
Multi-Scale Feature Fusion Network with Symmetric Attention for Land Cover Classification Using SAR and Optical Images


Abstract
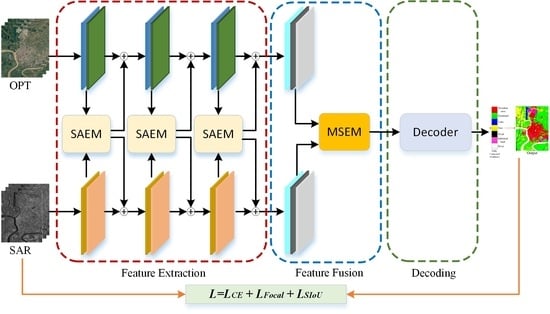
:
1. Introduction
- We propose a multi-modal segmentation model for the classification of optical and SAR images. It is an end-to-end network (SAMFNet) based on a multi-layer symmetric attention module and multi-scale feature fusion module. There are no other pretrained backbones in the framework.
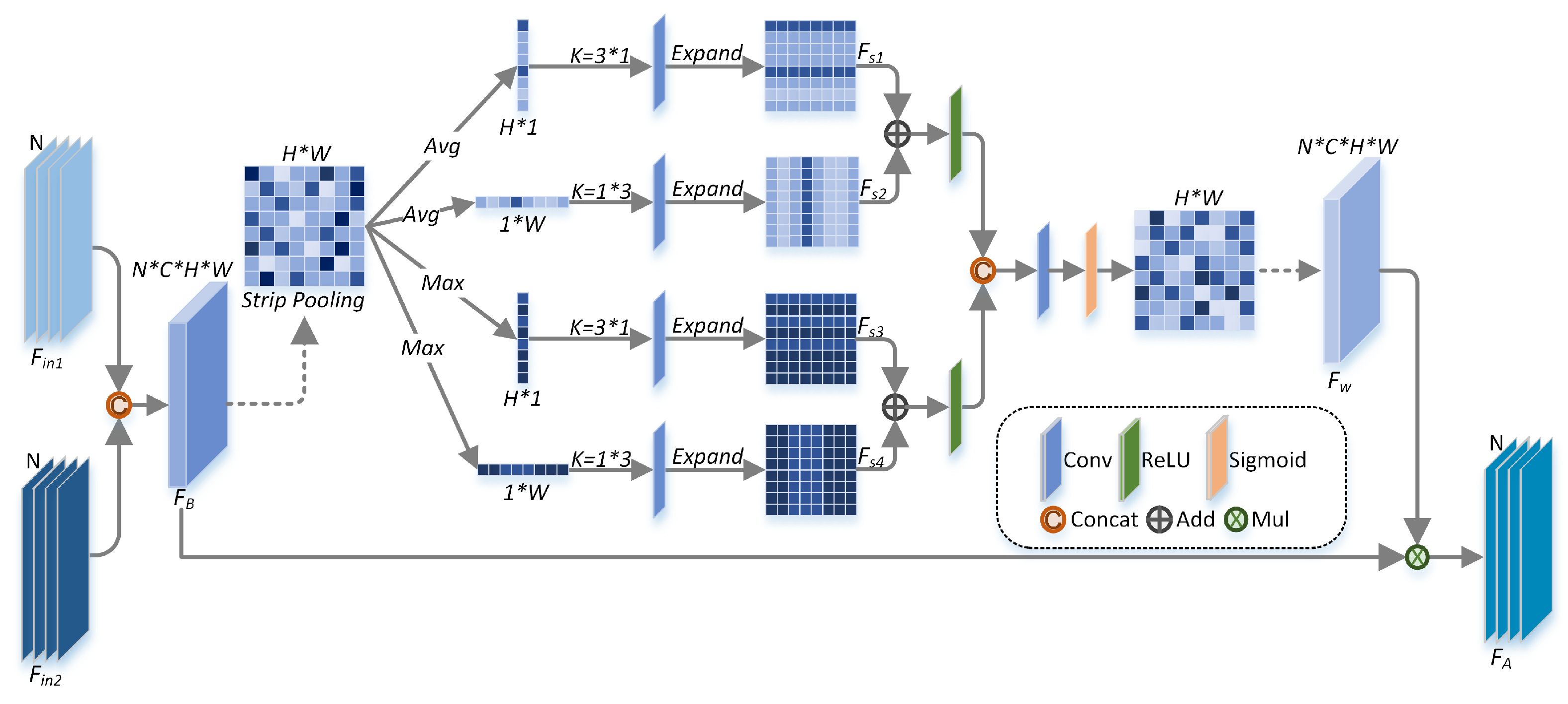
- A novel symmetric attention module is constructed with strip pooling. Multiple long receptive fields help to obtain more complementary and contextual information from the two branches. Atrous spatial pyramid pooling, varisized convolutions and skip connections are tactfully combined to fuse the multi-scale and multi-level semantic features.
- The proposed model achieves the best numerical and visual results on two available datasets. The applicability of the model is proven on another RGB–thermal segmentation task. The designed network is relatively lightweight, and the computational costs and parameters are low, considering its classification accuracy.
2. Materials and Methods
2.1. Data Preparations
2.2. Attention Mechanisms for SAR and Optical Image Classification
2.3. Proposed SAMFNet
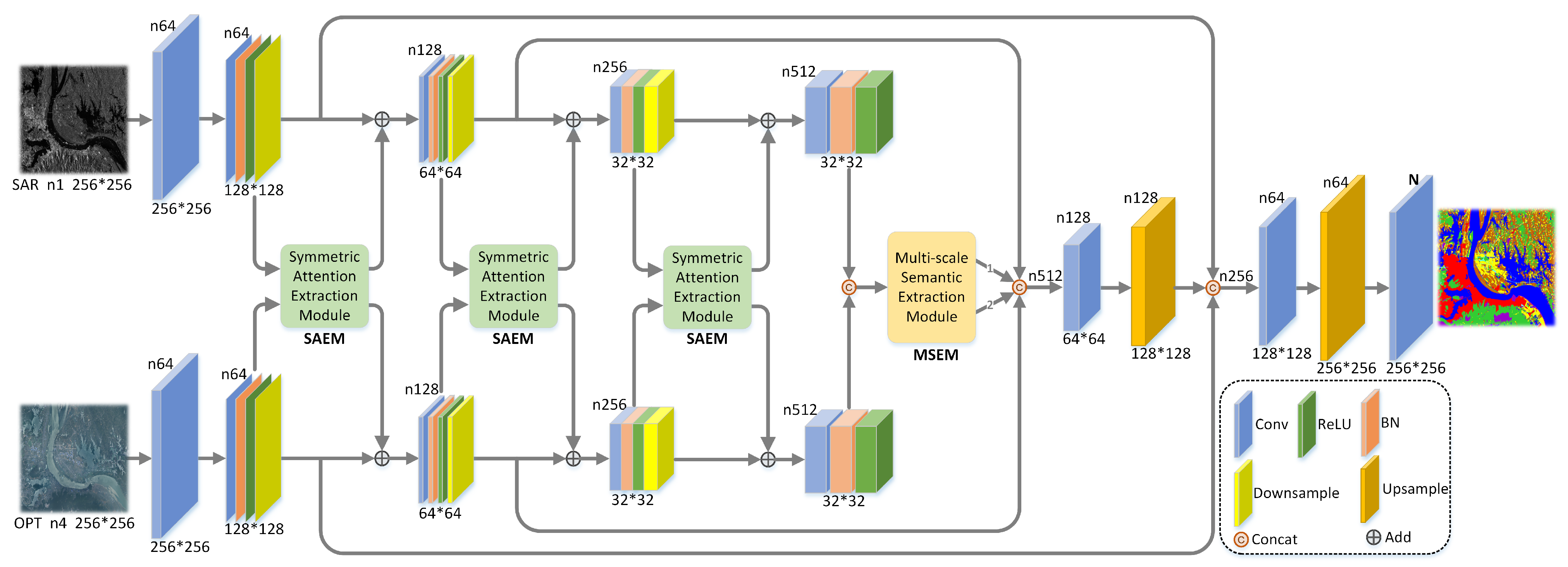
2.3.1. Framework of the SAMFNet
2.3.2. Symmetric Attention Extraction Module
2.3.3. Multi-Scale Semantic Extraction Module
2.3.4. Decoding Process
2.3.5. Joint Loss Function
3. Results
3.1. Experimental Settings
3.2. Evaluation Metrics
3.3. Experimental Analysis
3.3.1. Experiments on DFC2020 Dataset
3.3.2. Experiments on WHU-OPT-SAR Dataset
4. Discussion
4.1. Computational Complexity
4.2. Analysis of Different Attention Mechanisms
4.3. Analysis of Multi-Scale Feature Extraction
4.4. Analysis of the Joint Loss Function
4.5. Application in Other Multi-Modal Segmentation Tasks
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More Diverse Means Better: Multimodal Deep Learning Meets Remote-Sensing Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4340–4354. [Google Scholar] [CrossRef]
- Li, X.; Zhang, G.; Cui, H.; Hou, S.; Wang, S.; Li, X.; Chen, Y.; Li, Z.; Zhang, L. MCANet: A joint semantic segmentation framework of optical and SAR images for land use classification. Int. J. Appl. Earth Obs. 2022, 106, 102638. [Google Scholar] [CrossRef]
- Li, X.; Lei, L.; Sun, Y.; Li, M.; Kuang, G. Multimodal Bilinear Fusion Network With Second-Order Attention-Based Channel Selection for Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 1011–1026. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Ma, J. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Inform. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Li, X.; Lei, L.; Sun, Y.; Li, M.; Kuang, G. Collaborative Attention-Based Heterogeneous Gated Fusion Network for Land Cover Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3829–3845. [Google Scholar] [CrossRef]
- Meng, H.; Li, C.; Liu, Y.; Gong, Y.; He, W.; Zou, M. Corn Land Extraction Based on Integrating Optical and SAR Remote Sensing Images. Land 2023, 12, 398. [Google Scholar] [CrossRef]
- Li, W.; Sun, K.; Li, W.; Wei, J.; Miao, S.; Gao, S.; Zhou, Q. Aligning semantic distribution in fusing optical and SAR images for land use classification. ISPRS J. Photogramm. Remote Sens. 2023, 199, 272–288. [Google Scholar] [CrossRef]
- Li, X.; Lei, L.; Zhang, C.; Kuang, G. Dense Adaptive Grouping Distillation Network for Multimodal Land Cover Classification With Privileged Modality. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Kang, W.; Xiang, Y.; Wang, F.; You, H. CFNet: A Cross Fusion Network for Joint Land Cover Classification Using Optical and SAR Images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2022, 15, 1562–1574. [Google Scholar] [CrossRef]
- Zhang, H.; Wan, L.; Wang, T.; Lin, Y.; Lin, H.; Zheng, Z. Impervious Surface Estimation From Optical and Polarimetric SAR Data Using Small-Patched Deep Convolutional Networks: A Comparative Study. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 2374–2387. [Google Scholar] [CrossRef]
- Xu, X.; Li, W.; Ran, Q.; Du, Q.; Gao, L.; Zhang, B. Multisource Remote Sensing Data Classification Based on Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 937–949. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Talukdar, S.; Singha, P.; Mahato, S.; Shahfahad; Pal, S.; Liou, Y.A.; Rahman, A. Land-Use Land-Cover Classification by Machine Learning Classifiers for Satellite Observations—A Review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef]
- Ham, J.; Chen, Y.; Crawford, M.; Ghosh, J. Investigation of the random forest framework for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 492–501. [Google Scholar] [CrossRef]
- Blanzieri, E.; Melgani, F. Nearest Neighbor Classification of Remote Sensing Images With the Maximal Margin Principle. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1804–1811. [Google Scholar] [CrossRef]
- Li, K.; Wang, D.; Wang, X.; Liu, G.; Wu, Z.; Wang, Q. Mixing Self-Attention and Convolution: A Unified Framework for Multisource Remote Sensing Data Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5523216. [Google Scholar] [CrossRef]
- Ienco, D.; Interdonato, R.; Gaetano, R.; Ho Tong Minh, D. Combining Sentinel-1 and Sentinel-2 Satellite Image Time Series for land cover mapping via a multi-source deep learning architecture. ISPRS J. Photogramm. Remote Sens. 2019, 158, 11–22. [Google Scholar] [CrossRef]
- Liu, S.; Qi, Z.; Li, X.; Yeh, A.G.O. Integration of Convolutional Neural Networks and Object-Based Post-Classification Refinement for Land Use and Land Cover Mapping with Optical and SAR Data. Remote Sens. 2019, 11, 690. [Google Scholar] [CrossRef]
- Feng, Q.; Yang, J.; Zhu, D.; Liu, J.; Guo, H.; Bayartungalag, B.; Li, B. Integrating Multitemporal Sentinel-1/2 Data for Coastal Land Cover Classification Using a Multibranch Convolutional Neural Network: A Case of the Yellow River Delta. Remote Sens. 2019, 11, 1006. [Google Scholar] [CrossRef]
- Li, X.; Lei, L.; Kuang, G. Locality-Constrained Bilinear Network for Land Cover Classification Using Heterogeneous Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 2501305. [Google Scholar] [CrossRef]
- Gao, M.; Xu, J.; Yu, J.; Dong, Q. Distilled Heterogeneous Feature Alignment Network for SAR Image Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2023, 20, 4004705. [Google Scholar] [CrossRef]
- Kang, J.; Wang, Z.; Zhu, R.; Xia, J.; Sun, X.; Fernandez-Beltran, R.; Plaza, A. DisOptNet: Distilling Semantic Knowledge From Optical Images for Weather-Independent Building Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4706315. [Google Scholar] [CrossRef]
- Chen, Y.; Bruzzone, L. Self-Supervised SAR-Optical Data Fusion of Sentinel-1/-2 Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5406011. [Google Scholar] [CrossRef]
- Jain, P.; Schoen-Phelan, B.; Ross, R. Self-Supervised Learning for Invariant Representations From Multi-Spectral and SAR Images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2022, 15, 7797–7808. [Google Scholar] [CrossRef]
- Liu, C.; Sun, H.; Xu, Y.; Kuang, G. Multi-Source Remote Sensing Pretraining Based on Contrastive Self-Supervised Learning. Remote Sens. 2022, 14, 4632. [Google Scholar] [CrossRef]
- Gao, L.; Hong, D.; Yao, J.; Zhang, B.; Gamba, P.; Chanussot, J. Spectral Superresolution of Multispectral Imagery With Joint Sparse and Low-Rank Learning. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2269–2280. [Google Scholar] [CrossRef]
- Zhao, X.; Tao, R.; Li, W.; Li, H.C.; Du, Q.; Liao, W.; Philips, W. Joint Classification of Hyperspectral and LiDAR Data Using Hierarchical Random Walk and Deep CNN Architecture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7355–7370. [Google Scholar] [CrossRef]
- Schmitt, M.; Hughes, L.H.; Qiu, C.; Zhu, X.X. SEN12MS—A Curated Dataset of Georeferenced Multi-Spectral Sentinel-1/2 Imagery for Deep Learning and Data Fusion. arXiv 2019, arXiv:1906.07789. [Google Scholar] [CrossRef]
- Yokoya, N.; Ghamisi, P.; Haensch, R.; Schmitt, M. 2020 IEEE GRSS Data Fusion Contest: Global Land Cover Mapping With Weak Supervision [Technical Committees]. IEEE Geosci. Remote Sens. Mag. 2020, 8, 154–157. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T.S. CCNet: Criss-Cross Attention for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6896–6908. [Google Scholar] [CrossRef]
- Zhong, Z.; Lin, Z.Q.; Bidart, R.; Hu, X.; Daya, I.B.; Li, Z.; Zheng, W.S.; Li, J.; Wong, A. Squeeze-and-Attention Networks for Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13062–13071. [Google Scholar] [CrossRef]
- Yang, X.; Li, S.; Chen, Z.; Chanussot, J.; Jia, X.; Zhang, B.; Li, B.; Chen, P. An attention-fused network for semantic segmentation of very-high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 177, 238–262. [Google Scholar] [CrossRef]
- Xu, Z.; Zhu, J.; Geng, J.; Deng, X.; Jiang, W. Triplet Attention Feature Fusion Network for SAR and Optical Image Land Cover Classification. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4256–4259. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Tao, A.; Sapra, K.; Catanzaro, B. Hierarchical Multi-Scale Attention for Semantic Segmentation. arXiv 2020, arXiv:2005.10821. [Google Scholar]
- Yuan, M.; Ren, D.; Feng, Q.; Wang, Z.; Dong, Y.; Lu, F.; Wu, X. MCAFNet: A Multiscale Channel Attention Fusion Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2023, 15, 361. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4002–4011. [Google Scholar] [CrossRef]
- Song, Q.; Mei, K.; Huang, R. AttaNet: Attention-Augmented Network for Fast and Accurate Scene Parsing. arXiv 2021, arXiv:2103.05930. [Google Scholar] [CrossRef]
- Chen, K.; Dai, X.; Xia, M.; Weng, L.; Hu, K.; Lin, H. MSFANet: Multi-Scale Strip Feature Attention Network for Cloud and Cloud Shadow Segmentation. Remote Sens. 2023, 15, 4853. [Google Scholar] [CrossRef]
- Vaezi Joze, H.R.; Shaban, A.; Iuzzolino, M.L.; Koishida, K. MMTM: Multimodal Transfer Module for CNN Fusion. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13286–13296. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An Advanced Object Detection Network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for Semantic Segmentation in Street Scenes. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar] [CrossRef]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Class Accuracy | OA | Kappa | mIoU | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Forest | Shrubland | Grassland | Wetland | Cropland | Built-Up | Barren | Water | ||||
| DeepLabV3+ | 0.8802 | 0.5803 | 0.6421 | 0.5638 | 0.8410 | 0.8320 | 0.4996 | 0.9890 | 0.8297 | 0.7920 | 0.6106 |
| DenseASPP | 0.8115 | 0.4729 | 0.7517 | 0.5612 | 0.7774 | 0.8911 | 0.4681 | 0.9866 | 0.8109 | 0.7706 | 0.5831 |
| DANet | 0.8856 | 0.5513 | 0.6617 | 0.5593 | 0.8257 | 0.8347 | 0.4367 | 0.9881 | 0.8267 | 0.7882 | 0.6022 |
| CCNet | 0.9159 | 0.5784 | 0.7330 | 0.5985 | 0.8290 | 0.8407 | 0.4398 | 0.9723 | 0.8419 | 0.8070 | 0.5028 |
| TAFFN | 0.9137 | 0.1022 | 0.4898 | 0.3616 | 0.7219 | 0.8258 | 0.0230 | 0.9904 | 0.7491 | 0.6897 | 0.4439 |
| MCANet | 0.8880 | 0.5655 | 0.7372 | 0.5541 | 0.8149 | 0.8699 | 0.3978 | 0.9927 | 0.8374 | 0.8018 | 0.6127 |
| Proposed | 0.9291 | 0.6324 | 0.8247 | 0.6257 | 0.8423 | 0.8922 | 0.5890 | 0.9956 | 0.8763 | 0.8492 | 0.6853 |
| Models | Class Accuracy | OA | Kappa | mIoU | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Farmland | City | Village | Water | Forest | Road | Others | ||||
| DeepLabV3+ | 0.8277 | 0.7636 | 0.6289 | 0.7777 | 0.8988 | 0.5420 | 0.3132 | 0.8180 | 0.7427 | 0.4786 |
| DenseASPP | 0.8290 | 0.7632 | 0.6560 | 0.8088 | 0.8998 | 0.5433 | 0.3307 | 0.8251 | 0.7532 | 0.4912 |
| DANet | 0.8255 | 0.7632 | 0.6246 | 0.7856 | 0.8952 | 0.4970 | 0.2860 | 0.8158 | 0.7397 | 0.4726 |
| CCNet | 0.8370 | 0.7527 | 0.6380 | 0.8175 | 0.8990 | 0.5613 | 0.2913 | 0.8268 | 0.7551 | 0.4908 |
| TAFFN | 0.7951 | 0.7298 | 0.4018 | 0.7146 | 0.8681 | 0.1424 | 0.0005 | 0.7622 | 0.6598 | 0.3602 |
| MCANet | 0.8269 | 0.7367 | 0.6713 | 0.8039 | 0.8990 | 0.5423 | 0.3003 | 0.8225 | 0.7497 | 0.4837 |
| Proposed | 0.8379 | 0.7645 | 0.6698 | 0.8257 | 0.9025 | 0.5865 | 0.3646 | 0.8334 | 0.7652 | 0.5049 |
| Models | Params | FLOPs | Input Tensor |
|---|---|---|---|
| DeepLabV3+ | 39.05 M | 13.25G | SAR: [1,1,256,256] OPT: [1,4,256,256] |
| DenseASPP | 35.39 M | 39.40G | |
| DANet | 47.45 M | 14.41G | |
| CCNet | 70.95 M | 79.99G | |
| TAFFN | 0.31 M | 33.13G | |
| MCANet | 85.93 M | 102.39G | |
| Proposed | 19.60M | 28.78G |
| Models | OA | Kappa | mIoU |
|---|---|---|---|
| Att-CBAM | 0.8658 | 0.8363 | 0.6640 |
| Att-SP | 0.8680 | 0.8390 | 0.6681 |
| Proposed-SAEM | 0.8763 | 0.8492 | 0.6853 |
| Cases | Multi-Scale Module | OA | Kappa | mIoU | |
|---|---|---|---|---|---|
| ASPP | MSCK | ||||
| 1 | ✓ | - | 0.8734 | 0.8456 | 0.6784 |
| 2 | - | ✓ | 0.8724 | 0.8441 | 0.6739 |
| 3 | ✓ | ✓ | 0.8763 | 0.8492 | 0.6853 |
| Cases | Loss Function | OA | Kappa | mIoU | ||
|---|---|---|---|---|---|---|
| 1 | ✓ | - | - | 0.8691 | 0.8404 | 0.6730 |
| 2 | ✓ | ✓ | - | 0.8738 | 0.8460 | 0.6781 |
| 3 | ✓ | - | ✓ | 0.8736 | 0.8455 | 0.6758 |
| 4 | ✓ | ✓ | ✓ | 0.8763 | 0.8492 | 0.6853 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, D.; Li, Z.; Feng, H.; Wu, F.; Wang, Y. Multi-Scale Feature Fusion Network with Symmetric Attention for Land Cover Classification Using SAR and Optical Images. Remote Sens. 2024, 16, 957. https://doi.org/10.3390/rs16060957
Xu D, Li Z, Feng H, Wu F, Wang Y. Multi-Scale Feature Fusion Network with Symmetric Attention for Land Cover Classification Using SAR and Optical Images. Remote Sensing. 2024; 16(6):957. https://doi.org/10.3390/rs16060957
Chicago/Turabian StyleXu, Dongdong, Zheng Li, Hao Feng, Fanlu Wu, and Yongcheng Wang. 2024. "Multi-Scale Feature Fusion Network with Symmetric Attention for Land Cover Classification Using SAR and Optical Images" Remote Sensing 16, no. 6: 957. https://doi.org/10.3390/rs16060957
APA StyleXu, D., Li, Z., Feng, H., Wu, F., & Wang, Y. (2024). Multi-Scale Feature Fusion Network with Symmetric Attention for Land Cover Classification Using SAR and Optical Images. Remote Sensing, 16(6), 957. https://doi.org/10.3390/rs16060957