Canonical Coordinates for Retino-Cortical Magnification

Department of Mathematics and Computer Science, Eindhoven University of Technology, P.O. Box 513, Eindhoven NL-5600 MB, The Netherlands
Axioms 2014, 3(1), 70-81; https://doi.org/10.3390/axioms3010070
Submission received: 4 November 2013
/
Revised: 13 February 2014
/
Accepted: 14 February 2014
/
Published: 24 February 2014
(This article belongs to the Special Issue Discrete Differential Geometry and Its Applications to Imaging and Graphics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:A geometric model for a biologically-inspired visual front-end is proposed, based on an isotropic, scale-invariant two-form field. The model incorporates a foveal property typical of biological visual systems, with an approximately linear decrease of resolution as a function of eccentricity, and by a physical size constant that measures the radius of the geometric foveola, the central region characterized by maximal resolving power. It admits a description in singularity-free canonical coordinates generalizing the familiar log-polar coordinates and reducing to these in the asymptotic case of negligibly-sized geometric foveola or, equivalently, at peripheral locations in the visual field. It has predictive power to the extent that quantitative geometric relationships pertaining to retino-cortical magnification along the primary visual pathway, such as receptive field size distribution and spatial arrangement in retina and striate cortex, can be deduced in a principled manner. The biological plausibility of the model is demonstrated by comparison with known facts of human vision.
1. Introduction
The visual system of humans (and other mammalian species) interfaces the optical world via a sensorium (or visual front-end, the internal embodiment of the visual field) that is characterized by receptive fields, i.e., light sensitive cells, of various sizes and aperture profiles. Scale space theory provides a foundation for a rigorous taxonomy and functional interpretation of visual receptive fields as (exact) non-infinitesimal differential operators. The conjecture that the brain can be seen as a “geometry engine” has been introduced by Koenderink in his seminal papers and has been amply exploited in the image analysis literature [1,2,3,4,5,6,7,8,9,10,11]. The keyword is resolution (or its inverse, scale).
Conventional linear scale space theory, however, typically presumes (scale-wise) uniform sampling, ignoring the foveal properties and real-time dynamics typical of biological visual systems. For the temporal aspects, the reader is again referred to Koenderink for an interesting proposition [12]. The present article concerns the static foveation aspect of the visual front-end, de-emphasizing specific characteristics of visual receptive fields other than the size and spatial arrangement of their effective domains of support.
The visual system of humans shows a roughly linear decrease of visual acuity with eccentricity, is more or less rotationally invariant relative to the foveal point and exhibits a large degree of invariance to object size. Ample empirical evidence supports these claims, including quantitative studies of retino-cortical magnification [13]. Among others, this phenomenon is responsible for the fact that, in the case of humans, about half of the striate cortex is devoted to a foveal region covering only one percent of the visual field. The log-polar mapping arises naturally in simplified models of foveal systems endowed with the aforementioned properties, cf. [14]. Image processing algorithms, as well as space-variant CMOScameras [15,16] have been constructed to mimic this mapping. These dimensionality reducing sampling devices have turned out to be useful in computer vision, as they help to optimize visual tasks, such as time to impact calculations.
However, no previously proposed theory seems to provide a principled account of the spatial organization of the entire retina, including the fovea centralis (the central, avascular zone of the retina with maximal acuity), where the log-polar model breaks down, due to its physically void singularity. This shortcoming is reflected in the design of log-polar mapping algorithms and space-variant cameras, in which one typically employs some heuristics to handle the transition between periphery and central retina.
In this article, based on previous workshop papers [14,17], a model is presented that overcomes the difficulties of the log-polar paradigm. It is based on the same invariance principles, viz. global rotation invariance (with respect to the foveal point) and scale invariance, but explicitly incorporates a physical resolution limitation. The model admits so-called canonical coordinates, inducing a natural discrete grid for operational representation in software, hardware or biological “wetware”. Its biological merits will be discussed by comparison with known facts on human vision. To guide the reader not familiar with the biological terminology used in this article, a glossary of relevant biological terms has been appended.
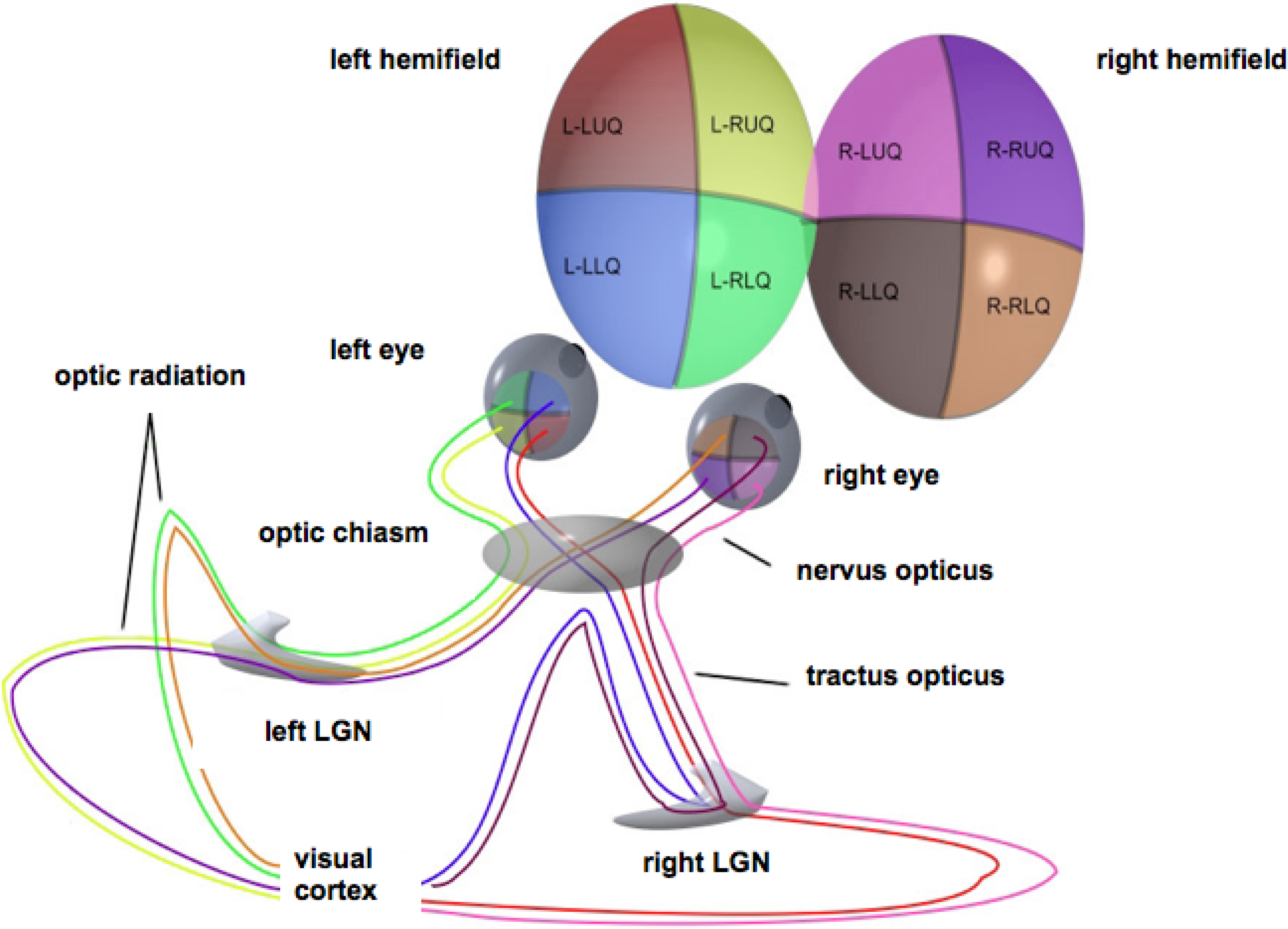
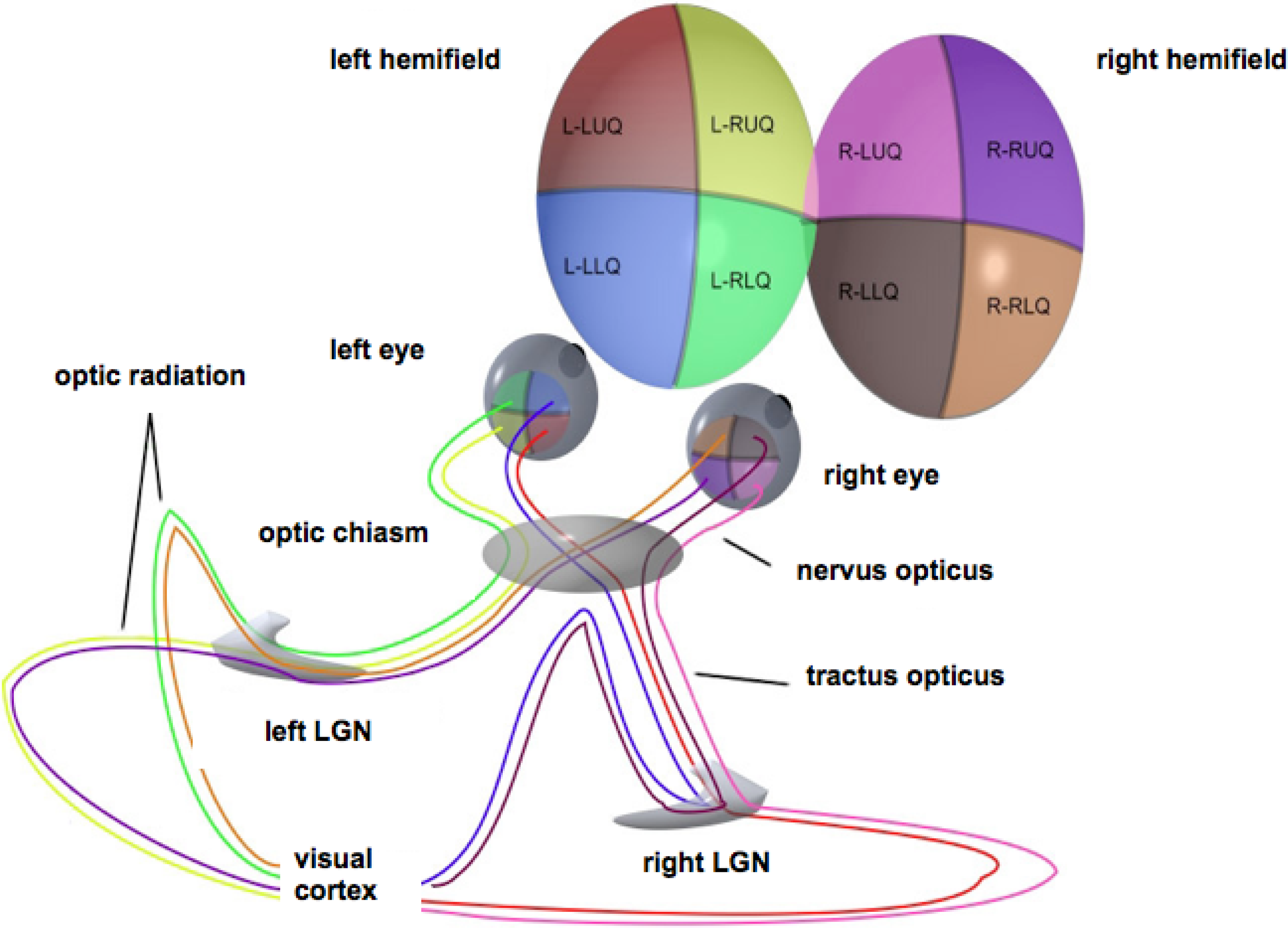
For simplicity, stereopsis will be ignored. The retina will be modeled as a flat disk, representing the domain of definition of the full visual field. This field comprises two hemifields, each of which projects onto a (contralateral) hemiretina, in turn projecting retinotopically to the primary visual (or striate) cortex through the optic radiation via the subcortical lateral geniculate nucleus. Thus, each lateral part of the visual cortex reflects the contralateral visual hemifield [13], cf. the sketch in Figure 1.
2. Theory
2.1. Modeling the Sensorium
Consider the basic scale invariant non-exact (the barred symbol, , is used to stress the anholonomic nature of the one-forms) one-forms:
in which are Cartesian coordinates. From an operational point of view, one could regard these as locally adaptive measurement rods, with the help of which, one may assign a numeric value to a vector depending on the base point to which it is attached. More precisely, if is such a vector, “living” at base point and expressed relative to globally-defined Cartesian unit vectors and , then:
Figure 1.
Schematic representation of the optic pathways from each of the four quadrants of view for both eyes. Adapted from Wikimedia Commons, original illustration by Ratznium. LGN, lateral geniculate nucleus.
Figure 1.
Schematic representation of the optic pathways from each of the four quadrants of view for both eyes. Adapted from Wikimedia Commons, original illustration by Ratznium. LGN, lateral geniculate nucleus.
These numeric values could be interpreted to represent the “visual significance” of the respective Cartesian vector components depending on the position in the visual field. Clearly, in order to be equally significant, the components of a vector at some peripheral location (large ) will need to be larger than those of a more central one (small ). The reason for this is to geometrically express the roughly linear increase of typical receptive field size (with a concomitant linear decrease of spatial resolving power) as a function of eccentricity . The (small) physical size parameter is needed to avoid a non-physical singularity at the center. Its visual significance will become apparent below.
We will confine the region of interest to a disk of radius R, which represents the radius of the geometric retina(). The parameter, a, represents a transient radius separating the geometric foveola(the geometric foveola is a construct of our model, to be distinguished from the biological foveolain the mammalian retina; terminology betrays a modest amount of foresight) () from its periphery().
The one-forms of Equation (1) induce a scale invariant area two-form, geometrically representing a spatially-weighted area of support (regardless of shape) of a Euclidean sensory element, , at position relative to the foveal center:
in which:
is the square root of the metric determinant associated with the two-dimensional spatial metric:
Again, the number in Equation (4) reflects the fact that a peripheral receptive field will need to have a larger area of support in order to be treated on par with a similar one closer to the foveal center.
As an aside, recall that the every two-dimensional Riemannian manifold is conformally flat and that the Ricci curvature tensor, , is always proportional to the metric tensor, viz.:
in which and are the components of and G, respectively. For the case at hand, Equation (5), the space-variant Ricci scalar (equal to twice the Gaussian curvature) equals:
This curvature scalar assumes appreciable values within the fovea centralis. The point of departure in previous work [14] was based on the assumption that for all . Combined with the aforementioned symmetries and applied to a conformally flat metric, this requirement admits a family of metrics, of which Equation (5) is a particular member, only if , leaving a spurious singularity at the origin. It is clearly not compatible with our regularized metric with .
2.2. Modeling Retino-Cortical Magnification
Consider the area (measured by the Riemannian metric of Equation (5)) of an infinitesimally narrow ring around the fovea:
Geometrically, the quantity:
measures the (Riemannian) perimeter of a the circle of radius ρ around the fovea. It is easy to see that there exists a maximal circle, with perimeter , demarcating the transition between the geometric foveola and periphery (whether this transient circle has a distinguished functional role in mammalian vision is not clear, but anatomical evidence does show a fairly sharp demarcation of the biological foveola [13]).
If we normalize , such that , and introduce the dimensionless quantities:
and:
with , and:
then:
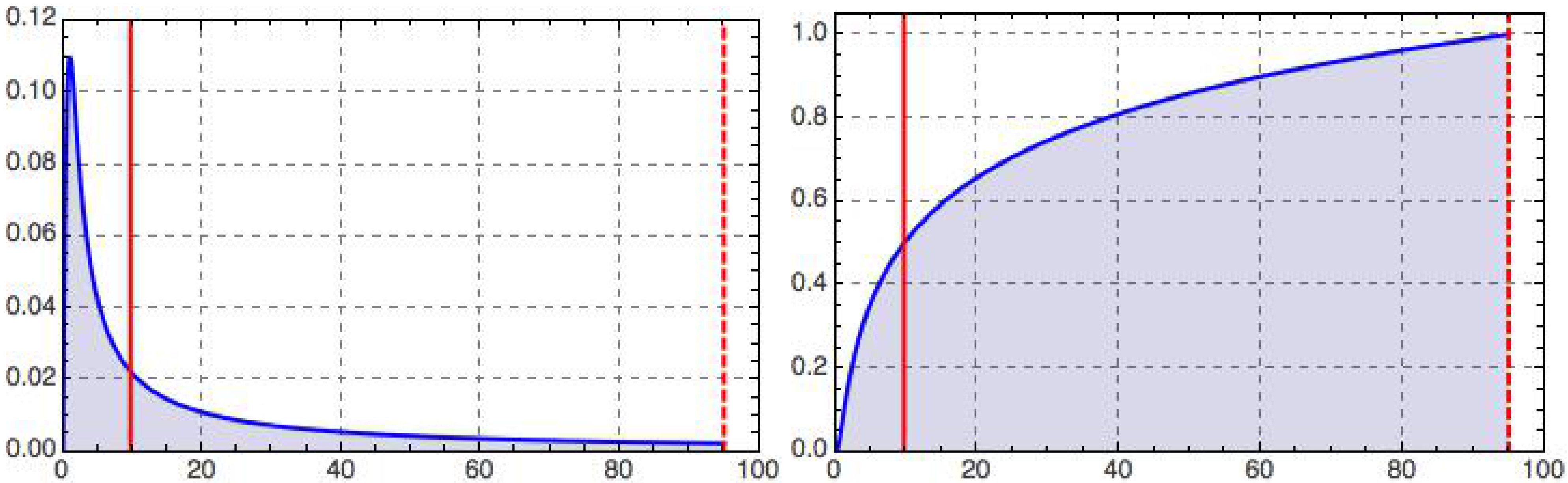
This integrated retino-cortical magnificationmeasures the relative capacity dedicated to the central region inside a foveal disk of radius relative to that of the full retina. Limiting cases are clearly and . For the foveola, we have ; cf. Figure 2 for an illustration.
To verify the biological plausibility of our model, consider the case of a peripheral ring with the same processing capacity as the enclosed foveal disk, i.e., Equation (13) with equipartitioning radius defined, such that:
A straightforward computation yields:
in which the approximation reflects the phenomenological case, . In other words, under this assumption, the theoretical equipartitioning radius approximately equals the geometric mean of the radii of the geometric foveola and geometric retina:
Generalizing Equations (14)–(16), we may define the α-partitioning radii , via:
yielding (the approximations hold for not too small α, i.e., well outside the geometric foveola):
or, in terms of physical length scales,
This prediction likewise admits experimental verification once consistent values of a and R are at hand.
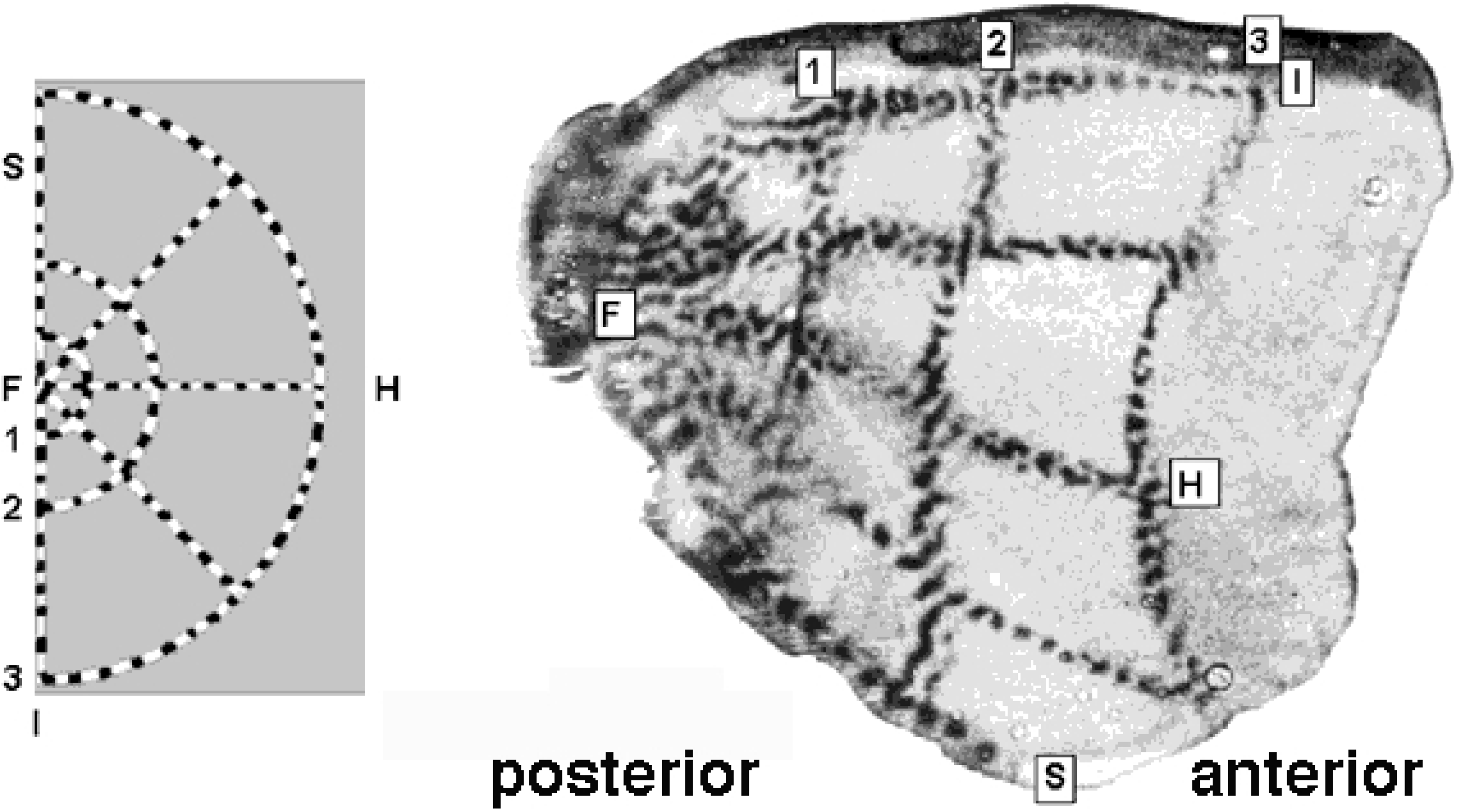
Vice versa, we may use Equations (16)–(19) to definethe constant, a, given empirical data for R and, say, . For instance, in the case of humans, it is known that about half of the striate cortex is devoted to the portion of the retina that lies within – of the fovea [13]. Assuming that the striate cortex has a homogeneous distribution of similar visual cells, the fractional size within it occupied by the retinotopically-mapped central portion of the visual field will be tantamount to its fractional processing capacity. A typical retina measures [18] ; of visual angle corresponds to approximately . The monocular visual field covers approximately ( [19]), or roughly in eccentricity when approximated by an isotropic figure for our purposes (Hartridge [20] reports a functional limit on visual field eccentricity of ). With these figures, we have (for the biological counterparts of the quantities involved) , from which one deduces with the help of Equations (12) and (15) that . The phenomenological value used in Figure 2 justifies our assumption, , and the predicted size of the geometric foveola happens to agree remarkably well with that of the human foveola (Rodieck ([13], Chapter 9) reports a value of ), which gives us a biological interpretation of the constant, a, and, at the same time, justifies the name “geometric foveola”; cf. Figure 3.
In the next section, we consider the modification of the log-polar map by taking into account the physical resolution limitation of the fovea centralis and show how the log-polar map emerges asymptotically.
Figure 2.
Retino-cortical magnification, (left), and its integral, (right), as a function of dimensionless eccentricity, t, illustrated for the case (dashed vertical line); recall Equations (12)–(15). The peak on the left occurs at and marks the border of the geometric foveola. The half maximum on the right is reached at , corresponding to the geometric equipartitioning radius (left vertical line), . With our choice of parameters (motivated in the text), the tiny geometric foveola has a relative processing capacity ; recall Equation (13).
Figure 2.
Retino-cortical magnification, (left), and its integral, (right), as a function of dimensionless eccentricity, t, illustrated for the case (dashed vertical line); recall Equations (12)–(15). The peak on the left occurs at and marks the border of the geometric foveola. The half maximum on the right is reached at , corresponding to the geometric equipartitioning radius (left vertical line), . With our choice of parameters (motivated in the text), the tiny geometric foveola has a relative processing capacity ; recall Equation (13).
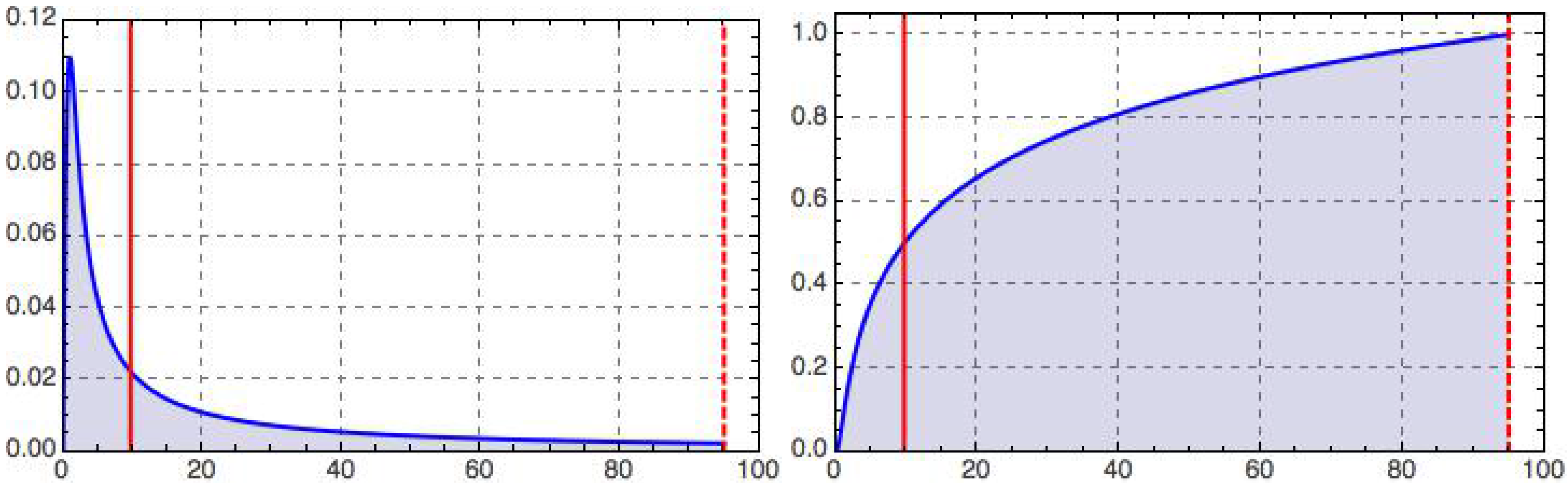
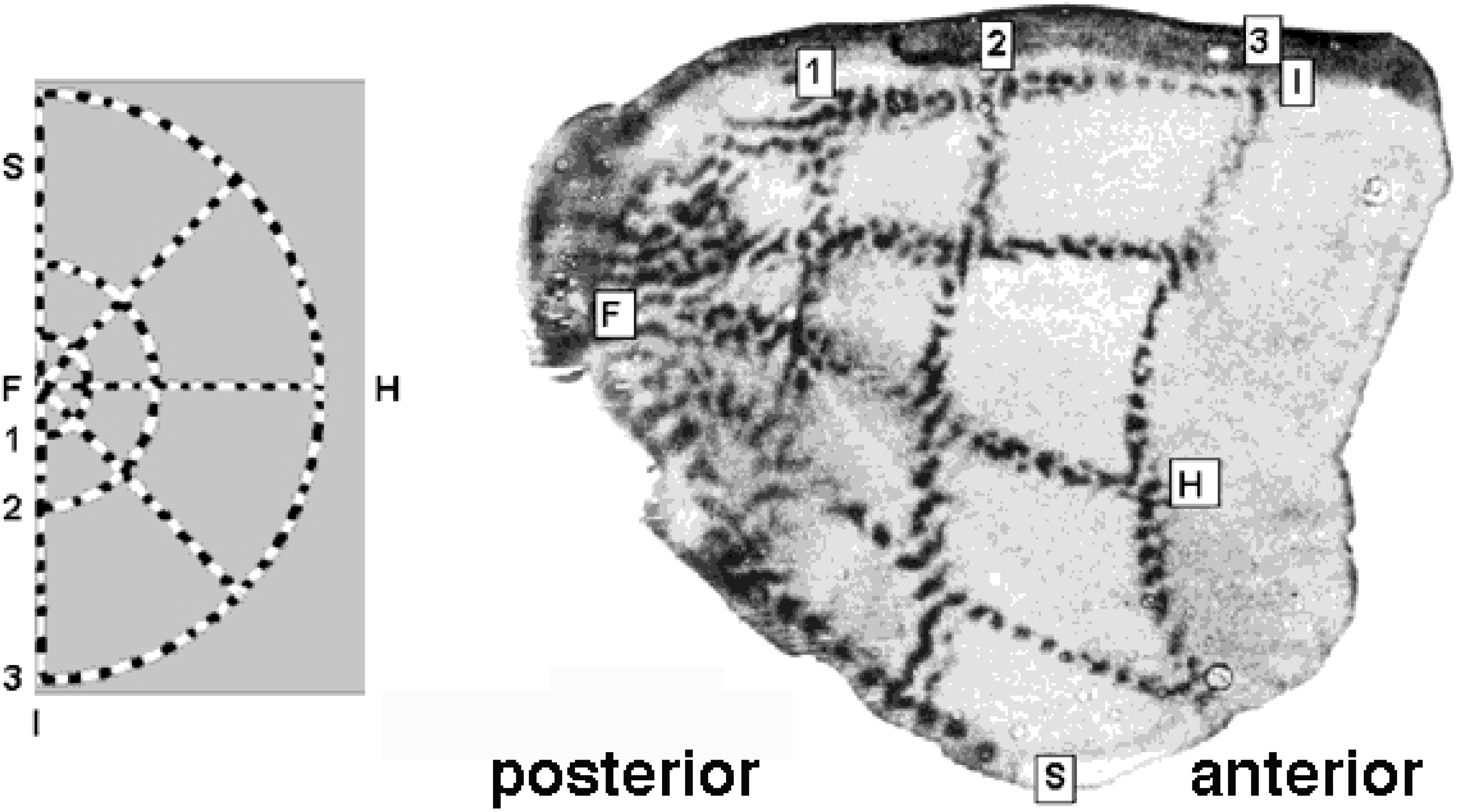
Figure 3.
Retino-cortical mapping of macaque monkey. (Left) Retina with spoke-wheel stimulus. (Right) Stimulus image retinotopically mapped onto the posterior part of (hemifield) striate cortex, a.k.a. calcarine sulcus. Source: Tootell et al. [21].
Figure 3.
Retino-cortical mapping of macaque monkey. (Left) Retina with spoke-wheel stimulus. (Right) Stimulus image retinotopically mapped onto the posterior part of (hemifield) striate cortex, a.k.a. calcarine sulcus. Source: Tootell et al. [21].
2.3. Canonical Coordinates
Retino-cortical magnification can be conveniently described in terms of canonical coordinates(recall that the primary visual cortex on one side of the brain represents a hemifield, hence the bounds on ϕ):
Using these canonical coordinates, it follows that the basic area two-form (recall Equation (3)) can be expressed as the wedge product of holonomic one-forms, warranting the attribute “canonical”:
Note that near the foveal point, we have:
In the periphery, we reobtain the familiar log-polar coordinates (up to an irrelevant offset):
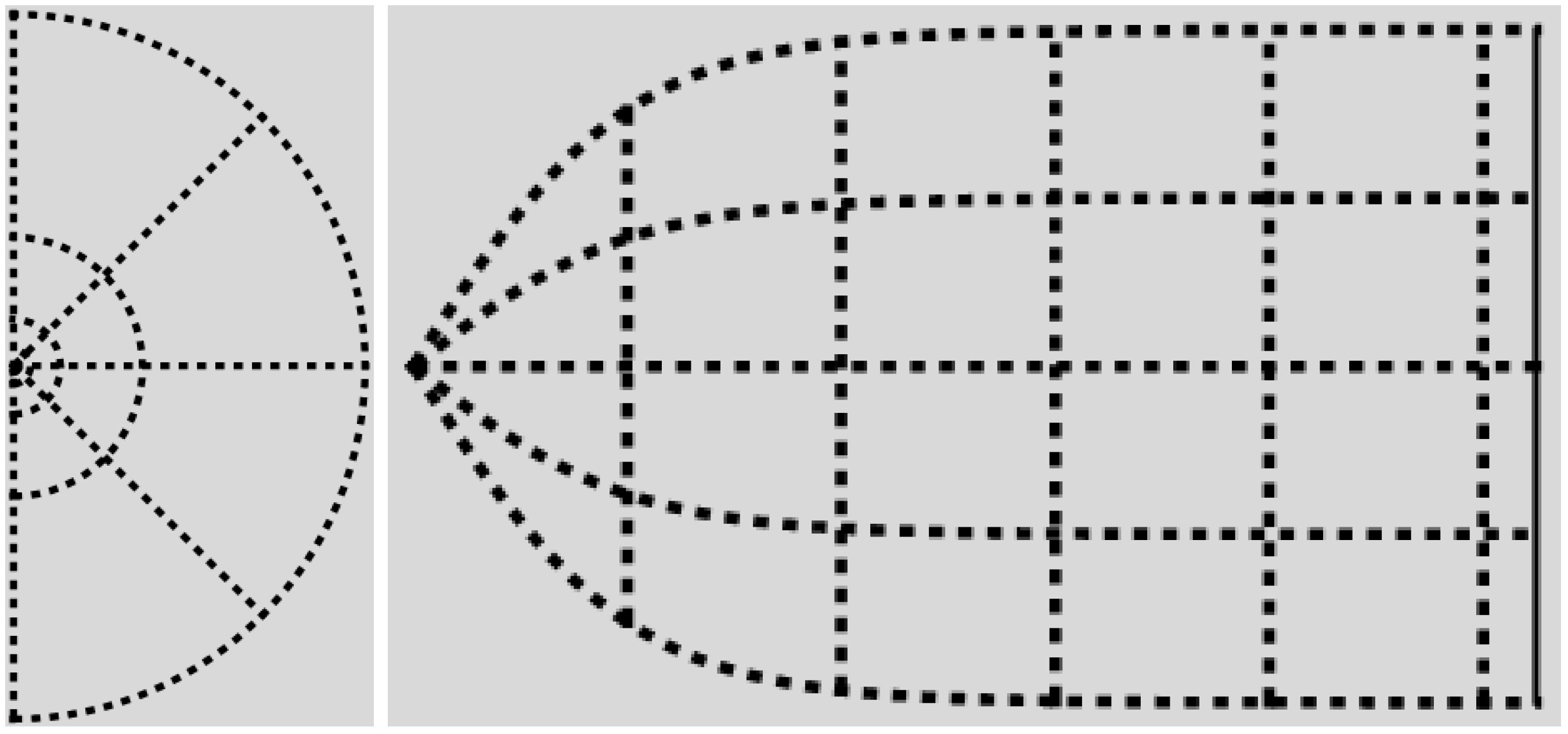
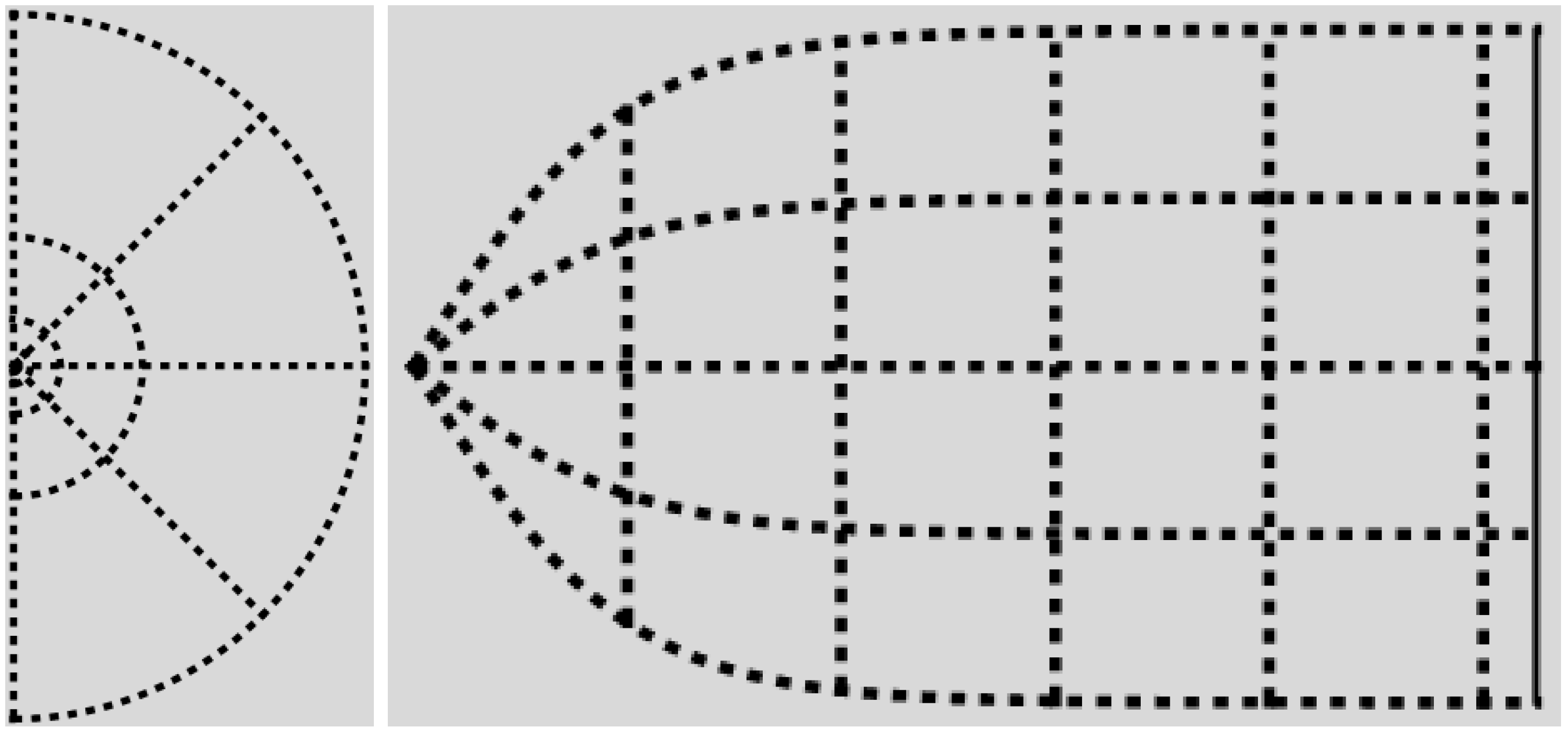
The physical part of the -domain is reminiscent of the actually observed shape of the cortical surface of V1; compare Figure 3 and Figure 4.
Figure 4.
The canonical -domain is the region between the graphs of and the lines and . On the left, are dimensionless radial and azimuthal coordinates. On the right, the canonical -coordinates are plotted as Cartesian coordinates, with p on the horizontal axis. Recall Equation (28), and compare with Figure 3.
Figure 4.
The canonical -domain is the region between the graphs of and the lines and . On the left, are dimensionless radial and azimuthal coordinates. On the right, the canonical -coordinates are plotted as Cartesian coordinates, with p on the horizontal axis. Recall Equation (28), and compare with Figure 3.
Expressed in canonical coordinates, the retino-cortical metric, Equation (5), looks rather more cumbersome:
It is evident that the -coordinate lines do not intersect perpendicularly, unlike with log-polar coordinates; cf. Figure 4. For the angle of intersection, α, at a fiducial point , we have:
For peripheral points, this is close to zero:
For central points, on the other hand, we have:
independent of eccentricity, revealing the non-orthogonal intersection of canonical coordinate lines away from the horizon (). The deviation from orthogonality remains nonetheless fairly small almost everywhere, reaching its maximum at the foveal point, with an intersection angle still close to . Typical measurements, such as Figure 3, lack resolving power to delineate foveal details in the most posterior part of the striate cortex and, thus, remain indecisive.
Let denote the full retinal domain. In -space this is the area in-between the graphs of:
and the lines and (to see this, express q as a function of p and parameter ϕ using Equation (20), and consider the boundary values ). By the same token, if denotes the fraction of the retinal domain on the left of the line , then a straightforward computation yields:
reproducing Equation (13) as expected. This confirms that the -coordinates of Equation (20) are indeed more natural than the commonly used log-polar coordinates. The latter arise in the limit of vanishing a. As such, log-polar coordinates fail to describe both foveal, as well as transient behavior, and are suited only for the peripheral field. Although the periphery represents by far the largest part of the visual field, it is much less significant in the visual brain.
As a final remark, note that, by construction, -space is most naturally discretized by a uniform sampling (with grid constants and of fixed aspect ratio). Biologically, one expects this to be reflected in a uniform spatial layout and the functional similarity of cortical receptive fields in the entire primary visual cortex.
3. Conclusion and Discussion
We have established a biologically plausible geometric model for an isotropic, scale-invariant foveal system that incorporates physical resolution limitations. The model is naturally described in terms of a canonical coordinate map that generalizes the familiar log-polar map typically used in the context of foveal systems. Unlike the latter, however, the generalized map has a globally valid domain of definition and handles the transition from the peripheral field (the classical log-polar regime) to fovea centralis in a graceful manner.
The model is consistent with certain known facts of biological vision, notably retino-cortical magnification. Other quantitative predictions may be inferred from it to assess its biological merits and, perhaps, even to predict hitherto unexplored properties about biological foveal systems. Empirical verification, however, will require methods of high resolving power in order to discriminate details within the foveola and its corresponding image in the striate cortex in order to be able to verify or refute the canonical paradigm stipulated in this article.
An important property that has not been accounted for in our model is the fact that at each spatial location in the retina or striate cortex, there exist ensembles of similar receptive fields differing only in size. The proposed model describes the inherent resolution limitation of the visual system by considering “typical” (e.g., minimal) size as a function of eccentricity. Geometric models that do take into account the local multiscale nature of the visual system have been proposed in the context of artificial and biological vision (cf. the Riemannian structure proposed by Eberly et al. [22] and, in a different application context, van Wijk and Nuij [23]; and the affine structure stipulated by Florack [24]). Koenderink has considered the surface geometry of an intensity cross-section induced by a visual stimulus [25]. Many intriguing questions remain, such as how these geometries (one of which does not necessarily exclude another!) contribute to our perception of the (geometry of the) visual world “outside”; cf. Koenderink et al. [26,27]. However, even rudimentary questions remain essentially unsolved, such as how the visual system, without the infinite regression inevitably arising from the tacit ministration of a homunculus—a little (wo)man inside the brain viewing an internal screen—is able to derive topological expertise from a massive body of essentially unordered, parallel neural signals [28].
Conflicts of Interest
The author declares no conflict of interest.
References
- Duits, R.; Florack, L.; de Graaf, J.; ter Haar Romeny, B. On the axioms of scale space theory. J. Math. Imaging Vis. 2004, 20, 267–298. [Google Scholar] [CrossRef]
- Florack, L.M.J.; Haar Romeny, B.M.; ter Koenderink, J.J.; Viergever, M.A. Linear scale-space. J. Math. Imaging Vis. 1994, 4, 325–351. [Google Scholar] [CrossRef]
- Florack, L.M.J. Image Structure: Computational Imaging and Vision Series; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1997; Volume 10. [Google Scholar]
- Iijima, T. Basic theory on normalization of a pattern (in case of typical one-dimensional pattern). Bull. Electr. Lab. 1962, 26, 368–388. (in Japanese). [Google Scholar]
- Koenderink, J.J. The structure of images. Biol. Cybern. 1984, 50, 363–370. [Google Scholar] [CrossRef] [PubMed]
- Koenderink, J.J.; van Doorn, A.J. Representation of local geometry in the visual system. Biol. Cybern. 1987, 55, 367–375. [Google Scholar] [CrossRef] [PubMed]
- Koenderink, J.J.; van Doorn, A.J. Operational significance of receptive field assemblies. Biol. Cybern. 1988, 58, 163–171. [Google Scholar] [CrossRef] [PubMed]
- Koenderink, J.J.; van Doorn, A.J. Receptive field families. Biol. Cybern. 1990, 63, 291–298. [Google Scholar] [CrossRef]
- Koenderink, J.J. The brain a geometry engine. Psychol. Res. 1990, 52, 122–127. [Google Scholar] [CrossRef] [PubMed]
- Weickert, J.A.; Ishikawa, S.; Imiya, A. Linear scale-space has first been proposed in Japan. J. Math. Imaging Vis. 1999, 10, 237–252. [Google Scholar] [CrossRef]
- Witkin, A.P. Scale-Space Filtering. In Proceedings of the International Joint Conference on Artificial Intelligence, Karlsruhe, Germany, 8–12 August 1983; pp. 1019–1022.
- Koenderink, J.J. Scale-time. Biol. Cybern. 1988, 58, 159–162. [Google Scholar] [CrossRef]
- Rodieck, R.W. The First Steps in Seeing; Sinauer Associates, Inc.: Sunderland, MA, USA, 1998. [Google Scholar]
- Florack, L.M.J. A Geometric Model for Cortical Magnification. In Biologically Motivated Computer Vision: Lecture Notes in Computer Science; Proceedings of the First IEEE International Workshop, BMCV 2000, Seoul, Korea, 15–17 May 2000; Lee, S.W., Bülthoff, H.H., Poggio, T., Eds.; Springer-Verlag: Berlin, Germany, 2000; Volume 1811, pp. 574–583. [Google Scholar]
- Tistarelli, M.; Sandini, G. On the advantages of polar and log-polar mapping for direct estimation of time-to-impact from optical flow. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 401–416. [Google Scholar] [CrossRef]
- Ho, C.G.; Young, R.C.D.; Chatwin, C.R. Sensor geometry and sampling methods for space-variant image processing. Pattern Anal. Appl. 2002, 5, 369–384. [Google Scholar] [CrossRef]
- Florack, L.M.J. Modeling Foveal Vision. In Scale Space and Variational Methods in Computer Vision: Lecture Notes in Computer Science; Proceedings of the First International Conference, SSVM 2007, Ischia, Italy, 30 May–2 June 2007; Sgallari, F., Murli, A., Paragios, N., Eds.; Springer-Verlag: Berlin, Germany, 2007; Volume 4485, pp. 919–928. [Google Scholar]
- webvision.med.utah.edu. Available online: http://webvision.med.utah.edu (accessed on 21 February 2014).
- Wandell, B.A. Foundations of Vision; Sinauer Associates, Inc.: Sunderland, MA, USA, 1995. [Google Scholar]
- Hartridge, H. The limit to peripheral vision. J. Physiol. 1919, 53, 17. [Google Scholar]
- Tootell, R.B.H.; Switkes, E.; Silverman, M.S.; Hamilton, S.L. Functional anatomy of macaque striate cortex. II. Retinotopic organization. J. Neurosci. 1988, 8, 1531–1568. [Google Scholar] [PubMed]
- Eberly, D. A Differential Geometric Approach to Anisotropic Diffusion. In Geometry-Driven Diffusion in Computer Vision: Computational Imaging and Vision Series; ter Haar Romeny, B.M., Ed.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1994; Volume 1, pp. 371–392. [Google Scholar]
- Van Wijk, J.J.; Nuij, W.A.A. Smooth and Efficient Zooming and Panning. In Proceedings of the IEEE Symposium on Information Visualization (InfoVis’2003), Seattle, WA, USA, 20–21 October 2003; Munzner, T., North, S., Eds.; IEEE Computer Society Press: Washington, DC, USA, 2003; pp. 15–22, Best paper award. [Google Scholar]
- Florack, L.M.J. Deep Structure from a Geometric Point of View. In Deep Structure Singularities and Computer Vision: Lecture Notes in Computer Science; Fogh Olsen, O., Florack, L.M.J., Kuijper, A., Eds.; Springer-Verlag: Berlin/Heidelberg, Germany, 2005; Volume 3753, pp. 135–145. [Google Scholar]
- Koenderink, J.J. A Generic Framework for Image Geometry. In Proceedings of the Conference on Applied Geometrical Algebras in Computer Science and Engineering, AGACSE 2001, Newnham, UK, 9–13 July 2001; Dorst, L., Doran, C., Lasenby, J., Eds.; Birkhaüser: Boston, MA, USA, 2002; pp. 319–332. [Google Scholar]
- Koenderink, J.J.; van Doorn, A.J. Exocentric Pointing; Cambridge University Press: Cambridge, UK, 1998; pp. 295–313. [Google Scholar]
- Koenderink, J.J.; van Doorn, A.J.; Lappin, J.S. Direct measurement of the curvature of visual space. Perception 2000, 29, 69–79. [Google Scholar] [CrossRef] [PubMed]
- Koenderink, J.J. The Concept of Local Sign. In Limits in Perception; Van Doorn, A.J., van der Grind, W.A.P.F.L., Koenderink, J.J., Eds.; VNU Science Press: Utrecht, The Netherlands, 1984; pp. 495–547. [Google Scholar]
Appendix: Biological Terms
avascular zone the central region of the retina without blood vessels, roughly coinciding with the fovea.
eccentricity the radial distance from the foveal center, usually measured in degrees.
fovea (centralis) the central part of the retina, accounting for sharp vision.
foveola the central part of the fovea, accounting for the highest visual acuity.
lateral geniculate nucleus the relay center for visual information in-between the retina and V1, cf. Figure 1.
LGN lateral geniculate nucleus.
optic radiation a.k.a. the geniculostriate pathway; the collection of axons connecting LGN and V1, cf. Figure 1.
primary visual cortex part of the cerebral cortex responsible for visual processing, cf. Figure 1.
receptive field the support region and sensitivity profile of a light-sensitive cell.
retina the light-sensitive inner surface of the eye.
retinotopic mapping mapping (i.c.retina to cortex) preserving neighborhood relations, cf. Figure 3 and Figure 4.
striate cortex same as the primary visual cortex.
V1 same as the primary visual cortex.
© 2014 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
MDPI and ACS Style
Florack, L. Canonical Coordinates for Retino-Cortical Magnification. Axioms 2014, 3, 70-81. https://doi.org/10.3390/axioms3010070
AMA Style
Florack L. Canonical Coordinates for Retino-Cortical Magnification. Axioms. 2014; 3(1):70-81. https://doi.org/10.3390/axioms3010070
Chicago/Turabian StyleFlorack, Luc. 2014. "Canonical Coordinates for Retino-Cortical Magnification" Axioms 3, no. 1: 70-81. https://doi.org/10.3390/axioms3010070