Abstract
Semantic segmentation is an important task for the interpretation of remote sensing images. Remote sensing images are large in size, contain substantial spatial semantic information, and generally exhibit strong symmetry, resulting in images exhibiting large intraclass variance and small interclass variance, thus leading to class imbalance and poor small-object segmentation. In this paper, we propose a new remote sensing image semantic segmentation network, called CAS-Net, which includes coordinate attention (CA) and SPD-Conv. In the model, we replace stepwise convolution with SPD-Conv convolution in the feature extraction network and add a pooling layer into the network to avoid the loss of detailed information, effectively improving the segmentation of small objects. The CA is introduced into the atrous spatial pyramid pooling (ASPP) module, thus improving the recognizability of classified objects and target localization accuracy in remote sensing images. Finally, the Dice coefficient was introduced into the cross-entropy loss function to maximize the gradient optimization of the model and solve the classification imbalance problem in the image. The proposed model is compared with several state-of-the-art models on the ISPRS Vaihingen dataset. The experimental results demonstrate that the proposed model significantly optimizes the segmentation effect of small objects in remote sensing images, effectively solves the problem of class imbalance in the dataset, and improves segmentation accuracy.
1. Introduction
With the continuous development of computer vision technology, machine learning provides a variety of techniques and tools applied to remote sensing data to identify and extract important symmetric features in remote sensing images [1,2,3]. However, different from natural images, having the characteristics of a wide imaging range and complex and diverse backgrounds, remote sensing images present more spectral channels and complex image structures than natural images [4]. The unbalance of categories in remote sensing images and the segmentation of small objects are the reasons that affect the semantic segmentation effect [5].
Convolutional neural networks (CNNs) have been successfully applied to many semantic segmentation tasks [6,7]. The classical semantic segmentation models and their contributions are shown in Table 1. Great efforts have been made to successfully apply deep learning methods for the segmentation of remote sensing data [8,9]. Compared with natural image datasets, those comprising remote sensing images have higher intraclass variance and lower interclass variance, making the labeling task difficult [10]. To deal with the special data structure of remotely sensed images, Geng et al. [11] have extended the long short-term memory (LSTM) network [12] to extract contextual relationship information, where the LSTM algorithm learns potential spatial correlations. Mou et al. [13] and Tao et al. [14] have designed the spatial relationship module and spatial information inference structure, respectively, in order to build more effective contextual spatial relationship models. In order to better acquire long-range contextual and location-sensitive information among features in remote sensing images, the multiscale module is improved in this paper. ASPP [15] uses dilated convolution to increase the size of the receptive field and control the number of parameters. However, when remote sensing images contain objects with large size disparity, the pyramid pooling module cannot capture small objects well [16]. In order to solve the problem of uneven data distribution among different tags in image segmentation, some researchers try to take symmetry into account in deep learning models and architectures [17,18,19,20]. Lv et al. proposed a new way to detect and track objects at night, inspired by symmetric neural networks, which involves using computer algorithms to enhance certain features of objects and location and appearance information [21]. Park et al. proposed a symmetric graph convolutional autoencoder which produces a low-dimensional latent representation from a graph [22]. These approaches not only enable to balance the data distribution but also reduce the complexity of the model. To solve the problem of unbalanced classes in remote sensing image datasets, Kampffmeyer et al. [23] and Kemker et al. [24] have proposed modifications to the cross-entropy loss function by introducing different weighting mechanisms. Inspired by this idea, in this paper, we propose a new loss function which can effectively improve the Jaccard index.

Table 1.
The classical semantic segmentation models and their contributions.
Moreover, attention mechanisms have been successfully applied in semantic segmentation [30,31] over the past few years, where introducing an attention mechanism into a semantic segmentation model allows the model to better focus on meaningful image features [32]. In CNNs, channel attention [33] is usually implemented after each convolution [34], while spatial attention is typically implemented at the end of the network [35]. As a symmetric semantic segmentation model, U-net can obtain the context information of an image while locating the segmentation boundary accurately. In U-Net-based networks, channel attention is usually added in each layer of the upsampling part [36]. However, channel attention only considers interchannel information and ignores the importance of location information, which is crucial for obtaining the object structure of remote sensing images [37]. To enhance the perception of information channels and important regions, Woo et al. [38] have proposed the convolutional block attention module (CBAM) by linking channel attention and spatial attention in tandem. However, convolution can only capture local relationships and ignores the relational information between distant objects. Therefore, Hou et al. [39] have proposed a new coordinate attention mechanism by embedding location information into channel attention and successfully applied it to the semantic segmentation of natural images.
The above methods in deep learning for remote sensing image classification imbalance and small objects do not fully utilize the spatial feature information and location-sensitive information in remote sensing images at different scales. In this paper, a novel semantic segmentation network, CAS-Net, is proposed which integrates coordinate attention and SPD-Conv [40] layers for remote sensing images. CAS-Net adopts SPD-Conv to adjust the backbone network to reduce the loss of fine-grained information and improve the learning efficiency of feature information. In the feature extraction stage, a coordinate attention mechanism is used to enable the model to capture directional perception and position-sensitive information at the same time, so as to locate small objects more accurately at multiple scales. In addition, the Dice coefficient is introduced into the cross-entropy loss function to enable the model to maximizes the cross-merge ratio of a direct metric region and reduce the classification accuracy problem caused by classification imbalance.
The main contributions of this paper are as follows:
- (1)
- A new segmentation method for small objects in remote sensing images is proposed. We construct an asymmetric encoder–decoder structure which, based on ResNet101 and added SPD-Conv layers, enables the model to reduce the loss of fine-grained information and improve the segmentation accuracy of small objects in images.
- (2)
- We adopted the coordinate attention mechanism in the feature extraction stage to obtain more orientation-sensitive and position-sensitive feature information in remote sensing images and improve the segmentation accuracy of node edges.
- (3)
- We introduce the Dice coefficient into the cross-entropy loss function, which can reflect the degree of overlap between the predicted and real regions when the classification is extremely unbalanced, reducing the accuracy problem caused by classification unbalance.
2. Related Work
In this section, we present a brief review of the existing literature on the semantic segmentation of remotely sensed images, particularly those with a focus on attention mechanisms and small objects.
2.1. Attention Mechanism
Evidence from human perceptual processes has demonstrated the importance of attention mechanisms [33] which employ high-level information to guide bottom-up feed-forward processes [41]. For the processing of remote sensing images, the joint use of channel attention and spatial attention mechanisms has been common in previous studies [42,43]. The channel attention mechanism [44] and spatial attention mechanism [45] may also be applied separately when processing hyperspectral images. Qi et al. [46] have combined a multiscale convolutional structure and attention mechanism with the LinkNet network to obtain ATD-LinkNet, which can effectively exploit the spatial and semantic information in remote sensing images. The attention module incorporates features from different scales to effectively exploit the rich spatial and semantic information in remote sensing images, while the decoder part uses dense upsampling convolution to refine the nonlinear boundaries of objects in the remote sensing images. Li et al. [47] have proposed a dual-path attention network (DPA-Net) with a self-attention mechanism to enhance the model’s ability to capture key local features in remotely sensed images, using a global attention module to extract pixel-level spatial information and a channel attention module to focus on different features in the image. The attention factor in the coordinate attention mechanism [39] decomposes the channel attention to aggregate features along two spatial directions. In this way, long-distance relationships are obtained, and accurate location information is retained. Then, the generated feature maps are encoded into pairs of direction-aware and location-sensitive attention information, respectively, which are fed into the feature maps to enhance the representation of the object of interest.
2.2. Small Objects
The segmentation of small objects in remote sensing images is generally a challenging task. Mnihetal et al. [48] have proposed a method for the automatic identification of small objects based on a restricted Boltzmann machine (RBM) which automatically extracts object locations such as roads, buildings, and trees from aerial images, requiring various pre- and postprocessing steps. In particular, the basic features of the remote sensing images are extracted by preprocessing, and the final road segmentation results are obtained by the postprocessing network, based on the results extracted by the basic network due to the discontinuity of road segmentation results. Kampffmeyer et al. [20] have compared pixel- and patch-based FCN, where the patch-based pixel classification uses 65 × 65 pixels blocks for dense segmentation, effectively improving the segmentation accuracy for small objects such as cars; meanwhile, as pixel-based segmentation is designed behind the convolution layer of the shrinkage path, and features are directly upsampled back to the original image resolution; this method may lose some fine information of the image. Saito et al. [49] have proposed a new channel suppression method by using the original pixel values in the aerial image as the input and then output the prediction using a three-channel labeled image softmax (CIS) function instead of the original softmax function, which has the advantage that it does not require preprocessing and can directly recognize small objects such as roads and buildings. Sunkara et al. [40] have proposed SPD-Conv, which completely gets rid of the stepwise convolution and maximum pooling used in previous models and is comprised of a space-to-depth (SPD) layer followed by a nonstrided convolution layer, which can be integrated into most CNN architectures. In this paper, we introduce SPD-Conv into the original network to improve the semantic segmentation accuracy of small objects in remote sensing images.
3. Method
To better capture location and spatial information during the semantic segmentation of remote sensing images, reduce segmentation accuracy problems caused by unbalanced distribution of features in the dataset, and improve the semantic segmentation accuracy of small objects, a new remote sensing image semantic segmentation network with coordinate attention and SPD-Conv is proposed in this paper. ResNet101 [50] has powerful generalization ability, the residual connection in ResNet forcibly breaks the symmetry of the network, improves the characterization ability of the network, and can extract more effective feature information. In order to improve the classification accuracy of small objects, detailed information is captured and input into multiscale modules together with low-level feature information in the feature extraction stage; we adapted the ResNet101 network by including SPD-Conv into the original network and adding a nonstrided convolutional layer in the downsampled feature map. As the intraclass variance of remote sensing images is high while the interclass variance is low, we added the coordinate attention mechanism to the generic ASPP module to encode channel relationships and contextual information with a precise location at a certain distance, thus effectively improving the segmentation accuracy. In order to solve the unbalance problem of ground object classification, the Dice coefficient was introduced into the cross-entropy loss function, and gradient optimization of training results was carried out. The semantic segmentation model proposed in this paper includes the feature extraction module, a pyramid pooling module based on the coordinate attention mechanism (CA-ASPP), and an upsampling module. The entire model is an asymmetric decoder–encoder structure that is trained in an end-to-end manner. The overall structure of the proposed model is depicted in Figure 1.
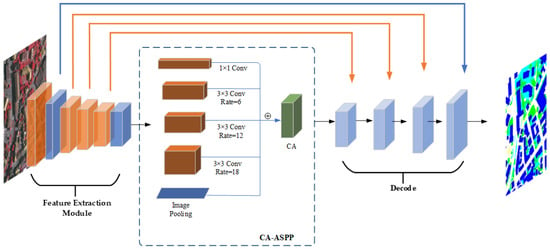
Figure 1.
General structure of CAS-Net.
3.1. Feature Extraction Module
ResNet uses shortcut connections to solve the problem of gradient disappearance, and the ResNet-101 structure was chosen as the backbone network for this paper. In the feature extraction module, an asymmetric convolution structure was constructed based on the ResNet101 backbone network to obtain the receptive field of various ground objects. ResNet was mainly used for image classification tasks initially, as feature extraction allows it to effectively ignore detailed information. Unlike image classification, segmentation tasks, especially semantic segmentation of remote sensing images, require detailed information of features to be retained. Therefore, on the basis of a network containing asymmetric convolution structures, we modified the ResNet-101 structure. ResNet-101 uses 4 convolutions with a stride of 2 and a maximum pooling layer. We added SPD-Conv to the ResNet-101 structure by replacing the four stride convolutions in ResNet-101 with SPD-Conv. As remote sensing images, even after being cropped, typically have a size much larger than 64 × 64 pixels, the maximum pooling layer was retained. SPD-Conv is comprised of a space-to-depth (SPD) layer followed by a nonstrided convolution layer. The SPD layer is an image transformation technique used within ResNet-101, namely throughout the downsampled feature map of ResNet-101. The SPD layer is a combination of an intermediate feature map cut out of a series of submaps ; this can be understood as first forming all submaps of , mapping each subsample down to proportionally, and finally stitching the subfeature maps along the channel dimension to obtain the feature map . The structure of the SPD layer is shown in Figure 2. Figure 2a–d gives an example when scale = 2. After the SPD feature transition layer, add a nonstrided (i.e., stride = 1) convolution layer with filters, where , as in shown in Figure 2e.
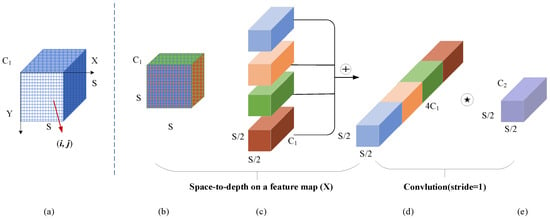
Figure 2.
SPD-Conv structure when scale = 2.  is a nonstrided (i.e., stride = 1) convolution layer with filters, where .
is a nonstrided (i.e., stride = 1) convolution layer with filters, where .
is a nonstrided (i.e., stride = 1) convolution layer with filters, where .
To retain as much valuable feature information as possible, a nonstrided convolution layer is added after the SPD layer. As there is a downsampling module before the first residual block in each stage of the ResNet-101 structure, the 1 × 1 convolution in each path of this downsampling module converts the input shape to the output shape of another path. This process leads to half of the information in the feature map being ignored; to solve this problem, we added a pooling layer before the 1 × 1 convolution. The improved ResNet-101 structure is detailed in Table 2. The feature information obtained in the feature extraction stage is input into the multiscale module for the next operation.
Table 2.
Improved ResNet-101 structure.
3.2. Multiscale Module Based on Coordinate Attention Mechanism (CA-ASPP)
The feature information obtained from the feature extraction module is input into the multiscale module. Atrous convolution can expand the perceptual field of the convolution kernel without downsampling, such that the resolution of the remote sensing images will not be lost. The upsampling part of ASPP in DeepLabV3+ has been improved by transforming 8 upsampling operations into 2 × 4 upsampling operations, providing richer semantic information and improving the effect of feature edge segmentation. For this paper, the ASPP module in DeepLabV3+ was selected as the multiscale module. The Squeeze-and-Excitation (SE) channel attention mechanism and CBAM are the most popular attention mechanisms. SE ignores the spatial dimensional features, and CBAM adds convolution based on channel pooling to weigh the spatial dimension; however, convolution does not allow us to obtain relevant information about distant objects. The CA uses global average pooling (GAP) to calculate channel attention weights and then globally encodes spatial information, allowing us to effectively obtain correlation information among distant objects. Therefore, CA coordinate attention was added to the end of ASPP in order to improve the model’s acquisition of orientation-aware and position-sensitive features of objects in remote sensing images, thus preserving long-distance dependencies and accurate position information (vertical (H) × horizontal (W)). First, global pooling is performed for each waveform feature in the spatial dimension, and the expression at the l channel is given as Equation (1):
where is the output of channel l, and denotes the value of at the coordinate .
To avoid the loss of spatial information, the global pooling is decomposed in the horizontal and vertical directions, and the outputs of the lth channel in the vertical direction and the horizontal direction w are expressed in Equations (2) and (3), respectively:
The decomposed feature maps are encoded to obtain two attention weights, and the aggregated features are connected and transformed, as expressed in Equation (4):
where denotes the series of spatial dimensions, is the nonlinear activation function, is the convolutional transformation function with a convolutional kernel of 1 × 1, and , where is used to control the block size reduction ratio.
Splitting independently into two tensors, and , along the space, the convolution kernel uses 1 × 1 convolutional transform functions and to transform and to the input values and .
The expressions are as shown in Equations (5) and (6), respectively, where is a sigmoid function:
Finally, the product of these two attention weights is weighted to obtain the final attention value, which allows different objects to maintain relevant information at a distance. The expression is given in Equation (7).
The structure of the CA module is shown in Figure 3. In this paper, a coordinate attention mechanism is added after the ASPP module to acquire direction-aware and position-sensitive features without losing long-range contextual information in remote sensing images.
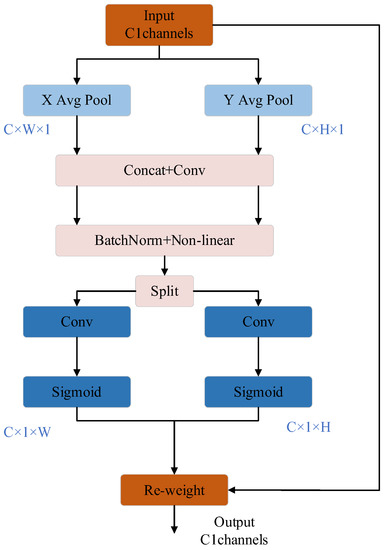
Figure 3.
CA module structure.
3.3. Loss Function
The most common loss function used in image semantic segmentation tasks is the cross-entropy loss function, which assigns weights to different classes to improve training on datasets with relatively balanced classes. However, the size of remote sensing imagery is typically relatively large and, so, it is likely that the classes of a remote sensing image dataset will be more unbalanced, and each batch of data may not contain all of the classes, which may lead to training errors. The Dice coefficient maximizes the cross-merge ratio of a direct metric region and improves model performance in the case of extremely unbalanced classes. Therefore, in this paper, the Dice coefficient is introduced into the cross-entropy loss function to solve the problem of class imbalance in the process of model training in the dataset. This was achieved by combining the cross-entropy loss function and Dice coefficient, according to the number of pixels of each classification in a batch image, and choosing the weighted cross-entropy loss function () and generalized Dice loss (), expressed as follows:
where [51] is the number of pixels in category , and is the weight of .
where and denote the predicted and true image elements from the total number of image elements, respectively, and is the number of categories.
where and denote the true and predicted values of , respectively.
The weighted cross-entropy loss function (WCELoss) and generalized Dice loss are combined as follows:
4. Experiments and Discussion
4.1. Data Set
Both the comparison and ablation experiments in this study were conducted on the publicly available ISPRS dataset [51]. The ISPRS dataset includes aerial image data from the Vaihingen and Potsdam areas. The ISPRS Vaihingen dataset contains 33 remote sensing images with a resolution of 0.09 m. The image size is in the range of 1000–4000 pixels × 1000–4000 pixels, and the images contain three bands: near-infrared (IR), red (R), and green (G). The dataset was labeled with six classifications, including impervious surfaces, buildings, low vegetation, trees, cars, and background. Example patches of the semantic object classification contest with (a) true orthophoto and (b) ground truth are shown in Figure 4. The 33 remote sensing images were randomly divided into training, validation, and test sets, and the data settings are shown in Table 3. As the size of single images in the dataset was too large and exceeded the GPU memory capacity, a sliding window with 30% overlap was used to crop the images. To prevent overfitting, the dataset used in this study adopts the symmetric augmentation method, in which the number of training samples was increased by using mirror flip and random rotation operations to finally obtain 20,600 images of size 256 × 256 pixels for training.

Figure 4.
Example patches of the semantic object classification contest with (a) true orthophoto and (b) ground truth of ISPRS Vaihingen dataset.
Table 3.
Details of ISPRS Vaihingen dataset.
The ISPRS Postdam dataset contains 38 remote sensing images of 6000 × 6000 pixels with a spatial resolution of 0.05 m. In this paper, images of near-infrared (IR), red (R), and green (G) bands are selected as training data. The dataset is labeled with impervious surfaces, buildings, low vegetation, trees, cars, and backgrounds. Example patches of the semantic object classification contest with (a) true orthophoto and (b) ground truth are shown in Figure 5. The images were cropped into 256 × 256 pixels images, and then data enhancement processing was carried out to obtain 2997 images. These images were randomly divided into training set, verification set, and test set at a ratio of 7:3:3 for training and prediction.

Figure 5.
Example patches of the semantic object classification contest with (a) true orthophoto and (b) ground truth of ISPRS Postdam dataset.
4.2. Evaluation Indicators
The overall accuracy (OA) reflects how many pixels the model result accurately matches, the F1-score value focuses on the low-accuracy categories, and the mean Intersection over Union (mIoU) is used to evaluate how accurately a model predicts more target shapes. In this study, OA, mIoU, and F1-score were used as evaluation metrics, which are calculated as follows:
where denotes the number of categories, denotes the number of pixels correctly classified, denotes the number of pixels where the background is determined as the target, denotes the number of pixels where the target is determined as the background, and denotes the number of pixels where the target is determined as the background.
4.3. Experimental Setup
In this study, considering GPU memory fusion and to avoid the overfitting phenomenon, the images in the original datasets were cropped, in addition to the data enhancement process, where the training image size was 256 × 256 pixels. Stochastic Gradient Descent (SGD) was used with the decay weight set to 0.0005, an initial learning rate of 0.01, and decay occurring 10 times every 15 cycles for 60 iterations with a step size of 4. All experiments in this paper were performed using an NVIDIA 3090Ti GPU.
4.4. Experimental Results
To verify the effectiveness of the proposed method, the proposed CAS-Net was compared with several state-of-the-art models, including FCN-8s, SegNet, PSPNet, DeepLabV3+, and ReSegNet. The segmentation accuracies of the different models are listed in Table 4 and Table 5. The confusion matrices of the proposed model in the two datasets are shown in Figure 6 and Figure 7. Note that the background classification was ignored in the ISPRS Vaihingen dataset due to the very low number of pixels.
Table 4.
Comparison of semantic segmentation accuracy of different models on the ISPRS Vaihingen test set.
Table 5.
Comparison of semantic segmentation accuracy of different models on the ISPRS Postdam test set.
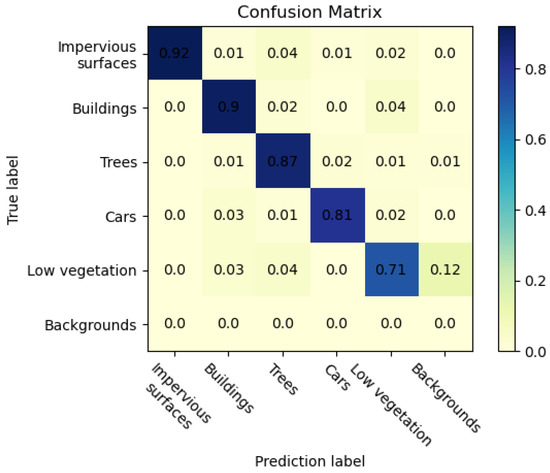
Figure 6.
Confusion matrix of results of the ISPRS Vaihingen dataset.
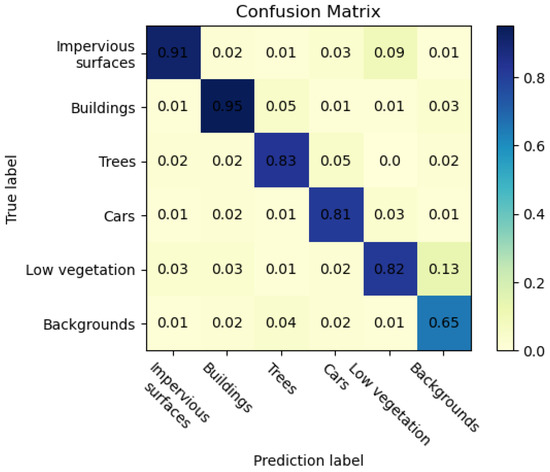
Figure 7.
Confusion matrix of results of the ISPRS Postdam dataset.
The experimental results on the ISPRS Vaihingen dataset are shown in Table 4. According to the experimental results, compared with the DeepLabV3+ model, the OA and mIoU of CAS-Net improved by 1.67% and 1.26%, respectively. Compared with the ReSegNet model proposed in 2019, the OA and mIoU of the proposed CAS-Net, after adjusting the backbone network and adding the attention mechanism to the multiscale module, were improved by 2.22% and 1.8%, respectively. In addition, compared with PSPNet, the F1-score of CAS-Net was improved by 5.25% and 7.11% for building and car classification, respectively. DeepLab V3+ had the best segmentation effect on low vegetation, with an F1-score of 82.35%, but it had a poor segmentation effect on impervious surfaces and trees. For the tree category, the F1-score of CAS-Net was 2.39% higher than ReSegNet’s and 3.12% higher than DeepLab V3+’s. ReSegNet had the best segmentation effect on the ground, with an F1-score of 91.37%, but it had a poor segmentation effect on cars and trees. According to Figure 6, many pixels belonging to cars are misclassified as impervious surfaces due to the small size of the cars and the diversity and shading of the edges, and these two categories are also confused in some test data due to the similar spectral characteristics of low vegetation and trees.
The above analysis shows that the CAS-Net proposed in this paper can effectively improve the overall accuracy of semantic segmentation in remote sensing images. These results indicate that it is effective to add a coordinate attention mechanism to the multiscale module to improve the model segmentation accuracy. In addition, adjusting the backbone network by SPD-Conv can effectively improve the segmentation accuracy of small objects.
The results of the ISPRS Postdam dataset are shown in Table 5. Since remote sensing images of the ISPRS Postdam dataset contain many small objects, the F1-score of CAS-Net on small objects such as trees and cars are 87.73% and 80.78%, respectively, which is significantly higher than that of other segmentation models. The SPD-Conv layer in the CAS-Net backbone network effectively captures details in the feature extraction stage. In the ISPRS Vaihingen dataset, the F1-score of ReSegNet on impervious surfaces is higher than that of CAS-Net. However, in the ISPRS Postdam dataset, due to low vegetation and impervious surfaces’ greater contact with trees, CAS-Net can capture more remote information, and the F1-scores for impervious surfaces and buildings are 1.81% and 1.13% higher than ReSegNet and 1.7% and 1.15% higher than DeepLab V3+, respectively, which shows the effectiveness of the coordinate attention mechanism in the feature extraction stage. The overall accuracy is more than 2% higher than other segmentation models. According to Figure 7, in this dataset, background is not ignored, and more pixels are misclassified as background because of their contact with other types. Due to the irregular shape and fuzzy boundary of low vegetation, it is easy to confuse background with background, resulting in poor classification of background.
To represent the segmentation results of the models more intuitively, the segmentation results of the different models are visualized in Figure 8, for which test images from SegNet, PSPNet, DeepLab V3+, and CAS-Net were selected for comparison. We used class activation mapping (CAM) to perform a feature heat map display on the feature extraction results of the last convolutional layer in the feature extraction trunk, and the visual analysis results are shown in Figure 8. The darker the red part, the more attention the model paid to that part of the image, followed by the yellow part. The bluer the heat map is, the more the model takes this part of redundant information into account and the less impact it has on the small objects. SegNet tends to ignore the background when near the building and easily divides individual trees within low vegetation into jointed trees. SegNet and PSPNet have a poor segmentation effect in the car category, which is easy to be mistakenly divided into impervious surfaces. DeepLab V3+ is better than SegNet and PSPNet in classifying small objects such as cars and trees, but DeepLab V3+ is prone to misclassify the background as impervious surfaces; the segmentation of building edges is also poor. It can be seen that CAS-Net classified small objects such as cars and buildings and single trees closer to the real labels than other models; furthermore, the shapes of the features in the segmentation results of CAS-Net were closer to the real values. Especially for the part connected by buildings, trees, and low vegetation, the segmentation effect of the proposed method is obviously better than other semantic segmentation methods. Therefore, CAS-Net can effectively improve the segmentation accuracy of small objects in remote sensing images.
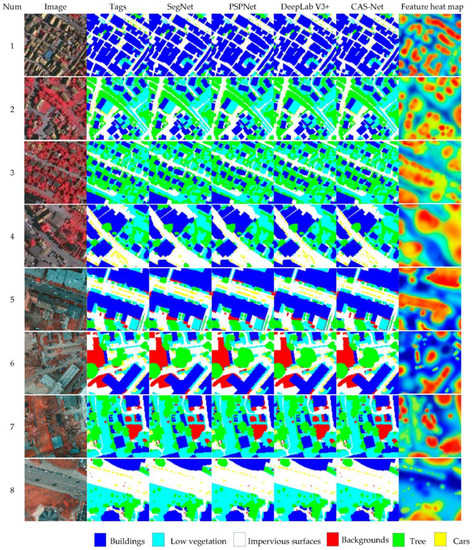
Figure 8.
Semantic segmentation results of different models on the ISPRS Vaihingen test set (1–4) and ISPRS Postdam test set (5–8).
4.5. Ablation Experiment
To evaluate the performance of each module in CAS-Net and the effectiveness of the CAS-Net model, ablation experiments were conducted on the ISPRS Vaihingen dataset. The experimental results are provided in Table 6. For this experiment, DeepLab V3+ was chosen as the benchmark, the backbone network was ResNet-101, and the multiscale module was ASPP using the cross-entropy loss function. On this basis, the improvements to the backbone network and the multiscale module based on the coordinate attention mechanism were gradually added. Overall, each module in CAS-Net was found to optimize the performance of the proposed model. The classification accuracy of the backbone network with the addition of SPD-Conv was improved by 2.23%, 3.05%, and 2.75% for buildings, trees, and cars, respectively, indicating that adding the SPD-Conv layer to the backbone network can effectively improve the segmentation of small objects. After adding the coordinate attention mechanism to the multiscale module, the OA was improved by 1.05%, and the mIoU improved by 1.31%, indicating that the coordinate attention mechanism helped the model to focus on critical distance contextual information and location-sensitive features. It shows that the addition of the coordinate attention mechanism can improve the model’s focus on the target of interest. In addition, the improvement of the loss function improved the overall accuracy of CAS-Net by 1.31% and mIoU by 1.51%, and it also improved the classification accuracy of small objects, indicating that the introduction of the Dice coefficient into the cross-entropy loss function could ameliorate the unbalanced class problem.
Table 6.
Comparison of semantic segmentation accuracy in ablation experiments on the ISPRS Vaihingen test set.
5. Conclusions
In this paper, we proposed a new semantic segmentation model for classification imbalance and small target segmentation in remote sensing images. The model improves the backbone network with SPD-Conv and adds the coordinate attention mechanism to the multiscale module. The SPD-Conv convolutional layer was added to the original network, which reduced the loss of fine-grained information and retained detailed information of features, thus improving the segmentation accuracy of the model for small objects. A multiscale module based on the coordinate attention mechanism is proposed. The coordinate attention mechanism enables the model to acquire the relationships between different objects and avoid the loss of spatial relationship information in remote sensing images. We combine the Dice loss and cross-entropy loss functions to effectively improve the accuracy problem caused by image category imbalance in type training. The experimental results show that on the ISPRS Vaihingen and ISPRS Postdam datasets, the F1-scores of trees reached 87.73% and 88.97%, respectively, and the F1-scores of cars reached 80.78% and 81.46%, respectively. The overall accuracy of the two datasets reached 89.83% and 89.94%, respectively. It shows that CAS-Net can effectively improve the segmentation accuracy and OA of small and medium targets in remote sensing images, which is an improvement on the existing semantic segmentation model.
Remote sensing images usually contain a great many symmetrical objects; in future research, we will aim to make full use of the symmetry of ground objects and reduce the number of parameters on the basis of symmetric quantization, moving toward a lightweight model while maintaining the demonstrated model performance.
Author Contributions
Conceptualization, Z.Y. and F.Z.; methodology, Z.Y.; software, X.Z.; validation, X.C., Q.W. and Y.G.; formal analysis, Q.W.; investigation, Z.Y.; resources, Q.W.; data curation, X.C. and Y.G.; writing—original draft preparation, Z.Y. and F.Z.; writing—review and editing, X.Z., X.C. and Y.G.; supervision, Q.W.; project administration, F.Z.; funding acquisition, Q.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Major Scientific and Technological Innovation Project of Shandong Province, grant number 2022CXGC010609.
Data Availability Statement
The datasets in this paper are available at https://www.isprs.org/education/benchmarks/UrbanSemLab/default.aspx (accessed on 7 January 2013).
Acknowledgments
The authors would like to thank the referees for their careful reading and helpful comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Xu, Z.Y.; Zhang, W.C.; Zhang, T.X.; Yang, Z.F.; Li, J.Y. Efficient transformer for remote sensing image segmentation. Remote Sens. 2021, 13, 3585. [Google Scholar] [CrossRef]
- Zhou, X.K.; Xu, X.S.; Liang, W.; Zeng, Z.; Yan, Z. Deep-Learning-Enhanced Multitarget Detection for End-Edge-Cloud Surveillance in Smart IoT. IEEE Internet Things J. 2021, 8, 12588–12596. [Google Scholar] [CrossRef]
- Ali, I.; Rehman, A.U.; Khan, D.M.; Khan, Z.; Shafiq, M.; Choi, J.-G. Model Selection Using K-Means Clustering Algorithm for the Symmetrical Segmentation of Remote Sensing Datasets. Symmetry 2022, 14, 1149. [Google Scholar] [CrossRef]
- Li, J.Y.; Huang, X.; Gong, J.Y. Deep neural network for remote-sensing image interpretation: Status and perspectives. Natl. Sci. Rev. 2019, 6, 1082–1086. [Google Scholar] [CrossRef]
- Chen, X.L.; Zhu, G.B.; Liu, M.Q. Remote sensing image scene classification with self-supervised learning based on partially unlabeled datasets. Remote Sens. 2022, 14, 5838. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer vision and Pattern Recognition, Las Vegas, NV, USA, 25 June–2 July 2016; pp. 3213–3223. [Google Scholar]
- Pan, J.S.; Wei, Z.Q.; Zhao, Y.H.; Zhou, Y. Enhanced FCN for farmland extraction from remote sensing image. Multimed. Tools Appl. 2022, 81, 38123–38150. [Google Scholar] [CrossRef]
- Liu, Y.; Gao, L.R.; Xiao, C.C.; Qu, Y.; Zheng, K. Hyperspectral image classification based on a shuffled group convolutional neural network with transfer learning. Remote Sens. 2020, 12, 1780. [Google Scholar] [CrossRef]
- Yuan, X.H.; Shi, J.F.; Gu, L.C. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Copa, L.; Kanevski, M.; Munoz-Mari, J. A survey of active learning algorithms for supervised remote sensing image classification. IEEE J. Sel. Top. Signal Process. 2011, 5, 606–617. [Google Scholar] [CrossRef]
- Geng, J.; Wang, H.Y.; Fan, J.C.; Ma, X.R. SAR image classification via deep recurrent encoding neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2255–2269. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Mou, L.C.; Hua, Y.S.; Zhu, X.X. Spatial relational reasoning in networks for improving semantic segmentation of aerial images. In Proceedings of the IEEE Conference on International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 5232–5235. [Google Scholar]
- Tao, C.; Qi, J.; Li, Y.S.; Wang, H.; Li, H.F. Spatial information inference net: Road extraction using road-specific contextual information. ISPRS J. Photogramm. Remote Sens. 2019, 158, 155–166. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- He, Q.; Dong, Z.; Chen, F. Pyramid: Enabling Hierarchical Neural Networks with Edge Computing. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 1860–1870. [Google Scholar]
- Wang, Z.; Zhang, J.; Xia, S.; Shi, B.; Bai, X.; Zhang, L. Symmetry-enhanced deep learning for spatiotemporal prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Los Angeles CA, USA, 15–21 June 2019; pp. 5989–5998. [Google Scholar]
- Ma, J.; Lu, D.; Li, Y.; Shi, G. CLHF-Net: A Channel-Level Hierarchical Feature Fusion Network for Remote Sensing Image Change Detection. Symmetry 2022, 14, 1138. [Google Scholar] [CrossRef]
- Qi, L.Y.; Yang, Y.H.; Zhou, X.K. Fast anomaly identification based on multiaspect data streams for intelligent intrusion detection toward secure industry 4.0. IEEE Trans. Ind. Inform. 2021, 18, 6503–6511. [Google Scholar] [CrossRef]
- Liang, W.; Hu, Y.; Zhou, X. Variational few-shot learning for microservice-oriented intrusion detection in distributed industrial IoT. IEEE Trans. Ind. Inform. 2021, 18, 5087–5095. [Google Scholar] [CrossRef]
- Lv, Y.; Feng, W.; Wang, S.; Dauphin, G.; Zhang, Y.; Xing, M. Spectral-Spatial Feature Enhancement Algorithm for Nighttime Object Detection and Tracking. Symmetry 2023, 15, 546. [Google Scholar] [CrossRef]
- Park, J.; Lee, M.; Chang, H.J.; Lee, K.; Choi, J.Y. Symmetric graph convolutional autoencoder for unsupervised graph representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Los Angeles CA, USA, 15–21 June 2019; pp. 6519–6528. [Google Scholar]
- Kampffmeyer, M.; Salberg, A.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Kemker, R.; Kanan, C. Self-taught feature learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2693–2705. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deepconvolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Sun, Y.; Tian, Y.; Xu, Y. Problems of encoder-decoder frame-works for high-resolution remote sensing image segmentation: Struc-tural stereotype and insufficient learning. Neurocomputing 2019, 330, 297–304. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, H.W.; Xiao, J.; Nie, L.Q. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Zhao, Q.; Liu, J.H.; Li, Y.W.; Zhang, H. Semantic segmentation with attention mechanism for remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5403913. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Warsaw, Poland, 17–19 September 2018; pp. 7132–7141. [Google Scholar]
- Tong, W.; Chen, W.T.; Han, W. Channel-attention-based DenseNet network for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Zhu, M.H.; Jiao, L.C.; Liu, F.; Yang, S.Y. Residual spectral–spatial attention network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 449–462. [Google Scholar] [CrossRef]
- Ren, Y.; Li, X.; Yang, X. Development of a dual-attention U-Net model for sea ice and open water classification on SAR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4010205. [Google Scholar] [CrossRef]
- Wang, H.; Zhu, Y.; Green, B. Axial-deeplab: Stand-alone axial-attention for panoptic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 108–126. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S. Coordinate attention for efficient mobile network design. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Beijing, China, 29 October–21 November 2021; pp. 13713–13722. [Google Scholar]
- Sunkara, R.; Luo, T. No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects. arXiv 2022, arXiv:2208.03641. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Advances in Neural Information Processing Systems 27, Proceedings of the 28th Annual Conference on Neural Information Processing Systems, Montreal, Canada, 8–13 December 2014; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2014. [Google Scholar]
- Zhang, S.Y.; Li, C.R.; Qiu, S. EMMCNN: An ETPS-based multi-scale and multi-feature method using CNN for high spatial resolution image land-cover classification. Remote Sens. 2019, 12, 66. [Google Scholar] [CrossRef]
- Gao, H.; Cao, L.; Yu, D.F. Semantic segmentation of marine remote sensing based on a cross direction attention mechanism. IEEE Access 2020, 8, 142483–142494. [Google Scholar] [CrossRef]
- Zheng, J.W.; Feng, Y.C.; Bai, C.; Zhang, J.L. Hyper spectral image classification using mixed convolutions and covariance pooling. IEEE Trans. Geosci. Remote Sens. 2021, 59, 522–534. [Google Scholar] [CrossRef]
- Zhou, M.; Zou, Z.; Shi, Z.; Zeng, W.J.; Gui, J. Local Attention networks for occluded airplane detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 17, 381–385. [Google Scholar] [CrossRef]
- Qi, X.; Li, K.; Liu, P.; Zhou, X.; Sun, M. Deep attention and multi-scale networks for accurate remote sensing image segmentation. IEEE Access 2020, 8, 146627–146639. [Google Scholar] [CrossRef]
- Li, J.; Xiu, J.; Yang, Z. Dual path attention net for remote sensing semantic image segmentation. ISPRS Int. J. Geo-Inf. 2020, 9, 571. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, Canada, 2013. [Google Scholar]
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple object extraction from aerial imagery with convolutional neural networks. Electron. Imaging 2016, 10, 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1063–6919. [Google Scholar]
- Rottensteiner, F.; Sohn, G.; Jung, J. The ISPRS benchmark on urban object classification and 3D building reconstruction. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 1, 293–298. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).