
Monitoring Environmental Quality by Sniffing Social Media


Abstract
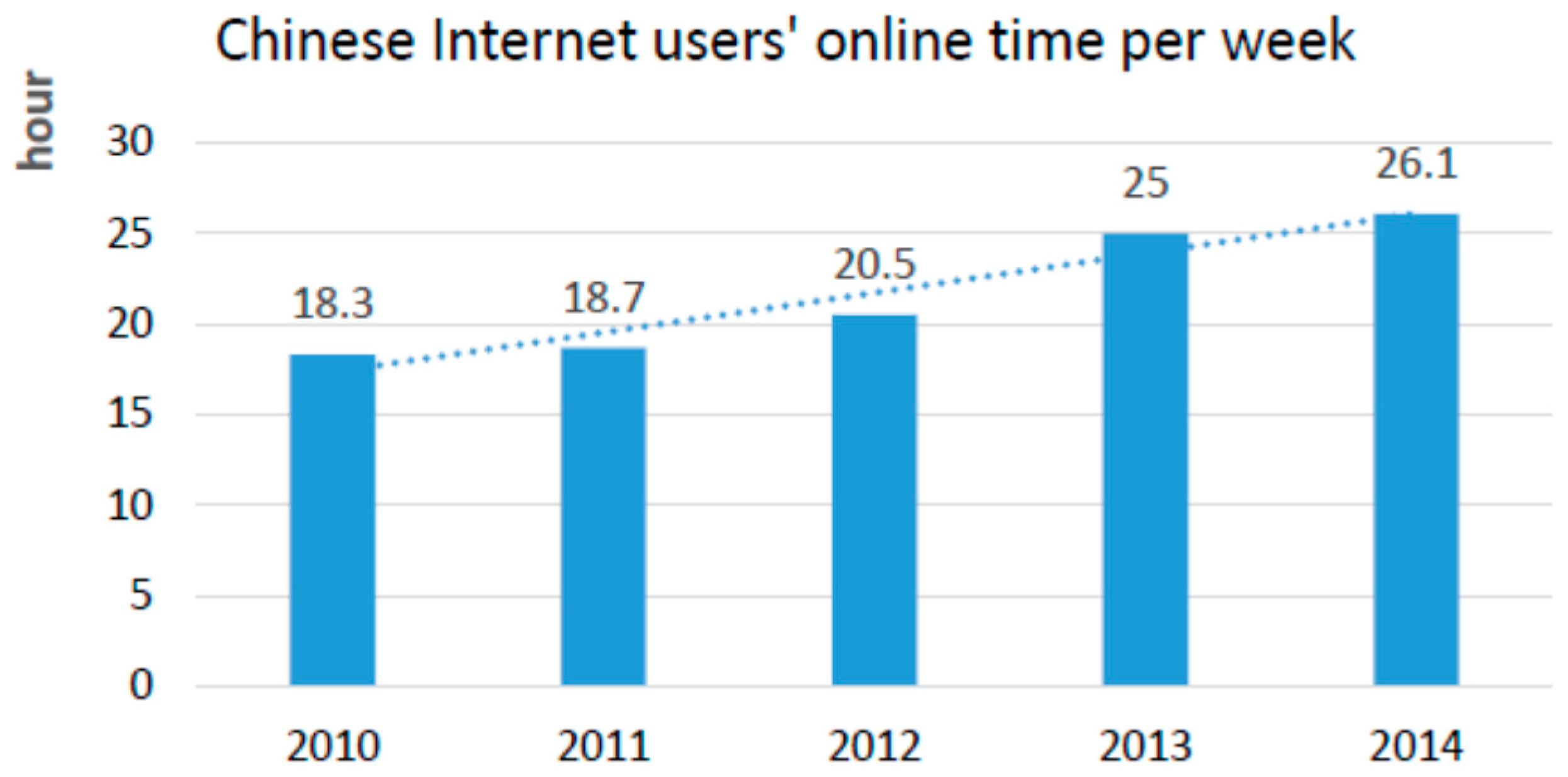
:1. Introduction
2. Methods
2.1. Formal Definition
2.2. Establishing the Emotional and Regional Dictionary
2.3. Filtering the Irrelevant Text Content
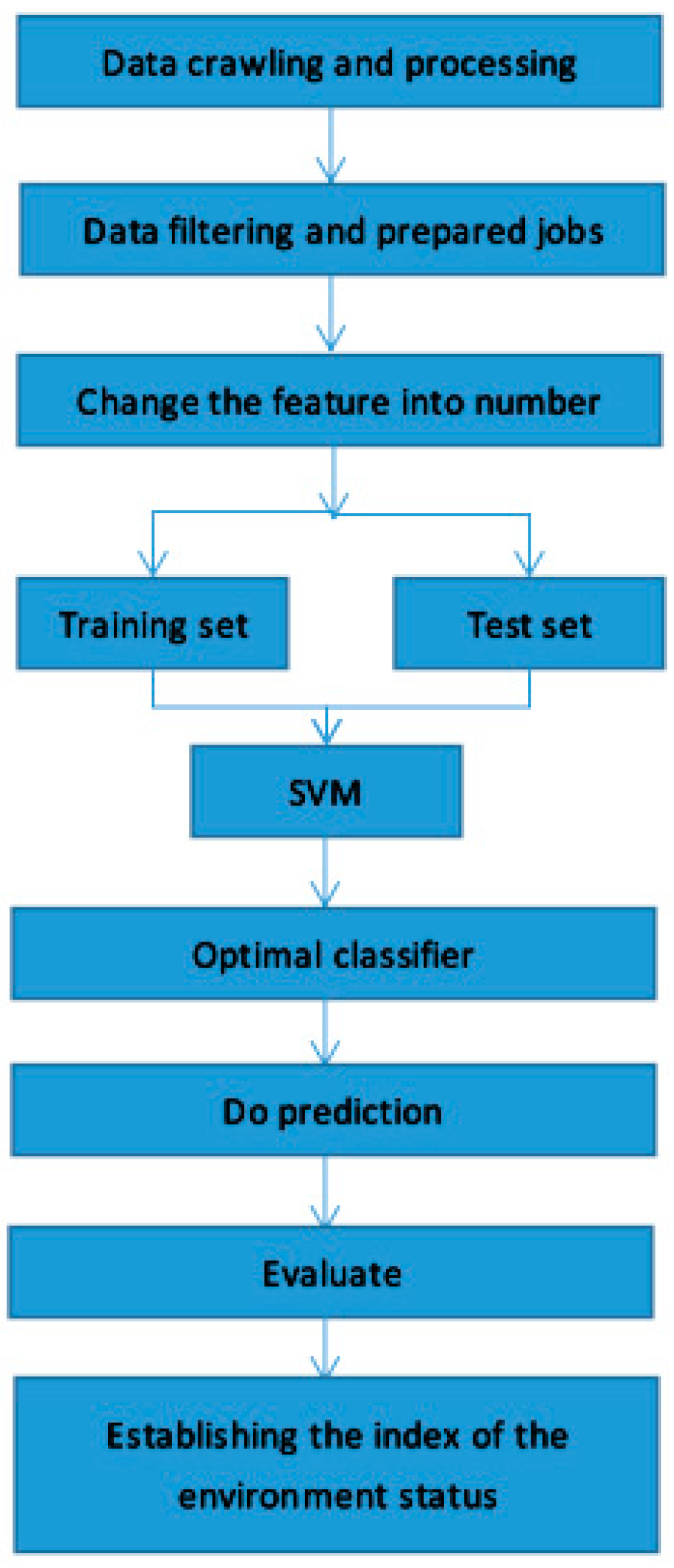
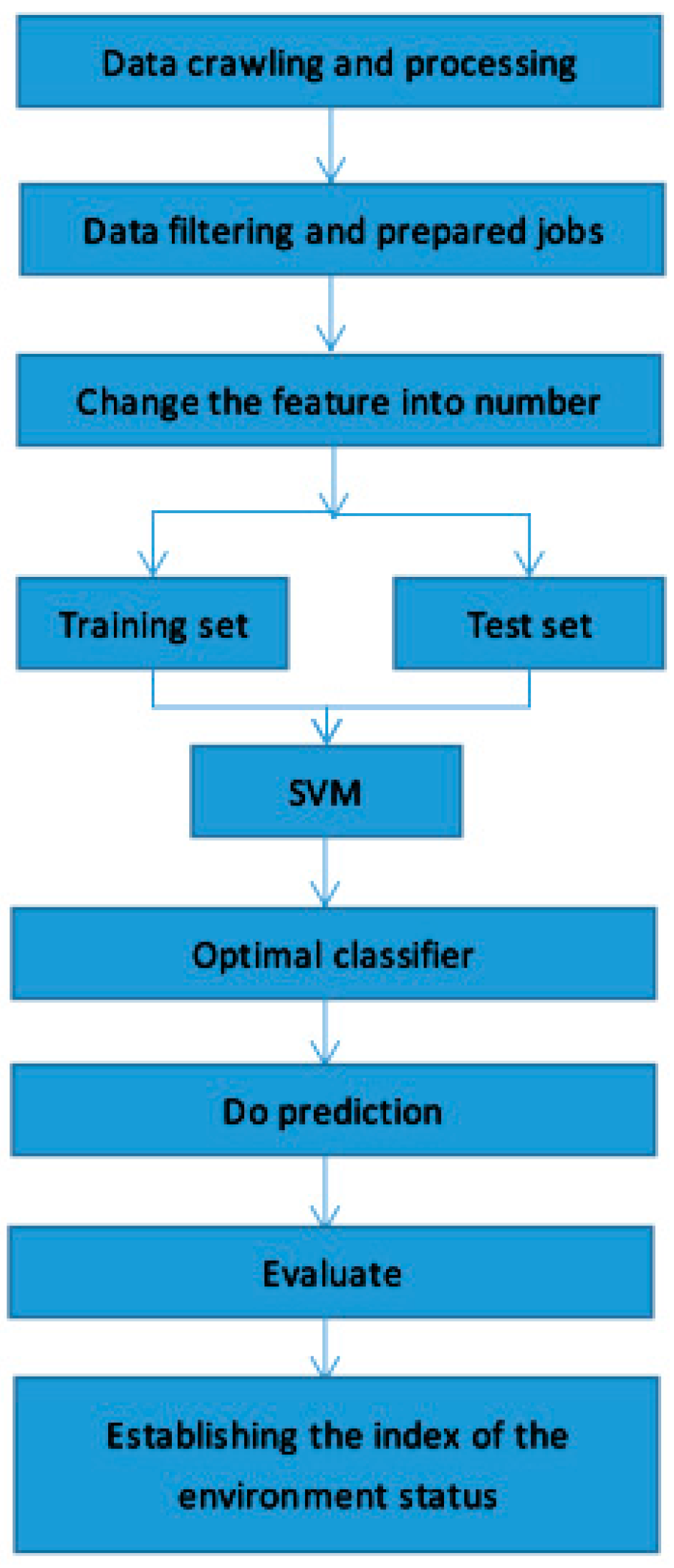
2.4. Environmental Quality Analysis Method Combining Support Vector Machine
- Input content:
- ①
- dataMatInTrain: processed data which has the characteristic about environment in Training set
- ②
- classLabelsTrain: the label for the Corresponding data in Training set
- ③
- C: threshold
- ④
- toler: fault tolerant rate
- ⑤
- maxIter: iterator number
- ⑥
- kTup: kernel function
- ⑦
- dataMatInTest: processed data which has the characteristic about environment in test set
- Output content:
- ①
- w: the normal vector for hyper plane
- ②
- b: the constant for hyper plane
- ③
- label: predicted label for data
- Pseudo code:
- Data = process data and get the characteristic toward environment
- Get data matrix:
- dataMatInTrain, classLabelsTrain = loadData (Data)
- Get key parameter:
- w, b = SMO (dataMatIn, classLabels, C, toler ,maxIter, kTup)
- Test the correct rate of this hyper plane:
- Rate = judgeData (w, data, classLabel, b)
- If Rate > n:
- Use this hyper plane to do the prediction:
- Label = Predict (w, data, b)
Else:- Change some input parameter or training data to increase the correct rate
- Do step 5
- Draw conclusions
2.5. Establishing the Environmental Quality Index
3. Experiment
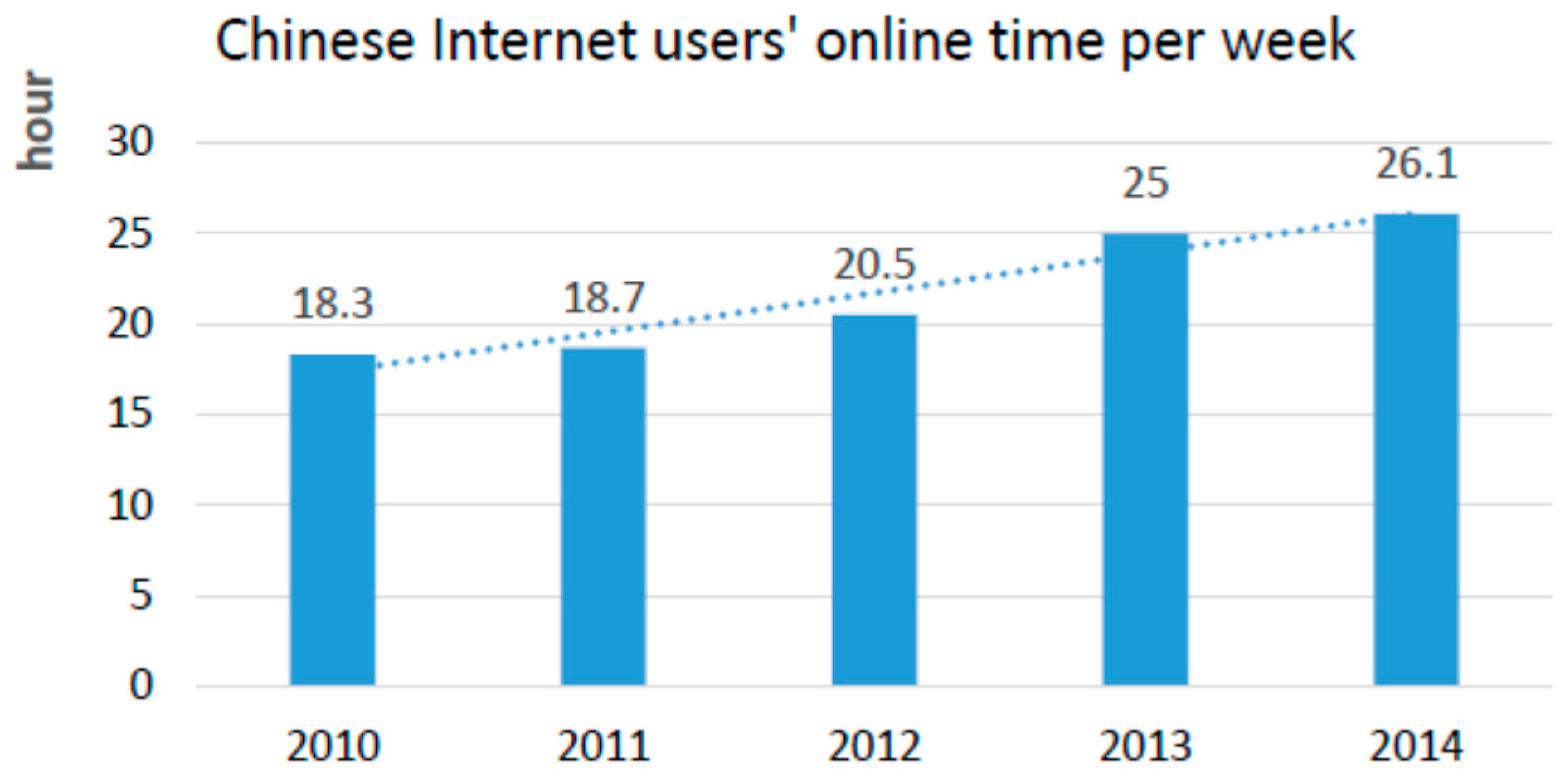
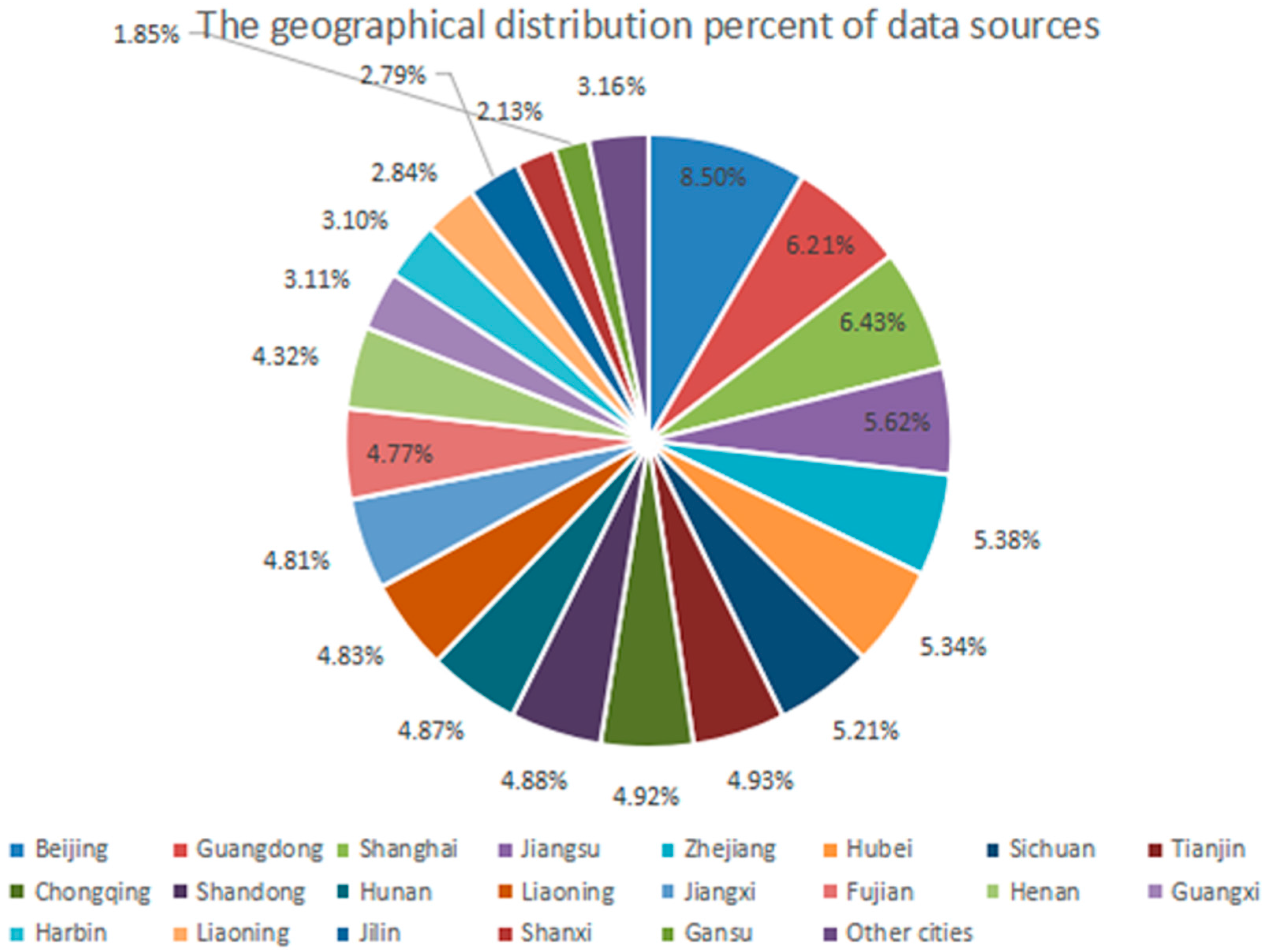
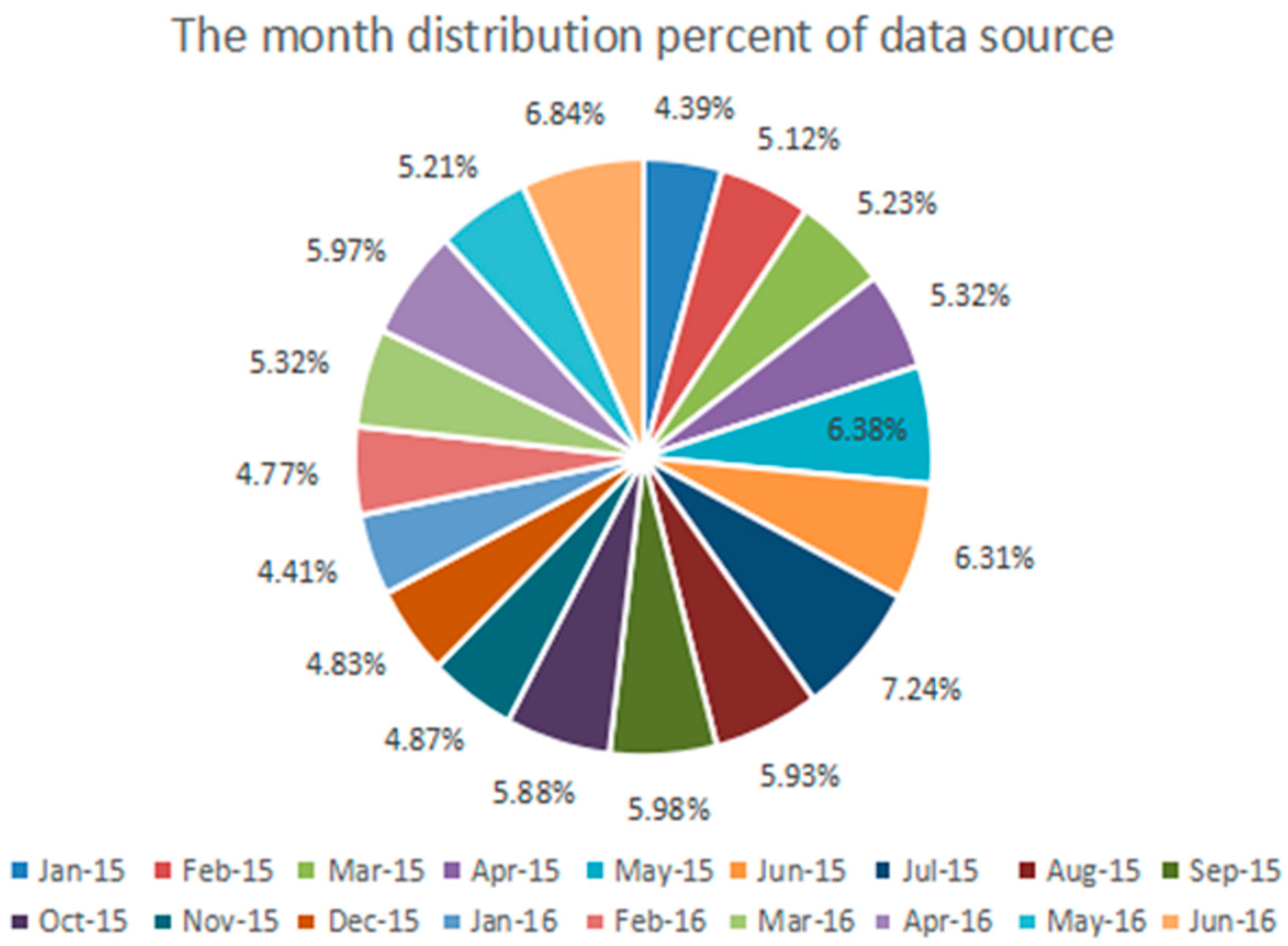
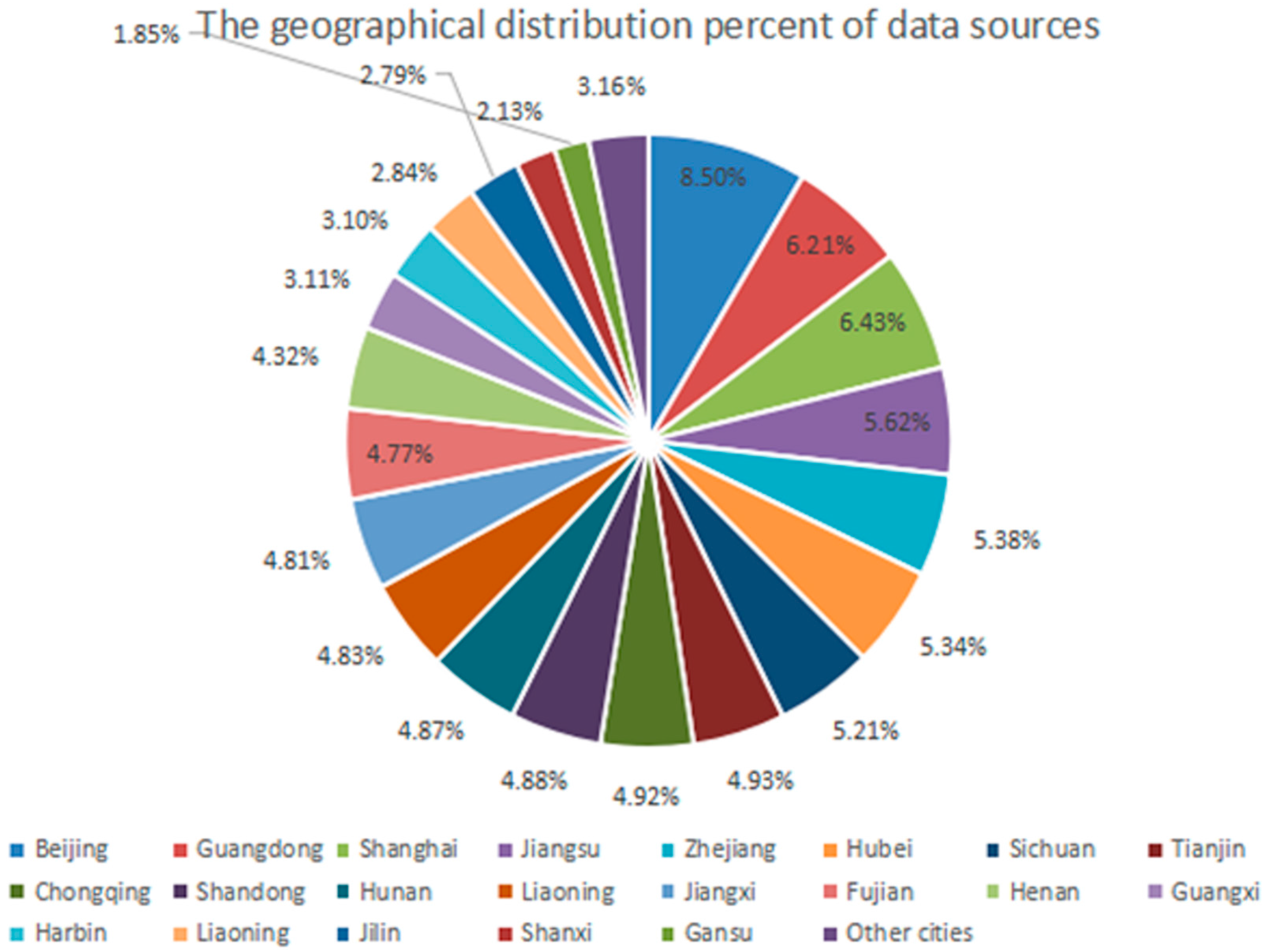
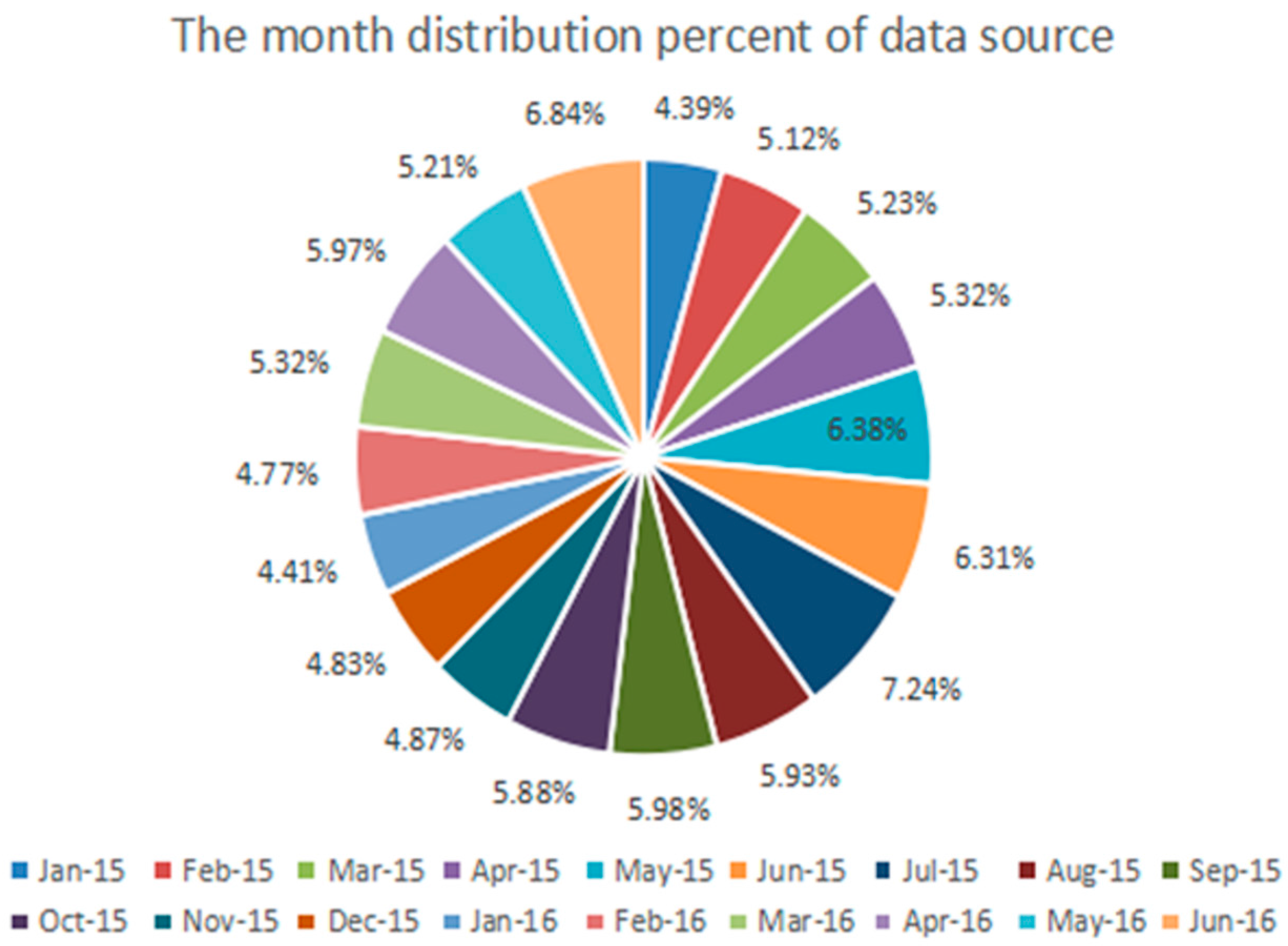
3.1. The Collection and Preprocessing of the Data
3.2. Further Filtering and Classification of Data
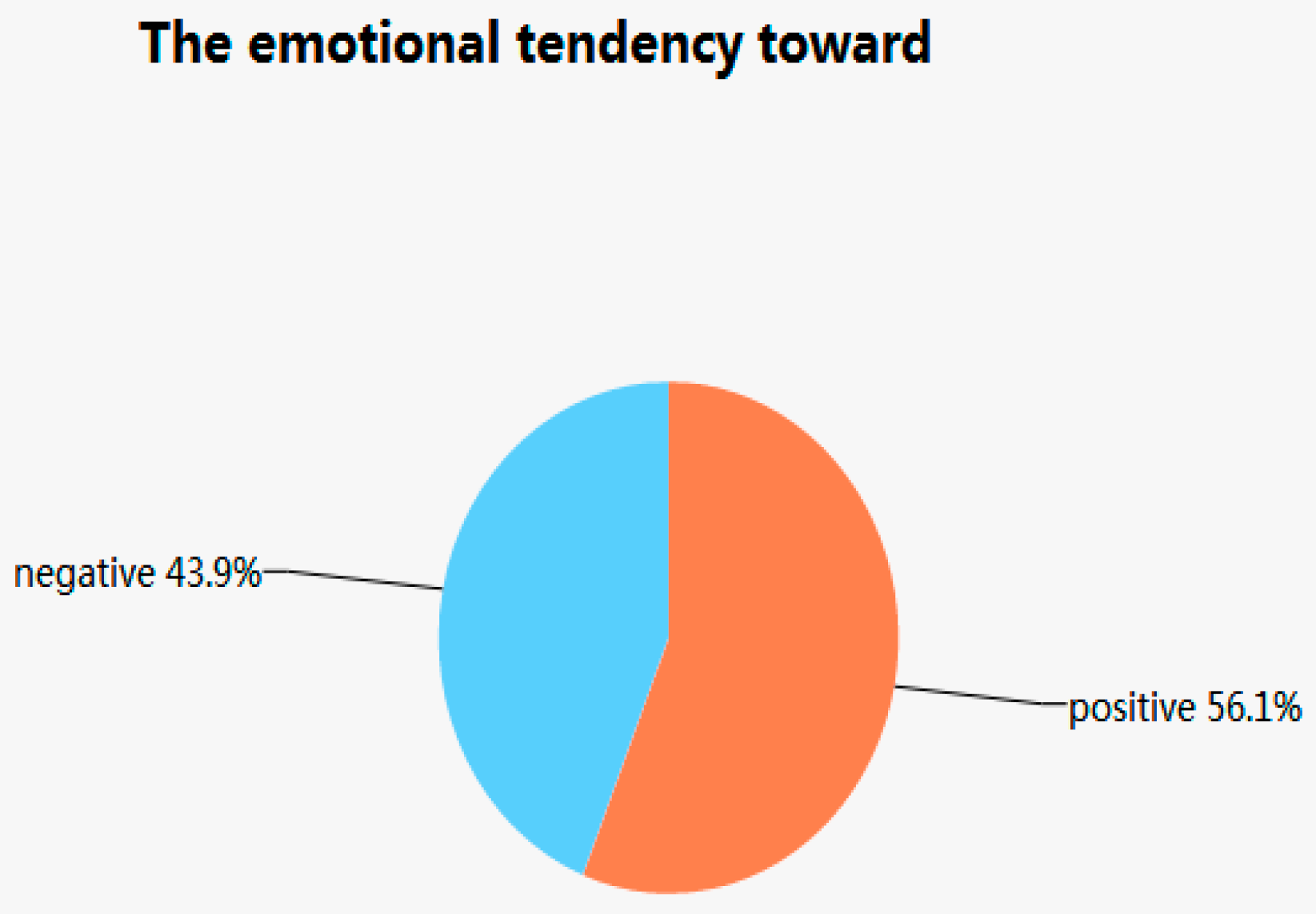
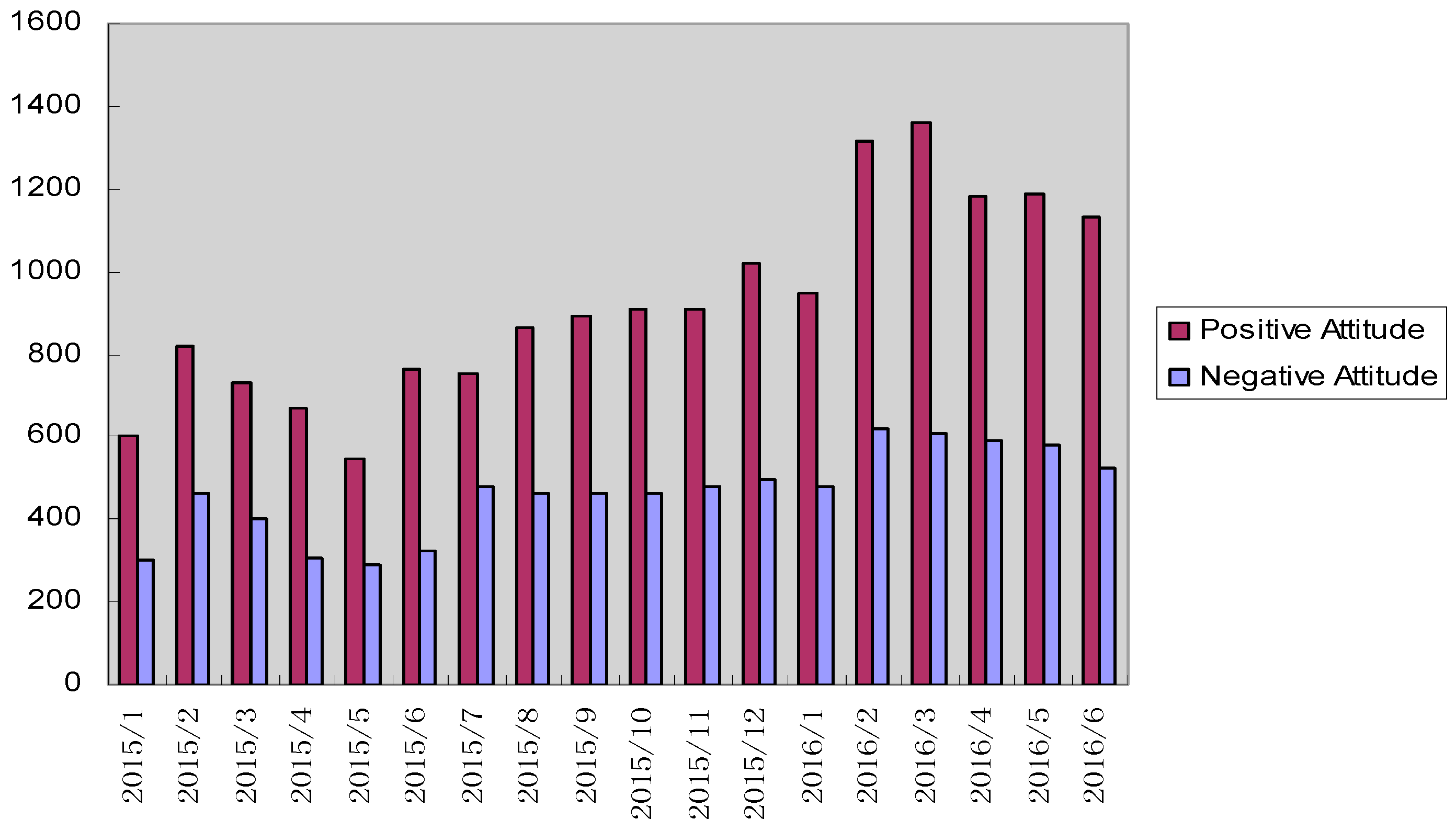
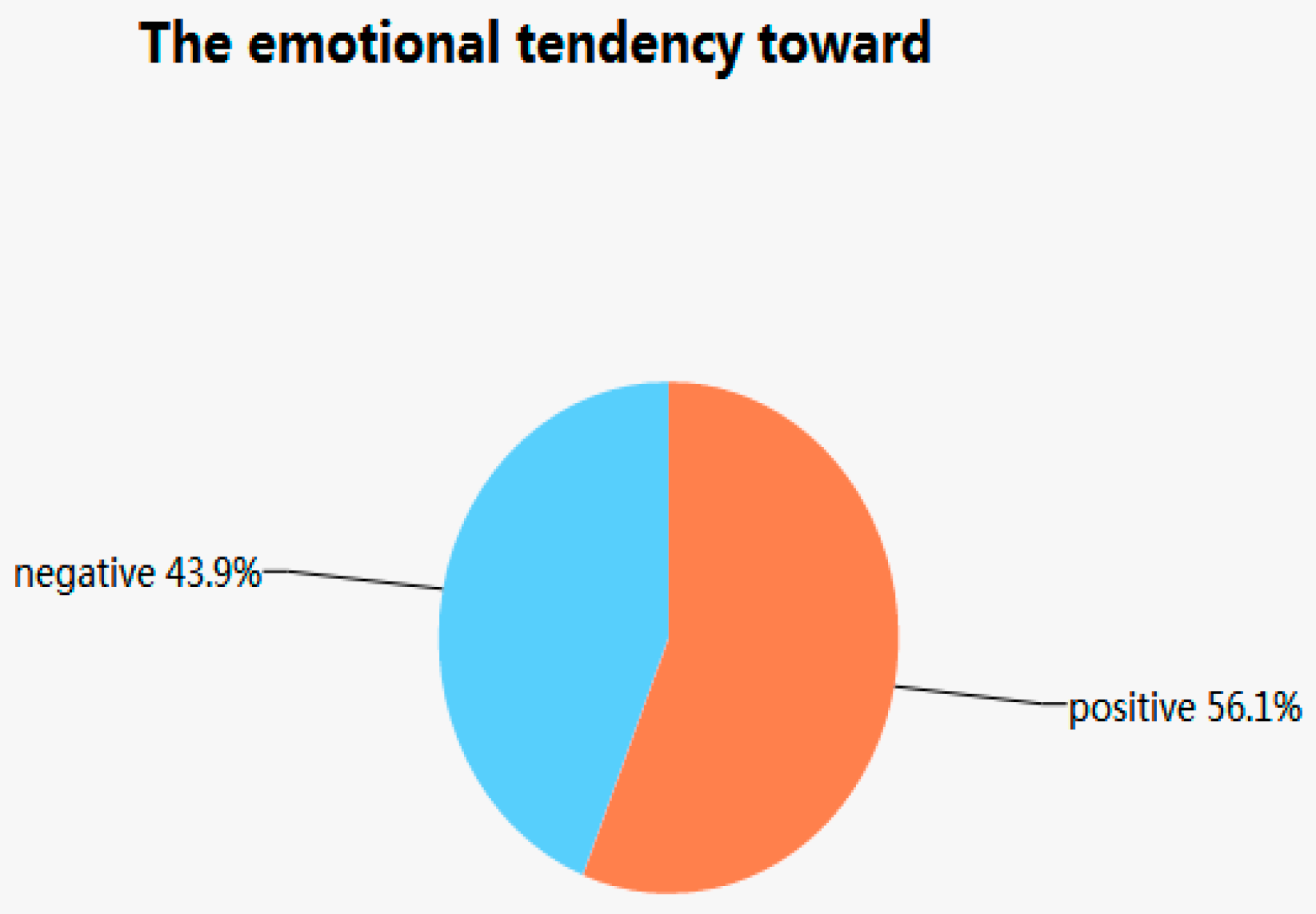
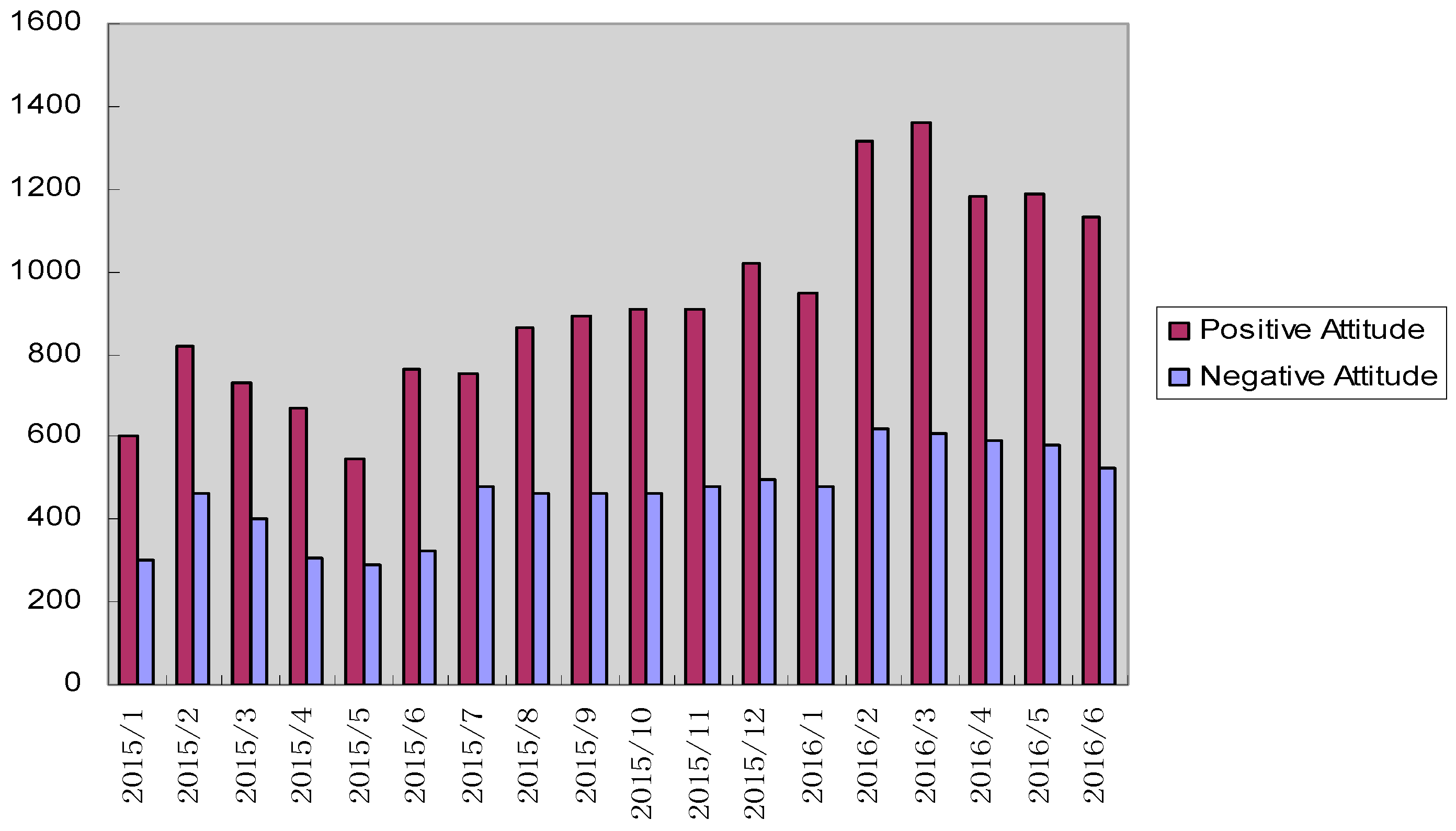
3.3. Using Support Vector Machine to Determine Emotional Attitudes toward Environment
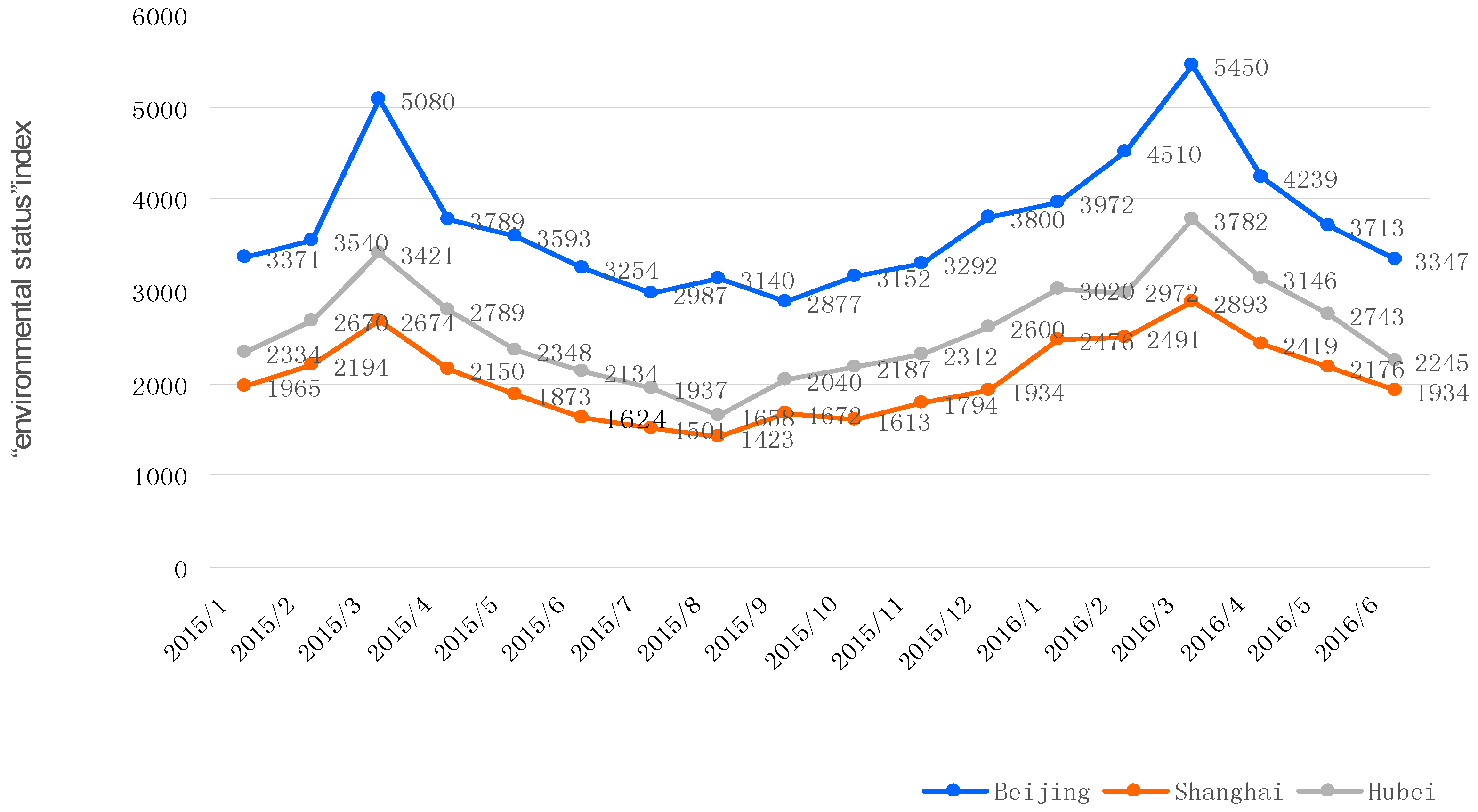
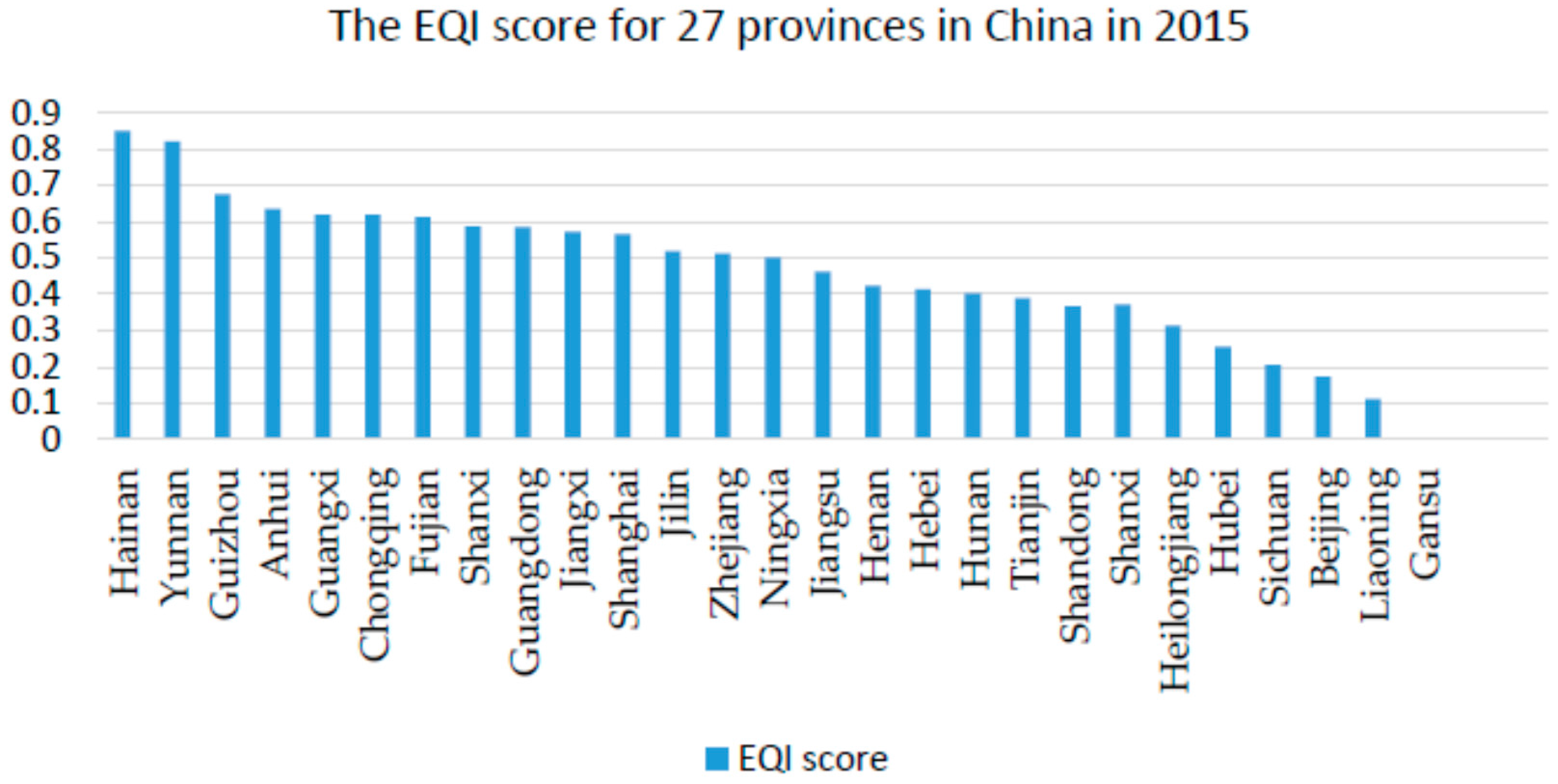
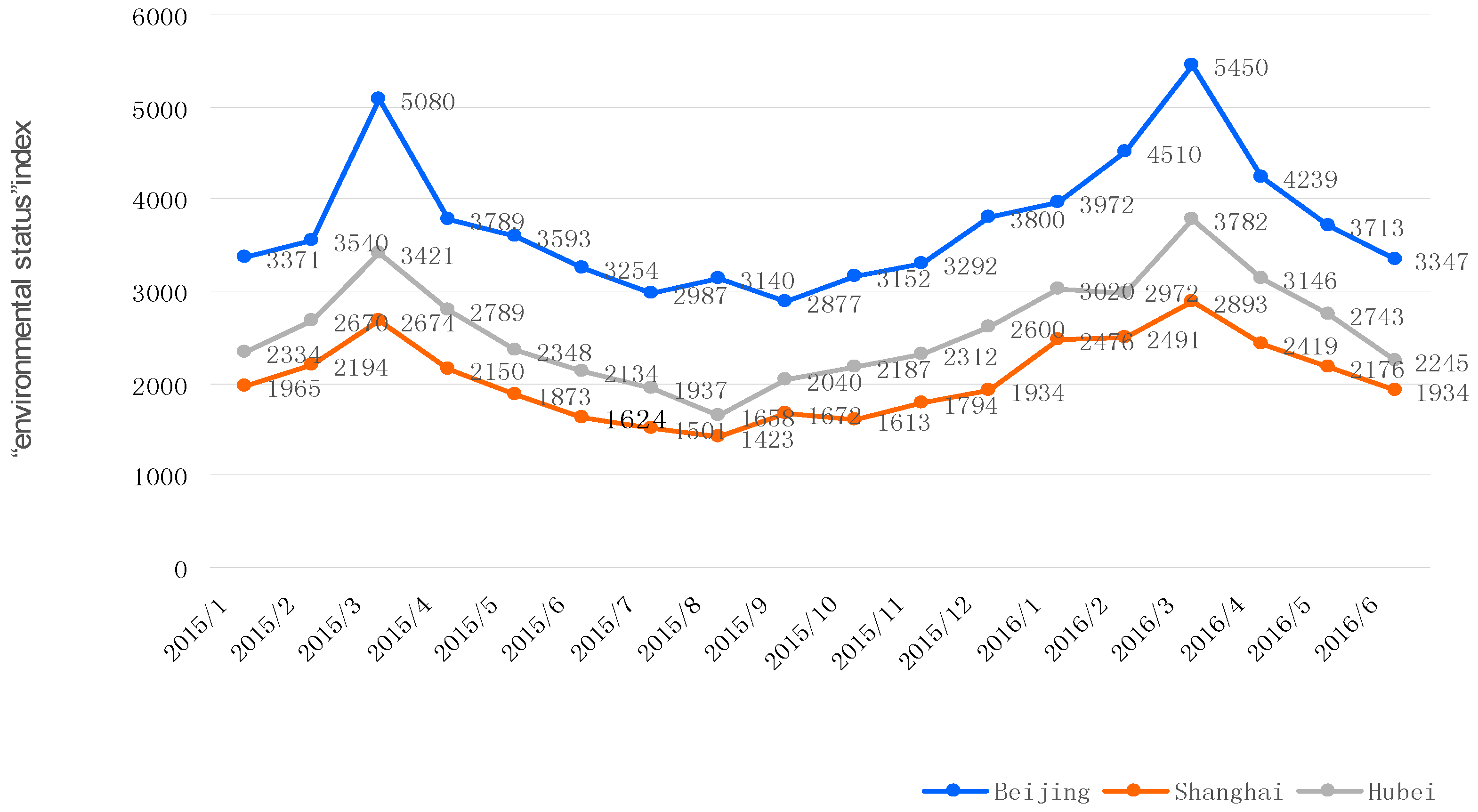
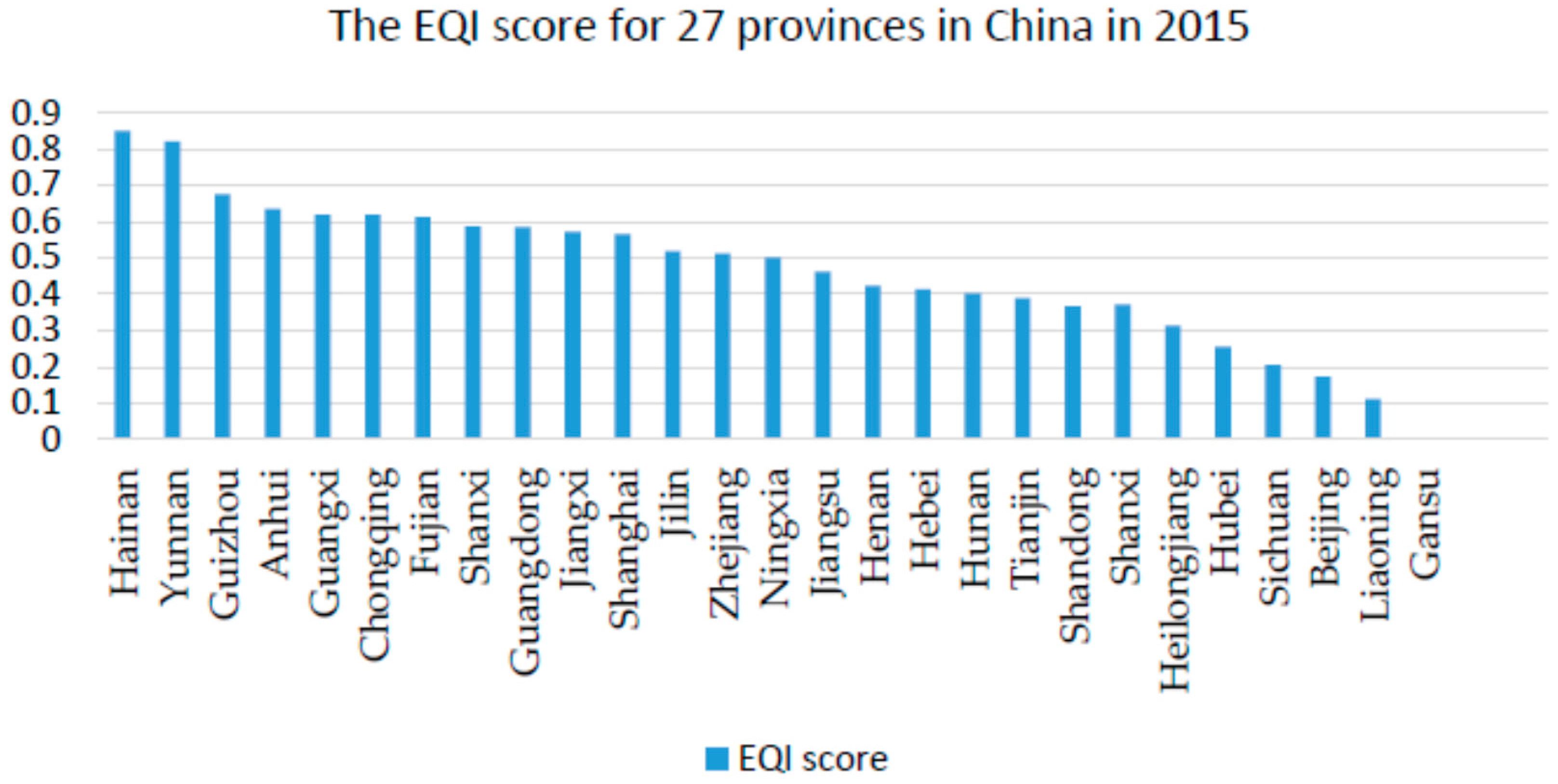
3.4. Calculating the EQI Score
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Cui, X.; Yang, N.; Wang, Z.; Hu, C.; Zhu, W.; Li, H.; Ji, Y.; Liu, C. Chinese social media analysis for disease surveillance. Pers. Ubiquitous Comput. 2015, 19, 1125–1132. [Google Scholar] [CrossRef]
- Wang, Z.; Cui, X.; Gao, L.; Yin, Q.; Ke, L.; Zhang, S. A hybrid model of sentimental entity recognition on mobile social media. EURASIP J. Wirel. Commun. Netw. 2016. [Google Scholar] [CrossRef]
- The Growing Impact of Social Media. Available online: http://www.sociallyawareblog.com/2012/11/21/time-americans-spendper-month-on-social-media-sites/ (accessed on 22 December 2016).
- Honicky, R.J.; Brewer, E.A.; Paulos, E.; White, R.M. N-Smarts: Networked Suite of Mobile Atmospheric Real-Time Sensors. In Proceedings of the Second ACM SIGCOMM Workshop on Networked Systems for Developing Regions, Seattle, WA, USA, 17–22 August 2008.
- Aoki, P.M.; Honicky, R.J.; Mainwaring, A.; Myers, C.; Paulos, E.; Subramanian, S.; Woodruff, A. A Vehicle for Research: Using Street Sweepers to Explore the Landscape of Environmental Community Action. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009.
- Xu, J.M.; Bhargava, A.; Nowak, R.; Zhu, X. Socioscope: Spatio-Temporal Signal Recovery from Social Media. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bristol, UK, 24–28 September 2012.
- Zheng, Y.; Liu, F.; Hsieh, H.P. U-Air: When Urban Air Quality Inference Meets Big Data. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013.
- Chen, J.; Chen, H.; Zheng, G.; Pan, J.Z.; Wu, H.; Zhang, N. Big Smog Meets Web Science: Smog Disaster Analysis Based on Social Media and Device Data on the Web. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014.
- Mei, S.; Li, H.; Fan, J.; Zhu, X.; Dyer, C.R. Inferring Air Pollution by Sniffing Social Media. In Proceedings of the 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Beijing, China, 17–20 August 2014.
- Kay, S.; Zhao, B.; Sui, D. Can social media clear the air? A case study of the air pollution problem in Chinese cities. Prof. Geogr. 2015, 67, 351–363. [Google Scholar] [CrossRef]
- Sammarco, M.; Tse, R.; Pau, G.; Marfia, G. Using geosocial search for urban air pollution monitoring. Pervasive Mob. Comput. 2016. [Google Scholar] [CrossRef]
- Tse, R.; Xiao, Y.; Pau, G.; Fdida, S.; Roccetti, M.; Marfia, G. Sensing pollution on online social networks: A transportation perspective. Mob. Netw. Appl. 2016, 21, 688–707. [Google Scholar] [CrossRef]
- Xu, L.; Lin, H.; Pan, Y.; Ren, H.; Chen, J. Constructing the affective lexicon ontology. J. China Soc. Sci. Tech. Inf. 2008, 2, 6. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Burges, C.J.C. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Platt, J.C. Fast training of support vector machines using sequential minimal optimization. In Advances in Kernel Methods; MIT Press: Cambridge, MA, USA, 1999; pp. 185–208. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing Human Actions: A Local SVM Approach. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 23–26 August 2004.
- Rakotomamonjy, A. Variable selection using SVM-based criteria. J. Mach. Learn. Res. 2003, 3, 1357–1370. [Google Scholar]
- Duan, K.; Keerthi, S.S.; Poo, A.N. Evaluation of simple performance measures for tuning SVM hyperparameters. Neurocomputing 2003, 51, 41–59. [Google Scholar] [CrossRef]
- Platt, J. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines. Available online: https://www.microsoft.com/en-us/research/publication/sequential-minimal-optimization-a-fast-algorithm-for-training-support-vector-machines/ (accessed on 22 December 2016).
- Forney, G.D. The Viterbi Algorithm. Available online: http://www.systems.caltech.edu/EE/Courses/EE127/EE127A/handout/ForneyViterbi.pdf (accessed on 22 December 2016).
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Texts. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, Bacelona, Spain, 21–26 July 2004.
- Xu, L.; Lin, H.; Pan, Y. Construction of ontology emotional vocabulary. J. China Soc. Sci. Tech. Inf. 2008, 27, 180–185. [Google Scholar]
- Joachims, T. Making large scale SVM learning practical. In Advances in Kernel Methods; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Appearance Rate (%) | |
|---|---|---|
| CHI Prescribing | TFIDF | |
| geographical thesaurus | 90.01% | 94.81% |
| emotional thesaurus | 92.63% | 96.13% |
| Classification | View | Emotion | Evaluation | Degree |
|---|---|---|---|---|
| −1 | 48 | −4 | 1 | 0 |
| −1 | 36 | −4 | 2 | 0 |
| 1 | 54 | 0 | 1 | 0 |
| 0 | 78 | 2 | 6 | 0 |
| −1 | 90 | −6 | 4 | 4 |
| Text Serial Number | Corresponding Feature Set (View, Emotion, Evaluation, Degree) | Output Results | Emotional Tendency |
|---|---|---|---|
| 1 | (15, 4, 1, 2) | 1 | Positive |
| 2 | (33, −4, −1, 0) | −1 | Negative |
| 3 | (45, −3, −3, 0) | −1 | Negative |
| 4 | (21, 2, 3, 1) | 1 | Positive |
| Rank | Province | Score | Rank | Province | Score | Rank | Province | Score |
|---|---|---|---|---|---|---|---|---|
| 1 | Hainan | 0.8501 | 10 | Jiangxi | 0.5723 | 21 | Tianjin | 0.3894 |
| 2 | Yunnan | 0.8209 | 11 | Shanghai | 0.5650 | 22 | Shandong | 0.3671 |
| 3 | Guizhou | 0.6753 | 12 | Jilin | 0.5192 | 21 | Shanxi | 0.3721 |
| 4 | Anhui | 0.6355 | 13 | Zhejiang | 0.5118 | 22 | Heilongjiang | 0.3142 |
| 5 | Guangxi | 0.6201 | 14 | Ningxia | 0.5014 | 23 | Hubei | 0.2561 |
| 6 | Chongqing | 0.6191 | 15 | Jiangsu | 0.4625 | 24 | Sichuan | 0.2054 |
| 7 | Fujian | 0.6121 | 16 | Henan | 0.4241 | 25 | Beijing | 0.1732 |
| 8 | Shanxi | 0.5864 | 17 | Hebei | 0.4138 | 26 | Liaoning | 0.1121 |
| 9 | Guangdong | 0.5852 | 18 | Hunan | 0.4031 | 27 | Gansu | 0 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Ke, L.; Cui, X.; Yin, Q.; Liao, L.; Gao, L.; Wang, Z. Monitoring Environmental Quality by Sniffing Social Media. Sustainability 2017, 9, 85. https://doi.org/10.3390/su9020085
Wang Z, Ke L, Cui X, Yin Q, Liao L, Gao L, Wang Z. Monitoring Environmental Quality by Sniffing Social Media. Sustainability. 2017; 9(2):85. https://doi.org/10.3390/su9020085
Chicago/Turabian StyleWang, Zhibo, Lei Ke, Xiaohui Cui, Qi Yin, Longfei Liao, Lu Gao, and Zhenyu Wang. 2017. "Monitoring Environmental Quality by Sniffing Social Media" Sustainability 9, no. 2: 85. https://doi.org/10.3390/su9020085