1. Introduction
Since the advent of global imaging satellites such as AVHRR, the production of data on land cover at global scales has been the focus of much effort internationally. Over the last decade several such products have been released, including the MODIS land cover product suite [
1,
2], the Global Land Cover 2000 product (GLC2000) [
3], and the GlobCover products [
4,
5]. An important use for these data is providing the spatial distribution of variables, such as Plant Functional Type (PFT), for Earth System Models of varying degrees of complexity. For example, [
6] used the AVHRR land cover map developed by [
7] to prescribe dominant cover in the US National Centre for Atmospheric Research (NCAR) land model, and [
8] parameterised a simple ecosystem model with MODIS land cover data to estimate the regional carbon budgets in the Mid-West US. Some Dynamic Global Vegetation Models (DGVMs) are able to ingest land cover data to initialise a dynamic run (
i.e., where the DGVM predicts competition between PFTs over time) or simply to prescribe static PFTs for the calculation of contemporary carbon budgets. Examples of the use of satellite-derived land cover in DGVMs are given by [
9,
10]. Some models of this type are designed to be used as the lower boundary for climate models, and any errors in the model outputs have the potential to feed into climate simulations. Satellite derived land cover data are also used in atmospheric transport model inversion-based estimates of land–atmosphere fluxes of various chemical species: [
11] use the continuous vegetation fields produced by [
12,
13] to analyse the results of global inversions of CO
and O
data; [
14] used MODIS land cover data to assign SiB3 biome types for estimating high resolution carbon fluxes using atmospheric inversion; [
15] used the GLC2000 product to delineate tropical forest for N
O emissions inventories.
Since remotely sensed land cover data inevitably contain mis-classifications, various methods have been proposed to characterise the uncertainty associated with land cover maps constructed by the the remote sensing community. Generally, quantifying uncertainty falls into one of three categories: comparison against ground data, analysis of classification statistics (e.g., measures of separation in spectral space), or comparisons between different land cover products. Comparison against ground truth provides, in principle, the fullest description of the errors in land cover data. The ideal scenario is that a very large number of sites are visited and the land cover present at each is compared with that in the remote sensing land cover map. This information is typically encoded in a confusion matrix, which provides the user of the data with an easily interpretable overview of which classes are most likely to be incorrectly classified (and as what classes) as well as an overall measure of mis-classification in the product. Further details are provided in
Section 2.2 and a comprehensive description of the construction of such matrices and issues surrounding them is given by [
16]. In practice, it is often prohibitively time consuming or too expensive to obtain enough samples. Furthermore, correctly representing the spatial scale of the satellite data from the ground samples is problematic. Consequently, it is becoming more common to construct confusion matrices against higher resolution satellite data that has been interpreted manually. Such a matrix is used in this study and is described in greater detail in the methods section. Classification statistics, such as entropy measures described by [
17], are not considered in this paper but may provide useful additional information in further studies. In essence, these methods assume that the more homogeneous the maximum likelihood of a given class is (
i.e., the lower its entropy) the more accurate the classification. If this assumption holds, then the information could, in principle, be used directly in the statistical model presented here. However, because the most readily available information on classification accuracy is typically in the form of a confusion matrix, this is the focus of the current study. Comparisons between land cover products, such as that presented by [
18], are useful for identifying problematic regions or classes but cannot provide a probabilistic measure of uncertainty and are hence not considered here.
Despite the efforts taken to describe the uncertainty in satellite derived land cover data, little has been done to assess the direct impact of these uncertainties on the predictions of large scale land surface models, such as DGVMs. Quaife
et al. [
19] used various 1
land cover data to prescribe PFT distribution for the Sheffield Dynamic Vegetation Model [
20] and compared the predicted carbon balance to that predicted by the same model using a nominally accurate land cover map of the UK. The results showed large discrepancies in the net carbon balance of the UK, depending on which land cover product was used. Poulter
et al. [
21] define an index of dissimilarity between several satellite land cover products to diagnose likely causes of uncertainties in modelled variables on global scales, but the uncertainties are not propagated through a model. Neither of these studies directly quantifies the impact of uncertainty in an individual land cover product on model outputs. Rather, they infer uncertainty by comparison with other land cover data sets. While these studies are undoubtedly valuable, there is an obvious need for techniques that connect the information on land cover uncertainty from the remote sensing community with the needs of the modelling community.
It is important to acknowledge that the confusion matrix does not encompass all of the errors associated with land cover data that might affect a land surface model. Perhaps the largest of these is the translation between land cover classes represented in the remote sensing product and the plant functional types required by a model. In some instances the translation is unambiguous; for example, if a land cover classification reports 100% presence of deciduous broadleaved trees, it is clear as to which PFT this should be assigned. However, this is rarely the case. Often classification schemes report mixed land cover classes with unspecified proportions or proportions within given ranges. This is true of many of classes in the GlobCover maps, which are the focus of this paper. Typically, the translation between land cover classification is done using subjective methods and hence contain potentially significant errors. This is explored in detail in [
21].
This papers focuses on errors in the classification alone. The motivation behind this is to illustrate a technique for producing estimates of uncertainty in satellite derived land cover maps on large scales, which can subsequently be propagated through a model so as to understand the sensitivity of its prognostics variables to likely classification errors. Future work will extend this to incorporate errors in land cover to PFT translation.
Often the remotely sensed pixels are aggregated to a site (in the order of
) for the user to incorporate into their model and represented as the proportion of different cover types within each grid–cell. This article provides a Bayesian hierarchical model from which we are able to simulate the proportions of true land cover types in each site, across the entire region, thereby providing spatially varying posterior standard deviations to quantify uncertainty. Since the remotely sensed pixels are potentially mis-classified, we treat the true land cover proportions in each site as latent variables and model them by combining a spatial prior distribution constructed from the remotely sensed recordings with data in the confusion matrix. The method not only models the spatial variation in the true land cover values, but also the spatial variation in the errors of the remotely sensed data through the confusion matrix. The spatial prior is constructed for the site-specific probabilities of true land classes and is an approximation to a Markov random field prior. The model for the region wide confusion matrix is similar to that of [
22,
23], but rather than modelling the probabilities of the true classes, conditioned on the remotely sensed map, we model the probabilities of the remote sensed map classes, conditioned on the true classes, and we allow these map error probabilities to vary spatially.
One advantage of our method is in allowing for a Monte Carlo simulation scheme that generates from the posterior distribution of true land cover proportions that easily computes when applied to large scale problems. The output of the simulation scheme can then be used as inputs to any model that requires land cover data as an input, and can consequently estimate likely errors in model outputs due to uncertainties in land cover information. The statistical method is described in detail in [
24], where it is demonstrated on a relatively small number of pixels representing a handful of PFTs. In this article, the method is applied to the GlobCover 2009 data set at the global scale, using the full range of land cover classes. This highlights the utility of the method for working with global land surface and climate models. The results show the spatial distribution of errors in the GlobCover data and the performance of a subset of the classes is explored.
3. Simulating the Distribution of True Land Cover Classes
The technique applied in this paper is specifically designed to model uncertainty in remotely sensed land cover maps that have been aggregated to coarser spatial resolutions. The technique incorporates the data in the confusion matrix, spatial correlation in true land cover, and spatial correlation in misclassification or error probabilities, with the advantage of permitting a simple Monte Carlo simulation scheme to draw from the posterior distribution of the true land cover classes. Standard deviations of this posterior distribution allows the quantification of uncertainty. Here we only describe the components required to illustrate the implementation of the simulation scheme and the analysis of uncertainty of the GlobCover data. The reader is directed to [
24] for more details on the statistical method and assumptions.
Say there are sites in a region, and each site contains recorded pixels, of which are classified as land cover type by the remote sensed map. Then , where p represents the total number of land classes under consideration. It is important to note that it is the true, but unknown, land class that we are interested in. We denote the true land class for a pixel as t. The relevant probability then is the conditional probability that the true land class at a pixel within site s is t, conditioned on the fact that the remote sensed map classified the pixel as . We denote this conditional probability as , for , and .
Write
to be a
vector representing the true land cover proportions for site
s. It is the posterior distributions of
from which we wish to simulate in order to provide uncertainty estimates for the proportions of land cover classes in each site. Given the
s and the
s, we can write the posterior distributions of these proportions as a mixture of multinomial distributions where
and
is the multinomial distribution over the
remotely sensed land cover types
in site
s. The vector
contains the conditional probabilities that at site
s the true land class cover is
t, given the remotely sensed land cover class being
.
We now describe how data from the remotely sensed observations and the confusion matrix are used to model . First, a prior distribution is constructed for the probability of the true land cover classes within site s, which we denote for . The remotely sensed land cover data itself is used to construct by averaging over the proportions of land class t in a neighbourhood of the site s, thereby capturing the spatial distribution of the true land cover probabilities. In this application, the neighbourhood is taken as the sites (i.e., area) adjacent to site s.
Second, the data in the confusion matrix are used to construct the likelihood used to model the error probabilities, defined as the probability that the remotely sensed land classification is
, conditioned on the fact that the true land class is
t. We denote this conditional probability
. Consider the region-wide error probability vector,
. The t
th column of the confusion matrix records the number of (mis)classifications, given the true land cover observed was
t. Modelling the t
th column, denoted
, as a multinomial observation with vector probability
and specifying a Dirichlet prior
, where
α is the
parameter vector for a Dirichlet distribution, results in the posterior distribution for the region-wide error probabilities as
It is natural to suppose that the error probabilities also exhibit some form of spatial correlation, in that neighbouring pixels are more likely to be misclassified in a similar fashion than pixels further apart. To explicitly incorporate spatial dependence among the error probabilities at a global scale, such as the application in this paper, would be computationally very demanding. Also, we have no information available to model spatial variability in the error probabilities. Instead, we induce spatial correlation implicitly by allowing the
s to vary randomly from the region wide vector
according to a Dirichlet distribution where
independently for each site in the region. This introduces a single parameter,
d, to control the degree of increased variability, and hence the degree of correlation at the pixel level. For our application, we set a value of
, representing rather high correlation. This represents a somewhat conservative estimate in the sense that it is likely to over-estimate the errors globally. Experiments with other values of
d (not shown here) exhibited only small sensitivities to the choice of parameter value (See [
24] for a discussion on the modelling of the spatial error probabilities and the robustness of the results for different values of
d).
Finally, given
and
, Bayes’ Theorem allows us to model each
as
that are required for Equation (1). A Monte Carlo algorithm to simulate N realisations from Equation (1) is then the following straightforward procedure:
For
(1) Simulate for
For
(2) Calculate for
(3) Simulate for
(4) Calculate for from Equation (2)
(5) Simulate
end
end.
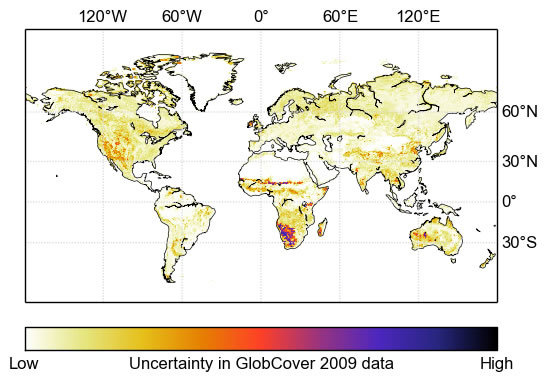
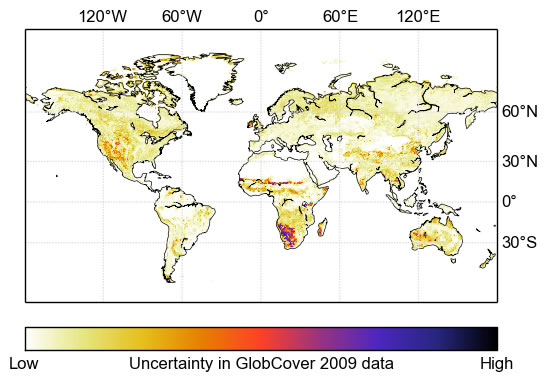
5. Discussion
5.1. Underlying Causes of Uncertainty
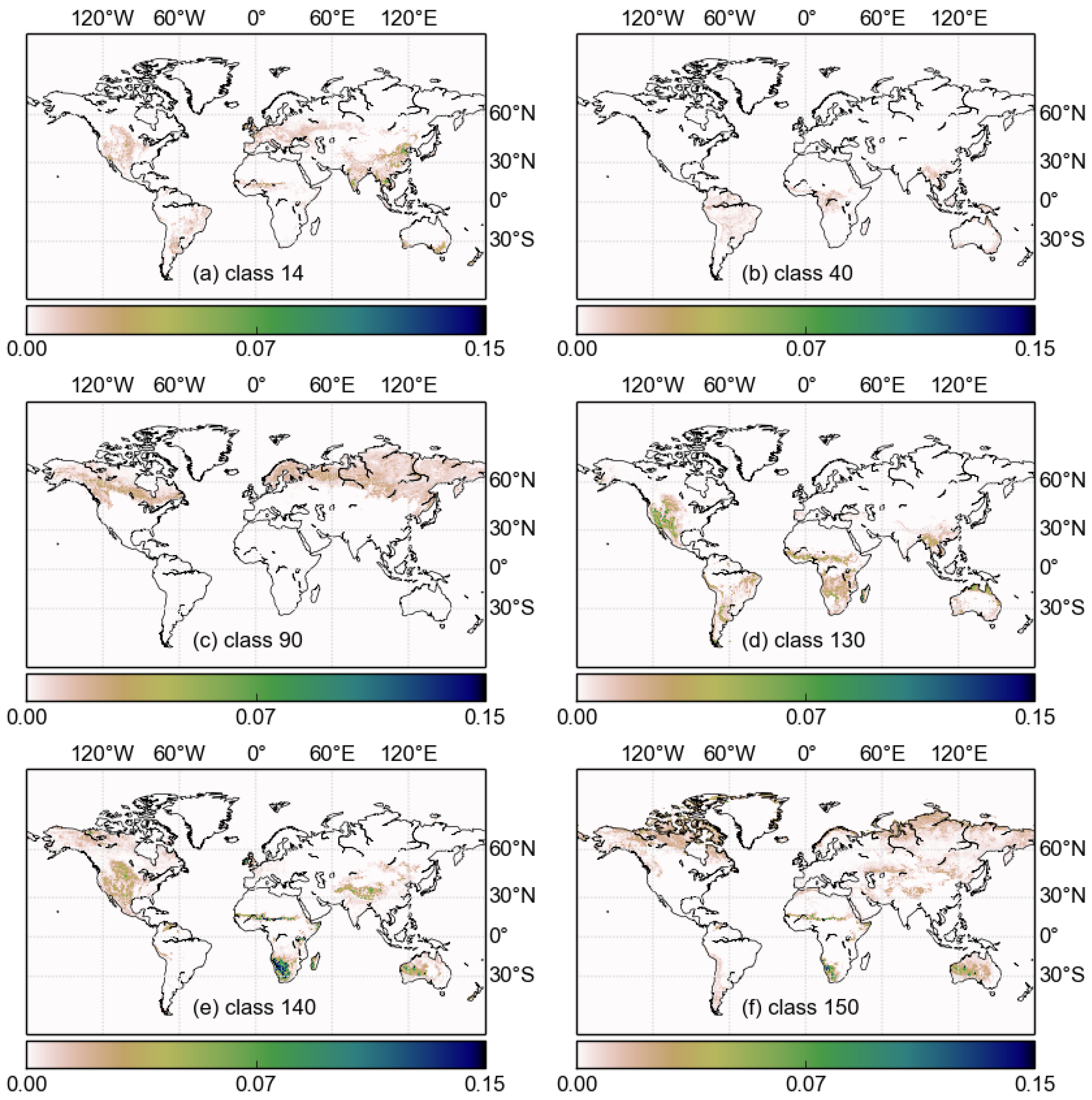
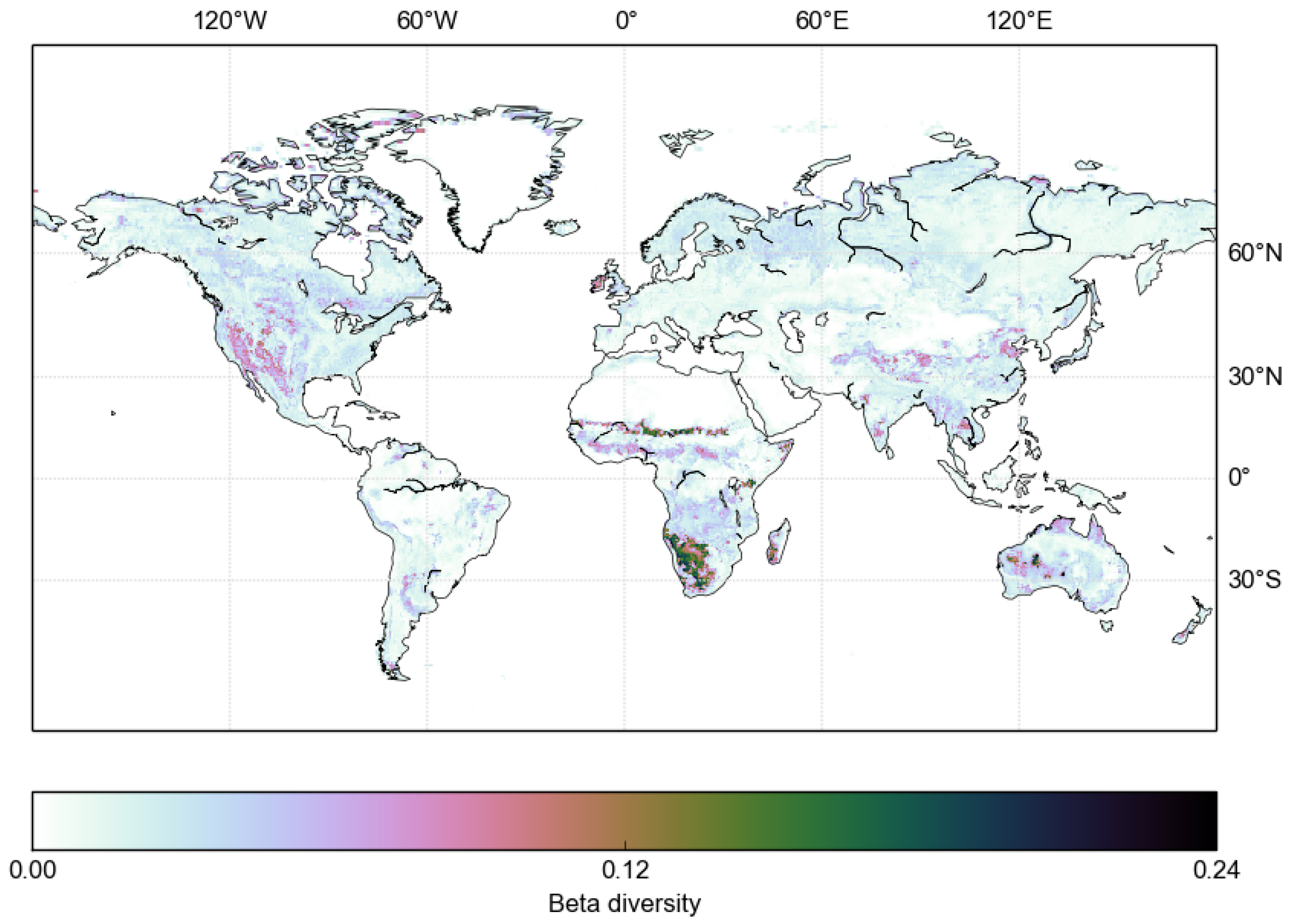
The pattern of uncertainties evident in the beta diversity shown in
Figure 6 is controlled by two factors: (1) the magnitude of the uncertainty of the classes present at any given point, and the degree to which they are confused with each other (
i.e., according to the confusion matrix) and; (2) the actual mix of classes present—even if a very confused class is present, the classes with which it is confused must also be present for it to become uncertain. Consequently, homogeneous areas such as the Amazon forest have very low uncertainty. Parts of southern Africa exhibit very high uncertainties, and these are due to the presence of class 140 (closed to open grassland) along with other classes that it is confused with. Class 140 itself is one of the most erroneous in the original confusion matrix.
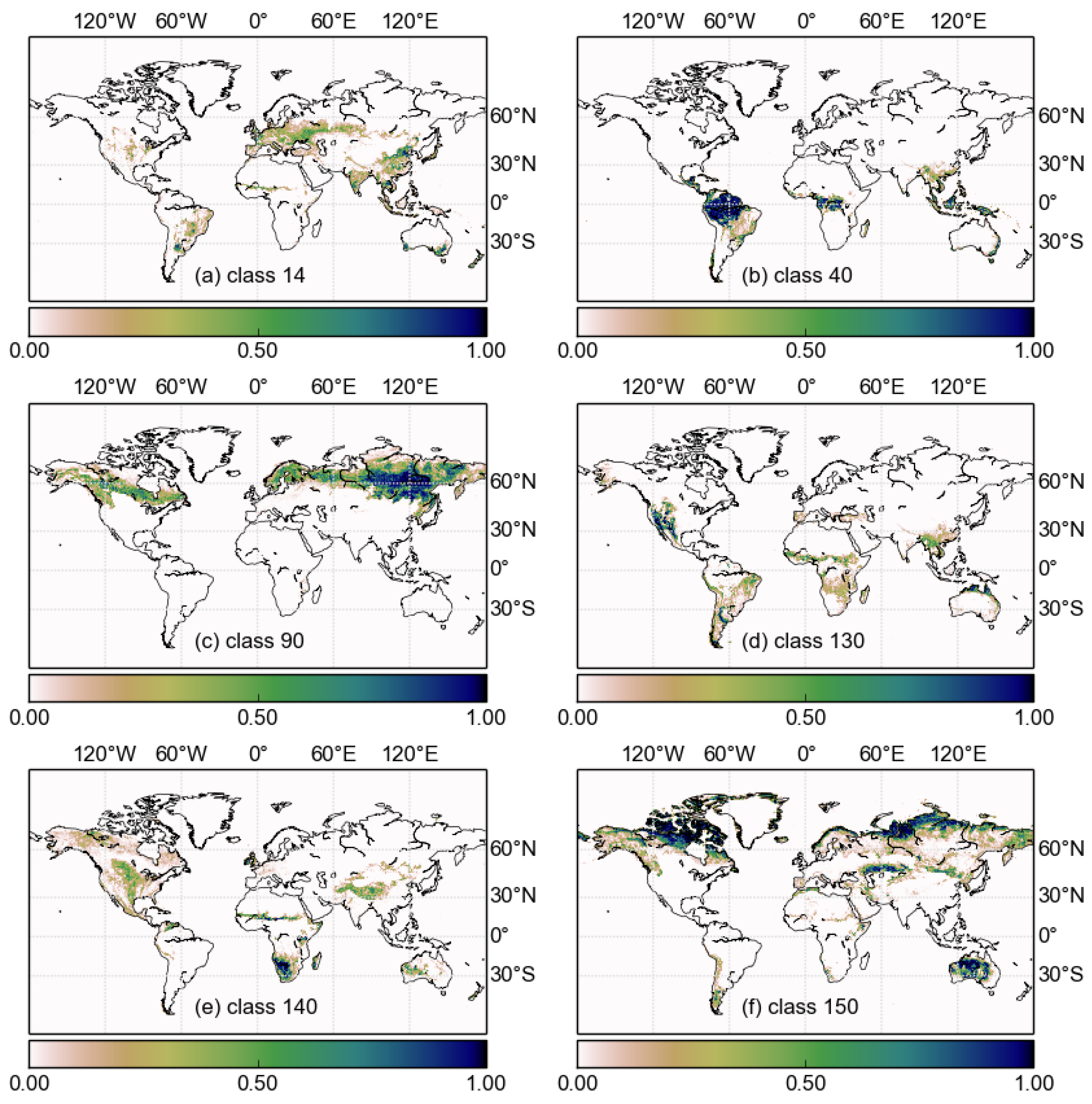
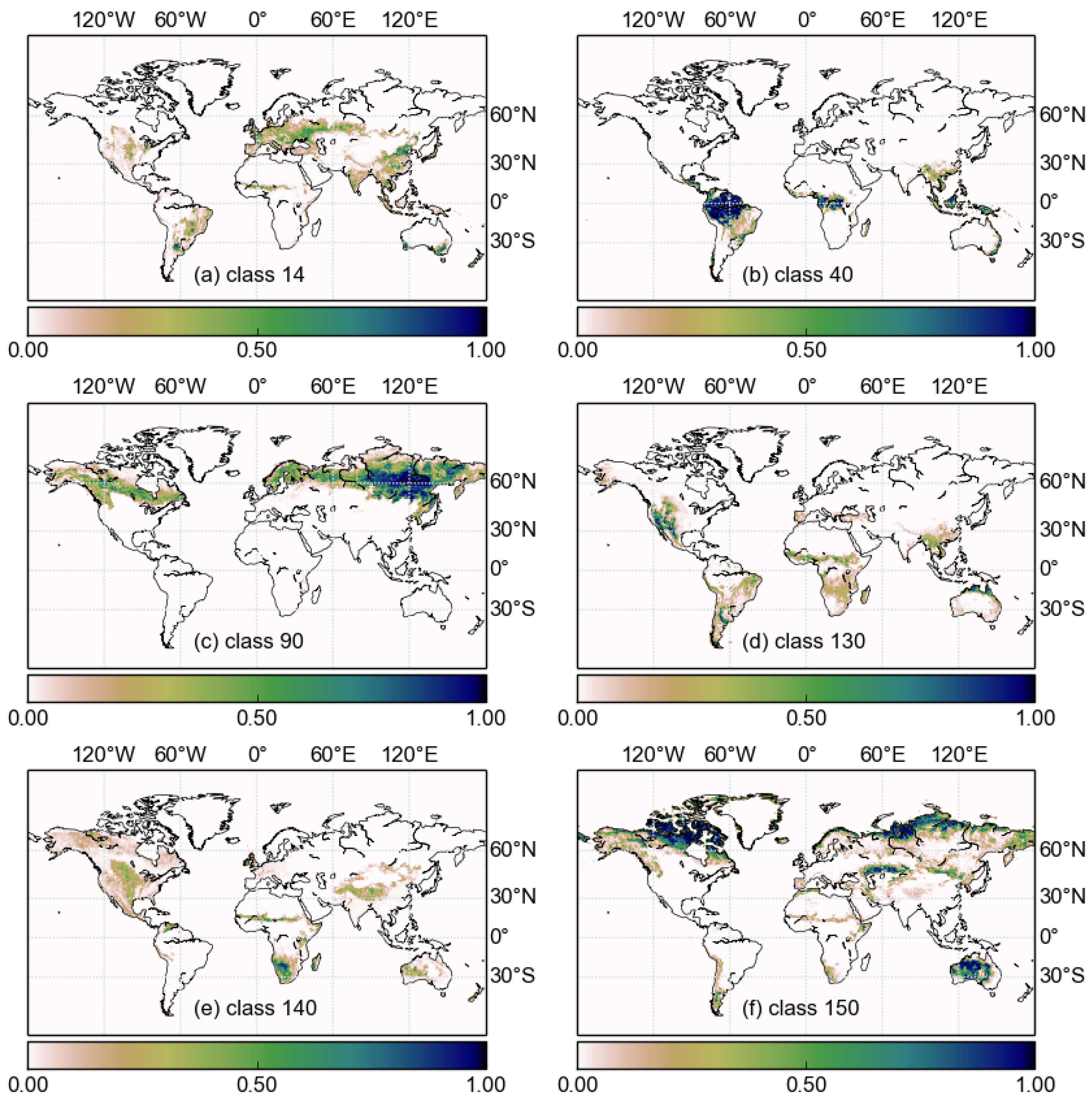
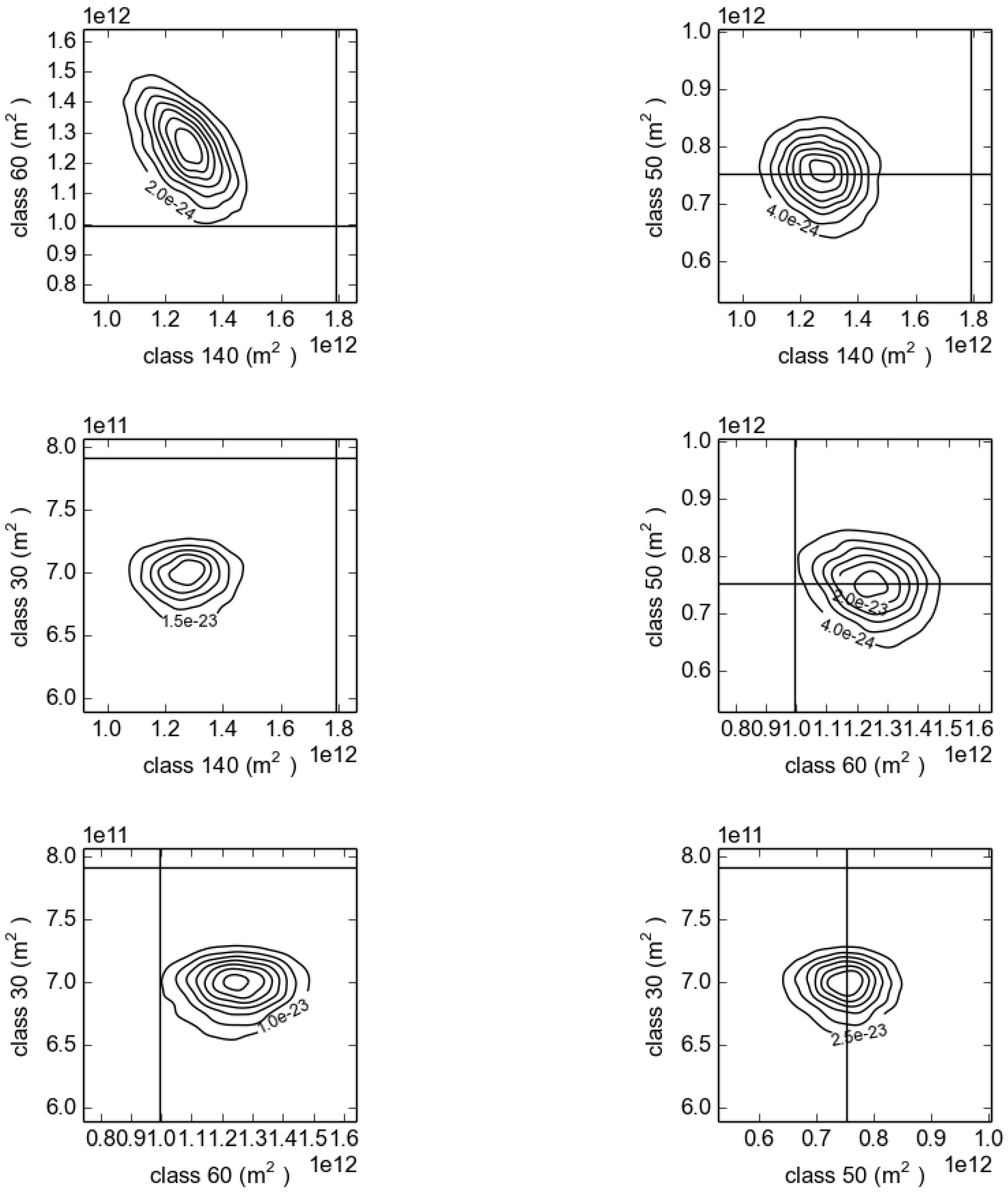
To examine the high uncertainties in southern Africa in more detail,
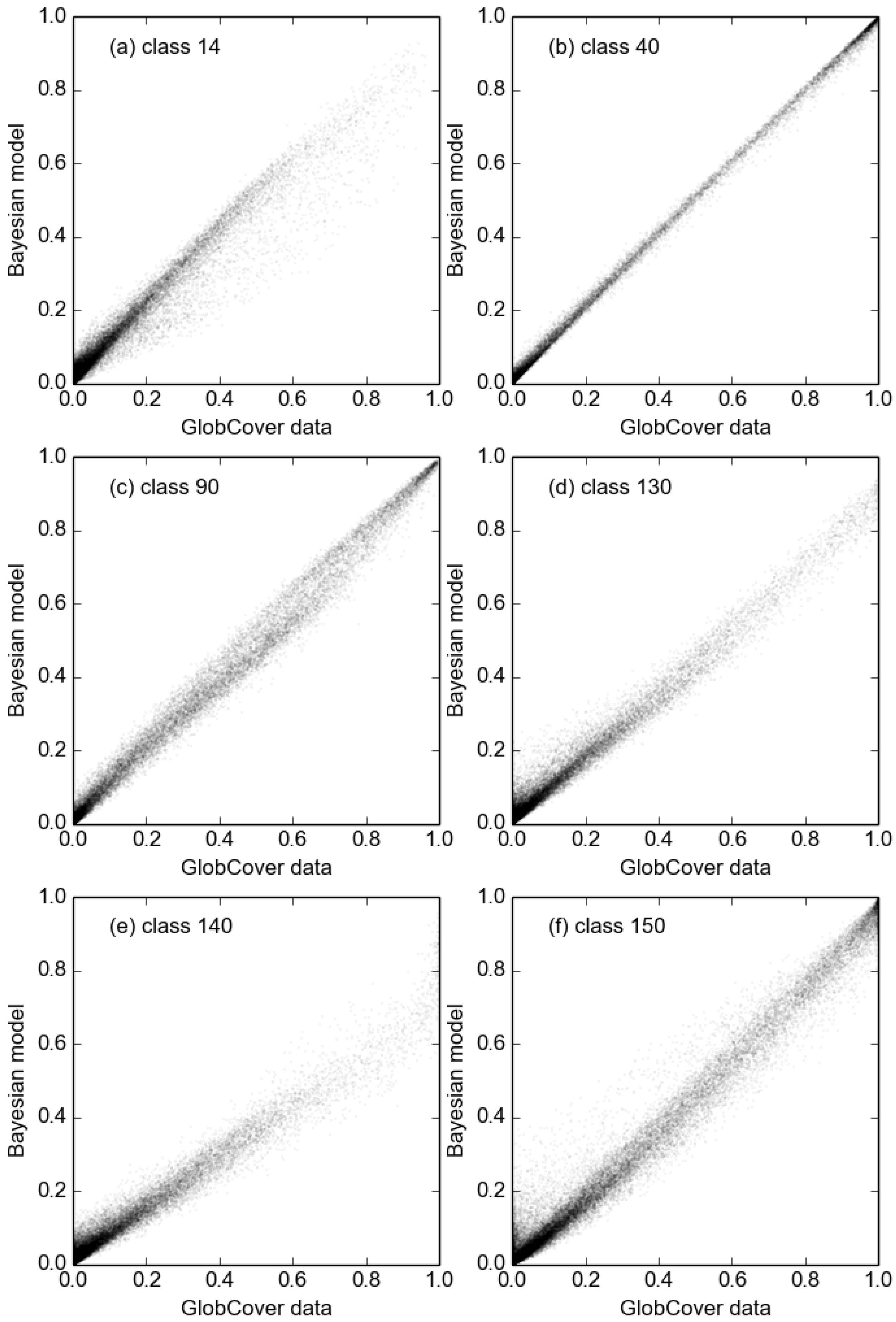
Figure 7 shows the two-dimensional marginal probability distributions. The land cover classes represented in the figure are those that are most abundant in the region: mosaic vegetation (grassland, shrubland, forest) and cropland (30), closed broadleaved deciduous forest (50), open broadleaved deciduous forest (60), and closed to open grassland (140). Contours in these plots are lines of equal likelihood of area covered by each class, and the vertical and horizontal lines are the values calculated from the original GlobCover data. Where a line bisects the centre of the distribution, this indicates no bias between the GlobCover and the statistical model. This is only the case for class 50, which agrees with the global area distributions in
Figure 5. The pattern of bias for the other classes also mimics the biases seen in the global data: classes 140 and 30 have a positive bias, whereas 60 has a negative bias. This illustrates an important shortcoming of the specific experiment presented here, rather than the technique in general. Because the uncertainty information comes from a confusion matrix that represents the whole globe, the pattern of uncertainties will be broadly the same for every location. In reality, this is not likely to be the case. This is discussed further in
Section 5.2.
One interesting feature of the results that is only visible in
Figure 7 is that some of the classes exhibit covariance. The most obvious example is the negative correlation between class 140 and class 60. In this case, a negative correlation implies that an error in one land class will correspond to an error in the opposite direction in the other. This can be seen in the global posterior distributions (
Figure 5), where the bias in the global area of classes 140 and 60 is in the opposite direction.
5.2. Assumptions and Limitations
One key assumption in the method presented in this paper is that the confusion matrix describes classification uncertainties that do not vary spatially. For example, confusion between grasses and crops is taken to be the same regardless of whether this occurs in, say, the United Sates or Asia. This may not hold true for two principal reasons: first, the amount and quality of data may not be the same from location to location (due to orbital characteristics and variable amount of clouds, for example) and second, because the spectral characteristics of a specific land cover may be different (for example, due to different soil types). In principle, it is possible to extend the method to cope with a spatially varying confusion matrix. The simplest way of achieving this being to have several regional confusion matrices, or matrices which are built from ground samples within a given range of a grid–cell. However, either of these approaches would need a much larger validation data set and is beyond the scope of this study.
Some cover types are poorly sampled in the confusion matrix, which is likely to make the results for these classes less reliable. Again, the only solution is to produce confusion matrices with larger numbers of observations. Practically this is very time consuming and resource intensive for global maps of this nature, and consequently requires coordinated input from relevant agencies. A recommendation from this paper is that such activities require a greater level of funding.
5.3. The Role of the Prior
In many ways, the maps of uncertainty produced can be viewed as a spatialisation of the confusion matrix. So what role does the prior play? To calculate Bayesian estimates of any quantity necessarily requires a prior estimate, and these are often subjective in nature. Prior information in this paper comes from a spatially smoothed version of the land cover map consisting of a moving average. Larger windows up to were tried and showed only marginal difference (results not shown). The same spatial patterns in uncertainty and distributions of bias in global areas were observed. One example of an alternative prior might be to use some estimate of the grid–cell heterogeneity in land cover (e.g., how “patchy” the landscape is). A less ad-hoc alternative would be to use the inherent information available in the classification procedure itself. There are a number of metrics, such as fuzzy classifications, typically based on measures of spectral separability between classes, that assign probabilities of membership of each pixel to a given land cover class. These may be a more informative prior for the statistical model used here. This information is not generally made available for global land cover products such as GlobCover, but the approach merits further investigation as a means of combining the spectral and validation data into a single estimate of uncertainty.
One important role that the prior plays in this study is that it excludes classes that are not present in the local region. To illustrate with an extreme example: the bare areas class (200) exhibits a small amount of confusion with permanent snow and ice (220). Based on the confusion matrix alone this would mean that there is a small probability of snow and ice existing anywhere that bare areas appear, including the Sahara desert. Clearly this is not desirable. However, because the prior contains zero proportion of class 220 in this region, it means that the posterior probability for it is also zero.
5.4. Application to Modelling
This paper has only demonstrated the application of the technique as far as producing posterior estimates of uncertainty from a land cover product. However, the motivation of this study is ultimately to provide a technique that will allow these uncertainties to be propagated through any environmental model that uses land cover data as an input, such as the Sheffield Dynamic Vegetation Model, SDGVM [
20], or the Joint UK Land Environment Simulator, JULES [
26]. An important part of this process that has not been considered in this paper is the conversion of land cover as represented in a remotely sensing product to the classes required by the models (typically called plant functional types). This is likely to have two main impacts: either where a PFT contains multiple land cover classes, or where a land cover class contains multiple PFTs. The first is likely to reduce uncertainty in the model predictions due to the land cover uncertainty, whereas the second will increase uncertainty. Further studies will look at the propagation of the derived uncertainties through such models to examine the impact on predictions of, for example, carbon and energy fluxes between the land surface and the atmosphere. Clearly the most important question to ask is not how much error there is in a given land cover product, but how this will impact a given application. Such experiments are computationally intensive and beyond the scope of this paper; future studies will address this issue.
The process by which the uncertainty estimates presented here can be propagated by a model is simple and requires no modification to the model. The sampler presented in
Section 3 is capable of producing an unlimited number of realisations of the true land cover. Each of these realisations can then be used as an instance of the land cover (or PFTs) for a model run, using as many runs as necessary to calculate the required statistics. Typically this could be between 100’s to 10000’s of model runs. The uncertainty in model predictions due to uncertainty in the land cover can then be calculated using the ensemble of model outputs that has been generated.
6. Conclusions
This paper applies a method of drawing samples from the posterior distribution of land cover proportions implied by the GlobCover 2009 global land cover data set and an associated uncertainty matrix. The method is designed to handle large data sets and was able to provide measures of uncertainty in the GlobCover 2009. The results highlight both the specific classes and the geographical regions in which the land cover product performs either poorly or well. Geographically, most uncertainty is seen in southern Africa (
Figure 6), in which exists a complex heterogeneous landscape consisting of shrubs and grass. In particular, this uncertainty is driven by the presence of a specific class (140) within this landscape. The largest overall biases in areal coverage reported by the GlobCover product shown in
Figure 5 are dominated by non-vegetated surfaces: bare areas, inland water bodies, and artificial surfaces. The largest biases in vegetation occur post-flooding or irrigated cropland and the two mosaic cropland/vegetation classes. Overall, however, the analysis shows the GlobCover 2009 product to be of high accuracy: biases for most classes are small, and PDFs are relatively narrow.
Future work is planned to propagate these uncertainties through a Global Vegetation Model to demonstrate the impacts on model predictions of the net carbon balance of the land surface. As part of this, it will also be necessary to address the uncertainties in the cross-walk between land cover and plant functional types; however, the work outlined here lays the foundation for this analysis. Although the focus in this study has been preparing to work with Global Vegetation Models, in principle the technique can be used for any model that requires land cover as an input—for example, climate models or hydrological models.
A strong recommendation arising from this work is that more funding is required to produce accuracy assessments of land cover products. With a greater level of sampling in the confusion matrix it would be possible to apply the method presented here on a regional level and ultimately provide more detailed analysis to inform onward use of the data. In addition, some classes are under-represented in the existing confusion matrix, and uncertainty estimates generated for these will be the least reliable.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}