1. Introduction
The quantitative useful information provided by high-resolution sensors is helpful to distinguish between different land cover classes with different spectral responses. Hyperspectral image (HSI) classification remains one of the most challenging problems due to within-class variation and spatial details [
1,
2,
3,
4,
5,
6]. In the past few decades, significant efforts have been made to develop various classification methods. For example, there have been a variety of studies that utilize spatial-spectral information for HSI classification [
7,
8]. However, most of the previous works mainly focus on various dense feature extractions, such as Gabor, patch-based [
9], scale-invariant feature transform (SIFT) [
10], local binary pattern (LBP) [
11], local Gabor binary pattern (LGBP) [
12], random project (RP) [
13] and the bag-of-visual-words (BOVW) [
14], where the extracted features are fed into k-nearest neighbor (K-NN), support vector machine (SVM) or Markov random field (MRF) [
15] to perform HSI classification. Besides, some feature-matching methods [
16,
17] in the computer vision area can also be generalized for HSI classification, but they have a prerequisite that the spectral features should be extracted in advance. However, these local features may be contradictory because of their overlapping with each other and result in less contribution to the classifiers.
Recently, researchers have exploited sparse representation (SR) techniques for HSI classification and other computer vision applications, e.g., [
18,
19]. Sparse representation classification (SRC) assumes the input samples of the same class lie in a class-dependent low-dimensional subspace, and a test sample can be sparsely represented as a linear combination of the labeled samples via
regularization. Different from the conventional classifiers aforementioned, it does not require training, and the class label of a test sample is determined to be the class whose dictionary atoms provide the minimal approximation error. Although SRC has achieved promising results in HSI classification [
20,
21], it suffers from instable representation coefficients across multiple classes, especially with the similar input features. After that, kernelized SRC (KSRC) [
22] and structured sparse priors, such as Laplacian regularized Lasso [
23] and low-rank group Lasso [
24], are presented for HSI classification, and improved accuracies are reported. Later on, a collaborative representation classification (CRC) via
regularization is introduced in face recognition and demonstrated that CRC can achieve comparable performance with SRC at much lower computational cost [
25]. Recently, CRC is actively adopted for HSI classification [
26], where the test sample is collaboratively represented with dictionary atoms from all of the classes, rather than the sparsity constraint as in SRC. However, CRC has limited discriminative ability when the labeled samples include mixed information.
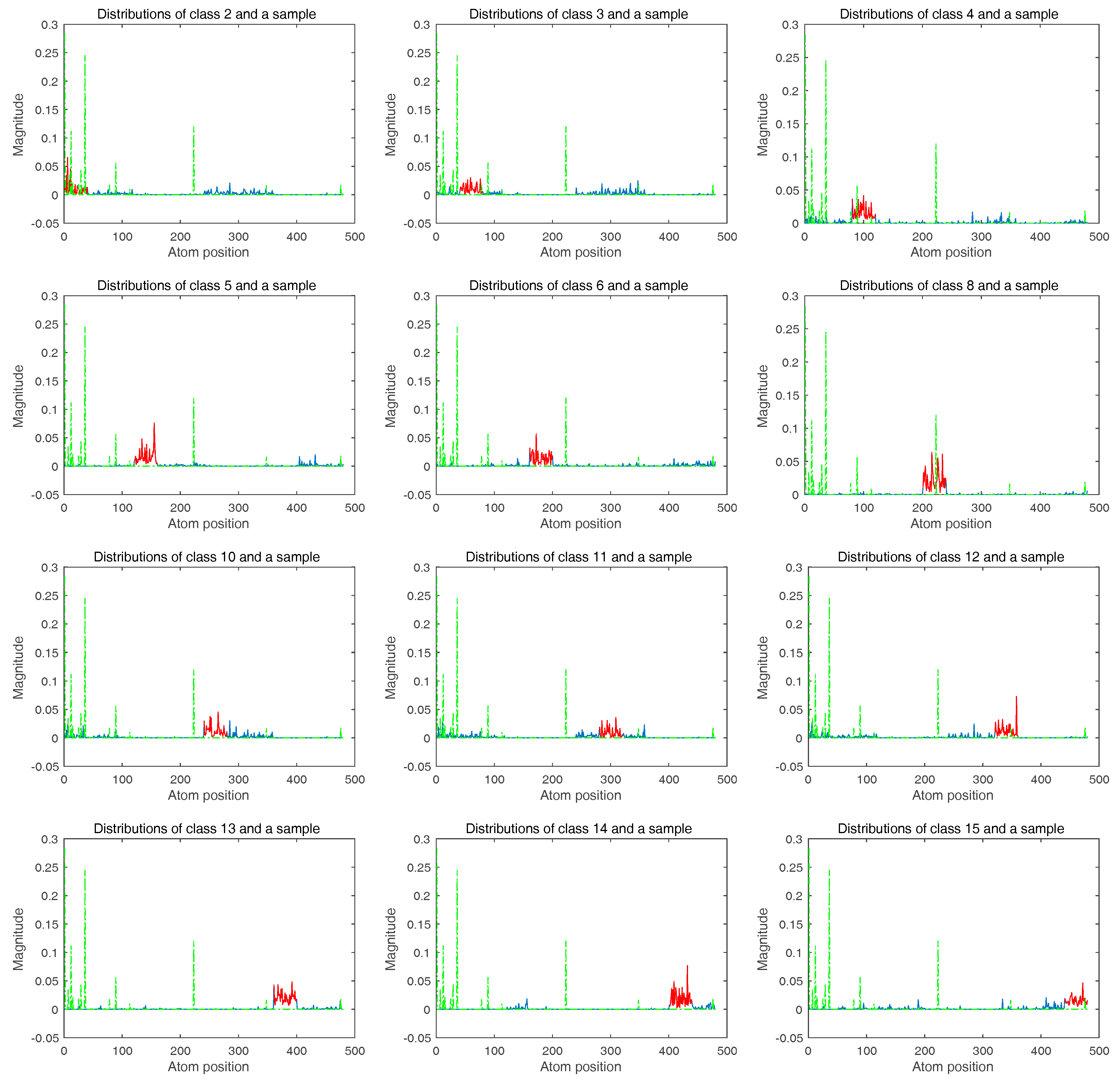
It is generally agreed that SR coefficients follow a class-dependent distribution, which means the nonzero entries of the recovered coefficients from the same class tend to locate at a specific sub-dictionary, and the magnitudes of the coefficients in accordance with the true class are larger than the others. Therefore, in [
27], the class-dependent sparse representation classifier (cdSRC) was proposed for HSI classification, where SRC combines K-NN in a class-wise manner to exploit both correlation and Euclidean distance between test and training samples, and the classification performance is increased. Furthermore, K-NN Euclidean distance and the spatial neighboring information of test pixels are introduced into the CR classifiers. In [
28], a nonlocal joint CR with a locally-adaptive dictionary is developed. In [
29], spatially multiscale adaptive sparse representation in a pixel-wise manner is utilized to construct a structural dictionary and outperforms its counterparts. However, the spatially multiscale pixel-wise operation requires extra computational cost. In [
30], the spatial filter banks were included to enhance the logistic classifier with group-Lasso regularization. In addition, kernelized CRC (KCRC) is investigated for HSI classification in [
31], and accumulated assignment using a sparse code histogram is discussed in [
32].
More recently, some sparse representation-based nearest neighbors (SRNN) and elastic net representation-based classification (ENRC) for HSI are also reported. In [
33], three sparse representation-based NN classifiers, i.e., SRNN, local SRNN and spatially-joint SRNN, were proposed to achieve much higher classification accuracy than the traditional Euclidean distance and representation residual. In [
34], the proposed ENRC classification method produces more robust weight coefficients via adopting
and
penalties in the objective function, thereby turning out to be more discriminative than the original SRC and CRC. In a word, such representation-based methods are designed to improve the stability of the sparse codes and their discriminability by modeling the spectral variations or collaboratively coding multiple samples.
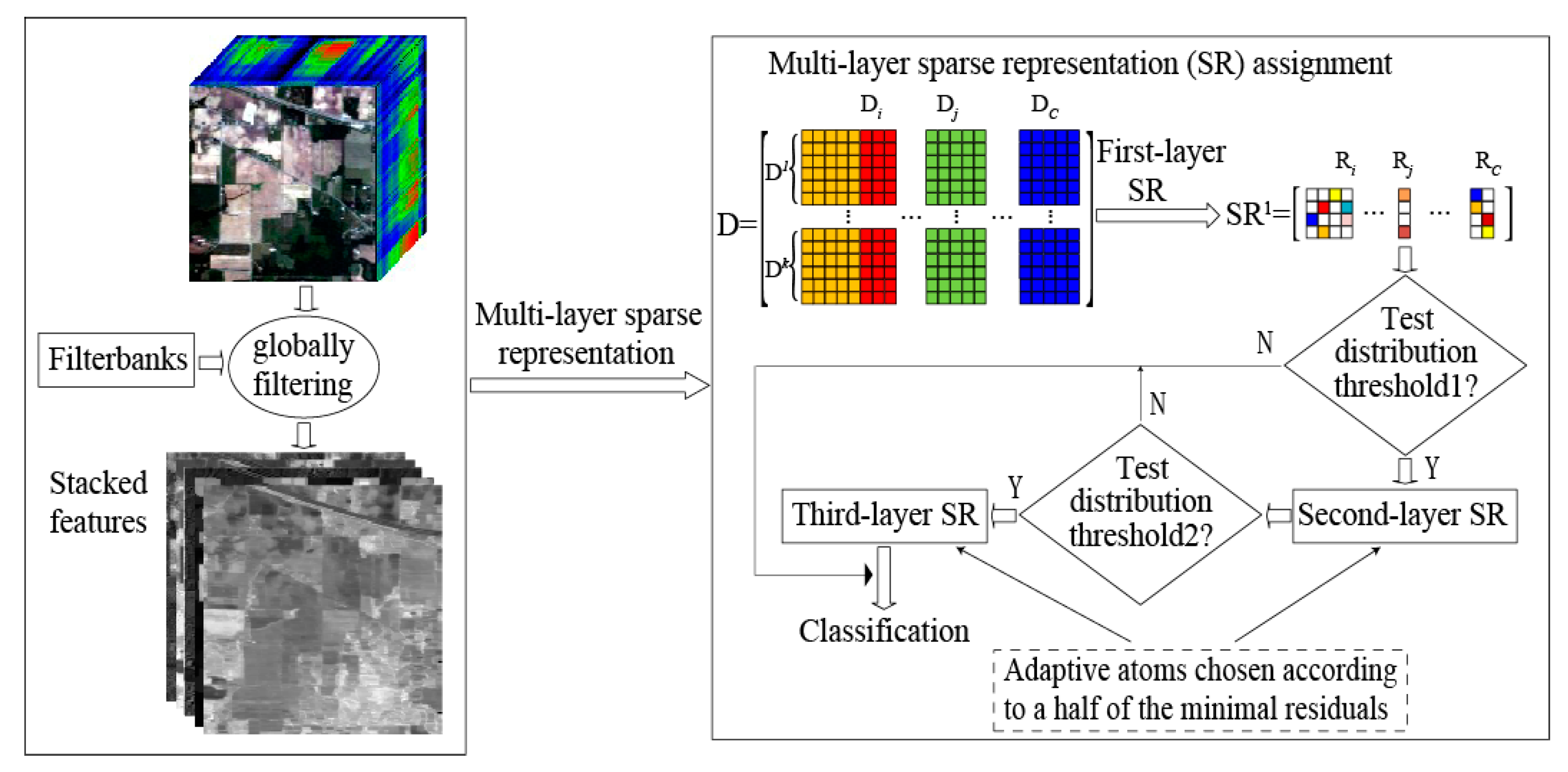
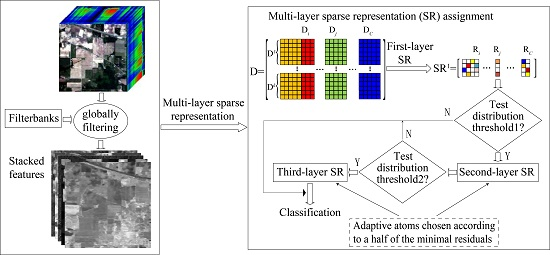
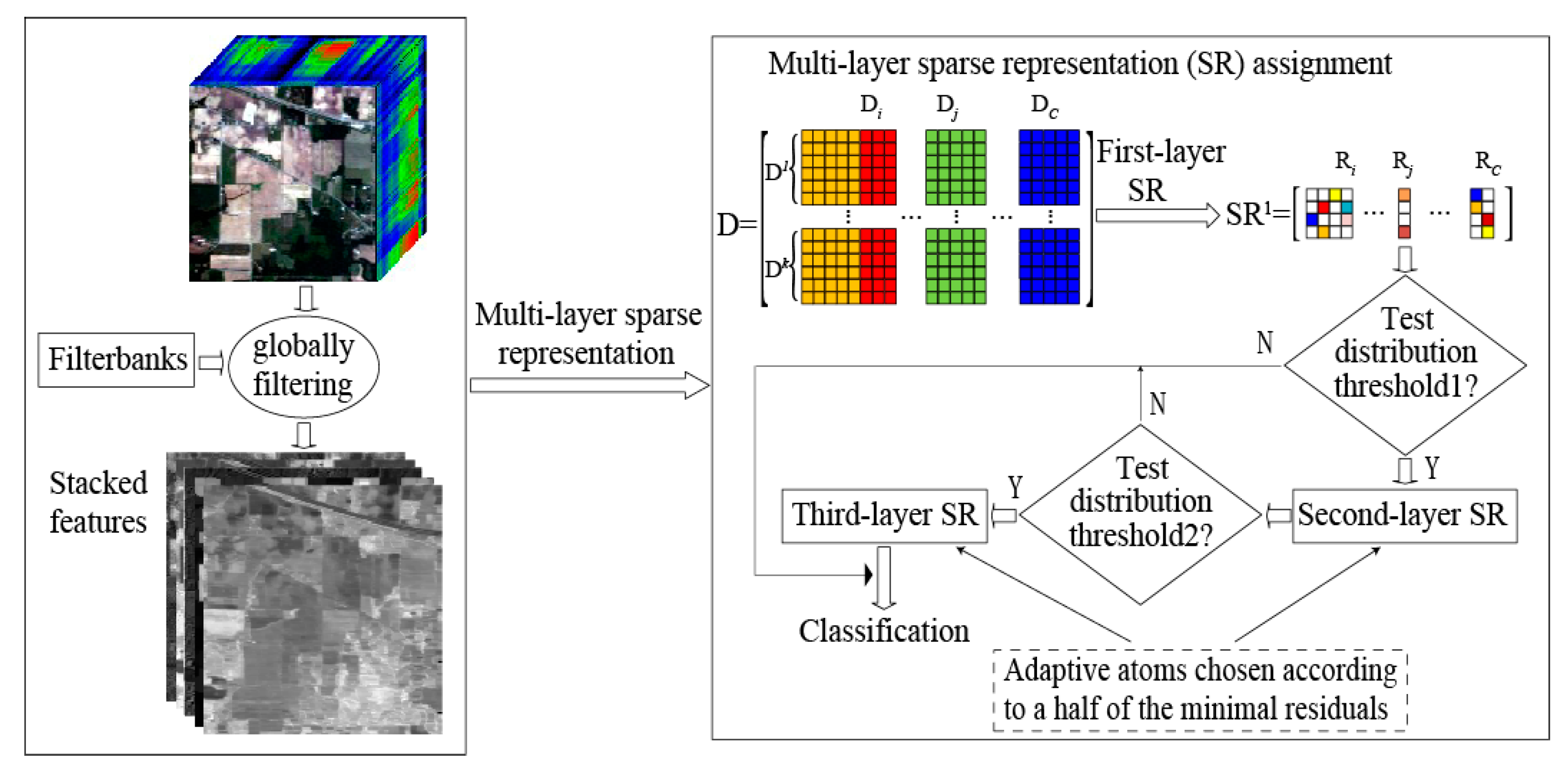
Although the aforementioned representation-based classification methods perform well to some extent, all of them reconstruct sparse coefficients in a single layer and still need to be further exploited in terms of how to estimate the “true” reconstruction coefficients for the test sample. In fact, a multi-layer sparse representation-based (mlSR) assignment framework is preferred to necessarily stabilize the sparse codes for representation-based classification. In this paper, we propose to investigate a multi-layer spatial-spectral SR assignment framework under the structural dictionary for HSI classification, which effectively combines the ideas of a multi-layer SR assignment framework with adaptive dictionary assembling and adaptive regularization parameter selection. Specifically, three SR algorithms, multi-layer SRC (mlSRC), multi-layer CRC (mlCRC) and multi-layer ENRC (mlENRC) are developed. The proposed mlSR assignment framework enforces the selected bases (dictionary atoms) into as few categories as possible, and the estimated reconstruction coefficients are refined thereby, which boosts the accurate discrimination of the model. This is one feature of our method. Another one is that the proposed mlSR assignment framework exploits the intrinsic class-dependent distribution, which is utilized to stabilize test distribution estimation across multiple classes and lead to a selective multi-layer representation-based classification framework. Moreover, we consider the construction of the structural dictionary, that is, a dictionary consisting of spectral and spatial features via the utilization of a group of globally-spatial filter banks is first constructed, thus integrating the spatial consistency of the dictionary atoms and allowing drastic savings in computational time. The proposed mlSR assignment framework is not only natural and simple, but also indeed beneficial toward HSI classification. Note that these features compose our major contributions in this work and make the proposed methods unique with regard to previously-proposed approaches in this area (e.g., [
29,
35,
36]). Our mlSR framework is different from [
35] in terms of the implementation principle, where the latter can be viewed as a kind of weighted sparse coding, and the classification is done by maximizing the feature probability, but without dictionary assembling; meanwhile, unlike [
29,
36], which are designed to capture spatial correlations by introducing the neighboring pixels of the test sample for sparse coding and often time consuming, our proposed methods are in essence a multi-layer framework, which involves assembling adaptive dictionaries for test samples. The experimental results demonstrate that classification accuracy can be consistently improved by the proposed mlSR assignment framework.
There are three main contributions in this work. First, a multi-layer spatial-spectral sparse representation (mlSR) framework for HSI classification is proposed. In the proposed framework, three algorithms, multi-layer SR classification (mlSRC), multi-layer collaborative representation classification (mlCRC) and multi-layer elastic net representation-based classification (mlENRC), are developed and achieve stable assignment distributions via the adaptive atoms selection in a multi-layer manner. Second, both the test distribution evaluation-based filtering rule and dictionary assembling based on the classes ranked within the top half of the minimal residuals are developed to convey discriminative information for classification and decrease the computational time. Last, but not least, a structural dictionary consisting of globally-filtered spatial and spectral information is constructed to further boost the classification performance. It is also worth mentioning that our proposed mlSR framework has another nice property that can be easily plugged into any representation-based classification model using different HSI features (e.g., spectral features, spatial features and spatial-spectral features). The proposed approach is evaluated using three real HSI datasets. The experimental results verify the effectiveness of our proposed methods as compared to state-of-the-art algorithms.
The remainder of this paper is organized as follows.
Section 2 briefly reviews representation-based techniques for HSI classification.
Section 3 presents the proposed mlSR framework and classification approaches in detail.
Section 4 evaluates the proposed approaches against various state-of-the-art methods on three real HSI datasets in terms of classification accuracy and computational time.
Section 5 includes discussions of our framework and method. Finally,
Section 6 concludes the paper.
4. Experiments
In this section, in order to demonstrate the superiority of the proposed method in HSI classification, the proposed multi-layer spatial-spectral sparse representation (mlSR) method is compared with various state-of-the-art methods on three benchmark hyperspectral remote sensing images: Indian Pines, University of Pavia and Salinas. Note that the proposed method utilizes a structural dictionary consisting of globally-filtered spatial feature such as 2D Gabor (scale = 2, orient = 8), morphological profiles and spectral feature along all bands. To further validate the effectiveness of the proposed model on exploring the structural consistency in the classification scenarios, we compare the proposed mlSR assignment framework with competitors built on only spectral features. Meanwhile, the number of the layers is set as three in order to balance computational complexity and classification performance. Additionally, we also analyze the influence of several key model parameters.
4.1. Hyperspectral Images and Experiment Setting
Three hyperspectral remote sensing images are utilized for extensive evaluations of the proposed approach in the experiments: Indian Pines image captured by AVIRIS (Airborne Visible/Infrared Imaging Spectrometer), University of Pavia image captured by ROSIS (Reflective Optics System Imaging Spectrometer) and Salinas image collected by AVIRIS sensor.
The Indian Pines image was acquired by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor over northwest Indiana’s Indian Pine test site in June 1992 [
39]. The image contained 16 classes of different crops at a 20-m spatial resolution with the size of 145 × 145 pixels. After uncalibrated and noisy bands were removed, 200 bands remained. We use the whole scene, and twelve large classes are investigated. The number of training and testing samples is shown in
Table 2.
The University of Pavia utilized in the experiments is of an urban area that was taken by the ROSIS-03 optical sensor over the University of Pavia, Italy [
40]. The image consists of 115 spectral channels of size 610 × 340 pixels with a spectral range from 0.43 to 0.86 μm with a spatial resolution of 1.3 m. The 12 noisy channels have been removed, and the remaining 103 bands were used for the experiments. The ground survey contains nine classes of interest, and all classes are considered. The number of training and testing samples is summarized in
Table 2.
The Salinas image was also collected by the AVIRIS sensor, capturing an area over Salinas Valley, CA, USA, with a spatial resolution of 3.7 m. The image comprises 512 × 217 pixels with 204 bands after 20 water absorption bands are removed. It mainly contains vegetables, bare soils and vineyard fields. The calibrated data are available online (along with detailed ground-truth information) from
http://www.ehu.es/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes. There are also 16 different classes, and all are utilized; the number of training and testing samples is listed in
Table 2.
The parameter settings in our experiments are given as follows.
(1) For training set generation, we first randomly select a subset of labeled samples from the ground truth. Then, we randomly choose some samples from the selected training set to build the dictionary. For all of the considered images, different training rates are employed to examine the classification performance of various algorithms. We randomly select a reduced number of labeled samples ({5, 10, 20, 40, 60, 80, 100, 120} samples per class) for training, and the rest are for testing. The classification results and maps of our approach and other compared methods are generated with 120 training samples per class.
(2) For classification, we report the overall accuracy (OA), average accuracy (AA), class-specific accuracies (%), kappa statistic (κ), standard deviation and computational time (including searching the optimal regularization parameters) derived from averaging the results after conducting ten independent runs with respect to the initial training set.
(3) For performance comparison, some strongly-related SR/CR-based methods, including kernelized SRC (KSRC) and KCRC, attribute profiles-based SRC (APSRC) and CRC (APCRC) and their multi-layer versions (i.e., mlAPSRC, mlAPCRC), have been implemented. As the basic classifiers, SVM and representation-based classification (SRC, CRC) and attribute profiles-based SVM (APSVM) are compared; furthermore, the elastic net representation-based classification (ENRC) method is also compared.
(4) For implementation details, to make the comparisons as meaningful as possible, we use the same experimental settings as [
41], and all results are originally reported. For Indian Pines and Salinas image datasets, the attribute profiles (APs) [
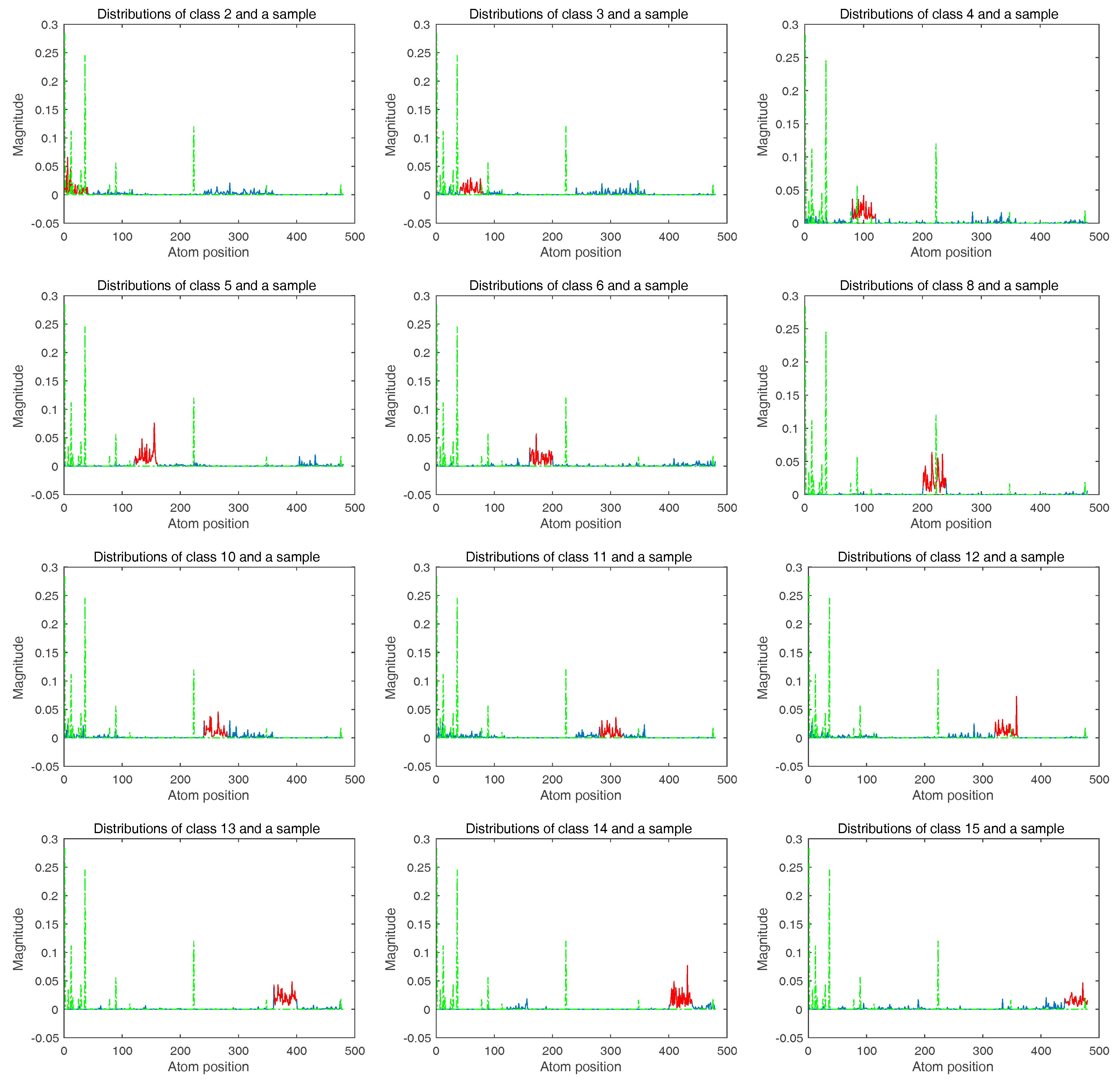
42] were built using threshold values in the range from 2.5% to 10% with respect to the mean of the individual features, with a step of 2.5% for the standard deviation attribute and thresholds of 200, 500 and 1000 for the area attribute, whereas the APs in the University of Pavia image were built using threshold values in the range from 2.5% to 10% with respect to the mean of the individual features and with a step of 2.5% for the definition of the criteria based on the standard deviation attribute. Values of 100, 200, 500 and 1000 were selected as references for the area attribute. The fluctuation epsilon in Equation (8) is heuristically found and 10% of the class atom position range in our experiments. It should be noted that each sample is normalized to be zero mean, unit standard deviation, and all of the results are reported over ten random partitions of the training and testing sets. All of the implementations were carried out using MATLAB R2015a on a desktop PC equipped with an Intel Core i7 CPU (3.4 GHz) and 32 GB of RAM.
4.2. Model Parameter Tuning
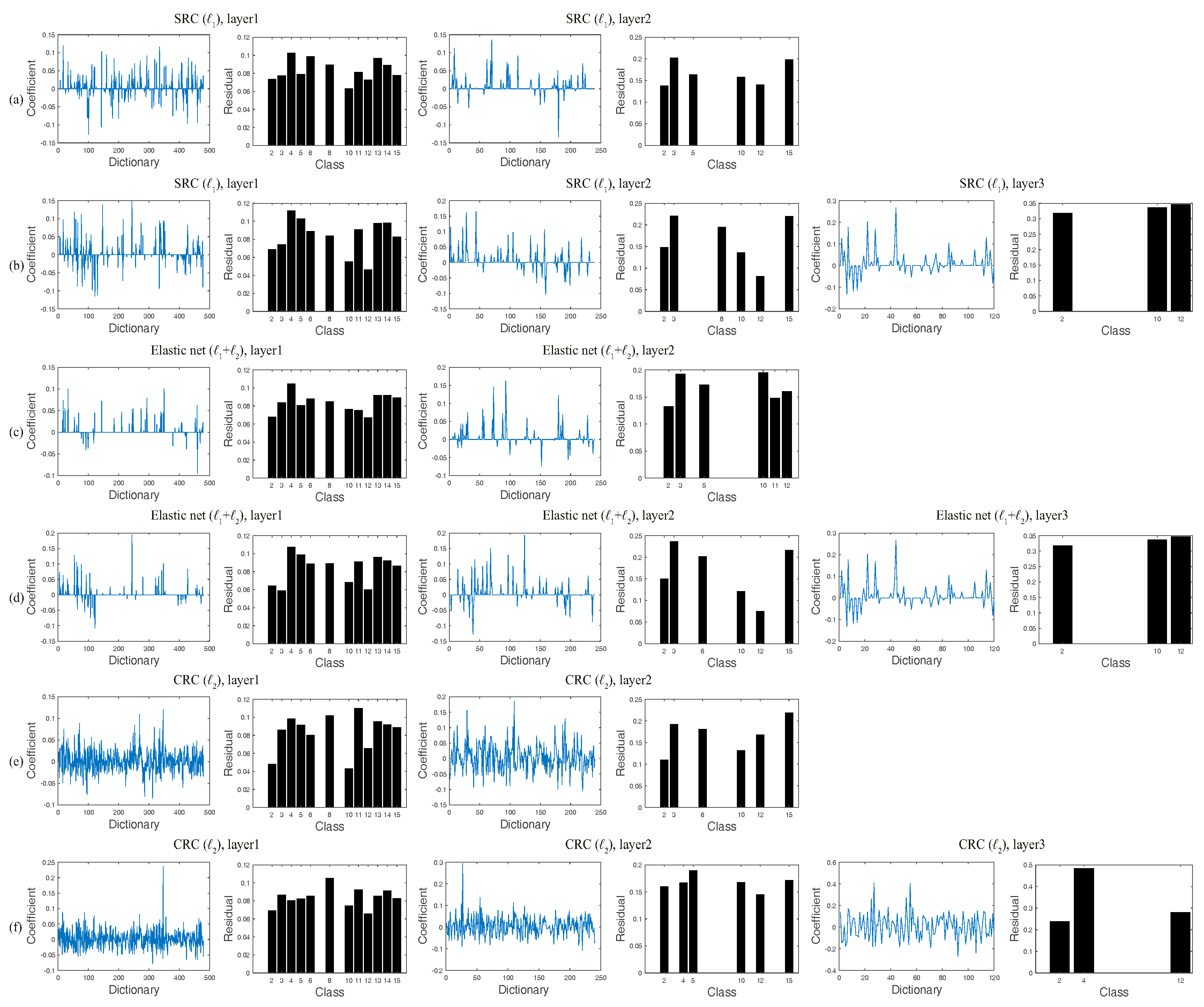
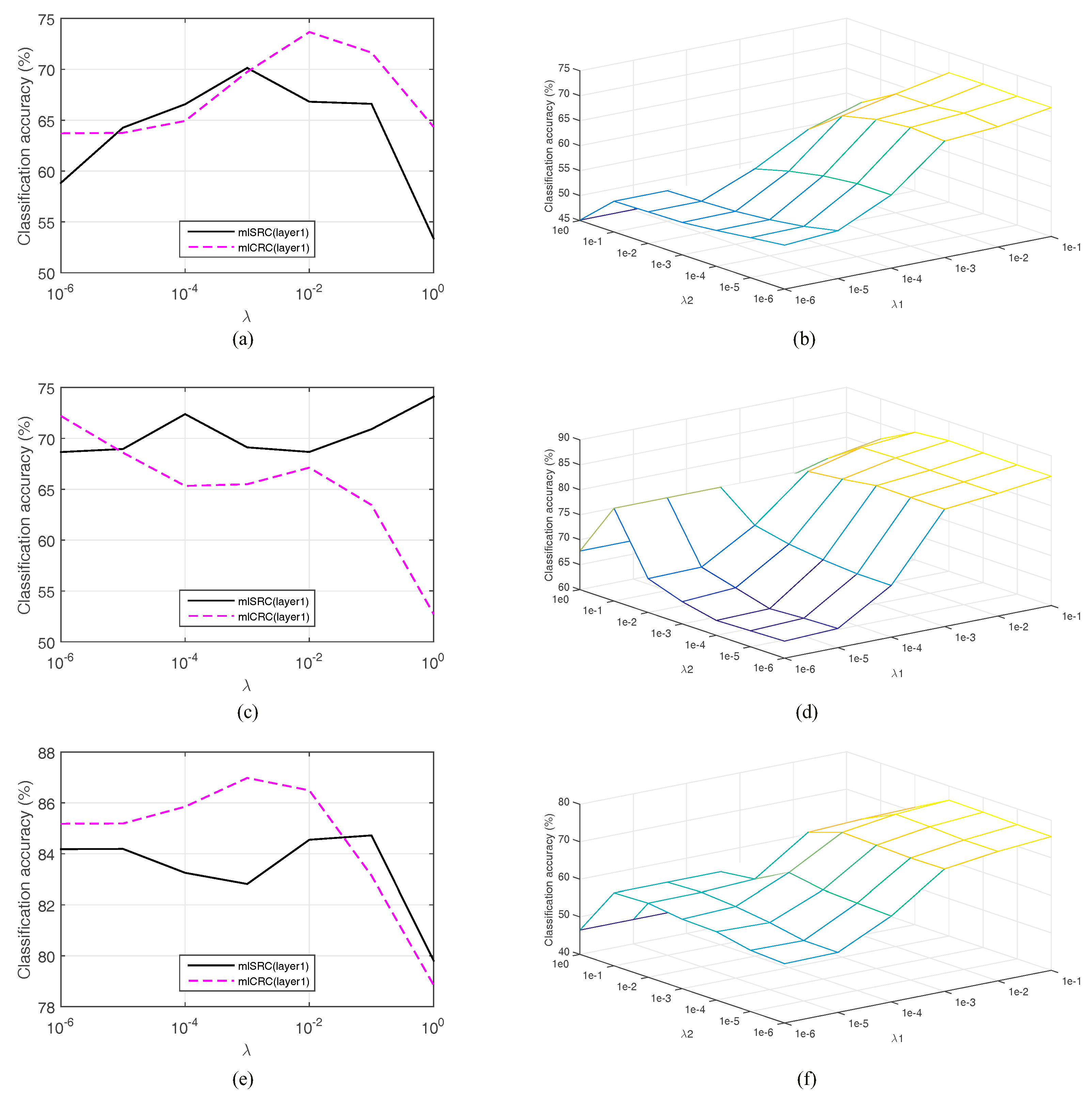
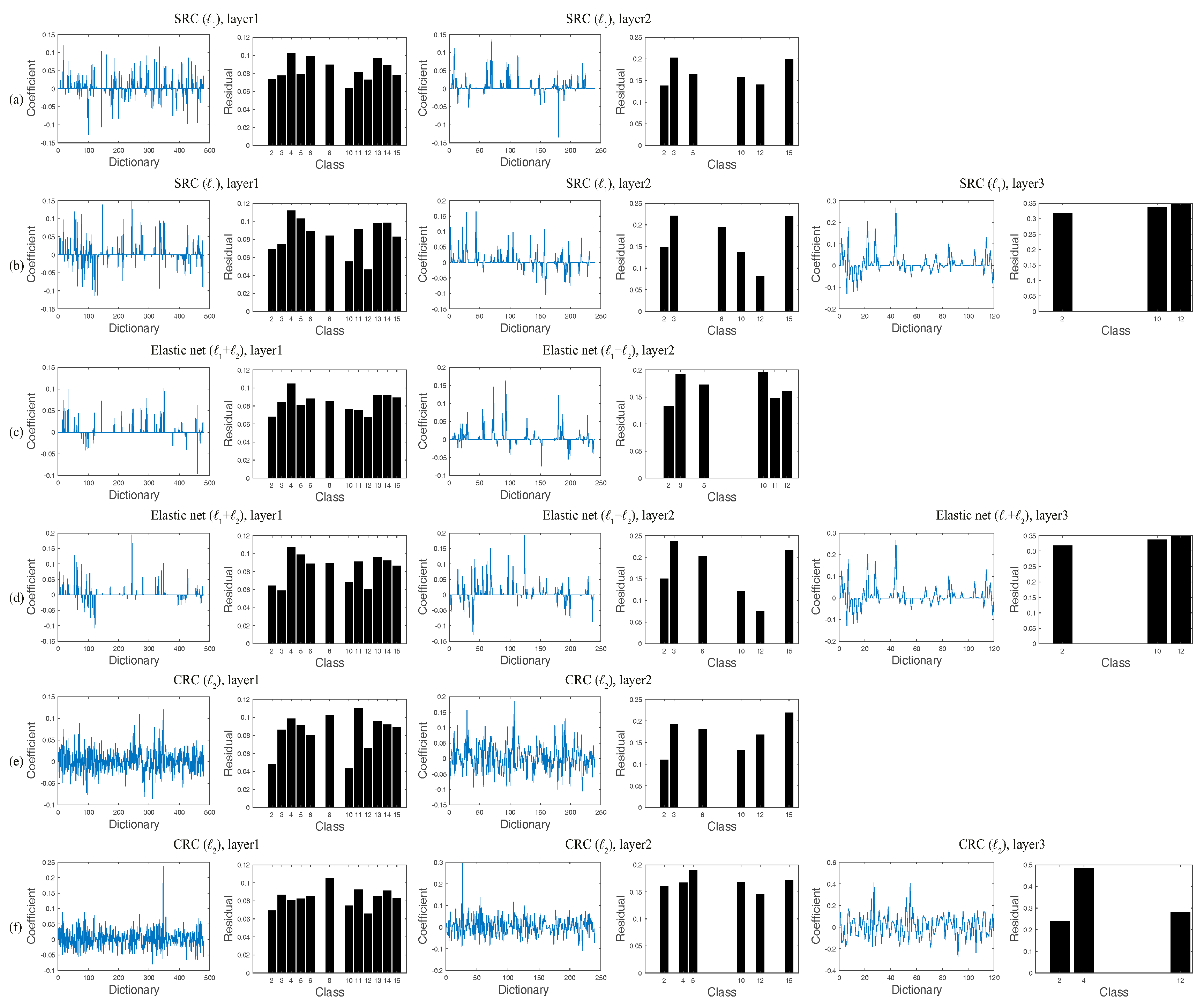
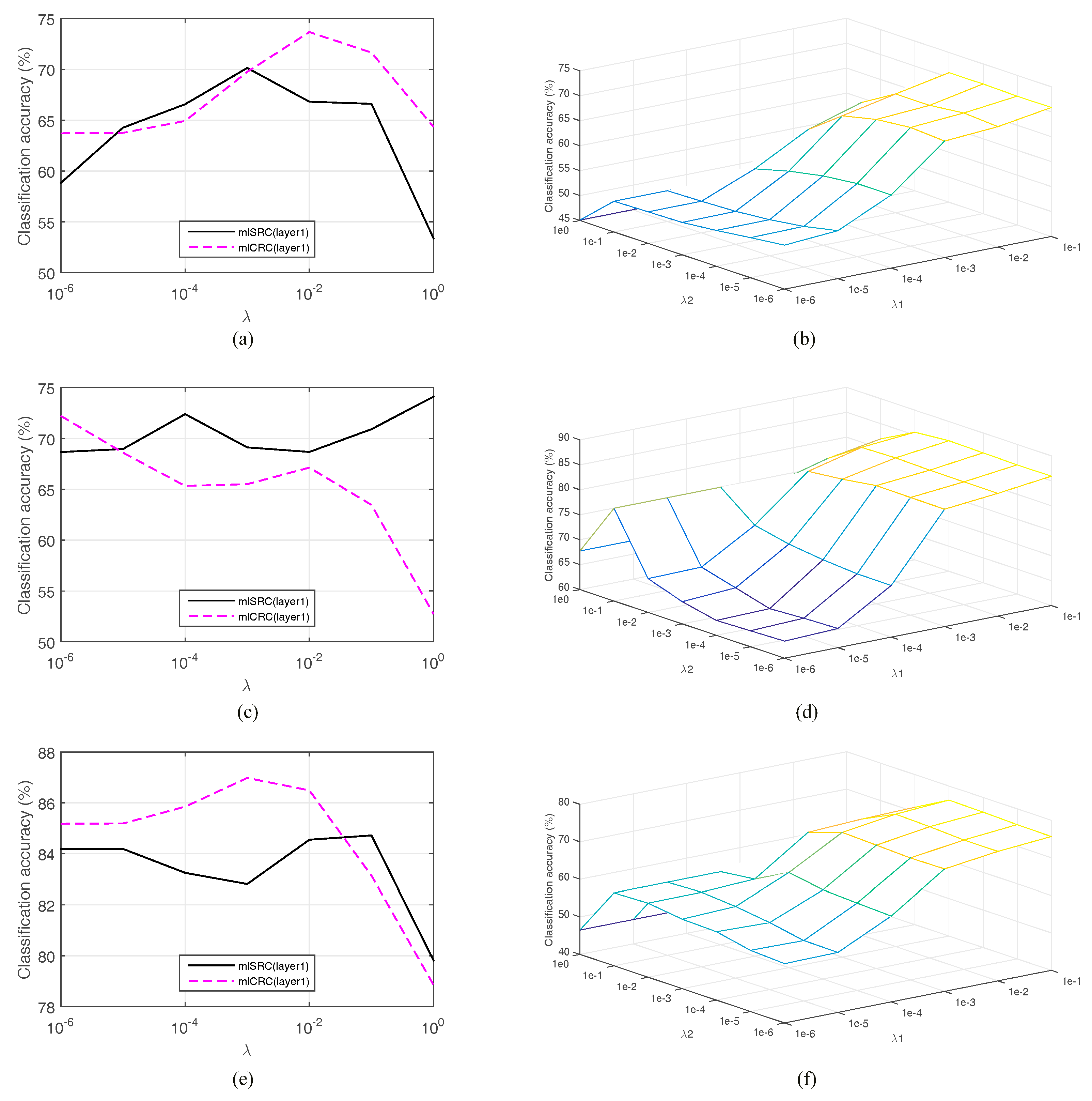
We investigate the parameters of the proposed classification framework. As a regularized parameter, the adjustment of
λ is important to the performance of representation-based classifiers. We conduct the five-fold cross-validation test using training data by a linear search in the range of [1 × 10
−6 1 × 10
−5 1 × 10
−4 1 × 10
−3 1 × 10
−2 1 × 10
−1 1] for the regularization parameter in the proposed method. The associated parameters for other considered methods are also done in the same way. We empirically found that best regularization parameters specific to individual methods led to good performance. It can be noted that the regularization parameters from the second layer in the proposed method are sub-dictionary dependent and specific; namely, the five-fold cross-validation from the second layer is done for each test sample, which can achieve higher accuracy, but requires more computational time. For simplicity,
Figure 4a–f show the overall classification accuracies of three proposed representation-based classifiers in the first layer versus the regularization parameter
λ for the Indian Pines, University of Pavia and Salinas images, respectively. Similarly, the parameter tuning of
λ for other investigated methods are also observed. Note that the optimal parameter
λ is varied according to different training rates.
4.3. Experiment 1: Results on the Indian Pines Classification
We perform a comparative evaluation of our proposed mlSR approach against several state-of-the-art sparse classification methods mentioned above, as summarized in
Table 3 and
Table 4. Based on the results in
Table 3, one can easily see that the classification performances of the proposed mlSRC, mlCRC and mlENRC approaches considerably and consistently outperform those of the other baseline algorithms (except APSVM and mlAPSRC) over a range of training samples.
Table 4 reports the average OA, AA, class-specific accuracies (%),
κ statistic and computational time of ten trials in seconds using one hundred and twenty training samples per class (mlAP-based and APSVM are not presented because of the limited column space). As expected, the third best method, mlENRC, with the obtained OA,
κ, and AA of 86.87%, 0.856 and 91.16%, respectively, which outperforms the single-layer baselines (e.g., SRC, CRC, ENRC and kernelized versions) and SVM, and the increases of OA,
κ, and AA range from 3.02% to 17.13%, 0.034 to 0.178 and 1.51% to 11.56%, respectively. The top two best methods are APSVM (91.23% at 120 training samples) and mlAPSRC (90.21% at the same training ratio) respectively, and the reason is that the attribute profiles provide better discriminative features than the globally-filtered features. To our best knowledge, this result is very competitive on this dataset, which indicates the effectiveness of the proposed mlSR framework.
As can be seen from
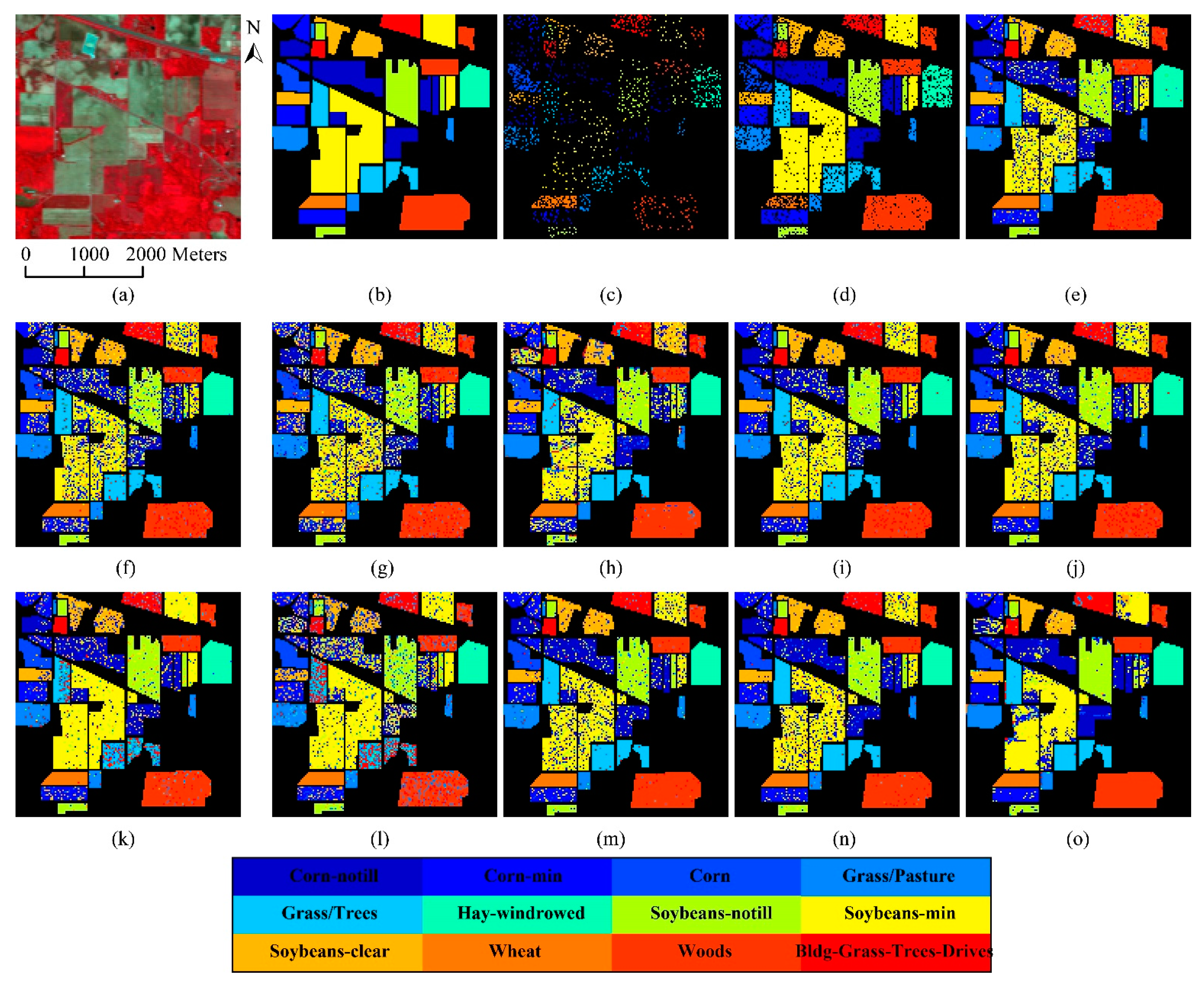
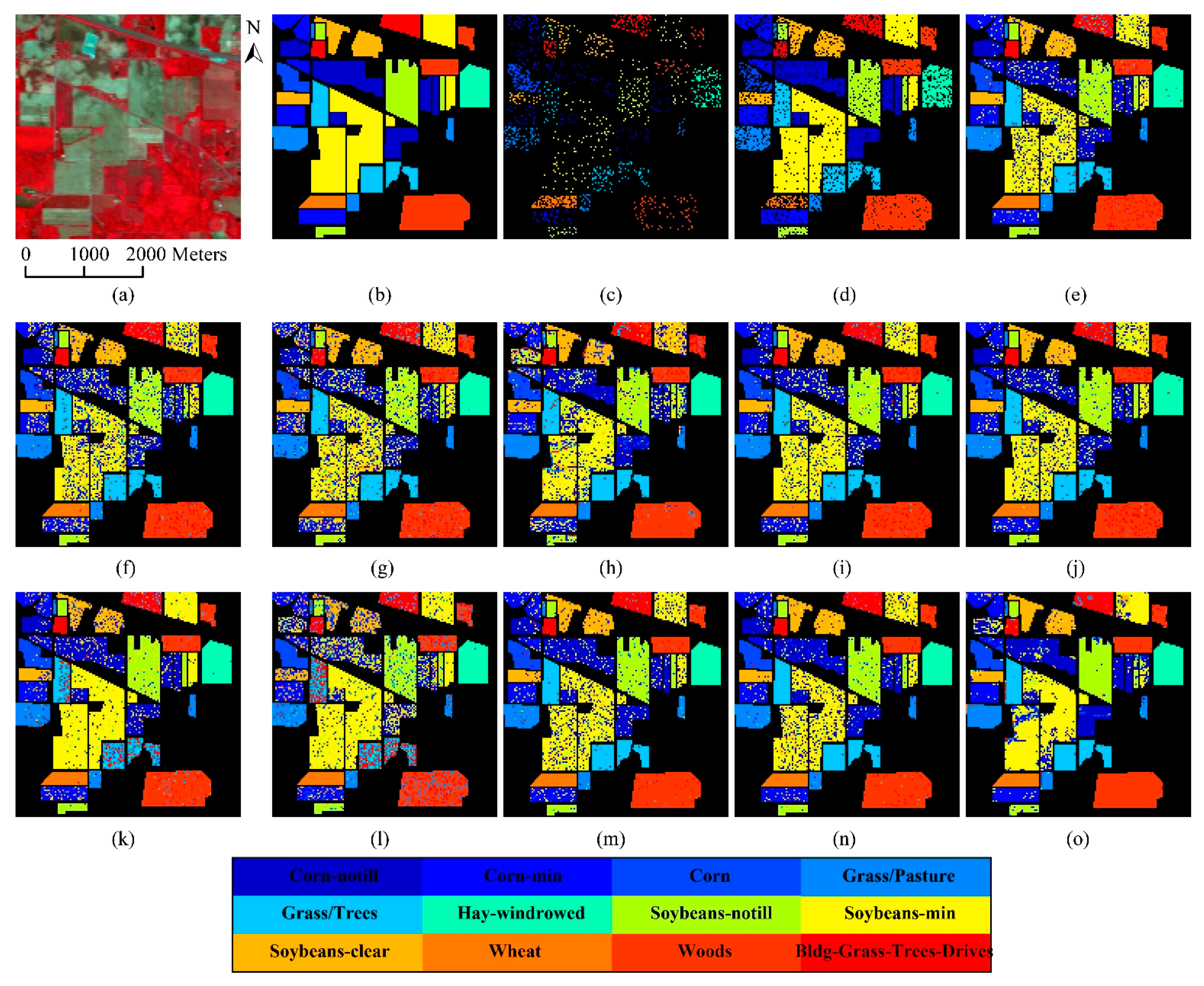
Table 4, SVM is the fastest, and our proposed mlSRC, mlCRC and mlENRC methods require a larger computational effort, but also achieve better classification accuracy than all competitors. Nevertheless, a fusion strategy using multiple parameters instead of cross-validation for regularization parameter selection at consequent layers can be utilized to reduce the computational time. The classification maps of the Indian Pines generated using the proposed methods and baseline algorithms are shown in
Figure 5 to test the generalization capability of these methods. It is shown in
Figure 5 that the three proposed mlSRC, mlCRC and mlENRC methods result in more accurate and “smoother” classification maps (with reduced salt-and-pepper classification noise) compared with traditional SRC/CRC, even kernelized SRC/CRC and SVM, which further validates the effectiveness and superiority of the proposed mlSR assignment framework for HSI classification. The results also show that the single-layer SRC, CRC and ENRC always produce inferior performances on this test set, most likely in part due to the instability of the single-layer SR. Our analysis also shows that the KSRC and KCRC have a comparable performance compared with SVM, mlENRC and mlAPCRC, as well.
The results in this experiment show that the proposed multi-layer assignment framework is effective to boost classification performance with an improved accuracy of about 3% to 14% via a multi-layer SR. The underlying mechanism of our methods accords with the observation that the sparse coefficients obtained from the second layer lead to a total correct label assignment, where the classes ranked within the top half of the minimal residuals are utilized to do dictionary assembling for each test sample. As a result, the classification performance is guaranteed to increase, which clearly denotes the effectiveness and superiority of the proposed mlSR assignment framework.
4.4. Experiment 2: Results on the University of Pavia Classification
The classification results of the proposed methods and baseline algorithms for the University of Pavia are summarized in
Table 5 and
Table 6. We compare the classification accuracies of our approaches with traditional SRC and CRC, kernelized SRC and CRC and SVM on this dataset. As in the Indian Pines experiments, our proposed mlSRC, mlCRC and mlENRC methods yield higher classification accuracies than any other baseline algorithms. Observing
Table 5, we can find that three proposed mlSRC, mlCRC and mlENRC approaches are consistently better than all baseline methods (except AP-based and mlAP-based) from a small number of training samples (five and ten per class) to a larger one (one hundred and twenty per class). Specifically, as provided in
Table 6 (mlAP-based and APSVM are not presented due to the limited column space), the OA,
κ and AA for our best approach, mlENRC, can be improved from 1.4% to 21.93%, 0.016 to 0.251 and 0.12% to 22.49%, respectively. More specifically, the increases for mlENRC in OA,
κ and AA are about 1.4%, 0.016% and 0.12% than that of the fourth best method, KSRC, respectively. Interestingly, the mlAP-based methods (i.e., mlAPSRC and mlAPCRC) achieve better accuracies than their counterparts (that is, APSRC and APCRC), respectively. This can be due to the better stability of proposed mlSR assignment framework. Moreover, we observe that our proposed methods require the largest time, mainly due to the cross-validation again from the second layer, but the classification performance is improved in spite of relatively slight improvements. In addition, CRC and KCRC are relatively lower than SRC and KSRC. For this dataset, small spatial homogeneity in this image might cause the training samples from other classes also to participate in the linear representation of the test samples, which leads to some misclassification. Visualization of the classification map using 120 training samples per class is shown in
Figure 6. The effectiveness of classification accuracies can be further confirmed by carefully visually checking the classification maps. The obvious misclassification among the class of asphalt and the class of shadow by CRC illustrates the inadequacy of the single-layer SR, which is greatly alleviated in
Figure 5m–o, and the best result is achieved in
Figure 5o. Therefore, the proposed mlSR framework in the classifiers helps in the discrimination of different types of land cover classes.
A similar phenomena can be observed that the multi-layer assignment framework achieves improvements of about 1.2% to 14% to a great extent. The highest accuracy is achieved by mlAPSRC in all training ratios (the second best method is mlAPCRC), which may be associated with the fact that the highly related samples after AP-based processing are chosen to produce a more discriminative power of SRC. Another interesting case is found that AP/mlAP-based methods are always better than non-AP-based ones.
4.5. Experiment 3: Results on the Salinas Classification
To validate the performance of the proposed mlSR, mlCRC and mlENRC with both under-complete and over-complete dictionaries, we have tested over a wide range of numbers of training samples, varying from five samples per class to 120 samples per class and the classification results for this dataset are shown in
Table 7 and
Table 8. Likewise, it can be observed from the results that the proposed mlSRC, mlCRC and mlENRC give a consistently better performance than other non-AP-based algorithms. It is obvious from
Table 8 (mlAP-based and APSVM are not presented due to the limited column space) that almost all of the class-specific accuracies are improved and hold for interpreting the consistency of the three proposed mlSRC, mlCRC and mlENRC algorithms. Overall, the OA,
κ and AA for this dataset can be improved from 2.35% to 6.91%, 0.026 to 0.074 and 0.88% to 5.19%, respectively. Specifically, the increases in OA,
κ and AA for the overall best method mlENRC over the fourth best method KCRC are 2.35%, 0.026 and 0.88%, respectively. The best approach is mlAPCRC, which reaches 97.67% when the training ratio is 120 per class. The proposed multi-layer assignment framework and large structure in this HSI may account for this. The classification maps shown in
Figure 7 are generated using the proposed algorithms and baselines. Based on the visual inspection in
Figure 7, the maps generated from classification using the multi-layer SR framework are less noisy and more accurate than those from using single-layer SR. For example, the classification map of mlENRC (
Figure 7o) is more accurate than the map of SVM (
Figure 7e). The misclassification of SVM mostly occurred between the class of grapes-untrained and vineyard-untrained. This is explained by the fact that most of the classes in the image represent large structures, and less spatial features could not well capture local structures. Similarly, the proposed methods are computationally intensive during testing. In this case, multiple parameter fusion instead of cross-validation can be employed in order to decrease the computational time. Therefore, the conclusion is that the classification performance of the proposed approaches can be greatly improved via a novel multi-layer SR framework.
As the previous two HSI datasets, the multi-layer assignment framework can obtain an increase of about between 2% and 11% by the introduction of multi-layer SR in the Salinas image, the proposed multi-layer framework accumulates the classification results from different layers, which results in a greater accuracy and is superior to the single-layer hard assignment due to unstable coefficients based on the minimal residual alone. Therefore, the proposed mlSR framework is competent to improve classification performance.
5. Discussion
The design of a proper SR-based classification framework is the first important issue we are facing, as HSI datasets are complex, and the within-class variation and spatial details in complex scenes cannot be well measured by the single-layer SR. In the design of the SR-based model, we propose a multi-layer SR framework to produce discriminative SR for the test samples and achieve stable assignment distributions via the adaptive atoms’ selection in a multi-layer manner, then three proposed approaches, mlSRC, mlCRC and mlENRC, are developed. The proposed mlSRC, mlCRC and mlENRC are based on the same idea, but adopt different sparse optimization criteria. The different criteria bring out the difference among them for HSI classification, and the difference of the three proposed methods is related to the constructing manner of the sparse optimization solver. In order to balance the classification performance and complexity of the framework, the three-layer SR is adopted. Meanwhile, a filtering rule is heuristically exploited to identify the obviously misclassified samples for the next layer SR; moreover, dictionary assembling and new cross-validation on the parameter searching for each test sample are conducted. These enhancements lead to a substantial improvement in performance and saves computational time during testing. Another important observation is that our proposed methods are computationally intensive; this is mainly due to the fact that the optimal regularization parameter for each test sample is searched via cross-validation again from the second layer. Thus, the multiple parameter fusion is expected to be a good alternative to cross-validation in computationally efficiency. Nevertheless, our proposed mlSR framework has another nice property that can be easily plugged into any representation-based classification model using different HSI features (e.g., spectral feature, spatial features and spatial-spectral features). Last, but not least, a structural dictionary consisting of globally-spatial and spectral information is constructed to further boost the classification performance.
Overall, by comparing the classification performances of Experiment 1, Experiment 2 and Experiment 3, it is clear that the proposed multi-layer assignment framework is superior to the single-layer competitors in terms of classification accuracy; this is expected. The improvements mainly come from the proposed multi-layer SR framework, which confirms our former statement. It is interesting to note that for small considered class, such as wheat (C13) in the Indian Pines image and metal sheets (C5) in the University of Pavia, and for difficult class, for instance, grapes (C8) in the Salinas image, the proposed methods exhibit very good generalization performance with an OA of 100% or of remarkable increase, which validates our observation well that mlSRC, mlCRC, mlENRC and mlAP-based methods can improve the performance of the learnt model for a specific class.
In order to further assess the performance of the proposed method, we select some methods that use joint/spectral-spatial sparse representation classification for comparison. Reference results were provided in [
34] for fused representation-based classification, sparse representation-based nearest neighbor classifier (SRNN), the local sparse representation-based nearest neighbor classifier (LSRNN), simultaneous orthogonal matching pursuit (SOMP) and the joint sparse representation-based nearest neighbor classifier (JSRNN) proposed in [
33]. Additionally, the reported accuracies from [
28] for joint sparse representation classification (JSRC), collaborative representation classification with a locally-adaptive dictionary (CRC-LAD) and nonlocal joint CR classification with a locally-adaptive dictionary (NJCRC-LAD) and from [
36] for pixel-wise learning sparse representation classification with spatial co-occurrence probabilities estimated point-wise without any regularization (suffi-P, i.e., LSRC-P) and the patch-based version (pLSRC-P) are shown. Finally, logistic regression via variable splitting and augmented Lagrangian-multilevel logistic (LORSAL-MLL), joint sparse representation model (JSRM) and multiscale joint sparse representation (MJSR) in [
29] are compared.
Table 9,
Table 10 and
Table 11 illustrate the classification overall accuracy of mlSRC, mlCRC, mlENRC, mlAPSRC and mlAPCRC in comparison with the above methods for the Indian Pines, University of Pavia and Salinas datasets, respectively. For a fair comparison, the same number of training samples in the same image is kept. As can be seen from
Table 9,
Table 10 and
Table 11, the classification accuracies in our approaches are comparable or better than the accuracies of the other compared methods in the same image. For the Indian Pines, the OA of mlENRC is 2.11% higher than CRC-LAD. For the Pavia University, the OA of mlAPSRC is 3.71% higher than NJCRC-LAD and 5.74% higher than JSRNN, respectively. For the Salinas, the improvement in OA of mlAPCRC over JSRM is 1.31%. The reason is that we use a multi-layer sparse representation framework with methods that are different from each other, and the classification performances are consistently improved.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}