
Innovations in Urdu Sentiment Analysis Using Machine and Deep Learning Techniques for Two-Class Classification of Symmetric Datasets


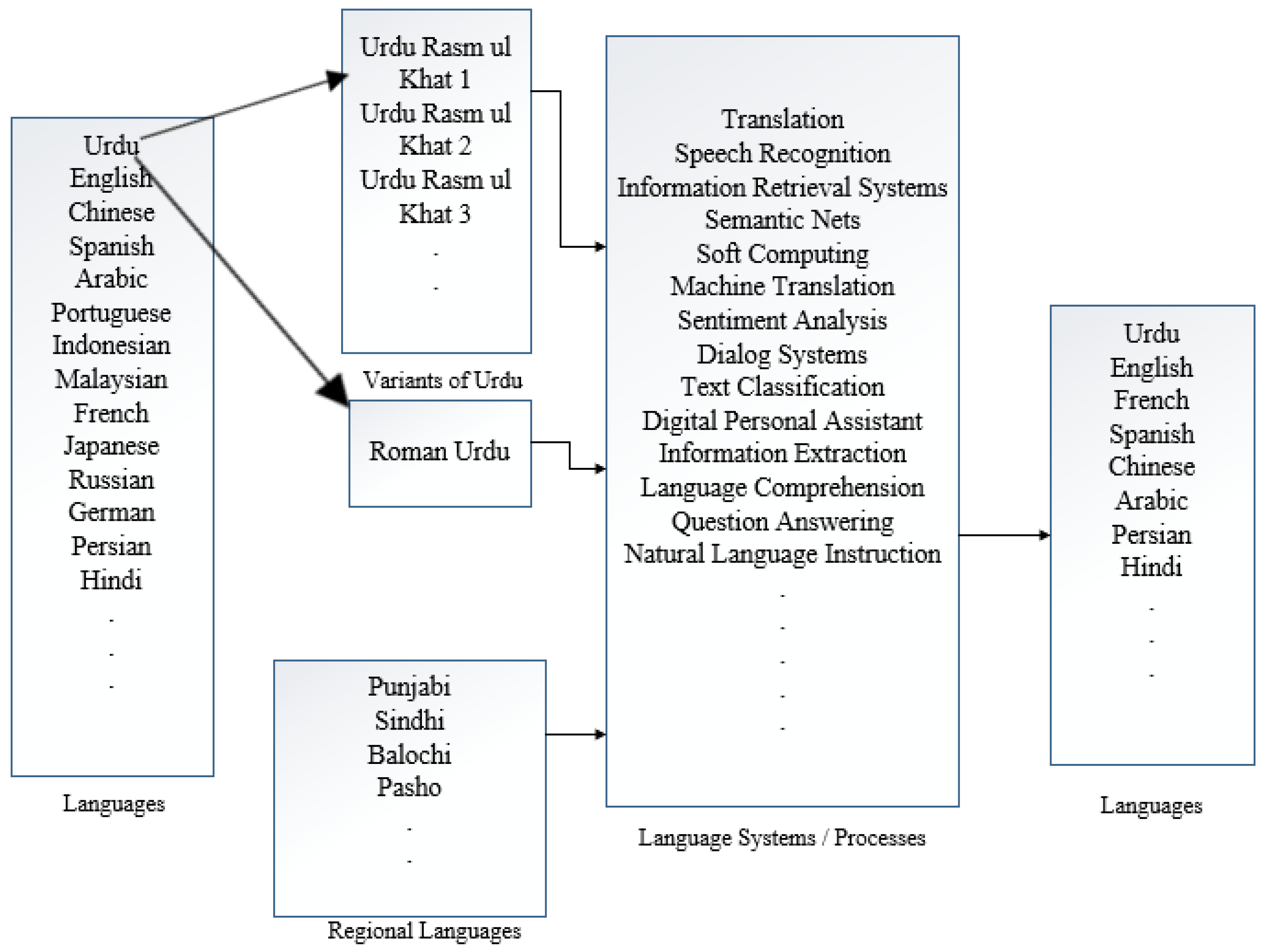{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
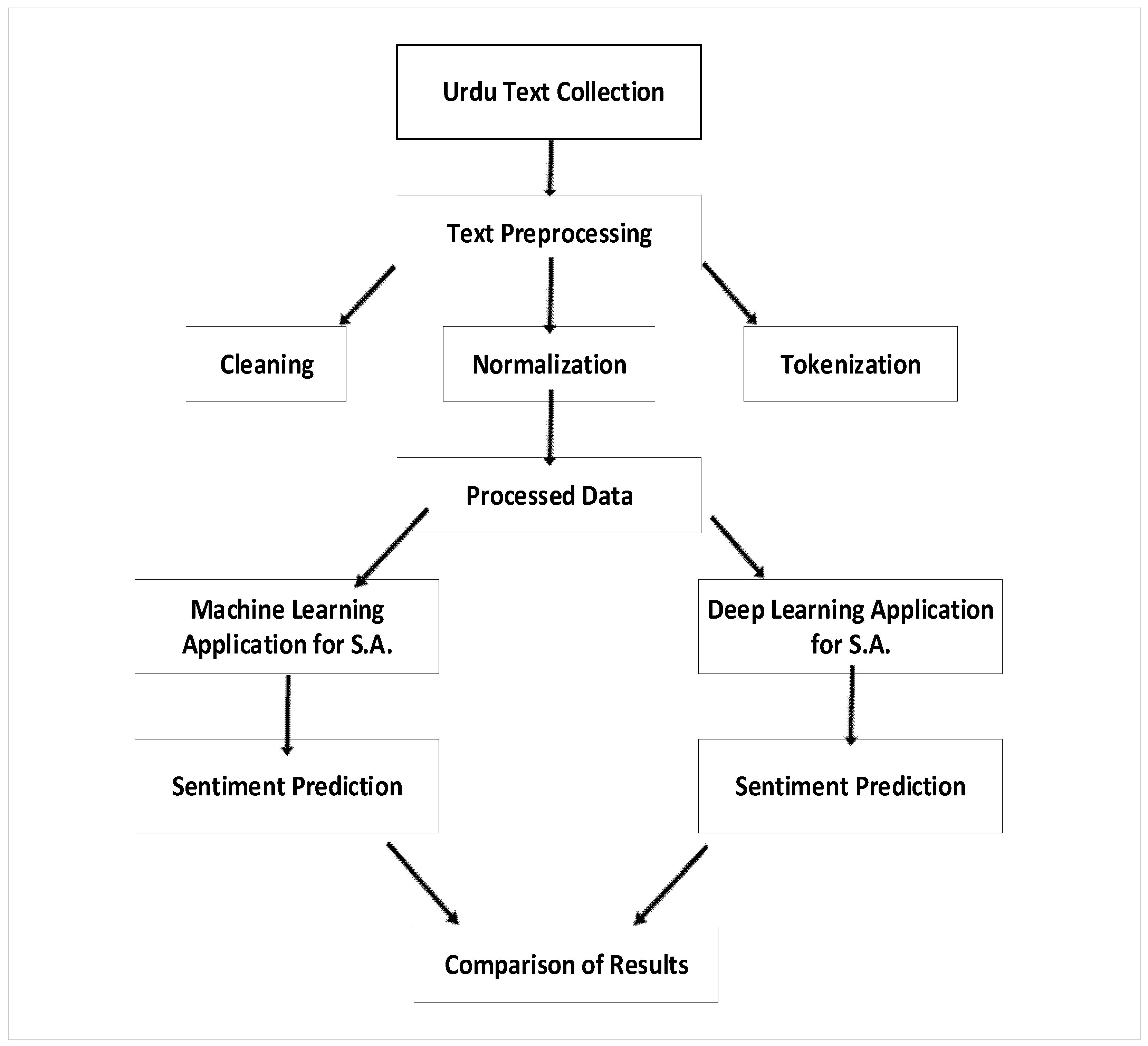{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Sentiment Analysis/Attitude Scrutiny
1.2. Attitude Scrutiny in Social Networks
1.3. Research Inspiration
- People provide their views on social media to express emotions about certain products/services, especially in the Urdu language.
- South Asian countries such as India, Pakistan, etc., use the Urdu language to express their feelings, comprising a huge online market for other countries.
- No work has previously been performed that combines the latest deep learning algorithms to conduct such an analysis.
1.4. Contributions and Obligations
- Elaborate the importance and utility of Urdu sentiments and perform an analysis thereof.
- Investigate methods to perform S.A. in Urdu.
- Apply machine learning and deep learning algorithms for S.A.
- Apply a combination of algorithms to propose a hybrid approach for S.A.
- Compare the applied algorithms to suggest the most effective ones for the Urdu language.
- Suggest future work.
1.5. Relation to Previous Work
2. Material and Methods
2.1. Research Questions
- Research Question 1: Is the pre-processing required for Urdu text justified?
- Research Question 2: How can the ML and DL methods be applied on Urdu text for extracted data?
- Research Question 3: Can we apply more than one algorithm simultaneously on the Urdu data?
- Research Question 4: Which algorithm was found to be more effective and accurate for Urdu language processing?
2.2. Technique and Criteria for Acceptance and Rejection
- IP1: Inclusion Principle: All articles to be selected matching title or some words.
- IP2: Inclusion Principle: Papers matching in abstract used to classify Urdu sentiments.
- IP3: Inclusion Principle: Papers including methods used in Urdu sentiment analysis.
- IP4: Inclusion Principle: Papers using some preprocessing for Urdu sentiment analysis.
- EP1: Exclusion Principle: Remove all papers not following the above inclusion principles.
- EP2: Exclusion Principle: Do not include any Roman Urdu papers.
2.3. Study Quality Evaluation
2.4. Survey Execution
2.4.1. Data Collection
2.4.2. Data Cleaning
3. Results
3.1. Research Question 1
- Is the preprocessing required for Urdu text justified?
- Data cleaning/noise removal;
- Data normalization;
- Tokenization and tagging.
3.1.1. Data Cleaning/Noise Removal
- Remove URLs from the tweets.
- Tokenize text.
- Remove email addresses.
- Remove new line characters.
- Remove all punctuation signs.
- Detokenize text.
- Convert list of text to ‘Numpy’ array.
- Apply text cleaning process to the data.
3.1.2. Normalization
3.1.3. Tokenization
3.1.4. Tagging
3.2. Research Question 2
- How can the ML and DL methods be applied on Urdu text for extracted data?
3.3. Research Question 3
- Can we apply more than one algorithm simultaneously on the Urdu data?
3.4. Research Question 4
- Which algorithm was found to be more effective and accurate for Urdu language processing?
4. Discussion
5. Conclusions
6. Future Work
7. Human and Animal Rights
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Weber, G. Top languages. World 2008, 11, 2009. [Google Scholar]
- Tao, J.; Zheng, F.; Li, A.; Li, Y. Advances in Chinese Natural Language Processing and Language Resources. In Proceedings of the 2009 Oriental COCOSDA International Conference on Speech Database and Assessments, Urumqi, China, 10–12 August 2009; pp. 13–18. [Google Scholar]
- Ahmad, W.; Edalati, M. Urdu Speech and Text Based Sentiment Analyzer. Comput. Lang. 2022. [Google Scholar] [CrossRef]
- Sehar, U.; Kanwal, S.; Dashtipur, K.; Gogate, M.; Khan, F. A Hybrid Dependency-Based Approach for Urdu Sentiment Analysis; Research Square: Durham, NC, USA, 2022. [Google Scholar]
- Rehman, I.; Soomro, T.R. Urdu Sentiment Analysis. Appl. Comput. Syst. 2022, 27, 30–42. [Google Scholar] [CrossRef]
- Masood, M.; Azam, F.; Anwar, M.; Rahman, J.U. Deep-Learning Based Framework for Sentiment Analysis in Urdu Language. In Proceedings of the 2022 2nd International Conference on Digital Futures and Transformative Technologies (ICoDT2), Rawalpindi, Pakistan, 24–26 May 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Mashooq, M.; Riaz, S.; Farooq, M. Urdu Sentiment Analysis: Future Extraction, Taxonomy, and Challenges. VFAST Trans. Softw. Eng. 2022, 10. [Google Scholar] [CrossRef]
- Khan, L.; Amjad, A.; Ashraf, N.; Chang, H.-T. Multi-class sentiment analysis of Urdu text using multilingual BERT. Sci. Rep. 2022, 12, 5436. [Google Scholar] [CrossRef] [PubMed]
- Mukhtar, N.; Khan, M.A.; Chiragh, N.; Nazir, S.; Jan, A.U. An intelligent unsupervised approach for handling context-dependent words in Urdu sentiment analysis. Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 1–15. [Google Scholar] [CrossRef]
- Sehar, U.; Kanwal, S.; Dashtipur, K.; Mir, U.; Abbasi, U.; Khan, F. Urdu Sentiment Analysis via Multimodal Data Mining Based on Deep Learning Algorithms. IEEE Access 2021, 9, 153072–153082. [Google Scholar] [CrossRef]
- Khan, I.U.; Khan, A.; Khan, W.; Su’ud, M.M.; Alam, M.M.; Subhan, F.; Asghar, M.Z. A Review of Urdu Sentiment Analysis with Multilingual Perspective: A Case of Urdu and Roman Urdu Language. Computers 2021, 11, 3. [Google Scholar] [CrossRef]
- Mukhtar, N.; Khan, M.A.; Chiragh, N. Effective Use of Evaluation Measures for the Validation of Best Classifier in Urdu Sentiment Analysis. Cogn. Comput. 2017, 9, 446–456. [Google Scholar] [CrossRef]
- Khan, M.Y.; Nizami, M.S. Urdu sentiment corpus (v1.0): Linguistic Exploration and Visualization of Labeled Dataset for Urdu Sentiment Analysis. In Proceedings of the 2020 International Conference on Information Science and Communication Technology (ICISCT), Karachi, Pakistan, 8–9 February 2020; pp. 1–15. [Google Scholar] [CrossRef]
- Hassan, M.; Shoaib, M. Opinion within opinion: Segmentation approach for Urdu sentiment analysis. Int. Arab. J. Inf. Technol. 2018, 15, 21–28. [Google Scholar]
- Mukhtar, N.; Khan, M.; Chiragh, N.; Nazir, S. Identification and handling of intensifiers for enhancing accuracy of Urdu sentiment analysis. Expert Syst. 2018, 35, e12317. [Google Scholar] [CrossRef]
- Rehman, Z.U.; Bajwa, I.S. Lexicon-Based Sentiment Analysis for Urdu Language. In Proceedings of the 2016 Sixth International Conference on Innovative Computing Technology (INTECH), Dublin, Ireland, 24–26 August 2016; pp. 497–501. [Google Scholar]
- Mukhtar, N.; Khan, M.; Chiragh, N.; Jan, A.; Nazir, S. Recognition and effective handling of negations in enhancing the accuracy of Urdu sentiment analyzer. Mehran Univ. Res. J. Eng. Technol. 2020, 39, 759–771. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Sattar, A.; Khan, A.; Ali, A.; Kundi, F.M.; Ahmad, S. Creating sentiment lexicon for sentiment analysis in Urdu: The case of a resource-poor language. Expert Syst. 2019, 36, e12397. [Google Scholar] [CrossRef]
- Liaqat, M.I.; Hassan, M.; Shoaib, M.; Khurshid, S.; Shamseldin, M.A. Sentiment analysis techniques, challenges, and opportunities: Urdu language-based analytical study. PeerJ. Comput. Sci. 2022, 8, e1032. [Google Scholar] [CrossRef]
- Safder, I.; Mahmood, Z.; Sarwar, R.; Hassan, S.; Zaman, F.; Nawab, R.M.A.; Bukhari, F.; Abbasi, R.A.; Alelyani, S.; Aljohani, N.R.; et al. Sentiment analysis for Urdu online reviews using deep learning models. Expert Syst. 2021, 38, e12751. [Google Scholar] [CrossRef]
- Khan, M.Y.; Emaduddin, S.; Junejo, K.N. Harnessing English Sentiment Lexicons for Polarity Detection in Urdu Tweets: A Baseline Approach. In Proceedings of the 2017 IEEE 11th International Conference on Semantic Computing (ICSC), San Diego, CA, USA, 30 January–1 February 2017; pp. 242–249. [Google Scholar]
- Bibi, R.; Qamar, U.; Ansar, M.; Shaheen, A. Sentiment Analysis for Urdu News Tweets Using Decision Tree. In Proceedings of the 2019 IEEE 17th International Conference on Software Engineering Research, Management and Applications (SERA), Honolulu, HI, USA, 29–31 May 2019; pp. 66–70. [Google Scholar] [CrossRef]
- Syed, A.Z.; Aslam, M.; Martinez-Enriquez, A.M. Lexicon Based Sentiment Analysis of Urdu Text Using SentiUnits. In Advances in Artificial Intelligence: 9th Mexican International Conference on Artificial Intelligence, MICAI 2010, Pachuca, Mexico, 8–13 November 2010, Proceedings, Part I 9; Springer: Berlin/Heidelberg, Germany, 2010; pp. 32–43. [Google Scholar]
- Nasim, Z.; Ghani, S. Sentiment analysis on Urdu tweets using markov chains. SN Comput. Sci. 2020, 1, 269. [Google Scholar] [CrossRef]
- Batra, R.; Kastrati, Z.; Imran, A.; Daudpota, S.; Ghafoor, A. A large-scale tweet dataset for Urdu text sentiment analysis. Comput. Sci. Math. 2021, 2021030572. [Google Scholar] [CrossRef]
- Asif, M.; Qureshi, M.; Abid, A.; Kamal, A. A Dataset for The Sentiment Analysis of Indo-Pak Music Industry. In Proceedings of the 2019 International Conference on Innovative Computing (ICIC), Lahore, Pakistan, 1–2 November 2019; pp. 1–6. [Google Scholar]
- Devi, G.D.; Kamalakkannan, S. Literature review on sentiment analysis in social media: Open challenges toward applications. Int. J. Adv. Sci. Technol. 2020, 29, 1462–1471. [Google Scholar]
- Altaf, A.; Anwar, M.W.; Jamal, M.H.; Hassan, S.; Bajwa, U.I.; Choi, G.S.; Ashraf, I. Deep Learning Based Cross Domain Sentiment Classification for Urdu Language. IEEE Access 2022, 10, 102135–102147. [Google Scholar] [CrossRef]
- Azam, N.; Tahir, B.; Mehmood, M.A. Sentiment and emotion analysis of text: A survey on approaches and resources. Lang. Technol. 2020, 87. [Google Scholar]
- Soomro, T.R.; Ghulam, S.M. Current status of Urdu on Twitter. Sukkur IBA J. Comput. Math. Sci. 2019, 3, 28–33. [Google Scholar] [CrossRef]
- Rabbani, S.; Qureshi, Z.A. Exploratory Data Analysis of Urdu Poetry. Sci. Stud. Read. 2021. [CrossRef]
- Rani, S.; Anwar, W. Resource Creation and Evaluation of Aspect Based Sentiment Analysis in Urdu. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, Suzhou, China, 4–7 December 2020; pp. 79–84. [Google Scholar]
- Ghulam, S.M.; Soomro, T.R. Twitter and Urdu. In Proceedings of the 2018 International Conference on Computing, Mathematics and Engineering Technologies (ICOMET), Sukkur, Pakistan, 3–4 March 2018; pp. 1–6. [Google Scholar]
- Khan, M.Y.; Ahmed, T.; Wasi, S.; Siddiqui, M.-m.S. Enhancing sarcasm and sentiment analysis with cognitive relationship: A context-aware approach for Urdu-a resource poor language. Comput. Intell. Neurosci. 2022, 8. [Google Scholar]
- Chhajro, M.A.; Arshad, A.; Luhana, K.; Wagan, A.; Muneed, M.; Umrani, A.I. Electronic Ledger Management: A mobile-enabled sentiment reviews analysis of Urdu Language. J. Tianjin Univ. Sci. Technolo 2022, 55, 6. [Google Scholar]
- Mukund, S.; Srihari, R.K. Analyzing Urdu Social Media for Sentiments Using Transfer Learning with Controlled Translations. In Proceedings of the Second Workshop on Language in Social Media, Montreal, QC, Canada, 7 June 2012; pp. 1–8. [Google Scholar]
- Malik, K.I. Urdu news content classification using machine learning algorithms. Lahore Garrison Univ. Res. J. Comput. Sci. 2022, 6, 22–31. [Google Scholar] [CrossRef]
- Ali, M.Z.; Javed, K.; Tariq, A. Sentiment and emotion classification of epidemic related bilingual data from social media. Comput. Lang. 2021. [Google Scholar] [CrossRef]
- Rasheed, I.; Banka, H.; Khan, H.M. A hybrid feature selection approach based on LSI for classification of Urdu text. Mach. Learn. Algorithms Ind. Appl. 2021, 907, 3–18. [Google Scholar]
- Bashir, M.F.; Javed, A.; Arshad, M.; Gadekallu, T.; Shahzad, W.; Beg, M.O. Context aware emotion detection from low resource Urdu language using deep neural network. Trans. Asian Low-Resour. Lang. Inf. Process. 2022. [Google Scholar] [CrossRef]
- Ashraf, N.; Khan, L.; Butt, S.; Chang, H.-T.; Sidorov, G.; Gelbukh, A. Multi-label emotion classification of Urdu tweets. PeerJ Comput. Sci. 2022, 8, e896. [Google Scholar] [CrossRef]
- Farooq, A.; Noreen, Z.; Batool, S.; Naz, F. Urdu News Classification: An Empirical Study Using Machine Learning Techniques. In Proceedings of the 2022 Mohammad Ali Jinnah University International Conference on Computing (MAJICC), Karachi, Pakistan, 27–28 October 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Akhter, M.P.; Jiangbin, Z.; Naqvi, I.; Abdelmajeed, M.; Fayyaz, M. Exploring deep learning approaches for Urdu text classification in product manufacturing. Enterp. Inf. Syst. 2022, 16, 223–248. [Google Scholar] [CrossRef]
- Shams, S.; Sadia, B.; Aslam, M. Intent Detection in Urdu Queries Using Fine-Tuned BERT Models. In Proceedings of the 2022 16th International Conference on Open Source Systems and Technologies (ICOSST), Lahore, Pakistan, 14–15 December 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Mehmood, A.; Farooq, M.S.; Naseem, A.; Rustam, F.; Villar, M.G.; Rodríguez, C.L.; Ashraf, I. Threatening URDU Language Detection from Tweets Using Machine Learning. Appl. Sci. 2022, 12, 10342. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muhammad, K.B.; Burney, S.M.A. Innovations in Urdu Sentiment Analysis Using Machine and Deep Learning Techniques for Two-Class Classification of Symmetric Datasets. Symmetry 2023, 15, 1027. https://doi.org/10.3390/sym15051027
Muhammad KB, Burney SMA. Innovations in Urdu Sentiment Analysis Using Machine and Deep Learning Techniques for Two-Class Classification of Symmetric Datasets. Symmetry. 2023; 15(5):1027. https://doi.org/10.3390/sym15051027
Chicago/Turabian StyleMuhammad, Khalid Bin, and S. M. Aqil Burney. 2023. "Innovations in Urdu Sentiment Analysis Using Machine and Deep Learning Techniques for Two-Class Classification of Symmetric Datasets" Symmetry 15, no. 5: 1027. https://doi.org/10.3390/sym15051027
APA StyleMuhammad, K. B., & Burney, S. M. A. (2023). Innovations in Urdu Sentiment Analysis Using Machine and Deep Learning Techniques for Two-Class Classification of Symmetric Datasets. Symmetry, 15(5), 1027. https://doi.org/10.3390/sym15051027