Modeling of Extreme Values via Exponential Normalization Compared with Linear and Power Normalization



1
Department of Mathematics, Faculty of Science, Zagazig University, 44519 Zagazig, Egypt
2
Department of Mathematics, Faculty of Science, Port said University, 42524 Port Said, Egypt
3
Department of Physics and Engineering Mathematics, Faculty of Engineering, Port Said University, 42524 Port Said, Egypt
*
Author to whom correspondence should be addressed.
Symmetry 2020, 12(11), 1876; https://doi.org/10.3390/sym12111876
Submission received: 20 October 2020
/
Revised: 30 October 2020
/
Accepted: 7 November 2020
/
Published: 14 November 2020
(This article belongs to the Special Issue Symmetric and Asymmetric Distributions: Theoretical Developments and Applications II)
Abstract
:Several new asymmetric distributions have arisen naturally in the modeling extreme values are uncovered and elucidated. The present paper deals with the extreme value theorem (EVT) under exponential normalization. An estimate of the shape parameter of the asymmetric generalized value distributions that related to this new extension of the EVT is obtained. Moreover, we develop the mathematical modeling of the extreme values by using this new extension of the EVT. We analyze the extreme values by modeling the occurrence of the exceedances over high thresholds. The natural distributions of such exceedances, new four generalized Pareto families of asymmetric distributions under exponential normalization (GPDEs), are described and their properties revealed. There is an evident symmetry between the new obtained GPDEs and those generalized Pareto distributions arisen from EVT under linear and power normalization. Estimates for the extreme value index of the four GPDEs are obtained. In addition, simulation studies are conducted in order to illustrate and validate the theoretical results. Finally, a comparison study between the different extreme models is done throughout real data sets.
1. Introduction
It has become necessary to study statistical models that have the ability to evaluate these rare phenomena to avoid its dangers due to the sudden rise of some natural harmful phenomena, such as earthquakes, Tsunami, air pollution, and other phenomena. In the last two decades, the EVT has emerged as one of the most significant statistical modeling disciplines for the applied sciences. The EVT can be applied to environmental studies, such as hydrology, pollution, rainfall, floods, wind gusts, and corrosion, in order to develop models for describing the distribution of extreme events. The distributional properties of the extreme and intermediate order statistics and exceedances over (below) high (low) thresholds are determined by the upper and lower tails of the underlying distribution. The most important challenges in any application of such extreme value models is the scarcity of extreme data, choosing the threshold, or beginning of the tail, and choosing the methods of estimating the unknown parameters. Much of the classical EVT is concerned substantially with distribution properties of the maximum of iid RVs and all of the results obtained for maximum of course lead to anologous results for minimum through the obvious relation The core of the EVT is the extreme value distributions, which are well known in the literature (cf. [1]), and they are used as approximations to DFs of normalized partial maximum of iid RVs. A DF F is said to belong to the l-max domain of attraction of an extreme value distribution G under linear normalization, denoted by if there exist norming constants and such that
where “” stands for weak convergence, as It is well known that the asymptotic relation (1) yields only three possible types of non-degenerate limiting DFs, which are Frèchet, Weibull, and Gumbel DFs. Moreover, any non-degenerate DF G is an extreme value distrbution (i.e., it is a limit in (1)) if and only if it satisfies the stability relation for every integer n, where and are some suitable constants (cf. [1,2]). For this reason, these limits are called l-max-stable laws. On the other hand, these l-max stable laws may be written in the von Mises−Jenkinson format
where and are the location and scale parameters, respectively, while is a shape parameter that is known as the extreme value index (EVI), which is the central issue in empirical research dealing with extreme events. It is obviously found that the DF which is known as the generalized extreme value distribution under linear normalization (GEVL), describes the Gumbel, Frèchet, and Weibull types with respect to the cases (interpreted as ), and The GEVL provides a prevailing parametric approache for modeling extreme events, which is known as the block maxima (BM). Its application consists of partitioning a data set into blocks of equal length, and fitting the GEVL to the set of block maxima. An extension of the BM approach is the peak over threshold (POT) approach (see [1]), where we only consider the observations which lie above an appropriate threshold. The generalized Pareto distribution under linear normalization (GPDL) introduced by [3,4] is considered as a foremost pillar of the POT approach. The GPDL is the limit distribution of scaled excesses over high thresholds, which has the form
In order to widen the class of limit laws in EVT for solving more approximation problems, the authors of [5] extended the EVT under power normalization where according to respectively. Another reason for using the power normalization in EVT is concerning the possibility of getting a better rate of convergence in EVT (cf. [6]). Clearly, the power normalization is a strictly monotone continuous transformation. Therefore, this transformation does not give rise to any wastage of information that the data contains (e.g., the sufficiency property is preserved under one to one transformation). Nevertheless, we might lose some flexibility if we used such normalization. For example, under this normalization we can not change the sign of the data or get rid of zero. The DF F is said to belong to the p-max domain of attraction of a non-degenerate DF H under power normalization, denoted by , if for some norming constants and
The possible p-types of limiting DFs H in (3) are the p-max stable laws satisfying the stability relation for every where and are some suitable sequences of constants. Here, two DFs, F and G, are of the same p-type if we can find and for which for all Consequently, any non-degenerate DF H is a p-max stable, or equivalently H is a limit in (3), if and only if for every the two DFs H and are of the same p-type. In [7] the author has exemplified these types by the von Mises representation Each of these families is called generalized extreme value distribution under power normalization (GEVP). It is well known that the p-max-stable laws attract more distributions than the l-max-stable laws. This fact virtually means that the linear model may be unsuccessful for fitting an extreme data set; on the contrary, the power model succeed to fit it (see [1]). The authors of [8] applied the BM approach under power normalization using the GEVPs. Moreover, in a series of papers, refs. [9,10,11,12,13] developed the modeling of extreme values under power normalization by defining and using the generalized Pareto distributions under power normalization (GPDPs), to a real extreme-value data (for more details regarding the power transformation, see [14,15,16,17,18]).
Once more, in order to widen the class of the limit laws in EVT, in [19] the authors extended the EVT under exponential normalization Under this transformation, we can say that the DFs F and G are of the same e-type if for some constants In this case, a non-degenerate DF is said to be an e-max-stable laws if there exists a DF F and norming constants , such that
If (4) is satisfied, then we can say that the DF F belongs to the e-max-domain of attraction of the non-degenerate DF under e-normalization, denoted by The authors of [19], showed that the possible limiting DFs in (4) are the e-max stable laws that satisfy the stability property that any non-degenerate DF is an e-max stable, or equivalently is a limit in (4), if and only if for every the two DFs and are of the same e-type (for more details about the exponential transformation, see [20]).
In [19], the authors showed that the possible limit laws arisen from (4) attract more DFs than the p-max-stable laws. This fact virtually means that the linear and power models may fail to fit the given extreme data, while the exponential model succeeds. This fact gives us a sufficient motivation for developing the modeling of extreme values via the exponential model, denoted by the e-model. The aimed development is the first object of this paper and it will be achieved within two stages. the first stage is to infer the generalized extreme value distributions related to the EVT under exponential normalization. These asymmetric DFs enable us to apply the BM approach. The second stage is deriving the possible generalized Pareto families of asymmetric distributions relating to the EVT under exponential normalization. These families will pave the way to applying the POT approach. The second object of this paper is comparing between the EVT under linear, power, and exponential normalization via a real data sets of air pollution.
The rest of this paper is structured, as follows: In Section 2, we deduce the generalized extreme value distributions relating to the EVT under exponential normalization (GEGEs). In Section 3, which is devoted to the theoretical details, we first suggest an estimate for the EVI in each of the GEGEs. This estimate corresponds to a Dubey estimate in the GEVL model (3) and the GEVP models (cf. [8]). Secondly, we derive the generalized Pareto distributions under exponential normalization (GPDEs). Finally, we propose estimators for the EVI in these GPDEs. Section 4 is devoted to a simulation study, which illustrates and corroborates the theoretical results. In Section 5, the EVT under linear, power, and exponential normalization is applied, with comparisons to several real data sets.
2. Preliminary Results
In [19], the authors derived the following a chain of equivalences between l-max-domains, p-max-domains and e-max-domains of attraction:
- where is an l-max stable DF, and and are p-max stable DFs.
- where is an p-max stable DF, and and are e-max stable laws.
In the above implications, denotes the DF of the RV X and “” stands for “if and only if”. Moreover, ref. [19] used these implications in order to determine e-max-stable laws, wherein the first six e-max-stable DFs have right endpoint and the subsequent six e-max-stable DFs have
We now totalize the limit laws (5) using the von Mises type representations. For any the types (5) are totalized by the following general von Mises type forms:
where is a given real number. When is defined as The DF yields laws of the same e-types as and according to and respectively. Each DF in (6) is called generalized extreme value distribution under exponential normalization (GEVE), denoted by GEVE Clearly, the parametric models in (6) enable us to apply the BM approach under exponential normalization, where, in this case, we have to assume that the data in hand form a random sample drwan from an exact GEVE
3. BM Approach and GPDEs
When considering the BM approach, let be the set of maximums of the given blocks. Clearly, in view of the shape of the e-types (6), the modeling under exponential normalization can only be applied if all values of these maximums belong to one and only one of the non-overlapping intervals and More specifically, if or or or we would select the model or or or respectively. Subsequently, we compute the maximum likelihood (ML) estimates of as the numerical solutions of the likelihood equations based on the selected model. The estimate of the shape parameter corresponds to a Dubey estimate in the GEVL model is linear combinations of ratios of spacing
where and Clearly, the statistic is invariant under the exponential transformation. Now, relaying on the obvious relations: (1) where or or or if or or or respectively, and is the sample DF, (2) for large we have and (3) we obtain
The relation (7), after some algebra, yields
if satisfy the equation Upon taking the logarithm of both sides of (8), we get the estimate
On the other hand, if for some we get the estimate family By taking we get
In Section 4, we will compare the ML method and estimate for estimating via the Moreover, we will detect the value of which gives the best estimate for It will be revealed that the estimate (9) is very poor for large values of ( Regardless of the fact that this estimate is based on the BM approach, this approach also suffers some other problems, among them is only considering several maxima within several blocks and ignoring most the other data. In a spirit of the result of [3,4], we propose applying the POT approach based on the EVT under exponential normalization, where we deal with the right tail for large i.e., we deal with top-order observations. In order to adapt this approach for the e-model we derive the GPDE. Our focus will be mainly on the case via Theorem 1. Clearly, the case covers most of the important practical applications of the EVT. However, the case will be briefly discussed in Theorem 3. In the next theorems and throughout the paper, we adopt the notations and “” to mean convergence as
Theorem 1.
- a.
- andif;
- b.
- andif
Proof.
The proof of Part [a]: In view of the EVT, we obtain
which, in view of the assumption implies that
Now, let n be chosen, such that where u is any real number such that (note that by putting in (11), we get ). Subsequently, (13) implies that Thus, put and apply again the modified Khinchin’s Theorem, (11) may be written in the form
Therefore, by putting in (14), we get
Theorem 2
(the peak over threshold stability property). The left truncated GPDE again yields a GPDE. This means that, for every we have where and Moreover, for every we have where and
Proof.
Let Subsequently,
where On the other hand, we have
where This completes the proof of Theorem 2. □
Theorem 3.
- c.
- if;
- d.
- if
Moreover, the limitsandsatisfy the peak over threshold stability property.
Proof.
The proof is very similar to the proof of Theorems 1 and 2, with the exception of only of obvious changes. □
Estimation of the EVI via GPDE Model
In this subsection, we derive estimates for the parametrs and in the GPDE These estimates consort with the Pickand’s estimates in the GEVL model (2) (cf. [4]). Let n be the sample size and be an integer much smaller than Let be the ith largest observation in the sample, The values will be treated as though they were the descending order statistics from a sample of size from the DF for some and Because, for any we have we get and Clearly,
which implies and To estimate and , we replace the population quantiles and by the sample quantiles and Therefore,
In the next section, we will consider the determination problem of m via a simulation study. Theoretically, the value should satisfy the two conditions and (cf. [4]).
4. Simulation Study
In Table 1, we compare the ML method and the Formula (9) for estimating the EVI via the first GEVE defined in (6). Additionally, from Table 1, we determine the value of which gives the best estimate for In Table 1, we present estimates for each value of by applying the ML method and computing the estimate that resulted from (9) for different quantiles This procedure is repeated 1000 times to obtain the average estimates (for the given different values of q) for and their mean square errors (MSE’s). Table 1 shows that the estimates (9) are poor when compared with the Ml estimates. Moreover, the precision of the estimate closely depends on the value of It was revealed that when the estimates computed by (9) became very poor, for this reason in Table 1 we only considered the values
In Table 2, for each value of we generate a random sample of size from Moreover, we choose the threshold values (in the interval ). In view of Theorem 2, the DF of the simulated data, which come after any threshold value has the same type of the DF Therefore, we can estimate the parameter by using the ML method for each of these threshold values. This procedure is repeated 1000 times to obtain the average estimates and their MSE’s. Finally, we determine the value which gives the best estimate for the parameter by using the ML method. Table 3 is devoted to display the computed estimates of by using (16). In Table 3, the same procedure is applied with the exception that we choose m instead of k as (note that m).
In both Table 2 and Table 3, the asterisk in the superscript of a value means that this value is the best. Here, the “best” is according to the closeness to the actual value of and then according to the value of MSE in the case of equal closeness to true value of of two or more estimates. Moreover, Table 2 and Table 3 show that the ML and (16) estimators for estimating the EVI via the GPDE have high accuracy when comparing with the estimates of via
5. Comparison Study between the Linear, Power and Exponential Models
Air pollution is a global problem, from which most countries across the world suffer (cf. [21,22,23]). In this section, we consider this problem via two data sets of pollutants, each of them consists of the maximum data of the three pollutants, nitric oxide (), nitrogen dioxide (), and particulate matter diameter less than 10 mm () (for some properties of these pollutants, see [1,22]). The first data set is taken from the site Lambeth–Streatham Green-Urban Background (denoted by LB6). The daily maximum of these pollutants was monitored and recorded every hour. Therefore, around 21,169 records are presented from 1 January 2014 to 31 July 2016. These data sets are publicly available from the following site: http://www.londonair.org.uk/london/asp/datadownload.asp.
Table 4 shows the summary statistics for these maximum data sets. Table 5 is devoted to the estimate parameters of the generalized extreme value distributions for LB6.
We checked the fitting of any family by the Kolmogorov–Smirnov (K-S) test, where, in this test, we have four functions H is equal to 0 or 1, P is the p-value, is the maximum difference between the data and the fitting curve and is a critical value. Therefore,
- we accept if and level of significant and
- we reject if and level of significant.
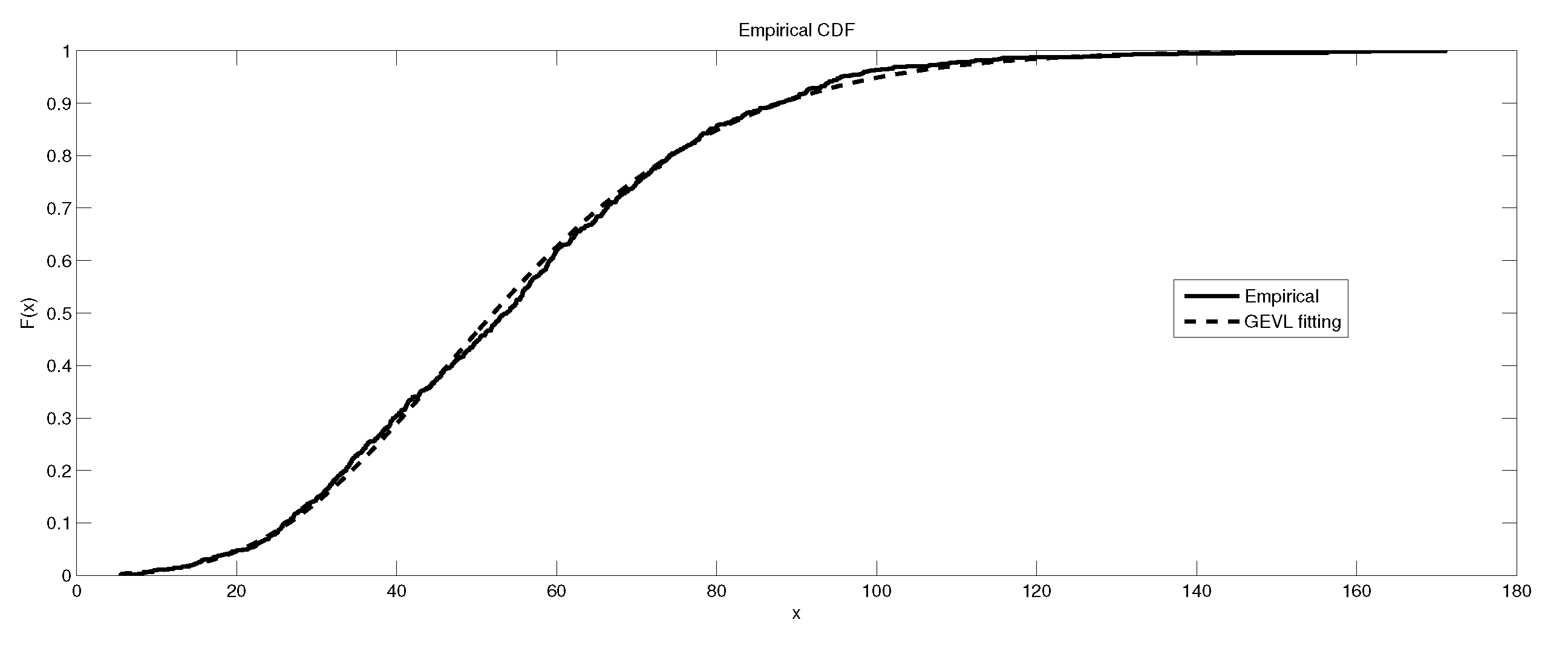
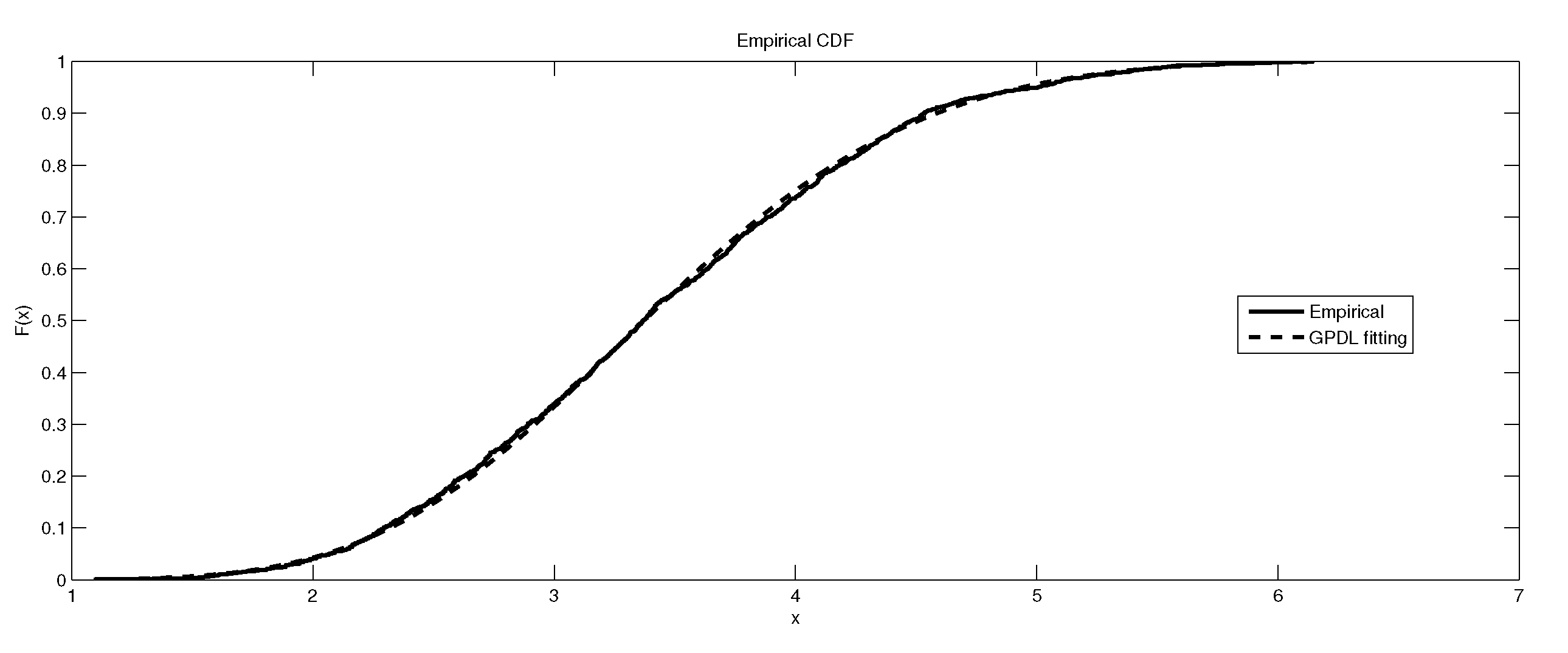
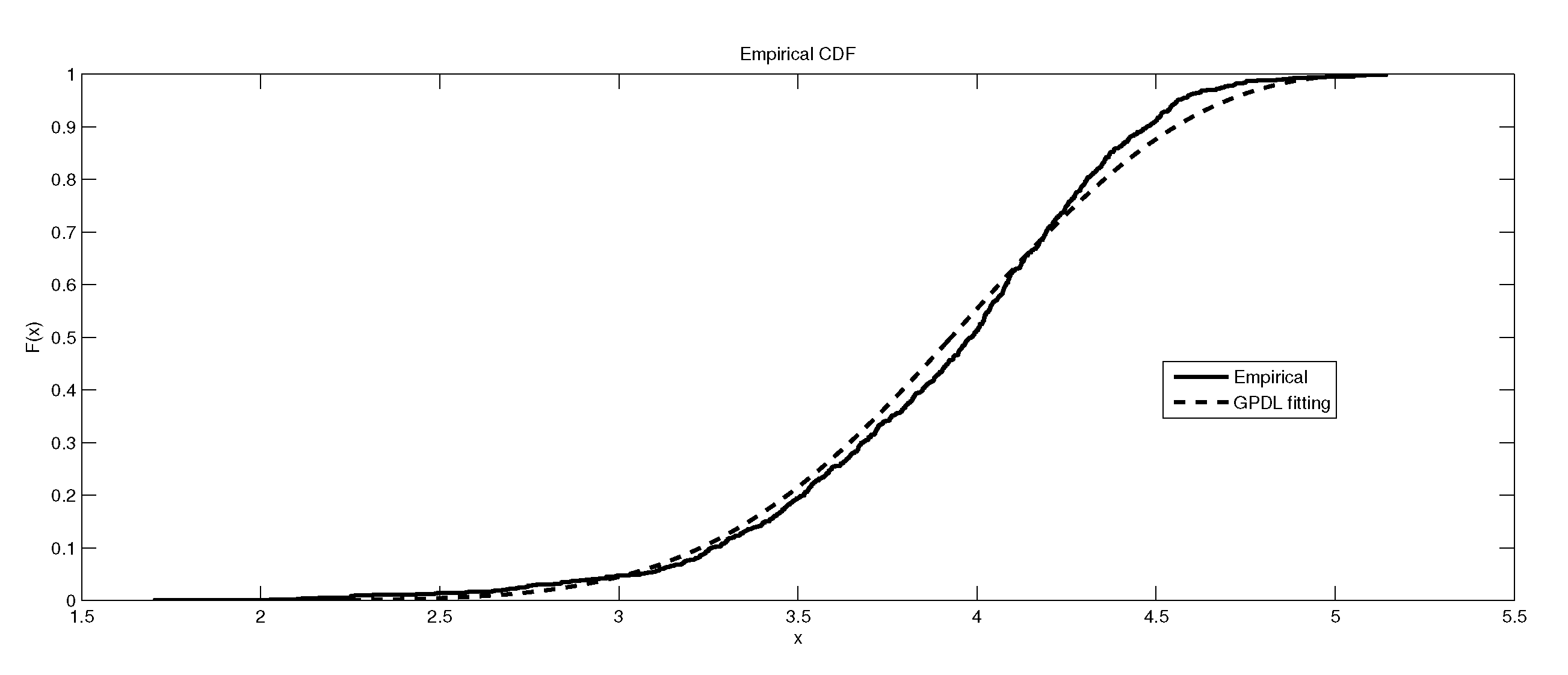
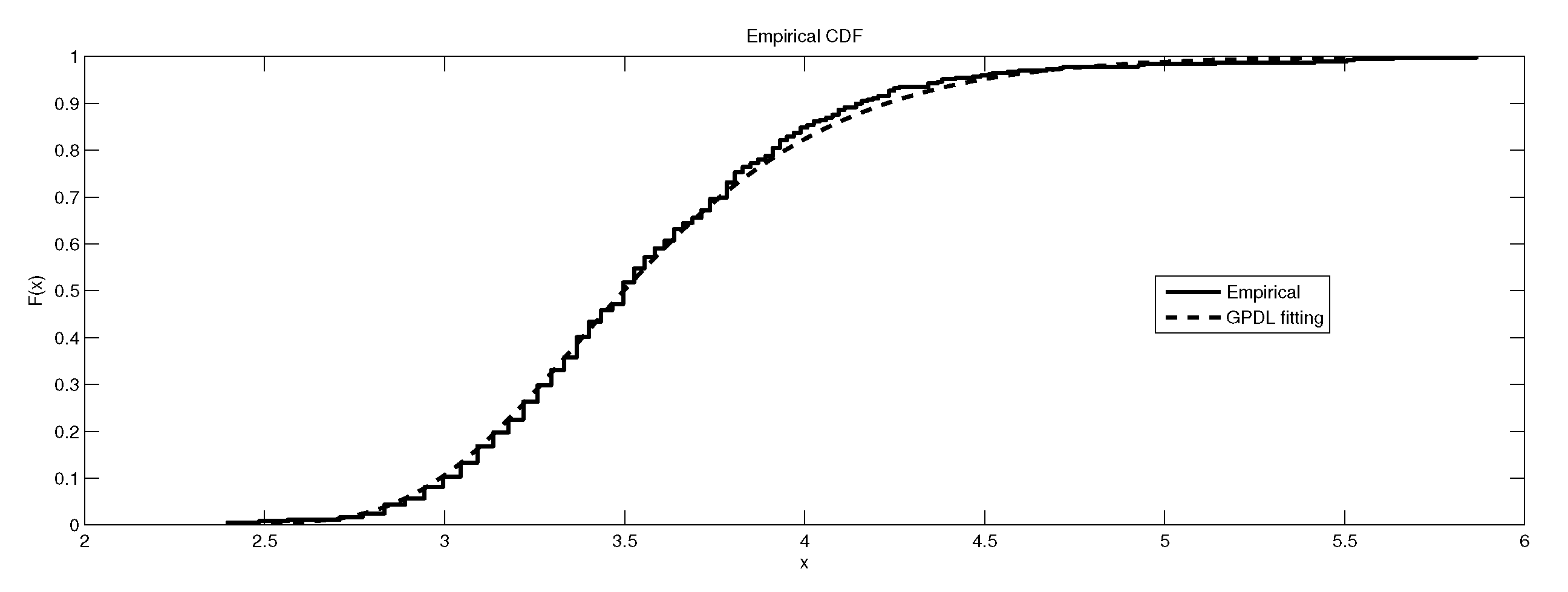
Table 6 gives the result of the Kolmogorov–Smirnov (K-S) test for fitting the three models , and to the maximum data sets from LB6. Table 7 illustrates the summary statistics for these maximum data set. Finally, the graphical representations of the data sets and the fitted distributions are given in Figure 1, Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9.
The second data set is taken from the site Greenwich-Eltham (denoted by GR4). The daily maxima of these pollutants are recorded every hour, so around 43,825 records are presented from 1 January 2014 to 31 December 2018. These data are publicly available from the following site: http://www.londonair.org.uk/london/asp/datadownload.asp.
Table 8 is devoted to the estimate parameters of the generalized extreme value distributions for GR4. Table 9 gives the result of the Kolmogorov–Smirnov (K-S) test for fitting the three models and to the maximum data sets from GR4. Finally, the graphical representations of the data set and the fitted distributions are given in Figure 10, Figure 11, Figure 12, Figure 13, Figure 14, Figure 15, Figure 16, Figure 17 and Figure 18.
The result summary of this study is given below, where the more favorable model is chosen among accepted models and has a minimum KSSTAT value.
- Only the power and exponential models are favorable in describing the pollutant that is monitored by LB6. The power model is the best one.
- The linear model is only the favorable model to describe the pollutant that is monitored by LB6.
- All of the models are favorable to describe the pollutant that is monitored by LB6. The best model is the linear model followed by the power model.
- Only the e-model is favorable to describe the pollutant , which is monitored by GR4.
- None of the three models is favorable to describe the pollutant that is monitored by GR4.
- All of the models are favorable to describe the pollutant that is monitored by GR4. The best model is the e-model followed by the linear model.
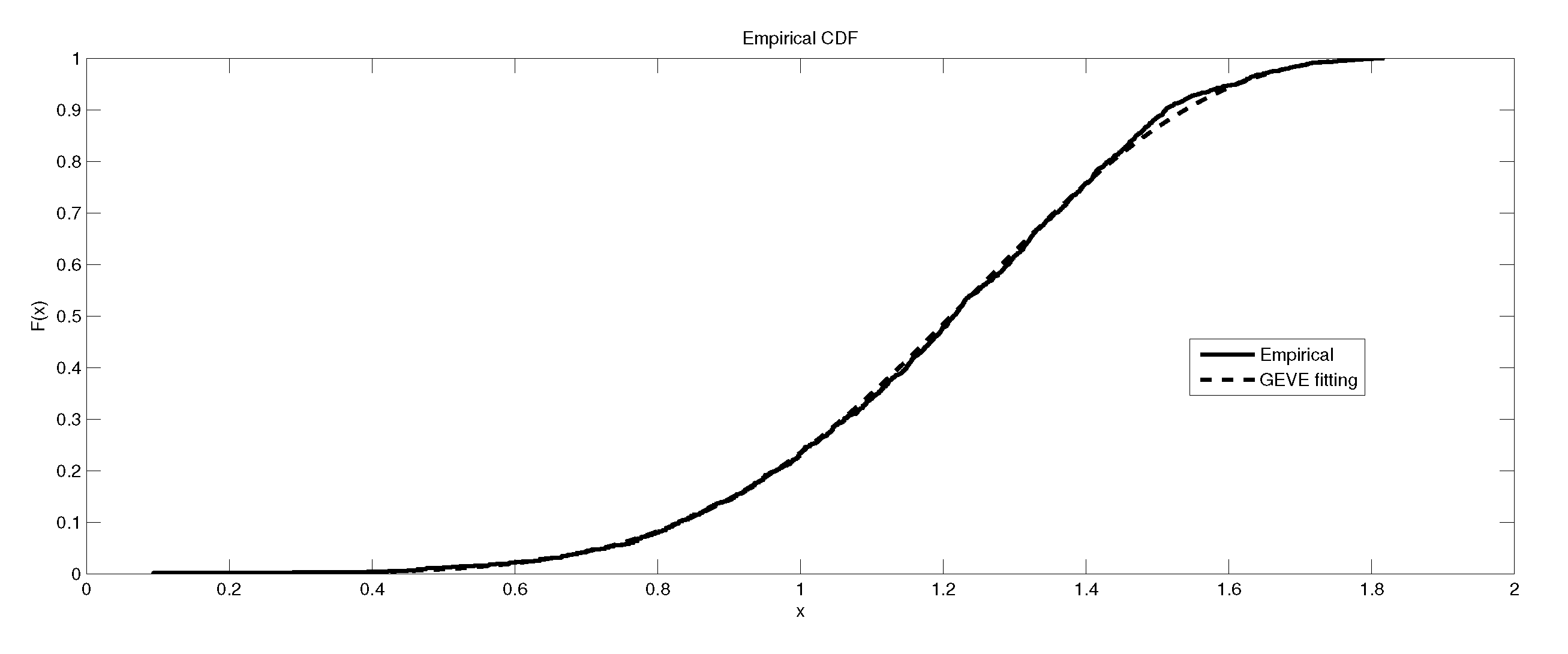
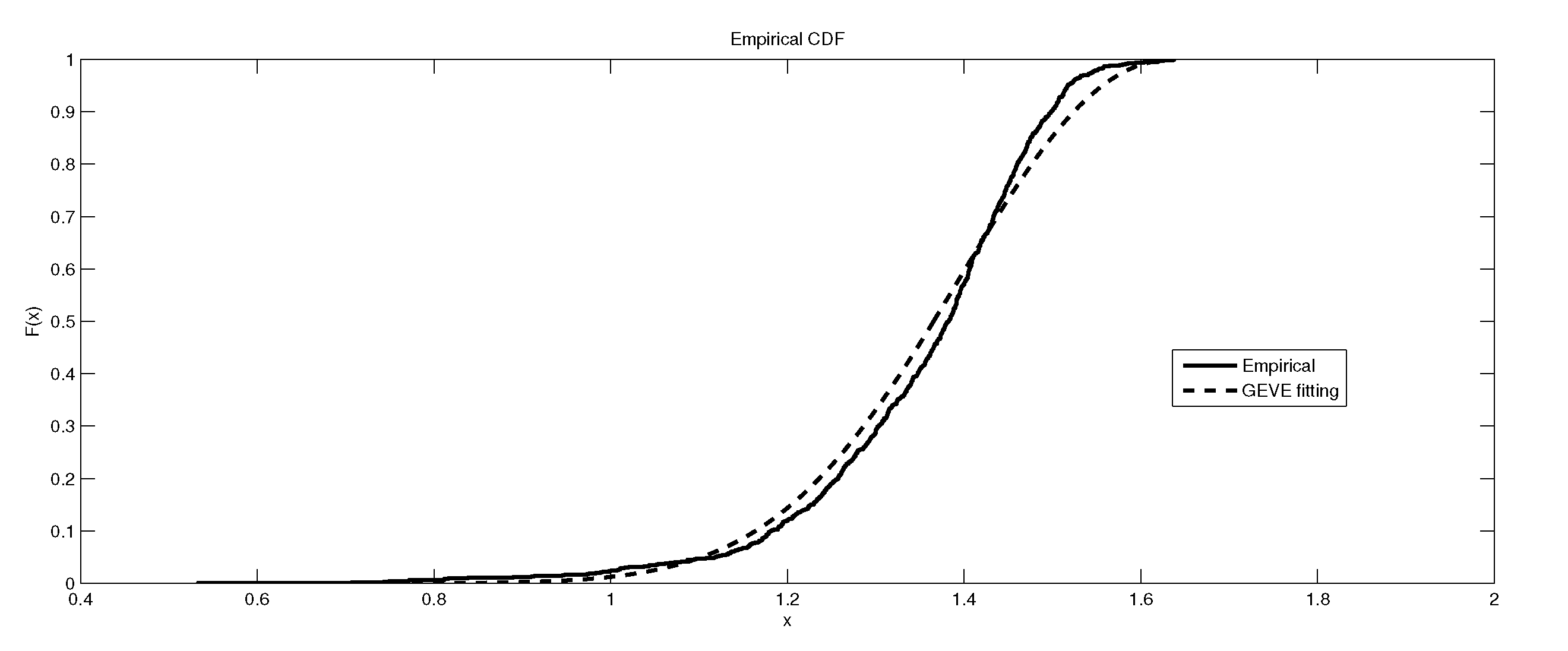
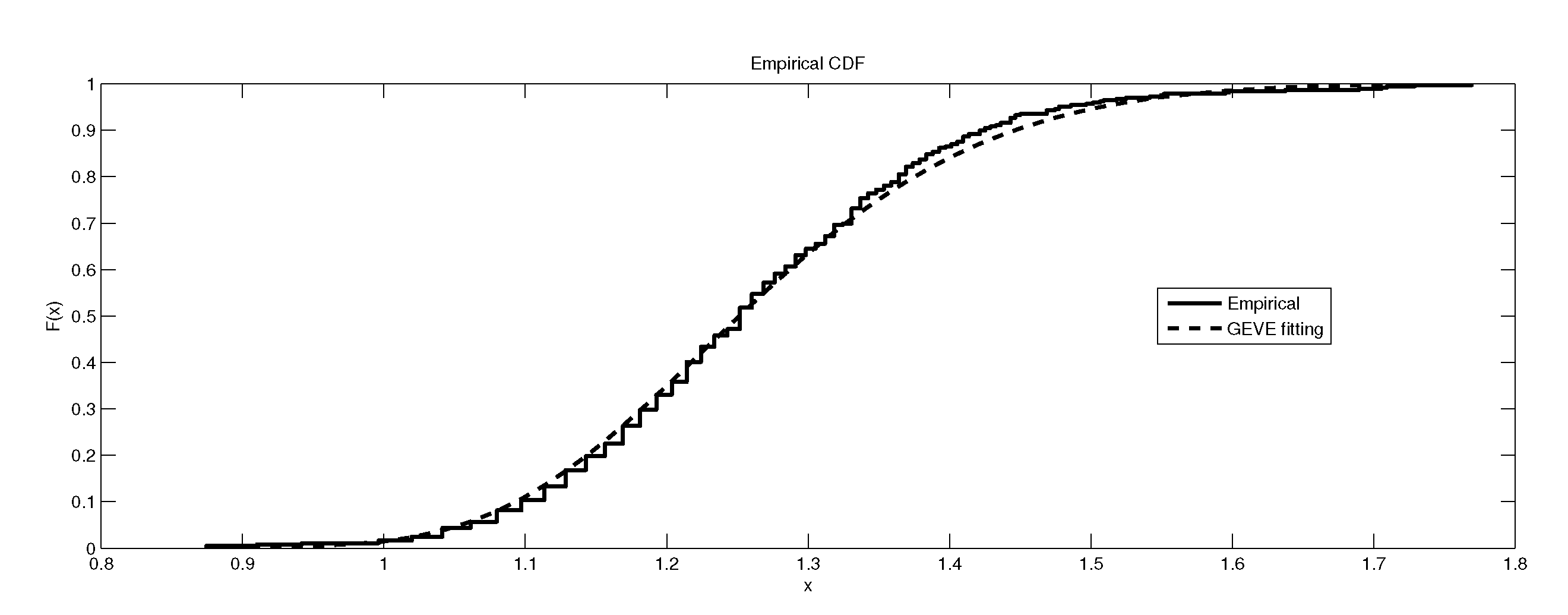
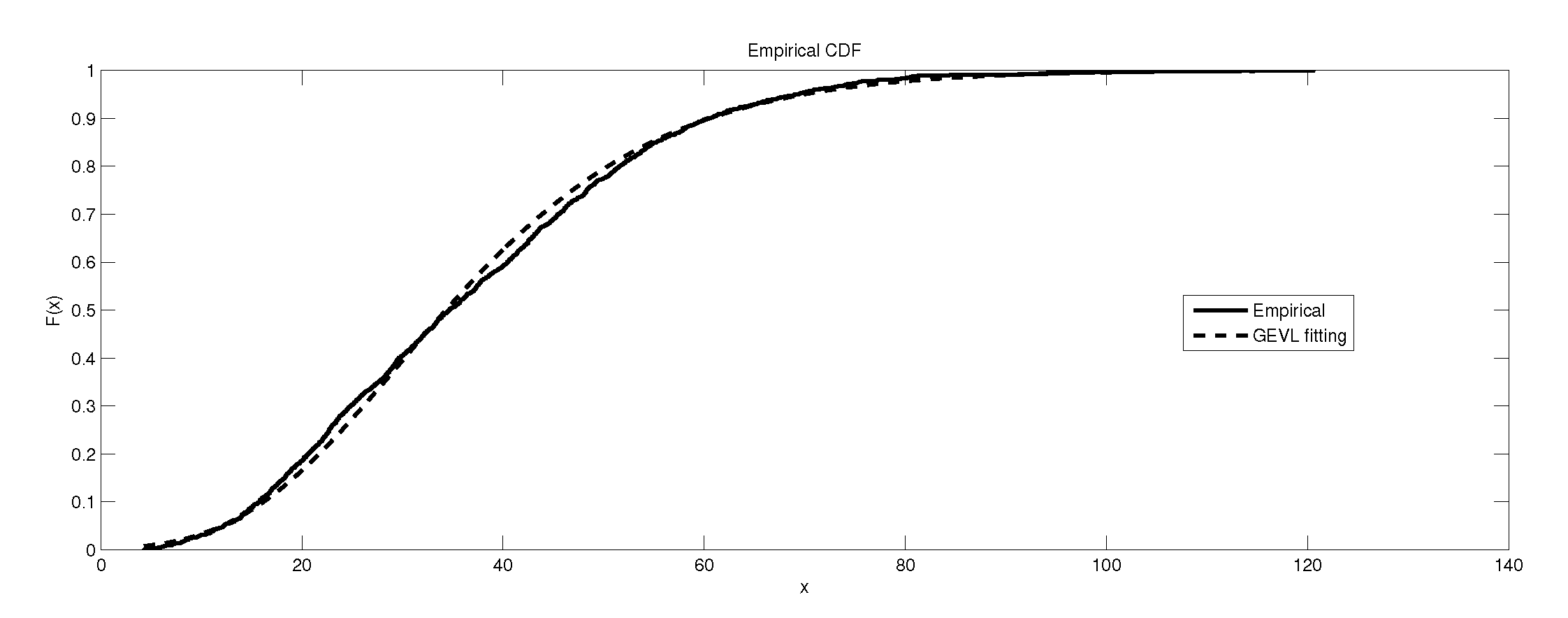
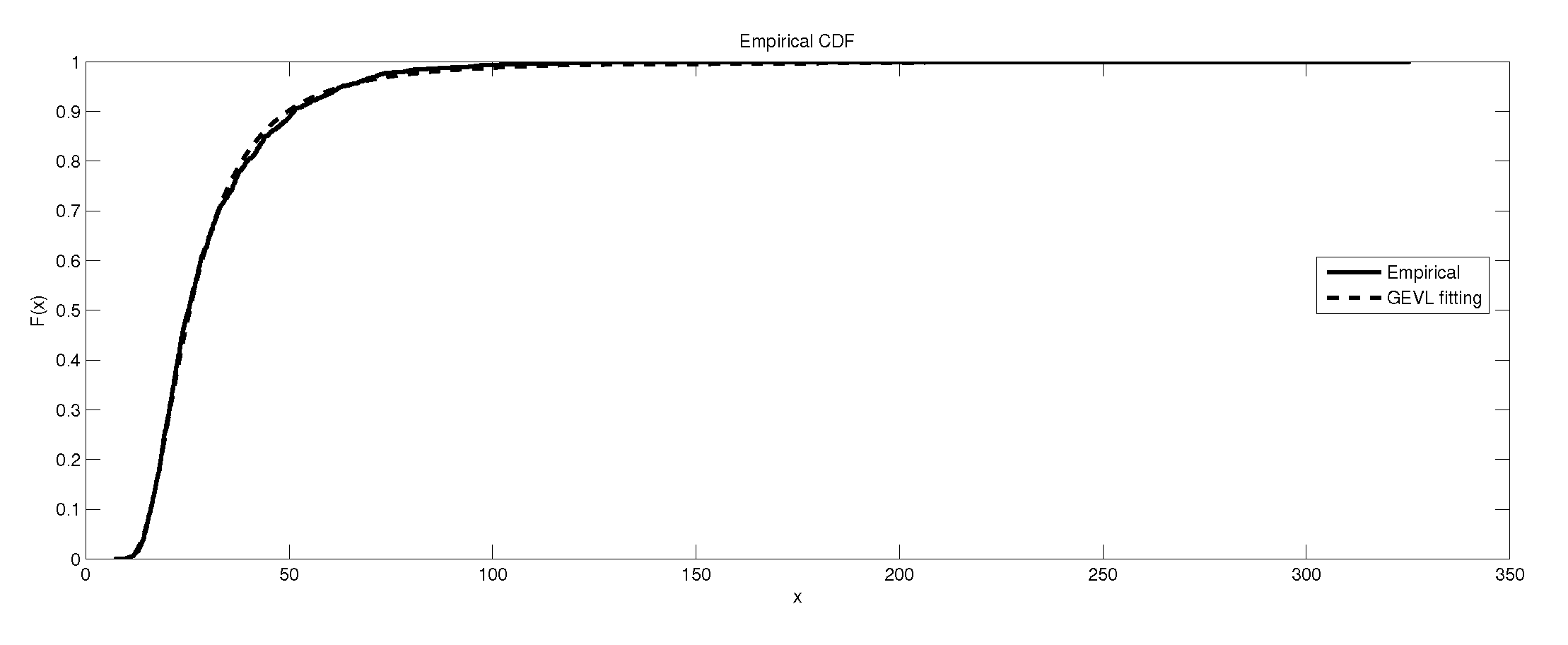
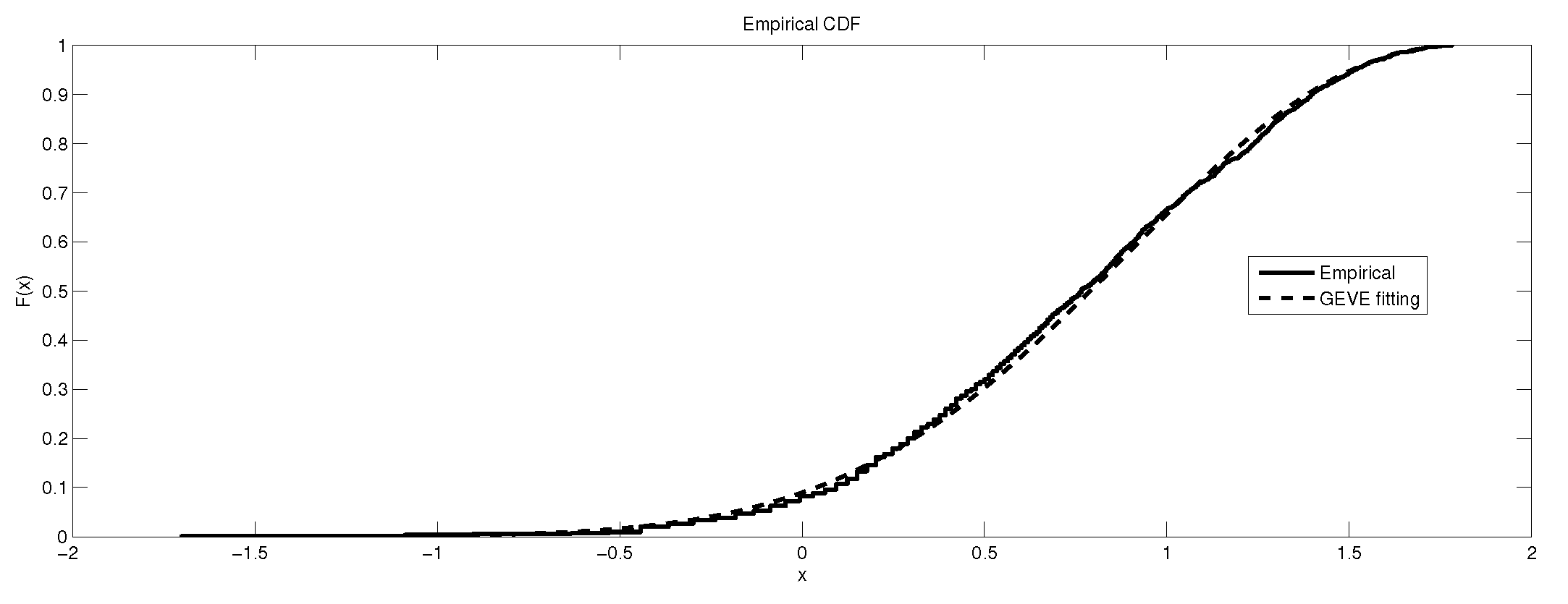
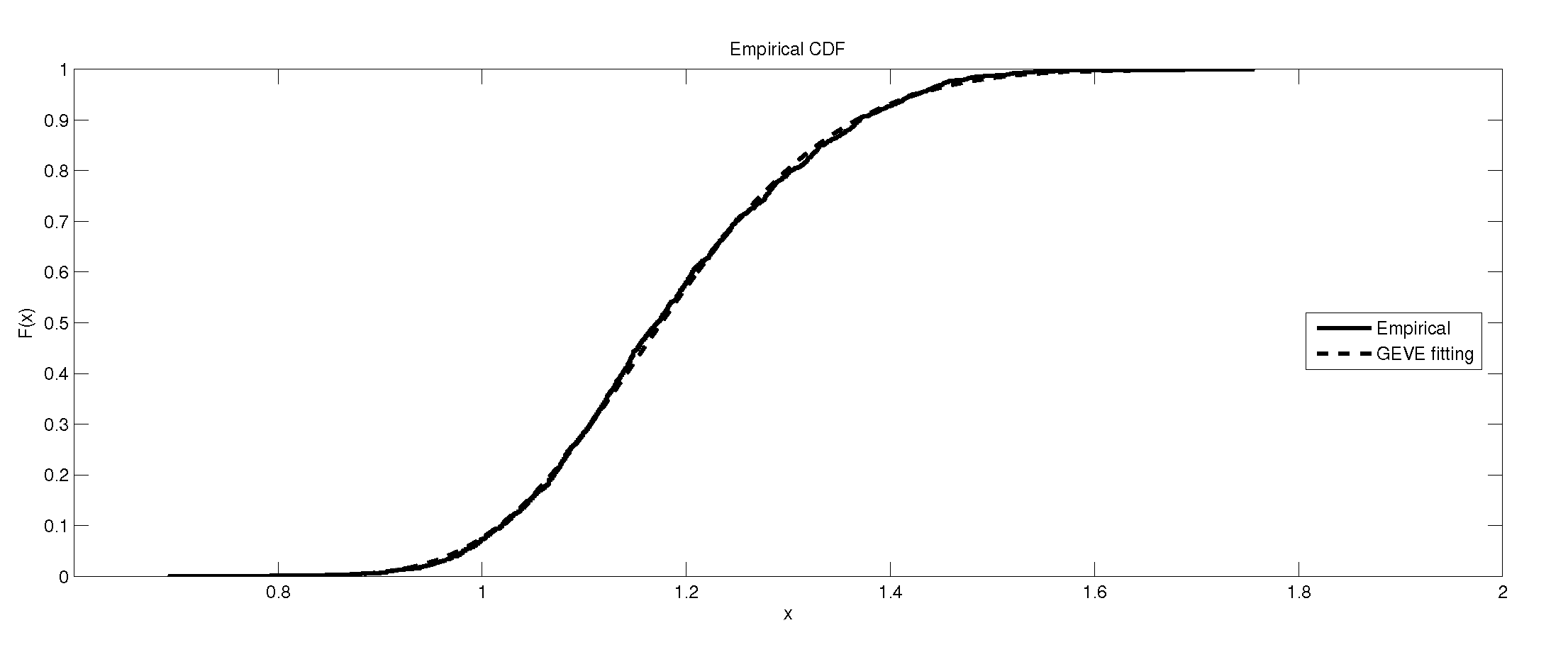
It is worth remarking that the study shows an interesting fact that the kurtosis of the data has an impact, to some extent, on the kind of the extreme model that describes the data, e.g., as the kurtosis increases, the e-model becomes more favorable. Moreover, the linear, power and exponential models become less favorable to fit the symmetric-platykurtic data set (for details about the description of data according to the skewness and kurtosis, see [24,25]), e.g., the case of pollutant Finally, a quick look at the Figure 1, Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12, Figure 13, Figure 14, Figure 15, Figure 16, Figure 17 and Figure 18 reveals that the curves of the empirical DF and the tested family nearly coincide when we accept (e.g., Figure 2, Figure 3 and Figure 4, Figure 6, Figure 7, Figure 9, Figure 12, Figure 15, Figure 16, and Figure 18), while, in the case of the rejection, the two curves diverge in some regions. This result endorses the results that are given in Table 6 and Table 9.
6. Conclusions
In this paper, we developed the EVT under exponential normalization to model extreme values, which are arisen in different natural phenomena. An estimate of the shape parameter of the generalized value distributions that related to the EVT under exponential normalization was proposed. New four generalized Pareto distributions related to the EVT under exponential normalization are obtained and their properties are elucidated. Estimates for the extreme value index of these distributions are suggested. The linear, power, and the suggested exponential models were applied, with a comparison, to several real data sets. The comparison between the three models revealed that the skewness and kurtosis of the data have an impact on the kind of the extreme model that describes the data.
Author Contributions
Data curation, O.M.K. and N.K.R.; Investigation, H.M.B.; Project administration, O.M.K.; Software, N.K.R.; Supervision, H.M.B. All authors have read and agreed to the published version of the manuscript.
Funding
This project was supported financially by the Academy of Scientific Research and Technology (ASRT), Egypt, Grant No 6656.
Acknowledgments
This work was funded through the Plan Science UP Faculty of Science from the National Academy of Scientific Research and Technology of Egypt, ASRT is the 2nd affiliation of this research. The authors thank the anonymous referees for the valuable comments and suggestions, which significantly improved the quality of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| GPDE | Generalized Pareto distributions under exponential normalization |
| EVT | Extreme value theory |
| iid | Independent identically distributed |
| RVs | Random variables |
| DF | Distribution function |
| EVI | Extreme value index |
| GEVL | Generalized extreme value distribution under linear normalization |
| BM | Block maxima |
| POT | Peak over threshold |
| GPDL | Generalized Pareto distribution under linear normalization |
| GEVP | Generalized extreme value distribution under power normalization |
| GPDP | Generalized Pareto distributions under power normalization |
| GEVE | Generalized extreme value distribution under exponential normalization |
| GPDE | Generalized Pareto distribution under exponential normalization |
| ML | Maximum likelihood |
| K-S | Kolmogorov-Smirnov |
| CV | Critical value |
References
- Barakat, H.M.; Nigm, E.M.; Khaled, O.M. Statistical Techniques for Modelling Extreme Value Data and Related Applications; Cambridge Scholars Publishing: Newcastle upon Tyne, UK, 2019. [Google Scholar]
- Galambos, J. The Asymptotic Theory of Extreme Order Statistics, 2nd ed.; Wiley: New York, NY, USA, 1987. [Google Scholar]
- Balkema, A.A.; de Haan, L. Residual life time at great age. Ann. Probab. 1974, 2, 792–804. [Google Scholar] [CrossRef]
- Pickands, J. Statistical inference using extreme order statistics. Ann. Stat. 1975, 3, 119–131. [Google Scholar]
- Pancheva, E. Limit theorems for extreme order statistics under nonlinear normalization. In Stability Problems for Stochastic Models; Lecture Notes in Math.; Springer: Berlin/Heidelberg, Germany, 1984. [Google Scholar]
- Barakat, H.M.; Nigm, E.M.; El-Adll, E.M. Comparison between the rates of convergence of extremes under linear and under power normalization. Stat. Pap. 2010, 51, 149–164. [Google Scholar] [CrossRef]
- Nasri-Roudsari, D. Limit distributions of generalized order statistics under power normalization. Commun. Stat. Theory Methods 1999, 28, 1379–1389. [Google Scholar] [CrossRef]
- Barakat, H.M.; Nigm, E.M.; Khaled, O.M. Extreme Value Modeling under Power Normalization. Appl. Math. Model. 2013, 37, 10162–10169. [Google Scholar] [CrossRef]
- Barakat, H.M.; Nigm, E.M.; Khaled, O.M. Statistical modeling of extremes under linear and power normalizations with applications to air pollutions. Kuwait J. Sci. Eng. 2014, 41, 1–19. [Google Scholar]
- Barakat, H.M.; Nigm, E.M.; Khaled, O.M.; Khan, F.M. Bootstrap order statistics and modeling study of the air pollution. Commun. Stat.-Simul. Comput. 2015, 44, 1477–1491. [Google Scholar] [CrossRef]
- Barakat, H.M.; Nigm, E.M.; Khaled, O.M.; Alaswed, H.A. The counterparts of Hill estimators under power normalization. J. Appl. Stat. Sci. 2016, 22, 87–98. [Google Scholar]
- Barakat, H.M.; Nigm, E.M.; Alaswed, H.A. The Hill estimators under power normalization. Appl. Math. Model. 2017, 45, 813–822. [Google Scholar] [CrossRef]
- Barakat, H.M.; Nigm, E.M.; Khaled, O.M.; Alaswed, H.A. The estimations under power normalization for the tail index, with comparison. AStA Adv. Stat. Anal. 2018, 102, 431–454. [Google Scholar] [CrossRef]
- Subramanya, U.R. On max domains of attraction of univariate p-max stable laws. Stat. Probab. Lett. 1994, 19, 271–279. [Google Scholar] [CrossRef]
- Christoph, G.; Falk, M. A note on domains of attraction of p-max stable laws. Stat. Probab. Lett. 1996, 28, 279–284. [Google Scholar] [CrossRef]
- Sreehari, M. General max-stable laws. Extremes 2009, 12, 187–200. [Google Scholar] [CrossRef]
- Pancheva, E. Max-semistability: A survey. ProbStat Forum 2010, 3, 11–24. [Google Scholar]
- Barakat, H.M.; Omar, A.R.; Khaled, O.M. A new flexible extreme value model for modeling the extreme value data, with an application to environmental data. Stat. Probab. Lett. 2017, 130, 25–31. [Google Scholar] [CrossRef]
- Ravi, S.; Mavitha, T.S. New limit distributions for extreme under a nonlinear normalization. PropStat Form 2016, 9, 1–20. [Google Scholar]
- Barakat, H.M.; Nigm, E.M.; Abo Zaid, E.O. Asymptotic distributions of record values under exponential normalization. Bull. Belg. Math. Soc. Simon Stevin 2019, 26, 743–758. [Google Scholar] [CrossRef]
- Alyousifi, Y.; Othman, M.; Sokkalingam, R.; Faye, I.; Silva, P.C.L. Predicting Daily Air Pollution Index Based on Fuzzy Time Series Markov Chain Model. Symmetry 2020, 12, 293. [Google Scholar] [CrossRef] [Green Version]
- Zhou, S.; Deng, Q.; Liu, W. Extreme air pollution events: Modeling and prediction. J. Cent. South Univ. 2012, 19, 1668–1672. [Google Scholar] [CrossRef]
- Marlier, M.E.; Amir, S.J.; Kinney, P.L.; DeFries, R.S. Extreme Air Pollution in Global Megacities. Curr. Clim. Chang. Rep. 2016, 2, 15–27. [Google Scholar] [CrossRef] [Green Version]
- Barakat, H.M. A new method for adding two parameters to a family of distributions with application to the normal and exponential families. Stat. Methods Appl. (SMA) 2015, 24, 359–372. [Google Scholar] [CrossRef]
- Barakat, H.M.; Khaled, O.M. Towards the establishment of a family of distributions that best fits any data set. Comm. Statis.-Sim. Comput. 2017, 46, 6129–6143. [Google Scholar] [CrossRef]
Figure 1.
The depiction of the data set of and the fitted GEVL for LB6.

Figure 2.
The depiction of the data set of and the fitted GEVL for LB6.

Figure 3.
The depiction of the data set of and the fitted GEVL for LB6.

Figure 4.
The depiction of the data set of and the fitted GEVP for LB6.

Figure 5.
The depiction of the data set of and the fitted GEVP for LB6.

Figure 6.
The depiction of the data set of and the fitted GEVP for LB6.

Figure 7.
The depiction of the data set of and the fitted GEVE for LB6.

Figure 8.
The depiction of the data set of and the fitted GEVE for LB6.

Figure 9.
The depiction of the data set of and the fitted GEVE for LB6.

Figure 10.
The depiction of the data set of and the fitted GEVL for GR4.

Figure 11.
The depiction of the data set of and the fitted GEVL for GR4.

Figure 12.
The depiction of the data set of and the fitted GEVL for GR4.

Figure 13.
The depiction of the data set of and the fitted GEVP for GR4.

Figure 14.
The depiction of the data set of and the fitted GEVP for GR4.

Figure 15.
The depiction of the data set of and the fitted GEVP for GR4.

Figure 16.
The depiction of the data set of and the fitted GEVE for GR4.

Figure 17.
The depiction of the data set of and the fitted GEVE for GR4.

Figure 18.
The depiction of the data set of and the fitted GEVE for GR4.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
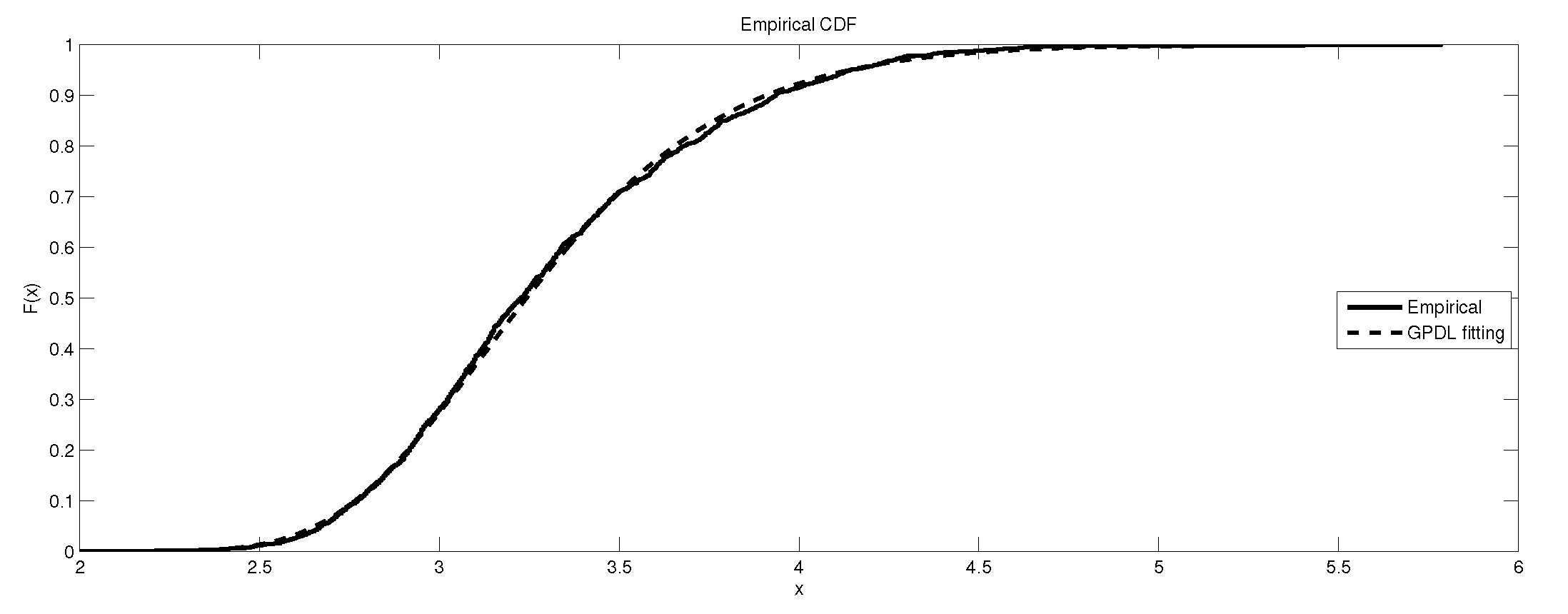{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Estimating the extreme value index (EVI) via by using the maximum likelihood (ML) and (9) estimators.
Table 1.
Estimating the extreme value index (EVI) via by using the maximum likelihood (ML) and (9) estimators.
| ML Estimate | The Estimate (9) | ||||||
|---|---|---|---|---|---|---|---|
| 0.08 | 0.0800 | −0.0267 | 0.0496 | 0.0520 | 0.0411 | 0.0819 | |
| MSE | 1.1394 | 0.0926 | 0.0786 | 0.1513 | |||
| 0.09 | 0.0896 | −0.0718 | 0.0062 | 0.0256 | 0.0871 | 0.1349 | |
| MSE | 2.6172 | 0.7018 | 0.4141 | 0.2015 | |||
| 0.1 | 0.1037 | 0.0341 | 0.1062 | 0.0899 | 0.1182 | 0.1700 | |
| MSE | 0.4344 | 0.0039 | 0.0101 | 0.0330 | 0.4899 | ||
| 0.11 | 0.1095 | 0.0327 | 0.1096 | 0.1094 | 0.1435 | 0.1992 | |
| MSE | 0.5977 | 0.1125 | 0.7959 | ||||
| 0.12 | 0.1215 | 0.0775 | 0.1517 | 0.1476 | 0.1872 | 0.2714 | |
| MSE | 0.1809 | 0.1003 | 0.0762 | 0.4511 | 2.2913 | ||
Table 2.
Estimating the EVI in the generalized Pareto distributions under exponential normalization (GPDE) by using the ML method.
Table 2.
Estimating the EVI in the generalized Pareto distributions under exponential normalization (GPDE) by using the ML method.
| k | 5000 | 4500 | 4000 | 3500 | 3000 | 2500 | 2000 | 1000 |
|---|---|---|---|---|---|---|---|---|
| The GPDE with | ||||||||
| 0.0486 | 0.0522 | 0.0618 | 0.0665 | 0.0679 | 0.0738 | 0.0756 | ||
| MSE | 0.0011 | 0.0009 | 0.0006 | 0.0003 | 0.0003 | 0.0003 | 0.0004 | 0.0004 |
| The GPDE with | ||||||||
| 0.0488 | 0.0475 | 0.0576 | 0.0653 | 0.0724 | 0.0729 | 0.0727 | ||
| MSE | 0.0018 | 0.0019 | 0.0012 | 0.0008 | 0.0005 | 0.0005 | 0.0006 | 0.0003 |
| The GPDE with | ||||||||
| 0.0700 | 0.0702 | 0.0724 | 0.0720 | 0.0794 | 0.0835 | 0.0924 | ||
| MSE | 0.0011 | 0.0012 | 0.0010 | 0.0010 | 0.0006 | 0.0005 | 0.0002 | 0.0003 |
| The GPDE with | ||||||||
| 0.0785 | 0.0854 | 0.0884 | 0.0920 | 0.0945 | 0.1006 | 0.1189 | ||
| MSE | 0.0011 | 0.0008 | 0.0007 | 0.0004 | 0.0004 | 0.0002 | 0.0002 | 0.0004 |
| The GPDE with | ||||||||
| 0.0894 | 0.0949 | 0.0983 | 0.1038 | 0.1113 | 0.1133 | 0.1143 | ||
| MSE | 0.0011 | 0.0007 | 0.0006 | 0.0004 | 0.0004 | 0.0011 | 0.0007 | 0.0005 |
Table 3.
Estimating the EVI in the GPDE by using the estimator (16).
Table 3.
Estimating the EVI in the GPDE by using the estimator (16).
| m | 125 | 250 | 375 | 500 | 625 | 750 | 1000 | 1250 |
|---|---|---|---|---|---|---|---|---|
| The GPDE with | ||||||||
| 0.0794 | 0.0858 | 0.0883 | 0.0818 | 0.0784 | 0.0819 | 0.0808 | ||
| MSE | 0.0047 | 0.0026 | 0.0021 | 0.0013 | 0.0012 | 0.0009 | 0.0007 | 0.0006 |
| The GPDE with | ||||||||
| 0.0924 | 0.0865 | 0.0845 | 0.0895 | 0.0911 | 0.0913 | 0.0917 | ||
| MSE | 0.0048 | 0.0024 | 0.0019 | 0.0016 | 0.0012 | 0.0010 | 0.0008 | 0.0007 |
| The GPDE with | ||||||||
| 0.1041 | 0.0967 | 0.0957 | 0.0992 | 0.0995 | 0.0987 | 0.1011 | ||
| MSE | 0.0061 | 0.0027 | 0.0018 | 0.0013 | 0.0015 | 0.0010 | 0.0009 | 0.0007 |
| The GPDE with | ||||||||
| 0.1166 | 0.1132 | 0.1103 | 0.1103 | 0.1137 | 0.1136 | 0.1136 | ||
| MSE | 0.0047 | 0.0028 | 0.0013 | 0.0014 | 0.0009 | 0.0010 | 0.0009 | 0.0008 |
| The GPDE with | ||||||||
| 0.1232 | 0.1209 | 0.1143 | 0.1168 | 0.1170 | 0.1167 | 0.1206 | ||
| MSE | 0.0058 | 0.0031 | 0.0017 | 0.0017 | 0.0011 | 0.0010 | 0.0009 | 0.0008 |
Table 4.
Summary statistics for maximum data from LB6.
| n | Minimum | Maximum | Median | Mean | SD | Skewness | Kurtosis | |
|---|---|---|---|---|---|---|---|---|
| 1601 | 3 | 466.10 | 29.05 | 45.94 | 50.84904 | 3.209211 | 14.44866 | |
| 838 | 5.5 | 171.1 | 53.75 | 55.21205 | 24.54528 | 0.768683 | 1.277585 | |
| 369 | 11 | 353 | 33 | 41.19241 | 33.964229 | 5.128280 | 34.681366 |
Table 5.
Estimate parameters of the generalized extreme value distributions for LB6.
| Estimate parameters of the GEVL via BM approach for LB6 | |||
| Pollutant | |||
| 0.5794 | 16.6815 | 21.5258 | |
| −0.0719 | 20.9257 | 44.5482 | |
| 0.3048 | 11.7537 | 28.6365 | |
| Parameter estimations of the GEVP via BM approach for LB6 | |||
| Pollutant | |||
| −0.2034 | 1.1971 | 0.0251 | |
| −0.3729 | 1.8877 | ||
| −0.0585 | 2.3911 | ||
| Estimate parameters of the GEVE via BM approach for LB6 | |||
| Pollutant | |||
| −0.3939 | 3.5125 | 0.0200 | |
| −0.4589 | 6.7161 | ||
| −0.1567 | 7.9032 | ||
Table 6.
Kolmogorov–Smirnov (K-S) test for the maximum data. from LB6.
| Fitting data of LB6 by the GEVL | |||
| Pollutant | P | Decision | |
| 0.0414 | 0.0347 | reject | |
| 0.4084 | 0.0305 | accept | |
| 0.9506 | 0.0266 | accept | |
| Fitting data of LB6 by the GEVP | |||
| Pollutant | P | Decision | |
| 0.3141 | 0.0189 | accept | |
| 0.0199 | 0.0481 | reject | |
| 0.5204 | 0.0293 | accept | |
| Fitting data of LB6 by the GEVE | |||
| Pollutant | P | Decision | |
| 0.1271 | 0.0253 | accept | |
| 0.0011 | 0.0635 | reject | |
| 0.4131 | 0.0342 | accept | |
Table 7.
Summary statistics for maximum data from GR4.
| n | Minimum | Maximum | Median | Mean | SD | Skewness | Kurtosis | |
|---|---|---|---|---|---|---|---|---|
| 1706 | 1.2 | 380.60 | 8.6 | 23.265 | 39.721 | 4.043 | 21.225 | |
| 1706 | 4.3 | 120.6 | 34.6 | 36.82 | 17.8640 | 0.6906 | 0.5265 | |
| 1471 | 7.4 | 325.29 | 25.2 | 30.529 | 18.527 | 4.7380 | 53.16945 |
Table 8.
Estimate parameters of the generalized extreme value distributions for GR4.
| Estimate parameters of the GEVL via BM approach for GR4 | |||
| Pollutant | |||
| 1.0065 | 5.6233 | 6.1006 | |
| −0.0537 | 14.9302 | 28.8916 | |
| 0.3007 | 8.5229 | 22.2351 | |
| Parameter estimations of the GEVP via BM approach for GR4 | |||
| Pollutant | |||
| −0.0013 | 1.0922 | 0.1334 | |
| −0.3830 | 1.7425 | 0.0031 | |
| −0.0739 | 2.5652 | ||
| Estimate parameters of the GEVE via BM approach for GR4 | |||
| Pollutant | |||
| −0.4550 | 1.7980 | 0.3384 | |
| −0.4795 | 5.4804 | 0.0015 | |
| −0.1741 | 7.8801 | ||
Table 9.
K-S test for the maximum data from GR4.
| Fitting data of GR4 by the GEVL | |||
| Pollutant | P | Decision | |
| 0.0086 | 0.0398 | reject | |
| 0.0184 | 0.0370 | reject | |
| 0.2332 | 0.0269 | accept | |
| Fitting data of GR4 by the GEVP | |||
| Pollutant | P | Decision | |
| 0.0061 | 0.0386 | reject | |
| 0.0098 | 0.0367 | reject | |
| 0.1073 | 0.0274 | accept | |
| Fitting data of GR4 by the GEVE | |||
| Pollutant | P | Decision | |
| 0.0817 | 0.0270 | accept | |
| 0.0474 | reject | ||
| 0.1752 | 0.0242 | accept | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Barakat, H.M.; Khaled, O.M.; Rakha, N.K. Modeling of Extreme Values via Exponential Normalization Compared with Linear and Power Normalization. Symmetry 2020, 12, 1876. https://doi.org/10.3390/sym12111876
AMA Style
Barakat HM, Khaled OM, Rakha NK. Modeling of Extreme Values via Exponential Normalization Compared with Linear and Power Normalization. Symmetry. 2020; 12(11):1876. https://doi.org/10.3390/sym12111876
Chicago/Turabian StyleBarakat, Haroon Mohamed, Osama Mohareb Khaled, and Nourhan Khalil Rakha. 2020. "Modeling of Extreme Values via Exponential Normalization Compared with Linear and Power Normalization" Symmetry 12, no. 11: 1876. https://doi.org/10.3390/sym12111876
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.