1. Introduction
Information on the distribution and sprawl of urban impervious surfaces (UIS) is crucial for urban planners and government decision-making. Currently, this information is widely used for urban land planning, urban heat island monitoring, illegal construction detection and environmental inspection [
1,
2]. Accurate UIS detection highly depends on the sensor type, quality, resolution, spectral and spatial information, and other features of remotely sensed data. Hyperspectral images (HSIs) generally provide moderate or relatively high spatial resolution and hundreds of spectral bands ranging from the visible to shortwave regions [
3,
4,
5]. These data provide sufficient detail to delineate landscapes and have advantages that improve the extraction accuracy of UIS.
However, UIS extraction from HSIs has several challenges: (1) The data have high spatial and spectral variability [
6]. HSIs with high spectral resolution provide fine spectral detail and rich information on land cover types but this easily leads to confusion in spatial domain, and the spectral information is relatively complex. (2) Unlabeled data affect the detection accuracy and the training sample and test sample selection [
7]. (3) Dimensionality reduction (DR) is especially challenging [
8] because HSIs have high dimensionality due to hundreds of spectral bands, resulting in the Hughes phenomenon [
3]. DR is required prior to feature extraction and classification.
To address these problems, many methods have been proposed and developed for UIS extraction in recent decades [
9]. Early on, machine learning methods were considered popular extraction methods for HSIs. Common methods include decision trees [
10], logistic regression (LR) [
11], minimum distance [
12], maximum likelihood [
13], k-nearest neighbor methods [
14], and random forest [
15]. A support vector machine (SVM) is a classical nonlinear classification algorithm, in which the number and type of samples are determined manually [
16,
17]. However, these extraction methods consist of a single-layer feature extraction model and deeper features cannot be extracted. Commonly, the spectral bands are selected from hundreds of bands and a transformation of the spectral matrix is performed, which results in information loss [
10]. In addition, these methods also have to consider DR and labeling of the samples. Therefore, a DR method for the full spectrum and deep-feature extraction methods are required.
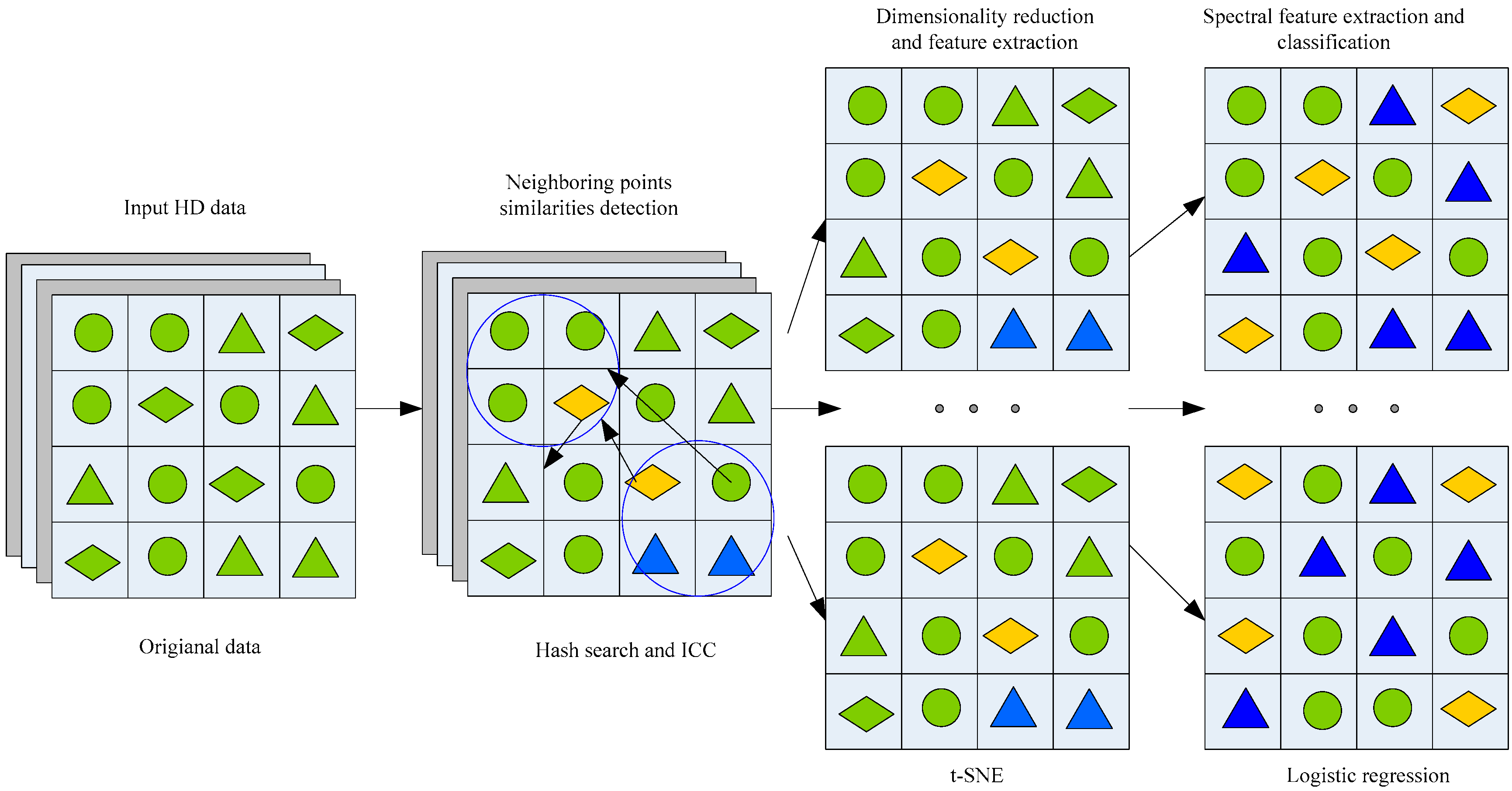
The goal of DR is to reduce the high-dimensional (HD) data to a low-dimensional (LD) subspace representation with intrinsic spatial-spectral features and attribute values. Generally, spectral-based DR methods are classified into supervised and unsupervised methods [
18]. Supervised DR methods use labeled samples in defined classes to identify land objects based on different features. These methods include linear discriminant analysis (LDA) [
19], local discriminant embedding (LDE) [
20], and local Fisher discriminant analysis (LFDA) [
21]. Unsupervised DR methods provide LD classification data by using a transformation matrix without labeled samples. Principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE) [
22] are two representative unsupervised DR algorithms. In the PCA method, a linear transformation matrix is created and its sum of squared errors is minimized [
23]. However, the method has poor performance for data with a subspace structure and is unsuitable for sparse matrices and large amounts of data. In comparison, the t-SNE method is considered a significantly better spectral-based DR algorithm and provides HD data visualization for HSIs [
24]. In the t-SNE method, a nonlinear transformation matrix from the HD space to an LD representation (e.g., 2-D or 3-D) is created. A t-distributed model is created that minimizes the distance between data points following the one-degree-of-freedom distribution in the LD space. In the HD space, the data points follow a Gaussian distribution. However, the cost function of the t-SNE algorithm does not guarantee a global optimum due to the large-scale computation with few labeled samples and lack of algorithm predictability. Therefore, the optimization of the method and the integration of a regression model are required for unsupervised spectral feature extraction.
Moreover, the use of spatial features can improve the classification accuracy of land covers. This method reduces the confusion between land cover classes with similar spectral features and improves the classification performance, which has been demonstrated in previous studies [
4,
25]. Several spatial/spectral-based extraction models have been proposed in recent years [
26,
27]. These methods consider both spatial and spectral information for features extraction. However, the traditional spatial feature extraction depends on the selection of spatial training samples. These training samples correspond to specific land cover classes and empirical knowledge is required for image interpretation. Additionally, spatial attributes are variable and cannot represent all land cover types and this affects the classification accuracy [
28].
Deep learning methods are considered more advanced machine learning approaches [
29] and consist of high-level and multi-layer networks for the automatic extraction of spatial features. Moreover, many unlabeled samples are not a problem for deep learning methods. Common deep learning approaches include deep Boltzmann machines (DBMs) [
30], stacked denoising auto-encoders (SDA) [
31], convolutional neural networks (CNNs) [
32], deep auto-encoders (DAE) [
33], and deep belief networks (DBNs) (see Abbreviations) [
27,
34]. However, these algorithms require fixed-scale detection windows, which is unsuitable for detecting spatially and spectrally variable land cover objects in HSIs. To address this problem, convolutional DBNs (CDBNs) have been proposed [
35]. The method represents an unsupervised learning approach for a two-dimensional (2D) image structure and is based on DBNs. It is a hierarchical generative model with full-sized image transformation and uses probabilistic max-pooling (PMP) in a multi-layer architecture for high-level representations and multi-layer edge detection. However, there is room for improvement regarding the shared weights of the layer connection.
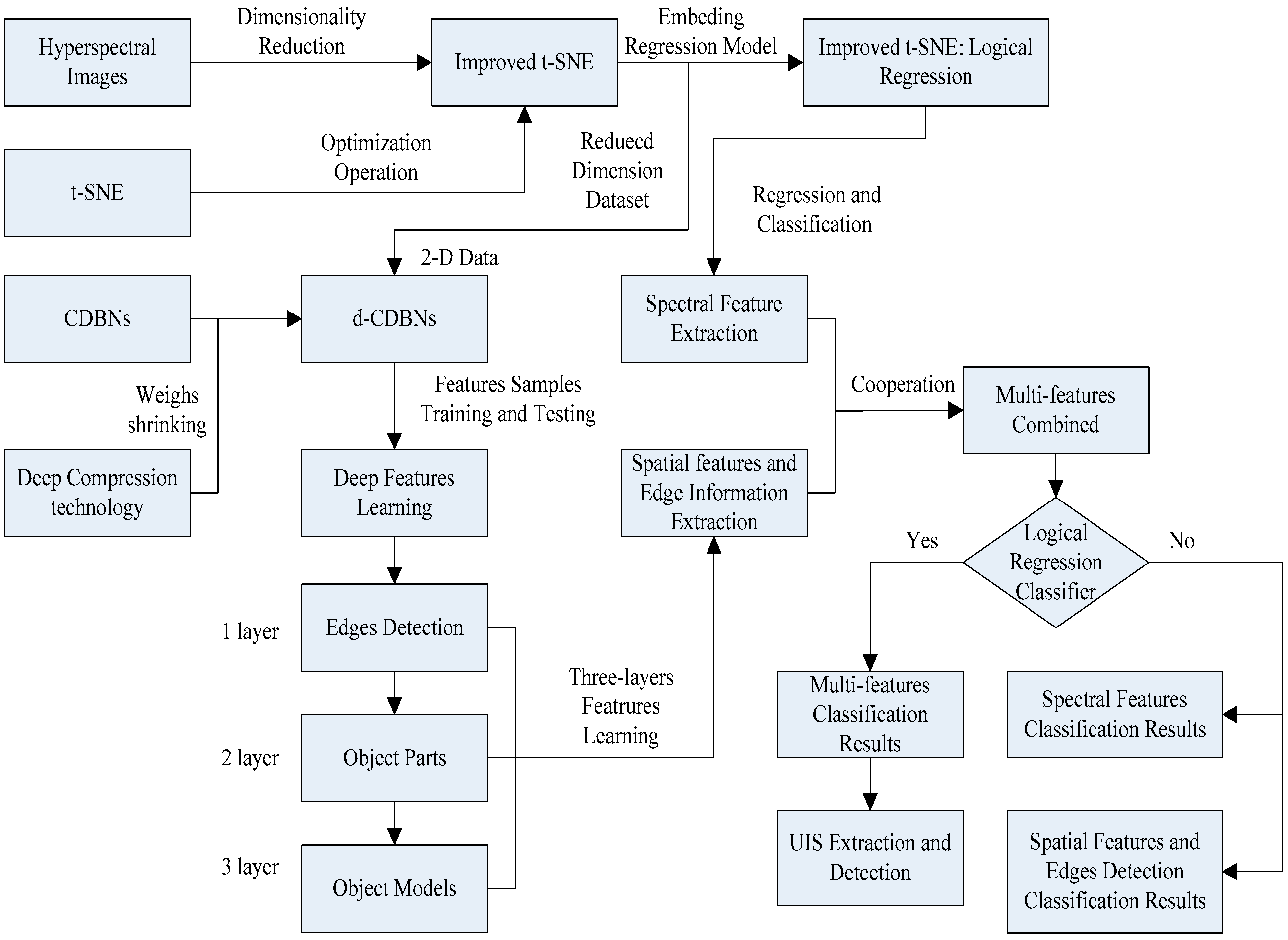
In this paper, we propose a multi-feature extraction model (MFEM) for UIS detection from HSIs. The model combines the t-SNE-based approach and the CDBNs-based framework for HSIs interpretation for spectral, spatial, and edge feature extraction. In the MFEM, we propose an improved t-SNE method. Comparing to the standard t-SNE, the improved version has the advantages of reduced time complexity, improved similarity of the interclass data points, and better predictability. The method combines DR and spectral feature extraction. In addition, we improved the CDBNs-based algorithm, which we call deep compression CDBNs (d-CDBNs). The d-CDBNs method can shrink sharing weights of the energy function and reduces the redundancy of features when analyzing full-scale images. The d-CDBNs method combines the features of a multi-layer convolutional restricted Boltzmann machine (CRBM) and (PMP). The two functions provide unsupervised learning and training for full-sized 2-D images. The d-CDBNs method extracts spatial features and detects edges using a hierarchical generative framework. Finally, the spectral features, spatial features, and edge information are combined using a multi-feature extraction strategy based on an LR classifier. The MFEM model has better characteristics than other commonly used methods (
Table 1). The main contributions of our work are as follows.
Development of the MFEM for UIS detection from HSIs. The MFEM model has three main components, i.e., DR and spectral feature extraction, spatial feature and edge detection, and multi-feature classification. The model is an integration of the improved t-SNE model, the d-CDBNs, and the LR. Compared with commonly used methods, the model uses an unsupervised and nonlinear DR method, requires fewer labeled samples, has multi-layer feature networks, and a multi-feature cooperation extraction mechanism.
Improvement of the t-SNE method. The improved t-SNE model has lower time complexity, improved similarity evaluation performance of the interclass data points, an embedded LR algorithm to determine the global and local optima, and better results. Compared with the standard t-SNE method, the improved method has a faster neighbor point search, better similarity detection performance, and a better prediction function.
Improvement of the CDBNs method. The proposed d-CDBNs method markedly reduces the redundancy of the shared weights of the layer connection. Unlike the original CDBNs method, the improved method provides deep compression for the shared weights to reduce the data volume and the weight redundancy of the layer connection for the convolution operation.
Edge information extraction from HSIs. The MFEM model detects edge information of landscapes using sparse regularization to reduce the confusion between UIS and other land cover classes with similar spectral information. The integration of the spatial and spectral features and the edge detection reduces the “salt and pepper” noise of the classification results.
The rest of paper is organized as follows. In
Section 2, the relationship between the t-SNE-based and the CDBNs-based architecture, as well as the improved methods and the MFEM framework are described. The experimental results of the analysis of two HSIs are presented in
Section 3. In the last section, results are discussed and we accordingly conclude our work.
3. Results
For the performance evaluation of the MFEM method, we used common evaluation indices including the producer’s accuracy (PA), user’s accuracy (UA), kappa coefficient (Kappa), overall accuracy (OA), and average accuracy (AA) (see Abbreviations). All experiments were performed using MATLAB R2016a on a Windows 7 (64-bit) Intel Core i5-4200 3.2 GHz 8 GB RAM machine.
3.1. Evaluation of the Improved t-SNE Method
3.1.1. Perplexity Configuration
In the improved t-SNE method, the perplexity (
) increases with increases in the Shannon entropy and increases the Gaussian variance
. This results in an increase in the number of nearest neighbor points. To determine the optimal
and obtain a suitable number of nearest neighbor points, we used the hash table search to replace the binary search algorithm. In the experiment, the perplexity (
) values were set at 10, 20, 30, 40, and 50, respectively, due to the larger number of discrete points, the unstable OA, and the poor robustness when
< 5 or
> 50. The dimensional space of the output embedded data was set as the default 2-D, the number of iterations was 1000, the correlation parameter was 0.75, and the minimum gradient descent was 1 × 10
−7. The ground-truth datasets were considered the reference for creating the confusion matrix. The evaluation indicators were used to assess the performance of the improved t-SNE method for the two datasets (
Table 5). The two datasets had different results when different
were used for the perplexities. The results show that the values of the evaluation indices increase with the increase in the perplexity
. However, the mean
exhibits a decreasing rate of growth once the perplexity’s predefined threshold value is reached. This also demonstrates that the optimal value range of the perplexity is from 5 to 50. The classification accuracy is higher for the city center scene than the university scene. The reason is that the city center scene has more reference data points than the university scene.
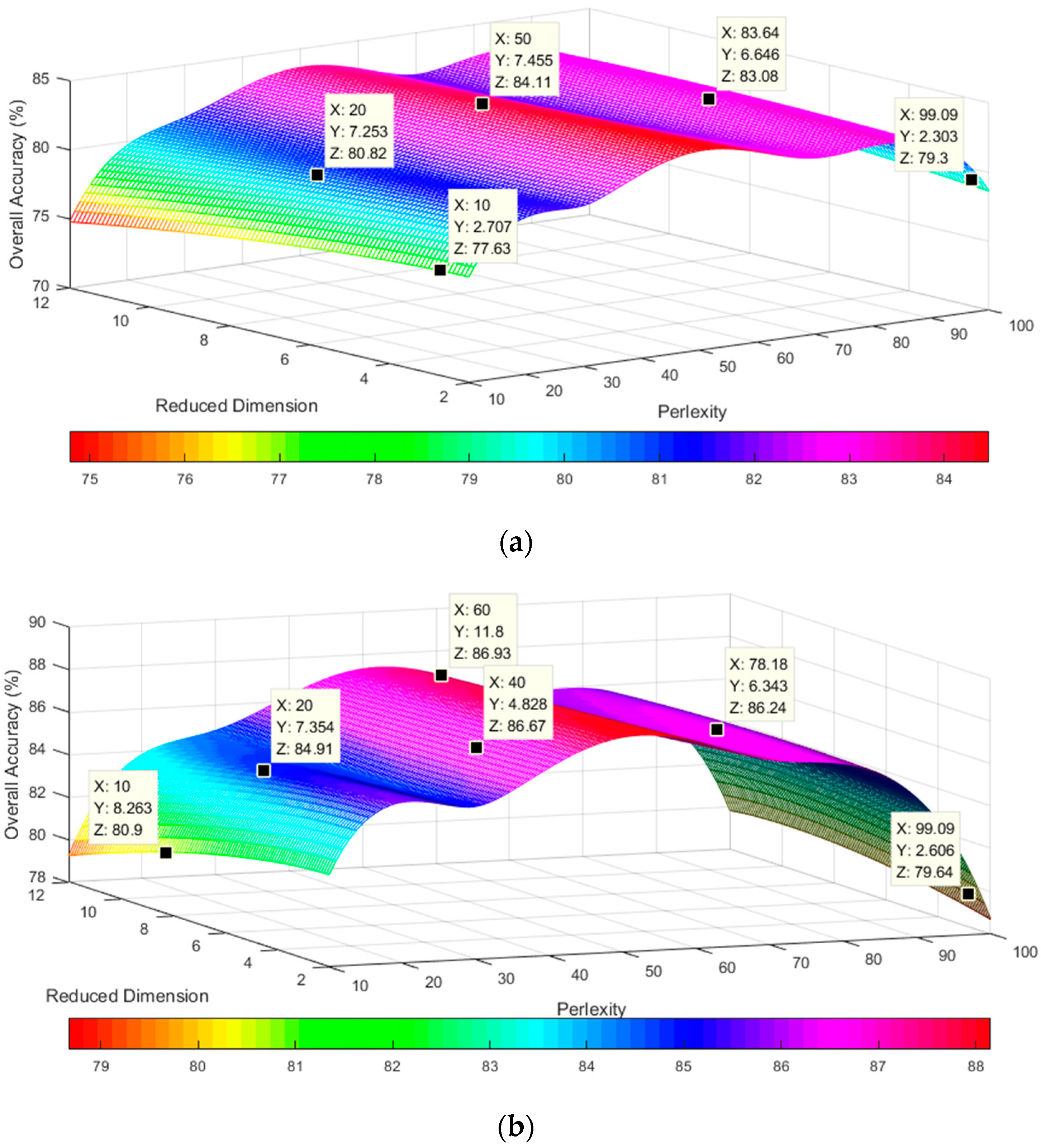
In addition, the number of dimensions (after executing the DR) influences the classification accuracy. We tested dimensions from 2 to 12 and perplexity values from 10 to 100 for the two datasets, as shown in
Figure 7. The OA of the two datasets exhibits different degrees of increase with an increasing number of dimensions. The results are similar for the different perplexity values.
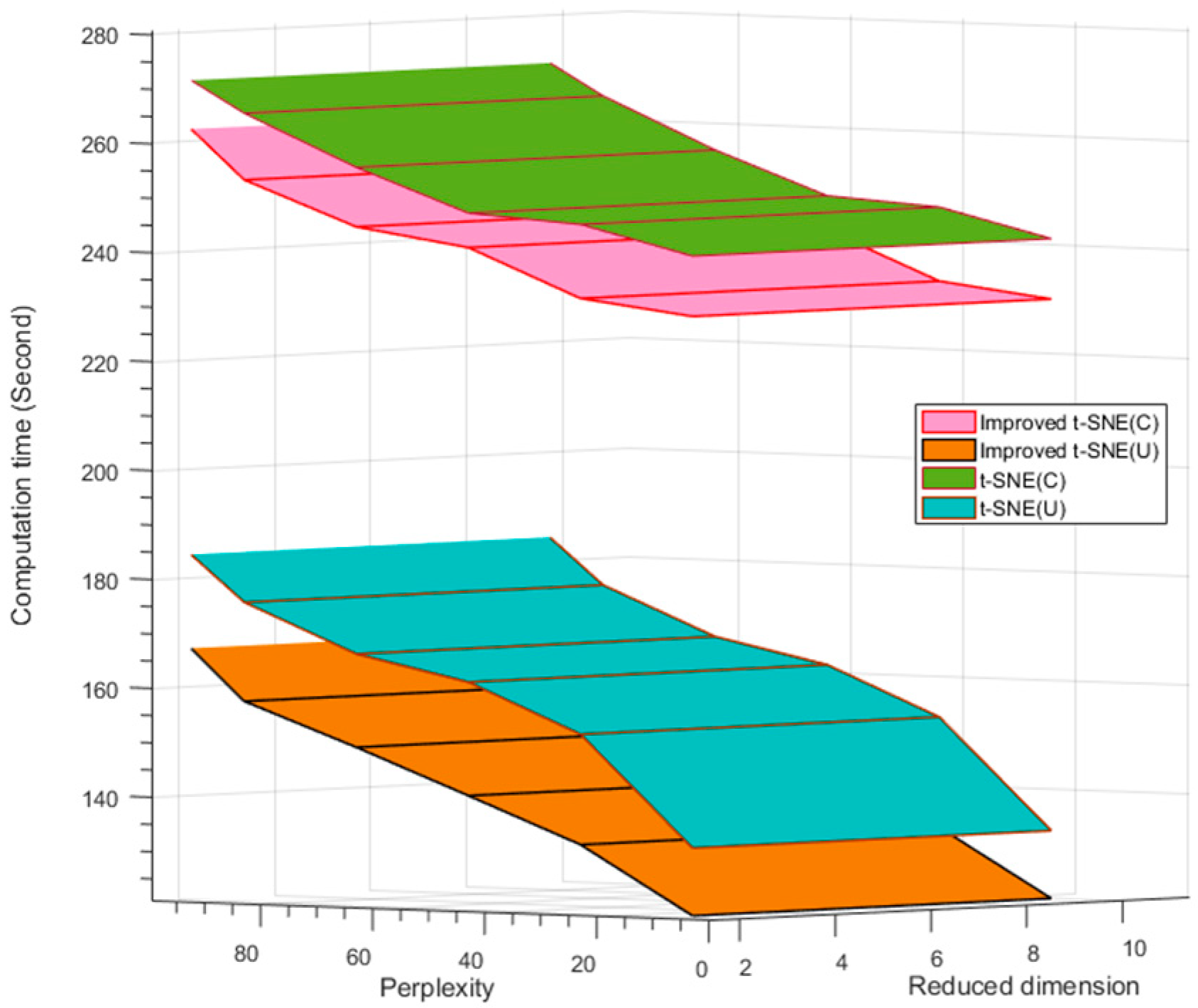
3.1.2. Computation Time
In the DR process, the major time cost is the search for the nearest neighbor points and the LD map embedding. To optimize the algorithm time complexity, the hash table search algorithm was implemented in the improved t-SNE and replaced the binary algorithm. We tested various perplexities and dimensions using the t-SNE method and improved t-SNE method for the two datasets, as shown in
Table 6 and
Figure 8. For the university scene, the average computation time is 10.85% less for the improved t-SNE method than the standard t-SNE method. However, the average computation time is only 4.11% less for the city center scene because of the larger data volume of the dense buildings. Overall, the computation time is lower for the improved t-SNE then the standard t-SNE, although the computation time increases for both methods and both datasets with an increase in the number of perplexities. This reason for this result is that the complexity is lower for the hash table search method than the binary search method. In addition, the minimum
KL divergence process reduces the time complexity due to the Barnes–Hut algorithm. An increase in the perplexity increases the number of nearest neighbor points of the kernel points. Additionally, the computational time cost is higher for the city center scene than the university scene due to the larger building density of the city center scene.
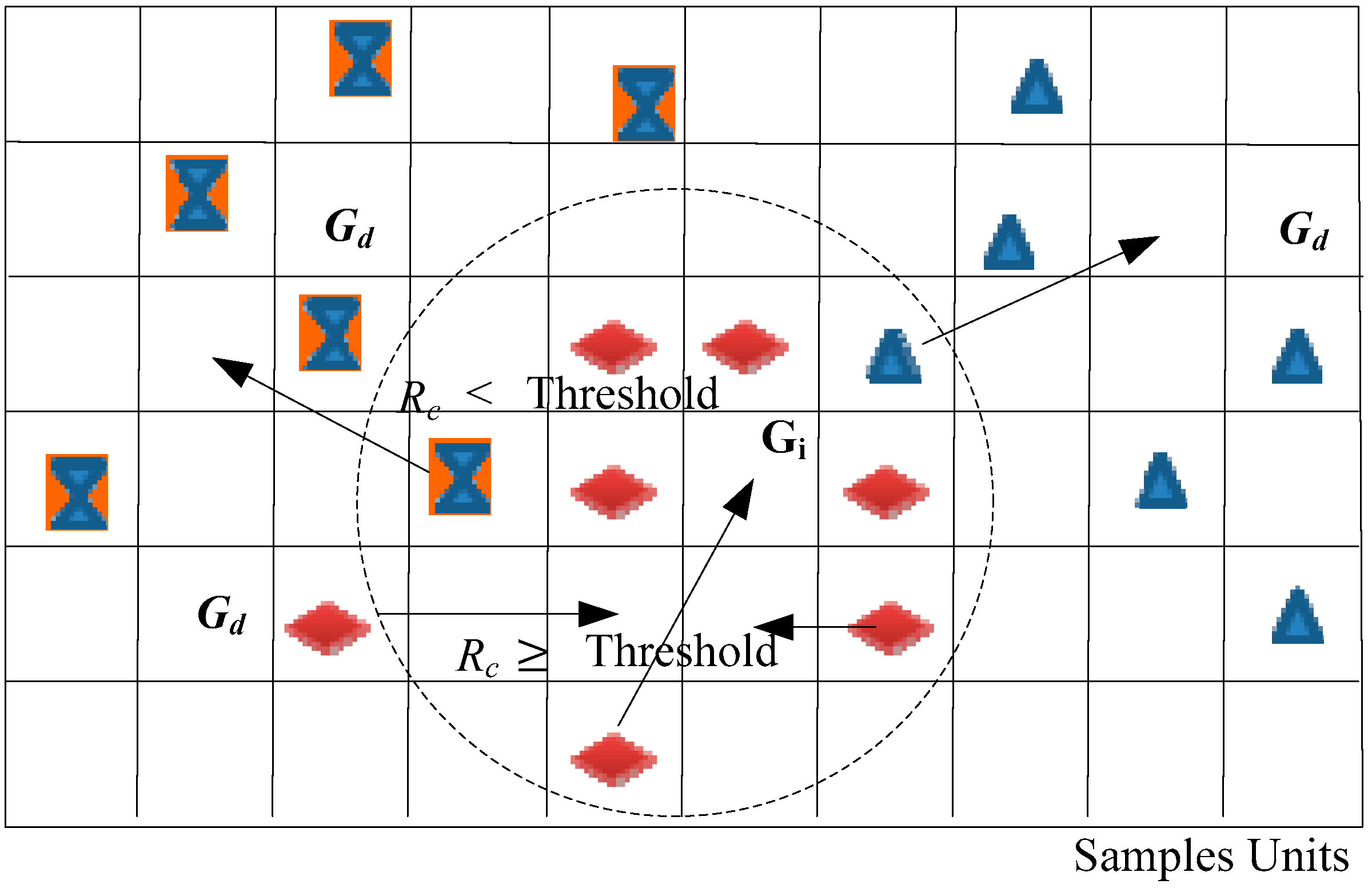
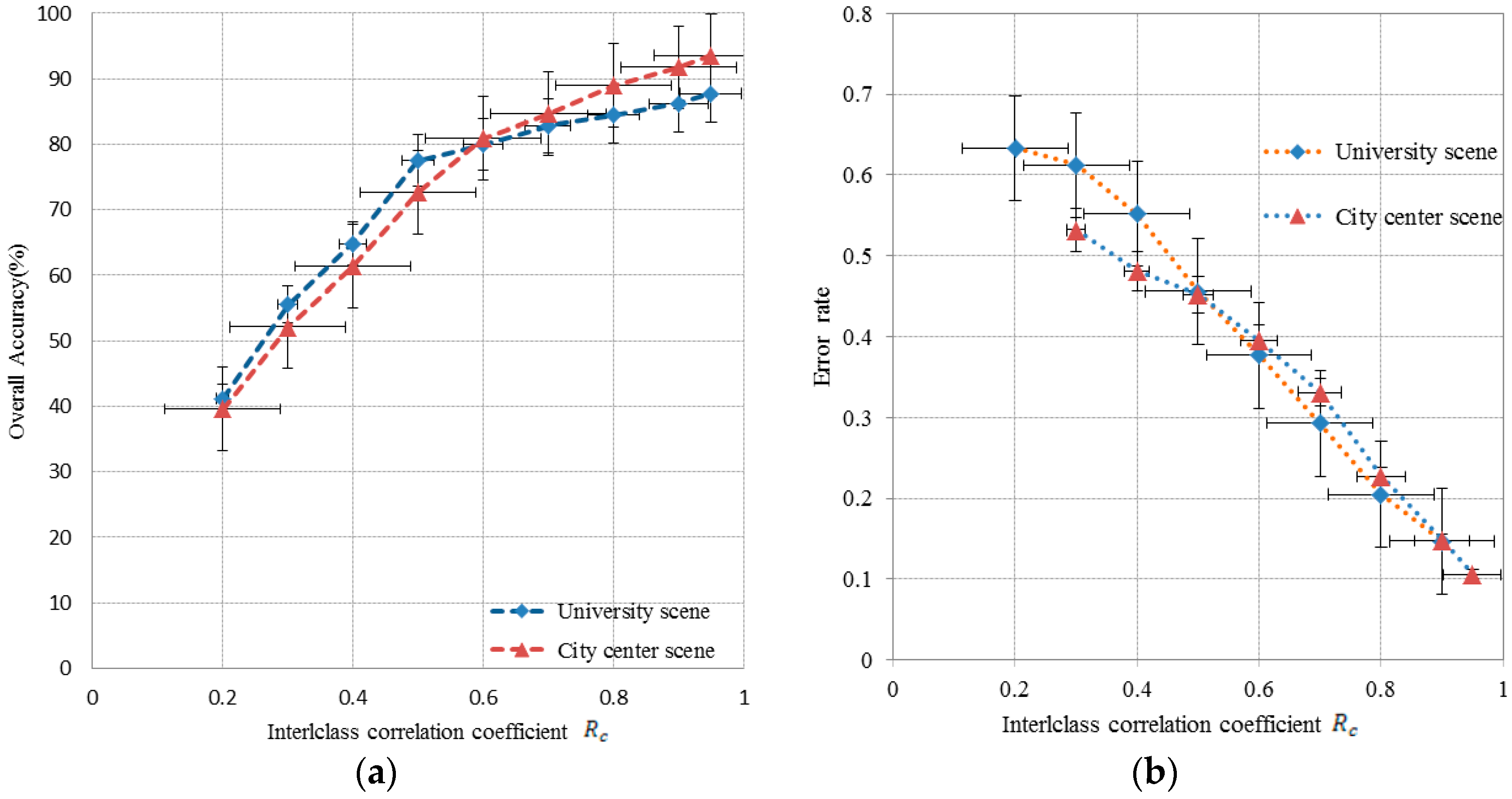
3.1.3. Interclass Correlation Configuration
The ICC algorithm evaluates the similarities of the nearest neighbor points and reduces the classification error in the interclass. For the evaluation of the ICC performance of the improved t-SNE model, we set the perplexity as 35 and the DR of the result dataset to 2. The reduced dimension dataset has the embedded LR algorithm and the interclass correlation
has a range of 0.2–0.95. The accuracy of the nearest neighbor points influences the spectral extraction and classification results (
Figure 9). As shown in
Figure 9a, the OA of the two datasets increases sharply when
< 0.6 and the results are better for the city center scene than the university scene when
> 0.6. The highest OA of the city center scene is 93.57%, which is 5.82% higher than the OA of the university scene. As shown in
Figure 9b, the classification error rate decreases with an increase in the value of the ICC
. The lowest classification error is 0.106 when
for the city center scene, i.e., the OA of similarities of nearest neighbor points achieves 89.4%. To minimize the influence of the threshold, we used
, which provides optimal efficiency in the experiments (see
Section 4 for the reasons).
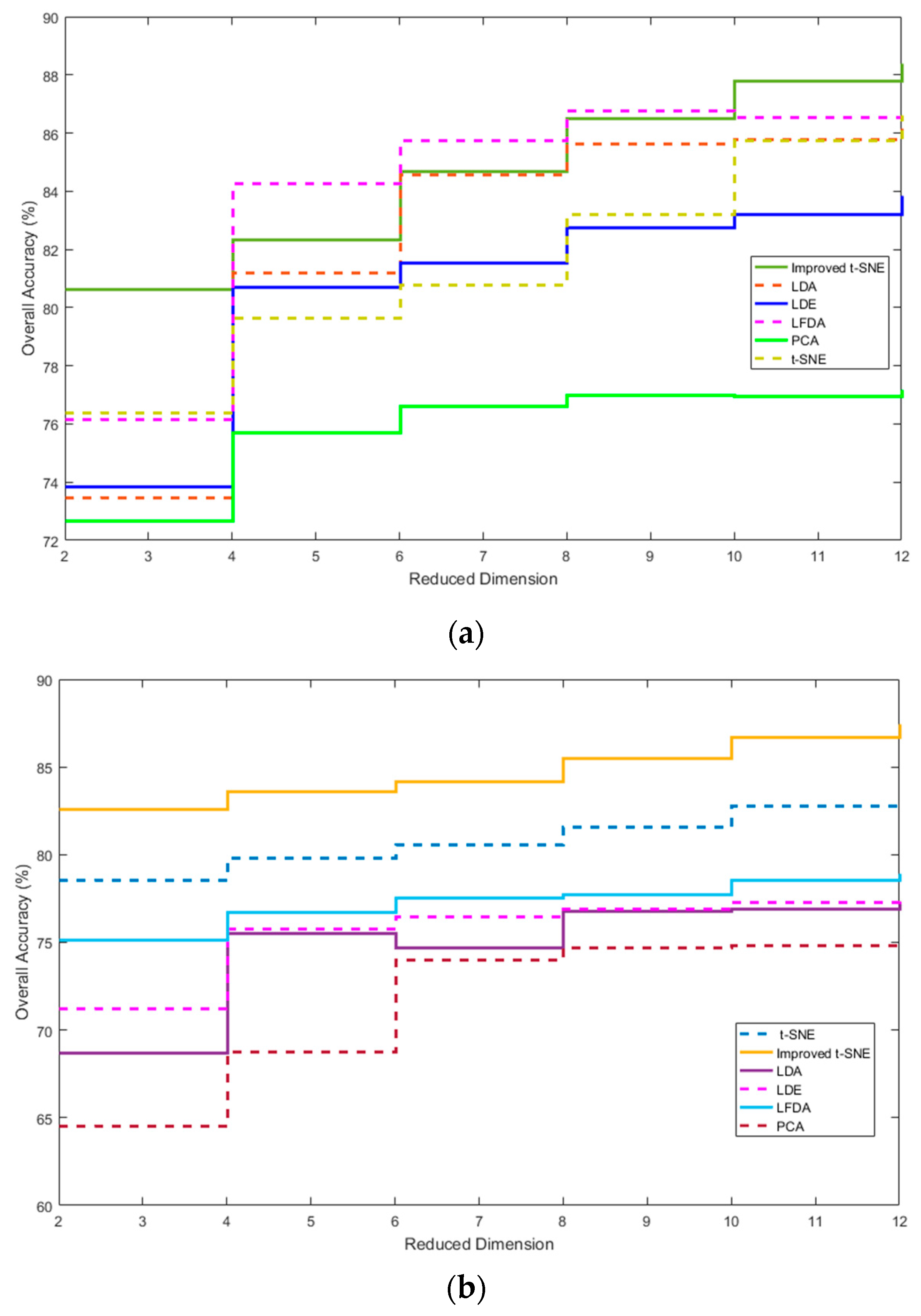
3.2. Comparison of the Spectral Feature Extraction Results with Other DR Methods
The improved t-SNE model has an embedded LR algorithm to improve the classification performance and predictability of the samples. This process allows for sequential spectral feature extraction for LD datasets and improves the classification accuracy. The results of the improved t-SNE model were compared with those of other frequently-used DR algorithms (
Table 7), including the supervised algorithms LDA, LDE, and LFDA [
43] and the unsupervised algorithms PCA and the standard t-SNE. The dimension was 2-D and the number of perplexities was 30. For the unsupervised algorithms, we selected 20 training samples randomly for each dataset and 260 unlabeled samples as test samples for each class.
Table 7 shows that the improved t-SNE model outperforms the other DR algorithms in terms of classification accuracy. All supervised DR algorithms have higher OA than the PCA. Specifically, the LFDA is more effective than the other supervised DR algorithm for the hyperspectral datasets. Under the same conditions, the improved t-SNE achieves a higher OA than the standard t-SNE and the accuracy improvements are 4.22% and 4.08%, respectively, for the university scene and city center scene.
The OA results for the different methods and reduced dimensionality values of 2–12 are shown in
Figure 10. It is evident that the OA increases for all methods as the dimensionality decreases, i.e., the values increase from 2 to 12. In the university scene dataset, the mean OA of the improved t-SNE is 85.07%, which is 3.827% higher than the mean value of the other DR methods. In the more complex city center scene dataset, the mean OA of the improved t-SNE is 8.747% higher than that of the other DR methods. The reason is the lower performance of the other methods in the more complex city center scene, whereas the improved t-SNE is less affected in accuracy by the complexity.
However, the classification results of the spectral extraction retain the “salt and pepper” noise effect and misclassification. The main reason of misclassification for areas with similar reflectivity values, such as confusion between shadow and asphalt in the university scene and confusion between bare soil and brick in the city center scene. This appearance needs to be counteracted by the spatial feature extraction.
3.3. Verification of the d-CDBNs Method
In the aforementioned experiment, we examined the performance of the improved t-SNE model and achieved good results. After using the improved t-SNE DR model, the two datasets were translated into a 2-D representative matrix. The results of the DR processing and spectral extraction were inputs for the d-CDBNs method. The d-CDBNs method consists of learning and training using three layers. In the first layer, i.e., the input layer, the university scene consists of 4148 binary units and the city center scene consists of 8160 binary units. In the second layer, the hidden layer consists of groups and each group has hidden units for the university scene and city center scene, respectively. In the third layer, i.e., the pooling layer, we used a shrink factor of and there were 65 and 128 binary units for the two scenes, respectively.
In the MFEM, the d-CDBNs method was used to extract the spatial features and edges. These features are then combined with the spectral features for a multi-feature UIS classification method. The multi-feature combination reduces the “salt and pepper” effect. To examine the performance of the d-CDBNs method, we randomly selected about 15% of the reference image pixels as training data and used the remaining 85% as testing data. We set the pixel filters for the 5 × 5 matrices and the learning rate was 0.05. The number of connection weights between the visible layer and the detection layer was set at and for the university scene and city center scene datasets, respectively, in the first layer. The other parameters were the default values.
3.3.1. Compression of the Shared Weights of the Layers for Spatial Feature Extraction
For testing the performance of the shared weight deep compression in the d-CDBNs method, we compared the results with that of the standard CDBNs method in terms of network connection number, number of weights, data size, and computation time (
Table 8 and
Table 9). In the d-CDBNs method, we set the compression ratio
at 4× and used two hidden layers for detecting and convolution. The results indicated that the d-CDBNs effectively reduce the number of network connections, shared weights, the data size, and the computation time. We only embedded the deep compression method in the first layer due to time and complexity considerations. Therefore, the number of weights is the same in the first layer and the second layer. In the third layer, the max-pooling shrinks the representation of the detection layer, which reduces the computational cost. The reason for the lower number of weights in the second layer of the CDBNs is that the shared weights replace part of the initial weights. After weight compression, the computation time and memory requirements are significantly lower, and do not negatively affect the accuracy of results, which was verified by Han et al. [
42].
3.3.2. Edge Detection
In the d-CDBNs, the first layer detects the edge information of the input dataset and the edges of the image objects are extracted in the second layer. We used a 5 × 5 pixel filter for the edge detection followed by the sparse regularization method, which was proposed by Lee et al. [
40]. As shown in
Figure 11, the results of detecting the edges in the university dataset are excellent and corners, contours, edge angles, and boundaries are extracted.
3.4. Accuracy Comparison of MFEM Model for Impervious Surface Detection
The MFEM model has three major functions: DR and spectral feature extraction, spatial feature and edge extraction, and multi-feature classification. To evaluate the MFEM model performance for UIS extraction, we compared the results with that of popular machine learning methods, including an SVM, CNNs, DBNs, and CDBNs. The input data for these methods are the results of the improved t-SNE. The classification accuracy results are shown in
Table 10. It is evident that the MFEM model has higher accuracy than the other machine learning methods. The MFEM model enhances the OA by 6.78% (university scene) and 5.19% (city center scene), comparing with average of other methods, as well as the Kappa by 6.81% (university scene) and 6.21% (city center scene). The classification accuracy is higher for the university scene than the city center scene. The reason is that the university scene has more concise outlines and clearer boundaries than the city center scene, which results in higher accuracy for the spatial feature extraction and edge detection.
The results of the UIS extraction were compared with those of the above-mentioned methods (
Figure 12). It was observed that, in the commonly used methods, the lower classification accuracy stems from the confusion between classes, such as bare soil and brick in the university scene and sediments in the shoal water and asphalt in the city center scene. The multi-feature extraction in the MFEM model reduces the confusion and minimizes the “salt and pepper” effect. In
Figure 12, from left to right are SVM, CNNs, DBNs, CDBNs and MFEM (see Abbreviations) results, respectively. At the bottom of each comparison figure, we added part of the zoom image to clarify the algorithm performance.
4. Discussion
In this paper, we propose the novel MFEM model based on multi-feature extraction for UIS detection from hyperspectral datasets. The model combines a nonlinear DR with the improved t-SNE and the deep learning d-CDBNs method. The improved t-SNE method is used to translate the HD data into LD data and extracts the spectral features. In the experiment, we used different dimension number and perplexity to test the two datasets, respectively, and explored the influence on the overall accuracy. We found that the overall accuracy would be improved with the increase of dimension number, but the influence of the change of perplexity on the overall accuracy would fluctuate. We took the perplexity and reduced dimension as the independent variables, overall accuracy as the dependent variable, built the 3-D surface figure such as
Figure 7. The maximum overall accuracy of the university scene and the city center scene datasets was 84.23% and 87.87%, respectively. The ICC algorithm evaluates the similarities of the nearest neighbor points, improves classification accuracy and reduces the classification error in the interclass. However, a higher interclass correlation threshold has a negative effect on the number of nearest neighbor points and the classification results. First, a higher interclass correlation threshold results in a smaller number of nearest neighbor points, thereby reducing the perplexity. Second, a higher interclass correlation threshold results in fewer nearest points in the interclass of a kernel point. Therefore, if a larger number of Gaussian kernel points are selected, the memory requirements and time cost of the improved t-SNE will increase.
The d-CDBNs method performs spatial feature and edge extraction. The method embedded deep compression strategy for shared weights. The experiments showed that the compression strategy effectively reduced the complexity of data, especially the workload of convolution operation, and improved the performance of d-CDBNs algorithm. The setting of the compression ratio
affects the compression effect and the accuracy of the algorithm, while the setting of a larger compression ratio will negatively affect the extraction accuracy. Generally, setting the compression ratio at 4× will not negatively affect the accuracy of the algorithm [
42].
It is worth mentioning that the shadows in the two datasets were considered pervious surfaces in this experiment. Most shadows occur in meadows or trees in the university scene and are cast by the sparse building. However, in the city center scene, some shadows occur in streets with asphalt, especially near dense and low buildings. These shadows are classified into the pervious surface classes, which caused a moderate reduction in the classification accuracy. The reason can be attributed to two factors: first, narrow streets have vegetation on both sides; and, second, the shadows cast by trees mostly occur in meadows or bare soils in green areas. To achieve a unified classification strategy for both scenes, we considered the shadows in both scenes as pervious surfaces.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}