1. Introduction
Accurate and detailed 3D models of the environment are now an essential tool in different scientific and applied fields, such as geology, biology, engineering, archaeology, among others. With advancements in photographic equipment and improvements in image processing and computational capabilities of computers, optical cameras are now widely used due to their low cost, ease of use, and sufficient accuracy of the resulting models for their scientific exploitation. The application of traditional aerial and terrestrial photogrammetry has greatly expanded in recent years, with commercial and custom-build camera systems and software solutions enabling a nearly black-box type of data processing (e.g., the works by the authors of [
1,
2,
3,
4]).
These rapid developments have also significantly benefited the field of underwater photogrammetry. The ability to produce accurate 3D models from monocular cameras under unfavorable properties of the water medium (i.e., light attenuation and scattering, among other effects) [
5], and advancements of unmanned underwater vehicles have given scientists unprecedented access to image the seafloor and its ecosystems from shallow waters to the deep ocean [
6,
7,
8,
9]. Optical seafloor imagery is now routinely acquired with deep sea vehicles, and often associated with other geophysical data (acoustic backscatter and multibeam bathymetry) and water column measurements (temperature, salinity, and chemical composition). High-resolution 3D models with associated textures are, thus, increasingly used in the representation and study of local areas of interest. However, most remotely operated vehicles (ROVs) or autonomous underwater vehicles (AUVs) that are currently used in science missions have limited optical sensing capabilities, commonly comprising a main camera used by the ROV-pilot, while larger workclass ROVs have additional cameras for maneuvering. Due to the nature of projective geometry, performing 3D reconstruction using only optical imagery acquired by monocular cameras results in a 3D model which is defined only up to scale, meaning that the unit in the model is not necessary a standard unit such as a meter [
10]. In order to correctly disambiguate the scale, it is essential to use additional information in the process of model building. Predominantly, solutions in subaerial applications are based on the fusion of image measurement with robust and dependable satellite references, such as Global Navigation Satellite System (GNSS) [
11,
12,
13], or ground control pointss (GCPs) [
14,
15,
16], due to their accuracy and ease of integration. On the contrary, the water medium not only hinders the possibility of accurately establishing the control points, but also prevents the use of global positioning system (GPS) due to the absorption of electromagnetic waves. Hence the scale is normally disambiguated either using a combination of acoustic positioning (e.g., Ultra-Short BaseLine (USBL)) and inertial navigation system (INS) [
17,
18,
19], or through the introduction of known distances between points in the scene [
20].
In shallow water environments, i.e., accessible by divers, researchers have often placed auxiliary objects (such as a scaling cube [
21], locknuts [
22], graduated bars [
23], etc.) into the scene, and used the knowledge of their dimensions to scale the model a posteriori. Such approaches, while applicable in certain scenarios, are limited to the use in small-scale reconstructions (e.g., a few tens of square meters), and in shallow water environments, due to the challenges in transporting and placing objects in deep sea environments. Similarly, laser scalers have been used since the late 1980s, projecting parallel laser beams onto the scene to estimate the scale of the observed area, given the known geometric setup of the lasers. Until recently, lasers have been mostly used in image-scaling methods, for measurements within individual images (e.g., Pilgrim et al. [
24] and Davis and Tusting [
25]). To provide proper scaling, we have recently proposed two novel approaches [
26], namely, a fully-unconstrained (FUM) and a partially-constrained method (PCM), to automatically estimate 3D model scale using a single optical image with identifiable laser projections. The proposed methods alleviate numerous restrictions imposed by earlier laser photogrammetry methods (e.g., laser alignment with the optical axis of the camera, perpendicularity of lasers with the scene), and remove the need for manual identification of identical points on the image and 3D model. The main drawback of these methods is the need for purposeful acquisition of images with laser projections, with the required additional acquisition time.
Alternatively, the model scaling can be disambiguated with known metric vehicle displacements (i.e., position and orientation from acoustic positioning, Doppler systems, and depth sensors [
19,
27,
28]). As this information is recorded throughout the mission, such data are normally available for arbitrary segments even if they have not been identified as interesting beforehand. The classic range-and-bearing position estimates from acoustic-based navigation, such as USBL, have an uncertainty that increases with increasing range (i.e., depth) in addition to possible loss of communication (navigation gaps). Consequently, the scale information is inferred from data which is often noisy, poorly resolved, or both. Hence the quality of the final dataset is contingent on the strategy used in the fusion of image and navigation information. Depending on the approach, the relative ambiguity can cause scale drift, i.e., a variation of scale along the model, causing distortions [
29]. Furthermore, building of large 3D models may require fusion of imagery acquired in multiple surveys. This merging often results in conflicting information from different dives, and affects preferentially areas of overlap between surveys, negatively impacting the measurements on the model (distances, areas, angles).
The need to validate the accuracy of image-based 3D models has soared as the development of both the hardware and the techniques enabled the use of standard imaging systems as a viable alternative to more complex and dedicated reconstruction techniques (e.g., structured light). Numerous evaluations of this accuracy are available for aerial and terrestrial 3D models (e.g., the works by the authors of [
2,
30,
31,
32]). Environmental conditions and limitations of underwater image acquisition preclude their transposition to underwater image acquisition and, to date, most underwater accuracy studies use known 3D models providing reference measurements. This leads to marine scientists nowadays being constantly faced with the dilemma of selecting appropriate analyses that could potentially be performed on the data derived from the reconstructed 3D models.
Early studies [
21,
33,
34,
35,
36,
37,
38] evaluated the accuracy of small-scale reconstructions (mainly on coral colonies), comparing model-based and laboratory-based volume and surface areas for specific corals. More recently, auxiliary objects (e.g., locknuts [
22], graduated bars [
23], special frames [
39,
40], and diver weights [
41]) have been used to avoid removal of objects from the environment. Reported inaccuracies range from
to
, while more recent methods achieve errors as low as 2–
[
22,
41]. Diver-based measurements and the placement of multiple objects at the seafloor both restrict the use of these methods in shallow water or experimental environments, and hinder such approaches in deep sea environments (e.g., scientific cruises), where reference-less evaluation is needed instead, which has been performed in only a few experiments.
Ferrari et al. [
38] evaluated their reconstruction method on a medium-size reef area (
) and a
long reef transect. Maximum heights of several quadrants within the model were compared to in situ measurements, coupled with an estimation of structural complexity (rugosity). The stated inaccuracies in reef height were
. This study split larger transects into approx
long sections to reduce potential drift, and hence model distortion. Similarly, Gonzales et al. [
42] reported
error in rugosity estimates from stereo imaging and compared them with results from a standard chain-tape method, along a
long transect. To the best of our knowledge, no other scale accuracy estimate of submarine large-area models has been published. Furthermore, although laser scalers are often used for qualitative visual scaling, they have never been used to evaluate the accuracy of underwater 3D models.
Objectives
Although a growing body of literature supports the belief that underwater image-based 3D reconstruction is a highly efficient and accurate method at small spatial extents, there is a clear absence of scale accuracy analyses of models produced at larger scales (often in deep sea scenarios). Validation of 3D reconstruction methods and associated error evaluation are, thus, required for large underwater scenes and to allow the quantitative measurements (distances and volumes, orientations, etc.) required for scientific and technical studies.
The main goal of this paper is to present and use an automatic scale accuracy estimation framework, applicable to models reconstructed from optical imagery and associated navigation data. We evaluate various reconstruction strategies, often used in research and industrial ROV deep sea surveys.
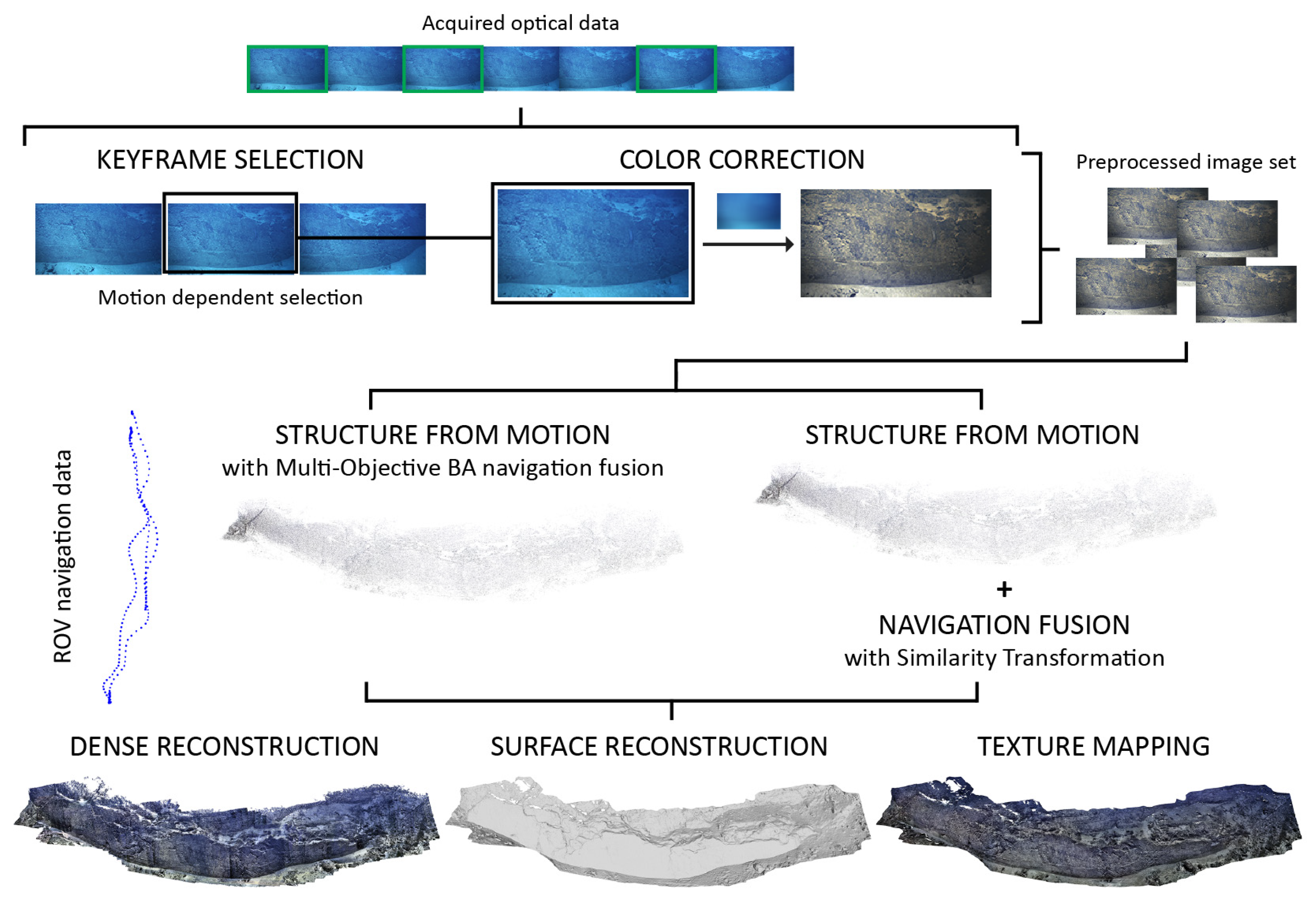
First, we present several methods of 3D reconstruction using underwater vehicle navigation, to provide both scaling and an absolute geographic reference. Most commonly, SfM uses either an incremental or a global strategy, while the vehicle navigation may be considered a priori as part of the optimization process, or a posteriori after full 3D model construction. Here, we compare four different strategies resulting from combination of Incremental/Global SfM and the a priori and a posteriori use of navigation data. We discuss the impact of each strategy in the final 3D model accuracy.
Second, the four methods are evaluated to identify which one is best suited to generate 3D models that combine data from multiple surveys, as this is often required under certain surveying scenarios. Navigation data from different surveys may have significant offsets at the same location (x, y, z, rotation), show noise differences, or both. The changes between different acquisitions of a single scene are taken into account differently by each 3D reconstruction strategy.
Third, prior approaches, recently presented by Istenič et al. [
26], to estimating model scale using laser scalers, namely FUM and PCM methods, are augmented with Monte Carlo simulations to evaluate the uncertainty of the obtained scale estimates. Furthermore, the results are compared to the kinds of estimates commonly used and suffering from parallax error.
Fourth, an automatic laser detection and uncertainty estimation method is presented. Accurate analyses require a multitude of reliable measurements spread across the 3D model, whose manual annotation is extremely labor-intensive, error-prone, and time-consuming, when not nearly impossible. Unlike previous detection methods, our method detects the centers of laser beams by considering the texture of the scene, and then determines their uncertainty, which, to the best of our knowledge, has not been presented in the literature hitherto.
With the data from the SUBSAINTES 2017 cruise (doi: 10.17600/17001000; [
43]) we evaluate the advantages and drawbacks of the different strategies to construct underwater 3D models, while providing quantitative error estimates. As indicated above, these methods are universal as they are not linked to data acquired using specific sensors (e.g., laser systems and stereo cameras), and can be applied to standard imagery acquired with underwater ROVs. Hence, it is possible to process legacy data from prior cruises and with different vehicles and/or imaging systems. Finally, we discuss the best practices for conducting optical surveys, based on the nature of targets and the characteristics of the underwater vehicle and sensors.
3. Model Evaluation Framework
Estimating the scale accuracy of 3D models reconstructed from underwater optical imagery and robot navigation data is of paramount importance since the input data is often noisy and erroneous. The noisy data commonly leads to inaccurate scale estimates and noticeable variations of scale within the model itself, which precludes use of such models for their intended research applications. Real underwater scenarios usually lack elements of known sizes that could be readily used as size references to evaluate the accuracy of 3D models. However, laser scalers are frequently used during underwater image collection to project laser beams onto the scene and can be used to provide such size reference.
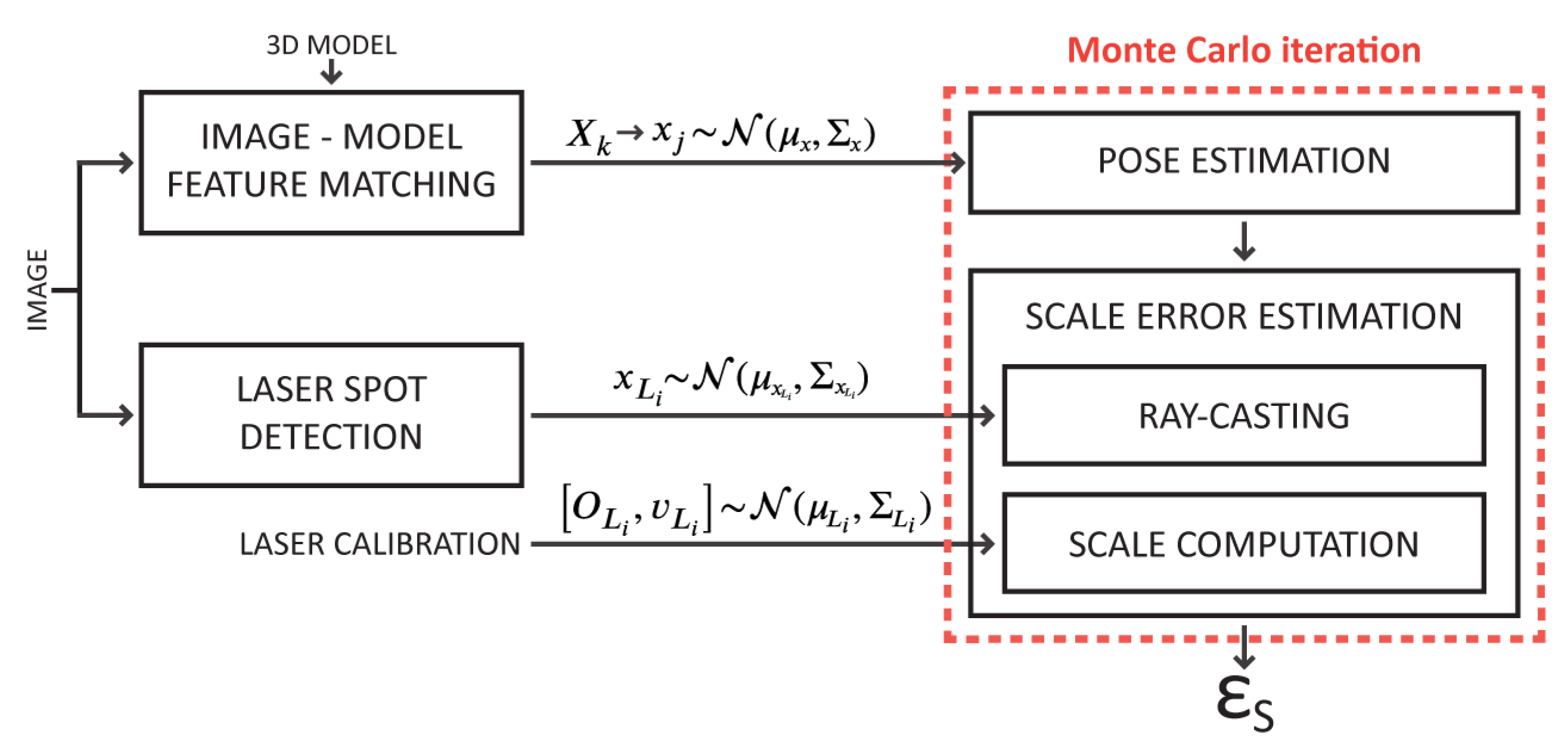
The framework we will describe builds upon two recently introduced methods [
26] for scale estimation of SfM-based 3D models using laser scalers. We extend the scale estimation process by including it into a Monte Carlo (MC) simulation, where we propagate the uncertainties associated with the image features and laser spot detections through the estimation process.
As the evaluated models are built with metric information (e.g., the vehicle navigation data, dimensions of auxiliary objects), their scale is expected to be consistent with the scale provided by the laser scaler (
). Therefore, any deviation from the expected scale value (
) can be regarded as an inaccuracy of the scale of the model (
). The error can be used to represent the percentage by which any spatial measurement using the model will be affected:
where
m and
represent a known metric quantity and its model based estimate.
3.1. Scale Estimation
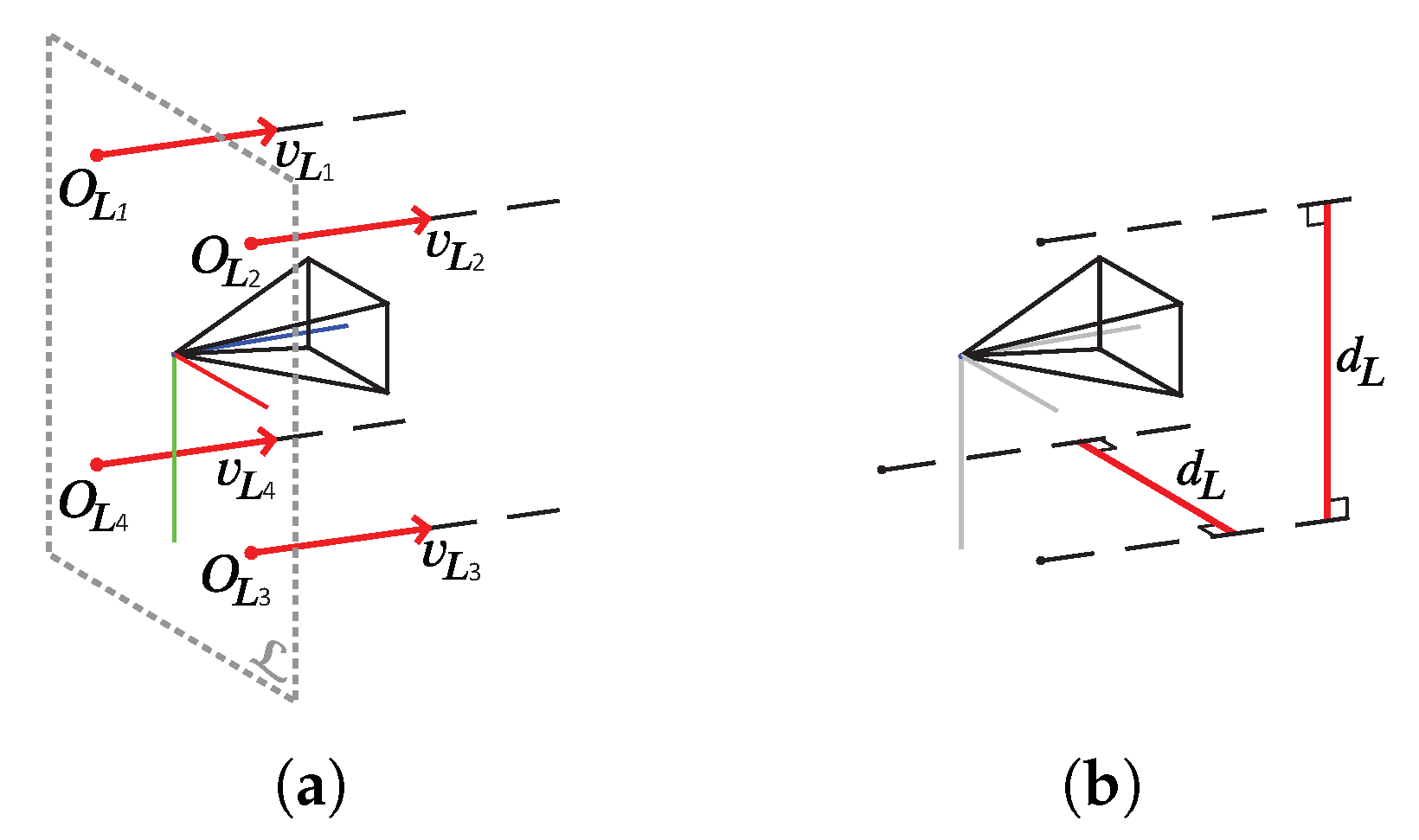
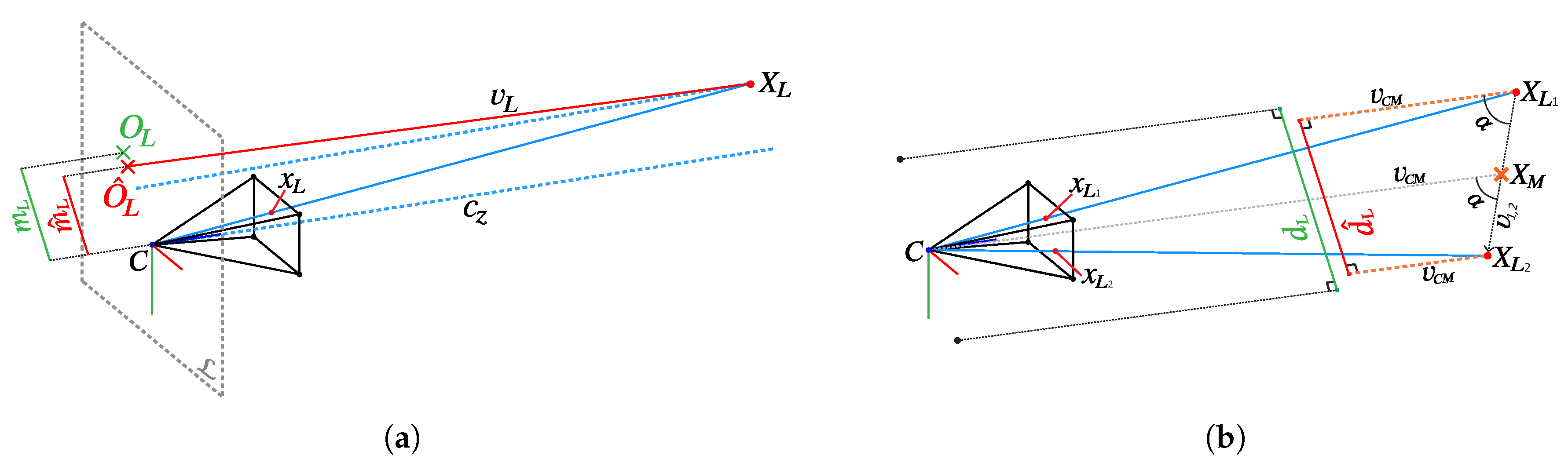
The two methods, namely, the fully-unconstrained method (FUM) and the partially-constrained method (PCM), are both suitable for different laser scaler configurations. FUM permits an arbitrary position and orientation for each of the lasers in the laser scaler, at the expense of requiring a full a priori knowledge of their geometry relative to the camera (
Figure 3a). On the other hand, the laser-camera constraints are significantly reduced when using the PCM method. The laser origins have to be equidistant from the camera center and laser pairs have to be parallel (
Figure 3b). However, in contrast to prior image scaling methods [
24,
25], the lasers do not have to be aligned with the optical axis of the camera.
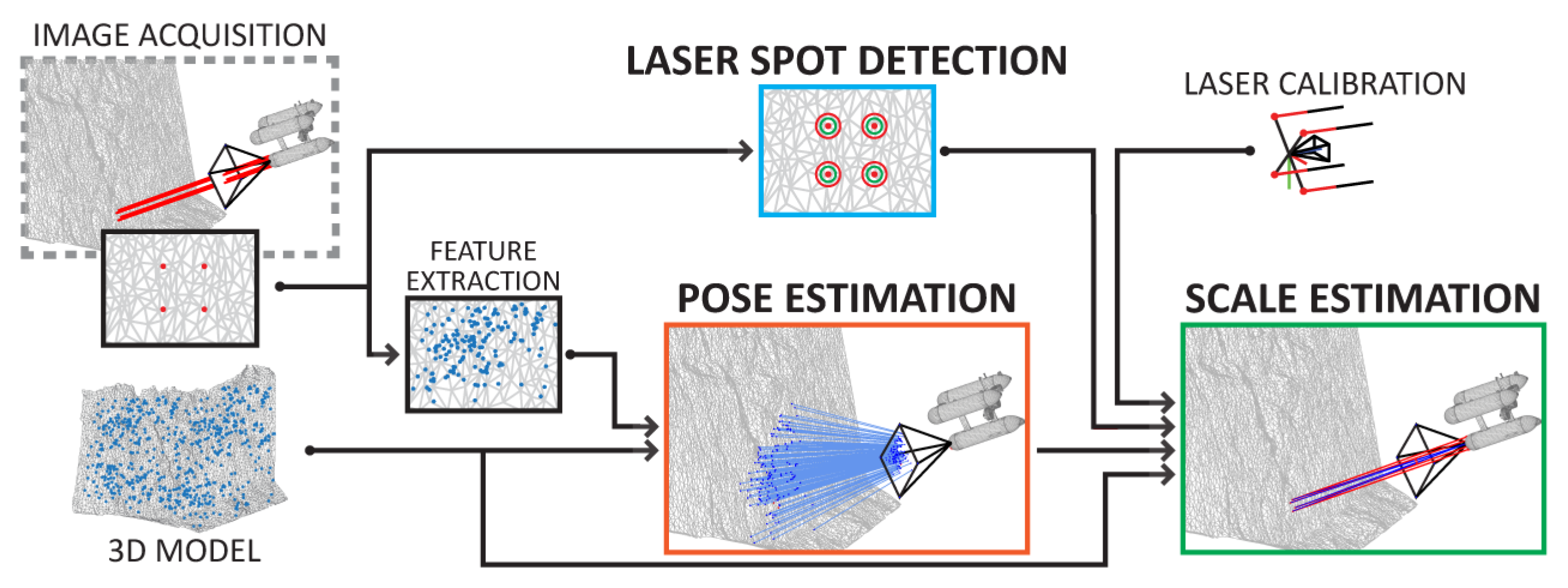
Both methods exploit images with visible intersections of the laser beams with the scene, not just the simple location of the laser spots. The model scale is estimated through a three step process: laser detection, pose estimation and scale estimation (
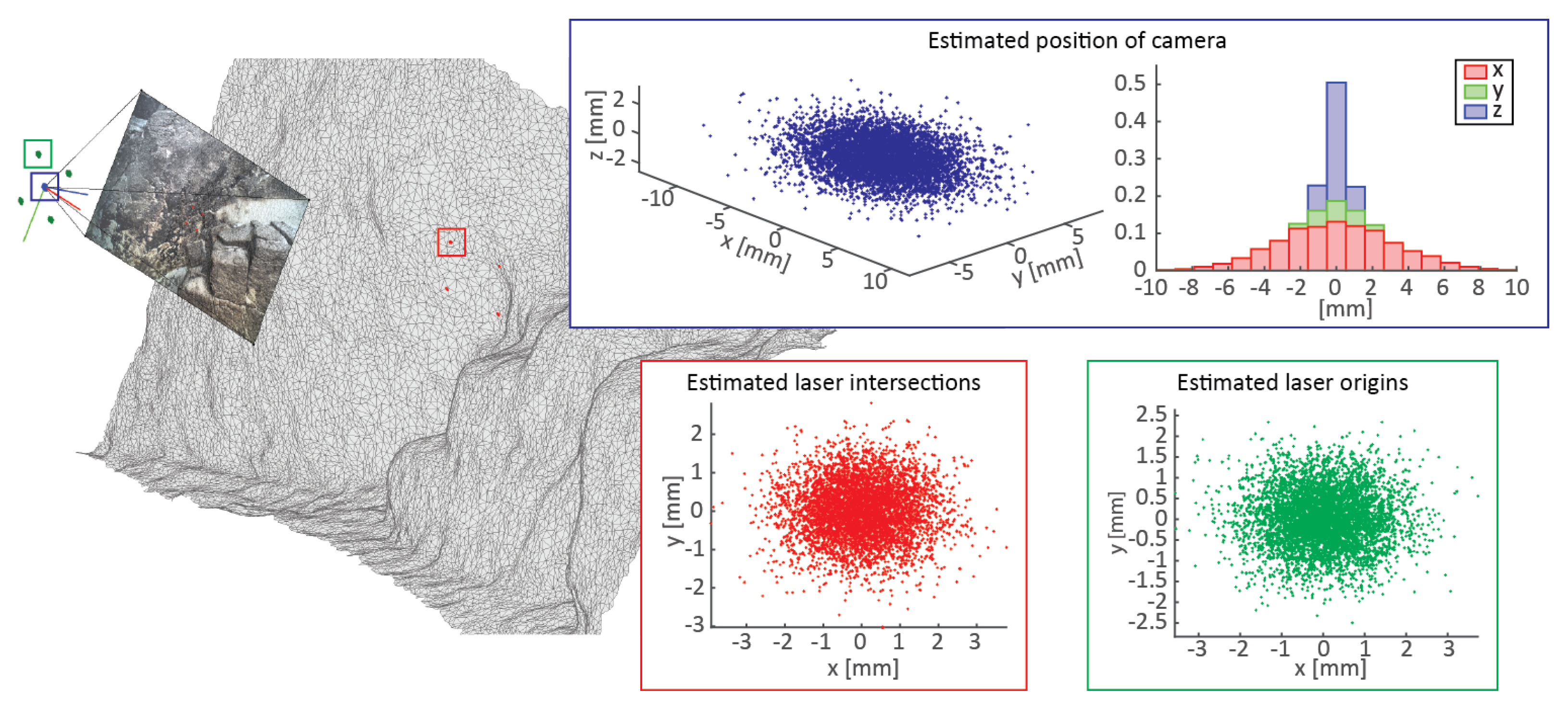
Figure 4). The two initial steps are identical in both methods: First, a laser detection method determines the locations of laser spots on an image; second, the pose of the camera (wrt. the 3D model) at the time of image acquisition is estimated through a feature-based localization process.
The initial camera-extrinsic values (and optionally also camera-intrinsics) are obtained by solving an Perspective-n-Point (PnP) problem [
65] using 3D–2D feature pairs. Each pair connects an individual image feature and a feature associated with the sparse set of points representing the model. As these observations and matches are expected to be noisy and can contain outliers, the process is performed in conjunction with a robust estimation method A-Contrario Ransac (AC-RANSAC) [
52]. The estimate is further refined through a nonlinear optimization (BA), minimizing the re-projection error of known (and fixed) 3D points and their 2D observation on the image.
The camera pose and location of the laser spots are lastly used either to estimate the position of the laser origin, so as to produce the recorded result (FUM), or else to estimate the perpendicular distance between the two parallel laser beams (PCM). As these predictions are based on the 3D model, they are directly affected by its scale, and can therefore be used to determine it through a comparison with a priori known values. As shown through an extensive evaluation in our previous work, both FUM and PCM can be used to estimate model scale regardless of the camera view angle, camera–scene distance, or terrain roughness [
26]. After the application of a maximum likelihood estimator (BA) and a robust estimation method (AC-RANSAC), the final scale estimation is minimally affected by noise in the detection of feature positions and the presence of outlier matches.
In the fully-unconstrained method (
Figure 5a), knowledge of the complete laser geometry is used (origins,
, and directions,
) to determine the position of laser emission
, and then produce the results observed on the image (Equation (
4)). The laser origins
are predicted by projecting 3D points
, representing the location of laser beam intersections with the model, using a known direction of the beam
. As the points
must be visible to the camera, i.e., be in the line-of-sight of the camera, their positions can be deduced by a ray-casting procedure using a ray starting in the camera center and passing through the laser spot
detected in the image. The final scale estimate can then be determined by comparing the displacement of the
with its a priori known value
.
where
is defined as the projection from world to camera frame and
represents the optical axis of the camera.
Alternatively, the partially-constrained method (
Figure 5b) can be used when laser pairs are parallel but with unknown relation to the camera. As opposed to other image scaling methods, laser alignment with the optical axis of the camera is not required, allowing its application to numerous scenarios in which strict rigidity between camera and lasers is undetermined or not maintained (e.g., legacy data). To overcome the lack of information on the direction of laser beams with respect to the camera, the equidistance between the laser origins and the camera center is exploited. Laser beam direction is thus approximated with the direction of the vector connecting the camera center and the middle point between the two points of lasers intersections with the model
. As we have shown in our previous work [
26], this approximation can lead to small scaling errors only in the most extreme cases where the distance discrepancy between two points on the model is disproportionately large compared to the camera–scene distance. As underwater surveys are always conducted at sufficiently large safety distances, this scenario is absent in underwater reconstructions.
3.2. Uncertainty Estimation
Uncertainty characterization of each scale estimate is crucial for quantitative studies (precise measurement of distances and volumes, orientations, etc.), as required in marine science studies where accurate metrology is essential (such as in geology, biology, engineering, archaeology and others). The effect of uncertainties in the input values on the final estimate is evaluated using a MC simulation method. The propagation of errors through the process is modeled by repeated computations of the same quantities, while statistically sampling the input values based on their probability distributions. The final uncertainty estimate in scale is derived from the independently computed values.
Figure 6 depicts the complete MC simulation designed to compute the probability distribution of an estimated scale error, computed from multiple laser observations in an image. We assume that the sparse 3D model points, associated with the 2D features in the localization process, are constant, and thus noise free. On the other hand, uncertainty in the imaging process and feature detection is characterized using the re-projection error obtained by the localization process. We also account for the plausible uncertainty in the laser calibration and laser spot detection, with each laser being considered independently.
4. Laser Spot Detection
The accurate quantification of scale errors affecting 3D models derived from imagery requires numerous reliable measurements that have to be distributed throughout the model. As scale estimates are obtained by exploiting the knowledge of laser spot positions on the images, the quantity and quality of such detections directly determine the number of useful scale estimates. Furthermore, to properly estimate the confidence levels of such estimated scales, the uncertainty of the laser spot detections needs to be known.
The laser beam center is commonly considered to be the point with the highest intensity in the laser spot, as the luminosity of laser spots normally overpowers the texture of the scene. However, due to the properties of the water medium, the laser light can be significantly attenuated on its path to the surface before being reflected back to the camera. In such cases, the final intensity of the beam reaching the camera might be overly influenced by the texture at the point of the impact (
Figure 7). As such, performing manual accurate annotations of laser spots tends to be extremely challenging and labor intensive, and even impossible in certain cases.
Considerable attention has been given to the development of the image processing components of laser scanners, namely on laser line detection [
66,
67], while the automatic detection of laser dots from underwater laser scalers has only been addressed in a few studies. Rzhanov et al. [
68] developed a toolbox (The Underwater Video Spot Detector (UVSD)), with a semiautomatic algorithm based on a Support Vector Machine (SVM) classifier. Training of this classifier requires user-provided detections. Although the algorithm can provide a segmented area of the laser dot, this information is not used for uncertainty evaluation. More recently, the authors of [
69] presented a web-based, adaptive learning laser point detection for benthic images. The process comprises a training step using k-means clustering on color features, followed by a detection step based on a k-nearest-neighbor (kNN) classifier. From this training on laser point patterns the algorithm deals with a wide range of input data, such as the cases of having lasers of different wavelengths, or acquisitions under different visibility conditions. However, neither the uncertainty in laser point detection nor the laser line calibration are addressed by this method.
To overcome the lack of tools capable of detecting and estimating the uncertainty in laser spot detection while still producing robust and accurate detections, we propose a new automatic laser detection method. To mitigate the effect of laser attenuation on the detection accuracy, scene texture is considered while estimating the laser beam center. Monte Carlo simulation is used to estimate the uncertainty of detections, considering the uncertainty of image intensities.
4.1. Detection
To determine laser spot positions on any image, the first step is a restriction of the search area to a patch where visible laser spots are expected (
Figure 8a). Although not compulsory, this restriction minimizes false detections and reduces computational complexity and cost. The predicted area may be determined from the general pose of the lasers with respect to the camera, and from the range of distances to the scene.
An auxiliary image is used to obtain a pixel-wise aligned description of the texture in the patch. This additional image is assumed to be acquired at a similar distance and with laser spots either absent or in different positions. This ensures visually similar texture information at the positions of the laser spots. This requirement is easily achievable for video acquisitions, as minor changes in camera pose sufficiently change the positions of the lasers. Alternatively, if still images are acquired, in addition to each image with visible laser spots, an additional image taken from a slightly different pose or in the absence of laser projections has to be recorded. The appropriate auxiliary patch is determined using normalized cross correlation in Fourier domain [
70] using the original patch and the auxiliary image. The patch is further refined using a homography transformation estimated by enhanced correlation coefficient maximization [
71] (
Figure 8b). Potential discrepancies caused by the changes in the environment between the acquisitions of the two images, are further reduced using histogram matching. Once estimated, the texture is removed from the original patch to reduce the impact of the texture on the laser beam spots. A low-pass filter further reduces noise and the effect of other artifacts (e.g., image compression), before detection using color thresholding (e.g., red color) in the HSV (Hue, Saturation, and Value) color space (
Figure 8d). Pixels with low saturation values are discarded as hue cannot be reliably computed. The remaining pixels are further filtered using mathematical morphology (opening operation). The final laser spots are selected by connected-component analysis (
Figure 8e).
Once the effects of the scene texture have been eliminated, the highest intensity point may be assigned to the laser beam center. In our procedure, the beam luminosity is characterized by the V channel of the HSV image representation.
Figure 8f,g depicts the estimate of the laser beam luminosity with and without texture removal. Our proposed texture removal step clearly recovers the characteristic shape of the beam, with radially decreasing intensity from the center. Fitting a 2D Gaussian distribution to each laser spot allows us to estimate the center of the beam, assuming a
probability that the center falls within the top
of the luminance values (
Figure 8h).
4.2. Uncertainty
Given that the estimation of the laser center is based on color information, it is important to consider the effect of image noise. Depending on the particularities of the image set, image noise is the result of the combined effects of sensor noise, image compression, and motion blur, among others. In our approach, the image noise is characterized by comparing the same area in two images taken within a short time interval (e.g., time between two consecutive frames), where the sensed difference can be safely attributed to image noise rather than an actual change in the environment.
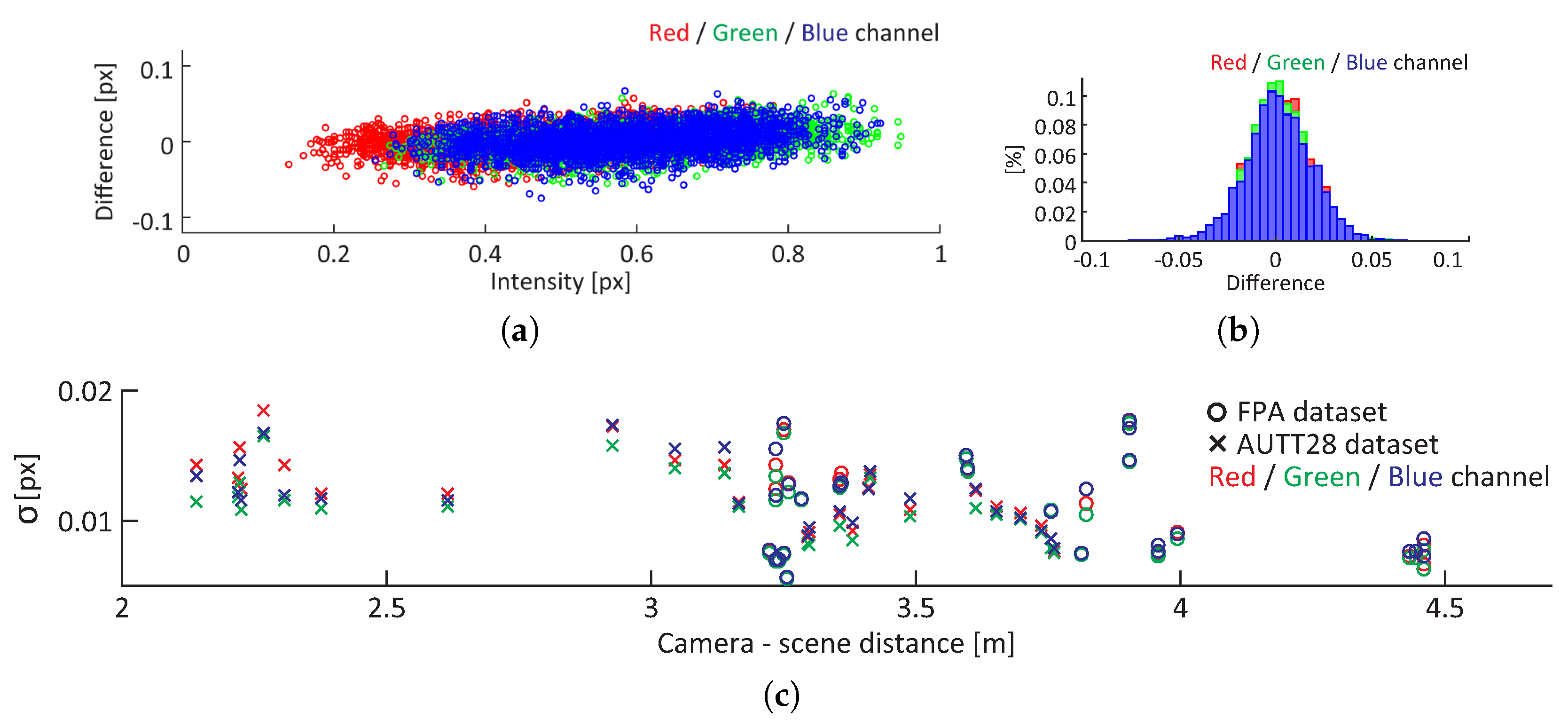
For a randomly selected image from dataset FPA, the relation between assumed image noise (pixel-wise difference of intensities) and pixel intensities per color channel is depicted in
Figure 9a, with the histogram of differences shown in
Figure 9b. The results clearly illustrate a lack of correlation between image noise and pixel intensity levels or color channels as well as the fact that the noise can be well described by a Gaussian distribution. Furthermore, the analysis of 52 images from both datasets (FPA and AUTT28), acquired at a wide range of camera–scene distances and locations, in which the image noise was approximated by Gaussian distribution, indicating that the distribution of noise remains bounded regardless of the dataset or camera–scene distance (
Figure 9c). While it is worth noting that the motion blur will be increasingly noticeable in images acquired at closer ranges, the analyzed range of distances is representative of the ones used for the evaluation presented in the following sections.
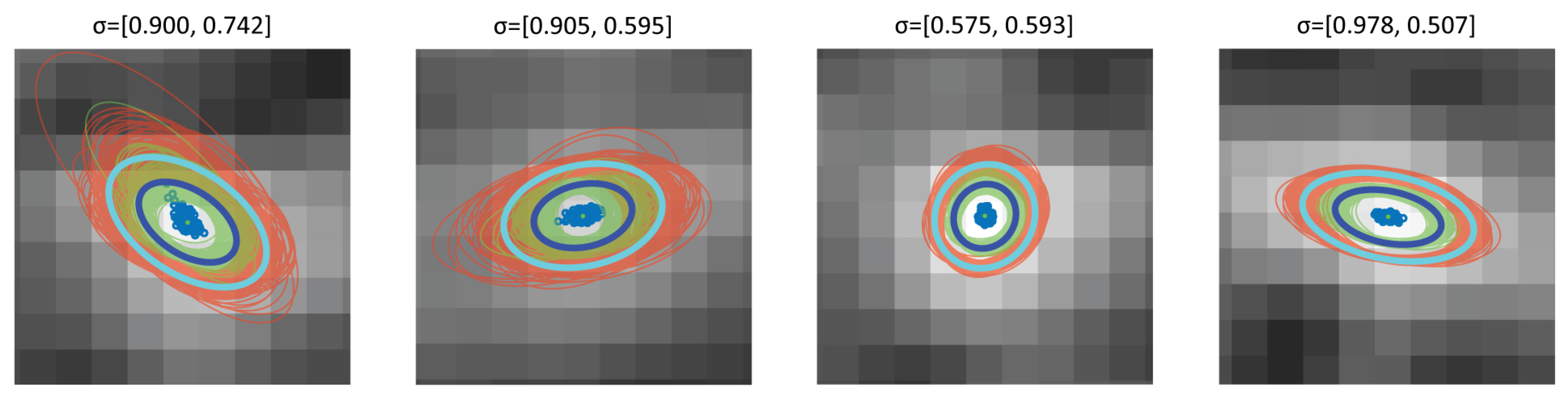
To obtain a final estimate of confidence levels of detection, the uncertainty of image intensities are propagated through the laser detection process using MC simulation. At each iteration the noise is added independently to each pixel before the described laser spots detection. The iterations yield a set of independent detections, each characterized by a Gaussian distribution (
Figure 8h). The final laser spot detection is subsequently obtained by determining an equivalent Gaussian using the Unscented Transform [
72] to make this process less computationally expensive. If the laser is not detected in more than
of iterations, the detection is considered unstable and discarded. A set of laser spot detections obtained by a MC simulation is shown in
Figure 10, together with the final joint estimation. Red and green ellipses represent
and
confidence levels for independent detections, while blue and cyan indicate the final (combined) uncertainty.
5. Dataset
During the SUBSAINTES 2017 cruise (doi: 10.17600/17001000) [
43] extensive seafloor imagery was acquired with the ROV VICTOR 6000 (IFREMER) [
73]. The cruise targeted tectonic and volcanic features off Les Saintes Islands (French Antilles), at the same location as that of the model published in an earlier study [
9], and derived from imagery of the ODEMAR cruise (doi: 10.17600/13030070). One of the main goals of this cruise was to study geological features associated with a recent earthquake—measuring the associated displacement along a fault rupture—while expanding a preliminary study that presented a first 3D model where this kind of measurement was performed [
9]. To achieve this, the imagery was acquired at more than 30 different sites along
, at the base of a submarine fault scarp. This is, therefore, one of the largest sets of image-derived underwater 3D models acquired with deep sea vehicles to date.
The ROV recorded HD video with a monocular camera (Sony FCB-H11 camera with corrective optics and dome port) at 30Hz, and with a resolution of
px (
Figure 11). Intrinsic camera parameters were determined using a standard calibration procedure [
74] assuming a pinhole model with the 3rd degree radial distortion model. The calibration data was collected underwater using a checkerboard of
squares, with identical optics and camera parameters as those later used throughout the entire acquisition process. The final root mean square (RMS) re-projection error of the calibration was (0.34 px, 0.30 px). Although small changes due to vibrations, temperature variation, etc. could occur, these changes are considered too small to significantly affect the final result.
Onboard navigation systems included a Doppler velocity log (Teledyne Marine Workhorse Navigator), fibre-optic gyrocompass (iXblue Octans), depth sensor (Paroscientific Digiquartz), and a long-range USBL acoustic positioning system (iXblue Posidonia) with a nominal accuracy of about of the depth. As the camera was positioned on a pan-and-tilt module lacking synchronization with the navigation data, only the ROV position can be reliably exploited.
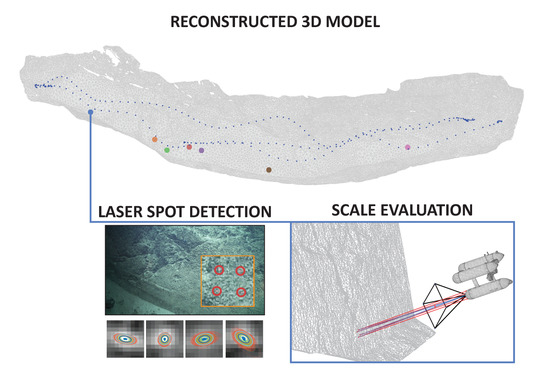
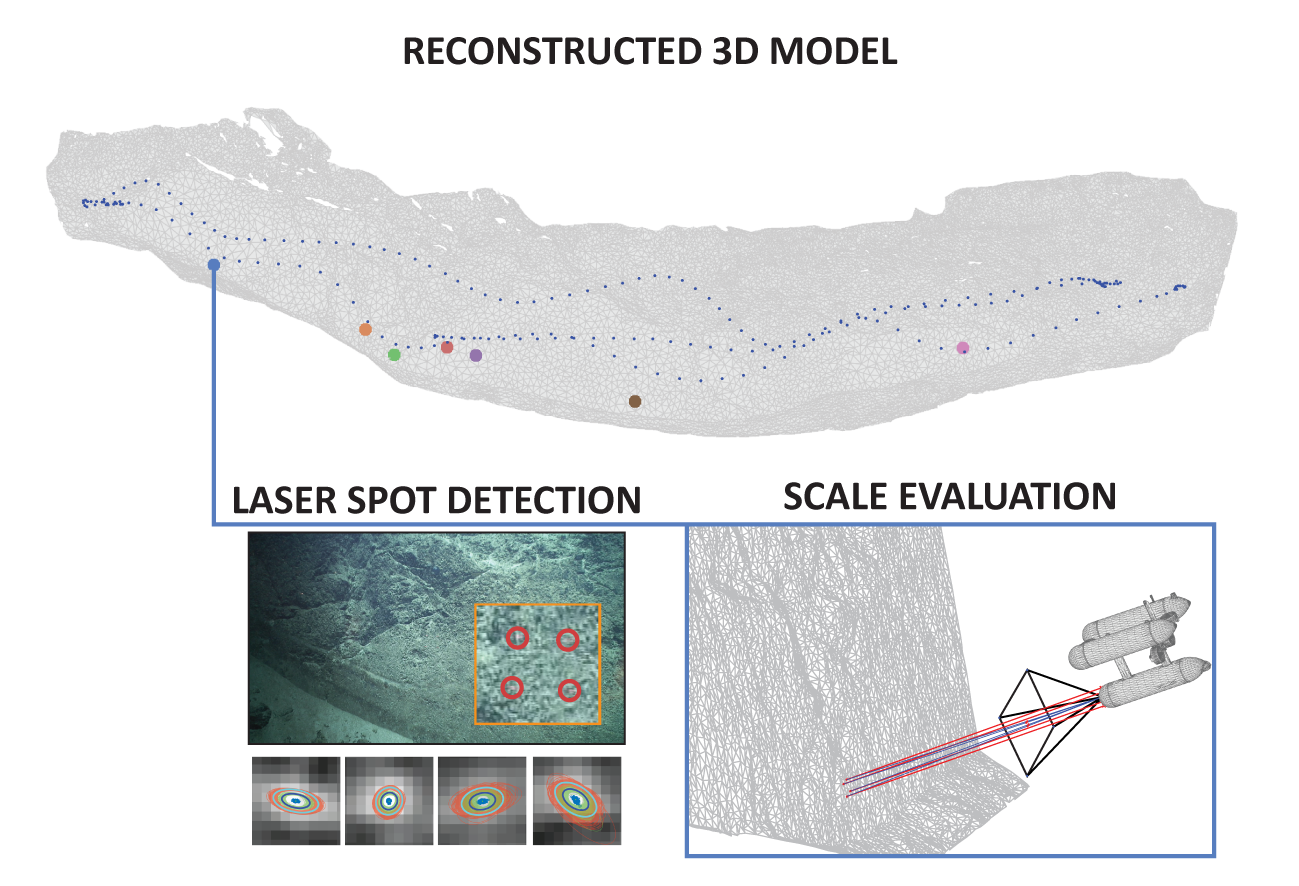
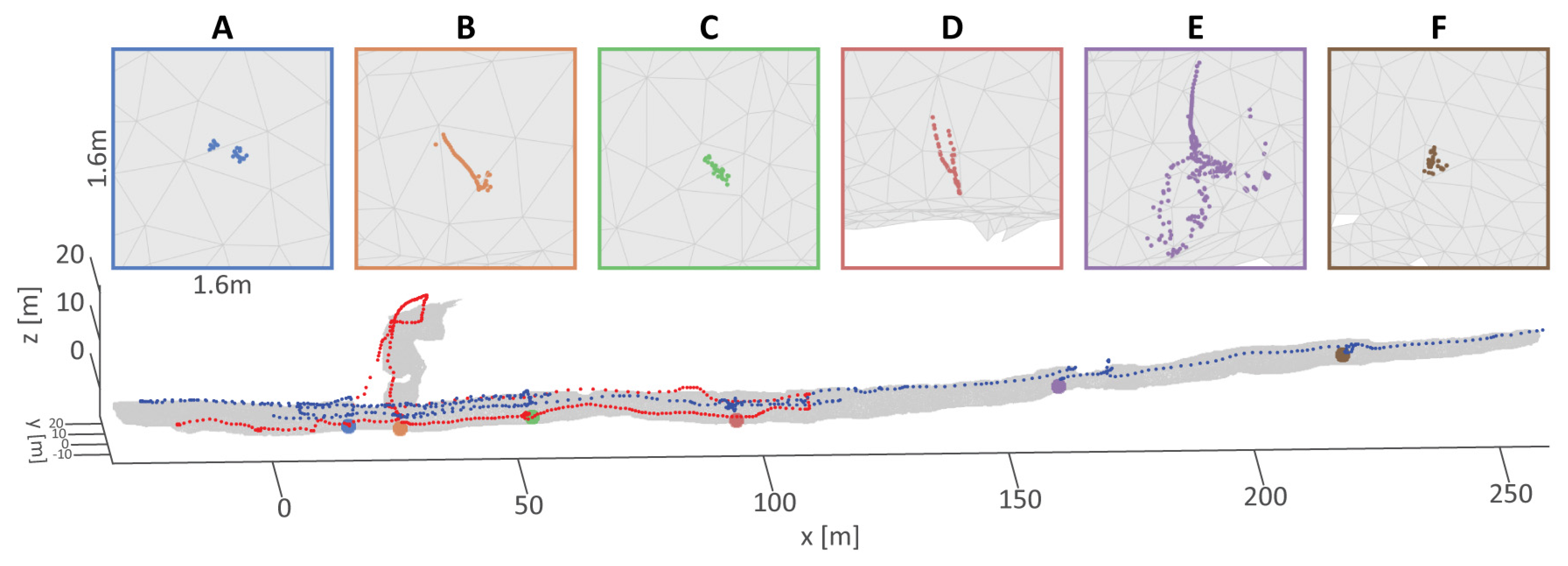
To date, 3D models have been built at more than 30 geological outcrops throughout the SUBSAINTES study area. Models vary in length between and horizontally, and extend vertically up to . Here we select two out of the 30 models (FPA and AUTT28), representative both of different survey patterns and spatial extents and complexity. Concurrently, evaluation data were collected with the same optical camera centered around a laser scaler consisting of four laser beams. For both selected datasets, numerous laser observations were collected, ensuring data spanning throughout the whole area. This enabled us to properly quantify the potential scale drifts within the models.
5.1. FPA
The first model (named FPA), extends laterally
and
vertically, and corresponds to a subvertical fault outcrop at a water depth of
. The associated imagery was acquired in a
video recording during a single ROV dive (VICTOR dive 654). To fully survey the outcrop, the ROV conducted multiple passes over the same area. In total, 218 images were selected and successfully processed to obtain the final model shown in
Figure 12. The final RMS re-projection errors of BA using different strategies are reported in
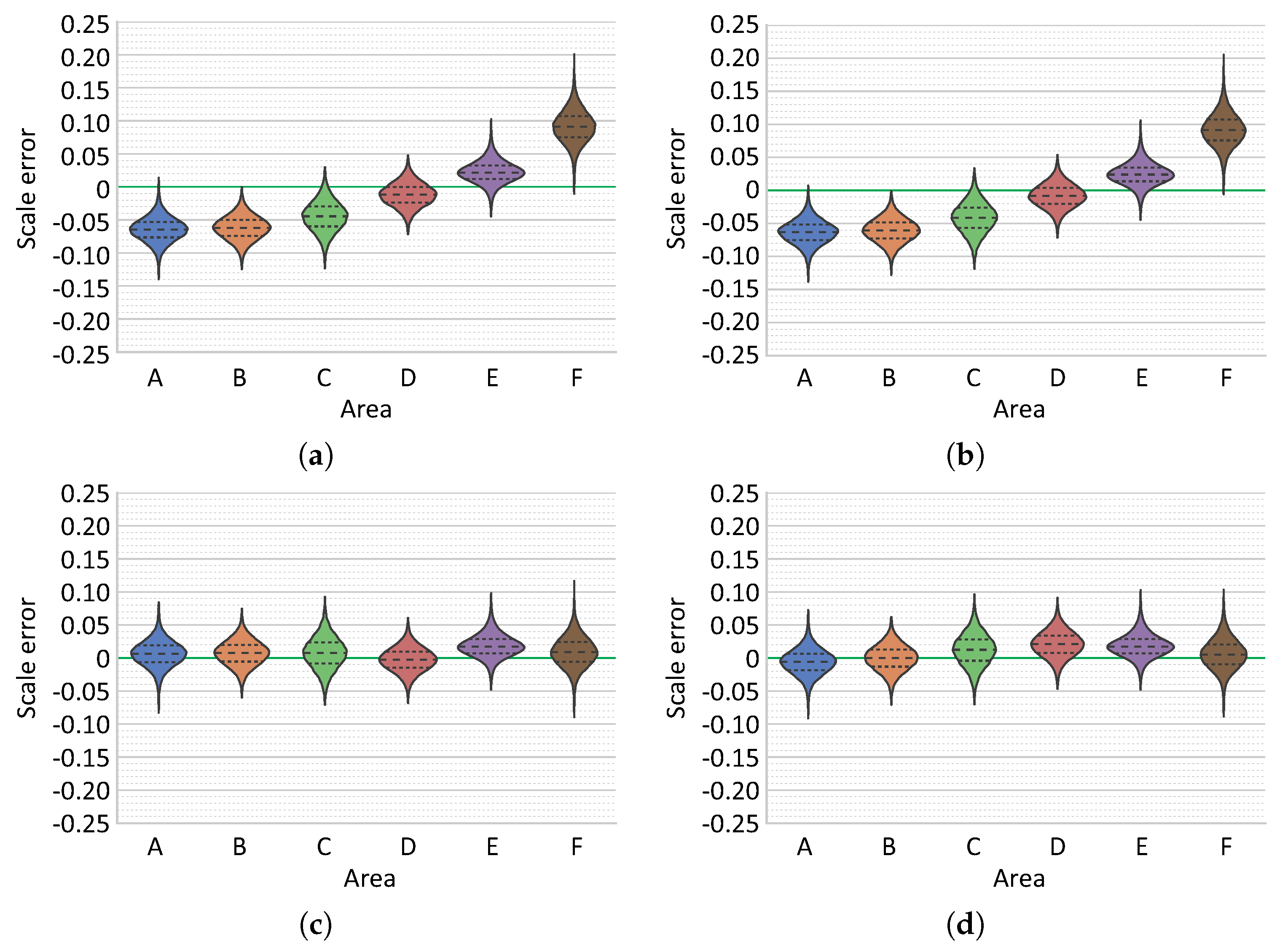
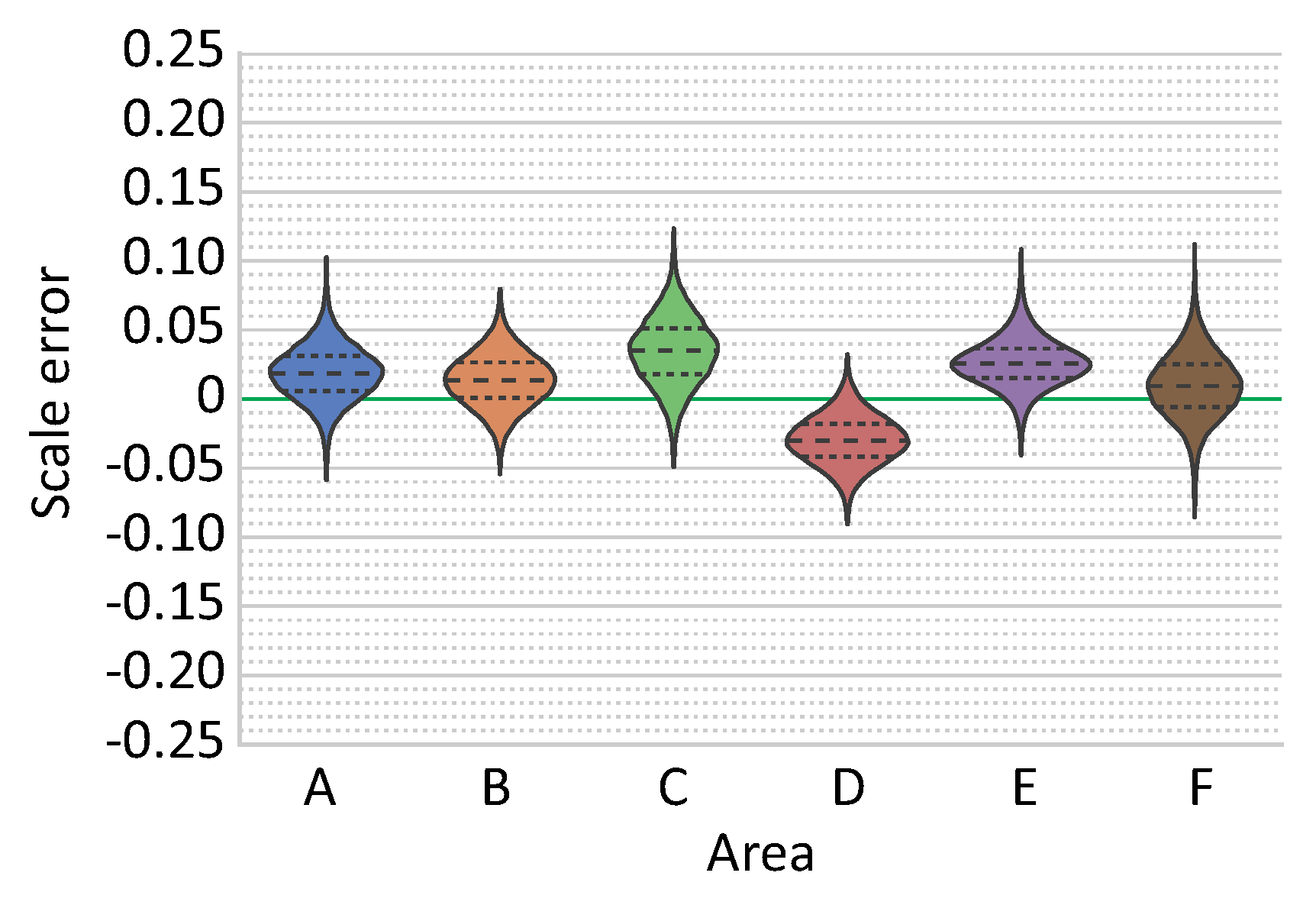
Table 1. As expected, the optimizations using solely visual information and incremental approach are able to achieve lower re-projection errors, which, however, is not sufficient proof of an accurate reconstruction.
5.2. AUTT28
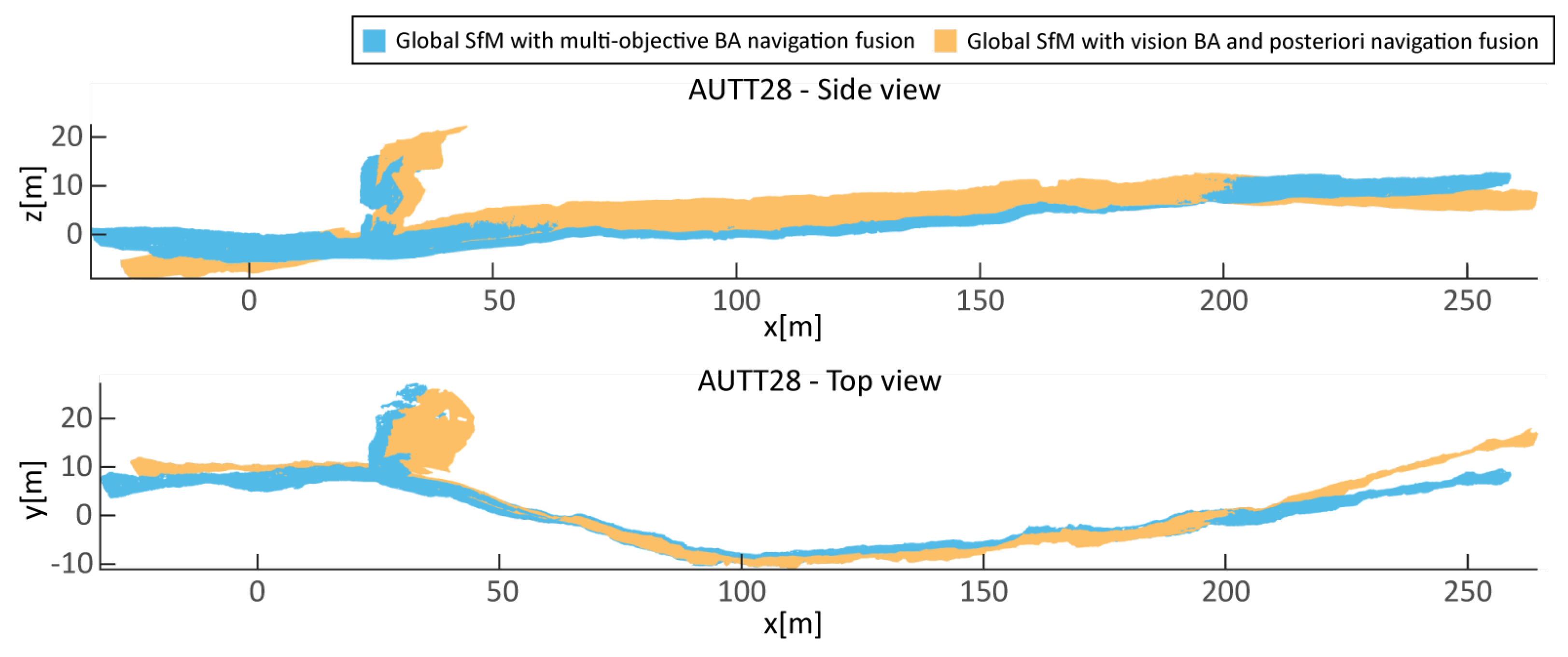
The second model (named AUTT28), shown in
Figure 13, is larger and required a more complex surveying scenario, as is often encountered in real oceanographic cruises. Initially, the planned area of interest was recorded during VICTOR dive 654. Following a preliminary onboard analysis of the data, a vertical extension of the model was required, which was subsequently surveyed during VICTOR dive 658. This second survey also partially overlapped with the prior dive, with overlapping images acquired at a closer range and thus providing higher textural detail. The survey also included a long ROV pass with the camera nearly parallel to the vertical fault outcrop, an extremely undesirable imaging setup. This second 3D model is the largest constructed in this area, covering a sub-vertical fault scarp spanning over
laterally and
vertically, with an additional section of approximately
in height from a vertical ROV travel. This model is thus well suited to evaluate scaling errors associated with drift as it includes several complexities (survey strategy and geometry, multiple dives, extensive length and size of the outcrop). After keyframe selection, 821 images were used out of a combined
and
of video imagery to obtain reconstructions with the RMS re-projection error, as reported in
Table 1.
5.2.1. Multiobjective BA Weight Selection
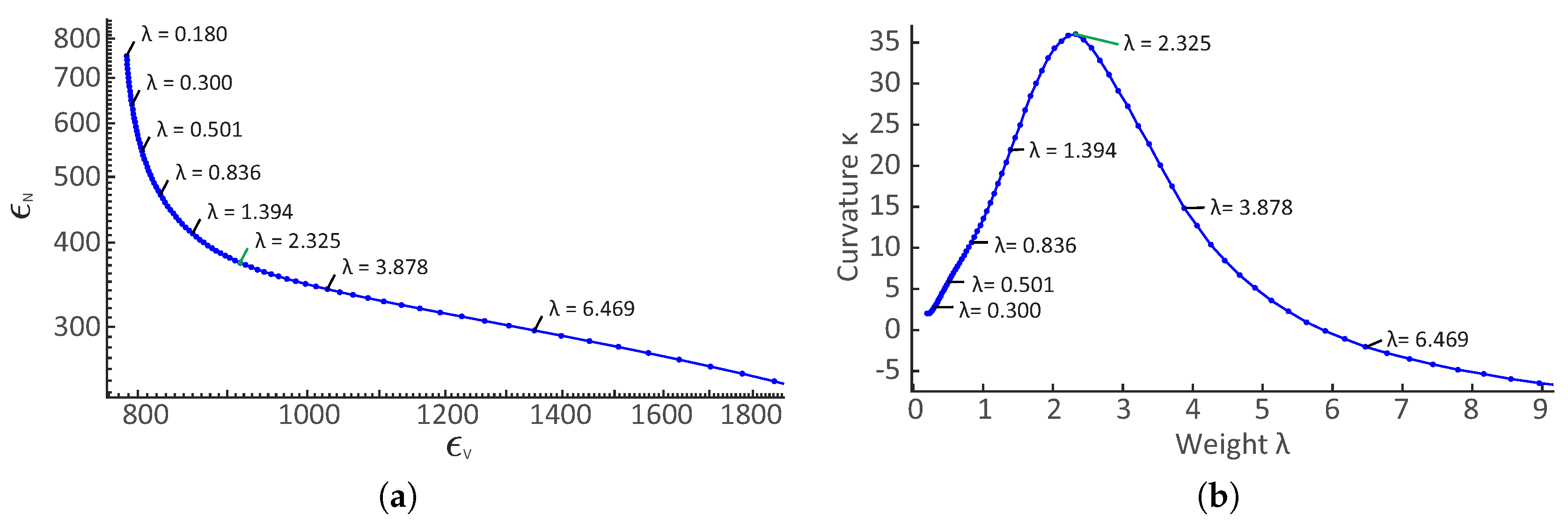
Models built with a priori navigation fusion through the multiobjective BA strategy require a weight selection which represents the ratio between re-projection and navigation fit errors. As uncertainties of the two quantities are in different units and, more importantly, not precisely known, this selection must be done either empirically or automatically. Due to the tedious and potentially ambiguous trial-and-error approach of empirical selection, the weight was determined using L-Curve analysis.
The curve, shown in
Figure 14a, uses the FPA dataset and 100 BA repetitions with weights
ranging from
to 18. As predicted, the shape of the curve resembles an “L”, with two dominant parts. The point of maximum curvature is determined to identify the weight with which neither objective has dominance (
Figure 14b). As noise levels of the camera and navigation sensors do not significantly change between the acquisition of different datasets, the same optimal weight
was used in all our multiobjective optimizations.
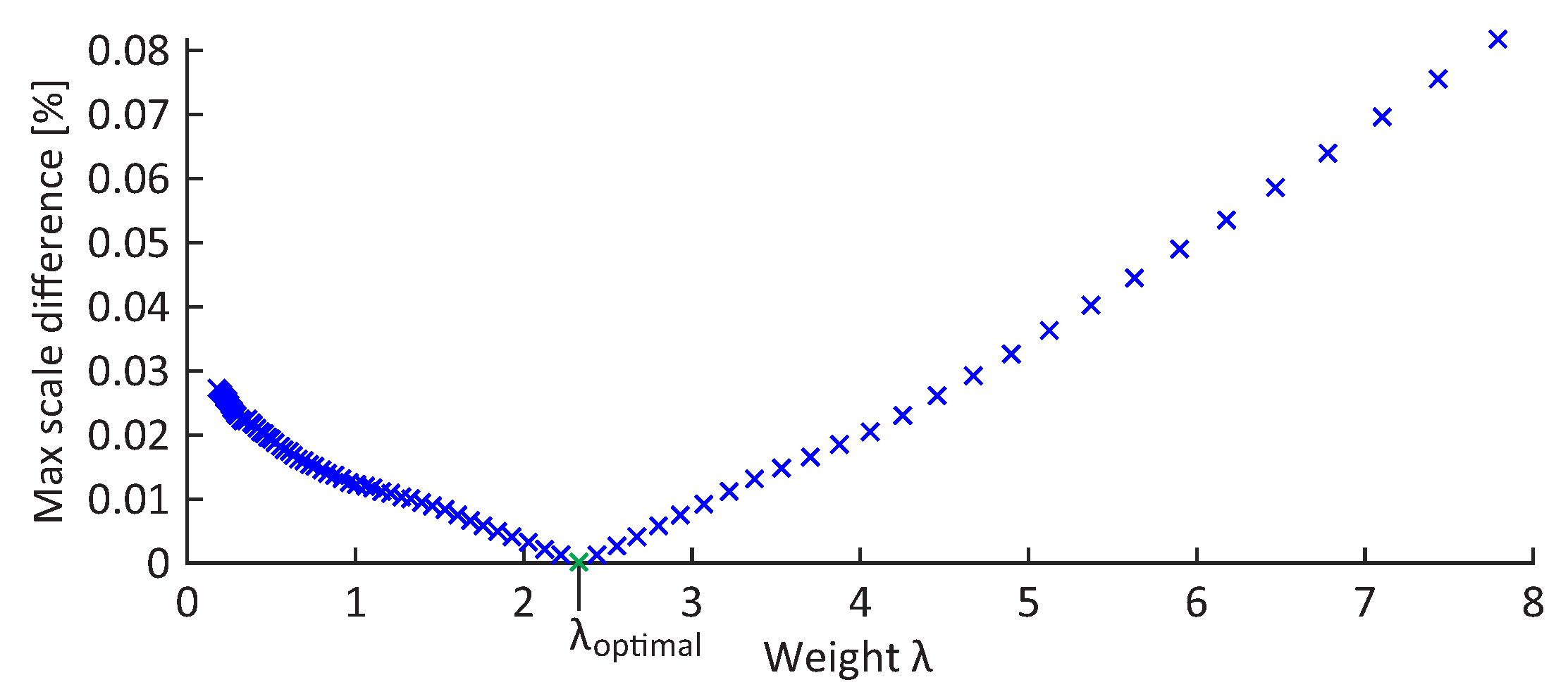
Given the heuristic nature of the optimal weight determination, it is important to evaluate the effects of the selection uncertainty on the final results.
Figure 15 depicts the maximum difference in scale between the reconstructions computed using different weights and the reconstruction obtained with the optimal weight. The maximum expected scale differences were determined by comparing the Euclidean distances between the cameras of various reconstructions. The scale of the model is not expected to change if the ratio between the position of cameras does not change. The results show that the scale difference increases for an approximately
with the increment or decrement of
by a value of one. Given that the optimal
can be determined with the uncertainty of less than
, as illustrated in
Figure 14b, it can be assumed that the uncertainty in the determination of optimal weight has no significant effect on the final result.
5.2.2. Multisurvey Data
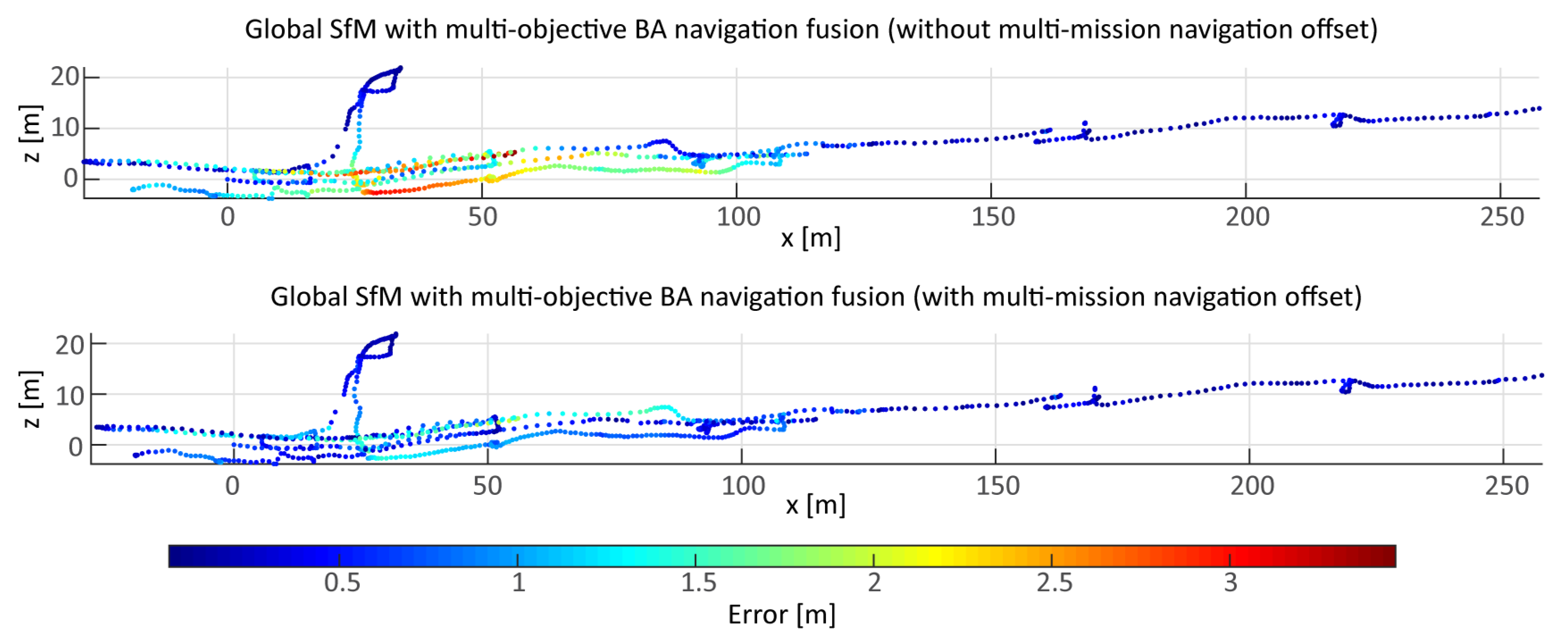
As is often the case in real cruise scenarios, the data for the AUTT28 model was acquired in multiple dives (
Figure 16). When combining the data, it is important to consider the consequences of the merger. Optical imagery can be simply combined, given the short period of time between the two dives, in which no significant changes are expected to occur in the scene. In contrast, the merging of navigation data may be challenging; ROV navigation is computed using smoothed USBL and pressure sensor data, with expected errors in acoustic positioning being ~
deep. As data was collected at roughly
depth, the expected nominal errors are
, or more in areas of poor acoustic conditions (e.g., close to vertical scarps casting acoustic shadows or reverberating acoustic pings). These errors, however, do not represent the relative uncertainty between nearby poses, but rather a general bias of the collected data for a given dive. Although constant within each dive, the errors can differ between the dives over the same area, and are problematic when data from multiple dives are fused. Models built with data from a single dive will only be affected by a small error in georeferencing, while multisurvey optimization may have to deal with contradicting navigation priors; images taken from identical positions would have different acoustic positions, with offsets of the order of several meters or more.
This is overcome by introducing an additional parameter to be estimated, in the form of a 3D vector for each additional dive, representing the difference between USBL-induced offsets. Each vector is estimated simultaneously with the rest of the parameters in the SfM. For the case of AUTT28, the offset between the dives 654 and 658 was estimated to be , , and in the x (E-W), y (N-S), and z (depth) directions, respectively. The disproportionately smaller z offset is due to the fact that the pressure sensor yields inter-dive discrepancies that are orders of magnitude smaller than the USBL positions.
5.3. Laser Calibration
Normally, the calibration process consists of the initial acquisition of images containing clearly visible laser beam intersections with a surface at a range of known or easily determined distances (e.g., using a checkerboard pattern). The 3D position of intersections, expressed relative to the camera, can be subsequently computed through the exploitation of the known 2D image positions and aforementioned camera–scene distances. Given a set of such 3D positions spread over a sufficient range of distances, the direction of the laser can be computed through a line-fitting procedure. Finally, the origin is determined as the point where the laser line intersect the image plane. Given the significant refraction at the air–acrylic–water interfaces of the laser housing, the images used in the calibration process must be collected under water.
In our case, the evaluation data was collected during multiple dives separated by several days, and with camera and lasers being mounted and dismounted several times. While the laser-scaler mounting brackets ensured that the laser origins remained constant, the laser directions with respect to the camera changed slightly with each installation. Due to operational constraints on the vessel, it was not possible to collect dedicated calibration data before each dive. However, given that the origins of the lasers are known a priori and remained fixed throughout the cruise, the only unknown in our setup is the inter-dive variation of the laser directions (relative to the camera and with respect to each other). The fact that independent laser directions do not encapsulate scale information (only the change of direction on an arbitrary unit) enables us to overcome the lack of dedicated calibration images and alternatively determine the set of points lying on each laser beam using images collected over the same area for which a 3D model has been constructed.
As our interest is only in the laser directions, the points used in the calibration can be affected by an arbitrary unknown scale factor, as long as this factor is constant for all of the points. Therefore, it is important to avoid models with scale drift, or to use data from multiple models with different scales. For each of the images used in the calibration, the camera was localized with respect to the model by solving an PnP problem [
65] as in the FUM and PCM and additionally refined through BA. Each of the individual laser points were then determined by a ray-cast process and expressed in the camera coordinate system, before the direction of each of the lasers was determined by line-fitting. To maximize the conditioning of line-fitting, the selection of a model with the widest distance range of such intersection points and the smallest scale drift is important. This is the case for the AUTT28 model built using Global SfM and multiobjective BA, selected here. The global nature of the SfM and internal fusion of navigation data is predicted to most efficiently reduce a potential scale drift. As noisy laser detections are used to obtain the 3D points utilized in the calibration, laser spot uncertainties were propagated to obtain the associated uncertainty of the estimated laser direction. A MC simulation with a 1000 repetitions was used. Together with the a priori known origin of the laser, this calibration provides us with all the information needed to perform scale estimation using the fully-unconstrained method.
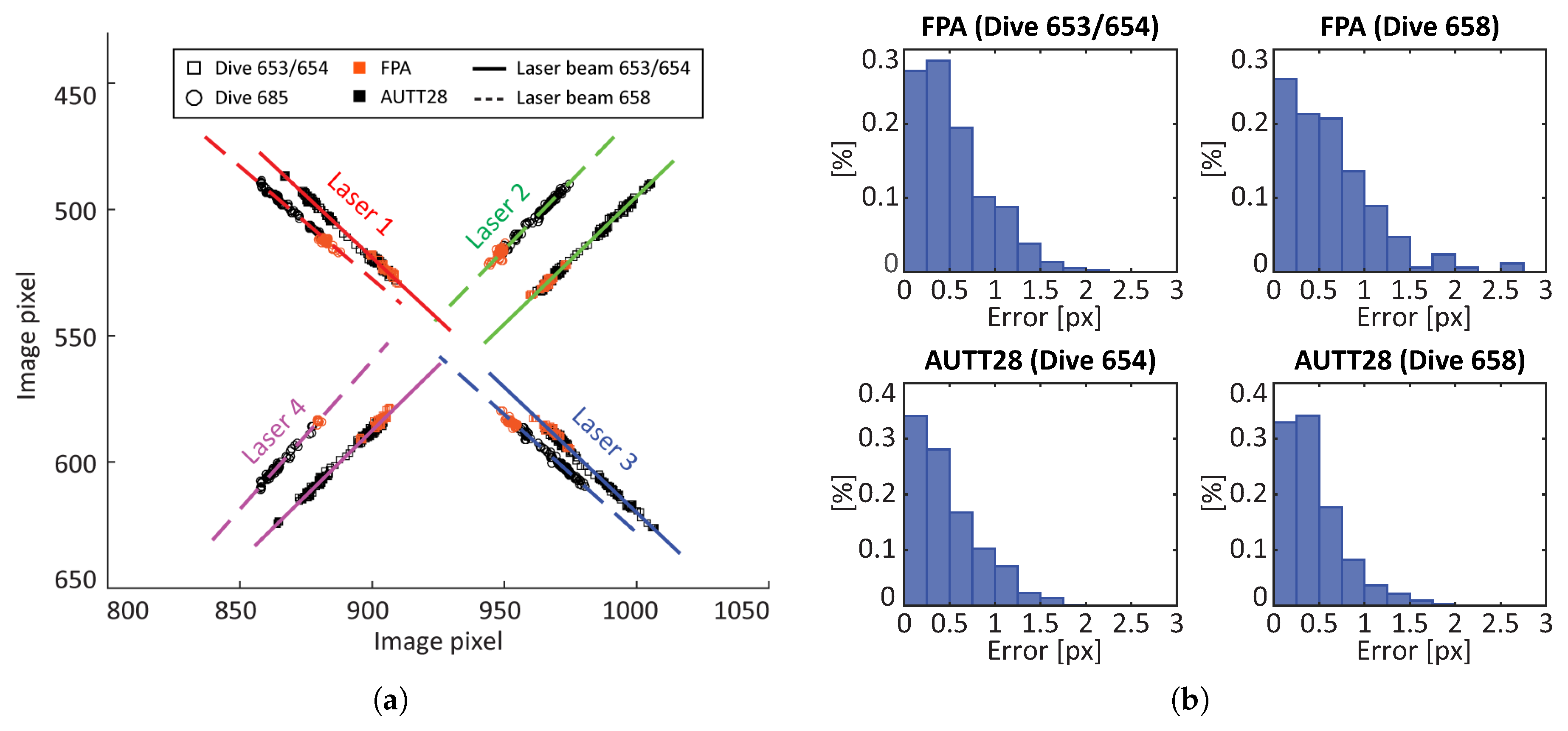
The evaluation data were collected on dives 653, 654, and 658. As no camera and laser dismounting/mounting occurred between dives 653 and 654, there are two distinct laser setups: one for dives 653 and 654 and one for dive 658.
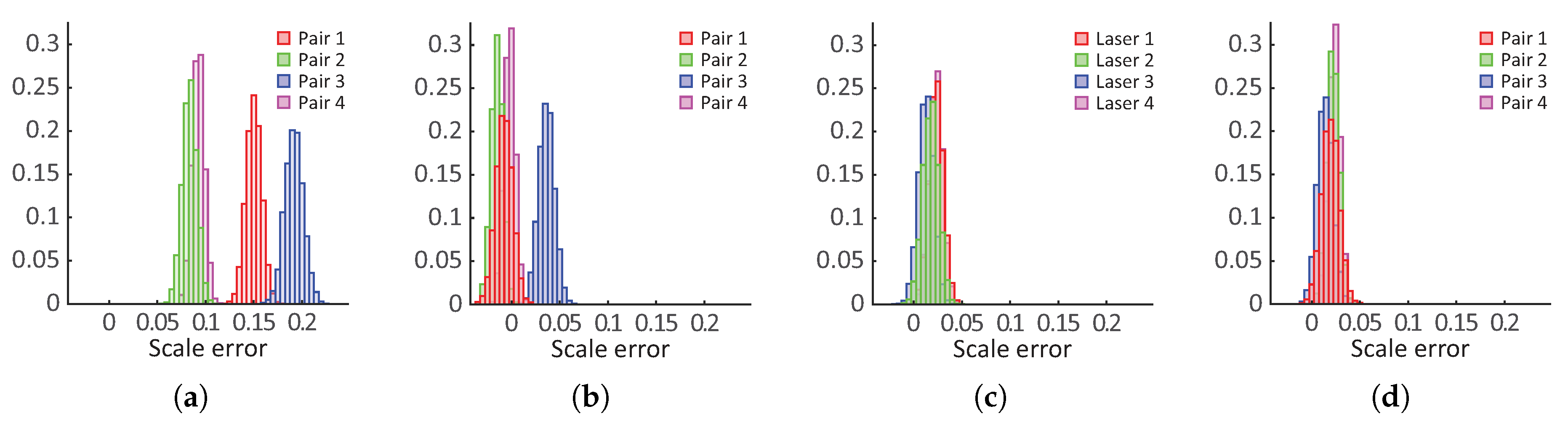
Figure 17a depicts all laser intersections with the scene (for both AUTT28 and FPA models), as well as the calibration results, projected onto an image plane. Intersections detected in 3D model AUTT28 are depicted in black, and those from 3D model FPA are shown in orange. Similarly, the squares and circles represent dives 653/654 and dive 658, respectively. The projections of the final laser beam estimations are presented as solid and dotted lines. The figure shows a good fit of estimated laser beams with the projections of the intersections, both in the AUTT28 and FPA models.
The distributions of calibration errors, measured as perpendicular distances between the calibrated laser beams and the projected laser intersections with the scene, are depicted in
Figure 17b, and the RMS errors are listed in
Table 2. The adequate fit to the vast majority of AUTT28 points (RMS error <
px) shows that the model used in the calibration had no significant scale drift. Furthermore, the fitting of the FPA related points (RMS error <
px), which were not used in the calibration and are affected by a different scale factor, confirms that the calibration of laser directions is independent of the 3D model used, as well as of different scalings. The broad spread of the black points relative to the orange ones also confirms that the choice of the AUTT28 over the FPA model was adequate for this analysis. Lastly, it is worth reiterating that the data from all the models cannot be combined for calibration, as they are affected by different scale factors.
8. Conclusions
This study presented a comprehensive scale error evaluation of four of the most commonly used image-based 3D reconstruction strategies of underwater scenes. This evaluation seeks to determine the advantages and limitations of the different methods, and to provide a quantitative estimate of model scaling, which is required for obtaining precise measurements for quantitative studies (such as distances, areas, volumes and others). The analysis was performed on two data sets acquired during a scientific cruise (SUBSAINTES 2017) with a scientific ROV (VICTOR6000), and therefore under realistic deep sea fieldwork conditions. For models built using multiobjective BA navigation fusion strategy, an L-Curve analysis was performed to determine the optimal weight between competing objectives of the optimization. Furthermore, the potential offset in navigation when using USBL-based positioning from different dives was addressed in a representative experiment.
Building upon our previous work, the lack of readily available measurements of objects of known sizes in large scale models was overcome with the fully-unconstrained method, which exploits laser scaler projections onto the scene. The confidence level for each of the scale error estimates was independently assessed with a propagation of the uncertainties associated with image features and laser spot detections using a Monte Carlo simulation. The number of iterations used in the simulation to satisfactorily represent the complexity of the process was validated through the analysis of the final estimate behavior.
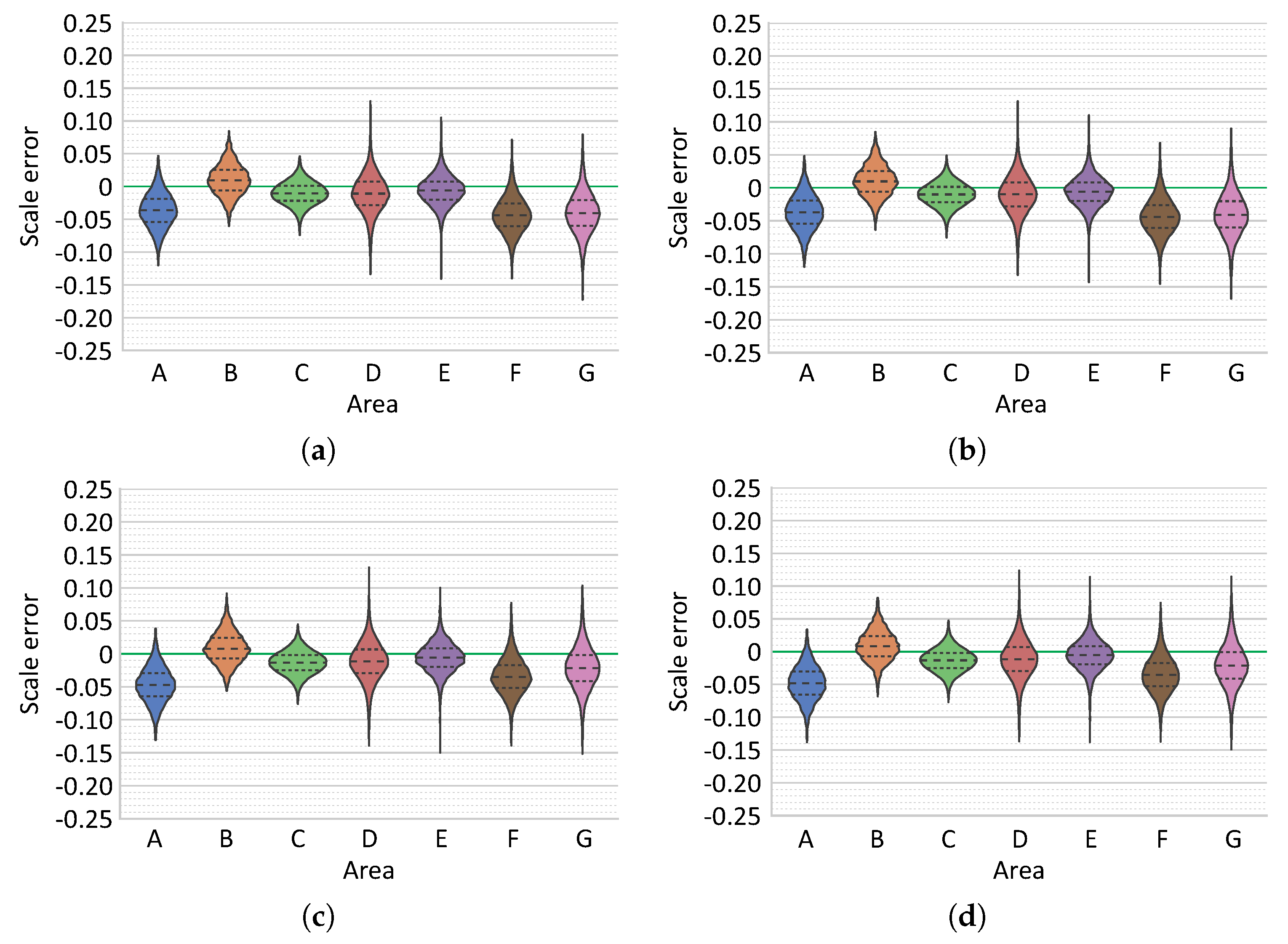
As each scale error estimate characterizes an error at a specific area of the model, independent evaluations across the models enable efficient determination of potential scale drifts. To obtain a sufficient number of accurate laser measurements, an automatic laser spot detector was also developed. By mitigating the effects of scene texture using an auxiliary image, a much larger number of accurate detections was possible, even with greatly attenuated laser beams. The requirement of having laser spots either not present or in at different position in the auxiliary image is easily satisfied in video acquisitions, while an additional image has to be recorded if still images are collected. Furthermore, the recovery of characteristic shapes of laser spots with radially decreasing intensities enabled additional determination of the uncertainty of laser spot detections. In total, the scale errors have been evaluated on a large set of measurements in both models (432/1378) spread across them.
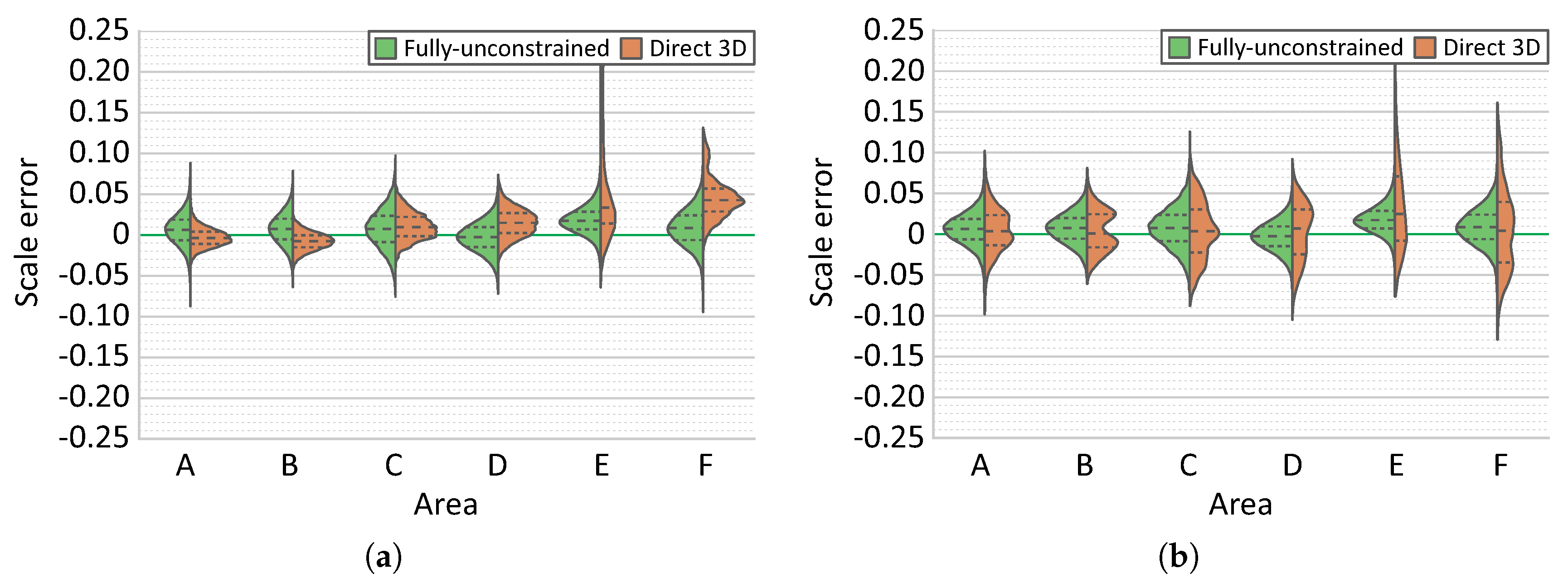
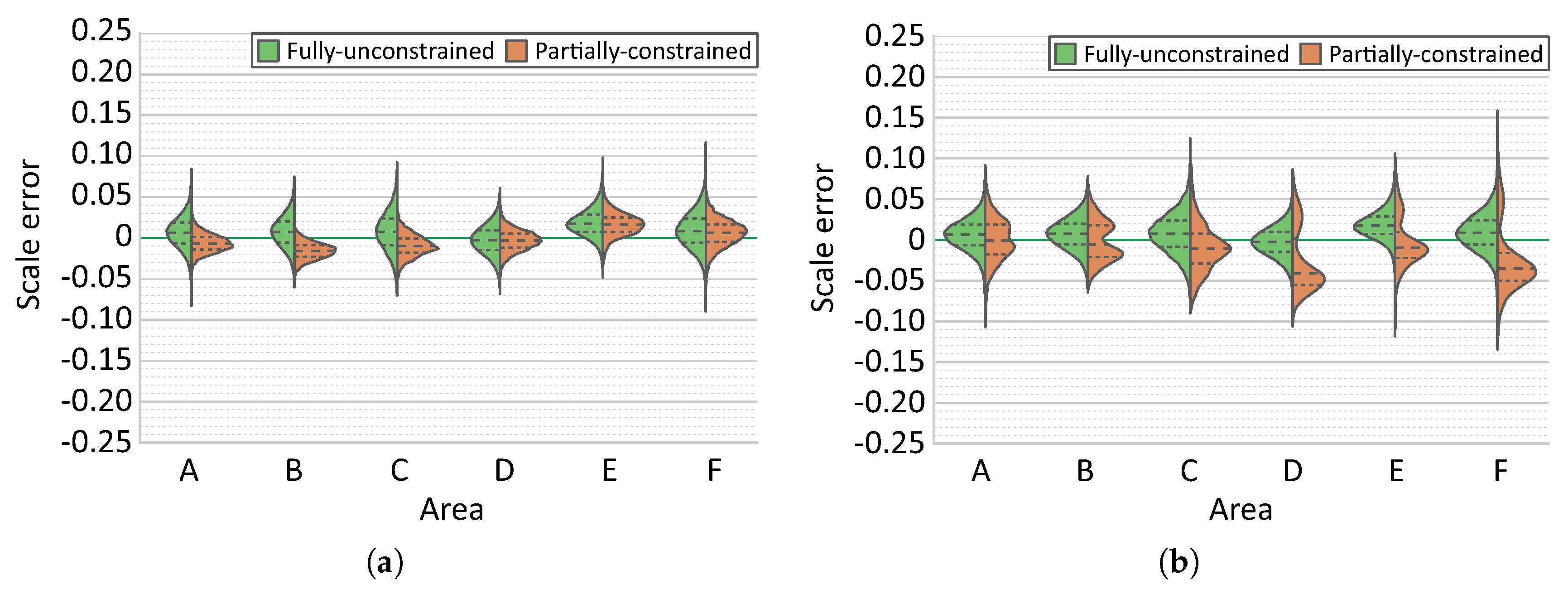
Finally, the comparison of results obtained using different reconstruction strategies were performed using two distinct survey scenarios. In surveys comprising a single dive and with multiple overlapping regions, the choice of reconstruction strategies is not critical, since all strategies perform adequately well. However, in more complex scenarios there is a significant benefit from using optimization including the navigation data. In all cases, the best reconstruction strategies produced models with scale errors inferior to , with errors on the majority of each model area being around . Acquisition of calibration data (points collected over a large range of distances) is indeed critical. Depending on laser setup, a modification of laser geometry is possible (e.g., during the process of diving due to pressure changes). As minor discrepancies in parallelism can cause significant offsets at the evaluating distance, performing a calibration in the field is desirable (e.g., approach of the scene illuminated with laser beams). Furthermore, our results also indicate and justify the importance of collecting a multitude of evaluation data at different locations and moments during the survey.

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}