A Multiscale Deeply Described Correlatons-Based Model for Land-Use Scene Classification





Abstract
:1. Introduction
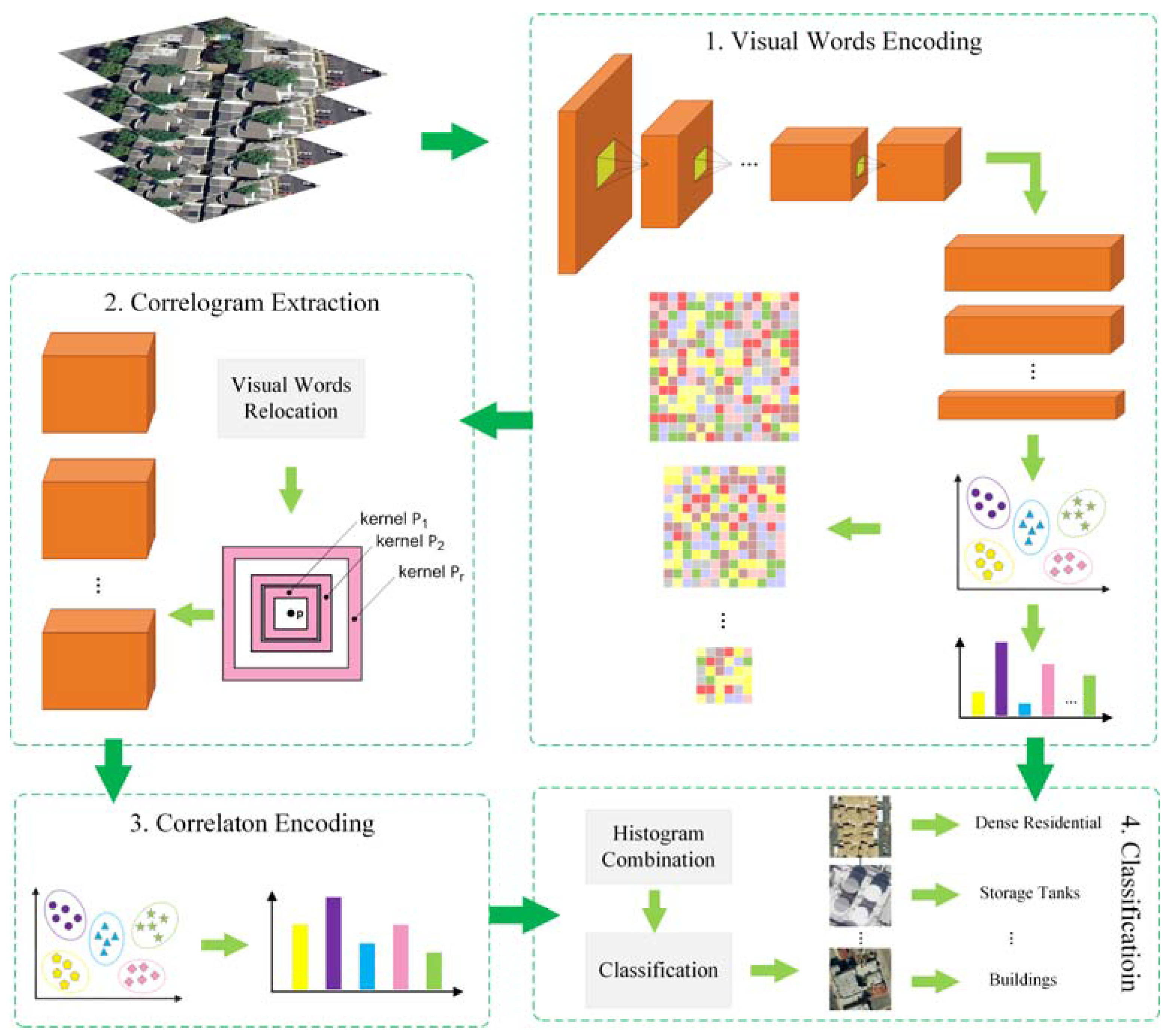
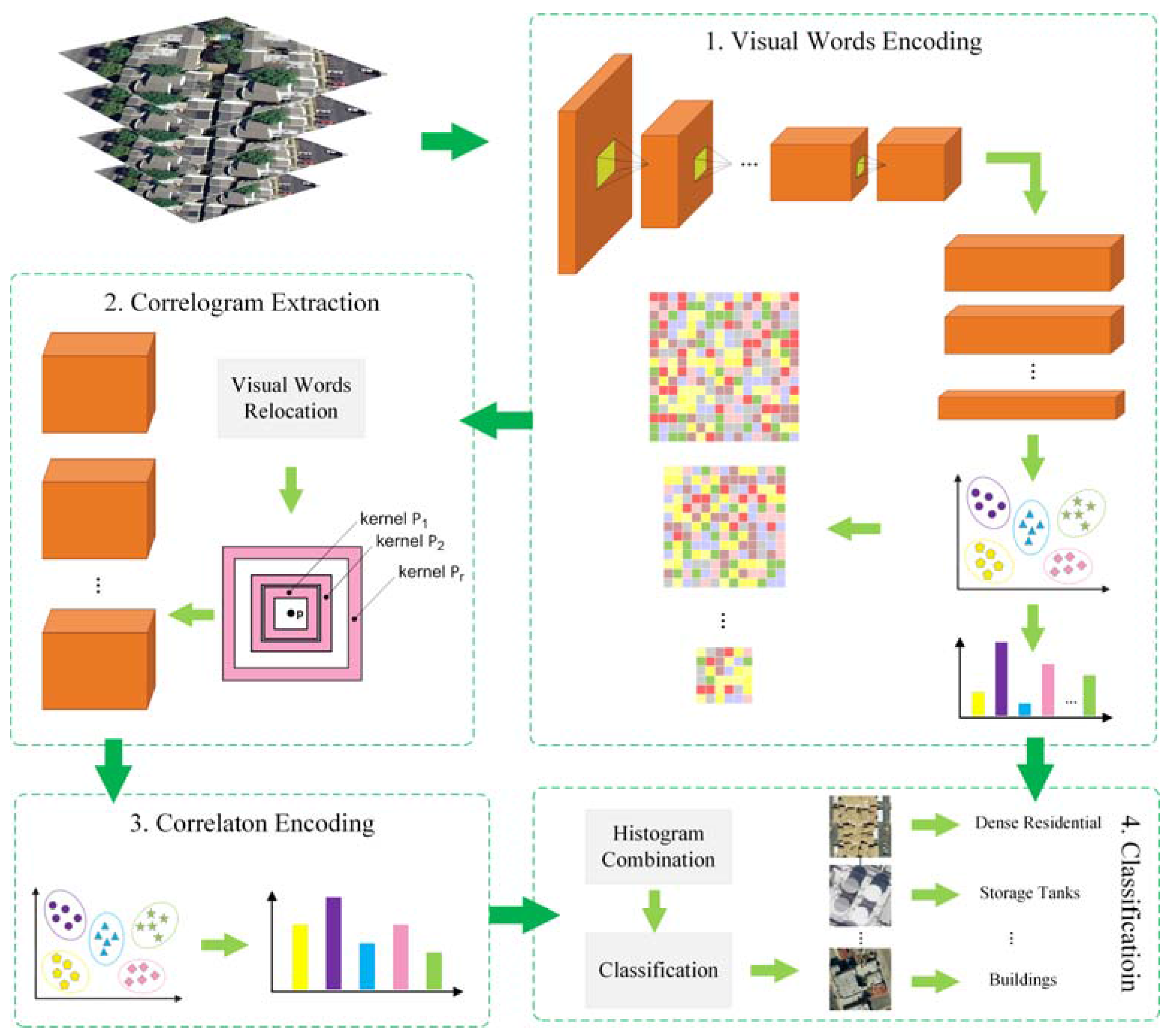
2. The Proposed Method
2.1. Multiscale Deeply Described Visual Words Encoding
2.2. Multiscale Correlograms
2.3. Modeling Land-Use Scene by Multiscale Correlotons
3. Experiments and Analysis
3.1. Experimental Setup
- UC Merced Land Use Dataset. The UC Merced dataset (UCM) is one of the first publicly available high-resolution remote sensing imagery data sets [4]. This dataset contains 21 typical land-use scene categories, each of which consists of 100 images measuring pixels with a pixel resolution of 30 cm in the red–green–blue color space. Figure 2 shows two examples of ground truth images from each class in this dataset. The classification of UCM dataset is challenging because of the high inter-class similarity among categories such as medium residential and dense residential areas.
- WHU-RS Dataset. The WHU-RS dataset is a publicly available dataset in which all the images are collected from Google Earth (Google Inc., Mountain View, CA, USA) [5]. This dataset consists of 950 images with a size of pixels distributed among 19 scene classes. Examples of ground truth images are shown in Figure 3. As compared to the UCM dataset, the scene categories in the WHU-RS dataset are more complicated due to the variation in scale, resolution, and viewpoint-dependent appearance.
3.2. Parameter Sensitivity Analysis
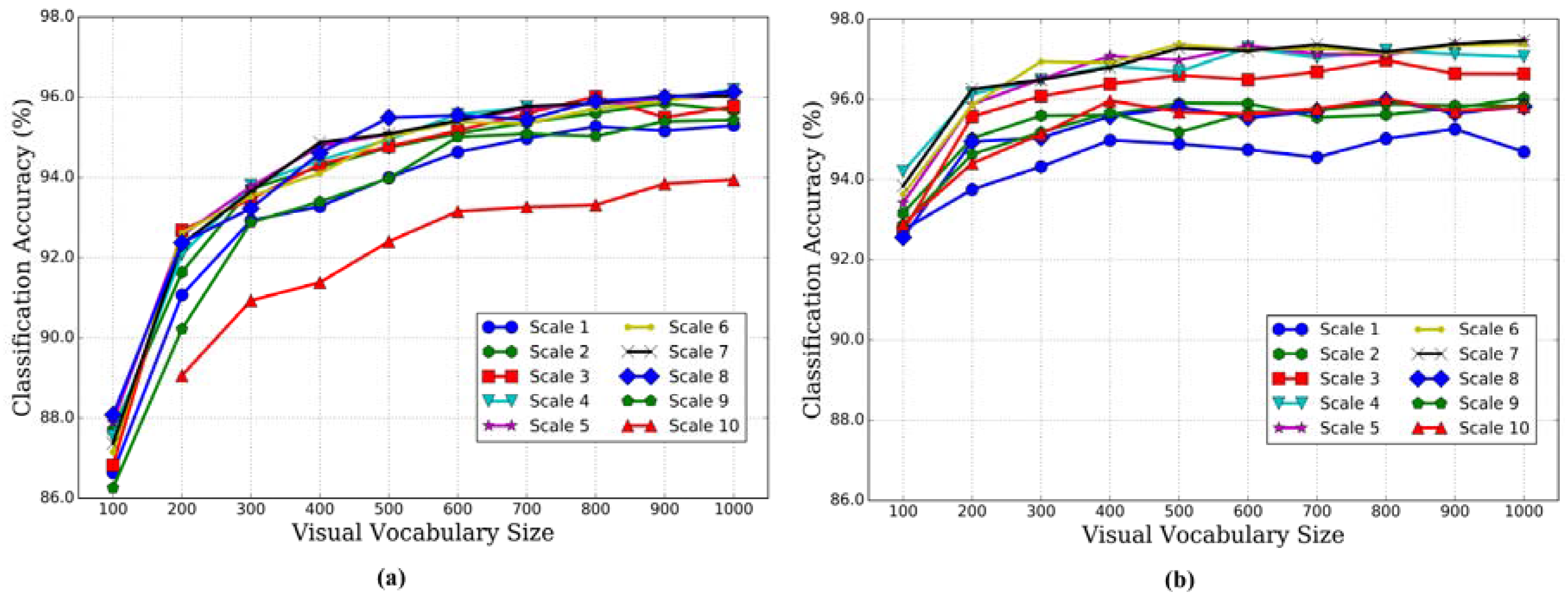
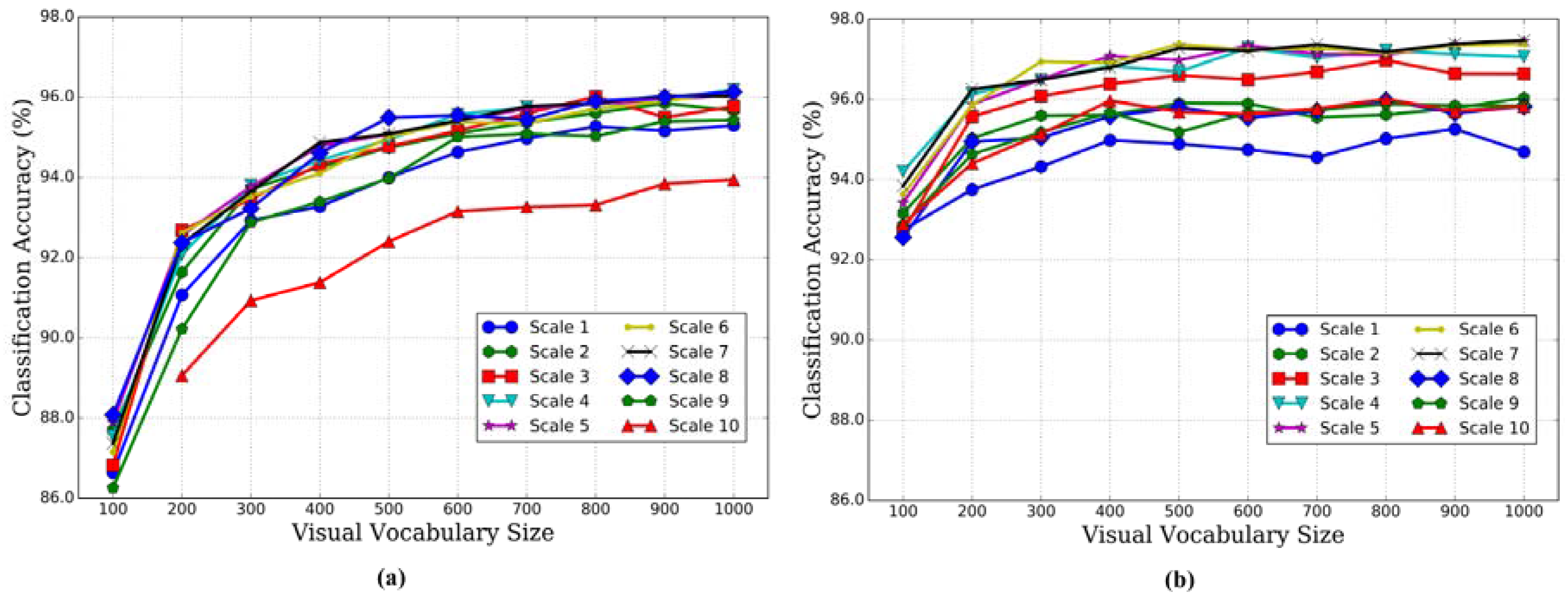
3.2.1. Effect of Multiscale Strategy
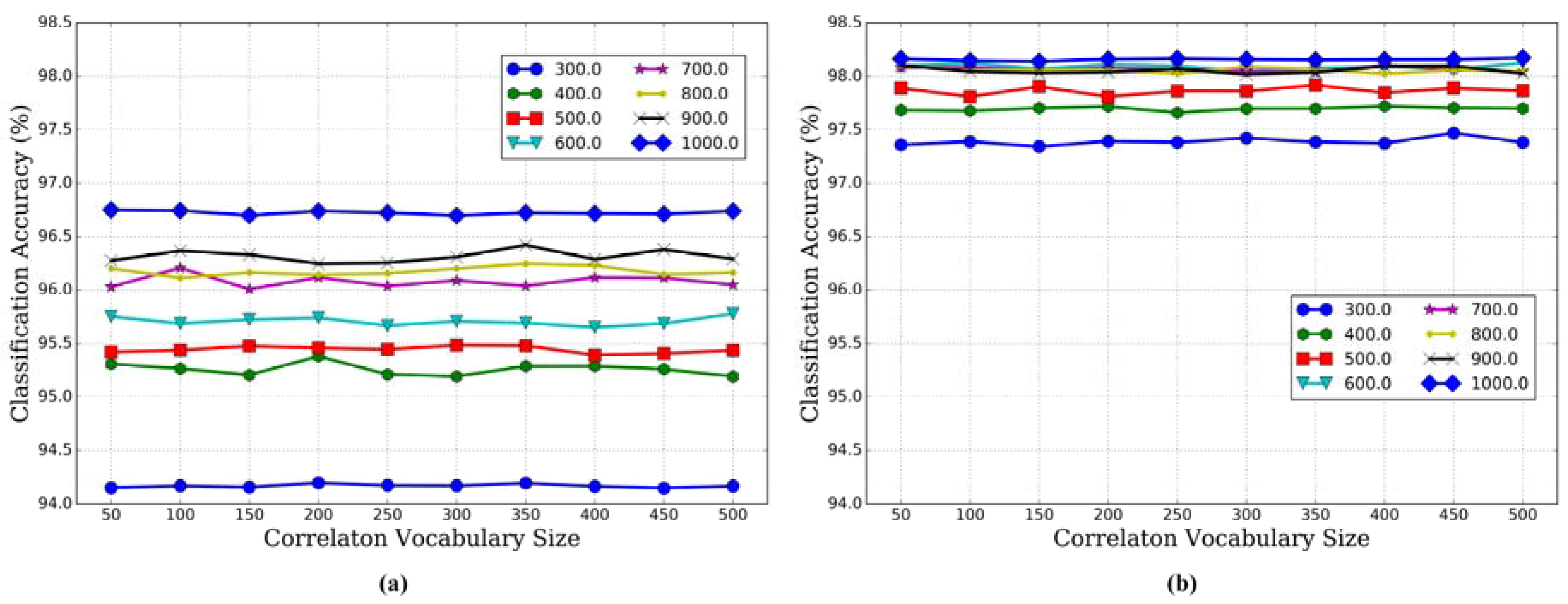
3.2.2. Effect of Correlaton Vocabulary Size
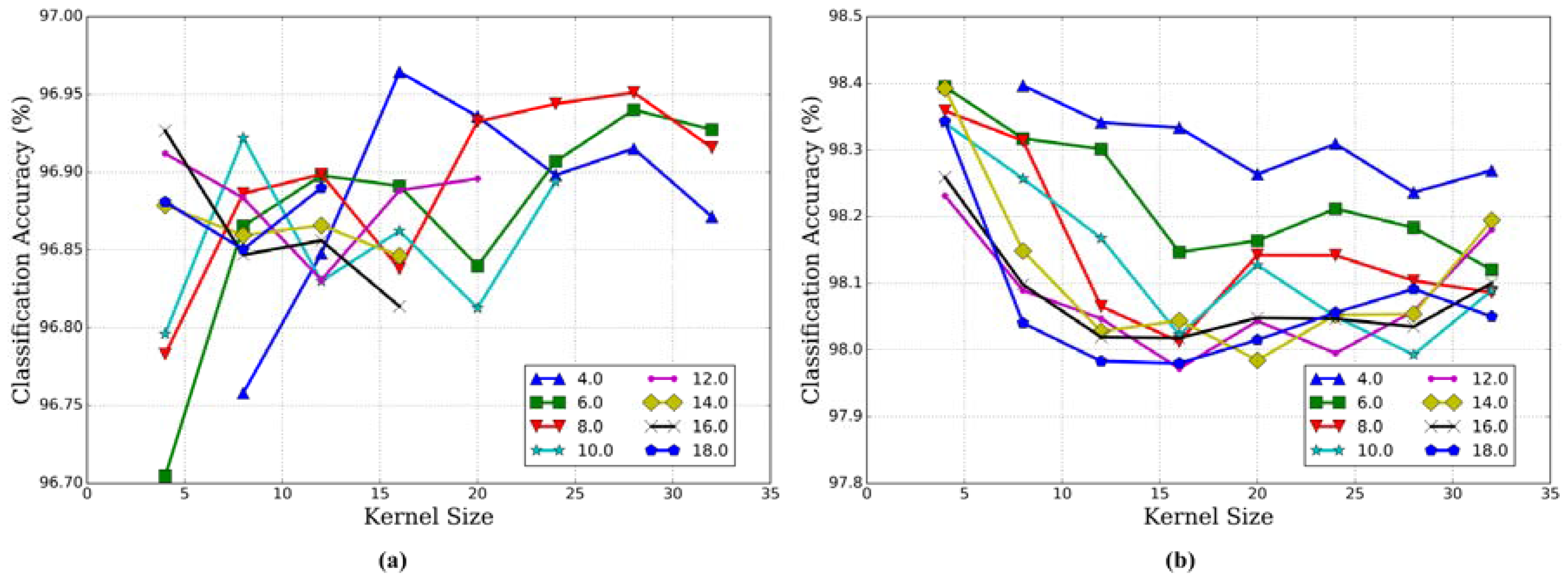
3.2.3. Kernel Size and Kernel Number
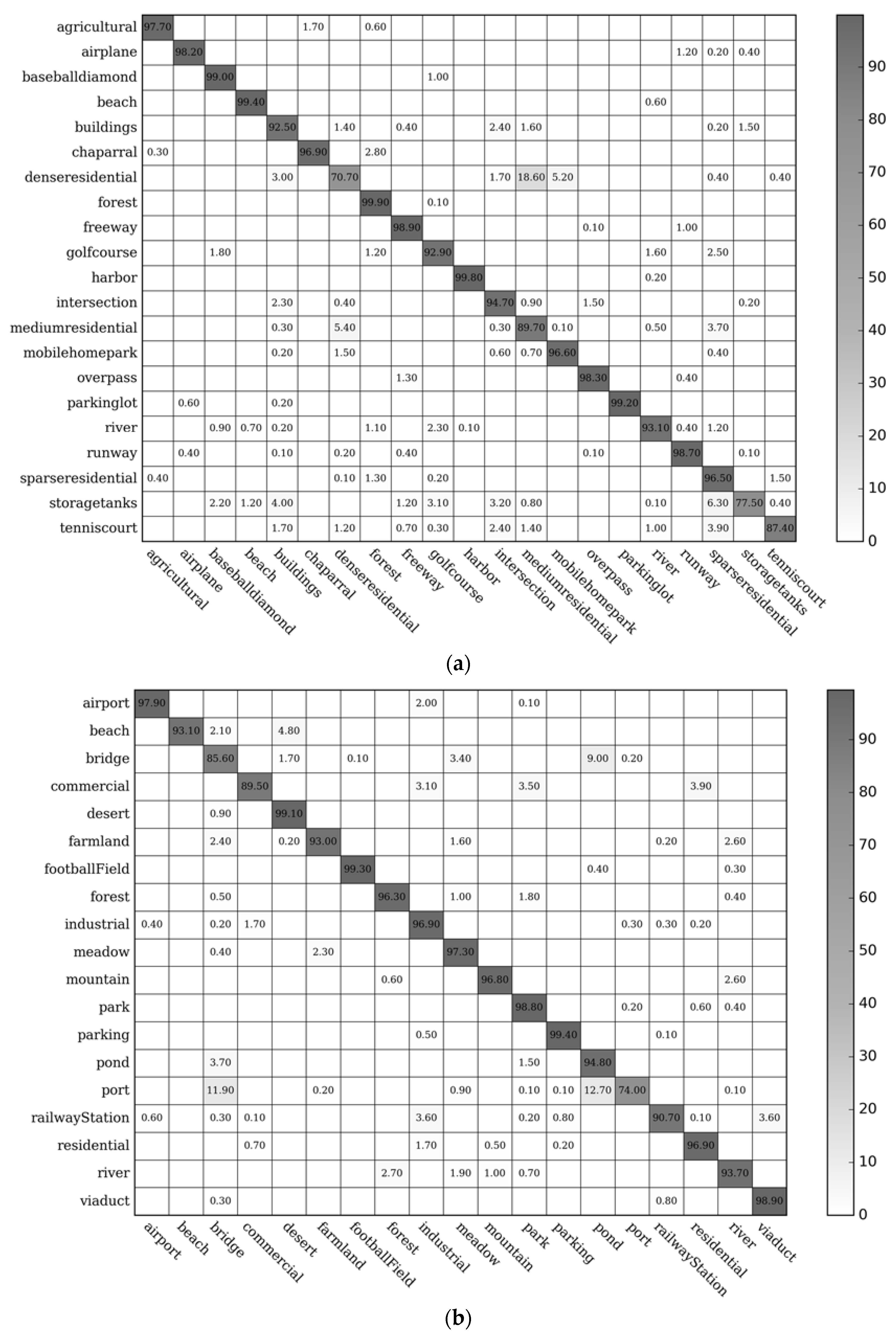
3.3. Confusion Matrix
3.4. Comparison with State-of-the-Art Methods
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zhou, W.; Troy, A. An object-oriented approach for analysing and characterizing urban landscape at the parcel level. Int. J. Remote Sens. 2008, 29, 3119–3135. [Google Scholar] [CrossRef]
- Zhang, H.; Lin, H.; Li, Y.; Zhang, Y. Feature extraction for high-resolution imagery based on human visual perception. Int. J. Remote Sens. 2013, 34, 1146–1163. [Google Scholar] [CrossRef]
- Rogan, J.; Chen, D. Remote sensing technology for mapping and monitoring land-cover and land-use change. Prog. Plan. 2004, 61, 301–325. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Xia, G.S.; Yang, W.; Delon, J.; Gousseau, Y.; Sun, H.; Maitre, H. Structrual high-resolution satellite image indexing. In Proceedings of the ISPRS, TC VII Symposium Part A: 100 Years ISPRS—Advancing Remote Sensing Science, Vienna, Austria, 5–7 July 2010. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Cheriyadat, A. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2175–2184. [Google Scholar] [CrossRef]
- Fan, J.; Tan, H.L.; Lu, S. Multipath sparse coding for scene classification in very high resolution satellite imagery. SPIE Remote Sens. 2015, 9643, 96430S. [Google Scholar]
- Hu, F.; Xia, G.; Wang, Z.; Huang, X.; Zhang, L.; Sun, H. Unsupervised feature learning via spectral clustering of multidimensional patches for remotely sensed scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2015–2030. [Google Scholar] [CrossRef]
- Fan, J.; Chen, T.; Lu, S. Unsupervised feature learning for land-use scene recognition. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2250–2261. [Google Scholar] [CrossRef]
- Chehdi, K.; Soltani, M.; Cariou, C. Pixel classification of large-size hyperspectral images by affinity propagation. J. Appl. Remote Sens. 2014, 8, 083567. [Google Scholar] [CrossRef]
- Yu, Q. Object-based detailed vegetation classification with airborne high spatial resolution remote sensing imagery. Photogramm. Eng. Remote Sens. 2006, 72, 799–811. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, L.; Li, P.; Huang, B. Classification of high spatial resolution imagery using improved gaussian markov random-field-based texture features. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1458–1468. [Google Scholar] [CrossRef]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 1470–1477. [Google Scholar]
- Csurka, G.; Dance, C.R.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the Workshop on Statistical Learning in Computer Vision, European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 1–22. [Google Scholar]
- Bosch, A.; Zisserman, A.; Muoz, X. Scene classification using a hybrid generative/discriminative approach. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 712–727. [Google Scholar] [CrossRef] [PubMed]
- Jegou, H.; Douze, M.; Schmid, C. Improving bag-of-features for large scale image search. Int. J. Comput. Vis. 2010, 87, 316–336. [Google Scholar] [CrossRef] [Green Version]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Qi, K.; Wu, H.; Shen, C.; Gong, J. Land-use scene classification in high-resolution remote sensing images using improved correlatons. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2403–2407. [Google Scholar] [CrossRef]
- Zhao, L.J.; Tang, P.; Huo, L.Z. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Chen, S.; Tian, Y. Pyramid of spatial relations for scene-level land use classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1947–1957. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 25–25 June 2005; pp. 886–893. [Google Scholar]
- Zhao, W.; Du, S. Scene classification using multi-scale deeply described visual words. Int. J. Remote Sens. 2016, 37, 4119–4131. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Twenty-Sixth Annual Conference on Neural Information Processing Systems, Lake Tahoe, NY, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Hariharan, B.; Arbelaez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 297–312. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 1–19. [Google Scholar] [CrossRef]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Vedaldi, A. Deep filter banks for texture recognition, description, and segmentation. Int. J. Comput. Vis. 2016, 118, 65–94. [Google Scholar] [CrossRef] [PubMed]
- Penatti, O.A.; Nogueira, K.; dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 12 June 2015; pp. 44–51. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A deep convolutional activation feature for generic visual recognition. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 647–655. [Google Scholar]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1717–1724. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Hu, F.; Xia, G.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Grauman, K.; Darrell, T. The pyramid match kernel: Discriminative classification with sets of image features. In Proceedings of the International Conference on Computer Vision, Beijing, China, 17–21 October 2005; pp. 1458–1465. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Zheng, X.; Yuan, Y. Remote sensing scene classification by unsupervised representation learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1–10. [Google Scholar] [CrossRef]
- Battiato, S.; Farinella, G.M.; Gallo, G.; Ravi, D. Spatial hierarchy of textons distributions for scene classification. In Proceedings of the Conference on Multimedia Modeling, Sophia Antipolis, France, 7–9 January 2009; pp. 333–343. [Google Scholar]
- Zhou, L.; Zhou, Z.; Hu, D. Scene classification using multi-resolution low-level feature combination. Neurocomputing 2013, 122, 284–297. [Google Scholar] [CrossRef]
- Huang, J.; Kumar, S.R.; Mitra, M.; Zhu, W.; Zabih, R. Image indexing using color correlograms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 17–18 June 1997; pp. 762–768. [Google Scholar]
- Savarese, S.; Winn, J.; Criminisi, A. Discriminative object class models of appearance and shape by correlatons. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 17–22 June 2006; pp. 2033–2040. [Google Scholar]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Qi, K.; Zhang, X.; Wu, B.; Wu, H. Sparse coding-based correlaton model for land-use scene classification in high-resolution remote-sensing images. J. Appl. Remote Sens. 2016, 10, 042005. [Google Scholar]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Fan, R.E.; Chang, K.W.; Hsieh, C.J.; Wang, X.R.; Lin, C.J. LIBLINEAR: A library for large linear classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Vedaldi, A.; Fulkerson, B. VLFeat: An open and portable library of computer vision algorithms. Available online: http://www.vlfeat.org/ (accessed on 16 November 2016).
- Vedaldi, A.; Lenc, K. MatConvNet: CNNs for MATLAB. Available online: http://www.vlfeat.org/matconvnet (accessed on 16 November 2016).
- MatConvNet Pretrained Models. Available online: http://www.vlfeat.org/matconvnet/pretrained/ (accessed on 16 November 2016).
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land Use Classification in Remote Sensing Images by Convolutional Neural Networks. Available online: http://arxiv.org/abs/1508.00092 (accessed on 30 March 2017).
- Gong, Y.; Wang, L.; Guo, R.; Lazebnik, S. Multi-scale orderless pooling of deep convolutional activation features. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 392–407. [Google Scholar]
- Qi, K.; Liu, W.; Yang, C.; Guan, Q.; Wu, H. Multi-task joint sparse and low-rank representation for the scene classification of high-resolution remote sensing image. Remote Sens. 2017, 9, 10. [Google Scholar] [CrossRef]
- Huang, L.; Chen, C.; Li, W.; Du, Q. Remote sensing image scene classification using multi-scale completed local binary patterns and fisher vectors. Remote Sens. 2016, 8, 483. [Google Scholar] [CrossRef]
- Negrel, R.; Picard, D.; Gosselin, P.H. Evaluation of second-order visual features for land-use classification. In Proceedings of the International Workshop on Content-Based Multimedia Indexing, Klagenfurt, Austria, 18–20 June 2014; pp. 1–5. [Google Scholar]
- Liu, C. Maximum likelihood estimation from incomplete data via EM-type Algorithms. In Advanced Medical Statistics; World Scientific Publishing Co.: Hackensack, NJ, USA, 2003; pp. 1051–1071. [Google Scholar]
- Krapac, J.; Verbeek, J.; Jurie, F. Modeling spatial layout with fisher vectors for image categorization. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1487–1494. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Values | Name | Values |
|---|---|---|---|
| Scale 1 | 1 | Scale 6 | |
| Scale 2 | Scale 7 | ||
| Scale 3 | Scale 8 | ||
| Scale 4 | Scale 9 | ||
| Scale 5 | Scale 10 |
| Method | Accuracy (Mean ± Std) |
|---|---|
| BoVW [15] | 71.86 |
| SPM [19] | 74.0 |
| SPCK++ [4] | 77.38 |
| MS-based Correlaton [20] | 81.32 ± 0.92 |
| UFL [7] | 81.67 ± 1.23 |
| SG + UFL [8] | 82.72 ± 1.18 |
| UFL-SC [10] | 90.26 ± 1.51 |
| UFC + MSC [11] | 91.95 ± 0.72 |
| CCM-BoVW [21] | 86.64 ± 0.81 |
| PSR [22] | 89.1 |
| MSIFT [6] | 90.97 ± 1.81 |
| MS-CLBP + FV [56] | 93.0 ± 1.2 |
| MTJSLRC [55] | 91.07 ± 0.67 |
| VLAT [57] | 94.3 |
| MBVW [25] | 96.14 |
| OverFeat [31] | 90.91 ± 1.19 |
| CaffeNet [31] | 93.42 ± 1.0 |
| GoogLeNet + Fine-tune [53] | 97.1 |
| Appearance-based | 96.05 ± 0.62 |
| MDDC | 96.92 ± 0.57 |
| Method | Accuracy (Mean ± Std) |
|---|---|
| Bag of SIFT [58] | 85.5 ± 1.2 |
| LTP-HF [59] | 77.6 |
| MS-CLBP [59] | 93.4 ± 1.1 |
| Multi-feature Concatenation [58] | 90.8 ± 0.7 |
| MTJSLRC [55] | 91.74 ± 1.14 |
| SIFT + LTP-HF + Color Histogram [48] | 93.6 |
| MS-CLBP + FV [56] | 94.32 ± 1.2 |
| Appearance-based | 97.34 ± 0.57 |
| MDDC | 98.27 ± 0.53 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, K.; Yang, C.; Guan, Q.; Wu, H.; Gong, J. A Multiscale Deeply Described Correlatons-Based Model for Land-Use Scene Classification. Remote Sens. 2017, 9, 917. https://doi.org/10.3390/rs9090917
Qi K, Yang C, Guan Q, Wu H, Gong J. A Multiscale Deeply Described Correlatons-Based Model for Land-Use Scene Classification. Remote Sensing. 2017; 9(9):917. https://doi.org/10.3390/rs9090917
Chicago/Turabian StyleQi, Kunlun, Chao Yang, Qingfeng Guan, Huayi Wu, and Jianya Gong. 2017. "A Multiscale Deeply Described Correlatons-Based Model for Land-Use Scene Classification" Remote Sensing 9, no. 9: 917. https://doi.org/10.3390/rs9090917
APA StyleQi, K., Yang, C., Guan, Q., Wu, H., & Gong, J. (2017). A Multiscale Deeply Described Correlatons-Based Model for Land-Use Scene Classification. Remote Sensing, 9(9), 917. https://doi.org/10.3390/rs9090917