1. Introduction
Ensuring food security through sustainable agricultural development sets a double challenge to agricultural systems: Food production must substantially increase to satisfy the demand of a continuously growing population while improving the stewardship of natural resources and minimizing environmental impacts [
1]. This transition towards sustainability is further challenged by the consequences of climate change and an increased competition for land, generating an urgent need for repetitive spatial information to help monitor the dynamics of the agricultural land-use systems at the regional and global scales.
Land use is defined as “the sequence of operations carried out with the purpose to obtain goods and services from the land” [
2]. Land-use systems (LUS) can thus be considered as coupled human–environment systems that can be characterized by two main aspects: land resources and management practices [
3]. LUS mapping originally consisted in the delineation of relatively homogeneous areas of land (referred to as land units), which are directly linked to a specific type of land use [
4,
5]. Regional-scale agricultural land-use systems (ALUS) maps typically represent the major agricultural zones for a given region, each agricultural zone (land unit) being directly linked to a particular agricultural system. The land units of a regional-scale ALUS map are naturally composed of multiple agricultural fields which are spatially “concentrated” and representative of a particular agricultural system, but also contain a mosaic of other land-cover types, e.g., patches of natural vegetation among the agricultural fields, due to their extent. The plotting of the land units’ boundaries is, however, challenged by limited access to spatially explicit and detailed land-use information over large areas, which may account for the general lack of LUS maps.
The few existing large-area LUS mapping approaches, such as the one developed by FAO [
2], are usually based on a subjective choice of socio-economic and environmental variables. These are derived from heterogeneous sources which are empirically categorized and combined to map the different land-use systems. The resulting LUS maps are subject to error propagation due to the disparity of spatial resolution, production date, and quality of the original data. In addition, access to the data is not always guaranteed, which limits the reproducibility of the LUS maps in time and across regions. As a result, the description and location of the different agricultural land-use systems remain highly unclear for most world regions.
Earth observation satellite systems can significantly contribute to LUS mapping since they provide timely and detailed land-use information over large areas due to their synoptic coverage and high revisiting frequency. In particular, remote sensing-derived time series of vegetation indices allow monitoring of the phenology (seasonal vegetation variation) and the intra-seasonal variations of the agricultural land cover (i.e., cropland, pastures, and rangelands), from which the agricultural land use (including some management practices) can be determined [
6,
7,
8,
9]. Furthermore, the geographic object-based image analysis (GEOBIA) [
10] segmentation techniques, which automatically delineate homogeneous objects at multiple scales, seem particularly adapted for the extraction of land units. Bisquert et al. [
11] introduced an innovative approach based on GEOBIA of spectral and textural variables derived from coarse-resolution vegetation index images that produced a spatial segmentation of the French territory in broad-scale land units. The resulting land units proved to be consistent in terms of land cover [
12], but remained unclassified, and the variables used are not descriptive enough for effective delineation of agricultural land-use systems since they do not account for the intra-seasonal variations that characterize agricultural land-use practices.
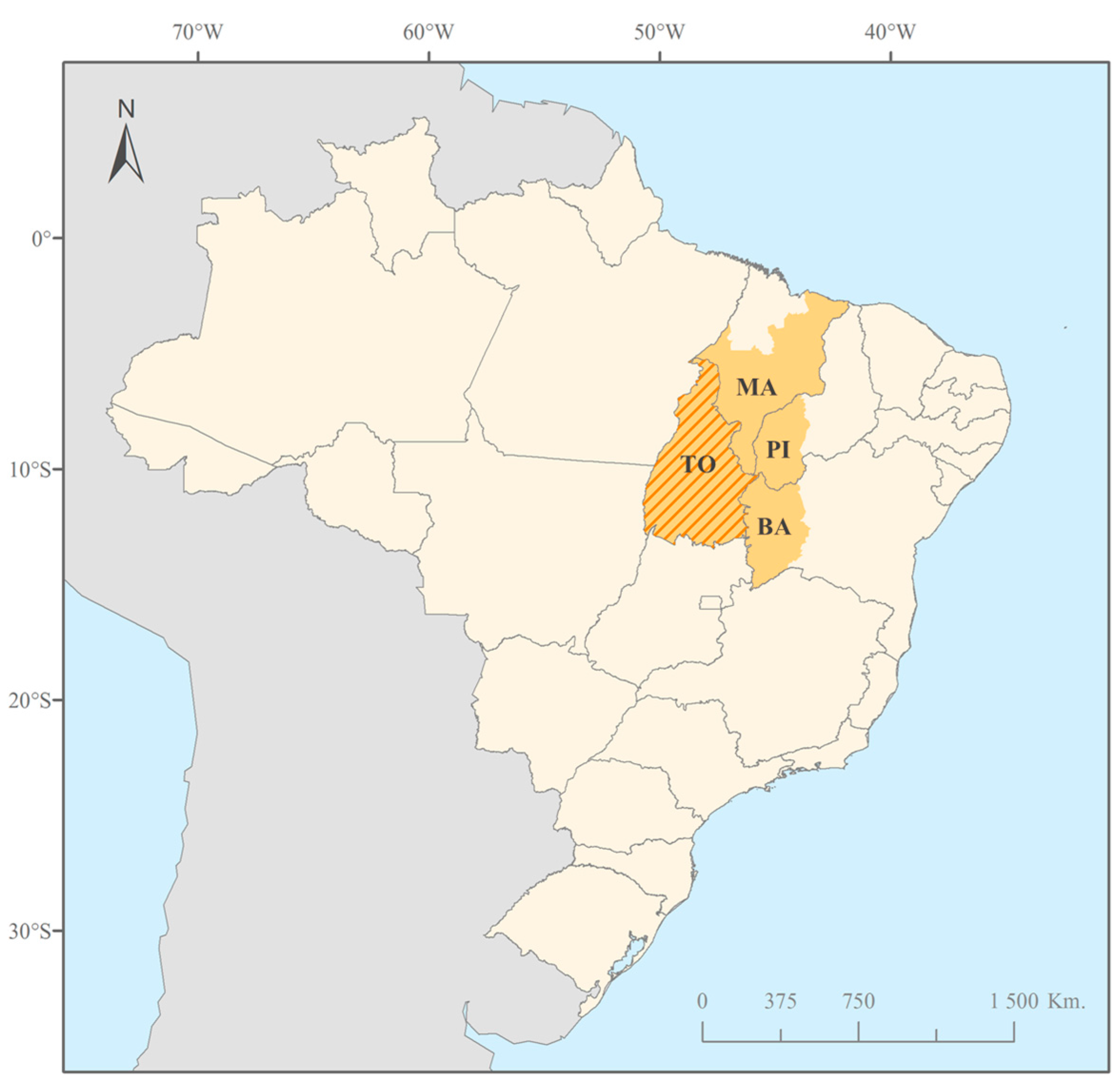
The aim of this work is to provide a simple and reproducible approach for regional-scale mapping of ALUS based on GEOBIA and vegetation index time series analysis. The presented approach involves the extraction of temporal variations of the vegetation cover in relation to agricultural land use from a vegetation index time series, by performing a principal components analysis and selecting the principal component images that capture the seasonal and intra-seasonal variability of the vegetation index time series. Segmentation and classification of the selected principal components images follow, finally producing an ALUS map. The approach was applied to an annual Moderate Resolution Imaging Spectroradiometer Normalized Difference Vegetation Index (MODIS NDVI) dataset and tested on a new agricultural expansion region of Brazil. The spatial distribution of the cropping systems in the final ALUS map was evaluated with the annual crop estimates of the Municipal Agricultural Production database (PAM) of the Brazilian Institute of Geography and Statistics (IBGE).
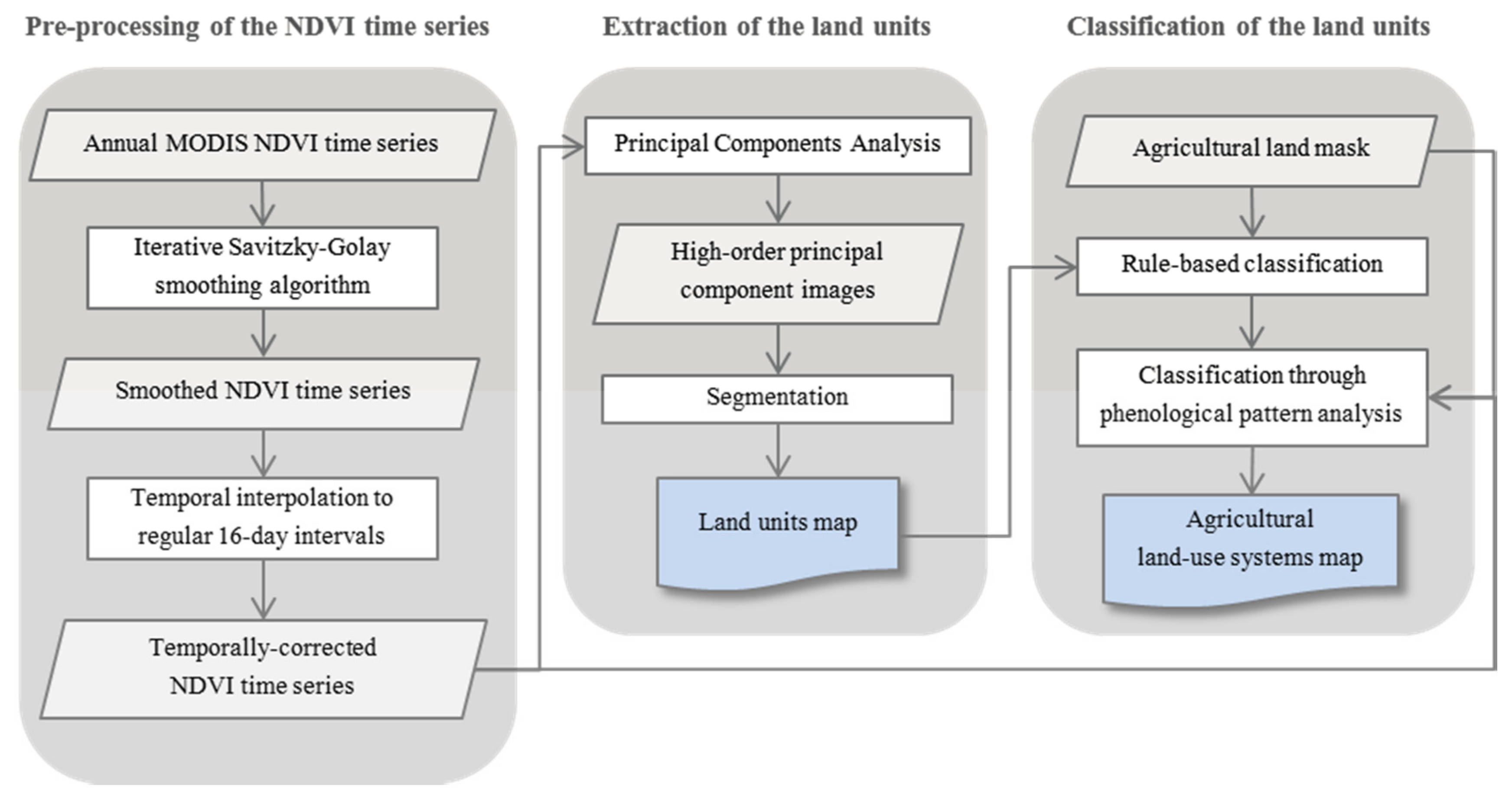
3. Methods
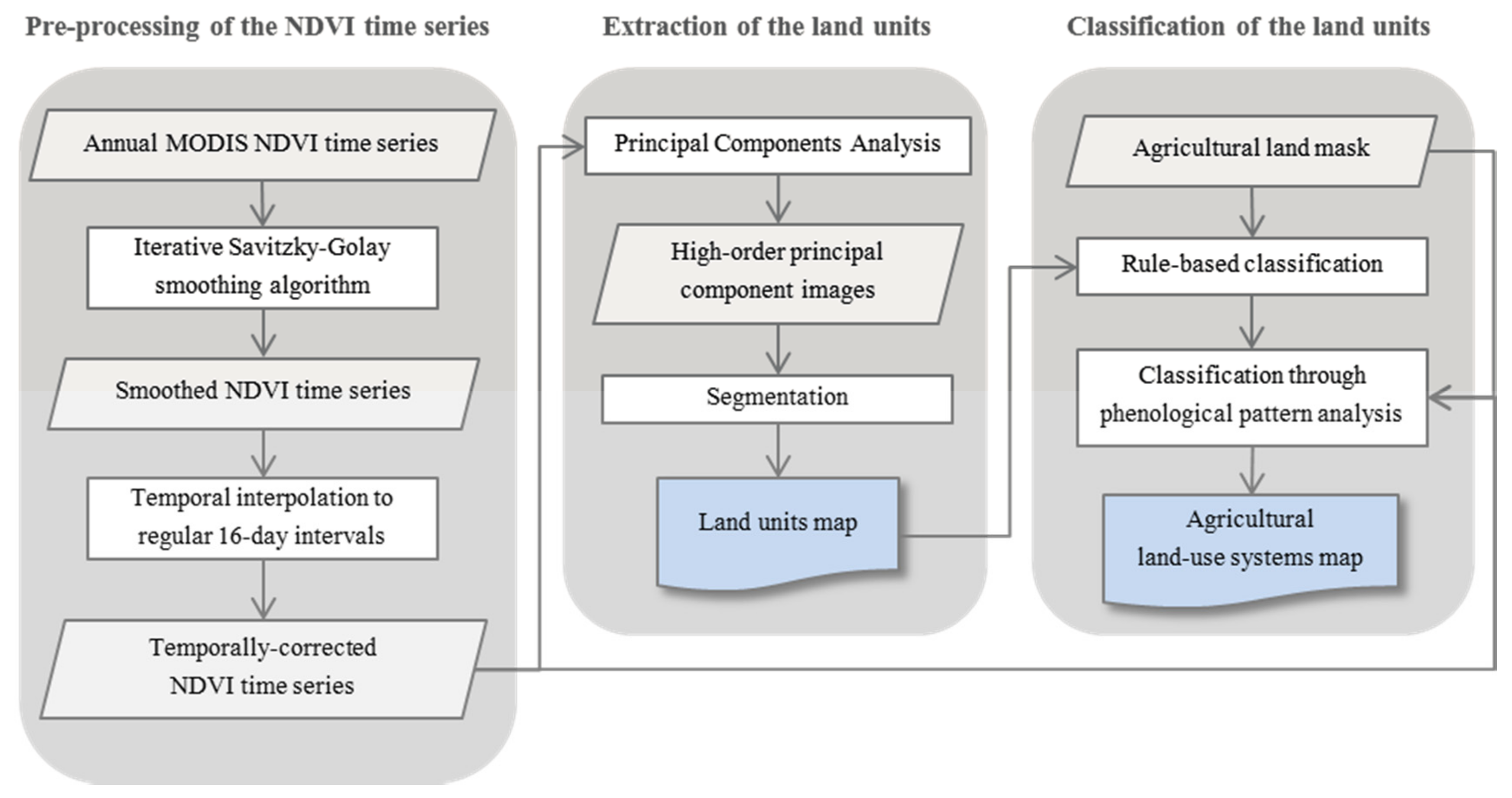
The methods applied in this study follow a typical GEOBIA approach [
10] through automatic image partition into meaningful image objects (the land units), and subsequent classification of the resulting objects by an assessment of their characteristics to generate new geographic information (the agricultural land-use systems (ALUS) map). The methodological framework is presented in
Figure 3 and described in the following three sub-sections: Pre-processing of the NDVI time series (
Section 3.1); Extraction of the land units (
Section 3.2); Classification of the land units (
Section 3.3). A final sub-section presents the unsupervised evaluation approach that was used to evaluate the cropping systems’ classification results of the ALUS map (see
Section 3.4. Unsupervised Evaluation of the Classification Results).
3.1. Pre-Processing of the NDVI Time Series
The compositing process of the MOD13Q1 product uses the Constrained View angle-Maximum Value Composite (CV-MVC) algorithm, which involves selecting (pixel-wise) the observation with the highest NDVI value and the smallest view angle out of all the observations made during a 16-day cycle [
22]. However, remaining effects such as cloudiness or bi-directional effects are still present in the dataset.
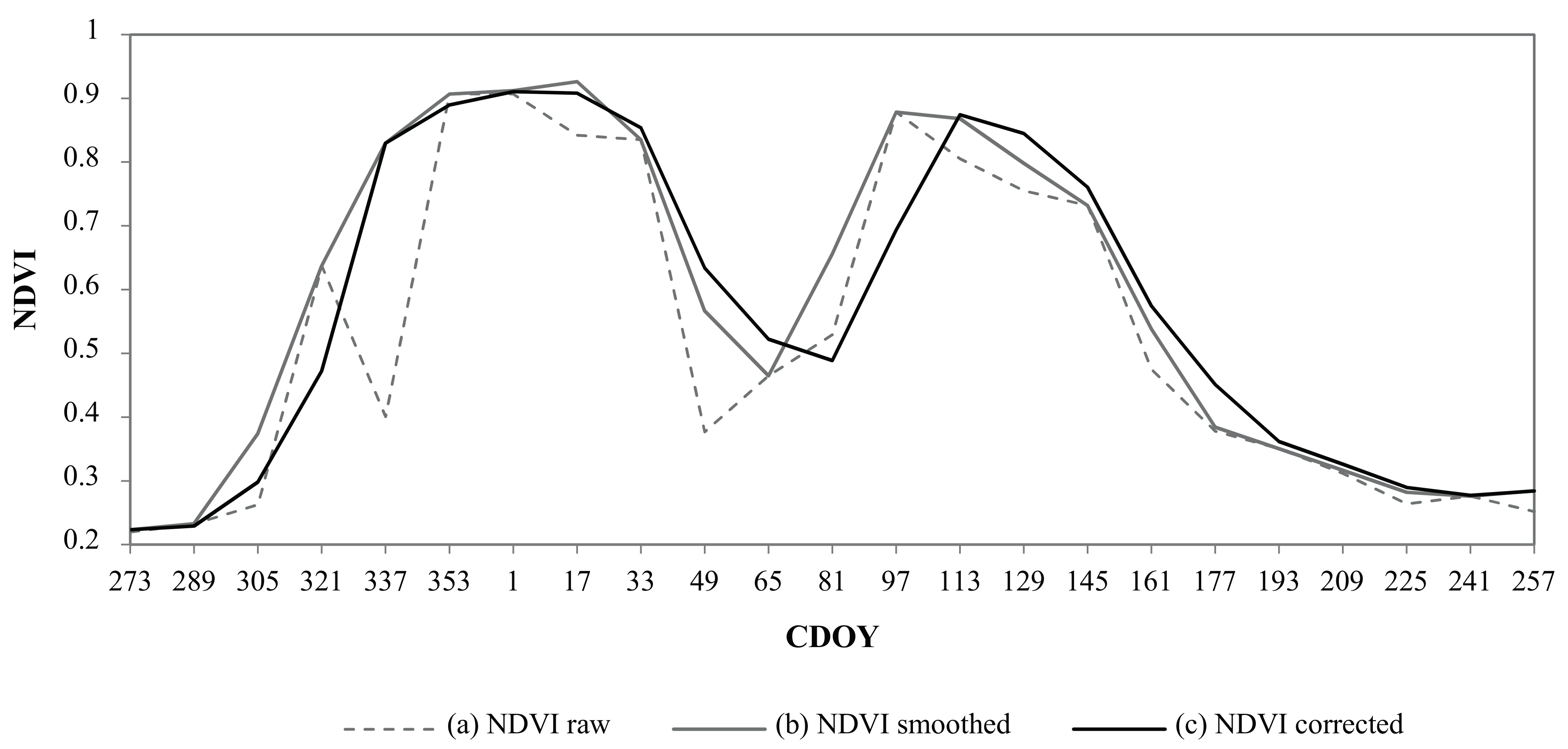
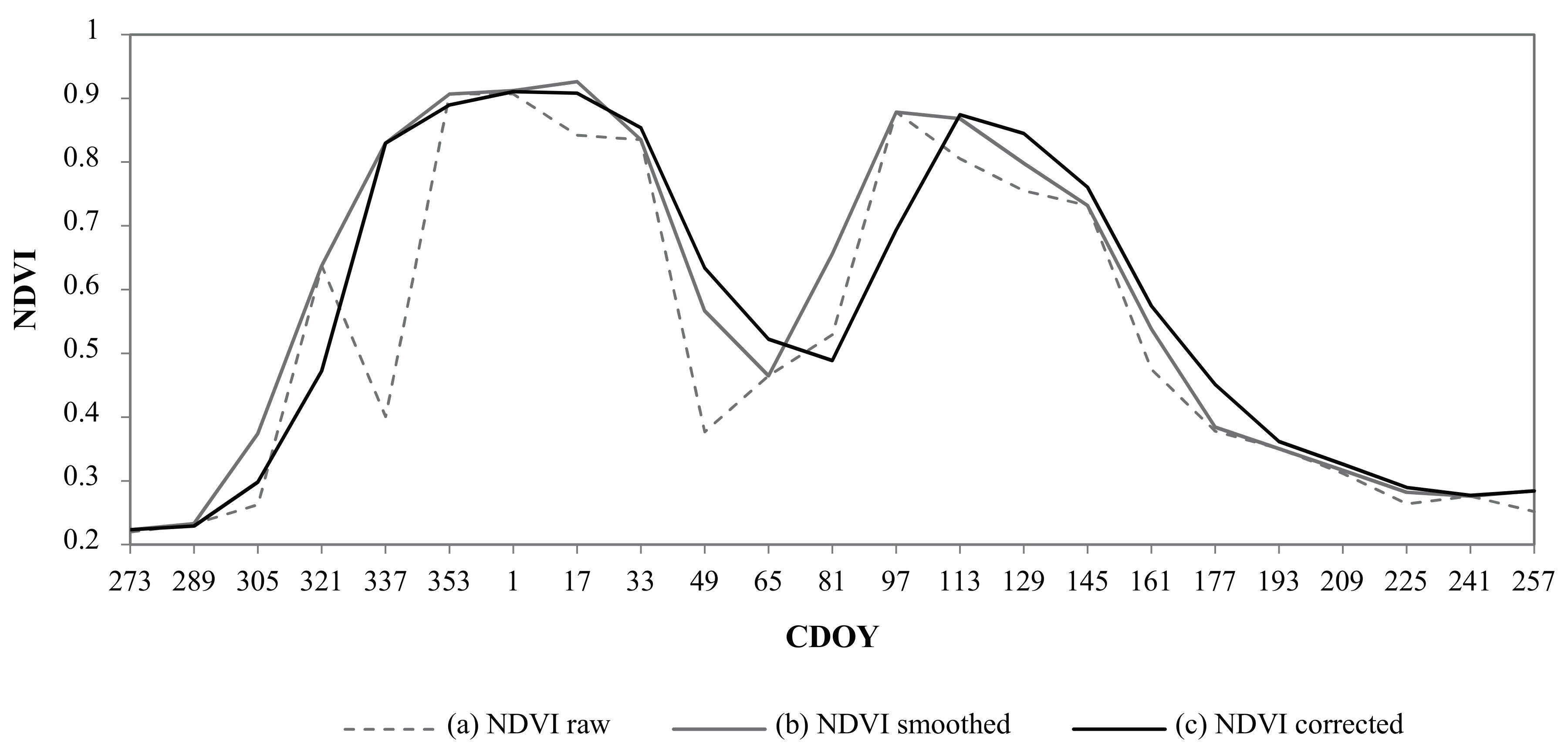
In order to generate a noise-reduced time series, an adapted version of the function-fitting smoothing method introduced by Chen et al. [
23] was applied. This noise-reduction algorithm is based on a linear interpolation of cloudy pixels, followed by the use of the Savitzky–Golay (SG) filter through an iteration process until the upper envelope of the original NDVI profile is best approached [
23,
24].
The cloud flag data supplied with the MOD13Q1 product (Pixel Reliability layer) showed systematic overestimations of clouds in the cropland areas, which are particularly evident during the harvest stages in the crop calendar. Consequently, only the pixels followed by an unnatural NDVI increase (greater than 0.4 between two composited images) were considered as cloudy dates and linearly interpolated. In order to reduce the noise of other residual effects such as consecutive cloudiness, the iterative SG filter was applied. After several tests, the parameters
d (degree of the smoothing polynomial) and
m (half-width of the smoothing window) of the SG filter (for the long-term change curve and for the fitting iteration) were set to
d = 2,
m = 2, and
d = 6,
m = 4, respectively. This smoothing method effectively improved the quality of the time series, reducing signal noise while preserving the detail of the NDVI temporal profiles (
Figure 4).
To avoid the temporal discontinuities generated by the compositing process (which affect the shape of the NDVI profiles), the values of the smoothed time series were linearly interpolated. This was done using their actual acquisition dates provided in the “Composite Day of Year (CDOY)” layer of the MOD13Q1 product, to place them at 16-day regular intervals.
3.2. Extraction of the Land Units
The extraction of the land units is developed in two steps which are described in the following sub-sections: Principal Components Analysis (
Section 3.2.1) and Delineation of the Land Units (
Section 3.2.2).
3.2.1. Principal Components Analysis
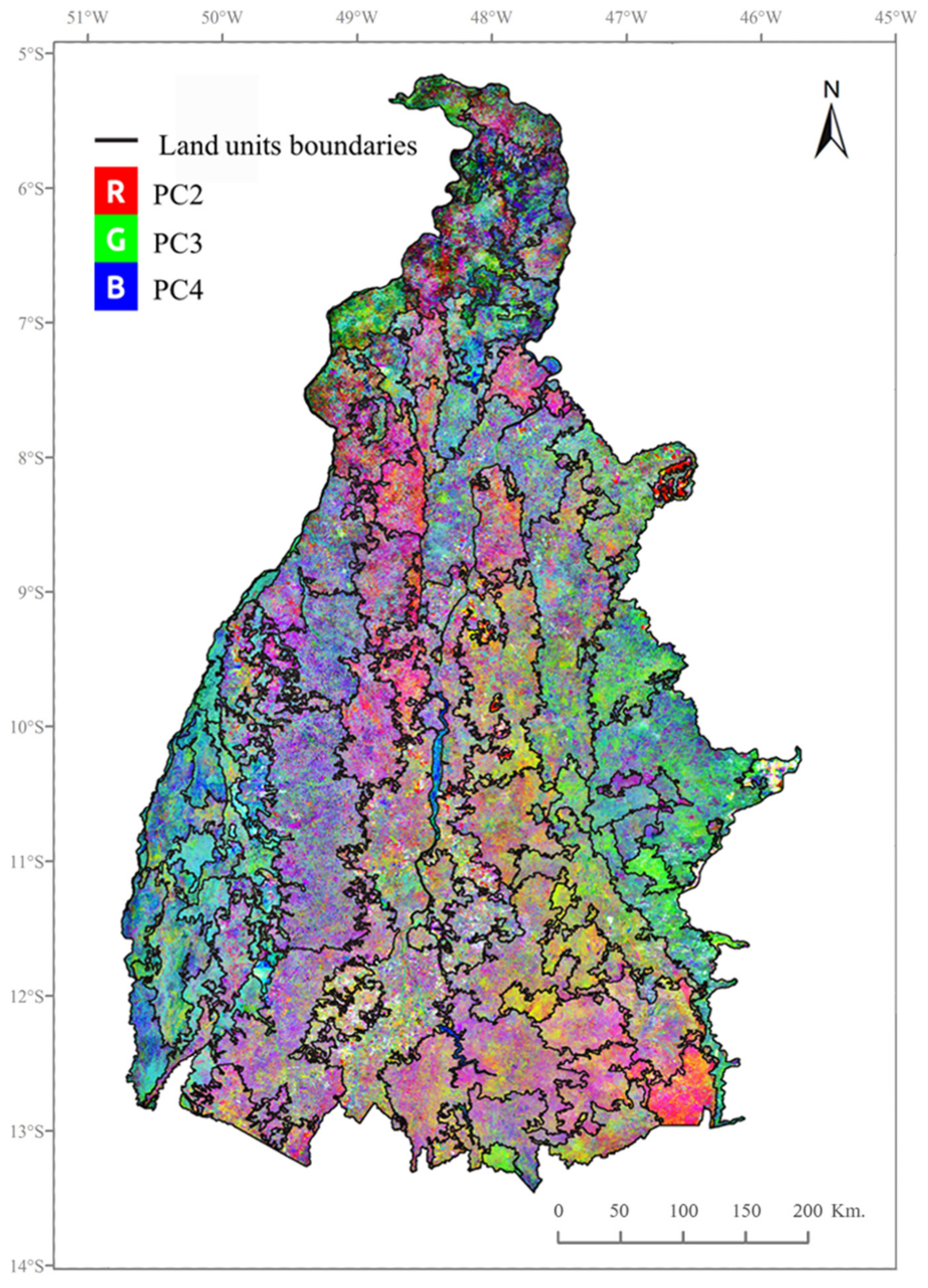
A principal components analysis (PCA) transformation was applied to the corrected NDVI time series. Originally formulated by Pearson (1901), the PCA technique consists of a linear orthogonal transformation (or rotation) of the original variables into a set of uncorrelated variables known as the principal components (PC). When applied to remote sensing time series, PCA computes new values for each pixel of the original time series’ images to produce a set of PC images (also known as eigenchannels). The resulting PC images are uncorrelated with one another and ordered according to the amount of variance retained within the total variance of the original time series dataset (from most to least). Low-order PC images (PC1, PC2) concentrate most of the variance and therefore inevitably capture the information redundancy among the original images, while the higher-order PC images capture less redundant information (associated with specific localized change events).
PCA has proven to be particularly effective (when applied to NDVI time series) at identifying seasonal changes of the land cover and revealing their relationship to different factors—mainly climate variability and human activities factors [
25,
26,
27,
28,
29,
30]. The type of information captured by each PC image will vary according to the characteristics of the input NDVI time series (temporal resolution and length of the time series, spatial resolution and extent) and the PCA method used (either unstandardized if the PC images are calculated using the covariance matrix, or standardized if the correlation matrix is used instead). However, some common outcomes are observed when the area under analysis is large enough to include different types of land cover: The first PC image captures the major element of variability in the NDVI time series (which for large areas corresponds to the spatial variability of the NDVI values, and is correlated to the integrated NDVI over all seasons), whilst the other PC images capture the seasonal and intra-seasonal variability of NDVI, each related to a particular factor or a combination of factors [
25,
26,
27,
28,
29,
30].
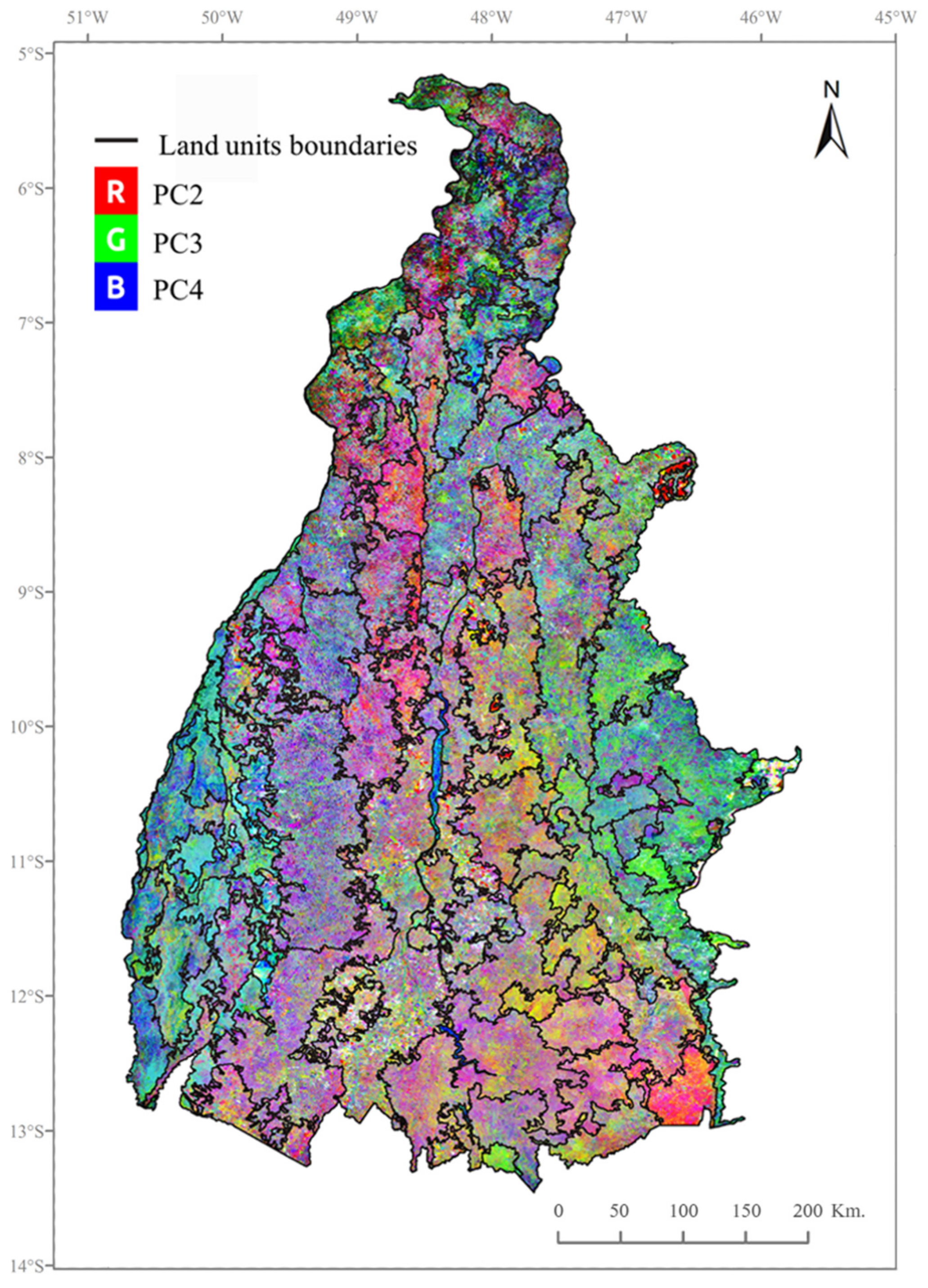
We expect the phenological patterns of different agricultural land-use systems (configured by seasonal development of the vegetation and intra-seasonal variability and short-term fluctuations induced by the agricultural practices), to be detectable in these latter PC images. Therefore, after performing a PCA on the corrected NDVI time series of 23 images, we retained the last 22 PC images (the high-order PC images) out of the 23 resulting PC images for further analysis, which contain 27% of the total variance. The first PC image was deliberately discarded after verification that the temporal variability of NDVI was not significantly captured, and that (as expected) the 73% of the total variance captured by the first PC image is mostly related to the spatial variability of the NDVI values, as shown in other studies (e.g., [
27,
28]).
The PCA was performed by means of the rasterPCA tool in the processing R package RStoolbox Version 0.1.8 [
31] and was based on the covariance matrix (unstandardized PCA). Unstandardized PCA is preferred since sudden changes in the magnitude of the NDVI related to land use (such as a rapid NDVI decrease due to crop harvest) will contribute significantly to the development of the new component images. Conversely, normalizing the input images through standardized PCA would weaken the contribution of these sudden change events by forcing all the original input images to have equal weight in the derivation of the PC images.
3.2.2. Delineation of the Land Units
The segmentation of the high-order PC images was performed using the iterative region-growing algorithm based on the Baatz and Schäpe criterion, implemented in the Multiresolution Segmentation tool of the object-orientated image analysis software eCognition
® Developer 9.0 [
32]. This algorithm starts with each pixel of the image forming an image object. At each iteration, neighboring objects are merged based on their similar characteristics described by a homogeneity criterion, until a user-defined threshold (known as the scale parameter) is reached. The multiresolution segmentation algorithm ensures a regular growth of the image objects over the whole scene, and so the resulting objects have a similar size, which is determined by the scale parameter threshold. In this way, a low scale parameter will lead to many objects of small size and, conversely, a high scale parameter will allow the growth of few large objects. The influence of the radiometry versus the shape in the definition of the homogeneity criterion is determined by the weight assigned to the color and shape parameters [
33].
The objective of the segmentation being the delineation of land units with relatively homogeneous phenological patterns, the shape of the objects in the definition of the homogeneity criterion becomes irrelevant and, therefore, we assign the total weight to the color by setting the color parameter to 1 and the shape parameter to 0. In practice, setting the color parameter to 1 means that the relative homogeneity of the resulting image objects (land units) will be entirely based on the pixel values of the PC images and their implicit information related to the temporal variability of the vegetation cover. Besides, each of the 22 PC images is made to contribute equally to the segmentation by setting the weight of each input PC image to 1.
A scale (according to Benz et al. [
34]) is defined as the level of aggregation and abstraction at which an object can be clearly described. Since our geographic objects of interest (the land units) do not relate to an inherent scale but can rather be described at different scales of analysis, we consider that there is no optimal segmentation scale and that different scale parameters should be tested in each particular case to approach adequately sized, thematically meaningful land units. We assume that the multiresolution segmentation algorithm based on homogeneity criterion delineates relatively homogeneous objects regardless of the scale parameter used. However, some simple guiding principles were followed in this study to choose among different scale parameters aiming at meaningful land units (in terms of relatively homogeneous phenological patterns): Objects should be larger than the minimum mapping unit of an agricultural land-use system (i.e., the field) and there should be a sensible trade-off between the number of objects for further analysis and their degree of heterogeneity. After testing several segmentation levels, the scale parameter threshold was empirically set to 850 (unitless).
3.3. Classification of the Land Units
The classification of the land units is developed in two steps which are described in the following sub-sections: Rule-based Classification (
Section 3.3.1) and Classification through Phenological Pattern Analysis (
Section 3.3.2).
3.3.1. Rule-Based Classification
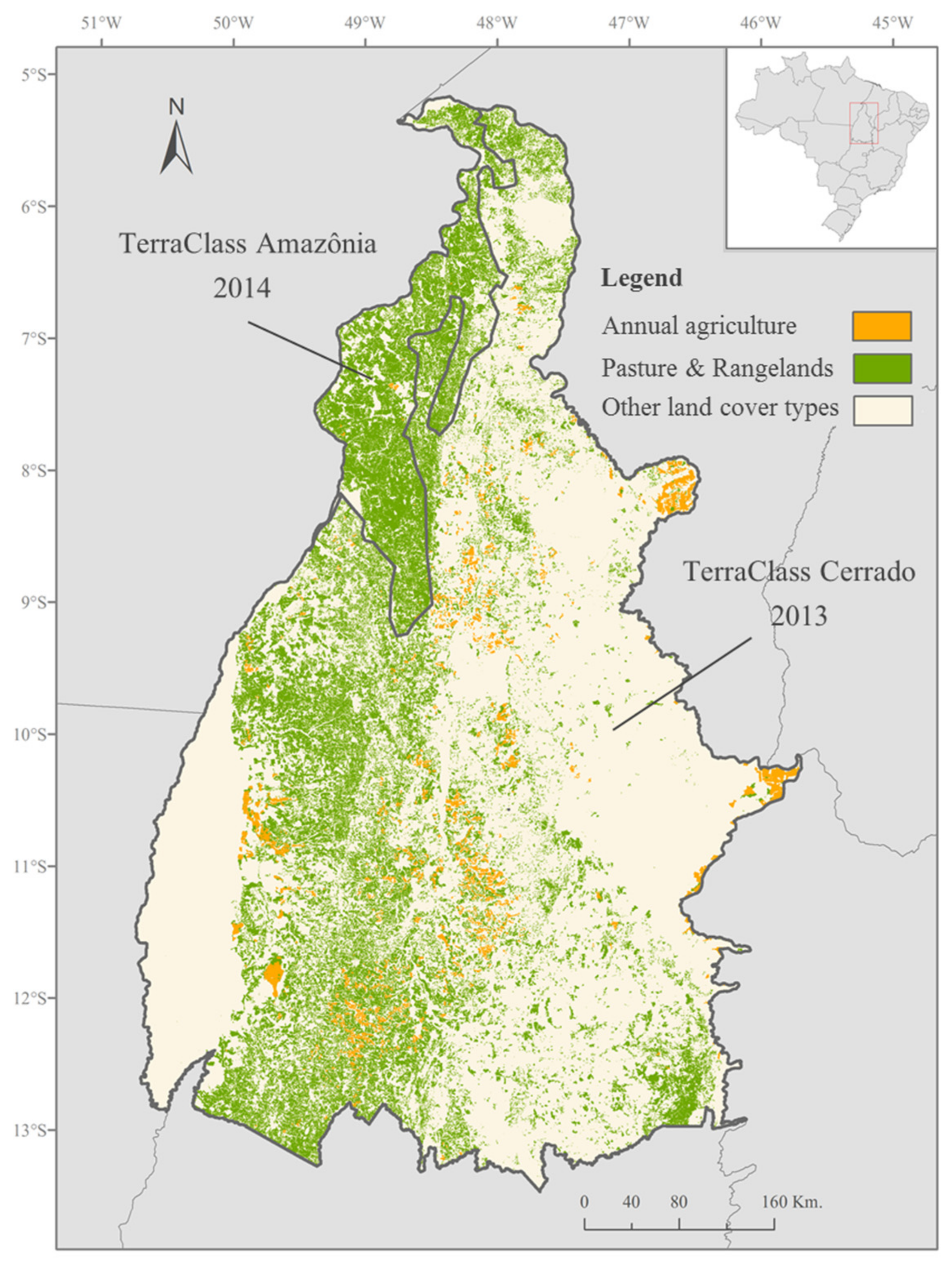
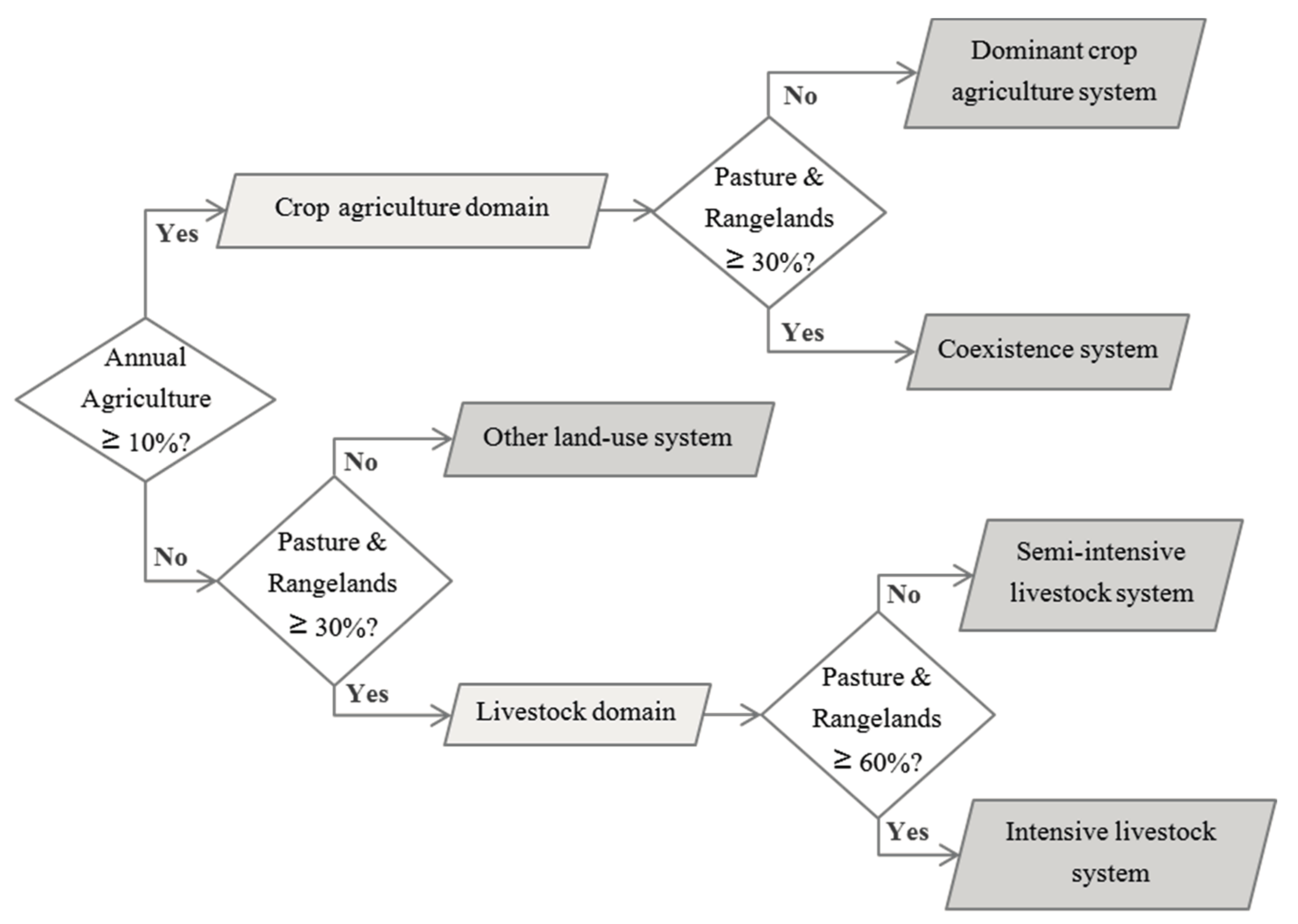
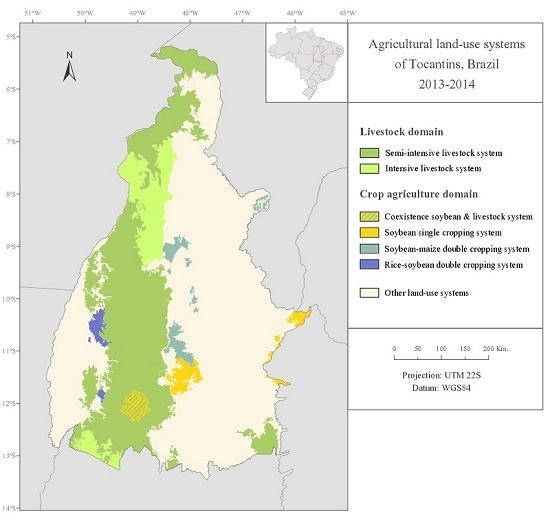
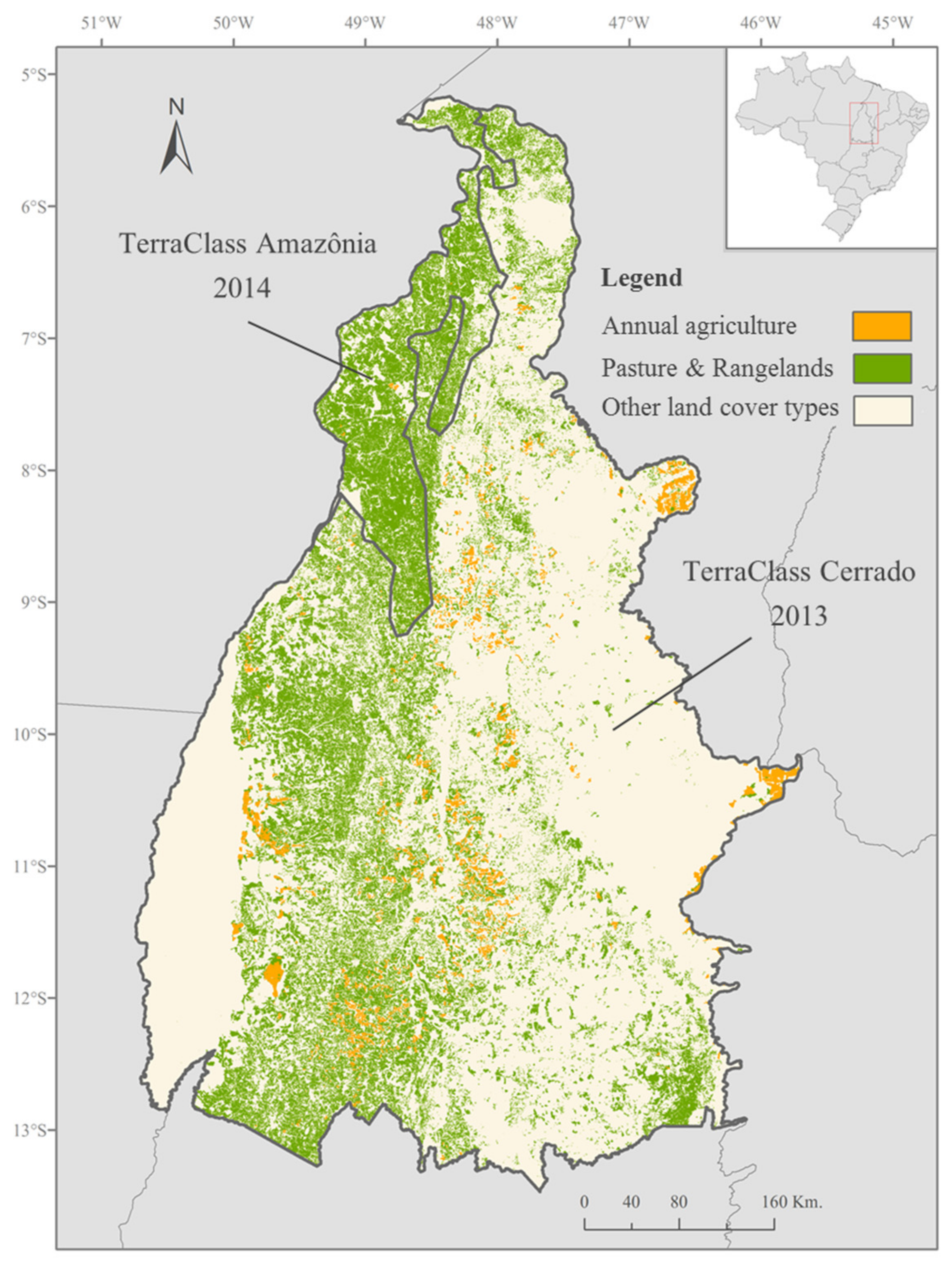
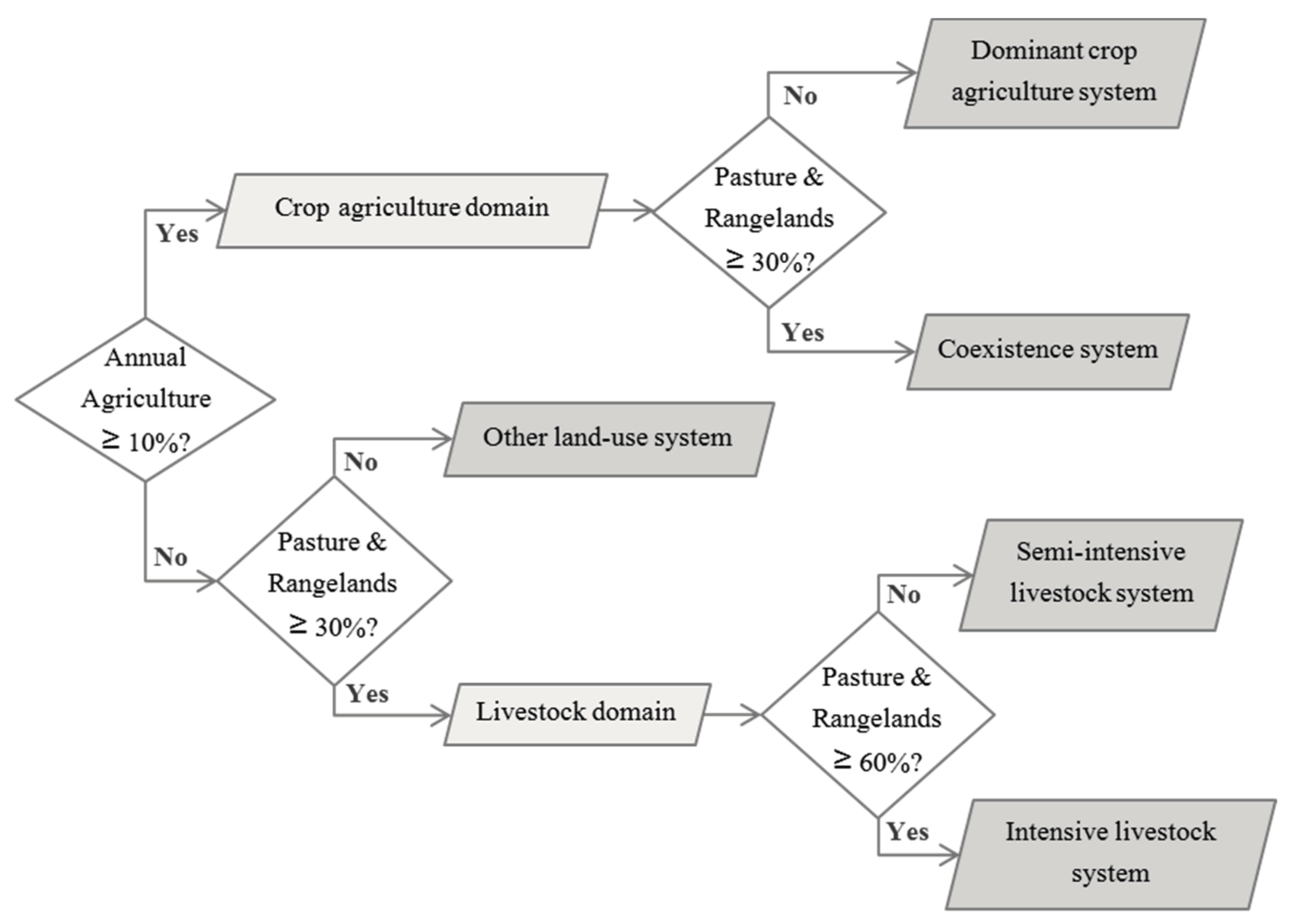
The agricultural land-cover map extracted from the TerraClass product was used for the classification of the land units belonging to the agricultural domain (either to the crop agriculture domain or to the livestock domain) into four major ALUS: Dominant crop agriculture system, coexistence (crop-livestock) system, semi-intensive livestock system, and intensive livestock system. This preliminary classification of the ALUS was performed following the decision tree ruleset developed by Almeida et al. [
35] for the localization of agricultural production systems in the Brazilian State Rondônia at the municipal level, presented in
Figure 5. This ruleset seems well adapted for the classification of the ALUS in the Tocantins state, owing to its closeness to the Rondônia state (in terms of land-cover and land-use systems’ characteristics).
3.3.2. Classification through Phenological Pattern Analysis
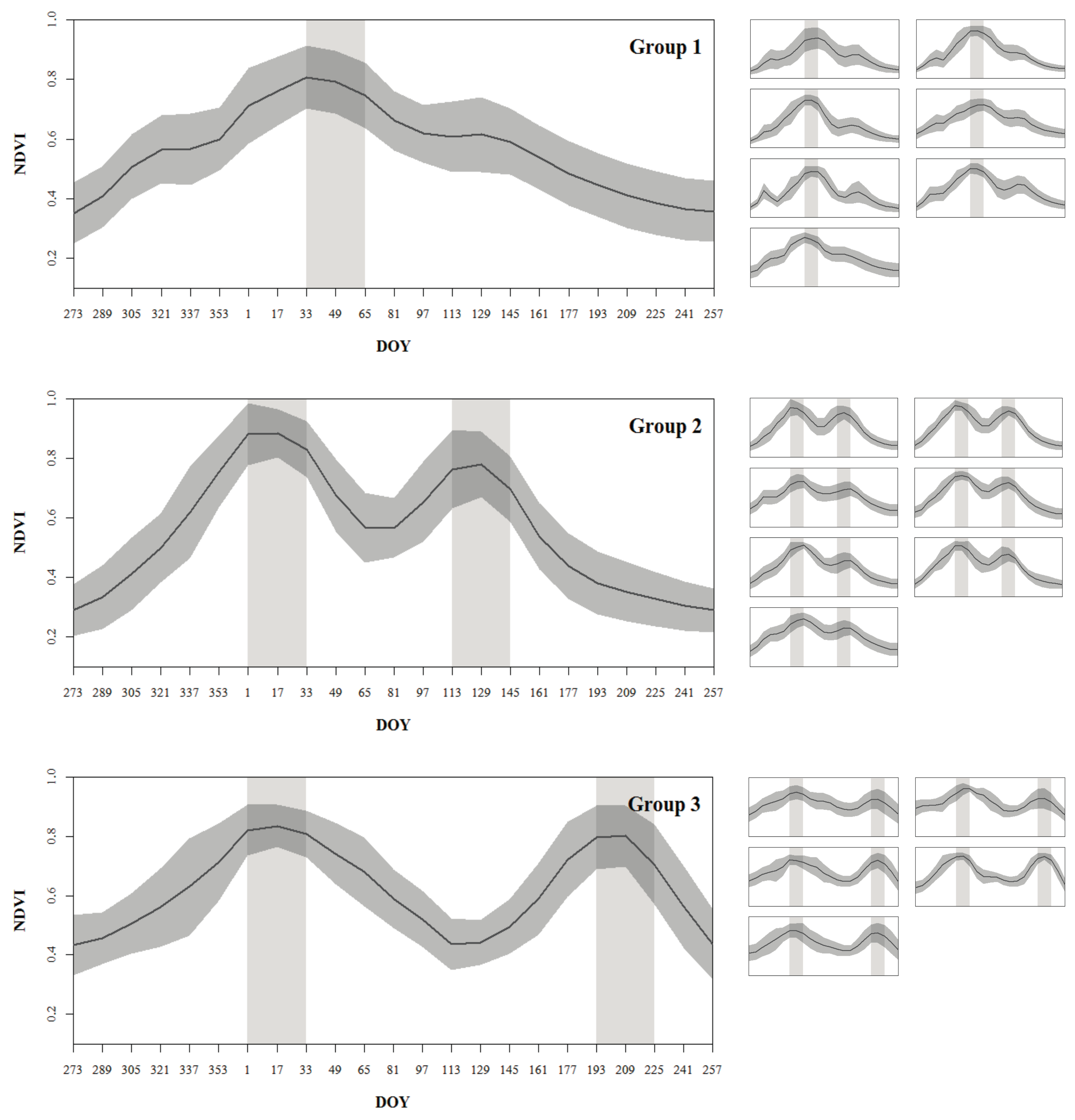
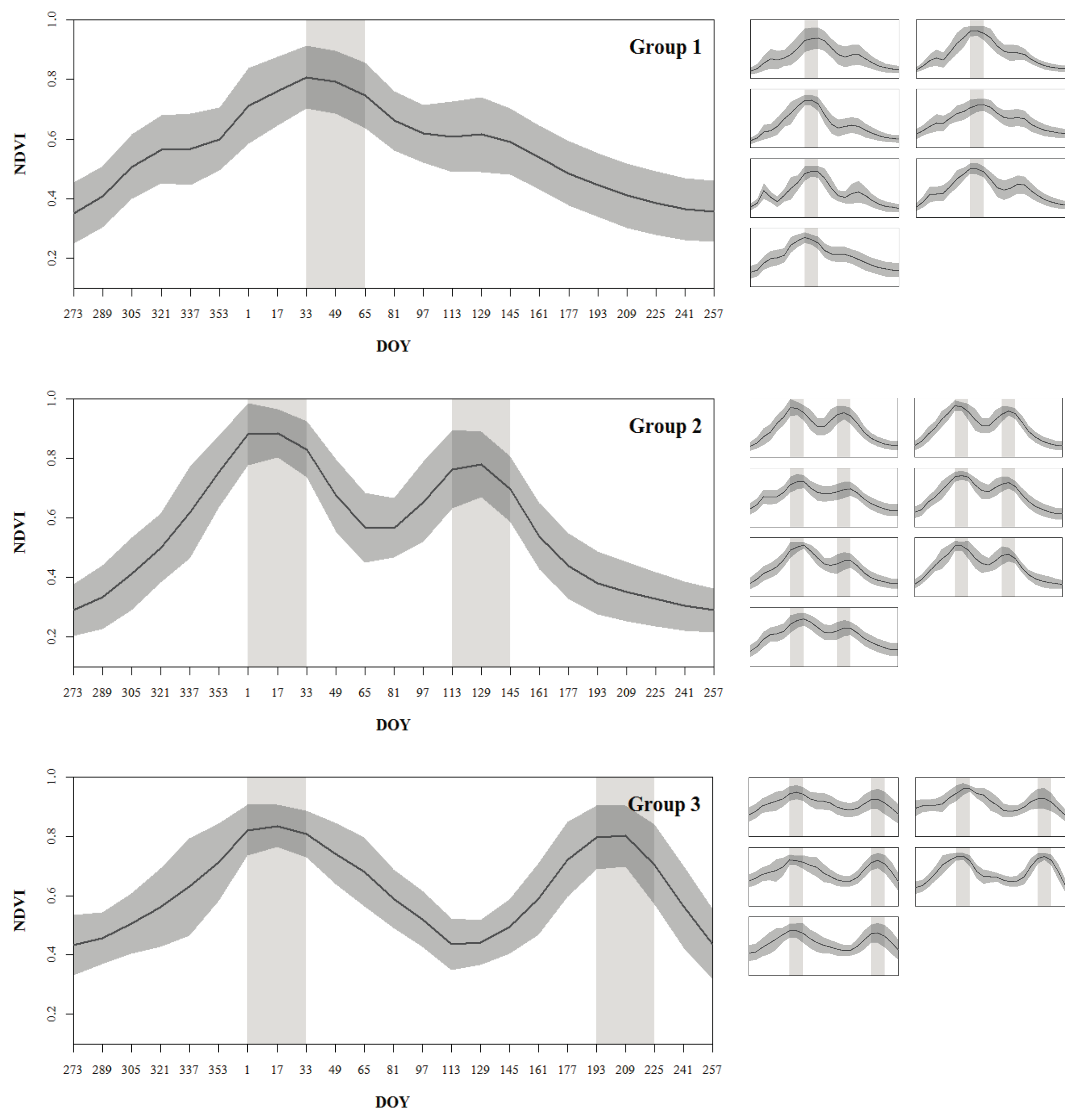
The land units belonging to the crop agriculture domain were further classified into different cropping systems based on the analysis of their phenological patterns. The mean temporal NDVI profile of the cropland cover inside each land unit was extracted from the MODIS NDVI time series using the TerraClass annual agriculture class as a mask. The general NDVI variations over the growing season were analyzed through visual interpretation of the shape of the resulting mean temporal NDVI profiles, which revealed the principal crop development stages of the cropland cover inside each land unit. The NDVI profiles with visually equivalent shapes were grouped together and were finally classified into different cropping systems by correspondence with the crop calendar of the main cropping systems of Tocantins.
3.4. Unsupervised Evaluation of the Classification Results
Since there are no available thematically-equivalent maps with which to validate the accuracy of the classification of the ALUS, an unsupervised evaluation was carried out with a reference map extracted from the official agricultural statistics (area estimates of the annual crops in the municipalities of Tocantins for the year 2014). The evaluation was only carried out for the cropping systems’ results since no official statistics were available on the pasture and rangelands with which to evaluate the livestock systems’ classification results.
In order to produce a synthetic reference map out of the detailed agricultural statistics dataset that could be compared to the cropping systems in the ALUS map, we first calculated the proportion of area occupied by each crop type in the municipalities with more than 2000 hectares of cultivated area. The predominant crop types (accounting for most of the cultivated area) were differentiated from minor crops and were used to characterize the main cropping system related to each municipality.
The ALUS map was finally evaluated based on the spatial agreement between the classified cropping systems and the cropping systems in the reference map.
5. Discussion
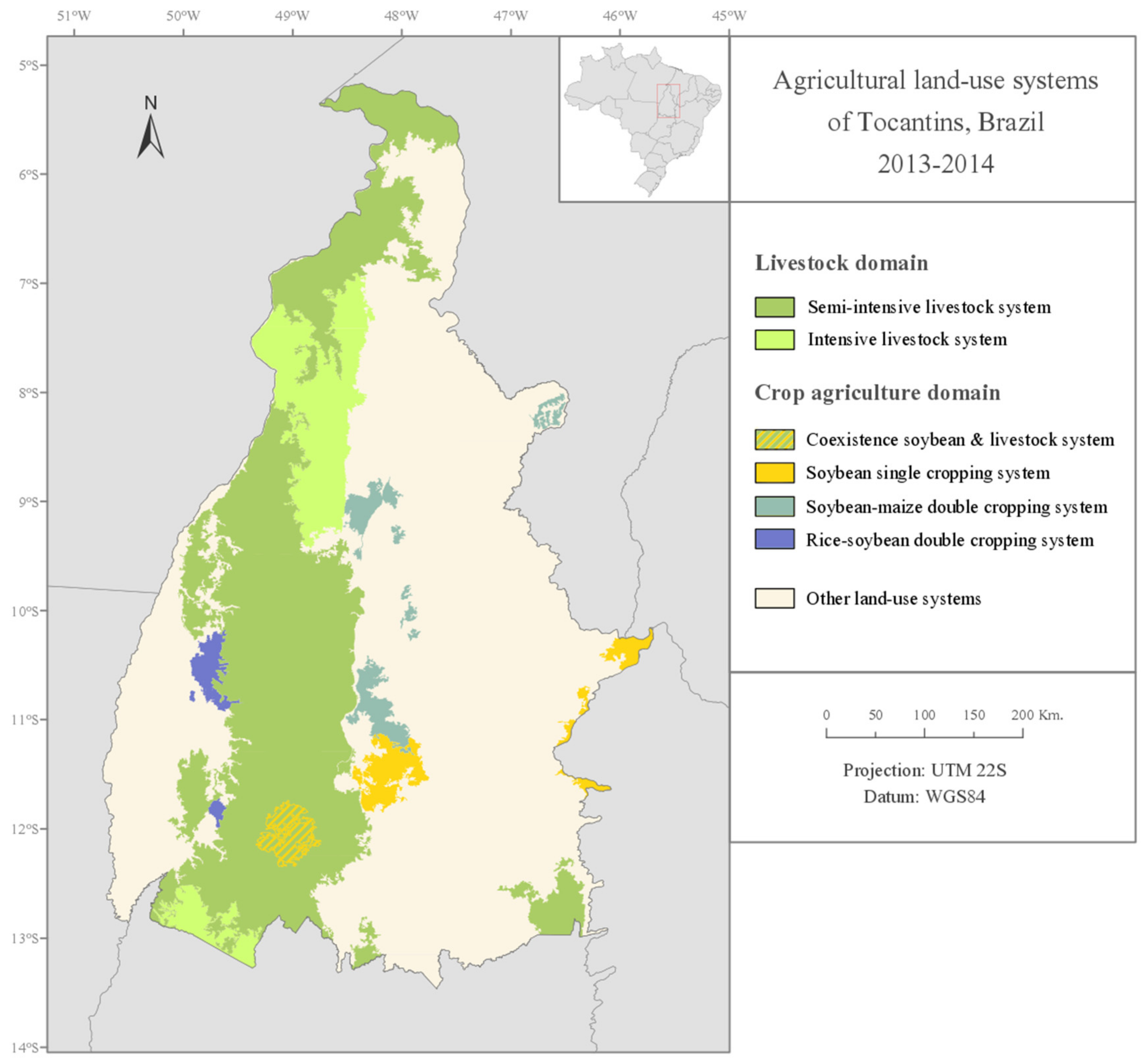
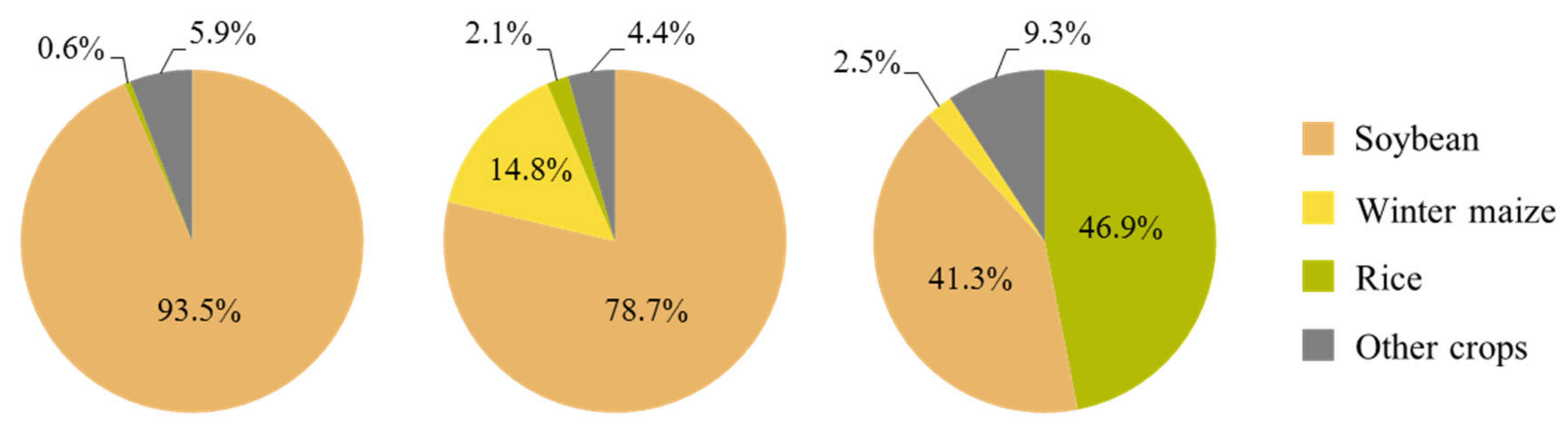
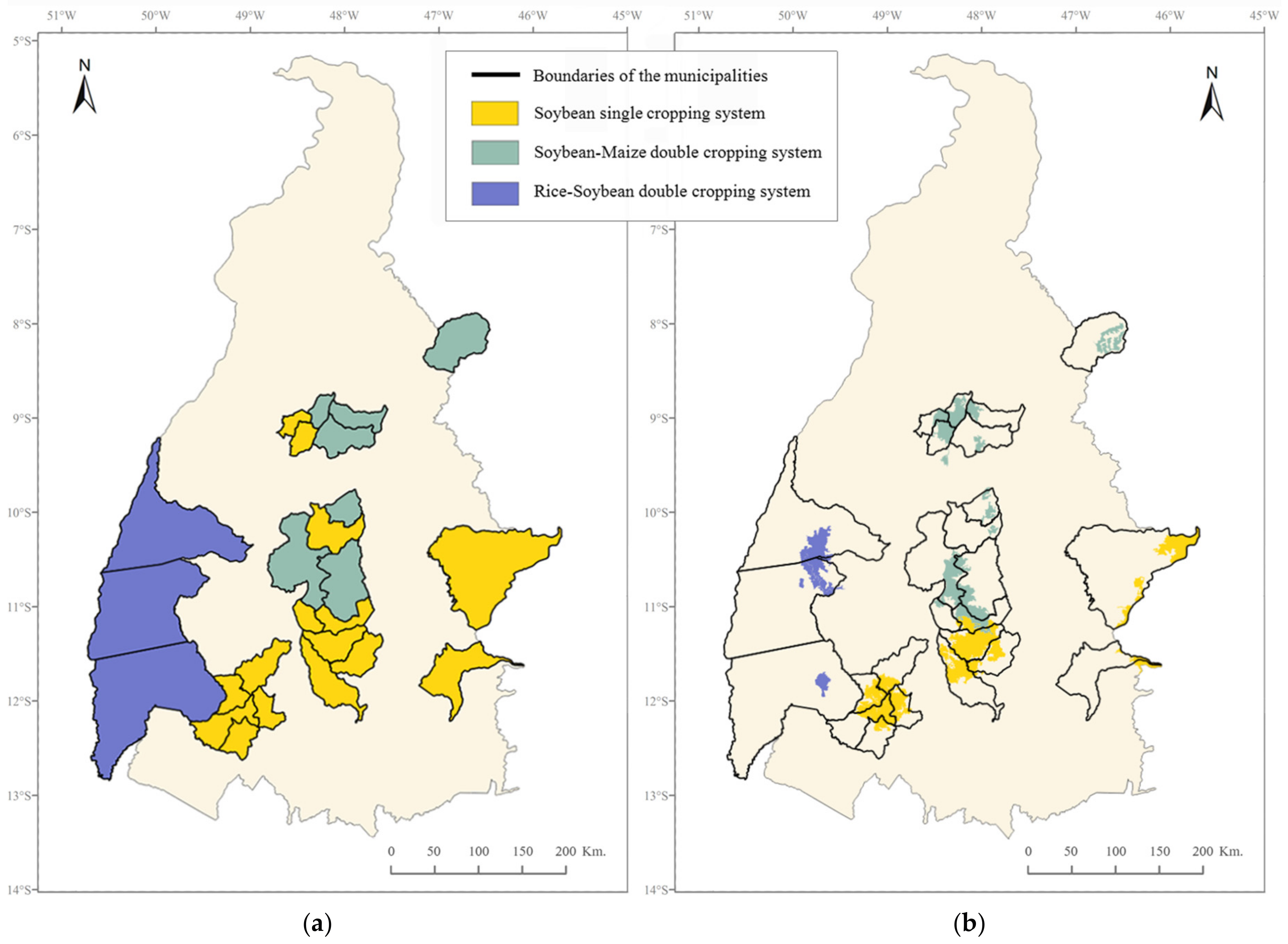
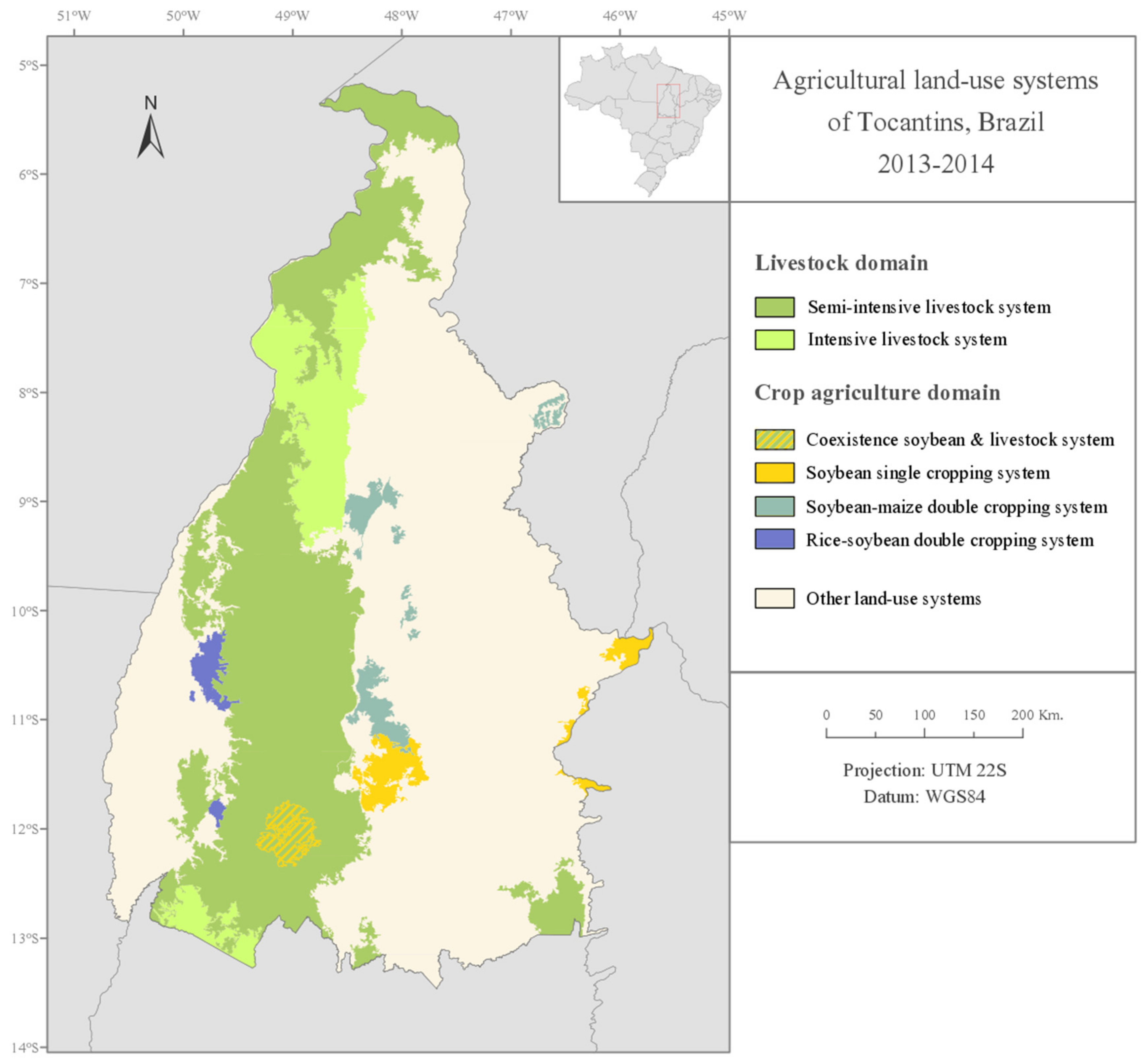
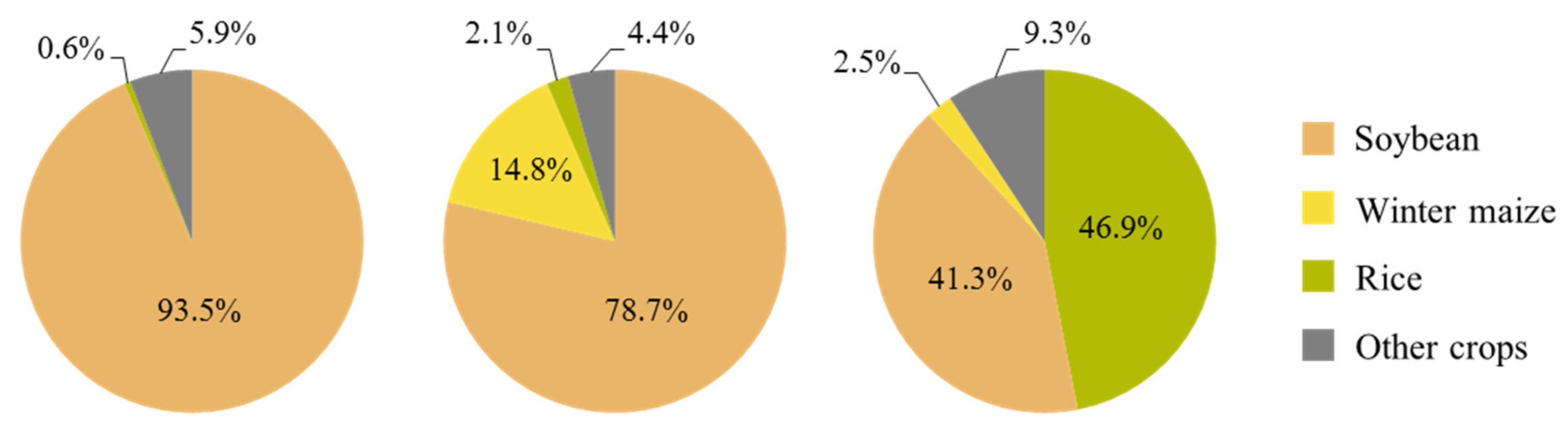
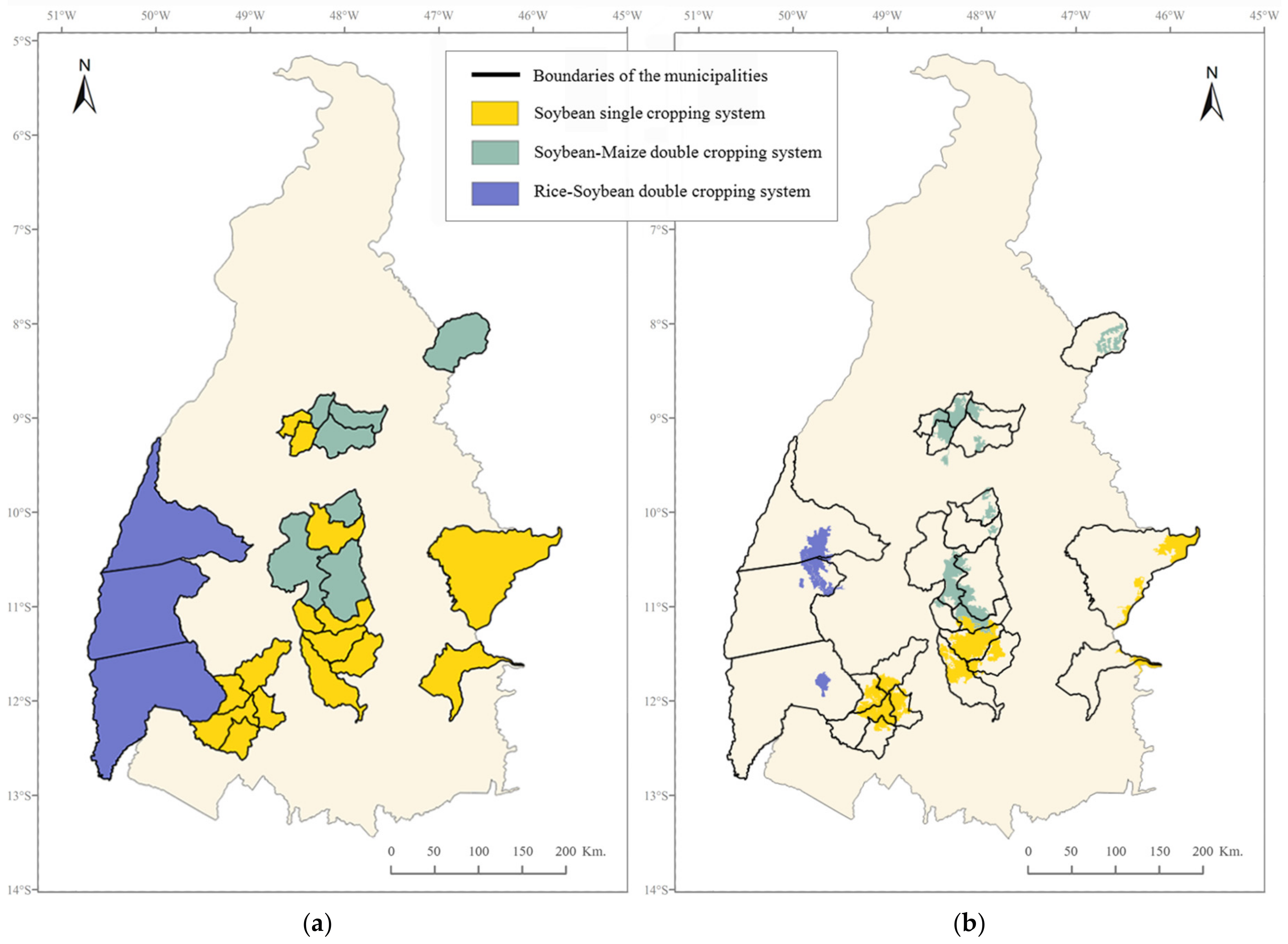
The study area was partitioned into relatively homogeneous land units that were linked to a specific type of agricultural land use, resulting in a regional level agricultural land-use systems’ map. Two livestock systems could be differentiated by the proportion of pasture and rangelands in the land units, and the three main cropping systems of the study area could be differentiated through the proportion of annual cropland in the land units and through their specific phenological patterns (
Figure 7); this allowed not only to characterize the land units in terms of the crop type but also in terms of the cropping pattern.
The results showed a general agreement between the location of the three main cropping systems in the final agricultural land-use systems map and the reference map, except for some localized overestimations of the presence of the soybean–maize double cropping system over some of the reference soybean single cropping system municipalities. This overestimation might be due to the non-inclusion of the non-commercial summer grass cover crops such as millet, sorghum, or brachiaria in the agricultural statistics and, therefore, in the reference map. Cover crops are sometimes sown after the winter soybean harvest instead of maize, as part of the widely adopted no-tillage system in the study area. These cover crops might contribute to the second peak of NDVI that is apparent in the NDVI temporal profiles of the land units, which partially intersect municipalities where only the soybean surface area has been officially censused.
The reference map that was used for the evaluation of the classification results shows that land-use systems’ maps can be produced from the agricultural statistics. However, the thematic resolution of this type of map is limited by the data available in the statistics, thus not accounting for certain systems (e.g., the livestock systems). Furthermore, the spatial accuracy is greatly limited by the data aggregation level (e.g., the municipal level)—the administrative boundaries not being representative of the actual spatial distribution of the land-use systems. The presented remote sensing approach produces a land-use systems’ map which overcomes these limitations, by automatically delineating boundaries which are representative of the actual physical differences between zones related to the temporal variations of the vegetation cover.
While the ability of principal components analysis to uncover significant intra-annual change events out of vegetation index time series has been widely proven (e.g., [
25,
26,
27,
28,
29,
30]), studies mainly focus on the low-order principal component (PC) images—generally the first three—which capture most of the variance. We decided to include the higher-order PC images in our analysis, since they are highly sensitive to subtle changes in the data and therefore capture change events which are localized both spatially and in time, such as the intra-seasonal variations and rapid changes induced by the agricultural practices. Overall, the results confirm that the high-order PC images do capture the information related to the temporal variability of the vegetation cover, which was the essential portion of information of the NDVI time series (represented by 27% of the total variance in the time series) needed for the segmentation of the study site in land units with relatively homogeneous phenological patterns. Furthermore, the phenological patterns shown in
Figure 7 reflected the intra-seasonal variations which were linked to cropping practices such as the approximate planting and harvesting dates of different crops.
The automatic extraction of relatively homogeneous land units in terms of phenological patterns, through a principal components analysis and an automatic segmentation, is a simple and innovative approach that can be reproduced in other regions. This approach overcomes the potential error propagation of the expert-based land units’ border delineation and the subjective choice and use of variables in the traditional land-use systems’ mapping approaches. Furthermore, the presented approach is scale-independent and therefore allows multi-scale analysis, which might help improve the understanding of the land-use systems by characterizing them at different organizational levels.
In addition, the decision tree ruleset used for the classification of four major agricultural land-use systems (presented in the
Figure 5—adapted from Almeida, et al. [
35]), is conceived with simple threshold rules based on the percentage cover of agricultural land, which can be easily adapted or directly applied, to other agricultural regions. This classification is, however, dependent on a land-cover map. Even if land-cover maps are now produced and available for many regions, their accuracy will condition the agricultural land-use systems’ classification results, and they may be rarely updated. Consequently, the rule-based classification step would largely benefit from the inclusion of an automatic remote sensing-based classification method to produce timely and accurate regional-scale agricultural land-cover maps at the field level. Some studies have shown that partitioning the study region into sub-regions improves the accuracy of regional-scale land-cover classifications [
36,
37]. Hence, the presented land units’ extraction approach could therefore also be used as a preliminary step for automatic remote sensing-based classifications, producing regional-scale land-cover and land-use maps at the field level.
6. Conclusions
Remote sensing-derived time series of NDVI represent an important source of spectral and temporal information related to agricultural land use and, when combined with GEOBIA techniques in the present study, allowed the discrimination of different land-use systems (in particular, cropping systems) at a regional scale. Remote sensing-based approaches, therefore, present a significant potential for agricultural land-use system mapping over large areas and benefit from the spatial and temporal continuity of the satellite data and technological advances such as the new high temporal and spatial resolution Sentinel-2 satellite systems of the Copernicus program.
The presented approach can be potentially reproduced in other regions with minimal adaptation to specific context, thus contributing to the development of generic and simple tools for the location and characterization of the agricultural land-use systems across regions. This baseline-detailed spatial information is highly valuable for further large-scale agronomic and environmental assessments. If reproduced periodically, this type of approach can help with long-term analysis of the dynamics of the major agricultural land-use systems, which can help monitor large-scale land-use change processes such as cropland expansion or intensification (being particularly useful in changing regions such as the MATOPIBA region, for effective land-use planning leading to sustainable use of the resources).


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}