
Automatic Differentiation for Inverse Problems in X-ray Imaging and Microscopy
by
 , , , and
, , , and
Francesco Guzzi
1,*,
Alessandra Gianoncelli
1,
Fulvio Billè
1,
Sergio Carrato
2 and
George Kourousias
1 1
Elettra—Sincrotrone Trieste, Strada Statale 14—km 163,500 in AREA Science Park, Basovizza, 34149 Trieste, Italy
2
Department of Engineering and Architecture (DIA), University of Trieste, 34127 Trieste, Italy
*
Author to whom correspondence should be addressed.
Life 2023, 13(3), 629; https://doi.org/10.3390/life13030629
Submission received: 27 December 2022
/
Revised: 17 February 2023
/
Accepted: 20 February 2023
/
Published: 23 February 2023
(This article belongs to the Special Issue Artificial Intelligence Applications for Imaging in Life Sciences)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Computational techniques allow breaking the limits of traditional imaging methods, such as time restrictions, resolution, and optics flaws. While simple computational methods can be enough for highly controlled microscope setups or just for previews, an increased level of complexity is instead required for advanced setups, acquisition modalities or where uncertainty is high; the need for complex computational methods clashes with rapid design and execution. In all these cases, Automatic Differentiation, one of the subtopics of Artificial Intelligence, may offer a functional solution, but only if a GPU implementation is available. In this paper, we show how a framework built to solve just one optimisation problem can be employed for many different X-ray imaging inverse problems.
1. Introduction
Inverse problems such as nanotomography [1], compressive sensing [2], super-resolution [3] and ptychography [4] are solved by exploiting the relation between data simulated through a model and what is detected during the measurements. Common iterative reconstruction algorithms make use of gradient-based optimisation to reconstruct the specimen x, which is the solution to the system of equations governing the model [5]. These approaches are powerful but can be problematic [6,7]: if a sophisticated method can simulate realistic behaviours, adding complexity results in error-prone expressions to be derived manually; this is especially true when the parameters must also be refined (e.g., in tomography [8,9]). If the object unknowns lie in a transform domain (e.g., wavelets), the complexity is also further increased. Pushed by Artificial Intelligence and machine learning research, Automatic Differentiation (AD) [10,11,12] methods represent an alternative in computational imaging, as they provide the key to prototypes in a simple manner for state-of-the-art reconstruction methods. Apart from being mathematically correct and powerful, resulting reconstruction algorithms are also fast if GPU/parallel implementations can be readily coded.
1.1. Paper Scope
The main scope of this manuscript is to showcase how AD-based methods can be used to open the black box of many computational imaging problems. Following our framework, it is possible to rapidly prototype state-of-the-art solutions for computational microscopy methods. Possible examples are: a compressive sensing reconstruction algorithm for sparse datasets, a single image super-resolution algorithm for recovering missing information from a low-resolution image, a 2D/3D tomography reconstruction algorithm that can deal with the missing wedge problem, sparse acquisition and axial misalignment, and a ptychography algorithm, which can retrieve many geometry parameters [13]. Even if the aforementioned solutions are purely “conventional”, the use of such an AI component as AD blurs out the distinction between classical and AI methods [12,14,15].
In Section 1.2, we introduce the concept of Automatic Differentiation; then, in Section 1.3, we describe the generic computational imaging problem statement. We also provide an introduction to the four imaging techniques discussed in this manuscript (that can eventually be skipped by experienced readers). In the method section, we describe the proposed AD-based computational framework, and finally, present the results that can be obtained.
1.2. Potential Uses of Automatic Differentiation
Calculating derivatives is a need for many numerical techniques that require numerical optimisation. While gradient-less methods [16] are used to explore solution spaces of a few dimensions (e.g., Bayesian methods to find hyper-parameters), gradients are essential in minimisation problems that involve a huge number of parameters, such as the training of neural networks [11,14,17] or a reconstruction of a computational imaging framework. Any use of finite difference methods would result in a very long process. On the other side, as the computational pipelines and the models become more complicated, computing gradients by hand becomes a challenging, time-consuming, difficult and error-prone task [12]. For many problems, computing derivatives analytically is simply impossible, and only an evaluation at certain points is feasible [12].
Hand-coded analytical gradients provide an exact expression (when available) but can be time-consuming to code properly (e.g., on hardware accelerators), error-prone, and not applicable to problems with implicit solutions [10,11].
Finite differentiation, on the other hand, is extremely easy to implement but is subject to fixed numerical precision and is slow, as the method requires one evaluation for each dimension [12]. This immediately makes it infeasible for many tasks involving direct image optimisation.
Symbolic differentiation addresses the weaknesses of both the manual and numerical methods but often results in complex and cryptic expressions plagued with the problem of “expression swell” [11], referring to the phenomenon of a much larger representation of the derivative as opposed to the representation of the original function [18]. In addition to this, symbolic differentiation tends to also be memory intensive, slow and cannot handle common statements (e.g., unbounded loops) [12].
Automatic Differentiation is a set of techniques aiming at evaluating the derivative of a mathematical function specified in a code. AD interprets the program by incorporating derivative values at each node of a computational graph and propagates their values following the chain rule of differential calculus [10]. In a differentiable programming language such as PyTorch [19], indeed, one can write a differentiable expression acting on a multi-dimensional numerical array, and a computational graph is built node-by-node as the temporary results are calculated. When the gradient of the leaf with respect to a particular node is requested, the computational graph is followed by reverse-concatenating the sequence of known partial derivatives, following the chain rule [10,19]. This constitutes the additional computational step that makes AD methods slower than a well-coded analytical gradient, which can be immediately calculated from a hand-typed and potentially well-simplified expression. However, this problem can be consistently alleviated if GPU-accelerated frameworks such as PyTorch are used.
1.3. Computational Imaging Problem Statement
Inverse problems are frequently solved through iterative procedures that refine the estimate of a desired latent quantity x; this refinement can be formalised as the minimisation of an error function , which measures how dissimilar the simulations are with respect to the acquired data points y. These simulations are produced by applying to the latent quantity x an operator describing the computational model of the particular technique at hand. Intuitively, a good estimate of x thus permits to simulate quantities that closely follow the measured dataset.
The complete loss expression for a generic image inverse problem is shown in Equation (1)
The Limited-memory-Broyden–Fletcher–Goldfarb–Shanno algorithm (L-BFGS) [20] or the Orthant-Wise Limited-memory Quasi-Newton method (OWL-QN) [21] are commonly used solvers, but a gradient expression is required. While for simple expressions one can manually calculate it, such as in Equation (2) (to refine x) and in Equation (3) (to refine
for cumbersome models (especially if complex-valued quantities are involved), AD methods come in handy, providing exact gradient expressions for the actual values [10]. The only requirement is to write a differentiable expression as a function of the tensors that should be optimised.
1.4. Compressive Sensing
Compressive sensing (CS) [2,22,23] refers to a particular sampling modality that explicitly violates the Nyquist rate. Any discrete signal x of dimension N can be expressed as a linear combination of N basis vectors. In many practical cases, the signal x is not sparse in the sampling domain, but it can be considered K-sparse coefficients are nonzero) if another set of basis vectors, e.g., from Discrete Cosine Transform (DCT) or Discrete Wavelet Transform (DWT), is chosen. When this condition is met, the signal is also compressible [22], and one can effectively reconstruct the whole latent image, even from the set of sparse measurements in the sampling domain [2].
During Scanning Transmission X-ray Microscopy (STXM) or X-ray Fluorescence (XRF) experiments [24], CS has been employed to dramatically reduce the time acquired for a single scan [25,26]: based on a rough STXM measurement, indeed, a spatial mask can be used to discriminate areas of sparse or fine scanning (for the subsequent XRF/STXM fine-measure). A different application is in Fourier Holography, where a CS framework is employed to solve for the values of the diffraction pattern, which are covered by a beam-stop at the detector plane [27].
The computational model for a CS reconstruction can be formalised exactly as in Equation (1), where is substituted by the matrix product as in the following expression:
denotes the 2D inverse cosine or wavelet transform operator applied on the transform coefficients vector x; in this latent space x, one can take into account energy considerations by leveraging the L1 regularisation. To reconstruct the latent image , the minimisation problems of Equation (4) have to be set. Finally, represents the sparse sampling operation, where only a fraction of the image pixels is measured.
The taxonomy [28,29] of the CS reconstruction methods (all iterative) involves typically three classes of algorithms: (1) iterative-thresholding algorithms based on Douglas–Rachford (DR) splitting [30,31]; (2) greedy algorithms such as Orthogonal Matching Pursuit (OMP) [32,33,34]; (3) gradient-based optimisations based on Equation (1).
When comparing these algorithms, gradient-based optimisation provides the best reconstruction accuracy, but at the cost of very high computational complexity. Greedy algorithms can be fast and very accurate but tend to stagnate for high-dimensional space and regular sampling, while the thresholding algorithms are fast and frequently used due to their simplicity but can provide severely blurred results [28].
Image inpainting is another common way to “fill the blanks” in the measured image [35]; This kind of method essentially solves a Partial Differential Equation describing how grey levels propagate inside missing regions [36], by continuing the lines of equal grey value (isophotes); in [35], a corrupted image is restored by solving the 2D Poisson Equation employing biharmonic functions; the Telea algorithm [36] aims at producing a very fast interpolation by taking into account a slow-varying “baseline” and the estimated value of the 2D gradient. The Naivier–Stokes (NS) method [37] works by assessing many similarities between 2D image quantities (intensity, isophote direction, smoothness, anisotropic diffusion) and fluid-related ones (stream function, fluid velocity, vorticity, fluid viscosity). Frequency Selective Reconstruction (FSR) [38] is a block-based algorithm that approximates the known samples by a weighted superposition of Fourier basis functions to estimate the lost pixels [39]; in some ways, it follows the reconstruction paradigm in CS.
1.5. Single Image Super Resolution
Single Image Super Resolution (SISR) [3] is a class of computational methods that aims at retrieving a High Resolution (HR) image from a single degraded Low Resolution (LR) one; indeed, finer details that are typically within the size of the former spatial sampling period can eventually be made visible.
One of the most used degradation models [40] is:
where y is the degraded LR frame, x is, as usual, the latent HR image, is the blur operator, is the down-sampling operator and n the noise. While the traditional super-resolution approach employs multiple frames to recover the missing information (e.g., in order to obtain a readable license plate image from a surveillance video [41]), the SISR inverse problem is extremely ill-posed as many more different HR images can be projected to the same LR one [42]. This issue clearly emerges when simple interpolation methods are used, leading to the blurring or the generation of artefacts around edges and corners [43].
The literature on SISR evolved (a recent review is in [40]) mainly in four different branches: (i) reconstruction-based methods [44] are the oldest ones and aim at recovering the latent HR image by approximating the degradation process via a composition of blurring, downsampling, and noise injection; the method in [45] solves a Maximum Likelihood optimisation problem by employing a set of well-behaving image priors for the noise and image distribution. Turbozoom [46] is a recent reconstruction-based algorithm that employs a fast Conjugate Gradient optimisation to solve the degradation problem in Equation (5). However, in the majority of works, many solutions adopt a simpler degradation model, e.g., directly downscaling an HR image using a gaussian or a bicubic kernel to generate the corresponding LR one [40].
(ii) Sparse-based algorithms [47] are another class of reconstruction methods where convergence is improved by exploiting the sparsity characteristics in the transform domain of the latent image, similar to a CS problem. One notable example is [48] where a CS framework is adapted for super-resolution by introducing a fixed blur kernel. The complete degradation model is thus composed of a blur operator and regular sparse scanning (sub-sampling) in the spatial domain. The regular sampling produces a structured mask, defining a critical condition for CS. By introducing the blur kernel, the (Restricted Isometry property) RIP condition is again met, making an OMP algorithm converge again.
(iii) Example/patch-based algorithms [40] historically provided the best results from a purely aesthetic point of view [49]; the inner working relies on generating a self-dictionary of high-resolution patches, which can be used to generate an HR frame [50]. As their use is questionable in the scientific, clinical or forensic cases, these kinds of algorithms are not considered in this manuscript.
SISR is currently receiving lots of attention from both the industry and the Image Processing research community, especially after the advent of (iv) Deep-Learning-based methods, which produce so-called “hallucinations” [40,42]: during a learning phase, a trainable model learns to estimate the most probable HR patch. Recent notable examples of these kinds of state-of-the-art methods involve the use of Convolutional Neural Networks (CNN), such as ESDR [51], ESPCN [52], FSRCNN [53], LAPSRN [54]) or Noise2Noise [42]; this is similar to the case of example-based SISR techniques where for natural images, the aesthetic factor can be privileged; in microscopy, instead, we need to assure that the reconstructed image holds high fidelity with the ground truth (the sample). The same reasoning can be applied to CNNs, if we are uncertain about their inner working [55], as the hallucinated images are strongly biased by the nature of the training dataset. As an example, the model used in [42] is provided pre-trained for different types of datasets, e.g., faces and walls, even if the task for what the model is trained is the same. The field of explainable AI [56] is growing in response to these assumptions [57], creating both less-opaque models and techniques to inspect the decisional process of AI [56,58].
1.6. Tomography
X-ray Computer tomography (CT) [59,60] is used to analyse biological samples in their native environment [61] in a non-destructive way. In its simplest form [62], we aim at reconstructing a 3D volume starting from a series of 2D projections , acquired at different rotation angles , where i denotes the ith observation [1]. This inverse problem is formally still another formulation of Equation (1), where is substituted with , such as in Equation (6)
The latent 3D object x is illuminated by a high-dose parallel field and is rotated on a vertical axis by the operator ; the rotation axis lays exactly in the middle of the object, its projection is in the middle of the detector and is perpendicular to the beam. A Riemann sum operator describes the ray-tracing within the sample, following the projection approximation [63] and the Lambert–Beer law [64]. The Crowther criterion [65] establishes the maximum angle step size that is required to fully recover the Fourier space of the sample. While the Filtered Back Projection (FBP)/gridrec [59,66] and the Algebraic Reconstruction (ART) [67] provides satisfactory reconstructions, in many micro/nano-CT experiments different technical difficulties can arise (here are just a few examples):
(i) Radiation damage sets limits on the beam intensity for each projection [68]; when the number of photons is scarce (e.g., due to dose fractionation criteria [69] or photon starvation [70]), common single-shot algorithms produce very noisy images [60]. Ex-post noise removal increases the output Signal-to-Noise-Ratio (SNR) at the expense of spatial resolution. A meaningful reconstruction can be obtained by employing a Maximum-Likelihood algorithm (e.g., with Expectation-Maximisation (MLEM) [71]), which exploits a priori information on the noise process.
(ii) Satisfying the Crowther criterion might not always be possible, e.g., due to time/dose restrictions as well as mechanical limitations; iterative algorithms [64], such as SIRT [72], PSIRT [73], or MLEM [71], make use of the same concepts of regularisation and sparsity discussed so far to restrict the solution space to likely values.
(iii) In micro/nano-CT, various sample configurations limit the range of accessible tilt angles to 100–120 (missing wedge [74]) due to crowded experimental chambers (e.g., cryo stage in cryo-nano-tomography [61,75]), nanopositioning stage limits or large absorption in the sample; while single-shot algorithms would produce severely corrupted reconstructions, iterative algorithms exploiting regularisation, and a CS approach [76] can at least provide good spatial resolution in a plane parallel to the detector [74,77].
The problems discussed so far produce very noticeable and characteristic artefacts in the reconstructions: while FBP output images are noisy, have poor contrast and are blurry [60], iterative methods might generate sub-optimal image texture, often referred to as “plastic” or “blotchy” [78]. In this context, AI can provide a huge help, as it can learn the correspondence between the latent object and the characteristic artefact/defect triggered in a well-defined reconstruction algorithm by a well-defined problem [79]. A review of methods is in [60].
In cryo-nanotomography [75,80], the aforementioned problems appear at the same time and are also exacerbated by unwanted and unknown movements in the sample stage [9,81,82]. A simple correction model employs serial cross-correlation between projections [83], also with cosine-stretching, reducing the risk of potentially propagating drifts in the correction [84]. Even if, in some cases, an algorithm might be able to create a set of landmarks from image features alone [85,86,87,88], marker-based alignment methods [84,89,90,91,92,93] provide the de-facto solution to the problem; at the cost of decreasing the sample visibility, gold-nanobeads are added to the sample solutions, providing a set of landmarks that are relatively easy to detect and track automatically (but manual tracking is often required for a variety of reasons [75,94]). Stretched cross-correlation is still used as a pre-alignment step. A different class of algorithms is formalised around the concept of tomography self-consistency, which tries to infer the alignment parameters while reconstructing the volume. These methods can exploit both gradient-less [81,94] or gradient-based optimisation [95,96] to infer the parameters of a model significantly more complex than the one in Equation (6).
1.7. Ptychography
Ptychography [4,97] aims to dramatically increase the space-bandwidth product of a microscopy experiment by exploiting a computational imaging approach [98]. In a transmission setup, an object is raster scanned with a spatially coherent, monochromatic and time-stationary illumination p; the field is a spherical wave emerging from a pinhole or a Fresnel Zone Plate (FZP) [4]. In the thin-sample approximation [99], the input field is simply modulated in magnitude and phase by the object transmission function x. A 2D detector, typically placed in the far-field [4] at a distance z, records the diffraction pattern of the transmitted field; the use of this regime is used to ease the computational part, as the computational propagation can be approximated with a 2D Fourier transform [4]. If only one diffraction pattern is collected, this approach corresponds to Keyhole-CDI [100], but when multiple diffraction patterns are acquired in an over-scan fashion, the overlap between different beam positions provides the diversity [98], which is required to over-constrain the computational problem [98], described by Equation (7)
where, differently from the previous cases, , p and are complex-valued quantities. The approach allows extending the Field Of View (FOV) of the acquired area ideally without limits, as long as a good overlap is maintained, paired with constancy in the illumination conditions. While the first proposed algorithm was a single-shot process [101], in conventional experiments, iterative algorithms based on the concepts of “projection” are extensively used: Ptychography Iterative Engine (PIE) [4], extended-PIE (ePIE) [102], Refined-PIE (rPIE) [103] and Alternating Projection (AP) [104] employ a sequential approach that is considered essential to exploring the solution space as much as possible; the Differential Map (DM) algorithm [105] instead makes an averaged update taking into account all the experiment data. A different approach based on a form of Equation (1) was also proposed [6] but initially considered too slow compared to projection-based methods. Apart from PIE, thanks to the diversity in the dataset, all the aforementioned algorithms can automatically solve for an estimate of the illumination field, similar to a blind-deconvolution process. The complications, which can be accounted for by extending the simple ptychography model of Equation (7), closely follow what has been described for tomography (here, just a few examples):
(i) In the case of a diffraction pattern with low SNR, knowledge on the noise statistics is essential; a Maximum Likelihood approach based on Gaussian or Poissonian noise has been described in [7], also with regularisation [106];
(ii) A trade-off between flux and spatial coherence of the beam is often required. When multiple propagating modes interfere, the resulting diffraction pattern appears blurred [107]. Based on the decomposition of the mutual intensity function [108], probe decomposition techniques such as [109,110,111,112] are often employed to computationally disentangle multiple modes.
(iii) Mechanical precision of the sample stage limits the spatial resolution of the reconstruction. Being a scanning technique, ptychography relies on accurate knowledge of the sample position (at the pixel level) for each acquired diffraction pattern . On many ptychography beamlines, an ex-post approach employing computational position refinement algorithms is inevitable. Many methods have been proposed, based both on a gradient-less, e.g., [113,114,115,116,117,118], or gradient-based approach, e.g., [6,13,119,120]
(iv) Ptychography relies on many other model parameters such as propagation distance, beam defocus and beam energy that allows correctly describing the experiment at hand. In [121], beam defocus is corrected through a complex genetic-algorithm optimisation; in [122], the authors demonstrate how position correction can mitigate beam energy and propagation distance errors, while in [123], a variant of the PIE algorithm is proposed (z-PIE) that automatically refines the propagation distance.
Similarly to the previous case, AI can be used to correct or to provide a good initialisation for a subsequent common iterative algorithm [124].
2. Materials and Methods
In this work, we show how an AD framework can be employed to rapidly design state-of-art solutions to computational imaging problems, starting from a set of acquired data y.
2.1. Compressive Sensing
In Section 1, we have seen how Equation (1) is adapted to model Compressive Sensing, resulting in Equation (4). A typical Python implementation of such gradient-base optimisation is shown in Listing 1, where Numpy [125] and Scipy [126] Python libraries are used for numerical computing. An optimiser object is initialised by providing the initial values of the latent array x, containing the transform values in the space of the 2D DCT. As can be seen, both a loss function and a hand-typed gradient expression are required (see line 20 of Listing 1). The loss comprises both a data fidelity term (the L2 norm of the difference ) and a regularisation term (L1 norm of the transform coefficients x), which are defined by using the functional representation of the matrix operators and ; these matrix operators are indeed substituted by functions (2D IDCT [127] and an element-wise multiplication). The use of the gradient-less algorithms specified in the method parameter in line 21 of Listing 1 would be impracticable. Note that this process is carried out on the CPU—single core—even if multiple CPUs are available. Porting this simple code on GPU is a non-trivial task.
| Listing 1. Example implementation for Compressive Sensing gradient-based optimisation. |
 |
The equivalent code in a GPU-accelerated environment such as PyTorch is reported in Listing 2, where no gradient expression at all has to be manually calculated and coded.
| Listing 2. AD implementation for the CS problem. |
 |
The loss function is defined as a closure function for the optimiser: in that function, the user describes all the steps required to produce the computational graph of the variable that has to be optimised (see params list in line 13 of Listing 2). At any iteration, the optimiser will (i) clear out the old gradient values; (ii) simulate the experiment in the forward pass; (iii) calculate the gradients by unrolling the computational graph from the loss value to the tensor x; (iv) calculate and apply a suitable update step for the variable in the list of params, following the particular algorithm at hand. The entire process is computed on the GPU with no memory transfers in the loop, as the functions (DCT transform [127] and generic float-array algebra) are defined and written to be executed through CUDA kernels and all the arrays have been moved to the GPU memory before the start of the optimisation loop (see line 8 and 12 in Listing 2). The resulting program is even faster than the previous single-threaded code, notwithstanding the hand-coded gradient in listing 1. While the optimiser itself is part of PyTorch [19], the interface used—pytorch-minimise [128]—allows writing a code, which is very familiar to experienced Numpy [125] users.
2.2. Single Image Super Resolution
The general degradation model in Equation (5) for Single Image Super Resolution can be formalised as an optimisation process similar to Equation (1), such as in Equation (8):
where x is the unknown HR image, is a 2D convolution operator that models the blur of the system with a convolution kernel h, and finally, represents a warp operator (downscale) modelling the pixel size increase. As reported in Section 1.5, this model describes the low-resolution image as the output of blur with an unknown convolution kernel (13 × 13 in our experiments) and a fixed downscale (x4). Note that without operator , Equation (8) is a blind deconvolution problem [129]. In [48], the blur and warp filter are modelled by only one filter, which is considered known (a gaussian with a width defined by the up-sample factor [46,129]); this represents a limiting factor.
In our SISR algorithm, we optmise both the HR image x and the deconvolution kernel H. To improve the quality of the result and the convergence, instead of the simple L2 norm , we used the Huber loss function [130], which is typically employed in Deep Learning problems:
where . This loss function allows to speed up the convergence when the loss value is smaller than a parameter , which, in our case, is set to 1. This process-guided switch between the L1 and the L2 norm would be very difficult to implement in a conventional optimisation procedure. As in this case we are directly optimising the values of the HR image, a good choice for the regularisation term is the Total Variation [131], defined by Equation (10):
which acts by reducing the variations along adjacent pixels for any row i and any column j. By favouring slowly varying borders, we avoid the generation of high-frequency artefacts. The amount of regularisation in the loss function is controlled by the hyperparameters and . The total loss function used to optimise the HR image x and blur kernel h values is thus:
which is implemented following the same reasoning in Listing 2.
2.3. Tomography
Even if the computational problem for CT is formally another formulation of Equation (1), for a real AD implementation the involved expressions start having a considerable complexity. For a parallel beam setup, the matrix is indeed the composition of many operators, as shown in Equation (12):
The main component is still the L2 norm of the difference between each simulation and the acquired data. As discussed in Section 1.6, a minimisation in the space of the transform coefficients x is required, especially in the case of peculiar sampling conditions (e.g., limited angle and/or sparse acquisitions) [75]; by applying the operator on each slice, the full 3D volume is obtained. acts on the 3D volume and rotates it along a vertical axis. Finally, describes the Riemann sum of the sample slice, simulating the X-ray matter interactions within the pure projection approximation [1]. The regularisation terms are weighted by the hyper-parameters and . In our implementation, similarly to the previous case, the matrix operator is substituted by a 2D IDWT [132] (Bi-orthogonal 4.4 [133]); employs an affine transform [13,17,134] to describe the rotation of degrees along an axis of parameterised coordinates . The Riemann sum is approximated with a sum along the propagation axis. All the functions are implemented in PyTorch and are GPU accelerated.
While the model described so far is sufficient for datasets that are dose-limited or with missing projections, it does not allow for geometrical parameter correction. One way to partially address the projection misalignment [81,94] described in Section 1.6 is to search for a set of detector shifts and a common detector tilt angle. To do this in AD, one can implement the model in Equation (13):
where the operator applies an affine transform, which describes for each radiography a shift in and a rotation that is global for the entire dataset. This operator is coded as . The total number of parameters for a dataset of N projections is indeed a 3D array containing the volume, floats defying the shifts and an additional float for the common detector angle.
2.4. Ptychography
By raster-scanning the sample with a constant illumination p and by recording the corresponding ith diffraction pattern, one can reconstruct the complex refraction index of the total illuminated area of the sample. To do so, a computational method is required, as the missed phase for each diffraction pattern has to be retrieved. The model for this acquisition modality is even more intricate than the one in Equation (12) and is shown in Equation (14):
where, again, the main loss component (what drives the reconstruction) is the sum of the L2 norms calculated for the difference between the simulations and the acquired data for each diffraction pattern. In this case, however, x is a complex-valued matrix describing the entire sample transmission function (entire Field Of View), is the multi-mode [109] complex valued illumination [109], is a cropping operator, which models the spatial scanning at the ith position [13]. Finally, is an operator that describes the wave propagation towards the detector up to the distance z [13]. Note that the complex differentiation is performed by AD in PyTorch employing intrinsically Wirtinger derivatives, similarly to other ptychography AD methods [119,120,123,135,136]. To do so, we wrote a small complex-algebra library [13], which can operate on a duplet datatype, where each 2D complex array is stored in its real and imaginary parts. To help the procedure correctly factorise the probe and the object, we included an L1 regularisation term, which takes into account energy conservation constraints: the object x cannot behave as a source, so the transmission function cannot present values larger than 1 in magnitude. indeed selectively penalises only the element with a magnitude greater than 1. The key element for such regularisation is the fancy indexing capability in PyTorch, inherited from Numpy.
The operator can be any single-pass wave-propagation routine; for the far-field case, the 2D Fourier Transform alone (implemented in PyTorch as a GPU function) reasonably approximates the field, as the ad hoc phase factors are automatically included in the probe p itself [4,103] during the reconstruction, thanks to the diversity in the dataset. In the case of near-field [137], the angular spectrum is a good compromise as it is relatively easy to implement, and it is also the most accurate solution [138]. To increase the execution speed, we cached the prefactors as much as possible [138], leaving only the Fourier Transform and the final element-wise multiplication to be calculated at run-time [13].
The model described so far can optimise the object x and the probe p, also in a multi-mode fashion [109]; to include the refinement of the prorogation distance z, we have to calculate more prefactors in at each iteration, making the algorithm inevitably slower.
In a typical ptychography code, the crop is simply obtained by slicing the array at a predefined set of coordinates and with fixed dimensions; this operation defines the so-called “computational box”. Slicing, however, is not differentiable as it involves integer quantities. Position refinement indeed requires a different type of crop operator, which can be emulated by an affine transform (which is differentiable). Such an operator exploits the same component described previously in the text and computes the 2D translation and rescale needed to produce the particular computational box at hand. More details on the generation of the affine transform matrix for each diffraction pattern can be found in [13,17]. Inevitably, the price to pay for the optimisation of new parameters is the use of a formalism that slows down the entire algorithm.
The final computational model is thus written as the composition of differentiable functions in the optimisable arrays , which are the parameters appearing on the left-hand member of Equation (14).
3. Results
In this section, we present the reconstructions obtained for each of the aforementioned techniques. The CS and ptychography datasets were acquired during an experiment carried out at TwinMic, the soft-X-ray spectromicroscopy beamline [24,139] of the Elettra synchrotron facility. The sample is composed of a group of chemically fixed mesothelial cells (Mesenchymal–Epithelial Transition Met5A) grown on silicon nitride windows and exposed to asbestos fibres [13,24,140]. An energy of 1260 eV was used, paired with a secondary source [24] of 15 .
3.1. CS Reconstructions
Differently from the work reported in [25,26], here we show an application of CS for a fast STXM measurement performed by using a regular but sparse sampling mask. This kind of acquisition can be employed to further speed up the acquisition of the final XRF sampling mask, which typically depends upon an inspection of the STXM map (see Section 2.1). Such scan modality is compatible with the position control system of the microscope, as the input can be a list of sorted coordinates. The total scan area spans a range of 80 × 80 , for a total of 400 × 400 pixels, providing a pixel size of 200. Using such a large area and high-resolution setup requires employing a dwell time of 80 per scan point, totalling more than 4 h for an acquisition. By using CS, we can sample just of the area (within one-tenth of the time) and recover the sample with a limited deterioration in quality.
Figure 1 displays the results of many CS algorithms described in Section 1.4, compared to the proposed AD method: panel (a) shows the ground truth STXM acquired with a dense raster scan. From this image, we can realistically simulate the effects of sparse sampling by employing a regular sensing mask—a zoomed version is in Figure 1b—where only 10% of the pixel values are actually measured. Figure 1c shows the output of a Douglas–Rachford (DR) iterative thresholding algorithm; even after 1000 iterations, the final result is extremely blurred. While the use of a regular mask allows for a computationally simple interpolation scheme [26], it mines the applicability of a regular CS algorithm such as OMP (Section 1.4); the Restricted Isometry Property (RIP condition) indeed requires complete incoherence (randomness) between the sampling matrix and the underlying signal. When this condition is not met, the OMP algorithm stagnates, producing completely unusable results, such as the one in Figure 1d. A similar result can be observed in the output produced by the Naiver–Stokes (NS) inpainting algorithm; see Figure 1e.
Figure 1f shows the output of our proposed AD-based algorithm, which provides the least amount of artefacts, also compared to Biharmonic inpainting (panel g), Telea inpainting (panel h) and FSR inpainting (panel i). While the output of the Telea algorithm appears sharp, it presents a very blocky appearance. Nearest-neighbours-interpolation artefacts can also be spotted for panel (g), where small black features are grown with respect to the ground truth (see Figure 2). A very unnatural appearance with blurred borders can be seen in panel (i), where artefacts build up, especially in the external region.
The likelihood of having instabilities during an experiment increases with the time required for the data acquisition procedure. STXM and XRF experiments are often cursed by this (note the stripes in each panel of Figure 1). Within an AD framework, one can easily implement a new computational model, which takes into account the presence of a slowly varying function (beam intensity), which modulates the latent object in magnitude. The new computational model is presented in Equation (15):
where the array w appears as a new trainable variable, with the same shape of x. In order to enforce a slow-varying behaviour that approximates slowly varying characteristics of the beam intensity, we apply a 1D version of the Total Variation regularisation on the serialised version of w. The output of this procedure is shown in Figure 1 panel (j), where the striping artefacts have been removed automatically during the reconstruction and not as the output of a post-processing filter; the estimated background, reshaped as x is shown in Figure 1k.
Figure 2 shows a detailed view of the CS reconstruction in Figure 1; note how the small circled dot in the ground truth (panel a) is blurred and increased in size for the Biharmonic and the Telea method (respectively panel b and c); the proposed method provides a good reconstruction of the fine detail both in the uncorrected (panel d) and background corrected version (panel e).
3.2. SISR Reconstructions
Single Image Super Resolution has been used to increase the level of detail of an STXM dataset, where the pixel size of 218 —fixed by the focusing characteristics of the FZP at 1260 eV—was not small enough to resolve the finer details. The sample is a different region of the Met5A sample, where many asbestos fibres aggregated, forming a cluster. Figure 3a shows the original STXM map of pixels and the results of different SISR methods applied to that image; each recovered HR image has a resolution of pixels ( up-sample factor).
In Figure 3a, each reconstruction is normalised and shown at the same level of contrast. Neither the bilinear or the bicubic interpolation provide a good reconstruction: a bogus feature builds up, appearing as a “cross-like” artefact between the top leftmost fibres (red rectangle). A recent very fast reconstruction-based SISR method, “turbozoom” [46], is unfortunately tricked into generating the “cross-like” artefact and fails at recovering the correct rod profile. We also tried a blind deconvolution method (implemented in the “miplib” package [129]) applied on a bilinear interpolation, but no apparent increase in quality was observed.
On the contrary, the proposed method based on Equation (11) correctly separates the three rods in the top red rectangle, enhancing the individual contrast characteristics of each fibre in the cluster. This avoids the generation of the “cross-like” artefact. Furthermore, the end of the rods in the purple rectangle is better resolved. Moreover, during the STXM scan, a strong drift of the sample was observed, much bigger than the one scan step. The proposed method correctly disentangles this spurious movement from the object, estimating a Point Spread Function (PSF) that closely describes a motion blur.
SISR is currently receiving lots of attention from both the industry and the Image Processing research community, especially after the advent of Deep-Learning-based methods. Indeed, we also decided to test four different state-of-the-art Convolutional Neural Networks (CNN)—SISR techniques (ESDR [51], ESPCN [52], FSRCNN [53], and LAPSRN [54]). Being trained on natural images, these tested methods generalise poorly on X-ray microscopy images (see the blocking artefacts in FSRCNN, likely triggered by the intrinsic nature of the noise of a scanning technique). However, ESDR is somehow resolving the top-left features of the rods (red rectangle) while still blurring the bottom-right ends (purple rectangle).
The Fourier Ring Correlation [129] can be used to estimate the increase in resolution; for each tested method, the corresponding curve has been calculated and is plotted on the same graph of Figure 3b: as can be seen, the curve corresponding to the proposed AD-based reconstruction method (blue) intercepts the 1 bit threshold at the highest spatial frequency, meaning that at that spatial frequency, the signal-to-noise ratio is the highest. The FRC curves are not monotonic, but after roughly half of the Nyquist rate, many curves rise again: this behaviour can likely be explained by the build-up of high-frequency artefacts; among the tested method, the proposed algorithm (blue curve) provides the finest details, while limiting the artefacts components.
3.3. Micro/Nano—Tomography Reconstructions
We tested our tomography reconstruction algorithm based on Equation (12) on two synchrotron radiation datasets and compared it against state-of-the art solutions (SIRT and MLEM, running on the GPU), implemented in the advanced TomoPy [141] software package. The first dataset is the “tooth” sinogram included in the TomoPy [141], also showcased in [142]. The original micro-CT dataset consists of 180 projections acquired with a step of 1°. The gridrec reconstruction of this dataset is shown in Figure 4a. To emulate a limited angle and sparsely acquired tomogram, we subsampled the dataset by a factor of two and reduced the rotation range to 120°, producing a resulting dataset of 60 projections. SIRT [72] (Figure 4b) and MLEM [71] (Figure 4c) were used to compare the performance of the proposed algorithm. To produce the reconstruction in panel (b), the SIRT algorithm was iterated for 500 iterations (20 s), but the algorithm reached a reasonably good convergence already after 20 iterations. The MLEM algorithm was used for 12 iterations (2 s); this number was chosen to reduce the number of artefacts in the reconstruction, which build up rapidly from iteration 13. The proposed method formalised in Equation (10) produced the reconstruction in panel (d), which appears sharp and with the highest degree of similarity to the ground truth. Note how the use of the CS-inspired minimisation in the transform domain (DWT) allowed for a good reconstruction of the global object shape; this can be seen especially at the border in the bottom-right part of the tooth, which was clearly in the unobserved angle range.
The second dataset is a different micro-CT scan performed at the Syrmep beamline [143] of the Elettra Synchrotron facility and used in [94,144]. A mouse femur [144] was acquired with an angle ranging between 0 and 180°, with steps of 0.4°, totalling 450 projections. The ground truth has been produced by using all the available projections with the SIRT algorithm, which was run for 100 iterations (Figure 5a). Similarly to the previous case, we simulated a sparsely sampled and limited-angle dataset by taking one projection of every three (step of 1.2°), again limiting the observations to 120°.
Figure 5b shows the output of the SIRT reconstruction algorithm, where the effects of the missing wedge problem are highly visible (smearing at the borders). MLEM (Figure 5c) produces an higher quality reconstruction compared to panel (b); similarly to the previous case, the proposed algorithm in panel (d) produces a reconstruction with crisper details and higher contrast.
To test the reconstruction method described by Equation (12), we used an electron tomography dataset published in [80,85] and well-known in the nanotomography community, being one of the tutorial datasets released for the Tomoj reconstruction software [145]. The Pyrodictium abyssi cell strain TAG11 dataset is composed of 91 projections, with a tilt step of 1.5°. The pixel size of each image is nm. As previously described, limited angle and large misalignment are co-occurring in the same nanotomography experiment, producing a dataset that can not be reconstructed in a straightforward manner. Figure 6 shows different reconstructions obtained with three alignment/reconstruction methods, in both the axial and longitudinal plane. The black dots are nanobeads, which are typically added to the sample before the cryostate, in order to create a set of landmarks for the semi-automatic registration of the tilt series [75,80]. To reduce the computation time, each projection was rescaled to pixel. Panel (a) displays the output of a manual alignment procedure carried out with Tomoj [80], where the automatically tracked landmarks were refined manually. This type of correction is considered the best we can obtain from this dataset; volume slices are well separated, and the gold nano-beads appear spherical in the axial plane. The aligned set of projections was processed by SIRT for 30 iterations.
Panel (b) instead displays the output of a fully automatic reconstruction procedure carried out by employing the joint alignment-reconstruction method described in [81,94] (for details, see Section 1.6): in this case, the correction model solely takes into account a set of shifts at the detector plane. The correction is indeed way simpler than the full 3D refinement model in [80], but it is the only algorithm of this type that is readily available in a CT reconstruction framework. SIRT was used as the base algorithm for the reconstruction, and in total, the optimisation routine iterated for 100 steps. In the axial plane, the beads appear elongated, which is a sign of an incomplete alignment.
Panel (c) shows the output of the proposed method (Equation (12)), which refines not only 2D shifts at the detector plane but also a detector tilt angle, which is common for all the projections. Compared to panel (b), the amount of misalignment is greatly reduced (see the axial plane). This kind of result can suffice for a preview, as the landmark detection and tracking alone (in the semi-automatic positions, refinement in panel (a)) takes the same time as the full reconstruction with the proposed method (5 min).
3.4. Ptychography Reconstructions
A different region of the Met5A sample has been observed through ptychography. The detector was placed in the far field , and the sample was illuminated with a curved wavefront produced by a defocused zone plate, with a focus-to-sample distance of 350 . The dataset is composed of a set of 121 diffraction patterns acquired with a Princeton CCD camera, with a regular scan path [24]. We demonstrated [118] that during real experiments, we do not need to use special sampling schemes to avoid the raster grid pathology, as the mechanical position errors of the sample stage add a pseudo-random jitter on each position. Diffraction patterns are dark subtracted, centred and cropped to a set of pixel images. The resulting pixel size is of roughly 36.
As already mentioned, the technique is very sensitive to geometrical parameter estimation. Indeed, the data analysis is typically performed by manually estimating the optical distances; a set of coarse reconstructions are performed by sweeping the parameters, then each reconstruction is carefully inspected to choose the best value. The positions vector is instead automatically refined [114,115,116,118]. Here we show the output of a ptychography reconstruction algorithm, which is automatically able to estimate the correct propagation distance [13]: Figure 7a shows the phase reconstruction of the sample. From a manually tuned virtual distance of , the method estimated instead a distance of . This final estimated value takes into account not only a mere distance correction but also positions and beam energy, as the exponential factor in the propagation operator is directly proportional to all these three parameters; this final value is the one corresponding to a minimum in the parameter-loss space. Figure 7b shows the effect of different reconstruction algorithms on a particular ROI of the sample. The algorithms involved are, respectively, DM [105], M-ePIE [102], M-rPIE [118] and, finally, the proposed AD-based algorithm [13].
4. Conclusions
In this manuscript, we described the results of an ongoing research on Automatic Differentiation methods applied to inverse microscopy problems. By realising that many computational imaging techniques can be solved by a common approach based on sampling, sparsity and error minimisation, we developed a modular framework that can be adapted to solve compressive sensing, super-resolution, tomography and ptychography. This allows the prototyping of ready-to-be-used algorithms in a fast manner, blurring out the border between the development and production phases. Fast prototyping allows us to experiment with multiple concepts across many fields and techniques. We showed how the proposed AD-based algorithms are not only easy to implement and reasonably fast but also provide comparable results, and in many cases superior to many state-of-the-art solutions. Prototypes for such reconstruction algorithms can be written in a reduced amount of time by non-experts and can also be adapted to parameter optimisation, mitigating various setup flaws. Even if an optimisation routine written by a software engineer will be the fastest solution, thanks to advanced GPU-enabled AD frameworks such as PyTorch the gap in speed can be underlooked if compared with the gain in reconstruction quality. If combined, these aspects make these methods available for a drop-in replacement within many analysis pipelines.
Author Contributions
Conceptualisation, F.G., G.K. and S.C.; methodology, F.G.; software, F.G.; validation, A.G., G.K., F.B. and S.C.; formal analysis, F.G. and G.K., investigation, F.G., G.K., A.G. and F.B.; resources, F.B., S.C. and G.K.; data curation, F.G., A.G. and F.B. All authors have contributed to the writing. All authors have read and agreed to the published version of the manuscript.
Funding
This research has been carried out within the Advanced Integrated Imaging Initiative (AI3)—project P2017004 of Elettra Sincrotrone Trieste.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Tomography dataset 1 is part of the Tomopy [141] software suite. Tomography dataset 2 was kindly donated by Dr. Francesco Brun and is available from [94]. Tomography dataset 3 has been used in [80] and is part of the Tomoj software suite tutorial [145]. The ptychography dataset/code is available from [13]. CS/SISR/CT code is available from [146].
Acknowledgments
We are grateful to Roberto Borghes for his fundamental work on the TwinMic microscope control system and to Iztok Gregori for his work on the HPC solution.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| AD | Automatic Differentiation |
| CCD | Charge-Coupled Device |
| CNN | Convolutional Neural Network |
| CS | Compressive Sensing |
| CT | Computed Tomography |
| DCT | Discrete Cosine Transform |
| DWT | Discrete Wavelets Transform |
| DL | Deep Learning |
| FOV | Field Of View |
| FRC | Fourier Ring Correlation |
| FZP | Fresnel Zone Plate |
| GPU | Graphics Processing Unit |
| PSF | Point Spread Function |
| SISR | Single Image Super Resolution |
| STXM | Scanning Transmission X-ray Microscopy |
| XRF | X-ray Fluorescence |
References
- De Andrade, V.; Nikitin, V.; Wojcik, M.; Deriy, A.; Bean, S.; Shu, D.; Mooney, T.; Peterson, K.; Kc, P.; Li, K.; et al. Fast X-ray Nanotomography with Sub-10 nm Resolution as a Powerful Imaging Tool for Nanotechnology and Energy Storage Applications. Adv. Mater. 2021, 33, 2008653. [Google Scholar] [CrossRef] [PubMed]
- Candes, E.; Wakin, M. An Introduction To Compressive Sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Chen, H.; He, X.; Qing, L.; Wu, Y.; Ren, C.; Sheriff, R.E.; Zhu, C. Real-world single image super-resolution: A brief review. Inf. Fusion 2022, 79, 124–145. [Google Scholar] [CrossRef]
- Rodenburg, J.M.; Faulkner, H.M. A phase retrieval algorithm for shifting illumination. Appl. Phys. Lett. 2004, 85, 4795–4797. [Google Scholar] [CrossRef] [Green Version]
- McCloskey, S. Computational Imaging. Adv. Comput. Vis. Pattern Recognit. 2022, 10, 41–62. [Google Scholar] [CrossRef]
- Guizar-Sicairos, M.; Fienup, J.R. Phase retrieval with transverse translation diversity: A nonlinear optimization approach. Opt. Express 2008, 16, 7264. [Google Scholar] [CrossRef] [PubMed]
- Thibault, P.; Guizar-Sicairos, M. Maximum-likelihood refinement for coherent diffractive imaging. New J. Phys. 2012, 14, 63004. [Google Scholar] [CrossRef]
- Donato, S.; Arana Peña, L.M.; Bonazza, D.; Formoso, V.; Longo, R.; Tromba, G.; Brombal, L. Optimization of pixel size and propagation distance in X-ray phase-contrast virtual histology. J. Instrum. 2022, 17, C05021. [Google Scholar] [CrossRef]
- Brombal, L.; Arana Peña, L.M.; Arfelli, F.; Longo, R.; Brun, F.; Contillo, A.; Di Lillo, F.; Tromba, G.; Di Trapani, V.; Donato, S.; et al. Motion artifacts assessment and correction using optical tracking in synchrotron radiation breast CT. Med. Phys. 2021, 48, 5343–5355. [Google Scholar] [CrossRef]
- Bartholomew-Biggs, M.; Brown, S.; Christianson, B.; Dixon, L. Automatic differentiation of algorithms. J. Comput. Appl. Math. 2000, 124, 171–190. [Google Scholar] [CrossRef] [Green Version]
- Güneş Baydin, A.; Pearlmutter, B.A.; Andreyevich Radul, A.; Mark Siskind, J. Automatic differentiation in machine learning: A survey. J. Mach. Learn. Res. 2018, 18, 1–43. [Google Scholar]
- Margossian, C.C. A review of automatic differentiation and its efficient implementation. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1305. [Google Scholar] [CrossRef] [Green Version]
- Guzzi, F.; Kourousias, G.; Gianoncelli, A.; Billè, F.; Carrato, S. A parameter refinement method for ptychography based on deep learning concepts. Condens. Matter 2021, 6, 36. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Li, T.M.; Gharbi, M.; Adams, A.; Durand, F.; Ragan-Kelley, J. Differentiable programming for image processing and deep learning in halide. ACM Trans. Graph. 2018, 37, 139:1’139:13. [Google Scholar] [CrossRef] [Green Version]
- Rios, L.M.; Sahinidis, N.V. Derivative-free optimization: A review of algorithms and comparison of software implementations. J. Glob. Optim. 2013, 56, 1247–1293. [Google Scholar] [CrossRef] [Green Version]
- Guzzi, F.; De Bortoli, L.; Molina, R.S.; Marsi, S.; Carrato, S.; Ramponi, G. Distillation of an end-to-end oracle for face verification and recognition sensors. Sensors 2020, 20, 1369. [Google Scholar] [CrossRef] [Green Version]
- Laue, S. On the Equivalence of Forward Mode Automatic Differentiation and Symbolic Differentiation. 2019. Available online: http://xxx.lanl.gov/abs/1904.02990 (accessed on 16 February 2023).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Liu, D.C.; Nocedal, J. On the limited memory BFGS method for large scale optimization. Math. Program. 1989, 45, 503–528. [Google Scholar] [CrossRef] [Green Version]
- Andrew, G.; Gao, J. Scalable training of L1-regularized log-linear models. In Proceedings of the ACM International Conference Proceeding Series; Association for Computing Machinery: New York, NY, USA, 2007; Volume 227, ICML ’07; pp. 33–40. [Google Scholar] [CrossRef]
- Baraniuk, R.G. Compressive Sensing [Lecture Notes]. IEEE Signal Process. Mag. 2007, 24, 118–121. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, C.; Zhao, D.; Gao, W. Image compressive sensing recovery using adaptively learned sparsifying basis via L0 minimization. Signal Process. 2014, 103, 114–126. [Google Scholar] [CrossRef] [Green Version]
- Gianoncelli, A.; Bonanni, V.; Gariani, G.; Guzzi, F.; Pascolo, L.; Borghes, R.; Billè, F.; Kourousias, G. Soft x-ray microscopy techniques for medical and biological imaging at twinmic–elettra. Appl. Sci. 2021, 11, 7216. [Google Scholar] [CrossRef]
- Kourousias, G.; Billè, F.; Borghes, R.; Alborini, A.; Sala, S.; Alberti, R.; Gianoncelli, A. Compressive Sensing for Dynamic XRF Scanning. Sci. Rep. 2020, 10, 9990. [Google Scholar] [CrossRef] [PubMed]
- Kourousias, G.; Billè, F.; Borghes, R.; Pascolo, L.; Gianoncelli, A. Megapixel scanning transmission soft X-ray microscopy imaging coupled with compressive sensing X-ray fluorescence for fast investigation of large biological tissues. Analyst 2021, 146, 5836–5842. [Google Scholar] [CrossRef]
- Vetal, A.P.; Singh, D.; Singh, R.K.; Mishra, D. Reconstruction of apertured Fourier Transform Hologram using compressed sensing. Opt. Lasers Eng. 2018, 111, 227–235. [Google Scholar] [CrossRef]
- Orović, I.; Papić, V.; Ioana, C.; Li, X.; Stanković, S. Compressive Sensing in Signal Processing: Algorithms and Transform Domain Formulations. Math. Probl. Eng. 2016, 2016, 7616393. [Google Scholar] [CrossRef] [Green Version]
- Pilastri, A.L.; Tavares, J.M.R. Reconstruction algorithms in compressive sensing: An overview. In Proceedings of the 11th Edition of the Doctoral Symposium in Informatics Engineering (DSIE-16), Porto, Portugal, 3 February 2016; pp. 127–137. [Google Scholar]
- Peyré, G. The numerical tours of signal processing part 2: Multiscale processings. Comput. Sci. Eng. 2011, 13, 68–71. [Google Scholar] [CrossRef]
- Li, S.; Qi, H. A Douglas-Rachford Splitting Approach to Compressed Sensing Image Recovery Using Low-Rank Regularization. IEEE Trans. Image Process. 2015, 24, 4240–4249. [Google Scholar] [CrossRef]
- Mallat, S.G.; Zhang, Z. Matching Pursuits With Time-Frequency Dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef] [Green Version]
- Cai, T.T.; Wang, L. Orthogonal matching pursuit for sparse signal recovery with noise. IEEE Trans. Inf. Theory 2011, 57, 4680–4688. [Google Scholar] [CrossRef]
- Zhu, H.; Chen, W.; Wu, Y. Efficient implementations for orthogonal matching pursuit. Electronics 2020, 9, 1507. [Google Scholar] [CrossRef]
- Damelin, S.B.; Hoang, N.S. On Surface Completion and Image Inpainting by Biharmonic Functions: Numerical Aspects. Int. J. Math. Math. Sci. 2018, 2018, 3950312. [Google Scholar] [CrossRef] [Green Version]
- Telea, A. An Image Inpainting Technique Based on the Fast Marching Method. J. Graph. Tools 2004, 9, 23–34. [Google Scholar] [CrossRef]
- Bertalmío, M.; Bertozzi, A.L.; Sapiro, G. Navier-Stokes, fluid dynamics, and image and video inpainting. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar] [CrossRef] [Green Version]
- Genser, N.; Seiler, J.; Schilling, F.; Kaup, A. Signal and Loss Geometry Aware Frequency Selective Extrapolation for Error Concealment. In Proceedings of the 2018 Picture Coding Symposium, PCS 2018—Proceedings, San Francisco, CA, USA, 24–27 June 2018; pp. 159–163. [Google Scholar] [CrossRef]
- Seiler, J.; Kaup, A. Complex-valued frequency selective extrapolation for fast image and video signal extrapolation. IEEE Signal Process. Lett. 2010, 17, 949–952. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Hoi, S. Deep Learning for Image Super-Resolution: A Survey. Inf. Fusion 2021, 43, 3365–3387. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guarnieri, G.; Fontani, M.; Guzzi, F.; Carrato, S.; Jerian, M. Perspective registration and multi-frame super-resolution of license plates in surveillance videos. Forensic Sci. Int. Digit. Investig. 2021, 36, 301087. [Google Scholar] [CrossRef]
- Lehtinen, J.; Munkberg, J.; Hasselgren, J.; Laine, S.; Karras, T.; Aittala, M.; Aila, T. Noise2Noise: Learning image restoration without clean data. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; PMLR: London, UK, 2018; Volume 7, pp. 4620–4631. [Google Scholar]
- Vicente, A.N.; Pedrini, H. A learning-based single-image super-resolution method for very low quality license plate images. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics, SMC 2016—Conference Proceedings, Budapest, Hungary, 9–12 October 2016; pp. 515–520. [Google Scholar] [CrossRef]
- Papyan, V.; Elad, M. Multi-Scale Patch-Based Image Restoration. IEEE Trans. Image Process. 2016, 25, 249–261. [Google Scholar] [CrossRef]
- Brifman, A.; Romano, Y.; Elad, M. Turning a denoiser into a super-resolver using plug and play priors. In Proceedings of the International Conference on Image Processing, ICIP, Phoenix, AZ, USA, 25–28 September 2016; Volume 2016, pp. 1404–1408. [Google Scholar] [CrossRef]
- Eilers, P.H.; Ruckebusch, C. Fast and simple super-resolution with single images. Sci. Rep. 2022, 12, 11241. [Google Scholar] [CrossRef]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Boissonnat, J.D., Chenin, P., Cohen, A., Gout, C., Lyche, T., Mazure, M.L., Schumaker, L.L., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 6920. [Google Scholar] [CrossRef]
- Sen, P.; Darabi, S. Compressive image super-resolution. In Proceedings of the Conference Record—Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–4 November 2009; pp. 1235–1242. [Google Scholar] [CrossRef]
- Freeman, W.T.; Jones, T.R.; Pasztor, E.C. Example-based super-resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65. [Google Scholar] [CrossRef] [Green Version]
- Glasner, D.; Bagon, S.; Irani, M. Super-resolution from a single image. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 349–356. [Google Scholar] [CrossRef] [Green Version]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; Volume 2017-July, pp. 1132–1140. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; Volume 2016-December, pp. 1874–1883. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9906. [Google Scholar] [CrossRef] [Green Version]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; Volume 2017-January, pp. 5835–5843. [Google Scholar] [CrossRef] [Green Version]
- Bruno, P.; Calimeri, F.; Marte, C.; Manna, M. Combining Deep Learning and ASP-Based Models for the Semantic Segmentation of Medical Images. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Moschoyiannis, S., Peñaloza, R., Vanthienen, J., Soylu, A., Roman, D., Eds.; Springer International Publishing: Cham, Switzerland, 2021; Volume 12851 LNCS, pp. 95–110. [Google Scholar] [CrossRef]
- Vo, T.H.; Nguyen, N.T.K.; Kha, Q.H.; Le, N.Q.K. On the road to explainable AI in drug-drug interactions prediction: A systematic review. Comput. Struct. Biotechnol. J. 2022, 20, 2112–2123. [Google Scholar] [CrossRef]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Definitions, methods, and applications in interpretable machine learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22071–22080. [Google Scholar] [CrossRef] [Green Version]
- Yang, X. An Overview of the Attention Mechanisms in Computer Vision. J. Phys. Conf. Ser. 2020, 1693, 12173. [Google Scholar] [CrossRef]
- Hounsfield, G.N. Computerized transverse axial scanning (tomography): I. Description of system. Br. J. Radiol. 1973, 46, 1016–1022. [Google Scholar] [CrossRef]
- Szczykutowicz, T.P.; Toia, G.V.; Dhanantwari, A.; Nett, B. A Review of Deep Learning CT Reconstruction: Concepts, Limitations, and Promise in Clinical Practice. Curr. Radiol. Rep. 2022, 10, 101–115. [Google Scholar] [CrossRef]
- Pereiro, E.; Nicolás, J.; Ferrer, S.; Howells, M.R. A soft X-ray beamline for transmission X-ray microscopy at ALBA. J. Synchrotron Radiat. 2009, 16, 505–512. [Google Scholar] [CrossRef]
- Withers, P.J.; Bouman, C.; Carmignato, S.; Cnudde, V.; Grimaldi, D.; Hagen, C.K.; Maire, E.; Manley, M.; Du Plessis, A.; Stock, S. X-ray computed tomography. Nat. Rev. Methods Prim. 2021, 1, 18. [Google Scholar] [CrossRef]
- Morgan, K.S.; Siu, K.K.; Paganin, D.M. The projection approximation versus an exact solution for X-ray phase contrast imaging, with a plane wave scattered by a dielectric cylinder. Opt. Commun. 2010, 283, 4601–4608. [Google Scholar] [CrossRef]
- Soleimani, M.; Pengpen, T. Introduction: A brief overview of iterative algorithms in X-ray computed tomography. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2015, 373, 20140399. [Google Scholar] [CrossRef] [PubMed]
- Jacobsen, C. Relaxation of the Crowther criterion in multislice tomography. Opt. Lett. 2018, 43, 4811. [Google Scholar] [CrossRef]
- Dowd, B.A.; Campbell, G.H.; Marr, R.B.; Nagarkar, V.V.; Tipnis, S.V.; Axe, L.; Siddons, D.P. Developments in synchrotron x-ray computed microtomography at the National Synchrotron Light Source. Dev. X-ray Tomogr. II 1999, 3772, 224–236. [Google Scholar] [CrossRef] [Green Version]
- Gordon, R.; Bender, R.; Herman, G.T. Algebraic Reconstruction Techniques (ART) for three-dimensional electron microscopy and X-ray photography. J. Theor. Biol. 1970, 29, 471–481. [Google Scholar] [CrossRef]
- Gianoncelli, A.; Vaccari, L.; Kourousias, G.; Cassese, D.; Bedolla, D.E.; Kenig, S.; Storici, P.; Lazzarino, M.; Kiskinova, M. Soft X-Ray Microscopy Radiation Damage On Fixed Cells Investigated With Synchrotron Radiation FTIR Microscopy. Sci. Rep. 2015, 5, 10250. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frachon, T.; Weber, L.; Hesse, B.; Rit, S.; Dong, P.; Olivier, C.; Peyrin, F.; Langer, M. Dose fractionation in synchrotron radiation x-ray phase micro-tomography. Phys. Med. Biol. 2015, 60, 7543–7566. [Google Scholar] [CrossRef] [Green Version]
- Mori, I.; Machida, Y.; Osanai, M.; Iinuma, K. Photon starvation artifacts of X-ray CT: Their true cause and a solution. Radiol. Phys. Technol. 2013, 6, 130–141. [Google Scholar] [CrossRef] [PubMed]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data Via the EM Algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–22. [Google Scholar] [CrossRef]
- van der Sluis, A.; van der Vorst, H.A. SIRT- and CG-type methods for the iterative solution of sparse linear least-squares problems. Linear Algebra Its Appl. 1990, 130, 257–303. [Google Scholar] [CrossRef] [Green Version]
- Gregor, J.; Benson, T. Computational analysis and improvement of SIRT. IEEE Trans. Med. Imaging 2008, 27, 918–924. [Google Scholar] [CrossRef] [PubMed]
- Kupsch, A.; Lange, A.; Hentschel, M.P.; Lück, S.; Schmidt, V.; Grothausmann, R.; Hilger, A.; Manke, I. Missing wedge computed tomography by iterative algorithm DIRECTT. J. Microsc. 2016, 261, 36–45. [Google Scholar] [CrossRef]
- Sorrentino, A.; Nicolás, J.; Valcárcel, R.; Chichón, F.J.; Rosanes, M.; Avila, J.; Tkachuk, A.; Irwin, J.; Ferrer, S.; Pereiro, E. MISTRAL: A transmission soft X-ray microscopy beamline for cryo nano-tomography of biological samples and magnetic domains imaging. J. Synchrotron Radiat. 2015, 22, 1112–1117. [Google Scholar] [CrossRef] [PubMed]
- Guay, M.D.; Czaja, W.; Aronova, M.A.; Leapman, R.D. Compressed sensing electron tomography for determining biological structure. Sci. Rep. 2016, 6, 27614. [Google Scholar] [CrossRef] [Green Version]
- Moebel, E.; Kervrann, C. A Monte Carlo framework for missing wedge restoration and noise removal in cryo-electron tomography. J. Struct. Biol. X 2020, 4, 100013. [Google Scholar] [CrossRef]
- Xu, J.; Mahesh, M.; Tsui, B.M. Is Iterative Reconstruction Ready for MDCT? J. Am. Coll. Radiol. 2009, 6, 274–276. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ding, G.; Liu, Y.; Zhang, R.; Xin, H.L. A joint deep learning model to recover information and reduce artifacts in missing-wedge sinograms for electron tomography and beyond. Sci. Rep. 2019, 9, 12803. [Google Scholar] [CrossRef] [Green Version]
- Sorzano, C.O.S.; Messaoudi, C.; Eibauer, M.; Bilbao-Castro, J.R.; Hegerl, R.; Nickell, S.; Marco, S.; Carazo, J.M. Marker-free image registration of electron tomography tilt-series. BMC Bioinform. 2009, 10, 124. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gürsoy, D.; Hong, Y.P.; He, K.; Hujsak, K.; Yoo, S.; Chen, S.; Li, Y.; Ge, M.; Miller, L.M.; Chu, Y.S.; et al. Rapid alignment of nanotomography data using joint iterative reconstruction and reprojection. Sci. Rep. 2017, 7, 11818. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bogensperger, L.; Kobler, E.; Pernitsch, D.; Kotzbeck, P.; Pieber, T.R.; Pock, T.; Kolb, D. A joint alignment and reconstruction algorithm for electron tomography to visualize in-depth cell-to-cell interactions. Histochem. Cell Biol. 2022, 157, 685–696. [Google Scholar] [CrossRef]
- Frank, J.; McEwen, B.F. Alignment by Cross-Correlation. In Electron Tomography; Frank, J., Ed.; Springer: Boston, MA, USA, 1992; pp. 205–213. [Google Scholar] [CrossRef]
- Kremer, J.R.; Mastronarde, D.N.; McIntosh, J.R. Computer visualization of three-dimensional image data using IMOD. J. Struct. Biol. 1996, 116, 71–76. [Google Scholar] [CrossRef] [Green Version]
- Sorzano, C.O.; de Isidro-Gómez, F.; Fernández-Giménez, E.; Herreros, D.; Marco, S.; Carazo, J.M.; Messaoudi, C. Improvements on marker-free images alignment for electron tomography. J. Struct. Biol. X 2020, 4, 100037. [Google Scholar] [CrossRef]
- Yu, H.; Xia, S.; Wei, C.; Mao, Y.; Larsson, D.; Xiao, X.; Pianetta, P.; Yu, Y.S.; Liu, Y. Automatic projection image registration for nanoscale X-ray tomographic reconstruction. J. Synchrotron Radiat. 2018, 25, 1819–1826. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, J.; Hu, J.; Jiang, Z.; Zhang, K.; Liu, P.; Wang, C.; Yuan, Q.; Pianetta, P.; Liu, Y. Automatic 3D image registration for nano-resolution chemical mapping using synchrotron spectro-tomography. J. Synchrotron Radiat. 2021, 28, 278–282. [Google Scholar] [CrossRef]
- Jun, K.; Yoon, S. Alignment Solution for CT Image Reconstruction using Fixed Point and Virtual Rotation Axis. Sci. Rep. 2017, 7, 41218. [Google Scholar] [CrossRef] [Green Version]
- Han, R.; Wang, L.; Liu, Z.; Sun, F.; Zhang, F. A novel fully automatic scheme for fiducial marker-based alignment in electron tomography. J. Struct. Biol. 2015, 192, 403–417. [Google Scholar] [CrossRef]
- Han, R.; Wan, X.; Wang, Z.; Hao, Y.; Zhang, J.; Chen, Y.; Gao, X.; Liu, Z.; Ren, F.; Sun, F.; et al. AuTom: A novel automatic platform for electron tomography reconstruction. J. Struct. Biol. 2017, 199, 196–208. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Woolcot, T.; Kousi, E.; Wells, E.; Aitken, K.; Taylor, H.; Schmidt, M.A. An evaluation of systematic errors on marker-based registration of computed tomography and magnetic resonance images of the liver. Phys. Imaging Radiat. Oncol. 2018, 7, 27–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, R.; Li, G.; Gao, X. Robust and ultrafast fiducial marker correspondence in electron tomography by a two-stage algorithm considering local constraints. Bioinformatics 2021, 37, 107–117. [Google Scholar] [CrossRef] [PubMed]
- Han, R.; Bao, Z.; Zeng, X.; Niu, T.; Zhang, F.; Xu, M.; Gao, X. A joint method for marker-free alignment of tilt series in electron tomography. Bioinformatics 2019, 35, i249–i259. [Google Scholar] [CrossRef] [Green Version]
- Guzzi, F.; Kourousias, G.; Gianoncelli, A.; Pascolo, L.; Sorrentino, A.; Billè, F.; Carrato, S. Improving a rapid alignment method of tomography projections by a parallel approach. Appl. Sci. 2021, 11, 7598. [Google Scholar] [CrossRef]
- Di, Z.W.; Chen, S.; Gursoy, D.; Paunesku, T.; Leyffer, S.; Wild, S.M.; Vogt, S. Optimization-based simultaneous alignment and reconstruction in multi-element tomography. Opt. Lett. 2019, 44, 4331–4334. [Google Scholar] [CrossRef]
- Odstrčil, M.; Holler, M.; Raabe, J.; Guizar-Sicairos, M. Alignment methods for nanotomography with deep subpixel accuracy. Opt. Express 2019, 27, 36637–36652. [Google Scholar] [CrossRef] [Green Version]
- Guizar-Sicairos, M.; Thibault, P. Ptychography: A solution to the phase problem. Phys. Today 2021, 74, 42–48. [Google Scholar] [CrossRef]
- Pfeiffer, F. X-ray ptychography. Nat. Photonics 2018, 12, 9–17. [Google Scholar] [CrossRef]
- Paganin, D.; Gureyev, T.E.; Mayo, S.C.; Stevenson, A.W.; Nesterets, Y.I.; Wilkins, S.W. X-ray omni microscopy. J. Microsc. 2004, 214, 315–327. [Google Scholar] [CrossRef] [PubMed]
- Abbey, B.; Nugent, K.A.; Williams, G.J.; Clark, J.N.; Peele, A.G.; Pfeifer, M.A.; De Jonge, M.; McNulty, I. Keyhole coherent diffractive imaging. Nat. Phys. 2008, 4, 394–398. [Google Scholar] [CrossRef] [Green Version]
- Rodenburg, J. The theory of super-resolution electron microscopy via Wigner-distribution deconvolution. Philos. Trans. R. Soc. Lond. Ser. A Phys. Eng. Sci. 1992, 339, 521–553. [Google Scholar] [CrossRef]
- Maiden, A.M.; Rodenburg, J.M. An improved ptychographical phase retrieval algorithm for diffractive imaging. Ultramicroscopy 2009, 109, 1256–1262. [Google Scholar] [CrossRef]
- Maiden, A.; Johnson, D.; Li, P. Further improvements to the ptychographical iterative engine. Optica 2017, 4, 736–745. [Google Scholar] [CrossRef]
- Marchesini, S.; Tu, Y.C.; Wu, H.T. Alternating projection, ptychographic imaging and phase synchronization. Appl. Comput. Harmon. Anal. 2016, 41, 815–851. [Google Scholar] [CrossRef] [Green Version]
- Thibault, P.; Dierolf, M.; Menzel, A.; Bunk, O.; David, C.; Pfeiffer, F. High-Resolution Scanning X-ray Diffraction Microscopy. Science 2008, 321, 379–382. [Google Scholar] [CrossRef]
- Pelz, P.M.; Qiu, W.X.; Bücker, R.; Kassier, G.; Miller, R.J.D. Low-dose cryo electron ptychography via non-convex Bayesian optimization. Sci. Rep. 2017, 7, 9883. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spence, J.; Weierstall, U.; Howells, M. Coherence and sampling requirements for diffractive imaging. Ultramicroscopy 2004, 101, 149–152. [Google Scholar] [CrossRef]
- Vartanyants, I.; Robinson, I. Origins of decoherence in coherent X-ray diffraction experiments. Opt. Commun. 2003, 222, 29–50. [Google Scholar] [CrossRef]
- Thibault, P.; Menzel, A. Reconstructing state mixtures from diffraction measurements. Nature 2013, 494, 68–71. [Google Scholar] [CrossRef]
- Li, P.; Batey, D.J.; Edo, T.B.; Parsons, A.D.; Rau, C.; Rodenburg, J.M. Multiple mode x-ray ptychography using a lens and a fixed diffuser optic. J. Opt. 2016, 18, 054008. [Google Scholar] [CrossRef]
- Shi, X.; Burdet, N.; Batey, D.; Robinson, I. Multi-Modal Ptychography: Recent Developments and Applications. Appl. Sci. 2018, 8, 1054. [Google Scholar] [CrossRef] [Green Version]
- Xu, W.; Ning, S.; Zhang, F. Numerical and experimental study of partial coherence for near-field and far-field ptychography. Opt. Express 2021, 29, 40652–40667. [Google Scholar] [CrossRef] [PubMed]
- Maiden, A.; Humphry, M.; Sarahan, M.; Kraus, B.; Rodenburg, J. An annealing algorithm to correct positioning errors in ptychography. Ultramicroscopy 2012, 120, 64–72. [Google Scholar] [CrossRef]
- Zhang, F.; Peterson, I.; Vila-Comamala, J.; Diaz, A.; Berenguer, F.; Bean, R.; Chen, B.; Menzel, A.; Robinson, I.K.; Rodenburg, J.M. Translation position determination in ptychographic coherent diffraction imaging. Opt. Express 2013, 21, 13592. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mandula, O.; Elzo Aizarna, M.; Eymery, J.; Burghammer, M.; Favre-Nicolin, V. PyNX.Ptycho: A computing library for X-ray coherent diffraction imaging of nanostructures. J. Appl. Crystallogr. 2016, 49, 1842–1848. [Google Scholar] [CrossRef]
- Guzzi, F.; Kourousias, G.; Billè, F.; Pugliese, R.; Reis, C.; Gianoncelli, A.; Carrato, S. Refining scan positions in Ptychography through error minimisation and potential application of Machine Learning. J. Instrum. 2018, 13, C06002. [Google Scholar] [CrossRef]
- Dwivedi, P.; Konijnenberg, A.P.; Pereira, S.F.; Meisner, J.; Urbach, H.P. Position correction in ptychography using hybrid input–output (HIO) and cross-correlation. J. Opt. 2019, 21, 035604. [Google Scholar] [CrossRef]
- Guzzi, F.; Kourousias, G.; Billè, F.; Pugliese, R.; Gianoncelli, A.; Carrato, S. A modular software framework for the design and implementation ofptychography algorithms. PeerJ Comput. Sci. 2022, 8, e1036. [Google Scholar] [CrossRef] [PubMed]
- Du, M.; Kandel, S.; Deng, J.; Huang, X.; Demortiere, A.; Nguyen, T.T.; Tucoulou, R.; De Andrade, V.; Jin, Q.; Jacobsen, C. Adorym: A multi-platform generic X-ray image reconstruction framework based on automatic differentiation. Opt. Express 2021, 29, 10000. [Google Scholar] [CrossRef]
- Du, M.; Nashed, Y.S.; Kandel, S.; Gürsoy, D.; Jacobsen, C. Three dimensions, two microscopes, one code: Automatic differentiation for x-ray nanotomography beyond the depth of focus limit. Sci. Adv. 2020, 6, eaay3700. [Google Scholar] [CrossRef] [Green Version]
- Shenfield, A.; Rodenburg, J.M. Evolutionary determination of experimental parameters for ptychographical imaging. J. Appl. Phys. 2011, 109, 124510. [Google Scholar] [CrossRef] [Green Version]
- Loetgering, L.; Rose, M.; Keskinbora, K.; Baluktsian, M.; Dogan, G.; Sanli, U.; Bykova, I.; Weigand, M.; Schütz, G.; Wilhein, T. Correction of axial position uncertainty and systematic detector errors in ptychographic diffraction imaging. Opt. Eng. 2018, 57, 1. [Google Scholar] [CrossRef]
- Loetgering, L.; Du, M.; Eikema, K.S.E.; Witte, S. zPIE: An autofocusing algorithm for ptychography. Opt. Lett. 2020, 45, 2030. [Google Scholar] [CrossRef]
- Guzzi, F.; Kourousias, G.; Billè, F.; Pugliese, R.; Gianoncelli, A.; Carrato, S. A Deep Prior Method for Fourier Ptychography Microscopy. In Proceedings of the 2021 44th International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 27 September–1 October 2021; pp. 1781–1786. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, Z. Pytorch-DCT. 2018. Available online: https://github.com/zh217/torch-dct (accessed on 13 February 2023).
- Feinman, R. Pytorch-Minimize. 2021. Available online: https://github.com/rfeinman/pytorch-minimize (accessed on 13 February 2023).
- Koho, S.; Tortarolo, G.; Castello, M.; Deguchi, T.; Diaspro, A.; Vicidomini, G. Fourier ring correlation simplifies image restoration in fluorescence microscopy. Nat. Commun. 2019, 10, 3103. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huber, P.J. Robust Estimation of a Location Parameter. Ann. Math. Stat. 1964, 35, 73–101. [Google Scholar] [CrossRef]
- Chambolle, A.; Duval, V.; Peyré, G.; Poon, C. Geometric properties of solutions to the total variation denoising problem. Inverse Probl. 2016, 33, 015002. [Google Scholar] [CrossRef] [Green Version]
- Cotter, F. Uses of Complex Wavelets in Deep Convolutional Neural Networks; Apollo—University of Cambridge Repository: Cambridge, UK, 2020. [Google Scholar] [CrossRef]
- A Wavelet Tour of Signal Processing; Elsevier: Amsterdam, The Netherlands, 1999. [CrossRef]
- E. Riba, D.; Mishkin, D.P.E.R.; Bradski, G. Kornia: An Open Source Differentiable Computer Vision Library for PyTorch. In Proceedings of the Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; 2020. [Google Scholar]
- Nashed, Y.S.; Peterka, T.; Deng, J.; Jacobsen, C. Distributed Automatic Differentiation for Ptychography. Procedia Comput. Sci. 2017, 108, 404–414. [Google Scholar] [CrossRef]
- Kandel, S.; Maddali, S.; Allain, M.; Hruszkewycz, S.O.; Jacobsen, C.; Nashed, Y.S.G. Using automatic differentiation as a general framework for ptychographic reconstruction. Opt. Express 2019, 27, 18653. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stockmar, M.; Cloetens, P.; Zanette, I.; Enders, B.; Dierolf, M.; Pfeiffer, F.; Thibault, P. Near-field ptychography: Phase retrieval for inline holography using a structured illumination. Sci. Rep. 2013, 3, 1927. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paganin, D.M. Coherent X-ray Optics; Oxford Series on Synchrotron Radiation; Oxford University Press: London, UK, 2013. [Google Scholar]
- Gianoncelli, A.; Kourousias, G.; Merolle, L.; Altissimo, M.; Bianco, A. Current status of the TwinMic beamline at Elettra: A soft X-ray transmission and emission microscopy station. J. Synchrotron Radiat. 2016, 23, 1526–1537. [Google Scholar] [CrossRef] [PubMed]
- Cammisuli, F.; Giordani, S.; Gianoncelli, A.; Rizzardi, C.; Radillo, L.; Zweyer, M.; Da Ros, T.; Salomé, M.; Melato, M.; Pascolo, L. Iron-related toxicity of single-walled carbon nanotubes and crocidolite fibres in human mesothelial cells investigated by Synchrotron XRF microscopy. Sci. Rep. 2018, 8, 706. [Google Scholar] [CrossRef] [Green Version]
- Gürsoy, D.; De Carlo, F.; Xiao, X.; Jacobsen, C. TomoPy: A framework for the analysis of synchrotron tomographic data. J. Synchrotron Radiat. 2014, 21, 1188–1193. [Google Scholar] [CrossRef] [Green Version]
- Pouchard, L.; Juhas, P.; Park, G.; Dam, H.V.; Campbell, S.I.; Stavitski, E.; Billinge, S.; Wright, C.J. Provenance Infrastructure for Multi-modal X-ray Experiments and Reproducible Analysis. In Handbook on Big Data and Machine Learning in the Physical Sciences; World Scientific Publishing Co Pte Ltd.: Singapore, 2020; Chapter 15; pp. 307–331. [Google Scholar] [CrossRef]
- Dullin, C.; di Lillo, F.; Svetlove, A.; Albers, J.; Wagner, W.; Markus, A.; Sodini, N.; Dreossi, D.; Alves, F.; Tromba, G. Multiscale biomedical imaging at the SYRMEP beamline of Elettra—Closing the gap between preclinical research and patient applications. Phys. Open 2021, 6, 100050. [Google Scholar] [CrossRef]
- Tavella, S.; Ruggiu, A.; Giuliani, A.; Brun, F.; Canciani, B.; Manescu, A.; Marozzi, K.; Cilli, M.; Costa, D.; Liu, Y.; et al. Bone Turnover in Wild Type and Pleiotrophin-Transgenic Mice Housed for Three Months in the International Space Station (ISS). PLoS ONE 2012, 7, e33179. [Google Scholar] [CrossRef]
- MessaoudiI, C.; Boudier, T.; Sorzano, C.O.S.; Marco, S. TomoJ: Tomography software for three-dimensional reconstruction in transmission electron microscopy. BMC Bioinform. 2007, 8, 288. [Google Scholar] [CrossRef] [Green Version]
- Guzzi, F.; Bille‘, F.; Carrato, S.; Gianoncelli, A. Kourousias, G Automatic Differentiation Methods for Computational Microscopy Experiments—Code. 2023. Available online: https://vuo.elettra.eu/pls/vuo/open_access_data_portal.show_view_investigation?FRM_ID=10664 (accessed on 16 February 2023).
Figure 1.
CS reconstruction with many algorithms. The red bar is 20 m long. Panel (a): original full STXM image (ground truth) of the Met5A cells; panel (b): regular sensing mask; all the subsequent panels show the output of each CS algorithm applied on the same sparsely sampled image; panel (c):DR algorithm; panel (d): OMP algorithm; panel (e): NS algorithm; panel (f): proposed AD-based method; panel (g): Biharmonic inpainting; panel (h): Telea inpainting algorithm; panel (i): FSR inpainting algorithm; panel (j): proposed background-corrected output; panel (k): background estimation during the reconstruction of (j).
Figure 1.
CS reconstruction with many algorithms. The red bar is 20 m long. Panel (a): original full STXM image (ground truth) of the Met5A cells; panel (b): regular sensing mask; all the subsequent panels show the output of each CS algorithm applied on the same sparsely sampled image; panel (c):DR algorithm; panel (d): OMP algorithm; panel (e): NS algorithm; panel (f): proposed AD-based method; panel (g): Biharmonic inpainting; panel (h): Telea inpainting algorithm; panel (i): FSR inpainting algorithm; panel (j): proposed background-corrected output; panel (k): background estimation during the reconstruction of (j).

Figure 2.
Detailed view of a zoomed area in Figure 1; ground truth (a), Biharmonic inpainting (b), Telea method (c); the proposed method provides a good reconstruction of the fine detail both in the uncorrected (panel d) and background corrected version (panel e).
Figure 2.
Detailed view of a zoomed area in Figure 1; ground truth (a), Biharmonic inpainting (b), Telea method (c); the proposed method provides a good reconstruction of the fine detail both in the uncorrected (panel d) and background corrected version (panel e).

Figure 3.
SISR reconstruction applied to a pixel STXM scan. Panel (a): Compared to many algorithms, the proposed method allows us to reconstruct the structure of each individual rod. The movement of the sample is described by a correctly estimated PSF; Panel (b) the Fourier Ring Correlation curves for each method in panel (a). The curve for the proposed method intercepts the 1 bit threshold (correlation factor of roughly 0.4) at the highest spatial frequency while maintaining a low amount of artefacts.
Figure 3.
SISR reconstruction applied to a pixel STXM scan. Panel (a): Compared to many algorithms, the proposed method allows us to reconstruct the structure of each individual rod. The movement of the sample is described by a correctly estimated PSF; Panel (b) the Fourier Ring Correlation curves for each method in panel (a). The curve for the proposed method intercepts the 1 bit threshold (correlation factor of roughly 0.4) at the highest spatial frequency while maintaining a low amount of artefacts.
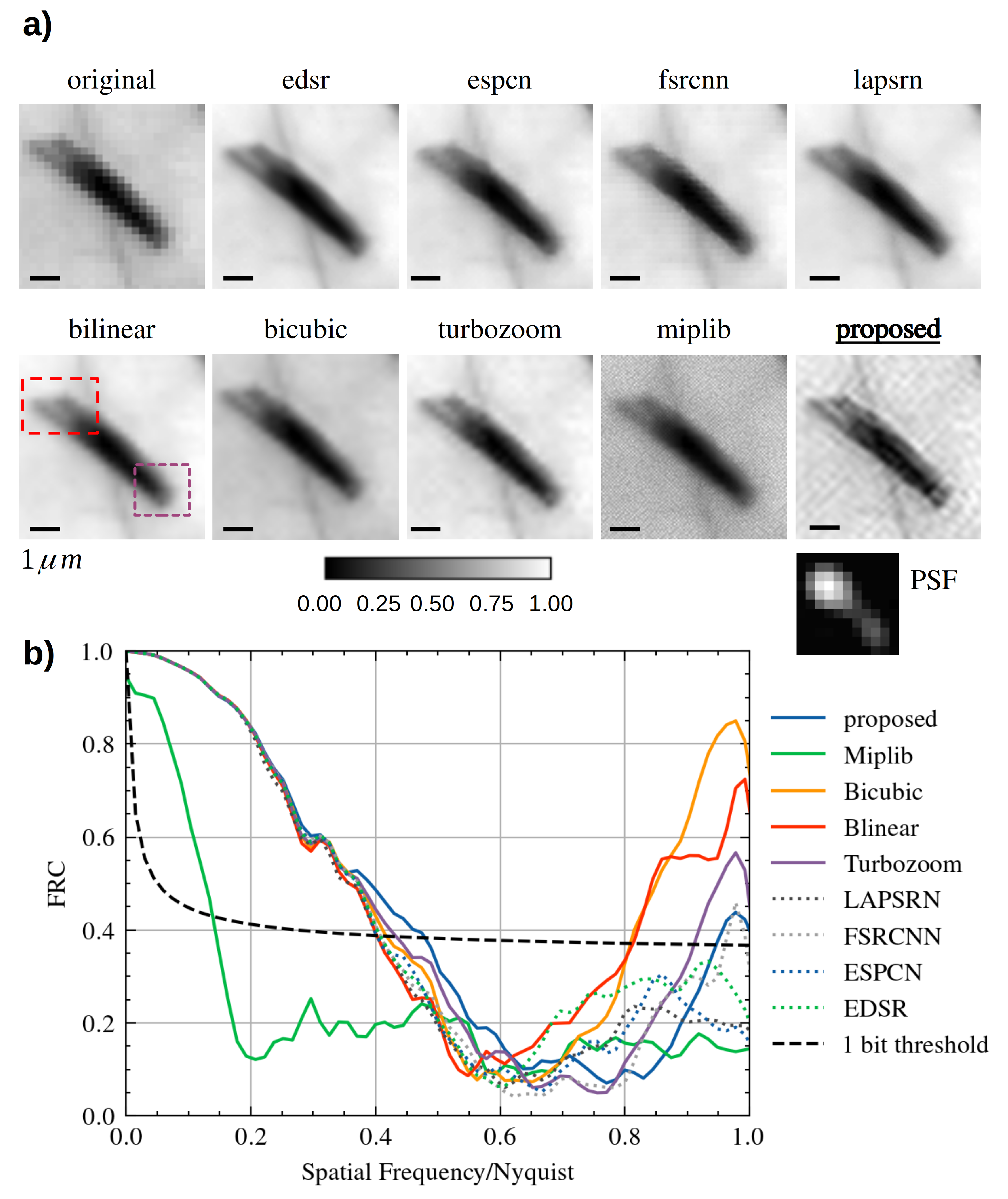
Figure 4.
Micro-CT dataset reconstruction of a tooth, from the Tomopy software package [141]: panel (a): gridrec ground truth employing all the 180 projections (1° step). A simulated dataset is obtained by reducing the angle range to 120° and by increasing the angle step to 2° and is reconstructed with SIRT (panel b), MLEM (panel c), and the proposed AD-based method (panel d).
Figure 4.
Micro-CT dataset reconstruction of a tooth, from the Tomopy software package [141]: panel (a): gridrec ground truth employing all the 180 projections (1° step). A simulated dataset is obtained by reducing the angle range to 120° and by increasing the angle step to 2° and is reconstructed with SIRT (panel b), MLEM (panel c), and the proposed AD-based method (panel d).

Figure 5.
Micro-CT dataset reconstructions of a mouse femur [144]; panel (a) was obtained employing SIRT for 100 iterations, using all the available projections; a limited angle (120°) and sparse version (1.2° step) of the dataset was synthetically produced; the same dataset was reconstructed with SIRT (100 iterations—Panel b), MLEM (50 iterations, panel c) and the proposed AD-based method (panel d). The white bar is 1 mm long.
Figure 5.
Micro-CT dataset reconstructions of a mouse femur [144]; panel (a) was obtained employing SIRT for 100 iterations, using all the available projections; a limited angle (120°) and sparse version (1.2° step) of the dataset was synthetically produced; the same dataset was reconstructed with SIRT (100 iterations—Panel b), MLEM (50 iterations, panel c) and the proposed AD-based method (panel d). The white bar is 1 mm long.

Figure 6.
Cryo-nano-tomography reconstruction of the Pyrodictium dataset [80,145]; panel (a) reconstruction of the manually refined dataset using TomoJ; panel (b) automatic alignment with a simple correction model (detector shifts only [81]); panel (c) automatic alignment with the proposed simple correction model (detector shifts and angle) implemented in the AD framework. The black bar is 200 nm long.
Figure 6.
Cryo-nano-tomography reconstruction of the Pyrodictium dataset [80,145]; panel (a) reconstruction of the manually refined dataset using TomoJ; panel (b) automatic alignment with a simple correction model (detector shifts only [81]); panel (c) automatic alignment with the proposed simple correction model (detector shifts and angle) implemented in the AD framework. The black bar is 200 nm long.

Figure 7.
Ptychography reconstruction through AD [13]; panel (a): phase reconstruction of a Met5A sample; panel (b): comparison of different methods (see text) for the same propagation distance. Only the proposed method (last) correctly refines the parameters.
Figure 7.
Ptychography reconstruction through AD [13]; panel (a): phase reconstruction of a Met5A sample; panel (b): comparison of different methods (see text) for the same propagation distance. Only the proposed method (last) correctly refines the parameters.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Guzzi, F.; Gianoncelli, A.; Billè, F.; Carrato, S.; Kourousias, G. Automatic Differentiation for Inverse Problems in X-ray Imaging and Microscopy. Life 2023, 13, 629. https://doi.org/10.3390/life13030629
AMA Style
Guzzi F, Gianoncelli A, Billè F, Carrato S, Kourousias G. Automatic Differentiation for Inverse Problems in X-ray Imaging and Microscopy. Life. 2023; 13(3):629. https://doi.org/10.3390/life13030629
Chicago/Turabian StyleGuzzi, Francesco, Alessandra Gianoncelli, Fulvio Billè, Sergio Carrato, and George Kourousias. 2023. "Automatic Differentiation for Inverse Problems in X-ray Imaging and Microscopy" Life 13, no. 3: 629. https://doi.org/10.3390/life13030629
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.