
A Geo-Clustering Approach for the Detection of Areas-of-Interest and Their Underlying Semantics †


Abstract
:1. Introduction
2. Related Work
2.1. Recommendations Using Socially-Generated Knowledge from Flickr
2.2. AOI Extraction
2.3. Extracting Places’ Semantics through Tag Exploitation
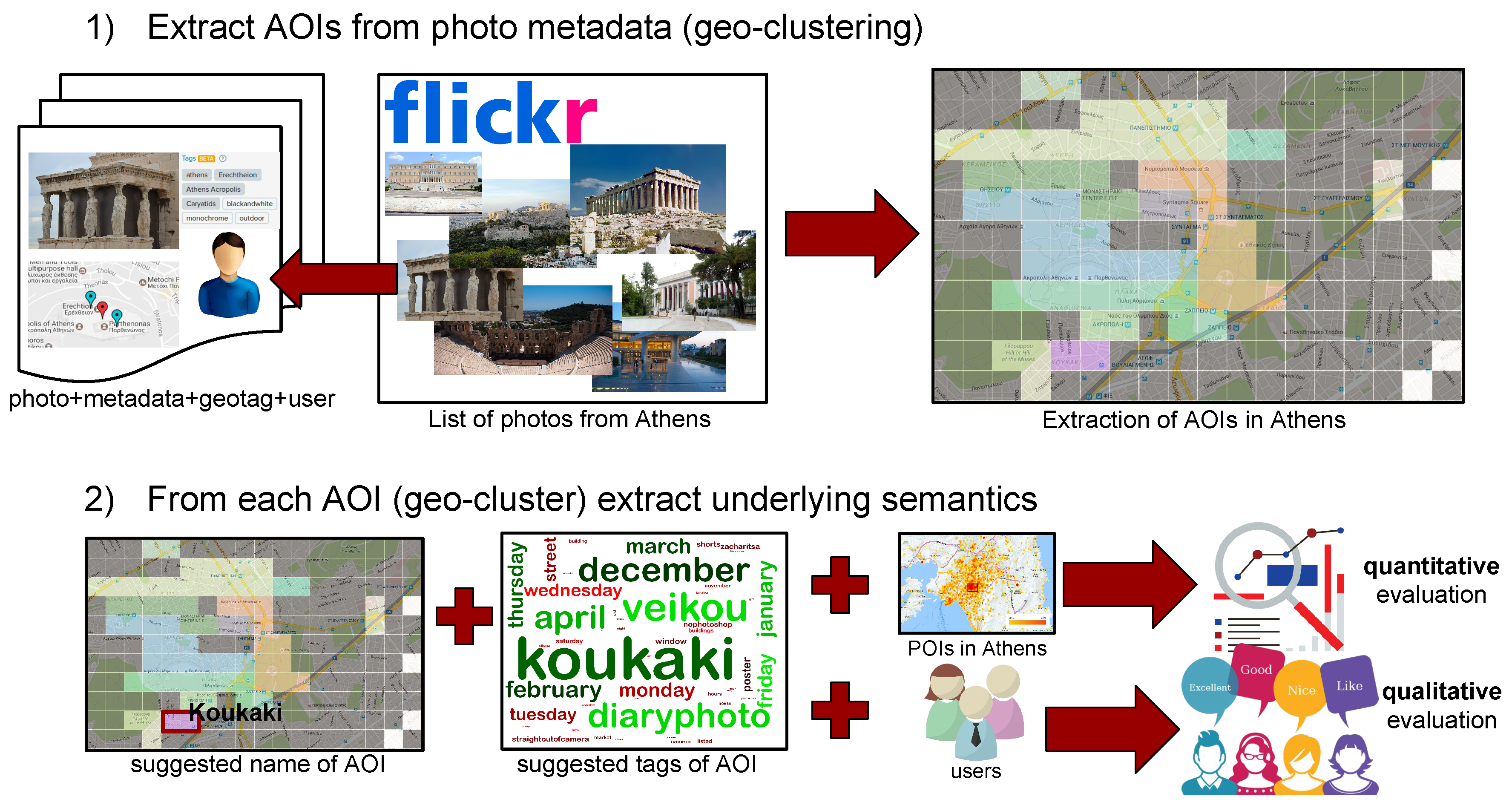
3. Proposed Methodology
3.1. Geo-Clustering Algorithm
3.1.1. Notation and Definitions
3.1.2. Region Description
3.1.3. Region Merging
| Algorithm 1: Semantic Geo-Clustering |
 |
| Algorithm 2: Jaccard Similarity |
 |
| Algorithm 3: Region Merging |
 |
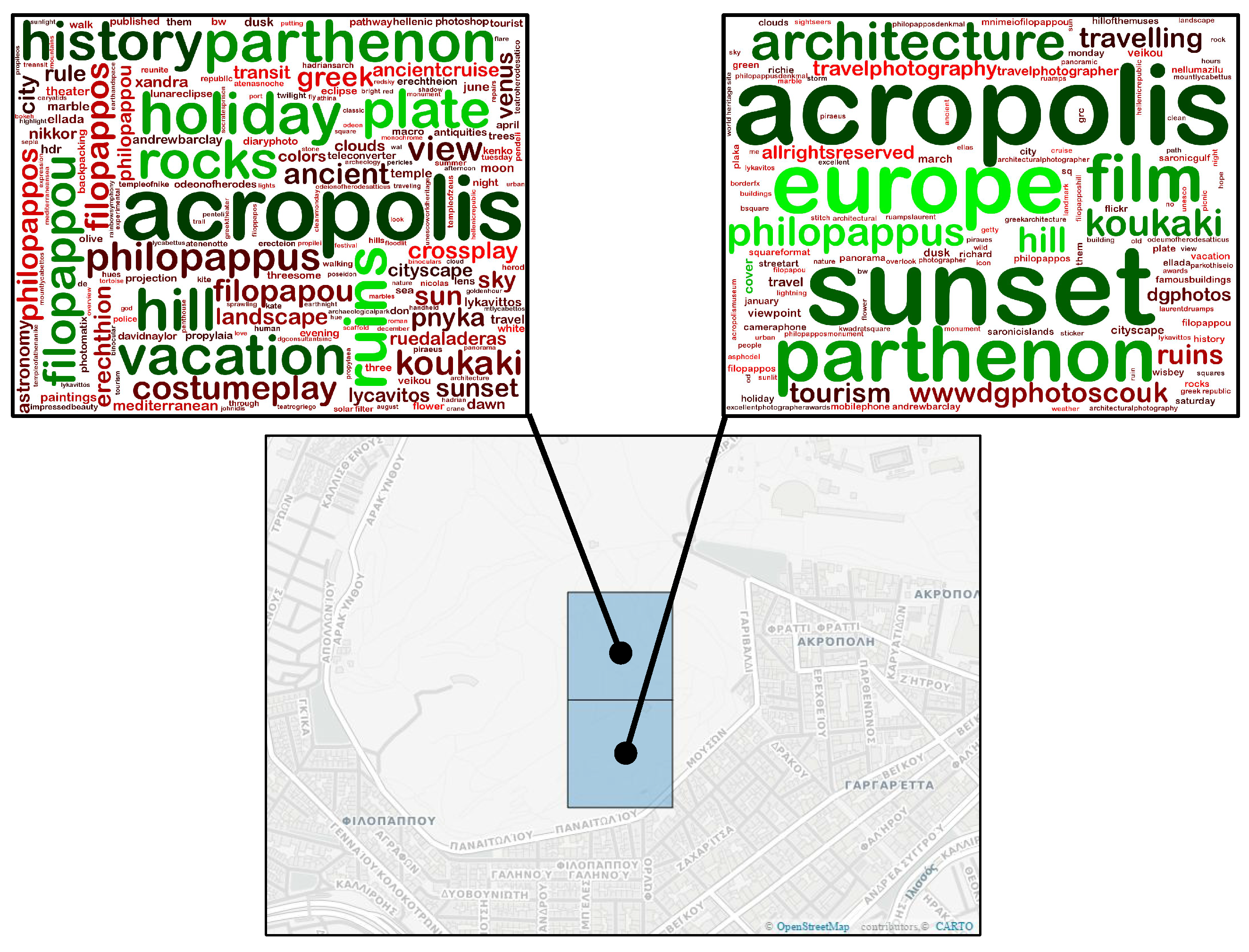
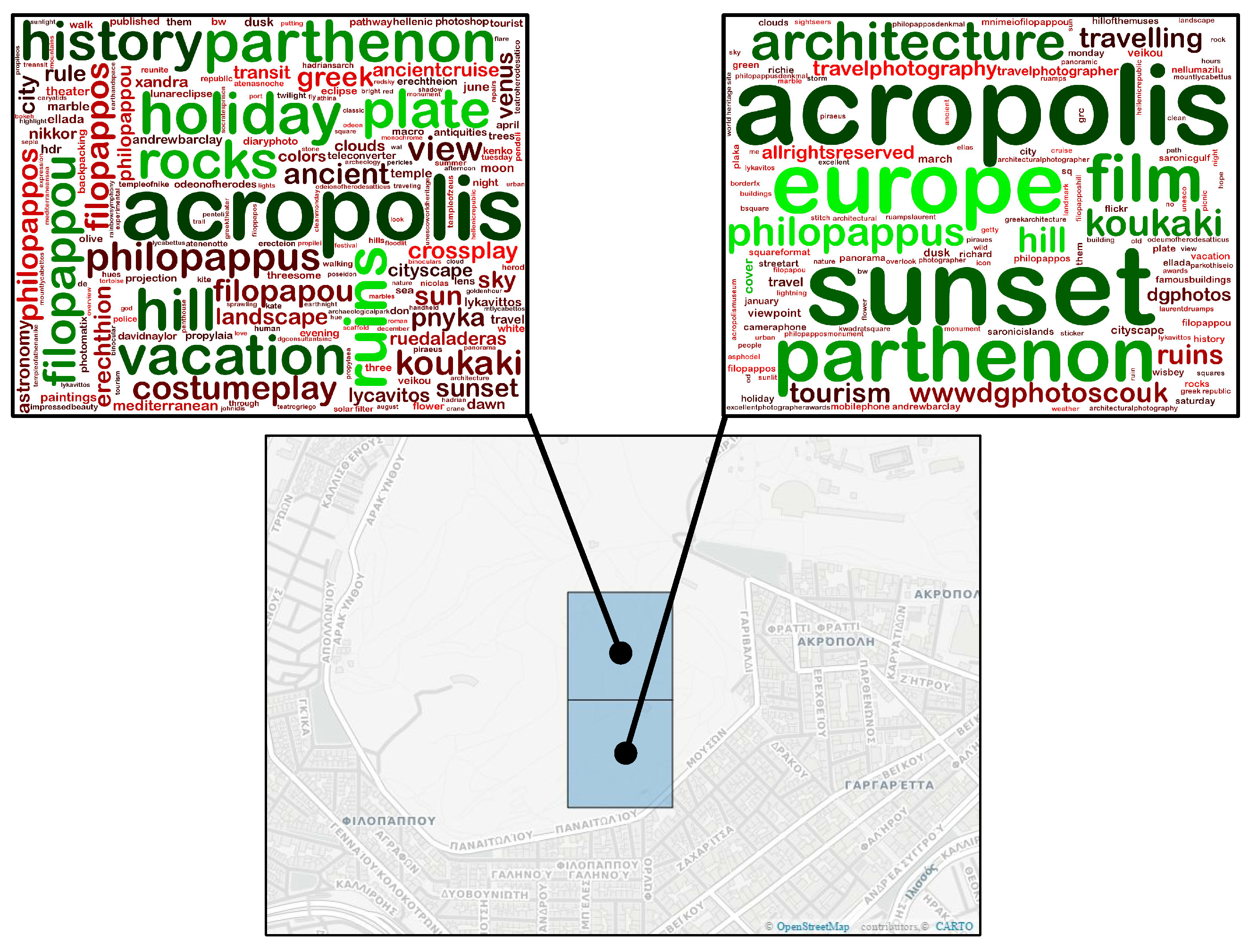
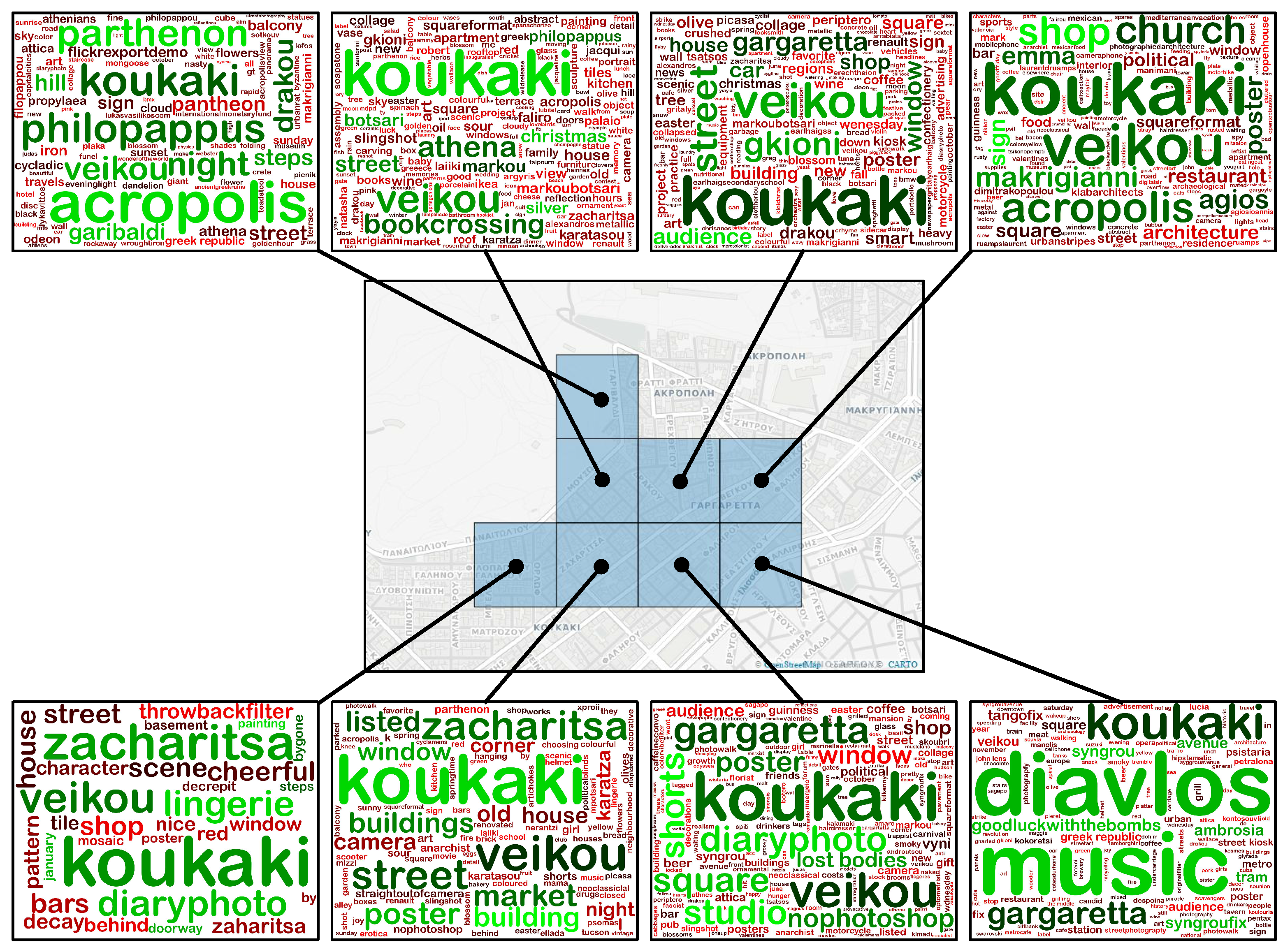
3.2. Ranking Geo-Cluster Tags
| Algorithm 4: Ranking Geo-Cluster Tags |
 |
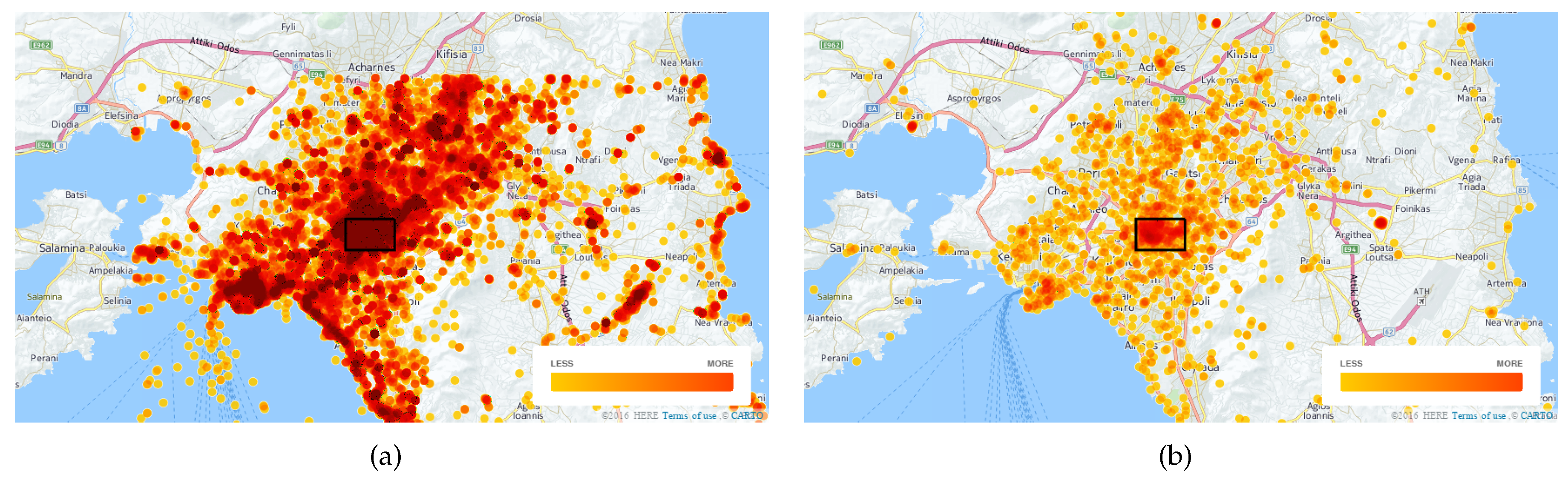
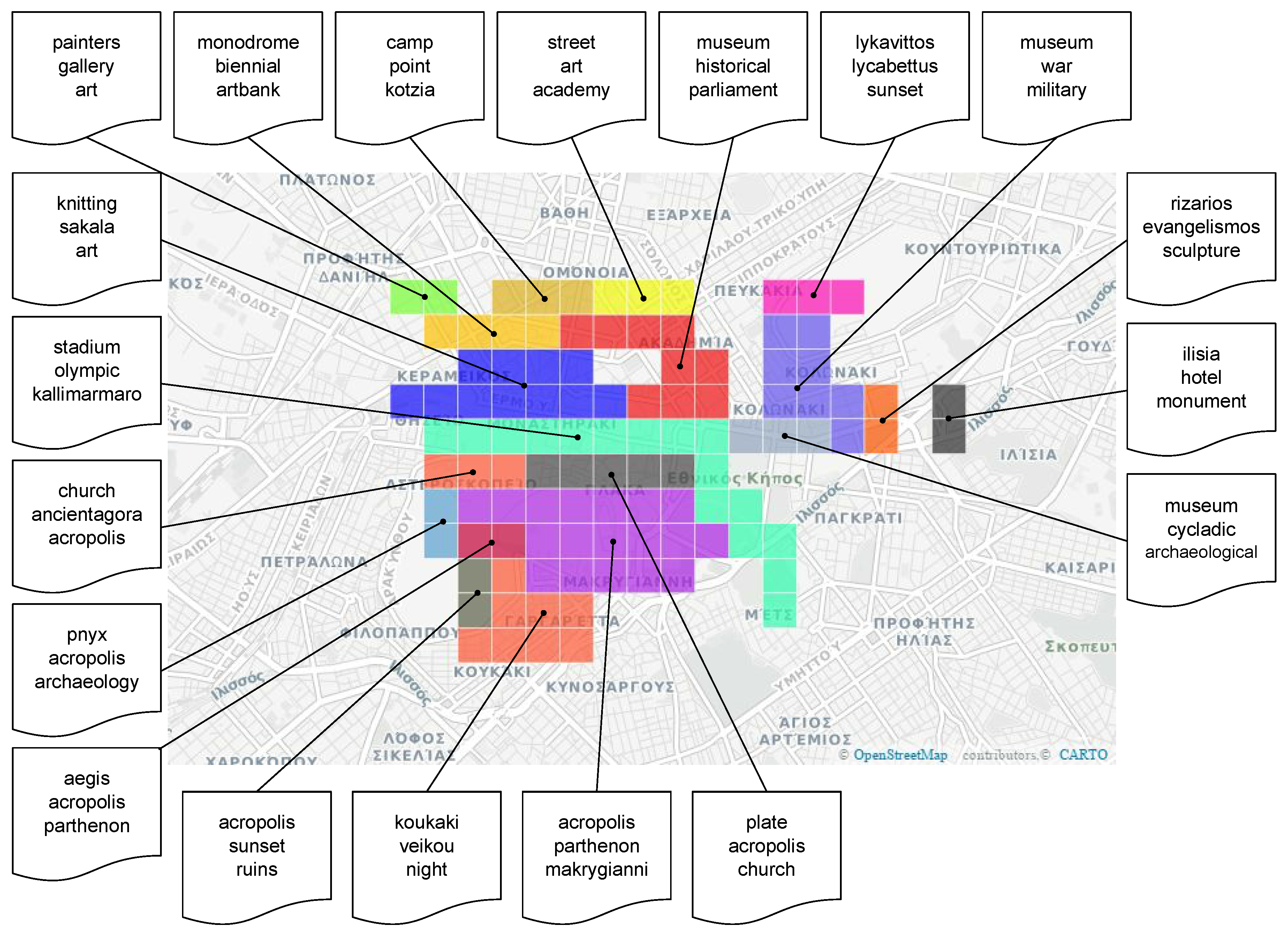
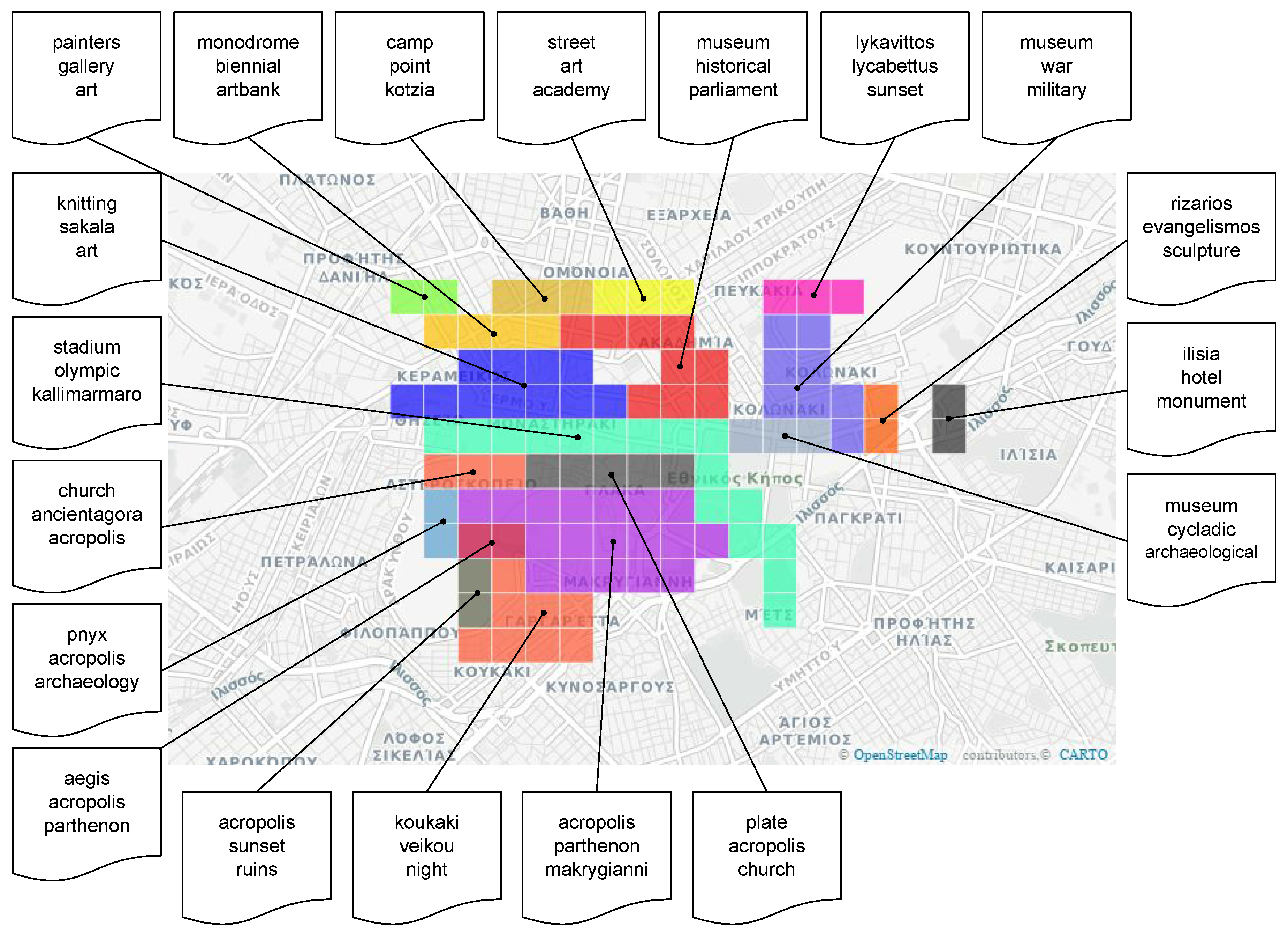
4. Experiments and Results
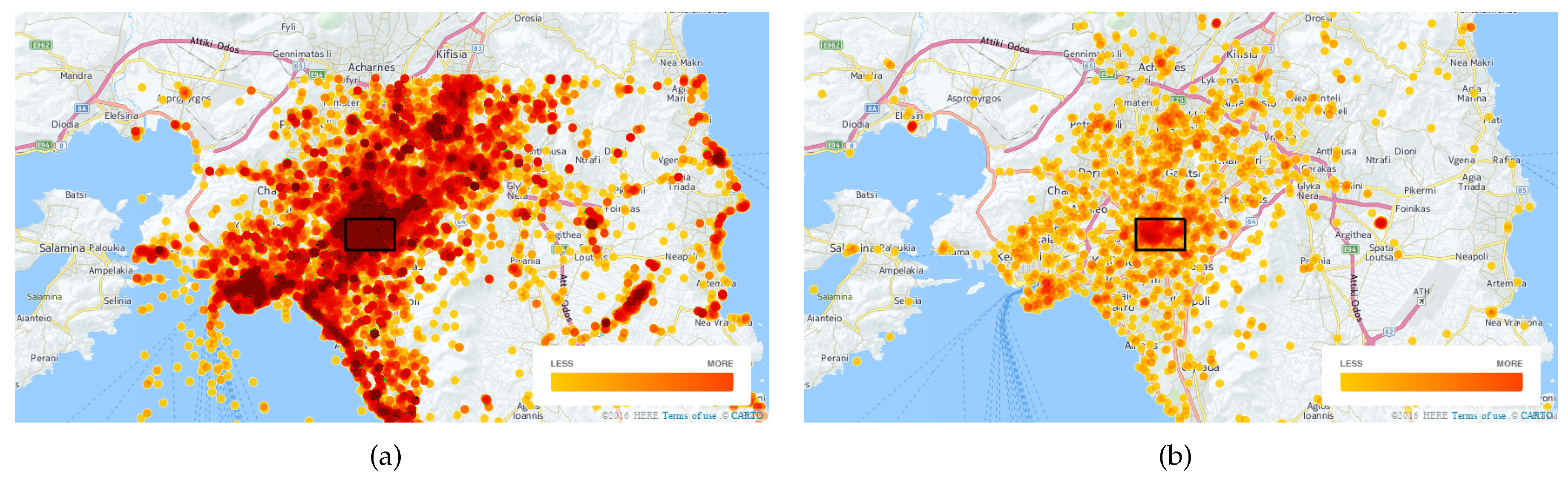
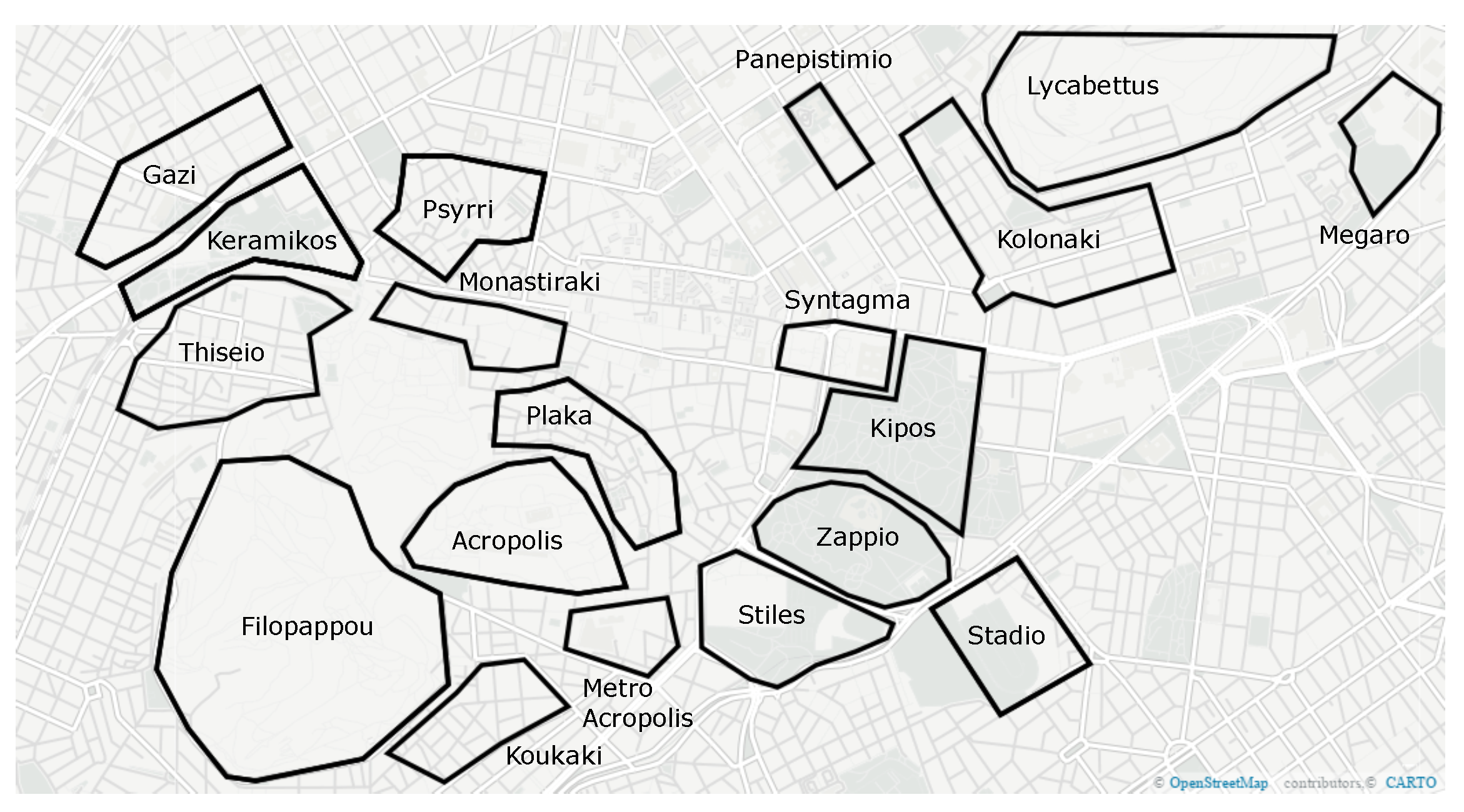
4.1. Data Set
4.2. Experimental Evaluation
4.2.1. Quantitative Results
- Avg. POIs per Geo-Cluster (APOIpGC) is the mean value of the number of POIs that are located within the n tiles that comprise a geo-cluster . This metric may be regarded as the “touristic value” of the geo-cluster and may be calculated as:where denotes the set of POIs for a given tile of and denotes set cardinality.
- Avg. Visitors per Geo-Cluster (AVpGC) is the average number of visitors for a geo-cluster and may be calculated as:where denotes the set of unique visitors, for a given tile of .
- Avg. Photos per Geo-Cluster (APpGC) is the mean value of the number of geo-tagged photos within a geo-cluster and may be calculated aswhere denotes the set of geo-tagged photos, for a given tile of .
- Avg. Geo-Cluster Size (AGCS) is the average area of a geo-cluster, in Km:where denotes a given geo-cluster and n is the number of produced geo-clusters.
- Avg. Tiles per Geo-Cluster (ATpGC). The mean value of the number of tiles that form a geo-cluster.where denotes a the set of tiles that comprise a given geo-cluster and n is the number of produced geo-clusters.
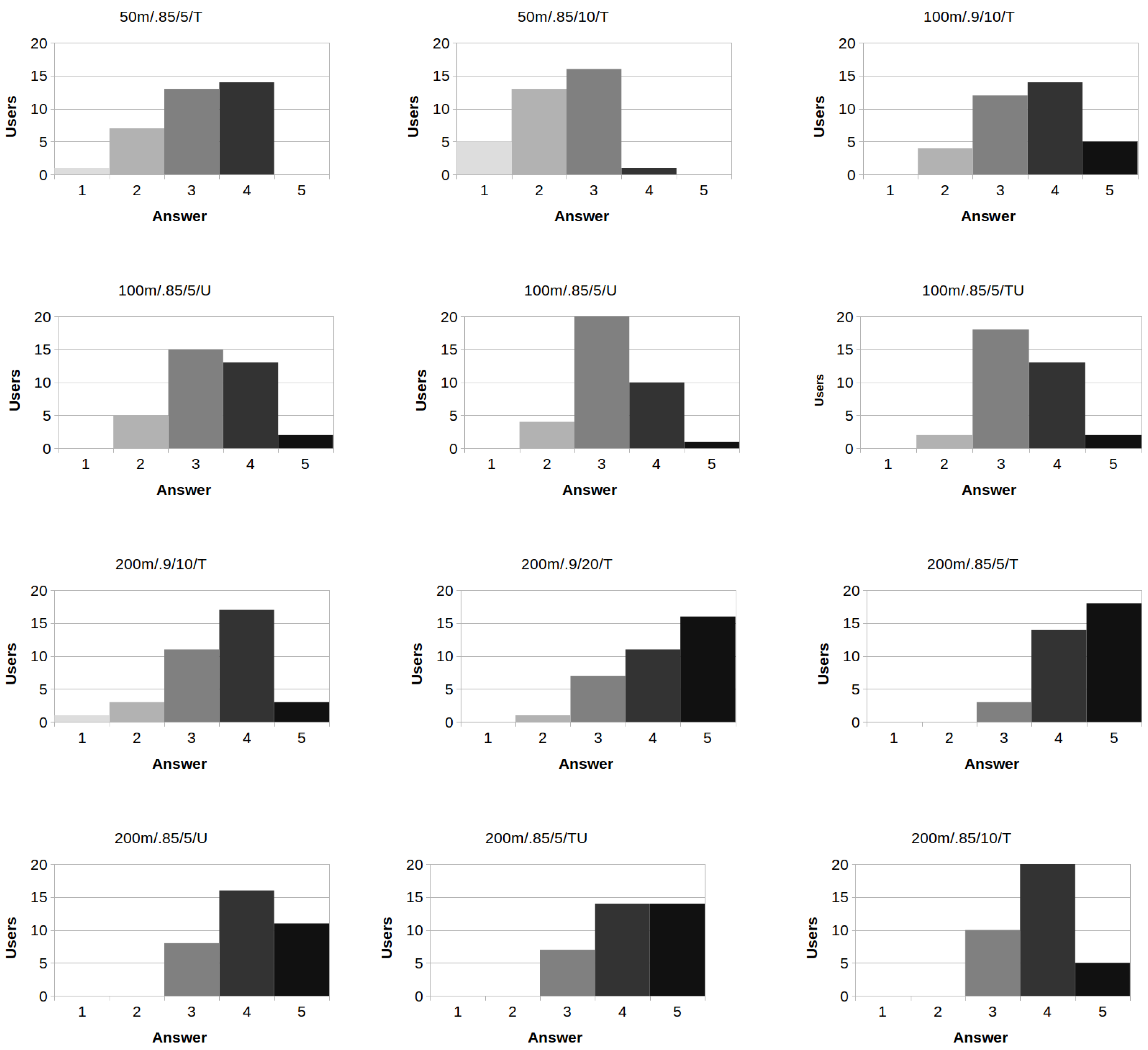
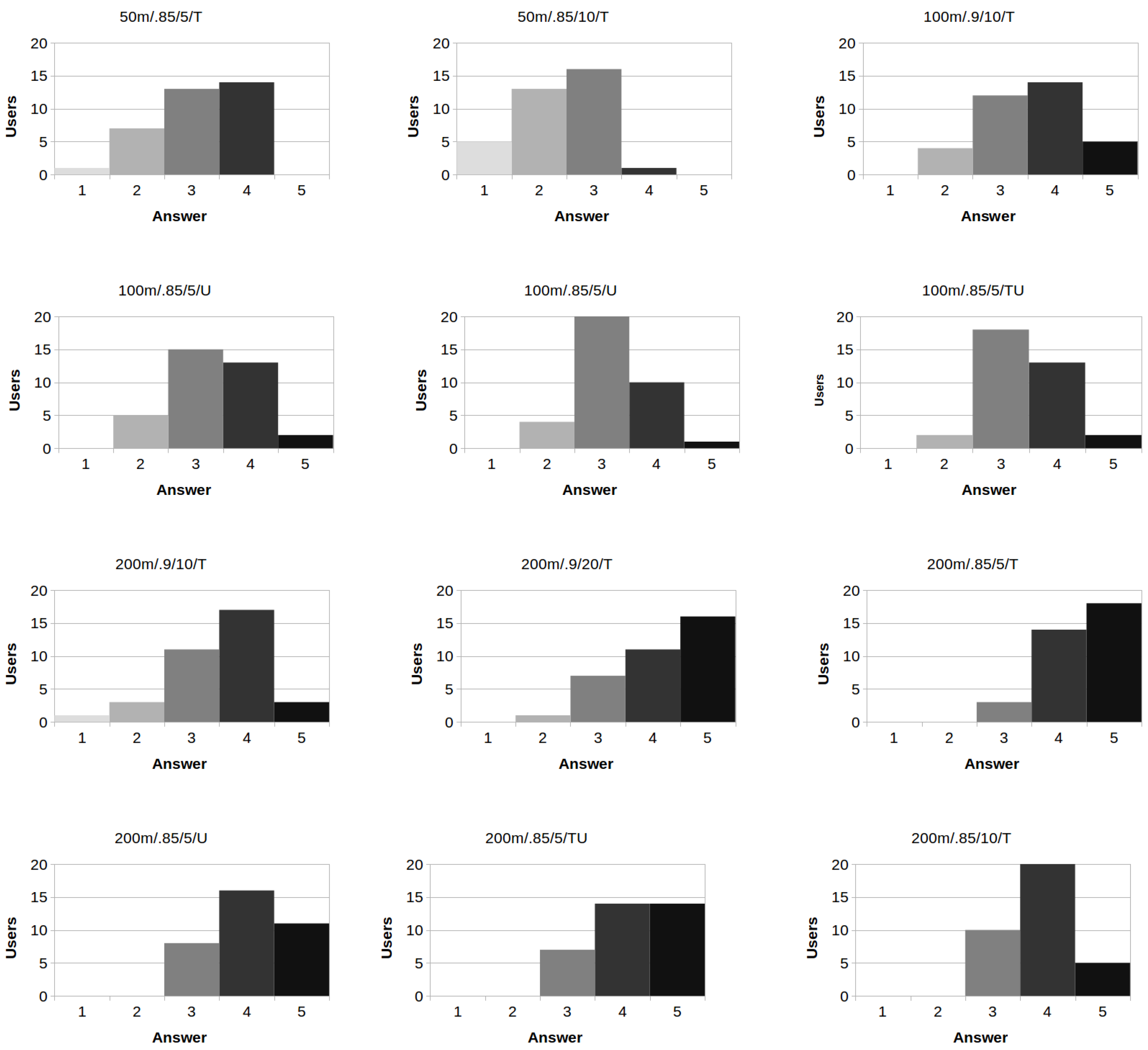
4.2.2. Qualitative Results
- Q1.
- Are you satisfied with the produced vernacular regions? (1: Very dissatisfied; 2: Somewhat dissatisfied; 3: Neither satisfied nor dissatisfied; 4: Somewhat satisfied; 5: Very satisfied)
- Q2.
- Is the name of the produced vernacular regions included within the top-3 extracted tags? (Yes/No)
5. Discussion and Conclusions
5.1. Discussion
5.2. Conclusions and Future Work
Author Contributions
Conflicts of Interest
Abbreviations
| AOI | Area of Interest |
| API | Application Programming Interface |
| GPS | Global Positioning System |
| POI | Place of Interest |
| TF-IDF | Term Frequency—Inverse Document Frequency |
References
- Lenhart, A. Teens, Social Media & Technology Overview 2015. Available online: http://www.pewinternet.org/2015/04/09/teens-social-media-technology-2015/ (accessed on 16 November 2016).
- Duggan, M. Photo and Video Sharing Grow Online. Available online: http://www.pewinternet.org/2013/10/28/photo-and-video-sharing-grow-online/ (accessed on 16 November 2016).
- Angus, E.; Thelwall, M. Motivations for image publishing and tagging on Flickr. In Proceedings of the International Conference on Electronic Publishing, Helsinki, Finland, 16–18 June 2010.
- Arase, Y.; Xie, X.; Hara, T.; Nishio, S. Mining people’s trips from large scale geo-tagged photos. In Proceedings of the ACM International Conference on Multimedia (MM), Firenze, Italy, 25–29 October 2010.
- Girardin, F.; Calabrese, F.; Dal Fiore, F.; Ratti, C.; Blat, J. Digital footprinting: Uncovering tourists with user-generated content. IEEE Pervasive Comput. 2008, 7, 36–43. [Google Scholar] [CrossRef]
- Waters, T.; Evans, A. Tools for web-based GIS mapping of a “fuzzy vernacular” geography. In Proceedings of the International Conference on GeoComputation, Southampton, UK, 8–10 September 2003.
- Montello, D.R. Regions in geography: Process and content. In Foundations of Geographic Information Science; CRC Press: Boca Raton, FL, USA, 2003; pp. 173–189. [Google Scholar]
- Egenhofer, M.J.; Mark, D.M. Naïve geography. In Proceedings of the International Conference on Spatial Information Theory, Ellicottville, NY, USA, 14–18 September 1995.
- Hu, Y.; Gao, S.; Janowicz, K.; Yu, B.; Li, W.; Prasad, S. Extracting and understanding urban areas of interest using geotagged photos. Comput. Environ. Urban Syst. 2015, 54, 240–254. [Google Scholar] [CrossRef]
- Jones, C.B.; Purves, R.S.; Clough, P.D.; Joho, H. Modelling vague places with knowledge from the Web. Int. J. Geogr. Inf. Sci. 2008, 22, 1045–1065. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Roy, A. Event detection from flickr data through wavelet-based spatial analysis. In Proceedings of the ACM Conference on Information and Knowledge Management (CIKM), Hong Kong, China, 2–6 November 2009.
- Van Canneyt, S.; Schockaert, S.; Van Laere, O.; Bart Dhoedt, B. Time-dependent recommendation of tourist attractions using Flickr. In Proceedings of the 23rd Benelux Conference on Artificial Intelligence (BNAIC), Ghent, Belgium, 3–4 November 2011.
- Kisilevich, S.; Keim, D.; Andrienko, N.; Andrienko, G. Towards Acquisition of Semantics of Places and Events by Multi-perspective Analysis of Geotagged Photo Collections. In Geospatial Visualisation; Springer: Berlin, Germany, 2013; pp. 211–233. [Google Scholar]
- Cao, L.; Luo, J.; Gallagher, A.; Jin, X.; Han, J.; Huang, T.S. A worldwide tourism recommendation system based on geotagged web photos. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, TX, USA, 15–19 March 2010.
- Serdyukov, P.; Murdock, V.; Van Zwol, R. Placing flickr photos on a map. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009.
- Twaroch, F.A.; Jones, C.B.; Abdelmoty, A.I. Acquisition of vernacular place names from web sources. In Weaving Services and People on the World Wide Web; Springer: Berlin/Heidelberg, Germany, 2009; pp. 195–214. [Google Scholar]
- Grothe, C.; Schaab, J. Automated footprint generation from geotags with kernel density estimation and support vector machines. Spat. Cogn. Comput. 2009, 9, 195–211. [Google Scholar] [CrossRef]
- Liu, J.; Huang, Z.; Chen, L.; Shen, H.T.; Yan, Z. Discovering areas of interest with geo-tagged images and check-ins. In Proceedings of the ACM International Conference on Multimedia (MM), Nara, Japan, 29 October–2 November 2012.
- Keßler, C.; Maue, P.; Heuer, J.T.; Bartoschek, T. Bottom-up gazetteers: Learning from the implicit semantics of geotags. In Proceedings of the International Conference on GeoSpatial Semantics, Mexico City, Mexico, 3–4 December 2009.
- Sharifzadeh, M.; Shahabi, C.; Knoblock, C.A. Learning approximate thematic maps from labeled geospatial data. In Next Generation Geospatial Information: From Digital Image Analysis to Spatiotemporal Databases; Taylor & Francis Group: London, UK, 2005; Volume 3, p. 129. [Google Scholar]
- Spielman, S.E.; Thill, J.C. Social area analysis, data mining, and GIS. Comput. Environ. Urban Syst. 2008, 32, 110–122. [Google Scholar] [CrossRef]
- Kohonen, T.; Somervuo, P. Self-organizing maps of symbol strings. Neurocomputing 1998, 21, 19–30. [Google Scholar] [CrossRef]
- Noulas, A.; Scellato, S.; Mascolo, C.; Pontil, M. Exploiting Semantic Annotations for Clustering Geographic Areas and Users in Location-based Social Networks. In Proceedings of the 2011 ICWSM Workshop, Social Mobile Web, Barcelona, Catalonia, Spain, 21 July 2011; Volume 11.
- Hollenstein, L.; Purves, R. Exploring place through user-generated content: Using Flickr tags to describe city cores. J. Spat. Inf. Sci. 2010, 21–48. [Google Scholar]
- Duckham, M.; Kulik, L.; Worboys, M.; Galton, A. Efficient generation of simple polygons for characterizing the shape of a set of points in the plane. Pattern Recognit. 2008, 41, 3224–3236. [Google Scholar] [CrossRef]
- Zhang, A.X.; Noulas, A.; Scellato, S.; Mascolo, C. Hoodsquare: Modeling and recommending neighborhoods in location-based social networks. In Proceedings of the International Conference on Social Computing (SocialCom), IEEE, Washington, DC, USA, 8–14 September 2013.
- Cranshaw, J.; Schwartz, R.; Hong, J.I.; Sadeh, N. The livehoods project: Utilizing social media to understand the dynamics of a city. In Proceedings of the International AAAI Conference on Weblogs and Social Media, Dublin, Ireland, 4–7 June 2012.
- Aadland, M.; Farah, C.; Magee, K. μ-shapes: Delineating Urban Neighborhoods using Volunteered Geographic Information. J. Spat. Inf. Sci. 2009. [Google Scholar] [CrossRef]
- Rattenbury, T.; Naaman, M. Methods for extracting place semantics from Flickr tags. In Proceedings of the ACM Transactions on the Web (TWEB); ACM: New York, NY, USA, 2009; Volume 3. [Google Scholar]
- Deng, D.P.; Chuang, T.R.; Lemmens, R. Conceptualization of place via spatial clustering and co-occurrence analysis. In Proceedings of the International Workshop on Location Based Social Networks, Seattle, WA, USA, 4–6 November 2009.
- Firan, C.S.; Georgescu, M.; Nejdl, W.; Paiu, R. Bringing order to your photos: event-driven classification of flickr images based on social knowledge. In Proceedings of the ACM International Conference on Information and Knowledge Management (CIKM), Toronto, ON, Canada, 26–30 October 2010.
- Baba, Y.; Ishikawa, F.; Honiden, S. Extracting Time and Location Concepts Related to Tags; Incentives for the Semantic Web (INSEMTIVE): Karlsruhe, Germany, 2008. [Google Scholar]
- Ahern, S.; Naaman, M.; Nair, R.; Yang, J.H.-I. World explorer: Visualizing aggregate data from unstructured text in geo-referenced collections. In Proceedings of the 7th ACM/IEEE-CS joint Conference on Digital libraries (JCDL), Vancouver, BC, Canada, 18–23 June 2007.
- Chaudhry, O.; Mackaness, W. Automated extraction and geographical structuring of Flickr tags. In Proceedings of the 4th International Conference on Advanced Geographic Information Systems, Applications, and Services (GEOProcessing), Valencia, Spain, 30 January–4 February 2012.
- Spyrou, E.; Psallas, A.; Charalampidis, V.; Mylonas, P. Discovering Areas of Interest using a Semantic Geo-Clustering Approach. In Proceedings of the Mining Humanistic Data Workshop (MHDW), located at the International Conference on Artificial Intelligence Applications and Innovations (AIAI), Thessaloniki, Greece, 16–18 September 2016.
- Spyrou, E.; Mylonas, Ph. Analyzing Flickr metadata to extract location-based information and semantically organize its photo content. Neurocomputing 2016, 172, 114–133. [Google Scholar] [CrossRef]
- Quack, T.; Leibe, B.; Van Gool, L. World-scale mining of objects and events from community photo collections. In Proceedings of the International Conference on Content-based Image and Video Retrieval (CIVR), Niagara Falls, ON, Canada, 7–9 July 2008.
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; Wiley: Hoboken, NJ, USA, 2001. [Google Scholar]
- Dubinko, M.; Kumar, R.; Magnani, J.; Novak, J.; Raghavan, P.; Tomkins, A. Visualizing tags over time. In Proceedings of the 15th International Conference on World Wide Web (WWW), Edinburgh, Scotland, UK, 22–26 May 2006.
- Jaffe, A.; Naaman, M.; Tassa, T.; Davis, M. Generating summaries and visualization for large collections of geo-referenced photographs. In Proceedings of the the ACM International Workshop on Multimedia Information Retrieval (MIR), Santa Barbara, CA, USA, 26–27 October 2006.
- Kennedy, L.; Naaman, M.; Ahern, S.; Nair, R.; Rattenbury, T. How flickr helps us make sense of the world: context and content in community-contributed media collections. In Proceedings of the International Conference on Multimedia (MM), Augsburg, Germany, 23–28 September 2007.
- Mackaness, W.A.; Chaudhry, O. Assessing the veracity of methods for extracting place semantics from flickr tags. Trans. GIS 2013, 17, 544–562. [Google Scholar] [CrossRef] [Green Version]
- Sun, A.; Bhowmick, S.S. Image tag clarity: in search of visual-representative tags for social images. In Proceedings of the SIGMM Workshop on Social Media, Beijing, China, 19–24 October 2009.
- Liu, Y.; Bian, J.; Agichtein, E. Predicting information seeker satisfaction in community question answering. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, Singapore, 20–24 July 2008.
- Likert, R. A Technique for the Measurement of Attitudes; Archives of Psychology; The Science Press: New York, NY, USA, 1932. [Google Scholar]
- Bertram, D. Likert Scales… Are the Meaning of Life. Available online: http://www.academia.edu/8160815/Likert_Scales_are_the_meaning_of_life (accessed on 16 March 2017).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| R | The whole area which is given as input to the proposed algorithm |
| P | The set of photos that have been geo-tagged within R |
| The i-th row and the j-th column of the square grid | |
| A square tile upon the initial division of R | |
| The size of each tile | |
| The set of photos that have been geo-tagged within | |
| The set of tags harvested from | |
| The set of neighboring tiles of tile | |
| A neighbor of . pos denotes its position. | |
| Semantic representation of tile | |
| Semantic representation of tile , using the L most popular tags | |
| Jaccard distance between sets A and B | |
| S | Similarity threshold for two sets to be merged |
| The frequency of a specific word t within a document d | |
| The overall number of documents in a collection that contain word t | |
| Set of geo-clusters resulted upon a run with p parameter set | |
| The i-th geo-cluster of | |
| Set of photos within the i-th geo-cluster of | |
| Set of tags within the photos in i-th geo-cluster of | |
| Ranked set of tags within the photos in i-th geo-cluster of | |
| Set of tags within P | |
| A tag within | |
| A tag within |
| m | m | m | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.85/5 (T) | 0.85/10 (T) | 0.9/10 (T) | 0.85/5 (T) | 0.85/5 (U) | 0.85/5 (TU) | 0.9/10 (T) | 0.9/20 (T) | 0.85/5 (T) | 0.85/5 (U) | 0.85/5 (TU) | 0.85/10 (T) | |
| AVpGC | 70.18 | 92.40 | 255.05 | 170.79 | 210.57 | 156.99 | 661.4 | 623.07 | 538.89 | 785.75 | 387.61 | 506.05 |
| APpGC | 299.10 | 374.22 | 1277.79 | 922.45 | 1071.79 | 606.95 | 4069.13 | 3801.5 | 3767.79 | 5422.67 | 1872.54 | 3065.5 |
| ATpGC | 3.16 | 2.79 | 3.46 | 4.14 | 3.57 | 2.70 | 4.6 | 3.14 | 5.58 | 5.83 | 2.85 | 4.36 |
| AGCS | 0.0079 | 0.0070 | 0.0346 | 0.0414 | 0.0357 | 0.0270 | 0.1840 | 0.1257 | 0.2232 | 0.2333 | 0.1139 | 0.1745 |
| APOIpGC | 0.89 | 1.01 | 3.28 | 3.19 | 3.02 | 2.08 | 13.87 | 9.64 | 14.16 | 18.92 | 7.45 | 11.27 |
| m | m | m | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.85/5 (T) | 0.85/10 (T) | 0.9/10 (T) | 0.85/5 (T) | 0.85/5 (U) | 0.85/5 (TU) | 0.9/10 (T) | 0.9/20 (T) | 0.85/5 (T) | 0.85/5 (U) | 0.85/5 (TU) | 0.85/10 (T) | |
| median | 3 | 2 | 4 | 3 | 3 | 3 | 4 | 4 | 5 | 4 | 4 | 4 |
| mode | 4 | 3 | 4 | 3 | 3 | 3 | 4 | 5 | 5 | 4 | 4 | 4 |
| q1 | 3 | 2 | 3 | 3 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 3 |
| q2 | 3 | 2 | 4 | 3 | 3 | 3 | 4 | 4 | 5 | 4 | 4 | 4 |
| q3 | 4 | 3 | 4 | 4 | 4 | 4 | 4 | 5 | 5 | 5 | 5 | 4 |
| q4 | 4 | 4 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| m | m | m | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.85/5 (T) | 0.85/10 (T) | 0.9/10 (T) | 0.85/5 (T) | 0.85/5 (U) | 0.85/5 (TU) | 0.9/10 (T) | 0.9/20 (T) | 0.85/5 (T) | 0.85/5 (U) | 0.85/5 (TU) | 0.85/10 (T) | |
| name (%) | 0.18 | 0.18 | 0.27 | 0.31 | 0.33 | 0.31 | 0.40 | 0.49 | 0.87 | 0.78 | 0.82 | 0.53 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Spyrou, E.; Korakakis, M.; Charalampidis, V.; Psallas, A.; Mylonas, P. A Geo-Clustering Approach for the Detection of Areas-of-Interest and Their Underlying Semantics. Algorithms 2017, 10, 35. https://doi.org/10.3390/a10010035
Spyrou E, Korakakis M, Charalampidis V, Psallas A, Mylonas P. A Geo-Clustering Approach for the Detection of Areas-of-Interest and Their Underlying Semantics. Algorithms. 2017; 10(1):35. https://doi.org/10.3390/a10010035
Chicago/Turabian StyleSpyrou, Evaggelos, Michalis Korakakis, Vasileios Charalampidis, Apostolos Psallas, and Phivos Mylonas. 2017. "A Geo-Clustering Approach for the Detection of Areas-of-Interest and Their Underlying Semantics" Algorithms 10, no. 1: 35. https://doi.org/10.3390/a10010035