1. Introduction
Detecting changes in land use and land cover (LULC) from space has long been the main goal of satellite remote sensing (RS) [
1,
2]. Although high-quality imagery opened from Landsat-8 and Sentinel-2 programs has provided an unprecedented source for satellite observation, various approaches and tools of change detection have been proposed and developed [
3,
4], and the potential of time series observations has also been demonstrated clearly [
5,
6], near real-time changes in LULC detected from spaceborne observations in a fully automated fashion are still not reliable. Clouds and their cast shadows found inevitably in an optical image are both very strong signals that represent a large fraction of changes by simply comparing two images. These unwelcome features suppress the real signal of surface changes and dominate the results of change detection if they are not removed completely from imagery. Clouds are some of the most common and dynamic features in satellite imagery of the earth’s surface, because approximately 52% of earth is covered by clouds at any moment [
7], and land is covered by 0.10–0.15 fewer clouds than the oceans (i.e., land (41.5–45.0%) and ocean (55.0–56.5%)) [
8]. A cloud can be defined as a mass of particles or droplets of dust, smoke, or steam, suspended in the atmosphere or existing in outer space [
9]. It has various types and forms and has been receiving a lot of research interest in meteorology. For applications in RS, the classification of clouds is also a crucial step in the pre-processing of optical imagery [
10]. The technology of object recognition advances very fast, and a lot of sound algorithms are available as well [
11,
12,
13]. However, the general technology of object recognition is not suited for classifying clouds from RS imagery, because the exact boundaries of clustered particles and aerosols are usually very difficult to determine. As for cloud-cast shadows, Zhu et al. [
14] have demonstrated that the view angle of a satellite sensor, the relative height of a cloud, as well as solar zenith and azimuth angles, can be used to generate corresponding shadow layers at quite a satisfying level, as long as the cloud layers are accurate. From the perspective of developing an automatic change detection system for LULC, therefore, the key task is to seek a reliable approach in classifying clouds first.
Generating a variety of thematic maps from satellite imagery has been approved and accepted as one of the major advantages of spaceborne observations back to the first introduction of the sensor Thematic Mapper in the Landsat-4 mission in 1982. Spectral, spatial, and radiometric resolutions kept being enhanced in the following Landsat missions, and also a lot of approaches were proposed to improve the accuracy of image classification, as reviewed by Zhu [
15]. Apart from the classification of LULC, clouds and their cast shadows vary every minute and need to be masked out before any kind of RS activity is performed [
10]. Zhu [
15] also presented a comprehensive review of the works of cloud classification. He concluded that more time series-based cloud and cloud shadow classification algorithms are anticipated to emerge in consideration of the importance of accurate cloud and cloud shadow classification. To support the automatic processing of huge amounts of Landsat-8 data, a new algorithm called Fmask (Function of mask) was derived to identify clouds, shadows, snow, and water. Together with the combination of normalized temperature probability, spectral variability probability, and brightness probability, potential cloud pixels can be separated from clear-sky pixels with an accuracy as high as 96.4% [
16]. To support the automatic processing of Sentinel-2 data, likewise, The European Space Agency (ESA) developed and released several free open source toolboxes, including Sen2cor, a processor for Sentinel-2 Level 2A product generation and formatting. Both Fmask and Sen2cor have pushed the general techniques of cloud classification to the limit, yet the current accuracy they can achieve is still insufficient to support the calculation of near real-time changes in LULC in a fully automated fashion.
Ball et al. [
17] made a comprehensive survey of deep learning (DL) in RS and referred to previous approaches to image classification as shallow learning (SL) for contrast, such as the approaches of support vector machines, Gaussian mixtures models, hidden Markov models, and conditional random fields. They reviewed recent developments in theories, tools, and challenges that can be used in DL for RS and pointed out the advantage of a convolutional neural network (CNN) in many perceptual tasks. Since Krizhevsky et al. [
18] accelerated operations in CNNs [
19] using graphics processing unit (GPU) parallel computing, a vigorous growth in image classification using CNN architecture was triggered [
20,
21]. It started from general image classification and extended to the recognition of medical images and other fields of applications. Xie et al. [
22] applied the excellent classification ability of CNNs to RS images for cloud classification and achieved quite a good recognition result. However, this CNN-based method was limited by the effect of clustering processing before CNN recognition. That is, cloud and cloud-free pixels might have been classified into the same group since the terrible clustering processing resulted in terrible cloud recognition results. While CNNs are widely employed in the field of image classification, another approach based on semantic images segmentation has also undergone tremendous changes due to the introduction of a fully convolutional neural network (FCN) in 2015 [
23]. FCNs extended the ability of CNNs from entire image classifications to single-pixel identification. In other words, FCNs could label each pixel of the input image instead of only determining which group the input image belonged to. After that, the development of FCN-based architecture began to grow rapidly in the field of semantic images segmentation [
24,
25]. Zhan et al. [
26] performed cloud classification tasks on Red-GreenBlue (RGB) images using FCN-based architecture. Drönner et al. [
27] further extended FCN-based architecture to an architecture that could identify RS multispectral data. So far, the downsampling technique (pooling or striding) has been adopted in most FCN-based architecture to extract features. Although the technique has been proven to have the ability to capture deep texture features effectively, it has the disadvantage of losing the spatial information of the image [
28]. However, we believe that in the field of RS, spatial information is more important than deep texture features. Compared to general image recognition tasks, the number of scenes in cloud classification applications is relatively small, so there is no need for too many deep texture features. In contrast, more spatial information is needed for training the model because thin and fractional clouds, which often appear at the boundaries of a normal cloud, are much more difficult to classify compared to the boundaries of objects from general image classification missions.
We propose an architecture called CloudNet, which was improved from the atrous spatial pyramid pooling (ASPP) module [
29] and has good feature extraction performance for different resolution images. Residual learning [
30] has improved the problem of gradient disappearance due to the increase in the number of layers in DL architecture. CloudNet incorporates residual learning to pass the spatial information of the upper layer to the next layer and prevents the loss of spatial information due to the increasing layers. The technique of downsampling (pooling or striding), used in CNNs and FCNs, was removed from CloudNet to keep the size of the input feature map in each layer consistent with the size of the output feature map. This design effectively avoided the loss of spatial information and achieved higher cirrus cloud recognition accuracy compared to existing methods. In the process of training CloudNet, we used the data augmentation technique [
18] to generate 31,250 times more training materials than the original data for training. The process of generating manually labeled data was time-consuming and cost-inefficient. The technique allowed CloudNet to have stable cirrus identification capability without extensive training data. To our knowledge, the FCN-based architecture Deeplab v3+ [
28] had the most outstanding performance in the field of semantic image segmentation in 2018. This study compared CloudNet to the classic method, scene classification (SCL) (produced by Sen2cor), and DL methods such as an FCN and Deeplab v3+. CloudNet had higher accuracy in cloud and haze classification than the other methods, and also had better performance in cirrus cloud recognition. It is worth mentioning that the number of training parameters in CloudNet was significantly smaller than in an FCN and Deeplab v3+, and thus the training time of CloudNet was less than the other two methods.
To summarize, a rigorous manually labeled Sentinel-2 cloud mask was released for a total of 5,017,600 pixels. The data augmentation technique allowed CloudNet to have stable cirrus identification capability without extensive training data. A novel DL architecture called CloudNet was proposed to pay more attention to spatial features than FCNs and Deeplab v3+ do, and thus it had better cirrus cloud classification performance than the other two methods. CloudNet is a flexible architecture that makes it easy to use any amount of spectral data as training material, and it is possible to map this method to other data from different satellites.
2. Training Dataset
Both the approaches of SL and DL for image classification require training, and the success of their application heavily relies on the quality and quantity of the training dataset. In the realm of RS, Ball [
17] has pointed out that training data are usually expensive and error-prone, for they require some expert interpretation, large amounts of field work, and a long time to postprocess the data. They need to be representative and general enough to avoid overtraining as well. To develop a DL model of cloud classification, we started from some existing and available algorithms and attempted to generate the required dataset of clouds by ourselves.
CFMask is an algorithm that uses decision trees to prospectively label pixels in the scene and validate or discard those labels according to scene-wide statistics. CFMask is made available by the Earth Resources Observation and Science Center of the U.S. Geological Survey (USGS) in order to provide standard Landsat Level-1 data products, including cloud, cloud confidence, cloud shadow, and snow/ice masks. It has been incorporated into the L-8 Automatic Image Processing System to process all scenes of Landsat-8 imagery covering the Taiwan area on an operational basis [
31]. However, CFMask has difficulties over bright targets, and thin clouds or haze are usually omitted.
Figure 1 gives an example of the problems of standard Landsat Level-1 data products in cloud classification.
Sen2cor is an algorithm that combines several state-of-the-art techniques for performing atmospheric, terrain, and cirrus correction. Sen2cor can create bottom-of-atmosphere (BOA)-, terrain-, and cirrus-corrected reflectance images, aerosol optical thickness, water vapor, SCL maps, and quality indicators for cloud and snow probabilities [
32]. Apart from official L2A products that are published on EO Browser and other Sentinel Hub services 48–60 h after L1C products are available, the Sen2cor tool can also be installed in our own server to process Level-2A data from L1C data directly. To process 10 granules covering the entirety of Taiwan, the time required for Level-2A data processing is approximately 20,800 s, using our personal computer based server. Like CFMask, the SCL maps of clouds also have difficulties over bright targets, and thin clouds and haze are usually omitted as well.
Figure 2 gives an example of the problems of standard Sentinel-2 Level-2A data products in cloud classification.
From the perspective of developing an automatic change detection system for LULC, the existing and available algorithms, such as CFMask and Sen2cor, are not accurate enough to generate the required dataset of clouds for training our DL model.
Figure 3 gives an example of automatic change detection of LULC in Jianshi Township, Hsinchu County, Taiwan, overlaid over Sentinel-2 true color images (TCI) taken on (a) 9 August 2017 and (b) 14 August 2017, respectively. The red, blue, and yellow polygons were determined by the deviation automatically calculated from the SCL map, normalized difference vegetation index (NDVI), and normalized difference water index (NDWI). This gives an example for LULC studies where important information about change dynamics is impeded by clouds.
One alternative was to employ an operational cloud database, such as in the work by Drönner et al. [
27], who used the well-validated Cloud Mask from the CLAAS-2 dataset [
33]. However, that dataset was derived from geostationary Meteosat Spinning Enhanced Visible and Infrared Imager (SEVIRI) measurements for the time frame 2004–2015, which was not appropriate in training our DL model of cloud classification in terms of spatial, spectral, or temporal resolution. Another alternative was to mask all clouds manually in a certain number of Sentinel-2 images and prepare a detailed database of cloud and haze by ourselves, such as the work by Oreopoulos et al. [
34], who used manual (visual) cloud masks developed at USGS for the collection of Landsat scenes. For two Sentinel-2 granules, the commercially available software Adobe Photoshop
® and ENVI
® were employed to determine and edit cloud masks in the level-1C product of a TCI, an enhanced RGB image composed of bands B04 (Red), B03 (Green), and B02 (Blue). To facilitate the training of DL, both the TCI and corresponding cloud masks were cut into a set of tiles with a uniform size of 224 × 224 pixels. A total of 100 tiles with 5,017,600 pixels were prepared in a week. This required a lot of labor, and the payback was a reliable database with high-quality data for training. Although the size and representativeness of the current training dataset were limited to these manually labeled tiles, they served as a reliable data source and a good start in developing and testing our new DL architecture. The training dataset of all TCIs and corresponding cloud masks, including a total of 100 tiles with a uniform size of 224 × 224 pixels, are available in the
Supplementary Materials.
4. Evaluation
The performance of DL is highly dependent on the configuration of hardware and software. In this research, CloudNet was trained by an ordinary personal computer equipped with a Central Processing Unitof Intel’s i7 4790 and a GPU of NVIDIA’s GTX 1080Ti packed with 11 Gbps GDDR5X memory. The operating system was Windows 10, and the DL algorithm was implemented by Python (version: 3.1.6) language with the Keras library (version: 2.1.6), a wrapper library for Tensorflow (version: 1.6.0).
A large amount of data is usually needed for training a DL model. For cases with an insufficient amount of training data, such as in our manual (visual) cloud masks, a couple of practical techniques of data augmentation can be employed to generate a large amount of training data [
18]. First, we used a 224 × 224 pixel window with a step size of 18 pixels to expand the original training data (2240 × 2240 pixels), resulting in a total of 12,769 images with partially overlapped pixels. A total of 2769 images were selected from the training set and reserved as validation data, while the remaining 10,000 sub-images were used as a training set. Second, the training data in each iteration was processed by different operations in a total of 250 training iterations, including horizontal flip (50% probability), vertical flip (50% probability), rotation (angle between −10 and +10 degrees), zooming (magnification from 1.1 to 1.4 times), and cropping (in the training image with a size of 224 × 224 pixels, a matrix of 200 × 200 pixels was randomly selected).
The training process was equivalent to the exploration of the minimum value on the plane of a loss function. We used a stochastic gradient descent with momentum for backpropagation. It was like putting a momentum ball on the plane of a loss function, and the ball would follow the gradient direction. In each training iteration, the ball would slowly adjust its direction until the lowest point of the plane was reached, which meant the training was completed. The total number of epochs was set to 250, the batch size was set to 16 samples, the momentum value was set to 0.95, the weight decay value was set to 0.00005, and the learning rate was described as
Note that these parameters were basically set as those values suggested by the work of Long et al. [
23]. Only a slight adjustment was introduced.
The following indicators were calculated to evaluate the performance of the segmentation in the test dataset with the model constructed in this study. These indicators may be useful in illustrating the context in which this method can apply. True positive (TP) indicates the number of cloud pixels that were predicted correctly. False positive (FP) means the number of the predicted cloud pixels that were incorrect. False negative (FN) is the number of cloud pixels that were not classified. True negative (TN) indicates the number of non-cloud pixels that were classified correctly. P represents the actual number of pixels in the cloud (TP + FN). N represents the number of pixels (FP + TN) that were not actually clouds.
The following indicators suggested from the literature were calculated to evaluate the performance of the segmentation in the test dataset with the model constructed in this study: (1) true positive rate (TPR) indicates the proportion of TPs to positives; (2) true negative rate (TNR) indicates the proportion of TNs to negatives; (3) precision represents the proportion of TPs in all pixels that were predicted to be clouds (TP + FP); (4) pixel accuracy indicates the proportion of the correct pixel count (TP + TN) in all pixels (P + N); (5) intersection over union (IoU or IU) indicates the proportion of the intersection of P and G in the union of P and G (note that P stands for the prediction results, and G stands for the ground truth), and all of the above indicators have been used in image segmentation studies [
23,
25,
28,
35]; (6) IoU (cloud) indicates the proportion of TP in (TP + FP + FN); (7) IoU (cloud-free) indicates the proportion of TN in (TN + FP + FN); (8) mIoU represents the average of IoU (cloud) and IoU (cloud-free); and (9) kappa is an evaluation standard that was used to compare the accuracies between model and random classifiers and was generally more representative in evaluating model than accuracy [
38].
5. Results
To evaluate the performance of various DL architectures in classifying clouds, standard Sentinel-2 Level-2A data products taken on 16 May 2018 covering granules T51QUG and T51QTG were selected. The union of their corresponding SCL map of thin clouds (class 10), high-probability clouds (class 9), and medium-probability clouds (class 8), was regarded as the SCL cloud mask. As aforementioned, manual (visual) cloud masks were used as the benchmark. The true color composite of BOA reflectance at bands B04 (Red), B03 (Green), and B02 (Blue) was used as the input image. The predicted cloud masks from FCN, Deeplab v3+, and CloudNet were compared to the benchmark of cloud masks, and a total of eight indicators are listed in
Table 1. The results indicate that CloudNet surpassed an FCN, Deeplab v3+, and an SCL for all indicators: TPR (cloud), TNR (cloud-free), precision, IoU (cloud), IoU (cloud-free), mIoU, kappa, and pixel accuracy. The accuracy of CloudNet was slightly less than the SCL only in terms of two exceptions: TNR (cloud-free) and precision, yet its overall precision (95.87%) was significantly higher than the SCL (89.18%). In other words, a slight sacrifice in CloudNet’s sensitivity to cloud-free pixels could further enhance its capability for classifying clouds. This is related to the designed architecture of CloudNet. Its capability to capture a deeper feature map would be weakened after removing the layers of downsampling. However, we could increase CloudNet’s receptive field by increasing its number of branches and hence compensate for the influence of removing downsampling layers.
To gain a better understanding of the pros and cons of each method in cloud classification, we present eight regions with different types and forms of a cloud as eight RGB images, as shown in the first row of
Table 2. The predicted cloud mask of each region from SCL, FCN, Deeplab v3+, and CloudNet are shown from rows 2 to 5. Apparently, the SCL failed to classify many cirrus cloud pixels, while the FCN successfully detected most cloud pixels in spite of its poor performance near the edge of clouds. Due to the process of downsampling, the FCN lost some details of images inevitably. Take column 3 in
Figure 9 as an example: The FCN (row 3) indeed captured more cloud pixels than the SCL (row 2) did. However, the FCN was only capable of depicting the boundary approximately, yet was incapable of delineating the details of cloud masks. The performance of Deeplab v3+ near the edge of clouds was better than the FCN’s, but it was difficult for Deeplab v3+ to identify those cases with more fractional clouds. Though there is a mechanism to retain spatial information (residual learning), some spatial information was still inevitably lost during the process of downsampling. For the cases of thin clouds (columns 5 and 6), CloudNet performed better than Deeplab v3+ in identifying those thin clouds in the middle. For the cases of clouds over bright objects (columns 8), a lot of misclassifications (houses and riverbeds) were found in the SCL, yet every DL model did a good job.
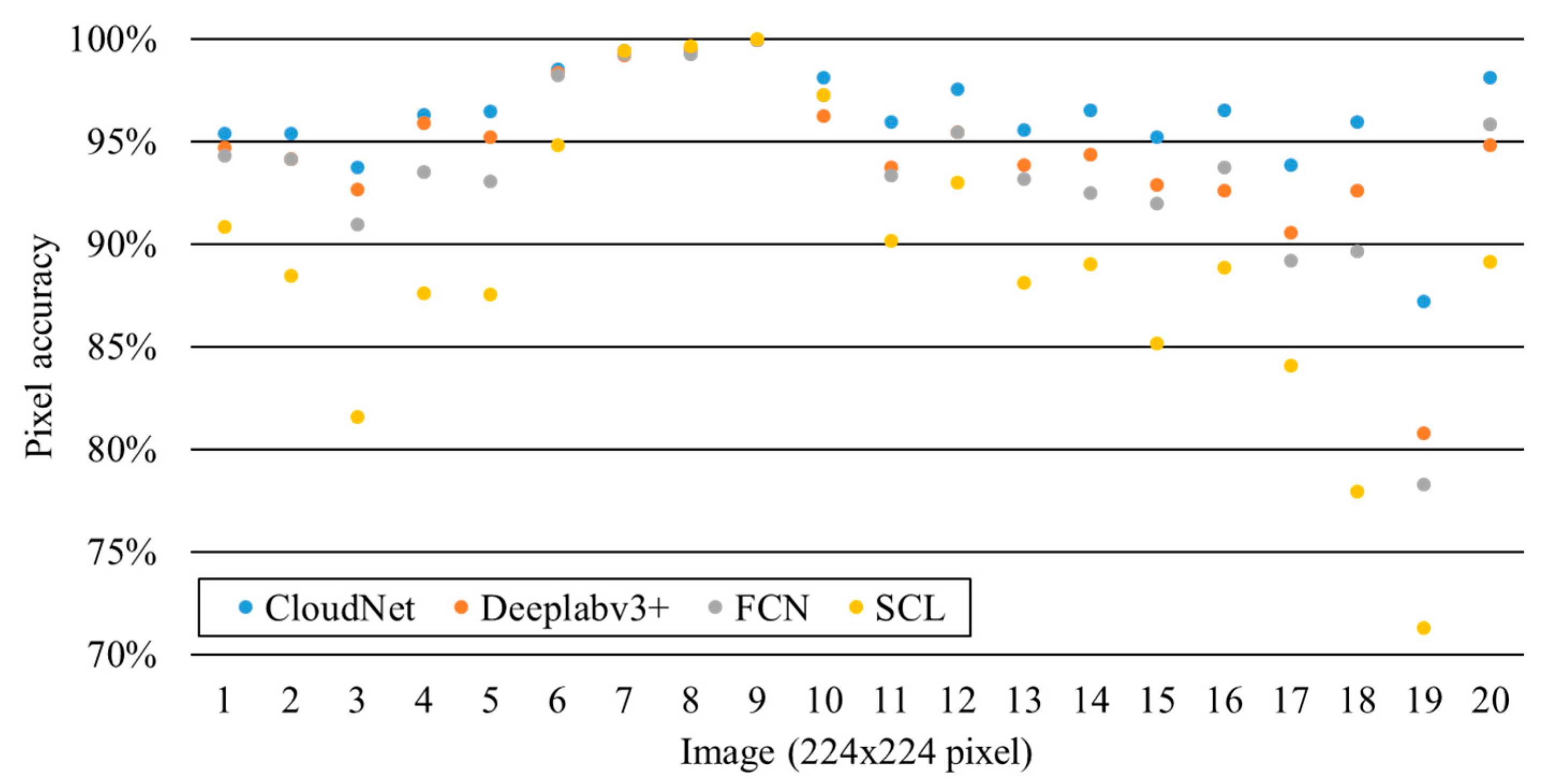
By repeating the same calculation of eight indicators for all 20 scenes (1,003,520 pixels in total), the results of pixel accuracy obtained from the SCL, the FCN, Deeplab v3+, and CloudNet are plotted in
Figure 10 for comparison. CloudNet was indeed capable of identifying most of the cloud pixels and achieved the highest pixel accuracy for all 20 scenes. The overall performance of the SCL, in contrast, was the worst among the four methods. In the scenes with fewer cirrus clouds (scenes 7 and 9), the performance of the SCL was nearly the same as the other methods. In the scenes with more cirrus cloud (scenes 6, 18, and 19), the merit of CloudNet in classifying clouds was apparent.
Another important evaluation of DL architecture is the required time for cloud classification, which is closely related to the number of parameters to be determined. General DL architecture, such as in an FCN, often requires a large number of filters to capture many features. For applications in cloud classification, however, the scene is not that complex, so the number of filters in CloudNet could be largely reduced to only 28 filters in each layer, compared to the FCN and Deeplab v3+, which often need more than 1000 filters in each layer. Excessive parameters not only require a huge amount of GPU memory, but also cost a lot of time to calculate. Take one image with 224 × 224 pixels as an example: The number of parameters and the time for cloud classification required by the FCN, Deeplab v3+, and CloudNet are compared in
Figure 11. The FCN had the largest number of parameters and the longest time for cloud detection, followed by Deeplab v3+, and then CloudNet.
6. Discussion
To meet the requirements for change detection from Sentinel-2 imagery on a regular and automatic basis in the future, we also conducted a few numerical experiments, with the intention of determining the optimized number of branches and layers to be used by CloudNet. The results shown in
Table 2 indicate that as the number of layers increased, the pixel accuracy increased accordingly and reached a peak value at a number of 12 layers, which suggests the optimized number of layers to be used in CloudNet is 12 layers. Note that when CloudNet was set to 6 layers, two indicators (TNR and precision) were the highest. This can be regarded as the benchmark for CloudNet for this scene, similar to the SCL, since the SCL also had the best results in the evaluation metrics of TNR and precision.
The results shown in
Table 3 indicate that as the number of branches increased, the pixel accuracy increased accordingly and reached a peak value at a number of 8 branches, which suggests the optimized number of branches to be used in CloudNet is 8 branches. To summarize, after optimizing the number of layers and branches, CloudNet performed the best under the architecture of 12 layers and 8 branches. Pixel accuracy reached 96.24%, and kappa was approximately 0.9.
The uniqueness in this paper for advancement of cloud classification methods is CloudNet, a new DL architecture with an enhanced capability of feature extraction for classifying clouds. This was achieved by employing parallel convolution layers for deep feature extraction, instead of the general practice of the downsampling technique adopted in most FCN-based architectures to extract features. A significant amount of GPU memory consumption was supposed to be the price that CloudNet had to pay. However, we conducted a sensitivity test and realized that the number of filters in each layer of CloudNet could be reduced from more than 1000 to only 28 without losing accuracy. This is attributed to the fact that clouds are not as complicated as other objects. Once the deep feature is extracted and the cloud boundary is retained, there is not much to differentiate in the cloud itself. In other words, CloudNet uses fewer amounts of filters to achieve the same or even higher cloud recognition capability, compared to a general deep learning model with more than 1000 filters in most layers. Another novel design of CloudNet is that the full spatial information in each layer is passed by the method described in Reference [
30], rather than the general method of ASPP that involves pooling. As a result, more spatial information is retained by CloudNet.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}