A Comparison of Regularization Techniques in Deep Neural Networks

Abstract
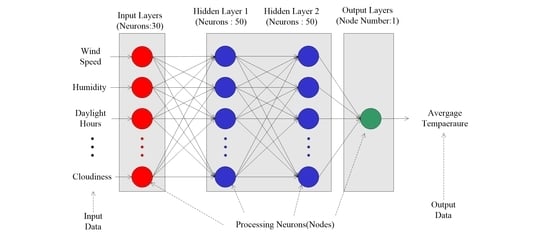
1. Introduction
2. Data and Methods
2.1. Methodology
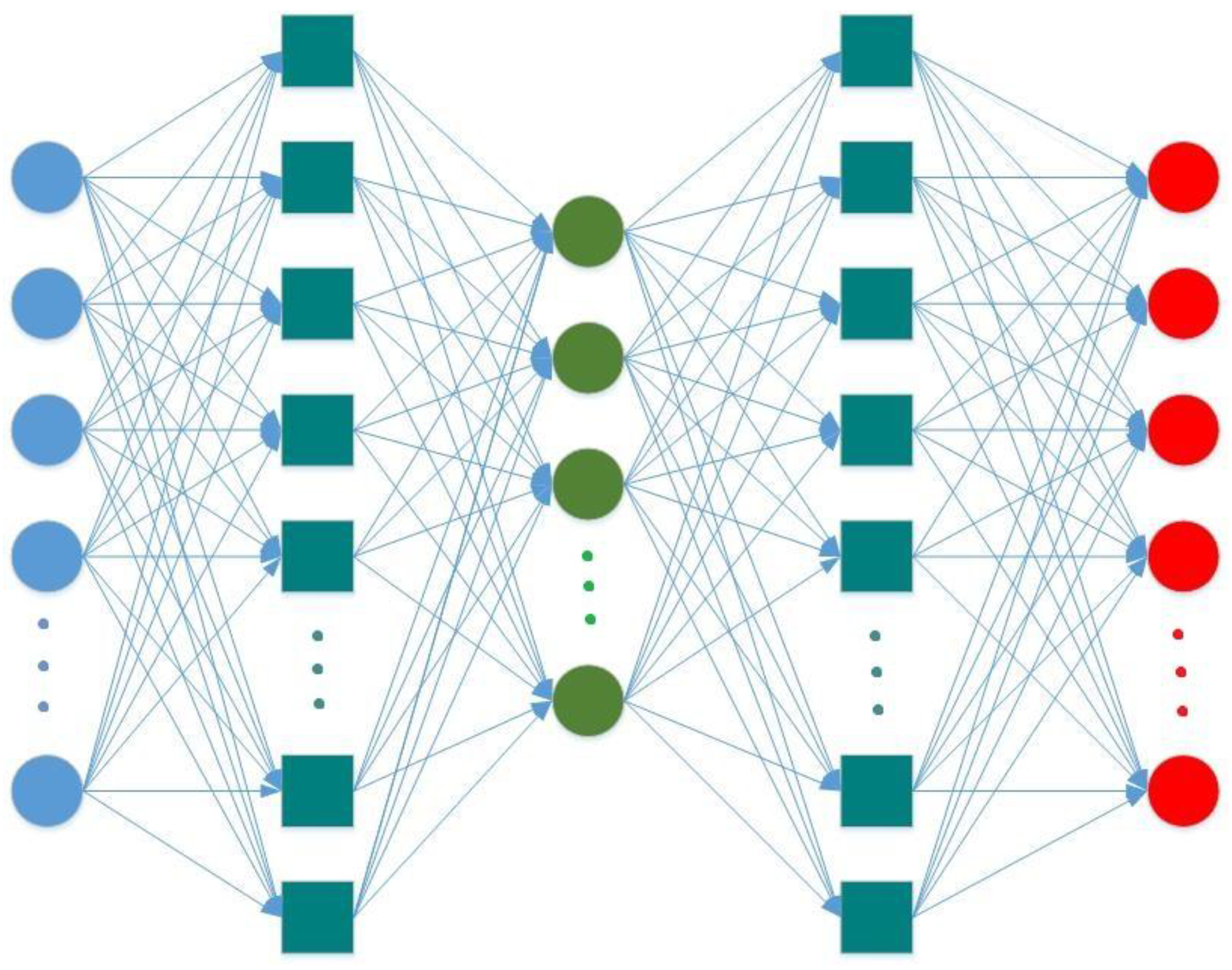
2.2. Applied Regularization Methods in the Experiment
2.3. Experiment Setup
- Without changing the model, our model could be run on local or distributed servers. In addition, without the need to record our model, our estimator-based model could run CPUs, GPUs, or tensor processing unit (TPU)s.
- It was much easier to develop a model with an estimator rather than low-level TensorFlow APIs.
- It could make a graph for us.
- Activation_fn: The activation function was for each layer of the neural network. By default, ReLU was fixed for the layers.
- Optimizer: In this feature of the class, we defined the optimizer type, which optimized the neural network model’s weights throughout the training process.
- Hidden_units: This contained the number of hidden units (neurons) per layer. For example, in [50], it means the first layer has 70 neurons and the second one has 50.
- Feature_columns: This argument contained the feature columns and data type used by the model.
- Model_dir: This was the directory for saving model parameters and graphs. In addition, it could be used to load checkpoints from the directory into the estimator to continue training a previously saved model.
- Dropout: We needed this feature for implementing a dropout regularization technique in our model.
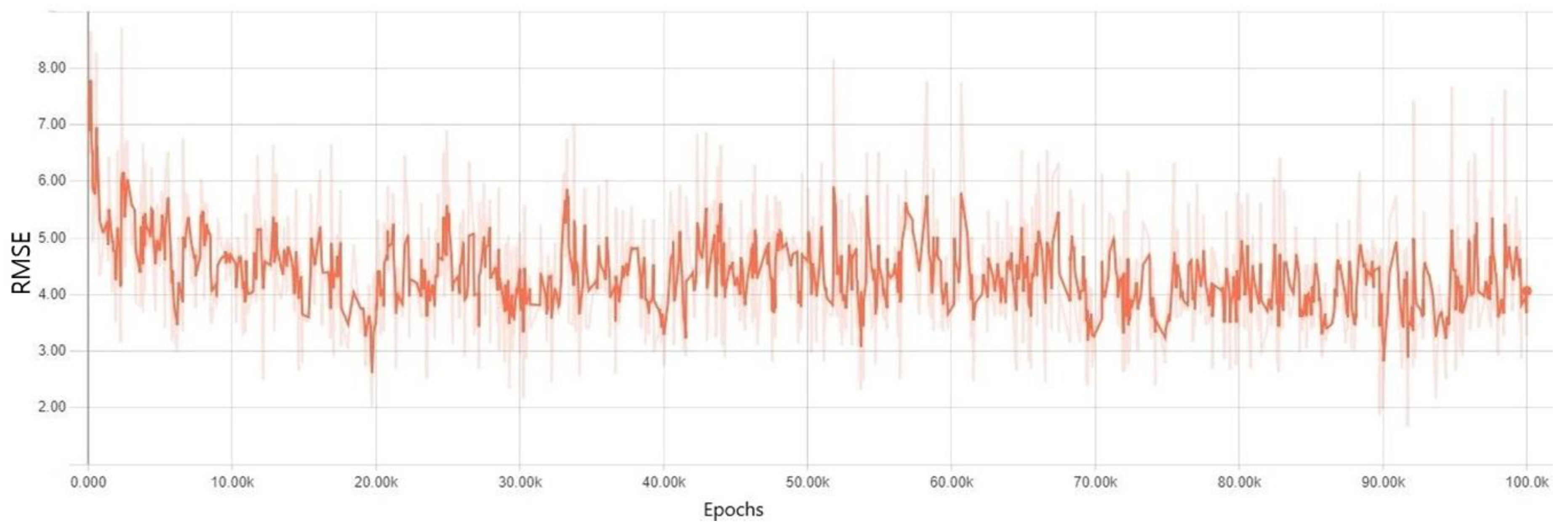
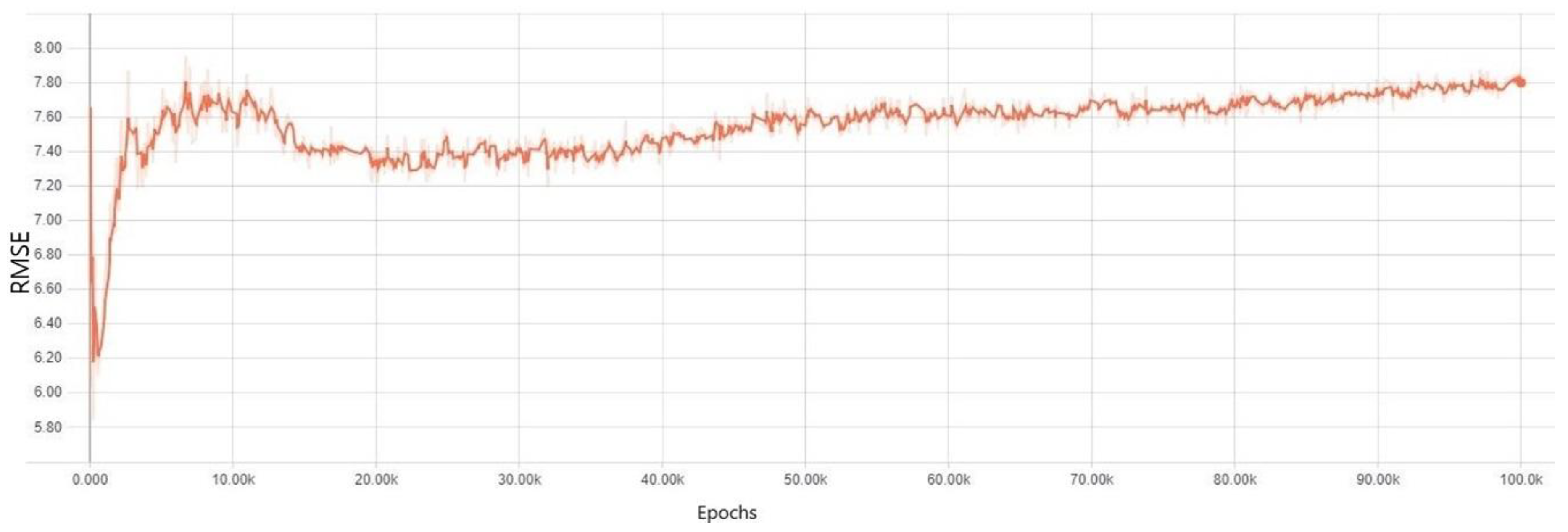
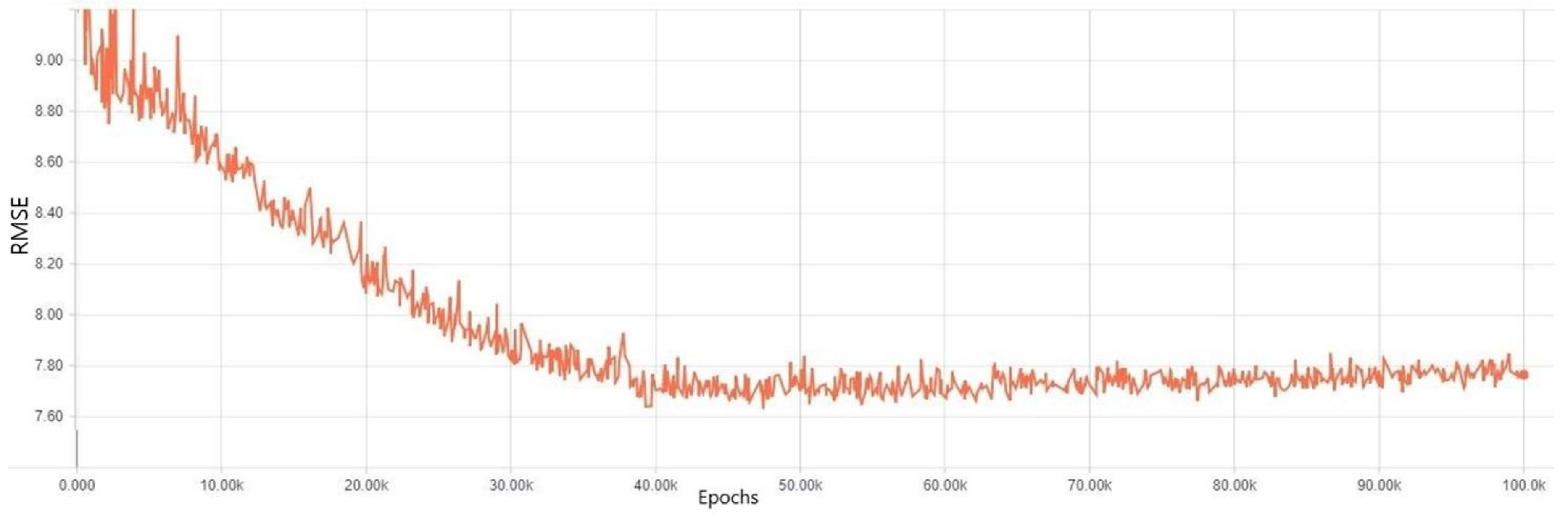
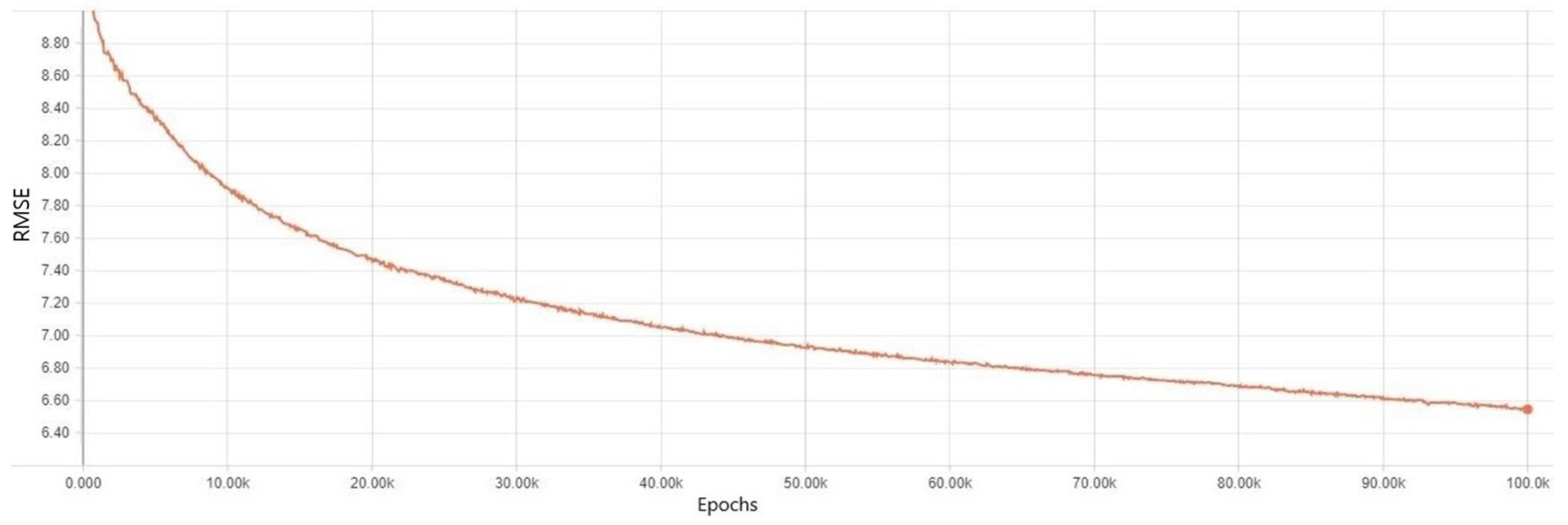
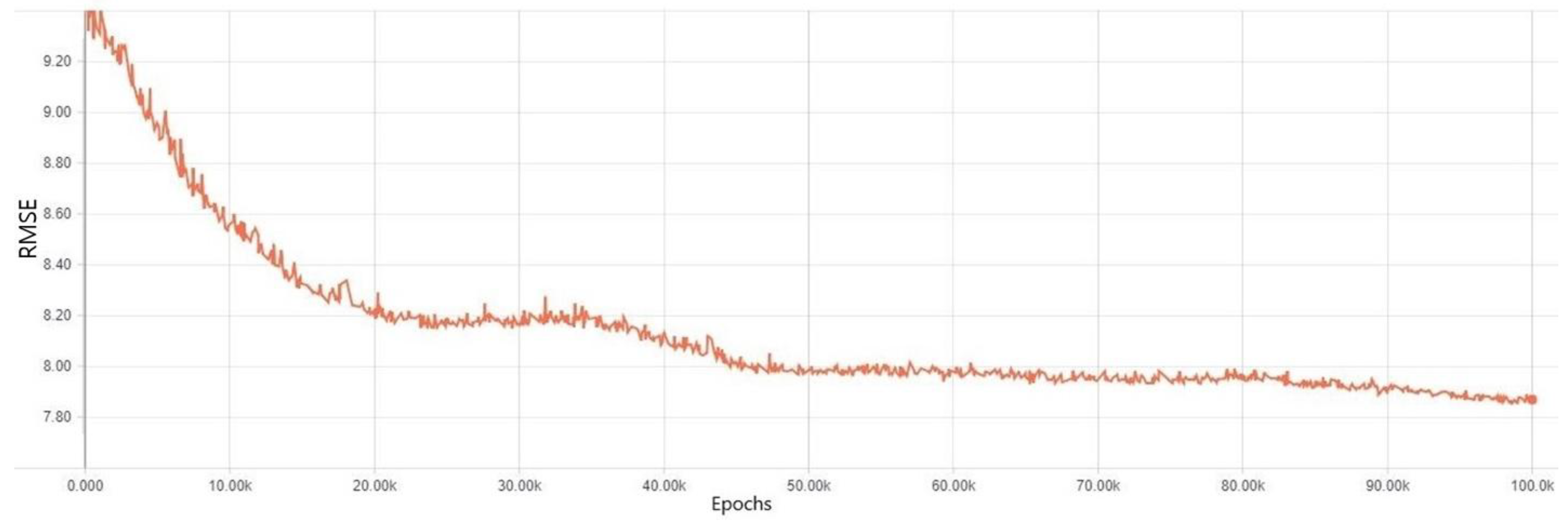
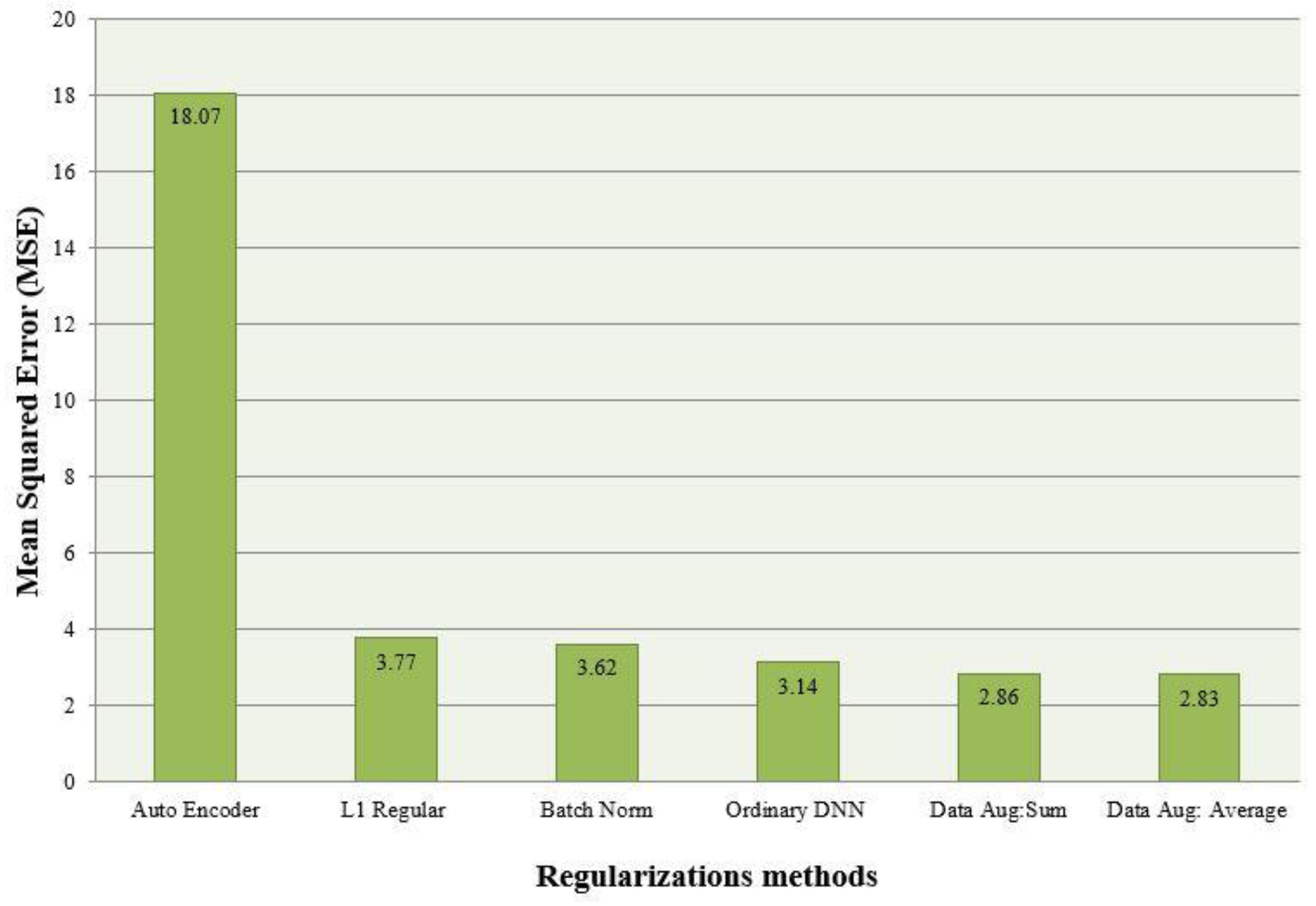
3. Results
Experiment Results for Each Regularization Method
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- McCulloch, W.S.; Pitts, W. A Logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- William, A.A. On the Efficiency of Learning Machines. IEEE Trans. on Syst. Sci. Cybern. 1967, 3, 111–116. [Google Scholar]
- Nicholas, V.F. Some New Approaches to Machine Learning. IEEE Trans. Syst. Sci. Cybern. 1969, 5, 173–182. [Google Scholar]
- Zhang, W.; Li, C.; Huang, T.; He, X. Synchronization of Memristor-Based Coupling Recurrent Neural Networks With Time-Varying Delays and Impulses. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 3308–3313. [Google Scholar] [CrossRef] [PubMed]
- Isomura, T. A Measure of Information Available for Inference. Entropy 2018, 20, 512. [Google Scholar] [CrossRef]
- Elusaí Millán-Ocampo, D.; Parrales-Bahena, A.; González-Rodríguez, J.G.; Silva-Martínez, S.; Porcayo-Calderón, J.; Hernández-Pérez, J.A. Modelling of Behavior for Inhibition Corrosion of Bronze Using Artificial Neural Network (ANN). Entropy 2018, 20, 409. [Google Scholar] [CrossRef]
- Jian, C.L.; Zhang, Y.; Yunxia, L. Non-Divergence of Stochastic Discrete Time Algorithms for PCA Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 394–399. [Google Scholar]
- Yin, Y.; Wang, L.; Gelenbe, E. Multi-layer neural networks for quality of service oriented server-state classification in cloud servers. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- Srivastava, N.; Geoffrey, H.; Alex, K.; Ilya, S.; Ruslan, S. Dropout: A simple way to prevent neural networks from over-fitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Suksri, S.; Warangkhana, K. Neural Network training model for weather forecasting using Fireworks Algorithm. In Proceedings of the 2016 International Computer Science and Engineering Conference (ICSEC), Chiang Mai, Thailand, 14–17 December 2016. [Google Scholar]
- Abdelhadi, L.; Abdelkader, B. Over-fitting avoidance in probabilistic neural networks. In Proceedings of the 2015 World Congress on Information Technology and Computer Applications (WCITCA), Hammamet, Tunisia, 11–13 June 2015. [Google Scholar]
- Singh, S.; Pankaj, B.; Jasmeen, G. Time series-based temperature prediction using back propagation with genetic algorithm technique. Int. J. Comput. Sci. Issues 2011, 8, 293–304. [Google Scholar]
- Abhishek, K. Weather forecasting model using artificial neural network. Procedia Tech. 2012, 4, 311–318. [Google Scholar] [CrossRef]
- Prasanta, R.J. Weather forecasting using artificial neural networks and data mining techniques. IJITR 2015, 3, 2534–2539. [Google Scholar]
- Smith, B.A.; Ronald, W.M.; Gerrit, H. Improving air temperature prediction with artificial neural networks. Int. J. Comput. Intell. 2006, 3, 179–186. [Google Scholar]
- Zhang, S.; Hou, Y.; Wang, B.; Song, D. Regularizing Neural Networks via Retaining Confident Connections. Entropy 2017, 19, 313. [Google Scholar] [CrossRef]
- Kaur, A.; Sharma, J.K.; Sunil, A. Artificial neural networks in forecasting maximum and minimum relative humidity. Int. J. Comput. Sci. Netw Secur. 2011, 11, 197–199. [Google Scholar]
- Alemu, H.Z.; Wu, W.; Zhao, J. Feedforward Neural Networks with a Hidden Layer Regularization Method. Symmetry 2018, 10, 525. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso: A retrospective. Royal Stat. Soc. 2011, 73, 273–282. [Google Scholar] [CrossRef]
- Hung, N.Q. An artificial neural network model for rainfall forecasting in Bangkok, Thailand. Hydrol. Earth Syst. Sci. 2009, 13, 1413–1425. [Google Scholar] [CrossRef]
- Chattopadhyay, S. Feed forward Artificial Neural Network model to predict the average summer-monsoon rainfall in India. Acta Geophys. 2007, 55, 369–382. [Google Scholar] [CrossRef]
- Khajure, S.; Mohod, S.W. Future weather forecasting using soft computing techniques. Procedia Comput. Sci. 2016, 78, 402–407. [Google Scholar] [CrossRef]
- Cui, X.; Goel, V.; Kingabury, B. Data augmentation for deep neural network acoustic modeling. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 1469–1477. [Google Scholar]
- Zhang, H.; Wang, Z.; Liu, D. A Comprehensive Review of Stability Analysis of Continuous-Time Recurrent Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1229–1262. [Google Scholar] [CrossRef]
- Zhang, S.; Xia, Y.; Wang, J. A Complex-Valued Projection Neural Network for Constrained Optimization of Real Functions in Complex Variables. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 3227–3238. [Google Scholar] [CrossRef] [PubMed]
- Takashi, M.; Hiroyuki, T. An Asynchronous Recurrent Network of Cellular Automaton-Based Neurons and Its Reproduction of Spiking Neural Network Activities. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 836–852. [Google Scholar]
- Hayati, M.; Zahra, M. Application of artificial neural networks for temperature forecasting. Int. J. Electr. Comput. Eng. 2007, 1, 662–666. [Google Scholar]
- Cao, W.; Yuan, J.; He, Z.; Zhang, Z. Fast Deep Neural Networks With Knowledge Guided Training and Predicted Regions of Interests for Real-Time Video Object Detection. IEEE Acc. 2018, 6, 8990–8999. [Google Scholar] [CrossRef]
- Wang, X.; Ma, H.; Chen, X.; You, S. Edge Preserving and Multi-Scale Contextual Neural Network for Salient Object Detection. IEEE Trans. Image Process. 2018, 27, 121–134. [Google Scholar] [CrossRef] [PubMed]
- Yue, S.; Rind, F.C. Collision detection in complex dynamic scenes using an LGMD-based visual neural network with feature enhancement. IEEE Trans. Neural Netw. 2006, 17, 705–716. [Google Scholar] [PubMed]
- Huang, S.-C.; Chen, B.-H. Highly Accurate Moving Object Detection in Variable Bit Rate Video-Based Traffic Monitoring Systems. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1920–1931. [Google Scholar] [CrossRef] [PubMed]
- Akcay, S.; Kundegorski, M.E.; Willcocks, C.G.; Breckon, T.P. Using Deep Convolutional Neural Network Architectures for Object Classification and Detection Within X-Ray Baggage Security Imagery. IEEE Trans. Inf. Forensic. Secur. 2018, 13, 2203–2215. [Google Scholar] [CrossRef]
- Sevo, I.; Avramovic, A. Convolutional Neural Network Based Automatic Object Detection on Aerial Images. IEEE Geo. Remote Sens. Lett. 2016, 13, 740–744. [Google Scholar] [CrossRef]
- Woźniak, M.; Połap, D. Object detection and recognition via clustered features. Neurocomputing 2018, 320, 76–84. [Google Scholar] [CrossRef]
- Vieira, S.; Pinaya, W.H.L.; Mechelli, A. Using deep learning to investigate the neuroimaging correlates of psychiatric and neurological disorders: Methods and applications. Neurosci. Biobehav. Rev. 2017, 74, 58–75. [Google Scholar] [CrossRef] [PubMed]
- Połap, D.; Winnicka, A.; Serwata, K.; Kęsik, K.; Woźniak, M. An Intelligent System for Monitoring Skin Diseases. Sensors 2018, 18, 2552. [Google Scholar] [CrossRef]
- Heaton, J.B.; Polson, N.G.; Witte, J.H. Deep learning for finance: Deep portfolios. Appl. Stochastic Models Bus. Ind. 2016, 33. [Google Scholar] [CrossRef]
- Woźniak, M.; Połap, D.; Capizzi, G.; Sciuto, G.L.; Kośmider, L.; Frankiewicz, K. Small lung nodules detection based on local variance analysis and probabilistic neural network. Compt. Methods Programs Biomed. 2018, 161, 173–180. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Laak, J.A.W.M.; Ginneken, B.v.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Woźniak, M.; Połap, D. Adaptive neuro-heuristic hybrid model for fruit peel defects detection. Neural Netw. 2018, 98, 16–33. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Ma, Y.; Zhang, L.; Gao, R.X.; Wu, D. Deep learning for smart manufacturing: Methods and applications. J. Manuf. Syst. 2018, 48, 144–156. [Google Scholar] [CrossRef]
- Mariel, A.-P.; Amadeo, A.C.; Isaac, C. Adaptive Identifier for Uncertain Complex Nonlinear Systems Based on Continuous Neural Networks. IEEE Trans. Neural Netw. Learn. 2014, 25, 483–494. [Google Scholar]
- Chang, C.H. Deep and Shallow Architecture of Multilayer Neural Networks. IEEE Trans. Neural Netw. Learn. 2015, 26, 2477–2486. [Google Scholar] [CrossRef] [PubMed]
- Tycho, M.S.; Pedro, A.M.M.; Murray, S. The Partial Information Decomposition of Generative Neural Network Models. Entropy 2017, 19, 474. [Google Scholar] [CrossRef]
- Xin, W.; Yuanchao, L.; Ming, L.; Chengjie, S.; Xiaolong, W. Understanding Gating Operations in Recurrent Neural Networks through Opinion Expression Extraction. Entropy 2016, 18, 294. [Google Scholar] [CrossRef]
- Sitian, Q.; Xiaoping, X. A Two-Layer Recurrent Neural Network for Nonsmooth Convex Optimization Problems. IEEE Trans. Neural Netw. Learn. 2015, 26, 1149–1160. [Google Scholar] [CrossRef] [PubMed]
- Saman, R.; Bryan, A. A New Formulation for Feedforward Neural Networks. IEEE Trans. Neural Netw. Learn. 2011, 22, 1588–1598. [Google Scholar]
- Nan, Z. Study on the prediction of energy demand based on master slave neural network. In Proceedings of the 2016 IEEE Information Technology, Networking, Electronic and Automation Control Conference, Chongqing, China, 20–22 May 2016. [Google Scholar]
- Feng, L.; Jacek, M.Z.; Yan, L.; Wei, W. Input Layer Regularization of Multilayer Feedforward Neural Networks. IEEE Access 2017, 5, 10979–10985. [Google Scholar]
- Armen, A. SoftTarget Regularization: An Effective Technique to Reduce Over-Fitting in Neural Networks. In Proceedings of the 2017 3rd IEEE International Conference on Cybernetics (CYBCONF), Exeter, UK, 21–23 June 2017. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters for Each Model | Typical DNN | Autoencoder | Data Augmentation | L1 Regularization | Batch Normalization |
|---|---|---|---|---|---|
| Number of input neurons | 35 | 35 | 35 | 35 | 35 |
| Number of hidden layers | 2 | 2 | 2 | 2 | 2 |
| Number of neurons in hidden layers | 50 | 50 | 50 | 50 | 50 |
| Number of output neurons | 1 | 1 | 1 | 1 | 1 |
| Learning rate | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 |
| Activation function | ReLU | ReLU | ReLU | ReLU | ReLU |
| Optimizer | Proximal Adagrad | Proximal Adagrad | Proximal Adagrad | Proximal Adagrad | Proximal Adagrad |
| Date | DNN without Regularization Methods (°C) | L1 Regularization (°C) | Autoencoder (°C) | Data August Sum (°C) | Data August: Average (°C) | Batch Normalization (°C) | Real Temperature (°C) |
|---|---|---|---|---|---|---|---|
| 2018.03.01 | 2.3 | 6.3 | 10.1 | 1.5 | 1.0 | 3.9 | 4.6 |
| 2018.03.02 | 1.1 | −1.9 | 17.6 | −0.2 | −0.8 | 1.0 | −0.7 |
| 2018.03.03 | 2.9 | −0.5 | 15.8 | 0.5 | 1.4 | 2.8 | 7.9 |
| 2018.03.04 | 3.5 | 17.1 | 15.1 | 1.9 | 0.6 | 10.3 | 9.8 |
| 2018.03.05 | 9.3 | 3.7 | 10.6 | 0.7 | 1.4 | 16.6 | 5.5 |
| 2018.03.06 | 4.3 | 2.7 | 17.7 | 4.8 | 4.5 | −0.1 | 4.5 |
| 2018.03.07 | 2.6 | 4.4 | 17.6 | 8.3 | 9.1 | 9.4 | 6.4 |
| 2018.03.08 | 3.1 | 7.2 | 15.2 | 12.4 | 7.8 | 5.6 | 4.6 |
| 2018.03.09 | 6.6 | 3.1 | 16.6 | 2.7 | 4.7 | 4.0 | 4.5 |
| 2018.03.10 | 1.4 | 6.1 | 18.8 | 4.3 | 4.9 | 4.9 | 4.6 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nusrat, I.; Jang, S.-B. A Comparison of Regularization Techniques in Deep Neural Networks. Symmetry 2018, 10, 648. https://doi.org/10.3390/sym10110648
Nusrat I, Jang S-B. A Comparison of Regularization Techniques in Deep Neural Networks. Symmetry. 2018; 10(11):648. https://doi.org/10.3390/sym10110648
Chicago/Turabian StyleNusrat, Ismoilov, and Sung-Bong Jang. 2018. "A Comparison of Regularization Techniques in Deep Neural Networks" Symmetry 10, no. 11: 648. https://doi.org/10.3390/sym10110648
APA StyleNusrat, I., & Jang, S.-B. (2018). A Comparison of Regularization Techniques in Deep Neural Networks. Symmetry, 10(11), 648. https://doi.org/10.3390/sym10110648