A Hierarchical Association Framework for Multi-Object Tracking in Airborne Videos


Abstract

1. Introduction
2. Related Works
3. Conceptual Framework
3.1. Framework Overview
3.2. Hierarchical Groups of Detections and Tracklets
- The active tracklets set includes the tracklets corresponding to the currently existing objects, composed of three disjoint subsets:where is the new active tracklet (recently generated tracklet) set with high confidence, the reliable active tracklet set with a high confidence and the unreliable active tracklet set with low confidence. They are formally defined as follows:where is a threshold on the tracklet length for distinguishing new from old and is a threshold on the tracklet confidence for characterizing whether or not the tracklet is reliable, meaning if it is likely to drift or be lost.
- The candidate tracklet set includes the tracklets waiting for enough matched detections in the third stage before being added as new active tracklets.
- The inactive tracklet set includes two disjoint subsets:where and represent the lost tracklet set and the terminated tracklet set, respectively. includes tracklets corresponding to the temporary lost objects due to long-term occlusions, whereas the terminated tracklet set includes objects that have disappeared. Each subset is defined as:where is a threshold for distinguishing active and non-active tracklets, is the last frame of the active tracklet and is a threshold to terminate the tracklet.
3.3. Online Detection
3.4. Tracklet Confidence
3.5. Appearance-Based Prediction
- Naive Bayes classifier update: The CT algorithm samples some positive samples near the current target location and negative samples far away from the object center. To represent the sample , CT uses a set of rectangle features and extracts the features with low dimensionality using a very sparse measurement matrix , . The high-dimensional image features () are formed by concatenating the convolved target images (represented as column vectors) with rectangle filters. , the lower-dimensional compressive features, are formed with . Each element in the low-dimensional feature a is a linear combination of spatially-distributed rectangle features at different scales. A simple Bayesian model is used to construct a classifier based on the positive () and negative () sample features. The compressive sensing algorithm assumes that all lower-dimensional samples of the target are independent of each other, . The parameters of the Naive Bayes classifier are incrementally updated according to the four parameters of the classifier’s Gaussian conditional distribution with an update rate .
- Target detection: The candidate region corresponding to the maximum is regarded as the tracking target location:
3.6. Motion-Based Prediction
4. Four-Stage Hierarchical Association Framework
4.1. Stage 1: Local Progressive Trajectory Construction
4.1.1. First Association via the Affinity Score
4.1.2. Tracklet Analysis and Update Based on Prediction
4.1.3. Detection Refinement
4.2. Stage 2: Handling Drifting Tracklets
4.2.1. Second Association via the Affinity Score
4.2.2. Tracklet Correction
4.3. Stage 3: New Active Tracklet Generation
4.4. Stage 4: Globally Linking Fragmented Tracklets
4.4.1. Fourth Association via the Affinity Score
4.4.2. Object Re-Identification via Tracklet Linking
5. Experiments
5.1. Datasets
5.2. Parameter Setting
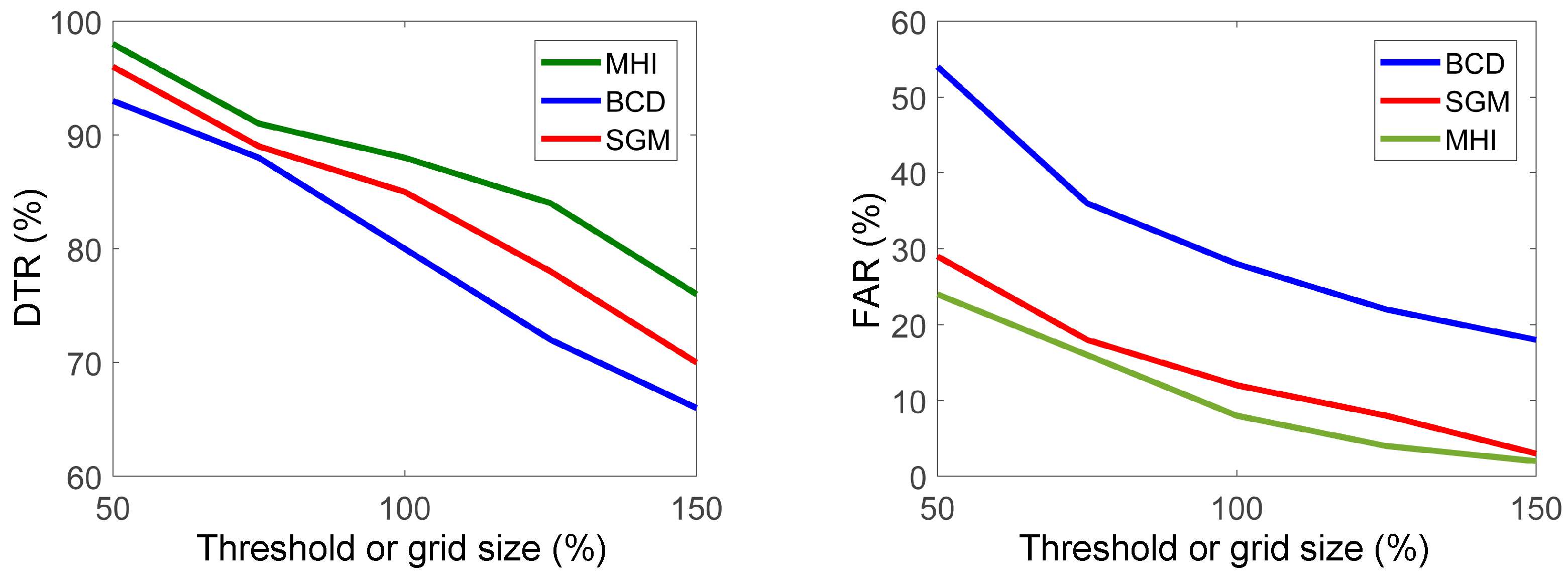
5.2.1. Detector Parameters
5.2.2. Hierarchical Framework Parameters
- The same threshold was used for the association score matrices , , and to determine the association results.
- For the FCT trackers in our experiments, the search radius for drawing positive samples in the online appearance-based classifier was set to = 4 to generate 45 positive samples. The inner and outer radii for the negative samples were set to and , respectively, to randomly select 50 negative samples. The initial learning rate of the classifier was set to 0.9. The size of the random matrix was set to 100.
- For the Kalman filter model, the process (Q) and measurement (R) noise covariance matrices were set as , and , respectively.
5.3. Comparison with State-of-the-Art Frameworks
5.3.1. Evaluation Metrics
5.3.2. Comparison of Data Association
- S corresponds to the framework without tracklets analysis and detection refinement. The method presented by [11] was used to estimate the tracklet state. The position and the velocity of the matched tracklets were updated with the associated detection, whereas the unmatched tracklets were updated using the KF motion-based predictions. The size of the object was updated by averaging the associated detection of the recent past frames.
- S is the fully-proposed framework as illustrated in Figure 1, denoted as HATAin the following.
5.3.3. Comparisons to Other MOT Frameworks
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wan, M.; Gu, G.; Qian, W.; Ren, K.; Chen, Q.; Zhang, H.; Maldague, X. Total Variation Regularization Term-Based Low-Rank and Sparse Matrix Representation Model for Infrared Moving Target Tracking. Remote Sens. 2018, 10, 510. [Google Scholar] [CrossRef]
- Skoglar, P.; Orguner, U.; Törnqvist, D.; Gustafsson, F. Road Target Search and Tracking with Gimballed Vision Sensor on an Unmanned Aerial Vehicle. Remote Sens. 2012, 4, 2076–2111. [Google Scholar] [CrossRef]
- Leitloff, J.; Rosenbaum, D.; Kurz, F.; Meynberg, O.; Reinartz, P. An Operational System for Estimating Road Traffic Information from Aerial Images. Remote Sens. 2014, 6, 11315–11341. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, G.; Yan, D.; Zhao, Z. Two Algorithms for the Detection and Tracking of Moving Vehicle Targets in Aerial Infrared Image Sequences. Remote Sens. 2016, 8, 28. [Google Scholar] [CrossRef]
- Dey, S.; Reilly, V.; Saleemi, I.; Shah, M. Detection of independently moving objects in non-planar scenes via multi-frame monocular epipolar constraint. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 860–873. [Google Scholar]
- Yang, B.; Nevatia, R. Multi-target tracking by online learning of non-linear motion patterns and robust appearance models. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1918–1925. [Google Scholar]
- Luo, W.; Zhao, X.; Kim, T.K. Multiple object tracking: A review. arXiv, 2014; arXiv:1409.7618. [Google Scholar]
- Reilly, V.; Idrees, H.; Shah, M. Detection and tracking of large number of targets in wide area surveillance. In Proceedings of the 11th European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 186–199. [Google Scholar]
- Berclaz, J.; Fleuret, F.; Turetken, E.; Fua, P. Multiple object tracking using k-shortest paths optimization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1806–1819. [Google Scholar] [CrossRef] [PubMed]
- Pirsiavash, H.; Ramanan, D.; Fowlkes, C.C. Globally-optimal greedy algorithms for tracking a variable number of objects. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1201–1208. [Google Scholar]
- Bae, S.H.; Yoon, K.J. Robust online multi-object tracking based on tracklet confidence and online discriminative appearance learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1218–1225. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-Insensitive and Context-Augmented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2337–2348. [Google Scholar] [CrossRef]
- Prokaj, J.; Duchaineau, M.; Medioni, G. Inferring tracklets for multi-object tracking. In Proceedings of the 2011 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Colorado Springs, CO, USA, 20–25 June 2011; pp. 37–44. [Google Scholar]
- Xiao, J.; Cheng, H.; Sawhney, H.; Han, F. Vehicle detection and tracking in wide field-of-view aerial video. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 679–684. [Google Scholar]
- Prokaj, J.; Zhao, X.; Medioni, G. Tracking many vehicles in wide area aerial surveillance. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 37–43. [Google Scholar]
- Pollard, T.; Antone, M. Detecting and tracking all moving objects in wide-area aerial video. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 15–22. [Google Scholar]
- Prokaj, J.; Medioni, G. Persistent Tracking for Wide Area Aerial Surveillance. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1186–1193. [Google Scholar]
- Yun, K.; Choi, J.Y. Robust and fast moving object detection in a non-stationary camera via foreground probability based sampling. In Proceedings of the 2015 IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 4897–4901. [Google Scholar]
- Yin, Z.; Collins, R. Moving object localization in thermal imagery by forward-backward MHI. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshop, New York, NY, USA, 17–22 June 2006; pp. 133–133. [Google Scholar]
- Yu, Q.; Medioni, G. Motion pattern interpretation and detection for tracking moving vehicles in airborne video. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2671–2678. [Google Scholar]
- Kim, S.W.; Yun, K.; Yi, K.M.; Kim, S.J.; Choi, J.Y. Detection of moving objects with a moving camera using non-panoramic background model. Mach. Vis. Appl. 2013, 24, 1015–1028. [Google Scholar] [CrossRef]
- Moo Yi, K.; Yun, K.; Wan Kim, S.; Jin Chang, H.; Young Choi, J. Detection of moving objects with non- stationary cameras in 5.8 ms: Bringing motion detection to your mobile device. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 27–34. [Google Scholar]
- Bae, S.H.; Yoon, K.J. Robust Online Multiobject Tracking With Data Association and Track Management. IEEE Trans. Image Process. 2014, 23, 2820–2833. [Google Scholar] [PubMed]
- Cao, X.; Wu, C.; Lan, J.; Yan, P. Vehicle Detection and Motion Analysis in Low-Altitude Airborne Video Under Urban Environment. IEEE Trans. Circ. Syst. Video Technol. 2011, 21, 1522–1533. [Google Scholar] [CrossRef]
- Xing, J.; Ai, H.; Lao, S. Multi-object tracking through occlusions by local tracklets filtering and global tracklets association with detection responses. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1200–1207. [Google Scholar]
- Breitenstein, M.D.; Reichlin, F.; Leibe, B.; Koller-Meier, E.; Van Gool, L. Online multiperson tracking-by- detection from a single, uncalibrated camera. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1820–1833. [Google Scholar] [CrossRef] [PubMed]
- Ju, J.; Kim, D.; Ku, B.; Han, D.K.; Ko, H. Online Multi-object Tracking Based on Hierarchical Association Framework. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 34–42. [Google Scholar]
- Zhang, K.; Zhang, L.; Yang, M.H. Real-time compressive tracking. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 864–877. [Google Scholar]
- Zhang, K.; Zhang, L.; Yang, M.H. Fast compressive tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2002–2015. [Google Scholar] [CrossRef] [PubMed]
- Ali, S.; Shah, M. COCOA: Tracking in aerial imagery. In Defense and Security Symposium; International Society for Optics and Photonics: Bellingham, WA, USA, 2006; p. 62090D. [Google Scholar]
- Alatas, O.; Yan, P.; Shah, M. Spatio-temporal regularity flow (SPREF): Its Estimation and applications. IEEE Trans. Circ. Syst. Video Technol. 2007, 17, 584–589. [Google Scholar] [CrossRef]
- Yalcin, H.; Hebert, M.; Collins, R.; Black, M.J. A flow-based approach to vehicle detection and background mosaicking in airborne video. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; p. 1202. [Google Scholar]
- Cao, X.; Lan, J.; Yan, P.; Li, X. Vehicle detection and tracking in airborne videos by multi-motion layer analysis. Mach. Vis. Appl. 2012, 23, 921–935. [Google Scholar] [CrossRef]
- Cao, X.; Gao, C.; Lan, J.; Yuan, Y.; Yan, P. Ego motion guided particle filter for vehicle tracking in airborne videos. Neurocomputing 2014, 124, 168–177. [Google Scholar] [CrossRef]
- Cao, X.; Shi, Z.; Yan, P.; Li, X. Tracking vehicles as groups in airborne videos. Neurocomputing 2013, 99, 38–45. [Google Scholar] [CrossRef]
- Liu, K.; Ma, B.; Zhang, W.; Huang, R. A spatio-temporal appearance representation for viceo-based pedestrian re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3810–3818. [Google Scholar]
- Zapletal, D.; Herout, A. Vehicle Re-Identification for Automatic Video Traffic Surveillance. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 25–31. [Google Scholar]
- Liu, X.; Liu, W.; Ma, H.; Fu, H. Large-scale vehicle re-identification in urban surveillance videos. In Proceedings of the 2016 IEEE International Conference on Multimedia and Expo, Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Liu, X.; Liu, W.; Mei, T.; Ma, H. A Deep Learning-Based Approach to Progressive Vehicle Re-identification for Urban Surveillance. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 869–884. [Google Scholar]
- Ahuja, R.K.; Magnanti, T.L.; Orlin, J.B. Network Flows: Theory, Algorithms, and Applications; Prentice Hall: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Kuo, C.H.; Huang, C.; Nevatia, R. Multi-target tracking by on-line learned discriminative appearance models. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 685–692. [Google Scholar]
- Qin, Z.; Shelton, C.R. Improving multi-target tracking via social grouping. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1972–1978. [Google Scholar]
- Yamaguchi, K.; Berg, A.C.; Ortiz, L.E.; Berg, T.L. Who are you with and Where are you going? In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1345–1352. [Google Scholar]
- Collins, R.; Zhou, X.; Teh, S.K. An open source tracking testbed and evaluation web site. In Proceedings of the IEEE International Workshop on Performance Evaluation of Tracking and Surveillance, Breckenridge, CO, USA, 7 January 2005; pp. 17–24. [Google Scholar]
- Li, Y.; Huang, C.; Nevatia, R. Learning to associate: Hybridboosted multi-target tracker for crowded scene. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2953–2960. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Sequence | Image Size | # of Frames | # of Targets | IV | SV | OCC | BOC | MV | IB | SI |
|---|---|---|---|---|---|---|---|---|---|---|---|
| VIVID | EgTest01 | 680 × 480 | 1821 | 6 | √ | √ | × | × | √ | × | √ |
| EgTest02 | 680 × 480 | 1302 | 6 | √ | √ | √ | × | √ | × | √ | |
| EgTest03 | 680 × 480 | 2571 | 6 | √ | √ | √ | × | √ | × | √ | |
| EgTest04 | 680 × 480 | 1833 | 5 | √ | × | × | √ | √ | √ | √ | |
| EgTest05 | 680 × 480 | 1764 | 4 | √ | √ | × | √ | √ | × | √ | |
| PkTest01 | 680 × 480 | 1460 | 5 | √ | √ | √ | √ | × | × | × | |
| PkTest02 | 680 × 480 | 1595 | 12 | √ | √ | × | √ | √ | × | × | |
| PkTest03 | 680 × 480 | 2011 | 7 | √ | × | × | √ | √ | × | × | |
| SAIIP | SpTest01 | 1920 × 1080 | 1763 | 37 | √ | × | × | × | × | × | × |
| SpTest02 | 1920 × 1080 | 1689 | 42 | √ | √ | × | × | √ | × | × | |
| SpTest03 | 1920 × 1080 | 1624 | 29 | √ | √ | × | × | √ | × | √ | |
| SpTest04 | 1920 × 1080 | 1206 | 46 | √ | √ | × | √ | √ | × | √ |
| Threshold | VIVID | SAIIP | ||||
|---|---|---|---|---|---|---|
| DTR% | FAR% | FPS | DTR% | FAR% | FPS | |
| 91.7 | 36.7 | 18 | 97.3 | 12.8 | 9 | |
| 85.6 | 28.4 | 22 | 94.4 | 10.3 | 12 | |
| 81.3 | 18.6 | 28 | 91.7 | 8.7 | 16 | |
| 72.9 | 14.2 | 32 | 88.5 | 6.6 | 20 | |
| 68.4 | 10.5 | 37 | 86.9 | 5.9 | 27 | |
| Name | Definition |
|---|---|
| PR | Correctly-matched objects/total output objects (frame-based); |
| GT | Number of Ground-Truth trajectories. |
| MT | Mostly Tracked: percentage of GT trajectories that are covered by the tracker’s output for more than 80% in length. |
| ML | Mostly Lost: percentage of GT trajectories that are covered by the tracker’s output for less than 20% in length. The smaller the better. |
| PT | Partially Tracked: 1.0-MT-ML. |
| IDS | ID Switches: the total of number of times that a tracked trajectory changes its matched GT identity. The smaller the better. |
| Method | MT (%) | ML (%) | IDS | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 86.6 | 80.6 | 76.3 | 3.8 | 8.6 | 16.4 | 24 | 20 | 27 | |
| 92.1 | 86.1 | 80.5 | 2.1 | 6.8 | 10.7 | 12 | 9 | 13 | |
| Sequence | GT | Method | PR (%) | MT (%) | ML (%) | PT (%) | IDS |
|---|---|---|---|---|---|---|---|
| EgTest01 | Bae et al. [11] | 90.7 | 94.4 | 3.6 | 2.0 | 2 | |
| 6 | Prokaj et al. [14] | 88.6 | 93.6 | 3.2 | 3.2 | 4 | |
| Proposed HATA | 94.8 | 96.8 | 2.9 | 0.3 | 2 | ||
| EgTest02 | Bae et al. [11] | 78.8 | 80.6 | 8.6 | 11.8 | 28 | |
| 6 | Prokaj et al. [14] | 70.5 | 69.3 | 5.4 | 25.3 | 41 | |
| Proposed HATA | 84.4 | 86.1 | 6.8 | 7.1 | 13 | ||
| EgTest03 | Bae et al. [11] | 82.6 | 80.7 | 6.8 | 12.5 | 20 | |
| 6 | Prokaj et al. [14] | 77.8 | 74.3 | 5.4 | 20.3 | 29 | |
| Proposed HATA | 87.1 | 83.6 | 4.7 | 11.7 | 11 | ||
| EgTest04 | Bae et al. [11] | 82.9 | 78.9 | 4.9 | 16.2 | 19 | |
| 5 | Prokaj et al. [14] | 76.4 | 73.2 | 6.6 | 20.2 | 28 | |
| Proposed HATA | 85.3 | 81.8 | 5.6 | 12.6 | 12 | ||
| EgTest05 | Bae et al. [11] | 68.9 | 75.2 | 6.7 | 18.1 | 42 | |
| 4 | Prokaj et al. [14] | 70.8 | 81.2 | 5.3 | 13.5 | 60 | |
| Proposed HATA | 78.6 | 86.4 | 5.7 | 7.9 | 23 | ||
| PkTest01 | Bae et al. [11] | 79.6 | 82.3 | 5.3 | 12.4 | 20 | |
| 5 | Prokaj et al. [14] | 74.3 | 78.7 | 10.2 | 11.1 | 36 | |
| Proposed HATA | 88.8 | 89.1 | 2.1 | 8.8 | 14 | ||
| PkTest02 | Bae et al. [11] | 76.9 | 73.8 | 5.9 | 20.3 | 23 | |
| 12 | Prokaj et al. [14] | 72.9 | 69.7 | 7.2 | 23.1 | 38 | |
| Proposed HATA | 83.4 | 79.4 | 5.1 | 15.5 | 15 | ||
| PkTest03 | Bae et al. [11] | 72.9 | 78.6 | 6.4 | 15.0 | 29 | |
| 7 | Prokaj et al. [14] | 68.4 | 74.5 | 8.2 | 17.3 | 42 | |
| Proposed HATA | 79.1 | 81.9 | 5.8 | 12.3 | 16 | ||
| SpTest01 | Bae et al. [11] | 97.6 | 94.7 | 0.9 | 5.4 | 5 | |
| 37 | Prokaj et al. [14] | 93.3 | 92.6 | 2.8 | 7.6 | 9 | |
| Proposed HATA | 98.5 | 96.4 | 0.5 | 3.1 | 2 | ||
| SpTest02 | Bae et al. [11] | 88.9 | 83.8 | 9.8 | 6.4 | 18 | |
| 42 | Prokaj et al. [14] | 82.9 | 77.9 | 12.2 | 9.9 | 22 | |
| Proposed HATA | 93.5 | 91.4 | 6.2 | 3.4 | 7 | ||
| SpTest03 | Bae et al. [11] | 87.2 | 85.6 | 10.8 | 3.6 | 17 | |
| 29 | Prokaj et al. [14] | 84.6 | 82.6 | 13.5 | 3.9 | 29 | |
| Proposed HATA | 89.8 | 91.2 | 6.9 | 1.9 | 11 | ||
| SpTest04 | Bae et al. [11] | 89.3 | 87.9 | 8.4 | 3.7 | 26 | |
| 46 | Prokaj et al. [14] | 81.6 | 81.3 | 13.6 | 5.1 | 31 | |
| Proposed HATA | 91.7 | 93.4 | 4.1 | 2.5 | 12 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, T.; Pennisi, A.; Li, Z.; Zhang, Y.; Sahli, H. A Hierarchical Association Framework for Multi-Object Tracking in Airborne Videos. Remote Sens. 2018, 10, 1347. https://doi.org/10.3390/rs10091347
Chen T, Pennisi A, Li Z, Zhang Y, Sahli H. A Hierarchical Association Framework for Multi-Object Tracking in Airborne Videos. Remote Sensing. 2018; 10(9):1347. https://doi.org/10.3390/rs10091347
Chicago/Turabian StyleChen, Ting, Andrea Pennisi, Zhi Li, Yanning Zhang, and Hichem Sahli. 2018. "A Hierarchical Association Framework for Multi-Object Tracking in Airborne Videos" Remote Sensing 10, no. 9: 1347. https://doi.org/10.3390/rs10091347
APA StyleChen, T., Pennisi, A., Li, Z., Zhang, Y., & Sahli, H. (2018). A Hierarchical Association Framework for Multi-Object Tracking in Airborne Videos. Remote Sensing, 10(9), 1347. https://doi.org/10.3390/rs10091347