3.2. Handcrafted Feature
Following the success of general DNN-based point cloud semantic segmentation methods, several recent works have used DNN models for forest point cloud segmentation [
7,
8,
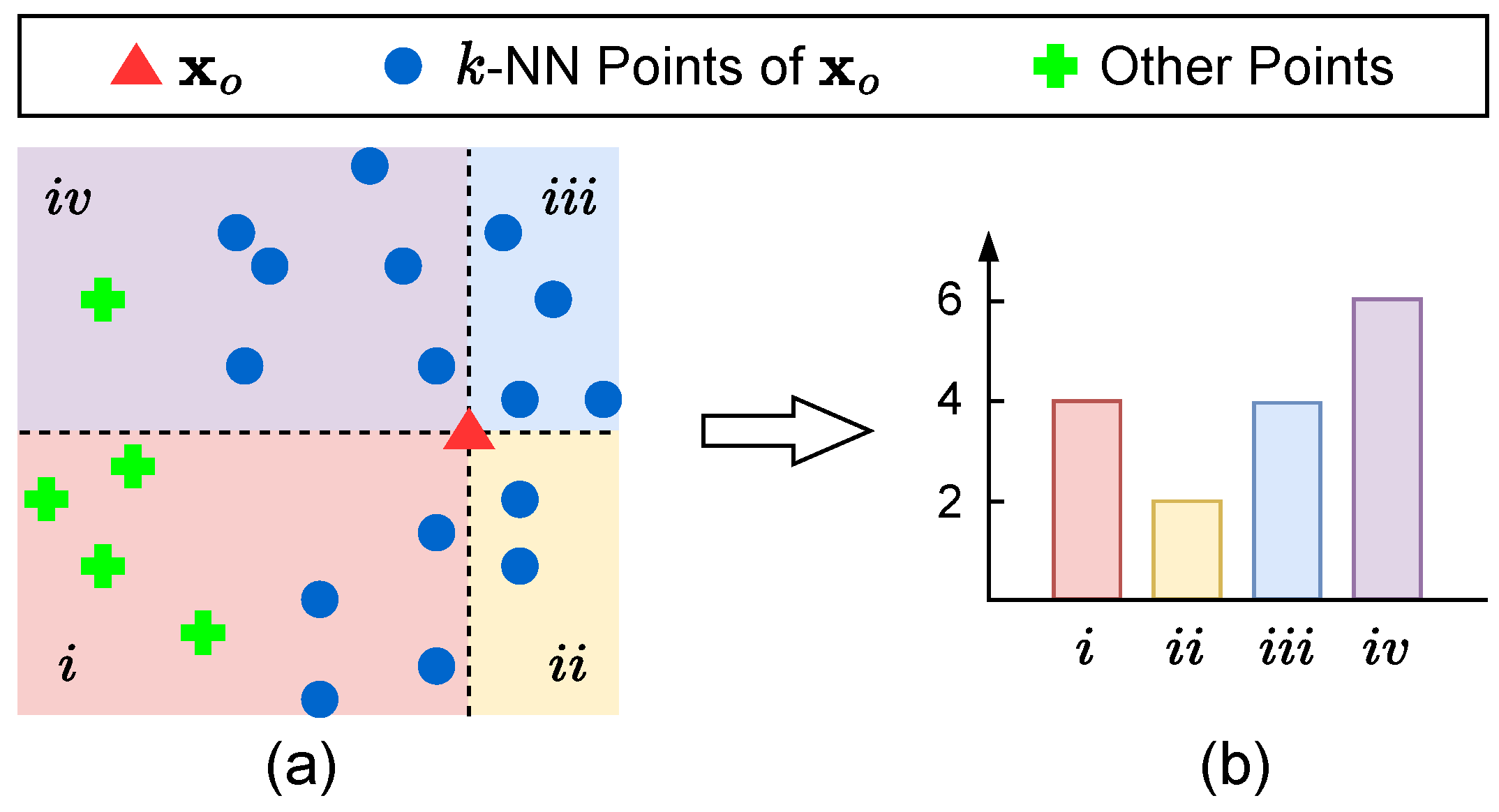
9]. However, general point cloud semantic segmentation and tree point cloud semantic segmentation tasks are essentially different since forest point clouds are much more difficult to annotate and the labelled forest point cloud datasets are much smaller. Therefore, using DNN-based methods alone may not be enough for learning effective representations from forest data. To obtain a better representation for the tree point cloud semantic segmentation task, we proposed a handcrafted feature that characterises the local interaction of points in an explicit manner. Motivated by our observation that stem and foliage points differ by the relative position of their neighbours, we design a histogram-based local feature [
70,
71] that encodes for each individual point the direction of its neighbour points.
More specifically, given a point coordinate
and the set of its surrounding points
selected by
k-NN search in the 3D space, we first compute the orientation of the vector
for each neighbor point
by projecting
onto each of the three 2D planes (i.e.,
,
, and
) and computing the three orientation angles corresponding to the three 2D components, i.e.,
where the function
computes the angle of the 2D vector given by its two input variables, i.e., when using the
in (
1) as example,
where the
in
r is a small positive value used to avoid zero denominator for
u and
v, and
is the binary indicator function.
For each of the three angles
,
, and
in (
1), we evenly divide the
interval into
B bins and assign the angle to one of the bins. Using the
in (
1) for example, the index of the bin to assign the angle is computed as follows,
where
is the floor operator for numbers. Then we compute the number of points assigned to each bin based on the orientations computed for all
, i.e.,
where
is the bin index. By the same token, we compute
and
for the other two angles
and
in (
1).
Finally, our histogram feature
is given by the vector of point numbers across all bins, i.e.,
We illustrate our method for computing
in
Figure 2.
The histogram feature
only contains the relative position information of points and does not utilise the original 3D point coordinates, while we empirically found it is beneficial to incorporate the point coordinates into our local feature. More specifically, we improve the descriptiveness of our local feature simply by concatenating the coordinate
with the corresponding local feature
, resulting in a feature dimension of
for each point. For clarity, we denote the improved feature as
, i.e.,
When using the handcrafted feature
alone as the segmentation method and not integrating with the DNN-based method, we train a simple multi-layer perceptron (MLP) classifier to predict the segmentation results. In this way, we achieve results on par with popular DNN-based segmentation methods. In
Section 3.3, we will combine the advantage of both our handcrafted feature and DNN-based methods for improved performance.
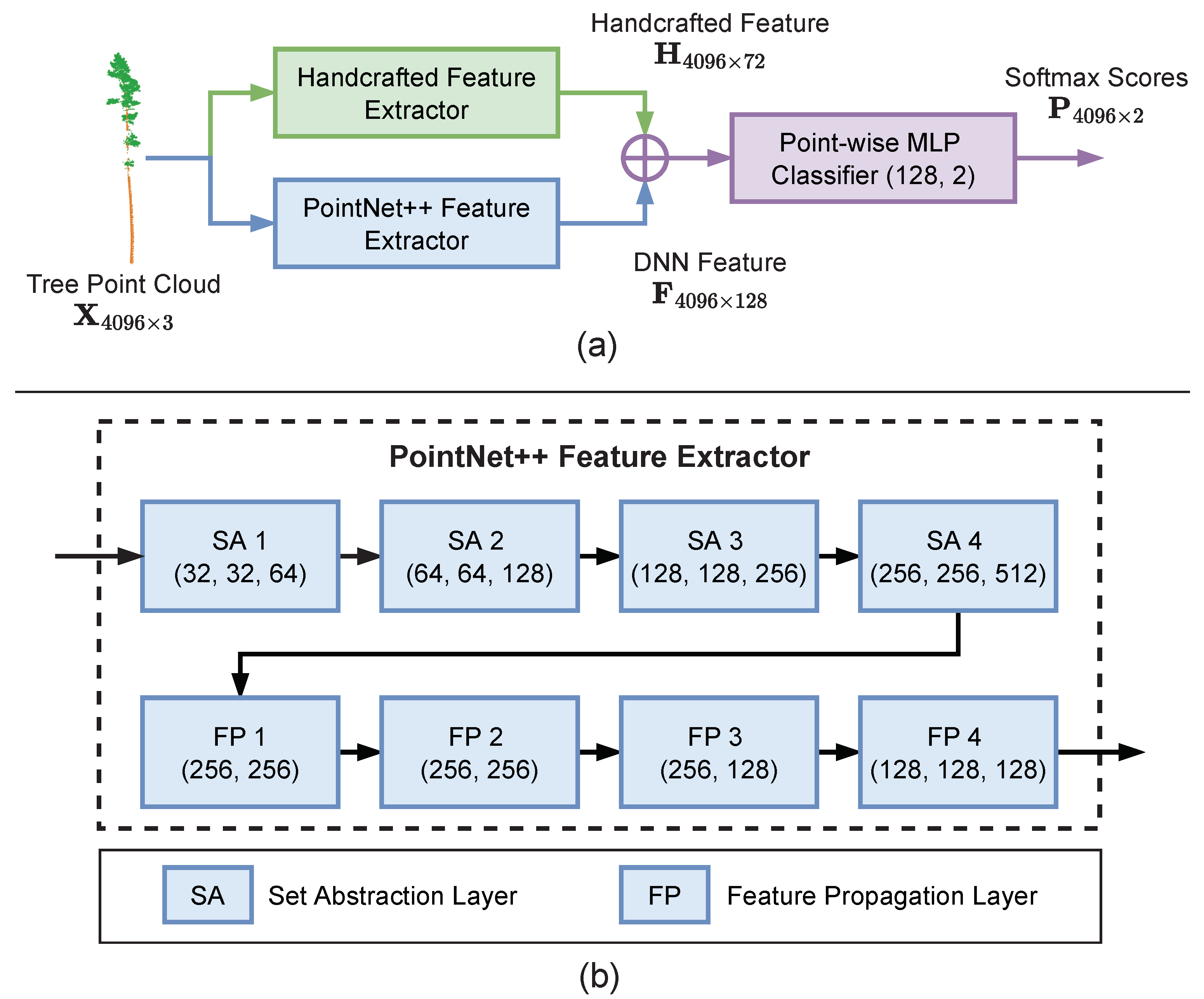
3.3. Point Cloud Segmentation Model
In this subsection, we introduce our backbone semantic segmentation model which we use for all the learning settings involved in this work, i.e., supervised learning, semi-supervised learning, and domain adaptation. Inspired by the success of existing works [
23,
24,
25,
26] which integrate DNN with a handcrafted feature for the image recognition and point cloud recognition tasks, we integrate our handcrafted local feature with a DNN model for the point cloud semantic segmentation task. In this way, our backbone point cloud semantic segmentation model can combine the benefits of both types of methods.
For the DNN component in our point cloud semantic segmentation model, we use the popular PointNet++ [
18] model. In the encoder network of PointNet++, the Farthest Point Sample algorithm [
72] is used to divide the points into local groups and several set abstraction modules are used to gradually capture semantics from a larger spatial extent. Then in the decoder, an interpolation strategy based on the spatial distance between point coordinates is used to propagate features from the semantically rich sampled points to all the original points.
To integrate our handcrafted feature with the PointNet++ model, for each individual point, we concatenate our handcrafted feature vector with the output feature vector of the last feature propagation layer in the decoder component of PointNet++. We illustrate our backbone point cloud semantic segmentation model in
Figure 3.
3.4. Learning Framework for Semi-Supervised Point Cloud Semantic Segmentation
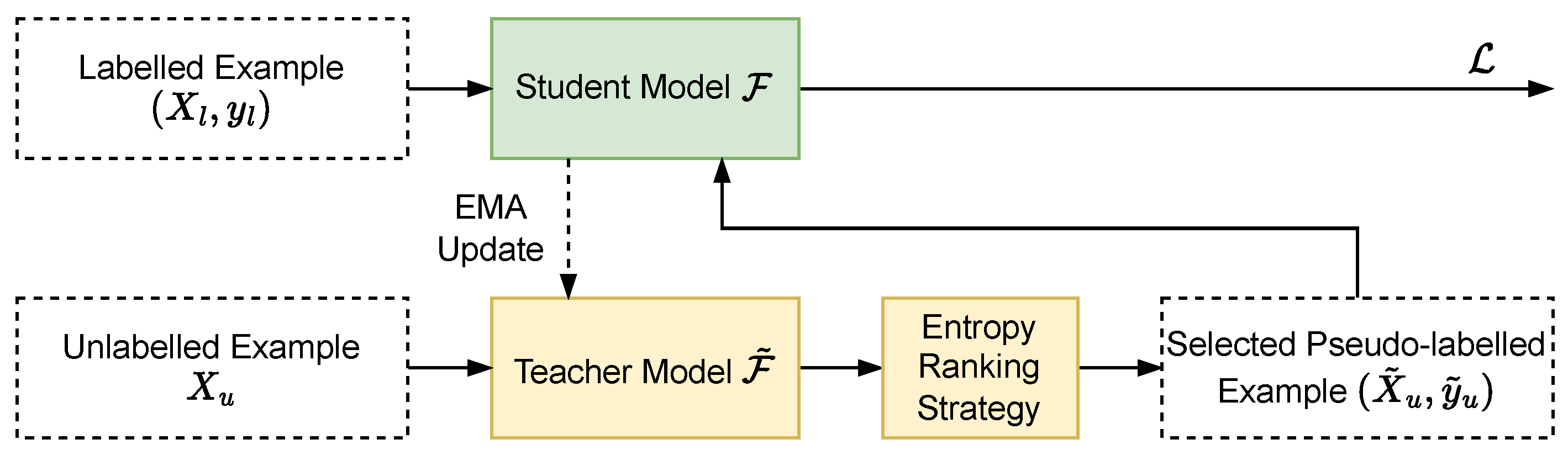
To address the issue of limited labelled data for training the semantic segmentation model, we utilise unlabelled examples for training the model by employing semi-supervised learning. We propose a learning framework based on pseudo-labelling and model ensembling to utilise the unlabelled training data.
Formally, we denote the labelled point cloud dataset as , where is a labelled example with being the number of points in and is the set of semantic labels corresponding to each point in with K being the total number of semantic classes.
Inspired by the model ensembling and distillation strategy [
52], in our learning framework, we employ two point cloud semantic segmentation models (i.e., one student model and one teacher model) with an identical architecture. During the training process, we first use the teacher model to produce pseudo-labels
for each unlabelled example
and train the student model on both the labelled examples and the pseudo-labelled examples, then update the variables in the teacher model by taking Exponential Moving Average (EMA) of the variables in the student model. More specifically, we denote the student model function as
, where the output is the prediction probability matrix over all points and semantic classes and
is the set of model variables with
j being the layer index of DNN model. Similarly, we use
to denote the teacher model function. We also use the indices
p and
k to indicate the
p-th point and the
k-th semantic class in the prediction probability matrix, respectively. Then we formulate our pseudo-labelling strategy, overall training loss function, and EMA update strategy for the teacher model as Equations (
7)–(
9) as follows,
where
is
p-th element in the pseudo-label vector
(i.e., the pseudo-label predicted by the teacher model for the
p-th point of
),
denotes the Cross-Entropy loss function,
w is a weight factor for balancing the two loss terms, and
is a constant factor called
momentum that is set to
in our experiments.
The main issue with the pseudo-labelling strategy is the quality of pseudo-labelled examples as the lack of variety can harm model performance. Inspired by [
73], we propose a pseudo-label selection strategy based on the entropy ranking of the individual points to select the pseudo-labelled points in each point cloud that are beneficial for training the segmentation model. More specifically, for each
, we compute the entropy of each individual point and select the
points with higher entropy as the pseudo-labelled points. Therefore, we denote the updated
with only the selected points and their corresponding pseudo-labels as
. In this way, we are selecting the hard examples which are better for the variety of the training dataset. We illustrate our complete learning framework for semi-supervised and cross-dataset point cloud semantic segmentation in
Figure 4.
3.5. Extending Semi-Supervised Learning Framework to Domain Adaptation
In practice, aside from the shortage in labelled training data, we often face situations where the training data and test data are collected from different scenes and do not follow the same data distribution. For example, in the forest inventory scenario, the training and test data can be of different tree species, or collected using different types of LiDAR devices or from different sites. In learning theory, this is known as the “domain adaptation” or cross-dataset generalisation problem, and the data distributions of the training and test data are called the source domain and the target domain, respectively. The domain adaptation problem is usually tackled by exploiting the training data from the target domain, while we tackle the more challenging setting of unsupervised domain adaptation where the target training data are unlabelled. Using unlabelled target training data is more advantageous than using labelled training data in real-world applications since it saves time and the cost of annotation.
For the cross-dataset point cloud semantic segmentation task, we can extend our semi-supervised learning framework in
Section 3.4 to the domain adaptation setting by simply replacing the training datasets, i.e., we replace the labelled dataset
and unlabelled dataset
with the labelled source dataset
and the unlabelled target dataset
, respectively. Different from the
and
in semi-supervised learning which are assumed to be drawn from the same data distribution, the
and
in domain adaptation are drawn from different data distributions.
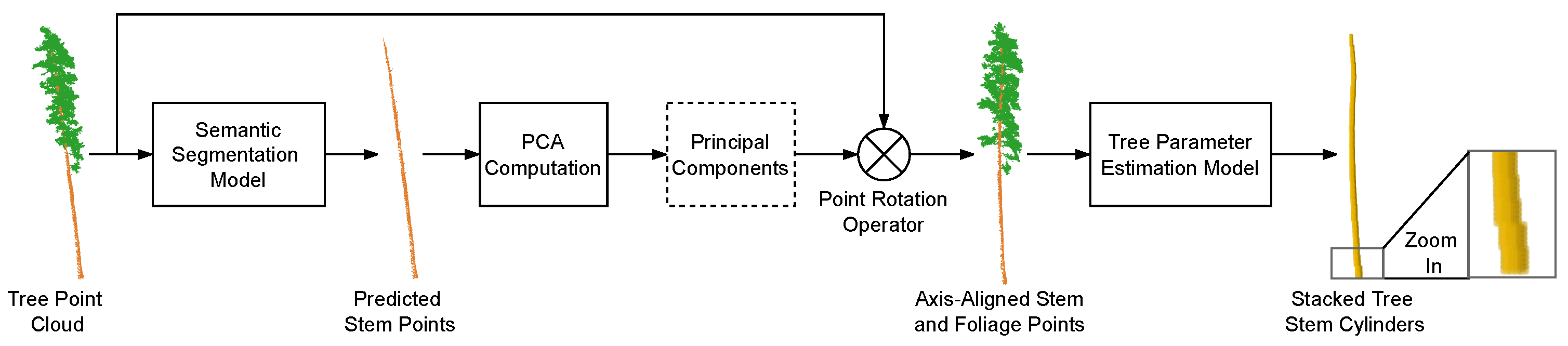
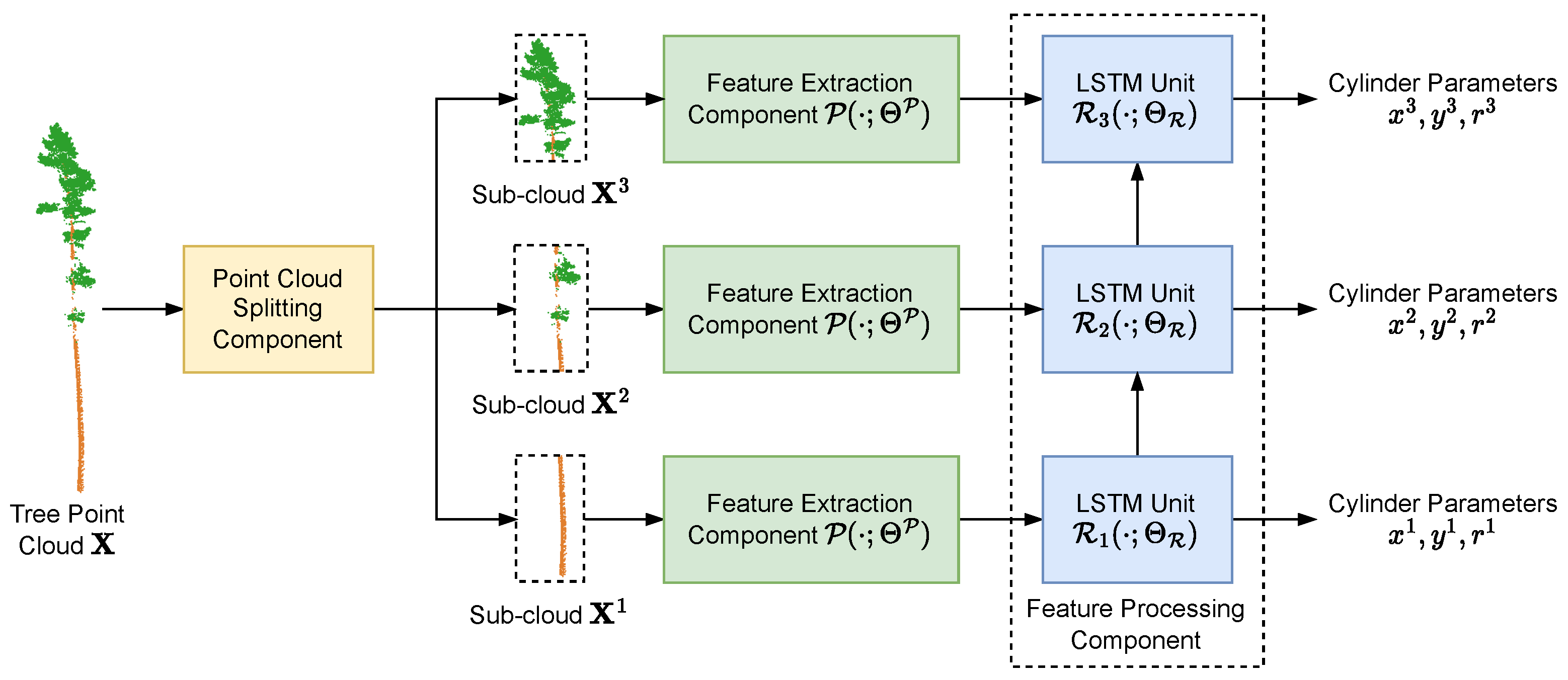
3.6. Tree Parameter Estimation Model
Existing works in tree parameter estimation mainly fit a parametric model to characterise the tree stem geometry for each tree point cloud individually. In contrast to the existing works, we propose a data-driven method for tree parameter estimation based on DNN to predict the cylindrical parameters of the tree stem [
10] while being able to learn from the variety of data for improved robustness and adaptability to geometric variations across different individual trees.
In particular, our DNN tree parameter estimation method consists of three components, splitting the point cloud into sub-clouds based on height, extracting features from each sub-cloud, and feature processing. Each individual tree point cloud
is first passed through the point cloud division component, where we first divide the height range from 0 to 50 m into
M segments, then group the subset of points (both stem and foliage points) fallen into the
m-th height segment as the tree point cloud segment
. Here we are overloading the denotation by using the superscript of
to indicate the tree segment index instead of the dataset as in
Section 3.4 and
Section 3.5. Then in the segment-wise feature extraction component, we use a PointNet [
17] feature extractor on each tree point cloud segment individually to extract segment-wise semantics, while the PointNet feature extractor for each individual tree segment has a shared set of model parameters. The features extracted across the segments of an individual tree naturally form a sequence. Finally, in the feature processing component, we employ a Long Short-Term Memory (LSTM) [
74] model to process the sequential features across all the tree segments
and predict the tree parameters for each segment, i.e., the planar center coordinates
of the stem segments along the
X- and
Y- axes and the stem segment radii
. For the ease of denotation, we write the tree parameters
,
, and
collectively as
.
Inspired by the recent works in point cloud object detection [
75,
76,
77], for estimating the coordinates
and
, we let our tree parameter estimation model predict the residual between
and the point centroid
of each point cloud segment instead of directly predict
. When computing each centroid
, we first compute the initial centroid
by simply averaging the
X- and
Y-coordinates of the points within the corresponding point cloud segment, then we evenly divide the
-plane centred on
into 16 directional bins. Finally, we compute
by randomly sampling a maximum of 4 points from each directional bin and taking the average on the
X- and
Y-coordinates of the sampled points. By refining
into
in this way, we can reduce the errors of the initial centroids caused by sampling bias during LiDAR scanning. Therefore, we formulate our total loss function across all the tree segments as follows,
where
is the centroid coordinate vector extended by an additional zero to match the dimension of
,
N is the number of tree point clouds in the dataset,
is the Huber loss function with the
coefficient set to 0.01,
and
are the model functions of the PointNet feature extraction component and the LSTM feature processing component, respectively.
maps each point cloud segment into a
D-dimensional feature vector while each
maps its input features into the tree parameters. We illustrate our tree parameter estimation model in
Figure 5.
In addition, we also use a data augmentation strategy during the training process to improve the robustness of our tree parameter estimation method. For each
, we apply a rotation with random angle along the vertical
Z-axis to the whole point cloud
while we also apply the same rotation to the
and
coordinates in each
across all
m. We denote this example-specific rotation operator as
. Therefore, by incorporating our data augmentation strategy into the training process, our loss function in (
10) is updated as,
Note in (
11) that our data transform
works differently for
and
since the
Z-coordinates in
are replaced by the radius in
, while we write
as the same type of transform for both
and
for the ease of denotation. We only use random rotation for
during the training process and we use the identity operator for
during testing.
In addition, we also propose a simple tree point cloud semantic segmentation model which is induced from our tree parameter estimation model. Intuitively, for each cylinder segment characterised by the parametric tree model, we classify a point within the corresponding point cloud segment as a stem if the point falls within the interior of the cylinder segment, otherwise we classify the point as foliage. More specifically, given a tree stem segment with parameters
and a point
from the corresponding point cloud segment, we classify
as stem if it falls within a distance threshold to
, i.e.,
where
is a positive coefficient we use to improve the robustness of the model. We name this induced tree point cloud semantic segmentation model the cylinder segmentation model. Following the procedure of our tree parameter estimation method, we use the PCA-transformed points in our cylinder segmentation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







