Inertia-Constrained Pixel-by-Pixel Nonnegative Matrix Factorisation: A Hyperspectral Unmixing Method Dealing with Intra-Class Variability

 , , and
, , and
Abstract
:1. Introduction
2. Intra-Class Variability
2.1. Problem Statement
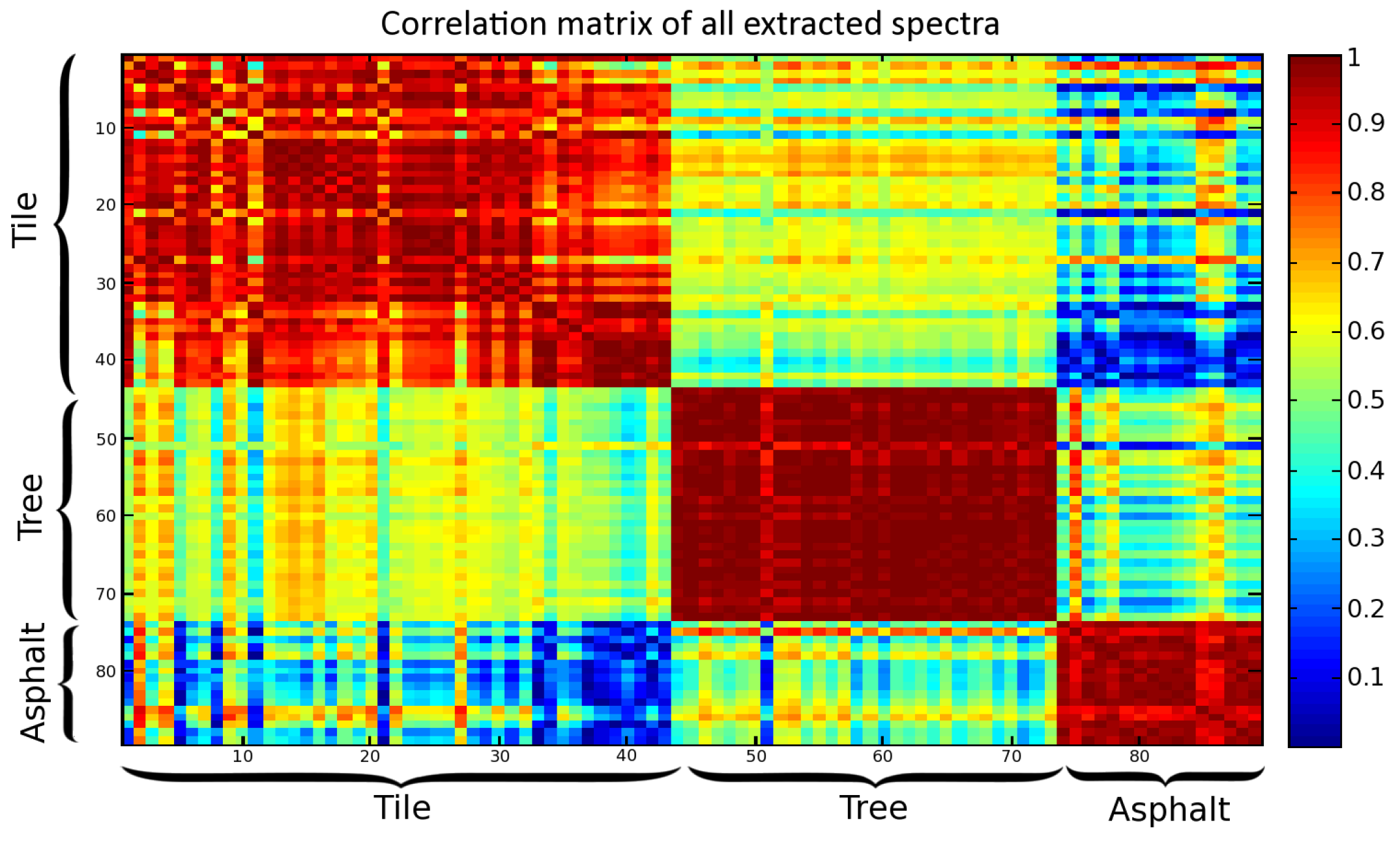
2.2. Data Description
- pure material spectra,
- various illumination conditions,
- representative of the spectral variability of the materials due to composition, weathering (tiles of various roofs, asphalt extracted from different places...).
2.3. Data Analysis
3. Unmixing Problem Statement
4. Unconstrained Pixel-By-Pixel Nonnegative Matrix Factorisation (UP-NMF)
4.1. Cost Function
4.2. Gradient Calculation
4.3. Update Algorithm
5. Inertia-Constrained Pixel-By-Pixel Nonnegative Matrix Factorisation (IP-NMF)
5.1. Cost Function
5.2. Gradient Calculation
5.3. Update Algorithm
| Algorithm 1: 1 Update of matrix |
 |
6. Test Results for Semi-Synthetic Data Set
6.1. Test Description
6.2. Evaluation Criteria
6.3. Results
7. Test Results for Real Images
7.1. Data Set
7.2. Test Description
- A standard NMF method [37] is applied to retrieve at the same time both the source spectra (one per class) and their associated abundance coefficients.
- IP-NMF is applied to obtain one set of endmembers per pixel and the associated coefficients.
7.3. Results
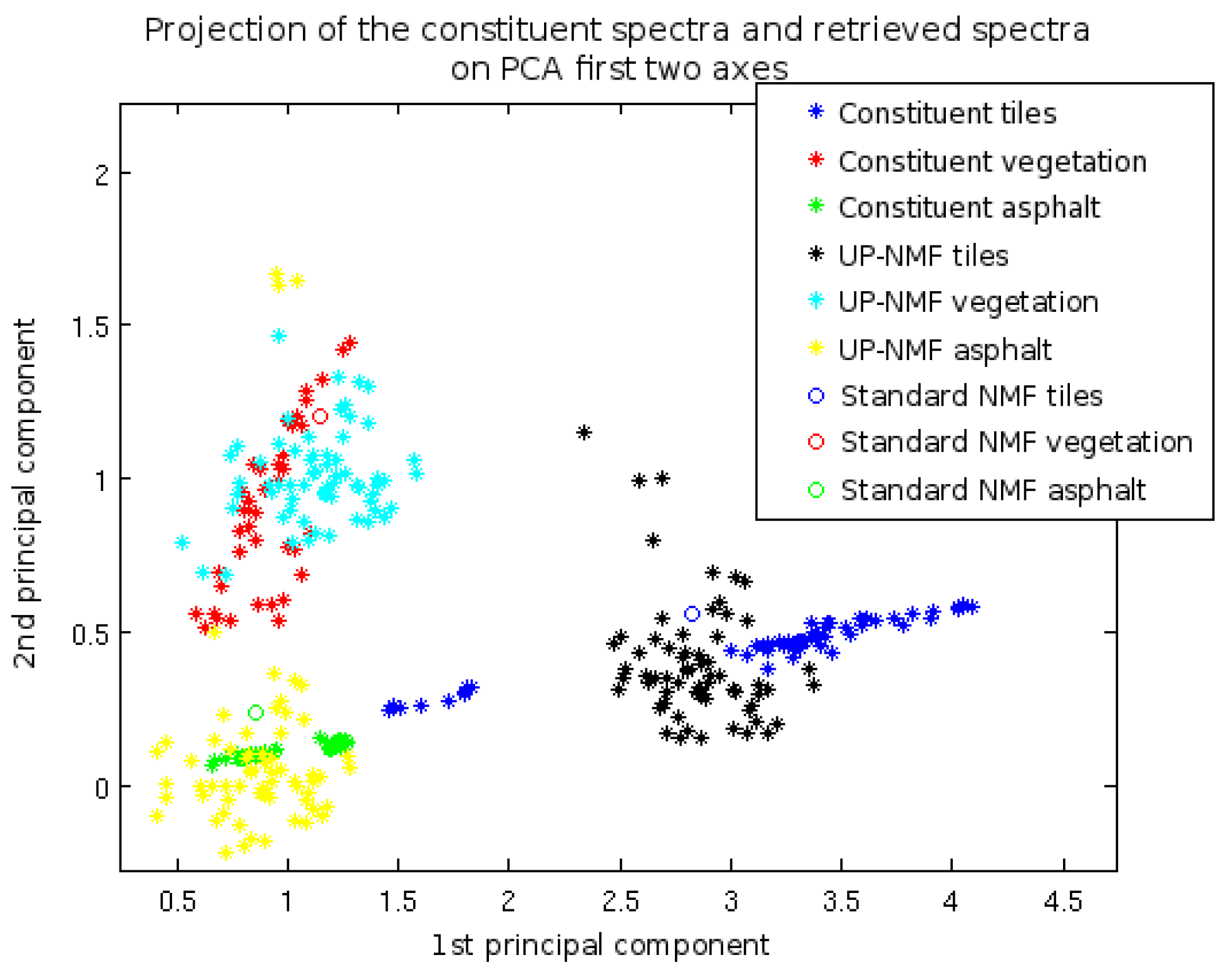
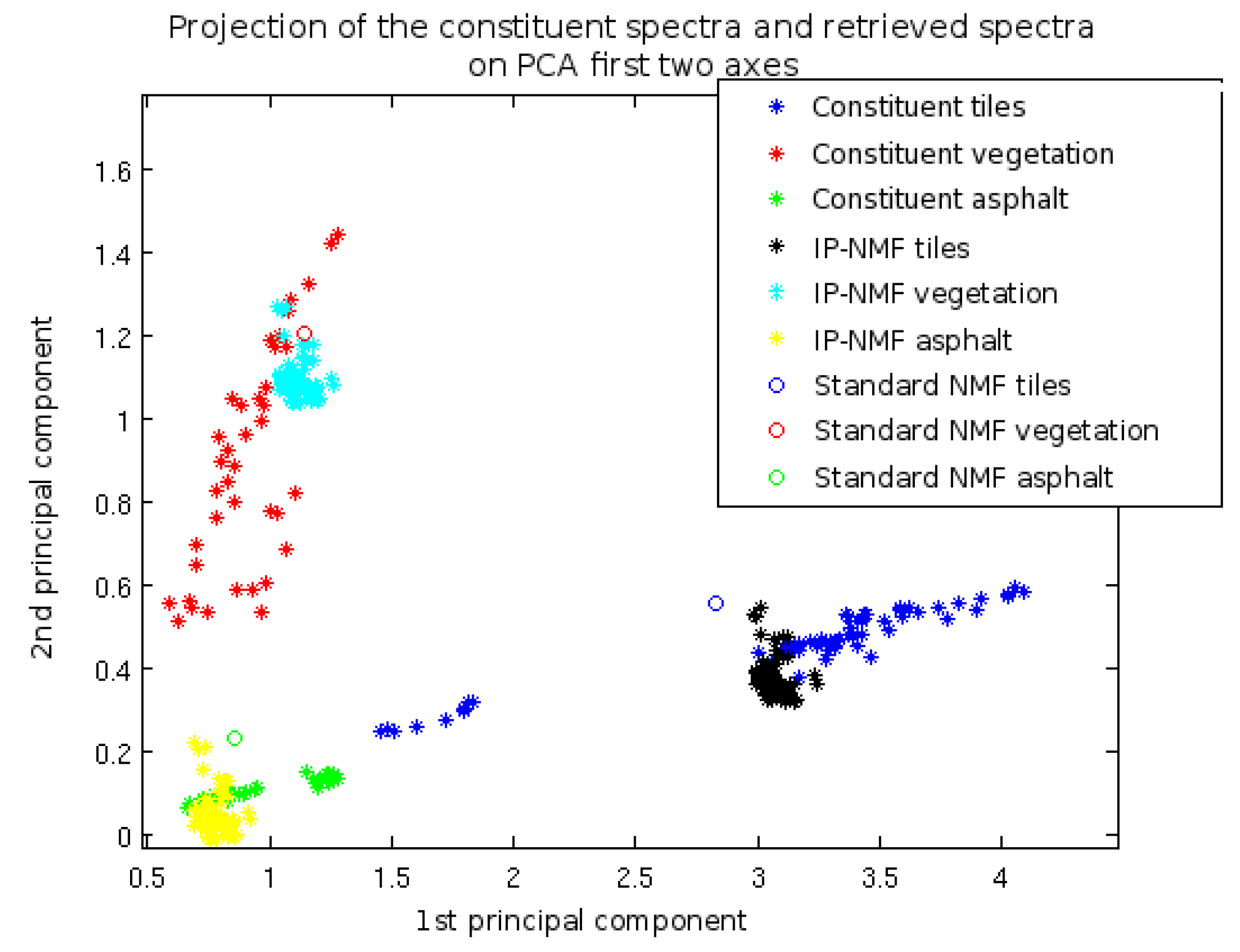
7.3.1. Results of Classical Unmixing Methods (One Set of Endmembers per Image)
7.3.2. Results of the IP-NMF Method Initialised with VCA
7.3.3. Results of the IP-NMF Method with Manual Initialisation
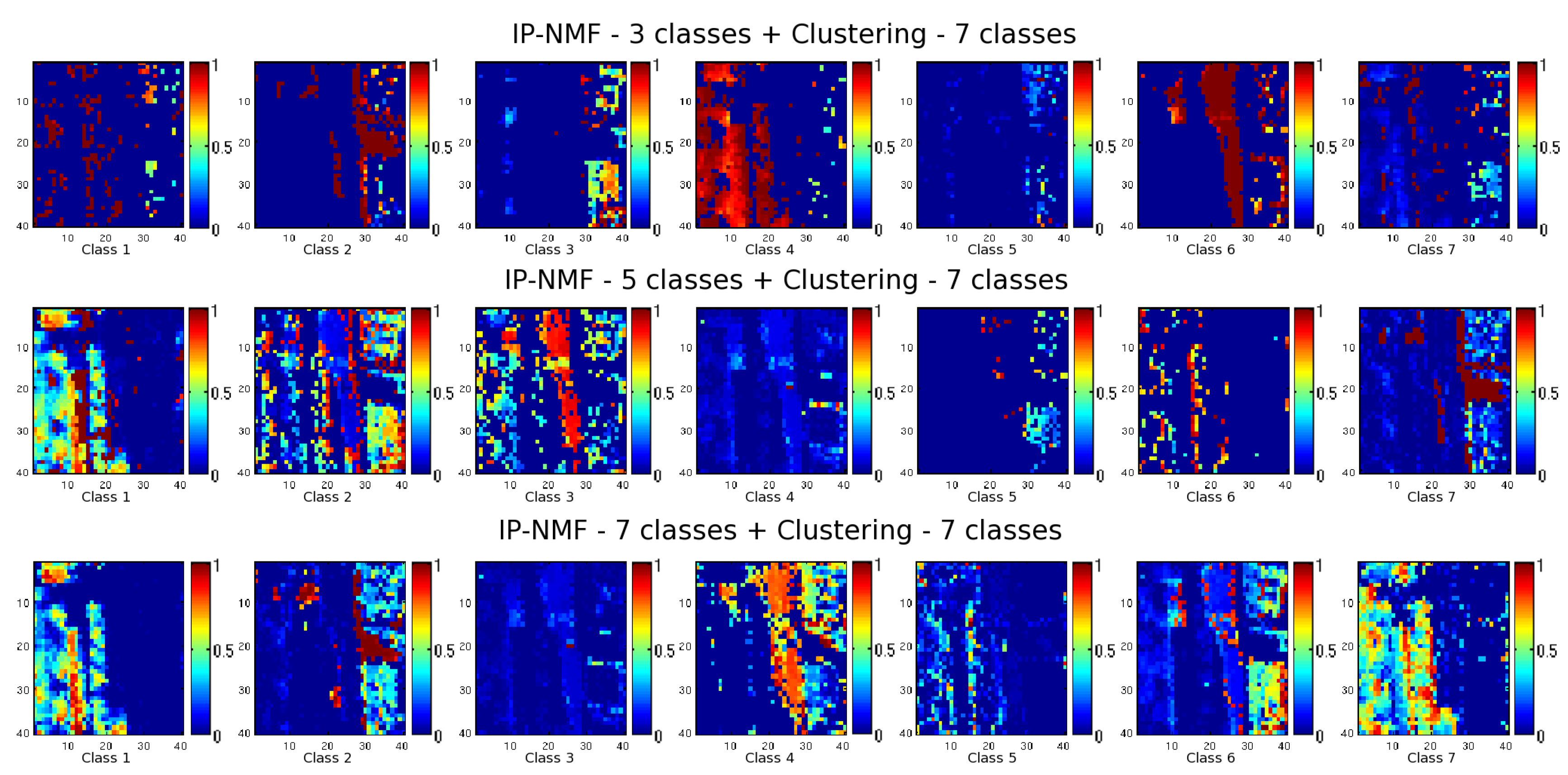
7.3.4. Result of Automated IP-NMF with a Post-Processing
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Pseudo-Code of the UP-NMF Update
| Algorithm A1: 1. Update of matrix |
 |
Appendix B. Gradient Calculation for the IP-NMF Method
References
- Keshava, N.; Mustard, J. Spectral unmixing. IEEE Signal Process. Mag. 2002, 19, 44–57. [Google Scholar] [CrossRef]
- Singer, R.B.; McCord, T.B. Mars—Large scale mixing of bright and dark surface materials and implications for analysis of spectral reflectance. In Proceedings of the Lunar and Planetary Science Conference, Houston, TX, USA, 19–23 March 1979; Volume 10, pp. 1835–1848. [Google Scholar]
- Meganem, I.; Deliot, P.; Briottet, X.; Deville, Y.; Hosseini, S. Linear Quadratic Mixing Model for Reflectances in Urban Environments. IEEE Trans. Geosci. Remote Sens. 2014, 52, 544–558. [Google Scholar] [CrossRef]
- Mustard, J.F.; Pieters, C.M. Quantitative abundance estimates from bidirectional reflectance measurements. J. Geophys. Res. 1987, 92, E617–E626. [Google Scholar] [CrossRef] [Green Version]
- Bioucas-Dias, J.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral Unmixing Overview: Geometrical, Statistical, and Sparse Regression-Based Approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef] [Green Version]
- Heylen, R.; Parente, M.; Gader, P. A Review of Nonlinear Hyperspectral Unmixing Methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1844–1868. [Google Scholar] [CrossRef]
- Zare, A.; Ho, K. Endmember Variability in Hyperspectral Analysis: Addressing Spectral Variability During Spectral Unmixing. IEEE Signal Process. Mag. 2014, 31, 95–104. [Google Scholar] [CrossRef]
- Roberts, D.A. Hierarchical Multiple Endmember Spectral Mixture Analysis (MESMA) of hyperspectral imagery for urban environments. Remote Sens. Environ. 2009, 113, 1712–1723. [Google Scholar] [CrossRef]
- Eches, O.; Dobigeon, N.; Mailhes, C.; Tourneret, J.Y. Bayesian Estimation of Linear Mixtures Using the Normal Compositional Model. IEEE Trans. Image Process. 2010, 19, 1403–1413. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dobigeon, N.; Moussaoui, S.; Coulon, M.; Tourneret, J.Y.; Hero, A. Joint Bayesian Endmember Extraction and Linear Unmixing for Hyperspectral Imagery. IEEE Trans. Signal Process. 2009, 57, 4355–4368. [Google Scholar] [CrossRef] [Green Version]
- Castrodad, A.; Xing, Z.; Greer, J.; Bosch, E.; Carin, L.; Sapiro, G. Learning Discriminative Sparse Representations for Modeling, Source Separation, and Mapping of Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4263–4281. [Google Scholar] [CrossRef]
- Somers, B.; Zortea, M.; Plaza, A.; Asner, G. Automated Extraction of Image-Based Endmember Bundles for Improved Spectral Unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 396–408. [Google Scholar] [CrossRef] [Green Version]
- Nascimento, J.M.P.; Bioucas Dias, J.M. Does Independent Component Analysis play a role in unmixing hyperspectral data? IEEE Trans. Geosci. Remote Sens. 2005, 43, 175–187. [Google Scholar] [CrossRef]
- Taleb, A. A generic framework for blind source separation in structured nonlinear models. IEEE Trans. Signal Process. 2002, 50, 1819–1830. [Google Scholar] [CrossRef]
- Sigurdsson, J.; Ulfarsson, M.O.; Sveinsson, J.R. Blind hyperspectral unmixing using total variation and lq sparse regularization. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6371–6384. [Google Scholar] [CrossRef]
- Addabbo, P.; di Bisceglie, M.; Galdi, C. The unmixing of atmospheric trace gases from hyperspectral satellite data. IEEE Trans. Geosci. Remote Sens. 2012, 50, 320–329. [Google Scholar] [CrossRef]
- Addabbo, P.; di Bisceglie, M.; Galdi, C.; Ullo, S.L. The hyperspectral unmixing of trace-gases from ESA SCIAMACHY reflectance data. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2130–2134. [Google Scholar] [CrossRef]
- Tits, L.; Somers, B.; Saeys, W.; Coppin, P. Site-specific plant condition monitoring through hyperspectral alternating least squares unmixing. IEEE J. Sel. Top. Earth Obs. Remote Sens. 2014, 7, 3606–3618. [Google Scholar] [CrossRef]
- Ceamanos, X.; Douté, S.; Luo, B.; Schmidt, F.; Jouannic, G.; Chanussot, J. Intercomparison and validation of techniques for spectral unmixing of hyperspectral images: a planetary case study. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4341–4358. [Google Scholar] [CrossRef]
- Huck, A.; Guillaume, M.; Blanc-Talon, J. Minimum dispersion constrained nonnegative matrix factorization to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2590–2602. [Google Scholar] [CrossRef]
- Drumetz, L.; Veganzones, M.-A.; Henrot, S.; Phlypo, R.; Chanussot, J.; Jutten, C. Blind hyperspectral unmixing using an extended linear mixing model to address spectral variability. IEEE Trans. Image Process. 2016, 25, 3890–3905. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Zhou, G.; Xie, S.; Ding, S.; Yang, J.-M.; Zhang, J. Blind spectral unmixing based on sparse nonnegative matrix factorization. IEEE Trans. Image Process. 2011, 20, 1112–1125. [Google Scholar] [CrossRef] [PubMed]
- Gutierrez-Navarro, O.; Campos-Delgado, D.U.; Arce-Santana, E.R.; Mendez, M.O.; Jo, J.A. Blind end-member and abundance extraction for multispectral fluorescence lifetime imaging microscopy data. IEEE J. Biomed. Health Inf. 2014, 18, 606–617. [Google Scholar] [CrossRef] [PubMed]
- Clark, R.N.; King, T.V.V.; Klejwa, M.; Swayze, G.A.; Vergo, N. High Spectral Resolution Reflectance Spectroscopy of Minerals. J. Geophys. Res. 1990, 95, 12653–12680. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Meganem, I.; Deville, Y.; Hosseini, S.; Déliot, P.; Briottet, X. Linear-quadratic blind source separation using NMF to unmix urban hyperspectral images. IEEE Trans. Signal Process. 2014, 62, 1822–1833. [Google Scholar] [CrossRef]
- Dennison, P.E.; Halligan, K.Q.; Roberts, D.A. A comparison of error metrics and constraints for multiple endmember spectral mixture analysis and spectral angle mapper. Remote Sens. Environ. 2004, 93, 359–367. [Google Scholar] [CrossRef]
- Lacherade, S.; Miesch, C.; Briottet, X.; Men, H.L. Spectral variability and bidirectional reflectance behaviour of urban materials at a 20 cm spatial resolution in the visible and near-infrared wavelengths. A case study over Toulouse (France). Int. J. Remote Sens. 2005, 26, 3859–3866. [Google Scholar] [CrossRef]
- Veganzones, M.; Drumetz, L.; Tochon, G.; Dalla Mura, M.; Plaza, A.; Bioucas-Dias, J.; Chanussot, J. A new extended linear mixing model to address spectral variability. In Proceedings of the 2014 6th Workshop on Hyperspectral Image and Signal Processing (WHISPERS), Lausanne, Switzerland, 25–27 June 2014. [Google Scholar]
- Nascimento, J.; Bioucas Dias, J. Vertex component analysis: a fast algorithm to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef] [Green Version]
- Bateson, C.; Asner, G.; Wessman, C. Endmember bundles: a new approach to incorporating endmember variability into spectral mixture analysis. IEEE Trans. Geosci. Remote Sens. 2000, 38, 1083–1094. [Google Scholar] [CrossRef]
- García-Haro, F.J.; Sommer, S.; Kemper, T. A new tool for variable multiple endmember spectral mixture analysis (VMESMA). Int. J. Remote Sens. 2005, 26, 2135–2162. [Google Scholar] [CrossRef] [Green Version]
- Adeline, K.; Briottet, X.; Paparoditis, N.; Gastellu-Etchegorry, J.P. Material reflectance retrieval in urban tree shadows with physics-based empirical atmospheric correction. In Proceedings of the Urban Remote Sensing Event (JURSE), Munich, Germany, 10–13 April 2013; pp. 279–283. [Google Scholar]
- Miesch, C.; Poutier, L.; Achard, V.; Briottet, X.; Lenot, X.; Boucher, Y. Direct and inverse radiative transfer solutions for visible and near-infrared hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1552–1562. [Google Scholar] [CrossRef]
- Qian, Y.; Jia, S.; Zhou, J.; Robles-Kelly, A. Hyperspectral Unmixing via Sparsity-Constrained Nonnegative Matrix Factorization. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4282–4297. [Google Scholar] [CrossRef]
- Hoyer, P.O.; Dayan, P. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 2004, 5, 1457–1469. [Google Scholar]
- Lin, C.J. Projected Gradient Methods for Nonnegative Matrix Factorization. Neural Comput. 2007, 19, 2756–2779. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Petersen, K.B.; Pedersen, M.S. The Matrix Cookbook; Technical Report; Version 20121115; Technical University of Denmark: Copenhagen, Denmark, 2012. [Google Scholar]
- Winter, M.E. N-FINDR: An algorithm for fast autonomous spectral end-member determination in hyperspectral data. In Proceedings of the SPIE’s International Symposium on Optical Science, Engineering, and Instrumentation, Denver, CO, USA, 18–23 July 1999; Volume 3753, pp. 266–275. [Google Scholar]
- Heinz, D.; Chang, C.I. Fully constrained least squares linear spectral mixture analysis method for material quantification in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2001, 39, 529–545. [Google Scholar] [CrossRef]
- Zhang, L.; Du, B.; Zhong, Y. Hybrid Detectors Based on Selective Endmembers. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2633–2646. [Google Scholar] [CrossRef]
- Broadwater, J.; Chellappa, R. Hybrid Detectors for Subpixel Targets. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1891–1903. [Google Scholar] [CrossRef] [PubMed]
- Grupo De Inteligencia Computacional, Universidad Del PaíS Vasco/Euskal Herriko Unibertsitatea (UPV/EHU). Endmember Induction Algorithms (EIAs) Toolbox. Available online: http://www.ehu.eus/ccwintco/index.php/Endmember_Induction_Algorithms (accessed on 24 October 2018).
- Bioucas-Dias, J.; Nascimento, J. Hyperspectral Subspace Identification. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2435–2445. [Google Scholar] [CrossRef] [Green Version]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations; The Regents of the University of California: Oakland, CA, USA, 1967. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N-FINDR + FCLS | Standard NMF | UP-NMF | IP-NMF () | IP-NMF () | |
|---|---|---|---|---|---|
| <0.1 | |||||
| (deg) | |||||
| (%) | |||||
| Time (s) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Revel, C.; Deville, Y.; Achard, V.; Briottet, X.; Weber, C. Inertia-Constrained Pixel-by-Pixel Nonnegative Matrix Factorisation: A Hyperspectral Unmixing Method Dealing with Intra-Class Variability. Remote Sens. 2018, 10, 1706. https://doi.org/10.3390/rs10111706
Revel C, Deville Y, Achard V, Briottet X, Weber C. Inertia-Constrained Pixel-by-Pixel Nonnegative Matrix Factorisation: A Hyperspectral Unmixing Method Dealing with Intra-Class Variability. Remote Sensing. 2018; 10(11):1706. https://doi.org/10.3390/rs10111706
Chicago/Turabian StyleRevel, Charlotte, Yannick Deville, Véronique Achard, Xavier Briottet, and Christiane Weber. 2018. "Inertia-Constrained Pixel-by-Pixel Nonnegative Matrix Factorisation: A Hyperspectral Unmixing Method Dealing with Intra-Class Variability" Remote Sensing 10, no. 11: 1706. https://doi.org/10.3390/rs10111706