1. Introduction
Quality function deployment (QFD) is a systematic, cross-functional team-based product planning technique used to ensure that customer requirements (CRs) are deployed throughout the research and development (R&D), engineering, and manufacturing stages of products [
1]. The QFD methodology originated in the late 1960s and early 1970s in Japan, and first used at the Kobe Shipyards of Mitsubishi Heavy Industries [
2]. Later, QFD has become a standard practice in most leading companies such as General Motors, Ford, Xerox, IBM, Procter & Gamble, and Hewlett-Packard [
3]. QFD is a customer-driven methodology that supports engineers to efficiently translate CRs into relevant design requirements (DRs) or engineering characteristics (ECs), and subsequently into parts characteristics, process plans and production requirements in the new product development. Generally, the implementation of QFD in an organization can improve engineering knowledge, productivity and quality, and reduce product costs, development cycle time and engineering changes [
4]. Due to its visibility and easiness, the QFD method has been successfully introduced in diverse industries as a quality tool to achieve higher product performance and customer satisfaction [
5,
6,
7].
In the application of QFD, a matrix configuration called house of quality (HoQ) is of fundamental and strategic importance, which is used to translate CRs (WHATs) into appropriate DRs (HOWs) graphically [
8]. Generally, constructing the HoQ comprises determining the weights of CRs, the relationship matrix between WHATs and HOWs, the interrelationship matrix among HOWs and the importance of DRs. Besides, QFD is a group decision behavior and often involves a group of cross-functional team members from marketing, design, quality, production, as well as a group of customers [
4]. The customers of a product or service in a targeted market are first selected for determining the importance weights of CRs. Then a QFD team is established for assessing the relationships between CRs and DRs and the interrelationships between DRs. The prioritization of DRs is a critical output of the QFD planning process, which guides engineering designers in resource allocation, decision-making and the subsequent QFD analysis [
9].
In the real-life world, there are many QFD problems with imperfect, vague and imprecise information due to the existence of conflicting goals, time press, lack of knowledge, etc. It is common for QFD team members to use linguistic terms to express their judgments [
4,
10]. Moreover, because of uncertainty and incompleteness in the early stage of new product development, a single linguistic term may not suitable or adequate for QFD team members to give their assessments in constructing the HoQ. The experts of a QFD team may prefer to use multiple linguistic terms for expressing their judgment information sufficiently. Therefore, QFD problems could use the linguistic modeling and computational methods in its solving process. Hesitant fuzzy linguistic term sets (HFLTSs) [
11] were proposed and used to deal with the situations in which decision makers may hesitate among several possible linguistic values or think of richer expressions for assessing an alternative. Compared with other fuzzy linguistic approaches, HFLTSs are more convenient and flexible to manage the hesitancy and uncertainty of decision makers in practical applications [
12]. Recently, HFLTSs have attracted more concerns of researchers and have been widely applied to many fields [
13,
14,
15]. Additionally, to calculate linguistic information without loss of information, the 2-tuple linguistic representation model was introduced by Herrera and Martínez [
16]. A well-known extension of the 2-tuple linguistic model is the interval 2-tuple linguistic model [
17], which uses uncertain linguistic variables called interval 2-tuples for computing with words. Due to its characteristics and capabilities, numerous studies have reported decision-making models and methods within the interval 2-tuple linguistic environment [
18,
19,
20].
On the other hand, prioritizing DRs in QFD can be viewed as a complex multiple criteria decision-making (MCDM) problem and MCDM methods have been found to be a useful tool to solve this kind of problem [
21]. The QUALIFLEX (qualitative flexible multiple criteria method), a variation of Jacquet-Lagreze’s permutation method, is a very useful outranking method proposed by Paelinck [
22] for MCDM in view of its simple logic, full utilization of information contained in the decision analysis, and easy computational procedure [
23]. The methodology of QUALIFLEX is based on a metric procedure that evaluates all possible permutations of the considered alternatives and identifies the optimal permutation that exhibits the greatest comprehensive concordance/discordance index [
24]. In recent years, the QUALIFLEX has been successfully applied to address different MCDM problems. For example, Chen et al. [
25] developed an extended QUALIFLEX method for dealing with MCDM problems in the context of interval type-2 fuzzy sets and applied it for medical decision-making. Chen [
26] presented an interval-valued intuitionistic fuzzy QUALIFLEX method with a likelihood-based comparison approach for multiple criteria decision analysis within the environment of interval-valued intuitionistic fuzzy sets. Based on the type-2 fuzzy framework, Wang et al. [
23] developed a likelihood-based QUALIFLEX method for multiple criteria group decision-making within the interval type-2 fuzzy decision setting. Zhang and Xu [
24] proposed a hesitant fuzzy QUALIFLEX with a signed distance-based comparison method for solving MCDM problems in which the assessments of alternatives and the weights of criteria are both expressed by hesitant fuzzy elements.
Based on the above discussions, this paper attempts to propose an extended QUALIFLEX approach based on hesitant 2-tuple linguistic term sets to capture imprecise or uncertain assessment information in constructing the HoQ and to enhance the analysis capability of the traditional QFD. Although a considerable number of MCDM methods have been adopted by previous QFD models for the prioritization of DRs, to the best of our knowledge, no study has been conducted on applying the QUALIFLEX approach in QFD problems. Therefore, we extend the QUALIFLEX algorithm within the hesitant 2-tuple linguistic environment to determine the priorities of DRs. In addition, the existing approaches proposed to improve QFD analysis only consider the situations where the information about CR weights is completely known; no or little attention has been paid to the QFD problems in which the CR weight information is incompletely known. In response, we propose a linear programming model to determine the weights of CRs for the QFD problem with incomplete weight information. Finally, the computational procedure of the new QFD model is illustrated by an illustrate example concerning market segment evaluation and selection.
The rest of this paper is organized as follows.
Section 2 briefly reviews the related work of QFD improvements. In
Section 3, we introduce some basic concepts concerning HFLTSs and interval 2-tuples. It is followed by a description of the proposed QFD framework using hesitant 2-tuple linguistic term sets and a modified QUALIFLEX approach. Next, a case study is presented in
Section 5 to illustrate the proposed QFD methodology, and a comparative analysis with other relevant QFD methods is also provided in this section. Finally, this article is concluded with discussion of key findings and future research suggestions in
Section 6.
2. Literature Review
Over the last two decades, a number of improvements have been developed to eliminate the restrictions and enhance the performance of the traditional QFD. Critical reviews have summarized the concepts and decision methods employed in the QFD process, see, for example, [
5,
27,
28]. In the sequel, we briefly review the existing QFD methodologies from the perspectives of CR weighting, vague assessments, and DR ranking in the HoQ construction.
Determining correct importance weights of CRs is essential in QFD since they significantly affect the target values set for DRs. Therefore, Armacost et al. [
29] first integrated analytic hierarchy process (AHP) with QFD to establish a framework for prioritizing CRs and applied it to the manufacture of industrialized housing. Kwong and Bai [
1] employed a fuzzy AHP with an extent analysis approach to determine the importance weights for the CRs in QFD. Aye Ho et al. [
3] proposed an integrated group decision-making approach to QFD, which first modifies the nominal group technique to obtain CRs and then integrates the agreed and individual criteria approaches to assign customers’ importance levels. Lam and Lai [
30] proposed an analytical network process (ANP)-QFD model for designing environmental sustainability, which makes use of the ANP to determine the importance degrees of CRs and DRs and to incorporate the inter-dependence between CRs and DRs in the HoQ. Liu et al. [
31] developed a fuzzy non-linear regression model using the minimum fuzziness criterion to identify the degree of compensation among CRs in QFD. Ji et al. [
32] developed a novel approach that integrates Kano model quantitatively into QFD to optimize product design to maximize customer satisfaction under cost and technical constraints.
In addition, the QFD team members or consumers participating the construction of HoQ may have vague assessments and cannot provide their opinions with exact numerical values. Therefore, to effectively capture inevitable vagueness and uncertainty in the QFD planning process, Chin et al. [
4] presented an evidential reasoning (ER)-based methodology for synthesizing various types of assessment information provided by customers and QFD team members. Chan and Wu [
8] suggested a systematic approach to QFD on the basis of symmetrical triangular fuzzy numbers (STFNs) to capture the vagueness in linguistic assessments from both customers and technicians. Zhang and Chu [
10] proposed a fuzzy group decision-making approach incorporating with two optimization models (i.e., logarithmic least squares model and weighted least squares model) to aggregate the multi-format and multi-granularity linguistic judgments of decision makers for constructing the HoQ. Yan and Ma [
33] proposed a two-stage group decision-making approach to tackle with human subjective perception and customer heterogeneity underlying QFD, in which the order-based semantics of linguistic information is used to derive the fuzzy preference relations of different DRs with respect to each customer and the fuzzy majority is used to synthesize all customers’ individual fuzzy preference relations to determine the prioritization of DRs.
As another key issue of QFD, the prioritization of DRs have been extensively researched and various methods have been suggested in the QFD literature. For example, Luo et al. [
34] proposed a new QFD-based product planning approach to determine the optimal target levels of DRs for a product market with heterogeneous CRs by integrating consumer choice behavior analysis. Zhong et al. [
35] constructed a fuzzy chance-constrained programming model to determine the target values of DRs in QFD and designed a hybrid intelligent algorithm by integrating fuzzy simulation and genetic algorithm to solve the proposed model. Jia et al. [
9] presented a method for quantifying the importance degree of DRs with a multi-level hierarchical structure in QFD, in which fuzzy ER algorithm is adopted to deal with the fuzziness and incompleteness during the evaluation process and fuzzy discrete Choquet integral is used to characterize the interactions among DRs during the aggregation process. Hosseini Motlagh et al. [
36] provided a fuzzy preference ranking organization method for enrichment evaluation (PROMETHEE) approach to rank DRs for the QFD process in multi-criteria product design. Song et al. [
21] proposed a group decision approach based on rough set theory and grey relational analysis (GRA) approach for prioritizing DRs in QFD under vague environment.
4. QFD Using Hesitant 2-Tuples and QUALIFLEX Method
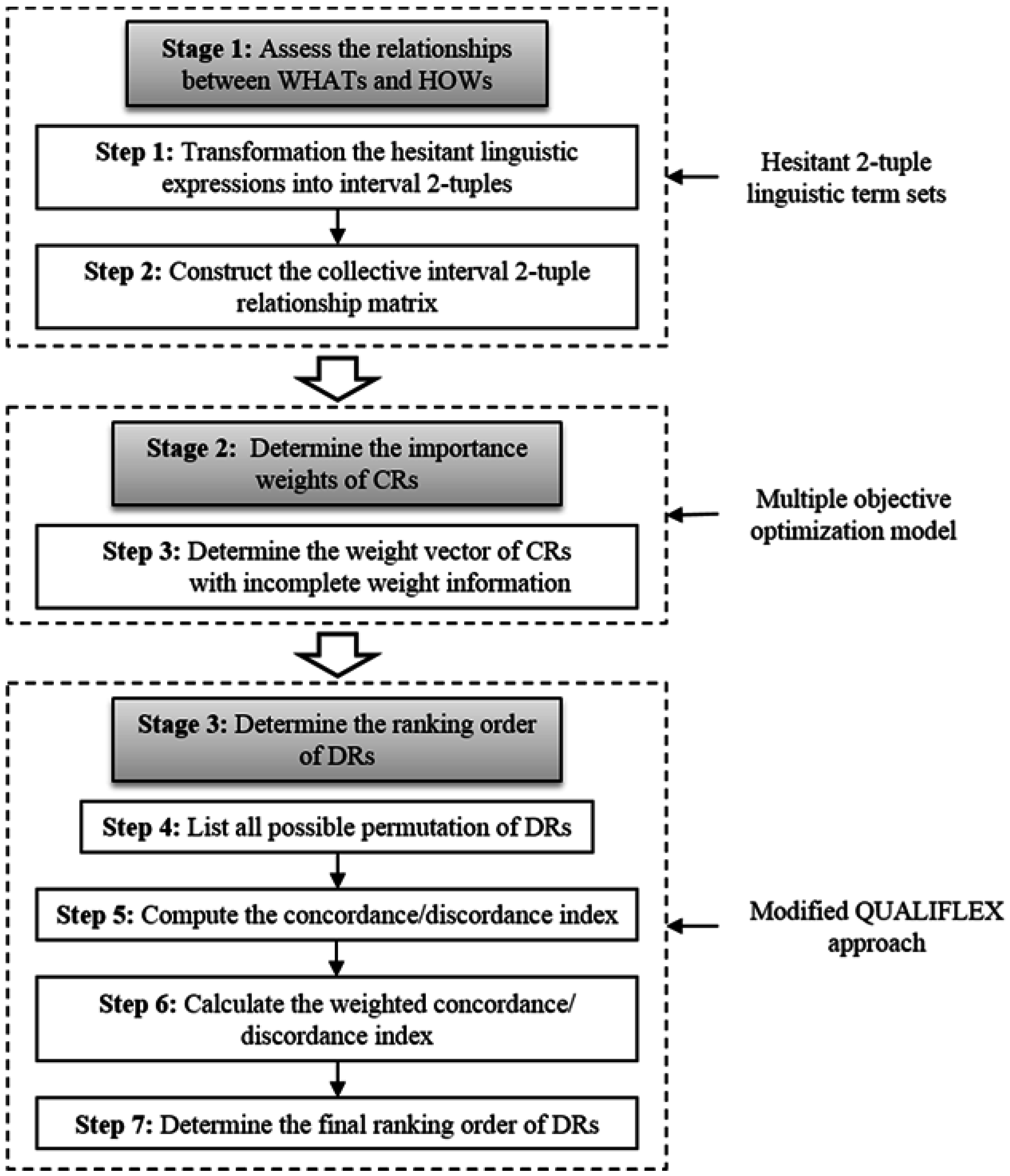
In this section, we propose a hybrid analytical model combining hesitant 2-tuple linguistic term sets and an extended QUALIFLEX approach for handling QFD problems with incomplete weight information. The flowchart of the proposed QFD algorithm is depicted in
Figure 1. In short, the proposed QFD approach is composed of three key stages: assessing relationships between CRs and DRs, determining importance weights of CRs, and determining the ranking order of DRs. In the first stage, the relationships between WHATs and HOWs are rated by integrating HFLTSs and interval 2-tuples to form the QFD problem within the hesitant 2-tuple linguistic environment. Then, an optimization model is established based on the GRA method, by which the importance degrees of CRs can be determined. Finally, a modified QUALIFLEX approach is developed for the determination of priority of each DR. In the following subsections, the procedure of the proposed group analytical approach for QFD is described in further detail.
4.1. Assess the Relationships between WHATs and HOWs
Assume that there are K team members in a QFD expert group responsible for the assessment of relationships between a set of WHATs and a set of HOWs using the linguistic term set . In our proposal, the QFD team members give their judgments on the relationships between CRs and DRs by means of the context-free grammar approach. Let be the linguistic assessment matrix of the kth team member, where indicates the hesitant linguistic expression provided by TMk over the relationship between CRi and DRj. Based on these assumptions and notations, the steps of dealing with the uncertain CR-DR relationship assessments are presented as follows:
Step 1: Transformation the hesitant linguistic expressions into interval 2-tuples
To homogenize all the judgments for the relationships between WHATs and HOWs, hesitant linguistic assessment matrices are provided by QFD team members by using linguistic expressions based on the context-free grammar
GH. After converting into corresponding HFLTSs according to the transformation function
EGH, every QFD team member’s hesitant linguistic expressions
can be transformed into linguistic intervals
by calculating the envelope of each HFLTS (as in Definition 4). Then, the linguistic intervals are represented using the interval 2-tuple linguistic approach and translated into
. As a result, the hesitant linguistic assessment information of QFD team members can be expressed by interval 2-tuple assessments as follows:
Step 2: Construct the collective interval 2-tuple relationship matrix
In this step, to relieve the influence of unfair arguments on the QFD results, the ITOWA operator is utilized to aggregate the QFD team members’ subjective assessments. That is, the collective interval 2-tuple assessments
for
and
are computed as follows:
where
is the
kth largest of the interval 2-tuples
,
is the ITOWA weight vector with
and
, which can be obtained via the argument-dependent approach developed by Wu et al. [
44].
As a result, a collective interval 2-tuple relationship matrix
can be produced based on the individual assessments of multiple QFD team members.
Note that the HOWs (DRs) are assumed to be independent in the above computations, which may not the case in some circumstances. Thus, for the QFD problems characterized by interdependent HOWs, the relationship matrix
between WHATs and HOWs is adjusted by [
33]:
where
is the correlation matrix of HOWs. Therefore, the correlations among HOWs can be incorporated into our QFD model with the adjusted collective interval 2-tuple relationship matrix
.
4.2. Determine the Importance Weights of CRs
In practical QFD circumstances, the information concerning relative importance of CRs is usually incompletely known due to time pressure, lack of knowledge or customer’s limited expertise. The management of incomplete information has been studied by many researchers [
45,
46], and lots of methods have been developed for the determination of criteria weights with incomplete information, such as those based on technique for order preference by similarity to an ideal solution (TOPSIS) [
19], distance measure [
47] and entropy method [
48]. In the QFD literature, however, little research has been conducted to estimate the weights of CRs when the weight information is incompletely known. The GRA, proposed by Deng [
49], is a kind of method for solving MCDM problems, which aims at choosing the alternative with the highest grey relational grade to the reference sequence. Therefore, in this part, we establish a multiple objective optimization model based on the GRA to determine the relative importance of CRs with partly known weight information.
Let
be the weight vector of CRs collected from the customer representatives in a targeted market, where
and
, the known weight information on CRs can be usually constructed using the following basic ranking forms [
26,
50], for
:
A weak ranking: ;
A strict ranking: ;
A ranking of differences: ;
A ranking with multiples: ;
An interval form: .
Let H denote the set of the known weight information of CRs given by a group of customers and , the specific steps to compute the CR weights are given below:
Step 3: Determine the weight vector of CRs
According to the basic principle of the GRA method, the most critical DR for customer satisfaction should have the “greatest relation grade” to the reference sequence (the vector of ideal relevance value of each DR with respect to CRs). Under the interval 2-tuple linguistic environment, the reference sequence denoted as
can be defined as follows [
43]:
For each CR of the associated DRs in QFD, the grey relation coefficient between
and
, i.e.,
, is calculated using the following equation:
where
,
,
for
,
is the distinguishing coefficient,
. Normally, the value of
is taken as 0.5 since it offers moderate distinguishing effects and good stability. Then the grey relational grade
between the reference sequence
and the comparative sequences
corresponding to
can be acquired by
In general, for the given weight vector of CRs, the larger
, the more important the DR
j will be. Thus, a reasonable weight vector of CRs should be determined so as to make all the grey relational grades
as larger as possible, which means to maximize the grey relational grade vector
under the condition
. As a result, we can reasonably form the following multiple objective optimization model:
Several approaches have been proposed to solve linear programming problems with multiple objectives. In this paper, the max-min operator [
26] is applied to integrate all the grey relational grades
into a single objective optimization model:
By solving Model (M−2), its optimal solution can be used as the weight vector of CRs.
4.3. Determine the Ranking Order of DRs
To prioritize DRs, in this subsection we develop a hesitant 2-tuple linguistic QUALIFLEX (HTL-QUALIFLEX) approach with the inclusion comparison method. Since the relationship assessments between WHATs and HOWs are transformed into interval 2-tuples in the first stage, this study utilizes the comparison approach of interval 2-tuples based on the inclusion comparison possibility to recognize the corresponding concordance/discordance index. The best priority order of DRs is generated based on the level of concordance and the most critical DRs can be identified for subsequent QFD analysis. Next, the algorithm of the HTL-QUALIFLEX approach for the ranking of DRs is summarized.
Step 4: List all possible permutation of DRs
Given the set of identified design requirements, i.e.,
, and assume that there exist
permutations of the ranking of the DRs. Let
denote the
ρth permutation as:
where
and
,
, are the DRs listed in QFD and
is ranked higher than or equal to
.
Step 5: Compute the concordance/discordance index
The concordance/discordance index
for each pair of design requirements
at the level of preorder with respect to the
ith customer requirement and the ranking corresponding to the
ρth permutation is defined as follows:
Based on the inclusion comparison possibility comparison method of interval 2-tuples, there are concordance, ex aequo and discordance if , , and , respectively.
Step 6: Calculate the weighted concordance/discordance index
By incorporating the weights of CRs
derived via Model (M−2), we can calculate the weighted concordance/discordance index
for each pair of design requirements
at the level of preorder with respect to the
m CRs and the ranking corresponding to the permutation
is determined by
Step 7: Determine the final ranking order of DRs
Finally, the comprehensive concordance/discordance index
for the
ρth permutation is computed as follows:
It is easily seen that the bigger the comprehensive concordance/discordance index value, the better the ranking order of the DRs. Therefore, the final ranking result of DRs should be the permutation with the greatest comprehensive concordance/discordance index , i.e., .
5. Illustrative Example
In this section, we provide a numerical example to illustrate the applicability and implementation process of the proposed QFD approach. This case study involves a QFD analysis for market segment evaluation and selection [
51].
5.1. Implementation
Market segment selection is an important marketing activity of a company in the highly competitive market. It can be regarded as a complex decision-making problem because many potential criteria and decision makers must be involved during the selection procedure and the outcomes of any choice are uncertain. QFD provides an effective framework for market segment evaluation and selection due to the multi-dimensional characteristics of market segments. Thuan Yen JSC is a trading service and transportation company located in northern Vietnam, which has more than 50 different sizes of trucks. This company has built a customer network in both domestic and international markets with ten years’ experience in providing trading and transportation services. To further expand the company’s business in the domestic and international markets, managers of this company have to select the most suitable segment to maximize its profit. Thus, the proposed QFD approach is applied to the first part of the entire market segment selection procedure for this company, i.e., determining the company’s business strengths (HOWs) based on market segment features (WHATs).
First, an expert team including five company decision makers,
, is set up to carry out the QFD analysis. Based on a survey of related literature and interviews with the company’s top managers and head of departments, the market segment features (CRs) are determined as segment growth rate (CR
1), expected profit (CR
2), competitive intensity (CR
3), capital required (CR
4), and level of technology utilization (CR
5), and the company business strengths (DRs) are selected as relative cost position (DR
1), delivery reliability (DR
2), technological position (DR
3), and management strength and depth (DR
4). Each member of the QFD team analyzes the match between the market segment features and the company’s business strengths (WHATs–HOWs), and judges the relationships between them by means of grammar-free expressions over a seven-point linguistic term set
S:
Table 1 shows the linguistic relationship assessments of the four DRs with respect to each CR provided by the five QFD team members.
In what follows, the proposed QFD approach is used to help the company obtain the ranking of HOWs for selecting market segments. First, the hesitant linguistic expressions of the QFD team members are converted into HFLTSs by applying the transformation function
EGH. Then, the linguistic intervals are yielded by calculating the envelope of each obtained HFLTS and the interval 2-tuple relationship matrix
of every QFD team member is subsequently constructed. For instance, the interval 2-tuple relationship matrix of TM
1 is presented in
Table 2. By implementing the ITOWA operator, the collective assessments regarding the relationship judgements between CRs and DRs are taken as the collective interval 2-tuple relationship matrix
, as shown in
Table 3. Note that the ITOWA operator weights are derived using the argument-dependent approach [
44].
In the second stage, it is assumed that the company’s managers can only provide their partial information for the CR weights using the basic ranking forms introduced in
Section 3.2, and the set of known weight information
H is shown as follows:
Because the weight information is incompletely known, we employ Model (M−2) to construct the following linear programming model to determine the weights of CRs.
By solving the above linear programming model, the weight vector of the five CRs is derived as .
In the third stage, there are 24 (=4!) permutations of the rankings for all the DRs that must be tested, which are expressed as follows:
P1 = (DR1, DR2, DR3, DR4), P2 = (DR1, DR2, DR4, DR3), P3 = (DR1, DR3, DR2, DR4),
P4 = (DR1, DR3, DR4, DR2), P5 = (DR1, DR4, DR2, DR3), P6 = (DR1, DR4, DR3, DR2),
P7 = (DR2, DR1, DR3, DR4), P8 = (DR2, DR1, DR4, DR3), P9 = (DR2, DR3, DR1, DR4),
P10 = (DR2, DR3, DR4, DR1), P11 = (DR2, DR4, DR1, DR3), P12 = (DR2, DR4, DR3, DR1),
P13 = (DR3, DR1, DR2, DR4), P14 = (DR3, DR1, DR4, DR2), P15 = (DR3, DR2, DR1, DR4),
P16 = (DR3, DR2, DR4, DR1), P17 = (DR3, DR4, DR1, DR2), P18 = (DR3, DR4, DR2, DR1),
P19 = (DR4, DR1, DR2, DR3), P20 = (DR4, DR1, DR3, DR2), P21 = (DR4, DR2, DR1, DR3),
P22 = (DR4, DR2, DR3, DR1), P23 = (DR4, DR3, DR1, DR2), P24 = (DR4, DR3, DR2, DR1).
In Step 5, we calculated the concordance/discordance index
using Equation (19) for each pair of DRs
in the permutation
in relation with CR
i . Considering the first permutation
P1 for example, the results of the concordance/discordance index are shown in
Table 4. In Step 6, we utilize Equation (20) to compute the weighted concordance/discordance index
for each pair of
in the permutation
, and the results are indicated in
Table 5. In Step 7, the comprehensive concordance/discordance index
is calculated by applying Equation (21) for each permutation
. The computation results are given as follows:
Based on the comprehensive concordance/discordance indexes produced, it is easily seen that the best permutation is P3 because gives the maximum value, and the final priory order of the four DRs is . Therefore, the most important company business strength for the considered case study is “relative cost position (DR1)”, which should be given the highest priority for selecting the optimal market segment, followed by DR3, DR2, and DR4.
5.2. Comparisons and Discussions
To validate the effectiveness of the proposed QFD, a comparative analysis with the conventional QFD and the fuzzy QFD [
51] methods is conducted on the same problem of market segments evaluation. In addition, an extended linguistic QFD approach based on discrete numbers [
52] is chosen to facilitate the comparative analysis. By applying these methods, the ranking results of the four DRs are generated as shown in
Table 6.
With respect to the proposed QFD approach,
Table 6 shows that our prioritization of the DRs is in accordance with the rankings yielded by the conventional QFD, the fuzzy QFD, and the linguistic QFD methods. Thus, the potential of the proposed QFD is validated through the comparative study. However, compared with the conventional QFD method and its various improvements, the QFD approach here proposed offers some additional advantages as follows:
Different types of uncertainties in the implementation of QFD, such as imprecision, uncertainty and hesitation, can be well modeled via the hesitant 2-tuple linguistic term sets. The QFD team members can use more flexible and richer expressions to express their subjective judgments.
By using the ITOWA operator, the proposed method can relieve the influence of unfair judgments concerning the relationships between CRs and DRs on the QFD analysis results, through assigning very low weights to those “false” or “biased” opinions.
The proposed approach is able to deal with QFD problems in which the information about CR weights is incompletely known. Under the condition of incomplete weight information, a multiple objective programming model can be established to solve the optimal weights of CRs.
The proposed methodology can get a more reasonable and credible ranking of DRs by using the modified QUALIFLEX approach, which makes the QFD analysis results certain and facilitates product planning decision-making.
The proposed model is suitable to solve complicated QFD problems with comprehensive CRs and limited DRs, since the number of CRs has little effect upon the implementation efficiency of the proposed method.
6. Conclusions
In this paper, we developed a hybrid group decision-making model using hesitant 2-tuple linguistic term sets and an extended QUALIFLEX method for handling QFD problems with incomplete weight information. The HFLTSs, a new effective tool to express human’s hesitancy in decision-making, was used to represent the diversity and uncertainty of subjective assessments given by QFD team members, and the interval 2-tuple linguistic model was employed to process the acquired linguistic assessment information, which can effectively avoid information loss and distortion in the linguistic computing. As a result, the hesitant 2-tuple linguistic approach for the expression of assessment information better reflects the deep-seated uncertainty in the implementation process of QFD. As the weight information of CRs is usually incomplete because additionally complex and abstract, a linear programming model was suggested to determine the optimal weight vector for CRs. Finally, the normal QUALIFLEX method has been modified to obtain the priority order of DRs and to detect the most important ones for the following design stages. The real-world efficacy of the proposed QFD approach was illustrated by using a market segment evaluation and selection problem.
In the future, the following research directions are recommended. First, the linguistic term sets that are uniformly and symmetrically distributed were used in the proposed analytical approach to model and manage QFD team members’ linguistic expressions. However, in some situations, the unbalanced linguistic term sets [
53] or the linguistic term sets with different granularity of uncertainty [
54,
55] may be employed by experts to express their opinions. Therefore, in future work, extending the proposed QFD approach to unbalanced linguistic or multi-granular linguistic context should be explored. Second, to obtain a more accurate DR ranking, complex computations are required in applying the QFD model being proposed. Thus, another direction for future research is to develop a computer-based application system using programming languages such as R to facilitate the implementation of the proposed QFD algorithm. Third, a market segment selection example was used in this paper to illustrate the effectiveness of the proposed QFD. In future research, other complex case studies of product development can be applied to further verify the feasibility and practicality of the proposed hybrid group decision-making model.



{kind=link}