Liao, S.; Lin, Y.; Kang, D.D.; Chandra, D.; Bon, J.; Kaminski, N.; Sciurba, F.C.; Tseng, G.C. Missing value imputation in high-dimensional phenomic data: Imputable or not, and how? BMC Bioinform. 2014, 15, 346. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, C.-H.; Tsai, C.-F.; Sue, K.-L.; Huang, M.-W. The Feature Selection Effect on Missing Value Imputation of Medical Datasets. Appl. Sci 2020, 10, 2344. [Google Scholar] [CrossRef] [Green Version]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing value estimation methods for DNA microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef] [Green Version]
- Van der Heijden, G.J.M.G.; Donders, A.R.T.; Stijnen, T.; Moons, K.G.M. Imputation of missing values is superior to complete case analysis and the missing-indicator method in multivariable diagnostic research: A clinical example. J. Clin. Epidemiol. 2006, 59, 1102–1109. [Google Scholar] [CrossRef]
- Arora, S.; Taylor, J.W. Forecasting electricity smart meter data using conditional kernel density estimation. Omega 2016, 59, 47–59. [Google Scholar] [CrossRef] [Green Version]
- Mouakher, A.; Inoubli, W.; Ounoughi, C.; Ko, A. EXPECT: EXplainable Prediction Model for Energy ConsumpTion. Mathematics 2022, 10, 248. [Google Scholar] [CrossRef]
- Peppanen, J.; Zhang, X.; Grijalva, S.; Reno, M.J. Handling bad or missing smart meter data through advanced data imputation. In Proceedings of the IEEE Power & Energy Society Innovative Smart Grid Technologies Conference, Minneapolis, MN, USA, 6–9 September 2016; pp. 1–5. [Google Scholar]
- Qu, F.; Liu, J.; Ma, Y.; Zang, D.; Fu, M. A novel wind turbine data imputation method with multiple optimizations based on GANs. Mech. Syst. Signal. Process 2020, 139, 106610. [Google Scholar] [CrossRef]
- Turrado, C.C.; Lasheras, F.S.; Calvo-Rolle, J.L.; Pinon-Pazos, A.J.; de Cos Juez, F.J. A new missing data imputation algorithm applied to electrical data loggers. Sensors 2015, 15, 31069–31082. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.-C.; Tsai, C.-F.; Lin, W.-C. Towards missing electric power data imputation for energy management systems. Expert Syst. Appl. 2021, 174, 14743. [Google Scholar] [CrossRef]
- Chen, W.; Zhou, K.; Yang, S.; Wu, C. Data quality of electricity consumption data in a smart grid environment. Renew. Sust. Energy Rev. 2017, 75, 98–105. [Google Scholar] [CrossRef]
- Moritz, S.; Bartz-Beielstein, T. imputeTS: Time Series Missing Value Imputation in R. R J. 2017, 9, 207. [Google Scholar] [CrossRef] [Green Version]
- Sefidian, A.M.; Daneshpour, N. Missing value imputation using a novel grey based fuzzy c-means, mutual information based feature selection, and regression model. Expert Syst. Appl. 2019, 115, 68–94. [Google Scholar]
- Bokde, N.; Beck, M.W.; Martínez Álvarez, F.; Kulat, K. A novel imputation methodology for time series based on pattern sequence forecasting. Pattern Recognit. Lett 2018, 116, 88–96. [Google Scholar] [CrossRef]
- Yadav, M.L.; Roychoudhury, B. Handling missing values: A study of popular imputation packages in R. Knowl. -Based Syst. 2018, 160, 104–118. [Google Scholar] [CrossRef]
- Rubin, D.B. Multiple Imputation for Nonresponse in Surveys; Wiley: New York, NY, USA, 1987. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. Royal Stat. Soc. B 1977, 39, 1–22. [Google Scholar]
- Vacek, P.; Ashikaga, T. An examination of the nearest neighbor rule for imputing missing values. In Proceedings of the Statistical Computing Section; American Statistical Association: Boston, MA, USA, 1980; pp. 326–331. [Google Scholar]
- Ford, B.L. An Overview of Hot-Deck Procedures, In Incomplete Data in Sample Surveys; Madow, W., Olkin, I., Rubin, D.B., Eds.; Academic Press: New York, NY, USA, 1983; pp. 185–207. [Google Scholar]
- Bashir, F.; Wei, H.-L. Handling missing data in multivariate time series using a vector autoregressive model-imputation (VAR-IM) algorithm. Neurocomputing 2018, 276, 23–30. [Google Scholar] [CrossRef]
- Guo, Z.; Wan, Y.; Hao, Y. A data imputation method for multivariate time series based on generative adversarial network. Neurocomputing 2019, 360, 185–197. [Google Scholar] [CrossRef]
- Su, T.; Shi, Y.; Yu, J.; Yue, C.; Zhou, F. Nonlinear compensation algorithm for multidimensional temporal data: A missing value imputation for the power grid applications. Knowl.-Based Syst. 2021, 215, 106743. [Google Scholar] [CrossRef]
- Velasco-Gallego, C.; Lazakis, I. Real-time data-driven missing data imputation for short-term sensor data of marine systems. A comparative study. Ocean. Eng. 2020, 218, 108261. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, B.; Cai, X.; Guo, W.; Ding, X.; Yuan, X. Missing value imputation in multivariate time series with end-to-end generative adversarial networks. Inf. Sci. 2021, 551, 67–82. [Google Scholar] [CrossRef]
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data, 2nd ed.; Wiley: Hoboken, NJ, USA, 2002. [Google Scholar]
- Garcia-Laencina, P.J.; Sancho-Gomez, J.-L.; Figueiras-Vidal, A.R. Pattern classification with missing data: A review. Neural. Comput. Appl 2010, 19, 263–282. [Google Scholar] [CrossRef]
- Strike, K.; Emam, K.E.; Madhavji, N. Software cost estimation with incomplete data. IEEE Trans. Power Syst 2001, 27, 890–908. [Google Scholar] [CrossRef] [Green Version]
- Lin, W.-C.; Tsai, C.-F. Missing value imputation: A review and analysis of the literature (2006–2017). Artif. Intell. Rev. 2019, 53, 1487–1509. [Google Scholar] [CrossRef]
- Moritz, S.; Sardá, A.; Bartz-Beielstein, T.; Zaefferer, M.; Stork, J. Comparison of different Methods for Univariate Time Series Imputation in R. arXiv 2015, arXiv:physics/1510.03924. [Google Scholar]
- Chen, S.X.; Gooi, H.B.; Wang, M. Solar radiation forecast based on fuzzy logic and neural networks. Renew. Energy 2013, 60, 195–201. [Google Scholar] [CrossRef]
- Mellit, A.; Pavan, A.M. A 24-h forecast of solar irradiance using artificial neural network: Application for performance prediction of a grid-connected PV plant at Trieste, Italy. Sol. Energy 2010, 84, 807–821. [Google Scholar] [CrossRef]
- Alberini, A.; Prettico, G.; Shen, C.; Torriti, J. Hot weather and residential hourly electricity demand in Italy. Energy 2019, 177, 44–56. [Google Scholar] [CrossRef]
- Hosein, S.; Hosein, P. Load forecasting using deep neural networks. In Proceedings of the 2017 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 23–26 April 2017; pp. 1–5. [Google Scholar]
- Jung, S.; Moon, J.; Park, S.; Rho, S.; Baik, S.W.; Hwang, E. Bagging Ensemble of Multilayer Perceptrons for Missing Electricity Consumption Data Imputation. Sensors 2020, 20, 1772. [Google Scholar] [CrossRef] [Green Version]
- Rogers, D.F.; Polak, G.G. Optimal clustering of time periods for electricity demand-side management. IEEE Trans. Power Syst. 2013, 28, 3842–3851. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | Number of Missing Values | Number of Gaps | The Longest Sequence of Missing Values | The Shortest Sequence of Missing Values | Average Length of Gaps |
|---|---|---|---|---|---|
| min. | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| perc05 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| perc10 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| perc25 | 3.00 | 1.00 | 2.00 | 1.00 | 1.00 |
| median | 9.00 | 2.00 | 4.00 | 1.00 | 1.00 |
| perc75 | 24.00 | 5.00 | 13.75 | 2.75 | 2.75 |
| perc90 | 41.50 | 14.00 | 24.00 | 24.00 | 24.00 |
| perc95 | 58.20 | 24.55 | 24.00 | 24.00 | 24.00 |
| max. | 463.00 | 456.00 | 48.00 | 48.00 | 48.00 |
| average | 18.80 | 7.62 | 9.47 | 6.00 | 6.00 |
| std. dev. | 37.10 | 32.82 | 11.22 | 10.27 | 10.27 |
| skewness | 8.55 | 12.26 | 1.61 | 2.27 | 2.27 |
| Type | Median | Average | Std. dev. | Q1 | Q3 | P95 | Maximum |
|---|---|---|---|---|---|---|---|
| 1_exponential_2 | 0.0839 | 0.7079 | 6.7368 | 0.0558 | 0.1767 | 0.8863 | 138.7501 |
| 1_exponential_4 | 0.0928 | 0.8223 | 7.4717 | 0.0592 | 0.1851 | 1.0359 | 135.6493 |
| 1_linear_2 | 0.0862 | 0.7250 | 6.6871 | 0.0576 | 0.1804 | 0.9667 | 133.3940 |
| 1_linear_4 | 0.1015 | 0.9349 | 8.4721 | 0.0643 | 0.2132 | 1.0910 | 131.2762 |
| 1_simple_2 | 0.0897 | 0.7515 | 6.6847 | 0.0600 | 0.1824 | 1.0264 | 125.3621 |
| 1_simple_4 | 0.1112 | 1.0507 | 9.7079 | 0.0711 | 0.2287 | 1.2522 | 167.9605 |
| 2_exponential_2 | 0.1064 | 0.7271 | 6.3287 | 0.0726 | 0.2012 | 1.0732 | 128.1718 |
| 2_exponential_4 | 0.1119 | 0.8446 | 7.1924 | 0.0762 | 0.2221 | 1.1276 | 127.3939 |
| 2_linear_2 | 0.1086 | 0.7397 | 6.2139 | 0.0739 | 0.2066 | 1.0861 | 120.6060 |
| 2_linear_4 | 0.1225 | 0.9561 | 8.2146 | 0.0825 | 0.2371 | 1.1803 | 128.4239 |
| 2_simple_2 | 0.1126 | 0.7592 | 6.1360 | 0.0769 | 0.2128 | 1.1063 | 109.2599 |
| 2_simple_4 | 0.1315 | 1.0714 | 9.4580 | 0.0890 | 0.2558 | 1.2476 | 166.3510 |
| 3_exponential_2 | 0.0304 | 0.1039 | 0.3207 | 0.0185 | 0.0784 | 0.3926 | 5.3415 |
| 3_exponential_4 | 0.0328 | 0.1151 | 0.3604 | 0.0209 | 0.0805 | 0.4403 | 5.7078 |
| 3_linear_2 | 0.0311 | 0.1065 | 0.3305 | 0.0192 | 0.0791 | 0.4002 | 5.5401 |
| 3_linear_4 | 0.0368 | 0.1282 | 0.4067 | 0.0234 | 0.0903 | 0.4614 | 6.1266 |
| 3_simple_2 | 0.0323 | 0.1106 | 0.3457 | 0.0202 | 0.0820 | 0.4189 | 5.8393 |
| 3_simple_4 | 0.0411 | 0.1422 | 0.4548 | 0.0264 | 0.0951 | 0.5120 | 6.5195 |
| Type | Median | Average | Std. dev. | Q1 | Q3 | P95 | Maximum |
|---|---|---|---|---|---|---|---|
| 1_exponential_2 | 0.0610 | 1.1626 | 19.8305 | 0.0289 | 0.1462 | 0.6266 | 441.9988 |
| 1_exponential_4 | 0.0724 | 1.1232 | 18.0315 | 0.0349 | 0.1615 | 0.6530 | 400.9493 |
| 1_linear_2 | 0.0630 | 1.1907 | 20.2304 | 0.0304 | 0.1588 | 0.6275 | 450.7924 |
| 1_linear_4 | 0.0827 | 1.1089 | 16.9140 | 0.0396 | 0.1707 | 0.6889 | 374.9546 |
| 1_simple_2 | 0.0677 | 1.2332 | 20.8335 | 0.0311 | 0.1589 | 0.6162 | 463.9826 |
| 1_simple_4 | 0.0926 | 1.0946 | 15.8026 | 0.0472 | 0.1877 | 0.7717 | 348.6892 |
| 2_exponential_2 | 0.0687 | 1.2020 | 20.0952 | 0.0355 | 0.1687 | 0.6805 | 447.9329 |
| 2_exponential_4 | 0.0785 | 1.1615 | 18.2931 | 0.0432 | 0.1861 | 0.6788 | 406.8329 |
| 2_linear_2 | 0.0727 | 1.2307 | 20.5044 | 0.0384 | 0.1729 | 0.6833 | 456.9361 |
| 2_linear_4 | 0.0906 | 1.1467 | 17.1765 | 0.0502 | 0.1971 | 0.7504 | 380.8784 |
| 2_simple_2 | 0.0770 | 1.2742 | 21.1213 | 0.0413 | 0.1848 | 0.6754 | 470.4410 |
| 2_simple_4 | 0.1046 | 1.1321 | 16.0648 | 0.0541 | 0.2183 | 0.7750 | 354.6354 |
| 3_exponential_2 | 0.0748 | 0.4681 | 5.2281 | 0.0358 | 0.1891 | 0.7914 | 115.6622 |
| 3_exponential_4 | 0.0759 | 0.4679 | 5.2271 | 0.0360 | 0.1897 | 0.7871 | 115.6617 |
| 3_linear_2 | 0.0759 | 0.4589 | 5.1854 | 0.0356 | 0.1857 | 0.7638 | 115.0321 |
| 3_linear_4 | 0.0759 | 0.4589 | 5.1840 | 0.0355 | 0.1872 | 0.7619 | 115.0314 |
| 3_simple_2 | 0.0759 | 0.4579 | 5.1803 | 0.0357 | 0.1860 | 0.7581 | 114.9646 |
| 3_simple_4 | 0.0760 | 0.4583 | 5.1793 | 0.0353 | 0.1884 | 0.7667 | 114.9636 |
| Type | Median | Average | Std. dev. | Q1 | Q3 | P95 | Maximum |
|---|---|---|---|---|---|---|---|
| 1_exponential_2 | 0.0698 | 0.3369 | 3.1054 | 0.0341 | 0.1631 | 0.4969 | 67.0417 |
| 1_exponential_4 | 0.0761 | 0.3900 | 3.0152 | 0.0387 | 0.1736 | 0.5692 | 57.1944 |
| 1_linear_2 | 0.0711 | 0.3297 | 2.8744 | 0.0361 | 0.1623 | 0.5008 | 61.5542 |
| 1_linear_4 | 0.0856 | 0.4432 | 3.5166 | 0.0445 | 0.1936 | 0.5701 | 60.6301 |
| 1_simple_2 | 0.0771 | 0.3194 | 2.5339 | 0.0379 | 0.1623 | 0.5344 | 53.3229 |
| 1_simple_4 | 0.0974 | 0.5117 | 4.6669 | 0.0493 | 0.2088 | 0.6651 | 95.9030 |
| 2_exponential_2 | 0.0762 | 0.3644 | 3.0108 | 0.0380 | 0.1749 | 0.6030 | 63.3403 |
| 2_exponential_4 | 0.0847 | 0.4182 | 2.9820 | 0.0438 | 0.1851 | 0.7336 | 54.7014 |
| 2_linear_2 | 0.0795 | 0.3577 | 2.7827 | 0.0396 | 0.1762 | 0.6618 | 57.9167 |
| 2_linear_4 | 0.0925 | 0.4692 | 3.4848 | 0.0501 | 0.2008 | 0.7265 | 60.6301 |
| 2_simple_2 | 0.0810 | 0.3481 | 2.4475 | 0.0412 | 0.1768 | 0.6051 | 49.7812 |
| 2_simple_4 | 0.1022 | 0.5352 | 4.6400 | 0.0562 | 0.2197 | 0.7672 | 95.9030 |
| 3_exponential_2 | 0.0359 | 0.1926 | 1.3696 | 0.0173 | 0.0965 | 0.4283 | 28.9840 |
| 3_exponential_4 | 0.0381 | 0.2257 | 1.5628 | 0.0192 | 0.1041 | 0.4395 | 27.2371 |
| 3_linear_2 | 0.0370 | 0.1960 | 1.3779 | 0.0175 | 0.1011 | 0.4446 | 29.1219 |
| 3_linear_4 | 0.0394 | 0.2587 | 1.9901 | 0.0216 | 0.1127 | 0.4611 | 34.6183 |
| 3_simple_2 | 0.0371 | 0.1997 | 1.3880 | 0.0175 | 0.1021 | 0.4404 | 29.3057 |
| 3_simple_4 | 0.0441 | 0.2924 | 2.5204 | 0.0229 | 0.1200 | 0.5053 | 49.2378 |
| Type | Median | Average | Std. dev. | Q1 | Q3 | P95 | Maximum |
|---|---|---|---|---|---|---|---|
| 1_exponential_2 | 192.1606 | 1435.9731 | 4922.151 | 6716.119 | 666.1800 | 6716.119 | 49,863.34 |
| 1_exponential_4 | 207.4420 | 1467.3281 | 4985.422 | 6669.177 | 701.3838 | 6669.177 | 48,732.12 |
| 1_linear_2 | 196.0299 | 1459.5901 | 5021.913 | 6540.056 | 686.6782 | 6540.056 | 50,309.75 |
| 1_linear_4 | 227.2977 | 1533.7125 | 5178.168 | 7153.797 | 734.2430 | 7153.797 | 51,900.50 |
| 1_simple_2 | 206.0445 | 1502.3407 | 5194.361 | 6641.748 | 714.4662 | 6641.748 | 51,531.03 |
| 1_simple_4 | 255.2485 | 1619.9814 | 5453.083 | 7181.493 | 812.5138 | 7181.493 | 55,188.93 |
| 2_exponential_2 | 244.8197 | 1606.4145 | 5679.998 | 6803.326 | 755.4154 | 6803.326 | 65,369.56 |
| 2_exponential_4 | 253.4706 | 1621.4475 | 5635.571 | 6836.370 | 784.0457 | 6836.370 | 64,811.75 |
| 2_linear_2 | 247.9669 | 1629.7881 | 5779.796 | 6632.659 | 766.1345 | 6632.659 | 67,139.35 |
| 2_linear_4 | 273.5827 | 1685.8397 | 5844.150 | 7064.499 | 830.4936 | 7064.499 | 69,261.74 |
| 2_simple_2 | 254.5287 | 1672.3070 | 5953.187 | 6776.913 | 785.7015 | 6776.913 | 69,962.12 |
| 2_simple_4 | 297.1194 | 1777.5822 | 6181.560 | 7149.959 | 887.0493 | 7149.959 | 75,569.45 |
| 3_exponential_2 | 80.0103 | 667.3803 | 2167.906 | 2906.804 | 332.5147 | 2906.804 | 26,231.43 |
| 3_exponential_4 | 85.5530 | 687.7242 | 2218.258 | 3009.515 | 352.9507 | 3009.515 | 25,449.99 |
| 3_linear_2 | 81.1205 | 676.9495 | 2193.493 | 2923.097 | 341.9984 | 2923.097 | 26,307.31 |
| 3_linear_4 | 93.9804 | 726.0771 | 2328.082 | 3090.166 | 383.9144 | 3090.166 | 25,450.96 |
| 3_simple_2 | 83.1870 | 694.8155 | 2245.569 | 2945.131 | 355.6474 | 2945.131 | 26,606.25 |
| 3_simple_4 | 100.0570 | 778.6808 | 2509.006 | 3271.714 | 401.5057 | 3271.714 | 26,981.26 |
| Type | Median | Average | Std. dev. | Q1 | Q3 | P95 | Maximum |
|---|---|---|---|---|---|---|---|
| 1_exponential_2 | 125.5122 | 1303.307 | 5915.684 | 6045.936 | 672.8637 | 6045.936 | 110,622.9 |
| 1_exponential_4 | 147.0003 | 1338.060 | 6168.844 | 6077.178 | 701.9186 | 6077.178 | 119,203.2 |
| 1_linear_2 | 124.7875 | 1305.832 | 5882.215 | 6098.225 | 675.9620 | 6098.225 | 110,724.1 |
| 1_linear_4 | 173.0705 | 1389.446 | 6405.333 | 6133.712 | 770.1902 | 6133.712 | 125,824.5 |
| 1_simple_2 | 135.5104 | 1316.439 | 5859.758 | 5914.193 | 690.8815 | 5914.193 | 111,086.7 |
| 1_simple_4 | 204.6888 | 1460.388 | 6706.472 | 6292.746 | 833.4499 | 6292.746 | 132,736.3 |
| 2_exponential_2 | 140.1250 | 1552.421 | 8579.709 | 6564.128 | 673.7960 | 6564.128 | 176,030.7 |
| 2_exponential_4 | 169.1431 | 1535.459 | 7920.725 | 6186.559 | 719.6874 | 6186.559 | 160,775.8 |
| 2_linear_2 | 150.9187 | 1537.193 | 8223.784 | 6471.902 | 696.2083 | 6471.902 | 167,956.6 |
| 2_linear_4 | 197.9992 | 1539.498 | 7264.910 | 6428.482 | 780.9942 | 6428.482 | 144,291.2 |
| 2_simple_2 | 166.2839 | 1520.573 | 7706.642 | 6316.463 | 737.4375 | 6316.463 | 155,845.3 |
| 2_simple_4 | 220.8806 | 1570.909 | 6783.569 | 6371.571 | 866.1808 | 6371.571 | 130,590.6 |
| 3_exponential_2 | 149.9771 | 1545.683 | 8837.987 | 6613.334 | 747.6411 | 6613.334 | 183,595.5 |
| 3_exponential_4 | 149.9898 | 1544.193 | 8834.488 | 6608.279 | 754.0734 | 6608.279 | 183,655.0 |
| 3_linear_2 | 149.8648 | 1546.627 | 9160.846 | 6533.728 | 744.0286 | 6533.728 | 192,179.4 |
| 3_linear_4 | 149.8723 | 1546.353 | 9159.699 | 6515.926 | 746.2735 | 6515.926 | 192,288.8 |
| 3_simple_2 | 149.6098 | 1546.969 | 9193.438 | 6556.608 | 737.3952 | 6556.608 | 193,132.0 |
| 3_simple_4 | 150.1604 | 1549.090 | 9195.696 | 6553.450 | 745.6235 | 6553.450 | 193,282.1 |
| Type | Median | Average | Std. dev. | Q1 | Q3 | P95 | Maximum |
|---|---|---|---|---|---|---|---|
| 1_exponential_2 | 134.9881 | 1814.0505 | 10,237.756 | 6070.180 | 615.6667 | 6070.180 | 197,800.00 |
| 1_exponential_4 | 153.0144 | 1851.1807 | 9985.260 | 6942.875 | 612.4934 | 6942.875 | 190,863.00 |
| 1_linear_2 | 135.6714 | 1827.7775 | 10,229.210 | 6479.405 | 626.6606 | 6479.405 | 197,200.00 |
| 1_linear_4 | 176.5047 | 1895.5239 | 9574.763 | 7516.181 | 705.8925 | 7516.181 | 178,201.82 |
| 1_simple_2 | 141.3125 | 1852.7049 | 10,232.072 | 6688.394 | 654.7261 | 6688.394 | 196,300.00 |
| 1_simple_4 | 197.4844 | 1967.2077 | 9241.462 | 8426.872 | 763.3424 | 8426.872 | 164,636.25 |
| 2_exponential_2 | 143.8694 | 2007.7018 | 10,737.351 | 7074.631 | 680.7083 | 7074.631 | 197,800.00 |
| 2_exponential_4 | 159.3135 | 2040.3169 | 10,506.338 | 7270.989 | 751.0931 | 7270.989 | 191,096.33 |
| 2_linear_2 | 150.3958 | 2019.7788 | 10,737.423 | 6940.350 | 723.1203 | 6940.350 | 197,200.00 |
| 2_linear_4 | 189.0303 | 2083.4211 | 10,163.768 | 8606.528 | 768.7449 | 8606.528 | 178,747.27 |
| 2_simple_2 | 157.3596 | 2042.6165 | 10,749.523 | 7308.142 | 762.7901 | 7308.142 | 196,300.00 |
| 2_simple_4 | 199.9375 | 2151.9671 | 9908.329 | 9159.259 | 798.1726 | 9159.259 | 165,511.25 |
| 3_exponential_2 | 81.1457 | 860.3691 | 2694.752 | 3578.629 | 370.9500 | 3578.629 | 31,575.38 |
| 3_exponential_4 | 89.3620 | 871.6876 | 2700.049 | 3635.239 | 380.0934 | 3635.239 | 30,548.94 |
| 3_linear_2 | 82.2700 | 871.9220 | 2717.038 | 3623.460 | 373.9550 | 3623.460 | 31,075.54 |
| 3_linear_4 | 92.8501 | 896.0751 | 2741.063 | 3683.842 | 380.8692 | 3683.842 | 29,327.73 |
| 3_simple_2 | 83.5511 | 888.1536 | 2752.627 | 3640.584 | 377.8576 | 3640.584 | 30,549.41 |
| 3_simple_4 | 98.7853 | 927.2893 | 2822.281 | 3703.337 | 417.6064 | 3703.337 | 28,478.29 |
| Method | MAE | MAPE |
|---|---|---|
| 1 | 10.8802 | 0.0570 |
| 2 | 18.6528 | 0.0927 |
| 3 | 5.8157 | 0.0342 |
| Method | MAE | MAPE |
|---|---|---|
| 1 | 1062.1979 | 0.2130 |
| 2 | 1154.7951 | 0.2324 |
| 3 | 905.0303 | 0.2191 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kowalska-Styczeń, A.; Owczarek, T.; Siwy, J.; Sojda, A.; Wolny, M. Analysis of Business Customers’ Energy Consumption Data Registered by Trading Companies in Poland. Energies 2022, 15, 5129. https://doi.org/10.3390/en15145129
Kowalska-Styczeń A, Owczarek T, Siwy J, Sojda A, Wolny M. Analysis of Business Customers’ Energy Consumption Data Registered by Trading Companies in Poland. Energies. 2022; 15(14):5129. https://doi.org/10.3390/en15145129
Chicago/Turabian StyleKowalska-Styczeń, Agnieszka, Tomasz Owczarek, Janusz Siwy, Adam Sojda, and Maciej Wolny. 2022. "Analysis of Business Customers’ Energy Consumption Data Registered by Trading Companies in Poland" Energies 15, no. 14: 5129. https://doi.org/10.3390/en15145129
APA StyleKowalska-Styczeń, A., Owczarek, T., Siwy, J., Sojda, A., & Wolny, M. (2022). Analysis of Business Customers’ Energy Consumption Data Registered by Trading Companies in Poland. Energies, 15(14), 5129. https://doi.org/10.3390/en15145129