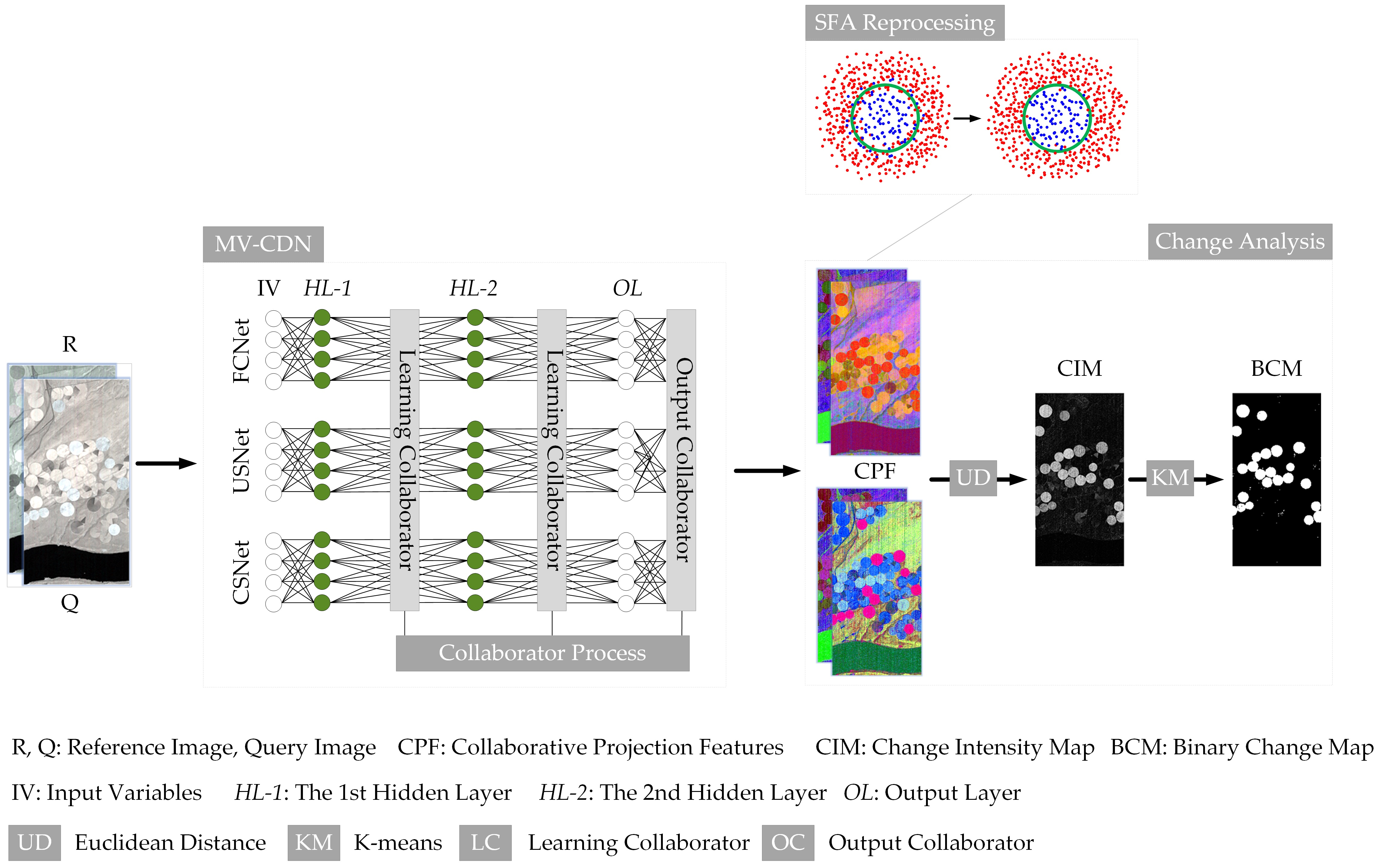
Figure 1.
Flowchart of proposed schema based on multi-visual collaborative deep network (MV-CDN), which consist of three collaborative network members: fully connected network (FCNet), unchanged sensitivity network (USNet), and changed sensitivity network (CSNet).
3.1. Architecture and Training Process of Proposed MV-CDN
In this section we describe the architecture of the MV-CDN and explain it mathematically in detail. The MV-CDN consists of three light-weight collaborative network members with similar structures and sensitivity disparity. In this work, the FCNet [
25] is regarded as the prototype of the particular collaborative network members. Extensive experiments have confirmed that the double-cycle of internal parameters W and b in the
HL-1/
HL-2 is more conducive to detecting changed pixels/unchanged pixels. Thus far, the construction of the USNet and CSNet, which we have proposed in our previous work [
26], is designed and implemented. Supposing there is no collaborator, each collaborative network member can independently generate the projection features for the change-detection analysis; with the MV-CDN mechanism, the collaborators are selectively applied to translate the group-thinking of the collaborative network members into a more robust field of vision.
We illustrate the architecture of the collaborative network members, FCNet, USNet, and CSNet, in
Figure 2 and demonstrate their corresponding parameter settings in
Table 2. In
Figure 2, the white nodes on the far left, denoted by X and Y, indicate the input variables (IV) of the double-temporal samples; the rightmost white nodes denoted by
/
/
and
/
/
indicate the symmetric projection features of the collaborative network members: FCNet denoted as
f, USNet denoted as
u, and CSNet denoted as
c; the green nodes on the rightmost stand for the output layer; consequently, the remaining two groups of green nodes represent the two hidden layers. In
Table 2, the 128, 6, and 10 indicate the numbers of nodes; B and b indicate the number of bands of each detected image and the number of bands of the corresponding mapped features, respectively.
Table 2 also lists the cycle layers, the activation function of each layer, and the dropout rate. Additionally, the learning rate, epoch, sampling range, and sample size, etc., are detailed in the experimental section.
We feed the symmetric samples X and Y to train the MV-CDN. The well-designed process of
HL-1 is formulated in proper order as (1)–(3).
where
f,
u, and
c respectively indicate the three collaborative network members: FCNet, USNet, and CSNet;
,
, and
are the corresponding activation functions,
,
; the superscript and subscript of internal parameters W and
b indicate the collaborative network members and the current layer, respectively; and the paired results
,
, and
are three outputs of the corresponding layer of the collaborative network members.
In the CDN-3C approach, the outputs of
HL-1 will then go through the LC of the collaborator process module to obtain the pair-wise data
, which are taken as the input of
HL-2, where ‘
upd’ means ‘
updated’. However, in the case of the other two subdivision approaches, the output of
HL-1 is regarded as the input of
HL-2. With LC, the
HL-2 process can be represented as (4)–(6).
where
,
, and
are the corresponding activation functions,
. Likewise, in the CDN-3C and CDN-2C approaches, the LC of the collaborator process module is used to obtain the updated paired data
, which will then go through the output layer to obtain the projection features. In the case of CDN-C approach, the output of
HL-2 is regarded as the input of the output layer. With LC, the process of the output layer can be expressed with (7)–(9).
where
,
, and
are the corresponding activation functions,
,
. Afterwards, OC is applied on the output layer to calculate the pair-wise CPF
, which are then used for further change analysis, where ‘
new’ means the new matrix updated from the projection features of the collaborative network members.
To train the MV-CDN model, we follow the loss function of DSFA [
25], which is derived from the feature invariance extraction known as SFA theory on double-temporal images. The SFA theory is summarized into an objective function and three restrictions [
25], which could be reconstructed into a generalized eigenproblem as (10).
where W and L stand for the generalized eigenvector matrix and diagonal matrix of eigenvalues, respectively; A and B denote the expectation of the covariance matrix for the first-order derivative of double-temporal features and the expectation of the covariance matrix for double-temporal features as (11) and (12), respectively.
where
and
are regarded as the
ith pair-wise pixels; T and
n indicate the transpose operation and the number of pixels of a whole image. In conditions where both
and
are non-negative and invertible, the generalized eigenproblem can be reformulated as (13).
where the square of
should be minimized to meet the feature invariance of SFA theory; thus, the loss function could be designed as (14).
where
tr denotes the trace of the matrix. Through the gradient descent algorithm detailed in part B of the methodology section of reference [
25], both pair-wise internal parameters
and
, which result from the learning of X and Y, are obtained.
3.2. Collaborator Process
In this section,
Figure 3 shows the collaborator process of subdivision approaches. In
HL-1 and
HL-2, LC is applied for the collaborative task, which is formulated as (15)–(17), and before that the data of tensor type to be processed should be converted to array type.
where
i and
d denote the pixel index and the absolute value of the difference between two values, respectively;
Min is an operator to take the minimum of three values; in the obtained
and
, the pair (
a,
b) is regarded as one of three pairs: (
f,
u), (
f,
c), and (
u,
c). Then, (16) is used for the revaluation of
and
.
where
Mean represents the arithmetic average operator,
HL-j signifies the
jth hidden layer, and naturally, the paired data
denote the re-evaluation results of the full image in
HL-j. To realize the network transmission, (17) is utilized to convert the new results to tensor type without destroying the calculation graph.
where the pair-wise data
act as two motherboard tensors;
stands for the tensor type of
, which has been obtained with (16); the mask is a binary matrix whose dimension is consistent with each tensor of paired data
. Moreover, in practice, all feature elements are regarded as updated; thus, the mask ought to be filled with 0. We calculate the Hadamard product on the pair-wise data
and mask, then add the tensor type of the paired data
marked with
to obtain the needed results
and
, which are regarded as the input of the next layer. In (17), the ‘
upd’ and ‘
new_tnr’ mean ‘
updated’ and ‘
new_tensor’, respectively. We especially note that the other two pairs of data
and
could also be taken as motherboard tensors and are involved with computing; in particular, we test with the pair-wise data
in the collaborator process.
Regarding the output layer, since the projection features no longer transmit in the network, (15) and (16) are utilized with (17) omitted to calculate the pair-wise data .
3.4. Change Analysis
In effect, it is impossible to artificially recognize the change areas from the double-temporal features
. Therefore, the Chi-square distance [
35], Euclidean distance [
34] and improved Mahalanobis distance [
36], etc., could be selectively applied to the calculation of the change-intensity map (CIM). In the tests, the Euclidean distance is employed to serve the computing of CIM using (19) and (20).
where
,
,
, and
stand for the pixel index, the band index, the number of pixels, and the number of bands, respectively. The
and
indicate the feature elements acquired from the pair-wise data
and
, respectively.
The computed result of Euclidean distance is regarded as the CIM, which could be applied for the initial detection of changes. Then the K-means clustering method is employed as automatic thresholding for image segmentation, and finally the binary change map is generated, in which the white and black marks uniquely identify the changed and unchanged areas, respectively. The pseudocode of the proposed schema is summarized and presented in Algorithm 1.
| Algorithm 1 Pseudocode of proposed schema for change detection of double-temporal hyperspectral images |
| Input: Double-temporal scene images R and Q; |
| Output: Detected binary change map (BCM); |
| 1: Select training samples X and Y based on BCM of pre-detection; |
| 2: Initialize parameters of MV-CDN as ; |
| 3: Configuration of epoch number, learning rate, sample size, etc.; |
| 4: Case CDN-C: |
| 5: Apply OC on OL; |
| 6: Go to line 13; |
| 7: Case CDN-2C: |
| 8: Apply OC on OL, and LC on HL-2; |
| 9: Go to line 13; |
| 10: Case CDN-3C: |
| 11: Apply OC on OL, and LC on HL-2& HL-1; |
| 12: Go to line 13; |
| 13: while i < epochs do |
| 14: Compute the double-temporal projection features of pair-wise samples X and Y: = f (X, ) and = f (Y, ); |
| 15: Compute the gradient of loss function ( ) = with L )/ and L ( )/; |
| 16: Update parameters; |
| 17: i++; |
| 18: end |
| 19: Generate the double-temporal projection features and of images R and Q; |
| 20: SFA reprocessing is applied to the CPF to generate the pair-wise data with: , ; |
| 21: Euclidean distance is used for the calculation of CIM; |
| 22: K-means is applied to obtain the BCM; |
| 23: return BCM; |
In the tests, we found that other distance methods have little influence on the detection results in comparison to the using of Euclidean distance; in addition, the K-means clustering algorithm could be replaced by other threshold algorithms such as Otsu [
37]. In particular, the designed example uniformly adopts the Euclidean distance and K-means threshold algorithm.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}