Exploiting the Symmetry of Integral Transforms for Featuring Anuran Calls


1
Ingeniería del Diseño, Escuela Politécnica Superior, Universidad de Sevilla, 41004 Sevilla, Spain
2
Tecnología Electrónica, Escuela Ingeniería Informática, Universidad de Sevilla, 41004 Sevilla, Spain
3
Tecnología Electrónica, Escuela Politécnica Superior, Universidad de Sevilla, 41004 Sevilla, Spain
*
Author to whom correspondence should be addressed.
Symmetry 2019, 11(3), 405; https://doi.org/10.3390/sym11030405
Submission received: 23 February 2019
/
Revised: 17 March 2019
/
Accepted: 18 March 2019
/
Published: 20 March 2019
(This article belongs to the Special Issue Integral Transforms and Operational Calculus)
Abstract
:The application of machine learning techniques to sound signals requires the previous characterization of said signals. In many cases, their description is made using cepstral coefficients that represent the sound spectra. In this paper, the performance in obtaining cepstral coefficients by two integral transforms, Discrete Fourier Transform (DFT) and Discrete Cosine Transform (DCT), are compared in the context of processing anuran calls. Due to the symmetry of sound spectra, it is shown that DCT clearly outperforms DFT, and decreases the error representing the spectrum by more than 30%. Additionally, it is demonstrated that DCT-based cepstral coefficients are less correlated than their DFT-based counterparts, which leads to a significant advantage for DCT-based cepstral coefficients if these features are later used in classification algorithms. Since the DCT superiority is based on the symmetry of sound spectra and not on any intrinsic advantage of the algorithm, the conclusions of this research can definitely be extrapolated to include any sound signal.
1. Introduction
Automatic processing of sound signals is a very active topic in many fields of science and engineering which find applications in multiple areas, such as speech recognition [1], speaker identification [2,3], emotion recognition [4], music classification [5], outlier detection [6], classification of animal species [7,8,9], detection of biomedical disease [10], and design of medical devices [11]. Sound processing is also applied in urban and industrial contexts, such as environmental noise control [12], mining [13], and transportation [14,15].
These applications typically include, among their first steps, the characterization of the sound: a process which is commonly known as feature extraction [16]. A recent survey of techniques employed in sound feature extraction can be found in [17], of which Spectrum-Temporal Parameters (STPs) [18], Linear Prediction Coding (LPC) coefficients [19], Linear Frequency Cepstral Coefficients (LFCC) [20], Pseudo Wigner-Ville Transform (PWVT) [21], and entropy coefficients [22] are of note.
Nevertheless, the Mel-Frequency Cepstral Coefficients (MFCC) [23] are probably the most widely employed set of features in sound characterization and the majority of the sound processing applications mentioned above are based on their use. Additionally, these features have also been successfully employed in other fields, such as analysis of electrocardiogram (ECG) signals [24], gait analysis [25,26], and disturbance interpretation in power grids [27].
On the other hand, the processing and classification of anuran calls have attracted the attention of the scientific community for biological studies and as indicators of climate change. This taxonomic group is regarded as an outstanding gauge of biodiversity. Nevertheless, frog populations have suffered a significant decrease in the last years due to habitat loss, climate change and invasive species [28]. So, the continual monitoring of frog populations is becoming increasingly important to develop adequate conservation policies [29].
It should be mentioned that the system of sound production in ectotherms is strongly affected by the ambient temperature. Therefore, the temperature can significantly influence the patterns of calling songs by modifying the beginning, duration, and intensity of calling episodes and, thus, the anuran reproductive activity. The presence or absence of certain anuran calls in a certain territory, and their evolution over time, can therefore be used as an indicator of climate change.
In our previous work, several classifiers for anuran calls are proposed that use non-sequential procedures [30] or temporally-aware algorithms [31], or that consider score series [32], mainly using a set of MPEG-7 features [33]. MPEG-7 is an ISO/IEC standard developed by MPEG (Moving Picture Experts Group). In [34], the comparison of MPEG-7 and MFCC are undertaken both in terms of classification performance and computational cost. Finally, the optimal values of MFCC options for the classification of anuran calls are derived in [35].
State of the art classification of sound relies on Convolutional Neural Networks (CNN) that take input from some form of the spectrogram [36] or even the raw waveform [37]. Moreover, CNN deep learning approaches have also been used in the identification of anuran sound [38]. In spite of that, studying and optimizing the process of extracting MFCC features is of great interest at least for three reasons. First, because sound processing goes beyond the classification task, including procedures such as compression, segmentation, semantic description, sound database retrieval, etc. Secondly, because the spectrograms that feed the state-of-the-art deep CNN classifiers can be constructed using MFCC [39]. And finally due to the fact that CNN classifiers based on spectrograms or raw waveforms require intensive computing resources which makes them unsuitable for implementation in low-cost low-power-consumption distributed nodes, as is the usual case in environmental monitoring networks [35].
As presented in greater detail later, the MFCC features are a representation of the sounds in the cepstral domain. They are derived after a first integral transform (from time to frequency domain), which obtains the sound spectrum, and then a second integral transform is carried out (from frequency to cepstral domain). In this paper, we will show that, by exploiting the symmetry of the sound spectra, it is possible to obtain a more accurate representation of the anuran calls and the derived features will therefore more precisely reflect the sound.
The main contribution of the paper is to offer a better understanding of the reason (symmetry) that justify and quantify why Discrete Cosine Transform (DCT) has been extensively used to compute MFCC. In more detail, the paper will show that DCT-based sound features yielded to a significantly lower error representing spectra, which is a very convenient result for several applications such as sound compression. Additionally, through the paper it will be demonstrated that symmetry-based features (DCT) are less correlated, which is an advantage to be exploited in later classification algorithms.
2. Materials and Methods
2.1. Extracting MFCC
The process of extracting the MFCC features from the samples of a certain sound requires 7 steps in 3 different domains, which are depicted in Figure 1, and can be summarized as follows:
- Pre-emphasis (time domain): The sound’s high frequencies are increased to compensate for the fact that the Signal-to-Noise Ratio (SNR) is usually lower at these frequencies.
- Framing (time domain): The samples of the full-length sound segment are split into frames of short duration ( samples, ). These frames are commonly obtained using non-rectangular overlapping windows (for instance, Hamming windows [40]). The subsequent steps are executed on the samples of each frame.
- Log-energy spectral density (spectral domain): Using the Discrete Fourier Transform (DFT) or its faster version, the Fast Fourier Transform (FFT), the samples of each frame are converted into the samples of an energy spectral density, which are usually represented in a log-scale.
- Mel bank filtering (spectral domain): The samples of each frame’s spectrum are grouped into banks of frequencies, using triangular filters centred according to the mel scale [41] and the mel Filter Bank Energy (mel-FBE) is obtained.
- Integral transform (cepstral domain): The samples of the mel-FBE (in the spectral domain) are converted into samples in the cepstral domain using an integral transform. In this article, it will be shown that the exploitation of the symmetry of the DFT integral transform obtained in step 3 yields a cepstral integral transform with a better performance.
- Reduction of cepstral coefficients (cepstral domain): The samples of the cepstrum are reduced to coefficients by discarding the least significant coefficients.
- Liftering (cepstral domain): The coefficients of the cepstrum are finally liftered to compensate for the fact that high quefrency coefficients are usually much smaller than their low quefrency counterparts.
In this process, integral transforms are used twice: in step 3 to move from the time domain into the spectral domain; and in step 5 to move forward into the cepstral domain. In this paper, the symmetric properties of the DFT integral transform in step 3 will be exploited for the selection of the most appropriate integral transform required in step 5.
2.2. Integral Transforms of Non-Symmetric Functions
As detailed in the previous subsection, a sound spectrum is featured in order to obtain the MFCC of a sound, specifically by characterizing the logarithm of its energy spectral density. In short, this would be a particular case of the characterization of a function by means of a reduced set of values where, in this case, is the spectrum of a sound. To address this problem, which is none other than that of the compression of information, several techniques have been proposed, from among which the frequency representation of the function stands out. In effect, the idea underlying this type of technique is to consider the original signal, expand it in Fourier series, and then approximate the function by means of a few terms of its expansion. Thus, instead of having to supply the values of the function corresponding to each value of , only the amplitude values (and eventually also the phase) of a reduced number of harmonics are provided.
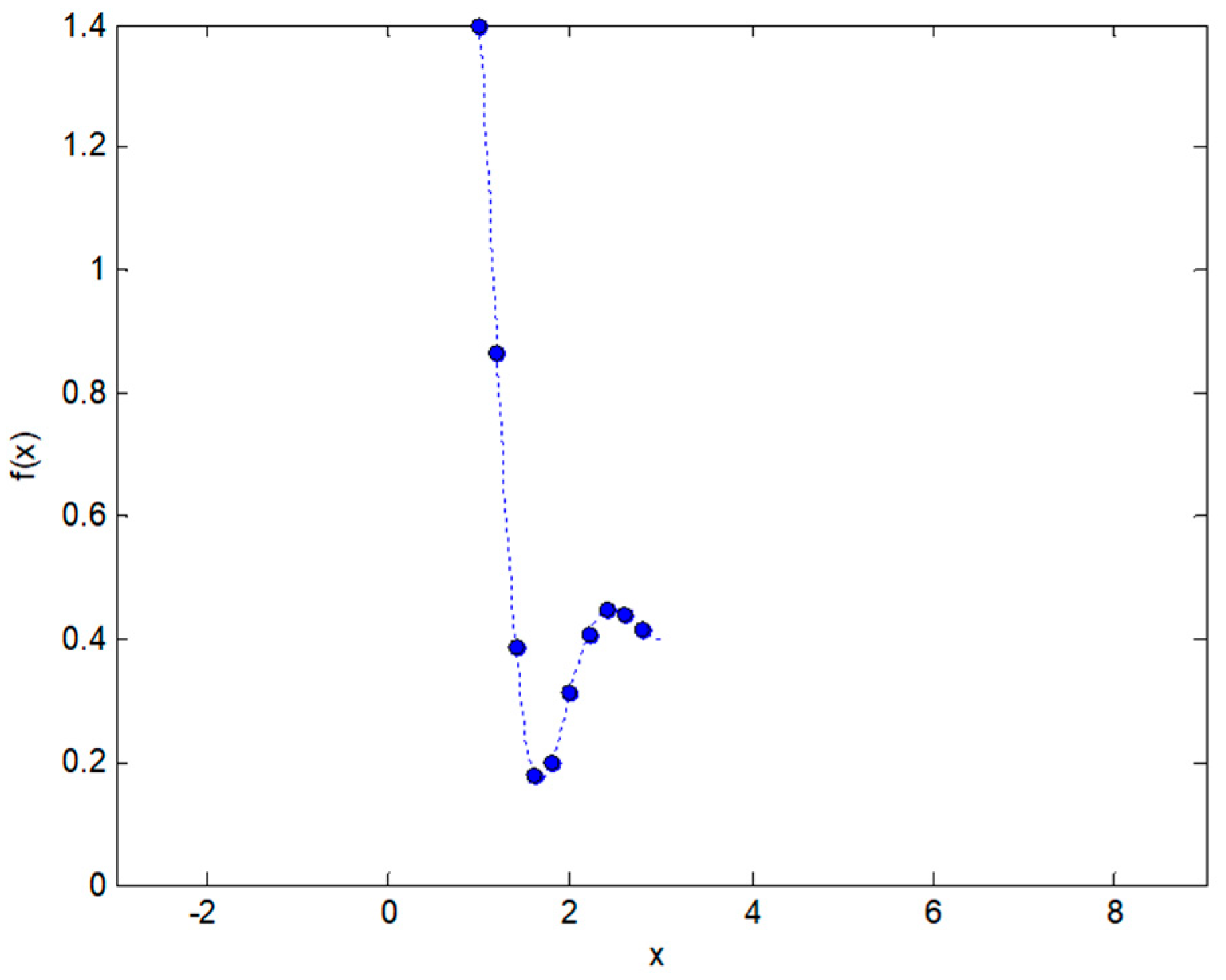
Let us consider an arbitrary example function , such as that shown in Figure 2, of which we know only one fragment in the interval (dashed line). Now let us consider that this function is sampled, and the values only at specific points for , separated at intervals , are known. By denoting as the total number of points (samples) in a period, we know that . The sampled function will be called where the hat () above represents a sampled function.
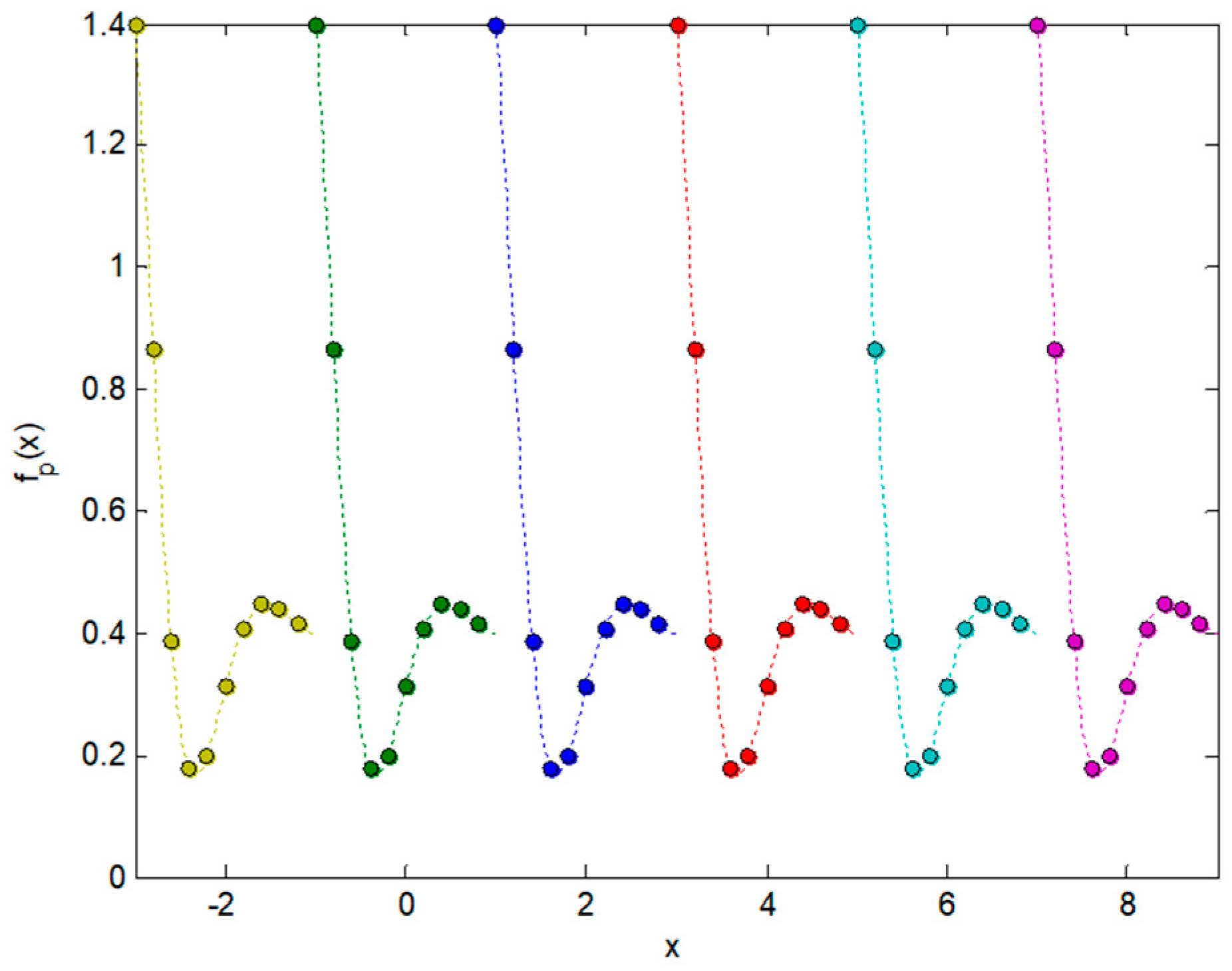
The usual way to obtain the spectrum of that function is to define a periodic function of period that coincides with the previous function in the known interval (see Figure 3), and to proceed to compute the spectrum of that new function. The spectral representation of the function is composed of the complex coefficients of the Fourier series expansion given by [42].
On the other hand, the sampled function, , will have a spectral representation that corresponds to , when the sampling of the variable is taken into account. Now let us call the integrand of Equation (1), i.e.,
and hence the spectral representation of the non-sampled function is featured by the coefficients
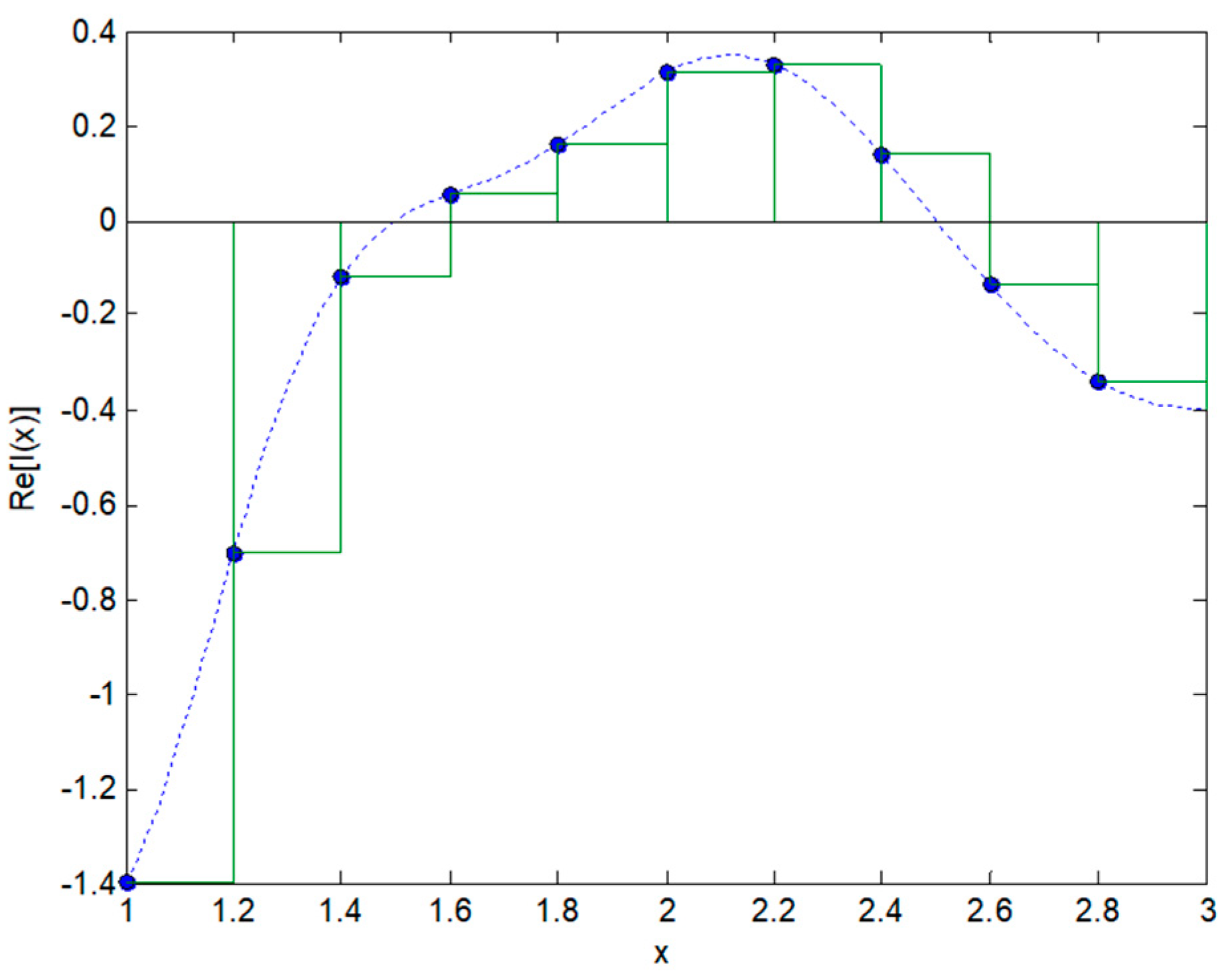
in order to obtain the values that take into account the sampling of the variable , the continuous calculation of the area that supposes the integral of the previous expression is substituted with the sum of the rectangles corresponding to the discrete values (sum of Riemann). In Figure 4, the calculation of the real part of is depicted for the example function .
Therefore,
From this equation it can be derived (see supplementary material) that
It can be observed that the spectral representation depends on the point selected as the origin of coordinates, due to the factor . This factor does not affect the amplitude spectrum (since its modulus is 1), but it does affect the phase spectrum corresponding to the known time-shift property of the Fourier Transform. For practical purposes, the origin of coordinates is usually considered to be the starting point of the sequence, that is, at , and hence the spectral representation finally becomes
This expression coincides with the usual definition of the Discrete Fourier Transform (DFT) [43]. In other words: The Discrete Fourier Transform of a known fragment of a function presupposes the periodic repetition of that fragment.
2.3. Integral Transforms of Symmetric Functions
Let us now again consider the function of which we know only sampled values of a fragment in the interval , as shown in Figure 2. An alternative way of representing its spectrum to that of periodically repeating the values as in Figure 3, lies in defining a sequence of values of length that coincides with in the interval , which is its symmetric in the interval , as depicted in Figure 5.
It can be observed that
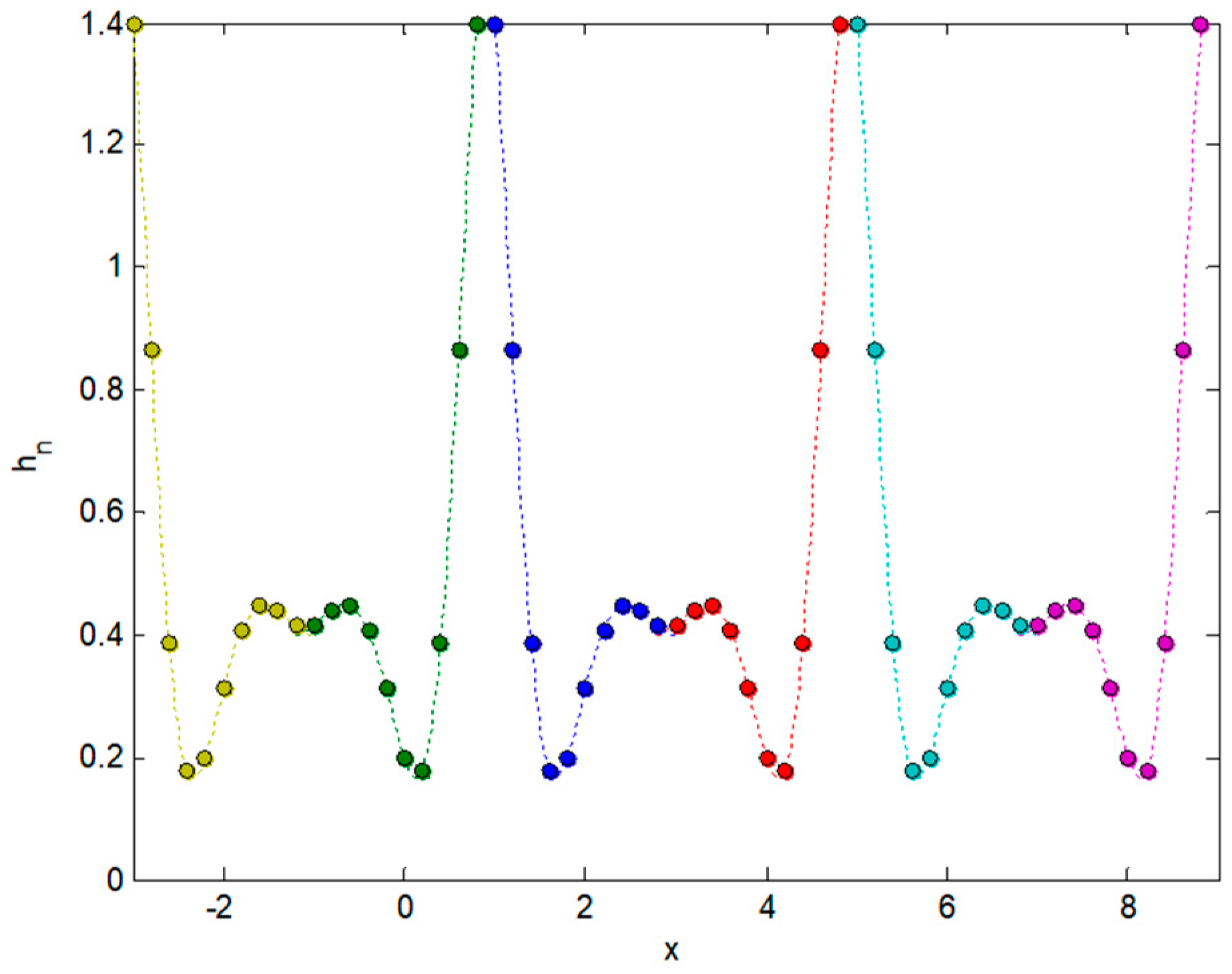
Subsequently, a sequence of periodic values of period is defined that coincides with in the interval , as shown in Figure 6.
In order to obtain the spectrum of the sequence of values it can be written that
From this equation it can be derived (see supplementary material) that
As can be observed, due to the factor , the spectral representation depends on the point where the origin of coordinates is defined. This factor does not affect the amplitude spectrum (since its modulus is 1), but it does affect the phase spectrum, which corresponds to the known time-shifting property of the Fourier transform. For practical purposes, the origin of coordinates is usually considered to be located the midpoint of the symmetric sequence , that is, , as shown in Figure 7.
Finally, the spectral representation becomes (see supplementary material)
This expression coincides with the usual definition of the Discrete Cosine Transform (DCT) [44]. In other words, the Discrete Cosine Transform of a known fragment of a function presupposes the periodic repetition of that fragment and its symmetric.
2.4. Representing Anuran Call Spectra
With this digression, we can now address the question posed at the beginning of Section 2.2 concerning the best way to characterize the spectrum of a sound by using the sum of its harmonics. Note that it is necessary to compute the spectrum (step 5) of a spectrum (step 4), that is, the trans-spectrum or the cepstrum, as previously discussed. The decision regarding whether this trans-spectrum (cepstrum) should be derived using either the Fourier transform, or the cosine transform, is based on the form of the fragment (in this case the spectral values of the sound). That is, it should be considered whether the best approximation to the spectrum is either a periodic repetition of or, in contrast, a periodic repetition of and its symmetric.
Although this is a general question, we have addressed it in the context of a specific application by featuring anuran calls for their further classification. The dataset employed contains 1 hour and 13 minutes of sounds which have been recorded at five different locations (four in Spain, and one in Portugal) [32] and they were subsequently sampled at 44.1 kHz. The recordings include 4 types of anuran calls and, since they have been taken in their natural habitat, are affected by highly significant surrounding environmental noise (such as that of wind, water, rain, traffic, and voices).
In this paper, the duration of the frames (step 2) was set to 10 ms, such that each frame has data points and a total of frames are considered. The log-energy spectral density (step 3) is obtained using a standard FFT algorithm, which obtains a spectrum with values. The mel-scaling (step 4) employs a set of filters, and hence the mel-FBE spectrum is characterised by this number of values (). In step 5, two different approaches for obtaining the cepstrum are used and compared: DFT and DCT. The results are then analysed for a different number of cepstral coefficients ().
In order to carry out a more systematic study of the spectrum approximation error, let us call the original mel-FBE spectrum of the -th frame (the result of step 4), where is the filter index (equivalent to the frequency in mel scale). Let us also call the spectrum of , that is, the cepstrum as obtained in step 5, where is the cepstral index (equivalent to the quefrency in mel scale). It can be written that , where represents either the DFT or the DCT Fourier expansions.
After reducing the number of cepstral coefficients to a value of , the resulting approximate cepstrum (step 6) will be called , where the tilde () above the represents an approximation. Using these values in the corresponding Fourier expansion leads to an approximation of the mel-FBE, that is, . The approximation error for the -th frame is therefore , that is, a different error for each value of , the filter index (or frequency in mel-scale). An error measure for the overall spectrum of the -th frame can be obtained using the Root Mean Square Error () defined as:
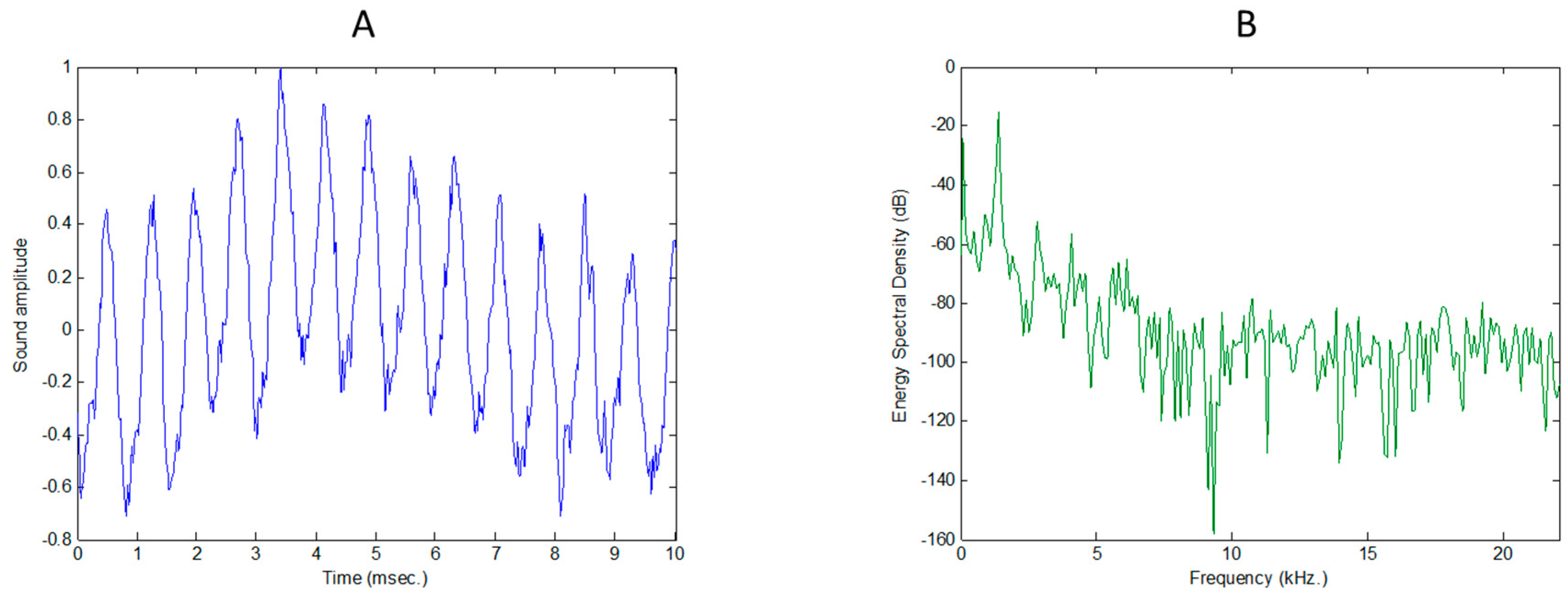
In this paper, an arbitrary selected single frame is first considered, mainly for illustration purposes. Its time-domain representation is depicted in Figure 8A while its spectrum is plotted in Figure 8B. Some other examples can be found in [32].
Additionally, in order to compare the performance of the 2 competing algorithms obtaining the cepstrum, an overall metric for the whole dataset is considered and defined as the mean RMSE for every frame, that is,
3. Results
Let us first consider a single frame, arbitrarily selected from the whole sound dataset. Although these results are limited to that specific sound frame, very similar results are obtained if a different frame is selected. Moreover, at the end of this section, the overall sound dataset is considered.
For the case of the single frame, the mel-FBE spectrum obtained in step 4 is depicted in Figure 9. This is the function whose spectrum (cepstrum in this case) must be computed in step 5.
For this frame, let us consider whether it is better to use either a DFT or a DCT. The decision depends on whether the function can be considered as a fragment of a periodic repetition of: (A) the fragment, as shown in Figure 10A, or (B) the function and its symmetric, as shown in Figure 10B. In the first case, the DFT should be more appropriate, while in the second case the DCT would obtain better results.
However, the mel-FBE is nothing but a rescaled and compressed way of presenting a spectrum. On the other hand, it is a well-known fact that the spectrum of a real signal is symmetric with respect to the vertical axis [43]. And finally, it is also known that the spectrum of a sampled signal is periodic [45]. For this reason, the repetition of the fragment of Figure 9 corresponds to Figure 10B and, therefore, using the DCT to compute its trans-spectrum (or cepstrum) should obtain better results. This hypothesis is verified in the following paragraphs for the selected frame, and, later in this section, it is verified for the whole dataset.
The number of coefficients obtained by applying either DCT or DFT is , that is, they have the same number of values that define the mel-FBE. The resulting cepstrum for the selected frame is shown in Figure 11.
The ability to compress information of the Fourier transforms (either in the DFT or DCT version) lies in the fact that it is not necessary to consider the full set of the coefficients of the Fourier expansion to obtain a good approximation of the original function. In Figure 12, the original mel-FBE spectrum is depicted for the example frame, and those spectra recovered using cepstral coefficients obtained using DCT.
Additionally, as expected, the DCT achieves approximations to the original spectrum that are, in general, significantly better than those obtained for the DFT with the same number of coefficients. In Figure 13, the original mel-FBE spectrum is depicted for the example frame, and those spectra recovered using cepstral coefficients obtained using DFT and DCT.
In order to quantify the error of recovering the selected mel-FBE spectrum using cepstral coefficients, the Root Mean Square Error (RMSE) is computed in accordance with Equation (11). The value of RMSE as a function of the number of cepstral coefficients used for the recovery of the spectrum is depicted in Figure 14, both for DFT and DCT.
This analysis can be extended to include the computation of the RMSE for the whole dataset in accordance with Equation (12). The value of RMSE as a function of the number of cepstral coefficients used for the recovery of the spectrum is depicted in Figure 15 for DFT and DCT separately.
4. Discussion
Let us first consider the for a single frame as depicted in Figure 14. Let us now regard the case where, for instance, the number of values required to describe the mel-FBE spectrum () is halved, and hence the number of cepstral coefficients used for the recovering an approximation of the spectrum is (in accordance with Equations (6) and (10)).
In this case, it can be observed that is for DFT, and for DCT. On the other hand, as depicted in Figure 9, the values of the mel-FBE spectrum lie within the range , with a mean value of . This means that the relative error of the spectrum representation is only for DFT ( for DCT) when the number of values employed for that representation are halved.
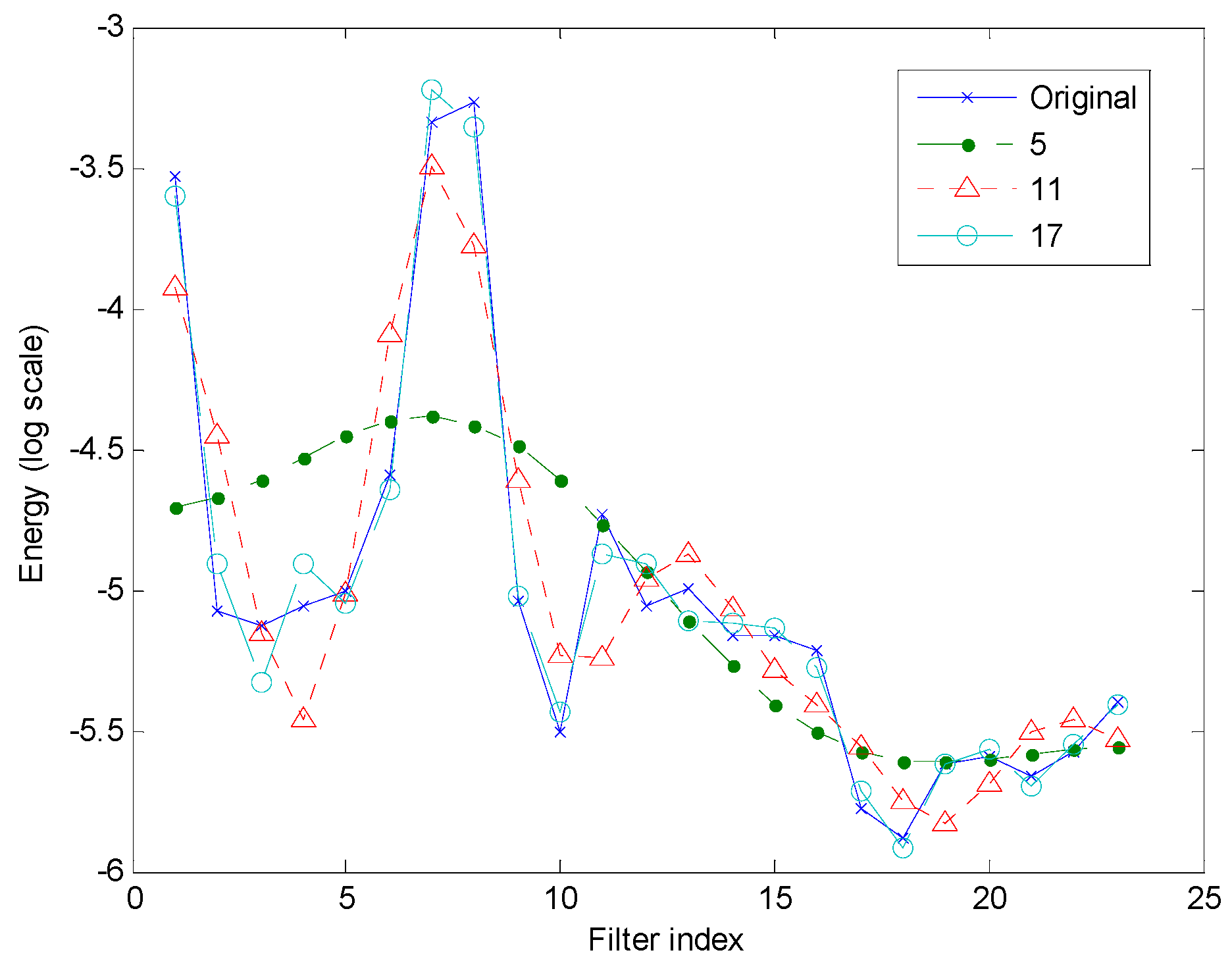
Let us now focus on the RMSE when the DFT is used (green line), either for a single frame (Figure 14) or for the whole dataset (Figure 15). In both cases, it can be observed that RMSE has values only for an odd number of cepstral coefficients. This fact can be explained by recalling that, according to Equation (6), every DFT cepstral coefficient is a complex number for and a real number for . On the other hand, according to Equation (10), the DCT cepstral coefficients are real numbers for every value of . Additionally, it has to be considered that DFT cepstrum is symmetric (green line in Figure 11). Therefore, for , it can be written that and, therefore, only one of these 2 terms have to be kept for recovery purposes. These circumstances jointly explain the odd number of DFT cepstral coefficients.
To clarify this idea, let us consider an example where and . The DCT cepstrum is then described using , , , and , that is, 5 real numbers which can be employed to approximately recover the mel-FBE spectrum. On the other hand, the DFT cepstrum is described using which is a real number, and and , which are complex numbers, that is, although 3 terms are used, a total of 5 values (coefficients) are required. However, to approximately recover the mel-FBE spectrum, the terms , , , and can be used since and .
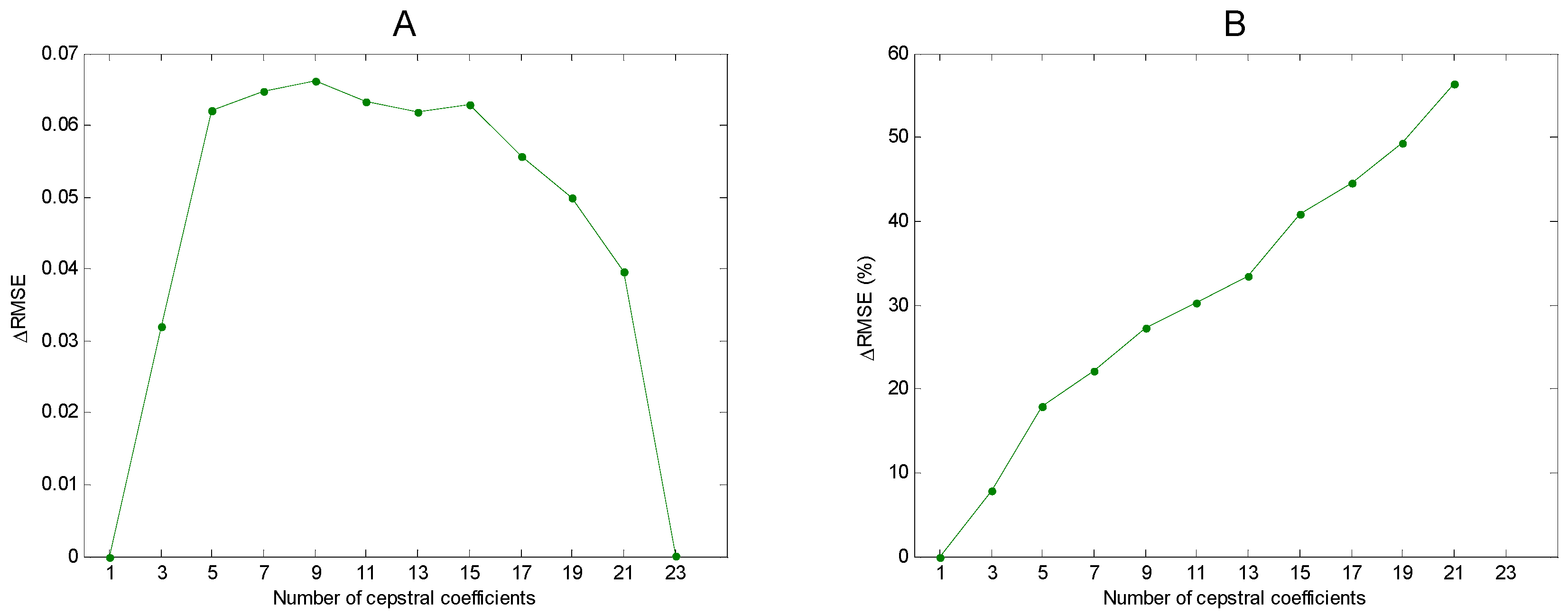
As regards the results obtained for the whole dataset (Figure 15), it can be seen that DCT is better at describing the mel-FBE spectra than is its DFT counterpart. This improvement (decrease of the RMSE), can be measured by defining (Figure 16A) or its relative value (Figure 16B). For example, for the RMSE is reduced from (DFT) to , which involves an improvement of approximately . For the degenerated cases where and , there is no improvement. In the first case, only is used which, according to Equations (6) and (10), is the mean value of the mel-FBE spectrum, that is, the DFT and DCT recovering methods have the same error. On the other hand, if then no reduction on the number of coefficients is achieved, and both equations exactly recover the original spectrum (no error).
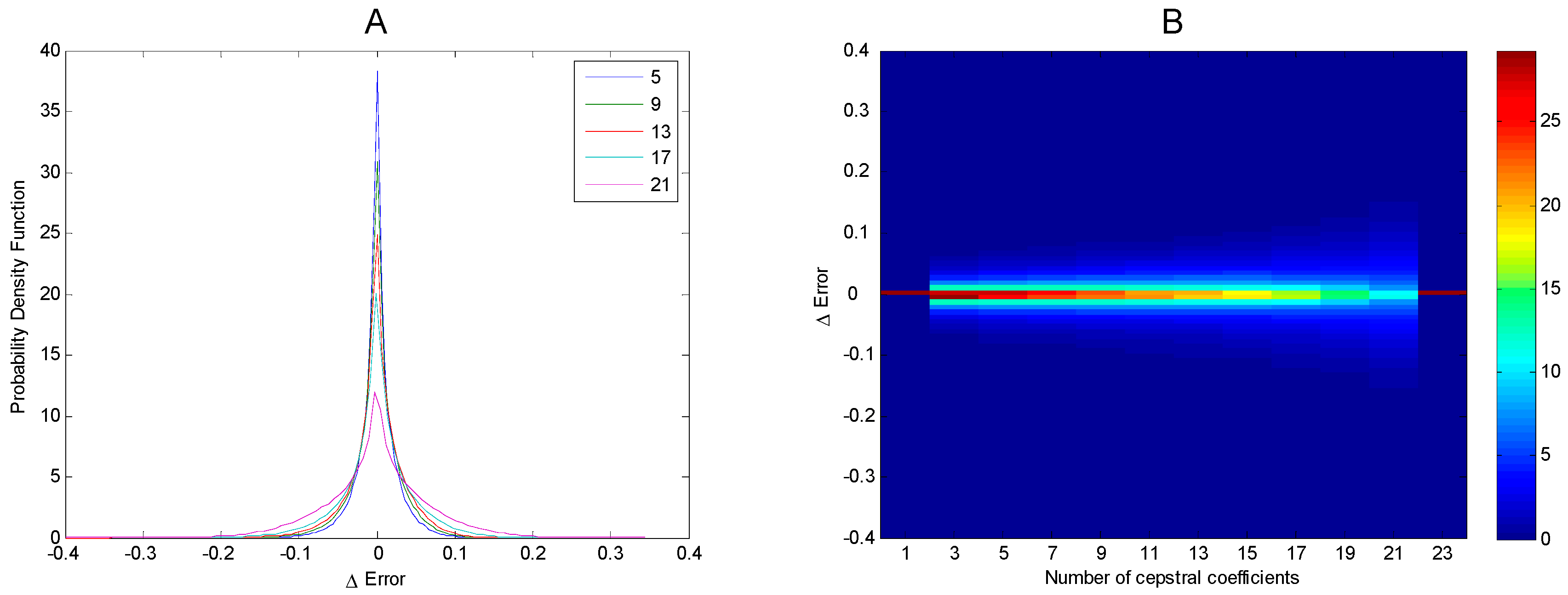
The above results concern the mean improvement of DCT over DFT for every frame in the dataset. In a more in-depth analysis, let us also compute its probability density function (pdf). The results are depicted in Figure 17. In panel A, the pdf is shown for several values of the number of cepstral coefficients (). In panel B, the value of the pdf is colour-coded as a function of the improvement ( and of the number of cepstral coefficients (). It can be observed that only a negligible number of the frames present a significant negative improvement, thereby demonstrating that DCT is superior to DFT.
The higher performance of DCT over DFT is due to the fact that the mel-FBE spectra are a special type of function derived from symmetric sound spectra. Consequently, if DCT and DFT were compared in the task of recovering arbitrary functions, they would each present equal performance. To demonstrate this claim, one million -value arbitrary functions are randomly generated (), and DFT and DCT are then employed to recover the original function with a reduced set of coefficients to measure the errors of that recovery. Finally, the improvement of DCT over DFT is computed. The results are depicted in Figure 18 where it can be observed that positive and negative improvements are symmetrically distributed around a zero-mean improvement. Therefore, it can be concluded that DCT and DFT have similar performance in describing arbitrary functions.
From the above results, it is clear that DCT offers superior performance featuring mel-FBE spectra and, therefore offers superior performance featuring sounds. When the purpose of these features is to be used as input to some kind of classifier, then DCT offers an additional advantage. It is a well-established result that classifiers obtain better results if their input features are low-correlated. The reason is clear: a classification algorithm that includes a new feature that is highly correlated with previous features adds almost no new information and, therefore, almost no classification improvement should be expected. Let us therefore examine the correlation between coefficients obtained by DFT and those by DCT.
Let us call the mean value of the -th coefficient describing the -th frame, obtained by
where is the total number of frames in the dataset. The variance of the -th coefficient can be obtained by
The correlation between the -th and the -th coefficient for the whole dataset is therefore given by
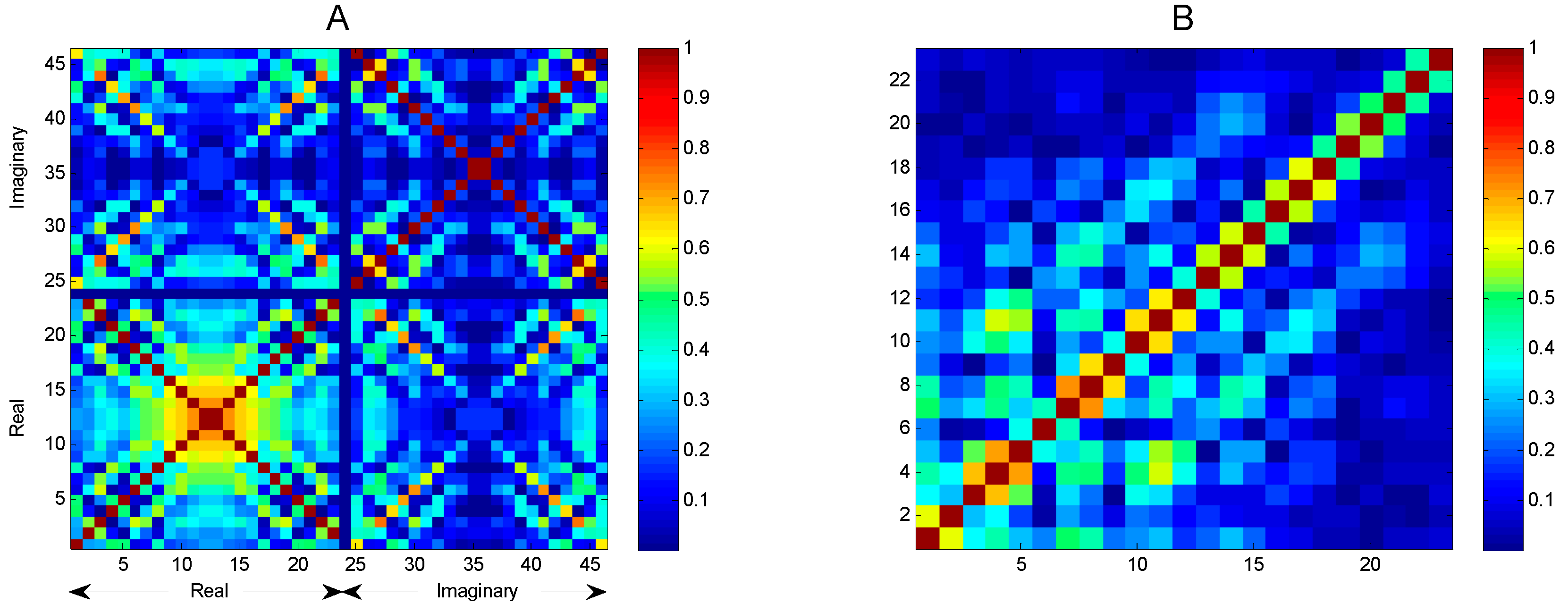
In Figure 19, the absolute values of the correlation are shown, whereby the values for the case are colour-coded. The correlations corresponding to the DFT are shown in panel A and those corresponding to DCT in panel B. In the DFT case, each factor is a complex number, and hence the total number of values is 46, whereby the first 23 coefficients represent the real parts and the last 23 the imaginary parts. By simply considering the colours in that figure, it is clear that DCT coefficients are less correlated.
An alternative way to present this result is by using a histogram of the values of the correlation coefficients, as depicted in Figure 20. Those corresponding to DCT are more frequent for the low values of correlation, that is, DCT-obtained features are less correlated than those obtained using DFT. Hence, classifiers of a more efficient nature should be expected from using DCT.
When the MFCC features are used as input of a later classification algorithm, the lower correlation of DCT-obtained features should yield to a better classification performance. The results obtained classifying anuran calls [35] do confirm a slight advantage for the DCT as it is reflected in Table 1. This table has been produced taking the best result (geometric mean of sensitivity and specificity) obtained through a set of ten classification procedures: minimum distance, maximum likelihood, decision trees, k-nearest neighbors, support vector machine, logistic regression, neural networks, discriminant function, Bayesian classifiers and hidden Markov models.
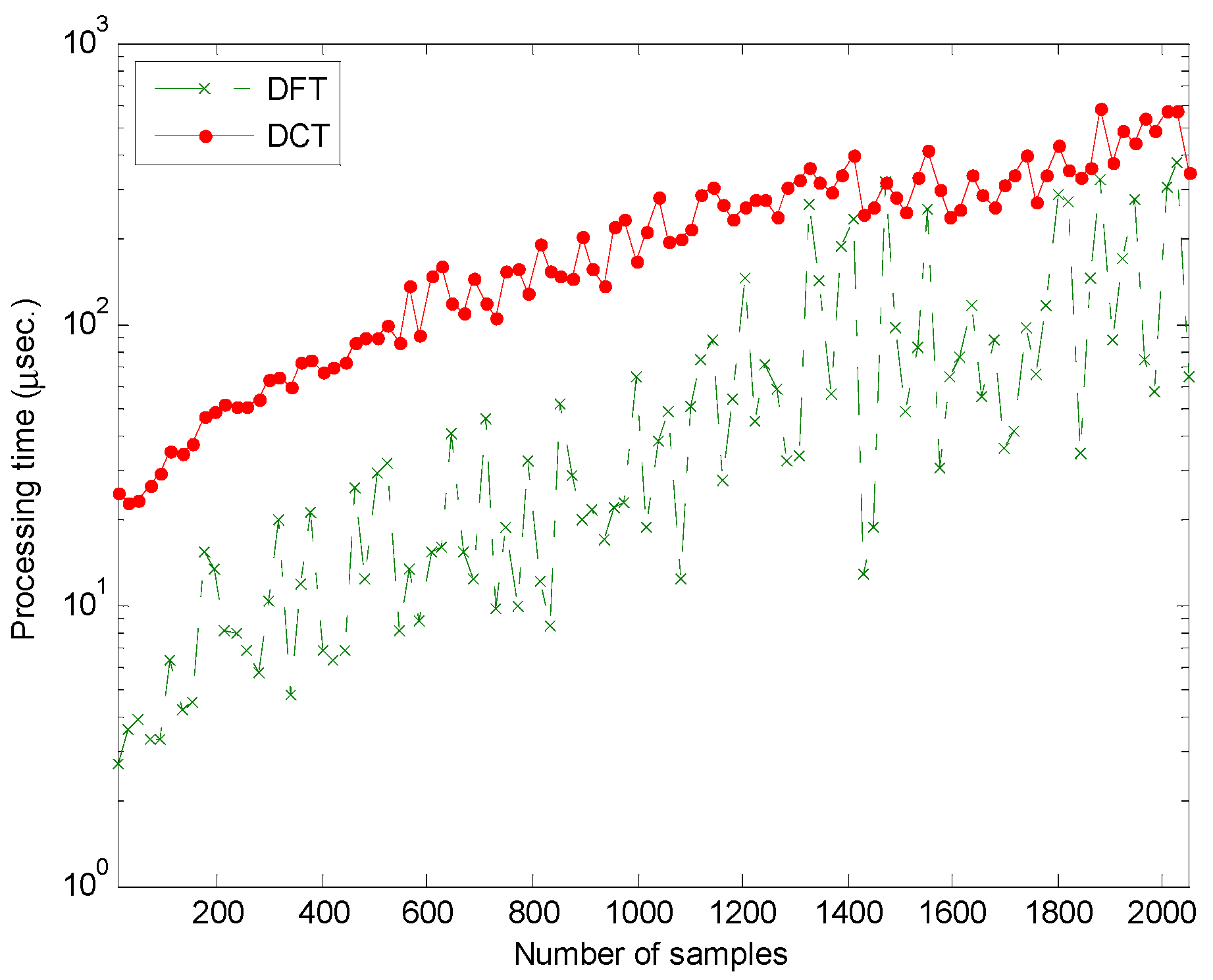
Let us finally consider the computing efforts required for these two algorithms which mainly depend on the number of samples defining the mel-FBE spectra. Fast versions of DFT and DCT algorithms have been tested on a conventional desktop personal computer. The results are depicted in Figure 21. It can be seen that DCT is about one order of magnitude slower than DFT. Although this fact is certainly a drawback of DCT it has a limited impact on conventional MFCC extraction process because the number of values describing the mel-FBE spectra is usually very low (about 20). Additional studies on processing times for anuran sounds classification can be found in [34].
5. Conclusions
In this article, it has been shown that DCT outperforms DFT in the task of representing sound spectra. It has also been shown that this improvement is due to the symmetry of the spectrum and not to any intrinsic advantage of DCT.
In representing the mel-FBE spectra required to obtain the MFCC features of anuran calls, DCT errors are approximately 30% lower than DFT errors. This type of spectra is therefore much better represented using DCT.
Additionally, it has been shown than MFCC features obtained using DCT are remarkably less correlated than those obtained using DFT. This result will make DCT-based MFCC features more powerful in later classification algorithms.
Although only one specific dataset has been analysed herein, the advantage of DCT can easily be extrapolated to include any sound since this advantage is based on the symmetry of the spectrum of the sound
Supplementary Materials
The following are available online at https://www.mdpi.com/2073-8994/11/3/405/s1, supplementary material: Derivation of integral transforms expressions.
Author Contributions
Conceptualization, A.L.; investigation, A.L., J.G.-B., A.C. and J.B.; writing—original draft, A.L., J.G.-B., A.C. and J.B.
Funding
This research received no external funding.
Acknowledgments
The authors would like to thank Rafael Ignacio Marquez Martinez de Orense (Museo Nacional de Ciencias Naturales) and Juan Francisco Beltrán Gala (Faculty of Biology, University of Seville) for their collaboration and support.
Conflicts of Interest
The authors declare there to be no conflict of interest.
References
- Haridas, A.V.; Marimuthu, R.; Sivakumar, V.G. A critical review and analysis on techniques of speech recognition: The road ahead. Int. J. Knowl.-Based Intell. Eng. Syst. 2018, 22, 39–57. [Google Scholar] [CrossRef]
- Gómez-García, J.A.; Moro-Velázquez, L.; Godino-Llorente, J.I. On the design of automatic voice condition analysis systems. Part II: Review of speaker recognition techniques and study on the effects of different variability factors. Biomed. Signal Process. Control 2019, 48, 128–143. [Google Scholar] [CrossRef]
- Vo, T.; Nguyen, T.; Le, C. Race Recognition Using Deep Convolutional Neural Networks. Symmetry 2018, 10, 564. [Google Scholar] [CrossRef]
- Dahake, P.P.; Shaw, K.; Malathi, P. Speaker dependent speech emotion recognition using MFCC and Support Vector Machine. In Proceedings of the 2016 International Conference on Automatic Control and Dynamic Optimization Techniques (ICACDOT), Pune, India, 9–10 September 2016; pp. 1080–1084. [Google Scholar]
- Chakraborty, S.S.; Parekh, R. Improved Musical Instrument Classification Using Cepstral Coefficients and Neural Networks. In Methodologies and Application Issues of Contemporary Computing Framework; Springer: Singapore, 2018; pp. 123–138. [Google Scholar]
- Panteli, M.; Benetos, E.; Dixon, S. A computational study on outliers in world music. PLoS ONE 2017, 12, e0189399. [Google Scholar] [CrossRef] [PubMed]
- Noda, J.J.; Sánchez-Rodríguez, D.; Travieso-González, C.M. A Methodology Based on Bioacoustic Information for Automatic Identification of Reptiles and Anurans. In Reptiles and Amphibians; IntechOpen: London, UK, 2018. [Google Scholar]
- Desai, N.P.; Lehman, C.; Munson, B.; Wilson, M. Supervised and unsupervised machine learning approaches to classifying chimpanzee vocalizations. J. Acoust. Soc. Am. 2018, 143, 1786. [Google Scholar] [CrossRef]
- Malfante, M.; Mars, J.I.; Dalla Mura, M.; Gervaise, C. Automatic fish sounds classification. J. Acoust. Soc. Am. 2018, 143, 2834–2846. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Sun, B.; Yang, X.; Meng, Q. Heart sound identification based on MFCC and short-term energy. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 7411–7415. [Google Scholar]
- Usman, M.; Zubair, M.; Shiblee, M.; Rodrigues, P.; Jaffar, S. Probabilistic Modeling of Speech in Spectral Domain using Maximum Likelihood Estimation. Symmetry 2018, 10, 750. [Google Scholar] [CrossRef]
- Cao, J.; Cao, M.; Wang, J.; Yin, C.; Wang, D.; Vidal, P.P. Urban noise recognition with convolutional neural network. Multimed. Tools Appl. 2018. [Google Scholar] [CrossRef]
- Xu, J.; Wang, Z.; Tan, C.; Lu, D.; Wu, B.; Su, Z.; Tang, Y. Cutting Pattern Identification for Coal Mining Shearer through Sound Signals Based on a Convolutional Neural Network. Symmetry 2018, 10, 736. [Google Scholar] [CrossRef]
- Lee, J.; Choi, H.; Park, D.; Chung, Y.; Kim, H.Y.; Yoon, S. Fault detection and diagnosis of railway point machines by sound analysis. Sensors 2016, 16, 549. [Google Scholar] [CrossRef]
- Choi, Y.; Atif, O.; Lee, J.; Park, D.; Chung, Y. Noise-Robust Sound-Event Classification System with Texture Analysis. Symmetry 2018, 10, 402. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to feature extraction. In Feature Extraction; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–25. [Google Scholar]
- Alías, F.; Socoró, J.; Sevillano, X. A review of physical and perceptual feature extraction techniques for speech, music and environmental sounds. Appl. Sci. 2016, 6, 143. [Google Scholar] [CrossRef]
- Zhang, H.; McLoughlin, I.; Song, Y. Robust sound event recognition using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 559–563. [Google Scholar]
- Dave, N. Feature extraction methods LPC, PLP and MFCC in speech recognition. Int. J. Adv. Res. Eng. Technol. 2013, 1, 1–4. [Google Scholar]
- Paul, D.; Pal, M.; Saha, G. Spectral features for synthetic speech detection. IEEE J. Sel. Top. Signal Process. 2017, 11, 605–617. [Google Scholar] [CrossRef]
- Taebi, A.; Mansy, H.A. Analysis of seismocardiographic signals using polynomial chirplet transform and smoothed pseudo Wigner-Ville distribution. In Proceedings of the 2017 IEEE Signal Processing in Medicine and Biology Symposium (SPMB), Philadelphia, PA, USA, 2 December 2017; pp. 1–6. [Google Scholar]
- Dayou, J.; Han, N.C.; Mun, H.C.; Ahmad, A.H.; Muniandy, S.V.; Dalimin, M.N. Classification and identification of frog sound based on entropy approach. In Proceedings of the 2011 International Conference on Life Science and Technology, Mumbai, India, 7–9 January 2011; Volume 3, pp. 184–187. [Google Scholar]
- Zheng, F.; Zhang, G.; Song, Z. Comparison of different implementations of MFCC. J. Comput. Sci. Technol. 2001, 16, 582–589. [Google Scholar] [CrossRef]
- Hussain, H.; Ting, C.M.; Numan, F.; Ibrahim, M.N.; Izan, N.F.; Mohammad, M.M.; Sh-Hussain, H. Analysis of ECG biosignal recognition for client identifiction. In Proceedings of the 2017 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuching, Malaysia, 12–14 September 2017; pp. 15–20. [Google Scholar]
- Nickel, C.; Brandt, H.; Busch, C. Classification of Acceleration Data for Biometric Gait Recognition on Mobile Devices. Biosig 2011, 11, 57–66. [Google Scholar]
- Muheidat, F.; Tyrer, W.H.; Popescu, M. Walk Identification using a smart carpet and Mel-Frequency Cepstral Coefficient (MFCC) features. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 4249–4252. [Google Scholar]
- Negi, S.S.; Kishor, N.; Negi, R.; Uhlen, K. Event signal characterization for disturbance interpretation in power grid. In Proceedings of the 2018 First International Colloquium on Smart Grid Metrology (SmaGriMet), Split, Croatia, 24–27 April 2018; pp. 1–5. [Google Scholar]
- Xie, J.; Towsey, M.; Zhang, J.; Roe, P. Frog call classification: A survey. Artif. Int. Rev. 2018, 49, 375–391. [Google Scholar] [CrossRef]
- Colonna, J.G.; Nakamura, E.F.; Rosso, O.A. Feature evaluation for unsupervised bioacoustic signal segmentation of anuran calls. Expert Syst. Appl. 2018, 106, 107–120. [Google Scholar] [CrossRef]
- Luque, A.; Romero-Lemos, J.; Carrasco, A.; Barbancho, J. Non-sequential automatic classification of anuran sounds for the estimation of climate-change indicators. Expert Syst. Appl. 2018, 95, 248–260. [Google Scholar] [CrossRef]
- Luque, A.; Romero-Lemos, J.; Carrasco, A.; Gonzalez-Abril, L. Temporally-aware algorithms for the classification of anuran sounds. PeerJ 2018, 6, e4732. [Google Scholar] [CrossRef] [Green Version]
- Luque, A.; Romero-Lemos, J.; Carrasco, A.; Barbancho, J. Improving Classification Algorithms by Considering Score Series in Wireless Acoustic Sensor Networks. Sensors 2018, 18, 2465. [Google Scholar] [CrossRef] [PubMed]
- Romero, J.; Luque, A.; Carrasco, A. Anuran sound classification using MPEG-7 frame descriptors. In Proceedings of the XVII Conferencia de la Asociación Española para la Inteligencia Artificial (CAEPIA), Salamanca, Spain, 14–16 September 2016; pp. 801–810. [Google Scholar]
- Luque, A.; Gómez-Bellido, J.; Carrasco, A.; Personal, E.; Leon, C. Evaluation of the processing times in anuran sound classification. Wireless Communications and Mobile Computing 2017. [Google Scholar] [CrossRef]
- Luque, A.; Gómez-Bellido, J.; Carrasco, A.; Barbancho, J. Optimal Representation of Anuran Call Spectrum in Environmental Monitoring Systems Using Wireless Sensor Networks. Sensors 2018, 18, 1803. [Google Scholar] [CrossRef] [PubMed]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar]
- Dai, W.; Dai, C.; Qu, S.; Li, J.; Das, S. Very deep convolutional neural networks for raw waveforms. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 421–425. [Google Scholar]
- Strout, J.; Rogan, B.; Seyednezhad, S.M.; Smart, K.; Bush, M.; Ribeiro, E. Anuran call classification with deep learning. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2662–2665. [Google Scholar]
- Colonna, J.; Peet, T.; Ferreira, C.A.; Jorge, A.M.; Gomes, E.F.; Gama, J. Automatic classification of anuran sounds using convolutional neural networks. In Proceedings of the Ninth International Conference on Computer Science & Software Engineering, Porto, Portugal, 20–22 July 2016; pp. 73–78. [Google Scholar]
- Podder, P.; Khan, T.Z.; Khan, M.H.; Rahman, M.M. Comparative performance analysis of hamming, hanning and blackman window. Int. J. Comput. Appl. 2014, 96, 1–7. [Google Scholar] [CrossRef]
- O’shaughnessy, D. Speech Communication: Human and Machine, 2nd ed.; Wiley-IEEE Press: Hoboken, NJ, USA, 1999; ISBN 978-0-7803-3449-6. [Google Scholar]
- Bhatia, R. Fourier Series; American Mathematical Society: Providence, RI, USA, 2005. [Google Scholar]
- Broughton, S.A.; Bryan, K. Discrete Fourier Analysis and Wavelets: Applications to Signal and Image Processing; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Rao, K.R.; Yip, P. Discrete Cosine Transform: Algorithms, Advantages, Applications; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Tan, L.; Jiang, J. Digital Signal Processing: Fundamentals and Applications; Academic Press: Cambridge, MA, USA, 2018. [Google Scholar]
Figure 1.
The process of extracting the Mel-Frequency Cepstral Coefficients (MFCC) features from a certain sound.
Figure 1.
The process of extracting the Mel-Frequency Cepstral Coefficients (MFCC) features from a certain sound.

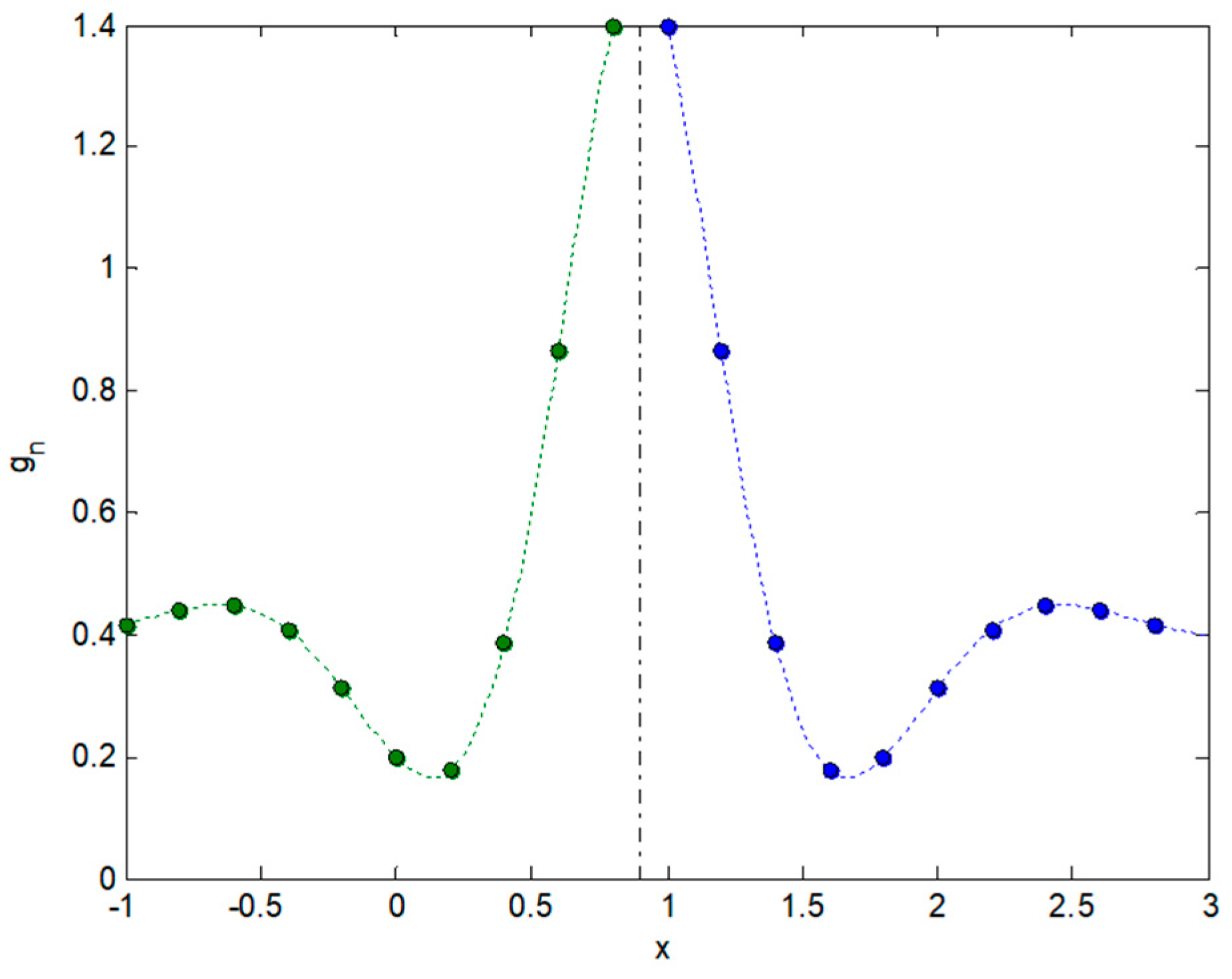
Figure 2.
Known fragment of an example function (dashed line) and its corresponding sampled function (dots).
Figure 2.
Known fragment of an example function (dashed line) and its corresponding sampled function (dots).

Figure 3.
Periodic function obtained by repetition of the known fragment of .

Figure 4.
Integration of sampled functions (sum of Riemann).

Figure 5.
Known fragment of a symmetric example function (dashed line) and its corresponding sampled function (dots). These functions are obtained by considering the original fragment of the example function (blue) and its symmetric (green).
Figure 5.
Known fragment of a symmetric example function (dashed line) and its corresponding sampled function (dots). These functions are obtained by considering the original fragment of the example function (blue) and its symmetric (green).

Figure 6.
Periodic function obtained by repetition of the known fragment of .

Figure 7.
Defining the origin of coordinates.

Figure 8.
Sound amplitude for an arbitrarily selected frame of an anuran call (A); and its log-scale Energy Spectral Density (B).
Figure 8.
Sound amplitude for an arbitrarily selected frame of an anuran call (A); and its log-scale Energy Spectral Density (B).

Figure 9.
Mel Filter Bank Energy (mel-FBE) spectrum for an arbitrarily selected frame of an anuran call.
Figure 9.
Mel Filter Bank Energy (mel-FBE) spectrum for an arbitrarily selected frame of an anuran call.

Figure 10.
Periodic repetition of the mel-FBE spectrum (A); and the mel-FBE spectrum and its symmetric (B).
Figure 10.
Periodic repetition of the mel-FBE spectrum (A); and the mel-FBE spectrum and its symmetric (B).

Figure 11.
Cepstral representation of the mel-FBE spectrum (cepstrum).

Figure 12.
Mel-FBE spectrum for an arbitrarily selected frame of an anuran call. Original spectrum and recovered spectra using a different number of Discrete Cosine Transform (DCT) cepstral coefficients.
Figure 12.
Mel-FBE spectrum for an arbitrarily selected frame of an anuran call. Original spectrum and recovered spectra using a different number of Discrete Cosine Transform (DCT) cepstral coefficients.

Figure 13.
Mel-FBE spectrum for an arbitrarily selected frame of an anuran call. Original spectrum and recovered spectrum using coefficients obtained using Discrete Fourier Transform (DFT) and DCT.
Figure 13.
Mel-FBE spectrum for an arbitrarily selected frame of an anuran call. Original spectrum and recovered spectrum using coefficients obtained using Discrete Fourier Transform (DFT) and DCT.

Figure 14.
Root Mean Square Error recovering the original mel-FBE spectrum when a different number of cepstral coefficients are used. The cepstral coefficients are obtained applying either DFT or DCT.
Figure 14.
Root Mean Square Error recovering the original mel-FBE spectrum when a different number of cepstral coefficients are used. The cepstral coefficients are obtained applying either DFT or DCT.

Figure 15.
Root Mean Square Error for the whole dataset when either DFT or DCT is employed.

Figure 16.
Improvement of DCT over DFT describing mel-FBE spectra. (A): . (B): .

Figure 17.
Improvement of DCT over DFT in describing mel-FBE spectra. (A): Probability density function for several values of the number of cepstral coefficients. (B): Probability density function for each value of the number of cepstral coefficients.
Figure 17.
Improvement of DCT over DFT in describing mel-FBE spectra. (A): Probability density function for several values of the number of cepstral coefficients. (B): Probability density function for each value of the number of cepstral coefficients.

Figure 18.
Improvement of DCT over DFT in describing arbitrary function. (A): Probability density function for several values of the number of cepstral coefficients. (B): Probability density function for each value of the number of cepstral coefficients.
Figure 18.
Improvement of DCT over DFT in describing arbitrary function. (A): Probability density function for several values of the number of cepstral coefficients. (B): Probability density function for each value of the number of cepstral coefficients.

Figure 19.
Correlation between cepstral coefficients describing mel-FBE spectra for DFT (panel A) and DCT (panel B).
Figure 19.
Correlation between cepstral coefficients describing mel-FBE spectra for DFT (panel A) and DCT (panel B).

Figure 20.
Histogram of the correlation among cepstral coefficients describing mel-FBE spectra for DFT and DCT.
Figure 20.
Histogram of the correlation among cepstral coefficients describing mel-FBE spectra for DFT and DCT.

Figure 21.
Processing time required to compute the DFT and DCT vs. the number of samples describing mel-FBE spectra.
Figure 21.
Processing time required to compute the DFT and DCT vs. the number of samples describing mel-FBE spectra.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Classification performance metrics for DCT and DFT.
| Cepstral Transform | ACC | PRC | F1 |
|---|---|---|---|
| DFT | 94.27% | 74.46% | 77.67% |
| DCT | 94.85% | 76.76% | 78.93% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Luque, A.; Gómez-Bellido, J.; Carrasco, A.; Barbancho, J. Exploiting the Symmetry of Integral Transforms for Featuring Anuran Calls. Symmetry 2019, 11, 405. https://doi.org/10.3390/sym11030405
AMA Style
Luque A, Gómez-Bellido J, Carrasco A, Barbancho J. Exploiting the Symmetry of Integral Transforms for Featuring Anuran Calls. Symmetry. 2019; 11(3):405. https://doi.org/10.3390/sym11030405
Chicago/Turabian StyleLuque, Amalia, Jesús Gómez-Bellido, Alejandro Carrasco, and Julio Barbancho. 2019. "Exploiting the Symmetry of Integral Transforms for Featuring Anuran Calls" Symmetry 11, no. 3: 405. https://doi.org/10.3390/sym11030405
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.