CraterIDNet: An End-to-End Fully Convolutional Neural Network for Crater Detection and Identification in Remotely Sensed Planetary Images

Abstract
1. Introduction
2. CraterIDNet
3. Methodology
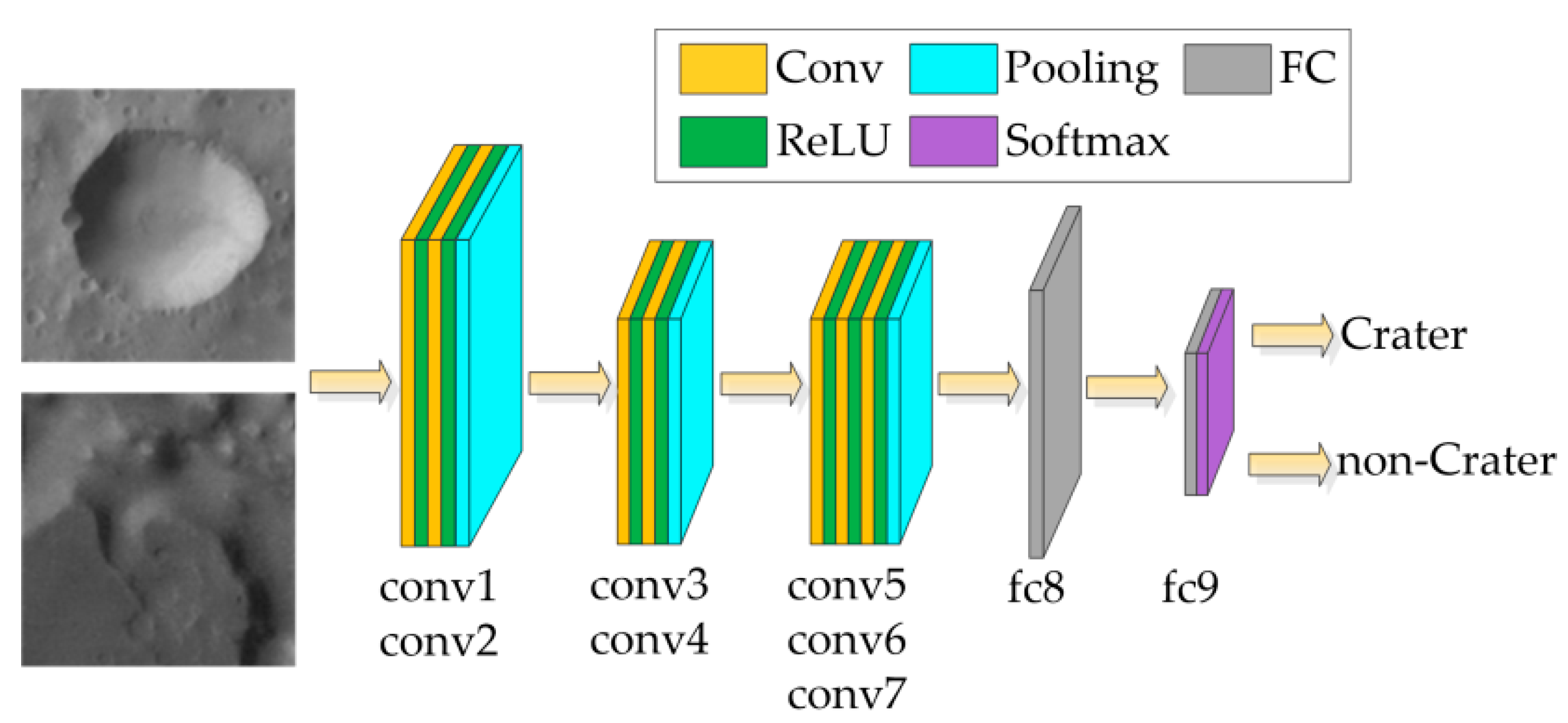
3.1. Pre-Trained Model
3.1.1. Dataset Generation and Training Method
3.1.2. Architecture
3.2. Crater Detection Pipeline (CDP)
3.2.1. CDP Architecture
| Algorithm 1: CDP crater detection. |
| input: remotely sensed image output: detected candidate crater 1 foreach input image do 2 calculate cls and reg results through forward propagation; 3 generate anchors; 4 foreach anchor do 5 if anchor.cls > threshold then 6 proposali ← anchor.transform(anchor, reg); 7 end if 8 end for 9 proposals.sort(cls); 10 crater_proposals ← NMS(proposals, nms_threshold); 11 crater.position ← crater_proposal.center; 12 crater.diameter ← crater_proposal.width; 13 return crater 14 end for |
3.2.2. Optimal Anchor Generation Strategy
3.2.3. Dataset Generation
3.2.4. Three-Step Alternating Training Method
- The pre-trained model proposed in Section 3.1 is used to initialize the convolutional layers conv1–conv7. The weights of other convolutional layers are initialized using the “Xavier” method, and biases are initialized with constant 0. The momentum and weight decay are set to 0.9 and 0.0005, respectively. The learning rates of the convolutional layers unique to CDP1 (i.e., conv4_1–conv4_3) are set to 0. Therefore, we only fine-tune conv1–conv7 and train layers unique to CDP2 by using the CDP2 dataset at this step. The network is trained for 50 epochs with a starting learning rate of 0.005 and then decreased by a factor of 0.8 every 10,000 iterations.
- The network is initialized by using the model trained in Step 1. Convolutional layers conv5–conv7 and the unique layers to CDP2 (i.e., conv7_1–conv7_3) are fixed, and the network is fine-tuned using the CDP1 dataset. The momentum and weight decay are set to 0.9 and 0.0005, respectively. The network is trained for 30 epochs with a starting learning rate of 0.001 and then decreased by a factor of 0.6 every 20,000 iterations.
- The network is initialized by applying the model trained in Step 2. The shared convolutional layers conv1–conv4 and the unique layers to CDP1 (i.e., conv4_1–conv4_3) are fixed, and the network is fine-tuned using the CDP2 dataset. The momentum and weight decay are set to 0.9 and 0.0005, respectively. The network is trained for 30 epochs with a starting learning rate of 0.0005 and then decreased by a factor of 0.8 every 15,000 iterations.
3.3. Crater Identification Pipeline (CIP)
3.3.1. Grid Pattern Layer
- Candidate crater selection. The altitude range for the remote sensing camera is assumed to be between Hmin and Hmax. Href is defined as the reference altitude when the training images were obtained. The craters within the detectable range at any altitude within the bounding range are selected as candidate craters. Therefore, the size of the candidate crater can be expressed as follows:where Dmin and Dmax denote the minimum and maximum apparent diameters of the candidate craters selected for identification when the crater images are acquired at altitude Href, respectively.
- Main crater selection. At least three craters are required within the camera field of view (FOV) to calculate the spacecraft surface relative position. We select 10 candidate craters that are closest to the center of the FOV as the main craters. If less than 10 candidate craters are found in the FOV, then all of them are selected as the main craters.
- Scale normalization. For each main crater, the distances between the main crater and its neighbor candidate craters are calculated and defined as the main distances. Let H denote the camera altitude; the main distances and apparent diameters of all candidate craters are normalized to a reference scale by a scale factor Href/H. The relative position of the neighbor candidate craters with respect to each main crater after scale normalization is then determined.
- Grid pattern generation. A grid of size 17 × 17 is oriented on each main crater and its closest neighboring crater. The side length of each grid cell is denoted as Lg. Each grid cell that contains at least one candidate crater is set to an active state, and its output intensity is calculated as the cumulative sum of the normalized apparent diameters of the candidate craters within this grid cell. The output intensity of the grid cells without any craters is set to 0.
3.3.2. Dataset Generation and Training Method
- For each candidate crater, a unique label is provided for identification.
- The side length of the grid cell is set to Lg = 24 pixels in this study. A total of 1008 groups of grid patterns are generated for each candidate crater. Each group contains 2000 grid patterns. Crater position and apparent diameter noises are added to each candidate crater before generating grid patterns. The crater position and apparent diameter noises are random variables that follow normal distributions N(0, 2.52) and N(1.5, 1.52), correspondingly.
- A total of 400 grid patterns are randomly selected from each group, and the information of a neighboring crater is randomly removed to simulate the situation where the detection result of this crater is a false negative (FN).
- To simulate the situation where FPs are detected by CDP, we randomly select 700 and 400 grid patterns from each group to add one and two false craters, respectively. The false craters are added in random positions in the grid pattern, and their apparent diameters are random variables that are uniformly distributed within the range of [20, 50] pixels.
- Eight sets of grid patterns are randomly selected from each group, and each set contains 100 grid patterns. The crater information in the blue region for each set that correspond to the eight cases depicted in Figure 8 is removed to simulate the situation where the main crater is close to the boundary of the FOV.
- In total, 2,016,000 grid pattern samples are generated. The dataset is then split into 10 mutually disjoint subsets utilizing the stratified sampling method. Each subset contains the same percentage of samples of each class as the complete set (i.e., 200 samples for each candidate craters).
3.3.3. CIP Architecture
| Algorithm 2: CIP crater identification. |
| input: detected craters output: identification results 1 candidate crater selection using Equation (14); 2 foreach candidate_crater do 3 calculate distance di between crater center and image center; 4 end for 5 candidate_craters.sort(d); 6 if candidate_craters.num > 10 then 7 main_craters ← candidate_craters[:10]; 8 else 9 main_craters ← candidate_craters; 10 end if 11 iden_results = zeros(main_crater.num); 12 foreach main_crater do 13 neighbor_craters ← candidate_crater.remove(main_crater); 14 calculate main distance between main_crater and its neightbor_craters; 15 scale normalization; 16 generate grid pattern image; 17 predict class through forward propagation; 18 iden_result ← class; 19 end for |
| 20 return iden_results |
4. Experimental Results
4.1. Validation of Crater Detection Performance
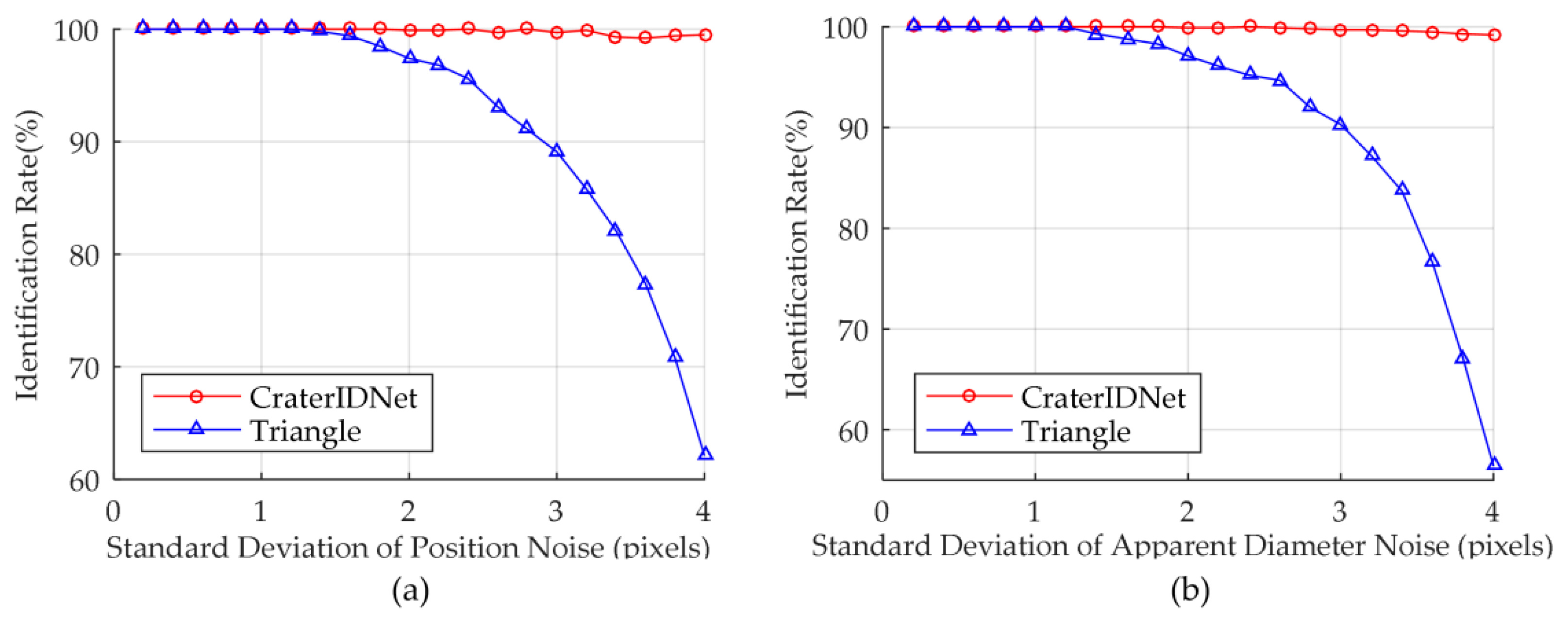
4.2. Validation of Crater Identification Performance
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Urbach, E.R.; Stepinski, T.F. Automatic detection of sub-km craters in high resolution planetary images. Planet. Space Sci. 2009, 57, 880–887. [Google Scholar] [CrossRef]
- Riedel, J.; Bhaskaran, S.; Synnott, S.; Bollman, W.; Null, G. An Autonomous Optical Navigation and Control System for Interplanetary Exploration Missions. In Proceedings of the 2nd IAA International Conference on Lost-Cost Planetary Missions, Laurel, MD, USA, 16–19 April 1996. [Google Scholar]
- Jun’; Kawaguchi, I.; Hashimoto, T.; Kubota, T.; Sawai, S.; Fujii, G. Autonomous optical guidance and navigation strategy around a small body. J. Guid. Control Dyn. 1997, 20, 1010–1017. [Google Scholar] [CrossRef]
- Cheng, Y.; Johnson, A.E.; Matthies, L.H.; Olson, C.F. Optical landmark detection for spacecraft navigation. In Proceedings of the 13th Annual AAS/AIAA Space Flight Mechanics Meeting, Ponce, Puerto Rico, 9–13 February 2003; pp. 1–19. [Google Scholar]
- Emami, E.; Bebis, G.; Nefian, A.; Fong, T. Automatic Crater Detection Using Convex Grouping and Convolutional Neural Networks. In Proceedings of the 11th International Symposium on Visual Computing, Las Vegas, NV, USA, 14–16 December 2015; pp. 213–224. [Google Scholar]
- Leroy, B.; Medioni, G.; Johnson, E.; Matthies, L. Crater detection for autonomous landing on asteroids. Image Vis. Comput. 2001, 19, 787–792. [Google Scholar] [CrossRef]
- Honda, R.; Iijima, Y.; Konishi, O. Mining of topographic feature from heterogeneous imagery and its application to lunar craters. In Progress in Discovery Science; Springer: Berlin, Germany, 2002; pp. 395–407. [Google Scholar]
- Barata, T.; Alves, E.I.; Saraiva, J.; Pina, P. Automatic recognition of impact craters on the surface of Mars. In Proceedings of the International Conference Image Analysis and Recognition, Proto, Portugal, 29 September–1 October 2004; pp. 489–496. [Google Scholar]
- Magee, M.; Chapman, C.; Dellenback, S.; Enke, B.; Merline, W.; Rigney, M. Automated identification of Martian craters using image processing. In Proceedings of the 34th Annual Lunar and Planetary Science Conference, League City, TX, USA, 17–21 March 2003. [Google Scholar]
- Saraiva, J.; Bandeira, L.; Pina, P. A structured approach to automated crater detection. In Proceedings of the 37th Annual Lunar and Planetary Science Conference, League City, TX, USA, 13–17 March 2006. [Google Scholar]
- Kim, J.R.; Muller, J.-P.; van Gasselt, S.; Morley, J.G.; Neukum, G. Automated crater detection, a new tool for Mars cartography and chronology. Photogramm. Eng. Remote Sens. 2005, 71, 1205–1217. [Google Scholar] [CrossRef]
- Hanak, F.C. Lost in Low Lunar Orbit Crater Pattern Detection and Identification. Ph.D. Thesis, The University of Texas at Austin, Austin, TX, USA, May 2009. [Google Scholar]
- Vinogradova, T.; Burl, M.; Mjolsness, E. Training of a crater detection algorithm for Mars crater imagery. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 9–16 March 2002; p. 7. [Google Scholar]
- Plesko, C.; Brumby, S.; Asphaug, E.; Chamberlain, D.; Engel, T. Automatic crater counts on Mars. In Proceedings of the 35th Lunar and Planetary Science Conference, League City, TX, USA, 15–19 March 2004. [Google Scholar]
- Plesko, C.; Werner, S.; Brumby, S.; Asphaug, E.; Neukum, G.; Team, H.I. A statistical analysis of automated crater counts in MOC and HRSC data. In Proceedings of the 37th Annual Lunar and Planetary Science Conference, League City, TX, USA, 13–17 March 2006. [Google Scholar]
- Wetzler, P.G.; Honda, R.; Enke, B.; Merline, W.J.; Chapman, C.R.; Burl, M.C. Learning to detect small impact craters. In Proceedings of the IEEE Application of Computer Vision, Breckenridge, CO, USA, 5–7 January 2005; pp. 178–184. [Google Scholar]
- Bandeira, L.; Ding, W.; Stepinski, T. Automatic detection of sub-km craters using shape and texture information. In Proceedings of the 41st Lunar and Planetary Science Conference, Woodlands, TX, USA, 1–5 March 2010; p. 1144. [Google Scholar]
- Martins, R.; Pina, P.; Marques, J.S.; Silveira, M. Crater detection by a boosting approach. IEEE Geosci. Remote Sens. Lett. 2009, 6, 127–131. [Google Scholar] [CrossRef]
- Cohen, J.P. Automated Crater Detection Using Machine Learning. Ph.D. Thesis, University of Massachusetts, Boston, MA, USA, May 2016. [Google Scholar]
- Cohen, J.P.; Lo, H.Z.; Lu, T.; Ding, W. Crater detection via convolutional neural networks. In Proceedings of the 47th Lunar and Planetary Science Conference, Woodlands, TX, USA, 21–25 March 2016. [Google Scholar]
- Palafox, L.F.; Hamilton, C.W.; Scheidt, S.P.; Alvarez, A.M. Automated detection of geological landforms on Mars using Convolutional Neural Networks. Comput. Geosci. 2017, 101, 48–56. [Google Scholar] [CrossRef] [PubMed]
- Glaude, Q. CraterNet: A Fully Convolutional Neural Network for Lunar Crater Detection Based on Remotely Sensed Data. Master’s Thesis, University of Liège, Liège, Wallonia, Belgium, June 2017. [Google Scholar]
- Cheng, Y.; Ansar, A. Landmark based position estimation for pinpoint landing on Mars. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 1573–1578. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Robbins, S.J.; Hynek, B.M. A new global database of Mars impact craters ≥1 km: 2. Global crater properties and regional variations of the simple-to-complex transition diameter. J. Geophys. Res. Planets 2012, 117. [Google Scholar] [CrossRef]
- Sivaramakrishnan, R.; Antani, S.; Candemir, S.; Xue, Z.; Abuya, J.; Kohli, M.; Alderson, P.; Thoma, G. Comparing deep learning models for population screening using chest radiography. In Proceedings of the 2018 SPIE Medical Imaging, Houston, TX, USA, 10–15 February 2018; p. 105751E. [Google Scholar]
- Eggert, C.; Zecha, D.; Brehm, S.; Lienhart, R. Improving Small Object Proposals for Company Logo Detection. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017; pp. 167–174. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. FaceBoxes: A CPU real-time face detector with high accuracy. In Proceedings of the 2017 International Joint Conference on Biometrics, Denver, CO, USA, 1–4 October 2017. [Google Scholar]
- Padgett, C.; Kreutz-Delgado, K. A grid algorithm for autonomous star identification. IEEE Trans. Aerosp. Electron. Syst. 1997, 33, 202–213. [Google Scholar] [CrossRef]
- Jaumann, R.; Neukum, G.; Behnke, T.; Duxbury, T.C.; Eichentopf, K.; Flohrer, J.; Gasselt, S.; Giese, B.; Gwinner, K.; Hauber, E. The high-resolution stereo camera (HRSC) experiment on Mars Express: Instrument aspects and experiment conduct from interplanetary cruise through the nominal mission. Planet. Space Sci. 2007, 55, 928–952. [Google Scholar] [CrossRef]
- Ding, W.; Stepinski, T.F.; Mu, Y.; Bandeira, L.; Ricardo, R.; Wu, Y.; Lu, Z.; Cao, T.; Wu, X. Subkilometer crater discovery with boosting and transfer learning. ACM Trans. Intell. Syst. Technol. 2011, 2, 39. [Google Scholar] [CrossRef]
- Senthilnath, J.; Kulkarni, S.; Benediktsson, J.A.; Yang, X.-S. A novel approach for multispectral satellite image classification based on the bat algorithm. IEEE Geosci. Remote Sens. Lett. 2016, 13, 599–603. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Level | Architecture | Layer Level | Architecture | Layer Level | Architecture |
|---|---|---|---|---|---|
| conv1 | 64 × 52, str 2 | conv4_3 | 9 × 12 | conv7_3 | 18 × 12 |
| conv2 | 64 × 52, pad 1 Pool 32, str 2 LRN | conv5 | 128 × 32, pad 1 | conv8 | 32 × 32, pad 1 Pool 32, str 2 LRN |
| conv3 | 96 × 32, pad 1 | conv6 | 128 × 32, pad 1 | conv9 | 64 × 32, pad 1 Pool 22, str 2 |
| conv4 | 96 × 32, pad 1 Pool 32, str 2 LRN | conv7 | 128 × 32, pad 1 | conv10 | 64 × 32 |
| conv4_1 | 96 × 32, pad 1 | conv7_1 | 128 × 32, pad 1 | conv11 | Num 1 × 22 |
| conv4_2 | 6 × 12 | conv7_2 | 12 × 12 |
| Footprint | Size (pixels) | Resolution (m/pixel) | Longitude | Latitude |
|---|---|---|---|---|
| h0905_0000 | 65,772 × 9451 | 12.5 | 49.102°W~47.128°W | 13.507°N~0.363°S |
| h1899_0000 | 13,5467 × 15,543 | 12.5 | 8.533°E~12.107°E | 1.462°N~27.101°S |
| h2956_0000 | 24,674 × 5567 | 25.0 | 15.181°E~17.680°E | 22.462°N~12.059°N |
| h6456_0000 | 88,581 × 11,347 | 12.5 | 6.618°W~4.208°W | 15.261°S~33.940°S |
| h6520_0000 | 37,964 × 7959 | 25.0 | 26.851°E~30.212°E | 13.868°S~29.872°S |
| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 |
|---|---|---|---|---|---|
| conv3-32 | conv3-64 | conv3-64 | conv5-64 | conv5-96 | conv5-64 |
| conv3-32 | conv3-64 | conv3-64 | conv5-64 | conv5-96 | conv5-64 |
| pool3 | pool3 | pool3 | pool3 | pool3 | pool3 |
| conv3-64 | conv3-96 | conv3-96 | conv3-96 | conv3-128 | conv3-96 |
| conv3-64 | conv3-96 | conv3-96 | conv3-96 | conv3-128 | conv3-96 |
| pool3 | pool3 | pool3 | pool3 | pool3 | conv3-96 |
| conv3-96 | conv3-128 | conv3-128 | conv3-128 | conv3-256 | pool3 |
| conv3-96 | conv3-128 | conv3-128 | conv3-128 | conv3-256 | conv3-128 |
| pool2 | pool2 | conv3-128 | conv3-128 | conv3-256 | conv3-128 |
| pool2 | pool2 | pool2 | conv3-128 | ||
| pool2 | |||||
| fc-256 | |||||
| fc-2 | |||||
| softmax | |||||
| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 |
|---|---|---|---|---|---|
| 0.9636 ± 0.0041 | 0.9741 ± 0.0033 | 0.9826 ± 0.0031 | 0.9903 ± 0.0018 | 0.9918 ± 0.0008 | 0.9912 ± 0.0009 |
| Layer Level | Architecture | Layer Level | Architecture | Layer Level | Architecture |
|---|---|---|---|---|---|
| conv1 | 64 × 52, str 2 | conv4 | 96 × 32, pad 1 Pool 32, str 2 LRN | conv7 | 128 × 32, pad 1 Pool 22, str 2 |
| conv2 | 64 × 52, pad 1 Pool 32, str 2 LRN | conv5 | 128 × 32, pad 1 | fc8 | 256 |
| conv3 | 96 × 32, pad 1 | conv6 | 128 × 32, pad 1 | fc9 | 2 |
| Size (pixels) | 0~12 | 12~30 | 30~60 | 60~100 | 100~160 | 160~300 | 300~500 | 500~ |
| Number | 1140 | 2188 | 273 | 44 | 8 | 4 | 0 | 1 |
| Network | Anchor Size | AGN | AVAN | DAF |
|---|---|---|---|---|
| CDP1 | 15 | 16.54 | 3.55 | 1 |
| CDP1 | 27 | 12.21 | 11.48 | 0 |
| CDP2 | 49 | 2.88 | 9.46 | 1 |
| CDP2 | 89 | 1.09 | 31.20 | 1 |
| CDP2 | 143 | 0.65 | 80.55 | 0 |
| CDP2 | 255 | 0.34 | 256.13 | −1 |
| Model 1 | Model 2 | Model 3 |
|---|---|---|
| conv3-16 | conv3-32 | conv3-64 |
| pool3 | pool3 | pool3 |
| conv3-32 | conv3-64 | conv3-64 |
| pool2 | pool2 | pool2 |
| conv3-32 | conv3-64 | conv3-128 |
| conv2-Num 1 | conv2-Num 1 | conv2-Num 1 |
| softmax | ||
| Model 1 | Model 2 | Model 3 |
|---|---|---|
| 0.9914 ± 0.0009 | 0.9974 ± 0.0007 | 0.9980 ± 0.0005 |
| Quality Metric | Tile 1_24 | Tile 1_25 | Tile 2_24 | Tile 2_25 | Tile 3_24 | Tile 3_25 | Mean |
|---|---|---|---|---|---|---|---|
| Precision | 85.94% | 86.26% | 85.02% | 83.14% | 89.84% | 91.02% | 86.87% |
| Recall | 95.76% | 96.58% | 97.31% | 96.76% | 95.81% | 96.92% | 96.52% |
| F1-score | 90.58% | 91.13% | 90.75% | 89.43% | 92.73% | 93.88% | 91.42% |
| Region | Urbach | Bandeira | Ding | CraterCNN | CraterIDNet |
|---|---|---|---|---|---|
| West | 67.89% | 85.33% | 83.89% | 88.78% | 90.86% |
| Center | 69.62% | 79.35% | 83.02% | 88.81% | 90.09% |
| East | 79.77% | 86.09% | 89.51% | 90.29% | 93.31% |
| Scene | Triangle | CraterIDNet |
|---|---|---|
| Tile 2_25 | 89.3% | 97.5% |
| Tile 3_24 | 94.6% | 100% |
| False Detection | 0 | 1 | 2 | 3 |
| Triangle | 20.56 | 23.42 | 27.58 | 34.91 |
| CraterIDNet | 0.60 | 0.61 | 0.60 | 0.60 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Jiang, J.; Zhang, G. CraterIDNet: An End-to-End Fully Convolutional Neural Network for Crater Detection and Identification in Remotely Sensed Planetary Images. Remote Sens. 2018, 10, 1067. https://doi.org/10.3390/rs10071067
Wang H, Jiang J, Zhang G. CraterIDNet: An End-to-End Fully Convolutional Neural Network for Crater Detection and Identification in Remotely Sensed Planetary Images. Remote Sensing. 2018; 10(7):1067. https://doi.org/10.3390/rs10071067
Chicago/Turabian StyleWang, Hao, Jie Jiang, and Guangjun Zhang. 2018. "CraterIDNet: An End-to-End Fully Convolutional Neural Network for Crater Detection and Identification in Remotely Sensed Planetary Images" Remote Sensing 10, no. 7: 1067. https://doi.org/10.3390/rs10071067
APA StyleWang, H., Jiang, J., & Zhang, G. (2018). CraterIDNet: An End-to-End Fully Convolutional Neural Network for Crater Detection and Identification in Remotely Sensed Planetary Images. Remote Sensing, 10(7), 1067. https://doi.org/10.3390/rs10071067