In order to develop a robust and accurate model for predicting tire wear, various approaches have been explored and applied to the reference database, which will be described in detail in the following section. This work primarily focuses on statistical methods based on machine learning as they offer valuable tools for building predictive models. Machine learning techniques allow the designing of mathematical models capable of learning and identifying patterns within a given database. They find applications in a wide range of fields, including:
Machine learning algorithms can be broadly categorized based on their learning process:
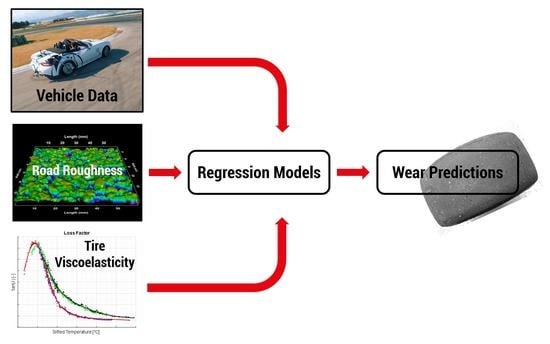
The tire wear prediction task, using the reference database available for this research, falls under the realm of supervised learning. This is because the database includes experimental measurements of tire wear, providing labeled data for all the analyzed conditions. Since tire wear represents the gradual thinning of the tread and does not have discrete values corresponding to specific classes, predicting tread wear assumes the form of a classical regression problem. During this research activity, three different statistical machine learning approaches have been adopted and they will be explained starting from the simplest to apply up to the one that requires the most detailed pre-processing phase of the starting database:
2.1. Feed Forward Neural Network
The first approach has been the use of an artificial neural network (ANN); it is a set of simple units, called neurons, which communicate with each other by sending signals through connections and which are often organized in different layers according to need. In most cases, an artificial neural network is an adaptive system that changes its structure based on information flowing through the network itself during the training or learning phase [
42]. They can be used to simulate complex relationships between inputs and outputs that other analytic functions cannot represent. Moreover, neural networks, through learning cycles (input–processing–output) more or less numerous, are able to generalize and provide correct outputs associated with inputs that are not part of the dataset with which the network is trained [
43]. To make a neural network work correctly, it is necessary to carry out an initial training phase; to do this, there are several training algorithms that meet specific needs and purposes. In the case of supervised learning, the network is provided with a set of inputs to which known outputs correspond. By analyzing them, the network learns the link that unites them. In this way it learns to generalize, that is, to calculate new correct input–output associations by processing inputs external to the main dataset used for the learning phase and without knowing the outputs. In this way, it is possible to predict certain results by knowing the main quantities on which they depend.
Each neuron has several inputs which can be either the input signals of the problem or signals deriving from previous neurons. The different inputs are added together in relation to the weightof their connections. In the training phase of the neural network, these weights are used to improve the learning of the network. The neuron is also characterized by a bias. It can be seen as a weight connected to a dummy input equal to unity that has the task of calibrating the neuron’s optimal working point. Another fundamental feature of the elementary unit is the activation function that defines the output of the neuron itself (
Figure 1). In particular, this function shapes the output of the neuron related to its internal potential, which is determined by the inputs, the weights of the connections, and the bias.
A widely used activation function, employed also in the proposed approach, is the sigmoid, since its non-linearity and its continuity allow us to build more complex and effective neural networks. The output of a generic
i-th neuron is evaluated as in Equation (
1).
in which
f is the activation function and
is the internal potential of the
i-th neuron, defined as in Equation (
2).
where
j indicates the number of inputs of the
i-th neuron; it is possible to identify the following terms:
The aggregation of multiple neurons designed as described and illustrated in
Figure 2 gives rise, as mentioned, to complex structures called neural networks, typically organized in various layers, with each layer being formed by a certain number of neurons. Usually, in a neural network, there is an input layer, an output layer, and one or more intermediate levels called hidden layers. The choice of the number of hidden layers depends on the objective and does not follow canonical rules. Regarding the number of neurons for each level, the same consideration applies as before.
In the literature, it is possible to find different configurations of neural networks [
44]. Having analyzed the nature of the problem under examination, in which the value to be predicted is not temporally correlated to the others (each series of KPIs identifies a different tire that corresponds to a different wear level), the NN with the simplest architecture, the feed-forward, has been chosen. Feed-forward Neural Networks are structures in which connections link neurons of a certain level only with neurons of a subsequent level. So, backward connections or connections between neurons of the same level are not allowed in these networks (
Figure 3). Feed-forward networks do not have memory about what occurred at previous times, so the output is determined only by the current inputs. These kinds of networks are the foundation for computer vision, natural language processing, and other work, such as making predictions concerning the future course of a quantity.
Once the network topology has been set, that is, once the type of network, the number of layers, and the number of neurons for each layer have been chosen, it is necessary to train the network. Training the network means solving the problem of optimizing the weights and biases related to the neurons referring to a certain subset of the total dataset, called the training set, with the aim of gradually reducing the prediction error. To evaluate the error and train the network correctly, an error or loss function and an algorithm must be introduced. Often, the backpropagation algorithm is used to implement the optimization routine for the weights and biases in order to reduce this error. The backpropagation algorithm is based on the gradient descent method or on methods similar to this and has the aim of reducing the error between the result of the network and the target up to a value suitable for the type of application. In simple terms, after each forward pass through a network, backpropagation performs a backward pass while adjusting the model’s parameters (weights and biases). So, the mechanism of backpropagation repeatedly adjusts the weights and biases of the connections in the network in order to minimize a measure of the difference between the actual output vector of the net and the desired output vector. More specifically, it happens that, at the beginning, the network initializes the weights and biases randomly and produces results. These results are compared with the target results and from this comparison the loss error function is evaluated. With the gradient descent method, it is possible to find the weights and biases that will yield a smaller loss in the next iteration by calculating the partial derivatives of the error function with respect to the single weights and biases of the neurons. So, the objective is to find out which node is responsible for most of the loss in every layer in order to penalize it by giving it a smaller weight value and thus lessening the total loss of the model.
In order to minimize the difference between the neural network’s output and the target output, we have to understand how the model performance changes with respect to each parameter in our model. To do that, it is necessary to calculate the partial derivatives between our loss function and each weight. For each epoch, that is, for each work cycle of the neural network, the backpropagation algorithm is used to subtract the corresponding derivatives from the weights multiplied by a “learning rate” (which avoids abrupt variations in the weights) in order to create the optimization routine. This procedure continues until the error function reaches a sufficiently low value in relation to our needs. It is important to observe that the minimization of an error function in the manner described requires, as mentioned, target values of the output, and so it is a situation of supervised learning, since for each input there is a desired output defined.
After the training phase, there is the validation phase, which exploits another subset of the total dataset, called the validation set. This phase serves to avoid the error reaching a definitive and specific minimum for the training set causing overfitting. Overfitting is the phenomenon for which the network fits the training data too well and adapts to it, invalidating the work of the net with another dataset and, therefore, obstructing the generalization process. So, the validation process is necessary to stop the training phase and iterations of this before overfitting occurs. In short, during this phase, the error relating to the validation set is evaluated and when this error starts to increase instead of decreasing, the training stops. Finally, there is a last phase, called the test phase, which uses an additional set of data, known as the test set, which aims to evaluate the performance and the quality of the network. Regarding the division of the dataset into the three subsets mentioned, typically an equal division is not used, as a larger subset is assigned to the computationally more expensive phase, which is that of training.
2.2. Principal Component Analysis—PCA
One issue encountered when dealing with a set of multivariate data is the sheer abundance of variables, making it challenging to employ simple techniques for obtaining an informative initial assessment of the data. Specifically, multivariate data analysis pertains to a statistical analysis category that involves more than two dependent variables, ultimately yielding a single output, as seen in the presented case study.
Principal Components Analysis (PCA) is a multivariate method designed to address this problem by aiming to reduce the dimensionality of a multivariate dataset while retaining as much of the original variation as possible. This objective is accomplished by transforming the original variables into a new set of variables known as principal components. These components are linear combinations of the original variables, and they are uncorrelated and ordered in a manner that prioritizes the first few components accounting for the majority of the variation observed across all the original variables. As a result, conducting a principal components analysis generates a limited number of new variables that can effectively serve as substitutes for the initial large number of variables [
34].
In other words, the main goal of principal components analysis is to describe variation in a set of correlated variables,
, in terms of a new set of uncorrelated variables,
, each of which is a linear combination of the
x variables. The new variables are derived in decreasing order of “importance” in the sense that
accounts for as much of the variation in the original data as possible amongst all linear combinations of
x. Then
is chosen to account for as much of the remaining variation as possible, subject to being uncorrelated with
, and so on. The new variables defined by this process,
, are the principal components (
Figure 4).
The general hope of principal components analysis is that the first few components will account for a substantial proportion of the variation in the original variables and can, consequently, be used to provide a convenient lower-dimensional summary of these variables that might prove useful for a variety of reasons. The first principal component of the observations is that linear combination of the original variables whose sample variance is greatest amongst all possible such linear combinations (Equation (
3)). The second principal component is defined as that linear combination of the original variables that accounts for a maximal proportion of the remaining variance subject to being uncorrelated with the first principal component. Subsequent components are defined similarly.
In order to perform a PCA, the following steps have to be carried out:
calculation of the covariance matrix of the normalized experimental data;
evaluation of the coefficients of the principal components as eigenvectors of the covariance matrix;
calculus of the Principal Components as a linear combination of the eigenvectors with normalized experimental data;
evaluation of the proportions, as in Equation (
4):
where
is the eigenvalue of the correlation matrix.
The PCA made it possible to understand which variables are able to explain the variance of the studied dataset. In the second approach proposed in this work, Principal Components will be used as starting variables to evaluate a multiple linear regression.
2.3. Multiple Linear Regression
Linear Regression is probably one of the most powerful and useful tools available to the applied statistician. This method uses one or more variables to explain the values of another. Statistics alone cannot prove a cause-and-effect relationship but it can show how changes in one set of measurements are associated with changes in the average values in another. With this approach, the data analyst specifies which of the variables are to be considered explanatory and which are the responses to these [
45].
This process requires a good understanding of the data and a preliminary study of them. A regression model does not imply a cause-and-effect relationship between the variables. Even though a strong empirical relationship may exist between two or more variables, this cannot be considered evidence that the regressor variables and the response are related in a cause-and-effect manner. To establish causality, the relationship between the regressors and the response must have a basis outside the sample data; for example, the relationship may be suggested by theoretical considerations. The regression equation is only an approximation to the true functional relationship between the variables of interest. These functional relationships are often based on physical or other engineering or scientific theory, that is, knowledge of the underlying mechanism [
32].
A regression model that involves more than one regressor variable is called a multiple regression model. The term “linear” is used because the general equation of this kind of model (Equation (
5)) is a linear function of
k regressors
and not because it is a linear function of the
xs.
This model describes a hyperplane in the
k-dimensional space of the regressor variables
[
32]. Models that include interaction effects may also be analyzed by multiple linear regression methods. For example, suppose that the model is expressed as in Equation (
6).
If
and
, then Equation (
6) can be written as Equation (
7).
which is a linear regression model.
It is more convenient to deal with multiple regression models if they are expressed in matrix notation (Equation (
8)). This allows a very compact display of the model, data, and results.
is a random variable (response variable) with a distribution that depends on a vector of known explanatory values
(predictor or regressor).
where the independent, normally distributed errors
have zero means and constant variances
. Additionally, it usually assumes that the errors are uncorrelated. This means that the value of one error does not depend on the value of any other error. The different terms presented in Equation (
8) can be described as follows:
X is an
matrix:
is an
vector:
The regression coefficients are parameters that need to be estimated from the observed data (, ). This process is also called fitting the model to the data or “training”. Thus, regression analysis is an iterative procedure in which data lead to a model and a fit of the model to the data is produced. The quality of the fit is then investigated, leading either to modification of the model or the fit or to the adoption of the model.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}