
Evaluation of the 2010 MODIS Collection 5.1 Land Cover Type Product over China


Abstract
:
1. Introduction
2. Data and Methods
2.1. Classification Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| False Easting | 0.00000000 |
| False Northing | 0.00000000 |
| Central Meridian | 105.0000000 |
| Standard Parallel_1 | 25.00000000 |
| Standard Parallel_2 | 47.00000000 |
| Latitude of Origin | 0.00000000 |
| Linear Unit | Meter |
| Geographic Coordinate System | GCS Krasovsky 1940 |
| Datum | D Krasovsky 1940 |
| Prime Meridian | Greenwich |
| Angular Unit | Degree data |
2.2. Generalized Land Cover Legend
| Class | New Legend | NLUD-C | IGBP |
|---|---|---|---|
| 1 | Croplands | Paddy Field Crop Dryland | Croplands |
| 2 | Shrublands | Shrublands | Closed Shrublands Open Shrublands |
| 3 | Forests | Forest Sparse Woodland Other Woodland | Evergreen Needleleaf Forests Evergreen Broadleaf Forests Deciduous Needleleaf Forests Deciduous Broadleaf Forests Mixed Forests Woody Savannas Savannas |
| 4 | Grass | High Coverage Grass Medium Coverage Grass Low Coverage Grass | Grasslands |
| 5 | Water Bodies | River/CanalLake Reservoir/Pond | Water Bodies |
| 6 | Snow and Ice | Glacier/Perpetual Snow | Snow and Ice |
| 7 | Wetlands | Tide Flats Bottomland Swampland | Permanent Wetlands |
| 8 | Urban and Built-Up | Urban Rural Construction/Traffic | Urban and Built-Up |
| 9 | Barren | Sandy Land Gobi Saline Land Bare Soil Bare Rock Other Unused Land | Barren |
| 10 | - | - | Croplands/Natural Vegetation Mosaics |

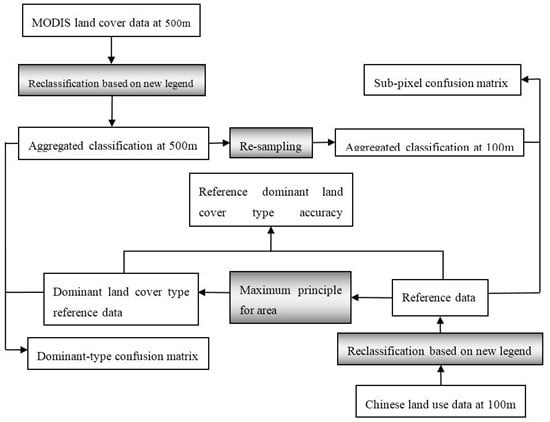
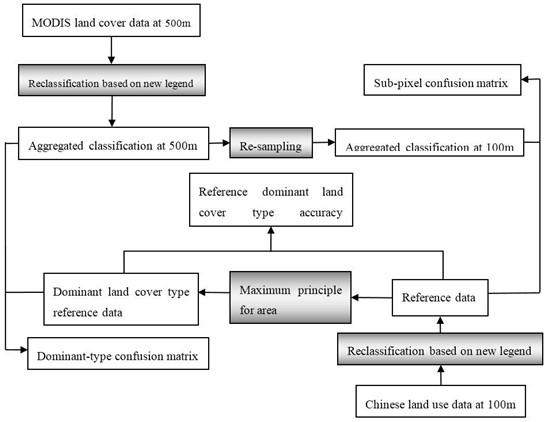
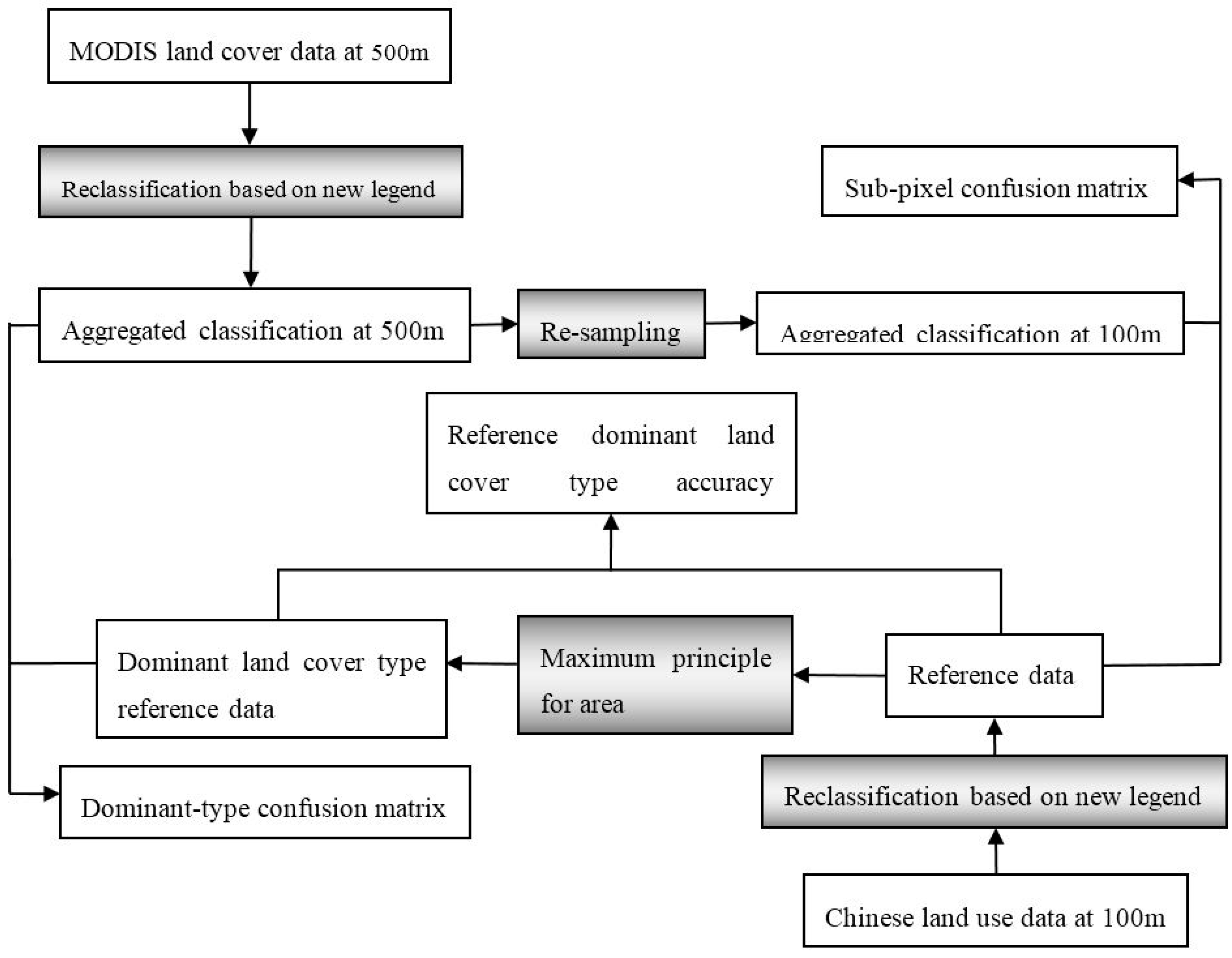
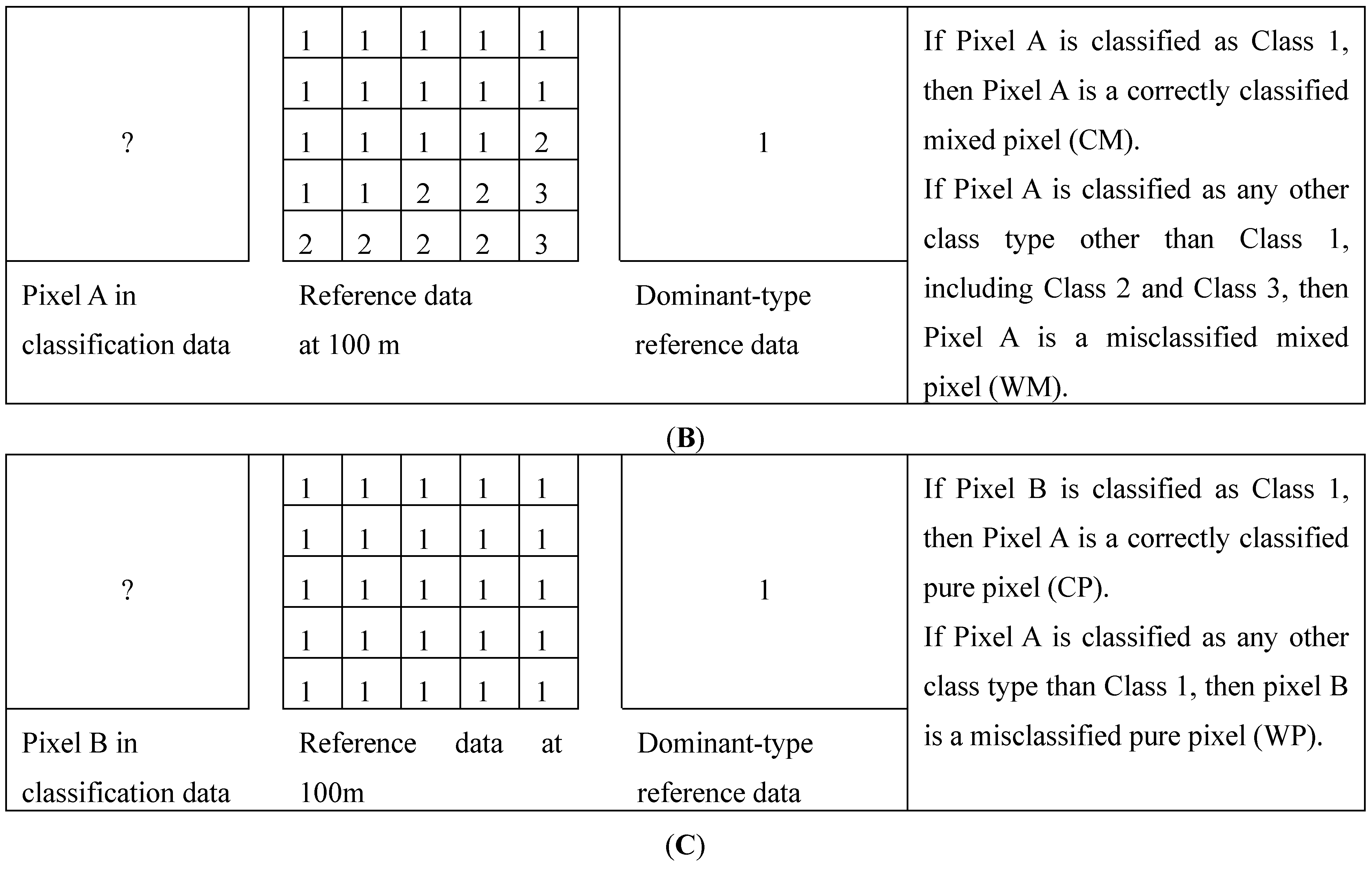
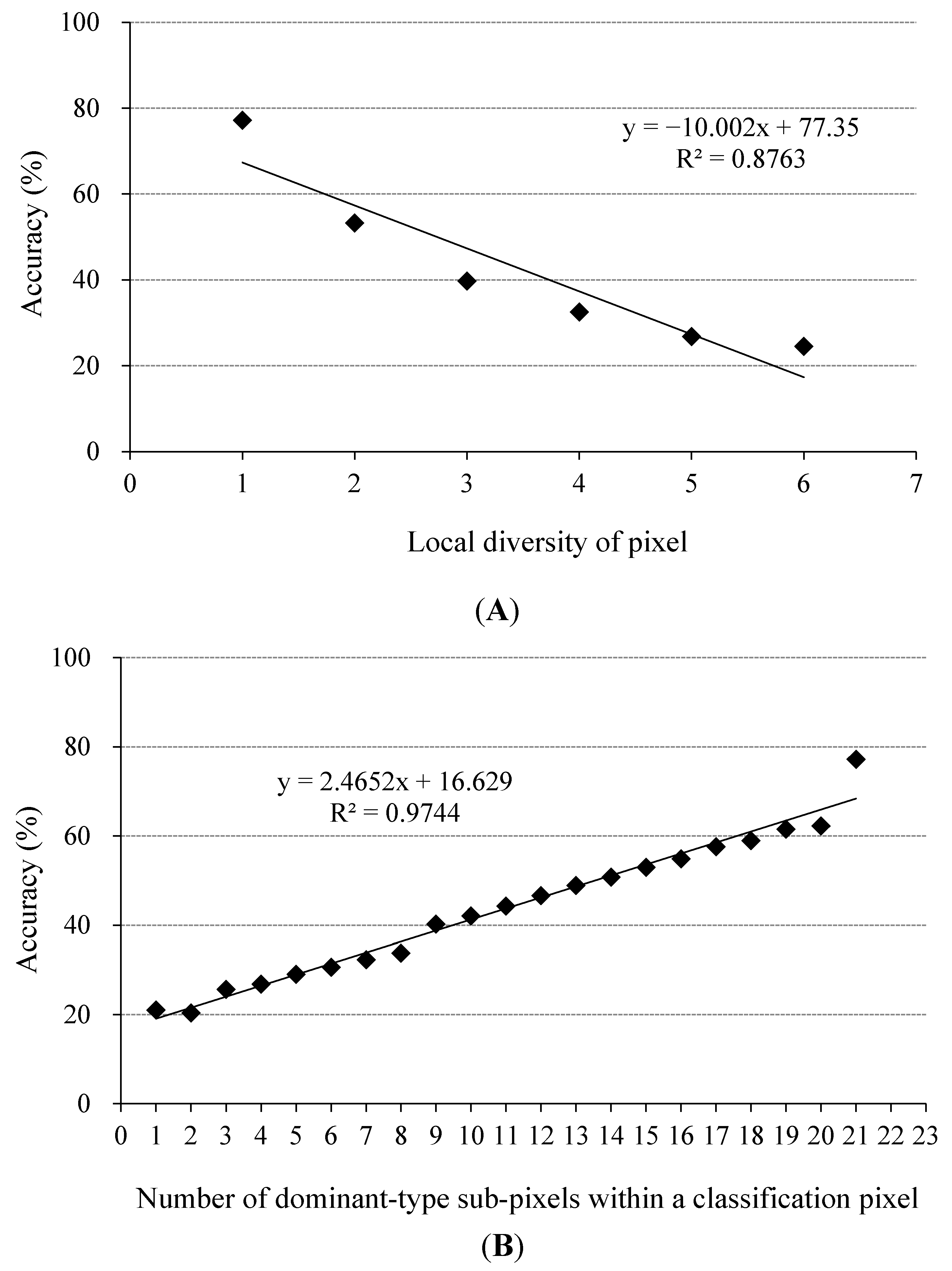
2.3. Dominant-Type and Sub-Pixel Confusion Matrices

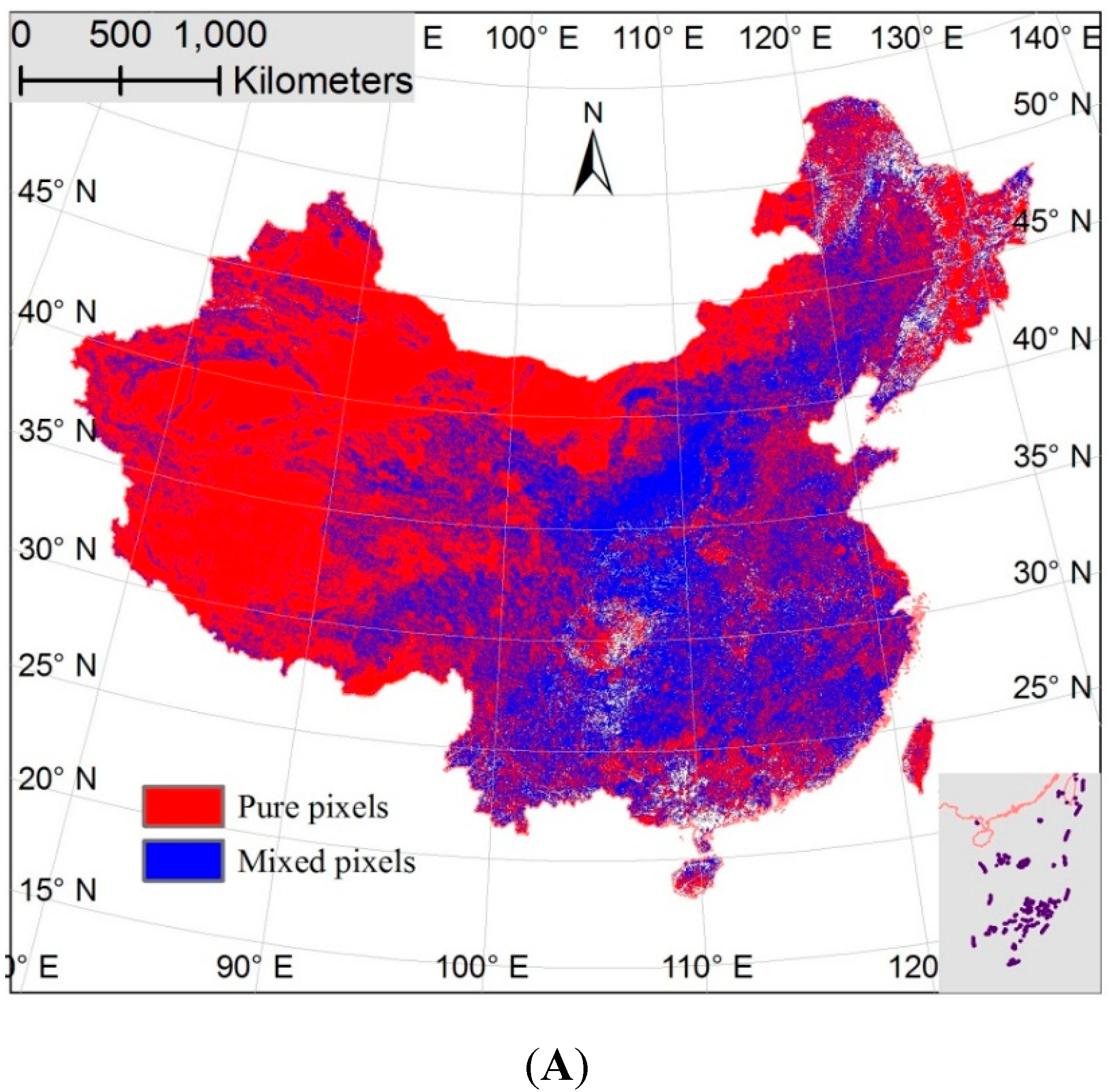
2.4. Mixed Pixel and Pure Pixel


3. Results and Discussion
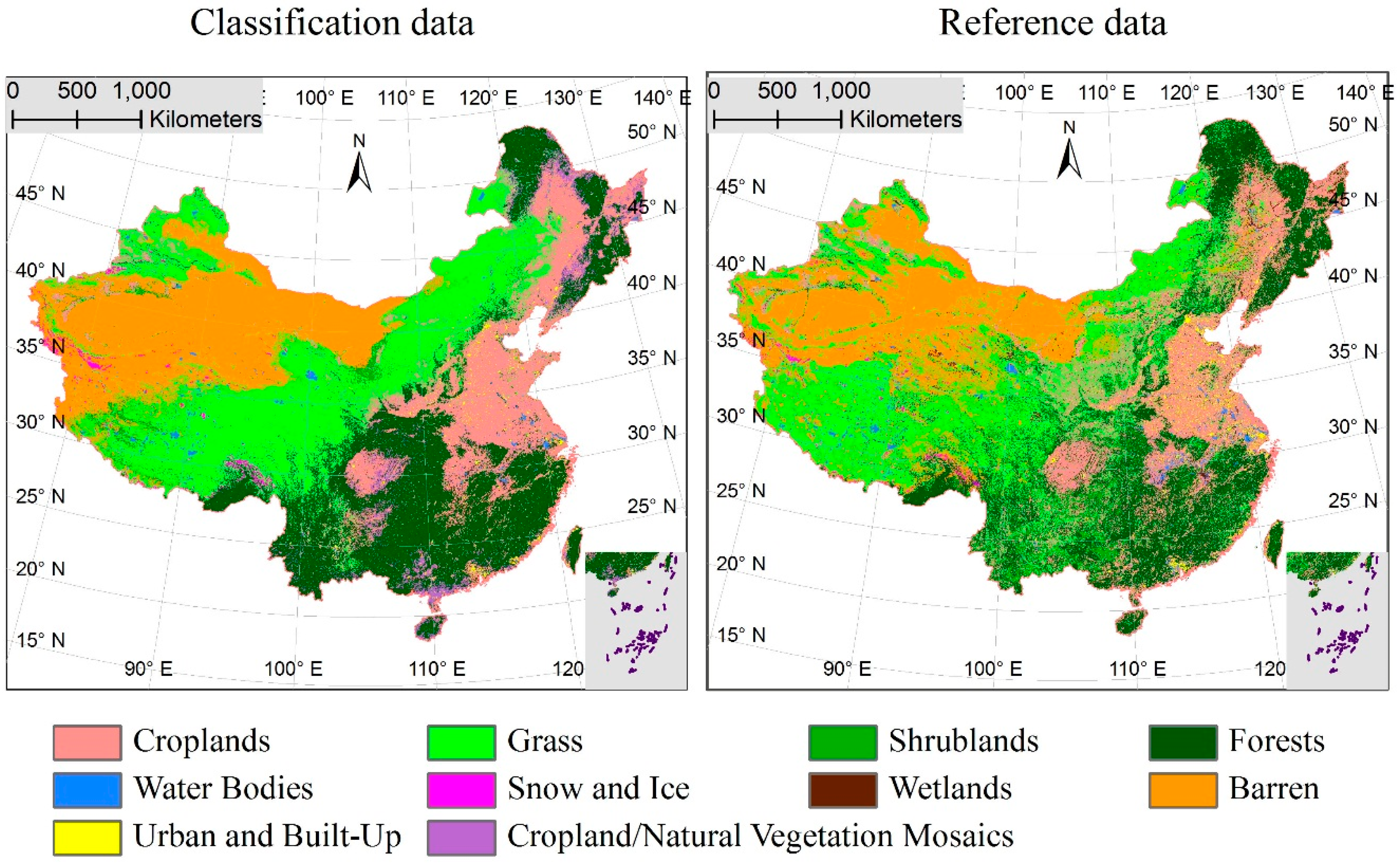
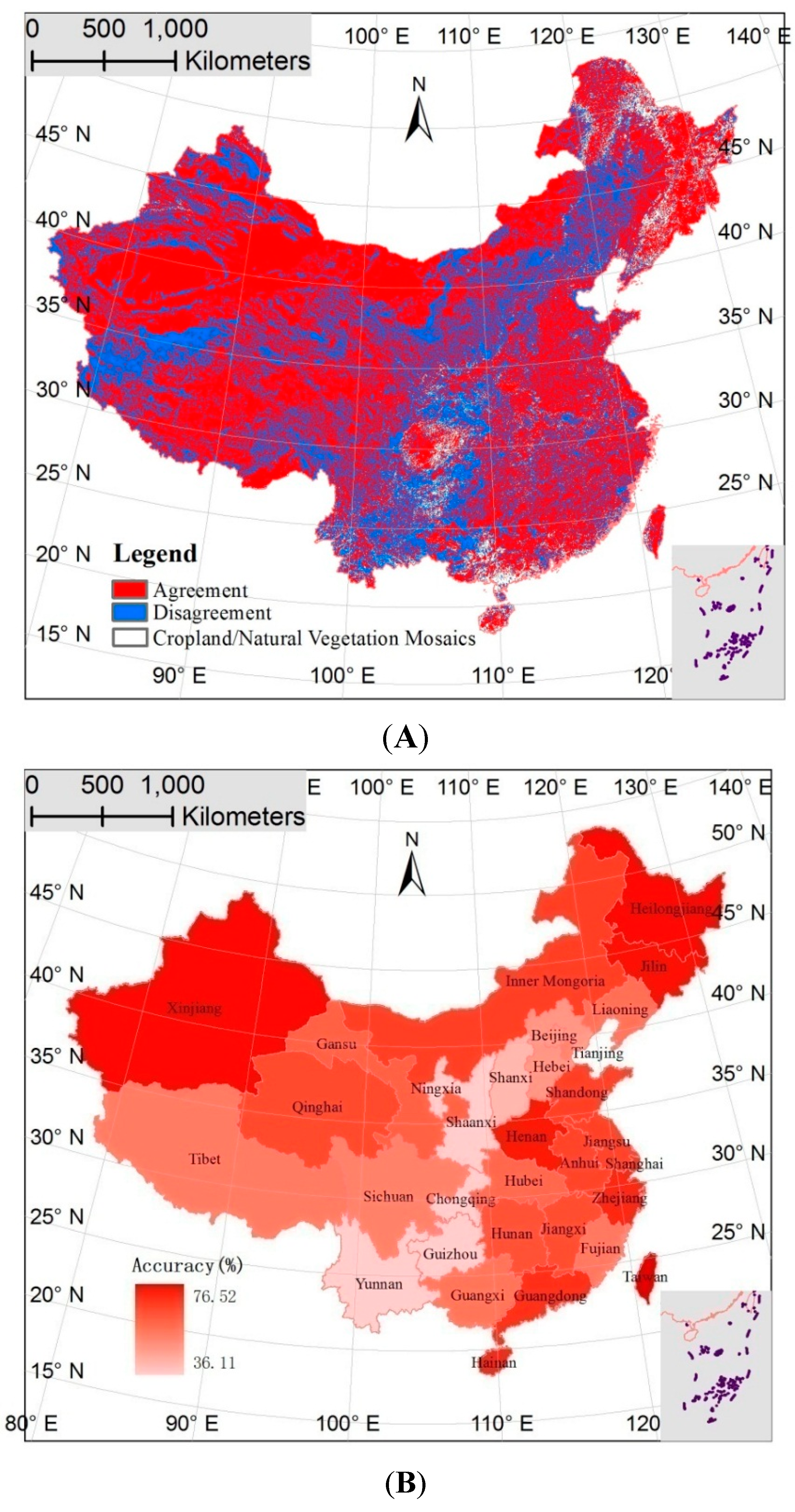
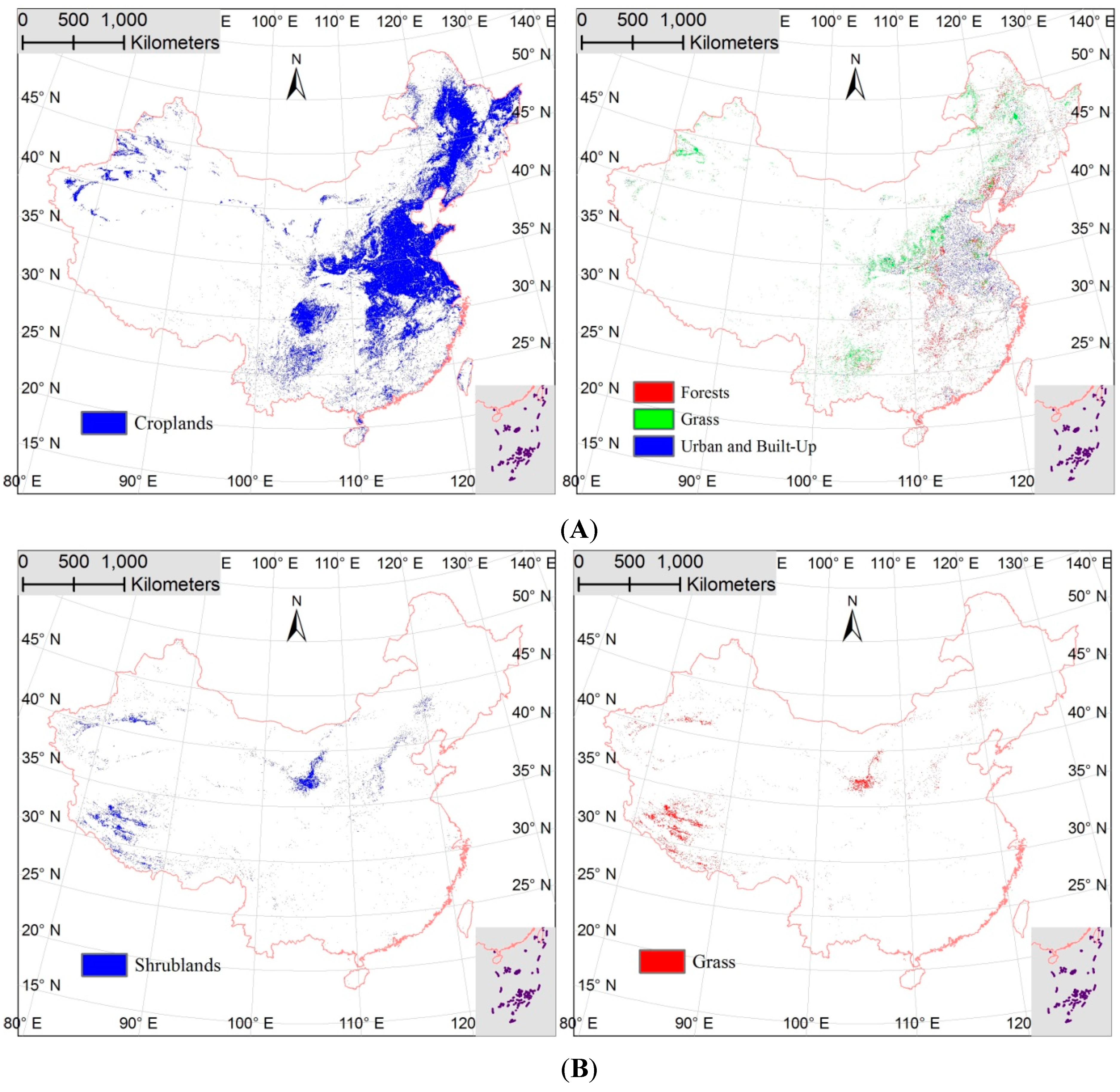
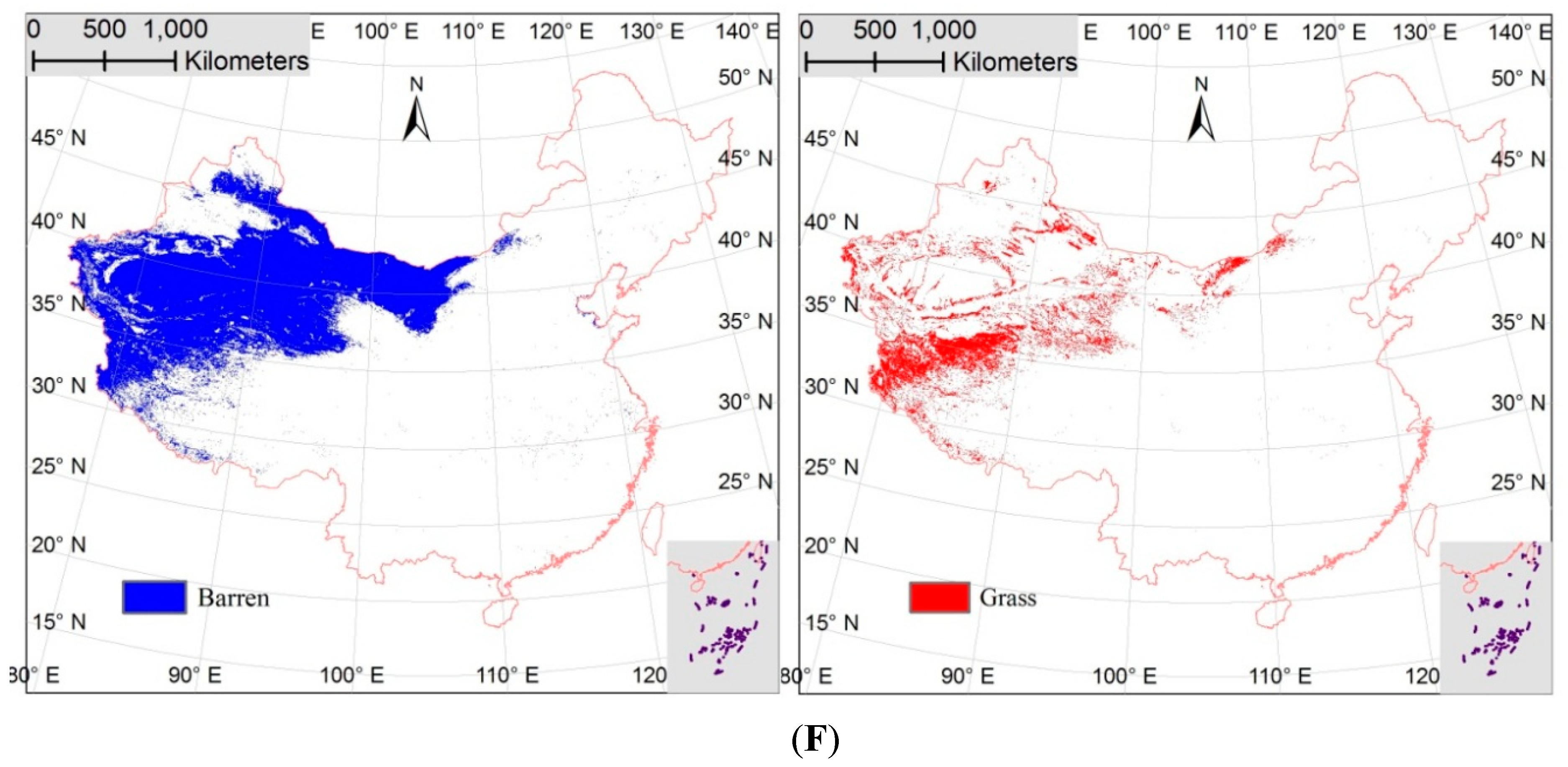
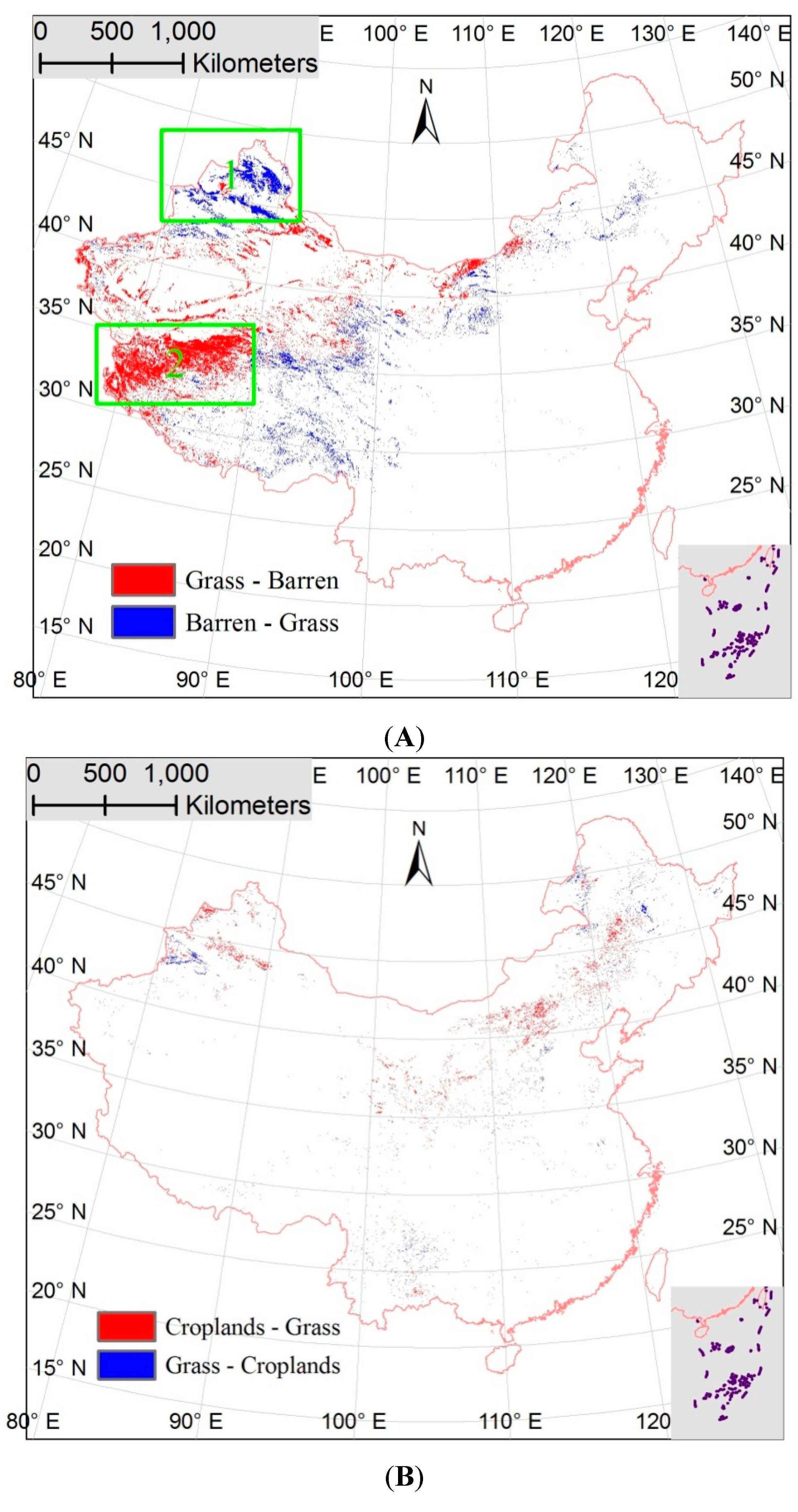
3.1. Spatial Agreement and Disagreement Analysis


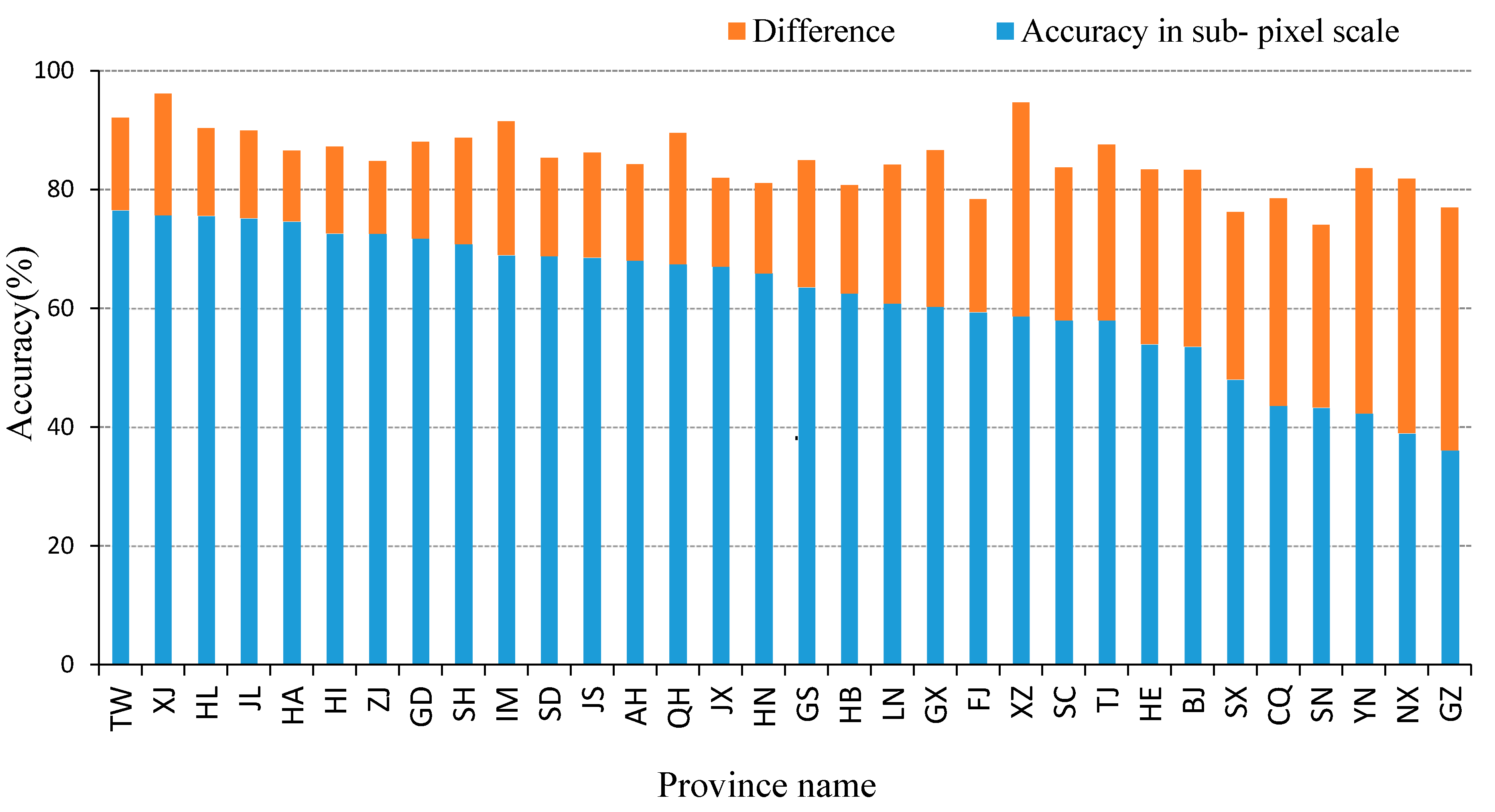
3.2. Spatial and Class Distributions of the Error in the Sub-Pixel Confusion Matrix
| User Accuracy (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Aggregated Classification at 100 m | Reference Data at 100 m | ||||||||
| Croplands | Shrublands | Forests | Grass | Water Bodies | Snow and Ice | Wetlands | Urban and Built-Up | Barren | |
| Croplands | 68.38 | 2.21 | 8.20 | 8.26 | 1.79 | 0.00 | 2.75 | 7.96 | 0.46 |
| Shrublands | 10.77 | 3.74 | 7.89 | 60.98 | 1.36 | 0.30 | 1.47 | 1.59 | 11.90 |
| Forests | 12.11 | 12.23 | 61.83 | 11.30 | 0.95 | 0.02 | 0.87 | 0.47 | 0.22 |
| Grass | 9.52 | 3.89 | 4.72 | 62.88 | 0.78 | 0.31 | 2.28 | 0.96 | 14.67 |
| Water bodies | 1.33 | 0.17 | 1.28 | 2.05 | 82.92 | 0.18 | 5.98 | 3.49 | 2.59 |
| Snow and ice | 0.21 | 0.27 | 0.79 | 6.58 | 0.58 | 47.01 | 0.24 | 0.08 | 44.23 |
| Wetlands | 26.70 | 2.44 | 25.57 | 3.46 | 31.39 | 0.00 | 7.45 | 2.84 | 0.16 |
| Urban and built-up | 35.44 | 0.78 | 4.81 | 3.23 | 2.57 | 0.00 | 0.76 | 51.92 | 0.50 |
| Barren | 0.22 | 0.19 | 0.22 | 24.83 | 0.60 | 0.21 | 0.88 | 0.21 | 72.63 |




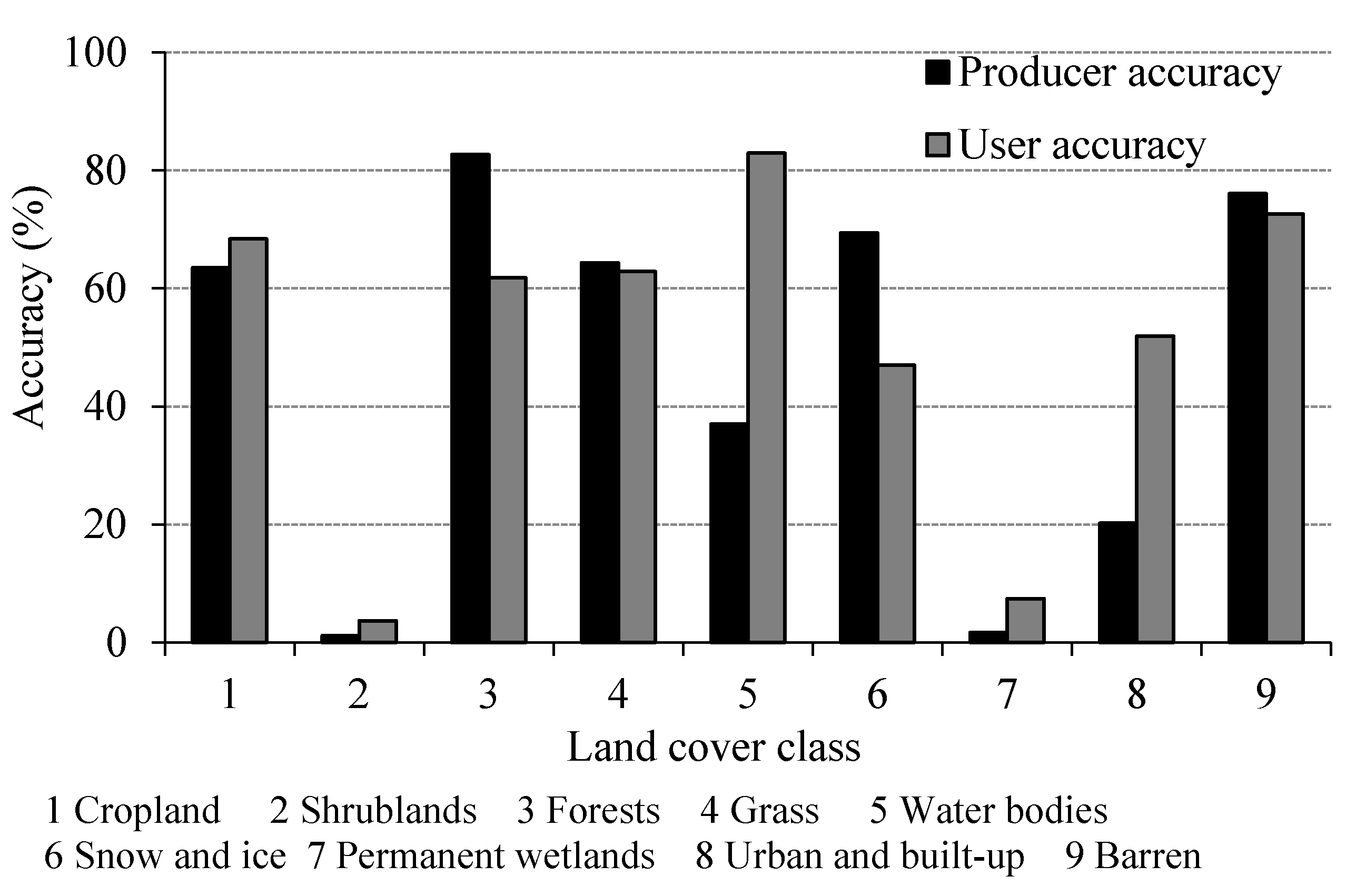
3.3. Analysis of Error According to the Dominant-Type Reference Data




3.4. Validation of Croplands/Natural Vegetation Mosaics
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Foley, J.A.; DeFries, R.; Asner, G.P.; Barford, C.; Carpenter, S.R.; Chapin, F.S.; Coe, M.T.; Dally, G.C.; Gibbs, H.K.; Helkowski, J.H.; et al. Global consequences of land use. Science 2005, 309, 570–574. [Google Scholar]
- Sterling, S.; Ducharne, A. Comprehensive data set of global land cover change for land surface model applications. Glob. Biogeochem. Cy. 2008, 22. [Google Scholar] [CrossRef]
- Pielke, R.A.; Pitman, A.; Niyogi, D.; Mahmood, R.; McAlpine, C.; Goldevijk, K.K.; Nair, U.; PBetts, R.; Fall, S.; et al. Land use/land cover changes and climate: Modeling analysis and observational evidence. Clim. Change 2011, 2, 828–850. [Google Scholar]
- Sellers, P.J.; Dickinson, R.E.; Randall, D.A.; Betts, A.K.; Hall, F.G.; Berry, J.A.; Collatz, G.J.; Denning, A.S.; Mooney, H.A.; Nobre, C.A.; et al. Modeling the exchanges of energy, water, and carbon between continents and the atmosphere. Science 1997, 275, 502–509. [Google Scholar]
- Ek, M.B.; Mitchell, K.E.; Lin, Y.; Rogers, E.; Grunmann, P.; Koren, V.; Gayno, G.; Tarpley, J.D. Implementation of Noah land surface model advances in the National Centers for Environmental Prediction operational mesoscale Eta model. J. Geophys. Res.: Atmos. 2003, 108. [Google Scholar] [CrossRef]
- Loveland, T.R.; Sohl, T.L.; Stehman, S.V.; Gallant, A.L.; Sayler, K.L.; Napton, D.E. A strategy for estimating the rates of recent United States land cover changes. Photogramm. Eng. Remote Sens. 2002, 68, 1091–1099. [Google Scholar]
- DeFries, R.S.; Townshend, J.G.R. NDVI derived land cover classifications at a global scale. Int. J. Remote Sens. 1994, 5, 3567–3586. [Google Scholar] [CrossRef]
- DeFries, R.S.; Hansen, M.; Townshend, J.R.G.; Sohlberg, R. Global land cover classifications at 8 km spatial resolution: The use of training data derived from Landsat imagery in decision tree classifiers. Int. J. Remote Sens. 1998, 19, 3141–3168. [Google Scholar] [CrossRef]
- Loveland, T.R.; Reed, B.C.; Brown, J.F.; Ohlen, D.O.; Zhu, Z.; Yang, L.; Merchant, J.W. Development of a global land cover characteristics database and IGBP-DIS Cover from 1 km AVHRR data. Int. J. Remote Sens. 2000, 21, 1303–1330. [Google Scholar] [CrossRef]
- Hansen, M.C.; DeFries, R.S.; Townshend, J.R. G.; Sohlberg, R. Global land cover classification at 1 km spatial resolution using a classification tree approach. Int. J. Remote Sens. 2000, 21, 1331–1364. [Google Scholar] [CrossRef]
- Friedl, M.A.; McIver, D.K.; Hodges, J.C.F.; Zhang, X.Y.; Muchoney, D.; Strahler, A.H.; Woodcock, C.E.; Gopal, S.; Schneider, A.; Cooper, A.; et al. Global land cover mapping from MODIS: Algorithms and early results. Remote Sens. Environ. 2002, 83, 287–302. [Google Scholar]
- Bartholome, E.; Belward, A.S. GLC2000: A new approach for global land cover mapping from Earth observation data. Int. J. Remote Sens. 2005, 26, 1959–1977. [Google Scholar] [CrossRef]
- Tateishi, R.; Uriyangqai, B.; AlBilbisi, H.; Ghar, M.A.; Tsend-Ayush, J.; Kobayashi, T.; Kasimu, A.; Hoan, N.T.; Shalaby, A.; Alsaaideh, B.; et al. Production of global land cover data, GLCNMO. Int. J. Digit. Earth 2011, 4, 22–49. [Google Scholar] [CrossRef]
- Arino, O.; Bicheron, P.; Achard, F.; Latham, J.; Witt, R.; Weber, J. GLOBCOVER—The most detailed portrait of Earth. ESA Bull. Eur. Space 2008, 136, 24–31. [Google Scholar]
- Friedl, M.A.; Sulla-Menashe, D.; Tan, B.; Schneider, A.; Ramankutty, N.; Sibley, A.; Huang, X.H. MODIS Collection 5 global land cover: Algorithm refinements and characterization of new datasets. Remote Sens. Environ. 2010, 114, 168–182. [Google Scholar] [CrossRef]
- Sophie, B.; Pierre, D.; Eric, V.B.; Arino, O.; Kalogirou, V. GLOBCOVER 2009; Products Description and Validation Report. Available online: http://epic.awi.de/31014/16/GLOBCOVER2009ValidationReport2–2.pdf (accessed on 18 February 2011).
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.Y.; Liang, L.; Niu, Z.G.; Huang, X.M.; Fu, M.M.; Liu, S.; Li, C.C.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar]
- Friedl, M.A. User Guide for the MODIS Land Cover Type Product (MCD12Q1). Available online: http://www.bu.edu/lcsc/files/2012/08/MCD12Q1_user_guide.pdf (accessed on 8 August 2012).
- Bicheron, P.; Defourny, P.; Brockmann, C.; Schouten, L.; Vancutsem, C.; Huc, M.; Bontemps, S.; Leroy, M.; Achard, F.; Herold, M.; et al. GLOBCOVER: Products Description and Validation Report, Toulouse: Medias France. Available online: http://ionia1.esrin.esa.int/docs/GLOBCOVERProductsDescriptionValidationReportI2.1.pdf (accessed on 4 December 2008).
- Giri, C.; Pengra, B.; Long, J.; Loveland, T.R. Next generation of global land cover characterization, mapping and monitoring. Int. J. Appl. Earth Obs. Geoinf. 2013, 25, 30–37. [Google Scholar] [CrossRef]
- Brown, J.F.; Loveland, T.R.; Ohlen, D.O.; Zhu, Z.L. The global land-cover characteristics database: The user’s perspective. Photogramm. Eng. Remote Sens. 1999, 65, 1069–1074. [Google Scholar]
- Justice, C.; Wolfe, R.; El-Saleous, N. The availability and status of MODIS land data products. Earth Obs. 2000, 12, 10–18. [Google Scholar]
- Cihlar, J.; Chen, J.; Li, Z. On the validation of satellite-derived products for land applications. Can. J. Remote Sens. 1997, 23, 381–389. [Google Scholar] [CrossRef]
- Morisette, J.T.; Privette, J.L.; Justice, C.O. A framework for the validation of MODIS Land products. Remote Sens. Environ. 2002, 83, 77–96. [Google Scholar] [CrossRef]
- McCallum, I.; Obersteiner, M.; Nilsson, S.; Shvidenko, A. A spatial comparison of four satellite derived 1 km global land cover datasets. Int. J. Appl. Obs. Geoinf. 2006, 8, 246–255. [Google Scholar] [CrossRef]
- Latifovic, R.; Olthof, I. Accuracy assessment using sub-pixel fractional error matrices of global land cover products derived from satellite data. Remote Sens. Environ. 2004, 90, 153–165. [Google Scholar] [CrossRef]
- Hansen, M.C.; Reed, B. A comparison of the IGBP DIS Cover and University of Maryland1 km global land cover products. Int. J. Remote Sens. 2000, 21, 1365–1373. [Google Scholar] [CrossRef]
- Giri, C.; Zhu, Z.L.; Reed, B. A comparative analysis of the Global Land Cover 2000 and MODIS land cover data sets. Remote Sens. Environ. 2005, 94, 123–132. [Google Scholar] [CrossRef]
- Herold, M.; Mayaux, P.; Woodcock, C.E.; Baccini, A.; Schmullius, C. Some challenges in global land cover mapping: An assessment of agreement and accuracy in existing 1 km datasets. Remote Sens. Environ. 2008, 112, 2538–2556. [Google Scholar] [CrossRef]
- Ran, Y.H.; Li, X.; Lu, L. Evaluation of four remote sensing based land cover products over China. Int. J. Remote Sens. 2010, 31(2), 391–401. [Google Scholar]
- Bosch, J.; Hewlett, J. A review of catchment experiments to determine the effect of vegetation changes on water yield and vapor-transpiration. J. Hydrol. 1982, 55, 1–23. [Google Scholar] [CrossRef]
- Penner, J.E. Atmospheric chemistry and air quality. In Changes in Land Use and Land Cover: A Global Perspective; Cambridge University Press: Cambridge, UK, 1994; pp. 175–209. [Google Scholar]
- Chapin, F.S.; Zavaleta, E.S.; Eviner, V.T.; Naylor, R.L.; Vitousek, P.M.; Reynolds, H.L.; Hooper, D.U.; Lavorel, S.; Sala, O.E.; Hobbie, S.E.; et al. Consequences of changing biodiversity. Nature 2000, 405, 234–242. [Google Scholar]
- Bounoua, L.; DeFries, R.S.; Collatz, G.J.; Sellers, P.; Khan, H. Effects of land cover conversion on surface climate. Clim. Change 2002, 52, 29–64. [Google Scholar] [CrossRef]
- Holmes, K.W.; Kyriakidis, P.C.; Chadwick, O.A.; Soares, J.V.; Roberts, D.A. Multi-scale variability in tropical soil nutrients following land-cover change. Biogeochemistry 2005, 74, 173–203. [Google Scholar] [CrossRef]
- NASA. Available online: http://reverb.echo.nasa.gov/reverb/ (accessed on 26 September 2014).
- Neumann, K.; Herold, M.; Hartley, A.; Schmullius, C. Comparative assessment of CORINE2000 and GLC2000: Spatial analysis of land cover data for Europe. Int. J. Appl. Earth Obs. Geoinf. 2007, 9, 425–437. [Google Scholar] [CrossRef]
- Zhang, Z.X.; Wang, X.; Zhao, X.L.; Liu, B.; Yi, L.; Zuo, L.J.; Wen, Q.K.; Liu, F.; Xu, J.Y.; Hu, S.G. A 2010 update of national land use/cover database of China at 1:100000 scale using medium spatial resolution satellite images. Remote Sens. Environ. 2014, 149, 142–154. [Google Scholar] [CrossRef]
- Zuo, L.J.; Zhang, Z.X.; Zhao, X.L.; Wang, X.; Wu, W.B.; Yi, L.; Liu, F. Multi-temporal analysis of cropland transition in a climate-sensitive area: A case study of the arid and semiarid region of northwest China. Reg. Environ. Change 2013, 14, 75–89. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Smits, P.C.; Dellepiane, S.G.; Schowengerdt, R.A. Quality assessment of image classification algorithms for land-cover mapping: A review and proposal for a cost-based approach. Int. J. Remote Sens. 1999, 20, 1461–1486. [Google Scholar] [CrossRef]
- The Forest Resources Assessment Programme. FRA 2000 Forest Cover Mapping & Monitoring with NOAA-AVHRR & Other Coarse Spatial Resolution Sensors. Available online: http://www.fao.org/docrep/007/ae161e/AE161E00.htm (accessed on 26 September 2014).
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, T.; Zhang, Z.; Zhao, X.; Wang, X.; Zuo, L. Evaluation of the 2010 MODIS Collection 5.1 Land Cover Type Product over China. Remote Sens. 2015, 7, 1981-2006. https://doi.org/10.3390/rs70201981
Zeng T, Zhang Z, Zhao X, Wang X, Zuo L. Evaluation of the 2010 MODIS Collection 5.1 Land Cover Type Product over China. Remote Sensing. 2015; 7(2):1981-2006. https://doi.org/10.3390/rs70201981
Chicago/Turabian StyleZeng, Tian, Zengxiang Zhang, Xiaoli Zhao, Xiao Wang, and Lijun Zuo. 2015. "Evaluation of the 2010 MODIS Collection 5.1 Land Cover Type Product over China" Remote Sensing 7, no. 2: 1981-2006. https://doi.org/10.3390/rs70201981
APA StyleZeng, T., Zhang, Z., Zhao, X., Wang, X., & Zuo, L. (2015). Evaluation of the 2010 MODIS Collection 5.1 Land Cover Type Product over China. Remote Sensing, 7(2), 1981-2006. https://doi.org/10.3390/rs70201981