This section outlines two primary methods to measure technical or efficiency change: SFA and DEA. SFA and DEA models are commonly represented by a form of frontier line that can be considered an optimal combination of outputs producible from a set of inputs (or an optimal combination of outputs with the lowest inefficiency). Observed shifts of the frontier line from one point in time to another suggest technical improvement, thereby implying, moreover, an institutionalized structural technological change in a given industry or company.
The rationale for developing two models concurrently is the fact that SFA and DEA have competitive advantages against each other and could be used complementarily. In detail, when the DEA frontier estimate is biased high because of outlier data beyond the true frontier, the DEA method erroneously extends the estimated frontier outward. If the SFA method can distinguish between inefficiency and noise with sufficient accuracy, then this method can be used to detect the DEA outlier problem. Similarly, DEA can be used to detect the type-II error in SFA when the SFA frontier line reduces to a standard linear regression line.
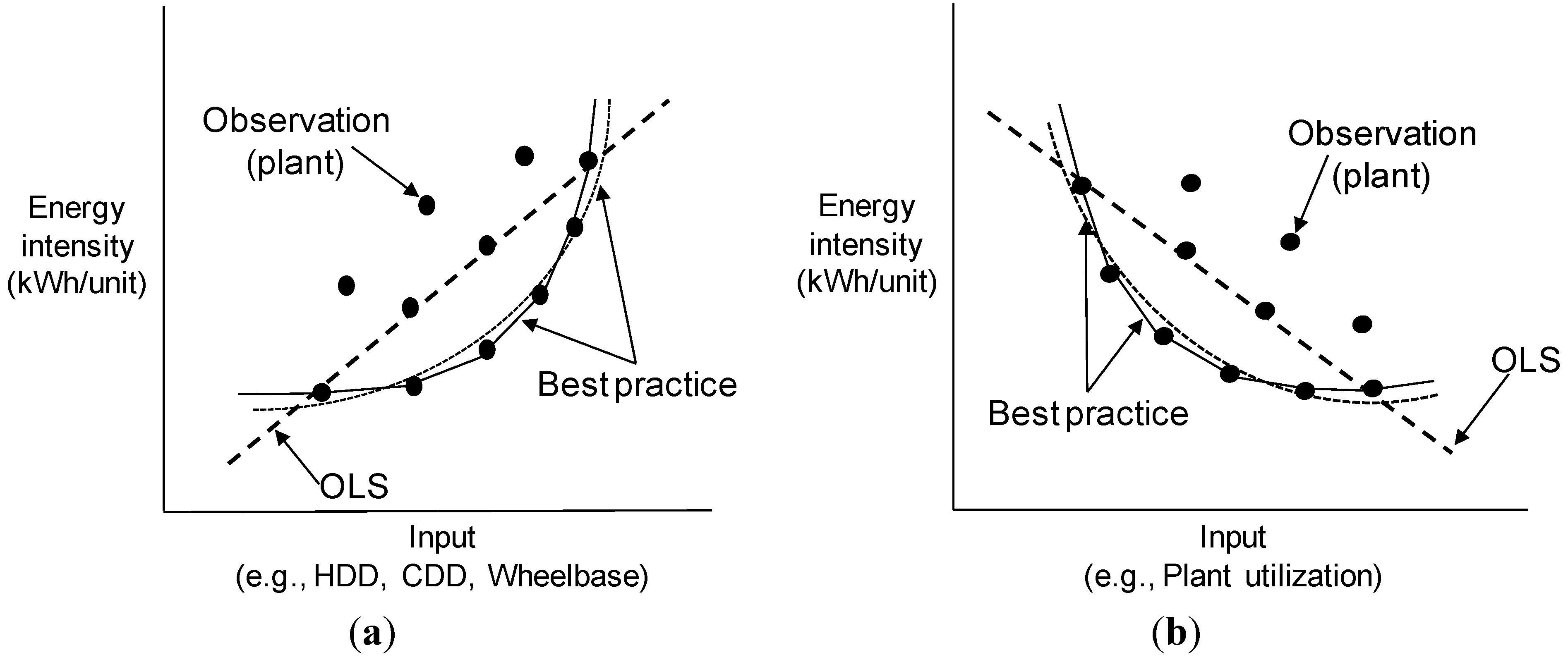
Figure 4 illustrates various relationships between energy intensity and non-energy factors (where the best practice indicates the lowest energy use achievable at the given operation conditions), with
Figure 4a,b depicting a concave-up increasing energy intensity and a concave-up decreasing energy intensity, respectively. The concave-up increasing patterns may be observed when the energy intensity increases as the input variables (e.g., HDD, CDD, or wheelbase) increase, while the concave-up decreasing patterns may be observed when the input variables (e.g., plant utilization) have a negative relationship with the energy intensity.
Figure 4.
Various relationships between energy intensity and non-energy factors (based on a cross-sectional data set). (a) Concave-up increasing energy intensity; (b) Concave-up decreasing energy intensity.
This study uses Spearman’s rank-order correlation coefficient test to determine the consistency in ranks between SFA and DEA models in the illustrative study. The rationale for using this test is that though efficiency levels (or scores) differ between models, these methods may nonetheless generate similar rankings. If the two models’ rankings are completely different, then any action taken based on the assessment may be temporary and depend on which frontier model is employed.
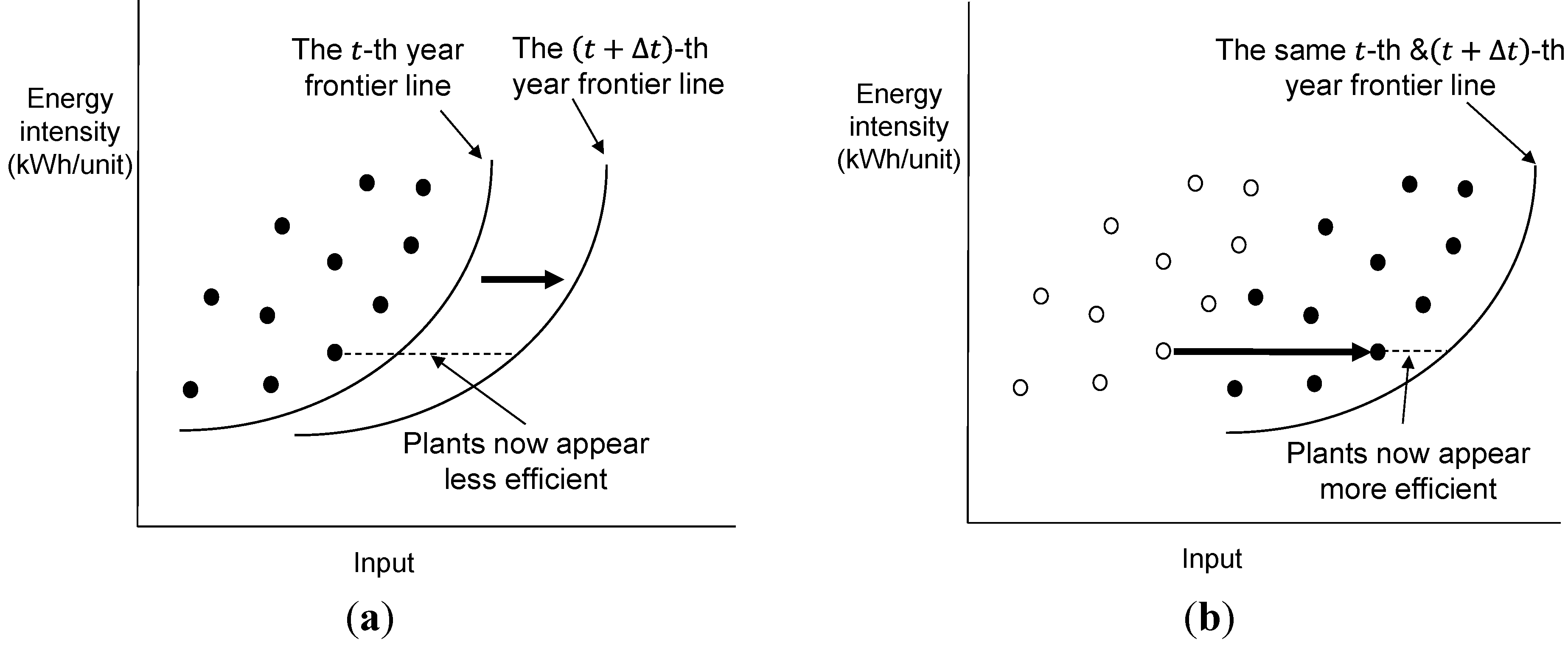
Figure 5.
Two main sources affecting changes in the plant energy efficiency over time. (a) Shifts in frontier line independent of a set of observations; (b) Movement of a set of observations closer to the frontier line.
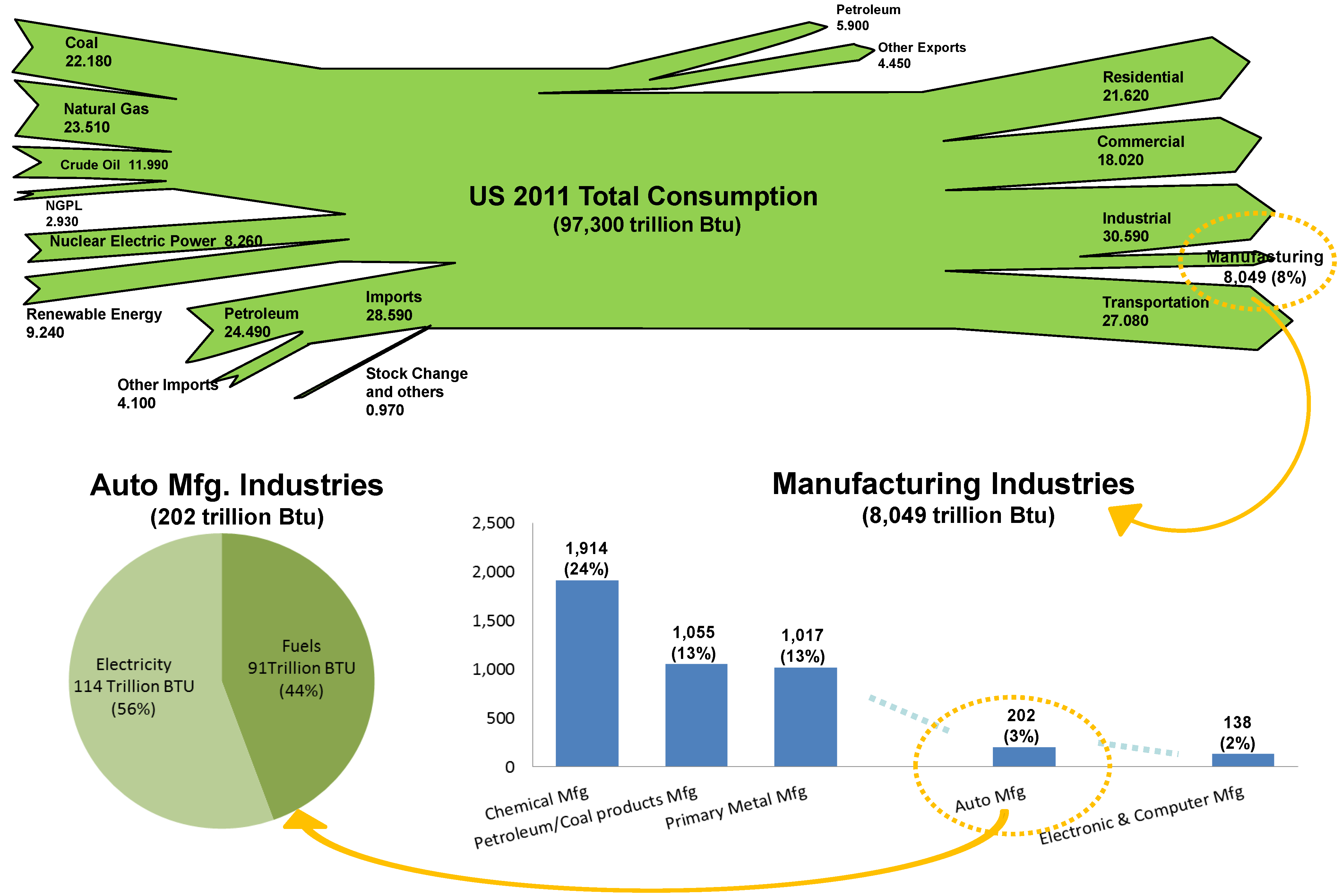
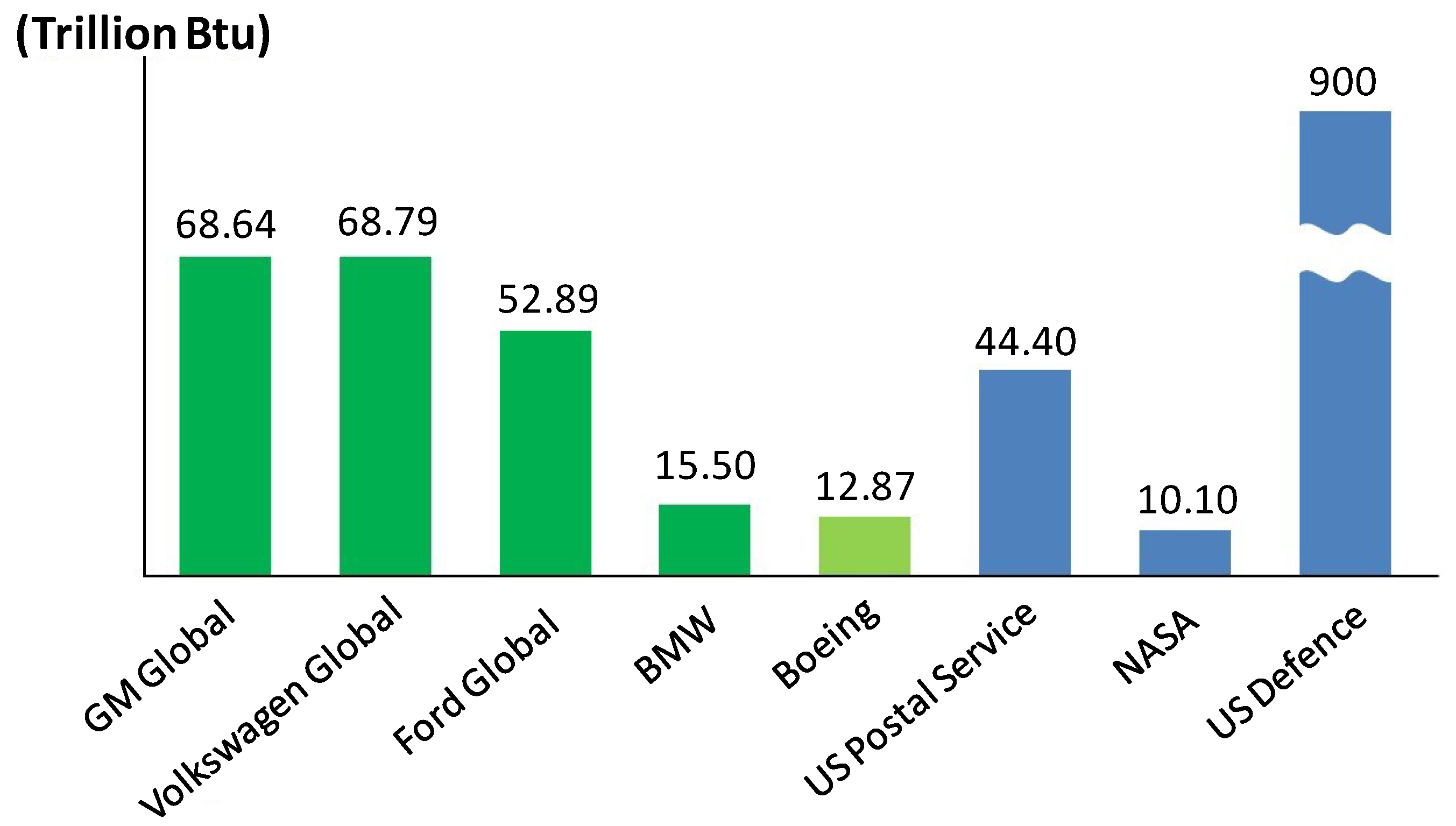
3.1. Background of the Vehicle Assembly Process
A typical automobile manufacturing process generally consists of three main processes: body shop, paint shop, and general assembly. The body shop transforms raw materials into the structure of the vehicle. Then, the paint shop applies a protective and visual coating to the product. Finally, the general assembly assembles all sub-components, such as the engine and seats, into the vehicle.
Two main types of energy utility used in a typical vehicle assembly plant are electricity and fuel (including natural gas). In general, fuel is used for direct heating or to generate steam that is considered as a secondary utility similar to compressed air in vehicle assembly plants. Steam is then used mainly in painting but is also utilized for space heating, car wash and other non-manufacturing activities. Electricity is the main energy source in vehicle assembly plants, and its main uses are painting, HVAC (heating, ventilation, and air conditioning), lighting, compressed air systems, and welding and materials handling/tools.
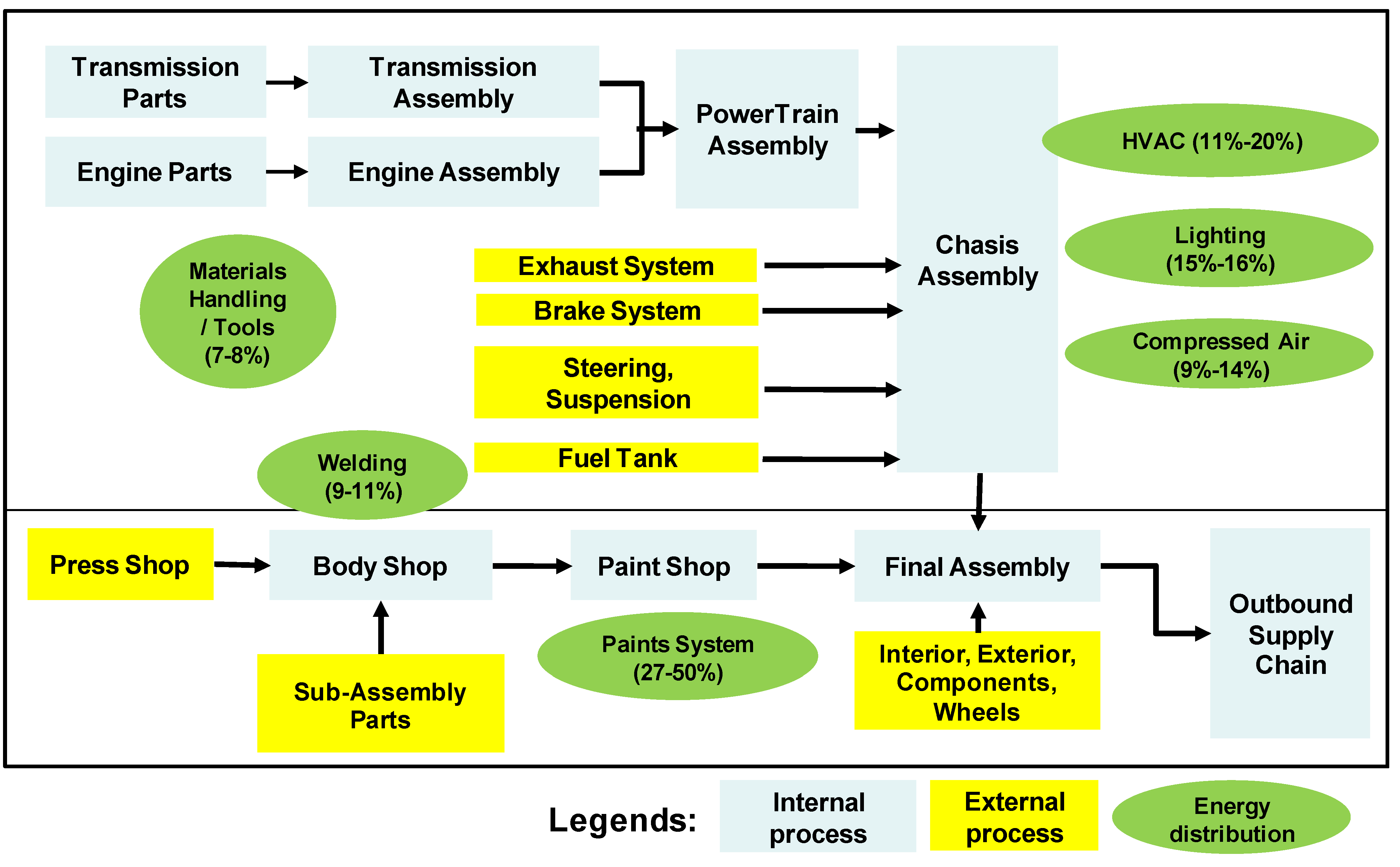
Figure 6 associates automotive manufacturing operations with the distribution of their energy use. Four identified largest energy-consuming operations are painting (27%–50%), HVAC and lighting (11%–20% and 15%–16%, respectively), and compressed air (9%–14%).
Figure 6.
A typical vehicle assembly process and its energy distribution (modified from [
21]).
Figure 6.
A typical vehicle assembly process and its energy distribution (modified from [
21]).
3.2. Stochastic Frontier Analysis (SFA)
The SFA models in this study follow the model specification proposed by Battese and Coelli [
15] and expands the cross-sectional data model specified by Boyd [
10] to a panel data model by incorporating two cross-sectional data sets. The YEAR variable involved in the resultant SFA models accounts for a Hicksian neutral technological change model. Note that Hicksian models assume special parameters that may shift the frontier line due to structural change, such as the year of the observation. Although this concept does not sufficiently account for the balance between parameters, this paper uses the Hicksian neutral technical change concept because the balance between parameters is likely to remain unchanged for the time period until a technical improvement occurs. This stability occurs because the parameters used in this paper (e.g., HDD, CDD, wheelbase, utilization) are exogenous variables, thus effecting different operation conditions in different plants. This study developed two stochastic frontier models for electricity and fuel because they are the main energy utilities consumed in vehicle manufacturing plants (note: the background on the inclusion of each term in each model is discussed in Boyd [
10]. For example, why are quadratic terms for HDD and CDD included in the electricity model and the quadratic term of plant utilization included in fuel model? Why is the wheelbase of a vehicle used as a control variable rather than some other variable(s) that may also reflect the vehicle size?). The proposed SFA model for electricity is:
where:
: Total site electricity use at plant in kWh;
: Number of vehicles produced;
: Wheelbase (the distance between its front and rear wheels) of the largest vehicle produced in the plant in inch;
: Thousand heating degree days for the plant location and year;
: squared;
: Thousand cooling degree days for the plant location and year;
: squared;
: Plant utilization rate, defined as output/capacity, where the denominator, capacity is a normalized capacity defined as equal to capacity line rate (or job per hour) × 235 working days × 16 working hours per day;
: and where is the time period at which a significant technical improvement in energy efficiency is observed; and
: Vector of parameters to be estimated.
Note that HDD is a metric for quantifying the amount of heating that buildings in a particular location require for a certain period (e.g., a specific month or year) such that HDD =
. Similar to HDD, CDD is a metric for quantifying the amount of cooling that buildings in a particular location require for a certain period (e.g., a specific month or year) such that CDD =
. Note that our study scales HDD and CDD by 1000. The variable
represents a measurement error to be distributed as a symmetric normal distribution, and
and the variable
account for a technical inefficiency to be distributed as a half normal distribution,
. Meanwhile, the proposed SFA model for fuel is:
where, all the notations are specified identically to Equation (1) except that
is the total site fuel use at plant
in 10
6 BTU. Note that this fuel model may not account for the real operation if the given plant uses steam-powered absorption chillers for air conditioning. Such chillers contribute more to the “fuel” load than the “electricity” load. If it is the case, CDD should be included in this model.
Equations (1) and (2) require several parameters to be solved, such as
,
and
. This paper uses the maximum likelihood method for parameter estimation and utilizes the parameterization of Battese and Corra [
22], who replaced
and
with
,
,
and
. This parameterization is useful for calculating the maximum likelihood estimates because the parameter
is now confined to exist between 0 and 1, a range that can be more easily searched to provide a good estimate in an iterative maximization process. The first step of the maximum likelihood method is defining the log-likelihood function of the model and the log of the density function for
:
with
N independent observations, the log of the joint density function
is:
To emphasize that the error term
depends on the parameter (vector)
, the log likelihood function can be expressed alternatively as:
The function
is the log-likelihood function, which depends on parameters to be estimated (in this cas
,
and
) and on the data (
), …, (
). The derivation of the log likelihood function is available in Bogetoft and Otto [
23]. With
replaced with
, first-order partial derivatives for the function can be obtained.
First, the partial derivative of
with respect to
is:
Second, the partial derivative of
with respect to
is:
Coelli
et al. [
24] suggested a one-sided likelihood-ratio test to determine whether the variation in inefficiency (
) is significant. The purpose of the test is to compare the parameter estimates in an ordinary least square regression model (OLS) with respect to the null-hypothesis,
, and the parameter estimates in SFA under the alternative hypothesis,
. The test value is calculated using Equation (3).
where,
and
are the values of the likelihood function under OLS and SFA, respectively. In the illustrative study, this paper will calculate and compare the
statistic with
, then determine to accept or reject the null hypothesis. In other words, if the
statistic exceeds
critical value, we reject the null hypothesis of no inefficiency effects. If the null hypothesis
is accepted, it would indicate that
is zero and hence that the inefficiency term
should be removed from the model, thus, specifying parameters that can be consistently estimated using OLS.
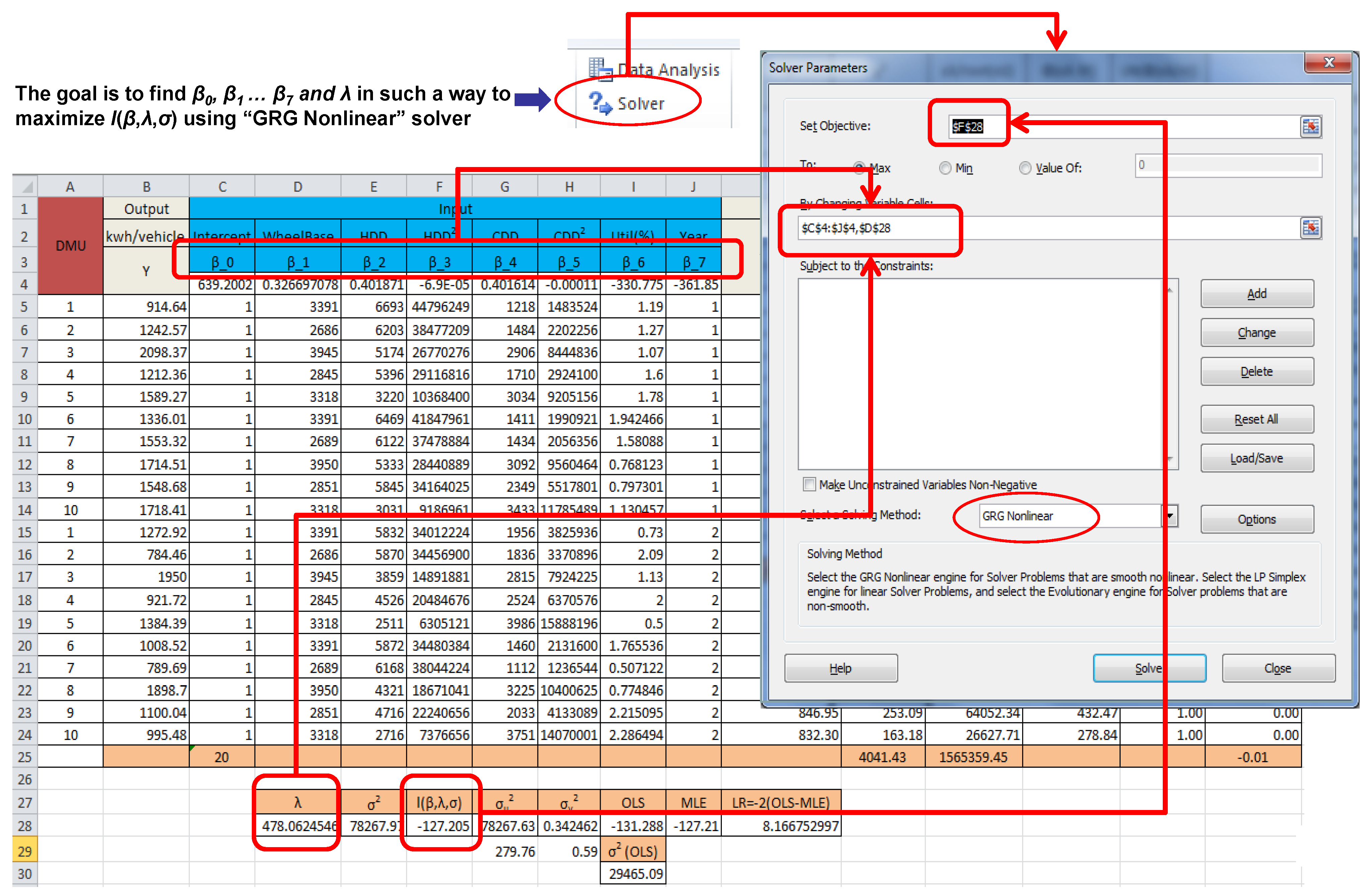
This study developed an Excel spreadsheet tool to obtain the maximum likelihood estimation of subset parameters in the aforementioned SFA models rapidly and intuitively. The tool can accommodate panel data, a half-normal inefficiency distribution and a normal measurement error distribution.
Section 4 will show what the tool looks like. Regarding an energy performance indicator developed by a credential governmental organization, the U.S. Environmental Protection Agency (EPA) introduced energy performance indicators (EPIs) through its ENERGY STAR program to encourage a variety of U.S. industries to use energy more efficiently. One of the EPIs was developed for a plant-level energy performance indicator to benchmark manufacturing energy use in the automobile industry based on the SFA model [10]. Because a typical SFA model has a composite error term including symmetric (normal) measurement errors denoted by
and one-sided (half-normal) inefficiencies denoted by
, the frontier model takes the form of the following equation, as in Equations (1) and (2):
where,
,
and
. In addition,
is the energy use of company
;
is the measured production or service measured of company
;
is the economic decision variables (
i.e., labor-hours worked, materials processed, plant capacity, or utilization rates) or external factors (
i.e., heating and cooling energy loads); and
is the vector of parameters to be estimated statistically.
Given company data, Equation (4) can be expressed as Equation (5), thereby providing a way to compute the difference between the actual energy use and the predicted frontier energy use:
Then, the EPI of company
i is calculated from the probability distribution of
as follows:
is the cumulative probability density function of the appropriate one-sided density function for
(e.g., gamma, exponential, truncated normal, and other functions). The value
in Equation (6) defines the EPI score and may be interpreted as a percentile ranking of the company’s energy efficiency. However, in practice, the only measureable value is
ui – v
i =
Ei/
Yi –
f(
X;
B). By implication, the EPI score
is affected by the random component of
, that is, the score will reflect the random influences that are not accounted for by the function
. Because this ranking is based on the distribution of inefficiency for the entire industry, but normalized to the specific regression factors of the given company, this statistical model enables the user to answer the hypothetical but practical question, “How does my company compare to everyone else’s in my industry, if all other companies were similar to mine?”. This study will calculate the EPI scores of each plant based on the proposed SFA models in
Section 4. Yee and Oh [
25] used the EPI score as described in this section for selecting the optimal supply partner for composing semantic web services, when performance metrics for sustainable supply chain are important for automatic business composition, particularly at the service matchmaking phase.
3.3. Data Envelopment Analysis (DEA)
When a panel data set is available and one is interested in measuring the technical improvement in energy efficiency, the Malmquist total factor productivity (TFP) index can be used to reveal a positive or negative technical change across two distinct years such as
and
. One advantage of using the Malmquist TFP index is that it can be decomposed into a structural technical change (improvement or deterioration) and a technical efficiency change, where the structural technical change may account for the technical improvement (e.g., frontier line shifts between two distinct years), while the efficiency change indicates how well companies are improving to the frontier line. For example, when a frontier line shifts independently of the DMU set, DMUs appear less efficient, reflecting a positive technical change. By contrast, when a set of DMUs moves independently closer to the frontier line, DMUs appear more efficient, resulting in a positive technical efficiency change. If the frontier line shifts to a higher efficiency and simultaneously, a set of DMUs shifts to a higher efficiency, a positive TFP has occurred. Depending on the orientation used to measure the efficiency, (
i.e., either output oriented or input oriented) the TFP indices differ. Recently, a new approach adopting a directional distance function was introduced to provide a flexibility in measurement by allowing negative input and output quantities. For more details on the underlying theory and application of directional distance function, see Nin
et al. [
26].
For the consistency between SFA and DEA models, a new vector variable
is introduced to represent the systematic external factors given for
i-th company or plant. Note that
takes the inverse of utilization because this study is based on the assumption of strong disposability where all the variables must have a non-decreasing relationship with the energy intensity. Then, our interest in defining the minimum energy intensity requirement to produce one unit of vehicle under the given external condition to
i-th plant is expressed in the following function:
Equation (7) motivates the minimal energy density requirement in terms of micro-economic concept. It is possible to connect this motivation expressed in Equation (7) with the interpretation of input distance function that we need to calculate TFP indices. For more specific details of the theoretical development on this connection, see Boyd [
27]. An input oriented distance function corresponding to Equation (7) is as follows:
Since a distance function is defined, it is possible to calculate the TFP index. In our context, the TFP index requires four distance function values, specifically, , , , and , where the notation represents the distance from the period observation to the period technology. Vector forms, and represent and , respectively. The subscript “I” has been introduced to remind that this is an input -orientated measures.
Note that each distance function has an equivalent DEA model. For example,
is identical to the following DEA model:
The remaining three DEA models are simple variants of this form.
Table 3 summarizes all the forms.
Table 3.
DEA models required to calculate Malmquist TFP indices.
Table 3.
DEA models required to calculate Malmquist TFP indices.
| Input Oriented Envelopment Forms |
|---|
| (10) |
| (11) |
| (12) |
LP (Linear Program) (9) is used to calculate the efficiency of the -th time period relative to -th time period technology, while LP (10) is used to calculate the efficiency of -th time period relative to -th time period technology. Similarly, LP (11) is used to calculate the efficiency of the -th time period relative to -th time period technology, while LP (12) is used to calculate the efficiency of the -th time period relative to -th time period technology.
Once , , , and are obtained, the Malmquist TFP index can be calculated and then rearranged such that it is equivalent to the product of a technical efficiency change index and an index of technical change.
The first and second term of Equation (13) correspond to an efficiency change and a structural technical change, respectively, as follows:
Note that the
and λ are likely to assume different values in the four DEA models in
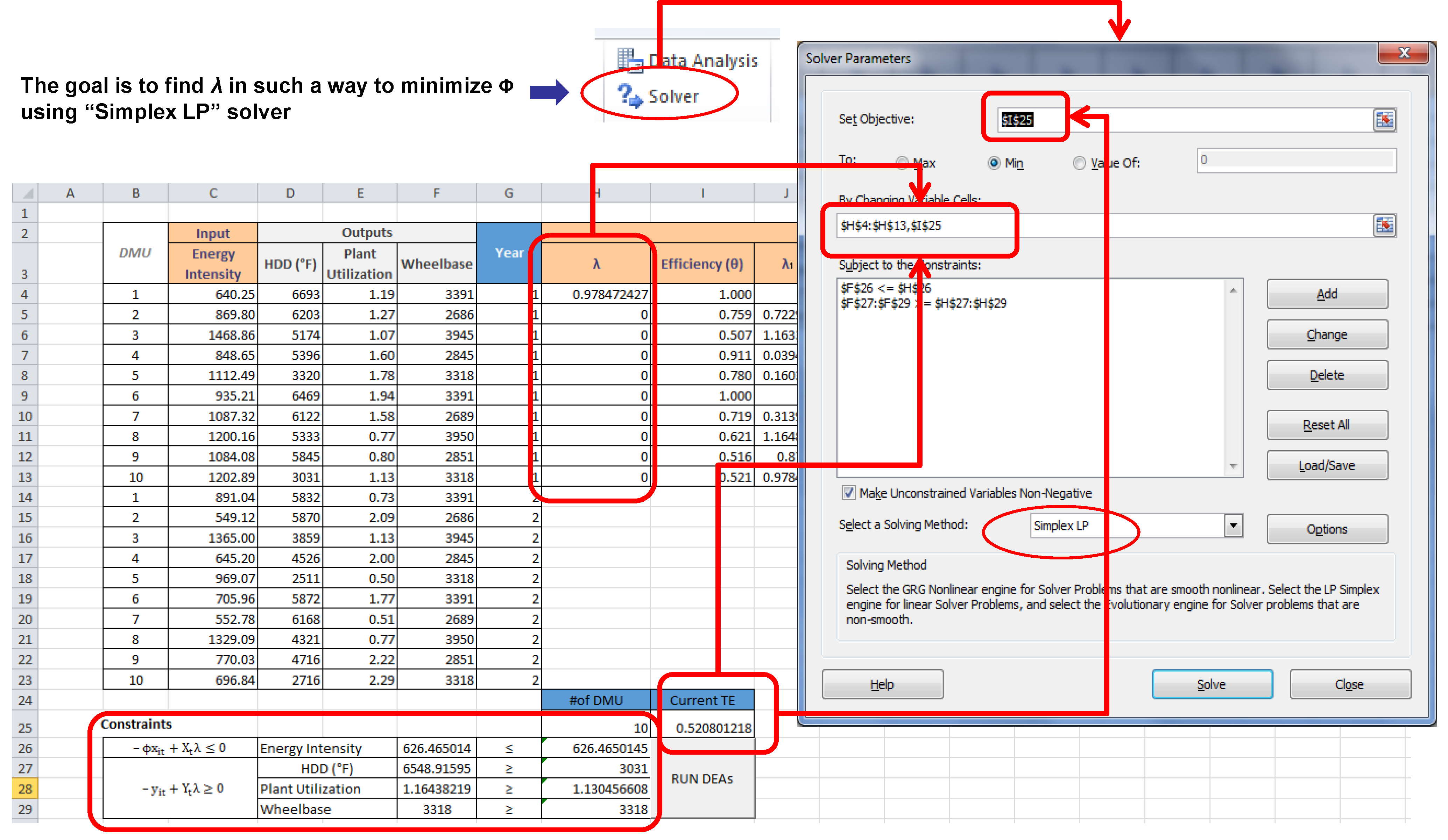
Table 3. Furthermore, these four models must be calculated for each plant in the sample. Thus, if there are 10 plants and two time periods, then 40 linear programing problems must be solved. To streamline this multiple calculation procedure, this study developed an Excel spreadsheet tool as does for the SFA models. The developed tool uses VBA in Excel and automates iterations for solving multiple linear programing models.
Section 4 will show what the tool looks like.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





