1. Introduction
Remotely sensed satellite imagery has unique characteristics and derived information products compared to imagery encountered in many other image analysis disciplines. Various sub-elements in such imagery may need to be recognized and their attributes quantified. Land-cover mapping is a common task in this context, where it is attempted to generate a partial or full description of a given area from Earth observation imagery, with an emphasis on element geometric and thematic accuracies. Geographic Object-Based Image Analysis (GEOBIA) has emerged as a viable avenue of approaches, or paradigm, to tackle such remote sensing image analysis tasks [
1,
2,
3,
4] due to the common spectral-textural-geometric and thematic correlations of elements of interest in satellite imagery [
5,
6,
7].
Incorporating a segmentation algorithm, which is central in many GEOBIA approaches, either for semantic object segmentation and description [
8], or for only allowing for the generation of richer attributes for classification, have been shown to be efficient in many real world applications [
2]. This is partly due to the h-res phenomenon [
9] encountered commonly when concerned with Very High Resolution (VHR) optical imagery, where the spatial resolution of captured imagery is finer than the geometry of the elements of interest and pixel-based discriminative methods are limited to produce adequate results (due to the so called salt-and-pepper effect [
10]). Also, such fidelity in resolution may be needed to identify elements, but intra element spectral variability may additionally cause problems in this process [
11]. Segmentation algorithms allowing for spatial aggregation in addition to observing spectral characteristics have been shown to be efficient in working towards identifying elements [
7,
11,
12,
13,
14]. Based on the characteristics of the desired information products and the nature of the data, the availability of commercial and freeware GEOBIA software [
2,
15,
16,
17] and the extent of the literature [
1,
2,
4], it is shown that GEOBIA is a promising paradigm [
1].
Although thematically accurate segments are commonly aimed for in a GEOBIA workflow, adequate segmentation is problematic to attain for single or multiclass elements using only a single pass of a given segmentation algorithm. This may be due to the complexity of the scene, especially when thematic and spectral correlations start to diverge, and limitations of the given segmentation algorithm. Various general approaches have been proposed to address the challenge of thematically accurate image segmentation and classification (semantic segmentation), including advocating rule-set or expert system’s approaches within GEOBIA [
1,
14], the development of new domain specific segmentation algorithms [
18], multi-scale image analysis [
6,
19,
20], using context information or spatial relationships among segments [
14,
21,
22], and hybridizing or interleaving classification and segmentation processes [
23,
24,
25]. Another general approach addressing the problem of segmentation within GEOBIA casts the creation of thematically accurate image segments as a search or optimization problem [
26,
27,
28,
29]. In such an approach the parameters of a given segmentation algorithm is automatically tuned based on the provision of a limited amount of user provided reference segments. The geometric aspects of provided reference segments are matched with generated segments in the iterative search process via spatial metrics.
In this work a novel variant of such a sample supervised segment generation approach is presented and quantitatively evaluated. The initial concept was presented in abstract from in [
30]. An enlarged search space is defined to include pixel-based classification processes. Derived probability images are used to direct a change in the original input imagery, such that the given segmentation algorithm may perform better on the given problem. The proposed method is compared with the generic formulation of sample supervised segment generation and results are demonstrated via the task of accurately segmenting structures in towns, villages and refugee camps on VHR optical remote sensing data. This contribution thus falls within the context of enlarged search spaces first presented in [
29], but proposes a methodology that uses spectral content contained within reference segments as opposed to adding data transformation or mapping functions.
Section 2 gives an overview of sample supervised segment generation and reviews related work. In
Section 3 a new variant of sample supervised segment generation is presented, incorporating classification in the segment generation process. In
Section 4 the data used is briefly described, with the comparative experimental methodologies outlined in
Section 5. In
Section 6 results are presented and discussed. Prospects and limitations are highlighted in
Section 7.
2. Background and Related Work
Sample supervised segment generation, or more generally sample supervised image processing/analysis, denotes the process of automatically tuning the parameters of a given segmentation algorithm or constructing image processing operators for segment generation based on the provision of exemplar output segments. A user typically needs to digitize or provide examples of desired segmentation results. Such an approach has attracted research attention in the imaging disciplines in general [
26,
28,
31,
32,
33,
34,
35] and also more specifically in the context of remote sensing image analysis [
27,
29,
36]. It is a feasible strategy if a scene contains numerous “similar” elements that are of interest, common in many mapping tasks. Unsupervised strategies, not requiring reference segments but using scene wide image statistics, are also pursued [
19]. It should be noted that the uses of efficient search methods are diverse in the imaging disciplines, with attribute selection and feature creation other common applications [
37,
38].
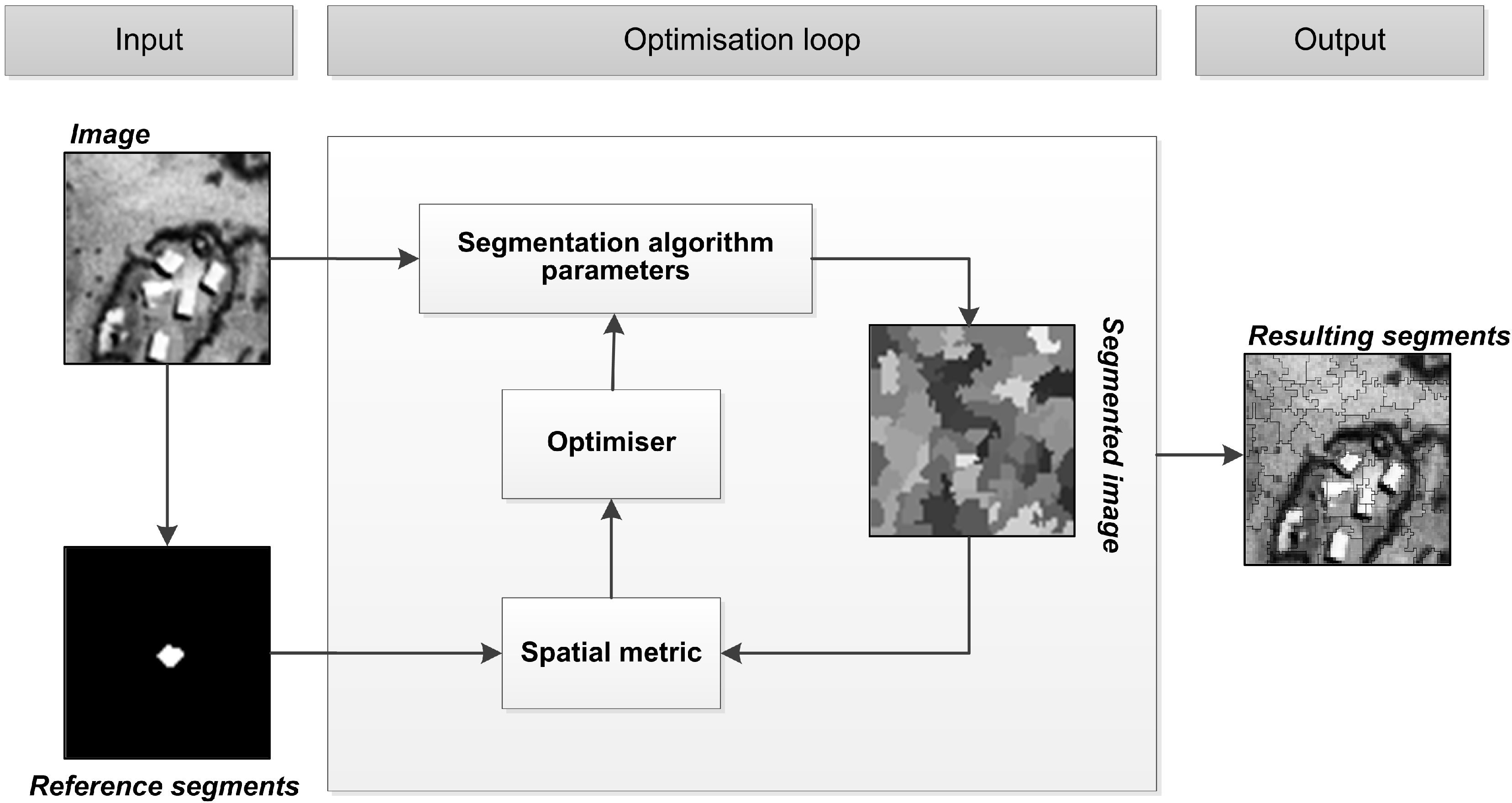
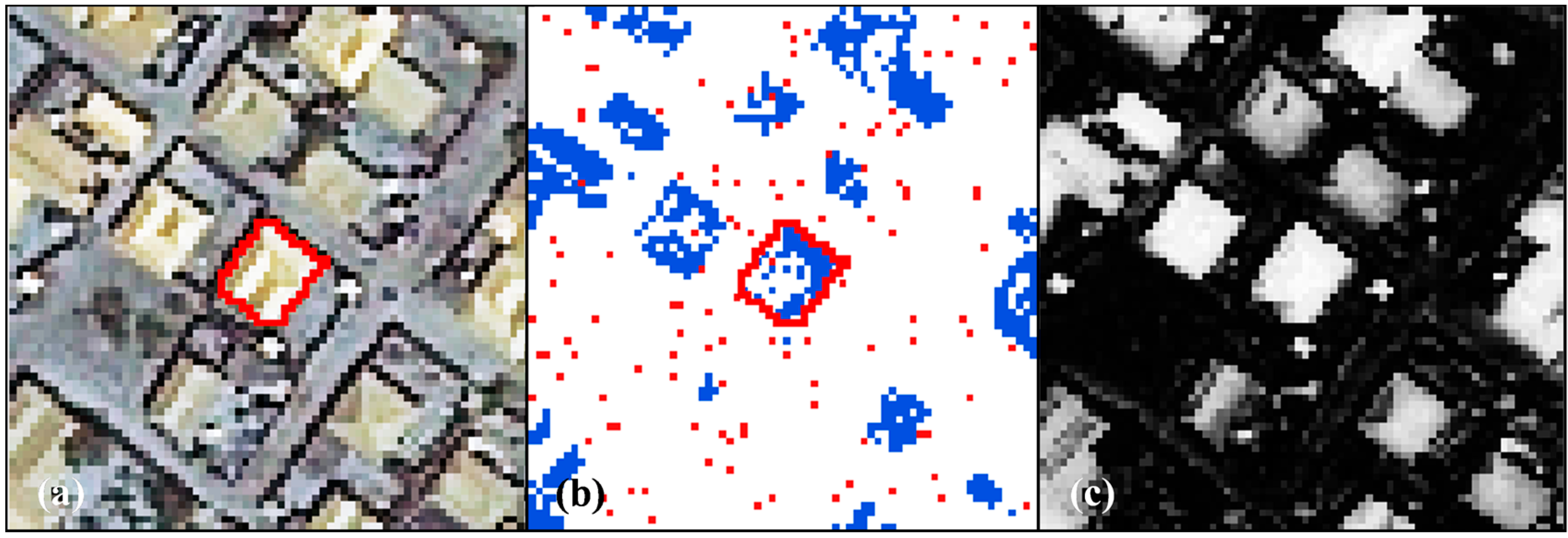
Figure 1 [
39] illustrates the generic formulation of such an approach. A user provides a selection of reference segments or objects, typically digitized or extracted with other tools [
40]. An iterative search process is invoked, where the parameter space of a given segmentation algorithm is searched. At iterations of the search process a specific parameter set is passed onto the segmentation algorithm from the optimizer. The tuned segmentation algorithm is executed on the image, typically subsets of the image covering areas around the provided reference segments. Empirical discrepancy, or spatial metrics [
41] are employed to match the generated segments to that of the user provided reference segments. This process is commonly referred to as the fitness evaluation. The optimizer uses the quality score generated by the metrics to direct the next iteration of the search. The method terminates when a certain number of search iterations have passed or a certain quality threshold has been reached, although various other stopping criteria may be considered. The parameter set resulting in the best metric score is given as the output. Subsequently, the entire scene may be segmented with the segmentation algorithm tuned with the output parameter set.
Figure 1.
Architecture of the generic formulation of sample supervised segment generation [
39].
Figure 1.
Architecture of the generic formulation of sample supervised segment generation [
39].
A sample supervised segment generation method typically advocates an interactive, user driven image analysis process. Segmentation is, generally computationally expensive, resulting in computationally expensive fitness evaluations. Searching the parameter space efficiently was a major driver for the development of this method [
26]. Metaheuristics, which are stochastic population based search methods, are well suited and studied in the context of this general approach [
26,
29,
42,
43], commonly leading to higher quality fitness scores in less search time compared to more general search strategies. Such a general approach may also be used to compare segmentation algorithms for a given task, or purely to test the general feasibility of a given algorithm for a given task. Also, this approach may find use alongside other, more encompassing, image analysis strategies. It could be used to work towards a final product in complex scene scenarios or used alongside traditional GEOBIA approaches such as rule set development [
14].
Research on this general method typically aims for generating better quality results in less time. Specific aspects investigated include the evaluation of the performances of different search methods [
29,
42,
43,
44], the applicability of various empirical discrepancy metrics (fitness functions) [
29,
36], the performances of various segmentation algorithms in such an approach [
29,
42,
45,
46,
47] and the extension of the concept to more modular image processing methods [
24,
45,
46,
47,
48,
49,
50]. Uncertainties remain surrounding the generalizability of such a method, its sampling size requirements and whether strong correlations exist between classification results and segmentation [
27,
29]. Research and freeware software in this vein are available [
29,
42,
51]. Having some
a priori knowledge on the capability of the segmentation algorithm seems necessary [
27].
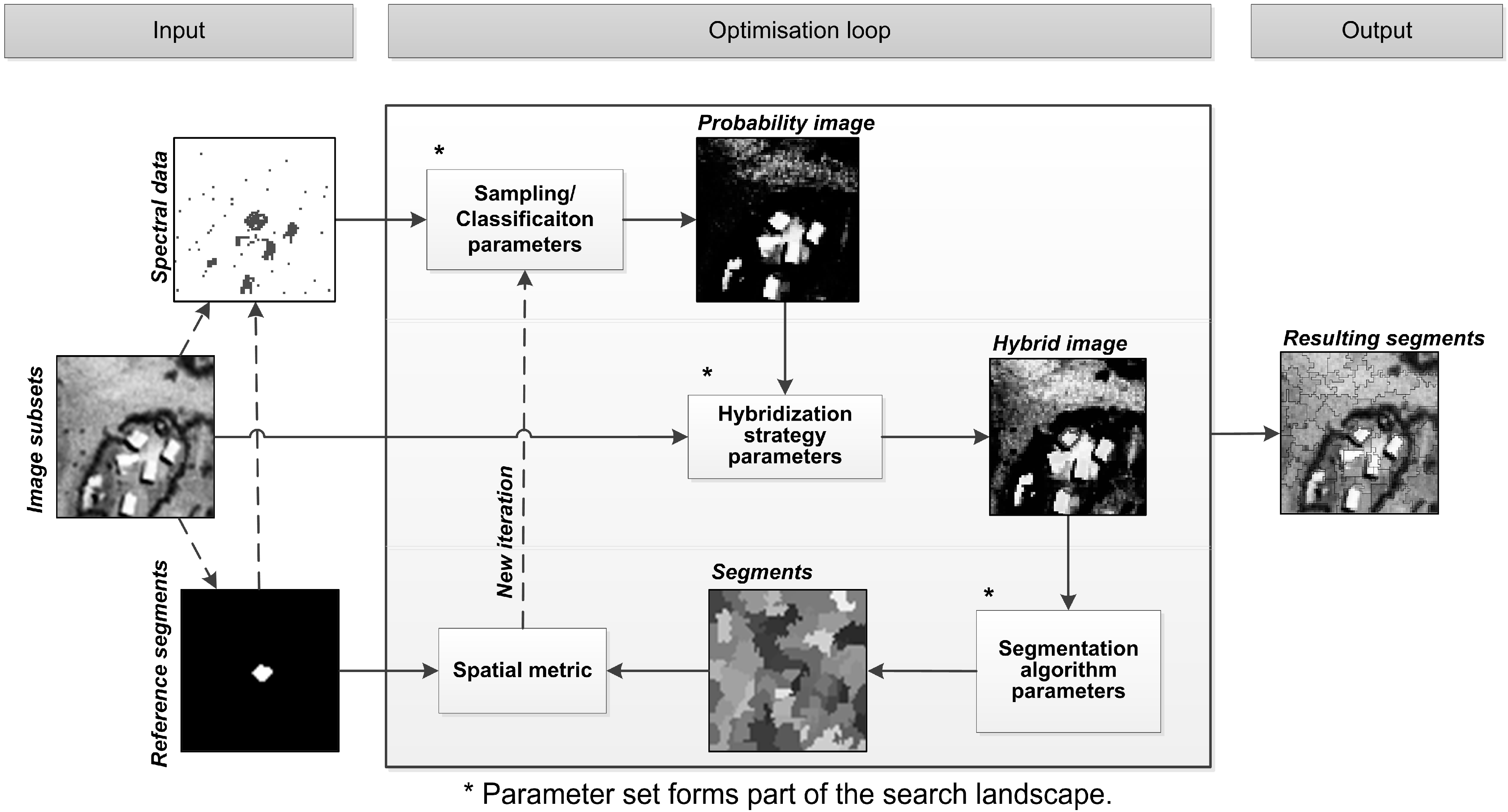
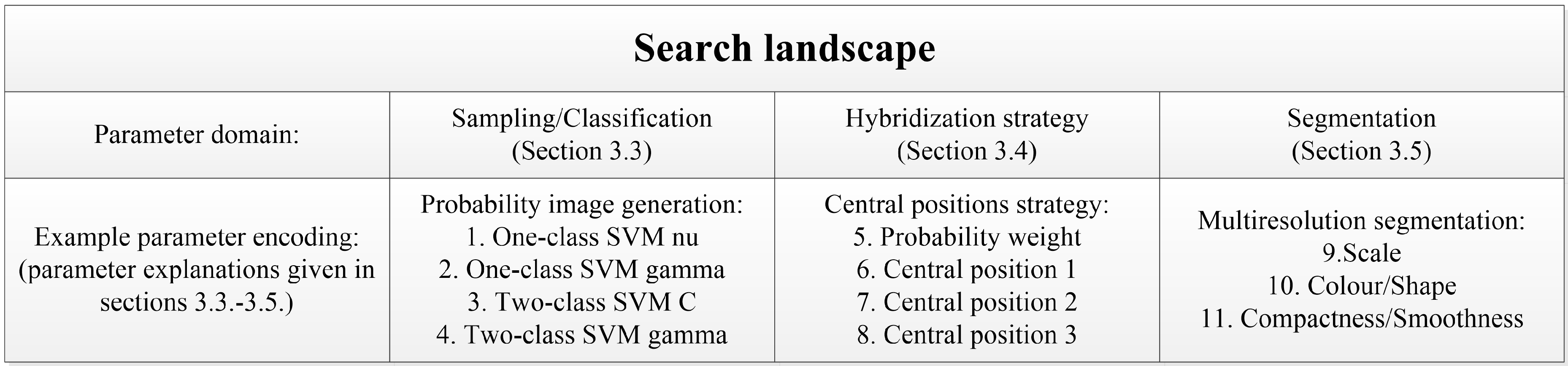
The search landscape may also be extended to include processes surrounding the core segmentation that may lead to better quality segments or classification results [
29,
45,
48]. A search landscape defines the n-dimensional surface of discrepancy metric results for all parameter value combinations, where
n is the number of parameters in the method. Additional processes may tailor the data to allow a given segmentation algorithm to perform better, for example by adding extra data transformation functions [
29], or by automatically performing post segmentation processes to further improve results. Such processes may be interdependent [
52] with segment generation and should subsequently be optimized simultaneously or interdependently with the segmentation algorithm parameters.
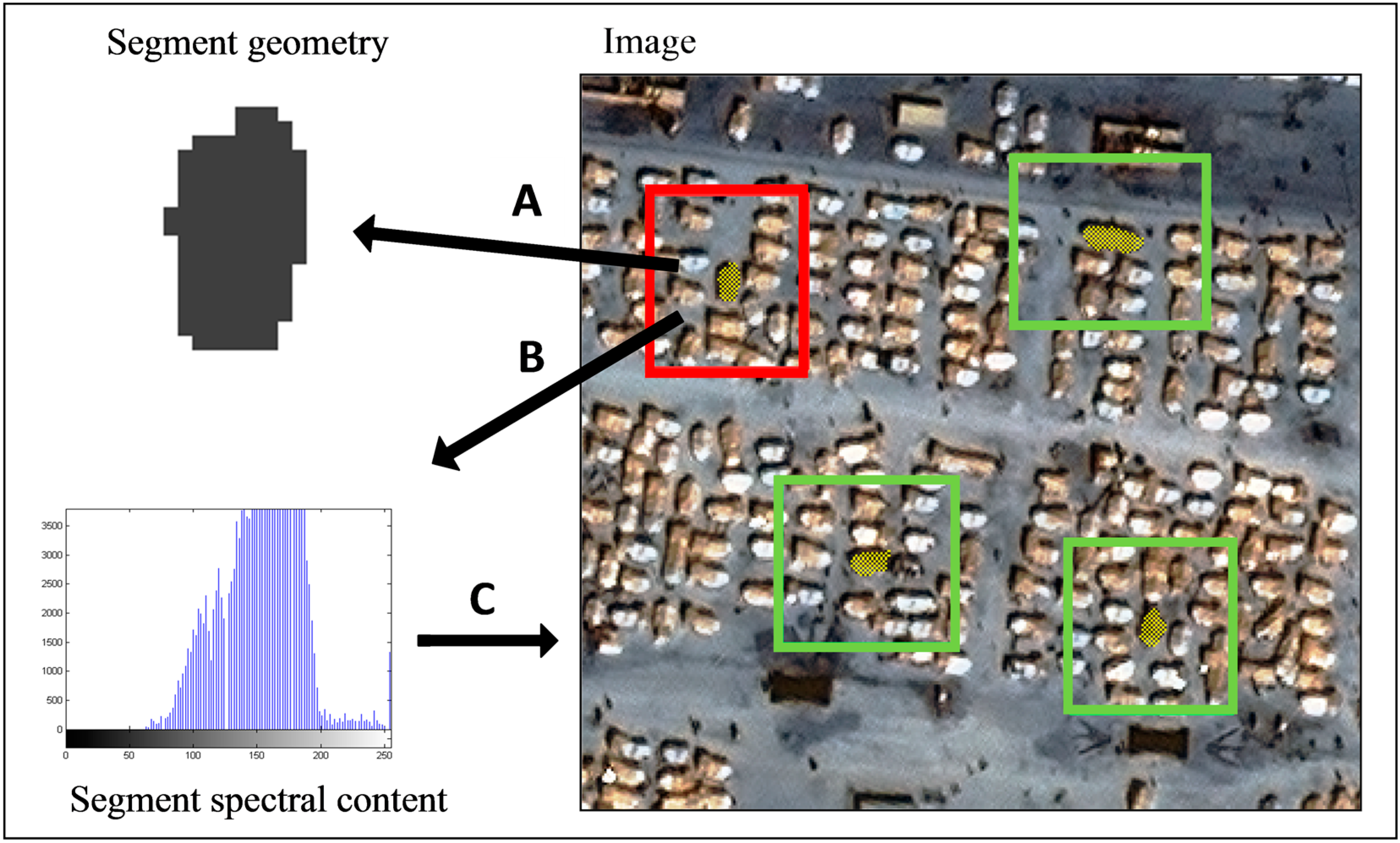
4. Data
The proposed approach is demonstrated and evaluated by generating segments on three VHR optical images. The images depict towns and refugee camps in central and east Africa. The images all contain a single thematic class-of-interest with the elements having varying degrees of thematic and spectral similarities, thus presenting the method with a range of problems in terms of difficulty. The aim is to generate a single segment layer, thematically accurate with respect to the land cover elements of interest. Practically, if segment results are adequate, they may be used as is. Otherwise, it may be considered as an initial segmentation, where additional image processing may be needed (e.g., [
14]).
The datasets are named after the settlement of interest in the image. The imagery was fully pre-processed (orthorectified, pansharpened), stretched to 8-bit quantization and subsets were extracted over parts of the settlements. For each site twenty elements are digitized, used as the reference segments.
Table 2 lists the metadata and some usage considerations of the three datasets.
Table 2.
Metadata of the datasets used.
Table 2.
Metadata of the datasets used.
| Test Site | Target Elements | Sensor | Spatial Resolution | Reference Segments | Channels | Date Captured |
|---|
| Bokolmanyo 1 | Tents | GeoEye-1 | 0.5 m | 20 | 1, 2, 3 | 2011/08/24 |
| Jowhaar 1 | Structures | GeoEye-1 | 1 m * | 20 | 1, 2, 3 | 2011/02/26 |
| Hagadera 2 | Structures | WorldView-2 | 0.75 m * | 20 | 4, 6, 3 | 2010/10/07 |
Figure 8.
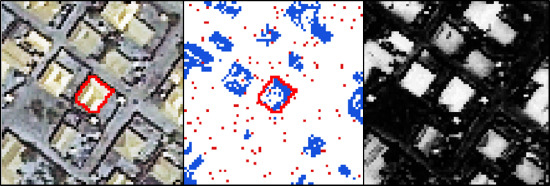
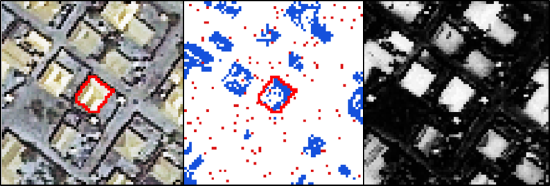
The datasets used for method evaluation, namely (a) Bokolmanyo; (b) Jowhaar and (c) Hagadera. The blue polygons in the enlarged subsets represent digitized reference segments.
Figure 8.
The datasets used for method evaluation, namely (a) Bokolmanyo; (b) Jowhaar and (c) Hagadera. The blue polygons in the enlarged subsets represent digitized reference segments.
Figure 8 shows the three image datasets, or problem instances, along with an enlargement over a small area illustrating the characteristics of the elements of interest. The Bokolmanyo site (a) constitutes an easier problem, where the elements of interest are nylon tents in a refugee camp. A thematic segmentation using the SLIC algorithm would be the aim using this image. The other two datasets, Jowhaar (b) and Hagadera (c), contain more divergence in spectral and thematic correlations of the elements of interest. The MS algorithm is used on these datasets. The aim on these two datasets would be to correctly segment all corrugated iron/steel roofed buildings.
5. Experimental Design
The described method (
Figure 3) variants are evaluated based on performances compared to the generic formulation (
Figure 1) of sample supervised segment generation. Various behavioral characteristics of the method are also quantified, related to the search progression, the feasibility of using different search methods and parameter domain interdependencies. Thus, a comparative experimentalism [
66,
69] is performed on problem specific datasets.
Due to uncertainty or randomness in terms of sampling (randomly initiated linked list) and classification, metaheuristic progression (initialization, stochastic nature) and segmentation algorithm seeding, multiple runs for experiments are advocated. Results are not specific and have some variation. None the less, in initial experimentation the variance of distributions of results are similar to other work in the context of enlarged search landscapes [
29], with statistically significantly different (student’s
t-test and Friedman rank test with Nemenyi
post hoc test) results observed on relatively small and large preliminary experimental test sets.
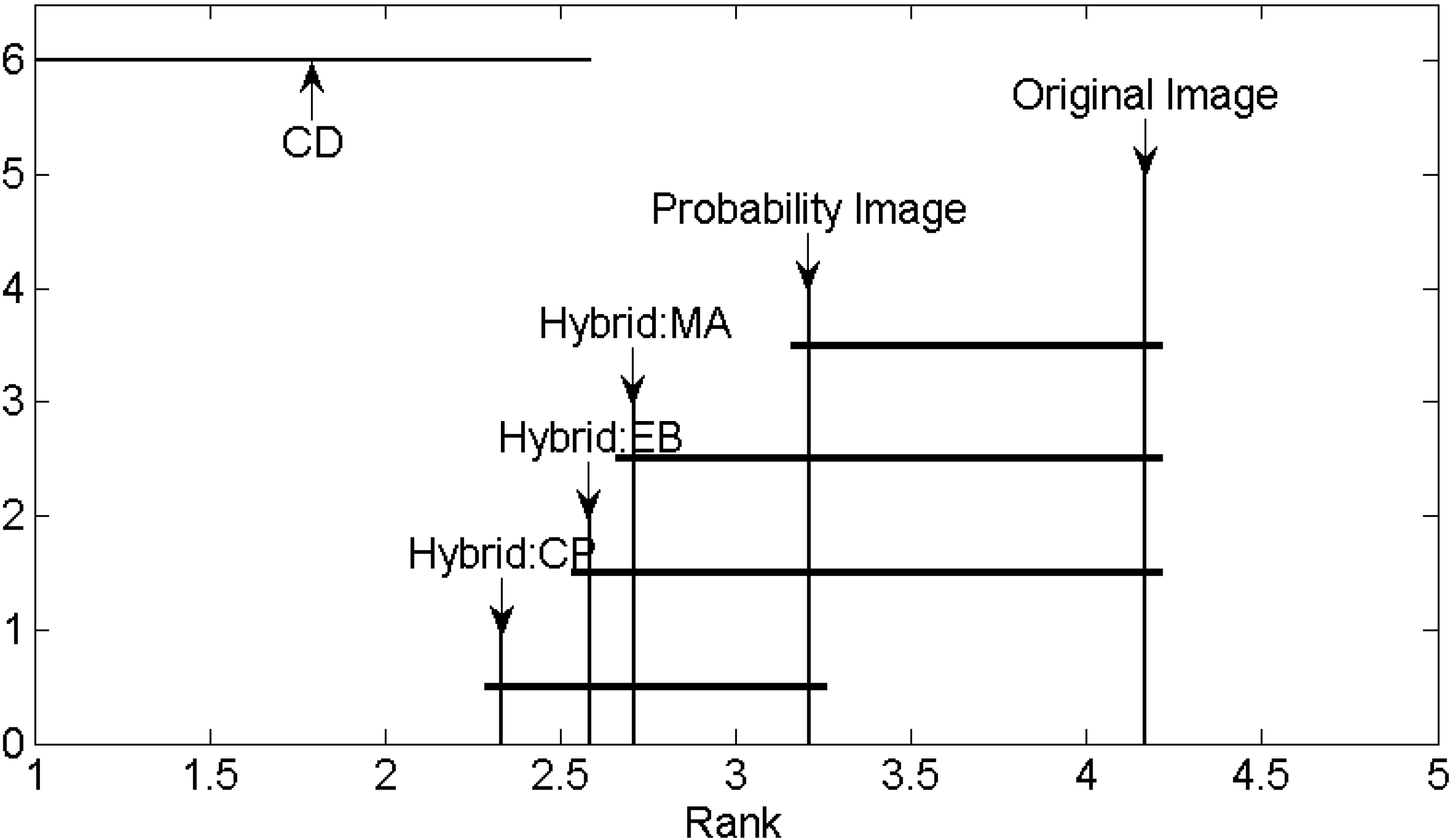
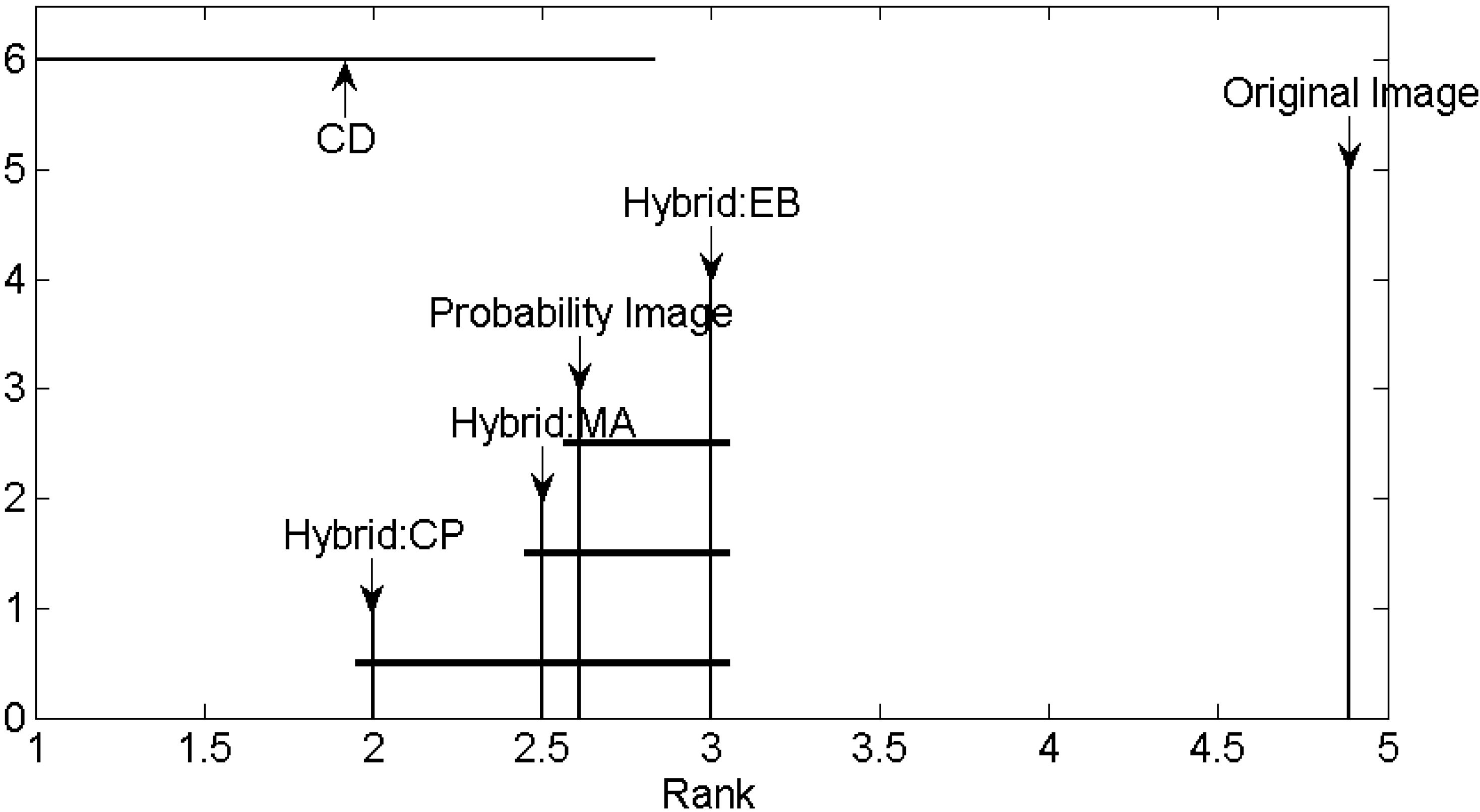
5.1. Segment Quality Comparison and Method Ranking
The generic formulation of sample supervised segment generation, the proposed variant using probability images for segmentation and three variants conducting image hybridization, namely Hybrid:EB, Hybrid:MA and Hybrid:CP, are quantitatively compared in terms of resultant segment quality. For each test site (Bokolmanyo, Jowhaar and Hagadera) all the method variants are run using the 20 provided reference segments and selected segmentation algorithm (SLIC for Bokolmanyo and MS for Jowhaar and Hagadera). Experimentation is conducted with the four metrics listed in
Table 1. In total, results are reported with 60 different experimental instances (combinations of methods, problem instances and metrics).
Experimental instances are repeated ten times with the averages, standard deviations and best results achieved reported. Each run consists of 2000 search method iterations using the DE metaheuristic, evaluating the 20 reference structures and taking the mean as the result. In total 24 million segmentation evaluations are performed over the 60 experimental instances. In addition to reporting and discussing the tabularized results, a Friedman test is conducted with a Nemenyi
post hoc test [
70] to rank the methods and describe their critical differences under all metric and problem type conditions. This is done to give some measure of generalizability [
71,
72] (commonly done when evaluating multiple classifiers over multiple problem instances), although problem instances and experimental variations are not exhaustive.
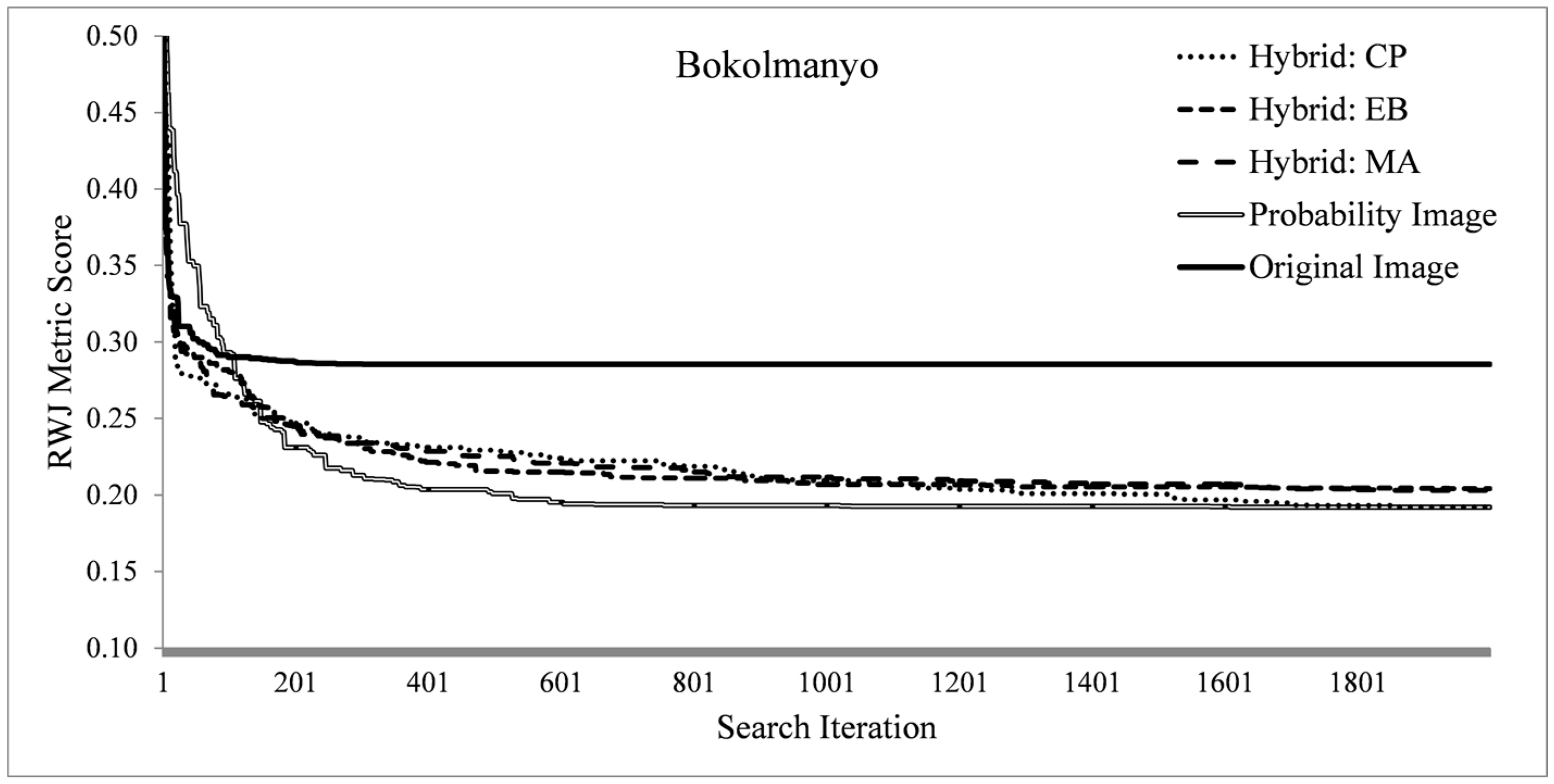
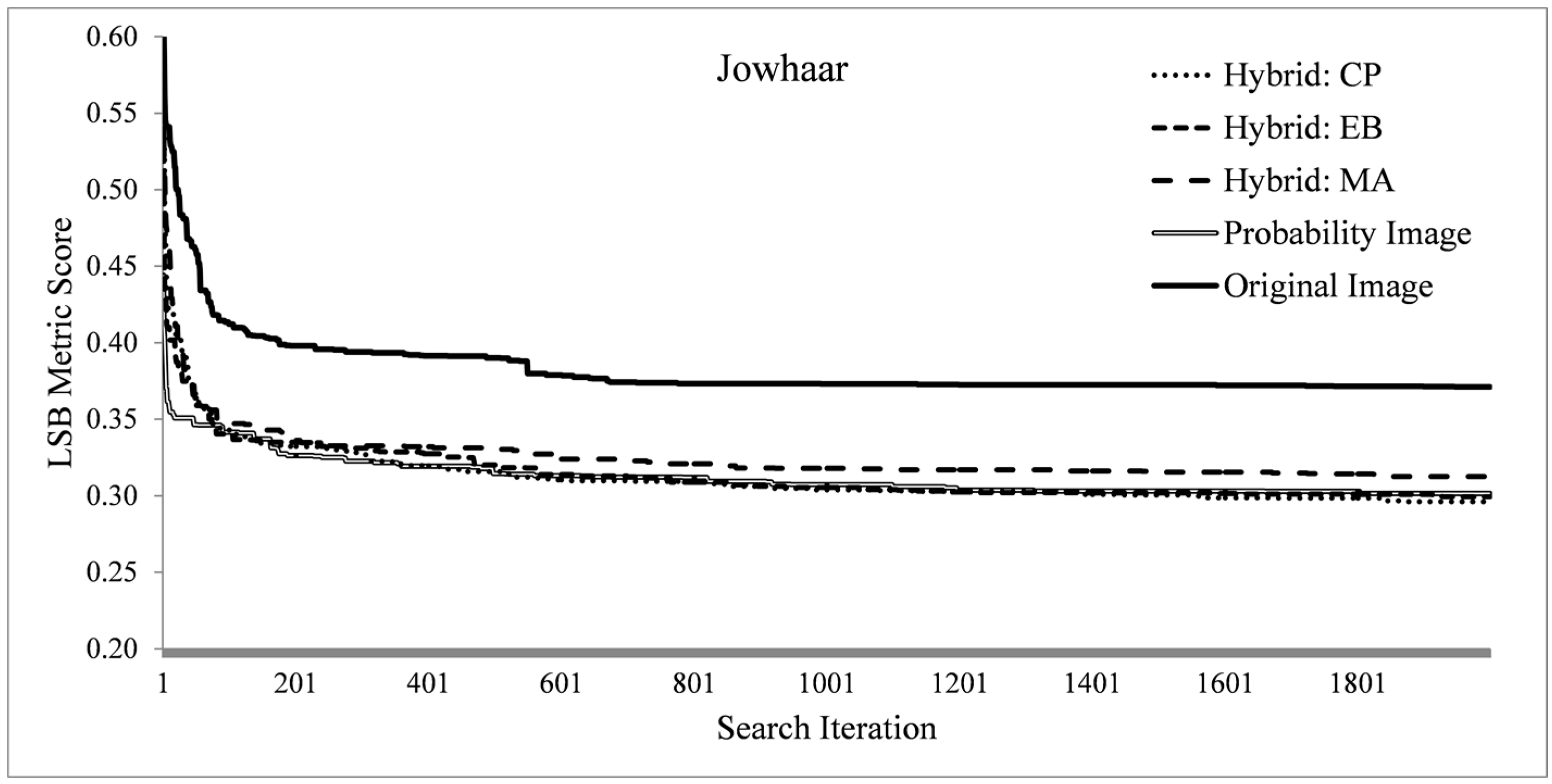
5.2. Search Process Characteristics
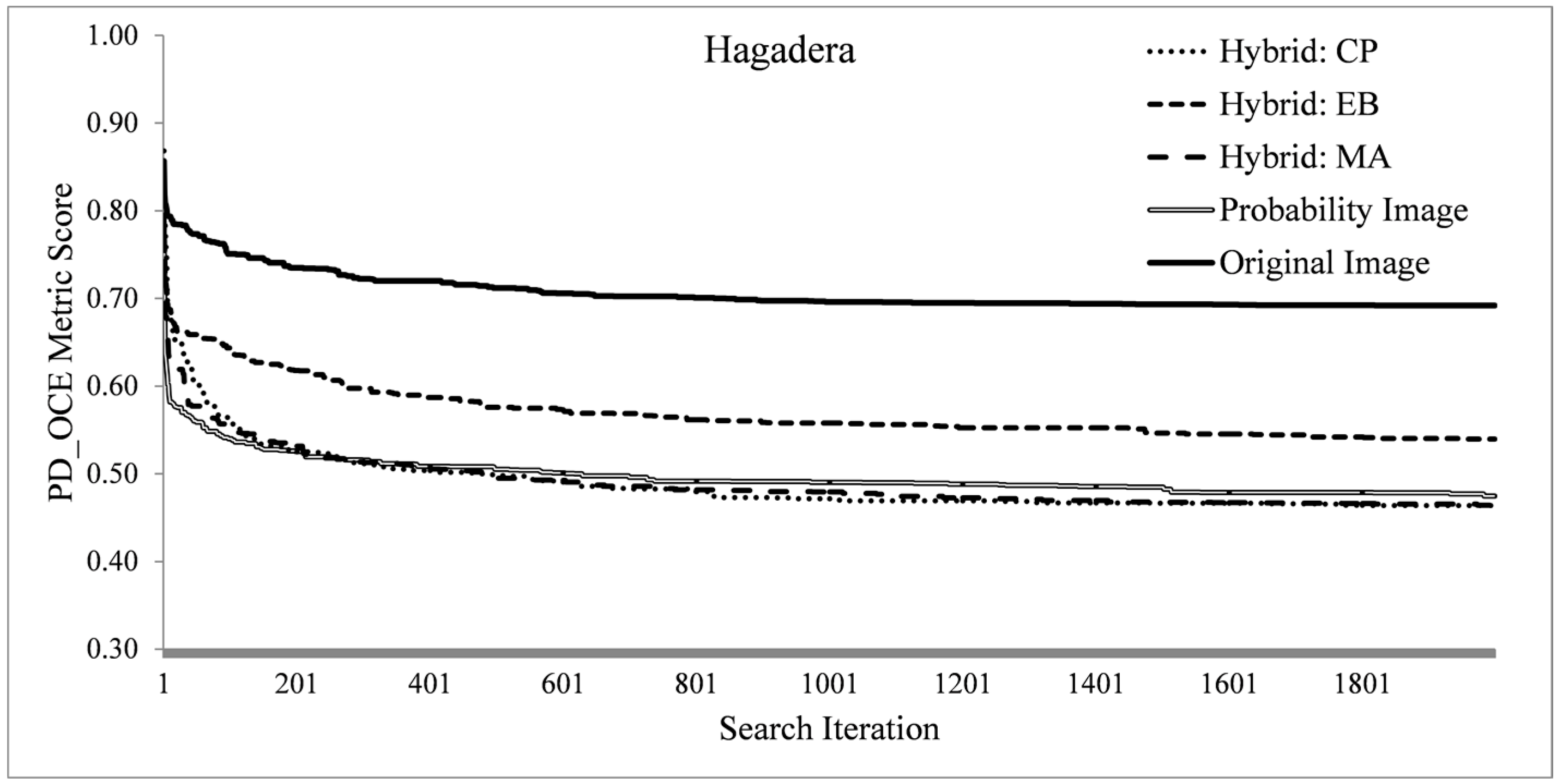
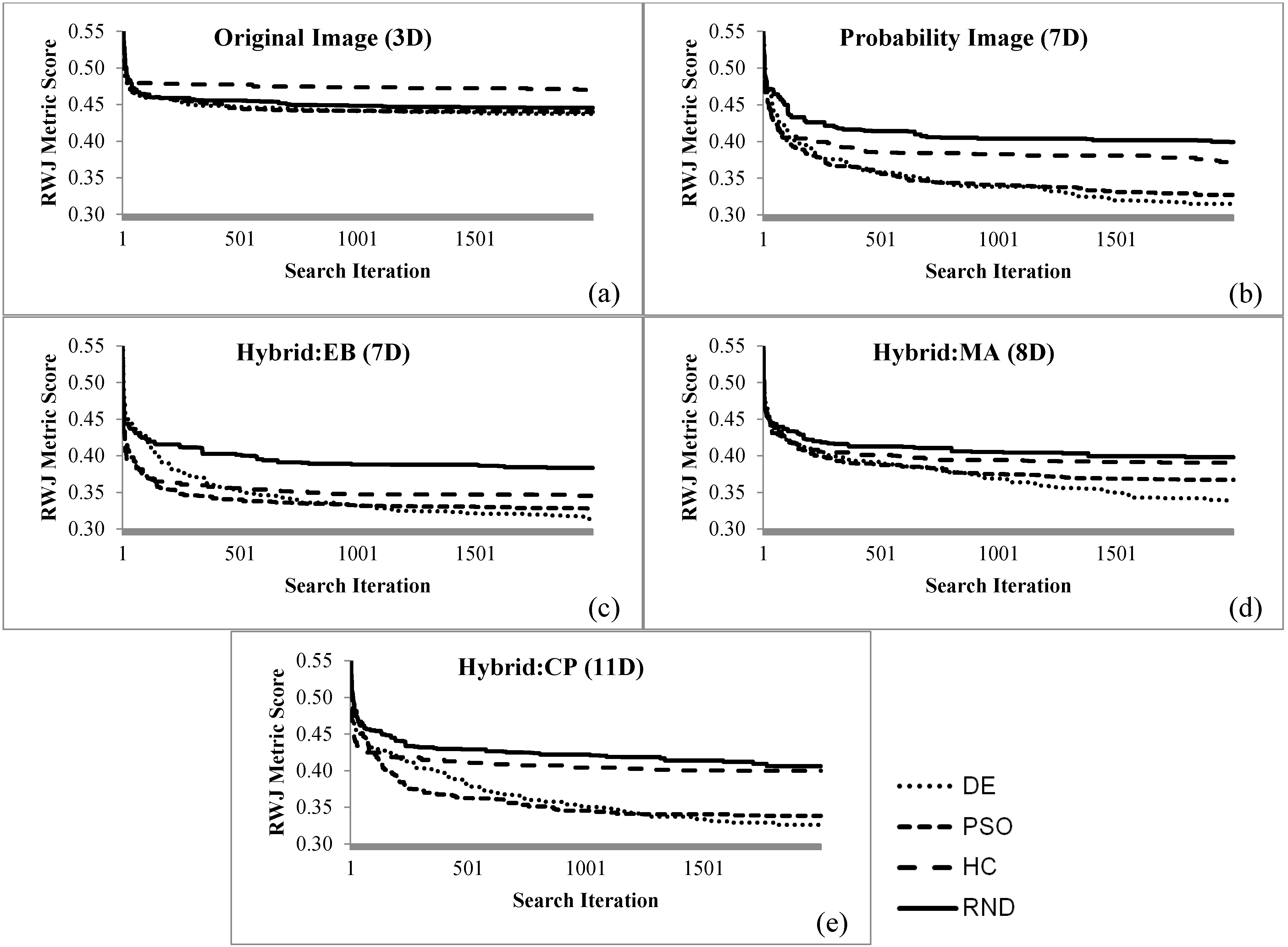
The search process is profiled over the three problem instances by recording the fitness traces over all method variants. It is investigated if the higher dimensional formulations of method variants have any significantly different search profiles. Such search-based methods should terminate as quickly as possible (computationally expensive), thus insight in the search progression is beneficial. For each problem instance a metric is selected, RWJ for Bokolmanyo, LSB for Jowhaar and PD_OCE for Hagadera, and the best metric scores (fitness) are plotted at each of the 2000 method iterations. This diversity in experimentation is introduced as a specific metric or segmentation algorithm (search landscape) might generate bias for a specific hybridization strategy.
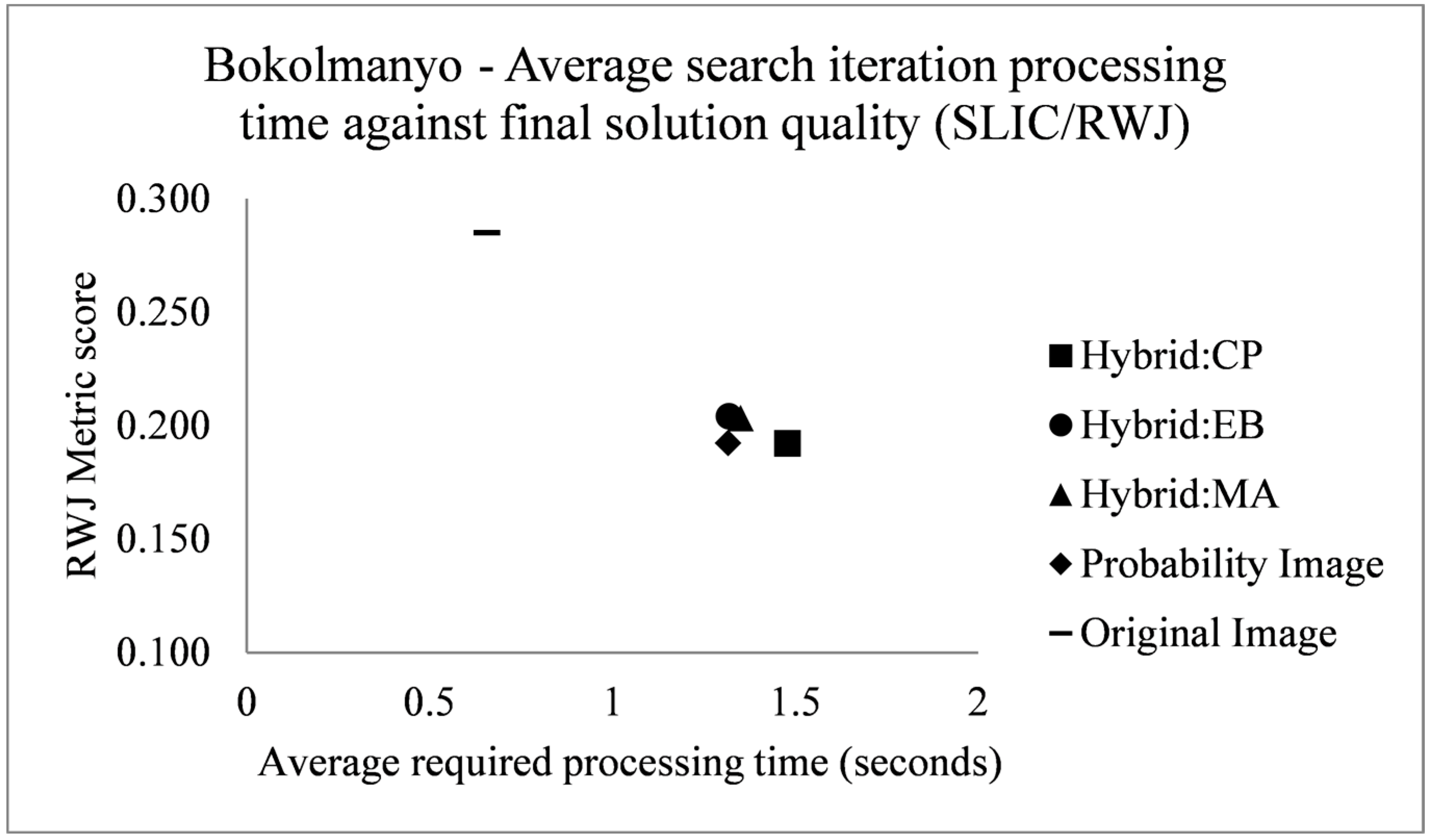
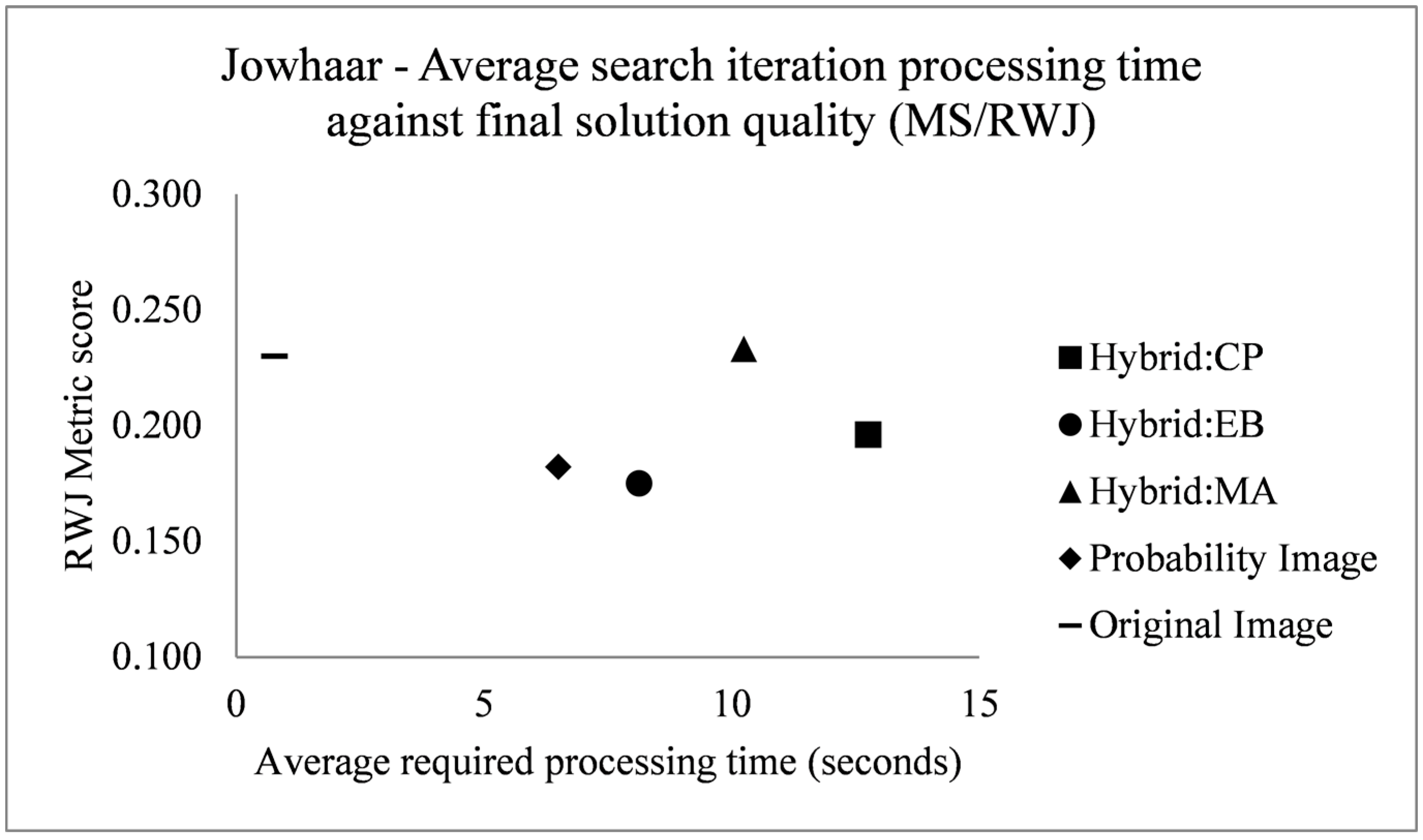
The fitness profiles are supplemented with a profiling of the required computing time of single fitness evaluations or iterations of the search process. This gives an indication, in the investigated problem contexts and utilized computer (Intel Xeon E5-2643 3.5 GHz processor with single core processing), of the required computing time to achieve optimal or near optimal results. For the Bokolmanyo and Jowhaar sites, average required computing time per evaluation is recorded and averaged over 100 iterations for all five method variants. Results are plotted against optimal achieved metric scores (2000 iterations) of the RWJ metric.
5.3. Parameter Interdependencies
It is investigated if parameter domain interdependencies exist between the segmentation and sampling/data hybridization components of the, probability, Hybrid:EB, Hybrid:MA and Hybrid:CP method variants. The utilized segmentation algorithms observe spectral aspects as merging criteria (strongly). Any process performing a modification of the spectral characteristics of the data on which the segmentation algorithms run, will inherently influence the optimal values of the segmentation algorithms’ parameters. Such interdependency requires the simultaneous optimization of data modification and segmentation algorithm parameters, thus leading to optimization problems with enlarged search spaces as opposed to separately solvable problems.
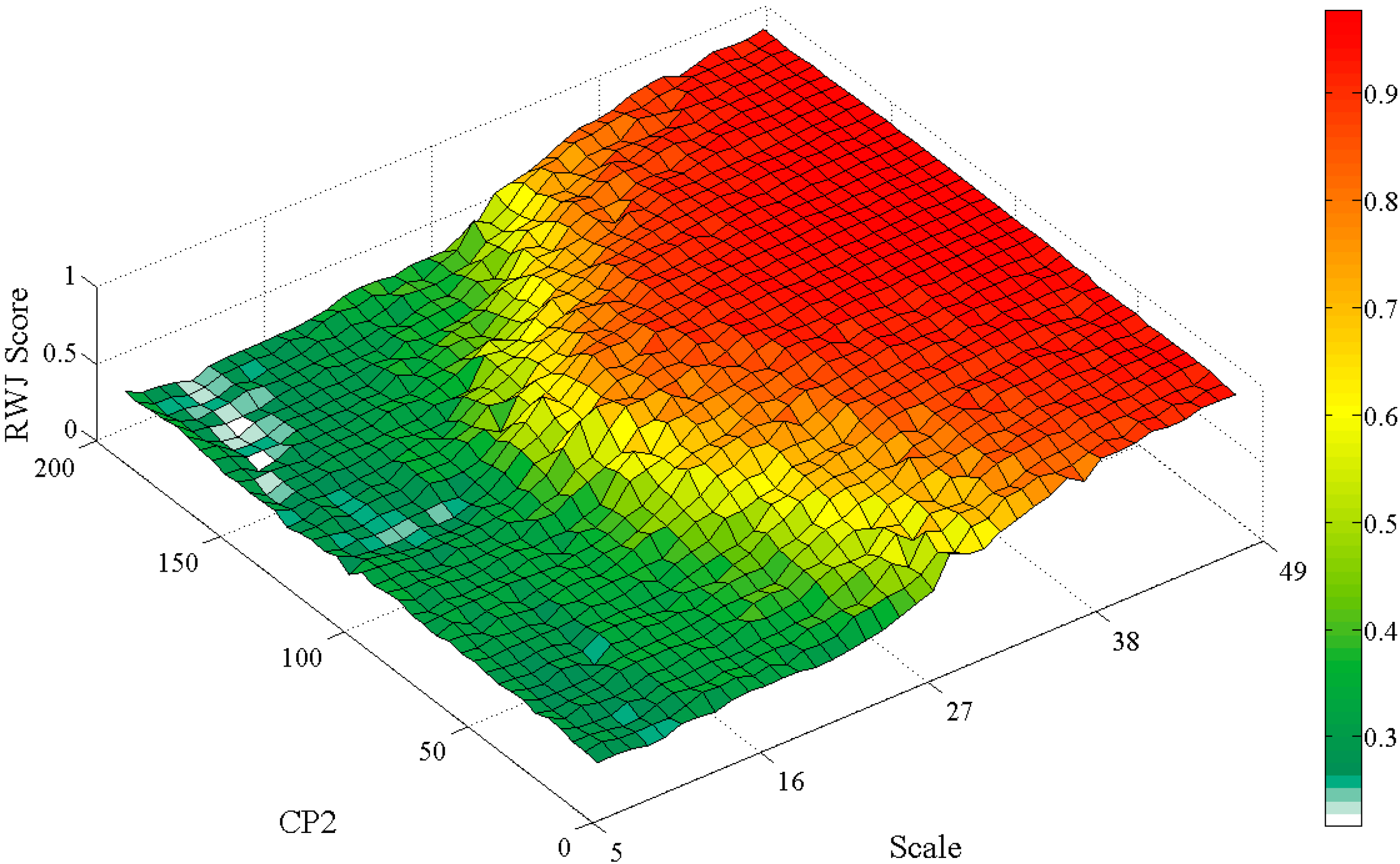
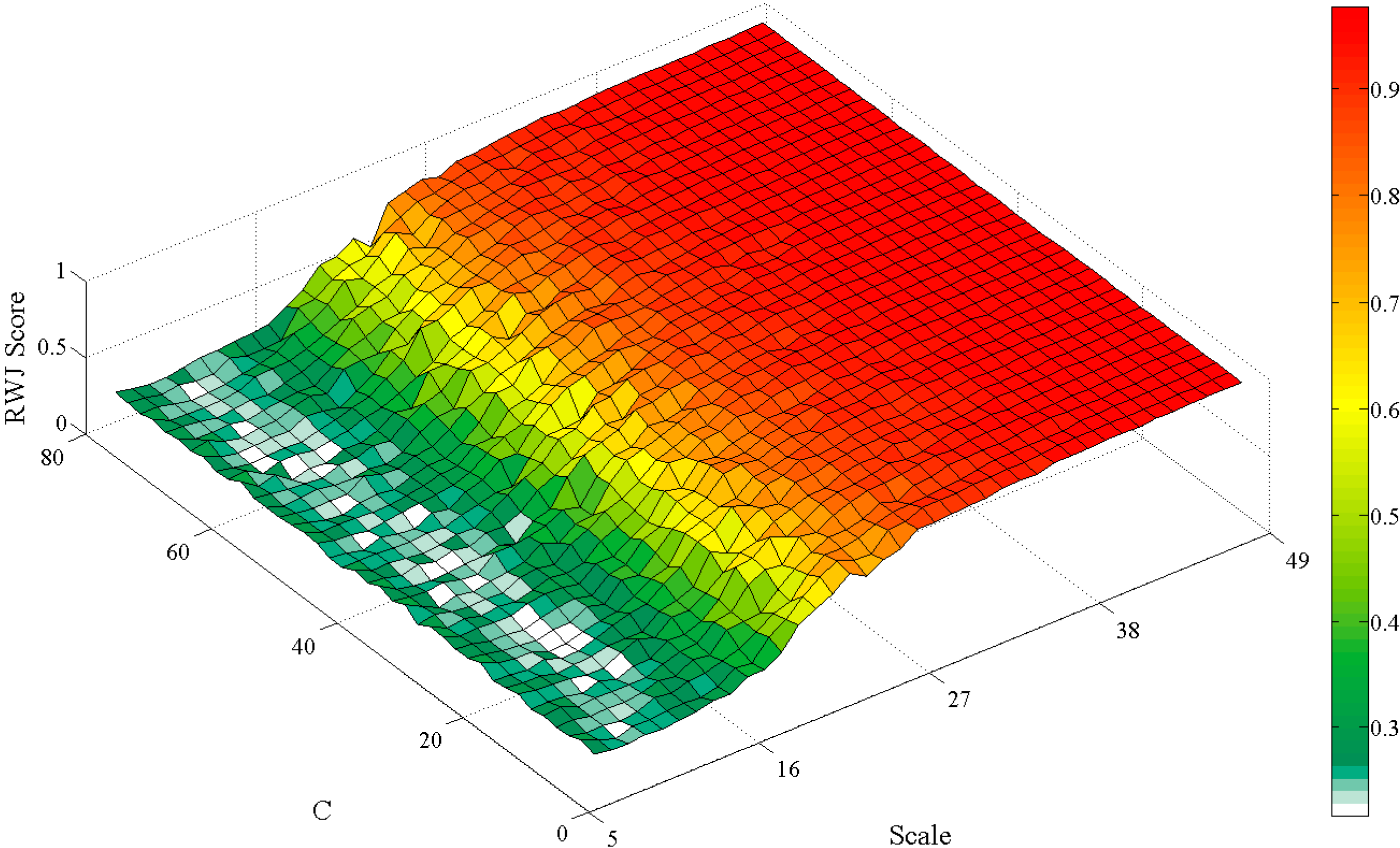
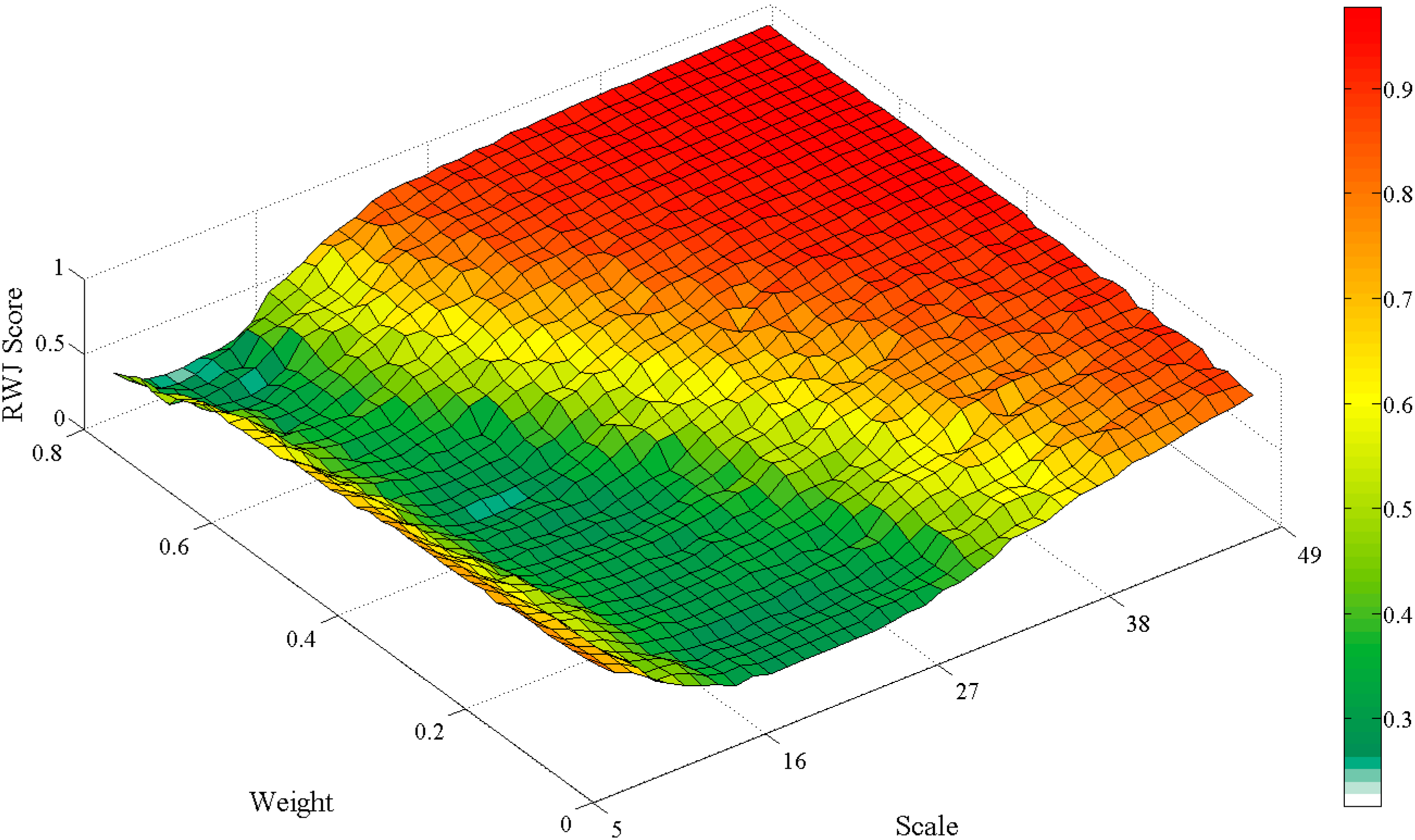
The optimally achieved segmentation algorithm parameters, sampling and classification parameters and the probability weighting parameter are recorded for experimental runs (2000 search iterations, averaged over ten runs) using the five method variants on the three problem instances considering the RWJ metric. The resultant sensitive “scale” parameters of the SLIC and MS segmentation algorithms, considering the proposed method variants, are specifically compared to the resultant parameters considering the generic variant of the method. A student’s t-test is performed to determine if differences are present. Three select two dimensional search surface combinations are also plotted (exhaustive fitness calculations) to visually check for, and demonstrate parameter interdependencies, specifically how the MS scale parameter interact with other parameters of the Hybrid:CP method variant in the Jowhaar problem instance.
7. Conclusions
A major driver behind the more elaborate methods encountered in the context of VHR optical image analysis is the divergence of the spectral and thematic correlations. Such correlations are stronger in lower resolution imagery and problem contexts. A novel method in the context of sample supervised segment generation was presented, where a classification process attempts to tailor the data such that closer thematic and spectral correlations exist. The given segmentation algorithm may thus perform better on the given problem. The method entails the creation of an enlarged search landscape, with added parameters controlling probability image generation and data hybridization method components. These components are tunable and do not deliver static results on their own. Their interaction is also tunable in some variants. Throughout the process, the aim is still quality segment generation for a specific element type and classification accuracy assessment is not conducted.
Four method variants were compared with the generic formulation of sample supervised segment generation in terms of resultant segment quality, illustrating the usefulness of such a method. The magnitude of improvements is dependent on the problem, metric, search method and method variant under consideration. In the current method formulation, a substantial amount of extra computing time is required, majorly due to the internal details of the used classifier (SVM). It should be noted that this impact is more pronounced during the training phase. The use of metaheuristics and the definition of enlarged search spaces were also justified. Although the proposed method variants improve results substantially in many problem instances, “perfect” metric scores were not achieved, suggesting that, as with the generic method formulation, additional image processing may be needed to obtain thematically accurate segments. Such segments may subsequently be classified for map production or information extraction.
Uncertainties exist with a sample supervised segment generation approach in general and the variants presented here in particular. In general, uncertainty remains if a given problem is feasible, and a method needs to be run to verify its applicability, which takes time. Expert knowledge on the characteristics of the used segmentation algorithm may help, but with the variants proposed here unintuitive, but correct or feasible results may also be generated. Some spectral and thematic correlation needs to exist for the elements of interest, not explicitly quantified or investigated in this study. Initial experimentation on synthetic datasets suggest that elements of interest may constitute up to three “regions” in the spectral domain, with more resulting in a significant drop in the usefulness of the generated probability image. Having elements of interest consist of six unique spectral regions (red, blue, green, yellow, cyan, and magenta) on synthetic data generated an almost completely monotone probability image (one-class SVM, RBF kernel). Nonetheless, if not found useful or even if detrimental, the probability image is simply not used (controlled via the weighting parameter). Quantifying the usefulness of such an approach on spectrally diversifying elements of interest would be a topic for future research.
The generalizability of such approaches under different sampling conditions should also be investigated [
29]. As a preliminary experiment in this work, sixteen method variants were tested under cross-validated and non-cross-validated sampling conditions (20–28 reference samples), all performing better than the generic formulation of the method. For operational use, on such large sample sets cross-validation would not be necessary. This could change with a sharp decrease in the number of samples used, observed in [
29]. Indicators of required sampling sizes would be useful and is planned for future work. In addition, a variant of this method is possible that could require a user to provide samples of the “other” class, removing the parameterized process of generating synthetic “other” class samples. This would require additional user interaction outside of the required class of interest.
The accuracy and convergence speed of the methods may be improved by performing meta-optimization, using metaheuristics with self-adapting meta-parameters or pursuing the state of the art in evolutionary computation. Additionally, most aspects of such methods could be designed to run in a parallel framework, especially the computationally expensive fitness evaluations. Sample supervised segment generation may well be integrated with more traditional GEOBIA approaches, such as rule set development, necessitating near real-time method executions. It would also be of interest to compare such an approach based on classifier directed transforms with a strategy that suggest the addition of low-level image processing to modify the data, or so called data transformation functions [
29]. Such transformation functions do not have the same computing overhead as some classification processes, but on the other hand they may not be able to achieve the same level of quality as classifier based transforms. Alternative classification algorithms could also be tested with such an approach.
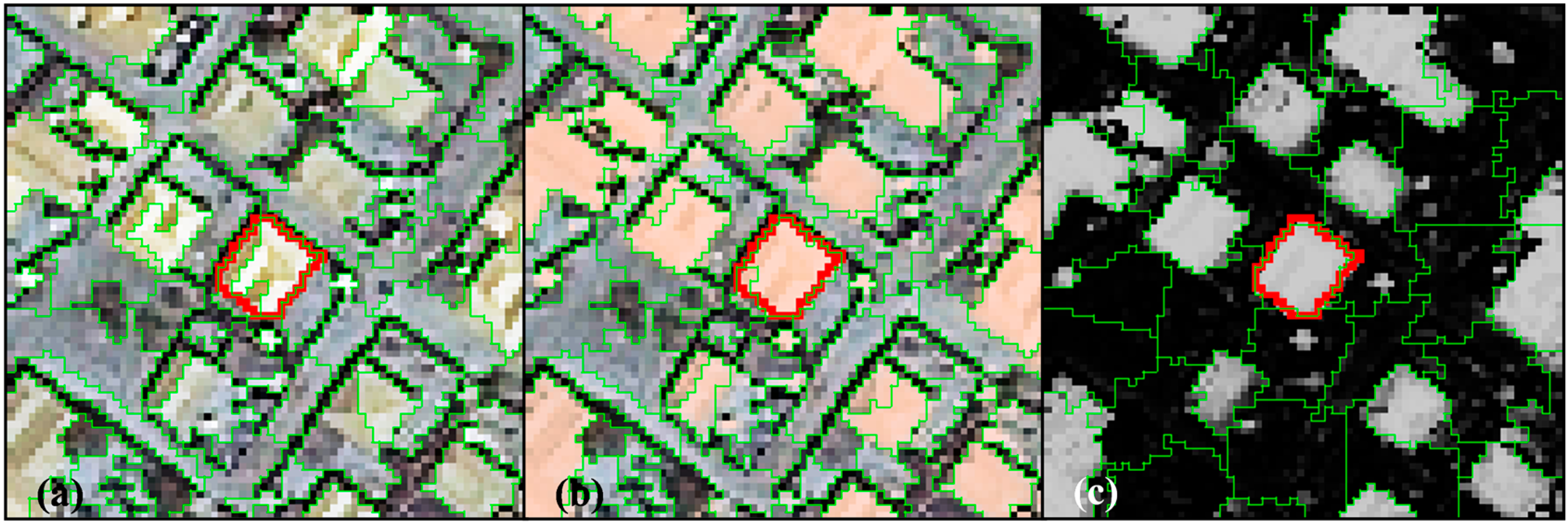
Finally, it should be noted that the method, and its variants presented here have an explicit implementation how sampling and classification is done, e.g.,
Figure 5. Various other encodings of sample collection, probability image generation and image hybridization are possible. A simple extension of the proposed method could see the sampling of the synthetic secondary class (
Figure 5b) grouped by underlying spectral content, with parameters controlling sub-selections used in classification. This would create more variation in the characteristics of probability image outputs. Also, the image hybridization strategies could be elaborated upon to include thresholds of probability values, to use neighborhood properties or spectral aspects or even to use parameter controlled band selection strategies. Additionally, more segmentation algorithms could be tested with this method.
Search landscape characteristics should always be kept in mind, as noise or too much randomization introduced by parameters controlling elaborate processes may create more “difficult” search landscapes.
Figure 17,
Figure 18 and
Figure 19 illustrate smooth or, conjectured, easily searchable landscapes. Work on metaheuristic performances on various search landscapes may prove useful in this regard [
75,
76].









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












