Deep Refinement Network for Natural Low-Light Image Enhancement in Symmetric Pathways

Abstract
:1. Introduction
- To the best of our knowledge, we are the first to apply deep refinement network to low-light image enhancement. In our approach, high-level features with global information are fused with the low-level features with local information. By means of the long-range residual links and connections, the proposed network can effectively propagate the gradient backwards to the earlier layers in the network;
- An effective loss for mixed noise is also designed to improve the performance of our method under the real low-light condition.
- In addition, whole images are used for our training process instead of image patches, which avoids the problem of dealing with small patches and helps our method to achieve better results.
- Through comprehensive experiments on natural and synthetic low-light images, the proposed LL-RefineNet is demonstrated to outperform state-of-the-art models compared with benchmark algorithms both qualitatively and quantitatively with high processing speed.
2. Related Work
2.1. Traditional Low-Light Image Enhancement Methods
2.2. Deep Learning Methods in Image Process Applications
2.3. Deep Learning Methods for Low-Light Image Enhancement
3. The Proposed Model
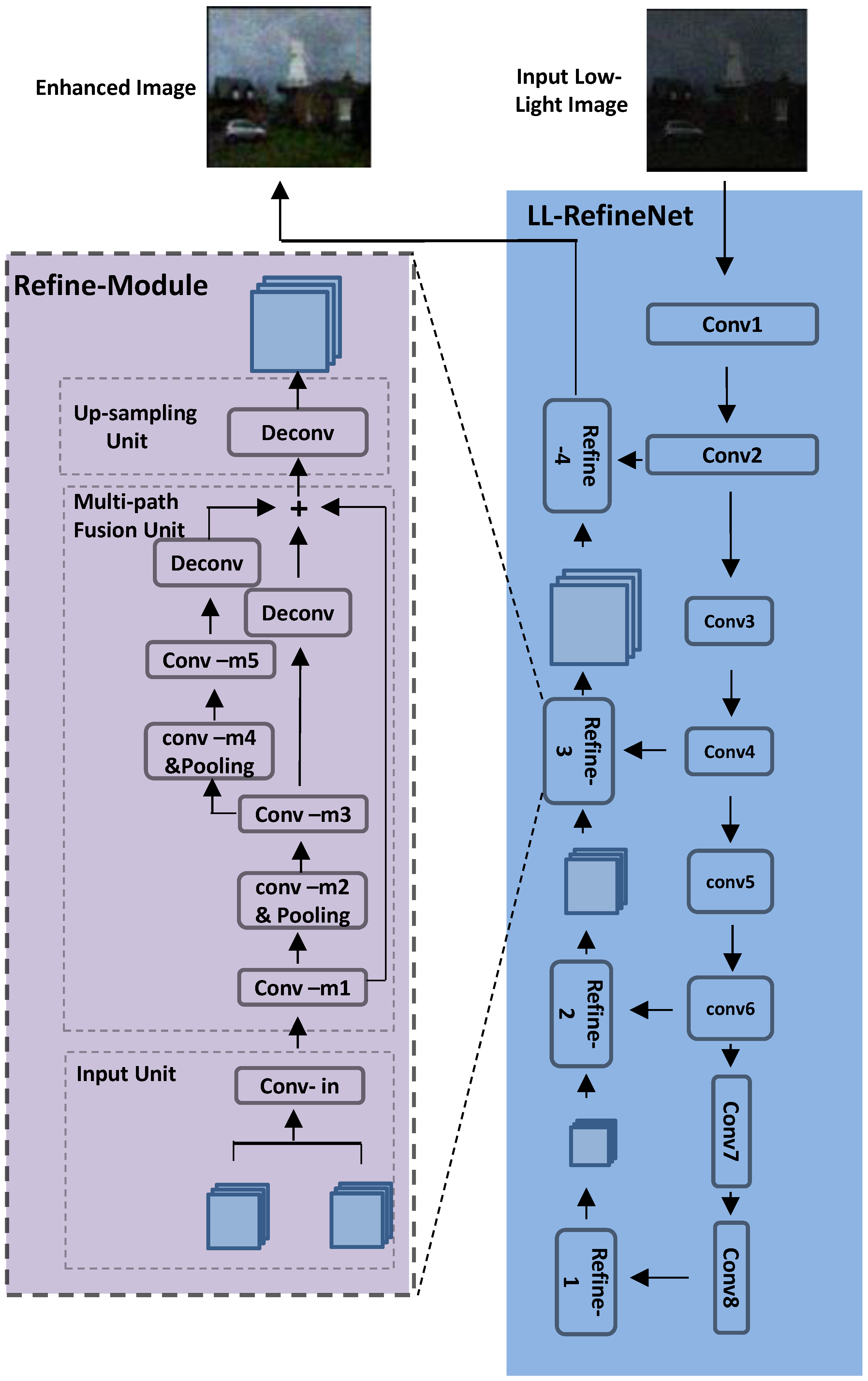
3.1. Refinement in Symmetric Pathways
3.2. LL-RefineNet
- Input unit:Two inputs are passed to each input unit, which are the feature maps generated by the previous refinement sub-net and the intermediate feature maps from the encoder part. The input unit performs concatenation for the two inputs, and then processes the inputs by a convolution layer (conv-in in Figure 2).
- Multi-path fusion unit:The network then passes the feature maps output by the input unit to the next module: the multi-path fusion unit. In this unit, context information is further learned from a larger receptive range. Features are extracted with the help of increasing window sizes, which are then fused to produce output feature maps for subsequent processing. We are motivated by the fact that multi-scale feature fusion performed by deep learning approaches can help the network to be more robust to the scales of images. The multi-path fusion unit is designed as a combination of multiple convolution layers (conv-m1 to conv-m5). Among these layers, two convolution layers (conv-m2 and conv-m4 ) are followed by pooling operations that are utilized to achieve a larger receptive field. Conv-m2 and conv-m3 further re-use the feature maps from conv-m1 to generate more complex feature representations. In a similar manner, conv-m4 and conv-m5 continue to use the feature maps generated by conv-m3. In the end, feature maps obtained from multiple paths are combined by summation, where deconvolution operations are used to achieve the same spatial resolutions.For the proposed multi-path fusion unit, the computation of output y with given input x is expressed as:where f represents the corresponding convolution function. In the proposed multi-path fusion unit, the multiple paths from the input to the output contribute to learning complex features. Furthermore, the various residual links help to perform direct gradient propagation and achieve more efficient end-to-end learning processes.
- Up-sampling unit:Following the multi-path fusion unit, the spatial resolution of the output features maps is enlarged by a deconvolution layer. The resulting features are then passed to the next refinement sub-net for further processing.
3.3. Loss for Mixed Noise
3.4. Network Training and Training Data Generation
4. Experiments and Results Analysis
4.1. Compared Methods
- Contrast-limiting adaptive histogram equalization (CLAHE)Different from the conventional histogram equalization algorithm, the contrast-limiting adaptive histogram equalization [26] (CLAHE) adds contrast limiting to further improve the enhancement result. In this method, each neighborhood in the input image is processed by the contrast limiting strategy instead of a global process in the traditional histogram equalization algorithm. The CLAHE approach also outperforms the previous histogram equalization approach as it suppresses the over-amplification of noise.
- Contrast-limiting adaptive histogram equalization with 3D block matching (CLAHE + BM3D)As one of the state-of-the-art algorithms for image denoising, BM3D [32] is also applied in the low-light enhancement task. Based on the 3D array of grouped image patches, the BM3D algorithm first utilizes Wiener filter in a collaborative form and then jointly performs the denoising process for the grouped patches. In the HE + BM3D method, equalize the image contrast using the CLAHE algorithm first and then apply BM3D to denoise the resulting images and get the final result.
- Gradient-based Total VariationThis work [51] studies gradient-based schemes for image denoising problems based on the discretized total variation (TV) minimization model with constraints. An acceleration of the well known dual approach is combined with the denoising problem with a novel monotone version of a fast iterative shrinkage/thresholding algorithm.
- Multiresolution Bilateral FilteringThis method [52] presents a new image denoising framework based on multi-resolution bilateral filtering, which turns out to be very effective in eliminating noise in real noisy images.
- Low-light convolutional neural network (LLCNN)In the LLCNN [48] framework, deep residual convolutional neural network is designed to enhance the input low-light images. In the training process, darkening and Gaussian noise are added to clear source images to generate the training data. The resulting network is used to enhance the low-light images. Our approach is closely related to LLCNN, while the proposed model shows superior performance and robustness to mixed noise.
4.2. Quantitative Evaluation
4.3. Qualitative Evaluation
4.4. Running Time
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 6, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Rezaee, H.; Abdollahi, F. A decentralized cooperative control scheme with obstacle avoidance for a team of mobile robots. IEEE Trans. Ind. Electron. 2014, 61, 347–354. [Google Scholar] [CrossRef]
- Luo, R.C.; Lai, C.C. Multisensor fusion-based concurrent environment mapping and moving object detection for intelligent service robotics. IEEE Trans. Ind. Electron. 2014, 61, 4043–4051. [Google Scholar] [CrossRef]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Gr. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Yamasaki, A.; Takauji, H.; Kaneko, S.I.; Kanade, T.; Ohki, H. Denighting: Enhancement of nighttime images for a surveillance camera. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Dong, X.; Wang, G.; Pang, Y.; Li, W.; Wen, J.; Meng, W.; Lu, Y. Fast efficient algorithm for enhancement of low lighting video. In Proceedings of the 2011 IEEE International Conference on Multimedia and Expo, Barcelona, Spain, 11–15 July 2011. [Google Scholar]
- Połap, D.; Winnicka, A.; Serwata, K.; Kęsik, K.; Woźniak, M. An Intelligent System for Monitoring Skin Diseases. Sensors 2018, 18, 2552. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Glowacz, A.; Glowacz, Z. Diagnosis of the three-phase induction motor using thermal imaging. Infrared Phys. Technol. 2016, 81, 7–16. [Google Scholar] [CrossRef]
- Wozniak, M.; Polap, D. Adaptive neuro-heuristic hybrid model for fruit peel defects detection. Neural Netw. 2018, 98, 16–33. [Google Scholar] [CrossRef] [PubMed]
- Wozniak, M.; Polap, D.; Capizzi, G.; Sciuto, G.L.; Kosmider, L.; Frankiewicz, K. Small lung nodules detection based on local variance analysis and probabilistic neural network. Comput. Methods Progr. Biomed. 2018, 161, 173–180. [Google Scholar] [CrossRef] [PubMed]
- Woźniak, M.; Połap, D. Bio-inspired methods modeled for respiratory disease detection from medical images. Swarm Evol. Comput. 2018, 41, 69–96. [Google Scholar] [CrossRef]
- Wozniak, M.; Polap, D.; Komider, L.; Clapa, T. Automated fluorescence microscopy image analysis of Pseudomonas aeruginosa bacteria in alive and dead stadium. Eng. Appl. Artif. Intell. 2018, 67, 100–110. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ganovska, B.; Molitoris, M.; Hosovsky, A.; Pitel, J.; Krolczyk, J.B.; Ruggierio, A.; Krolczyk, G.M.; Hloch, S. Design of the model for the on-line control of the AWJ technology based on neural networks. Indian J. Eng. Mater. Sci. 2016, 23, 279–287. [Google Scholar]
- Tadeusiewicz, R. Neural networks in mining sciences-general overview and some representative examples. Arch. Min. Sci. 2015, 60, 971–984. [Google Scholar] [CrossRef]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.S.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning. Cell 2018, 172, 1122–1131. [Google Scholar] [CrossRef] [PubMed]
- Jia, F.; Lei, Y.; Lu, N.; Xing, S. Deep normalized convolutional neural network for imbalanced fault classification of machinery and its understanding via visualization. Mech. Syst. Signal Process. 2018, 110, 349–367. [Google Scholar] [CrossRef]
- Gajewski, J.; Vališ, D. The determination of combustion engine condition and reliability using oil analysis by MLP and RBF neural networks. Tribol. Int. 2017, 115, 557–572. [Google Scholar] [CrossRef]
- Li, C.; Min, X.; Sun, S.; Lin, W.; Tang, Z. Deepgait: A learning deep convolutional representation for view-invariant gait recognition using joint bayesian. Appl. Sci. 2017, 7, 210. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Small Object Detection in Optical Remote Sensing Images via Modified Faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef]
- Pan, Z.; Jiang, G.; Jiang, H.; Yu, M.; Chen, F.; Zhang, Q. Stereoscopic Image Super-Resolution Method with View Incorporation and Convolutional Neural Networks. Appl. Sci. 2017, 7, 526. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Pisano, E.D.; Zong, S.; Hemminger, B.M.; DeLuca, M.; Johnston, R.E.; Muller, K.; Braeuning, M.P.; Pizer, S.M. Contrast limited adaptive histogram equalization image processing to improve the detection of simulated spiculations in dense mammograms. J. Digit. Imaging 1998, 11, 193. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.T. Contrast enhancement using brightness preserving bi-histogram equalization. IEEE Trans. Consum. Electron. 1997, 43, 1–8. [Google Scholar]
- Abdullah-Al-Wadud, M.; Kabir, M.H.; Dewan, M.A.A.; Chae, O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Kaur, M.; Kaur, J.; Kaur, J. Survey of contrast enhancement techniques based on histogram equalization. Int. J. Adv. Comput. Sci. Appl. 2011, 2, 84–90. [Google Scholar] [CrossRef]
- Wu, X. A linear programming approach for optimal contrast-tone mapping. IEEE Trans. Image Process. 2011, 20, 1262–1272. [Google Scholar] [PubMed]
- Chan, R.H.; Ho, C.W.; Nikolova, M. Salt-and-pepper noise removal by median-type noise detectors and detail-preserving regularization. IEEE Trans. Image Process. 2005, 14, 1479–1485. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dabov, K.; Foi, A.; Katkovnik, V. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Elad, M.; Aharon, M. Image denoising via sparse and redundant representations over learned dictionaries. IEEE Trans. Image Process. 2006, 15, 3736–3745. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Shen, P.; Luo, L.; Zhang, L.; Song, J. Enhancement and noise reduction of very low light level images. In Proceedings of the 21st International Conference on Pattern Recognition, Tsukuba, Japan, 11–15 November 2012; pp. 2034–2037. [Google Scholar]
- Fotiadou, K.; Tsagkatakis, G.; Tsakalides, P. Low light image enhancement via sparse representations. In Proceedings of the 2014 International Conference on Image Analysis and Recognition, Vilamoura, Algarve, Portugal, 22–24 October 2014; pp. 84–93. [Google Scholar]
- Hu, Z.; Cho, S.; Wang, J.; Yang, M.H. Deblurring low-light images with light streaks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3382–3389. [Google Scholar]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Jung, C.; Yang, Q.; Sun, T.; Fu, Q.; Song, H. Low light image enhancement with dual-tree complex wavelet transform. J. Vis. Commun. Image Represent. 2017, 42, 28–36. [Google Scholar] [CrossRef]
- Mahendran, A.; Vedaldi, A. Understanding deep image representations by inverting them. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5188–5196. [Google Scholar]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [PubMed]
- Lin, K.; Yang, H.F.; Hsiao, J.H.; Chen, C.S. Deep Learning of Binary Hash Codes for Fast Image Retrieval. In Proceedings of the IEEE International Conference on Vision and Pattern Recognition, Deep Vision Workshop, Boston, MA, USA, 7–12 June 2015; pp. 27–35. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international conference on Machine learning, Helsinki, Finland, 5–9 June 2008; pp. 1096–1103. [Google Scholar]
- Agostinelli, F.; Anderson, M.R.; Lee, H. Adaptive multi-column deep neural networks with application to robust image denoising. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 1493–1501. [Google Scholar]
- Burger, H.C.; Schuler, C.J.; Harmeling, S. Image denoising: Can plain neural networks compete with BM3D? In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2392–2399. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I.D. RefineNet: Multi-path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, HI, USA, 21–26 July 2017; pp. 5168–5177. [Google Scholar]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep joint rain detection and removal from a single image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1357–1366. [Google Scholar]
- Tao, L.; Zhu, C.; Xiang, G.; Li, Y.; Jia, H.; Xie, X. LLCNN: A convolutional neural network for low-light image enhancement. In Proceedings of the 2017 IEEE Conference on Visual Communications and Image Processing, Saint Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Beck, A.; Teboulle, M. Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems. IEEE Trans. Image Process. 2009, 18, 2419–2434. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Gunturk, B.K. Multiresolution bilateral filtering for image denoising. IEEE Trans. Image Process. 2008, 17, 2324–2333. [Google Scholar] [CrossRef] [PubMed]
- Santoso, A.J.; Nugroho, L.E.; Suparta, G.B.; Hidayat, R. Compression ratio and peak signal to noise ratio in grayscale image compression using wavelet. Int. J. Comput. Sci. Technol. 2011, 2, 7–11. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comparative Items | PSNR-S (dB) | SSIM-S | RSME-S | PSNR-R (dB) | SSIM-R | RSME-R |
|---|---|---|---|---|---|---|
| Low-Light | 12.1566 | 0.2443 | 19.5874 | 9.8208 | 0.2529 | 21.0653 |
| CLAHE | 20.7378 | 0.5573 | 14.3576 | 19.6647 | 0.5486 | 15.0286 |
| Bilateral Filtering | 20.8287 | 0.5531 | 14.2782 | 20.0634 | 0.5467 | 14.7386 |
| Total Variation | 20.1785 | 0.5602 | 14.7139 | 20.4581 | 0.5495 | 14.4862 |
| CLAHE + BM3D | 20.9753 | 0.5545 | 14.1687 | 20.3876 | 0.5487 | 14.5440 |
| LLCNN | 21.6134 | 0.5661 | 13.8470 | 20.5389 | 0.5380 | 14.4333 |
| Proposed + loss | 22.5876 | 0.6299 | 13.2358 | 21.4700 | 0.5954 | 13.9007 |
| Proposed + mixed noise loss | 22.7723 | 0.6549 | 13.0996 | 21.7579 | 0.6259 | 13.6957 |
| Methods | Average Run Time (Seconds) |
|---|---|
| CLAHE | 8.64 (Intel i5-4200U CPU) |
| Bilateral Filtering | 3.22 (Intel i5-4200U CPU) |
| Total Variation | 15.17 (Intel i5-4200U CPU) |
| CLAHE + BM3D | 10.13 (Intel i5-4200U CPU) |
| LLCNN | 1.26 (K80 GPU) |
| Proposed method | 0.85 (K80 GPU) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, L.; Jing, Y.; Hu, S.; Ge, B.; Xiao, W. Deep Refinement Network for Natural Low-Light Image Enhancement in Symmetric Pathways. Symmetry 2018, 10, 491. https://doi.org/10.3390/sym10100491
Jiang L, Jing Y, Hu S, Ge B, Xiao W. Deep Refinement Network for Natural Low-Light Image Enhancement in Symmetric Pathways. Symmetry. 2018; 10(10):491. https://doi.org/10.3390/sym10100491
Chicago/Turabian StyleJiang, Lincheng, Yumei Jing, Shengze Hu, Bin Ge, and Weidong Xiao. 2018. "Deep Refinement Network for Natural Low-Light Image Enhancement in Symmetric Pathways" Symmetry 10, no. 10: 491. https://doi.org/10.3390/sym10100491
APA StyleJiang, L., Jing, Y., Hu, S., Ge, B., & Xiao, W. (2018). Deep Refinement Network for Natural Low-Light Image Enhancement in Symmetric Pathways. Symmetry, 10(10), 491. https://doi.org/10.3390/sym10100491