Comparing the Cost of Protecting Selected Lightweight Block Ciphers against Differential Power Analysis in Low-Cost FPGAs †


Abstract
:1. Introduction
- Non-completeness. Every function is independent of at least one share of each of the input variables. Defined formally, if , and and are divided into shares, thenIn other words, If zi does not depend on xi and yi, it cannot leak information about xi or yi.
- Correctness. The sum of the output shares gives the desired output. Formally
- Uniformity. A realization of sharing is uniform if, for all distributions of the inputs and , the output distribution preserves the input distribution. In other words, if the input function is a permutation, the output function should also be a permutation.
2. Results
2.1. Implementations of Ciphers with 3-Share TI Protection against DPA
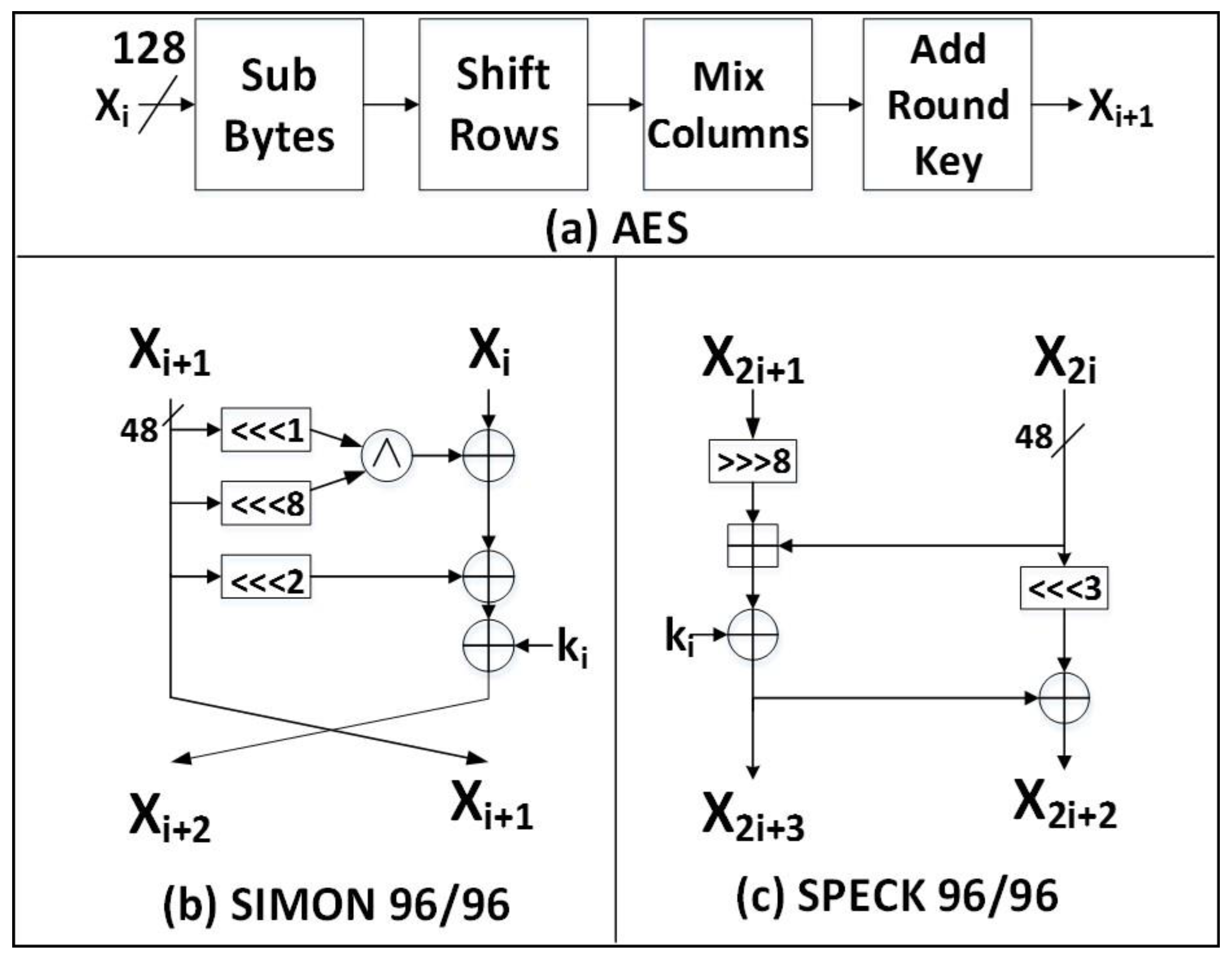
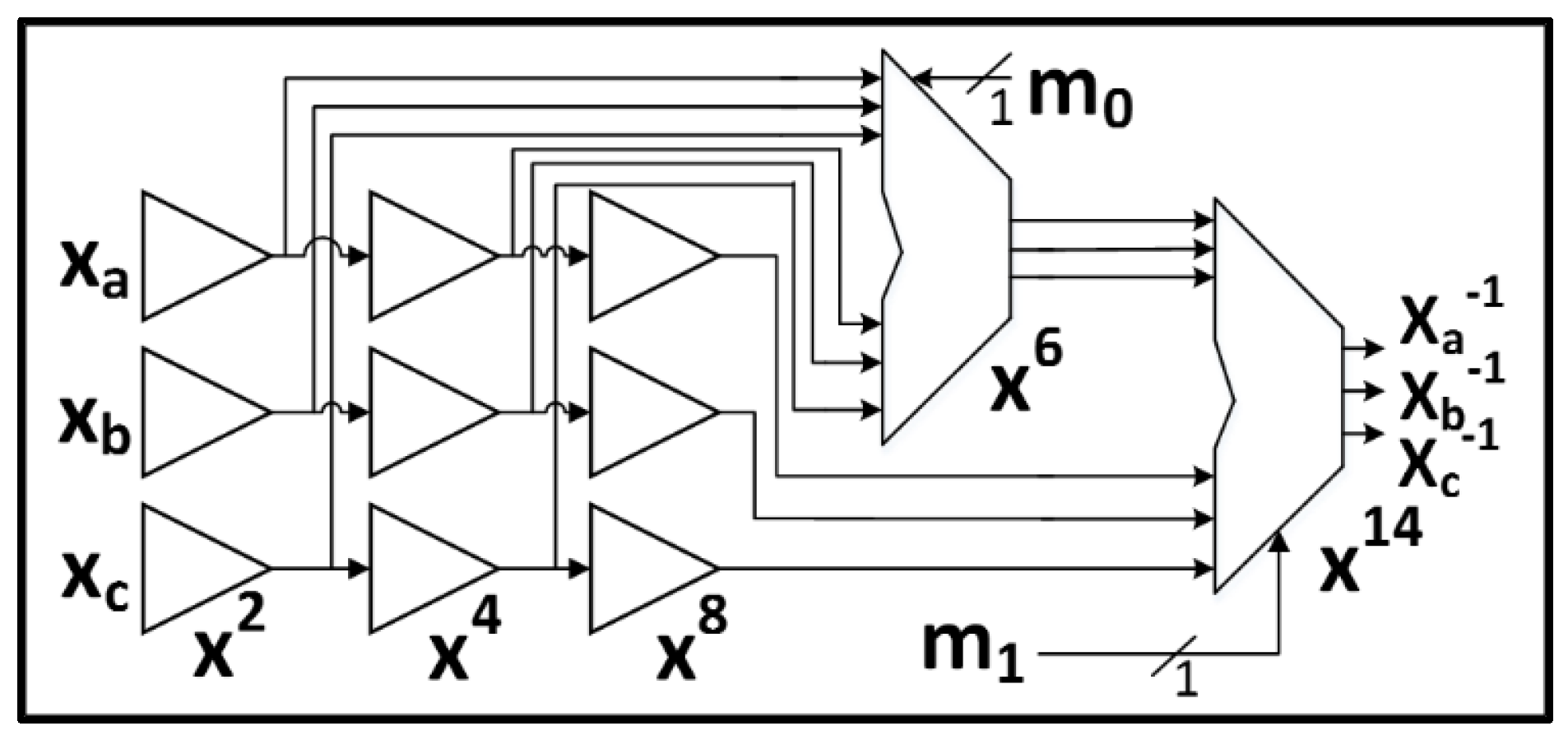
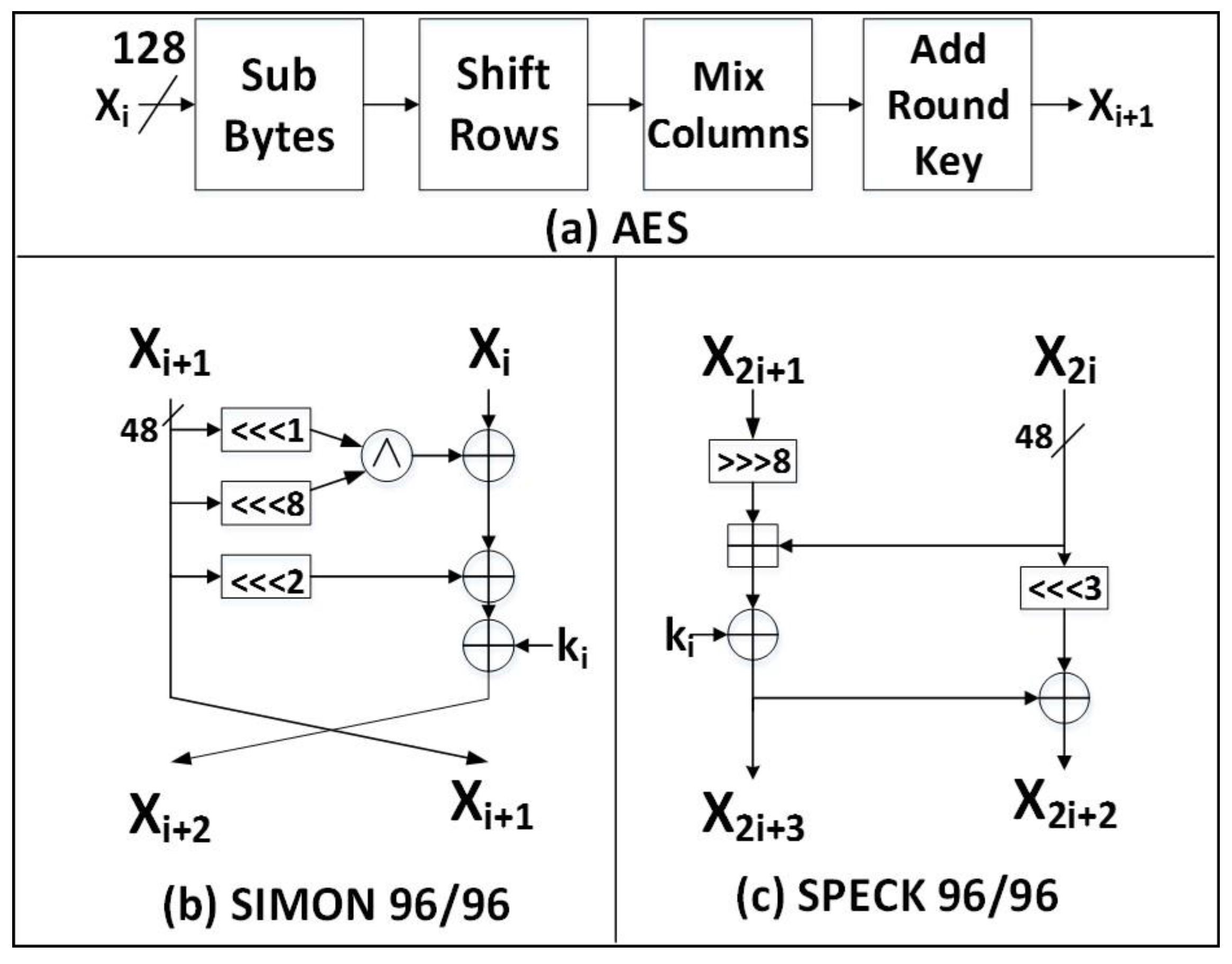
2.1.1. AES
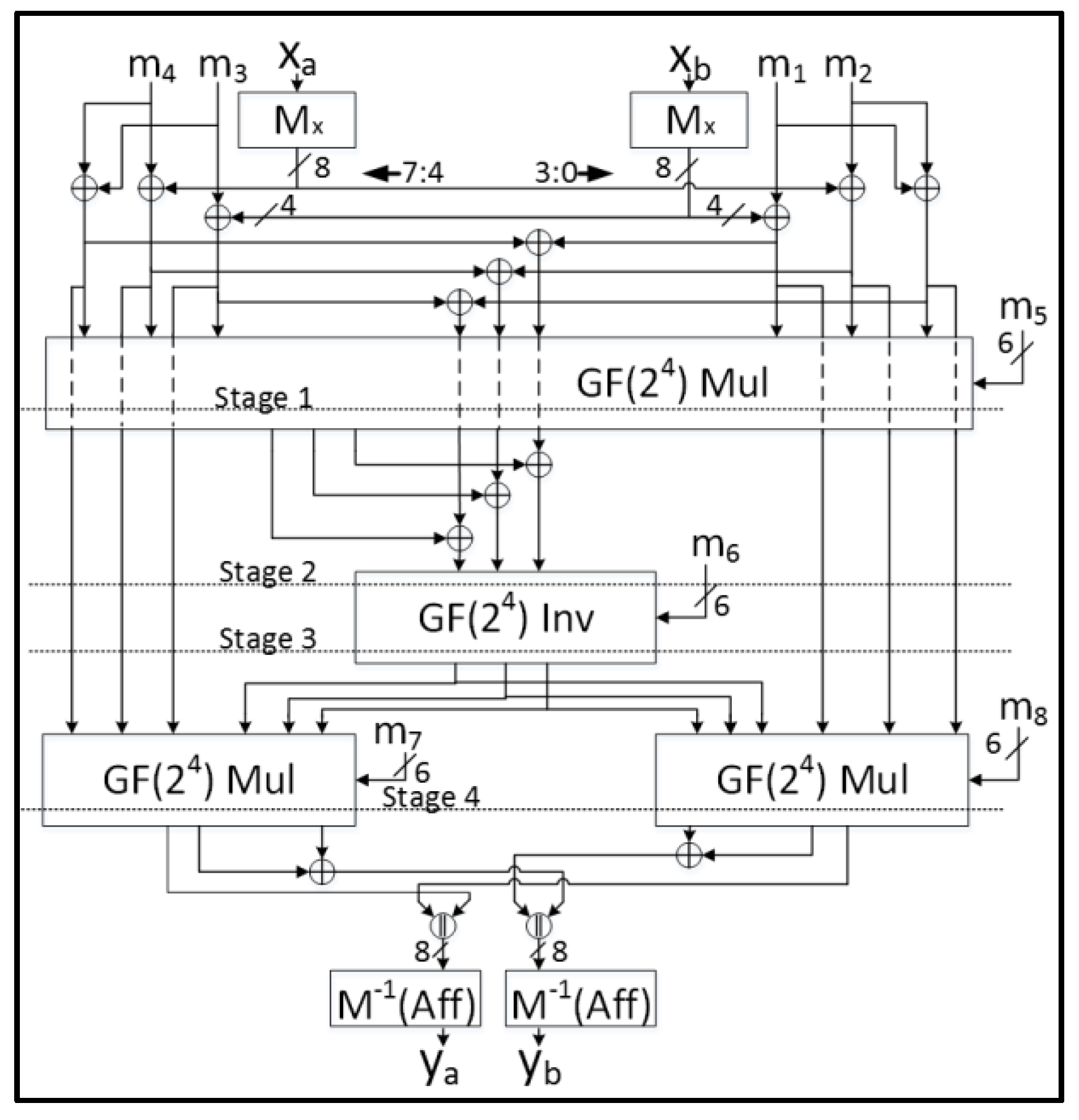
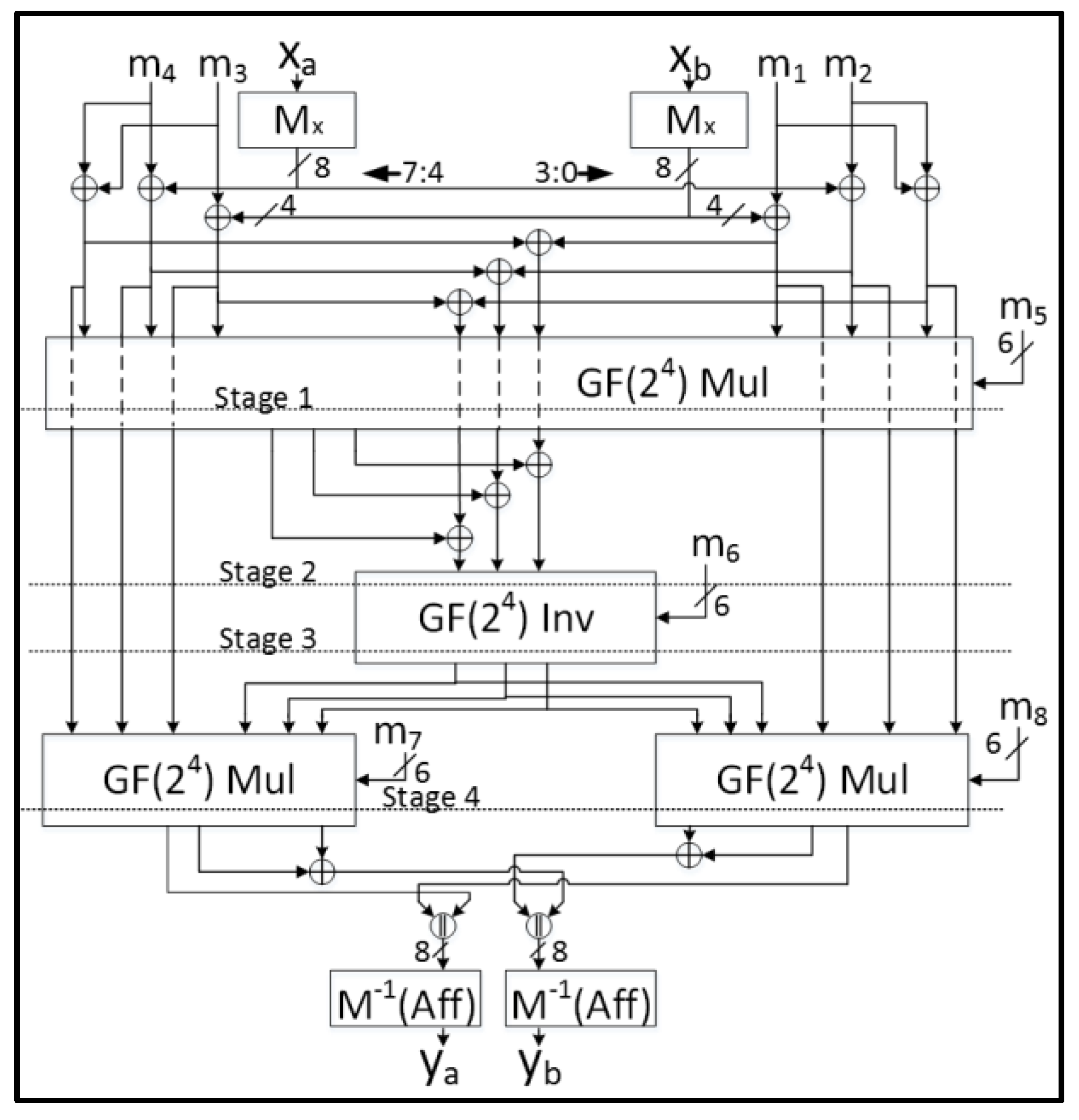
- Each 8-bit S-Box using Tower Fields requires nine GF(22) regular multiplications and three GF(22) scaled multiplications, which is enormously costly when implementing multiple S-Boxes;
- The Tower Fields approach results in multiple cascaded non-linear sharings which could cause long glitch-dependent circuit paths.
2.1.2. SIMON
2.1.3. SPECK
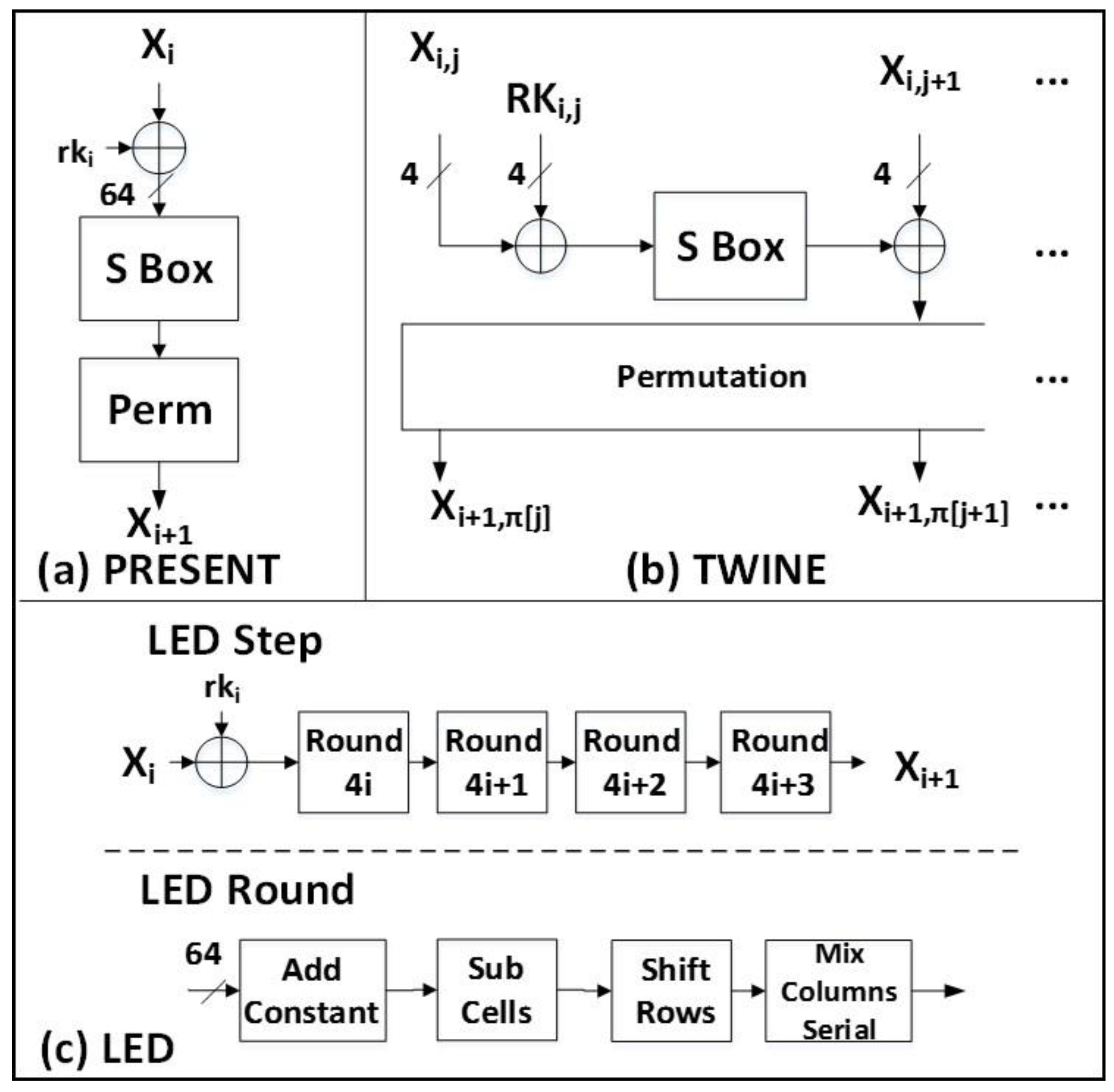
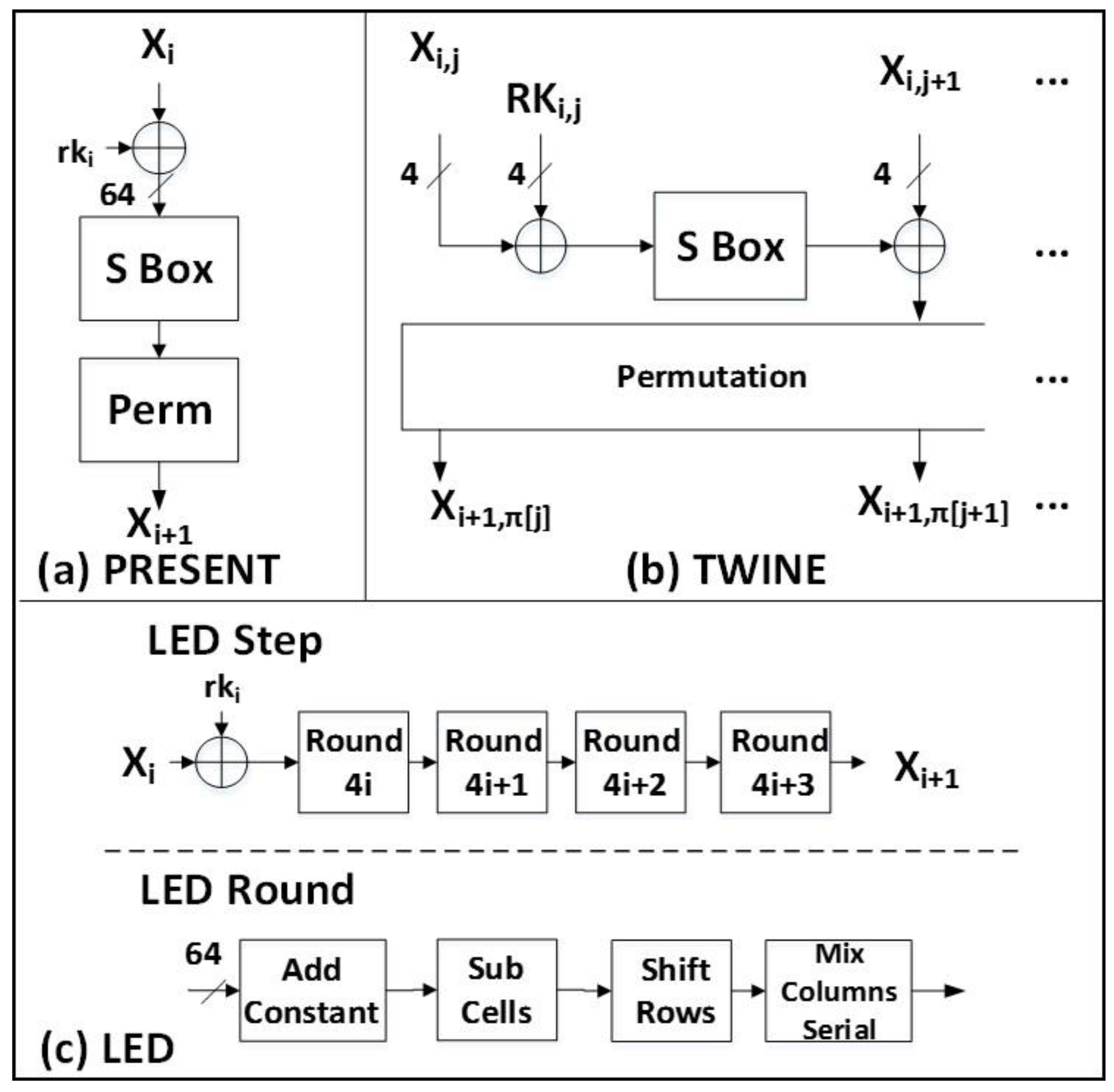
2.1.4. PRESENT
2.1.5. LED
2.1.6. TWINE
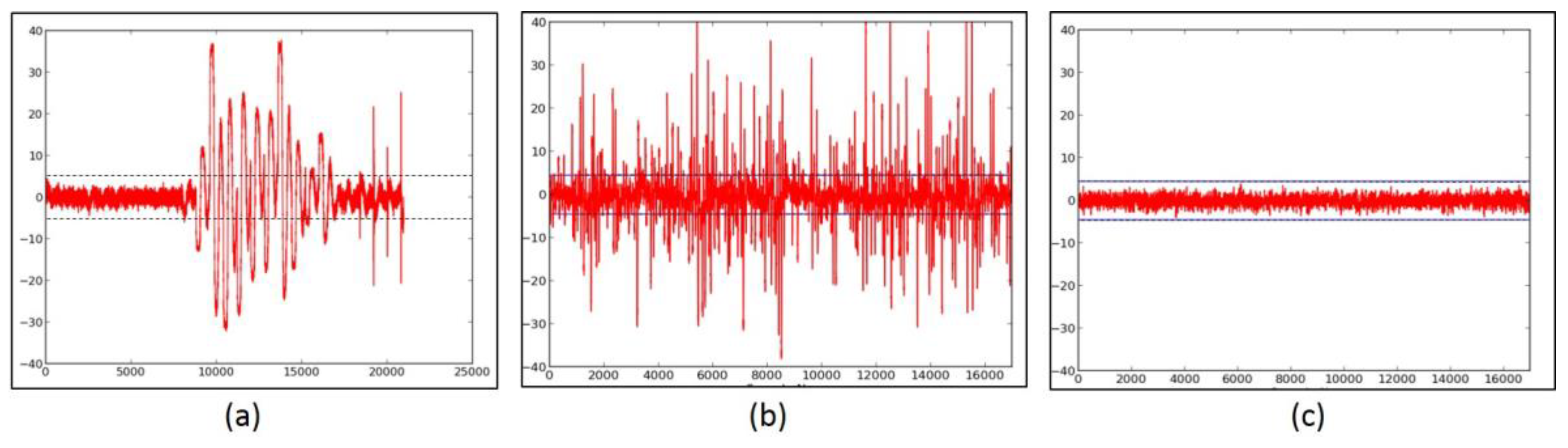
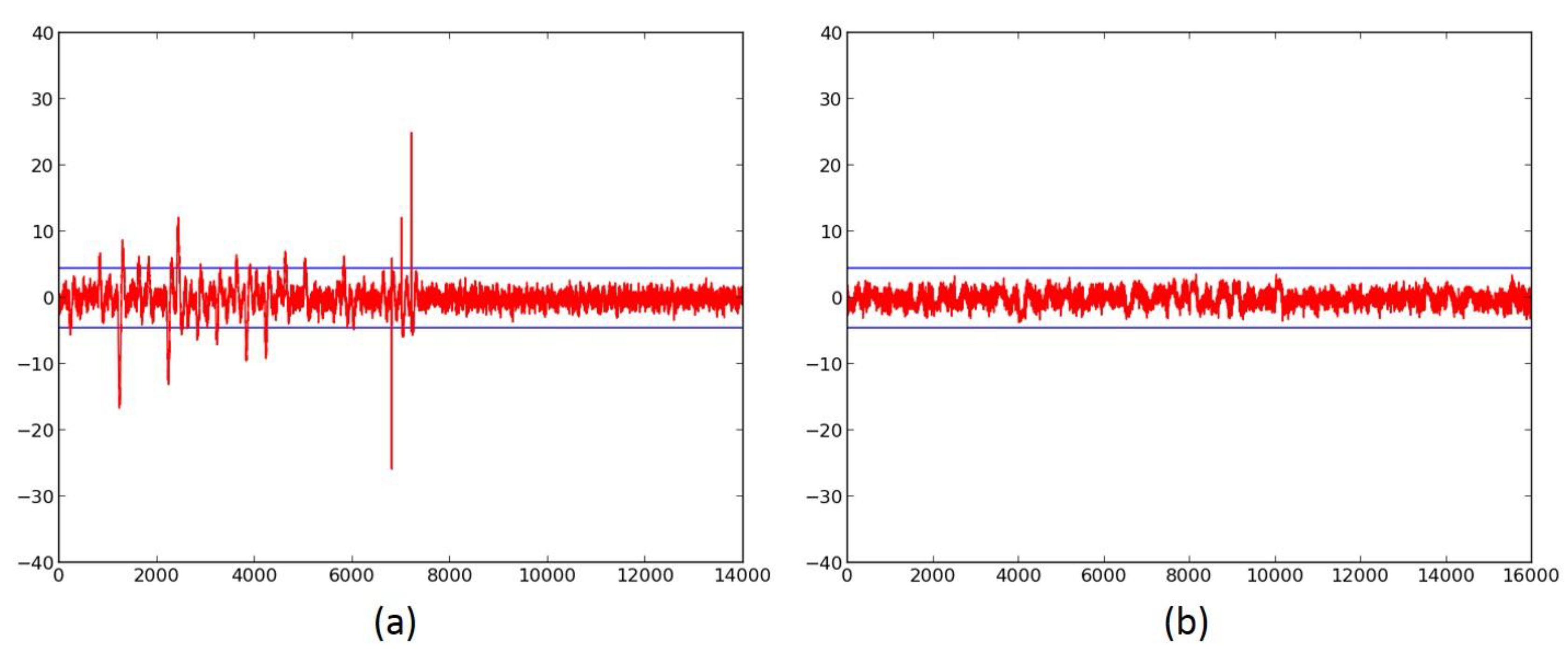
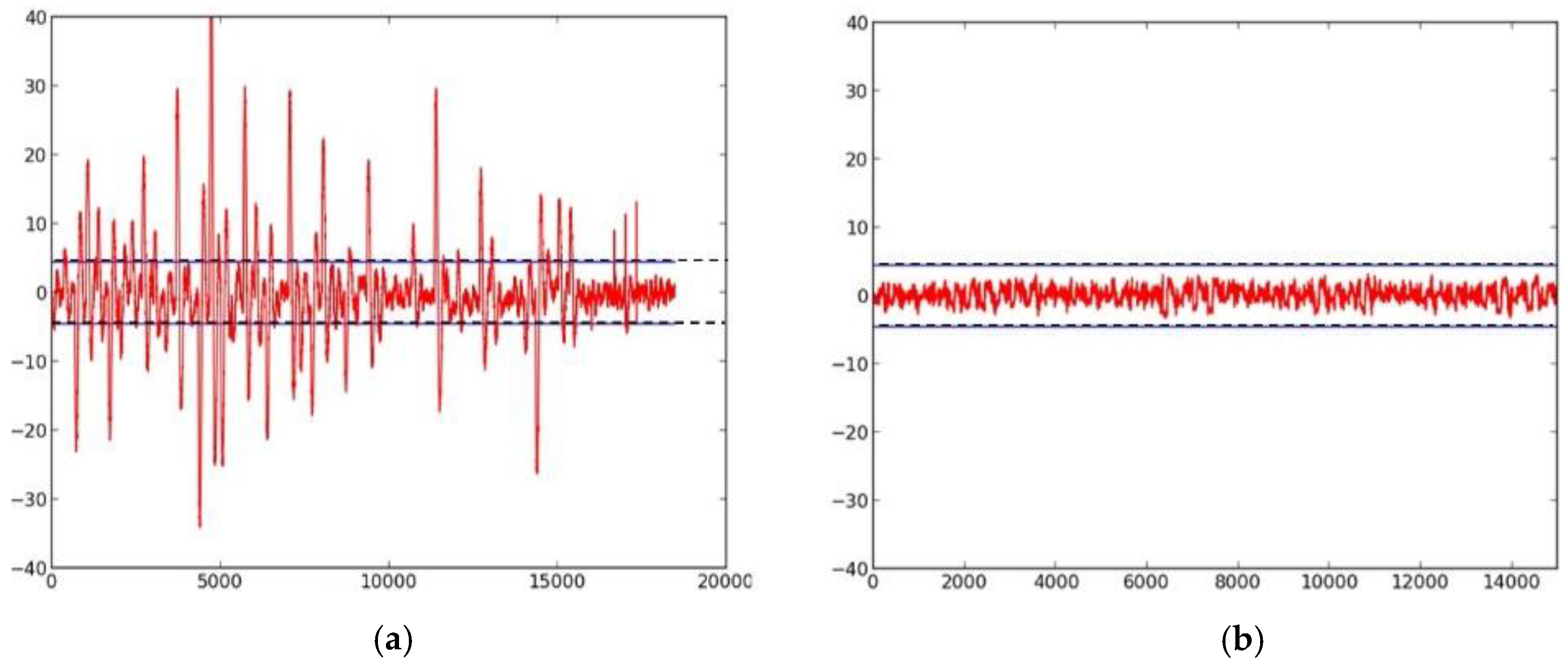
2.2. Side-Channel Resistance of Unprotected Versions
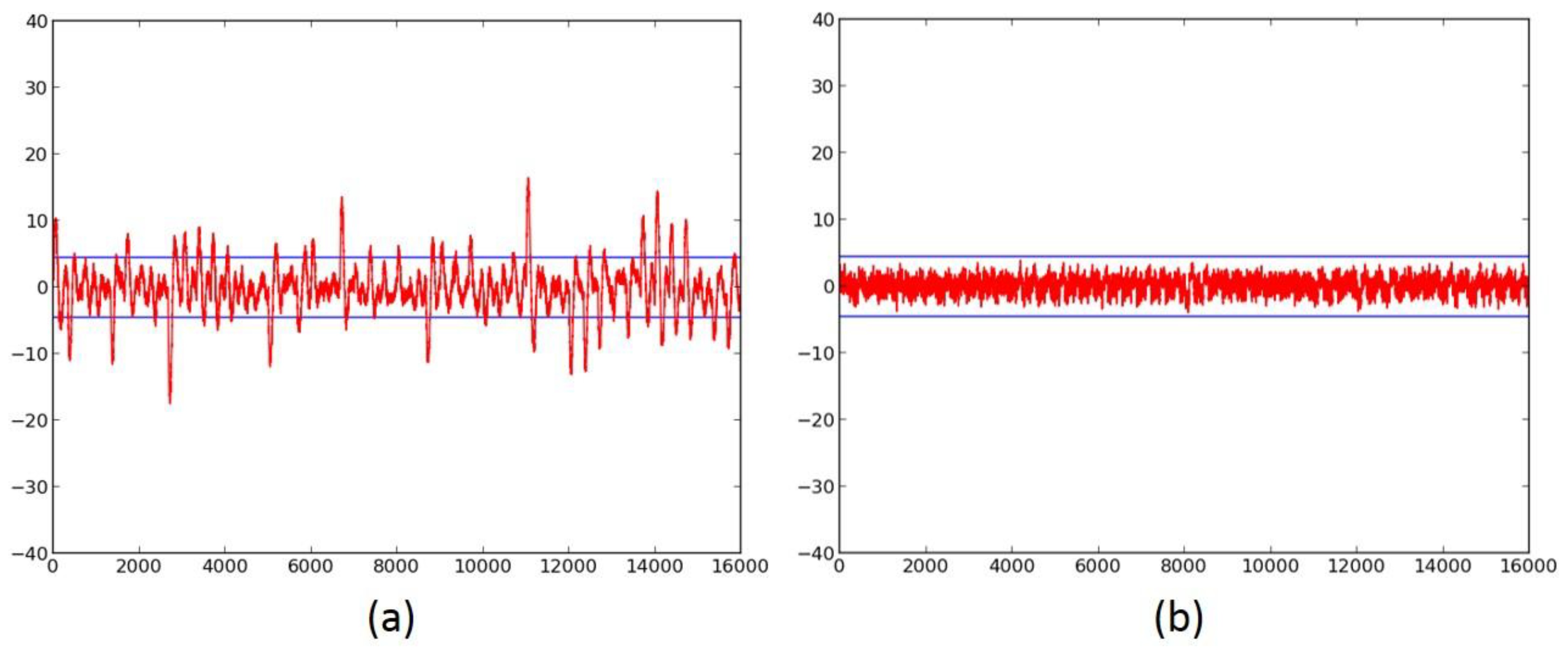
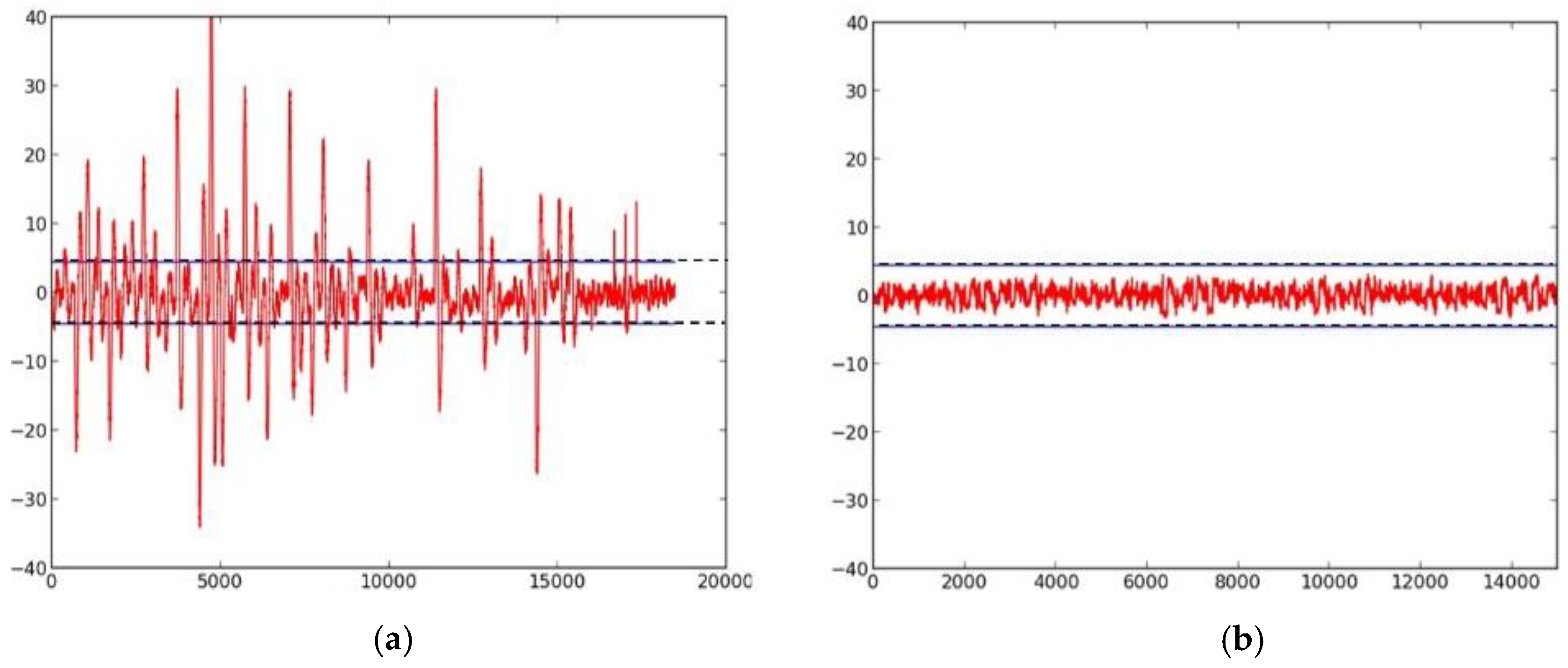
2.3. Failed Attempts at Protection
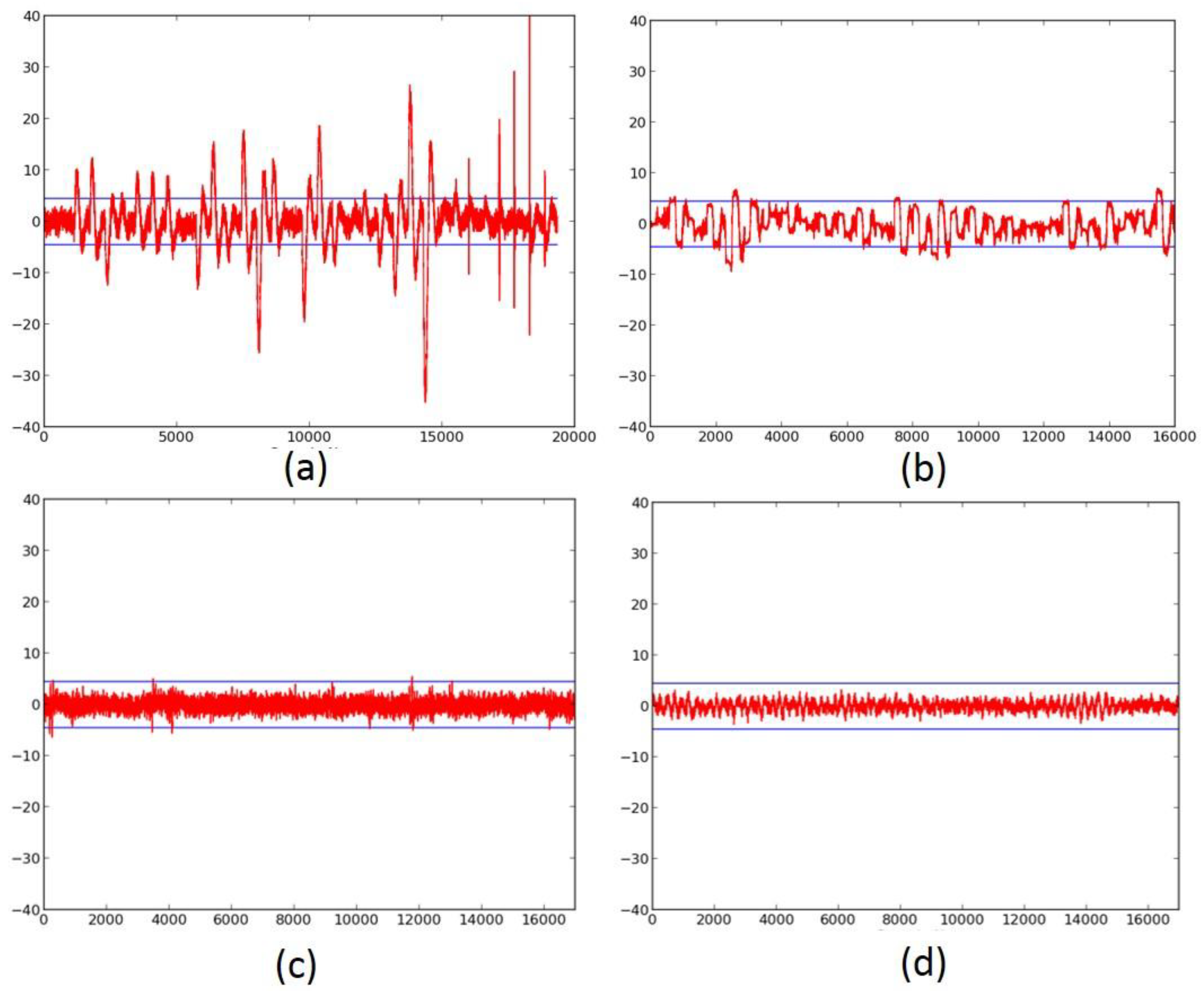
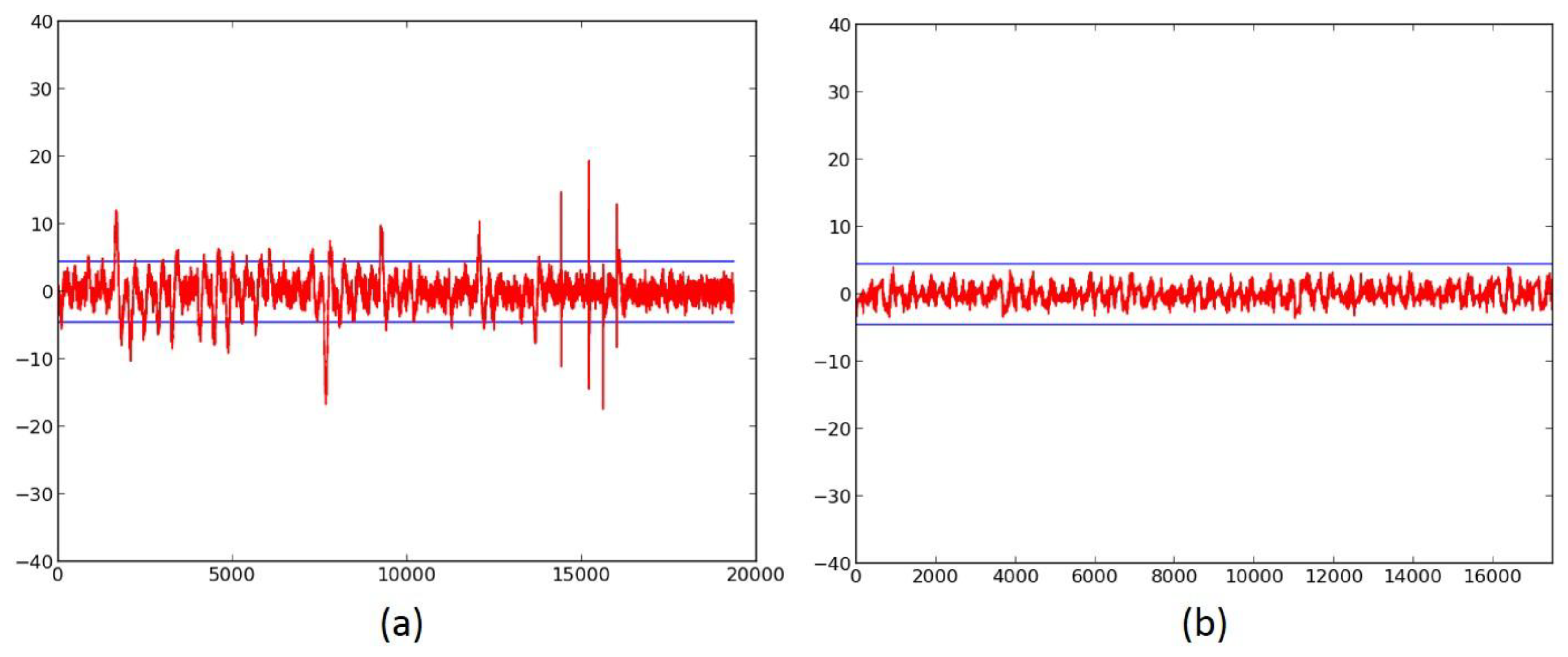
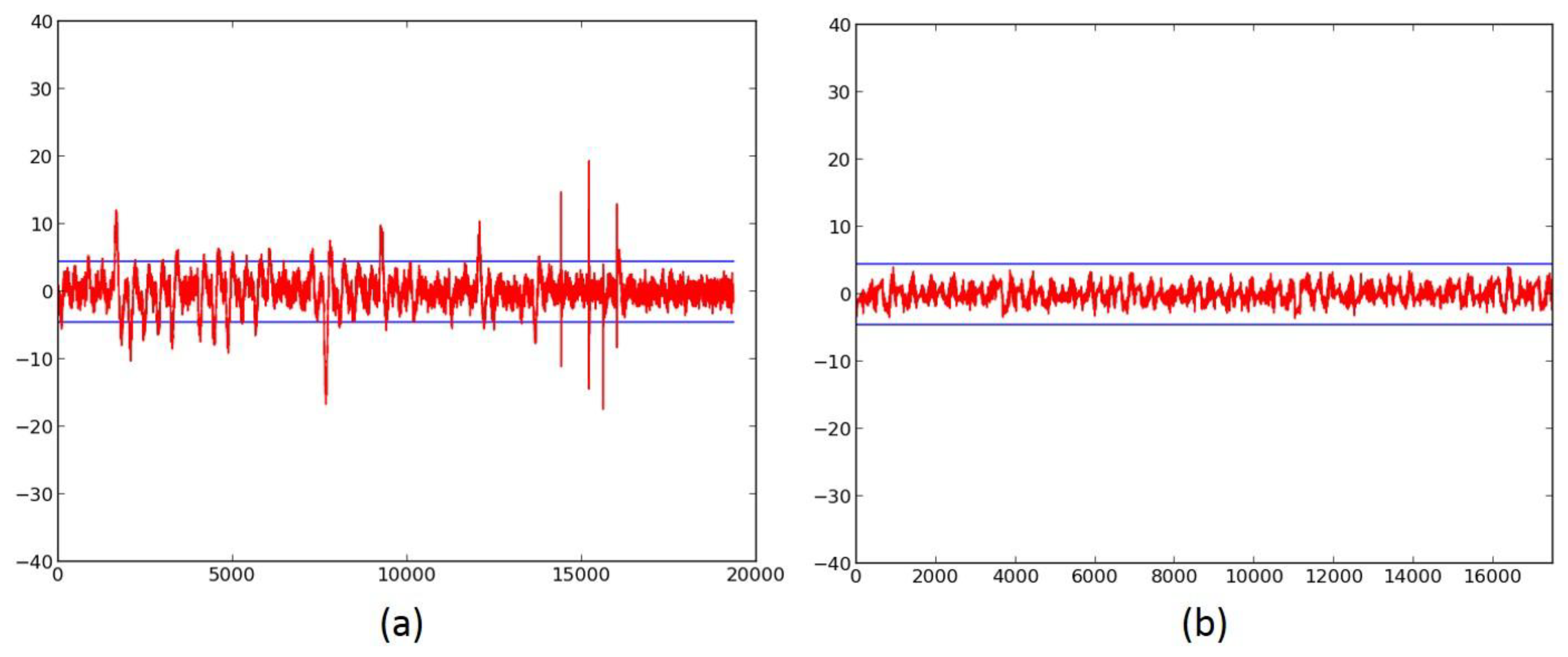
2.4. Successful 3-Share TI Protected Ciphers
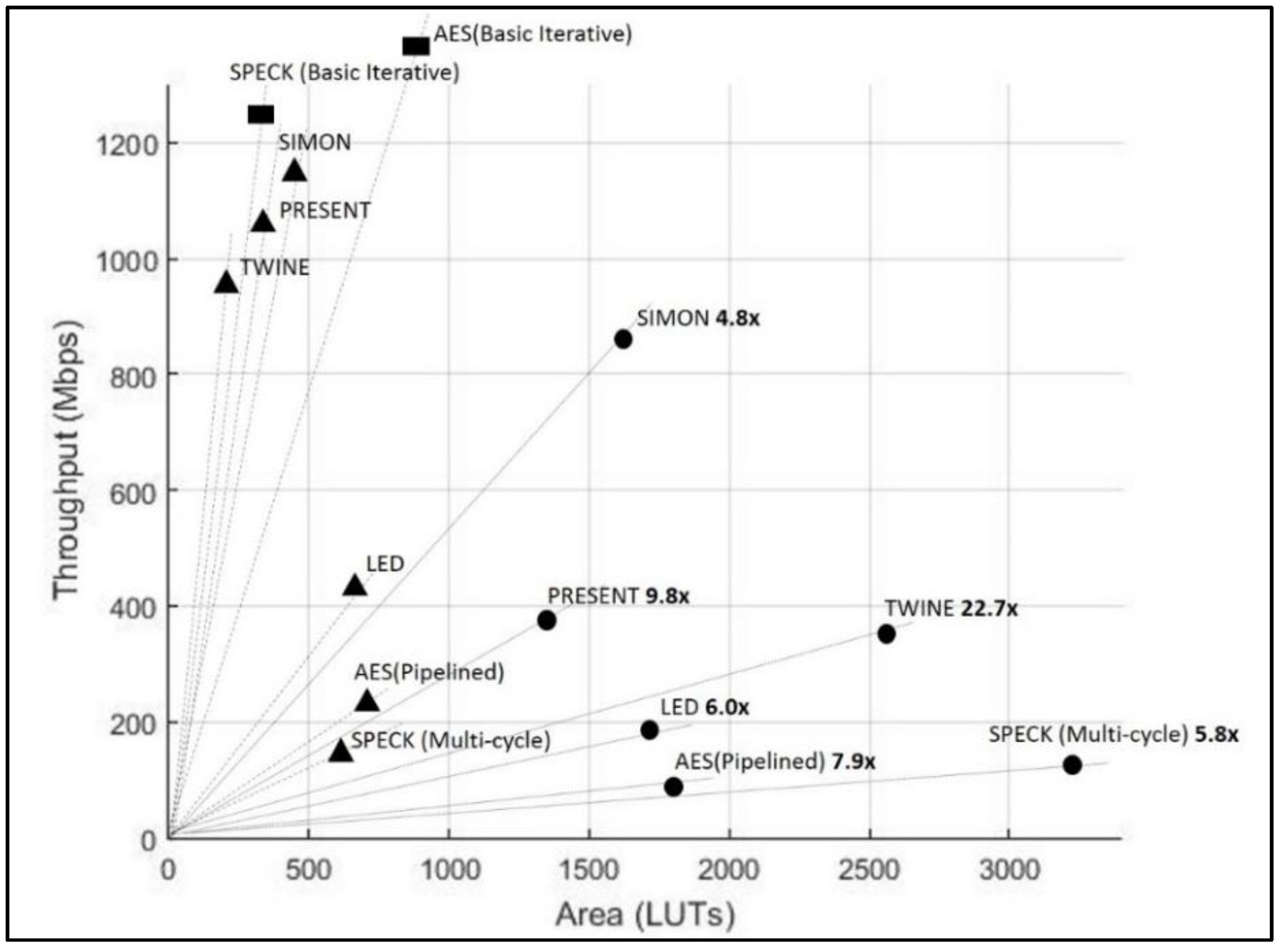
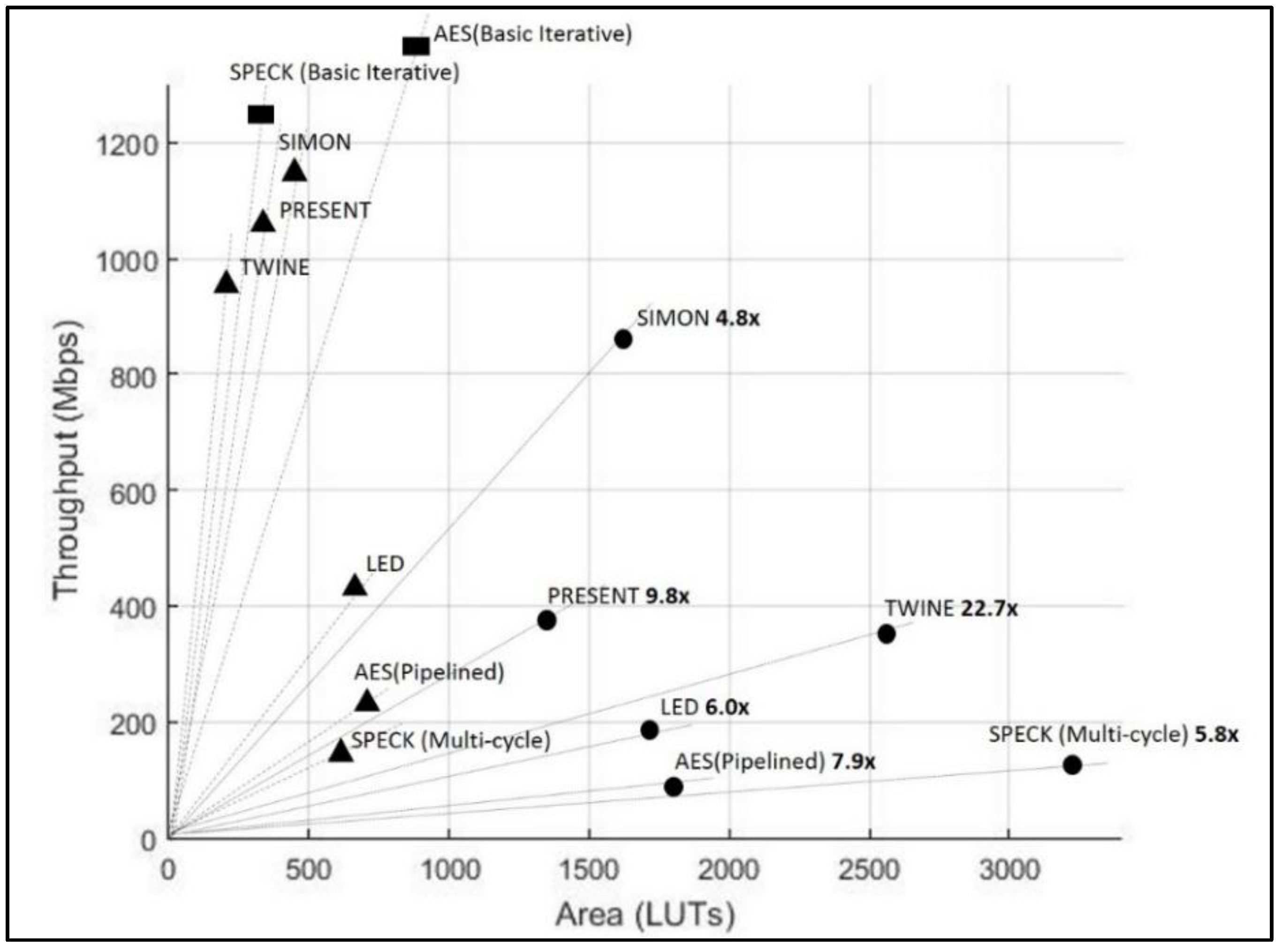
2.5. Benchmarking of Results
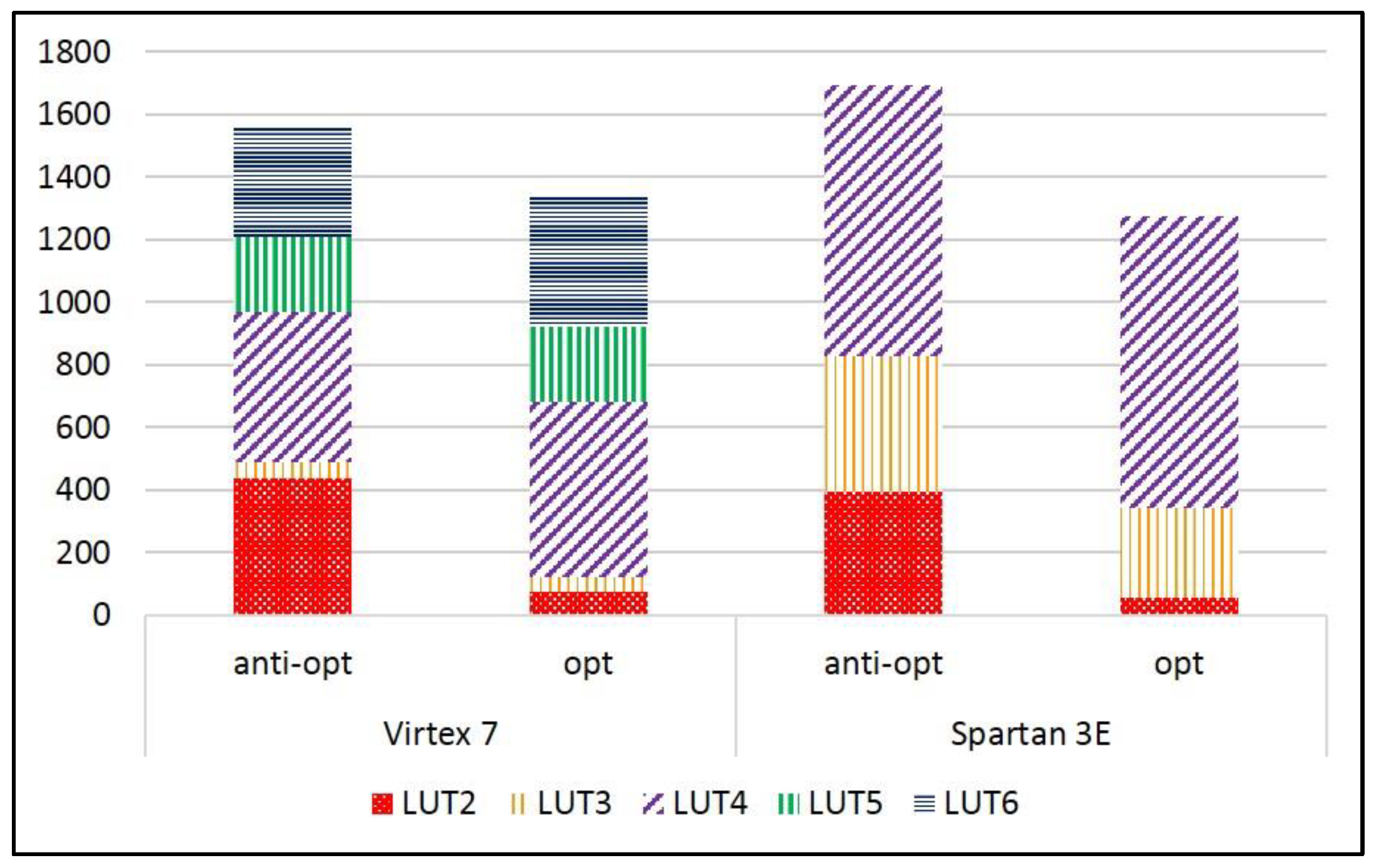
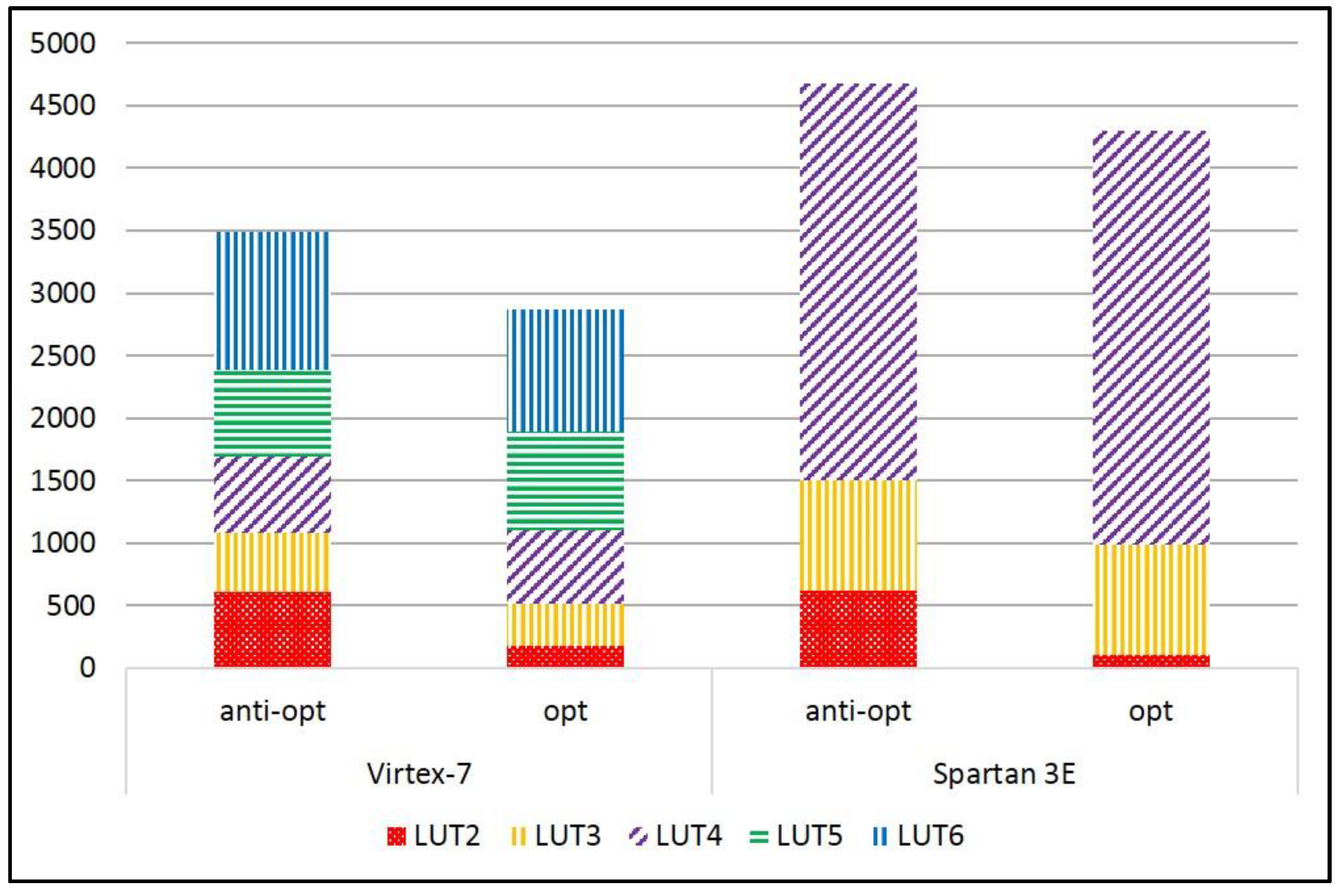
2.6. Cost of Anti-Optimization Constraints
3. Discussion
- Changes in the cipher protection schemes affect frequency as well as area;
- The factors of throughput and area are needed to normalize the ciphers that have different block sizes, different architectures, and varying clock cycles per block.
4. Materials and Methods
- We develop implementations for the six ciphers using register transfer level (RTL) methodology in VHDL. Unprotected cipher implementations are either developed entirely by the authors of this research or adopted from publicly-available source codes as annotated above. In order to maximize the throughput-to-area (TP/A) ratio, we use a full-width datapath (that is, the maximum internal datapath corresponding to the full block size in terms of bits), basic iterative architecture (that is, one round in one clock cycle) when possible.
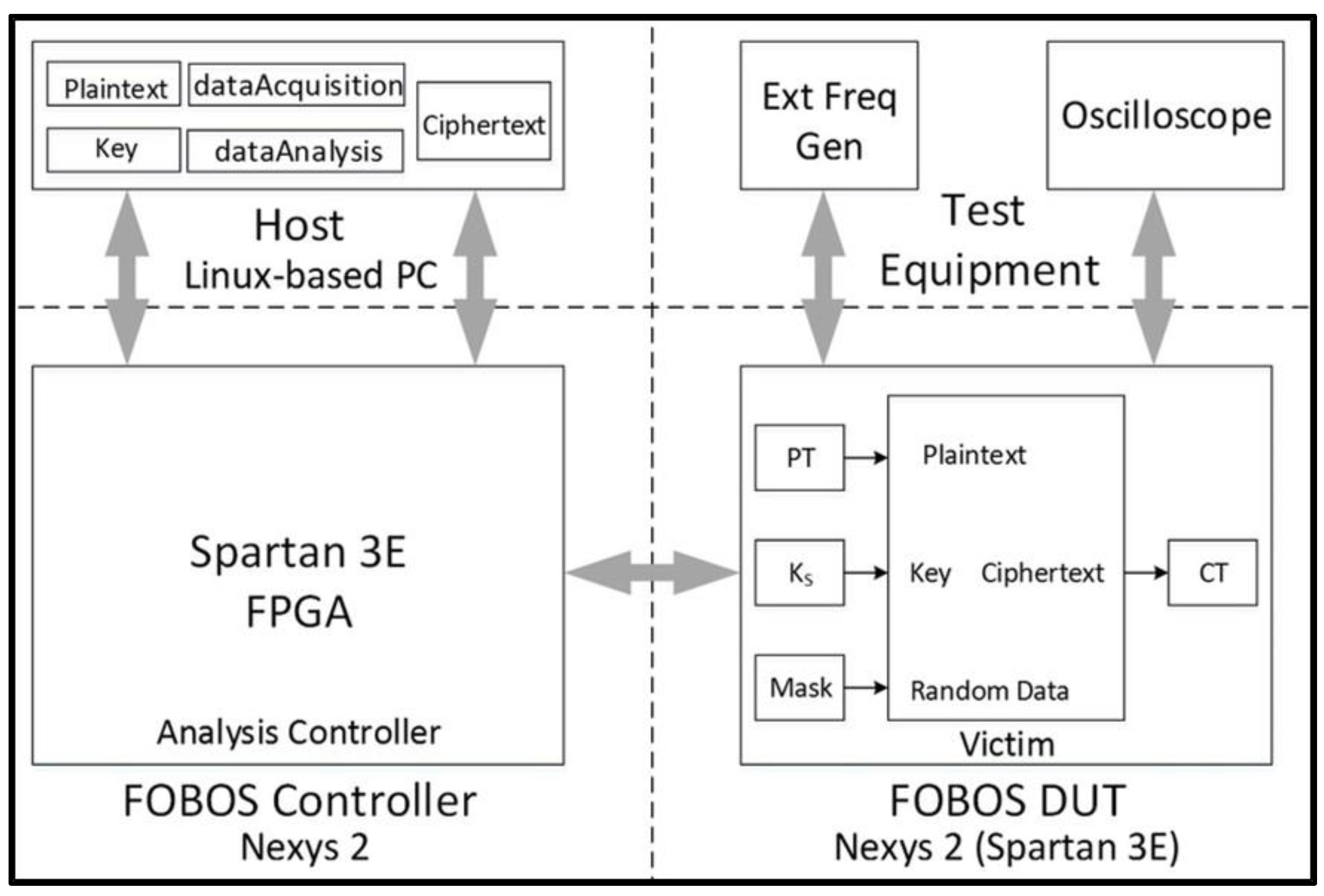
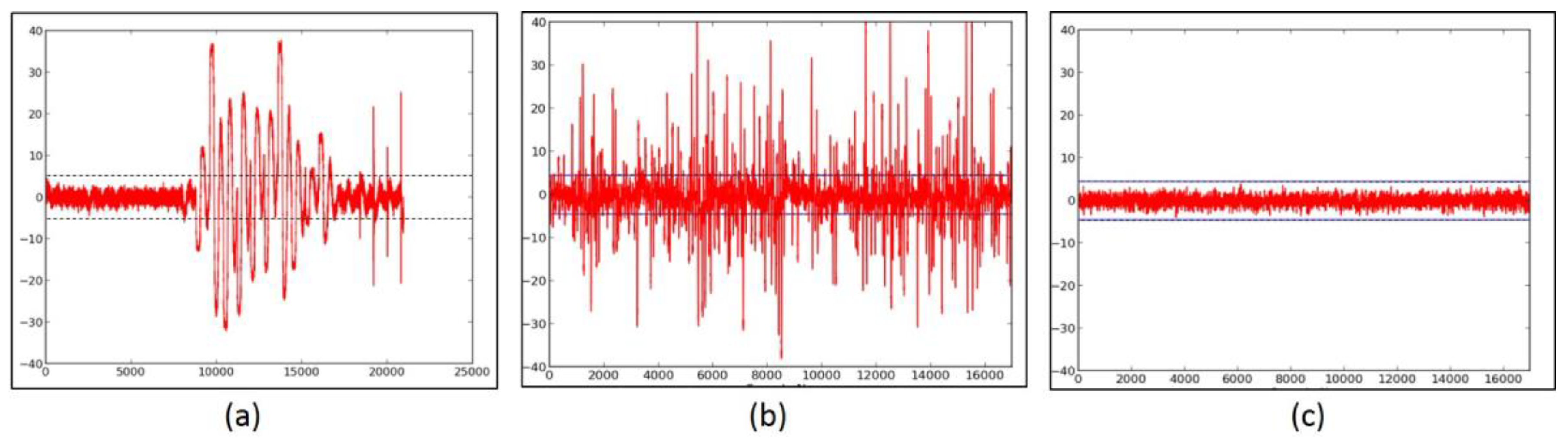
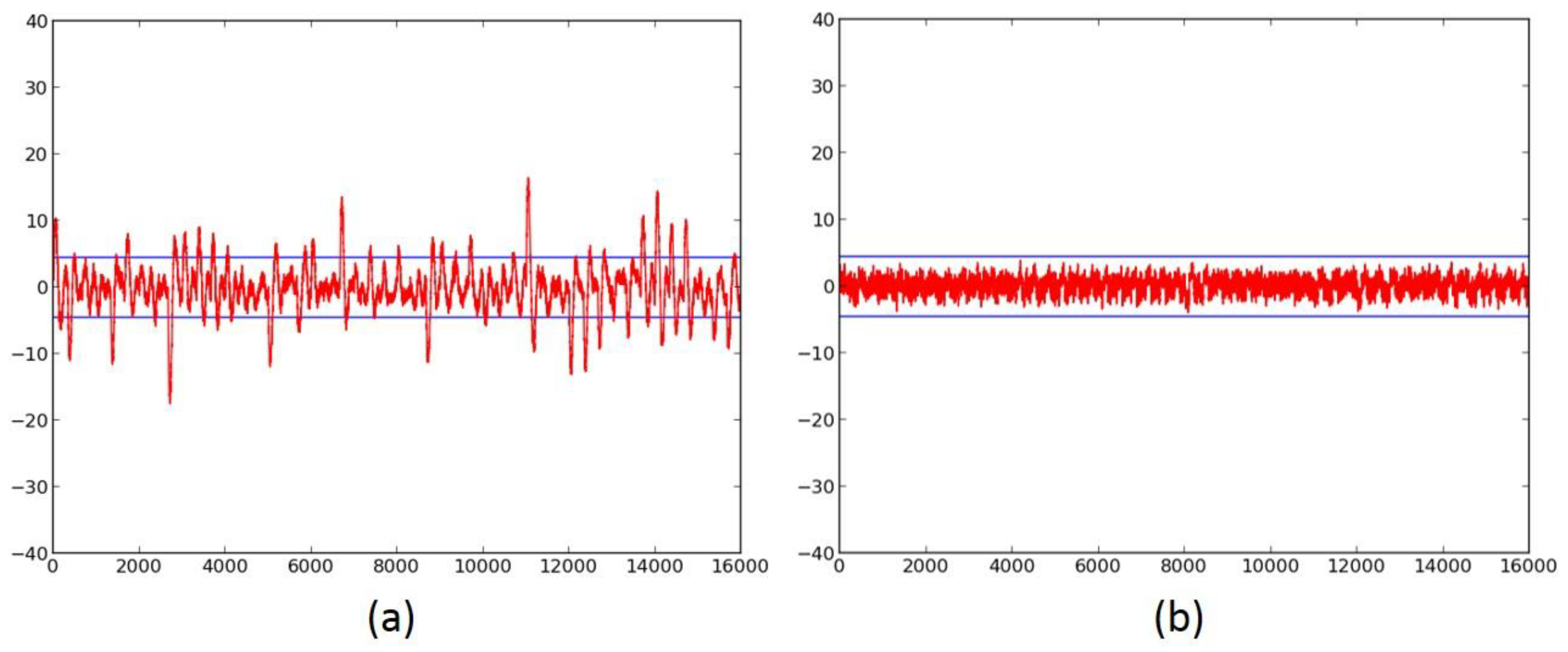
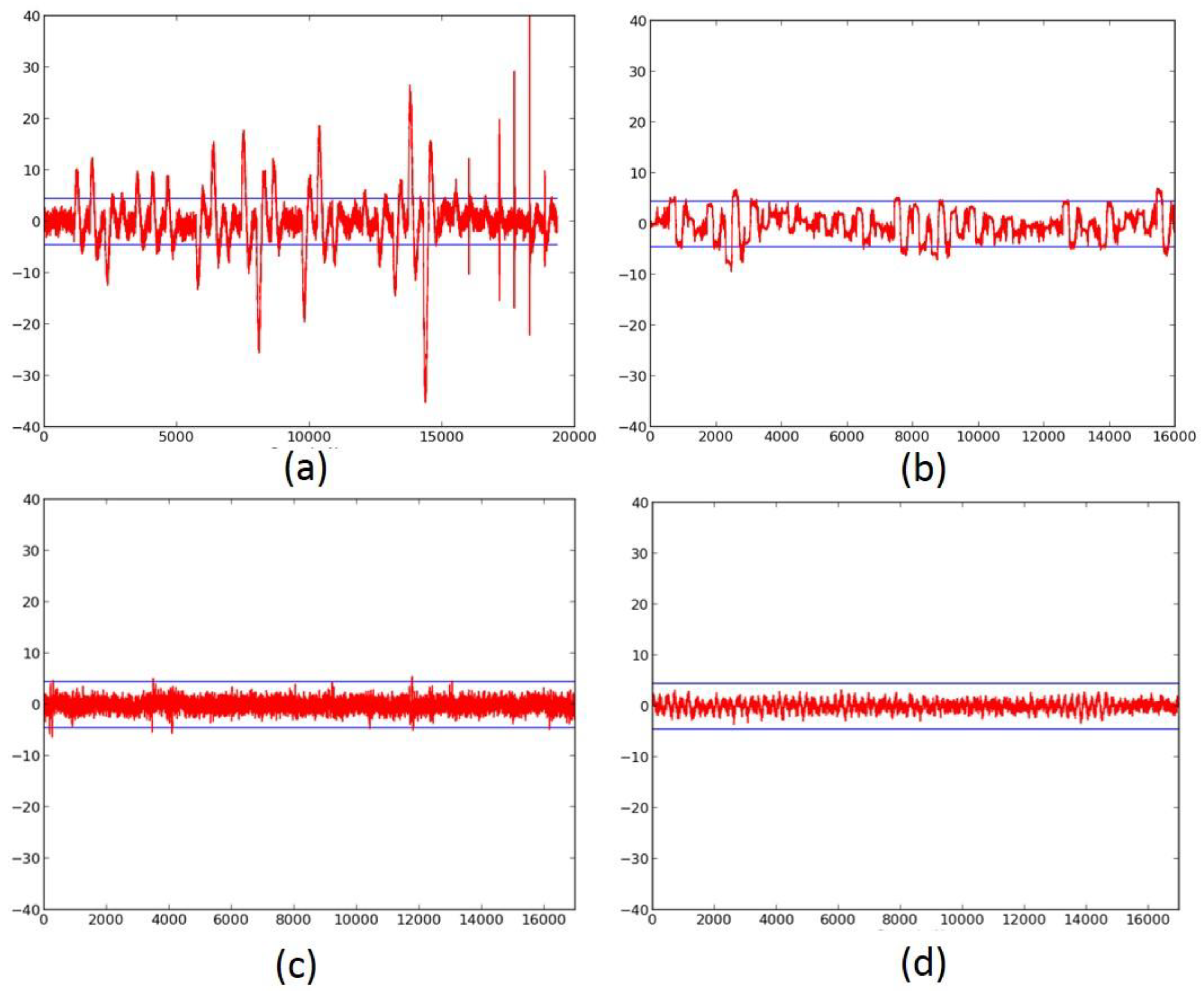
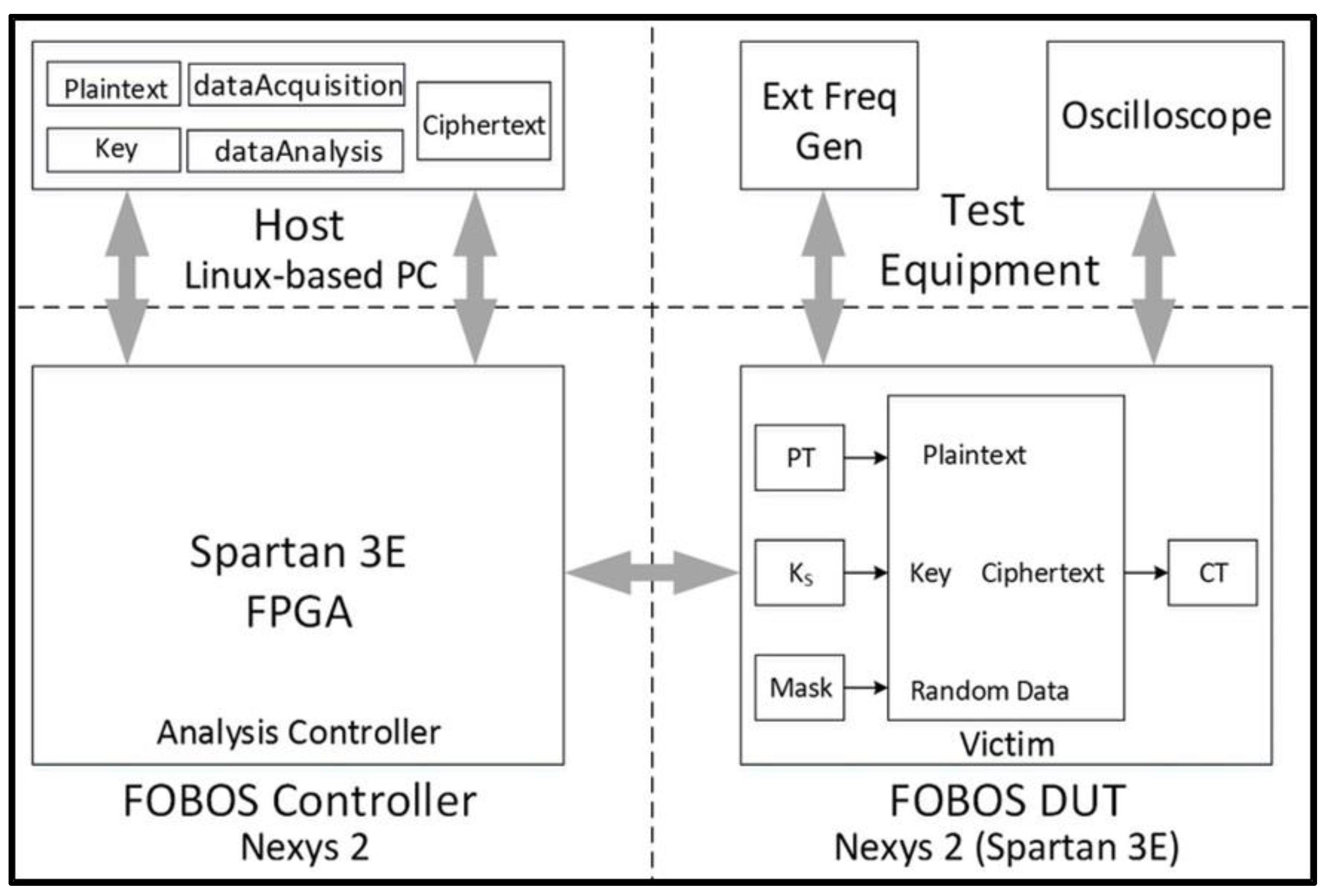
- We evaluate the DPA resistance of the unprotected ciphers using the FOBOS framework (see below description) [18] and the Test Vector Leakage Assessment (TVLA) (that is, the Welch’s t-test) leakage detection methodology [15,16,17]. Leakage is evaluated using a non-specific “fixed-versus-random” t-test consisting of 2000 high-fidelity (that is, 16,000–20,000 samples per block encryption) traces, on a custom-modified Spartan-3E FPGA clocked externally at 500 KHz to minimize inductive and capacitive leakage attenuation.
- We modify the victim ciphers to include a maximum of three shares of TI protection (3-share TI) and try to minimize the additional required randomness for refreshing and resharing masks.
- We verify the improved DPA resistance of the protected ciphers on FOBOS using the methodology described above. Per the recommendations of Reference [17], we verify the results of the fixed-versus-random t-test with at least two sets of fixed data.
- Although the DPA resistances are verified in only one FPGA (Spartan-3E), we implement (that is, gather Place & Route (PAR) results) all versions on two FPGAs, the Spartan-3E (xc3s500e vq100 -5) (that is, a low-cost device used in the FOBOS architecture) and in the Virtex-7 (xc7vx300t ffg1157 -3) (that is, an expensive high-end FPGA). Implementations use the Xilinx 14.7 ISE® design suite. We prevent Block RAM (BRAM) and Digital Signal Processor DSP instantiation during benchmarking in order to ensure a fair comparison between ciphers. Ciphers are compared in terms of area (Look-up Tables, or “LUTs”), throughput (Mbps), and throughput-to-area (TP/A) ratio.
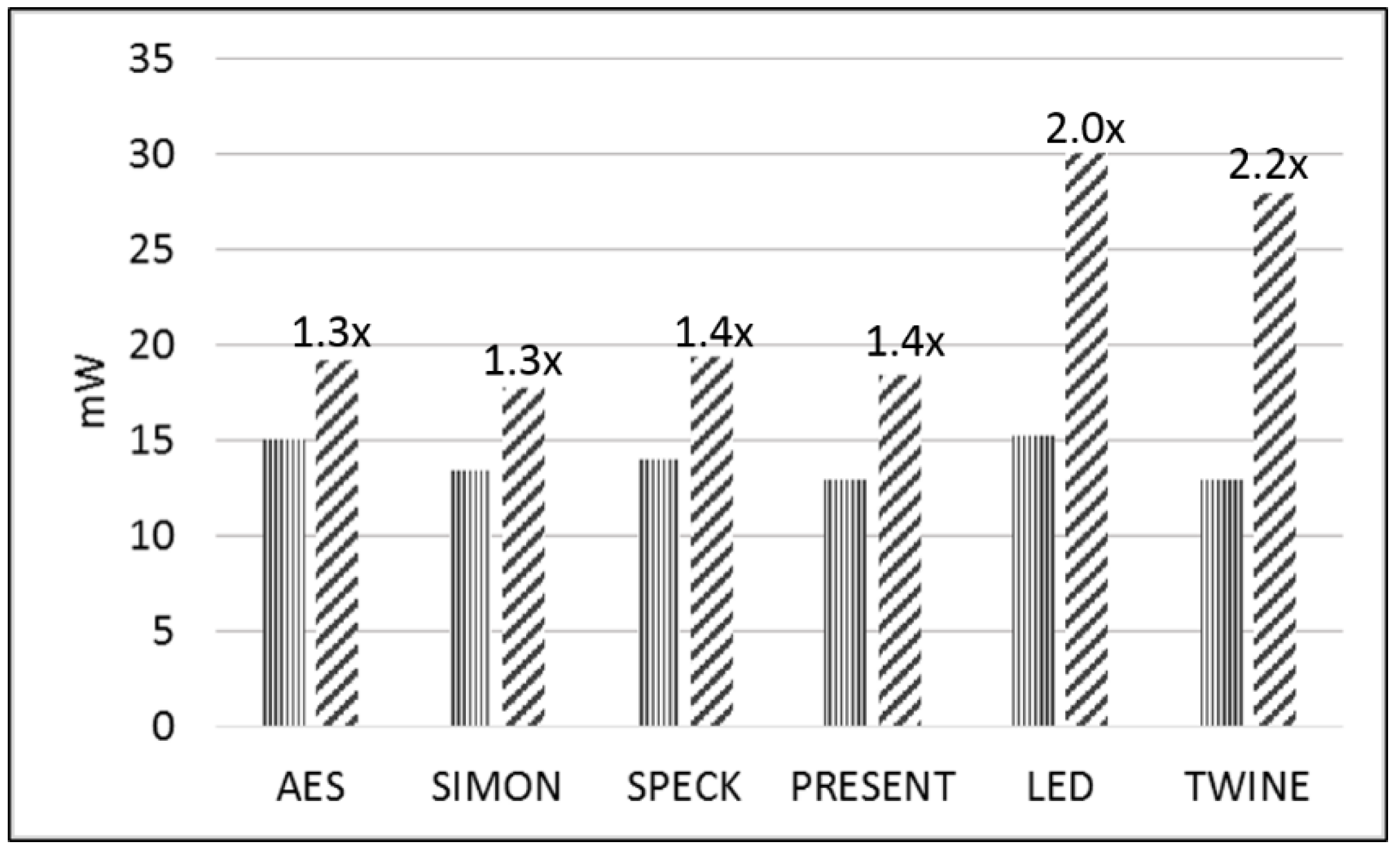
- We measure the actual power (mW) for each version on the Spartan-3E FPGA at a fixed frequency of 5 MHz and compute the energy per bit (E/bit) (nJ/bit) by measuring an amplified voltage (using the TI INA225 amplifier) across a 1 Ω shunt resistor coupled to the FOBOS test bench.
- “Fixed-versus-random” test vectors are pre-generated using Python scripts. Random data (generated in software) is substituted for random instances of plaintext. Plaintext and key files are stored in a working directory in the host PC.
- The victim cipher is instantiated inside a thin wrapper on the FOBOS Device-Under-Test (DUT) board which consists of registers to pre-store plaintext (), key (), and random data () prior to a block encryption.
- The user launches the dataAcquisition.py program from the host PC. The acquisition program sends the next block of plaintext and random mask data (used for initial masking of sensitive data) at the start of each trace. The secret key is fixed in this research.
- The Analysis Controller (located on the FOBOS Controller board) forwards data to the victim cipher and sends a trigger to the oscilloscope (Agilent Technologies DSO6054A) for each trace. Data from the current probe (Tektronix CT2) is transmitted by the oscilloscope to the host PC and stored in a .npy format to allow for post-run analysis [52]. Ciphertext from each trace is stored in the Ciphertext file on the host PC. Although ciphertext is not used for side-channel analysis in this research, it is valuable to examine the ciphertext output to ensure the correct operation of the device.
- At the completion of all traces, the user conditions the .npy file containing all traces, and “splits” the file into data sets and , in accordance with a “fixed-versus-random” choice metadata file created during test-vector generation.
- The user runs the t-test utility on data sets and , and notes the results.
- Any required round keys are computed “on-the-fly;”
- Only the encryption case is implemented, as the use of the encryption mode is often sufficient to implement both encryption and decryption in an authenticated cipher based on a given block cipher;
- Only round functions are masked; key scheduling is not masked (with the exception of SIMON, where key sharing is required to achieve uniformity and is relatively of low cost). As discussed in Reference [26], a relevant comparison of ciphers is achieved without key masking;
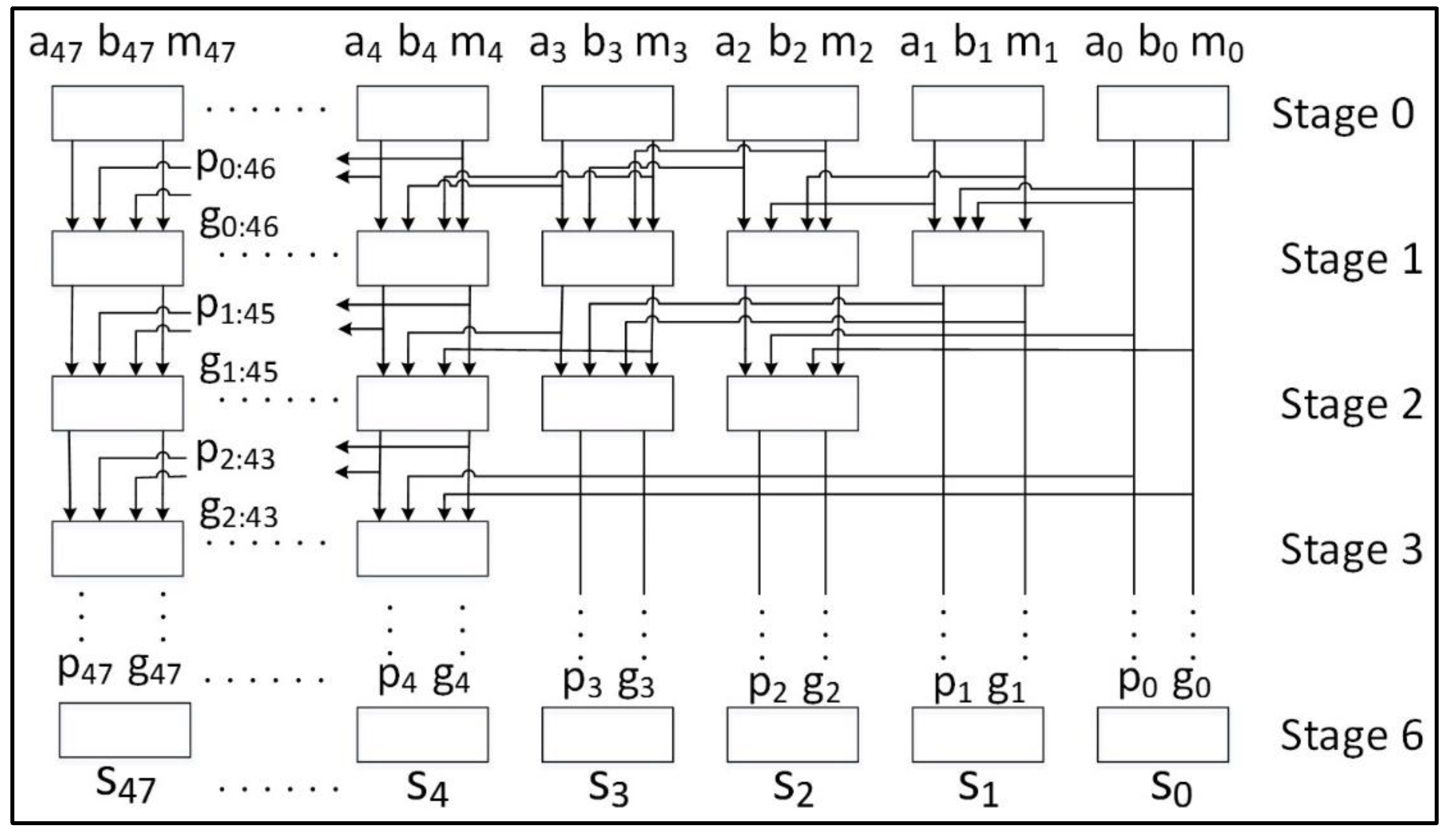
- Randomness is simulated by ingesting a large number of random bits (for example, 256 bits for AES) and reusing them after rotations by prime numbers (such as 43 or 61 bits) since an integrated PRNG would require significant additional resources. This assumption of randomness does not affect our tests for a short number of total clock cycles (that is, 30–250 cycles) but is not secure for long-term cipher operation.
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Diehl, W.; Abdulgadir, A.; Kaps, J.-P.; Gaj, K. Comparing the cost of protecting selected lightweight block ciphers against differential power analysis in low-cost FPGAs. In Proceedings of the International Conference on Field Programmable Technologies (FPT 2017), Melbourne, Australia, 11–13 December 2017; pp. 128–135. [Google Scholar]
- Kocher, P.C.; Jaffe, J.; Jun, B. Differential power analysis. In Proceedings of the CRYPTO ’99—19th International Conference on Cryptology, Santa Barbara, CA, USA, 15–19 August 1999. [Google Scholar]
- Kocher, P.; Jaffe, J.; Jun, B.; Rohatgi, P. Introduction to Differential Power Analysis. J. Cryptogr. Eng. 2011, 1, 5–27. [Google Scholar] [CrossRef]
- CAESAR: Competition for Authenticated Encryption: Security, Applicability, and Robustness. Available online: http://competitions.cr.yp.to/caesar.html (accessed on 31 March 2018).
- Bernstein, D. Cryptographic Competitions. Google Groups, 16 July 2016. Available online: https://groups.google.com/forum/#!forum/crypto-competitions (accessed on 27 February 2018).
- National Institute of Standards and Technology (NIST). Lightweight Cryptography. Available online: https://www.nist.gov/programs-projects/lightweight-cryptography (accessed on 31 March 2018).
- McKay, K.; Bassham, L.; Turan, M.; Mouha, N. Report on Lightweight Cryptography (NISTIR 8114); National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2017. Available online: http://nvlpubs.nist.gov/nistpubs/ir/2017/NIST.IR.8114.pdf (accessed on 27 February 2018).
- Federal Information Processing Standards Publication 197, Advanced Encryption Standard (AES). Available online: https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.197.pdf (accessed on 16 April 2018).
- Beaulieu, R.; Treatman-Clark, S.; Shors, D.; Weeks, B.; Smith, J.; Wingers, L. The SIMON and SPECK lightweight block ciphers. In Proceedings of the 2015 52nd ACM/EDAC/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 8–12 June 2015; pp. 1–6. [Google Scholar]
- Bogdanov, A.; Knudsen, L.; Leander, G.; Paar, C.; Poschmann, A.; Robshaw, M.; Seurin, Y.; Vikkelsoe, C.; Paillier, P.; Verbauwhede, I. PRESENT: An ultra-lightweight block cipher. In Proceedings of the Cryptographic Hardware and Embedded Systems—CHES 2007: 9th International Workshop, Vienna, Austria, 10–13 September 2007; pp. 450–466. [Google Scholar]
- Guo, J.; Peyrin, T.; Poschmann, A.; Robshaw, M. The LED block cipher. In Proceedings of the Cryptographic Hardware and Embedded Systems (CHES 2011): 13th International Workshop, Nara, Japan, 28 September–1 October 2011; pp. 326–341. [Google Scholar]
- Suzaki, T.; Minematsu, K.; Morioka, S.; Kobayashi, E. TWINE: A Lightweight Block Cipher for Multiple Platforms. SAC 2012, 7707, 339–354. [Google Scholar]
- Iwata, T.; Minematsu, K.; Guo, J.; Morioka, S.; Kobayashi, E. CLOC and SILC v3. September 2016. Available online: https://competitions.cr.yp.to/round3/clocsilcv3.pdf (accessed on 31 March 2018).
- Wu, H.; Huang, T. JAMBU Lightweight Authenticated Encryption Mode. 2016. Available online: http://www3.ntu.edu.sg/home/wuhj/research/caesar/caesar.html (accessed on 27 February 2018).
- Cooper, J.; DeMulder, E.; Goodwill, G.; Jaffe, J.; Kenworthy, G.; Rohatgi, P. Test Vector Leakage Assessment (TVLA) methodology in practice. In Proceedings of the International Cryptographic Module Conference, Gaithersburg, MD, USA, 24–26 September 2013. [Google Scholar]
- Goodwill, G.; Jun, B.; Jaffe, J.; Rohatgi, P. A testing methodology for side channel resistance validation. In Proceedings of the NIST Non-Invasive Attack Testing Workshop, Nara, Japan, 25–27 September 2011. [Google Scholar]
- Schneider, T.; Moradi, A. Leakage Assessment Methodology. J. Cryptogr. Eng. 2016, 6, 85–89. [Google Scholar] [CrossRef]
- Cryptographic Engineering Research Group. Flexible Open-Source WorkBench fOr Side-Channel Analysis (FOBOS). 25 October 2016. Available online: https://cryptography.gmu.edu/fobos/ (accessed on 27 February 2018).
- Nikova, S.; Rechberger, C.; Rijmen, V. Threshold implementations against side-channel attacks and glitches. In Proceedings of the 8th International Conference on Information and Communications Security, Raleigh, NC, USA, 4–7 December 2006; Volume 4307, pp. 529–545. [Google Scholar]
- Shamir, A. How to Share a Secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Yao, A. Protocols for secure computation. In Proceedings of the 23rd Annual Symposium on Foundations of Computer Science (sfcs 1982), Chicago, IL, USA, 3–5 November 1982; pp. 160–164. [Google Scholar]
- Mangard, S.; Pramstaller, N.; Oswald, E. Successfully attacking masked AES hardware implementations. In International Workshop on Cryptographic Hardware and Embedded Systems; Springer: Heidelberg/Berlin, Germany, 2005; Volume 3659, pp. 157–171. [Google Scholar]
- Bilgin, B.; Gierlichs, B.; Nikova, S.; Nikov, V.; Rijmen, V. A more efficient AES threshold implementation. In Proceedings of the 7th International Conference on Cryptology in Africa (AFRICACRYPT 2014), Marrakesh, Morocco, 28–30 May 2014; pp. 267–284. [Google Scholar]
- Moradi, A.; Poschmann, A.; Ling, S.; Paar, C.; Wang, H. Pushing the limits: A very compact and a threshold implementation of AES. In Proceedings of the 30th Annual International Conference on the Theory and Applications of Cryptographic Techniques (EUROCRYPT 2011), Tallinn, Estonia, 15–19 May 2011; pp. 69–98. [Google Scholar]
- Poschmann, A.; Moradi, A.; Khoo, K.; Lim, C.; Wang, H.; Ling, S. Side-Channel Resistant Crypto for Less than 2300 GE. J. Cryptol. 2011, 24, 322–345. [Google Scholar] [CrossRef]
- Kutzner, S.; Nguyen, P.; Poschmann, A.; Wang, H. On 3-share threshold implementations for 4-Bit S-boxes. In Proceedings of the Constructive Side-Channel Analysis and Secure Design: 4th International Workshop, COSADE 2013, Paris, France, 6–8 March 2013; pp. 99–113. [Google Scholar]
- Shahverdi, A.; Taha, M.; Eisenbarth, T. Lightweight Side Channel Resistance: Threshold Implementations of Simon. IEEE Trans. Comput. 2017, 66, 661–671. [Google Scholar] [CrossRef]
- Chen, C.; Inci, M.S.; Taha, M.; Eisenbarth, T. SpecTre: A tiny side-channel resistant speck core for FPGAs. In Proceedings of the Smart Card Research and Advanced Applications: 15th International Conference, CARDIS 2016, Cannes, France, 7–9 November 2016; pp. 73–88. [Google Scholar]
- Schneider, T.; Moradi, A.; Güneysu, T. ParTI—Towards combined hardware countermeasures against side-channel and fault-injection attacks. In Proceedings of the 36th Annual International Cryptology Conference on Advances in Cryptology (CRYPTO 2016), Santa Barbara, CA, USA, 14–18 August 2016; pp. 302–332. [Google Scholar]
- Sadhukhan, R.; Patranabis, S.; Ghoshal, A.; Mukhopadhyay, D.; Saraswat, V.; Ghosh, S. An Evaluation of Lightweight Block Ciphers for Resource-Constrained Applications: Area, Performance, and Security. J. Hardw. Syst. Secur. 2017, 1, 203–218. [Google Scholar] [CrossRef]
- Canright, D.; Batina, L. A Very Compact ‘Perfectly Masked’ S-box for AES. In Proceedings of the 6th International Conference on Applied Cryptography and Network Security, ANCS 2008, New York, NY USA, 3–6 June 2008; Volume 5037, pp. 446–459. [Google Scholar]
- Gaj, K.; Chodowiec, P. FPGA and ASIC implementations of AES. In Cryptographic Engineering; Koç, Ç.K., Ed.; Springer Science & Business Media: New York, NY, USA, 2009; pp. 235–294. [Google Scholar]
- Goubin, L. A sound method for switching between Boolean and arithmetic masking. In Proceedings of the Cryptographic Hardware and Embedded Systems—CHES 2001, Third International Workshop, Paris, France, 14–16 May 2001; Volume 2162, pp. 3–15. [Google Scholar]
- Messerges, T. Securing the AES finalists against power analysis attacks. In Fast Software Encryption; Springer: Heidelberg/Berlin, Germany, 2002; Volume 1978, pp. 150–164. [Google Scholar]
- Coron, J.S.; Tchulkine, A. A New algorithm for switching from arithmetic to Boolean masking. In Proceedings of the Cryptographic Hardware and Embedded Systems—CHES 2003: 5th International Workshop, Cologne, Germany, 8–10 September 2003; pp. 89–97. [Google Scholar]
- Debraize, B. Efficient and provably secure methods for switching from arithmetic to Boolean masking. In Proceedings of the 14th International Conference on Cryptographic Hardware and Embedded Systems—CHES 2012, Leuven, Belgium, 9–12 September 2012; Volume 7428 of the Series Lecture Notes in Computer Science. pp. 107–121. [Google Scholar]
- Golic, J. Techniques for random masking in Hardware. In IEEE Transactions on Circuits and Systems I: Regular Papers; IEEE: Piscataway, NJ, USA, 2007; Volume 54, pp. 291–300. [Google Scholar]
- Coron, J.; Großschädl, J.; Vadnala, P. Secure conversion between Boolean and arithmetic masking of any order. In Proceedings of the Cryptographic Hardware and Embedded Systems—CHES 2014, 16th International Workshop, Busan, Korea, 23–26 September 2014. [Google Scholar]
- Schneider, T.; Moradi, A.; Güneysu, T. Arithmetic addition over Boolean Masking. In Proceedings of the Applied Cryptography and Network Security: 13th International Conference, ACNS 2015, New York, NY, USA, 2–5 June 2015; pp. 559–578. [Google Scholar]
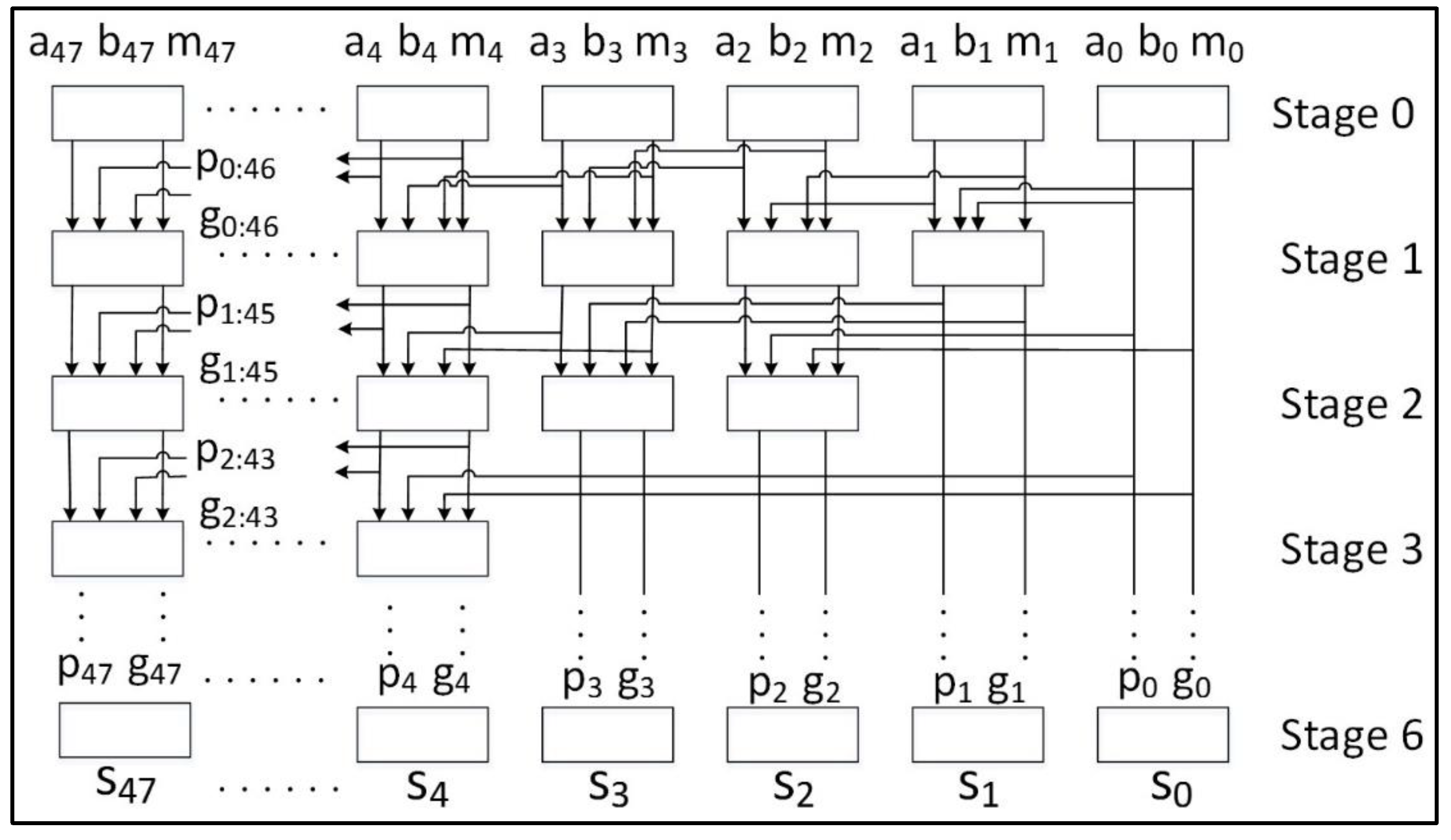
- Kogge, P.; Stone, H. A Parallel Algorithm for the Efficient Solution of a General Class of Recurrence Equations. IEEE Trans. Comput. 1973, 100, 786–793. [Google Scholar] [CrossRef]
- Rivain, M.; Prouff, E. Provably secure higher-order masking of AES. In Proceedings of the Cryptographic Hardware and Embedded Systems, CHES 2010, 12th International Workshop, Santa Barbara, CA, USA, 17–20 August 2010; Volume 6225, pp. 413–427. [Google Scholar]
- Xilinx. UG625 Constraints Guide (v. 14.5). Available online: https://www.xilinx.com/support/documentation/sw_manuals/xilinx14_7/cgd.pdf (accessed on 16 April 2018).
- Bilgin, B.; Nikova, S.; Nikov, V.; Rijmen, V. Threshold implementation of all 3 × 3 and 4 × 4 S-boxes. In Proceedings of the Cryptographic Hardware and Embedded Systems CHES 2012: 14th International Workshop, Leuven, Belgium, 9–12 September 2012; pp. 76–91. [Google Scholar]
- Aysu, A.; Gulcan, E.; Schaumont, P. SIMON Says: Break Area Records of Block Ciphers on FPGAs. IEEE Embed. Syst. Lett. 2014, 6, 37–40. [Google Scholar] [CrossRef]
- Ambrose, J.; Ignjatovic, A.; Parameswaran, S. Power Analysis Side Channel Attacks: The Processor Design-Level Context; VDM Publishing: Saarbrücken, Germany, 2010. [Google Scholar]
- Ishai, Y.; Sahai, A.; Wagner, D. Private Circuits: Securing Hardware against Probing Attacks. In Advances in Cryptology, CRYPTO 2003; Volume 2729 of Lecture Notes in Computer Science; Springer: Heidelberg/Berlin, Germany, 2003; pp. 463–481. [Google Scholar]
- Tiri, K.; Verbauwhede, I. A logic level design methodology for a secure DPA Resistant ASIC or FPGA implementation. In Proceedings of the Design, Automation and Test in Europe Conference and Exhibition, Paris, France, 16–20 February 2004; pp. 246–251. [Google Scholar]
- Yu, P.; Schaumont, P. Secure FPGA circuits using controlled placement and routing. In Proceedings of the 5th IEEE/ACM International Conference on Hardware/Software Codesign and System Synthesis, Salzburg, Austria, 30 September–3 October 2007; pp. 45–50. [Google Scholar]
- Velegalati, R.; Kaps, J.P. DPA resistance for light-weight implementations of cryptographic algorithms on FPGAs. In Proceedings of the 2009 International Conference on Field Programmable Logic and Applications, Prague, Czech Republic, 31 August–2 September 2009; pp. 385–390. [Google Scholar]
- Ambrose, J.A.; Parameswaran, S.; Ignjatovic, A. MUTE-AES: A multiprocessor architecture to prevent power analysis-based side channel attack of the AES algorithm. In Proceedings of the 2008 IEEE/ACM International Conference on Computer-Aided Design, San Jose, CA, USA, 10–13 November 2008; pp. 678–684. [Google Scholar]
- Diehl, W.; Gaj, K. Implementation of a Boolean masking scheme for the SCREAM cipher. In Proceedings of the 2016 Euromicro Conference on Digital System Design (DSD), Limassol, Cyprus, 31 August–2 September 2016; pp. 723–726. [Google Scholar]
- Kern, R. A Simple File Format for NumPy Arrays. 20 December 2007. Available online: https://docs.scipy.org/doc/numpy-dev/neps/npy-format.html (accessed on 27 February 2018).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cipher | Block Size | Key Size | Rounds | Type | Basic Operations |
|---|---|---|---|---|---|
| AES-128 | 128 | 128 | 10 | SPN 1 | SubBytes, ShiftRows, MixColumns, AddRoundKey |
| SIMON 96/96 | 96 | 96 | 52 | Feistel | AND, rotation, XOR |
| SPECK 96/96 | 96 | 96 | 28 | Feistel, ARX 2 | ADD, rotation, XOR |
| PRESENT-80 | 64 | 80 | 31 | SPN | S-Box, permutation, XOR |
| LED-80 | 64 | 80 | 48 | SPN | AddConstant, SubCells, ShiftRows, MixColumnsSerial, XOR |
| TWINE-80 | 64 | 80 | 36 | SPN, Feistel | S-Box, permutation, XOR |
| Device | AES | AES | SIMON | SPECK | SPECK | PRESENT | LED | TWINE | |
|---|---|---|---|---|---|---|---|---|---|
| Architecture | Full | Pipl 1 | Full | Full | MC 2 | Full | Full | Full | |
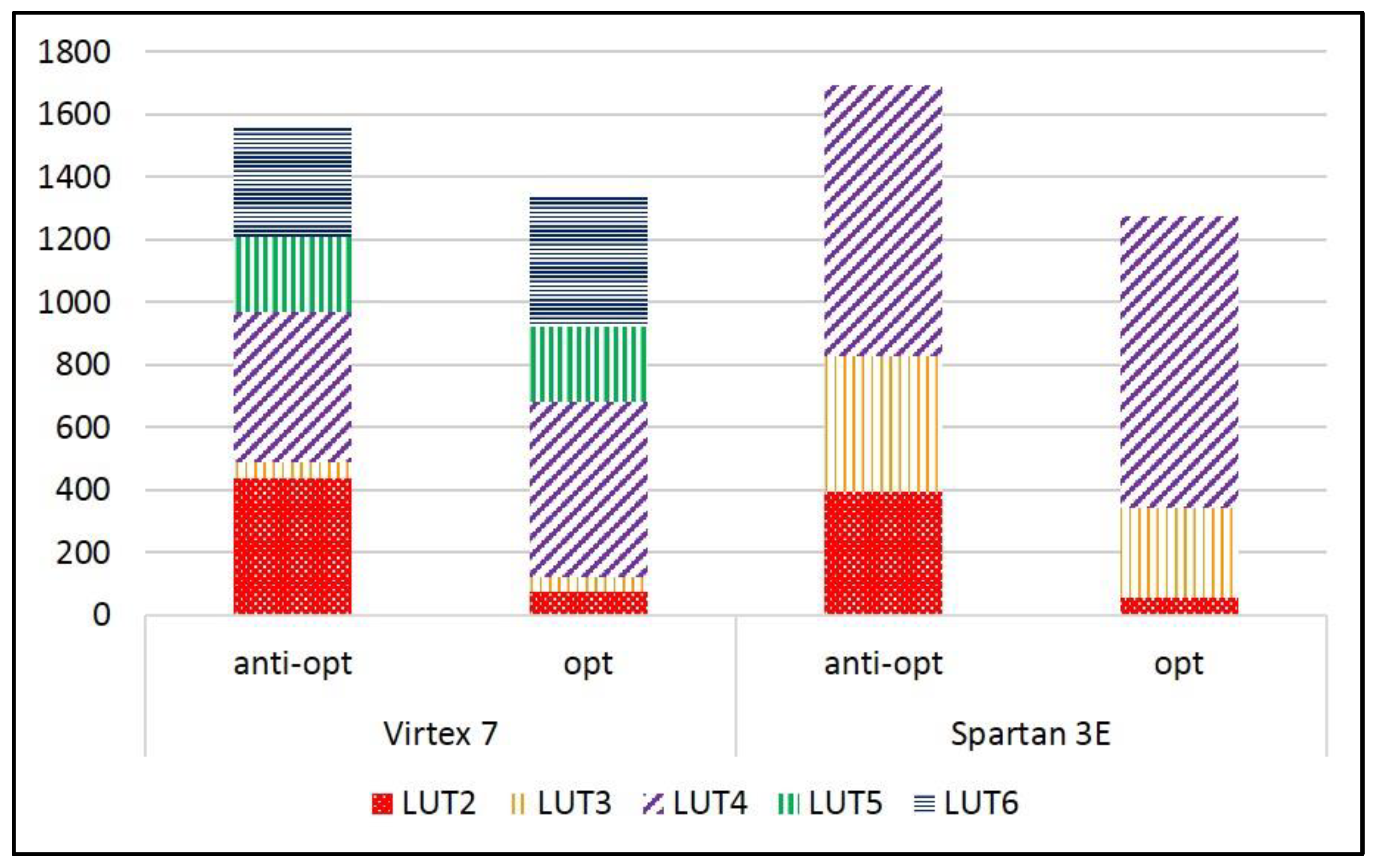
| Area (LUT) | Virtex-7 | 2620 | 697 | 435 | 385 | 649 | 381 | 602 | 302 |
| Spartan-3E | 2845 | 1182 | 565 | 634 | 1021 | 595 | 727 | 296 | |
| Area (Slice) | Virtex-7 | 991 | 253 | 146 | 130 | 202 | 133 | 211 | 122 |
| Spartan-3E | 1691 | 806 | 403 | 462 | 664 | 408 | 486 | 229 | |
| Frequency (MHz) | Virtex-7 | 229 | 326 | 624 | 363 | 374 | 537 | 309 | 552 |
| Spartan-3E | 73 | 128 | 176 | 111 | 116 | 177 | 116 | 200 | |
| TP (Mbps) | Virtex-7 | 2937 | 238 | 1152 | 1245 | 160 | 1108 | 411 | 982 |
| Spartan-3E | 934 | 94 | 329 | 380 | 49.7 | 366 | 134 | 355 | |
| TP/A (Mbps/LUT) | Virtex-7 | 1.12 | 0.34 | 2.65 | 3.24 | 0.25 | 2.91 | 0.68 | 3.25 |
| Spartan-3E | 0.33 | 0.08 | 0.57 | 0.61 | 0.05 | 0.62 | 0.19 | 1.2 | |
| Rank | |||||||||
| Area | Virtex-7 | 8 | 7 | 4 | 3 | 6 | 2 | 5 | 1 |
| TP | Virtex-7 | 1 | 7 | 3 | 2 | 8 | 4 | 6 | 5 |
| TP/A | Virtex-7 | 5 | 7 | 4 | 2 | 8 | 3 | 6 | 1 |
| Device | AES | SIMON | SPECK | PRESENT | LED | TWINE | |
|---|---|---|---|---|---|---|---|
| Architecture | Pipl 1 | Full | MC 2 | Full | Full | Full | |
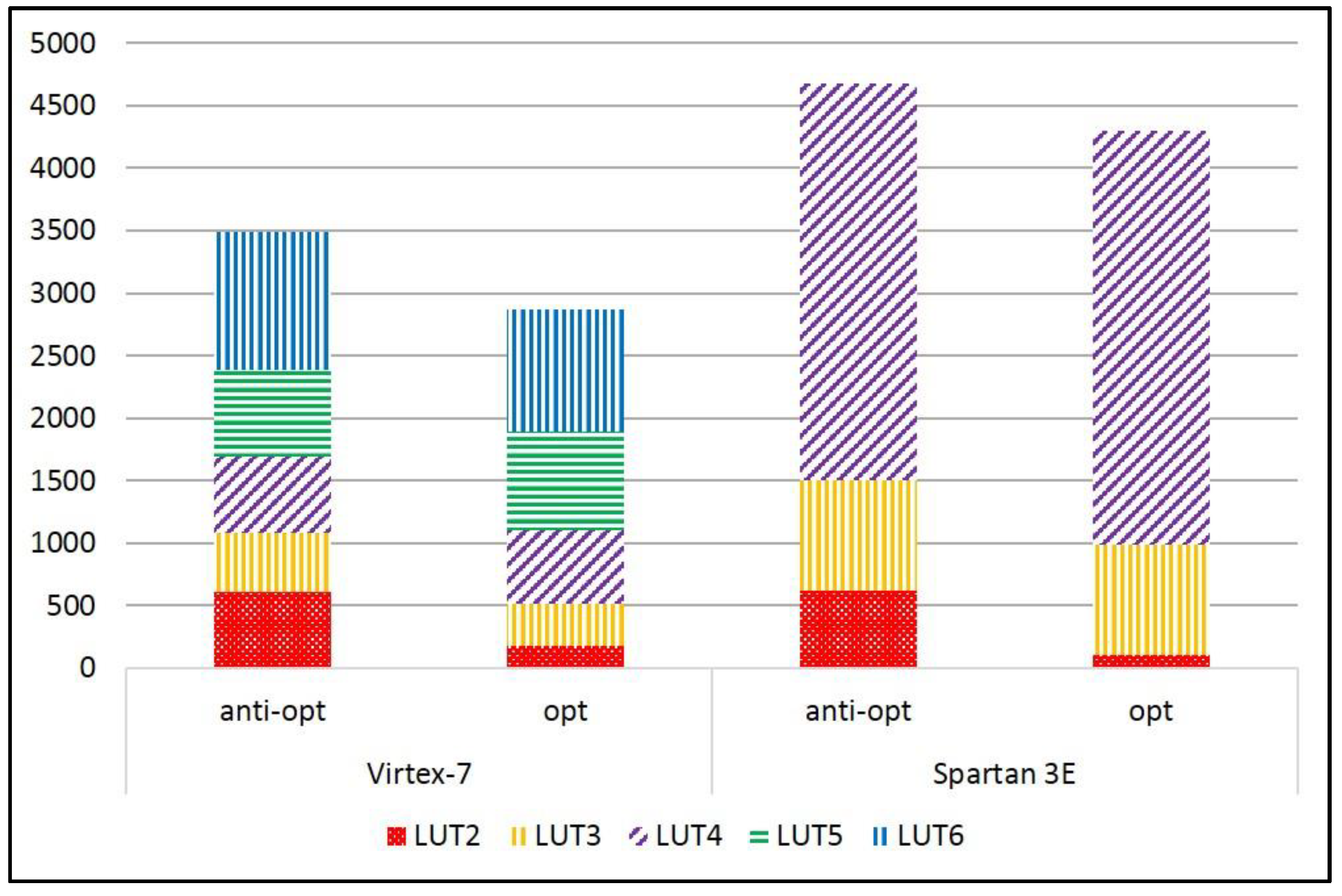
| Area (LUT) | Virtex-7 | 1791 | 1520 | 3328 | 1317 | 1691 | 2573 |
| Spartan-3E | 2387 | 2151 | 4792 | 1707 | 2175 | 2946 | |
| Area (Slice) | Virtex-7 | 902 | 434 | 1714 | 429 | 928 | 1256 |
| Spartan-3E | 1736 | 1404 | 3958 | 1221 | 1290 | 1777 | |
| Frequency (MHz) | Virtex-7 | 106 | 456 | 334 | 189 | 145 | 207 |
| Spartan-3E | 86 | 176 | 108 | 70 | 55 | 67 | |
| TP (Mbps) | Virtex-7 | 77 | 841 | 143 | 390 | 193 | 367 |
| Spartan-3E | 63 | 326 | 46 | 143 | 73 | 118 | |
| TP/A (Mbps/LUT) | Virtex-7 | 0.043 | 0.553 | 0.043 | 0.296 | 0.114 | 0.143 |
| Spartan-3E | 0.026 | 0.151 | 0.010 | 0.084 | 0.033 | 0.040 | |
| Random bits | 40 | 0 | 34 | 0 | 0 | 16 | |
| Rank | |||||||
| Area | Virtex-7 | 4 | 2 | 6 | 1 | 3 | 5 |
| TP | Virtex-7 | 6 | 1 | 5 | 2 | 4 | 3 |
| TP/A | Virtex-7 | 5 | 1 | 6 | 2 | 4 | 3 |
| Cipher | LUT (Growth Factor) | TP (Reduction Factor) | TP/A (Reduction Factor) | Ranking | |||
|---|---|---|---|---|---|---|---|
| V7 | S3E | V7 | S3E | V7 | S3E | ||
| AES | 2.57 | 2.03 | 3.13 | 1.49 | 7.94 | 3.03 | 4 |
| SIMON | 3.49 | 3.81 | 1.37 | 1.00 | 4.76 | 3.85 | 1 |
| SPECK | 5.13 | 4.69 | 1.12 | 1.08 | 5.81 | 5.00 | 2 |
| PRESENT | 3.46 | 2.87 | 2.86 | 2.56 | 9.80 | 7.41 | 5 |
| LED | 2.81 | 2.99 | 2.13 | 1.83 | 5.95 | 5.75 | 3 |
| TWINE | 8.52 | 9.95 | 2.70 | 3.03 | 22.7 | 30.3 | 6 |
| AES | SIMON | SPECK | PRESENT | LED | TWINE | |
|---|---|---|---|---|---|---|
| Unprotected | ||||||
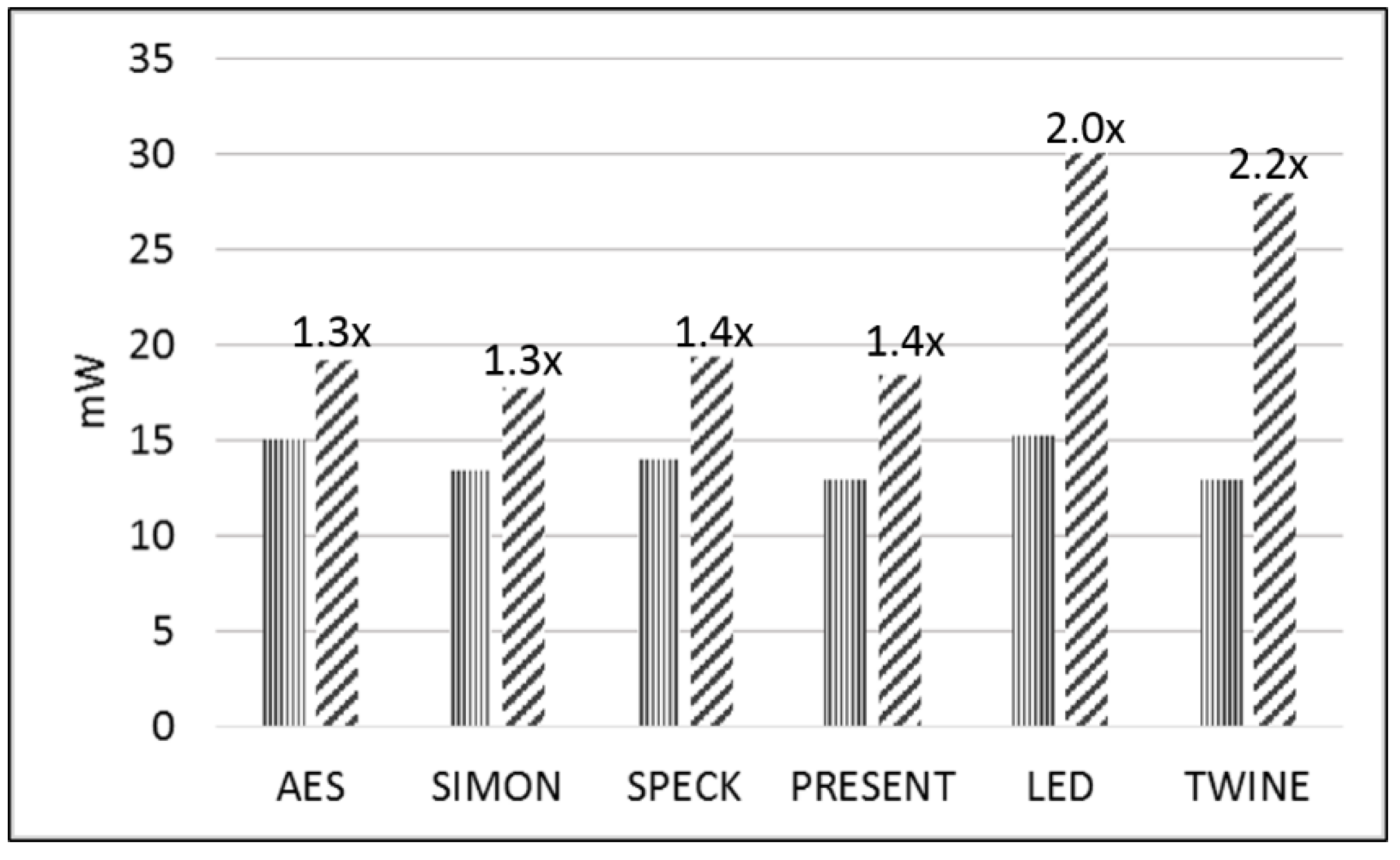
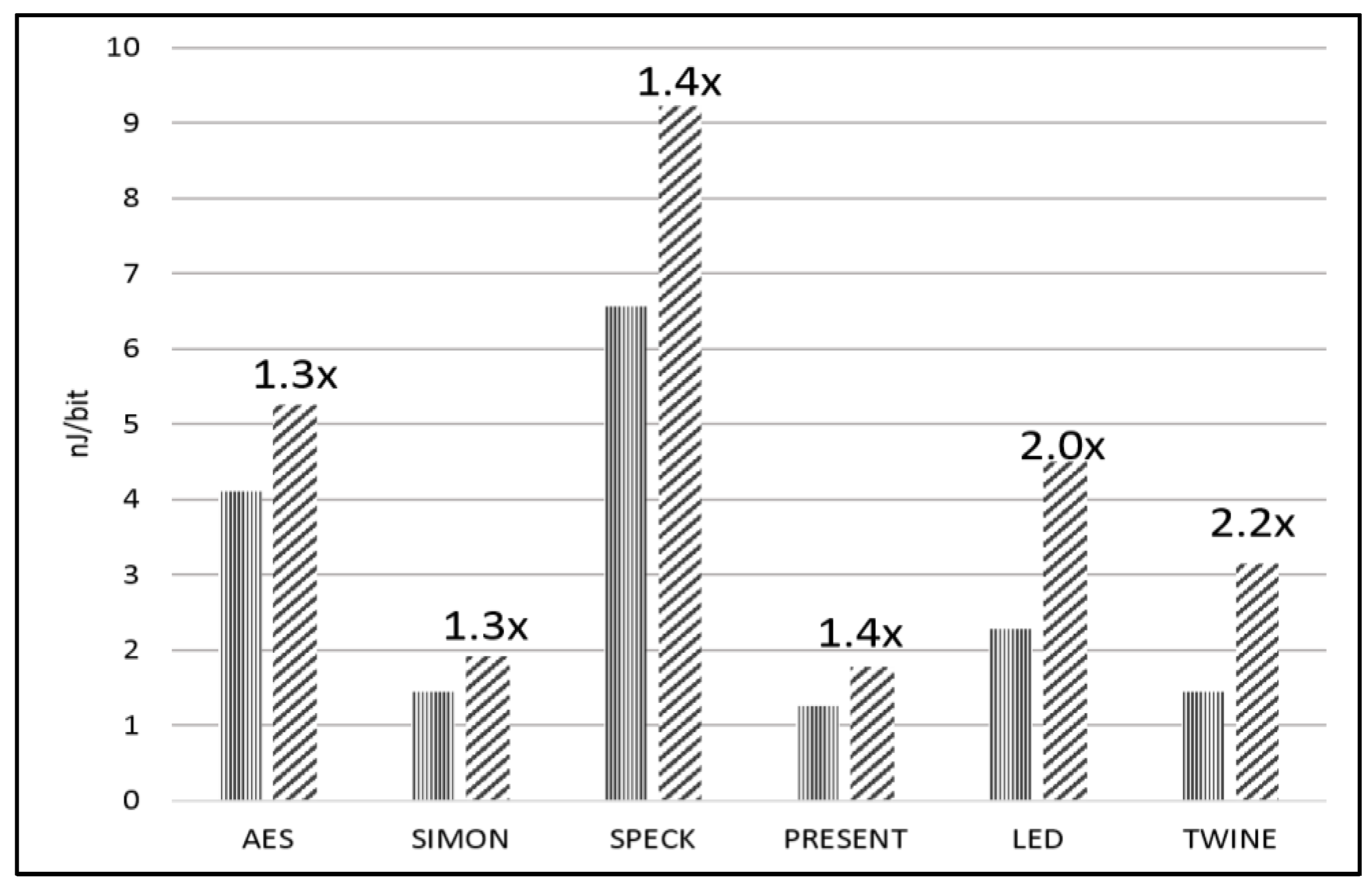
| Average Power (mW) | 15.0 | 13.4 | 14.0 | 12.9 | 15.2 | 12.9 |
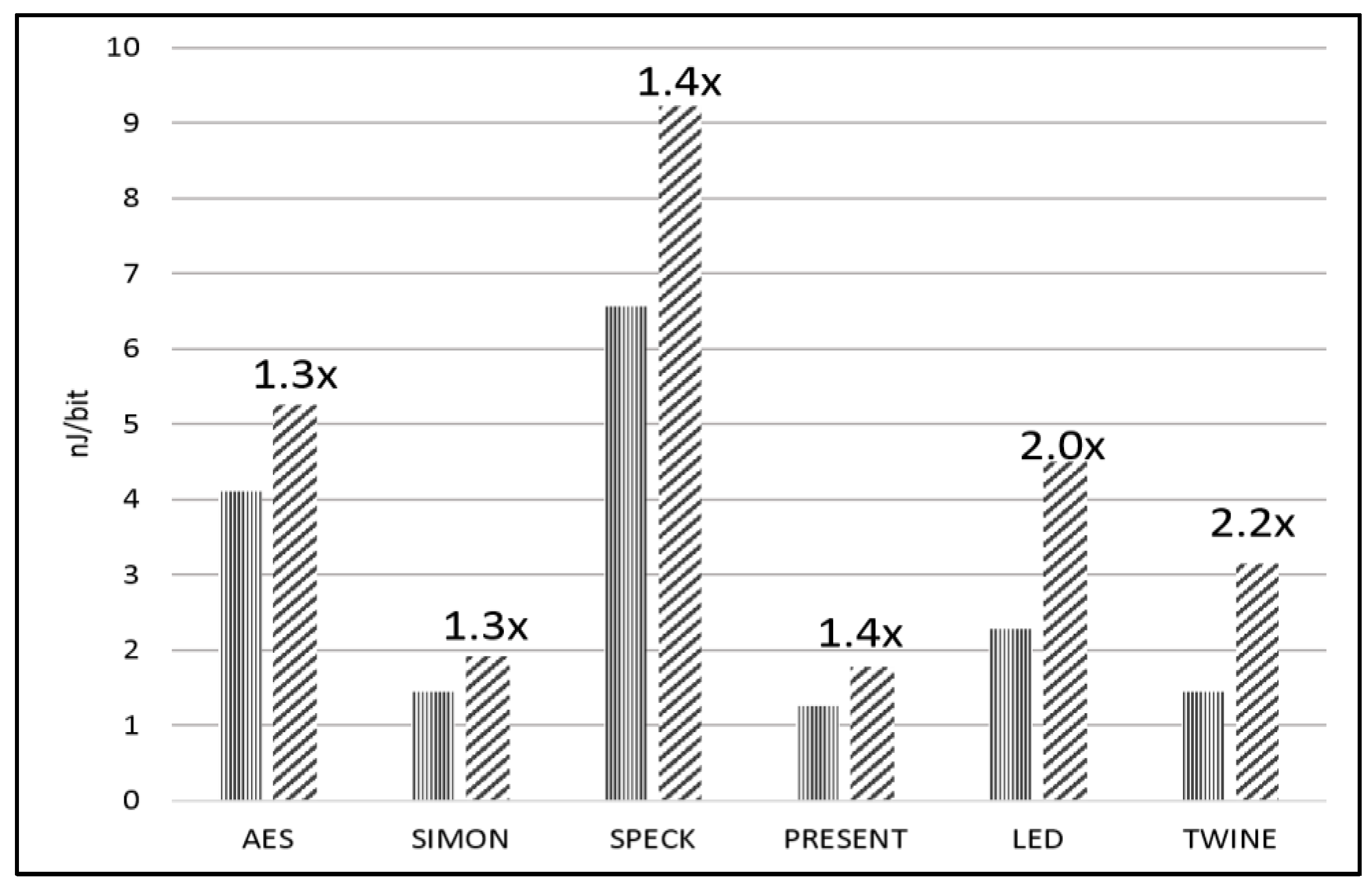
| E/bit (nJ/bit) | 4.10 | 1.45 | 6.56 | 1.25 | 2.28 | 1.45 |
| Protected | ||||||
| Average Power (mW) | 19.2 | 17.7 | 19.4 | 18.4 | 30.0 | 27.9 |
| E/bit (nJ/bit) | 5.25 | 1.92 | 9.22 | 1.78 | 4.50 | 3.14 |
| Protected-to-Unprotected Ratio | 1.3 | 1.3 | 1.4 | 1.4 | 2.0 | 2.2 |
| Area | TP | TP/A | Area | TP | TP/A | |
|---|---|---|---|---|---|---|
| Virtex-7 | Spartan-3E | |||||
| AES | 1.129 | 0.926 | 0.82 | 1.082 | 0.838 | 0.755 |
| SIMON | 1.123 | 0.866 | 0.721 | 1.251 | 0.986 | 0.788 |
| SPECK | 1.286 | 0.972 | 0.756 | 1.071 | 0.935 | 0.873 |
| PRESENT | 1.254 | 1.415 | 1.126 | 1.047 | 0.647 | 0.678 |
| LED | 1.028 | 0.742 | 0.722 | 0.889 | 0.806 | 0.907 |
| TWINE | 1.501 | 0.843 | 0.562 | 0.994 | 0.803 | 0.807 |
| Average | 1.220 | 0.961 | 0.785 | 1.056 | 0.836 | 0.801 |
| AES | AES | PRESENT | PRESENT | SIMON | SPECK | LED | |
|---|---|---|---|---|---|---|---|
| Reference | [24] | [23] | [25] | [26] | [27,44] | [28] | [29] |
| Width (bits) | 8 | 8 | 4 | 4 | 1 | 1 | 64 |
| Architecture | 5-pipl 1 | 3-pipl | Serial | Serial | Serial | Serial | 2-pipl |
| Technology | 180 2 | 180 | 180 | 180 | Spartan-3E | Spartan-3E | 180 |
| Unprotected (UnPr) | 2400 | 2400 | 1111 | 1111 | 36 | 43 | - |
| Protected (Pr) | 10,793 | 8171 | 2282 | 2105 | 96 | 99 | 20,212 |
| Ratio (Pr/UnPr) | 4.50 | 3.40 | 2.05 | 1.89 | 2.67 | 2.30 | - |
| Shares | 3 | 2-/3- | 3 | 3 | 3 | 3 | 3 |
| Random bits | 48 | 44 | 0 | 0 | 0 | 0 | 0 |
| Cycles | 266 | 256 | 547 | 2996 | 4835 | 2048 | 96 |
| This Work | [30] | |||||||
|---|---|---|---|---|---|---|---|---|
| Cipher | Block/Key | Cycles/Block | Virtex-7 (LUT) | Virtex-7 (Ratio) | Block/Key | Cycles/Block | ASIC (GE) | ASIC (Ratio) |
| AES | 128/128 | 175 | 1791 | 2.57 | 128/128 | 266 | 6340 | 2.62 |
| SIMON | 96/96 | 52 | 1520 | 3.49 | 128/128 | 2912 | 5686 | 4.61 |
| SPECK | 96/96 | 224 | 3328 | 5.13 | 128/128 | 2048 | 5940 | 2.94 |
| PRESENT | 64/80 | 31 | 1317 | 3.46 | 64/80 | 547 | 5236 | 3.23 |
| Type of Countermeasure | Cost | Example | Reference |
|---|---|---|---|
| Algorithmic | Boolean Masking | [46,51] | |
| Algorithmic | Threshold Implementation | [19], This work | |
| Non-algorithmic | Dual-rail Pre-charge Logic (DPL) | [47] | |
| Non-algorithmic | Wave Dynamic Differential Logic (WDDL) | [48] | |
| Non-algorithmic | Separated Dynamic and Differential Logic (SDDL) | [49] | |
| Non-algorithmic | Multiprocessor Balancing for AES (MUTE-AES) | [50] |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diehl, W.; Abdulgadir, A.; Kaps, J.-P.; Gaj, K. Comparing the Cost of Protecting Selected Lightweight Block Ciphers against Differential Power Analysis in Low-Cost FPGAs. Computers 2018, 7, 28. https://doi.org/10.3390/computers7020028
Diehl W, Abdulgadir A, Kaps J-P, Gaj K. Comparing the Cost of Protecting Selected Lightweight Block Ciphers against Differential Power Analysis in Low-Cost FPGAs. Computers. 2018; 7(2):28. https://doi.org/10.3390/computers7020028
Chicago/Turabian StyleDiehl, William, Abubakr Abdulgadir, Jens-Peter Kaps, and Kris Gaj. 2018. "Comparing the Cost of Protecting Selected Lightweight Block Ciphers against Differential Power Analysis in Low-Cost FPGAs" Computers 7, no. 2: 28. https://doi.org/10.3390/computers7020028
APA StyleDiehl, W., Abdulgadir, A., Kaps, J. -P., & Gaj, K. (2018). Comparing the Cost of Protecting Selected Lightweight Block Ciphers against Differential Power Analysis in Low-Cost FPGAs. Computers, 7(2), 28. https://doi.org/10.3390/computers7020028