Cluster Sampling Filters for Non-Gaussian Data Assimilation


1
Mathematics and Computer Science Division, Argonne National Laboratory, Argonne, IL 60439, USA
2
Computational Science Laboratory, Department of Computer Science, Virginia Polytechnic Institute and State University, Blacksburg, VA 24061, USA
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Atmosphere 2018, 9(6), 213; https://doi.org/10.3390/atmos9060213
Submission received: 20 March 2018
/
Revised: 2 May 2018
/
Accepted: 2 May 2018
/
Published: 31 May 2018
(This article belongs to the Special Issue Efficient Formulation and Implementation of Data Assimilation Methods)
Abstract
:This paper presents a fully non-Gaussian filter for sequential data assimilation. The filter is named the “cluster sampling filter”, and works by directly sampling the posterior distribution following a Markov Chain Monte-Carlo (MCMC) approach, while the prior distribution is approximated using a Gaussian Mixture Model (GMM). Specifically, a clustering step is introduced after the forecast phase of the filter, and the prior density function is estimated by fitting a GMM to the prior ensemble. Using the data likelihood function, the posterior density is then formulated as a mixture density, and is sampled following an MCMC approach. Four versions of the proposed filter, namely , , MC-, and MC- are presented. uses a Gaussian proposal density to sample the posterior, and is an extension to the Hamiltonian Monte-Carlo (HMC) sampling filter. MC- and MC- are multi-chain versions of the cluster sampling filters and respectively. The multi-chain versions are proposed to guarantee that samples are taken from the vicinities of all probability modes of the formulated posterior. The new methodologies are tested using a simple one-dimensional example, and a quasi-geostrophic (QG) model with double-gyre wind forcing and bi-harmonic friction. Numerical results demonstrate the usefulness of using GMMs to relax the Gaussian prior assumption especially in the HMC filtering paradigm.
1. Introduction
Data assimilation (DA) is a complex process that involves combining information from different sources in order to produce accurate estimates of the true state of a physical system such as the atmosphere. Sources of information include computational models of the system, a background probability distribution, and observations collected at discrete time instances. With model state denoted by the prior probability density encapsulates the knowledge about the system state before incorporating any other source of information such as the observations. Let be a measurement (observation) vector. The observation likelihood function quantifies the mismatch between the model predictions (of observed quantities) and the collected measurements. A standard application of Bayes’ theorem provides the posterior probability distribution that provides an improved description of the unknown true state of the system of interest.
In the ideal case where the underlying probability distributions are Gaussian, the model dynamics is linear, and the observations are linearly related to the model state, the posterior can be obtained analytically for example by applying Kalman filter (KF) Equations [1,2]. For large dimensional problems the computational cost of the standard Kalman filter is prohibitive, and in practice the probability distributions are approximated using small ensembles. The ensemble-based approximation has led to the ensemble Kalman filter (EnKF) family of methods [3,4,5,6]. Several modifications of EnKF, for example [7,8,9,10,11,12], have been introduced in the literature to solve practical DA problems of different complexities.
One of the drawbacks of the EnKF family is the reliance on an ensemble update formula that comes from the linear Gaussian theory. Several approaches have been proposed in the literature to alleviate the limitations of the Gaussian assumptions. The maximum likelihood ensemble filter (MLEF) [13,14,15] computes the maximum a posteriori estimate of the state in the ensemble space. The iterative EnKF [10,16] (IEnKF) extends MLEF to handle nonlinearity in models as well as in observations. IEnKF, however, assumes that the underlying probability distributions are Gaussian and the analysis state is best estimated by the posterior mode.
These families of filters can generally be tuned (e.g., using inflation and localization) for optimal performance on the problem at hand. However, if the posterior is a multimodal distribution, these filters are expected to diverge, or at best capture a single probability mode, especially in the case of long-term forecasts. Only a small number of filtering methodologies designed to work in the presence of highly non-Gaussian errors are available, and their efficiency with realistic models is yet to be established. These promising methods can be classified into two classes, particle filtering, and MCMC sampling. In this work, we focus on using MCMC to sample the posterior distribution.
The Hybrid/Hamiltonian Monte Carlo (HMC) sampling filter was proposed in [17] as a fully non-Gaussian filtering algorithm, and has been extended to the four-dimensional (smoothing) setting in [17,18,19,20]. The HMC sampling filter is a sequential DA filtering scheme that works by directly sampling the posterior probability distribution via an HMC approach [21,22]. The HMC filter is designed to handle cases where the underlying probability distributions are non-Gaussian. Nevertheless, the first HMC formulation presented in [17] assumes that the prior distribution can always be approximated by a Gaussian distribution. This assumption was introduced for simplicity of implementation; however, it can be too restrictive in many cases, and may lead to inaccurate conclusions. This strong assumption needs to be relaxed in order to accurately sample from the true posterior, while preserving computational efficiency.
In this work, we propose relaxing the Gaussian prior assumption, using a Gaussian Mixture Model (GMM) to approximate the prior distribution. Specifically, in the forecast phase of the filter, the prior is represented by a GMM that is fitted to the forecast ensemble via a clustering step. The posterior is formulated accordingly. In the analysis step the resulting mixture posterior is sampled following an MCMC approach. The resulting algorithm is named the “cluster MCMC () sampling filter”, and the version in which HMC is used to sample the posterior is named cluster HMC () sampling filter. In order to improve the sampling from the mixture posterior, more efficient versions namely “multi-chain (MC-)“, and “multi-chain (MC-)“, filters are also discussed.
The proposed MCMC filtering algorithms are not suggested as replacements for EnKF in the linear-Gaussian settings. MCMC algorithms are generally expensive, compared to EnKF, and should be considered only when the linear-Gaussian assumption is highly violated, which can cause the conventional EnKF to fail. The numerical experiments presented herein, are carried out in both linear and nonlinear settings. Experiments with linear settings aim to compare the performance of the proposed algorithms, in the presence of benchmark results produced by EnKF. This has the benefit of demonstrating the advantage of replacing the Gaussian prior with a GMM, for MCMC sampling, even in the simplified linear settings. Numerical results with nonlinear settings, where EnKF fails, suggest that the proposed relaxation of the Gaussian-prior assumption is beneficial, especially for the sequential application of MCMC sampling filters in the presence of nonlinearities.
Using a GMM to approximate the prior density, given the forecast ensemble, was presented in [11,23] as a means to solve the nonlinear filtering problem. In [23], a continuous approximation of the prior density was built as a sum of Gaussian kernels, where the number of kernels is equal to the ensemble size. Assuming a Gaussian likelihood function, the posterior was formulated as a GMM with updated mixture parameters. The updated means and covariance matrices of the GMM posterior were obtained by applying the convolution rule of Gaussians to the prior mixture components and the likelihood, and the analysis ensemble was generated by direct sampling from the GMM posterior. On the other hand, the approach presented in [11] works by fitting a GMM to the prior ensemble with the number of mixture components detected using Akaike information criterion. The EnKF equations are applied to each of the components in the mixture distribution to generate an analysis ensemble from the GMM posterior.
Unlike the existing approaches [11,23], the methodology proposed herein is fully non-Gaussian, and does not limit the posterior density to a Gaussian mixture distribution or Gaussian likelihood functions. Moreover, the posterior distribution is directly sampled, and is not approximated by a Gaussian mixture distribution.
The remaining part of the paper is organized as follows. Section 2 reviews the original formulation of the HMC sampling filter. Section 3 explains how GMM can be used to approximate the prior distribution, and presents the new cluster sampling filters. Numerical results and discussions are presented in Section 4. Conclusions are drawn in Section 5.
2. The HMC Sampling Filter
In this section we present a brief overview of the HMC sampling methodology, followed by the original formulation of the HMC sampling filter.
2.1. HMC Sampling
HMC sampling follows an auxiliary-variable approach [24,25] to accelerate the sampling process of Markov chain Monte-Carlo (MCMC) algorithms. In this approach, the MCMC sampler is devoted to sampling the joint probability density of the target variable, along with an auxiliary variable. The auxiliary variable is chosen carefully to allow for the construction of a Markov chain that mixes faster, and is easier to simulate than sampling the marginal density of the target variable [26].
The main component of the HMC sampling scheme is an auxiliary Hamiltonian system that plays the role of the proposal (jumping) distribution. The Hamiltonian dynamical system operates in a phase space of points where the individual variables are the position and the momentum . The total energy of the system, given the position and the momentum, is described by the Hamiltonian function . A general formulation of the Hamiltonian function (the Hamiltonian) of the system is given by:
where is a symmetric positive definite matrix referred to as the mass matrix. The first term in the sum (1) quantifies the kinetic energy of the Hamiltonian system, while the second term is the associated potential energy.
The dynamics of the Hamiltonian system in time is described by the following ordinary differential equations (ODEs):
The time evolution of the system (2) in the phase space is described by the flow: [27,28]
which maps the initial state of the system to the state of the system at time T. In practical applications, the analytic flow is replaced by a numerical solution using a time reversible and symplectic numerical integration method [28,29]. The length of the Hamiltonian trajectory T can generally be long, and may lead to instability of the time integrator if the step size is set to T. In order to accurately approximate the symplectic integrator typically takes m steps of size where h is chosen such as to maintain stability. We will use hereafter to represent the numerical approximation of the Hamiltonian flow.
Given the formulation of the Hamiltonian (1), the dynamics of the Hamiltonian system is governed by the equations
The canonical probability distribution of the state of the Hamiltonian system in the phase space up to a scaling factor, is given by
The product form of this joint probability distribution shows that the two variables are independent [29]. The marginal distribution of the momentum variable is Gaussian, while the marginal distribution of the position variable is proportional to the negative-logarithm (negative-log) of the potential energy, that is . Here is the normalized marginal density of the position variable, while drops the scaling factor (e.g., the normalization constant) of the density function.
In order to draw samples from a given probability distribution HMC makes the following analogy with the Hamiltonian mechanical system (2). The state is viewed as a position variable, and an auxiliary momentum variable is included. The negative-log of the target probability density is viewed as the potential energy of an auxiliary Hamiltonian system. The kinetic energy of the system is given by the negative-log of the Gaussian distribution of the auxiliary momentum variable. The mass matrix is a user-defined parameter that is assumed to be symmetric positive definite. To achieve favorable performance of the HMC sampler, is generally assumed to be diagonal, with values on the diagonal chosen to reflect the scale of the components of the target variable under the target density [17,27]. The HMC sampler proceeds by constructing a Markov chain whose stationary distribution is set to the canonical joint density (5). The chain is initialized to some position and momentum values, and at each step of the chain, a Hamiltonian trajectory starting at the current state is constructed to propose a new state. A Metropolis-Hastings-like acceptance rule is used to either accept or reject the proposed state. Since both position and momentum are statistically independent, the retained position samples are actually sampled from the target density . The collected momentum samples are discarded, and the position samples are returned as the samples from the target probability distribution .
The performance of the HMC sampling scheme is greatly influenced by the settings of the Hamiltonian trajectory, that is the choice of the two parameters . The step size h should be small enough to maintain stability, while m should be generally large for the sampler to reach distant points in the state space. The parameters of the Hamiltonian trajectory can be set empirically [27] to achieve an acceptable rejection rate of at most or be automatically adapted using tuning schemes such as the No-U-Turn sampler(NUTS) [30], or the Riemannian Manifold HMC sampler (RMHMC) [31].
The ideas presented in this work can be easily extended to incorporate any of the HMC sampling algorithms with automatically tuned parameters. In this paper we tune the parameters of the Hamiltonian trajectory following the empirical approach, and focus on the sampler performance due to the choice of the prior distribution in the sequential filtering context.
2.2. HMC Sampling Filter
In the filtering framework, following a perfect-model approach, the posterior distribution at a time instance follows from Bayes’ theorem:
where is the prior distribution, is the likelihood function, all at time instance . acts as a scaling factor and is ignored in the HMC context.
As mentioned in Section 1, the formulation of the HMC sampling filter proposed in [17] assumes that the prior distribution can be represented by a Gaussian distribution that is
where is the background state, and is the background error covariance matrix. The background state is generally taken as the mean of an ensemble of forecasts obtained by forward model runs from a previous assimilation cycle. The associated weighted norm is defined as:
Under the traditional, yet non-restrictive assumption, that the observation errors are distributed according to a Gaussian distribution with zero mean, and observation error covariance matrix the likelihood function takes the form
where is the observation operator that maps a given state to the observation space at time instance . The dimension of the observation space m is generally much smaller than the state space dimension, that is .
The posterior follows immediately from (6), (7), and (9)
where is the negative-log of the posterior distribution (10b). The derivative of with respect to the system state is given by
where is the linearized observation operator (e.g., the Jacobian).
The HMC sampling filter [17] proceeds in two steps, namely a forecast step and an analysis step. Given an analysis ensemble of states at time an ensemble of forecasts at time is generated using the forward model :
In the analysis step, the posterior (10) is sampled by running a HMC sampler with potential energy set to (10b), where is approximated using the available ensemble of forecasts.
The formulation of the HMC filter presented in [17], and reviewed above, tends to be restrictive due to the assumption that the prior is always approximated by a Gaussian distribution. The prior distribution can be viewed as the result of propagating the posterior of the previous assimilation cycle using model dynamics. In the case of nonlinear model dynamics, the prior distribution is a nonlinear transformation of a non-Gaussian distribution which is generally expected to be non-Gaussian. Tracking the prior distribution exactly however is not possible, and a relaxation assumption must take place.
We propose conducting a more accurate density estimation of the prior, by fitting a GMM to the available prior ensemble, replacing the Gaussian prior with a Gaussian mixture prior.
3. Cluster Sampling Filters
Section 3.1 provides a brief overviews on mixture distributions, and review how a GMM can be used to represent the prior distribution given an ensemble of forecasts. Section 3.2 describes the posterior distribution, and presents the new cluster sampling filters.
3.1. Mixture Models
The probability distribution is said to be a mixture of probability distributions , if takes the form:
The weights are commonly referred to as the mixing weights, and are the densities of the mixing components.
3.1.1. Gaussian Mixture Models (GMM)
A GMM is a special case of (13) where the mixture components are Gaussian densities, that is with being the parameters of the ith Gaussian component.
Fitting a GMM to a given data set is one of the most popular approaches for density estimation [32,33,34]. Given a data set sampled from an unknown probability distribution , one can estimate the density function by a GMM; the parameters of the GMM, i.e., the mixing weights , the means , and the covariances of the mixture components, can be inferred from the data.
The most popular approach to obtain the maximum likelihood estimate of the GMM parameters is the expectation-maximization (EM) algorithm [34]. EM is an iterative procedure that alternates between two steps, expectation (E) and maximization (M). At iteration the E-step computes the expectation of the complete log-likelihood based on the posterior probability of belonging to the ith component, with the parameters from the previous iteration. In particular, the following quantity is evaluated:
Here is the parameter set of all the mixture components, and is the probability that the eth ensemble member lies under the ith mixture component.
In the M-step, the new parameters are obtained by maximizing the conditional probability Q in (14) with respect to the parameters . The updated parameters are given by the analytical formulas:
To initialize the parameters for the EM iterations, the mixing weights are simply chosen to be equal , the means can be randomly selected from the given ensemble, and the covariance matrices of the components can be all set to covariance matrix of the full ensemble. Regardless of the initialization, the convergence of the EM algorithm is ensured by the fact that it monotonically increases the observed data log-likelihood at each iteration [34], that is:
EM algorithm achieves the improvement of the data log-likelihood indirectly by improving the quantity over consecutive iterations, i.e., .
3.1.2. Model Selection
Before EM iterations start, the number of mixture components must be detected. To decide on the number of components in the prior mixture, model selection is employed. This process refers to the statistical decision of choosing a model, out of a set of candidate models, to give the best trade-off between model fit and complexity. Here, the best number of components can be selected with common model selection methodologies such as Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC):
where is the set of optimal parameters for the candidate GMM model with components.
The best number of components minimizes the AIC or BIC criterion [35,36]. The main difference between the two criteria, as explained by the second terms in Equation (16), is that BIC imposes greater penalty on the number of parameters () of the candidate GMM model. For small or moderate numbers of samples BIC often chooses models that are too simple because of its heavy penalty on complexity.
3.2. Cluster Sampling Filters
The prior distribution is approximated by a GMM fitted to the forecast ensemble, e.g., using an EM clustering step. The prior PDF reads:
where the weights quantify the probability that an ensemble member belongs to the ith component, and are the mean and the covariance matrix associated with the ith component of the mixture model at time instance .
Assuming Gaussian observation errors, the posterior can be formulated using Equations (6), (9), and (17) as follows:
In general the posterior PDF (18) will not correspond to a Gaussian mixture due to the nonlinearity of the observation operator. This makes analytical solutions not possible. Here we seek to sample directly from the posterior PDF (18) following a MCMC approach. A proposal distribution and acceptance/rejection criterion, are the backbones of any MCMC sampler.
The simplest proposal is a Gaussian centered around the current state of the Markov chain. Specifically, at the rth iteration of the chain, the proposal is , where is the current state of the chain, and is the ensemble-based covariance matrix
where is the forecast ensemble mean. The Metropolis-Hastings acceptance/rejection, in this case, can be evaluated using the acceptance probability , where is the proposed state, e.g., sampled from . We refer to this approach of filtering as the cluster MCMC () sampling filter.
Gradient-based MCMC sampling methods, such as the HMC sampler, use the gradient of the negative log-posterior to direct the sampler towards high-probability regions, and thus yielding low rejection rates. Specifically, the HMC sampler require setting the potential energy term in the Hamiltonian (1) to the negative-log of the posterior distribution (18). The potential energy term
Equation (20) is expected to suffer from numerical difficulties due to evaluating the logarithm of a sum of very small values. To address the accumulation of roundoff errors, and without loss of generality, we assume from now on that the terms in Equation (20) under the sum are sorted in decreasing order, i.e., , . The potential energy function (20) is rewritten as:
The gradient of the potential energy (21) is:
The cluster HMC sampling filter () results by replacing the potential energy function (10b) and its derivative (11) in the HMC sampling filter, with Equations (21) and (22) respectively. The steps of the sampling filter are explained in Algorithm 1.
Note that in the case where the mixture contains a single component (one Gaussian distribution), the potential energy function (21) and its gradient (22) reduce to the following, respectively:
This shows that the sampling filter proposed herein, reduces to the original HMC filter when the EM algorithm detects a single component during the prior density approximation phase.
The Sampling Algorithm
As in the HMC sampling filter, information about the analysis probability density at the previous time is captured by the analysis ensemble of states . The forecast step consists of two stages. First, the model (12) is used to integrate each analysis ensemble member forward to time where observations are available. Next, a clustering scheme (e.g., EM) is used to generate the parameters of the GMM. The analysis step constructs a Markov chain starting from an initial state , and proceeds by sampling the posterior PDF (18) at stationarity. Here the superscript over refers to the iteration number in the Markov chain.
It is worth mentioning that the Hamiltonian system used as a mechanism to generate proposals for the Markov Chain, along with its associated pseudo time-step settings, are independent from the physical model being simulated.
As discussed in [17], Algorithm 1 can be used either as a non-Gaussian filter, or as a replenishment tool for parallel implementations of the traditional filters such as EnKF.
| Algorithm 1 Cluster HMC sampling filter () |
|
3.3. Computational Considerations
To initialize the Markov chain one seeks a state that is likely with respect to the analysis distribution. Therefore one can start with the background ensemble mean, or with the mean of the component that has the highest weight. Alternatively, one can apply a traditional EnKF step and use the mean analysis to initialize the chain.
The joint ensemble mean and covariance matrix can be evaluated using the forecast ensemble, or using the GMM parameters. Given the GMM parameters , the joint background mean and covariance matrix are, respectively:
Both the potential energy (21) and its gradient (22) require evaluating the determinants of the covariance matrices associated with the mixture components. This is a computationally expensive process that is best avoided for large-scale problems. A simple remedy is to force the covariance matrices to be diagonal while constructing the GMM.
When the Algorithm 1 is applied sequentially, at some steps a single mixture component could be detected in the prior ensemble. In this case, forcing a diagonal covariance structure does not help, and we fall back to the standard HMC sampler, where the full ensemble covariance matrix is utilized.
3.4. A Multi-Chain Version of the Filter (MC-)
Given the special geometry of the posterior mixture distribution, one can construct separate Markov chains for different components of the posterior. These chains can run in parallel to independently sample different regions of the analysis distribution. By running a Markov chain starting at each component of the mixture distribution we ensure that the proposed algorithm navigates all modes of the posterior, and covers all regions of high probability. The parameters of the jumping distribution for each of the chains can be tuned locally based on the statistics of the ensemble points belonging to the corresponding component in the mixture.
A multi-chain version of the filter (MC-) is developed by choosing the proposal of the ith chain to be .
Running an HMC sampling chain under each of the posterior mixture components formulates the multi-chain (MC-) sampling filter. In this case, the diagonal of the mass matrix can be set globally for all components, for example using the diagonal of the precision matrix of the forecast ensemble, or can be chosen locally based on the second-order moments estimated from the prior ensemble under the corresponding component in the prior mixture. This local choice of the mass matrix does not change the marginal density of the target variable.
The local ensemble size (sample size per chain) can be specified based on the prior weight of the corresponding component multiplied by the likelihood of the mean of that component. Every chain is initialized to the mean of the corresponding component in the prior mixture.
The computational cost of the original HMC sampling filter depends greatly on the parameters of the Markov chain. A comprehensive discussion of the cost of the HMC sampling filter is given in Section 4.1 [17]. The sampling filter replaces the Gaussian prior with a GMM, which introduces an additional cost for utilizing the EM algorithm. This added cost, however, is negligible compared to cost of the sampling step. Moreover, MC- allows running the chains in parallel, which reduces the computational cost by a factor of up to the number of posterior probability modes . This approach is potentially very efficient, not only because it reduces the total running time of the sampler, but also because it favors an increased acceptance rate.
4. Numerical Results
We first apply the proposed algorithms to sample a simple one-dimensional mixture distribution. The cluster HMC sampling filters are then tested using a quasi-geostrophic (QG) model and compared against the original HMC sampling filter and against EnKF. We mainly use a nonlinear 1.5-layer reduced-gravity QG model with double-gyre wind forcing and bi-harmonic friction [37]. The data assimilation testing suite (DATeS) [38,39] is used to carry out the numerical experiments presented in this work.
4.1. One-Dimensional Test Problem
We start with a prior ensemble generated from a GMM with and the following mixture parameters:
The EM algorithm is used to construct a GMM approximation of the true probability distribution from which the given prior ensemble is drawn. The model selection criterion used here is AIC. The generated GMM approximation of the prior has and the following parameters:
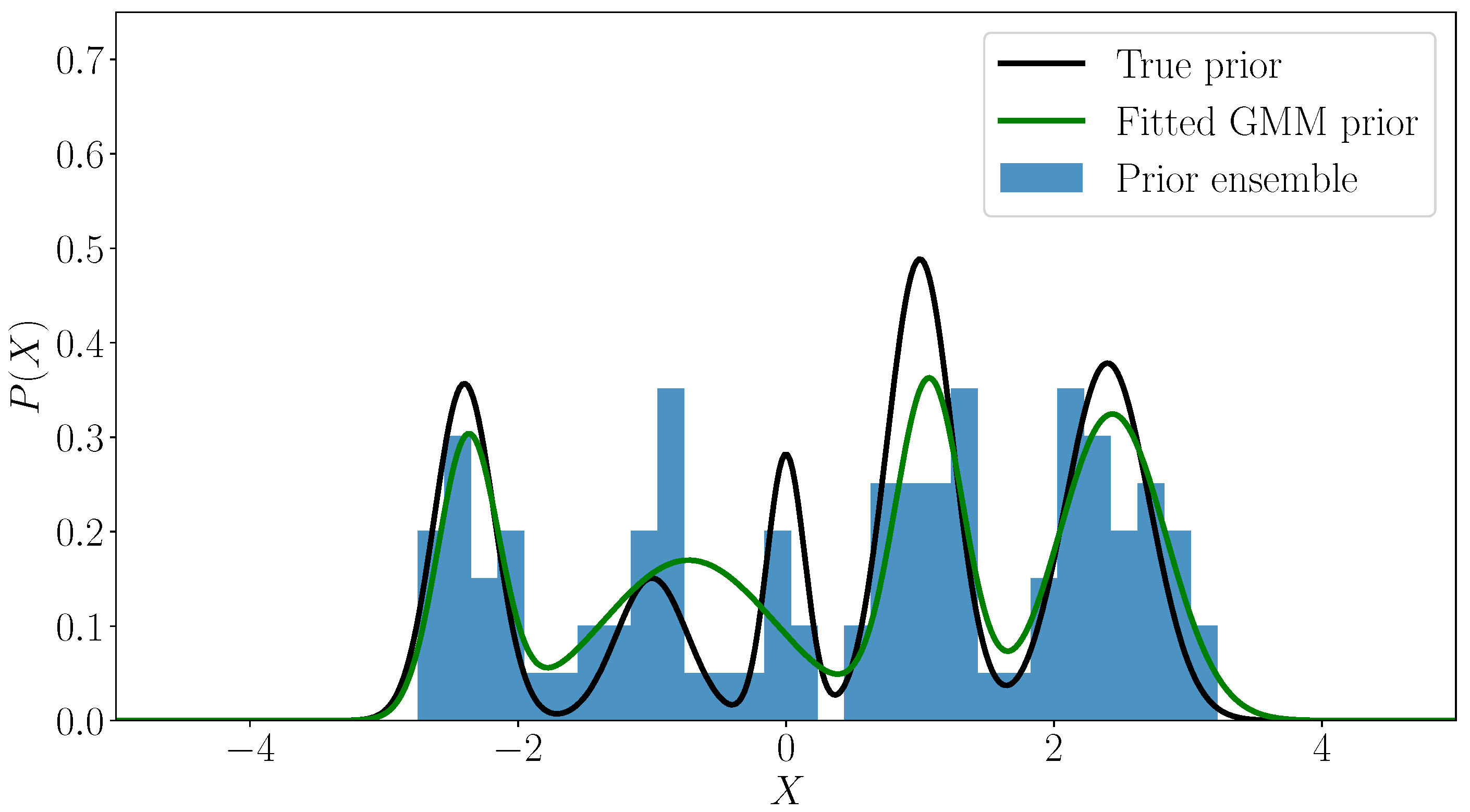
The true prior, the prior ensemble, and the GMM approximation fitted to the prior ensemble, are shown in Figure 1.
Assuming the observation likelihood function is given by:
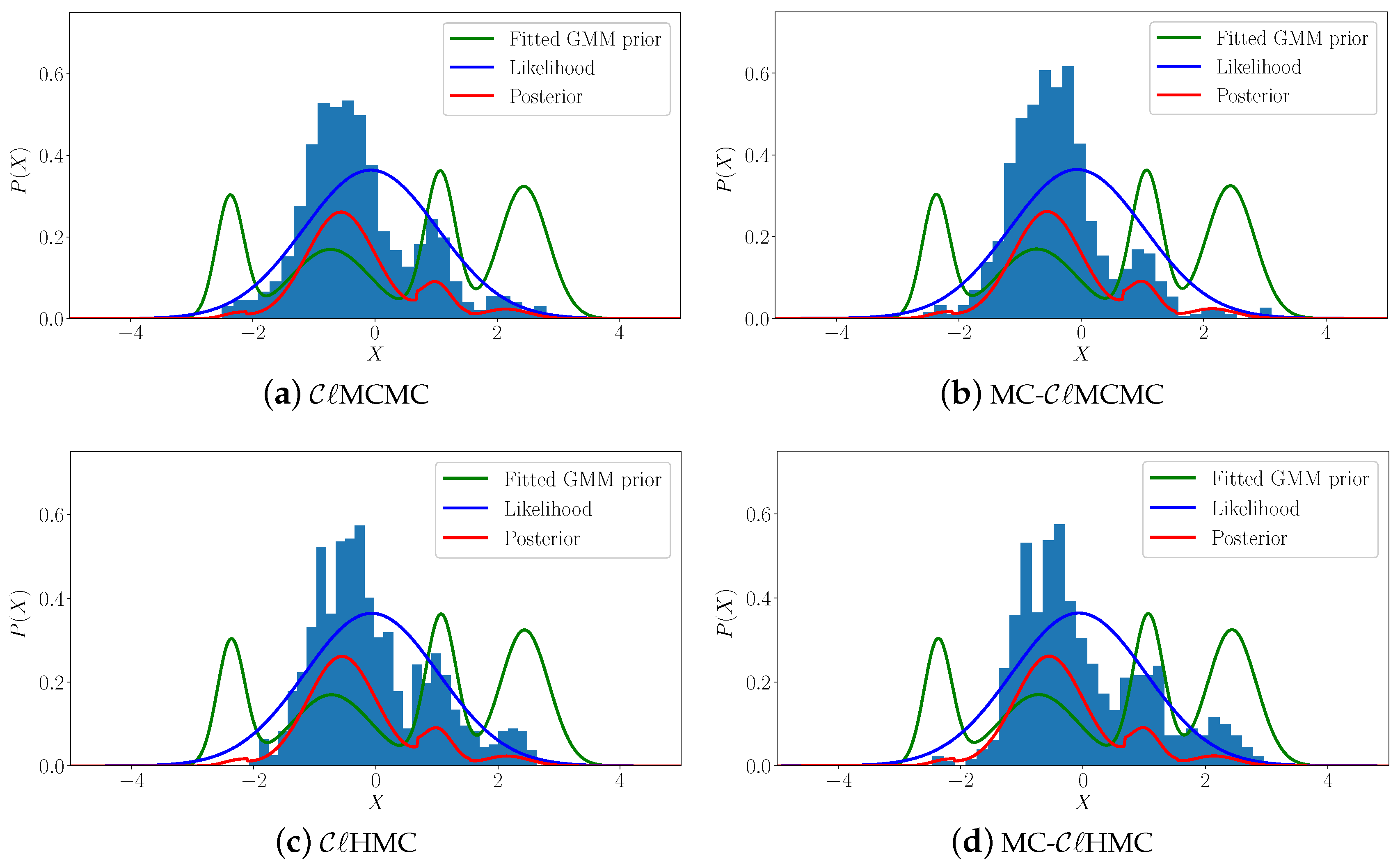
with an observation , the posterior and the histograms of sample points generated by , MC-, , and MC- algorithms, are shown in Figure 2. The acceptance rates of the cluster sampling filters are given in Table 1. In this example, the symplectic integrator used for the HMC-based filters, is Verlet with pseudo-time stepping parameters with , and . Since the chains are initialized to the means of the prior mixture components, the burn-in stage is waived, i.e., the number of burn-in steps is set to zero. To reduce the correlation between the ensemble members of one chain we discard 20 states (mixing steps) between each two consecutive sampled points. In MC-, and MC- filters, the ensemble size per component (per chain) is set to , where is the likelihood of the mean of the component in the prior mixture.
The results reported in Figure 2 show that the four versions of the cluster sampling filter, and MC-, and MC- are capable of generating ensembles with mass distribution accurately representing the underlying target posterior. The serial version , however fails to sample one of the probability modes (the leftmost probability mode in Figure 2c), while the multi-chain version MC- generates samples from the vicinities of all posterior probability modes. Moreover, the acceptance rates shown in Table 1 explain that the HMC-based samplers yield much lower rejection rates, and thus are more favorable.
In large-scale settings, the filter and the multi-chain version MC-, are expected to suffer from random walk behavior, and would require large ensemble sizes to cover all probability modes properly. Unlike , the sampler is suited for high-dimensional settings, and can explore the probability space quickly with small ensemble size. This is mainly because the HMC proposals target high-probability regions more frequently. The performance of the original HMC sampling filter was evaluated, and its usefulness in nonlinear settings was demonstrated, e.g., in [17]. The remainder of this Section is devoted to assessing the benefit of using a GMM, to relax the Gaussian-prior assumption posed by the original HMC filter, in sequential non-Gaussian filtering, and in relatively high-dimensional settings. Thus, in the numerical experiments shown in Section 4.2, we focus only on results of the , and MC- cluster sampling filters.
4.2. Quasi-Geostrophic Model
We employ the QG-1.5 model described by Sakov and Oke [37]. This model is a numerical approximation of the equations:
where and is either the stream function or the surface elevation. We use the values of the model coefficients (29) from [37], as follows: , , and . The domain of the model is a [space units] square, with and is discretized by a grid of size (including boundaries). Boundary conditions used are . The model state dimension is , while the model trajectories belong to affine subspaces with dimensions of the order of [37].
The time integration scheme used is the fourth-order Runge-Kutta scheme with a time step [time units].
For all experiments in this work, the model is run over 1000 model time steps, with observations made available every 10 time steps. In this synthetic model the scales are not relevant, and we use generic space, time, and solution amplitude units.
4.2.1. Observations and Observation Operators
Two observation operators are used with this model.
- First we use a standard linear operator to observe 300 components of . The observation error variance is [units squared]. Synthetic the observations are obtained by adding white noise to measurements of the sea surface height (SSH) extracted from a model run with lower viscosity.
- The second observation operator measures the magnitude of the flow velocity . The flow velocity components are obtained using a finite difference approximation of the following relations to the stream function:
In both cases, the observed components are uniformly distributed over the state vector length, with a random offset, that is updated at each assimilation cycle. As mentioned in [37], the observational settings used here are motivated by typical distribution of satellite altimetry for oceanic applications.
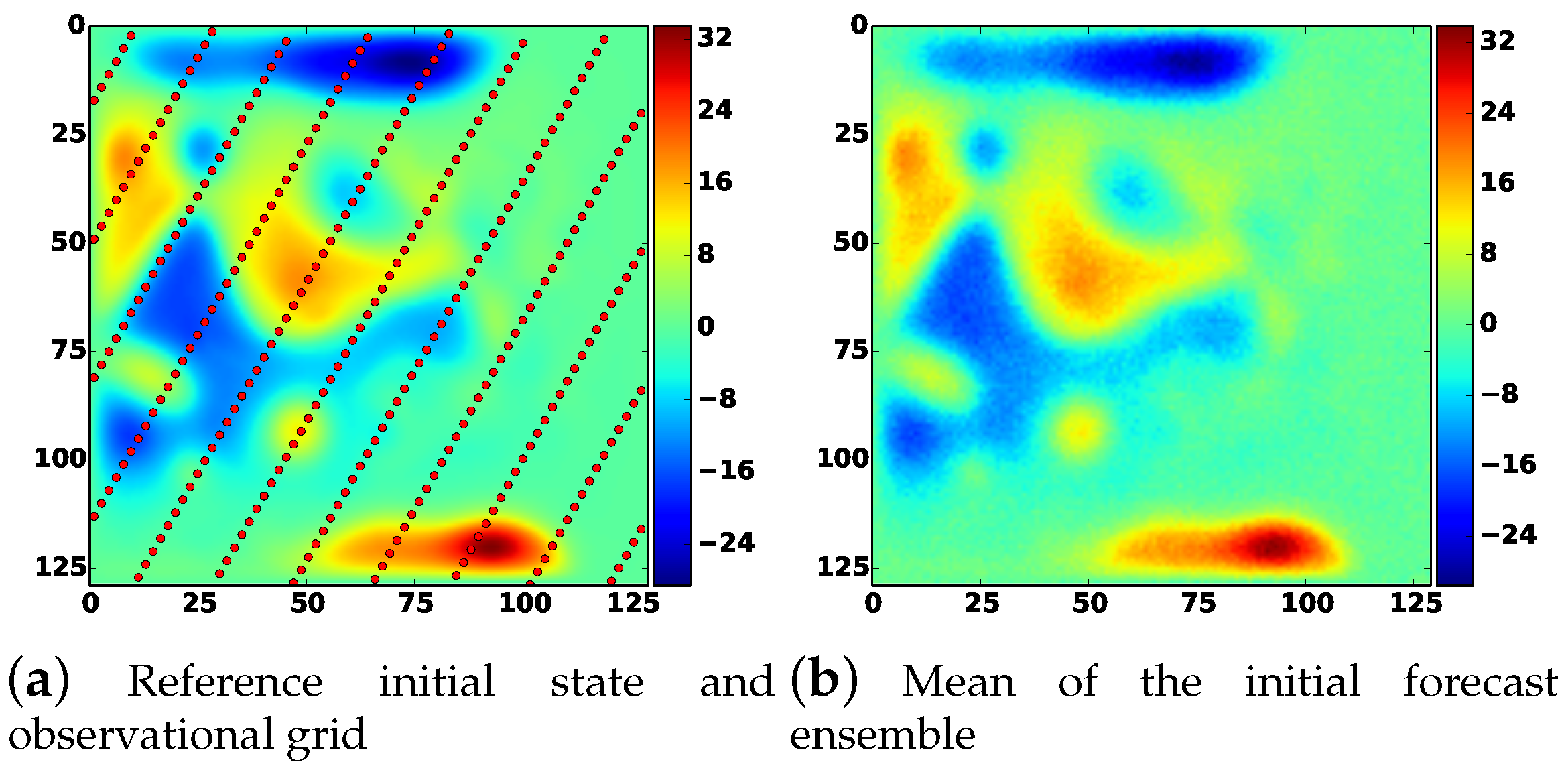
The reference initial state along with an example of the observational grid used, and the initial forecast state are shown in Figure 3.
4.2.2. Filter Tuning
We used a deterministic implementation of EnKF (DEnKF) with parameters tuned as suggested in [37]. Specifically, we apply a covariance localization by means of a Hadamard product as explained in [8]. The localization function used is Gaspari-Cohn [40] with localization radius set to 12 grid cells. Inflation is applied with factor to the analysis ensemble of anomalies at the end of each assimilation cycle of DEnKF.
The parameters of the HMC and sampling filters are tuned empirically in a preprocessing step in the HMC filter to guarantee a rejection rate at most between to . Here we tune the parameters of the Hamiltonian trajectory only once at the beginning of the assimilation experiment. Specifically, the step size parameters of the symplectic integrator are set to in the presence of the linear observation operator, and are set to when the nonlinear observation operator (30) is used. The integrator used for the Hamiltonian system in all experiments is the three-stage symplectic integrator [17,29]. The mass matrix is chosen to be a diagonal matrix whose nonzero entries are equal to the precisions, i.e., reciprocal of the variances, of the forecast ensemble. In the current experiments, the first 50 steps of the Markov chains are discarded as a burn-in stage. Alternatively, one can run a suboptimal minimization of the negative-log of the posterior to achieve convergence to the posterior.
The parameters of the MC- filter are set as follows. The step size parameters of the symplectic integrator are set to , in the experiments with linear observation operator, and , in the case of the nonlinear observation operator (30). The mass matrix is a diagonal matrix whose diagonal is set to the diagonal of the precision matrix of the forecast ensemble labeled under the corresponding mixture component. To avoid numerical problems related to very small ensemble variances, for example in the case of outliers, the variances are averaged with the modeled forecast variances of 5 units squared.
The prior GMM is built with number of components determined using AIC model selection criteria, with a lower bound of 5 of the number of ensemble members belonging to each component of the mixture. This lower bound is enforced as a means to ameliorate the effect of outliers on the GMM construction. In all experiments involving , and MC-, the diagonal covariances relaxation assumption is imposed. However, this structure is not imposed if only one mixture component is detected, and and MC- filters fall back to the original HMC filter. For cases where a component contains a very small number of ensemble members covariance tapering [41] can prove useful.
The ensemble size for all filters used here is set to .
4.2.3. Assessment Metrics
To assess the accuracy of the tested filters we use the root mean squared error (RMSE):
where is the reference state of the system and is the analysis state, e.g., the average of the analysis ensemble. Here is the dimension of the model state. We also use Talagrand (rank) histogram [42,43] to assess the quality of the ensemble spread around the true state.
4.2.4. Results with Linear Observation Operator
In the linear settings of this experiment, EnKF produces the best possible results, under both RMSE and Rank histogram uniformity metrics. Our main goal in this section, is to test the performance of the proposed algorithms, and MC- against the original HMC sampling filter, with EnKF results as a benchmark. The results below suggest that relaxing the Gaussian-prior using an ensemble-based GMM estimate could be dangerous, unless the sampler is guaranteed to cover all posterior probability modes.
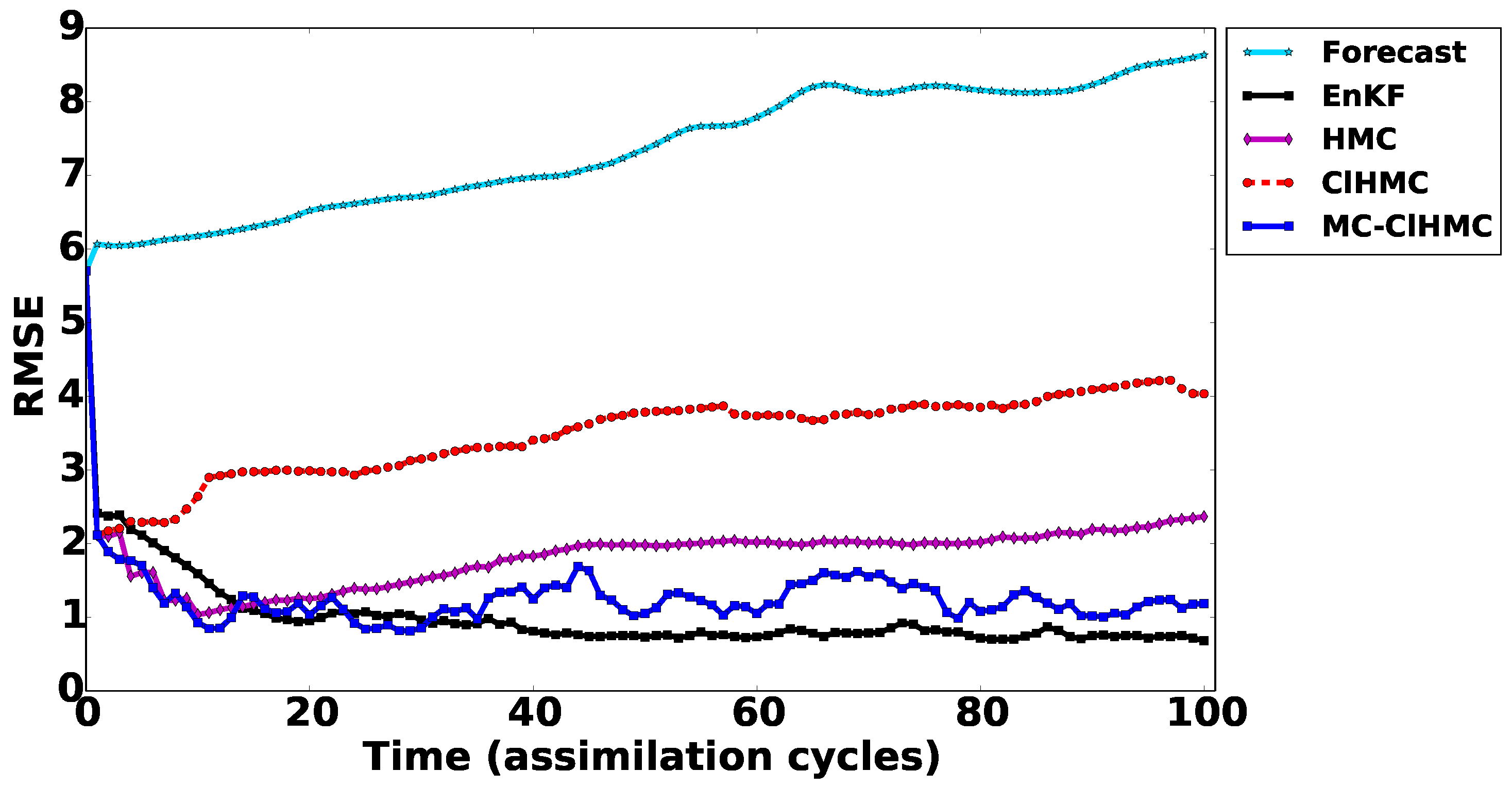
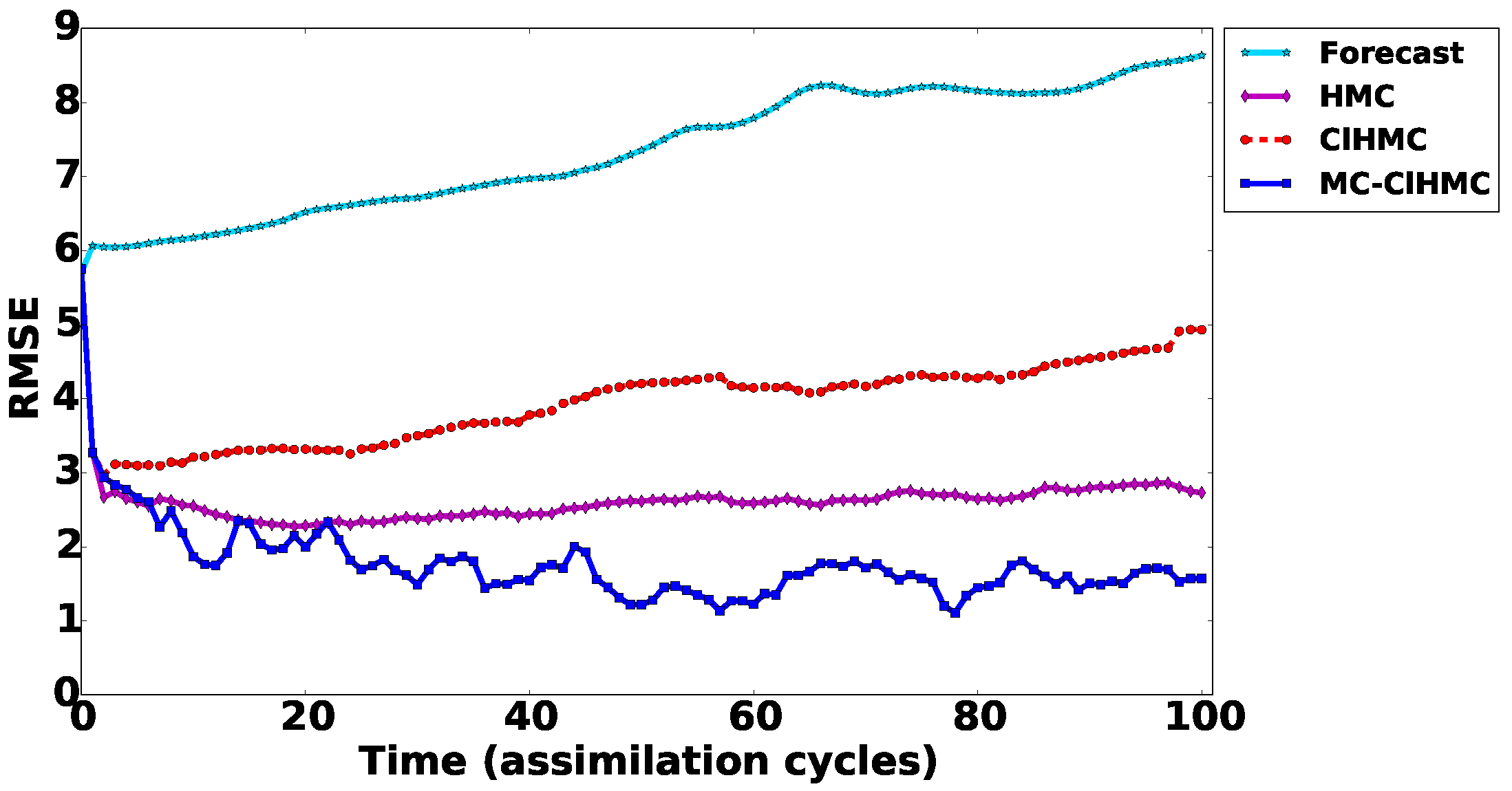
Figure 4 presents the RMSE (31) results of the analyses obtained using EnKF, HMC, , and MC- filters in the presence of a linear observation operator. Figure 4 shows that the results of all HMC filter versions improve quickly at the first few assimilation windows. While the results of the original HMC filter improve quickly at the first few assimilation windows, the performance of the original HMC filter degrades compared to the DEnKF filter performance especially in the long run. We believe that the two main factors contribute to the HMC filter degradation are the parameter tuning, and the development of non-Gaussianity in the prior distribution. The analysis drifts away quickly from the true trajectory. This is mainly because the HMC sampling strategy is unable to cover all probability modes in the posterior distribution. To guarantee that the sampling filter covers the truth well, the sampler has to be able to sample properly from all posterior probability modes. This is achieved by design by the MC- filter. The MC- version produces RMSE results comparable to the RMSE obtained by DEnKF.
As discussed in [17] the performance of HMC filter can be further enhanced by automatically tuning the parameters of the symplectic integrator at the beginning of each assimilation cycle. Here however we are mainly interested in assessing the performance of the new methodologies compared to the original HMC filter using equivalent settings.
It is important to note that the MC- filter requires shorter Hamiltonian trajectories to explore the space under each local mixture component, which results in computational savings. Additional savings can be obtains by running the chains in parallel to sample different regions of the posterior.
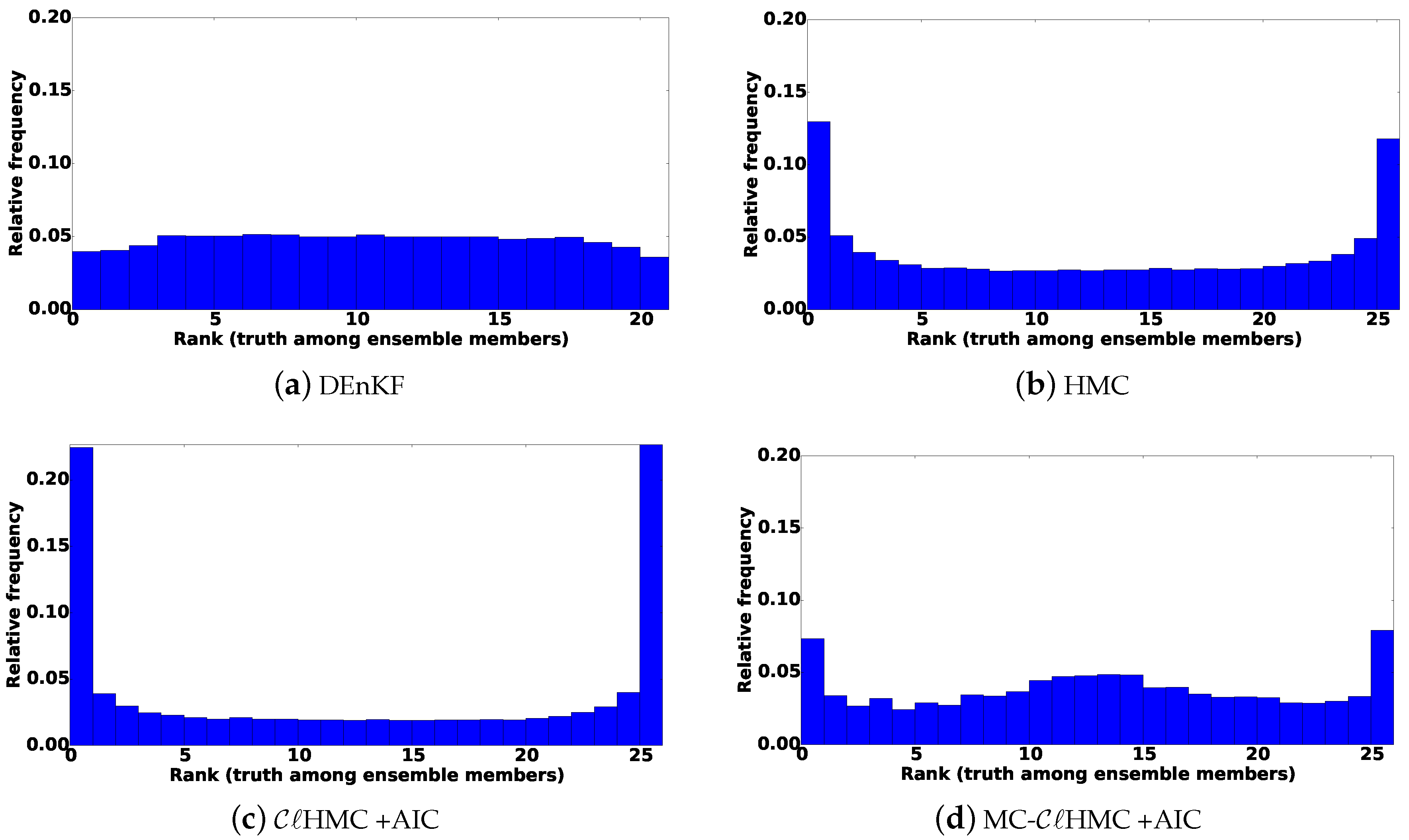
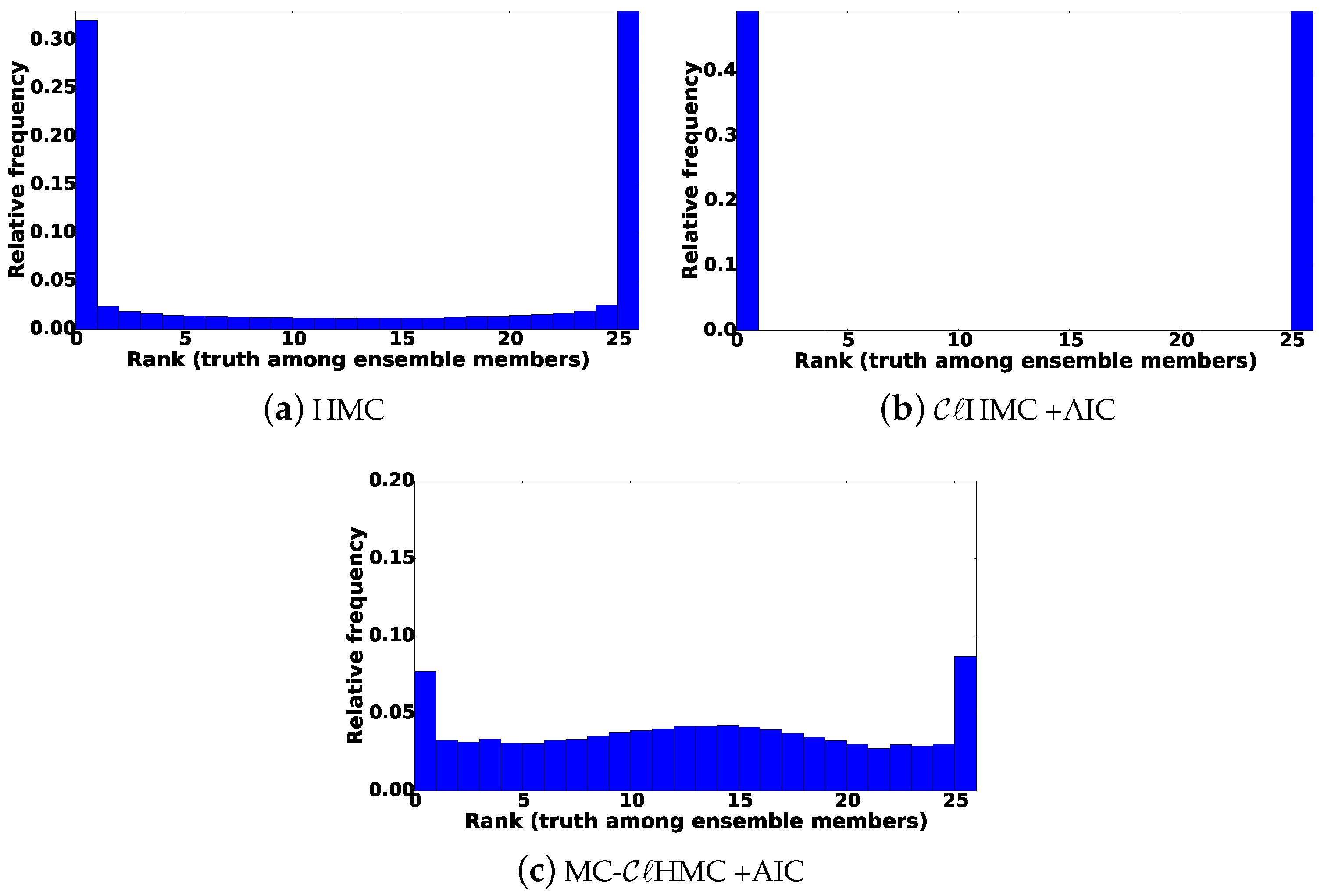
Since we are not interested in only a single best estimate of the true state of the system, RMSE alone is not sufficient to judge the quality of the filtering system. The analysis ensemble sampled from the posterior should be spread widely enough to cover the truth and avoid filter collapse. The rank histograms of the analysis ensembles are shown in Figure 5. Generally speaking, Talagrand diagram is a histogram constructed by calculating the rank of the true state, compared to the ensemble members ordered increasingly in magnitude. The ranks are calculated over several assimilation cycles, for individual entries of the true state with respect to the corresponding entries of the ensemble members. Observations are used instead of model states in real experiments where the truth is unknown. A U-shaped rank histogram indicates an under-dispersed ensemble, while a mound rank histogram indicates over-dispersion. A nearly-uniform rank histogram is desirable, and suggests that the truth is indistinguishable from the ensemble members.
The two small spikes in Figure 5b suggest that the performance of the original HMC filter could be enhanced by increasing the length of the Hamiltonian trajectories in some assimilation cycles.
The rank histogram shown in Figure 5c shows that the analysis ensembles produced by the filter tend to be under-dispersed. Since the ensemble size is relatively small and the prior GMM is multimodal, with regions of low-probability between the different mixture components, a multimodal mixture posterior with isolated components is obtained. As explained in [44], this is a case where HMC sampling in general can suffer from being entrapped in a local minimum (and fails to jump between different high probability modes). This behavior is expected to result in ensemble collapse, as seen in Figure 5c, leading to filter degradation in the long run as illustrated by the RMS errors shown in Figure 4.
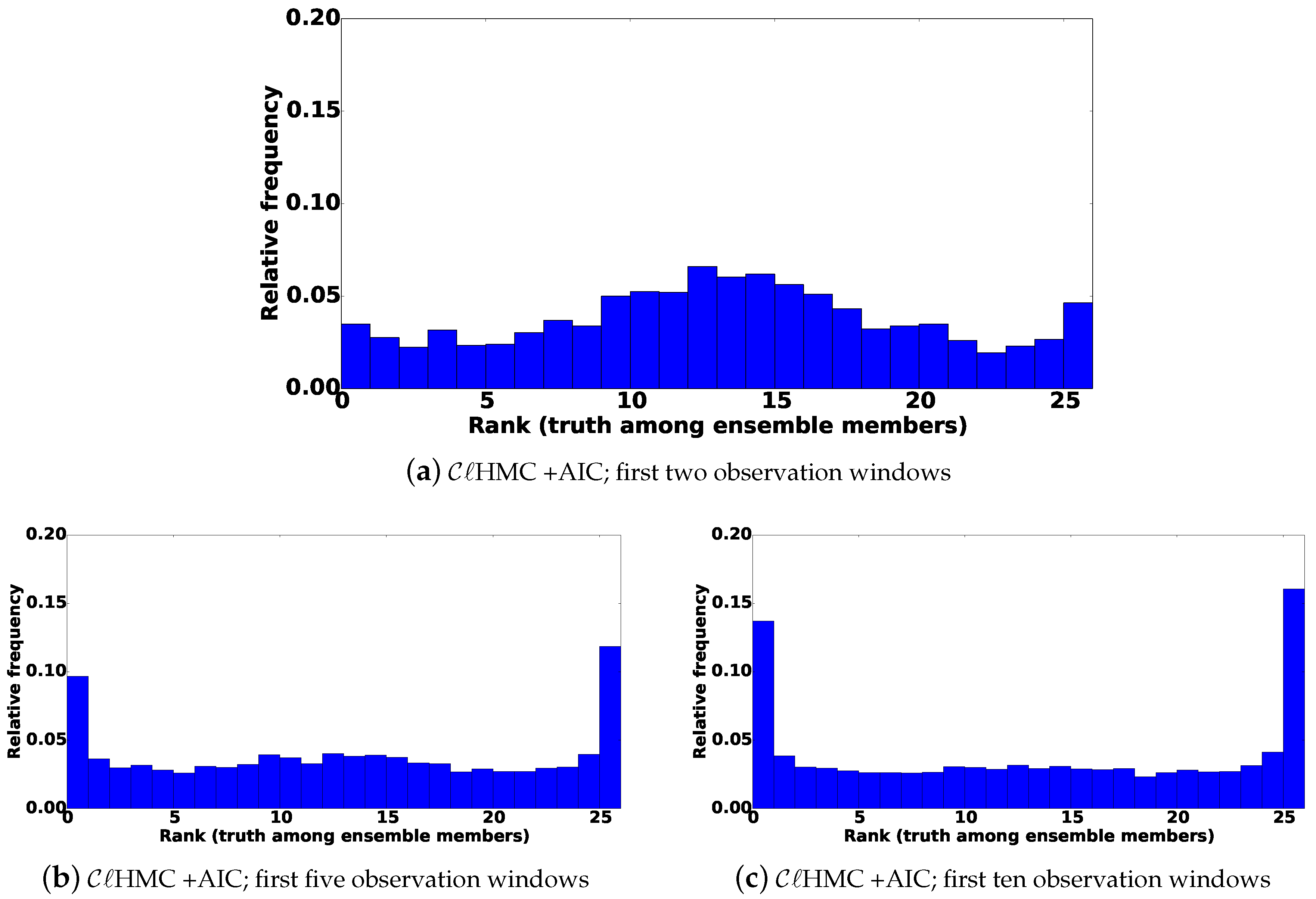
The results shown in Figure 5c suggest that the analysis ensemble collected by fails to cover all mixture components, thereby losing its dispersion when it is applied repetitively. This is supported by the results in Figure 6, where the rank histograms are plotted using results from the first two, five, and 10 cycles, respectively.
The ensemble collapse can be avoided if we force the sampler to collect ensemble members from all the probability modes. This is illustrated by the rank histograms of results obtained using the MC- filter with AIC criteria as shown in Figure 5d.
We believe that having isolated regions of high probability, e.g., with very small number of ensemble members in each component, can be the critical factor leading the poor long-term performance of . This is alleviated here by imposing a minimum number of 3 ensemble points in each component, e.g., via hard assignment, of the mixture while constructing the GMM approximation of the prior.
With automatic tuning of the Hamiltonian parameters the performance of both HMC and MC- filters is expected to be greatly enhanced. We have only shown the results of , and MC- with AIC information criterion; experiments carried out using other model selection criteria such as BIC have proven to be very similar.
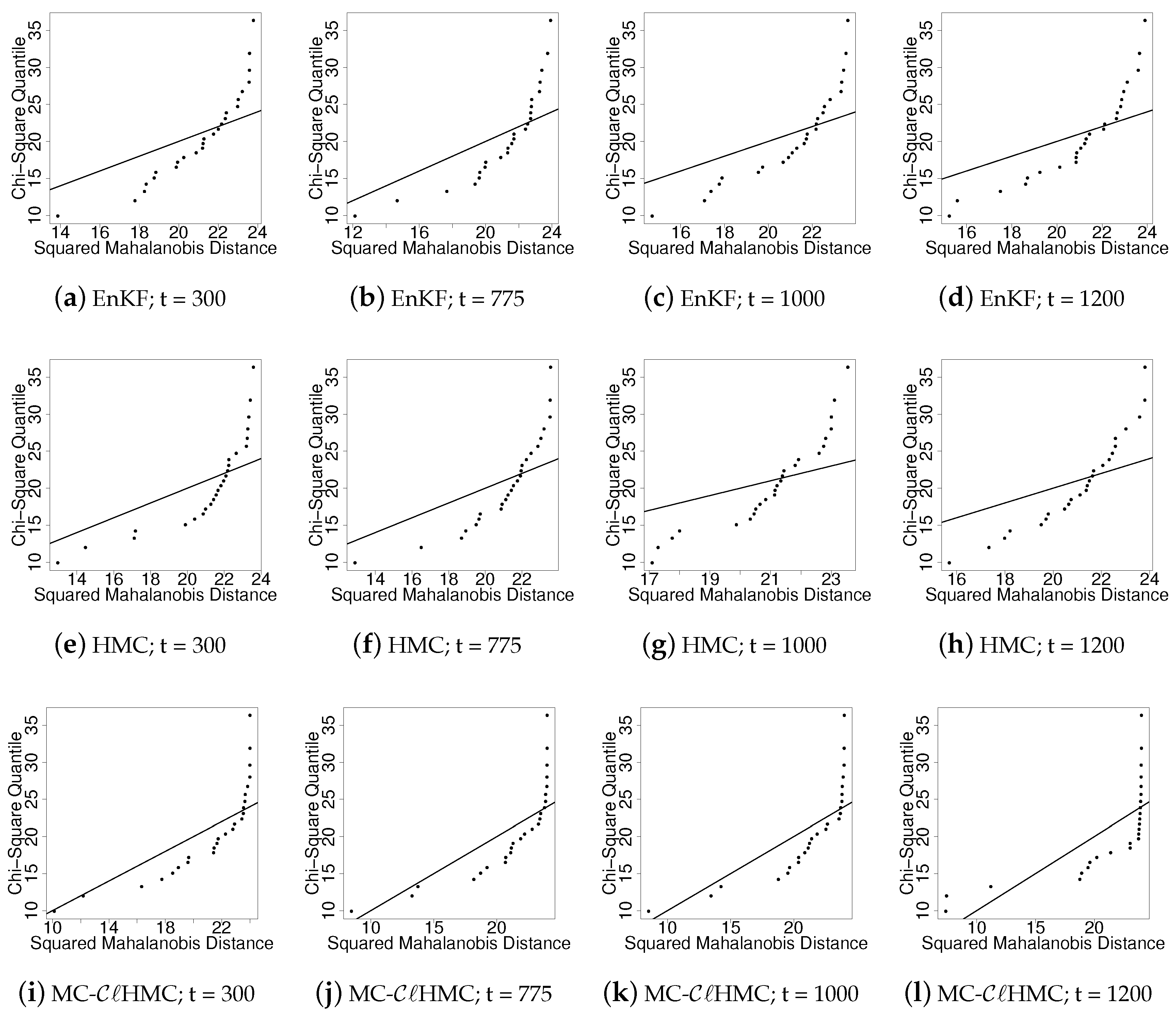
To help decide whether to apply the original formulation of the HMC filter, or the proposed methodology, one can run tests of non-Gaussianity on the forecast ensemble. To asses non-Gaussianity of the forecast several numeric or visualization normality tests are available, e.g., the Mardia test [45] based on multivariate extensions of skewness and kurtosis measures. Indication of non-Gaussianity can be found by visually inspecting several bivariate contour plots of the joint distribution of selected components in the state vector. Visualization methods for multivariate normality assessment such as chi-square QQ-plots can be very useful as well. Given a multivariate normal random variable , the squared Mahalanobis distance follow a Chi-Squared distribution. Multivariate QQ-plot assesses the normality of a random variable , by comparing the quantiles of a sample of Mahalanobis distances to the quantiles of the correct Chi-Squared distribution, under the normality assumption. Deviations from the true distribution, e.g., the solid line in Figure 7, indicate possible departure of the sampled variable from multivariate normality.
Figure 7 shows several chi-square Q-Q plots of the forecast ensembles generated from the result of EnKF, HMC, and MC- filters at different time instances. These plots show strong signs of non-Gaussianity in the forecast ensemble, and suggest that the Gaussian-prior assumption may in general lead to inaccurate conclusions.
4.2.5. Results with Nonlinear Wind-Magnitude Observations
In the presence of a nonlinear observation operator the distribution is expected to show even stronger signs of non-Gaussianity. With stronger non-Gaussianity, the cluster methodology is expected to outperform the original formulation of the HMC sampling filter. In the settings used in this Section, EnKF diverges after the third cycle, and its results are omitted for clarity.
Figure 8 shows RMSE results, with the nonlinear observation operator (30), for the analyses obtained by HMC, , MC- filtering systems. While EnKF diverges quickly under these settings, the HMC algorithms, i.e., HMC, , and MC- sampling filters, continue to show behavior similar to the case where the linear observation operator is used (Section 4.2.4).
Figure 9 shows rank histograms of HMC, , and MC-, with a nonlinear observation operator. We can see that performance is similar to the case when the linear observation operator is used. It seems to be entrapped into a local minimum losing its dispersion quickly. The results of the MC- filter avoid this effect and show a reasonable spread.
The results presented here suggest that the cluster formulation of the HMC sampling filter is advantageous, especially in the presence of highly nonlinear observation operator, or strong indication of non-Gaussianity.
5. Conclusions and Future Work
This work presents a set of fully non-Gaussian sampling filters for sequential data assimilation. The filters use a GMM to approximate the prior distribution, given the forecast ensemble. The posterior mixture distribution is directly sampled following a MCMC approach. Several proposals are suggested for the MCMC sampling step. The filter uses a Gaussian proposal, and follows a HMC approach for sampling the posterior, using a single Markov chain. These two versions may suffer from high-rejection rates, and may fail to sample all posterior probability modes, especially in highly non-linear settings. More efficient multi-chain versions of and , namely MC- and MC- respectively, are developed in order to alleviate such difficulties.
Numerical experiments are carried out using a simple one-dimensional example, and a nonlinear 1.5-layer reduced-gravity quasi geostrophic model in the presence of observation operators of different levels of nonlinearity. The results show that the new methodologies are much more efficient that the original HMC sampling filter especially in the presence of a highly nonlinear observation operator.
The multi-chain cluster sampling filters, MC- and MC-, deserve further investigation. For example the local sample sizes here are selected based on the prior weight multiplied by the likelihood of the corresponding component mean. An optimal selection of the local ensemble size is required to guarantee efficient sampling from the target distribution.
Instead of using MC- filter, one can use with geometrically tempered Hamiltonian sampler as recently proposed in [44], such as to guarantee navigation between separate modes of the posterior. Alternatively, the posterior distribution can be split into target distributions with different potential energy functions and associated gradients. This is equivalent to running independent HMC sampling filters in different regions of the state space under the target posterior.
The authors have started to investigate the ideas discussed here, in addition to testing the proposed methodologies with automatically tuned HMC samplers.
Author Contributions
A.A. and A.S. conceived and designed the experiments; A.A. and A.M. performed the experiments and analyzed the data; A.A., A.M., and A.S. wrote the paper.
Acknowledgments
This work was supported in part by the Air Force Office of Scientific Research (AFOSR) Dynamic Data Driven Application Systems program, by the National Science Foundation award NSF CCF (Algorithmic foundations)–1218454, and by the Computational Science Laboratory (CSL) in the Department of Computer Science at Virginia Tech. The submitted manuscript has been created by UChicago Argonne, LLC, Operator of Argonne National Laboratory (“Argonne"). Argonne, a U.S. Department of Energy Office of Science laboratory, is operated under Contract No. DE-AC02-06CH11357. The U.S. Government retains for itself, and others acting on its behalf, a paid-up nonexclusive, irrevocable worldwide license in said article to reproduce, prepare derivative works, distribute copies to the public, and perform publicly and display publicly, by or on behalf of the Government.
Conflicts of Interest
The authors declare no conflict of interest. The founding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
References
- Kalman, R.E. A new approach to linear filtering and prediction problems. Trans. ASME 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Kalman, R.E.; Bucy, R.S. New results in linear filtering and prediction theory. J. Basic Eng. 1961, 83, 95–108. [Google Scholar] [CrossRef]
- Burgers, G.; Jan van Leeuwen, P.; Evensen, G. Analysis scheme in the Ensemble Kalman Filter. Mon. Weather Rev. 1998, 126, 1719–1724. [Google Scholar] [CrossRef]
- Evensen, G. Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forcast error statistics. J. Geophys. Res. 1994, 99, 10143–10162. [Google Scholar] [CrossRef]
- Evensen, G. The Ensemble Kalman Filter: theoretical formulation and practical implementation. Ocean Dyn. 2003, 53, 343–367. [Google Scholar] [CrossRef]
- Houtekamer, P.L.; Mitchell, H.L. Data assimilation using an ensemble Kalman filter technique. Mon. Weather Rev. 1998, 126, 796–811. [Google Scholar] [CrossRef]
- Hamill, T.M.; Whitaker, J.S.; Snyder, C. Distance-dependent filtering of background error covariance estimates in an ensemble Kalman filter. Mon. Weather Rev. 2001, 129, 2776–2790. [Google Scholar] [CrossRef]
- Houtekamer, P.L.; Mitchell, H.L. A sequential ensemble Kalman filter for atmospheric data assimilation. Mon. Weather Rev. 2001, 129, 123–137. [Google Scholar] [CrossRef]
- Whitaker, J.S.; Hamill, T.M. Ensemble data assimilation without perturbed observations. Mon. Weather Rev. 2002, 130, 1913–1924. [Google Scholar] [CrossRef]
- Sakov, P.; Oliver, D.S.; Bertino, L. An iterative EnKF for strongly nonlinear systems. Mon. Weather Rev. 2012, 140, 1988–2004. [Google Scholar] [CrossRef]
- Smith, K.W. Cluster ensemble Kalman filter. Tellus A 2007, 59, 749–757. [Google Scholar] [CrossRef]
- Tippett, M.K.; Anderson, J.L.; Bishop, C.H.; Hamill, T.M.; Whitaker, J.S. Ensemble square root filters. Mon. Weather Rev. 2003, 131, 1485–1490. [Google Scholar] [CrossRef]
- Lorenc, A.C. Analysis methods for numerical weather prediction. Q. J. R. Meteorol. Soc. 1986, 112, 1177–1194. [Google Scholar] [CrossRef]
- Zupanski, M. Maximum likelihood ensemble filter: Theoretical aspects. Mon. Weather Rev. 2005, 133, 1710–1726. [Google Scholar] [CrossRef]
- Zupanski, M.; Navon, I.M.; Zupanski, D. The Maximum Likelihood Ensemble Filter as a non-differentiable minimization algorithm. Q. J. R. Meteorol. Soc. 2008, 134, 1039–1050. [Google Scholar] [CrossRef]
- Gu, Y.; Oliver, D.S. An iterative ensemble Kalman filter for multiphase fluid flow data assimilation. SPE J. 2007, 12, 438–446. [Google Scholar] [CrossRef]
- Attia, A.; Sandu, A. A Hybrid Monte Carlo sampling filter for non-Gaussian data assimilation. AIMS Geosci. 2015, 1, 41–78. [Google Scholar] [CrossRef]
- Attia, A.; Rao, V.; Sandu, A. A sampling approach for four dimensional data assimilation. In Dynamic Data-Driven Environmental Systems Science; Springer: Heidelberg/Berlin, Germany, 2015; pp. 215–226. [Google Scholar]
- Attia, A.; Rao, V.; Sandu, A. A Hybrid Monte-Carlo sampling smoother for four dimensional data assimilation. Int. J. Nume. Methods Fluids 2016, 83, 90–112. [Google Scholar] [CrossRef]
- Attia, A.; Stefanescu, R.; Sandu, A. The Reduced-Order Hybrid Monte Carlo Sampling Smoother. Int. J. Nume. Methods Fluids 2016, 83, 28–51. [Google Scholar] [CrossRef]
- Duane, S.; Kennedy, A.; Pendleton, B.J.; Roweth, D. Hybrid Monte Carlo. Phys. Lett. B 1987, 195, 216–222. [Google Scholar] [CrossRef]
- Toral, R.; Ferreira, A. A general class of hybrid Monte Carlo methods. Proc. Phys. Comput. 1994, 94, 265–268. [Google Scholar]
- Anderson, J.L.; Anderson, S.L. A Monte Carlo implementation of the nonlinear filtering problem to produce ensemble assimilations and forecasts. Mon. Weather Rev. 1999, 127, 2741–2758. [Google Scholar] [CrossRef]
- Besag, J.; Green, P.J. Spatial Statistics and Bayesian Computation; Wiley: Hoboken, NJ, USA, 1993; pp. 25–37. [Google Scholar]
- Sokal, A. Monte Carlo Methods in Statistical Mechanics: Foundations and New Algorithms; Springer: Heidelberg/Berlin, Germany, 1997. [Google Scholar]
- Higdon, D.M. Auxiliary variable methods for Markov chain Monte Carlo with applications. J. Am. Stat. Assoc. 1998, 93, 585–595. [Google Scholar] [CrossRef]
- Neal, R. MCMC using Hamiltonian dynamics. In Handbook of Markov Chain Monte Carlo; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Sanz-Serna, J.; Calvo, M.-P. Numerical Hamiltonian Problems; Chapman & Hall: London, UK, 1994; Volume 7. [Google Scholar]
- Sanz-Serna, J. Markov chain Monte Carlo and numerical differential equations. In Current Challenges in Stability Issues for Numerical Differential Equations; Springer: Heidelberg/Berlin, Germany, 2014; pp. 39–88. [Google Scholar]
- Homan, M.; Gelman, A. The no-U-turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo. J. Mach. Learn. Res. 2014, 15, 1593–1623. [Google Scholar]
- Girolami, M.; Calderhead, B. Riemann manifold langevin and hamiltonian monte carlo methods. J. R. Stat. Soc. Ser. B 2011, 73, 123–214. [Google Scholar] [CrossRef]
- Bilmes, J.A. A gentle tutorial of the EM algorithm and its application to parameter estimation for Gaussian mixture and hidden Markov models. Int. Comput. Sci. Institute 1998, 4, 126. [Google Scholar]
- Shalizi, C.R. Advanced Data Analysis from an Elementary Point of View; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–38. [Google Scholar]
- Hu, X.; Xu, L. Investigation on several model selection criteria for determining the number of cluster. Neur. Inf. Proc. Lett. Rev. 2004, 4, 1–10. [Google Scholar]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Sakov, P.; Oke, P.R. A deterministic formulation of the ensemble Kalman filter: an alternative to ensemble square root filters. Tellus A 2008, 60, 361–371. [Google Scholar] [CrossRef]
- Attia, A.; Sandu, A. DATeS: A Highly-Extensible Data Assimilation Testing Suite. arXiv, 2018; arXiv:1704.05594. [Google Scholar]
- Attia, A.; Glandon, R.; Tranquilli, P.; Narayanamurthi, M.; Sarshar, A.; Sandu, A. DATeS: A Highly-Extensible Data Assimilation Testing Suite. 2016. Available online: people.cs.vt.edu/~attia/DATeS (accessed on 28 May 2012).
- Gaspari, G.; Cohn, S.E. Construction of correlation functions in two and three dimensions. Q. J. R. Meteorol. Soc. 1999, 125, 723–757. [Google Scholar] [CrossRef]
- Furrer, R.; Genton, M.G.; Nychka, D. Covariance tapering for interpolation of large spatial datasets. J. Comput. Gr. Stat. 2006, 15, 502–523. [Google Scholar] [CrossRef]
- Anderson, J.L. A method for producing and evaluating probabilistic forecasts from ensemble model integrations. J. Clim. 1996, 9, 1518–1530. [Google Scholar] [CrossRef]
- Candille, G.; Talagrand, O. Evaluation of probabilistic prediction systems for a scalar variable. Q. J. R. Meteorol. Soc. 2005, 131, 2131–2150. [Google Scholar] [CrossRef]
- Nishimura, A.; Dunson, D. Geometrically Tempered Hamiltonian Monte Carlo. arXiv, 2016; arXiv:1604.00872. [Google Scholar]
- Mardia, K.V. Measures of multivariate skewness and kurtosis with applications. Biometrika 1970, 57, 519–530. [Google Scholar] [CrossRef]
Figure 1.
The one-dimensional example. A random sample of size generated from the “true” GMM prior with parameters given by (26), and a GMM constructed by EM algorithm with AIC model selection criterion.
Figure 1.
The one-dimensional example. A random sample of size generated from the “true” GMM prior with parameters given by (26), and a GMM constructed by EM algorithm with AIC model selection criterion.

Figure 2.
The one-dimensional example. A GMM prior, a Gaussian likelihood, and the resulting posterior, along with histograms of 1000 sample points generated by the (a), MC- (b), (c), and the MC- (d) sampling algorithms. The symplectic integrator used for HMC filters is Verlet with pseudo-time stepping parameters with , and . The number of burn-in steps is zero, and the number of mixing steps is 20.
Figure 2.
The one-dimensional example. A GMM prior, a Gaussian likelihood, and the resulting posterior, along with histograms of 1000 sample points generated by the (a), MC- (b), (c), and the MC- (d) sampling algorithms. The symplectic integrator used for HMC filters is Verlet with pseudo-time stepping parameters with , and . The number of burn-in steps is zero, and the number of mixing steps is 20.

Figure 3.
The QG-1.5 model. The red dots in (a) indicate the location of observations for one of the test cases employed.
Figure 3.
The QG-1.5 model. The red dots in (a) indicate the location of observations for one of the test cases employed.

Figure 4.
Data assimilation results with the linear observation operator. RMSE of the (31) analyses obtained by EnKF, HMC, , and MC- filters. Forecast results here refer to the RMSE obtained from a free run of the dynamical model, with initial condition set to the forecast state at the initial time.
Figure 4.
Data assimilation results with the linear observation operator. RMSE of the (31) analyses obtained by EnKF, HMC, , and MC- filters. Forecast results here refer to the RMSE obtained from a free run of the dynamical model, with initial condition set to the forecast state at the initial time.

Figure 5.
Data assimilation results with the linear observation operator. The rank histograms of where the truth ranks among posterior ensemble members. The ranks are evaluated for every 16th variable in the state vector (past the correlation bound) at 100 assimilation times.
Figure 5.
Data assimilation results with the linear observation operator. The rank histograms of where the truth ranks among posterior ensemble members. The ranks are evaluated for every 16th variable in the state vector (past the correlation bound) at 100 assimilation times.

Figure 6.
Data assimilation results using a linear observation operator. Rank histograms of where the truth ranks among posterior ensemble members. The ranks are evaluated for every 16th variable in the state vector (past the correlation bound). Rank histograms of results obtained at the first two, five, and 10 assimilation cycles, respectively, are shown. The model selection criterion used is AIC.
Figure 6.
Data assimilation results using a linear observation operator. Rank histograms of where the truth ranks among posterior ensemble members. The ranks are evaluated for every 16th variable in the state vector (past the correlation bound). Rank histograms of results obtained at the first two, five, and 10 assimilation cycles, respectively, are shown. The model selection criterion used is AIC.

Figure 7.
Data assimilation with a linear observation operator. Chi-square Q-Q plots for the forecast ensembles obtained from propagating analyses of EnKF, HMC, and MC- filtering systems to times t = 300, 775, 1000, and 1200 provide a strong indication of non-Gaussianity. The filtering methodology, and the assimilation time are given under each panel. Localization is applied to the ensemble covariance matrix to avoid singularity while evaluating the Mahalanobis distances of the ensemble members.
Figure 7.
Data assimilation with a linear observation operator. Chi-square Q-Q plots for the forecast ensembles obtained from propagating analyses of EnKF, HMC, and MC- filtering systems to times t = 300, 775, 1000, and 1200 provide a strong indication of non-Gaussianity. The filtering methodology, and the assimilation time are given under each panel. Localization is applied to the ensemble covariance matrix to avoid singularity while evaluating the Mahalanobis distances of the ensemble members.

Figure 8.
Data assimilation results with the nonlinear observation operator (30). RMSE of the analyses obtained by HMC, , and MC- filtering schemes. The Forecast RMSE results are obtained from a free run of the dynamical model.
Figure 8.
Data assimilation results with the nonlinear observation operator (30). RMSE of the analyses obtained by HMC, , and MC- filtering schemes. The Forecast RMSE results are obtained from a free run of the dynamical model.

Figure 9.
Data assimilation results using the nonlinear observation operator (30). The rank histograms of where the truth ranks among posterior ensemble members. The ranks are evaluated for every 16th variable in the state vector (past the correlation bound) at 100 assimilation times. The filtering scheme used is indicated under each panel.
Figure 9.
Data assimilation results using the nonlinear observation operator (30). The rank histograms of where the truth ranks among posterior ensemble members. The ranks are evaluated for every 16th variable in the state vector (past the correlation bound) at 100 assimilation times. The filtering scheme used is indicated under each panel.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Acceptance rates of the cluster sampling filters, for the one-dimensional example.
| Sampling Filter | ||||
|---|---|---|---|---|
| MC- | MC- | |||
| Acceptance rate | 44.32 | 77.39 | 99.21 | 99.23 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Attia, A.; Moosavi, A.; Sandu, A. Cluster Sampling Filters for Non-Gaussian Data Assimilation. Atmosphere 2018, 9, 213. https://doi.org/10.3390/atmos9060213
AMA Style
Attia A, Moosavi A, Sandu A. Cluster Sampling Filters for Non-Gaussian Data Assimilation. Atmosphere. 2018; 9(6):213. https://doi.org/10.3390/atmos9060213
Chicago/Turabian StyleAttia, Ahmed, Azam Moosavi, and Adrian Sandu. 2018. "Cluster Sampling Filters for Non-Gaussian Data Assimilation" Atmosphere 9, no. 6: 213. https://doi.org/10.3390/atmos9060213
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.