1. Introduction
Semi-arid and arid regions cover nearly 41% of the Earth’s surface and are home to more than 38% of the population [
1]. These regions typically receive limited precipitation during the agricultural growing season of April to October, averaging 0.1–0.8 m annually, and experience hotter, drier summers than other regions of the world [
2]. Most vegetation is likely to be dead or in a stage of senescence during the hot summer months unless supplemental water is available for plant consumption. As a result, semi-arid and arid regions rely heavily on irrigation to support agriculture. For example, in the western United States, agriculture accounts for over 90% of consumptive groundwater and surface water use [
3]. The 17 conterminous western states alone account for 85% of water withdrawals in the United States and 74% of irrigated acres, with the states of California, Texas, and Idaho consistently leading the nation in total water withdrawals [
3]. Given the reliance of these regions on irrigation, it is essential to develop an understanding of spatial and temporal patterns of water use and food production. In addition to the food security implications, use of irrigation in the agricultural landscape is of particular interest because it affects groundwater quality and quantity, ecological processes, climate, and biogeochemical and hydrologic cycles [
4].
Accurate mapping of the distribution of irrigated land at a regional scale can facilitate an improved understanding of patterns of water use and food production on an annual to decadal basis. As the frequency of precipitation events declines during the summer months, anomalies in plant greenness or water content can be attributed to irrigation practices. Specifically, the presence of green, healthy vegetation during the summer growing season can most likely be attributed to irrigation water applications [
5]. Remote sensing yields a source of readily available data that can be used to identify and quantify irrigated area on an annual timescale based on within-season trends in greenness. In particular, the Normalized Difference Vegetation Index (NDVI), derived using near infrared and red reflectance, has been used for mapping irrigated areas on the local scale and is effective because of differential spectral responses between irrigated and non-irrigated croplands [
6].
Using NDVI as an indicator of vegetation phenology reduces the amount of computational storage needed, improves processing time, and provides a simple means for classifying complex landscapes [
7]. There is overwhelming agreement that NDVI can be a vegetation monitoring tool [
8,
9,
10,
11]. NDVI and plant moisture availability are closely related [
12], which makes NDVI a sufficiently good indicator of irrigation presence [
13,
14,
15,
16]. Studies using NDVI have been used to distinguish irrigated from non-irrigated land use in semi-arid and arid regions in India and Turkey [
5,
7,
17]. NDVI has also been used to classify land use and land cover in which irrigated area is one of multiple classification categories [
4,
18,
19].
Moderate Resolution Imaging Spectroradiometer (MODIS) and Landsat have been found to be the most effective imagery for observing differences in NDVI in semi-arid and arid regions [
6]. The MODIS instrument, aboard NASA’s Aqua and Terra satellites, has been applied to map land use using multiple reflectance spectra and vegetation indices [
17,
20]. Likewise, the Landsat remote sensing system has proven a useful tool for producing land-use maps [
21,
22]. Each of these remote sensing products has its spatial and temporal advantages and disadvantages: MODIS gathers higher-frequency, daily data, but at a relatively coarse, 250-m or 500-m spatial resolution, whereas Landsat has a lower-frequency return interval of approximately 16 days, but a relatively fine, 30-m spatial resolution. A shorter return interval is advantageous when cloud cover renders some images during the agricultural growing season unusable; a finer spatial resolution is advantageous because it captures water use patterns at the scale of the individual field.
Ozdogan et al. [
5,
6] demonstrate that using a single observation date for NDVI, preferably during the peak of the growing season, is sufficient for distinguishing irrigated from non-irrigated land use using Landsat data in southeastern Turkey. When applying this method to other regions, however, classification errors may arise if farmers use inconsistent harvesting and irrigation practices. For example, alfalfa may be harvested multiple times throughout the growing season, potentially lowering its NDVI (and other index) values just after harvest. Likewise, irrigated water may have been cut off before the selected single image date, again potentially lowering NDVI values. Moreover, the optimal choice of observation date may differ across space and across years due to differences in summer precipitation events, for example.
To address these challenges, we test methods that have the potential to identify areas that are irrigated at any point throughout the entire growing season. We thus introduce methods that extend the window of observation from a single date to a time interval that captures within-season differences in greenness trajectories between irrigated and non-irrigated sites. We evaluate two new algorithms and the existing, single-date algorithm from Ozdogan et al. [
5,
6] for classifying irrigated lands in semi-arid and arid regions using multispectral data from both MODIS and Landsat. The two new algorithms classify land use based on summary statistics that describe the trajectory of greenness over the duration of the growing season (April to October). The first, which we call the greenness-duration approach, develops a threshold based on the difference in area below the spectral index curve for irrigated and non-irrigated sites. The second, which we call the seasonal maximum approach, develops a threshold based on the difference in the maximum of each spectral index between irrigated and non-irrigated sites (where the maximum for each index may fall on a different date). These new algorithms and the single-date algorithm are implemented using three vegetation indices—The Normalized Difference Vegetation Index (NDVI), Enhanced Vegetation Index (EVI), and the Normalized Difference Moisture Index (NDMI)—derived from both MODIS and Landsat imagery. Our objective is to contrast the performance of each algorithm-spectral index-dataset combination in terms of classification accuracy and to quantify the spatiotemporal patterns of irrigated land in our study region.
2. Study Region
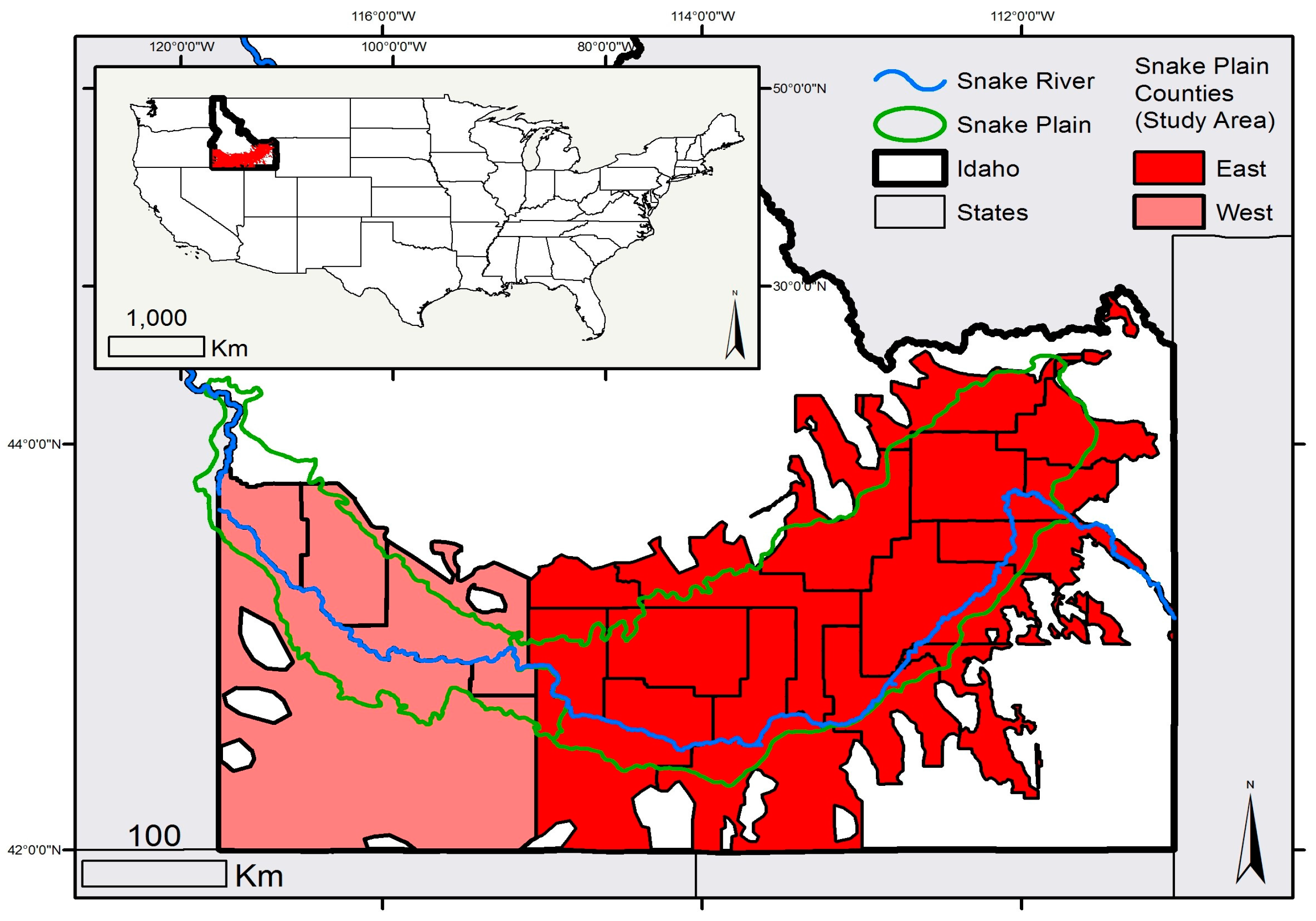
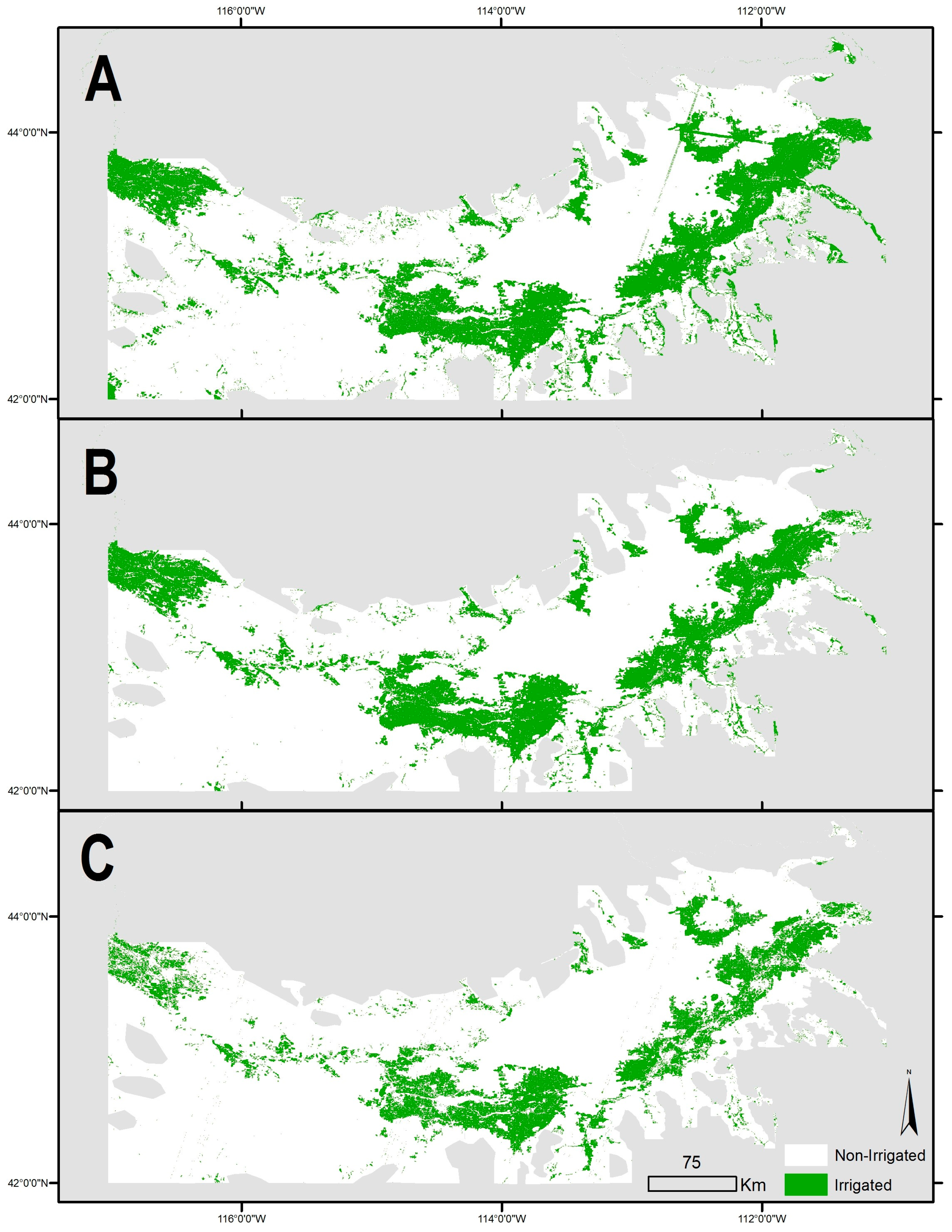
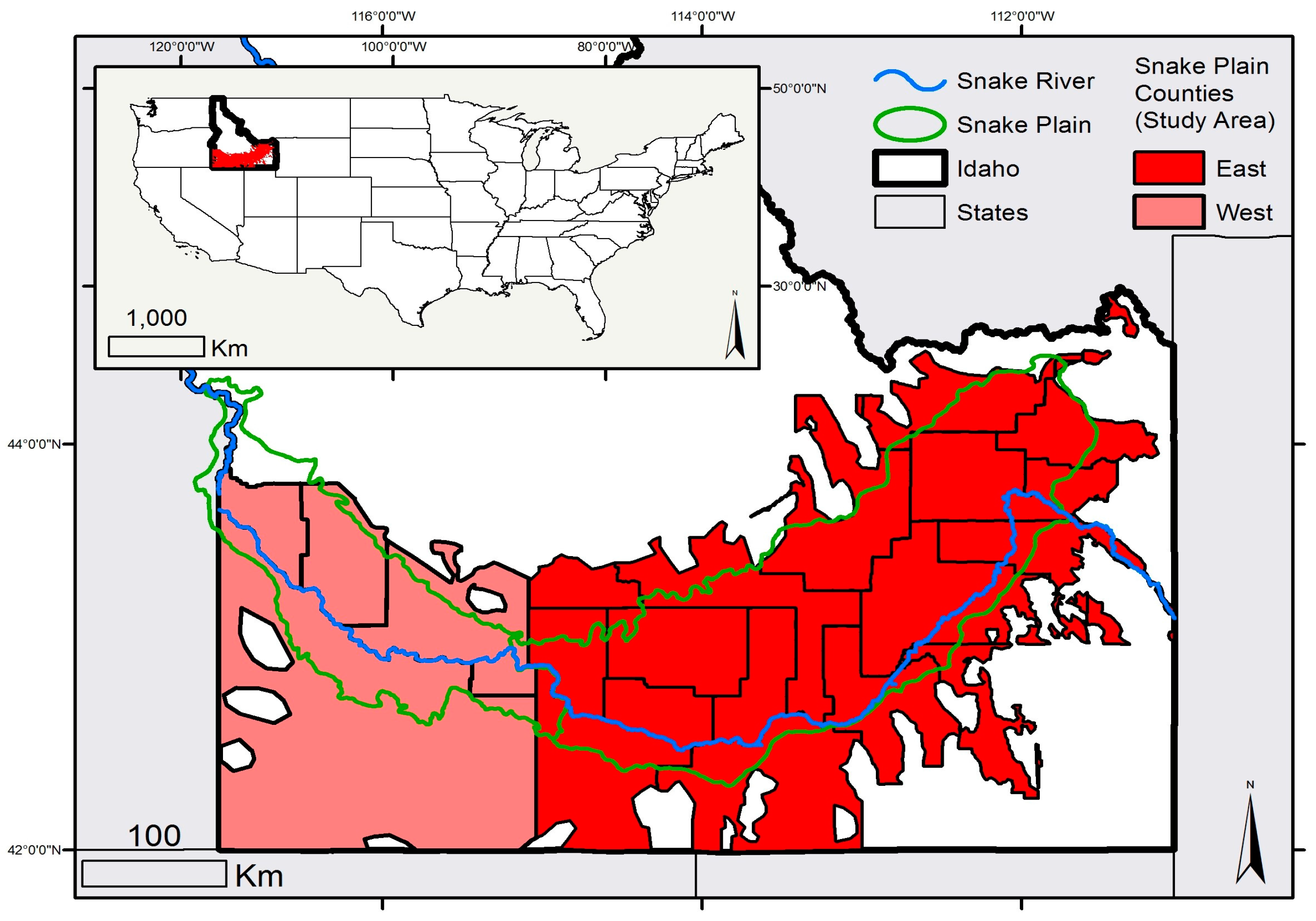
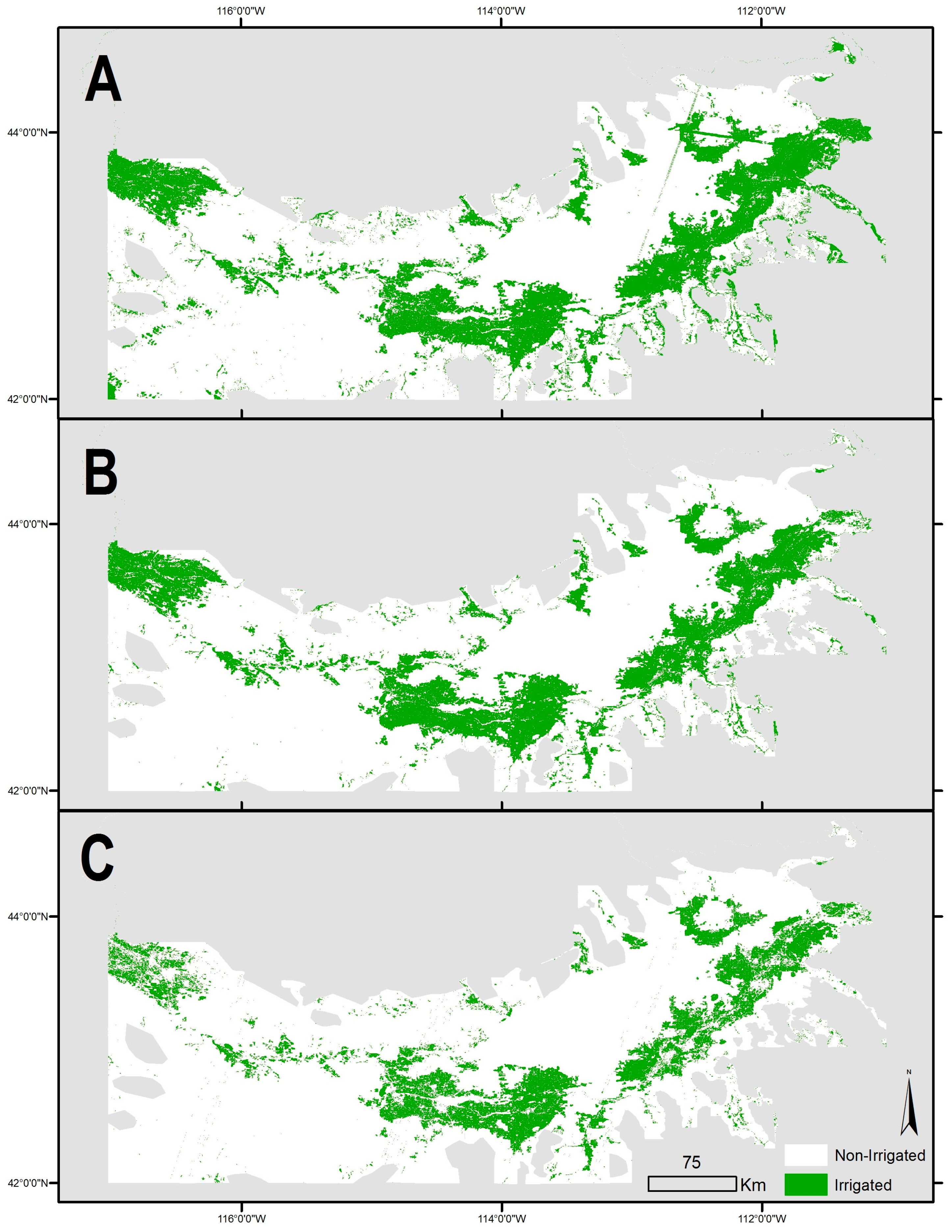
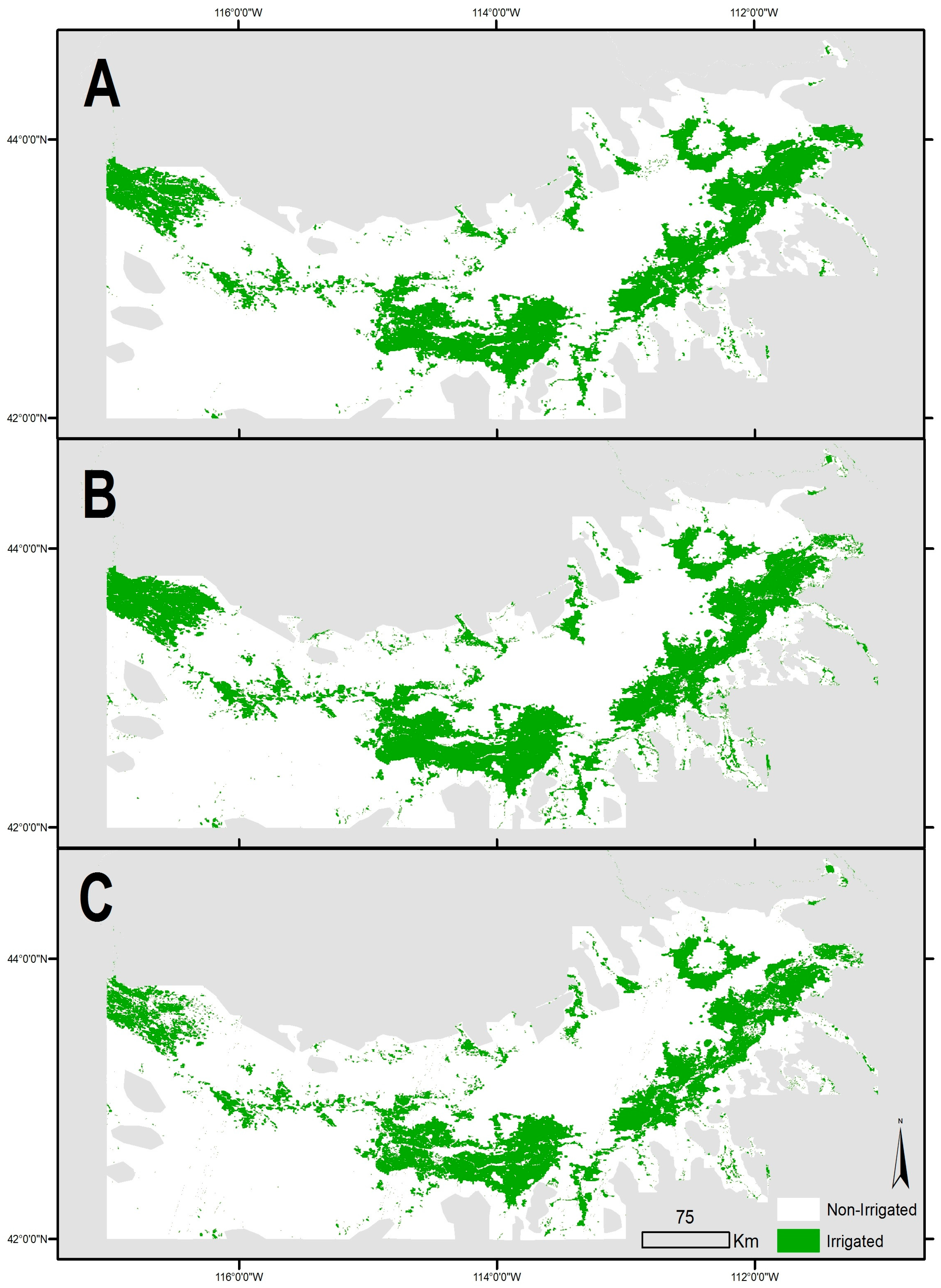
Our study region is the counties containing the Snake River Plain (SRP) of Idaho, United States (
Figure 1). The region is approximately 500 km east to west, and spans the majority of southern Idaho. The SRP has a Mediterranean-style semi-arid to arid climate in which the summer months have lower precipitation compared to other months of the year. The entire study area exhibits a “summer dry” climate, which allows us to explore methods to map irrigated land use via changes to the Earth’s surface reflectance spectra caused by irrigation. However, there are significant differences in elevation, temperatures, and precipitation between the western and eastern SRP (distinguished by a black line in
Figure 1). Relative to the eastern portion of the SRP, the western portion is at a higher elevation, with generally higher temperatures and more precipitation. Mean annual temperature is at its maximum in the western portion of the Snake Plain at 13 °C, and precipitation generally increases west to east from approximately 25 cm annually to 35 cm annually, the majority of this comes during winter months. Much lower temperatures and higher precipitations occur on the surrounding mountains. Elevations of the plain vary from approximately 680 m above sea level in the west to 1680 m in the east (higher elevations can be found in adjacent mountain peaks, several of which are in excess of 2800 m). Differences in climate between the eastern and western portions of the SRP are primarily controlled by Pacific Ocean-derived moisture and topography [
23].
In the SRP, agricultural productivity, the value of agricultural land, and farmers’ land-use decisions are driven by the availability of water for irrigation. Idaho alone ranks third in the United States in terms of the volume of water withdrawn, and first in terms of water withdrawals per capita [
24]. Over 98% of all water withdrawn in Idaho goes to counties that lie completely or partially within the SRP, with the majority of that water, 85.6%, used for irrigation [
25]. Based on the 2011 USDA Cropland Data Layer, within the SRP’s cultivated lands 28% was growing spring and winter wheat, 26% was alfalfa, 12% was barley, 10% was corn, 10% was potato, 6% was sugar beet, 2% was dry beans and 4% was growing other crops. Approximately 20% of the study region is in agriculture. Water for irrigation is supplied predominantly by winter snowpack, rendering this region particularly vulnerable to the effects of climate change [
26]. Recent research shows that climate has already begun to impact the timing of snowmelt runoff and suggests increased variability in the timing and magnitude of available water derived from winter snowmelt in the future [
27]. Increased variability in water resources during the late summer months, at a time when water is critical for crop growth, will introduce uncertainty into agricultural production. This uncertainty is likely to influence land-use patterns, and thus the economy, hydrology, and ecology of the region.
3. Materials and Methods
As is evident in
Figure 1, our study area is relatively large and encompasses multiple Landsat scenes (i.e., Landsat paths 38–42 and rows 29–31). For the multitemporal Landsat analysis, this introduces “big data” computational challenges, with large data volumes (terabytes) and high performance computing requirements for image processing. Therefore, we utilize the Google Earth Engine API platform for our multitemporal algorithms. As part of the platform, Google maintains the Landsat and MODIS satellite archives, with Landsat data pre-processed to reflectance. Using this interface, we use the Landsat reflectance products with masked clouds identified by the Fmask algorithm [
28]. Our index calculations and algorithm computations are also performed in this environment.
3.1. Vegetation and Plant-Water Indices at High and Moderate Spatial Resolutions
This study classifies irrigated land using two common vegetation mapping indices (i.e., NDVI and EVI) and a plant–water index, NDMI, which is designed to be more sensitive to changes in canopy water content.
NDVI is defined as:
where ρ
nir and ρ
red represent near infrared and red reflectances, respectively [
29]. EVI is a refined version of NDVI that corrects for additional atmospheric influences, reduces saturation, and accounts for canopy effects [
20,
30,
31]. EVI is defined as:
where G, C1, C2 and L are sensor-specific constants for gain (G), aerosol resistance (C1 and C2), and a canopy adjustment term (L).
NDMI, also referred to as the Normalized Difference Water Index (NDWI), is defined as:
where ρ
swir1 represents short wave infrared (1.55–1.75 μm) reflectance [
32].
We calculate each index at high (Landsat, 30-m) and moderate (MODIS, 250-m and 500-m) spatial resolution.
Table 1 provides a summary of the data products used in this study. The MODIS global data product (MOD13Q1) includes cloud-free 16-day mosaics of NDVI and EVI. Landsat 5 surface reflectance (SR) data were used to provide high resolution versions of NDVI, EVI, and NDMI. Existing NDVI, EVI, and NDMI cloud-free 32-day top of atmosphere (TOA) composites were used (LT5_L1T_32DAY, provided by Google Earth Engine). It should be noted that the size of the study area necessitated using images composited over several days for the single date approach in order to get a single image that covers the study area. In addition, the Google composites generally use the most recent image in the given time period unless it is cloud impacted.
Table A1 lists the start date of each composite used.
3.2. Development of a Training Dataset
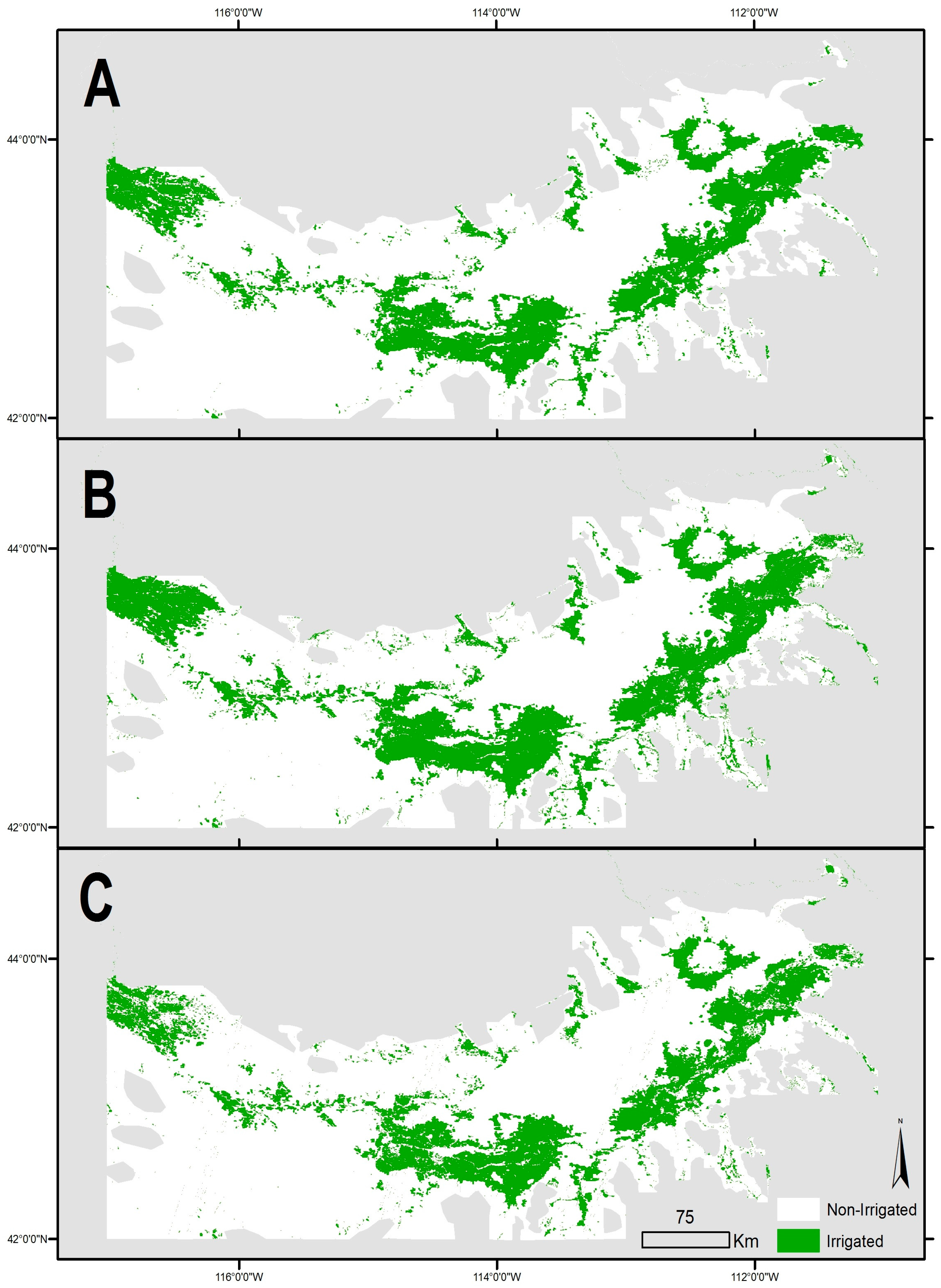
A training dataset of known land-use points was developed using manual interpretation of the National Agriculture Imagery Product (NAIP), which consists of high resolution aerial photographs. In our study region, NAIP images are available for the 2003, 2004, 2006, and 2009 growing seasons. Approximately 10 irrigated and 10 non-irrigated points were identified within each of 21 counties. The final training dataset contains a total of 404 control points. Points were generally located near the center of fields or away from edge areas to avoid mixed pixels, however for the at the 500 m resolution of some of the MODIS data some mixing is likely inevitable.
Figure 2 illustrates these control points as well as several example points for Twin Falls County in 2007.
3.3. Three Pixel-Scale Thresholding Approaches for Classification
We investigate three classification algorithms using each of the spectral indices (NDVI, EVI and NDMI) developed using data from MODIS and Landsat 5. Each algorithm is implemented for two years—the 2002 and 2007 growing seasons. The classification itself is performed at the scale of the individual pixel. We report classification accuracy metrics at this spatial scale for each algorithm-index-dataset combination. In addition, the years 2002 and 2007 correspond to the years of the USDA Agricultural Census, which allows us to use aggregate, county level statistics as a second benchmark against which we test the classification accuracy of each algorithm-spectral index-dataset combination.
3.3.1. Single-Date Algorithm
The first algorithm uses single-date imagery, as in Ozdogan et al. [
5,
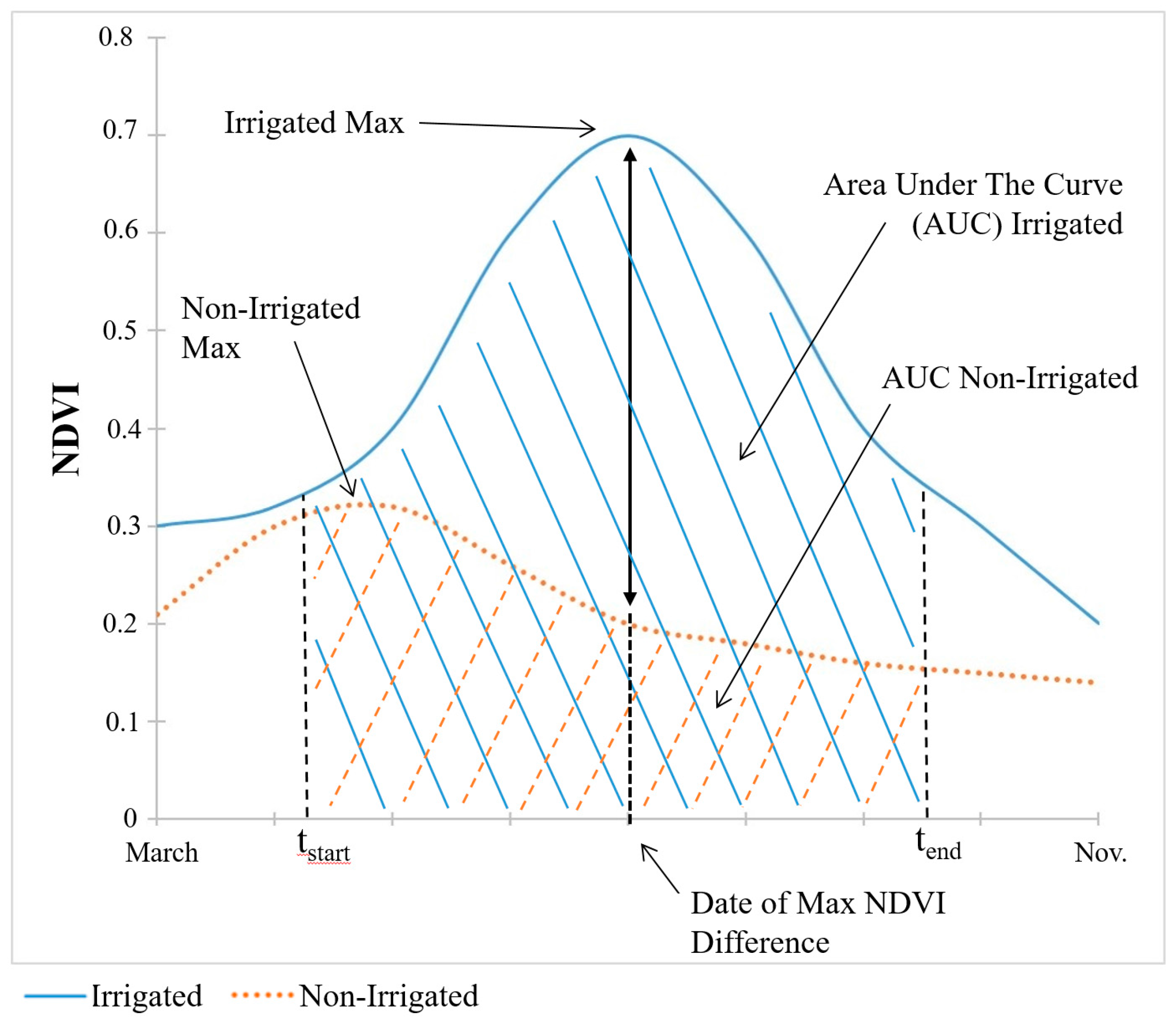
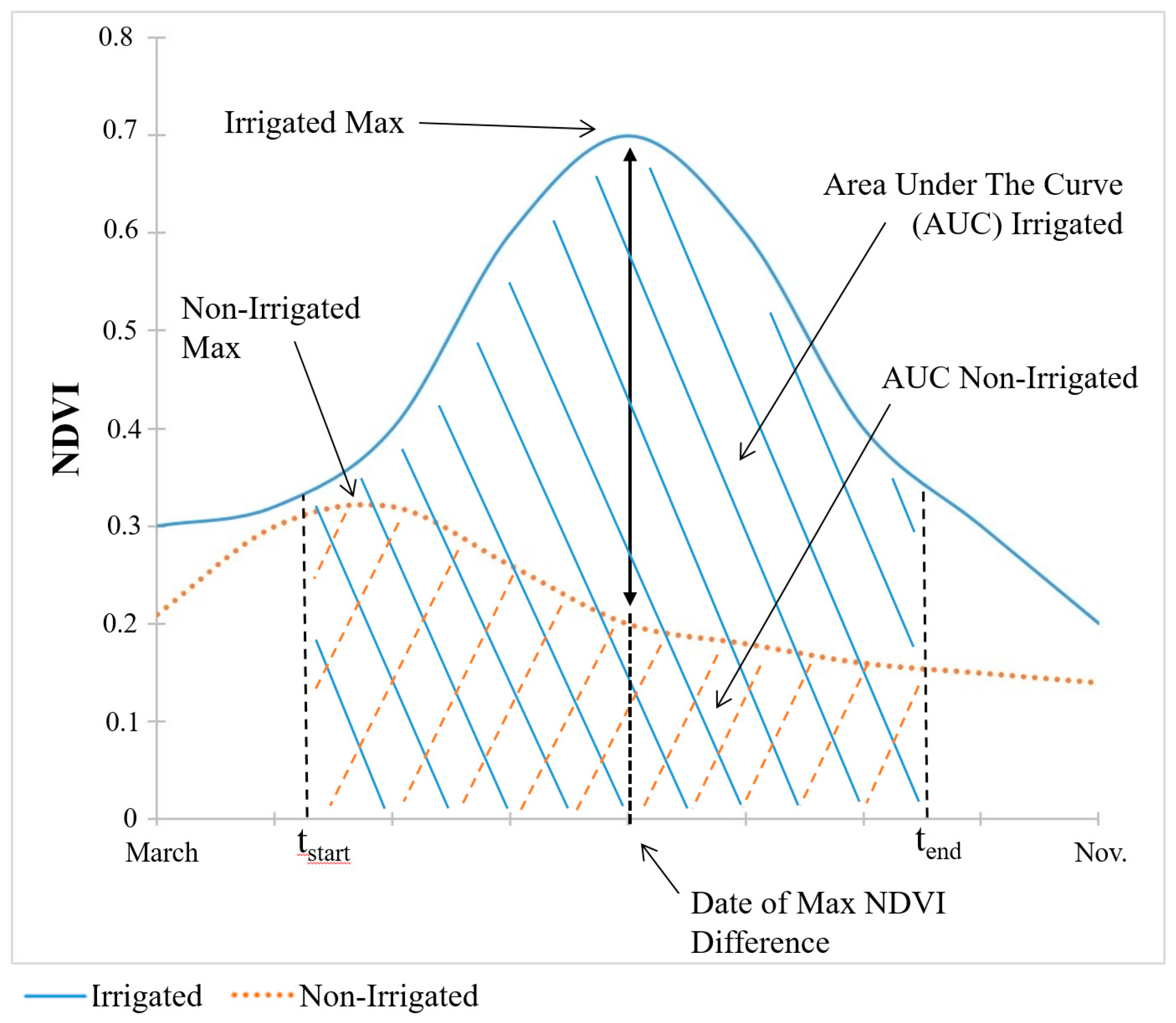
6]. This method requires that we first determine the observation date at which the difference in the spectral index value between irrigated and non-irrigated land is at its maximum. The date at which the maximum difference in the spectral index between irrigated and non-irrigated pixels is observed is illustrated conceptually for NDVI by the vertical black arrow in
Figure 3 (the conceptual diagram is the same for EVI and NDMI). For each year we select the composite image for which the irrigated and non-irrigated index values are at their greatest separation by calculating the difference between the sum of all spectral index values for the training dataset of known irrigated points and the sum for non-irrigated points for each available image date within the growing season. As discussed by Ozdogan et al. [
5], the best window to apply this classification scheme is near the timing of peak green-up.
We then derive a threshold value that maximizes classification accuracy for both land-use categories. To do so, we fit a separate nonparametric kernel density function to the observed spectral index values for irrigated and non-irrigated control points in the training dataset. This is done using the kdensity function in Matlab, which uses a frequency of 1/100th the range of the data. Using those fitted distributions, we calculate the probability that a pixel is irrigated or non-irrigated at a range of potential threshold values based on both kernel density functions. We select the threshold value at which the probability of classifying the pixel as irrigated or non-irrigated is equal, which represents the point at which the fitted normal kernel density functions intersect (which simultaneously minimizes type II error for both distributions). Observations above the threshold are classified as irrigated; those below the threshold are classified as non-irrigated. Threshold values used for each year and classification method are listed in
Appendix A (
Table A1).
3.3.2. Greenness-Duration Algorithm
The second thresholding method distinguishes irrigated from non-irrigated land using the area under a spectral index curve over the duration of the growing season, rather than at a single date. The differences in the areas under the spectral index curve for irrigated and non-irrigated points are illustrated for NDVI with cross-hatching in
Figure 3. The area under each spectral index curve is computed by calculating the integral of the time series from 1 April to 31 October and deriving the threshold value that most accurately classifies both land-use categories using the same probability based approach used for the single-date algorithm.
Peak green-up, the time at which crops are at or nearly at their maximum index values, typically occurs in mid-summer. However, using the greenness-duration approach, we find that the greatest difference in the areas under the spectral index curves tends to fall later in the growing season. This occurs because following peak green-up, non-irrigated crops typically begin to show a reduction in vegetation index values while irrigated control point values maintain elevated levels for multiple images.
This approach also mitigates some classification error that arises when crops are harvested multiple times during the growing season, such as alfalfa, which is one of the top crops grown in the SRP. Irrigated alfalfa may be harvested 4–5 times during a growing season, while dryland alfalfa yields fewer cuttings. Multiple cuttings result in multiple peaks in spectral indices during the growing season, muddying the signal in peak green-up for the single-date approach. By accounting for the area under the curves, the greenness-duration approach better captures the difference in spectral index for irrigated and non-irrigated crops across multiple cuttings.
3.3.3. Seasonal-Maximum Algorithm
In our third approach, we use a single threshold value for the region based on the seasonal maximum for each spectral index, where both the date and the level of the seasonal maximum of irrigated crops may differ from that of non-irrigated crops, as illustrated in
Figure 3. We compute the seasonal maximum for each growing season (again defined as 1 April to 31 October) in Google Earth Engine. Here we use the same probability based approach to select the optimal threshold as described for the single-date and greenness-duration algorithms.
When using the Landsat NDMI data for this algorithm, error may be introduced into the classification due to variability in NDMI from climate, farm equipment, or other anomalies. To address this challenge and increase the reliability of the training dataset for this particular algorithm-index-dataset combination, we extract a nine-pixel square around each control point. We remove from the dataset any pixel values outside two standard deviations of the mean NDMI within the nine-pixel square. We also control for differences in climate across the study region through the inclusion of average annual precipitation data for each control point or nine-pixel square [
33]. We use average precipitation data because spatially explicit annual precipitation data are not available for the entire study period. Using discriminant analysis for the 2003 growing season, we test the effect of controlling for precipitation.
3.4. Validation and Accuracy Assessment
We validate the classification from each algorithm-index-dataset combination at the individual pixel level using two different validation datasets. The first (which we refer to as the symmetrical validation dataset) uses 75 known irrigated and 75 known non-irrigated points. The second validation dataset (which we refer to as the supplemental land-use validation dataset) uses NAIP imagery to differentiate between irrigated land and multiple non-irrigated land uses, including dryland agriculture and development. In addition to these pixel-scale validation approaches, we compare the classified area in irrigated and dryland agriculture to county level statistics from the USDA Census of Agriculture.
For the pixel-scale symmetrical validation dataset, we create a sample dataset of randomly selected points in the region and determine whether they are irrigated or non-irrigated agriculture in 2002 and 2007 using NAIP and Google Earth imagery. We supplement this dataset with randomly generated points that lie within the geospatial boundaries of the place of use for prior appropriation water rights [
34]. Farmers are restricted to applying water for irrigation within the place of use specified as part of a water right [
35,
36]. Using these supplementary data facilitate the process of identifying control points that are irrigated. Large forested areas, which mainly occur along the outer edge of the study region, are hand-delineated and removed from the analysis to attain an appropriate measure of accuracy in classifying irrigated area. In comparison to irrigated NDVI trends, the NDVI values of forested locations show far less variability than irrigated land use over the same time period.
From a randomly selected sample of potential validation points, we exclude points that were primarily in agricultural areas that appeared, based on NAIP imagery, to have been non-irrigated at some point between 2002 and 2007. In addition, we exclude points for which it is unclear whether they are irrigated or non-irrigated. Examples include areas with visible irrigation infrastructure where the crops appeared non-irrigated or areas where no visible irrigation infrastructure was present but the crops were greener than nearby nonagricultural areas. We also exclude points that are close to the edge of a field or points that contain multiple land-use types. The final pixel-level symmetrical validation dataset contains 150 points (75 irrigated and 75 non-irrigated) that can be definitively identified as irrigated or non-irrigated for our entire study period. We use these selected points to generate a confusion matrix with commonly used classification accuracy metrics, including overall accuracy, user’s accuracy, producer’s accuracy, and the kappa coefficient, as a comparison of the observed accuracy to random chance.
For the pixel-scale supplementary land use validation dataset, we randomly select 320 points in the study region, 20% of which are irrigated or dryland agriculture, and 3% of which are suburban or urban development. This land-use composition is representative of the region based on the 2006 National Land Cover Dataset [
37]. We use NAIP imagery to determine land cover for 2007, but areas that are not irrigated are broken down into four classes: desert (sparsely vegetated), non-agricultural but vegetated (green areas, usually riparian or covered with woody vegetation), dryland (non-irrigated) agriculture, and developed (urban and suburban areas). Points are only adjusted if they were too close to the edge of a field, or to ensure that there were representative proportions of agriculture, non-agriculture, and developed lands (20% agriculture, 3% developed and 77% other). The percentage of points correctly classified in each of these categories is calculated, as well as the overall percent correctly classified.
As an additional assessment of our results, we compare our findings to data from the USDA Census of Agriculture. Here, we calculate irrigated and non-irrigated areas by county for each year and compare our area total to that from the USDA Census of Agriculture for the years 2002 and 2007. The Census data are based on surveys of individual farmers, but is reported at the county scale. This provides an independent third-party assessment of our algorithm-index-dataset combinations. We compute the coefficient of determination (R2) as an indication of the variance of the area reported in the Census that is explained by our model outputs. We also report the root mean squared error (RMSE) as a measure of the difference in predicted irrigated area relative to USDA Census statistics.
5. Discussion
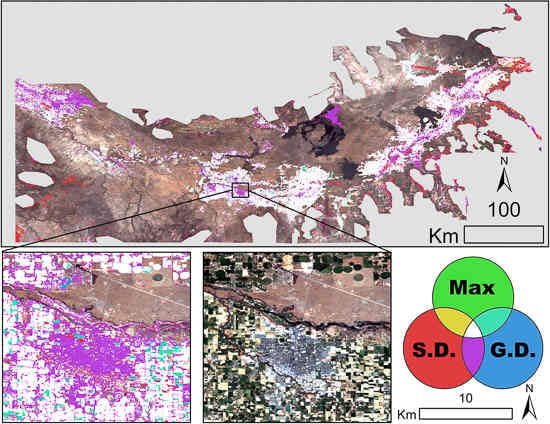
Examination of the multi-temporal trends of NDVI, EVI, and NDMI for our training dataset reveals distinct temporal patterns in elevated index values for irrigated land. The majority of irrigated points exhibit elevated index values following the timing of peak green-up for six composite product cycles (96 days), or approximately three months, prior to declining, likely due to harvest. Other observed trends include: rapidly changing spectra multiple times during the duration of the growing season due to the presence of multi-harvest crops (namely alfalfa); peak response in the late spring and early summer months for spring-planted, irrigated crops; and peak index response during the late summer and early fall months caused by delayed planting. These trends help to explain why the seasonal-maximum algorithm better distinguishes between irrigated agriculture and other areas where vegetation might be green, such as the riparian zone along the Snake River and the urban vegetated environment. Both of these latter scenarios could be considered instances of partial irrigation, characterized by a lesser volume and duration of water use than that for irrigated agriculture. Although the seasonal duration is essentially the same and the contrast between vegetated and non-vegetated land is evident based on all three algorithms, the maximum spectral index value for irrigated land will be greater because vegetation will grow more with additional water use.
The seasonal-maximum algorithm also allows us to accommodate a particular feature of the way that water is allocated to irrigated farms under the state’s system of water rights. Water rights are fulfilled based on the priority (or seniority) of water rights in the region, such that those water rights with an earlier priority date are fulfilled before those with later priority dates. Those fields irrigated with low priority water rights may only have access to water during the beginning of the irrigation season or sporadically thereafter based on available inflows throughout the growing season. In these cases, the seasonal maximum method is best suited to identify areas that were irrigated at any point during the growing season, as this method is more likely to capture short-duration, elevated spectral index values.
The relatively poor performance of the 2002 MODIS NDMI maximum algorithm is due to unmasked clouds, but it highlights one drawback of using the seasonal maximum method: it is more susceptible to errors due to poor masking. A single image during the year containing unmasked clouds, snow, standing water or other extreme values will be the seasonal maximum for that location, and thus will be carried through to the final composite image. These erroneous values would also alter a seasonal average or median image or a smoothed time series, but its impact would be offset by additional correct values and the magnitude of its effect on the final composite would be smaller.
5.1. Sources of Uncertainty
Some sources of uncertainty should be considered. One potential source of error is the influence of precipitation events that temporarily increase vegetative growth and spectral index values in some regions. In non-irrigated agricultural areas, precipitation during the growing season could cause the index values at these areas to be erroneously classified as irrigated. In addition, rain-fed crops tend to maintain elevated index values longer into the growing season relative to other non-agricultural lands, making discrimination between irrigated and non-irrigated areas subtler and leading to larger irrigated area estimates when compared to the USDA Census.
Selection of training/validation data points for this study is likely another source of error. These datasets are limited and the observation points may not be representative of the region as a whole. This is important to consider when evaluating the pixel level accuracy assessments. All the methods performed relatively well at the pixel scale, so small differences in the performance between methods may only represent classification changes at one or two validation points. The data were developed using NAIP imagery, which is simply a one-time image of the land surface, to locate points that appeared to exhibit irrigated and non-irrigated characteristics. Because these images are snapshot in time and land use can change rapidly, it is possible that irrigation was used at other times during the season. It should also be noted that for the initial point validation (using the symmetrical dataset) only points that could be definitively identified as irrigated or non-irrigated based on the NAIP imagery were included. These points may be easier to classify than the landscape as a whole, and could contribute to the relatively high pixel scale accuracy of all of the methods. Having access to a larger dataset of known land-use points has the potential to significantly improve classification accuracy. Individual-level data on land and water use, such as that collected as part of the USDA Census, are typically private, but improved information on field-scale water use would improve the accuracy with which irrigated lands can be mapped. Finally, inclusion of higher-resolution spatial data quantifying annual precipitation amounts and timing may also improve classification accuracies.
5.2. Future Extensions of This Research
Using the Landsat remote sensing dataset from Google Earth Engine to apply our classification algorithm to the full satellite record can allow for accounting of irrigator decision-making over time. A longer data record would support data-driven studies of the impacts of climate change on land-use decision-making. Additional benefits of using the Landsat remote sensing dataset include the increased spatial resolution from MODIS’s 250-m to 30-m. This allows for a more accurate analysis on the sub-MODIS pixel scale, which reduces errors in small-scale plot classification [
38]. For example, multiple irrigated and non-irrigated parcels may reside within one 250-m MODIS pixel, leading to a classification error based upon the intensity of irrigation and the resulting influence on the composited NDVI for that pixel. Research has shown that using data at a finer spatial resolution to map irrigated land improves classification accuracy [
5]. The downside with Landsat, however, is that the temporal resolution increases to approximately 16 days between each image capture. If insufficient cloud-free images are available, it is challenging to accurately describe the trajectory of NDMI over the growing season and difficult to implement the greenness-duration or seasonal-maximum algorithms. Researchers may thus be forced to accept a tradeoff between spatial resolution and classification accuracy. The decision of which dataset and algorithm(s) to use will depend on the particular research question at hand and the spatial scale at which decision-making processes operate.
Limiting the study region to areas suitable for agriculture is also an important component of this analysis. Forested regions and riparian zones show elevated NDVI and other spectral index values, similar to irrigated areas, meaning they appear as though they are irrigated. Because the influence of riparian zones is limited in our study region, our main focus is on masking out forested areas. The presence of forests poses a significant problem when attempting to quantify irrigated land use at the county scale, likely resulting in an overestimation of irrigated land use. There appear to be distinct patterns in the NDVI curves including the timing of green-up, the slope of the decline in greenness during the growing season, and the timing of rapid NDVI drop-off near the end of the year, likely attributable to the presence of snow or defoliation of undergrowth in inter-canopy spaces. With further exploration of these patterns, a method for removing these regions could be developed.
Lastly, we must discuss the broader applications of our classification method for mapping other semi-arid to arid regions. The developed method relies on region specific training data to calculate each threshold. Since the thresholds are data driven, this method is likely applicable to other regions once a training dataset has been created and could be applied to other types of smoothed time series or composites. Our methods are directly applicable to areas with a “summer dry” climate because they fundamentally rely on a lack of available water for plant consumption during the summer months to identify locations that receive supplemental irrigation water. Because of this assumption, our approaches will be less accurate in areas with “summer wet” climates. It is possible to apply our method to these regions by adjusting the timing and length of the observation window. The required change to the observation period would depend on the timing and length of the growing season along with the timing and magnitude of precipitation. If there is a significant amount of time in which precipitation is low and temperatures are high during the growing season, this method could be applied to map irrigated agricultural land use in areas with “monsoon-driven” semi-arid to arid climates.
6. Conclusions
At the regional scale, we demonstrate that the top performing algorithm in terms of classification accuracy is the seasonal-maximum algorithm, primarily due to its out-performance of the other approaches in appropriately classifying lands in riparian and developed areas. While the most accurate method in terms of county scale RMSE and R
2 is the seasonal maximum of Landsat 5 NDMI, it only marginally outperforms the next best method (Landsat 5, EVI seasonal maximum). Differences in classification accuracy between spectral indices and sensors are fairly modest, but larger differences can be seen between image compositing algorithms. The seasonal maximum algorithm reduces county scale RMSE by an average of 60% over the single-date algorithm, and yields a consistent improvement in classification accuracy across virtually all years and spectral indices. The improved ability of the seasonal-maximum algorithm to classify irrigated and non-irrigated lands at a regional scale is a critical tool for water managers that can support improved predictions of changes in competition for increasingly scarce water resources and provide the information needed to support more efficient water management techniques [
5].
Using the seasonal-maximum of spectral vegetation indices, we develop an efficient and computationally inexpensive method for mapping irrigated land use that is broadly applicable to “summer dry” Mediterranean style semi-arid to arid climates. Results show an average percent error reduction when compared to the single-date algorithm of Ozdogan et al. [
5]. This is encouraging, given the variability across our study region in terms of topography, precipitation, and temperatures, which represents a significant difference between our analysis and the relatively homogeneous study area in Turkey evaluated by Ozdogan et al. [
5].


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}