
Unmixing-Guided Convolutional Transformer for Spectral Reconstruction






Abstract
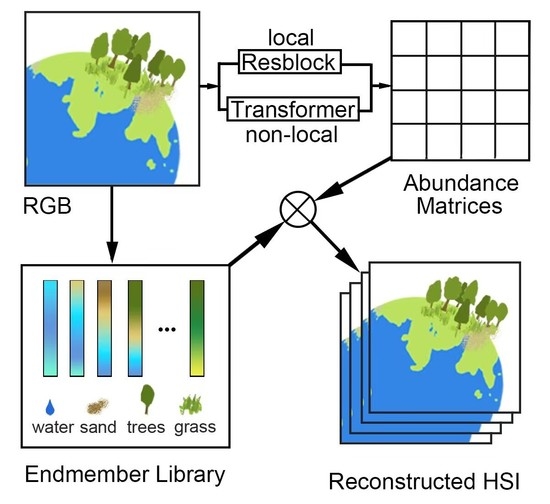
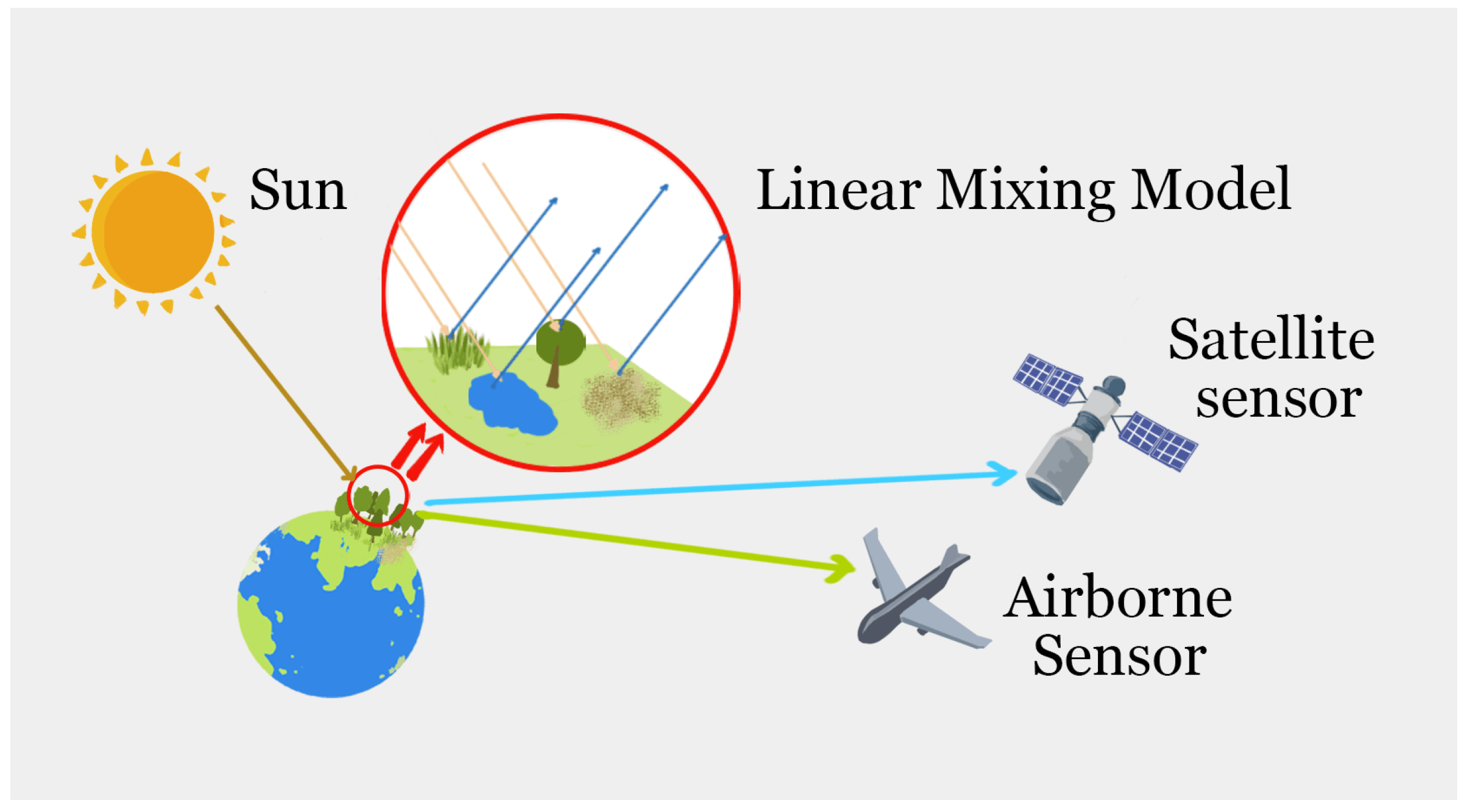
1. Introduction
- 1.
- We introduce an SR network, the UGCT, which tackles HSI recovery from RGB tasks using the LMM as a foundation while employing convolutional transformer to drive fine spectral reconstruction. By employing an unmixing technique and convolutional transformer block, the reconstruction performance of mixed pixels has been notably enhanced. The experiments on two datasets demonstrate that our method’s performance is state of the art in the SR task.
- 2.
- The Spectral–Spatial Aggregation Module (S2AM) adeptly fuses transformer-based and convolution-based features, thereby enhancing the feature merging capability within the convolutional transformer block. We embed the channel position encoding of the transformer into ResBlock to address positional inaccuracies during the generation of abundance matrices. Notably, such errors can lead to spectral response curve distortions in the reconstructed HSIs.
- 3.
- The Paralleled-Residual Multi-Head Self-Attention (PMSA) module generates a more comprehensive spectral feature by synergistically leveraging the transformer’s exceptional complex feature extraction capabilities and the CNN’s geometric invariance. To the best of our knowledge, we are among the first to incorporate a parallel convolutional transformer block within the single-image SR.
2. Related Work
2.1. Spectral Reconstruction (SR) with Deep Learning
2.2. Deep Learning-Based Hyperspectral Unmixing
2.3. Convolutional Transformer Module
3. The Proposed Method
3.1. Hu-Based Modeling
3.2. The Struction of UGCT
3.3. Paralleled-Residual Multi-Head Self-Attention
3.4. Spectral–Spatial Aggregation Module
3.5. Loss Function and Details
4. Experiments and Results
4.1. Spectral Library
4.2. Datasets and Training Setup
4.3. Comparision with Other Networks
5. Discussion
5.1. Network Details
5.2. Module Ablation Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Shi, Y.; Wang, K.; Xi, B.; Li, J.; Gamba, P. Target detection with unconstrained linear mixture model and hierarchical denoising autoencoder in hyperspectral imagery. IEEE Trans. Image Process. 2022, 31, 1418–1432. [Google Scholar] [CrossRef] [PubMed]
- Chhapariya, K.; Buddhiraju, K.M.; Kumar, A. CNN-Based Salient Object Detection on Hyperspectral Images Using Extended Morphology. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6015705. [Google Scholar] [CrossRef]
- Liu, H.; Yu, T.; Hu, B.; Hou, X.; Zhang, Z.; Liu, X.; Liu, J.; Wang, X.; Zhong, J.; Tan, Z.; et al. Uav-borne hyperspectral imaging remote sensing system based on acousto-optic tunable filter for water quality monitoring. Remote Sens. 2021, 13, 4069. [Google Scholar] [CrossRef]
- Niroumand-Jadidi, M.; Bovolo, F.; Bruzzone, L. Water quality retrieval from PRISMA hyperspectral images: First experience in a turbid lake and comparison with sentinel-2. Remote Sens. 2020, 12, 3984. [Google Scholar] [CrossRef]
- Niu, C.; Tan, K.; Jia, X.; Wang, X. Deep learning based regression for optically inactive inland water quality parameter estimation using airborne hyperspectral imagery. Environ. Pollut. 2021, 286, 117534. [Google Scholar] [CrossRef] [PubMed]
- Li, K.Y.; Sampaio de Lima, R.; Burnside, N.G.; Vahtmäe, E.; Kutser, T.; Sepp, K.; Cabral Pinheiro, V.H.; Yang, M.D.; Vain, A.; Sepp, K. Toward automated machine learning-based hyperspectral image analysis in crop yield and biomass estimation. Remote Sens. 2022, 14, 1114. [Google Scholar] [CrossRef]
- Arias, F.; Zambrano, M.; Broce, K.; Medina, C.; Pacheco, H.; Nunez, Y. Hyperspectral imaging for rice cultivation: Applications, methods and challenges. AIMS Agric. Food 2021, 6, 273–307. [Google Scholar] [CrossRef]
- Khan, A.; Vibhute, A.D.; Mali, S.; Patil, C. A systematic review on hyperspectral imaging technology with a machine and deep learning methodology for agricultural applications. Ecol. Inform. 2022, 69, 101678. [Google Scholar] [CrossRef]
- Chakraborty, R.; Kereszturi, G.; Pullanagari, R.; Durance, P.; Ashraf, S.; Anderson, C. Mineral prospecting from biogeochemical and geological information using hyperspectral remote sensing-Feasibility and challenges. J. Geochem. Explor. 2022, 232, 106900. [Google Scholar] [CrossRef]
- Pan, Z.; Liu, J.; Ma, L.; Chen, F.; Zhu, G.; Qin, F.; Zhang, H.; Huang, J.; Li, Y.; Wang, J. Research on hyperspectral identification of altered minerals in Yemaquan West Gold Field, Xinjiang. Sustainability 2019, 11, 428. [Google Scholar] [CrossRef]
- Yao, J.; Hong, D.; Chanussot, J.; Meng, D.; Zhu, X.; Xu, Z. Cross-attention in coupled unmixing nets for unsupervised hyperspectral super-resolution. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference (Part XXIX 16), Glasgow, UK, 23–28 August 2020; pp. 208–224. [Google Scholar]
- Hu, J.F.; Huang, T.Z.; Deng, L.J.; Jiang, T.X.; Vivone, G.; Chanussot, J. Hyperspectral image super-resolution via deep spatiospectral attention convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 7251–7265. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.F.; Huang, T.Z.; Deng, L.J.; Dou, H.X.; Hong, D.; Vivone, G. Fusformer: A transformer-based fusion network for hyperspectral image super-resolution. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6012305. [Google Scholar] [CrossRef]
- Cai, Y.; Lin, J.; Lin, Z.; Wang, H.; Zhang, Y.; Pfister, H.; Timofte, R.; Van Gool, L. Mst++: Multi-stage spectral-wise transformer for efficient spectral reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 745–755. [Google Scholar]
- Shi, Z.; Chen, C.; Xiong, Z.; Liu, D.; Wu, F. Hscnn+: Advanced cnn-based hyperspectral recovery from rgb images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 939–947. [Google Scholar]
- Li, J.; Wu, C.; Song, R.; Li, Y.; Liu, F. Adaptive weighted attention network with camera spectral sensitivity prior for spectral reconstruction from RGB images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 462–463. [Google Scholar]
- Hu, X.; Cai, Y.; Lin, J.; Wang, H.; Yuan, X.; Zhang, Y.; Timofte, R.; Van Gool, L. Hdnet: High-resolution dual-domain learning for spectral compressive imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17542–17551. [Google Scholar]
- Koundinya, S.; Sharma, H.; Sharma, M.; Upadhyay, A.; Manekar, R.; Mukhopadhyay, R.; Karmakar, A.; Chaudhury, S. 2D-3D CNN based architectures for spectral reconstruction from RGB images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 844–851. [Google Scholar]
- Zhao, Y.; Po, L.M.; Yan, Q.; Liu, W.; Lin, T. Hierarchical regression network for spectral reconstruction from RGB images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 422–423. [Google Scholar]
- Arad, B.; Ben-Shahar, O.; Timofte, R.N.; Van Gool, L.; Zhang, L.; Yang, M.N. Challenge on spectral reconstruction from RGB images. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 18–22. [Google Scholar]
- Arad, B.; Timofte, R.; Ben-Shahar, O.; Lin, Y.T.; Finlayson, G.D. Ntire 2020 challenge on spectral reconstruction from an rgb image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 446–447. [Google Scholar]
- Arad, B.; Ben-Shahar, O. Sparse recovery of hyperspectral signal from natural RGB images. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference (Part VII 14), Amsterdam, The Netherlands, 11–14 October 2016; pp. 19–34. [Google Scholar]
- He, J.; Yuan, Q.; Li, J.; Xiao, Y.; Liu, X.; Zou, Y. DsTer: A dense spectral transformer for remote sensing spectral super-resolution. Int. J. Appl. Earth Obs. Geoinf. 2022, 109, 102773. [Google Scholar] [CrossRef]
- Yuan, D.; Wu, L.; Jiang, H.; Zhang, B.; Li, J. LSTNet: A Reference-Based Learning Spectral Transformer Network for Spectral Super-Resolution. Sensors 2022, 22, 1978. [Google Scholar] [CrossRef]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12175–12185. [Google Scholar]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, S.; Li, W.; Lu, J.; Wu, Y.; Sun, S.; Li, C.; Yang, L. Convtransformer: A convolutional transformer network for video frame synthesis. arXiv 2020, arXiv:2011.10185. [Google Scholar]
- He, J.; Yuan, Q.; Li, J.; Zhang, L. PoNet: A universal physical optimization-based spectral super-resolution network for arbitrary multispectral images. Inf. Fusion 2022, 80, 205–225. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L.; Cerra, D.; Pato, M.; Carmona, E.; Prasad, S.; Yokoya, N.; Hänsch, R.; Le Saux, B. Advanced multi-sensor optical remote sensing for urban land use and land cover classification: Outcome of the 2018 IEEE GRSS data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1709–1724. [Google Scholar] [CrossRef]
- Liu, L.; Li, W.; Shi, Z.; Zou, Z. Physics-informed hyperspectral remote sensing image synthesis with deep conditional generative adversarial networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5528215. [Google Scholar] [CrossRef]
- Mishra, K.; Garg, R.D. Single-Frame Super-Resolution of Real-World Spaceborne Hyperspectral Data. In Proceedings of the 2022 12th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Rome, Italy, 13–16 September 2022; pp. 1–5. [Google Scholar]
- West, B.T.; Welch, K.B.; Galecki, A.T. Linear Mixed Models: A Practical Guide Using Statistical Software; CRC Press: Boca Raton, FL, USA, 2022. [Google Scholar]
- Luo, W.; Gao, L.; Zhang, R.; Marinoni, A.; Zhang, B. Bilinear normal mixing model for spectral unmixing. IET Image Process. 2019, 13, 344–354. [Google Scholar] [CrossRef]
- Wang, M.; Zhao, M.; Chen, J.; Rahardja, S. Nonlinear unmixing of hyperspectral data via deep autoencoder networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1467–1471. [Google Scholar] [CrossRef]
- Liu, L.; Zou, Z.; Shi, Z. Hyperspectral Remote Sensing Image Synthesis based on Implicit Neural Spectral Mixing Models. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5500514. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Dong, W.; Zhou, C.; Wu, F.; Wu, J.; Shi, G.; Li, X. Model-guided deep hyperspectral image super-resolution. IEEE Trans. Image Process. 2021, 30, 5754–5768. [Google Scholar] [CrossRef]
- Guo, Q.; Zhang, J.; Zhong, C.; Zhang, Y. Change detection for hyperspectral images via convolutional sparse analysis and temporal spectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4417–4426. [Google Scholar] [CrossRef]
- Zou, C.; Huang, X. Hyperspectral image super-resolution combining with deep learning and spectral unmixing. Signal Process. Image Commun. 2020, 84, 115833. [Google Scholar] [CrossRef]
- Su, L.; Sui, Y.; Yuan, Y. An Unmixing-Based Multi-Attention GAN for Unsupervised Hyperspectral and Multispectral Image Fusion. Remote Sens. 2023, 15, 936. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yao, J.; Yokoya, N.; Chanussot, J.; Heiden, U.; Zhang, B. Endmember-guided unmixing network (EGU-Net): A general deep learning framework for self-supervised hyperspectral unmixing. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6518–6531. [Google Scholar] [CrossRef]
- Zhao, M.; Yan, L.; Chen, J. LSTM-DNN based autoencoder network for nonlinear hyperspectral image unmixing. IEEE J. Sel. Top. Signal Process. 2021, 15, 295–309. [Google Scholar] [CrossRef]
- Zhou, H.Y.; Lu, C.; Yang, S.; Yu, Y. ConvNets vs. Transformers: Whose visual representations are more transferable? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2230–2238. [Google Scholar]
- Heo, B.; Yun, S.; Han, D.; Chun, S.; Choe, J.; Oh, S.J. Rethinking spatial dimensions of vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11936–11945. [Google Scholar]
- Manolakis, D.; Siracusa, C.; Shaw, G. Hyperspectral subpixel target detection using the linear mixing model. IEEE Trans. Geosci. Remote Sens. 2001, 39, 1392–1409. [Google Scholar] [CrossRef]
- Xu, X.; Shi, Z.; Pan, B. ℓ0-based sparse hyperspectral unmixing using spectral information and a multi-objectives formulation. ISPRS J. Photogramm. Remote Sens. 2018, 141, 46–58. [Google Scholar] [CrossRef]
- Clark, R.N.; Swayze, G.A.; Wise, R.A.; Livo, K.E.; Hoefen, T.M.; Kokaly, R.F.; Sutley, S.J. USGS Digital Spectral Library Splib06a; Technical Report; US Geological Survey: Reston, VA, USA, 2007.
- Green, R.O.; Eastwood, M.L.; Sarture, C.M.; Chrien, T.G.; Aronsson, M.; Chippendale, B.J.; Faust, J.A.; Pavri, B.E.; Chovit, C.J.; Solis, M.; et al. Imaging spectroscopy and the airborne visible/infrared imaging spectrometer (AVIRIS). Remote Sens. Environ. 1998, 65, 227–248. [Google Scholar] [CrossRef]
- Kokaly, R.; Clark, R.; Swayze, G.; Livo, K.; Hoefen, T.; Pearson, N.; Wise, R.; Benzel, W.; Lowers, H.; Driscoll, R.; et al. Usgs Spectral Library Version 7 Data: Us Geological Survey Data Release; United States Geological Survey (USGS): Reston, VA, USA, 2017.
- AVIRIS Homepage. Available online: https://aviris.jpl.nasa.gov/ (accessed on 22 March 2023).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Cai, Y.; Lin, J.; Hu, X.; Wang, H.; Yuan, X.; Zhang, Y.; Timofte, R.; Van Gool, L. Mask-guided spectral-wise transformer for efficient hyperspectral image reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17502–17511. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 14821–14831. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | RMSE ↓ | MRAE ↓ | SSIM ↑ | SAM ↓ |
|---|---|---|---|---|
| HRNet [19] | 0.2020 | 0.1630 | 0.882 | 8.53 |
| AWAN [16] | 0.1027 | 0.0757 | 0.970 | 4.64 |
| HSCNN+ [15] | 0.1001 | 0.0724 | 0.967 | 4.09 |
| MST++ [14] | 0.0914 | 0.0649 | 0.972 | 4.17 |
| Restormer [55] | 0.0973 | 0.0668 | 0.971 | 3.96 |
| Ours− | 0.0954 | 0.0614 | 0.977 | 3.89 |
| Ours | 0.0866 | 0.0587 | 0.979 | 3.91 |
| Method | RMSE ↓ | MRAE ↓ | SSIM ↑ | SAM ↓ |
|---|---|---|---|---|
| HRNet [19] | 0.1400 | 0.8158 | 0.105 | 59.63 |
| AWAN [16] | 0.0408 | 0.2141 | 0.779 | 12.30 |
| HSCNN+ [15] | 0.0775 | 0.4744 | 0.716 | 9.08 |
| MST++ [14] | 0.0446 | 0.2806 | 0.748 | 12.61 |
| Restormer [55] | 0.0324 | 0.1883 | 0.846 | 8.38 |
| Ours− | 0.0357 | 0.2424 | 0.875 | 7.71 |
| Ours | 0.0271 | 0.1451 | 0.886 | 6.80 |
| Spectral Dim | RMSE | MRAE | SSIM | PNSR |
|---|---|---|---|---|
| 8 | 0.0924 | 0.0624 | 0.976 | 25.39 |
| 16 | 0.0943 | 0.0667 | 0.973 | 25.34 |
| 32 | 0.0865 | 0.0587 | 0.979 | 25.69 |
| 48 | 0.0877 | 0.0602 | 0.978 | 25.60 |
| Block Number | Params | RMSE | MRAE | SSIM |
| 5 | 2.41M | 0.0882 | 0.0618 | 0.977 |
| 7 | 9.56M | 0.0865 | 0.0587 | 0.979 |
| 9 | 38.12M | 0.0975 | 0.0678 | 0.969 |
| Description | Ours | |||||
|---|---|---|---|---|---|---|
| LMM | ✔ | ✔ | ✔ | ✗ | ✗ | ✔ |
| S2AM | ✗ | ✗ | ✗ | ✗ | ✔ | ✔ |
| Resblock | ✔ | ✗ | ✔ | ✔ | ✔ | ✔ |
| Transformer | ✔ | ✔ | ✗ | ✔ | ✔ | ✔ |
| MRAE ↓ | 0.0638 | 0.0642 | 0.0712 | 0.0674 | 0.0614 | 0.0587 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, S.; Li, J.; Song, R.; Li, Y.; Du, Q. Unmixing-Guided Convolutional Transformer for Spectral Reconstruction. Remote Sens. 2023, 15, 2619. https://doi.org/10.3390/rs15102619
Duan S, Li J, Song R, Li Y, Du Q. Unmixing-Guided Convolutional Transformer for Spectral Reconstruction. Remote Sensing. 2023; 15(10):2619. https://doi.org/10.3390/rs15102619
Chicago/Turabian StyleDuan, Shiyao, Jiaojiao Li, Rui Song, Yunsong Li, and Qian Du. 2023. "Unmixing-Guided Convolutional Transformer for Spectral Reconstruction" Remote Sensing 15, no. 10: 2619. https://doi.org/10.3390/rs15102619
APA StyleDuan, S., Li, J., Song, R., Li, Y., & Du, Q. (2023). Unmixing-Guided Convolutional Transformer for Spectral Reconstruction. Remote Sensing, 15(10), 2619. https://doi.org/10.3390/rs15102619