2.1. Principle of Least Squares SVM (LS-SVM)
In this study, SVM was selected as the basic algorithm with which to construct forecasting models because this algorithm is often viewed as a “universal approximator”. It has been proven to provide a good arbitrary approximation of any continuous function. Therefore, the model is used here to simulate mutual relationships between historical data and the forecast power output. The models have the ability to provide flexible mapping between inputs and outputs. The SVM model of a data set is given by the formula described below.
Consider an
n set of data{(
x1,
y1), …, (
xN,
yN)}, where
xi is the
ith input vector and
yi is the corresponding desired output. Because
i = 1, 2, …,
N, where
N is the size of the sample, the estimating function assumes the following form:
where
w is the weight vector,
b is the bias and
ϕ(
x) is the high-dimensional feature space nonlinearly mapped from the input space, and (·) represents the inner product.
This leads to the optimisation problem associated with standard SVM:
where
γ is a positive real constant that determines the penalty for estimation errors and
is the estimation error measured by the experimental risk and loss function. Usually, the
ε- insensitive loss function is adopted because of its excellent sparsity:
For least-squares SVM (LS-SVM), the two norms of the estimation error are adopted as the loss function in the objective function and equality constraints instead of inequality constraints. Therefore, the optimisation problem is described as:
where
ξi is a slack variable,
ξi ≥ 0. It is a variable added to an inequality constraint to transform it to equality. It is non-negative number in this paper.
After the introduction of Lagrange multipliers
αi, the Lagrange function is constructed as:
According to
KKT conditions which can transform inequality constraints into equality constraints, defined as:
The following equation can then be obtained:
After eliminating
w and
γ, we obtain:
where Θ = [1, …, 1]
1×N, I is a unit matrix, Ω is a square matrix and the element of Ω is expressed as: Ω
ij =
ϕ(
xi)
T ϕ(
xj). In the equation (8),
α = [
α1, …,
αN],
y = [
y1, …,
yN].
By solving Equation (7), values of
α and
b are obtained. According to Mercer's condition, there exists a kernel function with a value that is equal to the inner product of the two vectors
xi and
xj in the feature spaces
ϕ(
xi) and
ϕ(
xj); that is,
K(
xi,
xj) =
ϕ(
xi)
T ϕ(
xj). Then, the LS-SVM model for regression is expressed as:
2.3. Group Model Based on LS-SVM
As mentioned above, each group consists of 10 forecasting models. We need to select a subset of representatives to improve ensemble efficiency. It is clear that it is a necessary requirement of diverse models for making fuzzy group decisions. In this study, a decorrelation maximisation method was used to select the appropriate number of ensemble members. As noted previously, the basic starting point of the decorrelation maximisation algorithm is the principle of ensemble model diversity; that is, the correlations between the selected models should be as small as possible. If there are
p models (
f1,
f2, …,
fp) with n forecast values, an error matrix (
e1,
e2, …,
ep) of p predictors can be represented by:
From the matrix, the mean, variance and covariance of E can be calculated as:
Considering Equations (17) and (18), we can obtain a variance covariance matrix:
Based on the variance-covariance matrix, correlation matrix
R can be calculated using the following equations:
where
rij is the correlation coefficient, representing the degrees of correlation classifiers
fi and
fj.
Subsequently, the plural-correlation coefficient
ρfi|(
f1,
f2, …,
fi−1,
fi+1, …,
fp) between classifier
fi and other
p − 1 classifiers can be computed based on the results of Equations (20) and (21). For convenience,
ρfi|(
f1,
f2, …,
fi−1, f
i+1, …,
fp) is abbreviated as
ρi, representing the degree of correlation between
fi and (
f1,
f2, …,
fi−1, f
i+1, …,
fp). To calculate the plural-correlation coefficient, the correlation matrix
R can be represented by a block matrix; that is:
where
R −
i denotes the deleted correlation matrix. It should be noted that
rii = 1(
i = 1, 2, …,
p). Next, the plural-correlation coefficient can be calculated by:
For a pre-specified threshold θ, if ρi2 > θ, then model fi should be removed from p models. Otherwise, model fi should be retained. Generally, the decorrelation maximisation algorithm can be summarised in the following steps:
Computing the variance-covariance matrix Vij and the correlation matrix R with Equations (19) and (20). For the ith classifier (i = 1, 2, …, p), the plural-correlation coefficient ρi can be calculated using Equation (23).
For a pre-specified threshold θ, if ρi < θ, then the ith classifier should be deleted from the ρ classifiers. Conversely, if ρi > θ, then the ith classifier should be retained. For each group of models, we select eight as the representative for the subsequent step.
2.4. Fuzzy Group Prediction
For a specified forecasting problem, different experts usually give different estimations based on a set of criteria
X = (
c1,
c2, ...,
cm). Some experts give optimistic estimates, some prefer pessimistic estimates, and others present the most likely estimates. To incorporate these different judgements into the final forecasting result and to make full use of the different estimates, a process of fuzzification is used. In this paper, a typical triangular fuzzy number can be used to describe the forecasting results provided by the experts; that is:
Like human experts, individual LS-SVM forecasting groups can also generate different forecasting results by using different parameter settings and training sets. For example, the first forecasting group (univariate LS-SVM model group) generates eight different forecasting results from the eight models (selected from the first 10 models;
Section 2.3) of different hidden neurons or different initial weights. The entire first group can be considered an expert in forecasting. Assume that this expert produces
k different results,
, for a specified applicant “
A” over a set of models of different hidden neurons or different initial weights in this group. To make full use of all of the information provided by these results, without loss of generalisation, we use the triangular fuzzy number to construct the fuzzy opinion for consistency; that is the smallest, average and largest of the
k forecasting results are used as the left-, medium- and right-membership degrees, respectively. In other words, the smallest and largest scores are seen as optimistic and pessimistic evaluations, respectively, and the average forecasting result is considered to be the most likely score. Of course, the median can also be used as the most likely score to construct the triangular fuzzy number. However, that approach can cause the loss of certain useful information because some other scores are ignored. Therefore, the average is selected as the most likely power output to incorporate the full information from all of the models into the fuzzy judgement. Using this fuzzification method, the expert can make a fuzzy forecast for each point. More precisely, the triangular fuzzy number used for forecasting can be represented as:
Suppose there are p experts, and let
be the aggregation of p fuzzy judgements, where ψ() is an aggregation function. Many methods have been developed to determine the aggregation function. Usually, fuzzy judgements of the
p group members are aggregated by using a common linear additive procedure; that is:
where
wi is the weight of the
ith fuzzy judgement,
i = 1, 2, ...,
p. The weights usually satisfy the following normalisation condition:
At this point, the goal is to determine the optimal weight
wi of the
ith fuzzy expert. In this study, three groups of models are used as experts, and we give them the same weight of 1/3 each. After completing aggregation, a fuzzy group consensus can be obtained using Equation (25). To obtain a crisp value of the credit score, we use a defuzzification procedure to obtain the crisp value for decision-making purposes. According to Bortolan and Degani, the defuzzified value of a triangular fuzzy number
can be determined by its centroid, which is computed by:
At this point, a final group consensus has been computed using the above process. To summarise, the proposed intelligent-agent-based fuzzy group forecasting model is comprised of five steps:
- (1)
Three forecasting groups are presented, and each group has eight models with varied structures and initial data, for example.
- (2)
Based on the datasets, each forecasting group can produce eight different forecasting results from the different models.
- (3)
For the different forecasting results, Equation (25) is used to fuzzify the judgements of intelligent agents into fuzzy opinions.
- (4)
The fuzzy opinions are aggregated into a group consensus, using the optimisation method proposed above, in terms of the maximum agreement principle.
- (5)
The aggregated fuzzy group consensus is defuzzified into a crisp value. This defuzzified value can be used as the final forecasting result.
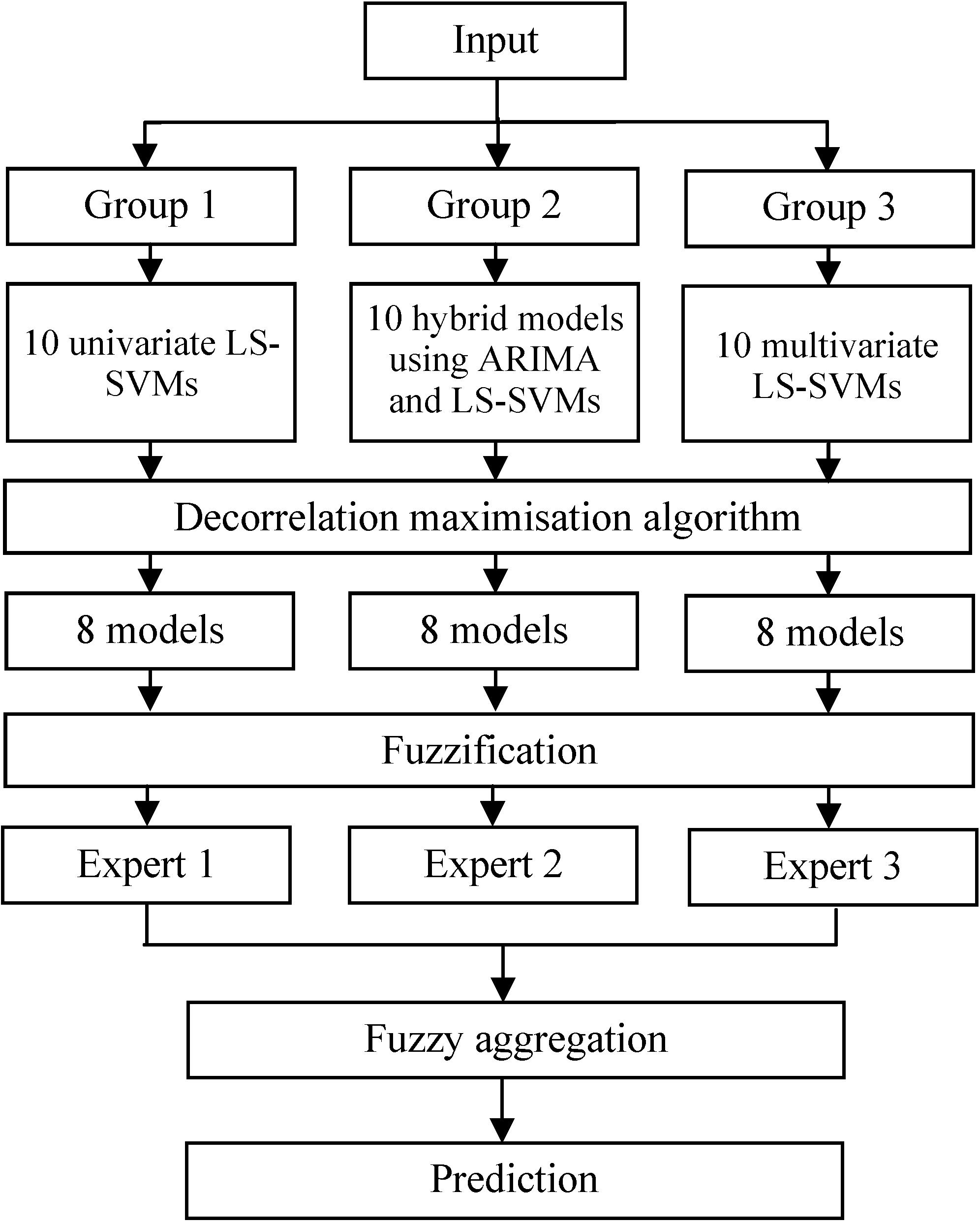
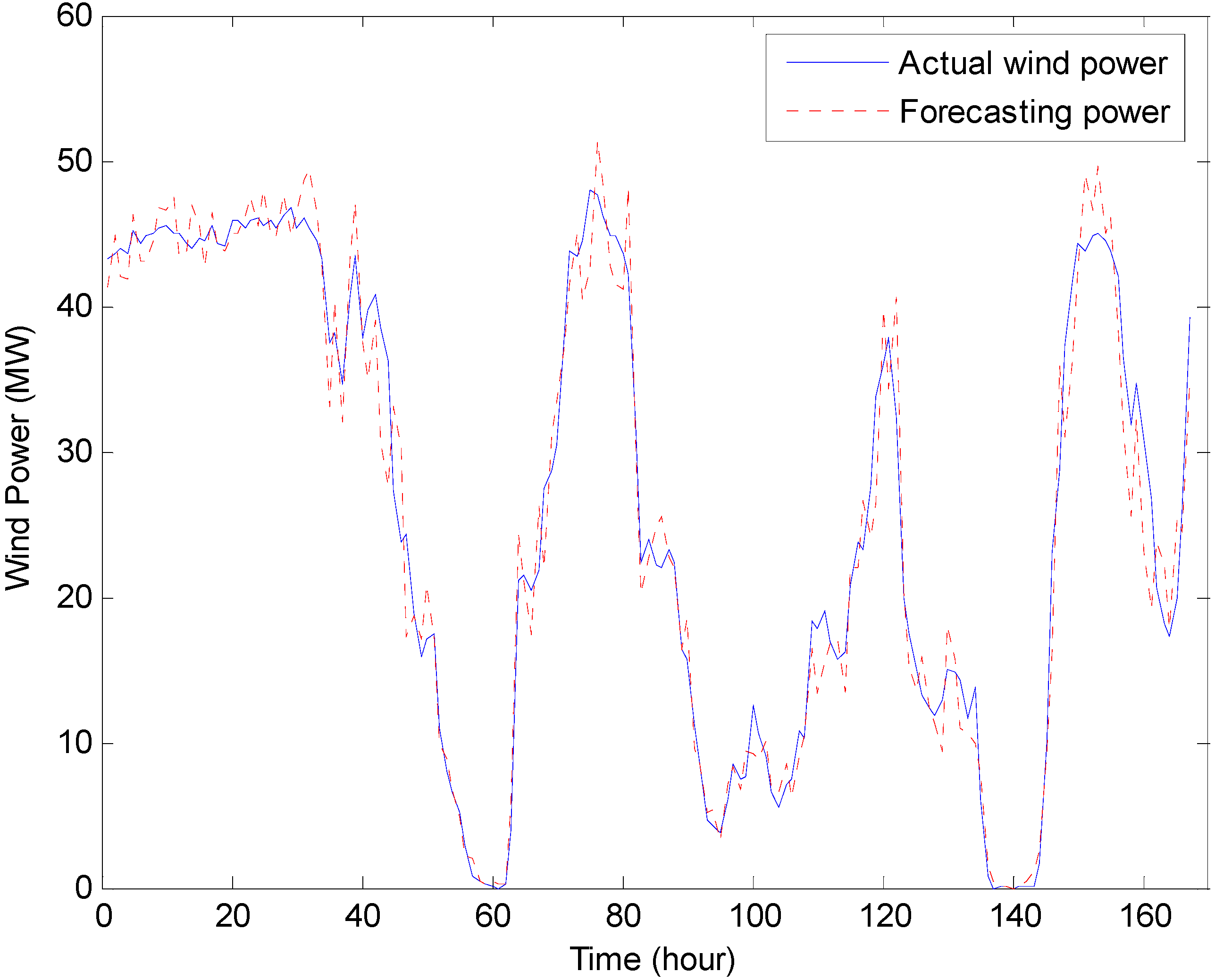
To illustrate and verify the proposed intelligent-agent-based fuzzy group forecasting model, the following section presents an illustrative numerical example of real-world data. The flow chart of the entire procedure is shown in
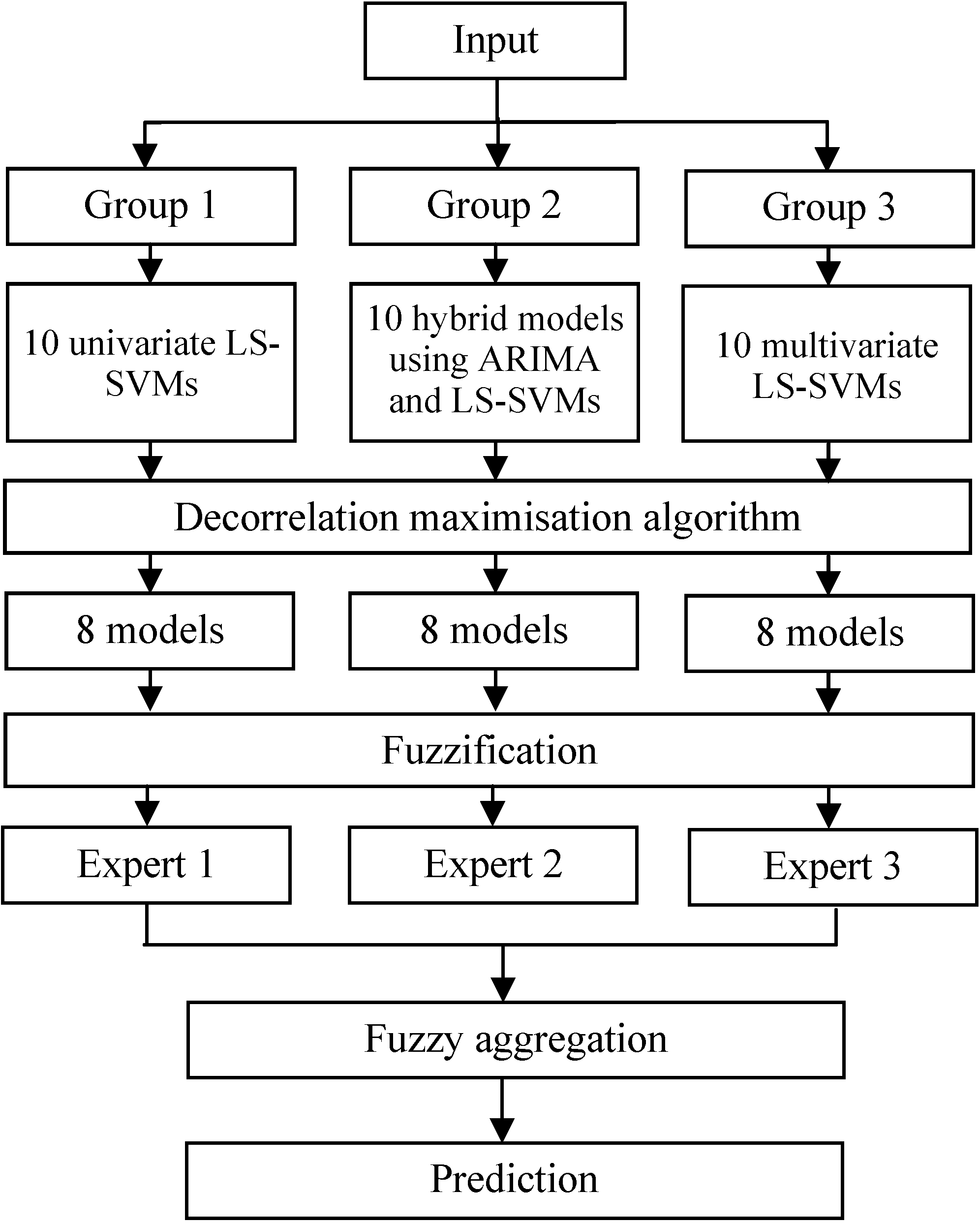
Figure 1.
Figure 1.
Procedure flow chart.
Figure 1.
Procedure flow chart.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}