1. Introduction
The geographic object-based image analysis (GEOBIA) framework has gained increasing interest for the last decade, especially when dealing with very high resolution remote sensing images [
1]. One of its key advantages is the hierarchical image representation through a tree structure, where objects-of-interest can be revealed at various scales (nodes) and where the topological relationship between objects (e.g., A is part of B, or B consists of A) can be easily modeled (edges). In the classification context, however, most papers in the literature deal with only one scale, as pointed out in [
2].
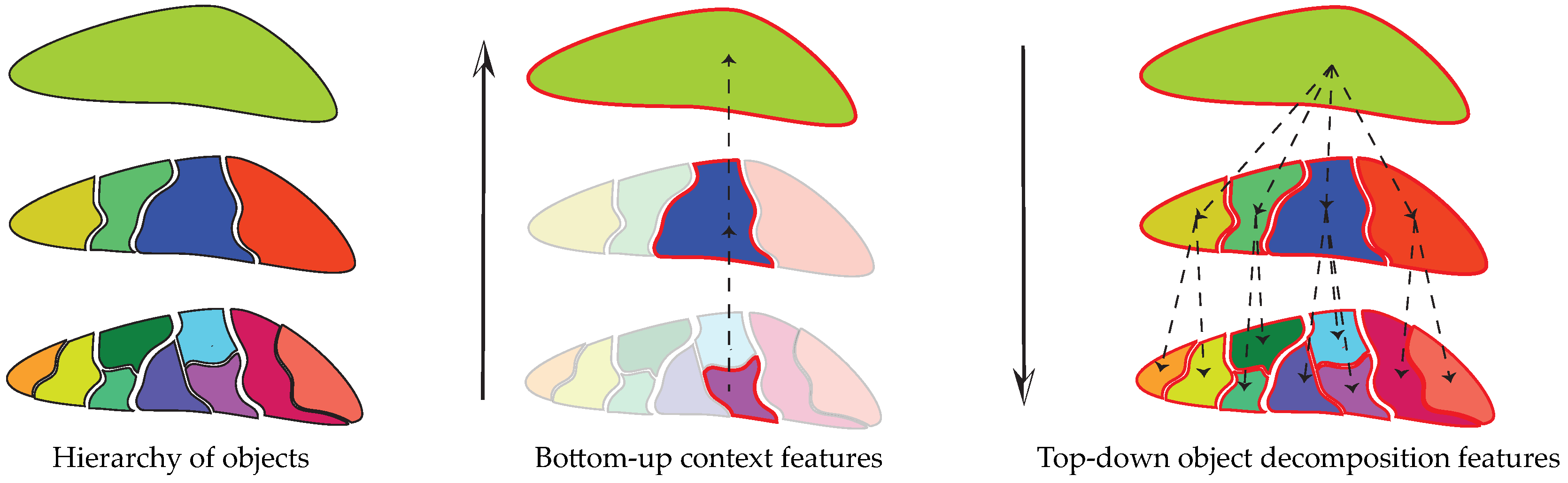
Under the GEOBIA framework, we can extract, depending on the problem at hand, different types of topological features across the scales from a hierarchical representation: bottom-up context features or top-down object decomposition features, as illustrated in
Figure 1.
Bottom-up context features (
Figure 1, center) model the evolution of a region (leaf of the hierarchical representation) and describe it by its ancestor regions at multiple scales. Such context information helps to disambiguate similar regions during the classification phase [
3]. For instance, individual tree species at the bottom scale can be classified into residential area instead of forest zone given surrounding regions being buildings and roads. Integrating such information leads to classification accuracy improvement and produces a spatially smoother classification map [
3,
4,
5].
Top-down object decomposition features (
Figure 1, right) model the composition of an object (top of the hierarchical representation) and the topological relationships among its subparts. For instance, a residential area is much easier to identify when knowing it is composed of houses and roads. Including such information can improve the classification rate, especially in high resolution remote sensing imagery cases where the decomposition of objects can be better revealed [
6,
7].
Although features extracted from the hierarchical representations are considered as discriminative characteristics for classification, dedicated machine learning algorithms still remain largely unexploited for learning directly on these features. In the GEOBIA framework, the most common way to take into account such features is through constructing rules for classifying objects and refining classification results [
4,
8,
9,
10]. However, such a knowledge-based subjective rule-set designing strategy is highly reliant on human involvement and interpretation, which makes it difficult to be adapted to new locations and datasets and makes the processing of data in large remote sensing archives practically impossible. Dedicated machine learning methods that are able to fully benefit from the hierarchical representations remain largely underdeveloped. Our previous work in [
11] introduced a structured kernel operating on paths (or sequences of nodes) that allows learning from the bottom-up context features, and in [
12], we proposed a structured kernel on trees that makes modeling the top-down object decomposition features possible. Despite their superiority for improving the classification accuracy, the major issue of the proposed structured kernels is the computation complexity. This limits the application of these kernels, which are only suitable for small data volume and small structure size.
Meanwhile, data fusion approaches have gained increasing interest recently in the remote sensing community [
13]. These techniques aim to integrate information from different sources and to produce fused data with more detailed information. For instance, combining high-resolution imagery and LiDAR data allows better accuracy achievements in an urban area classification task [
14]. As the availability of multi-resolution remote sensing data is rapidly increasing, developing methods able to fuse data from multiple sources and multiple resolutions to improve classification accuracy is becoming an important topic in remote sensing [
13,
15].
In this paper (this paper is an extended version of the conference paper presented at GEOBIA 2016 [
16]), we propose a structured kernel based on the concept of the subpath that extracts vertical hierarchical relationships among nodes in the structured data. It can be considered as a kernel operating on paths (or sequences of nodes) that allows learning from the bottom-up context features or a kernel working on trees that models the top-down object decomposition features. The kernel computation is done by explicit mapping of the kernel into a randomized low dimensional feature space using random Fourier features (RFF). The inner product of the transformed feature vector on low dimensional feature space approximates the kernel on structured data. It yields a linear complexity
w.r.t. size
S (i.e., the number of nodes) of structured data
and a linear complexity
w.r.t. number
n of training samples. Therefore, the resulting approximation scheme makes the kernel applicable for large-scale real-world problems. We call the kernel scalable bag of subpaths kernel (SBoSK). When referring to the exact computation scheme, we will write BoSK (bag of subpaths kernel).
We also introduce a novel multi-source classification approach operating on a hierarchical image representation built from two images at different resolutions. Both images capture the same geographical area with different sensors and are naturally fused together through the hierarchical representation, where coarser levels are built from a low spatial resolution (LSR) or a medium spatial resolution (MSR) image, while finer levels are generated from a high spatial resolution (HSR) or a very high spatial resolution (VHSR) image. SBoSK is then used to perform machine learning directly on the constructed hierarchical representation.
The paper is organized as follows: a brief review of related works is provided in
Section 2. We then describe in
Section 3 the structured kernel (BoSK) and its approximated computation using RFF (SBoSK). The multi-source classification approach relying on BoSK/SBoSK is proposed and evaluated on an urban classification task in
Section 4. Evaluations on two additional publicly available remote sensing datasets are given in
Section 5 before we conclude the paper and provide future research directions.
4. Image Classification with Multi-Source Images
We focus on urban land-use classification in the south of Strasbourg city, France. We consider eight thematic classes of urban patterns described in
Table 1 and in
Figure 4c (ground truth image). Two images are considered, both capturing the same geographical area with different sources:
an MSR image, captured by a Spot-4 sensor, containing
pixels at a 20-m spatial resolution, described by four spectral bands: green, red, NIR, MIR (
Figure 4a).
a VHSR image, captured by a Pleiades satellite, containing
pixels at a 0.5-m spatial resolution (obtained with pan-sharpening technique), described by four spectral bands: red, green, blue, NIR (
Figure 4b).
More details about the images can be found in [
49].
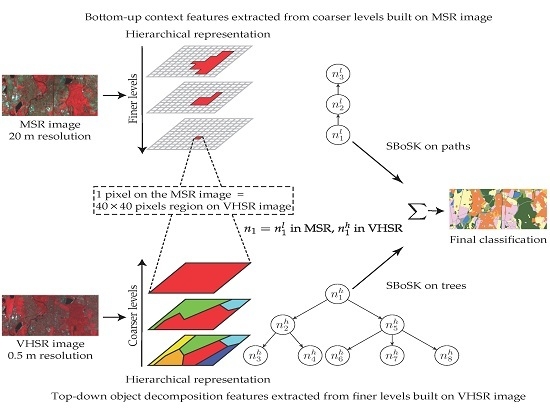
We fuse the two different resolution images into a single hierarchical representation through two separate steps: (i) use the MSR image to construct the coarser levels of the hierarchy where bottom-up context features can be computed on the one side; (ii) use the VHSR image to generate the finer levels of the tree, where top-down object decomposition features are extracted on the other side. The overall process is illustrated in
Figure 5.
Firstly, we initialize the segmentation at the pixel level on the MSR image and construct iteratively the coarser levels. Let be a data instance to be classified. Within the MSR image, it corresponds to a pixel and can be featured as a path that models the evolution of the pixel through the hierarchy. Each node is described by a d-dimensional feature that encodes the region characteristics, e.g., spectral information, size, shape, etc.
Secondly, we use the VHSR image to provide the fine details of the observed scene for each data instance . Indeed, one pixel of the MSR image always corresponds to a pixels square region of the VHSR image . To do so, we initialize the top level of the multiscale segmentation to be the square regions, then construct the finer levels. Through the hierarchy, the data instance can be modeled as a tree rooted in , which encodes object decomposition and the topological relationships among its subparts. The characteristics of region are also described by a d-dimensional feature .
In the end, each data instance can be represented by an ascending path from the MSR image and a descending tree generated from the VHSR image. Such a hierarchical representation allows one to benefit from the bottom-up context features on the coarser levels built from the MSR image, and of the top-down object decomposition features on the finer levels built from the VHSR image.
To generate the hierarchical image representation, we can rely on any multiscale segmentation algorithm. Here, we use HSeg [
50], whose parameters have been empirically fixed as follows:
On the MSR image, we generate, from the bottom (leaves) level of single pixels, seven additional levels of multiscale segmentation by increasing the region dissimilarity criteria . We observe that with such parameters, the number of segmented regions is roughly decreasing by a factor of two between each level.
On the VHSR image, we generate, from the top (root) level of each square region of size pixels (i.e., equivalent to a single pixel in Strasbourg Spot-4 dataset), four additional levels of multiscale segmentation by decreasing the region dissimilarity criteria . Using such parameters, we observe that the number of segmented regions is roughly increasing by a factor of two between each level.
Each region in the hierarchical representation is described by an eight-dimensional feature vector
, which includes the region average of the four original multi-spectral bands, soil brightness index (BI) and NDVI, as well as two Haralick texture measurements computed with the gray level co-occurrence matrix, namely homogeneity and standard deviation. These features are considered as standard ones in the urban analysis context [
51].
To perform image classification from a hierarchical representation, we propose to combine structured kernels computed on two types of structured data: SBoSK on paths allows learning from the bottom-up context features at coarse levels on the MSR image, while SBoSK on trees on the VHSR image makes the modeling of the object decomposition features possible. Both kernels exploit complementary information from the hierarchical representation, thus combined together through vector concatenation at the end as:
where
is BoSK (Equation (
1)) on paths,
is BoSK on trees,
and
are the RFF embedding of
and
, respectively, according to Equation (
9), with a parameter
that controls the importance ratio between the two kernels. The evaluation of these different kernels is provided in
Section 4.2,
Section 4.3 and
Section 4.4, respectively.
We consider a one-against-one SVM classifier (using the Python implementation of LibSVM [
52]) with the Gaussian kernel as the atomic kernel. All free parameters are determined by five-fold cross-validation, which include: the bandwidth
γ of Gaussian kernel and the SVM regularization parameter
C over potential values, the weight
between the two structured kernels and the maximum considered subpath length
. The RFF dimension
D is chosen empirically as a trade off between computational complexity and the classification accuracy (and will be further analyzed in
Section 4.1).
4.1. Random Fourier Features Analysis
In this section, we compare, in terms of classification accuracy and computation time, BoSK as introduced in [
11,
12] with the SBoSK proposed here.
We firstly analyze the impact of the number of RFF dimensions in terms of accuracy. To do so, we conduct the experiments on the MSR image considering SBoSK on paths and on the VHSR image relying on SBoSK on trees. We compare BoSK and SBoSK with
. For both experiments, we use 400 training samples per class and the rest for testing and report the results computed over 10 repetitions. As we can observe in
Figure 6, when the RFF dimension increases, the accuracy increases until it converges to the accuracy obtained with the exact computation scheme. However, such a classification accuracy convergence rate is problem dependent, and the number of RFF dimensions needed to be used is commonly set empirically [
39].
Secondly, we analyze the impact of RFF dimensions in terms of computation time. To do so, we follow the previous setting and use differing training samples per class
(except when
, we use all 1434 available samples for collective housing blocks). As we can see in
Figure 7, the computation time increases linearly w.r.t.
n for SBoSK, while for its exact computation, it increases quadratically. This indicates the efficiency of the proposed RFF approximation in the context of large-scale machine learning. In addition, we can also observe for SBoSK that the computation time increases linearly w.r.t. dimension
D, while the accuracy shown in
Figure 6 improves only slightly when
D is large. Therefore, one might have to compromise on the quality of approximation and time consumption. Henceforth, in this section, we empirically fix the RFF dimension to be
as a trade off between the approximation quality and the complexity.
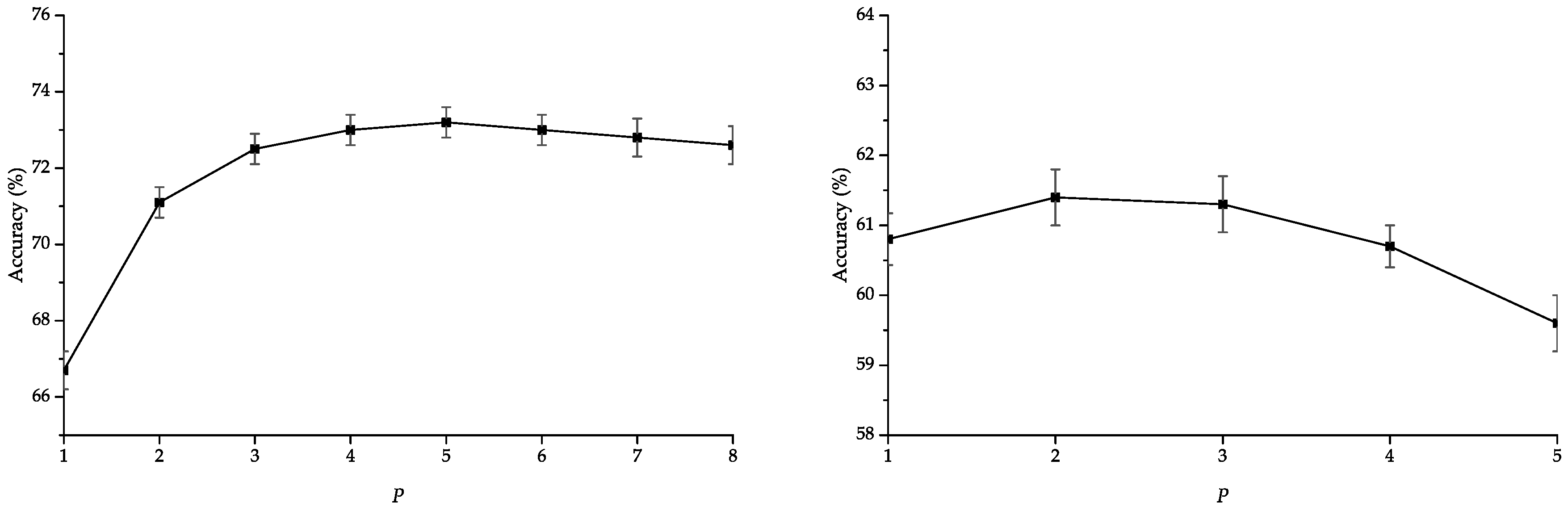
In addition, we analyze the impact of maximum considered subpath length
P using our proposed
normalization strategy for SBoSK in
Section 3.3.
Figure 8 shows that the accuracies improve when considering subpath with different lengths compared to using only nodes i.e.,
. However, the accuracies might decrease when adding the features extracted from longer subpath patterns, thus calling for penalization of longer subpath patterns. Besides, we propose to set a maximum subpath length for SBoSK, leading to a smaller vector size to be fed into machine learning algorithms, which can further reduce the computational time as smaller patterns are being considered.
4.2. Bottom-Up Context Features
In this section, we evaluate SBoSK taking into account bottom-up context features extracted from hierarchical representation built on the Strasbourg MSR image. Each pixel in the image is the data instance to be classified and is represented as a path that can be handled with SBoSK.
For comparison purposes, we consider the Gaussian kernel on the pixel level (without any context/spatial information) as the baseline and compare our work with several well-known techniques for spatial/spectral remote sensing image classification. The spatial-spectral kernel [
21] has been introduced to take into account the pixel spectral value and spatial information through accessing the nesting region. We thus implement the spatial-spectral kernel based on the multiscale segmentation commonly used in this paper and select the best level (determined by a cross-validation strategy) to extract spatial information. The attribute profile [
22] is considered as one of the most powerful techniques to describe image content through context features. The spatial information is extracted from hierarchical representations (min-tree and max-tree) using multiple thresholds according to different region attributes, e.g., area of the region, standard deviation of spectral information inside the region. We use full multi-spectral bands with automatic level selection for the area attribute and the standard deviation attribute, as detailed in [
53]. The stacked vector was adopted in [
3,
5,
54] and relies on features extracted from hierarchical representation. We use a Gaussian kernel with the stacked vector that concatenates all nodes from ascending paths generated from our multiscale segmentation. The comparison is done by randomly choosing
samples for training and the rest for testing. All reported results are computed over 10 repetitions for each run.
The classification accuracies with different methods are shown in
Table 2. We also give the per-class accuracies using
training samples in
Figure 9.
When compared to the Gaussian kernel on the pixel level using only spectral information, SBoSK taking into account bottom-up context features can significantly improve the classification accuracies. We observe about accuracy improvement for different training sample sizes. Per-class accuracies indicate that this improvement concentrates on all classes, except two, water surface and forest areas, for which classification accuracies remain similar, since context features extracted from ancestor regions through hierarchy are mostly homogeneous.
SBoSK achieves about
improvement over the spatial-spectral kernel and attribute profile for various training sample sizes. For these two state-of-the-art methods considering spatial information, the results actually depend on the selected scales. However, for the spatial-spectral kernel relying on a single scale, it is hard to define such a single scale that fits all objects, as it is commonly known in the GEOBIA framework that objects are often revealed through various scales. Therefore, for certain classes, e.g., urban vegetation, it might yield good results with the selected scale. However, it is difficult to generalize for all classes. On the other hand, the attribute profile requires setting the thresholds for different attributes in order to achieve good classification results. However, as indicated in [
55], generic strategies for filter parameters’ selection for different attributes are still lacking.
Comparing to the Gaussian kernel with stacked vector, SBoSK achieves about
classification accuracy improvement for various training sample sizes. Since both kernels rely on the same paths, it demonstrates the superiority of SBoSK for taking into account context features extracted from a hierarchical representation. In fact, the Gaussian kernel with the stacked vector is actually a special case of BoSK with the subpath length equal to the maximum (illustrated in our previous study [
11]). However, structured kernels built only on the largest substructures are usually not robust [
11]. Indeed, larger substructures are often penalized when building the structured kernels [
35]. In our experiment, this superiority is presented in the per-class accuracies for all except two homogeneous classes: water surface and forest areas.
4.3. Top-Down Object Decomposition Features
In this section, we evaluate SBoSK taking into account top-down object decomposition features extracted from hierarchical representation built on the Strasbourg VHSR image. Each square region of pixels in the image is the data instance to be classified and is represented as a tree that can be handled with SBoSK.
For comparison, we consider the SPM model [
25], which is well known in the computer vision community for taking into account the spatial relationship between a region and its subregions. The SPM relies on a quad-tree image segmentation, which splits each image region iteratively into four square regions. In this representation, the pyramid Level 0 (root) corresponds to the whole image, and Level 2 (L2) segments image regions into 16 square regions. For a fair comparison, we build SBoSK on the same spatial pyramid representation. However, let us recall that SBoSK can rely on an arbitrary hierarchical representation. We thus also report the results computed on a hierarchical representation generated using the Hseg segmentation tool. The comparison is done by randomly choosing
samples for training and the rest for testing. All reported results are computed over 10 repetitions of each run.
The classification accuracies obtained with different methods are shown in
Table 3. We also provide per-class accuracies using
training samples in
Figure 10.
When compared to the Gaussian kernel computed on root regions, SBoSK consistently improves the classification results for various numbers of training samples. Furthermore, the improvements increase when more training samples are added, i.e., from OA/ AA improvement with 50 training samples per class to OA/ AA with 400 training samples per class. Analysis of the per-class accuracies leads to observing that industrial blocks and individual housing blocks, two semantically similar classes, benefit from the highest improvement among all classes. This is due to SBoSK ability to consider top-down object decomposition features and spatial relationship among its subparts.
As far as the SPM model is concerned, we can see that it performs poorly with various training samples: the results drop down to compared to the kernel computed on the root region. Although SPM has been proven to be effective in the computer vision domain due to its capacity of coping with subregions and spatial arrangement between subregions, its one-to-one region matching strategy with the exact spatial location constraint seems overstrict for remote sensing image classification. Indeed, it lacks image orientation invariance, which is required when dealing with nadir observation. To illustrate, in both individual and collective housing block classes, the orientation and absolute location of objects, such as the houses in each image ( pixels region), are not discriminated, and thus, this is not helpful for improving classification accuracy. However, such irrelevant features cannot be excluded in the SPM model due to its matching strategy. Therefore, two images with similar content, but with different spatial locations and orientations might be classified into two different classes.
We also compare SBoSK applied on different hierarchical representations. Results show that SBoSK on Hseg segmentation leads to better results than when computed on spatial pyramid representation. From per-class accuracies, we can see that the industrial blocks, individual housing blocks and collective housing blocks, i.e., semantically similar classes, are better classified. This can be easily explained by the shapes of the segmented regions: while spatial pyramid representation splits the image into four square regions independently of the actual image content, the Hseg segmentation provides a more accurate segmentation, since similar regions are naturally merged together into larger regions iteratively through the hierarchy.
4.4. Combining Context and Object Decomposition Features
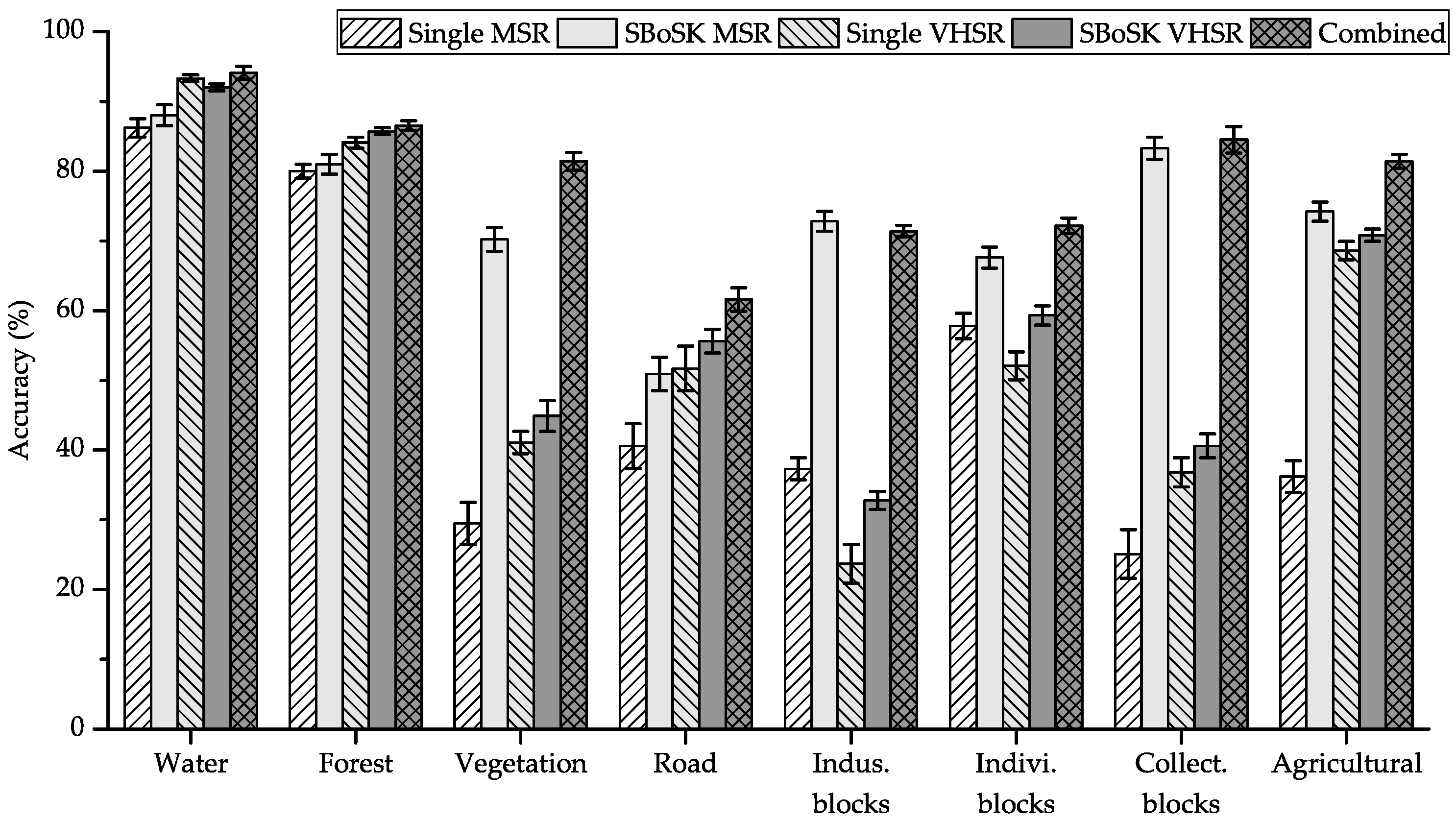
In this section, we evaluate our proposed multi-source images classification technique and represent each data instance by both an ascending path in the MSR image and a descending tree in the VHSR image.
For comparison purpose, the following scenarios are considered: (i) Scenario 1: Gaussian kernel at single level on the MSR image vs. SBoSK taking into account the bottom-up context features at multiple levels on the MSR image; (ii) Scenario 2: Gaussian kernel at single level on the VHSR image vs. SBoSK taking into account the top-down object decomposition features at multiple levels on the VHSR image; (iii) Scenario 3: combining both the context and object decomposition features extracted from a hierarchical representation using both MSR and VHSR images.
The classification accuracies achieved with the different methods are shown in
Table 4 using various numbers of training samples
. We also show the per-class accuracies for eight different classes using
training samples in
Figure 11.
The classification results show that combining bottom-up and top-down topological features lead to a significant improvement. Indeed, we observe, for various training sample sizes, more than improvement over SBoSK on a single MSR image and more than improvement over SBoSK on a single VHSR image. From an analysis of per-class accuracies achieved with SBoSK, we can see that some classes (urban vegetation, industrial blocks, individual and collective housing blocks and agricultural zones) yield higher accuracies on the MSR image, while some other classes (water surfaces, forest areas, roads) obtained better accuracies on the VHSR image. Nevertheless, combining both kernels allows benefiting from the advantages of the two complementary features, thus yielding the best accuracies for all classes. Indeed, we can state that the prediction achieves a spatial regularization for the large regions (e.g., industrial and individual housing blocks) thanks to the context features, while providing precision for the small structures (such as road networks) thanks to the detailed object decomposition features.
When compared with the Gaussian kernel computed on a single image at a single level, combining both SBoSK built on two different image sources achieves OA improvement when using and OA improvement when using . This demonstrates the superiority of our proposed multi-source classification method that is able exploiting topological features across multiple scales within the GEOBIA framework.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}