Nearest-Regularized Subspace Classification for PolSAR Imagery Using Polarimetric Feature Vector and Spatial Information


Abstract
:1. Introduction
- We construct a comprehensive polarimetric feature vector including 79 TD features. By using the labeled data, the representation-based classifier can exploit the discriminative information within classes contained in the 79-dimensional feature spaces.
- We introduce the NRS classifier considering within-class variations to measure the similarity of the polarimetric feature vector between the test pixel and the labeled pixels and further employ the GC algorithm for spatial information mining.
- We propose a PolSAR imagery-oriented transformation function that connects the residual from NRS and the probability for the MRF model.
2. Methodology
2.1. Polarimetric Feature Vector Construction
2.1.1. PolSAR Data Representations
2.1.2. Kennaugh Matrix-Based Decompositions
2.1.3. Eigenvector-Based Decompositions
2.1.4. Model-Based Decompositions
2.1.5. Coherent Decompositions
2.2. Nearest Regularized Subspace
2.3. MRF Model
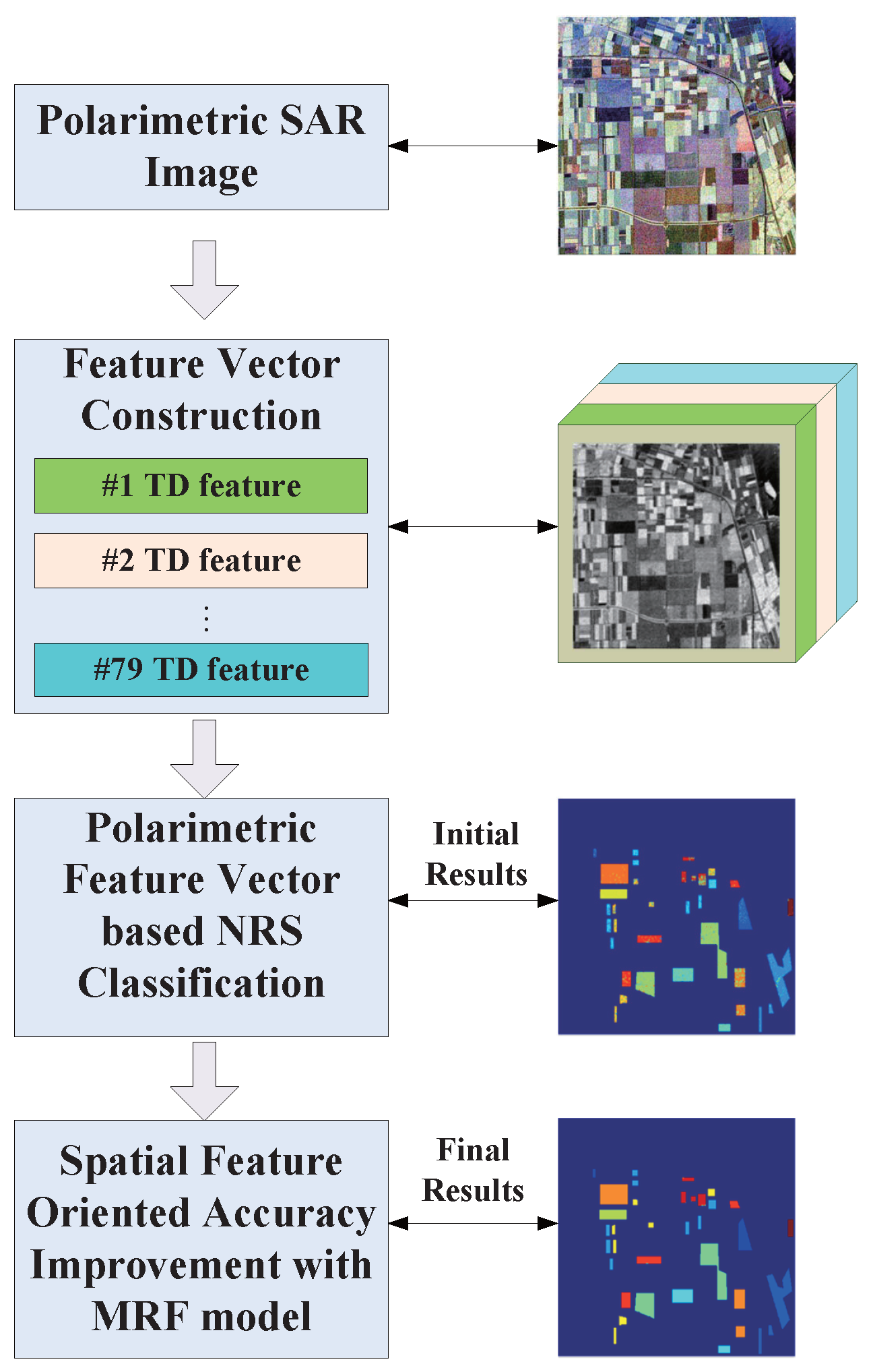
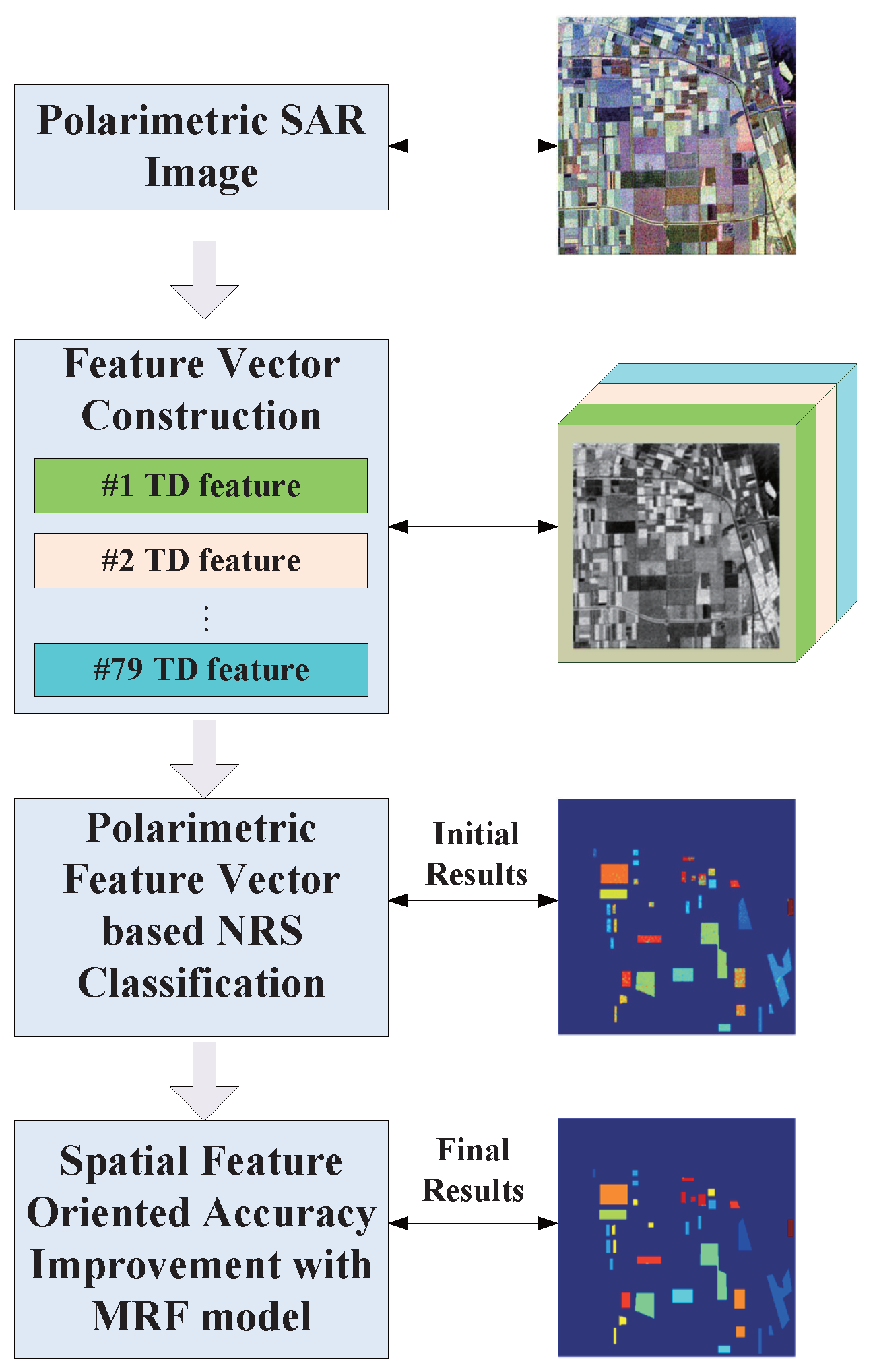
3. Proposed Method
3.1. Feature Vector Construction and Similarity Measurement
3.2. Parameter Tuning of Transformation Function
3.3. Feature Vector-Based NRS-MRF Classification
| Algorithm 1 The feature vector-based NRS-MRF classifier. |
Input: Fully polarimetric SAR image |
Output: Class labels of the entire test image pixels.
|
4. Experimental Results and Analysis
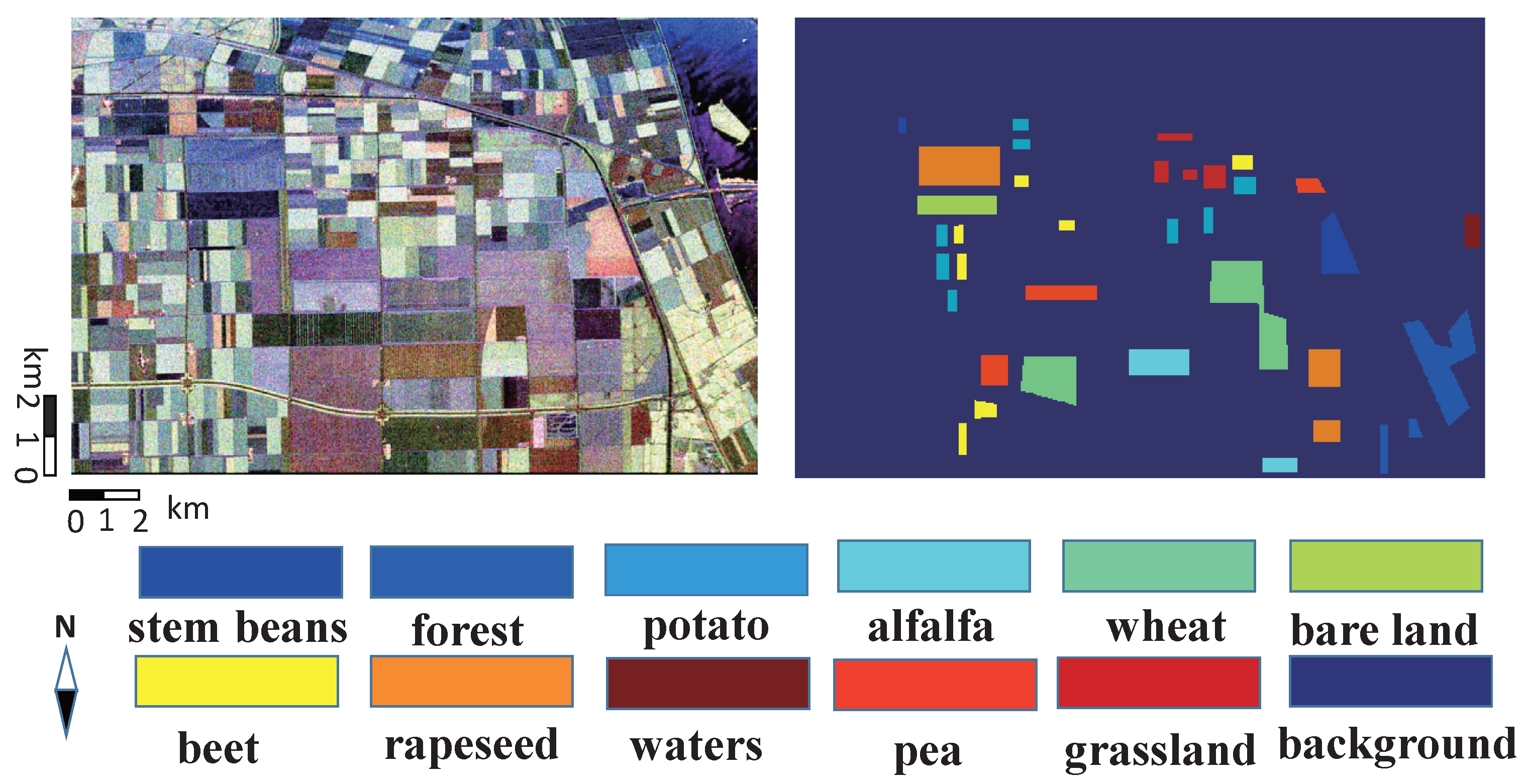
4.1. Experiment Data
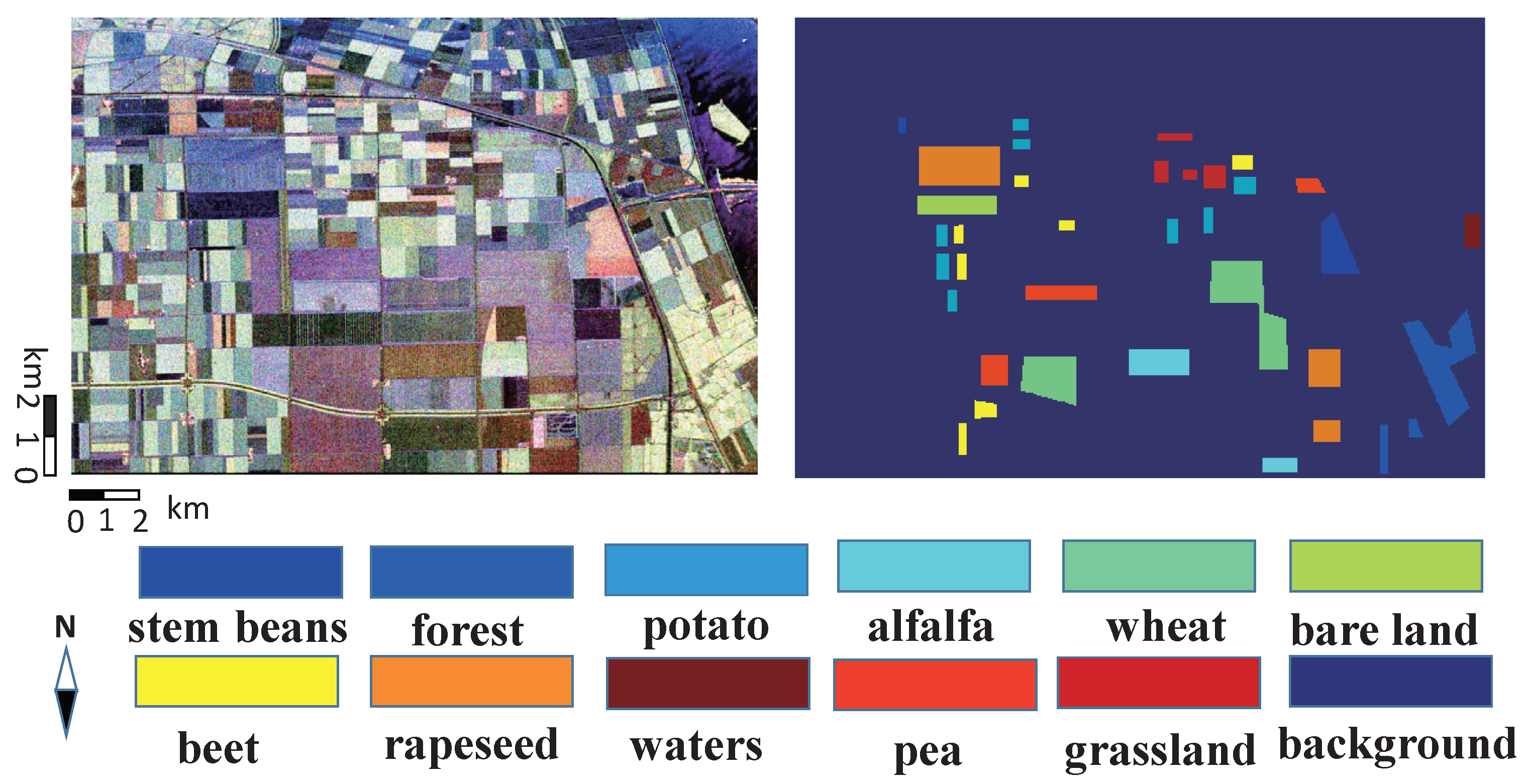
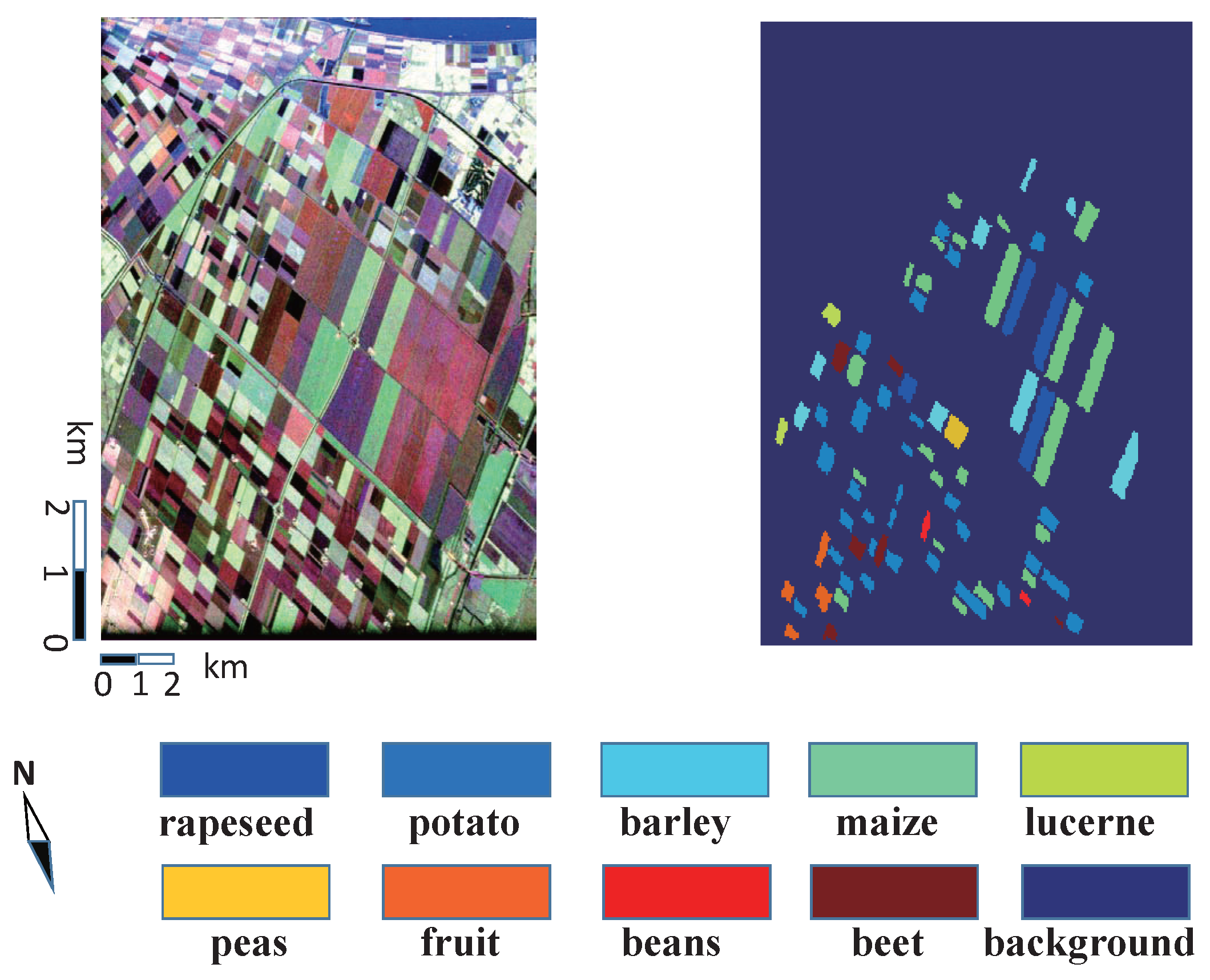
4.1.1. AIRSAR Data in Flevoland I
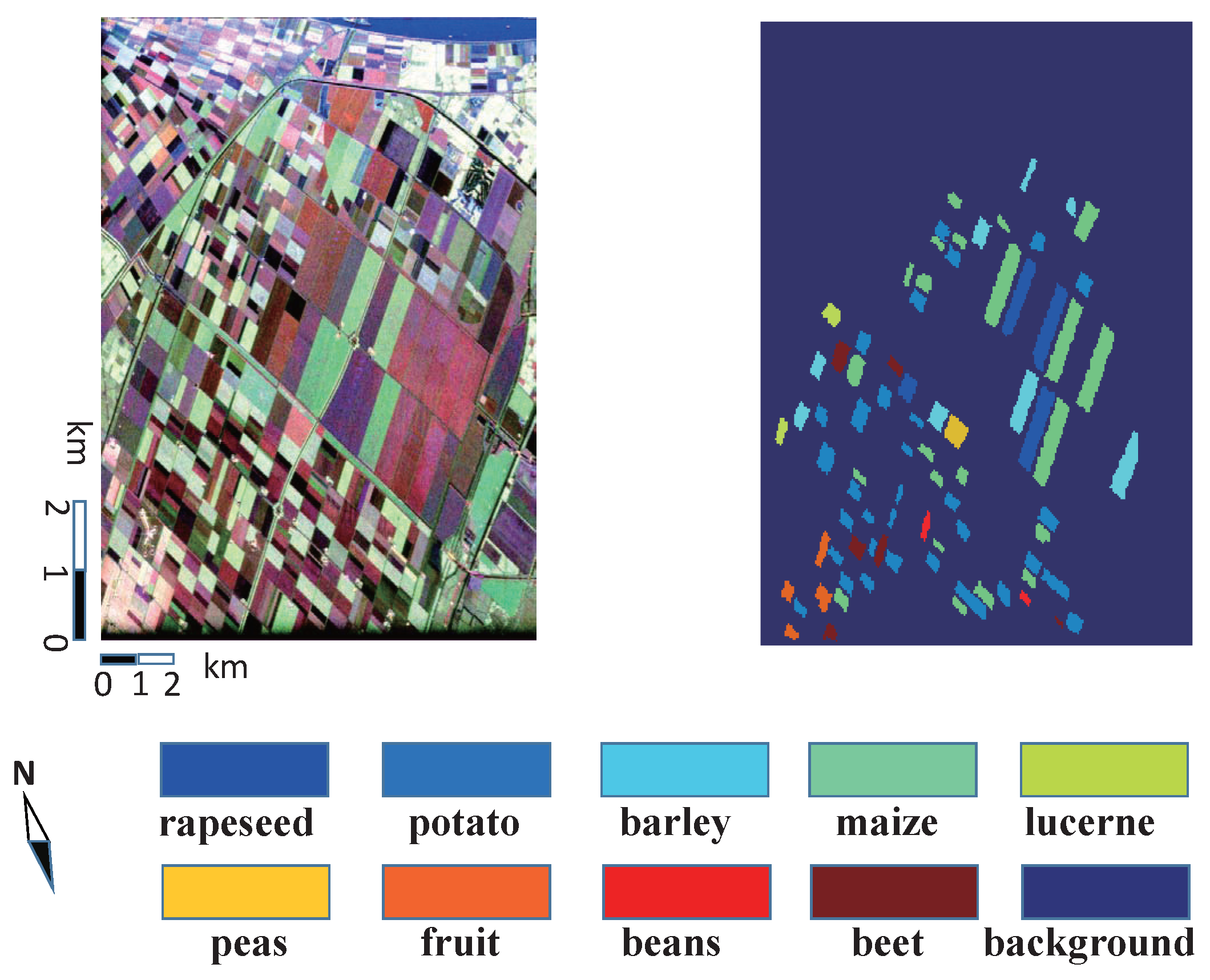
4.1.2. AIRSAR Data in Flevoland II
4.2. Polarimetric Feature Vector
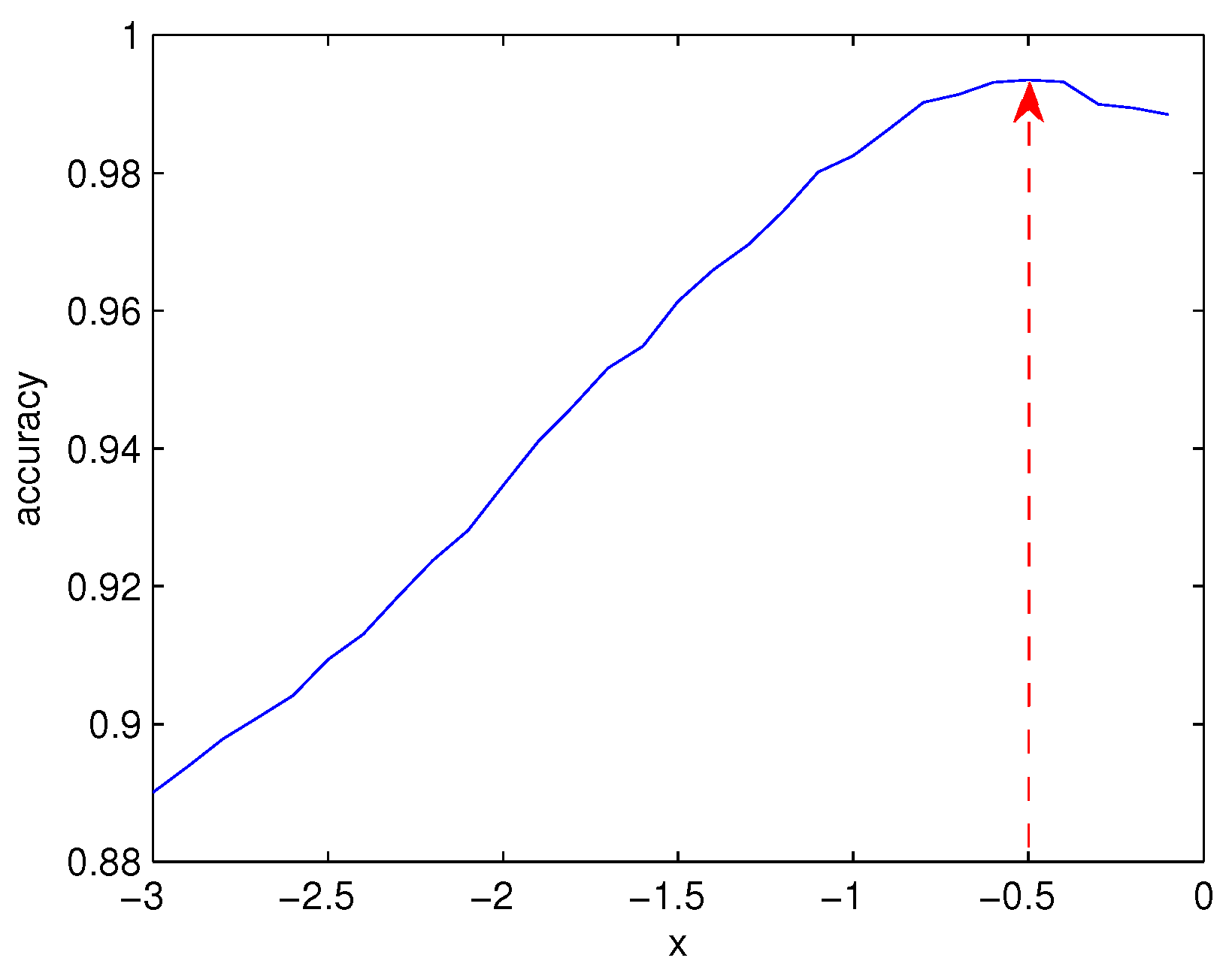
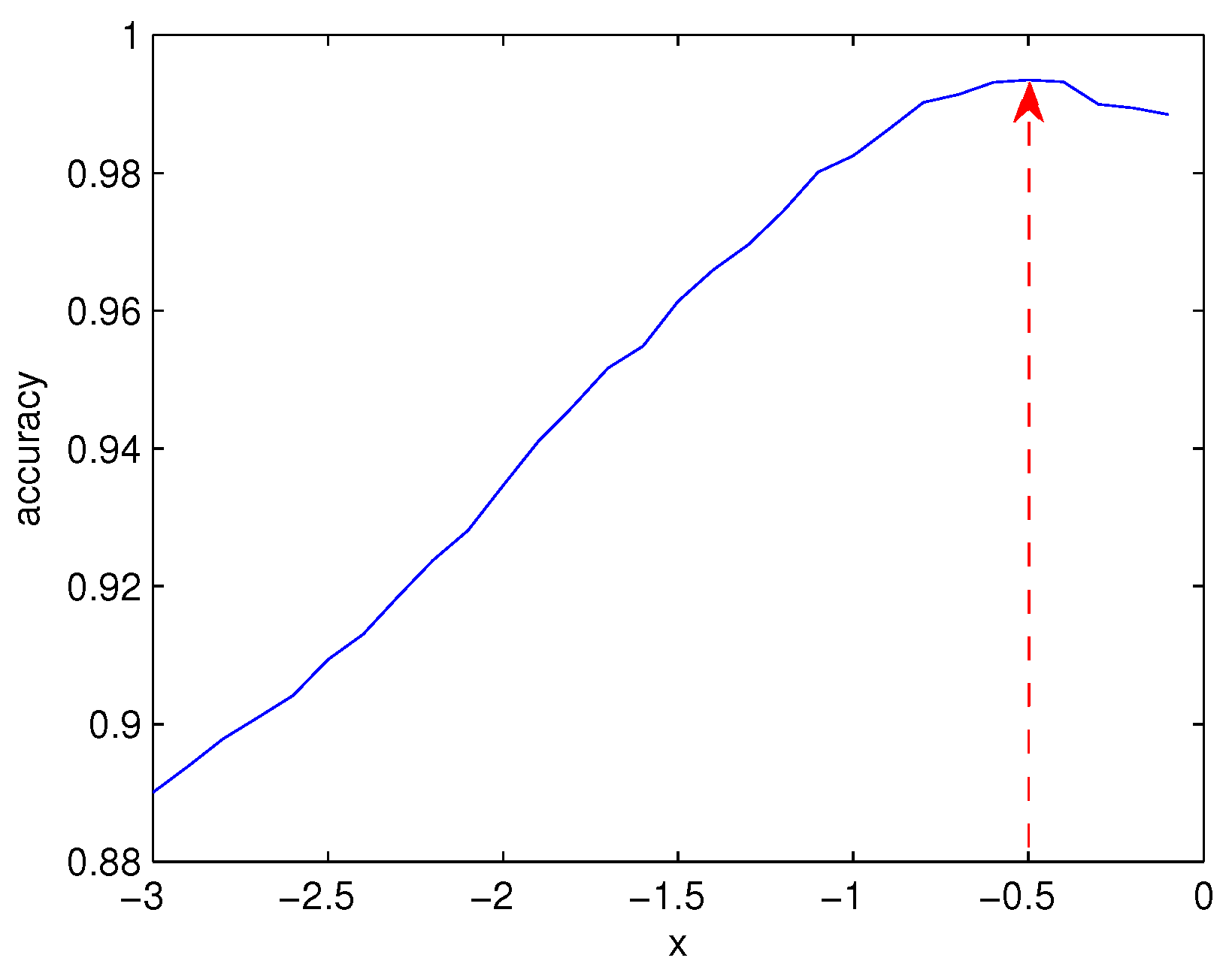
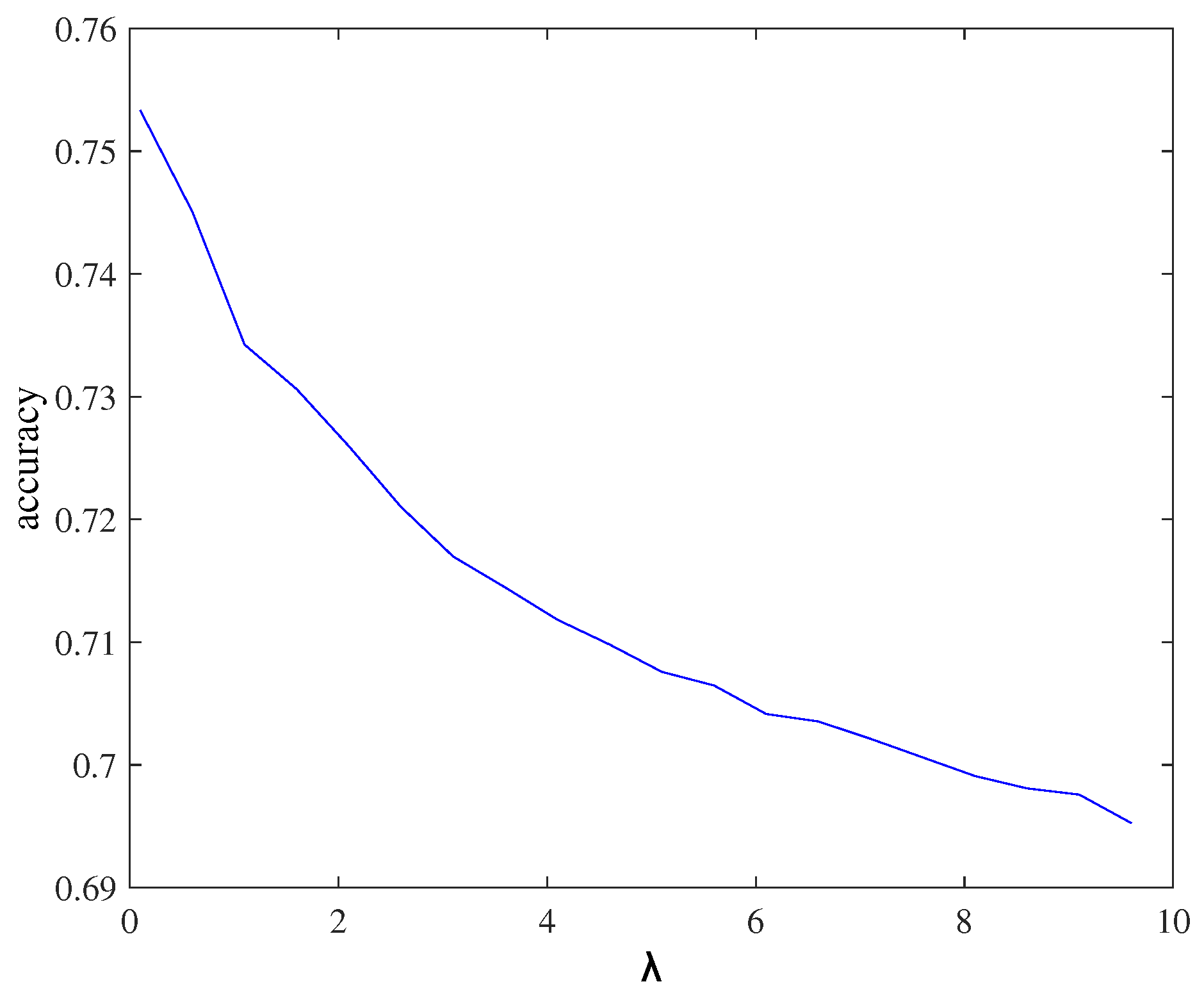
4.3. Classifier Parameter Tuning
4.4. Classification Accuracy
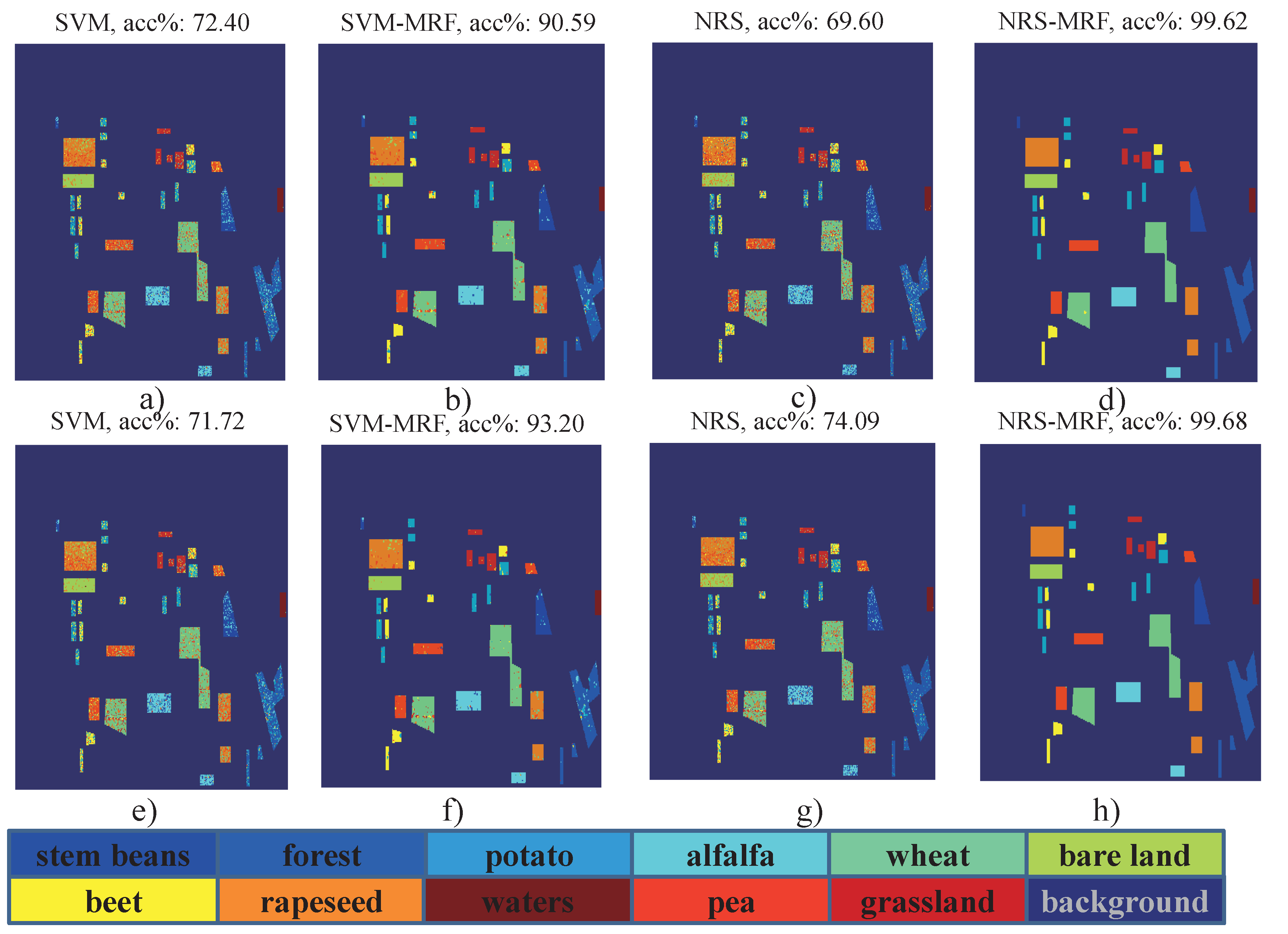
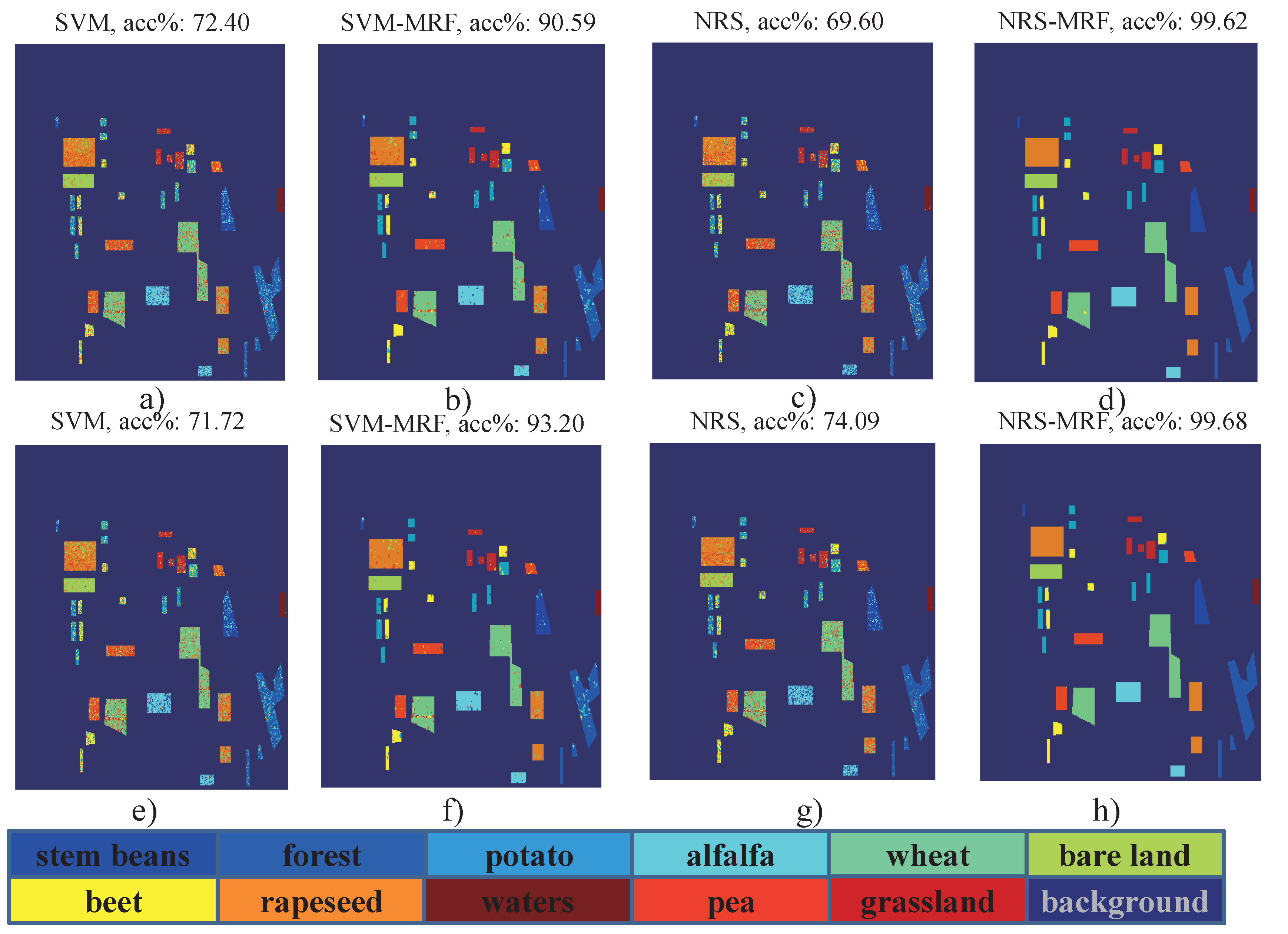
4.4.1. Results and Analysis of Flevoland I Data
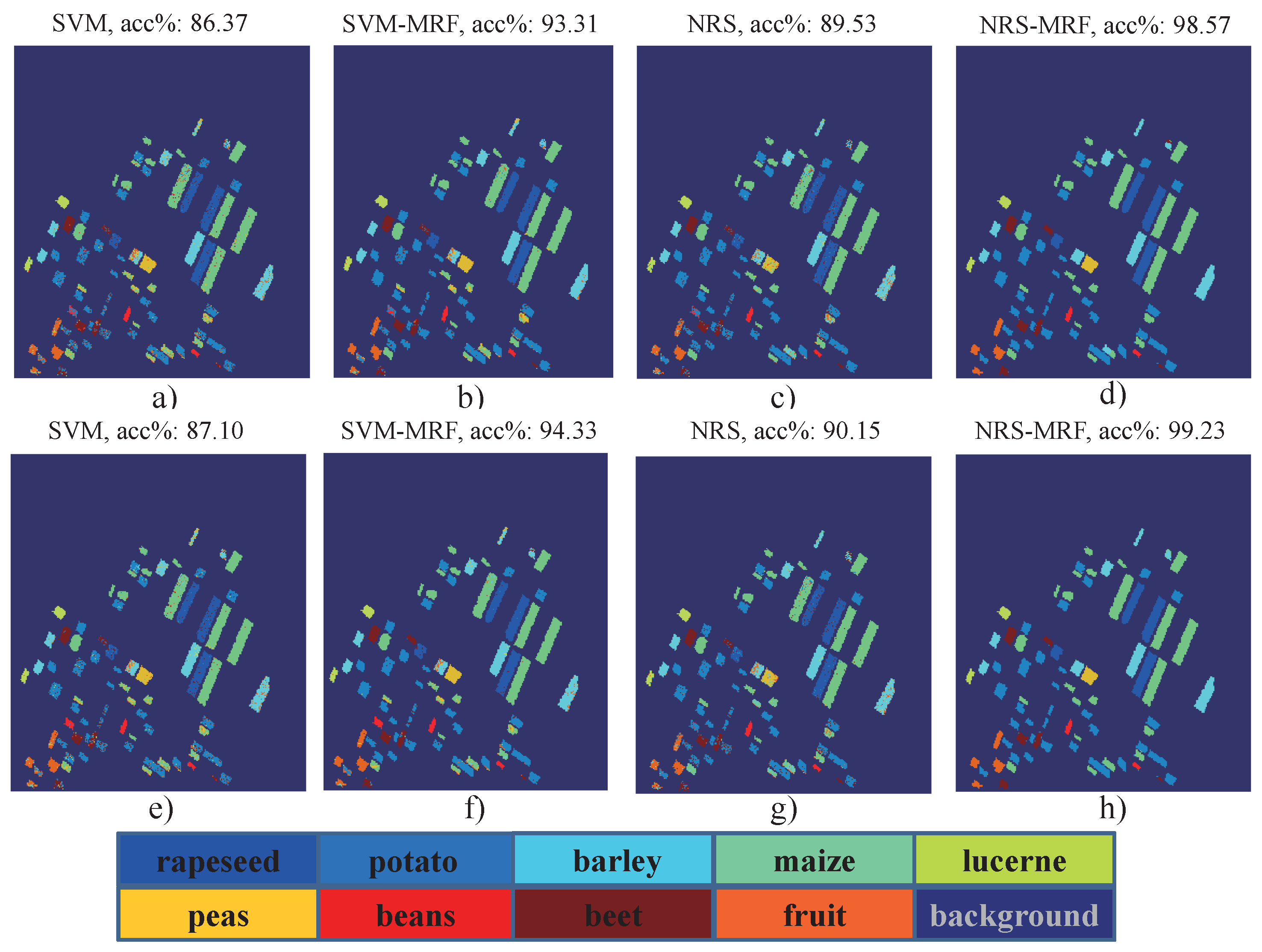
4.4.2. Results and Analysis on Flevoland II Data
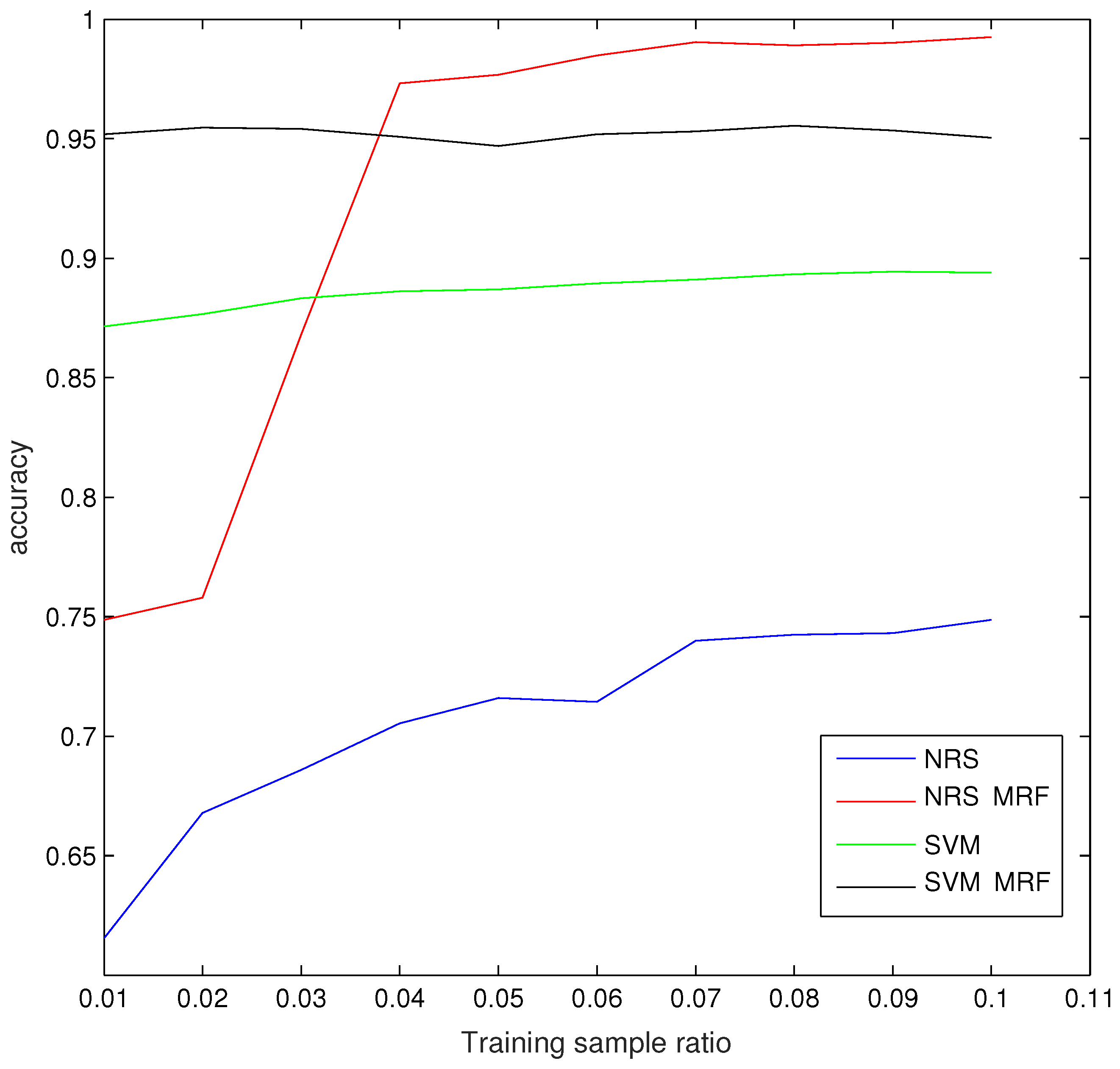
4.5. The Influence of Training Size
4.6. The Analysis of Classification Performance
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| SAR | Synthetic aperture radar |
| PolSAR | Polarimetric SAR |
| TD | Target decomposition |
| NRS | Nearest regularized subspace |
| MRF | Markov random field |
| GC | Graph cuts |
References
- Moreira, A.; Prats-iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K. A Tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Grunes, M.; Ainsworth, T.; Du, L.; Schuler, D.; Cloude, S. Unsupervised classification using polarimetric decomposition and the complex Wishart classifier. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2249–2258. [Google Scholar]
- Lee, J.; Grunes, M.; Pottier, E. Quantitative comparison of classification capability: Fully polarimetric versus dual and single-polarization SAR. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2343–2351. [Google Scholar]
- Oh, Y.; Sarabandi, K.; Ulaby, F.T. An empirical model and an inversion technique for radar scattering from bare soil surfaces. IEEE Trans. Geosci. Remote Sens. 1992, 30, 370–381. [Google Scholar] [CrossRef]
- Dubois, P.C.; Van Zyl, J.; Engman, T. Measuring soil moisture with imaging radars. IEEE Trans. Geosci. Remote Sens. 1995, 33, 915–926. [Google Scholar] [CrossRef]
- Hajnsek, I. Inversion of Surface Parameters from Polarimetric SAR Data. Ph.D. Thesis, Friedrich Schiller University of Jena (FSU), Jena, Germany, 2001. [Google Scholar]
- Yin, Q.; Hong, W.; Li, Y.; Lin, Y. Soil moisture change detection model for slightly rough surface based on interferometric phase. J. Appl. Remote Sens. 2015, 9, 095981. [Google Scholar] [CrossRef]
- Li, Y.; Hong, W.; Pottier, E. Topography retrieval from single-pass POLSAR data based on the polarization-dependent intensity ratio. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3160–3177. [Google Scholar]
- Gao, G.; Shi, G. CFAR Ship Detection in Nonhomogeneous Sea Clutter Using Polarimetric SAR Data Based on the Notch Filter. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4811–4824. [Google Scholar] [CrossRef]
- Wei, J.; Li, P.; Yang, J.; Zhang, J.; Lang, F. A New Automatic Ship Detection Method Using L-Band Polarimetric SAR Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 7, 1383–1393. [Google Scholar]
- Masjedi, A.; Zoej, M.; Maghsoudi, Y. Classification of polarimetric SAR images based on modeling contextual information and using texture features. IEEE Trans. Geosci. Remote Sens. 2016, 54, 932–943. [Google Scholar] [CrossRef]
- Xiang, D.; Ban, Y.; Su, Y. Model-based decomposition with cross scattering for polarimetric SAR urban areas. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2496–2500. [Google Scholar] [CrossRef]
- Cao, F.; Hong, W.; Wu, Y.; Pottier, E. An Unsupervised Segmentation with an Adaptive Number of Clusters Using the SPAN/H/α/A Space and the Complex Wishart Clustering for Fully Polarimetric SAR Data Analysis. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3454–3467. [Google Scholar] [CrossRef]
- Fukuda, S.; Hirosawa, H. Support vector machine classification of land cover: Application to polarimetric SAR data. In Proceedings of the 2001 IEEE International Geoscience and Remote Sensing Symposium (IGARSS’01), Sydney, Australia, 9–13 July 2001; Volume 1, pp. 187–189. [Google Scholar]
- Qi, Z.; Yeh, A.; Li, X.; Lin, Z. A novel algorithm for land use and land cover classification using RADARSAT-2 polarimetric SAR data. Remote Sens. Environ. 2012, 118, 21–39. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, D.; Yang, S.; Hou, B.; Gou, S.; Xiong, T.; Jiao, L. Semisupervised Feature Extraction with Neighborhood Constraints for Polarimetric SAR Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3001–3015. [Google Scholar] [CrossRef]
- Buono, A.; Nunziata, F.; Migliaccio, M.; Yang, X.; Li, X. Classification of the Yellow River delta area using fully polarimetric SAR measurements. Int. J. Remote Sens. 2017, 38, 6714–6734. [Google Scholar] [CrossRef]
- Lee, J.; Grunes, M.; Grandi, G.D. Polarimetric SAR speckle filtering and its implication for classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2363–2373. [Google Scholar]
- Foucher, S.; Lopez-Martinez, C. Analysis, evaluation, and comparison of polarimetric SAR speckle filtering techniques. IEEE Trans. Image Process. 2014, 23, 1751–1764. [Google Scholar] [CrossRef] [PubMed]
- Huynen, J.R. Phenomenological Theory of Radar Targets. Ph.D. Thesis, Technical University, Delft, The Netherlands, 1970. [Google Scholar]
- Freeman, A. Fitting a two-component scattering model to polarimetric SAR data from forests. IEEE Trans. Geosci. Remote Sens. 2007, 45, 2583–2592. [Google Scholar] [CrossRef]
- Freeman, A.; van Zyl, J.J.; Klein, J.D.; Zebker, H.A.; Shen, Y. Calibration of Stokes and scattering matrix format polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1992, 30, 531–539. [Google Scholar] [CrossRef]
- Neumann, M.; Ferro-Famil, L.; Pottier, E. A general model-based polarimetric decomposition scheme for vegetated areas. In Proceedings of the International Workshop Science Applications SAR Polarimetry Polarimetric Inferometry (POLINSAR), Frascati, Italy, 26–30 January 2009. [Google Scholar]
- Krogager, E. New decomposition of the radar target scattering matrix. Electron. Lett. 1990, 26, 1525–1527. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. An entropy based classification scheme for land applications of polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar] [CrossRef]
- Yamaguchi, Y.; Yajima, Y.; Yamada, H. A four-component decomposition of POLSAR images based on the coherency matrix. IEEE Geosci. Remote Sens. Lett. 2006, 3, 292–296. [Google Scholar] [CrossRef]
- Yang, J.; Peng, Y.N.; Yamaguchi, Y.; Yamada, H. On Huynen’s decomposition of a Kennaugh matrix. IEEE Geosci. Remote Sens. Lett. 2006, 3, 369–372. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. A review of target decomposition theorems in radar polarimetry. IEEE Trans. Geosci. Remote Sens. 1996, 34, 498–518. [Google Scholar] [CrossRef]
- Barnes, R.M. Roll-invariant decompositions for the polarization covariance matrix. In Proceedings of the Polarimetry Technology Workshop, Redstone Arsenal, AL, USA, 16–18 Agust 1988; pp. 1–15. [Google Scholar]
- Shi, L.; Zhang, L.; Yang, J.; Zhang, L.; Li, P. Supervised graph embedding for polarimetric SAR image classification. IEEE Geosci. Remote Sens. Lett. 2013, 10, 216–220. [Google Scholar] [CrossRef]
- Feng, J.; Cao, Z.; Pi, Y. Polarimetric contextual classification of PolSAR images using sparse representation and superpixels. Remote Sens. 2014, 6, 7158–7181. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, L.; Zou, B.; Moon, W. Fully polarimetric SAR image classification via sparse representation and polarimetric features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3923–3932. [Google Scholar] [CrossRef]
- Hou, B.; Ren, B.; Ju, G.; Li, H.; Jiao, L.; Zhao, J. SAR image classification via hierarchical sparse representation and multisize patch features. IEEE Geosci. Remote Sens. Lett. 2016, 13, 33–37. [Google Scholar] [CrossRef]
- Gou, S.; Li, X.; Yang, X. Coastal zone classification with fully polarimetric SAR imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1616–1620. [Google Scholar] [CrossRef]
- Pajares, G.; Lopez-Martinez, C.; Sanchez-Liado, F.; Molina, I. Improving Wishart classification of polarimetric SAR data using the Hopfield Neural Network optimization approach. Remote Sens. 2012, 4, 3571–3595. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Tramel, E.W.; Prasad, S. Nearest regularized subspace for hyperspectral classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 477–489. [Google Scholar] [CrossRef]
- Li, W.; Du, Q.; Xiong, M. Kernel Collaborative Representation With Tikhonov Regularization for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 48–52. [Google Scholar]
- Zhang, L.; Yang, M.; Feng, X. Sparse representation or collaborative representation: Which helps face recognition? In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 471–478. [Google Scholar]
- Geng, J.; Fan, J.; Wang, H.; Fu, A.; Hu, Y. Joint collaborative representation for polarimetric SAR image classification. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 3066–3069. [Google Scholar]
- Fukuda, S.; Hirosawa, H. A wavelet-based texture feature set applied to classification of multifrequency polarimetric SAR images. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2282–2286. [Google Scholar] [CrossRef]
- Schick, A.; Bauml, M.; Stiefelhagen, R. Improving Foreground Segmentations with Probabilistic Superpixel Markov Random Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 27–31. [Google Scholar]
- Ghamisi, P.; Benediktsson, J.A.; Ulfarsson, M.O. Spectral-spatial classification of hyperspectral images based on hidden Markov random fields. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2565–2574. [Google Scholar] [CrossRef]
- Borges, J.S.; Bioucas-Dias, J.M.; Marcal, A.R. Bayesian hyperspectral image segmentation with discriminative class learning. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2151–2164. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Boykov, Y.Y.; Jolly, M.P. Interactive graph cuts for optimal boundary and region segmentation of objects in ND images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 7–14 July 2001; pp. 105–112. [Google Scholar]
- Li, W.; Prasad, S.; Fowler, J. Hyperspectral image classification using Gaussian mixture models and Markov random fields. IEEE Geosci. Remote Sens. Lett. 2015, 11, 153–157. [Google Scholar] [CrossRef]
- Wu, Y.; Ji, K.; Yu, W.; Su, Y. Region-based classification of polarimetric SAR images using Wishart MRF. IEEE Geosci. Remote Sens. Lett. 2008, 5, 668–672. [Google Scholar] [CrossRef]
- Lee, J.S.; Pottier, E. Polarimetric Radar Imaging: From Basics to Applications; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Cloude, S.R. Target decomposition theorems in radar scattering. Electron. Lett. 1985, 21, 22–24. [Google Scholar] [CrossRef]
- Holm, W.A.; Barnes, R.M. On radar polarization mixed target state decomposition techniques. In Proceedings of the IEEE National Radar Conference, Ann Arbor, MI, USA, 20–21 April 1988; pp. 249–254. [Google Scholar]
- Zou, B.; Lu, D.; Zhang, L.; Moon, W.M. Eigen-decomposition-based four-component decomposition for PolSAR data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1286–1296. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S.L. A three-component scattering model for polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef]
- Touzi, R. Target scattering decomposition of one-look and multi-look SAR data using a new coherent scattering model: The TSVM. In Proceedings of the 2004 IEEE International Geoscience and Remote Sensing Symposium (IGARSS’04), Anchorage, AK, USA, 20–24 September 2004; Volume 4, pp. 2491–2494. [Google Scholar]
- Khokher, M.R.; Ghafoor, A.; Siddiqui, A.M. Image segmentation using multilevel graph cuts and graph development using fuzzy rule-based system. IET Image Process. 2013, 7, 201–211. [Google Scholar] [CrossRef]
- Kolmogorov, V.; Zabin, R. What energy functions can be minimized via graph cuts? IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 147–159. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decomposition | Order Numbers | Components |
|---|---|---|
| H//A | 1–11 | , , , , , , , |
| , , , | ||
| Yang (3 components) | 12–14 | |
| Yang (4 components) | 15–18 | |
| Barnes (i) | 19–21 | |
| Barnes (ii) | 22–24 | |
| Cloude | 25–27 | |
| Freeman | 28–29 | |
| Freeman–Durden | 30–32 | |
| Holm (1) | 33–35 | |
| Holm (2) | 36–38 | |
| Huynen | 39–41 | |
| Krogager | 42–44 | |
| MCSM | 45–50 | |
| Neuman | 51-53 | |
| Tsvm | 54-69 | |
| Van zyl | 70-72 | |
| Yamaguchi (3 components) | 73-75 | |
| Yamaguchi (4 components) | 76-79 | |
| Total | 79 |
| Class | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3189 | 116 | 83 | 725 | 1 | - | 3 | - | 1 | 3 | - | 77.38 |
| 2 | 408 | 7157 | 1410 | 817 | 81 | - | 163 | 1 | 9 | 63 | - | 70.8 |
| 3 | 74 | 557 | 3169 | 104 | 30 | - | 818 | 2 | 43 | 51 | - | 65.37 |
| 4 | 783 | 287 | 122 | 3763 | 30 | - | 39 | 1 | - | 104 | 3 | 73.32 |
| 5 | 1 | 59 | 87 | 41 | 11,592 | 6 | 345 | 789 | 1002 | 608 | 57 | 79.47 |
| 6 | - | - | - | - | 6 | 3208 | 4 | 202 | 19 | - | 12 | 92.96 |
| 7 | 5 | 66 | 940 | 21 | 41 | - | 2343 | 15 | 279 | 267 | - | 58.91 |
| 8 | - | 9 | 10 | - | 1055 | 1171 | 153 | 7622 | 2324 | 94 | 31 | 61.13 |
| 9 | - | 19 | 27 | - | 359 | 12 | 344 | 1144 | 3146 | 281 | 5 | 58.95 |
| 10 | 1 | 24 | 26 | 65 | 56 | - | 146 | 19 | 98 | 2503 | - | 85.19 |
| 11 | - | - | - | - | 2 | - | - | 1 | - | - | 1216 | 99.75 |
| Total | 71.72 |
| Class | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3324 | 220 | 33 | 534 | - | - | 8 | - | - | 2 | - | 80.66 |
| 2 | 249 | 8802 | 710 | 251 | 14 | - | 32 | 2 | 4 | 45 | - | 87.07 |
| 3 | 20 | 1023 | 3029 | 31 | 12 | - | 689 | - | 22 | 22 | - | 62.48 |
| 4 | 878 | 698 | 59 | 3366 | 17 | - | 17 | 1 | - | 96 | - | 65.59 |
| 5 | 1 | 99 | 287 | 62 | 11,328 | 2 | 287 | 772 | 1192 | 557 | - | 77.66 |
| 6 | - | - | - | - | 23 | 2848 | - | 554 | 14 | - | 12 | 82.53 |
| 7 | - | 87 | 929 | 2 | 20 | - | 2553 | 8 | 164 | 214 | - | 64.19 |
| 8 | - | 8 | 32 | 1 | 1114 | 283 | 131 | 8246 | 2533 | 120 | 1 | 66.13 |
| 9 | - | 16 | 59 | - | 457 | - | 304 | 975 | 3230 | 296 | - | 60.52 |
| 10 | 5 | 50 | 28 | 38 | 48 | - | 104 | 24 | 50 | 2591 | - | 88.19 |
| 11 | - | - | 2 | - | 2 | 5 | - | 5 | - | - | 1205 | 98.85 |
| Total | 74.09 |
| Class | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | Accuracy(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3900 | 13 | 24 | 183 | - | - | - | - | - | 1 | - | 94.64 |
| 2 | 121 | 9101 | 354 | 453 | 20 | - | 42 | - | 1 | 17 | - | 90.03 |
| 3 | 3 | 113 | 4552 | 16 | 14 | - | 132 | 1 | 12 | 5 | - | 93.89 |
| 4 | 123 | 84 | 28 | 4831 | 22 | - | 9 | - | - | 35 | - | 94.13 |
| 5 | - | 14 | 18 | 15 | 13,899 | - | 130 | 57 | 176 | 278 | - | 95.28 |
| 6 | - | - | - | - | - | 3386 | - | 65 | - | - | - | 98.12 |
| 7 | - | 15 | 257 | - | 1 | - | 3601 | - | 22 | 81 | - | 90.55 |
| 8 | - | 9 | - | - | 350 | 332 | 18 | 11,283 | 446 | 31 | - | 90.49 |
| 9 | - | 20 | 6 | - | 27 | - | 77 | 149 | 4928 | 130 | - | 92.34 |
| 10 | - | 13 | - | - | 1 | - | 48 | - | 20 | 2856 | - | 97.21 |
| 11 | - | - | - | - | - | - | - | - | - | - | 1219 | 100 |
| Total | 93.21 |
| Class | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 4120 | 1 | - | - | - | - | - | - | - | - | - | 99.98 |
| 2 | - | 10,109 | - | - | - | - | - | - | - | - | - | 100 |
| 3 | - | - | 4848 | - | - | - | - | - | - | - | - | 100 |
| 4 | - | - | - | 5132 | - | - | - | - | - | - | - | 100 |
| 5 | - | - | 8 | - | 14,579 | - | - | - | - | - | - | 99.95 |
| 6 | - | - | - | - | - | 3451 | - | - | - | - | - | 100 |
| 7 | - | - | 162 | - | - | - | 3815 | - | - | - | - | 95.93 |
| 8 | - | - | - | - | 26 | - | - | 12,443 | - | - | - | 99.79 |
| 9 | - | - | 1 | - | 23 | - | - | - | 5313 | - | - | 99.55 |
| 10 | - | - | - | - | - | - | - | - | - | 2938 | - | 100 |
| 11 | - | - | - | - | - | - | - | - | - | - | 1219 | 100 |
| Total | 99.68 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Ni, J.; Yin, Q.; Li, W.; Li, Z.; Liu, Y.; Hong, W. Nearest-Regularized Subspace Classification for PolSAR Imagery Using Polarimetric Feature Vector and Spatial Information. Remote Sens. 2017, 9, 1114. https://doi.org/10.3390/rs9111114
Zhang F, Ni J, Yin Q, Li W, Li Z, Liu Y, Hong W. Nearest-Regularized Subspace Classification for PolSAR Imagery Using Polarimetric Feature Vector and Spatial Information. Remote Sensing. 2017; 9(11):1114. https://doi.org/10.3390/rs9111114
Chicago/Turabian StyleZhang, Fan, Jun Ni, Qiang Yin, Wei Li, Zheng Li, Yifan Liu, and Wen Hong. 2017. "Nearest-Regularized Subspace Classification for PolSAR Imagery Using Polarimetric Feature Vector and Spatial Information" Remote Sensing 9, no. 11: 1114. https://doi.org/10.3390/rs9111114