
Severity Classification of Diabetic Retinopathy Using an Ensemble Learning Algorithm through Analyzing Retinal Images

 ,
,  ,
,  , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Employed Dataset and Prior Works on It
2.2. Pre-Processing of the Employed Dataset
2.2.1. Dealing with Excessively Noisy Images
2.2.2. Dealing with Duplicate Images
| Algorithm 1: An algorithm to detect duplicate images of the same size | ||
| Input Output | : : | Two-color images, and . A decision on whether or not is a duplicate of . 0 → is not a duplicate of 1 → is a duplicate of |
| Step-1 | : | Determine the resolution of and : height & width of (in pixel). height & width of (in pixel). if == Determine using Equation (1) for three channels. else return 0 |
| Step-2 | : | if==1 for all three channels return 1 else return 0 |
2.2.3. Dealing with Unwanted Black Borders
| Algorithm 2: An algorithm for image crop | |||
| Input Output | : : | A retinal image, A cropped image without black borders, | |
| Step-1 | : | Determine the resolution of and . height & width of (in pixel). | |
| Step-2 | : | Determine the center pixel of the image: ; | |
| Step-3 | : | Identify the first non-black pixel directly above the center pixel: for to if > 10 in all three channels ; break directly left to the center pixel: for to if > 10 in all three channels ; break | directly below the center pixel: for to if > 10 in all three channels ; break directly right to the center pixel: for to if > 10 in all three channels ; break |
| Step-4 | : | Crop the image: for to | |
| Step-5 | : | return | |
2.2.4. Dealing with Uneven Image Resolution
2.2.5. Dealing with Uneven Sample Sizes
2.2.6. Increasing the Sharpness of the Images
2.2.7. Image Pre-Processing
2.3. Feature Set Creation
2.3.1. Histogram Feature Extraction
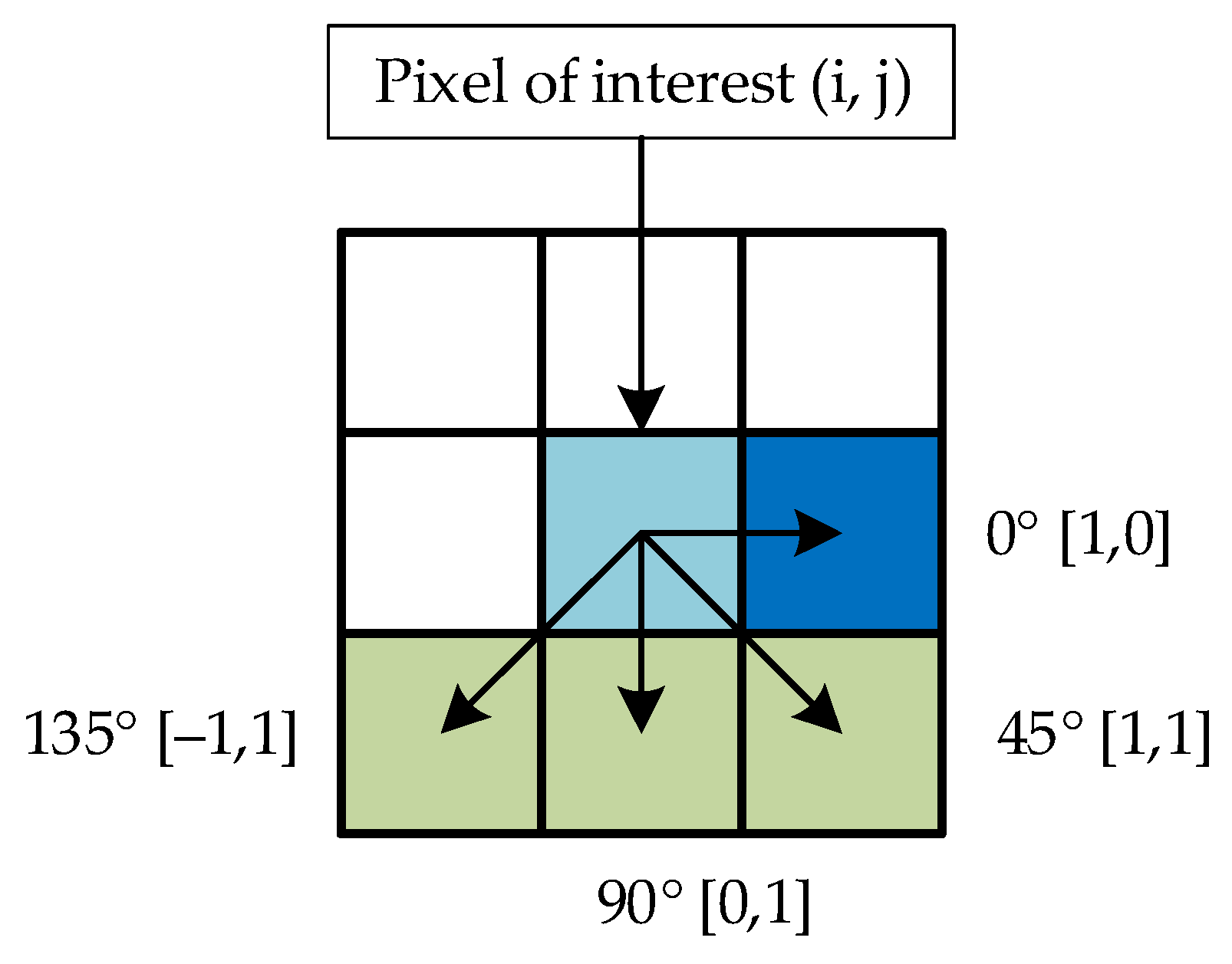
2.3.2. Gray-Level Co-Occurrence Information Extraction
2.3.3. Feature Concatenation
2.3.4. Selection of the Most Relevant Features
| Algorithm 3: Steps of feature selection using basic GA | ||
| Input Output | : : | A set of features and labels, Fitness function, 𝒻 (∙,∙) Fitness threshold, Population size, A set of strong (the fittest) features |
| Step-1 | : | population of random individuals, |
| Step-2 | : | for = to sum Compute the fitness of the population: for each individual sum sum + if return Compute the selection probabilities: for each individual Select and breed: for to select based on crossover mutate mutate |
2.4. DR Image Classification
3. Results and Discussion
3.1. Classification Outcomes Based on the Entire Feature Set
3.2. Classification Outcomes Based on the Selected Features
3.3. DR Classification Performace Comparison
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


References
- International Diabetes Federation—Facts & Figures. Available online: https://www.idf.org/aboutdiabetes/what-is-diabetes/facts-figures.html (accessed on 13 November 2020).
- Diabetes. Available online: https://www.who.int/news-room/fact-sheets/detail/diabetes (accessed on 13 November 2020).
- Diabetes Treatment: Using Insulin to Manage Blood Sugar—Mayo Clinic. Available online: https://www.mayoclinic.org/diseases-conditions/diabetes/in-depth/diabetes-treatment/art-20044084 (accessed on 13 November 2020).
- Diabetic Retinopathy Data and Statistics | National Eye Institute. Available online: https://www.nei.nih.gov/learn-about-eye-health/resources-for-health-educators/eye-health-data-and-statistics/diabetic-retinopathy-data-and-statistics (accessed on 13 November 2020).
- Diabetes and You: Healthy Eyes Matter! 2014. Available online: https://www.cdc.gov/diabetes/ndep/pdfs/149-healthy-eyes-matter.pdf (accessed on 13 November 2020).
- National Diabetes Statistics Report, 2020 | CDC. Available online: https://www.cdc.gov/diabetes/data/statistics-report/index.html (accessed on 13 November 2020).
- Key Facts About Diabetic Retinopathy [Infographic] | Welch Allyn. Available online: https://www.welchallyn.com/en/education-and-research/research-articles/key-facts-about-diabetic-retinopathy-infographic.html (accessed on 5 March 2021).
- Islam, M.M.; Yang, H.-C.; Poly, T.N.; Jian, W.-S.; Li, Y.-C. Deep Learning Algorithms for Detection of Diabetic Retinopathy in Retinal Fundus Photographs: A Systematic Review and Meta-Analysis. Comput. Methods Programs Biomed. 2020, 191, 105320. [Google Scholar] [CrossRef]
- Hemanth, D.J.; Deperlioglu, O.; Kose, U. An enhanced diabetic retinopathy detection and classification approach using deep convolutional neural network. Neural Comput. Appl. 2020, 32, 707–721. [Google Scholar] [CrossRef]
- Shankar, K.; Sait, A.R.W.; Gupta, D.; Lakshmanaprabu, S.K.; Khanna, A.; Pandey, H.M. Automated detection and classification of fundus diabetic retinopathy images using synergic deep learning model. Pattern Recognit. Lett. 2020, 133, 210–216. [Google Scholar] [CrossRef]
- Gayathri, S.; Gopi, V.P.; Palanisamy, P. A lightweight CNN for Diabetic Retinopathy classification from fundus images. Biomed. Signal Process. Control 2020, 62, 102115. [Google Scholar] [CrossRef]
- Liu, H.; Yue, K.; Cheng, S.; Pan, C.; Sun, J.; Li, W. Hybrid model structure for diabetic retinopathy classification. J. Healthc. Eng. 2020, 2020, 8840174. [Google Scholar] [CrossRef]
- Shankar, K.; Zhang, Y.; Liu, Y.; Wu, L.; Chen, C.H. Hyperparameter Tuning Deep Learning for Diabetic Retinopathy Fundus Image Classification. IEEE Access 2020, 8, 118164–118173. [Google Scholar] [CrossRef]
- Li, X.; Hu, X.; Yu, L.; Zhu, L.; Fu, C.W.; Heng, P.A. CANet: Cross-Disease Attention Network for Joint Diabetic Retinopathy and Diabetic Macular Edema Grading. IEEE Trans. Med. Imaging 2020, 39, 1483–1493. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.H.; Yeh, N.N.; Chen, S.J.; Chung, Y.C. Computer-Assisted Diagnosis for Diabetic Retinopathy Based on Fundus Images Using Deep Convolutional Neural Network. Mob. Inf. Syst. 2019, 2019, 6142839. [Google Scholar] [CrossRef]
- Sayres, R.; Taly, A.; Rahimy, E.; Blumer, K.; Coz, D.; Hammel, N.; Krause, J.; Narayanaswamy, A.; Rastegar, Z.; Wu, D.; et al. Using a Deep Learning Algorithm and Integrated Gradients Explanation to Assist Grading for Diabetic Retinopathy. Ophthalmology 2019, 126, 552–564. [Google Scholar] [CrossRef] [Green Version]
- Zeng, X.; Chen, H.; Luo, Y.; Ye, W. Automated diabetic retinopathy detection based on binocular siamese-like convolutional neural network. IEEE Access 2019, 7, 30744–30753. [Google Scholar] [CrossRef]
- Zhang, W.; Zhong, J.; Yang, S.; Gao, Z.; Hu, J.; Chen, Y.; Yi, Z. Automated identification and grading system of diabetic retinopathy using deep neural networks. Knowl.-Based Syst. 2019, 175, 12–25. [Google Scholar] [CrossRef]
- De la Torre, J.; Valls, A.; Puig, D. A deep learning interpretable classifier for diabetic retinopathy disease grading. Neurocomputing 2020, 396, 465–476. [Google Scholar] [CrossRef] [Green Version]
- Pires, R.; Avila, S.; Wainer, J.; Valle, E.; Abramoff, M.D.; Rocha, A. A data-driven approach to referable diabetic retinopathy detection. Artif. Intell. Med. 2019, 96, 93–106. [Google Scholar] [CrossRef] [PubMed]
- Akram, M.U.; Khalid, S.; Khan, S.A. Identification and classification of microaneurysms for early detection of diabetic retinopathy. Pattern Recognit. 2013, 46, 107–116. [Google Scholar] [CrossRef]
- Antal, B.; Hajdu, A. An ensemble-based system for automatic screening of diabetic retinopathy. Knowl.-Based Syst. 2014, 60, 20–27. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Yin, Y.; Cao, G.; Wei, B.; Zheng, Y.; Yang, G. Hierarchical retinal blood vessel segmentation based on feature and ensemble learning. Neurocomputing 2015, 149, 708–717. [Google Scholar] [CrossRef]
- Mane, V.M.; Jadhav, D.V. Holoentropy enabled-decision tree for automatic classification of diabetic retinopathy using retinal fundus images. Biomed. Tech. 2017, 62, 321–332. [Google Scholar] [CrossRef] [PubMed]
- Saleh, E.; Błaszczyński, J.; Moreno, A.; Valls, A.; Romero-Aroca, P.; de la Riva-Fernández, S.; Słowiński, R. Learning ensemble classifiers for diabetic retinopathy assessment. Artif. Intell. Med. 2018, 85, 50–63. [Google Scholar] [CrossRef]
- Jebaseeli, T.J.; Deva Durai, C.A.; Peter, J.D. Retinal blood vessel segmentation from diabetic retinopathy images using tandem PCNN model and deep learning based SVM. Optik 2019, 199, 163328. [Google Scholar] [CrossRef]
- APTOS 2019 Blindness Detection. Available online: https://www.kaggle.com/c/aptos2019-blindness-detection/ (accessed on 10 June 2020).
- Singh, K.; Drzewicki, D. Neural Style Transfer for Medical Image Augmentation. 2019. Available online: https://d1wqtxts1xzle7.cloudfront.net/61446211/CS_510_Final_Paper20191206-59878-1p0uljy.pdf?1575691593=&response-content-disposition=inline%3B+filename%3DNeural_Style_Transfer_for_Medical_Image.pdf&Expires=1618004702&Signature=FVvYtpXJQ9qScw8U~r4NkQ6wXTYxsBBSKf19u7LmebwMkFjHW8iKPj2yplIvzffZmZwW3BTWmhz0smIKNUclFZhwg3ysQ2vh~~BLXHWAePSWISrqBN8E1CNGBm-GXgNoM6r71NfQH0Z8TGRnNb-Okak8dIkhcUOLZDSywke30ZzGZvm6G-komU2BwbTaEq3Up4tSUezIEx9wHjaIRwtD~9Yv6uA4hJsRXEc9amIyiBXX1GZB2MtZl7dS17XkSSeULlvFR6GOiYxsdwxUrQfZYhv5IVkLQTaQ~evjAvOpHsIGNeh1msK1T3xKYBVuFAps4bPwG6~8T51wYfEnKsmOAg__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA (accessed on 13 November 2020).
- Kassani, S.H.; Kassani, P.H.; Khazaeinezhad, R.; Wesolowski, M.J.; Schneider, K.A.; Deters, R. Diabetic Retinopathy Classification Using a Modified Xception Architecture. In Proceedings of the 2019 IEEE 19th International Symposium on Signal Processing and Information Technology, ISSPIT 2019, IEEE, Ajman, United Arab Emirates, 10–12 December 2019; pp. 1–6. [Google Scholar]
- Dekhil, O.; Naglah, A.; Shaban, M.; Ghazal, M.; Taher, F.; Elbaz, A. Deep Learning Based Method for Computer Aided Diagnosis of Diabetic Retinopathy. In Proceedings of the IST 2019—IEEE International Conference on Imaging Systems and Techniques, Proceedings, IEEE, Abu Dhabi, United Arab Emirates, 9–10 December 2019; pp. 1–4. [Google Scholar]
- Sikder, N.; Chowdhury, M.S.; Shamim Mohammad Arif, A.; Nahid, A.-A. Early Blindness Detection Based on Retinal Images Using Ensemble Learning. In Proceedings of the 2019 22nd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 18–20 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, L.; Schaefer, A. Diagnosing Diabetic Retinopathy from Images of the Eye Fundus. Available online: Cs230.Stanford.Edu (accessed on 13 November 2020).
- Sheikh, S.O. Diabetic Retinopathy Classification Using Deep Learning. 2020. Available online: https://qspace.qu.edu.qa/bitstream/handle/10576/15230/Sarah%20Obaid%20Sheikh%20_OGS%20Approved%20Thesis.pdf?sequence=1&isAllowed=y (accessed on 13 November 2020).
- Sheikh, S.; Qidwai, U. Smartphone-based diabetic retinopathy severity classification using convolution neural networks. In Proceedings of the Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2021; Volume 1252, pp. 469–481. [Google Scholar]
- Pak, A.; Ziyaden, A.; Tukeshev, K.; Jaxylykova, A.; Abdullina, D. Comparative analysis of deep learning methods of detection of diabetic retinopathy. Cogent Eng. 2020, 7, 1805144. [Google Scholar] [CrossRef]
- Gangwar, A.K.; Ravi, V. Diabetic Retinopathy Detection Using Transfer Learning and Deep Learning. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2021; Volume 1176, pp. 679–689. ISBN 9789811557873. [Google Scholar]
- Bodapati, J.D.; Veeranjaneyulu, N.; Shareef, S.N.; Hakak, S.; Bilal, M.; Maddikunta, P.K.R.; Jo, O. Blended multi-modal deep convnet features for diabetic retinopathy severity prediction. Electronics 2020, 9, 914. [Google Scholar] [CrossRef]
- Kueterman, N. Comparative Study of Classification Methods for the Mitigation of Class Imbalance Issues in Medical Imaging Applications. 2020. Available online: https://etd.ohiolink.edu/apexprod/rws_etd/send_file/send?accession=dayton1591611376235015&disposition=inline (accessed on 13 November 2020).
- Patel, R.; Chaware, A. Transfer Learning with Fine-Tuned MobileNetV2 for Diabetic Retinopathy. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), IEEE, Belgaum, India, 5–7 June 2020; pp. 1–4. [Google Scholar]
- Liu, S.; Gong, L.; Ma, K.; Zheng, Y. GREEN: A Graph REsidual rE-ranking Network for Grading Diabetic Retinopathy. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2020; pp. 585–594. [Google Scholar]
- Dondeti, V.; Bodapati, J.D.; Shareef, S.N.; Naralasetti, V. Deep convolution features in non-linear embedding space for fundus image classification. Rev. Intell. Artif. 2020, 34, 307–313. [Google Scholar] [CrossRef]
- Zhuang, H.; Ettehadi, N. Classification of Diabetic Retinopathy via Fundus Photography: Utilization of Deep Learning Approaches to Speed up Disease Detection. arXiv 2020, arXiv:2007.09478. [Google Scholar]
- Riaz, H.; Park, J.; Choi, H.; Kim, H.; Kim, J. Deep and densely connected networks for classification of diabetic retinopathy. Diagnostics 2020, 10, 24. [Google Scholar] [CrossRef] [Green Version]
- Poplin, R.; Varadarajan, A.V.; Blumer, K.; Liu, Y.; McConnell, M.V.; Corrado, G.S.; Peng, L.; Webster, D.R. Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning. Nat. Biomed. Eng. 2018, 2, 158–164. [Google Scholar] [CrossRef]
- Noda, I. Generalized two-dimensional correlation method applicable to infrared, Raman, and other types of spectroscopy. Appl. Spectrosc. 1993, 47, 1329–1336. [Google Scholar] [CrossRef]
- Geitner, R.; Fritzsch, R.; Popp, J.; Bocklitz, T.W. Corr2d: Implementation of two-dimensional correlation analysis in R. J. Stat. Softw. 2019, 90. [Google Scholar] [CrossRef] [Green Version]
- Masud, M.; Sikder, N.; Nahid, A.-A.; Bairagi, A.K.; Alzain, M.A. A machine learning approach to diagnosing lung and colon cancer using a deep learning-based classification framework. Sensors 2021, 21, 748. [Google Scholar] [CrossRef]
- Ramponi, G. A cubic unsharp masking technique for contrast enhancement. Signal Process. 1998, 67, 211–222. [Google Scholar] [CrossRef]
- Jain, A.K. Fundamentals of Digital Image Processing; Prentice Hall: Englewood Cliffs, NJ, USA, 1989; ISBN 978-0133361650. [Google Scholar]
- Banterle, F.; Artusi, A.; Debattista, K.; Chalmers, A. Advanced High Dynamic Range Imaging; CRC Press: Boca Raton, FL, USA, 2017; ISBN 9781498706940. Available online: https://www.routledge.com/Advanced-High-Dynamic-Range-Imaging/Banterle-Artusi-Debattista-Chalmers/p/book/9781498706940 (accessed on 13 November 2020).
- Masud, M.; Bairagi, A.K.; Nahid, A.A.; Sikder, N.; Rubaiee, S.; Ahmed, A.; Anand, D. A Pneumonia Diagnosis Scheme Based on Hybrid Features Extracted from Chest Radiographs Using an Ensemble Learning Algorithm. J. Healthc. Eng. 2021, 2021, 8862089. [Google Scholar] [CrossRef]
- Haralick, R.M.; Dinstein, I.; Shanmugam, K. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Haralick, R.M.; Shapiro, L.G. Computer and Robot Vision; Addison-Wesley Reading: Boston, MA, USA, 1992; Volume 1, Available online: https://dl.acm.org/doi/book/10.5555/57 (accessed on 13 November 2020).
- Hall-Beyer, M. GLCM Texture: A Tutorial. v. 3.0. 2017. Available online: https://prism.ucalgary.ca/bitstream/handle/1880/51900/texture%20tutorial%20v%203_0%20180206.pdf?sequence=11&isAllowed=y (accessed on 13 November 2020).
- Choraś, R.S. Texture Based Firearm Striations Analysis for Forensics Image Retrieval BT—Image Processing and Communications Challenges 4; Choraś, R.S., Ed.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 25–31. [Google Scholar]
- Bellman, R.E. Adaptive Control Processes: A Guided Tour; Princeton University Press: Princeton, NJ, USA, 2015; Volume 2045, ISBN 1400874661. Available online: https://press.princeton.edu/books/paperback/9780691625850/adaptive-control-processes (accessed on 13 November 2020).
- García-Martínez, C.; Rodriguez, F.J.; Lozano, M. Genetic Algorithms BT—Handbook of Heuristics; Martí, R., Pardalos, P.M., Resende, M.G.C., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 431–464. ISBN 978-3-319-07124-4. [Google Scholar]
- Coley, D.A. An Introduction to Genetic Algorithms for Scientists and Engineers; World Scientific Publishing Company: Singapore, 1999; ISBN 9813105313. Available online: https://www.worldscientific.com/worldscibooks/10.1142/3904 (accessed on 13 November 2020).
- Liu, H.; Motoda, H. Computational Methods of Feature Selection; CRC Press: Boca Raton, FL, USA, 2007; ISBN 1584888792. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- XGBoost, C.; LightGBM, S.N.L.P.; Quinto, B. Next-Generation Machine Learning with Spark. Available online: https://link.springer.com/book/10.1007/978-1-4842-5669-5 (accessed on 13 November 2020).
- Ren, X.; Guo, H.; Li, S.; Wang, S.; Li, J. A novel image classification method with CNN-XGBoost model. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Kraetzer, C., Shi, Y.-Q., Dittmann, J., Kim, H.J., Eds.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10431, pp. 378–390. [Google Scholar]
- Li, M.; Fu, X.; Li, D. Diabetes Prediction Based on XGBoost Algorithm. IOP Conf. Ser. Mater. Sci. Eng. 2020, 768, 072093. [Google Scholar] [CrossRef]
- Notes on Parameter Tuning—Xgboost 1.3.0-SNAPSHOT Documentation. Available online: https://xgboost.readthedocs.io/en/latest/tutorials/param_tuning.html (accessed on 7 November 2020).
- Wang, L.; Wang, X.; Chen, A.; Jin, X.; Che, H. Prediction of Type 2 Diabetes Risk and Its Effect Evaluation Based on the XGBoost Model. Healthcare 2020, 8, 247. [Google Scholar] [CrossRef]
- Nahid, A.-A.; Sikder, N.; Bairagi, A.K.; Razzaque, M.A.; Masud, M.Z.; Kouzani, A.; Mahmud, M.A.P. A Novel Method to Identify Pneumonia through Analyzing Chest Radiographs Employing a Multichannel Convolutional Neural Network. Sensors 2020, 20, 3482. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Classification Method | Accuracy (%) | Precision (%) | Recall (%) | Specificity (%) | F-Measure (%) |
|---|---|---|---|---|---|---|
| [28] | Pre-trained VGG-19 | 82.70 | 43.00 | 62.00 | – | 50.78 |
| [29] | InceptionV3, MobileNet, ResNet50, and Xception | 83.09 | – | 88.24 | 87.00 | – |
| [30] | ImageNet (transfer learning) | 77.00 | – | – | – | – |
| [31] | ExtraTree | 91.07 | 90.40 | 89.54 | – | 89.97 |
| [32] | MobileNetV2 | 78.47 | 68.66 | 60.01 | – | 64.04 |
| [33] | MobileNetV2 | 91.68 | 77.64 | 83.17 | 80.11 | 80.31 |
| [34] | DenseNet121 | 90.50 | 93.00 | 90.00 | 87.00 | 88.47 |
| [35] | EfficientNet-b4 | 79.00 | – | – | – | – |
| [36] | Hybrid Inception ResNet-v2 (transfer learning) | 82.18 | – | – | – | – |
| [37] | Pre-trained ConvNet | 80.96 | 80 | 81 | – | 80 |
| [38] | ResNet50 + SVM | 82.40 | ≈63 | ≈71 | ≈95 | ≈66 |
| [39] | Tuned MobileNetV2 | 81.63 | – | – | – | – |
| [40] | EfficientNet-b0 + GREEN | 81.60 | – | – | – | 78.20 |
| [41] | ⱱ-SVM | 77.90 | 75.00 | 77.00 | – | 76.50 |
| [42] | Modified Efficientnet-B3 | 77.87 | – | – | – | – |
| Proposed (All features) | Tuned XGBoost | 94.20 | 94.34 | 92.68 | 96.44 | 93.51 |
| Proposed (Selected features) | Tuned XGBoost | 93.70 | 93.06 | 91.71 | 92.38 |
| DR Severity | Class ID | Dataset | After Noisy and Duplicate Image Exclusion | After Augmentation | ||
|---|---|---|---|---|---|---|
| No DR | NO | 1875 | 1406 | 47.17% | 1406 | 26.60% |
| Mild DR | MI | 370 | 308 | 10.33% | 1232 | 23.31% |
| Moderate DR | MO | 999 | 807 | 27.07% | 807 | 15.27% |
| Severe DR | SE | 193 | 185 | 6.20% | 740 | 14.00% |
| Prolific DR | PR | 295 | 275 | 9.23% | 1100 | 20.82% |
| Total | 3662 | 2981 | 100% | 5285 | 100% | |
| Parameter | Varied between | Picked |
|---|---|---|
| n_estimators | 100–500 | 475 |
| max_depth | 3–6 | 5 |
| min_child_weight | 0 | 0 |
| subsample | 0.5–1.0 | 0.7 |
| random_state | 9 | 9 |
| learning_rate | 0.1–1.0 | 0.1 |
| Fold | Accuracy (%) | Precision (%) | Recall (%) | QWK (%) | F-Measure (%) |
|---|---|---|---|---|---|
| 1st | 94.62 | 94.82 | 93.49 | 96.91 | 94.15 |
| 2nd | 94.85 | 95.00 | 93.73 | 97.18 | 94.36 |
| 3rd | 94.92 | 95.29 | 93.69 | 97.10 | 94.48 |
| 4th | 94.32 | 94.55 | 92.87 | 96.86 | 93.70 |
| 5th | 94.32 | 94.98 | 92.91 | 96.07 | 93.93 |
| 6th | 93.86 | 94.38 | 92.16 | 96.44 | 93.26 |
| 7th | 94.01 | 94.07 | 92.26 | 95.96 | 93.15 |
| 8th | 94.17 | 94.47 | 92.51 | 96.24 | 93.48 |
| 9th | 93.71 | 93.49 | 91.91 | 95.91 | 92.70 |
| 10th | 93.18 | 92.37 | 91.24 | 95.72 | 91.80 |
| Avg | 94.20 | 94.34 | 92.68 | 96.44 | 93.51 |
| Class | Precision (%) | Recall (%) | Specificity (%) | F-Measure (%) |
|---|---|---|---|---|
| NO | 95.43 | 98.04 | 99.29 | 96.72 |
| MI | 91.80 | 99.97 | 99.98 | 95.71 |
| MO | 93.77 | 71.63 | 95.21 | 81.22 |
| SE | 96.38 | 96.33 | 99.38 | 96.35 |
| PR | 94.35 | 97.49 | 99.35 | 95.89 |
| Avg | 94.34 | 92.69 | 98.64 | 93.51 |
| Parameter | Value |
|---|---|
| estimator | XGBoost |
| cross_validation | 10 |
| scoring | “accuracy” |
| max_features | 300 |
| n_population | 100 |
| crossover_proba | 0.5 |
| mutation_proba | 0.05 |
| n_generations | 100 |
| tournament_size | 5 |
| n_gen_no_change | 10 |
| Fold | Without Image Exclusion | Without Unsharp Masking | Without Tone Mapping | Proposed | ||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | F-Measure | Accuracy | F-Measure | Accuracy | F-Measure | Accuracy | F-Measure | |
| 1 | 0.916 | 0.906 | 0.918 | 0.906 | 0.933 | 0.924 | 0.946 | 0.941 |
| 2 | 0.908 | 0.896 | 0.915 | 0.904 | 0.937 | 0.931 | 0.948 | 0.943 |
| 3 | 0.909 | 0.902 | 0.909 | 0.897 | 0.924 | 0.917 | 0.949 | 0.944 |
| 4 | 0.921 | 0.917 | 0.909 | 0.898 | 0.937 | 0.931 | 0.943 | 0.937 |
| 5 | 0.925 | 0.919 | 0.908 | 0.894 | 0.927 | 0.919 | 0.943 | 0.939 |
| 6 | 0.925 | 0.919 | 0.915 | 0.902 | 0.928 | 0.921 | 0.938 | 0.932 |
| 7 | 0.918 | 0.912 | 0.913 | 0.898 | 0.931 | 0.924 | 0.940 | 0.931 |
| 8 | 0.922 | 0.915 | 0.909 | 0.896 | 0.934 | 0.924 | 0.941 | 0.934 |
| 9 | 0.923 | 0.916 | 0.917 | 0.904 | 0.935 | 0.927 | 0.937 | 0.927 |
| 10 | 0.919 | 0.909 | 0.919 | 0.908 | 0.940 | 0.931 | 0.931 | 0.918 |
| Avg | 0.918 | 0.911 | 0.913 | 0.901 | 0.933 | 0.925 | 0.942 | 0.935 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sikder, N.; Masud, M.; Bairagi, A.K.; Arif, A.S.M.; Nahid, A.-A.; Alhumyani, H.A. Severity Classification of Diabetic Retinopathy Using an Ensemble Learning Algorithm through Analyzing Retinal Images. Symmetry 2021, 13, 670. https://doi.org/10.3390/sym13040670
Sikder N, Masud M, Bairagi AK, Arif ASM, Nahid A-A, Alhumyani HA. Severity Classification of Diabetic Retinopathy Using an Ensemble Learning Algorithm through Analyzing Retinal Images. Symmetry. 2021; 13(4):670. https://doi.org/10.3390/sym13040670
Chicago/Turabian StyleSikder, Niloy, Mehedi Masud, Anupam Kumar Bairagi, Abu Shamim Mohammad Arif, Abdullah-Al Nahid, and Hesham A. Alhumyani. 2021. "Severity Classification of Diabetic Retinopathy Using an Ensemble Learning Algorithm through Analyzing Retinal Images" Symmetry 13, no. 4: 670. https://doi.org/10.3390/sym13040670