1. Introduction
Women remain starkly under-represented in STEM (Science, Technology, Engineering, and Mathematics) professional occupations in the United States. Over the past two decades, researchers and policy makers have focused on “leaky pipelines” and challenges to the recruitment and retention of girls and women in STEM education, and women have made some gains there. However, women with college and advanced degrees remain underrepresented in many STEM fields [
1,
2]. Policy makers and academics view the paucity of women in academic STEM as placing limits on scientific creativity [
3,
4] and contributing to the national shortage of STEM professionals [
5,
6,
7].
This paper focuses on tenured and tenure-track academic engineering faculty positions in research-focused universities [
8,
9,
10]. The ways that gendered barriers may persist in academic hiring are not fully understood. Experimental studies have found that women can be held to double standards and stricter standards compared to men [
11,
12], especially when the highest levels of competence are demanded [
13,
14]. In contrast, another study that distributed a set of hypothetical short lifestyle descriptions of faculty job candidates without details of technical qualifications found that women had a higher chance than men of being chosen [
15].
However, there is a dearth of research regarding how the faculty hiring process unfolds within real departmental contexts. Moreover, we are aware of no study that considers whether gender barriers are salient for women and men who have risen to the top of a large applicant pool and been added to the “short list” of finalists invited for a campus interview.
We analyze this issue with a case study of short-listed applicants, who have been invited to campus to interview for tenure-track faculty appointments within five male-dominated engineering departments across two Research 1 universities.
1 Case-oriented research is not intended to be generalizable but rather sheds light on under-studied social processes. Our data come from the most important segment of the job interview: the “job talk”, a seminar in which the candidate presents his or her original research to the academic department. Our paper assesses whether in these talks, women candidates face greater scrutiny and stricter standards, manifesting as more questions, compared to men candidates.
We analyze the number of questions presenters receive from the audience, which is mostly composed of department faculty and graduate students. By asking questions, faculty try to assess whether the candidate is fully in command of his or her research project and its larger implications. Some interruptions may indicate audience engagement, while others may indicate that the speaker was unclear or that the audience questions the presenter’s competence.
To preview our results, we find that compared to men presenters, women face more questions during their job talk seminars, are confronted with more follow-up questions, and spend a higher proportion of time listening to audience speech. Moreover, we find that questions directed to women and men candidates are more prevalent in more highly male-dominated departments, compared to departments that have a somewhat higher proportion of women on the faculty. More senior candidates generally receive fewer questions than more junior ones, but women face more questioning and scrutiny compared to men with the same level of experience.
As noted in the conclusion section, our data have some limitations. Our IRB agreement allows us research access to this treasure trove of video recordings collected for other purposes but does not permit us to examine which candidates were actually offered a job. Even if job offer data were available, it would be of limited value. Many candidates withdraw from consideration after receiving preferable offers from other universities, so the absence of an offer does not reliably indicate a candidate’s lack of success with the interview. The data do show that, regardless of gender, the number of questions is correlated with candidates’ statements and actions indicating they are rushing to finish their slides and conclude their talk. To our knowledge, this is the first study of whether there are gender differences in the degree to which faculty candidates are interrupted during job talks.
The next section will present our theoretical framework, which motivates our research questions. We adopt the broad sociological perspective that gender frames expectations and interactions within academic departments. We briefly present literature on implicit biases, which automatically give men more credit than similar women for competence. We then examine how these processes can unfold in ways consistent with double or stricter standards, which could manifest as evaluators posing more questions during the job talk. We therefore turn to insights from a literature on interruptions in workplace or task-oriented interactions.
Following that, we present our data and methods. Next, we provide descriptive and multivariate results. Our discussion and conclusion section also presents study limitations and policy implications.
2. Theoretical Framework and Research Questions
Extensive research documents broadly shared implicit biases, which can automatically filter assessments of professionals in ways that penalize women, while giving men automatic credit for competence [
16,
17,
18]. Assumptions that women are less competent are particularly prevalent in male-dominated settings [
14,
19,
20]. This is important in our case study. Engineering has historically been seen as a “masculine” profession, because it is numerically male-dominated, and because the culture and ethos of the industry are considered masculine [
21,
22]. Further, in male-dominated disciplines such as engineering, academic success has been understood to depend on raw brilliance, a quality less frequently attributed to women [
23].
The processes of biased evaluation are illuminated by studies of how, under the illusion of meritocracy, evaluators can apply double standards in evaluation and hiring. Studies of academic hiring, based on detailed candidate information that is real or believed to be real by faculty evaluators, discover that women candidates are seen as less competent, less qualified, and less hirable, compared to men with similar qualifications. In an analysis of real candidate applications selected for a prestigious medical research fellowship, faculty evaluators gave women applicants less credit than men for their publications [
24]. In a study of psychology professor applications, faculty assessing one ostensibly real CV with a female name gave this candidate less credit for her qualifications and were less likely to recommend hiring her, compared to other participants, who viewed an identical CV with a male name [
25]. Another experimental study used physics, chemistry, and biology professors as participants to examine an ostensibly real CV of either a man or a woman science student applying for a lab manager position [
26]. Compared to equally qualified women candidates, the men were more likely to be rated as competent and hirable and were offered a higher salary.
A line of experimental research by Foschi and colleagues examines how subjects evaluating results of participants’ simulated tasks are implicitly aware of status characteristics such as gender. These studies show that evaluators generally hold women to more scrutiny and harsher standards in the inference of competence. In contrast, they will tend to assess similar performances by men with more lenient standards and give them the benefit of the doubt [
11,
12,
14]. Particularly when tasks are seen as masculine, evaluators generally assume that the man candidate has more ability than a comparable woman and apply more lenient standards for him than for her [
14].
2In contrast to the broad direction of the literature cited above, one study found that evaluators were more likely to rate a woman academic candidate than a man academic candidate as hirable [
15]. However, this study relied on short narrative summaries of similarly strong men and women candidates. Importantly, the narrative summaries described a hypothetical search committee’s evaluations of the job candidates, and assigned the hypothetical men and women candidates identical numerical scores for their interviews and job talks.
3 The provision of only narrative summaries and secondary judgments allows evaluators to rely on others’ assessments of the job candidates instead of forming their own judgment about the hypothetical candidates based on detailed objective information generally provided in academic job searches, such as education credentials and research productivity, alongside any implicit gender biases that may exist. Moreover, the assignment of identical scores obviates the double standards phenomenon that the literature shows generally favors men in masculine-typed occupations.
4In other research, Biernat and Kobrynowicz [
13] found that for inferences of minimum ability, lower standards are set for the lower status group (such as women) and higher standards are set for the higher status group (men). However, when inferences about
greater ability had to be made, the reverse pattern emerged. Women were held to stricter standards and men to more lenient standards. Similar results were found in other studies (see [
11] for review, e.g. [
27]). Further, women were similarly or more likely to be considered competent enough to be short-listed when compared to the lower standards generally set for women but they were held to harsher standards in objective rankings as well as in promotion and hiring decisions [
28,
29].
Thus, scope conditions for double standards becoming stricter standards and greater scrutiny for women include masculine-typed settings when confirmatory decisions (that require higher assessments of ability) are being made. These scope conditions fit our study.
Overall, this line of research suggests that in an actual engineering faculty job search, with real stakes and zero-sum decisions involved, women who have made it to the short list may confront heavier scrutiny and stricter standards than short-listed men during the interview. This reasoning suggests that women job candidates may be implicitly assumed to be less competent, will be challenged more than men candidates and face more questions by faculty members during their job talk. Patterns of evaluators’ closer scrutiny and stricter standards for women are manifestations of “prove it again” bias [
18]. More broadly, by studying audience—candidate interactions in recorded job talks, we assess whether gender barriers emerge within the social context of actual departments as work units and if such barriers vary depending on social structural features of departments [
30].
We now turn specifically to the literature on interruptions. Here, this literature will help us formulate specific research questions. Later, we return to the interruptions literature as we operationalize questions and interruptions.
The literature on conversational interruptions abounds with examples of gender effects. The classic study by Zimmerman and West [
31] found that men interrupt women more than the other way around. One experimental study of task-oriented groups found that the odds of a man interrupting another man are less than half of the odds that a man will interrupt a woman. Further, men’s interruptions of men are generally more positive and affirming, while men’s interruptions of women are more negative. In contrast, women interrupt women and men equally [
32]. Fewer interruptions were found in all-male groups than in mixed-gender or all-female groups [
33].
Other studies have found that a host of variables are predictive of interruptions, and may be more significant than gender in particular situations. For example, Irish and Hall [
34] found that patients interrupt more than their physicians do, but also patients tend to interrupt with statements whereas physicians interrupt by asking questions. In conversations between managers and employees, Johnson [
35] found that “formal legitimate authority severely attenuates the effect of gender in these groups”. While authority, status, topic, setting, group size and composition, and many other factors have been shown to play significant roles in predicting conversational interruptions, considerable research has supported the basic gender effect that men interrupt more than women do [
36,
37,
38], and that women are more frequently interrupted than men [
32,
39].
These studies on gender and implicit bias, double standards and interruptions motivate our research questions.
- RQ1a:
Among job candidates, do women experience more questions than men?
- RQ1b:
Relative to men, is a higher share of women’s candidate time taken up by audience speech?
We also examine variation by department. Studies of gender in other workplace settings find that women face more equal treatment when they are in gender-integrated work settings, even within male-dominated occupations and industries [
40,
41]. As we explain below, the proportion of women among the faculty in the departments we study ranges from 4% to 18%. Although none of our departments are gender-balanced, the departments at the higher end are among those with the largest share of women faculty among the top 50 engineering schools in the nation. We study whether higher share of women in the departmental faculty is associated with fewer interruptions at the job talks in those departments.
- RQ2:
Net of gender, do candidates presenting in departments with a smaller proportion of women on the faculty experience more questions than candidates presenting in departments with a larger proportion of women on the faculty?
Further, we are interested in whether the job candidate’s post-Ph.D. experience matters. Previous research on faculty CVs suggests that gender bias is more pronounced when candidates are more junior, and their potential is judged more subjectively, compared to when candidates are more senior and have a clear and unambiguous track record of achievement [
25]. Moreover, in the interruptions literature, authority dampens the effect of gender on conversational interruptions [
35].
- RQ3:
Do junior candidates experience more questions than more senior candidates?
3. Data and Methods
Case-oriented research identifies a small, non-random sample and investigates it deeply; this is not meant to be generalizable but rather illuminates the complexity of the context under study [
42,
43,
44].
5 For our case study, we analyze interruptions in job talks in highly ranked engineering departments, in order to examine whether gendered processes unfold despite formal commitments to meritocracy and fairness.
3.1. Data
Our data of 119 recorded job talks come from five departments across two Universities, whose engineering divisions each rank in the national top 50.
6 The departments are Computer Science (CS), Electrical Engineering (EE), and Mechanical Engineering (ME). CS and EE are studied at both University 1 and University 2. ME is only considered at University 1. The share of women on the faculty ranges from 4% to 18%. We analyze 92 talks from University 1 and 27 from University 2.
The talks existed as archived videos that were already recorded by departments during two years of hiring, for purposes unrelated to this study. Some departments want to have recordings for faculty who are out of town to be able to evaluate the candidate’s talk. Other departments wish to have the recordings available as a resource for their graduate students.
In our data, the job talks take place in a campus conference room. The candidate is evaluated on his or her performance in presenting their original research and responding to questions. All departments in the study schedule job talks for nominally one hour. Candidates are given their schedules in advance. Both candidates and audience members generally also know that there is no hard stop at the one-hour mark, since running over will merely subtract some minutes from the next event, which is typically lunch, or a break.
Talks are generally advertised by posting flyers and by sending e-mail to faculty, postdocs, and graduate students in the academic department conducting the search for faculty candidates. The e-mail may get forwarded to people with related research interests in other departments, and it is common to have a few audience members from other departments. Faculty are the most active members of the audience and the ones most likely to ask the presenter questions.
We lack consistent data on the gender of audience members who ask questions. The presenter wears a microphone for clear audio and is consistently in the field of view of the camera. However, the audience members who ask questions may not be visible in the picture, and the audio sometimes leaves their gender unclear.
We constructed a sample of the archived videos in five engineering departments hosting job searches over two recent academic years.
7 For these departments, women applicants represent roughly 15% to 20% of all job applicants. Due to the small numbers of interviewees, the percentages of women in the interview pool varies from 0% to about 33% across different department job searches. Given the small proportion of women presenters in the population, we over-sampled women as follows. We used all the videos from women candidates, and attempted to match each woman with two men of the same seniority from the same department. Seniority is measured by the number of years post-Ph.D. Seniority ranges from 0 (people still finishing up their dissertations, called, colloquially, ABDs (All but Dissertation) or “baby Ph.D.s”) to candidates with multiple years of experience post-Ph.D.
There were a few instances when the matching process was not exact. For example, three women ABD candidates were matched with five (rather than six) men ABDs, because there were not six men available in that seniority category in that department. In another example, a woman candidate seven years out after awarded a Ph.D. was matched with men who are seven and eight years out, because there were not two men available who were seven years out.
We refer to the faculty candidate as the “presenter”, and the time they spend formally presenting their slides (excluding time responding to interruptions) as the “presentation”. In our context of the job talk, we are concerned with the amount of time taken away from the candidate’s nominal one hour of presentation time. Because we are interested in the presentation time and how interruptions and questions could affect the outcome of the talk or whether it is brought to conclusion, our analysis excludes the dedicated Question and Answer (Q & A) segment after the presenter has formally concluded the talk.
To code our data, we watched the videos with a playback that shows minute and second.
When an audience member asked a question, the coder paused the video and noted minute and second for the question start time, as well as end time. Likewise, the start and end times for answers were noted. The coding process involves a judgment call by the coder to decide what constitutes the end of an answer, when the presenter returns to the presentation.
3.2. Defining Types of Interruptions, Our Dependent Variables
In some previous studies, conversational interruptions have been defined in terms of syllabic measurements, for example as simultaneous talk which begins more than two syllables from the end of a current speaker’s sentence [
49] or in terms of grammatical, turn-construction units that are “hearably complete” [
50]. Interruptions have also been defined in more contextual ways, for example taking into account whether a speaker has already made a point, or whether they are repairing a previous violation of their speaking turn [
51,
52].
Since much past research has focused primarily on interruptions in turn-taking conversation, it has required definitions of interruptions appropriate to that context. By comparison, there have been few studies of interruptions in scenarios with an audience and a presenter. Furthermore, in these latter studies, for example a psychology experiment involving hecklers during a speech [
53] or an examination of television coverage of a political speech [
54], determining the existence of an interruption was straightforward and not a focus of the study.
Within the pre-Q & A period under analysis, we are concerned with any time that an audience member speaks, regardless of syntactic positioning. We define three types of speaking by audience members:
An acknowledged question is one where the audience member raises his or her hand, and is acknowledged by the presenter. This definition relies on the audience member’s hand gesture and presenter’s acknowledgement.
A follow-up question corresponds to a situation where the presenter has just finished answering a question from the audience, and a member of the audience asks another (follow-up) question. In this case, the audience member does not raise his or her hand but would not generally be expected to do so.
An
unacknowledged interruption happens in one of two ways:
- (1)
If the presenter is presenting (rather than answering a question), then we expect an audience member to raise a hand, and so an unacknowledged interruption is defined by the audience member speaking without first raising his or her hand, even if the presenter has completed a sentence or a section of the talk. Thus, this definition relies on the lack of audience member hand gesture and presenter acknowledgement.
- (2)
If the presenter is answering a question, then an unacknowledged interruption is defined by an audience member speaking before the presenter has finished their answer. (In a few rare cases, an interruption arises from an audience member having a speaking overlap with another audience member). Our distinction between this case and the earlier definition of a follow-up question depends upon the contextual information about the presenter’s completion of an answer.
The motivation for these definitions is as follows. When the presenter is presenting, there is a presumption that an audience member should ask permission to speak, so politeness is defined by raising a hand. In that phase, an audience member can speak either by asking permission (raising their hand and getting acknowledged, which is considered polite) or by interrupting (starting to speak without raising their hand, which is considered impolite whether or not the presenter has just finished a sentence, or a section of the talk). This speaking without raising one’s hand is our first type of interrupting.
However, once the presenter has begun answering a question, the situation may be considered to have shifted into one more like conversational turn-taking, in which conversational politeness or lack thereof is defined by allowing the current speaker to complete their thought. Thus, in this phase, an audience member can speak either by waiting for the other person (presenter or other audience questioner) to finish his or her thought, in which case it is a follow-up question (which may be seen as questioning the presenter’s authority but is not conversationally impolite) or by interrupting (not letting the presenter finish their answer, which is considered impolite). This speaking with speech overlap while the presenter is giving an answer is our second type of interrupting. Once the presenter returns to presenting, the situation returns to one in which the audience member should raise their hand to get permission to speak. We combine the two types of interrupting into one category, since they both indicate lack of politeness.
3.3. Meanings of Zero Questions
Based on our own experience in similar departments, and in conversation with other engineering faculty, we are aware of three meanings of “zero questions”.
- (1)
The talk is very clear, so no questions are needed.
- (2)
The talk is way below the bar, so nobody bothers asking questions.
- (3)
The departmental culture does not involve asking questions before the formal Q & A period.
We cannot adjudicate between meanings 1 and 2. It is likely that meaning 3, the departmental culture explanation, does not apply to the five departments in our study. In each department, in most of the talks (91% overall), candidates received questions during the Pre-Q & A period.
8Table 1 provides an example of the collected data. Presentation time begins at 1 min 22 s; the time prior to that is the introduction. This composite example illustrates the situations that the coder must recognize: presenting yielding to an acknowledged question at 11:26 (hand gesture, acknowledgement), a presenter transitioning from answering a question back into presenting at 11:47 (context), presenter getting interrupted at 15:40 (no acknowledgement), a follow-up question at 15:51 (context), and an answer getting interrupted at 16:09 (context).
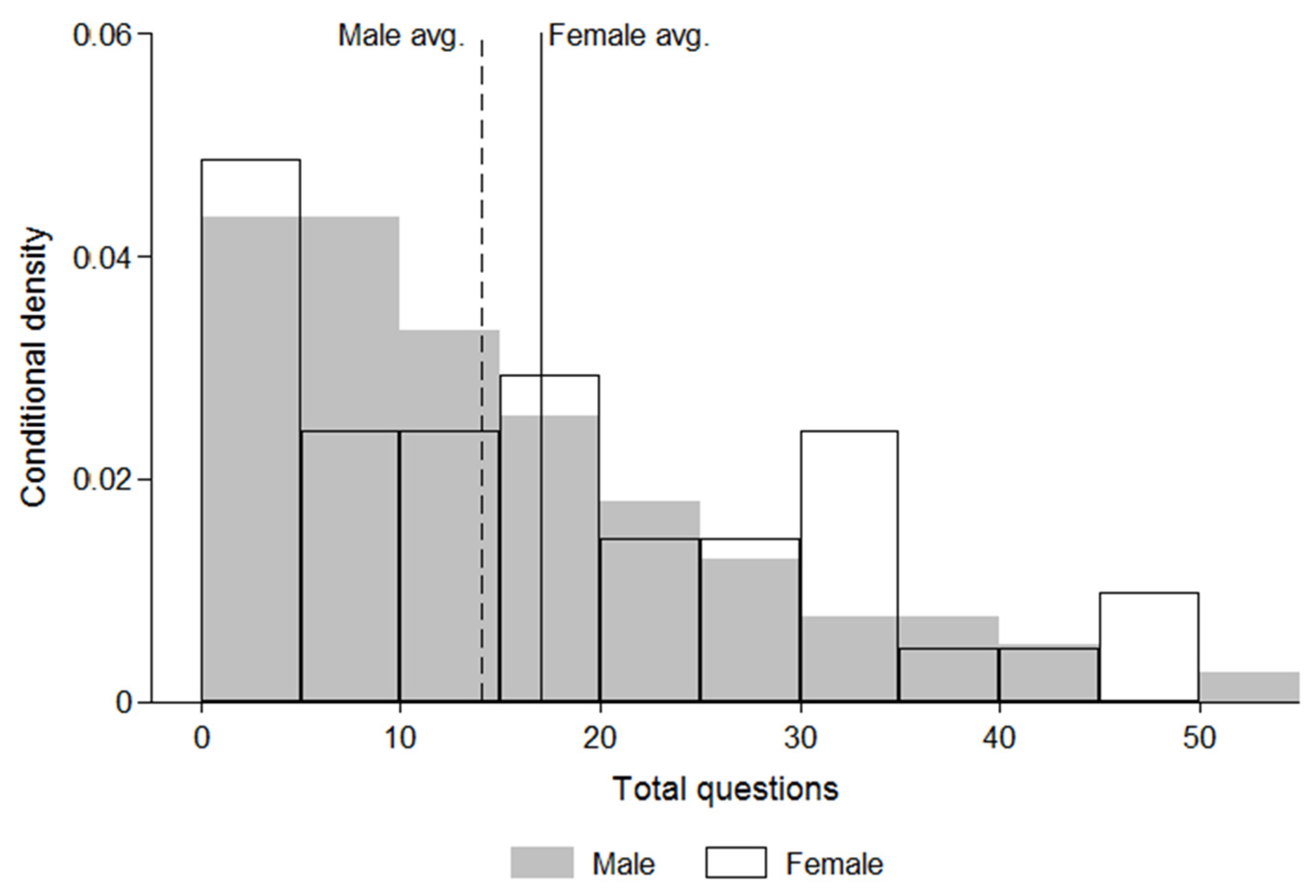
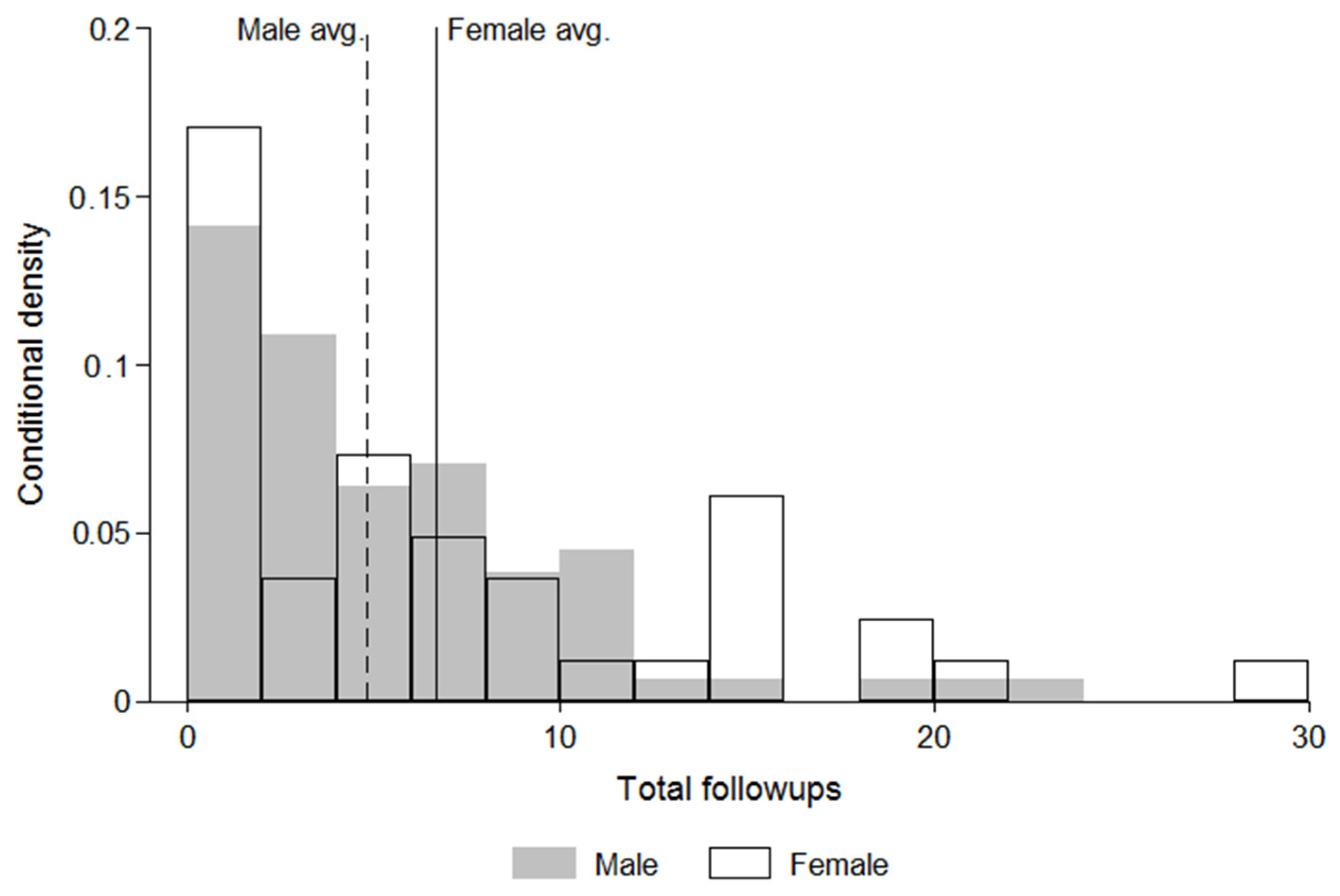
Our dependent variables also include the total number of questions, which is the sum of acknowledged questions, unacknowledged interruptions, and follow-up questions during one presenter’s seminar. We also measure the audience time as the proportion of the pre-Q & A talk time taken up by audience members’ questions (audience time/total pre-Q & A time). As noted above, all of these dependent variables are indicators of interruptions in a broader sense, because all of them occur before the final segment of the seminar, officially designated as the Q & A period.
5. Multivariate Results
To more formally assess the results illustrated in the histograms, we need to choose which model to use. The dependent variables for this analysis are counts of the number of questions of different types received by each candidate. In addition to being integer-valued,
Figure 1 and
Figure 2 show that these counts are non-negative and are not normally distributed. To accurately model these data, therefore, we choose to use a count data method. The standard choices for modeling count data are a Poisson model, negative binomial model, or a zero-inflated version of either of these models [
55]. We prefer a zero-inflated, negative binomial (ZINB) model for this analysis for empirical and theoretical reasons.
Table 2 shows that the variance of each dependent variable is high relative to the mean, indicating that the data are over-dispersed. This feature means that the negative binomial model is more suitable than a Poisson model. Theoretically, department norms about whether to ask questions during a job talk also mean that some talks are more likely to have zero questions, making a zero-inflated model more appropriate.
10The ZINB model simultaneously fits two models. One model estimates the probability of observing zero questions. Since there are two possible states—zero questions or positive questions—this model uses a logit regression. The other model estimates the number of questions, conditional on the candidate receiving at least one question. This model operates like a typical negative binomial regression. Together, these models account for both the excess number of zero observations and for the positive-value count data. In the results shown below, the model for zero-question observations is shown in the bottom panel of the table, and the model for positive values is shown in the top panel.
We now estimate ZINB models to address
our first research question: do women get more questions than men during the job talk?
Table 4 shows that the answer is yes, in part. We focus on the top panel of the table, the model for positive values. For each row, the table lists the coefficient from the ZINB model. Below that is the exponentiated coefficient, and below that is the standard error in parentheses.
11 Consistent with
Figure 1 and
Figure 2, the top panel of
Table 4 shows that women face more total questions and more follow-up questions than men. Specifically, the coefficient for female is statistically significant in the models predicting the number of follow-up questions (model 3) and the number of total questions (model 4), controlling for the percent of departmental faculty who are women.
12 However, there is no gender difference in the number of unacknowledged interruptions.
Taking the exponential of the coefficients, as shown below each ZINB coefficient in
Table 4, is helpful for interpretation. The coefficients for the positive values have a similar interpretation to the percent change—they now represent the factor by which the number of questions goes up when that variable increases by one.
13 Since the female coefficient of the number of follow-up questions (model 3) is 0.35, then exp(0.35) = 1.4, indicating that women get about 1.4 times more follow-up questions than men.
14 Similarly, since the female coefficient for total questions (model 4) is 0.22, then exp(0.22) = 1.2, indicating that women get about 1.2
times more total questions than men, on average, conditional on getting more than zero questions. The exponential of the intercept shows that, conditional on being asked at least one question, the average male candidate would receive about 30 total questions from a hypothetical department composed of only male faculty. Thus, under this condition,
women get about 1.2 × 30 = 36, or six more total questions than men do, on average.Table 4 also answers
Research Question 2. Departments with a larger proportion of the faculty who are women pose fewer interruptions, acknowledged questions, follow-up questions, and, of course, total questions than departments with a smaller share of women faculty.
We now address
Research Question 1b, whether women candidates, compared to men, generally find that a higher share of the total talk time is spent on audience time. Similar to count data, ratios are best handled by a specialized nonlinear estimation strategy. The standard practice is to use a binomial family estimator with a logit or probit link [
56].
Table 5 presents results of a binomial estimator and logit link.
15The binomial model in
Table 5 performs similarly to an OLS model (results not shown). The binomial model should be interpreted as percent changes. It indicates that for female candidates, 1.3 times as much time is taken up by questions. From the summary statistics in
Table 2, one can see that the audience takes up 4.3% of the total talk time, on average. The results from the model indicate, therefore, that roughly 5% of an average talk by a female candidate is taken up by the audience while 3.8% of an average talk by a male candidate is audience time.
We now turn to
Research Question 3: Do junior candidates experience more questions than senior candidates? The ZINB models in
Table 6 examine whether the presenter’s professional experience mitigates interruptions. Here, we focus on the number of follow-up questions as the dependent variable.
Model 2 shows that there is a modest, yet statistically significant, decline in the number of follow up questions candidates receive if they have more experience. However, women still face more follow-up questions than men after controlling for years since Ph.D. In Model 3, the interaction term of woman candidate times experience is not statistically significant. In other words, having more experience does not differentially help women candidates. Men and women with more experience receive fewer questions than men and women with less experience, respectively, and this negative effect of years since Ph.D. on number of follow-up questions is the same for men and women.
The data presented so far do not indicate whether having more questions helps or hurts a candidate. We do not have measures of job offers. However, while coding the video recordings, we did monitor in qualitative language when candidates’ verbal cues clearly indicate that they are rushing to get through their carefully prepared slide decks and reach the punch line of their talk. Example statements that indicate rushing include “For the sake of time, I’m going to skip this part”, “There’s not much time left; I will rush through this”, “I’m going to skip to the end”, “I’m going really quick here because I want to get to the second part of the talk” and “We’re running out of time so I’m not going into the details”. We find that rushing, as indicated by these cues, is correlated with the number of total questions (Pearson correlation coefficient 0.22) and with the number of follow-ups (Pearson coefficient 0.19). This suggests that having many questions may prevent a candidate from delivering all their prepared content and may rush them in covering the key sections that are often placed at the end (summary of results, impact of results, future work).
6. Discussion
Our analyses shed light on a key set of interactional processes linked to the persistent under-representation of women faculty in academic engineering departments. Women academics who have made it to the short list in competitive academic job searches in top departments face more follow-up questions and more total questions during their job talks than men do, on average, even after controlling for years of experience post-Ph.D. Under the condition of at least one question being asked during the talk, women receive six more questions than men do, on average. Further, a higher proportion of women’s talk time is spent on audience members’ speech. This means that, generally, women have less time to present their prepared talk and slides.
The larger number of questions women receive on average is mostly driven by the larger number of follow-up questions. These are questions piled on to previous questions and thus may indicate a challenge to the presenter’s competence—not only in their prepared talk but also in their response to questions. Consistent with research on greater scrutiny and stricter standards for higher prizes in masculine-typed occupations and “prove it again” bias, we find a Catch 22 for women. Even short-listed women with impressive CVs may still be assumed to be less competent, are challenged, sometimes excessively, and therefore have less time to present a coherent and compelling talk.
We have revealed subtle conversational patterns of which most engineering faculty are likely unaware. It is a form of almost invisible bias, which allows a climate of challenging women’s competence to persist. These patterns may be linked to the small numbers of women faculty hired into these departments. Indeed, departments with a larger share of women faculty tend to ask fewer questions of all candidates (women and men), take up less of their time in audience speech, and thereby give candidates more time to complete their presentations.
6.1. Policy Recommendations
Our data set shows that a few candidates, both women and men, receive a very large number of questions, in the range of 30 to 50. In some cases, a presenter rushes through slides at the end, or decides to skip a large number of slides. In other cases, the talk runs over by 15–20 min, and the audience dwindles. It may be advisable for each talk to have a facilitator, perhaps a senior faculty member who introduces the presenter, who will pay attention to the number and also the tone of questions being asked. If the number of questions becomes large and especially if the tone seems hostile or the presenter seems to be rushing, the facilitator could ask the audience to hold their remaining questions for the Q & A session at the end. Sometimes presenters may make this request themselves, but it may be difficult for a young ABD candidate to make this request to an audience of senior faculty. If there is no assigned facilitator, it may be appropriate for a senior faculty member in the audience to make this request.
When the suggestion of having a facilitator stop questions was made in one department, a faculty member protested that if he did not ask his questions as the talk went along, he would not understand the subsequent material, and the remainder of the talk would be useless. While this is a legitimate argument, his preference to ask multiple questions should be balanced against the preferences of others in the audience who may be fully understanding the talk and would be better served by having the presenter complete the material.
It would also be helpful for young faculty applicants to be aware that there are large differences in university or departmental culture, so that they are prepared for this. For the five engineering departments in this study, only 9% of talks had zero questions. In contrast, the Biomedical Engineering Department that was excluded from the study, 81% of talks had zero questions. Especially candidates in interdisciplinary sub-fields may be surprised if they have a mixed audience with differing cultures in this regard. Applicants should also know that some talks get derailed by questions, and it is an acceptable option for the presenter to ask the audience to hold remaining questions for the Q & A session at the end. We encourage advisors and mentors to share this knowledge with their graduate students and postdoctoral fellows.
6.2. Limitations
Case studies are, by design, not necessarily representative of other organizations. Our analysis of job talk video recordings is pioneering. However, the data have a number of limitations. We were limited to the departments which had archival video recordings. We constructed a theoretical framework from well-established literature on the unequal treatment by gender in terms of competence and hirability evaluations and the likelihood of being interrupted. Future research should adapt these insights to the study of the effects of candidate race. Moreover, the nature of our access to the archival video recordings precluded us from measuring which candidates were later voted by departmental faculty as worthy of receiving job offers. Note that even if it had been possible for us to investigate job offers in our data, defining this outcome would be problematic. Some top candidates may not receive a formal offer if they have already received—and potentially accepted—offers from other departments further ahead in their recruitment process. We encourage future researchers to investigate these issues in other research-oriented STEM departments.


 ,
, 

{kind=link}
{kind=link}