2.3.2. Classification of Satellite Imagery
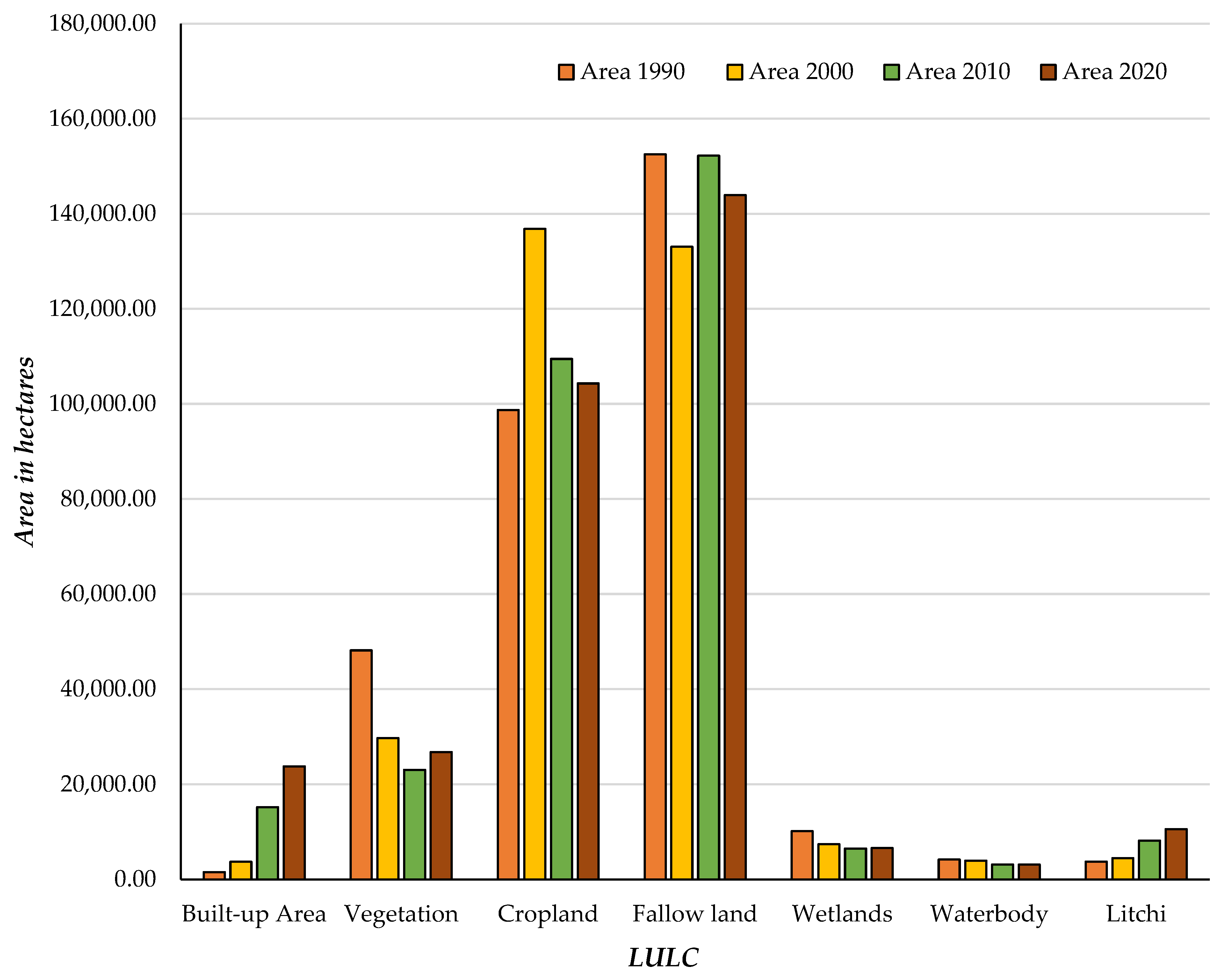
Landsat data for the corresponding years were classified to create the LULC maps for 1990, 2000, 2010, and 2020, using a support vector machine classifier, separately, in ENVI 5.1 software. The seven main LULC classes examined in this study are: built-up areas, vegetation, fallow lands, croplands, litchi cultivation areas, wetlands, and waterbodies.
Supervised classification is based on the spectral signatures of the designated LULC classes. We used a support vector machine algorithm for classifying the images of all the dates. The support vector machine (SVM) is a supervised non-parametric statistical learning approach that was previously designed for binary classification. The SVM is based on the hypothesis that the training set is linearly unique. The SVM detects the optimal line, which splits up the training set without errors and maximizes the gap between the objects of each class and the optima line. The SVM uses only those training samples that designate class boundaries (support vectors). The SVM essentially involves parameterizing a Support Vector Classifier (SVC) based entirely on the reference information and the classification of the image data. Training signatures for classification were selected based on the visual image interpretation, augmented with statistical training class estimates in the form of mean, variance, and covariance matrix. We chose approximately 400 spectral signatures, equally distributed among the designated LULC classes.
To evaluate the accuracy of the classification output, the confusion matrix was created. The accuracy was measured using a variety of metrics, including the overall accuracy (OA), user’s accuracy (UA), producer’s accuracy (PA), and kappa coefficient (Kc). Kappa coefficient (
) is mathematically expressed as:
where
r represents the number of rows in the error matrix; Xii represents the number. of observations in row I and column I; Xi+ is the total of observations in row I; X+I is the total of observations in column I; N is the total number of observations included in the matrix.
2.3.3. LULC Change Analysis
The LULC modifications in the CA-ANN model are described using the modification potential from the ANN learning process. The MOLUSCE plugin is used to carry out this strategy. Several LULCC maps have been made, and area alterations were used to assess change in various LULC classes. Using the MOLUSCE plugin, change maps were produced for the period of 1990 through to 2020. During this time, the locations that belonged to the same change detection class and the conversion from every LULC type were made public. The MOLUSCE plugin is a set of tools for evaluating and simulating LULC modification. The inclusion of user-specified change causes enables users to map alterations, identify transitions across LULC classes, model, and predict future landscape conditions [
28].
The uncertainty in the registration of the satellite images was assessed using the association between the topographical variables and was analyzed using joint information uncertainty, through Pearson’s correlation [
29]. The technique generates a transition matrix, which shows the percentage of pixels that change from one kind to another. Pearson’s correlation coefficient gauges the strength of a linear relationship between two data sets. The greater the overall value, the higher the linear association. The relationship coefficient among the four decades is seen in
Table 2. The findings indicate a very high registration efficiency between 1990 and the anticipated 2020, preceded by the years between 1990 to 2010, and 1990 to 2000.
2.3.4. Prediction of Future LULC
The LULC maps for the start year (1990) and end year (2010) are the first phases in this model.
Figure 3 depicts several geographical variables included in the model, such as DEM, Slope, Euclidean distance to the railway line, Euclidean distance to a river, Euclidean distance to road, and Euclidean distance to existing settlements. This model utilized these data as inputs to produce a simulation map of land use and land cover variations, allowing the identification of the study area’s shifting pattern between 1990 and 2020.
The plugin also produces a transition probability matrix that shows the proportion of classes that have changed to other classes and calculates the proportion of area changes in a particular year. Additionally, the plugin creates a change map from 1990 to 2020 for each of the seven classes of built-up area, vegetation, cropland, litchi cultivation area, fallow land, wetlands, and waterbody. This was conducted using the ANN-(Multi-layer perception) plugin to forecast the variations in LULC [
28,
29]. Based on the raster maps from 1990 and 2020, the LULC alterations for 2030 and 2050 are also projected. Future LULC maps are anticipated based on the dynamics and pattern of the existing LULC.
The plugin works by generating the transition potential (TP) maps by feeding data from an ANN-TP model with information about relevant spatial drivers. These potential determinants of LULC shift from one place to another. Explanatory variables can be divided into two categories: constraints and factors. Future modifications to LULC will omit the Boolean map that describes the limitations. The urban class was assigned as a constraint in this research. It served as a proxy for other, more difficult-to-generate socioeconomic factors, including population, economic activity, and employment opportunities. A number of factors determine changes in a region’s appropriateness. The CA-ANN model included in ANN-TP was used to construct the transition potential map after associations between all of the components, and each land transition was tested. ANN of the feedforward variety uses a supervised backpropagation technique. It is composed of three layers: input, hidden, and output. The input layer is responsible for feeding information into the network’s neurons, whereas the output layer is where the network’s output may be accessed. There are three distinct layers: an input layer, an output layer, and a hidden layer that can identify a deviation in the input and output patterns. For this procedure, each neuron calculates a value that is the product of the values stored in the nodes of the layer above it and the network weights between them. To further train the neurons, the backpropagation technique was employed. This approach iteratively adjusts the neural network’s weights to reduce the gap between the node’s actual output and the desired output. To do this, CA-ANN generates a random sample of cells in each land transition submodel, some of which have undergone the LULC transition, while the rest have not. Using the critical land transitions and explanatory variables, a new network of neurons, with weights, was created. The samples in these cells were split in half and used for training and testing purposes, respectively. The training procedure involved adjusting the weights of each connection to decrease the inaccuracy. Once the MLPNN had been run for many iterations, a higher accuracy rate was achieved. It is suggested that the accuracy rate is greater than 80%. After ANN-TP was implemented, transition possibilities were created for all material land changes. These generated transition potentials were then used to make LULC predictions in the latter part.
The forecast of LULC is only considered reliable when it has been confirmed using the referenced LULC classes. Therefore, the validation process has been conducted in the MOLUSCE plugin for the actual LULC of 2020, with simulated LULC of 2020 using cellular automata. The same validation approach has been used to estimate the LULC map for 2030 and 2050. The four-kappa statistic metrics that the validation module calculates—kappa histogram, overall kappa, kappa location, and percentage of correctness—are used to judge the model’s accuracy and are listed below:
Pij denotes the I jth cell of the frequency distribution, PiT means the total of all cells in the ith row, PTj means the sum among all cells in the jth cell, and c is the number of raster classes in the I jth cell of the frequency distribution. By contrasting the categorized raster with the LULC projected raster, the degree of agreement here between rasters and their probability may be assessed. The K location evaluates the simulation’s capacity to detect location, whereas K overall evaluates the simulation’s overall performance. A value of 100% in kappa statistics denotes seamless agreement, while a rate of 0% denotes no agreement.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}