Mapping of Cold-Water Coral Carbonate Mounds Based on Geomorphometric Features: An Object-Based Approach



Geological Survey of Norway, Postal Box 6315 Torgarden, NO-7491 Trondheim, Norway
*
Author to whom correspondence should be addressed.
Geosciences 2018, 8(2), 34; https://doi.org/10.3390/geosciences8020034
Submission received: 14 December 2017
/
Revised: 18 January 2018
/
Accepted: 20 January 2018
/
Published: 23 January 2018
(This article belongs to the Special Issue Marine Geomorphometry)
Abstract
:Cold-water coral reefs are rich, yet fragile ecosystems found in colder oceanic waters. Knowledge of their spatial distribution on continental shelves, slopes, seamounts and ridge systems is vital for marine spatial planning and conservation. Cold-water corals frequently form conspicuous carbonate mounds of varying sizes, which are identifiable from multibeam echosounder bathymetry and derived geomorphometric attributes. However, the often-large number of mounds makes manual interpretation and mapping a tedious process. We present a methodology that combines image segmentation and random forest spatial prediction with the aim to derive maps of carbonate mounds and an associated measure of confidence. We demonstrate our method based on multibeam echosounder data from Iverryggen on the mid-Norwegian shelf. We identified the image-object mean planar curvature as the most important predictor. The presence and absence of carbonate mounds is mapped with high accuracy. Spatially-explicit confidence in the predictions is derived from the predicted probability and whether the predictions are within or outside the modelled range of values and is generally high. We plan to apply the showcased method to other areas of the Norwegian continental shelf and slope where multibeam echosounder data have been collected with the aim to provide crucial information for marine spatial planning.
1. Introduction
Cold-water coral (CWC) reefs are complex three-dimensional habitats that provide niches for many species and hence are notable for their high biodiversity [1]. Such reefs might also function as nurseries for fish larvae [2] and fish habitat [3], although such claims are contested [4]. Moreover, CWC are of importance as archives of palaeo-environmental changes due to their longevity, cosmopolitan distribution and banded skeletal structure [1].
At the same time, human activities threaten these ecosystems in at least three ways [1]: (i) physical damage through demersal fishing [5,6,7,8], (ii) potential impacts from hydrocarbon drilling [9,10] and (iii) likely effects of ocean acidification on calcifying reef fauna [11,12,13,14]. Therefore, knowledge on the spatial distribution of CWC reefs is vital for effective marine spatial planning and conservation. Deriving the necessary spatial information is typically attempted by spatial distribution modelling for selected framework-forming CWC species [15,16]. However, data on CWC species’ presence and absence are often sparse and important predictor variables frequently only exist at a coarse spatial resolution. Consequently, the resulting maps of CWC species distributions are frequently too coarse for many management applications.
The geological products of CWC reefs are ‘cold-water coral carbonate mounds’, positive topographic features that owe their origin, partially or entirely, to the framework-building capacity of CWCs [17]. In the following, we will refer to these structures as carbonate mounds. Such carbonate mounds are identifiable from multibeam echosounder (MBES) data; however, the large number of carbonate mounds that can be seen in MBES data makes manual interpretation and mapping a tedious process.
In Norway, ‘bioclastic sediments’ associated with carbonate mounds have been mapped as part of the MAREANO (Marine AREA database for NOrwegian coast and sea areas) seabed mapping programme. Such maps give a good approximation of the occurrence of carbonate mounds [18]. However, for many applications including marine spatial planning and conservation, these products are too generalised as they do not pinpoint individual mounds, nor do they convey the confidence in the map products in a spatially explicit manner.
The objectives of this research are therefore to develop a quick, repeatable and validated methodology that allows mapping of carbonate mounds with high spatial detail and that expresses the confidence in the mapped outputs in a spatially explicit way.
2. Materials and Methods
2.1. Site
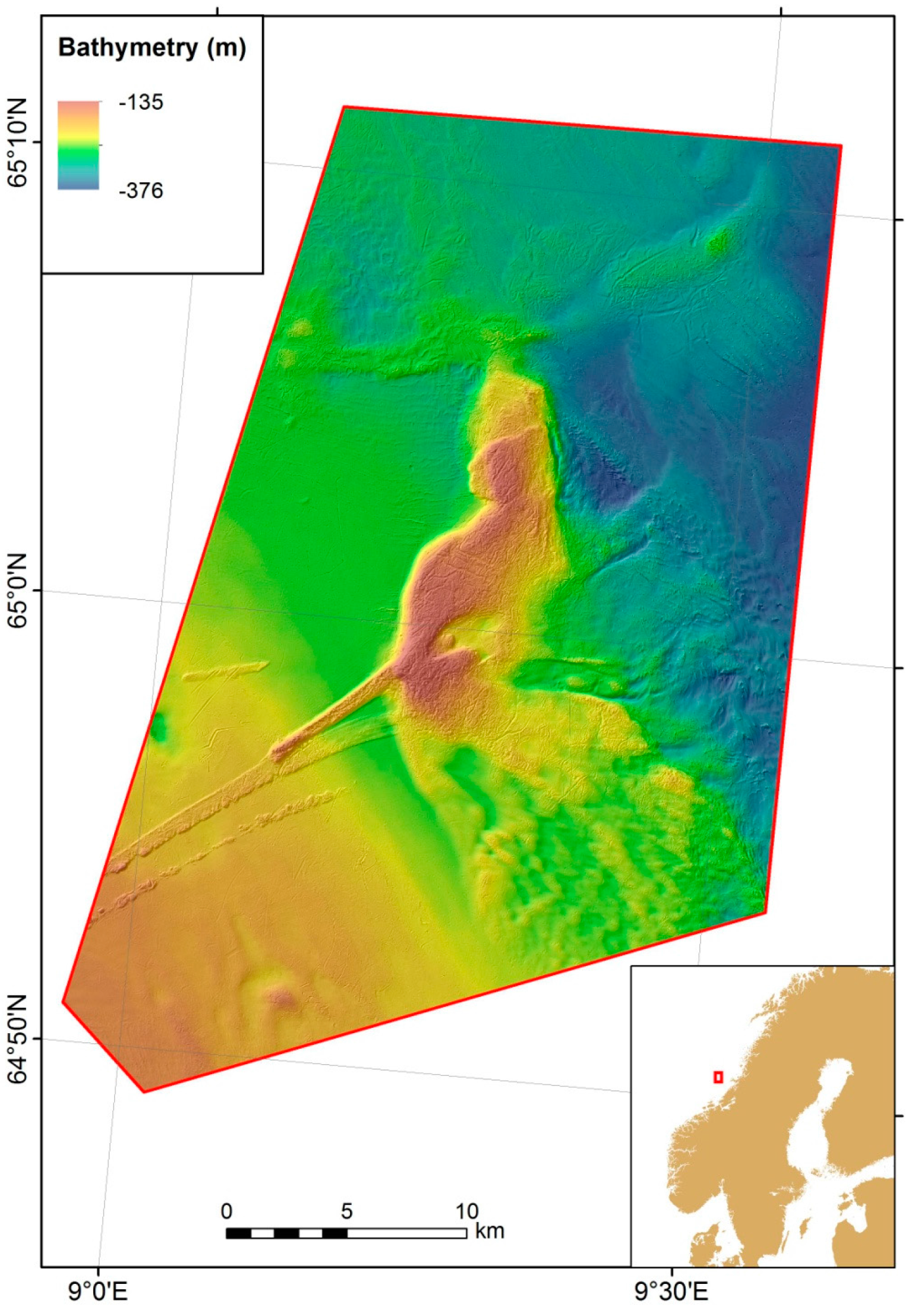
Iverryggen is situated on the mid-Norwegian shelf approximately 75 km west of the Norwegian coast. It is a nearly 20 km long N–S trending ridge (Figure 1), 7 km wide and up to 120 m high [19]. The Iverryggen ridge is interpreted as the product of glacitectonic processes, where compressive subglacial stresses from a westward ice-sheet during the Late Weichselian glaciation caused thrusting and build-up of the ridge. The stresses were induced by basal freezing close to a thin ice-sheet margin. The seabed sediments on the ridge are dominated by gravelly deposits on the highest, central parts of the ridge, with sand and gravelly sand in the fringe areas. Sandy mud and gravelly sandy mud dominate around the ridge [20]. CWC reefs on Iverryggen have been known to fishermen since bottom-trawling started in the area in the 1990s. Following scientific investigations in the late 1990s that indicated extensive trawl damage to the reefs, the area was closed to bottom trawling in 2000 [21].
2.2. Data
MBES data were collected and processed by the Norwegian Mapping Authority, Division Hydrographic Service, in April 2012 with a Kongsberg EM710 system onboard the Norwegian survey vessel Hydrograf. The surveyed area has a size of 918 km2. The raw MBES data were processed with software Neptune and a digital elevation model (DEM) with a grid cell size of 5 m produced. Bathymetric derivatives were calculated from the 3 × 3 Lee-filtered DEM as 32-bit floating point raster files (Table 1). Additionally, the bathymetric position index with a radius of 3 pixels (bpi3) was transformed to an 8-bit raster image used for image segmentation (see below). All layers were projected to UTM Zone 33 North.
A pre-existing shapefile showing bioclastic sediments [18] was used as a spatial constraint. This was extracted from [20]. The layer was derived by visual analysis of MBES data and digitisation and is depicting areas where bioclastic sediments, including those associated with carbonate mounds, are likely to exist. The following analysis was restricted to areas highlighted as bioclastic sediments and a 25-m buffer around these.
2.3. Research Strategy
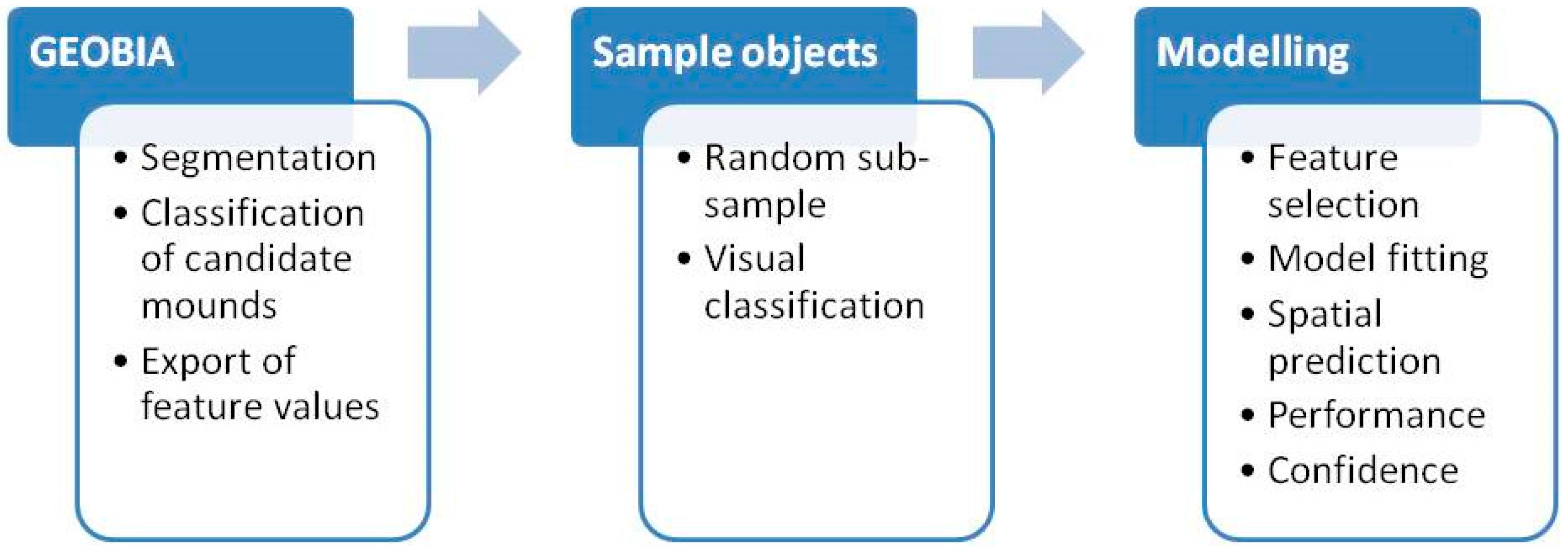
The general research strategy consisted of three major elements and is outlined in Figure 2: geographic object-based image analysis (GEOBIA) [26,27], visual classification of sample objects and modelling the spatial distribution of carbonate mounds. Initially, image segmentation was carried out to derive image objects (polygons) from suitable raster derivative layers. The aim was to form objects that were either complete mounds (especially smaller ones) or parts of these (e.g., top, slope, foot). In a subsequent step, candidate mounds were defined by applying a simple rule-based classification. These candidate mounds would ideally contain all true mounds, but unavoidably also a certain number of features that have similar characteristics, but are not carbonate mounds. A wide range of object features was extracted for these candidate mounds and used for further analysis.
A randomly selected subset of the candidate mounds was visually inspected and classified into objects that either belonged to a carbonate mound or not. This dataset was subsequently split into objects used for feature selection and model fitting and those used to assess the performance and accuracy of the model. Finally, the model was applied to all image objects and mapping confidence was assessed.
2.4. Image Segmentation
Image segmentation is a vital step in GEOBIA, which is a two-step approach consisting of segmentation and classification. Segmentation is the process of complete partitioning of an image into non-overlapping polygons in image space [28] on the basis of homogeneity [27]. The aim of the segmentation is to divide the image into meaningful polygons of variable sizes, based on their spectral and spatial characteristics. The resulting image objects can be characterised by various features such as layer values (mean, standard deviation etc.), geometry (extent, shape etc.), image texture and many others. Classification is then based on user-specified combinations of these image object features or by applying statistical methods of spatial prediction.
Segmentation was carried out using the multi-resolution segmentation algorithm in eCognition 9.2.0. This algorithm is an optimisation procedure, which locally minimises the average heterogeneity of image objects for a given resolution of image objects. Starting from an individual pixel, it consecutively merges pixels until a certain threshold, defined by the scale parameter, is reached. The scale parameter is an abstract term that determines the maximum allowable heterogeneity for the resulting image objects.
The object heterogeneity, to which the scale parameter refers, is defined by the ‘composition of homogeneity’ criterion. This criterion defines the relative importance of ‘colour’ (pixel value) versus shape of objects. If high weight is given to colour then the object boundaries will be predominantly determined by variations in colour of the image. Further on, the shape criterion has contributions from smoothness and compactness, both of which can be weighted. A high value for smoothness will lead to smoother boundaries of the objects. High values of compactness will increase the overall compactness of image objects.
Image segmentation was carried out on the BPI3 8-bit layer and the buffered bioclastic sediments shapefile, using the multi-resolution segmentation algorithm with a scale factor of 10, shape of 0.1 and compactness of 0.5. The selection of the segmentation parameters was made after trialling different combinations and assessing the results visually.
2.5. Classification of Candidate Mounds
Candidate mounds were classified with the zero-mean bathymetry (Table 1) ≥0.05 m within buffered areas of bioclastic sediments.
2.6. Export of Feature Values
Image objects classified as candidate mounds were exported as a shapefile together with 24 image-object features (Table 2). These included object mean values of derivatives, maximum pixel values of selected derivatives and geometry features (extent and shape features). Documentation of the eCognition rule-set (RuleSetDocu.txt) is provided as supplementary material.
2.7. Defining Sample Objects
One thousand image objects were randomly selected using the NOAA Sampling Design Tool (https://www.arcgis.com/home/item.html?id=ecbe1fc44f35465f9dea42ef9b63e785) in ArcGIS 10.4.1. Based on shaded relief and bpi3 maps, image objects were manually classified as belonging to a carbonate mound or otherwise. In total 573 image objects indicated the presence of carbonate mounds and 427 image objects the absence of mounds. The selected sample objects were split into training and test data with a ratio of 2:1 using a stratified random approach to ensure the same class frequencies in both training and test data (Table 3). Subsequent feature selection and model fitting was conducted with the training data, while the test set was used to estimate model performance. The training data set (Iverryggen_training_data.txt) is provided as supplementary material.
2.8. Feature Selection
The feature selection approach consisted of two steps: Initially, all relevant features were identified with the Boruta algorithm. Subsequently, the set of predictors was reduced to uncorrelated features.
The Boruta variable selection wrapper algorithm [29] was employed for the identification of all relevant predictor features. Wrapper algorithms identify relevant features by performing multiple runs of predictive models, testing the performance of different subsets [30]. The Boruta algorithm creates copies of all features and randomises them. These so-called shadow features are added to the predictor feature data set and the random forest algorithm (see below) is run to compute feature importance scores for predictor and shadow features. The maximum importance score among the shadow features (MZSA) is determined. For every predictor feature, a two-sided test of equality is performed with the MZSA. Predictor features that have a feature importance score significantly higher than the MZSA are deemed important. Likewise, predictor features that have a variable importance score significantly lower than the MZSA are deemed unimportant. Tentative features have a variable importance score that is not significantly different from the MZSA. The Boruta algorithm was run with a maximum of 500 iterations and a p-value of 0.05. Only important features were retained for further analysis. A further feature selection step removed correlated features from the set of predictors used in the final model. Out of any two features with a correlation coefficient above 0.7, only the feature with the higher importance measured as the mean decrease in accuracy (see below) was retained in the final set of predictors. The variance inflation factor (VIF) was used as an indicator to assess the remaining degree of multicollinearity in the data. The R script (FeatureSelection.r) is provided as supplementary material.
2.9. Model Fitting
The random forest (RF) prediction algorithm [31] was chosen as the modelling tool for the analysis because it has shown high predictive performance in a number of domains [32,33,34,35]. RF can be used without extensive parameter tuning, it can handle a large number of predictor variables, is insensitive to the inclusion of some noisy/irrelevant features, makes no assumptions regarding the shape of distributions of the response or predictor variables [36] and is therefore suitable for this analysis. The RF is an ensemble technique that ‘grows’ many classification trees. Two elements of randomness are introduced: Firstly, each tree is constructed from a bootstrapped sample of the training data. Secondly, only a random subset of the predictor features is used at each split in the tree building process. This has the effect of making every tree in the forest unique. The underlying principle of the technique is that although each tree in the forest may individually be a poor predictor and that any two trees could give different answers, by aggregating the predictions over a large number of uncorrelated trees, prediction variance is reduced and accuracy improved ([37], p. 316). For binary classifications, probability predictions are initially derived based on the fraction of votes given for a specified class by the ensemble of trees. These are subsequently dichotomised by applying suitable thresholds (see below).
Two parameters can be specified when fitting a RF model. These are the number of trees to grow (ntree) and the number of features available for splitting (mtry). We varied ntree between 500 and 5000 (steps of 500) to investigate the effect on the accuracy and stability of the model. Varying ntree had little influence on model accuracy but model stability increased with the number of trees. We selected ntree = 2000 as a compromise between stability and processing time. For mtry the default value, equal to the square root of the number of predictor variables (rounded down), was chosen.
RF also provides a relative estimate of predictor variable importance. This is measured as the mean decrease in accuracy associated with each variable when it is assigned random but realistic values and the rest of the variables are left unchanged. The worse a model performs when a predictor is randomised, the more important that predictor is in predicting the response variable. The mean decrease in accuracy was left unscaled, i.e., it was not divided by the standard deviation of the differences in prediction errors, and is reported as a fraction ranging from 0 to 1.
The randomForest package [38], executed via the Marine Geospatial Ecology Tools v08a.67 [39], was used for the implementation of the model. The resultant Rdata file (rf2000_2.Rdata) and model statistics (rf2000_2_model_stats.txt) are provided as supplementary materials.
2.10. Spatial Prediction
The selected RF model was applied to the whole dataset to predict the probability of carbonate mound presence for each image object. For the dichotomisation of the probabilistic outputs, a threshold was calculated from the training data by maximising the Youden index [40].
2.11. Model Performance
Model performance of presence-absence predictions was assessed with the receiver-operating characteristic (ROC) curve by plotting sensitivity against 1—specificity for various thresholds. Sensitivity is the amount of true presence predictions as a proportion of the total number of presence observations (Table 4 and Equation (2)). Specificity is the amount of true absence predictions as a proportion of the total number of absence observations (Table 4 and Equation (3)). The area under the ROC curve, or AUC, was used to assess the model performance. An AUC value of 0.5 is indicating discrimination ability no better than random and a value of 1 is indicative of perfect discrimination.
We assessed the accuracy of the dichotomised predictions with three widely applied metrics, which can be derived from a contingency table (Table 4), namely the overall accuracy (percent classified correctly, PCC), sensitivity and specificity. PCC is the proportion of correctly classified presences and absences. The accuracy metrics were calculated with the caret package [41] in R. The R script (MapAccuracy.r) is provided as supplementary material.
2.12. Confidence
The predicted probabilities were also employed to assign a confidence score to the outputs similar to reference [42]: To indicate high confidence in the absence of carbonate mounds, a sensitivity value of 0.95 was selected. In other words, we requested that 95% of the predicted presence of mounds is correct based on the test set. Likewise, to indicate high confidence in the presence of mounds, a specificity value of 0.95 was required, equal to 95% of absence of mounds correctly classified based on the test set. The choices for the selected values of sensitivity and specificity are somewhat arbitrary here. However, they were selected for illustrative purposes and will be discussed in greater detail later on. Additionally, we considered whether the predictions were within or outside the modelled range of values of the RF model. Scores of 0 and 1 were given for low and high confidence for both aspects of the predictive model and summed to give total confidence scores of 0 (low confidence), 1 (medium confidence) or 2 (high confidence). The Presence Absence [43] and ROCR [44] packages were used in R to calculate thresholds for required values of sensitivity and specificity and create diagnostic plots. The R script (BinaryClassification.r) and the input data file (rf2000_2_export_for_PresenceAbsence.txt) are provided as supplementary materials.
2.13. Representation on Maps
Since carbonate mounds are small features compared to the size of the study area, we represent them in an aggregated form by calculating the fraction of mound area per 1 km2 block. We also display the mean total confidence score in a similar way.
3. Results
3.1. Feature Selection
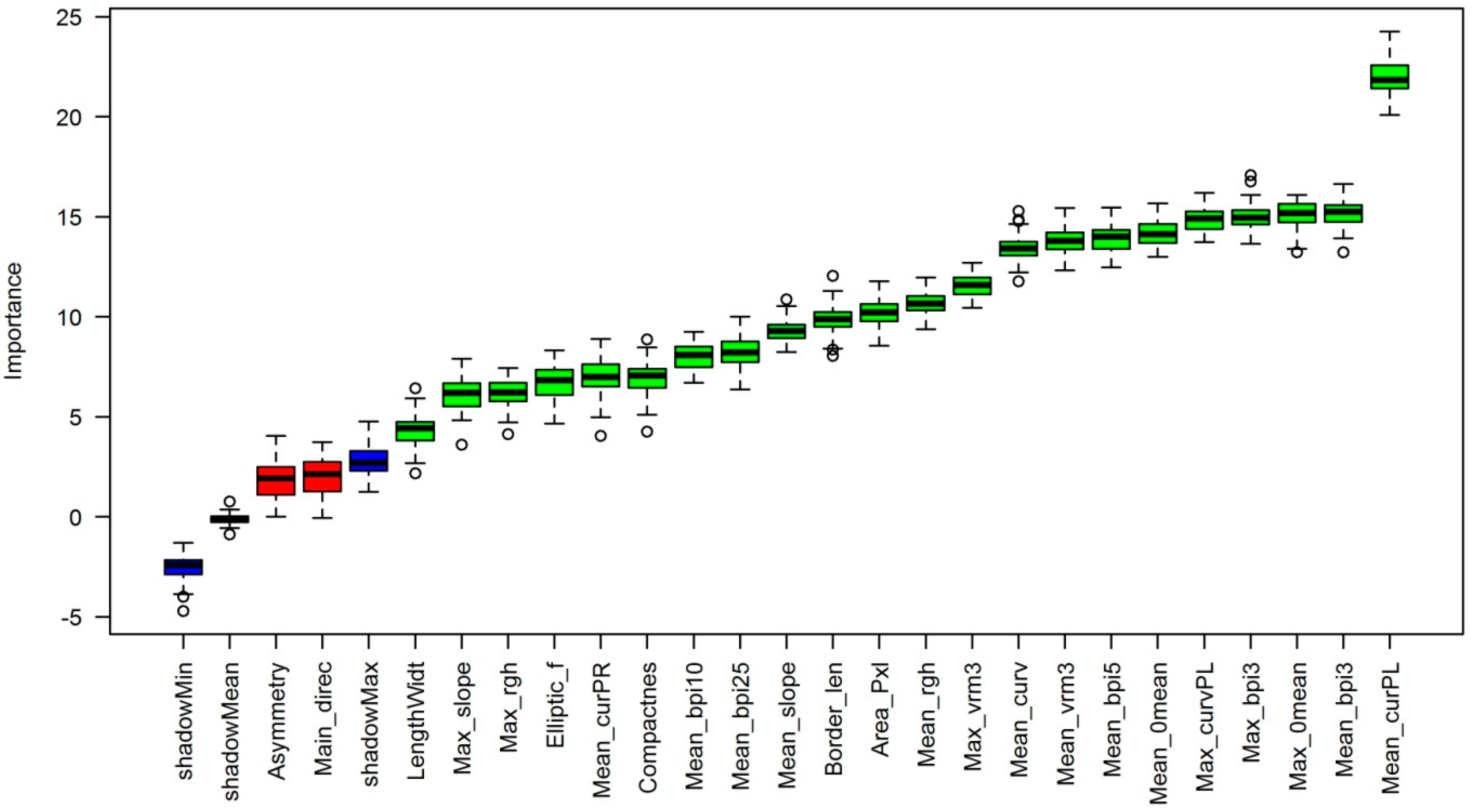
The Boruta feature selection reduced the number of predictor features from 24 to 22 (Figure 3). Two features were deemed unimportant (Asymmetry, Main_direc). The subsequent correlation analysis reduced the number of predictor features to six. All VIFs were below 3 indicating a low degree of multicollinearity in the remaining predictors (Table 5). Mean_curPL, Mean_rgh, Mean_curPR, Area_Pxl, LengthWidt and Mean_bpi25 were used to build the final model.
3.2. Model Performance and Confidence
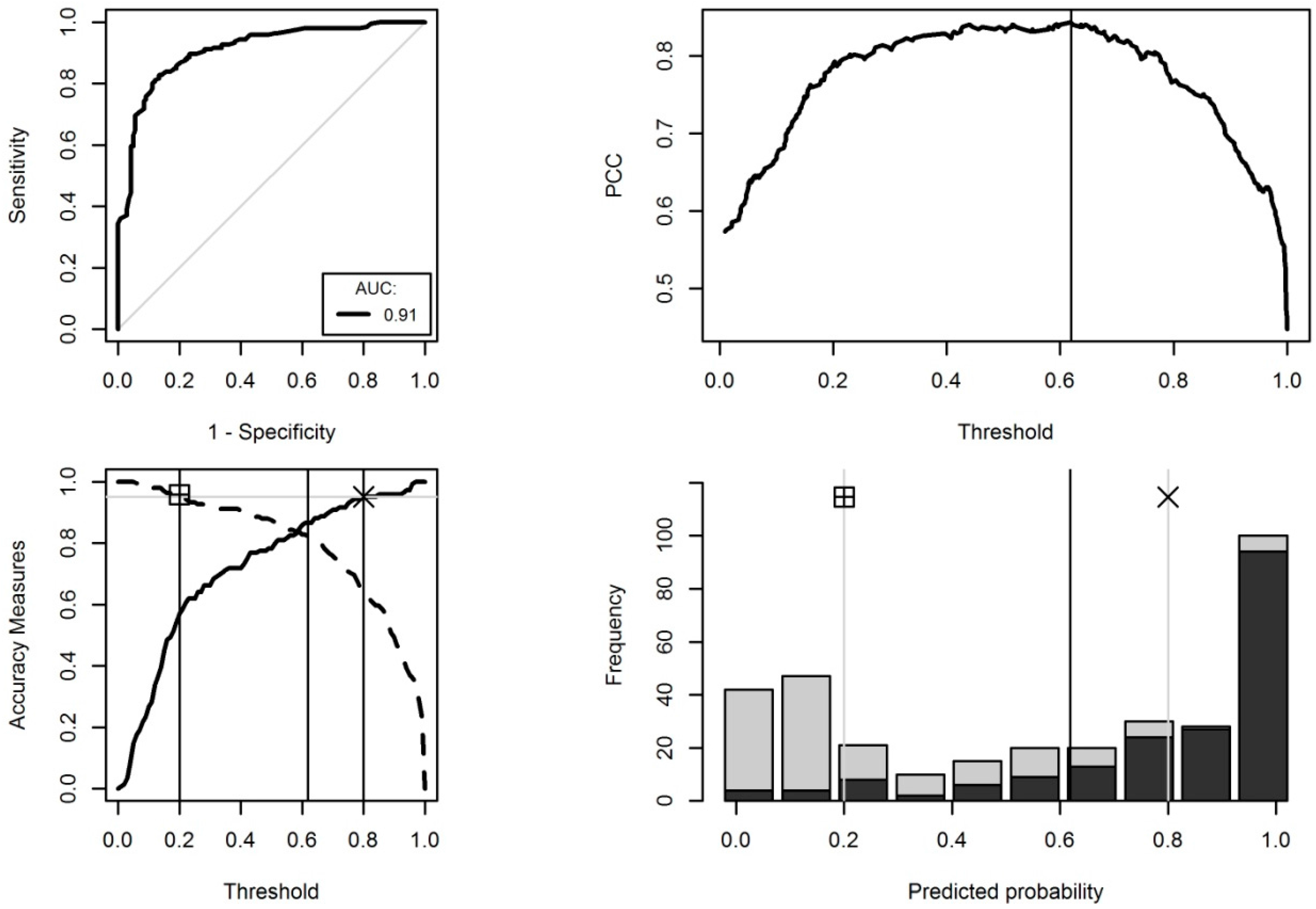
The model had an AUC = 0.91, which indicates a well-performing model with excellent discriminatory ability (Figure 4, top left). The probability threshold for maximising the Youden index was 0.619. The selected threshold also coincided with a maximum in PCC (Figure 4, top right). Probabilities above this threshold were classified as presence of carbonate mounds. Accuracy statistics associated with this threshold are as follows: 84.4% of objects were correctly classified (PCC = 0.844; 95% confidence intervals: (0.8003, 0.8811)). This is significantly higher (p < 2 × 10−16) than the no information rate (NIR = 0.574), which was taken to be the largest class percentage in the data. The model had a high sensitivity (Sens = 0.827) and specificity (Spec = 0.866).
Probability thresholds for Sens = 0.95 and Spec = 0.95 were 0.20 and 0.80, respectively (Figure 4, bottom left). These were employed to typify confidence in the predictions: Confidence is high for probabilities below 0.20 (high confidence in absence) and equal to or greater than 0.80 (high confidence in presence) as indicated by the low proportion of incorrectly classified objects seen in Figure 4 (bottom right). Confidence is low for intermediate probability values. In 1.5% of the cases were the predictions outside the range of modelled values, leading to low confidence in this aspect of the model. Predictions were inside the modelled range for 98.5% of the cases and high confidence was associated with these predictions. Total confidence was high in 67.42%, medium in 32.13% and low in 0.45% of the cases.
3.3. Spatial Representation
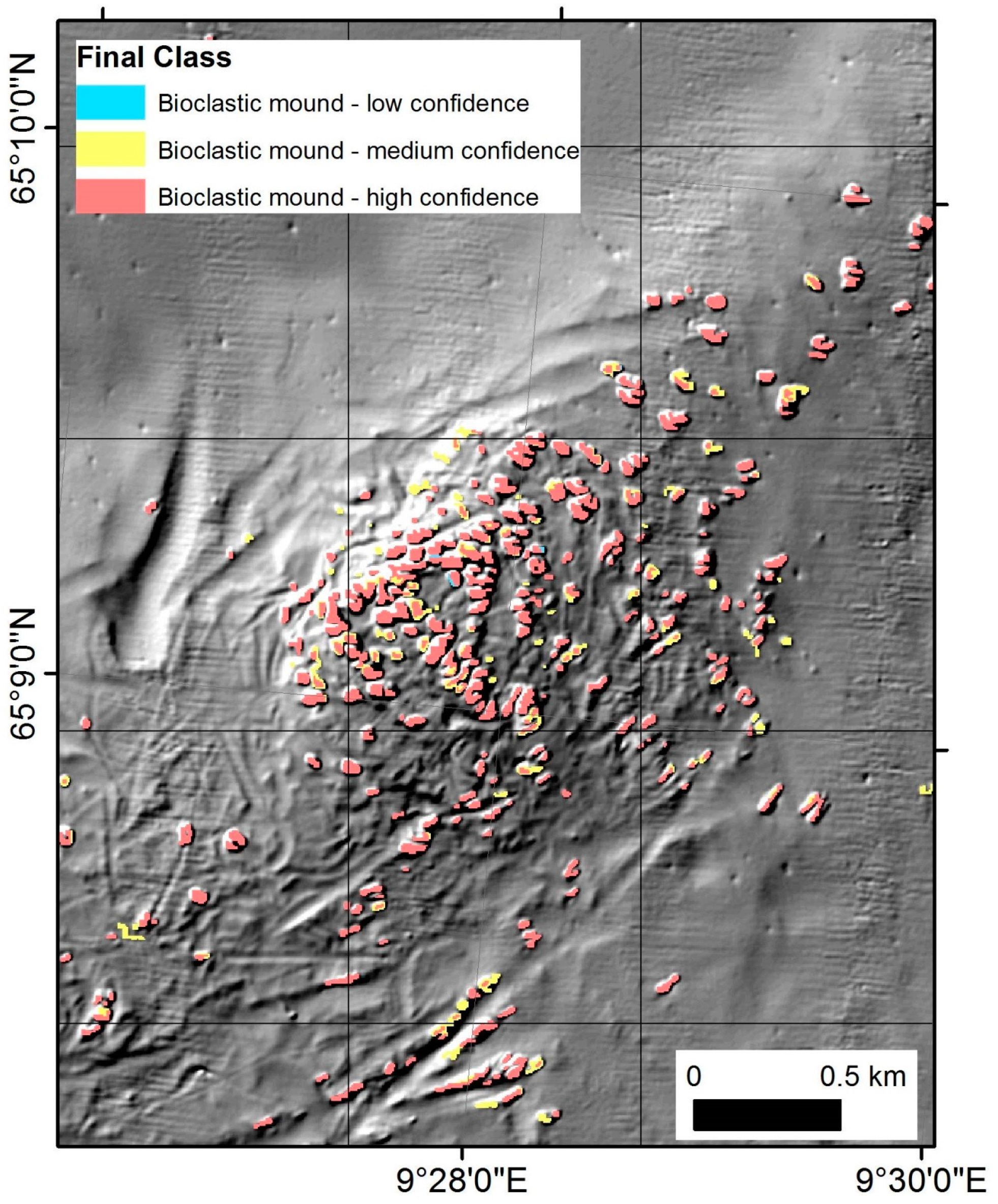
Figure 5 shows an example detail of the results with predicted carbonate mounds mapped with three levels of total confidence. These are overlaid on a hillshade image of the bathymetry.
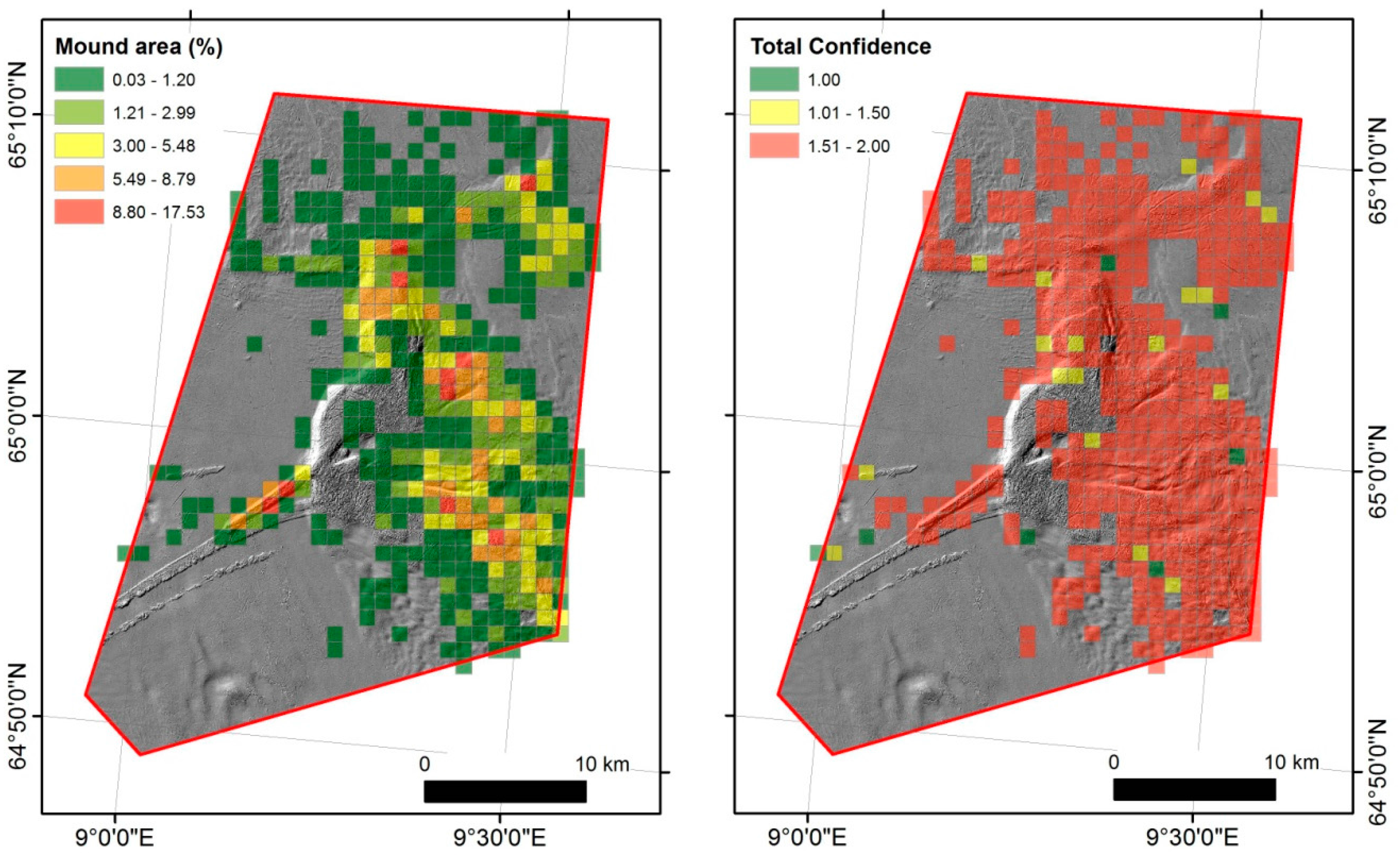
The relative mound area (Figure 6) varies between 0% and close to 18%; however, the distribution is uneven with mound areas below 1% in more than half of the blocks (and not including blocks with a mound area equal to 0%). Mounds occur predominantly in a NNW-SSE trending zone. Confidence in the predictions is high overall.
3.4. Predictor Feature Importance
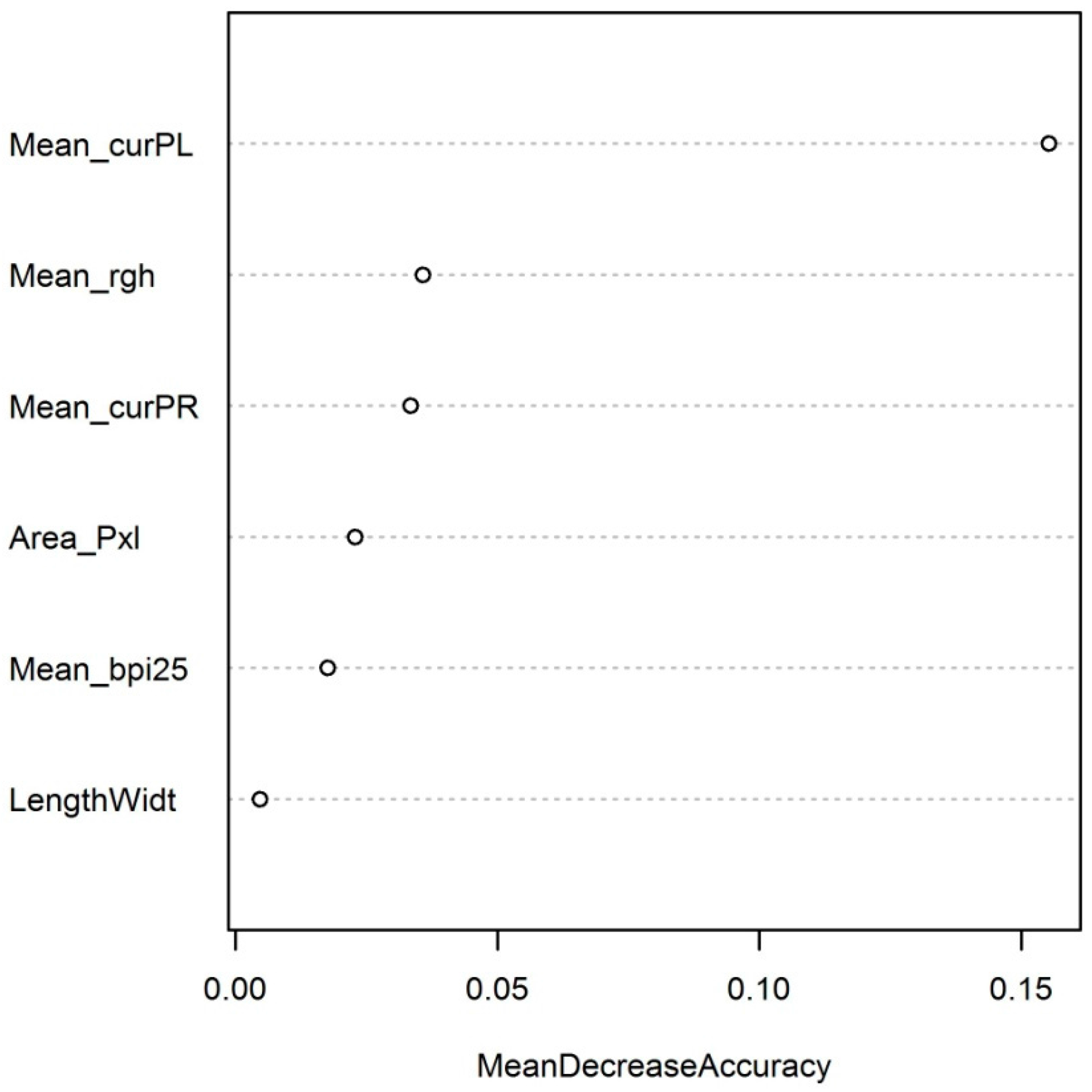
Mean_curvPL was by far the most important predictor feature with a mean decrease in accuracy of approximately 15% (Figure 7). Other features were significantly less important with mean decreases in accuracy below 5%. However, it should be noted that other features that have been removed from the model due to high correlation with those features included in the model may also be useful predictors for carbonate mounds. Based on the feature importance scores of the Boruta analysis (Figure 3), the most likely candidates are Mean_bpi3, Max_0mean, Max_bpi3, Max_curvPL, Mean_0mean, Mean_bpi5, Mean_vrm3 and Mean_curv.
4. Discussion
We have demonstrated how carbonate mounds can be mapped from derivatives of MBES bathymetry in an efficient and validated way with high accuracy by combining image segmentation with presence-absence spatial predictions. This approach is reasonably quick; the most time-consuming steps being data preparation (calculation of derivatives etc.) and classification of sample objects, both of which took approximately one working day. All in all, it took about one working week to derive the showcased maps. This is considerably faster than manual interpretation of the MBES data.
Image segmentation was a vital step in the mapping approach for two reasons: First, it allowed selecting sample objects for visual classification. Such a step would have been difficult to exercise based on image pixels. Second, additional features other than image layer values were extracted and utilised in the spatial prediction. The final model did not only include object mean values, but also extent features, which contributed to the final predictions.
We used a pre-existing bioclastic sediments [18] map layer as a spatial constraint for the analysis. Although this might carry the risk of missing some of the mounds present in the area, we judge the chances of this being the case as low. The main benefit of spatially constraining the analysis were that the total number of image objects used in the analysis was markedly smaller (23,602 instead of 83,085 image objects) and, more importantly, the presence-absence ratio was higher. Initial trials without a spatial constraint at a different but similar site showed that it was still possible to derive meaningful results with high accuracy, but more sample objects are required to give a sufficiently high number of mound presences.
The predictive model was trained and tested with samples that were derived by visually assessing a sub-set of image objects. This approach is arguably prone to introducing error due to the incorrect classification of an unknown number of sample objects. However, we caution that ground-truth information derived from underwater stills or video is equally not free of error due to mis-classification [45]. Moreover, ground-truth information is often difficult and costly to obtain, and these factors typically limit the number of samples available for an analysis. Our approach allowed us to select a large amount of sample objects without the additional costs. We believe that the approach was justified as carbonate mounds are typically conspicuous objects on the seabed readily identifiable from MBES data but do not recommend utilising this approach in situations where the target classes are less obvious.
It is important to assess the performance of a model to understand how reliable the predictions are. In this case, discriminatory ability (AUC) and accuracy (PCC, Sens and Spec) of the predictions were generally high. However, model performance statistics are either global or class-specific, giving no information on the accuracy of the prediction in a spatially explicit way [46]. Maps that portrait the spatial variation of mapping error or uncertainty can be highly informative: They might be used to guide future ground-truth sampling campaigns or provide managers with information on the reliability of predictions when making decisions. Here, we have adopted and modified a scheme to assess the confidence in spatial predictions developed for mapping bedrock outcrops on the United Kingdom’s continental shelf [42]. The confidence in the presence of carbonate mounds is high where probabilities are 0.8 or higher and the predictions are within the modelled range of values of the RF model. Medium confidence in the presence of carbonate mounds means that one of the two criteria is not fulfilled, and low confidence is assigned when both criteria are not fulfilled, but probabilities are higher than 0.619. In this way, we express confidence in the predictions in a way that is simple to understand; yet, confidence is based on objective and measurable criteria rather than scoring systems and it is spatially explicit.
As mentioned earlier, the choice of sensitivity and specificity values of 0.95 was somewhat arbitrary and used for illustrative purposes. Preferably, the selection of those values should be informed by the objectives of the mapping task. Increasing the value for the required specificity will reduce the number of false positives, i.e., the number of image objects incorrectly classified as carbonate mounds will be reduced. For example, increasing the required specificity from 0.95 to 0.99 will increase the probability threshold from 0.8 to 0.96. Consequently, the number of image objects classified accordingly will be reduced from 10,107 to 5868. This might be useful when a high level of certainty in the presence of carbonate mounds is required, for example when a field survey is planned, and targeted stations should correspond to carbonate mounds as frequently as possible.
This approach allows mapping carbonate mounds from MBES data with high accuracy and confidence. Carbonate mounds are the geological product of CWCs [17]; however, it is important to note that the cover of such mounds with live corals can vary dramatically. In fact, mounds might exhibit live coral cover approaching 100% or be completely devoid of live corals, even in close proximity, as shown by detailed results from the Mingulay Reef Complex west of Scotland [47]. Although it has been demonstrated that the likelihood of live coral presence can be spatially predicted [47], it will still require detailed ground-truthing, for example with video or stills images, to establish whether or not carbonate mounds are occupied by live corals and to what degree.
In this case study, Mean_curPL was by far the most important predictor for the presence of carbonate mounds. However, other features relating to terrain variability, curvature and relative position are expected to be suitable predictors for carbonate mounds as well, but were strongly correlated with Mean_curPL and hence removed from the analysis. The comparatively small size of the mounds in relation to the resolution of the terrain data means that small neighbourhood sizes of 3 and 5 were the most relevant. We recommend that other studies attempting to predict carbonate mounds should consider features of terrain variability, curvature and relative position [22] at a relevant scale that reflects both the size of the mounds to be mapped and the resolution of the data utilised.
Future work will include a comparison of the results presented here with ground-truth information from underwater video tows. This information might also be used to add another layer of confidence: Image objects that coincide with interpreted video frames and agree with the interpretation might be given a higher confidence score [42,48]. In a next step, the developed methodology will be applied to areas of the Norwegian continental shelf and slope where MBES data have been collected. Previous research has shown that carbonate mounds are identifiable from MBES data in areas of flat seabed, iceberg ploughmarks and glacial lineations, while slide scar environments and bedrock outcrops limit the ability to detect carbonate mounds [18]. To what extent the presented method is capable of mapping carbonate mounds in such challenging environments remains to be tested. Further work might include the extraction of additional morphometric variables such as the maximum height of a mound above the surrounding seabed and the volume of a mound. Such metrics could be used to derive the amount of inorganic carbon stored in carbonate mounds on the Norwegian seabed, information that is critical for a better understanding of the importance of CWC reefs as carbonate sinks [49] and possible impacts of climate change (warming and acidification) on those carbon stores [12].
Supplementary Materials
The following are available online at https://www.mdpi.com/2076-3263/8/2/34/s1, RuleSetDocu.txt: Documentation of the eCognition rule-set (Chapters 2.4–2.6); Iverryggen_training_data.txt: Model training data set containing observed classes (carbonate mound presence and absence) and predictor feature values; FeatureSelection.r: R script for feature selection (Chapter 2.8); rf2000_2.Rdata: Output from MGET random forest model fitting (Chapter 2.9); rf2000_2_model_stats.txt: Model performance summary and confusion matrix as provided by MGET; MapAccuracy.r: R script for calculation of accuracy statistics (Chapter 2.11); rf2000_2_export_for_PresenceAbsence.txt: Text file containing observed classes (test data) and predicted probabilities; BinaryClassification.r: R script to derive thresholds for selected sensitivity and specificity and model performance plots (Chapter 2.12).
Acknowledgments
This study was funded by the Geological Survey of Norway. The bathymetry data were made available by the Norwegian Mapping Authority, Division Hydrographic Service, funded by the MAREANO programme.
Author Contributions
Markus Diesing and Terje Thorsnes conceived and designed the study; Markus Diesing performed the analysis; Markus Diesing analysed the data; Markus Diesing and Terje Thorsnes wrote the paper.
Conflicts of Interest
The authors declare no conflict of interest. The founding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
References
- Roberts, J.M.; Wheeler, A.J.; Freiwald, A. Reefs of the Deep: The Biology and Geology of Cold-Water Coral Ecosystems. Science 2006, 312, 543–547. [Google Scholar] [CrossRef] [PubMed]
- Baillon, S.; Hamel, J.-F.; Wareham, V.E.; Mercier, A. Deep cold-water corals as nurseries for fish larvae. Front. Ecol. Environ. 2012, 10, 351–356. [Google Scholar] [CrossRef]
- Costello, M.J.; McCrea, M.; Freiwald, A.; Lundälv, T.; Jonsson, L.; Bett, B.J.; van Weering, T.C.E.; de Haas, H.; Roberts, J.M.; Allen, D. Role of cold-water Lophelia pertusa coral reefs as fish habitat in the NE Atlantic. In Cold-Water Corals and Ecosystems; Freiwald, A., Roberts, J.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 771–805. ISBN 978-3-540-27673-9. [Google Scholar]
- Auster, P.J. Are deep-water corals important habitats for fishes? In Cold-Water Corals and Ecosystems; Freiwald, A., Roberts, J.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 747–760. ISBN 978-3-540-27673-9. [Google Scholar]
- Althaus, F.; Williams, A.; Schlacher, T.; Kloser, R.J.; Green, M.; Barker, B.; Bax, N.; Brodie, P. Impacts of bottom trawling on deep-coral ecosystems of seamounts are long-lasting. Mar. Ecol. Prog. Ser. 2009, 397, 279–294. [Google Scholar] [CrossRef]
- Hall-Spencer, J.; Allain, V.; Fosså, J.H. Trawling damage to Northeast Atlantic ancient coral reefs. Proc. R. Soc. Lond. Ser. B Biol. Sci. 2002, 269, 507–511. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fosså, J.H.; Mortensen, P.B.; Furevik, D.M. The deep-water coral Lophelia pertusa in Norwegian waters: Distribution and fishery impacts. Hydrobiologia 2002, 471, 1–12. [Google Scholar] [CrossRef]
- Huvenne, V.A.I.; Bett, B.J.; Masson, D.G.; Le Bas, T.P.; Wheeler, A.J. Effectiveness of a deep-sea cold-water coral Marine Protected Area, following eight years of fisheries closure. Biol. Conserv. 2016, 200, 60–69. [Google Scholar] [CrossRef] [Green Version]
- Fisher, C.R.; Hsing, P.-Y.; Kaiser, C.L.; Yoerger, D.R.; Roberts, H.H.; Shedd, W.W.; Cordes, E.E.; Shank, T.M.; Berlet, S.P.; Saunders, M.G.; et al. Footprint of Deepwater Horizon blowout impact to deep-water coral communities. Proc. Natl. Acad. Sci. USA 2014, 111, 11744–11749. [Google Scholar] [CrossRef] [PubMed]
- Purser, A.; Thomsen, L. Monitoring strategies for drill cutting discharge in the vicinity of cold-water coral ecosystems. Mar. Pollut. Bull. 2012, 64, 2309–2316. [Google Scholar] [CrossRef] [PubMed]
- Guinotte, J.M.; Orr, J.; Cairns, S.; Freiwald, A.; Morgan, L.; George, R. Will human-induced changes in seawater chemistry alter the distribution of deep-sea scleractinian corals? Front. Ecol. Environ. 2006, 4, 141–146. [Google Scholar] [CrossRef]
- Hoegh-Guldberg, O.; Poloczanska, E.S.; Skirving, W.; Dove, S. Coral Reef Ecosystems under Climate Change and Ocean Acidification. Front. Mar. Sci. 2017, 4, 158. [Google Scholar] [CrossRef]
- Maier, C.; Watremez, P.; Taviani, M.; Weinbauer, M.G.; Gattuso, J.P. Calcification rates and the effect of ocean acidification on Mediterranean cold-water corals. Proc. R. Soc. Lond. Ser. B Biol. Sci. 2012, 279, 1716–1723. [Google Scholar] [CrossRef] [PubMed]
- Büscher, J.V.; Form, A.U.; Riebesell, U. Interactive Effects of Ocean Acidification and Warming on Growth, Fitness and Survival of the Cold-Water Coral Lophelia pertusa under Different Food Availabilities. Front. Mar. Sci. 2017, 4, 101. [Google Scholar] [CrossRef]
- Davies, A.J.; Wisshak, M.; Orr, J.C.; Murray Roberts, J. Predicting suitable habitat for the cold-water coral Lophelia pertusa (Scleractinia). Deep Sea Res. Part I Oceanogr. Res. Pap. 2008, 55, 1048–1062. [Google Scholar] [CrossRef]
- Davies, A.J.; Guinotte, J.M. Global Habitat Suitability for Framework-Forming Cold-Water Corals. PLoS ONE 2011, 6, e18483. [Google Scholar] [CrossRef] [PubMed]
- Wheeler, A.J.; Beyer, A.; Freiwald, A.; de Haas, H.; Huvenne, V.A.I.; Kozachenko, M.; Olu-Le Roy, K.; Opderbecke, J. Morphology and environment of cold-water coral carbonate mounds on the NW European margin. Int. J. Earth Sci. 2007, 96, 37–56. [Google Scholar] [CrossRef]
- Bellec, V.K.; Thorsnes, T.; Bøe, R. Mapping of Bioclastic Sediments—Data, Methods and Confidence. Available online: http://www.ngu.no/upload/Publikasjoner/Rapporter/2014/2014_006.pdf (accessed on 10 November 2017).
- Thorsnes, T.; Bellec, V.; Baeten, N.; Plassen, L.; Bjarnadóttir, L.; Ottesen, D.; Dolan, M.; Elvenes, S.; Rise, L.; Longva, O.; et al. The Seabed - Marine Landscapes, Geology and Processes. Available online: http://mareano.no/resources/images/2015/chapter-7.pdf (accessed on 10 November 2017).
- Bjarnadóttir, L.R.; Ottesen, D.; Bellec, V.; Lepland, A.; Elvenes, S.; Dolan, M.; Bøe, R.; Rise, L.; Thorsnes, T.; Selboskar, O.H. Geologisk Havbunnskart, KART 65000900, Mai 2017. M 1: 100 000. 2017. Available online: http://www.ngu.no/upload/Publikasjoner/Kart/Maringeologi/Geologisk_havbunnskart_65000900.pdf (accessed on 10 December 2017).
- Buhl-Mortensen, P.; Buhl-Mortensen, L.; Dolan, M. Bottom Habitats and Fauna. Available online: http://mareano.no/resources/images/2015/chapter-7.pdf (accessed on 10 November 2017).
- Wilson, M.F.J.; O’Connell, B.; Brown, C.; Guinan, J.C.; Grehan, A.J. Multiscale Terrain Analysis of Multibeam Bathymetry Data for Habitat Mapping on the Continental Slope. Mar. Geodesy 2007, 30, 3–35. [Google Scholar] [CrossRef]
- Sappington, J.M.; Longshore, K.M.; Thompson, D.B. Quantifying Landscape Ruggedness for Animal Habitat Analysis: A Case Study Using Bighorn Sheep in the Mojave Desert. J. Wildl. Manag. 2007, 71, 1419–1426. [Google Scholar] [CrossRef]
- Lundblad, E.R.; Wright, D.J.; Miller, J.; Larkin, E.M.; Rinehart, R.; Naar, D.F.; Donahue, B.T.; Anderson, S.M.; Battista, T. A Benthic Terrain Classification Scheme for American Samoa. Mar. Geodesy 2006, 29, 89–111. [Google Scholar] [CrossRef]
- Krämer, K.; Holler, P.; Herbst, G.; Bratek, A.; Ahmerkamp, S.; Neumann, A.; Bartholomä, A.; van Beusekom, J.E.E.; Holtappels, M.; Winter, C. Abrupt emergence of a large pockmark field in the German Bight, southeastern North Sea. Sci. Rep. 2017, 7, 5150. [Google Scholar] [CrossRef] [PubMed]
- Hay, G.J.; Castilla, G. Geographic Object-Based Image Analysis (GEOBIA): A new name for a new discipline. In Object-Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications; Blaschke, T., Lang, S., Hay, G.J., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 75–89. [Google Scholar]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, R.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a new paradigm. J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Schiewe, J. Segmentation of high-resolution remotely sensed data—Concepts, applications and problems. In Proceedings of the Symposium on Geospatial Theory, Processing and Applications, Ottawa, ON, Canada, 9–12 July 2002. [Google Scholar]
- Kursa, M.; Rudnicki, W. Feature selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–11. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Prasad, A.M.; Iverson, L.R.; Liaw, A. Newer classification and regression tree techniques: Bagging and random forests for ecological prediction. Ecosystems 2006, 9, 181–199. [Google Scholar] [CrossRef]
- Huang, Z.; Siwabessy, J.; Nichol, S.L.; Brooke, B.P. Predictive mapping of seabed substrata using high-resolution multibeam sonar data: A case study from a shelf with complex geomorphology. Mar. Geol. 2014, 357, 37–52. [Google Scholar]
- Diesing, M.; Kröger, S.; Parker, R.; Jenkins, C.; Mason, C.; Weston, K. Predicting the standing stock of organic carbon in surface sediments of the North–West European continental shelf. Biogeochemistry 2017, 135, 183–200. [Google Scholar] [CrossRef]
- Hasan, R.C.; Ierodiaconou, D.; Monk, J. Evaluation of Four Supervised Learning Methods for Benthic Habitat Mapping Using Backscatter from Multi-Beam Sonar. Remote Sens. 2012, 4, 3427–3443. [Google Scholar] [CrossRef]
- Cutler, D.; Edwards, T.; Beards, K.; Cutler, A.; Hess, K.; Gibson, J.; Lawler, J. Random Forests for classification in Ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef] [PubMed]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; ISBN 9781461471370. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar] [CrossRef]
- Roberts, J.J.; Best, B.D.; Dunn, D.C.; Treml, E.A.; Halpin, P.N. Marine Geospatial Ecology Tools: An integrated framework for ecological geoprocessing with ArcGIS, Python, R, MATLAB, and C++. Environ. Model. Softw. 2010, 25, 1197–1207. [Google Scholar] [CrossRef]
- Perkins, N.J.; Schisterman, E.F. The inconsistency of “optimal” cutpoints obtained using two criteria based on the receiver operating characteristic curve. Am. J. Epidemiol. 2006, 163, 670–675. [Google Scholar] [CrossRef] [PubMed]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Downie, A.L.; Dove, D.; Westhead, R.K.; Diesing, M.; Green, S.; Cooper, R. Semi-Automated Mapping of Rock in the North Sea; JNCC Report 592; JNCC: Peterborough, UK, 2016. [Google Scholar] [CrossRef]
- Freeman, E.A.; Moisen, G. PresenceAbsence: An R Package for Presence Absence Analysis. J. Stat. Softw. 2008, 23, 1–31. [Google Scholar] [CrossRef]
- Sing, T.; Sander, O.; Beerenwinkel, N.; Lengauer, T. ROCR: Visualizing classifier performance in R. Bioinformatics 2005, 21, 3940–3941. [Google Scholar] [CrossRef] [PubMed]
- Rattray, A.J.; Ierodiaconou, D.; Monk, J.; Laurenson, L.; Kennedy, P. Quantification of Spatial and Thematic Uncertainty in the Application of Underwater Video for Benthic Habitat Mapping. Mar. Geodesy 2014, 37, 315–336. [Google Scholar] [CrossRef]
- Diesing, M.; Mitchell, P.; Stephens, D. Image-based seabed classification: What can we learn from terrestrial remote sensing? ICES J. Mar. Sci. 2016, 73, 2425–2441. [Google Scholar] [CrossRef]
- De Clippele, L.H.; Gafeira, J.; Robert, K.; Hennige, S.; Lavaleye, M.S.; Duineveld, G.C.A.; Huvenne, V.A.I.; Roberts, J.M. Using novel acoustic and visual mapping tools to predict the small-scale spatial distribution of live biogenic reef framework in cold-water coral habitats. Coral Reefs 2017, 36, 255–268. [Google Scholar] [CrossRef]
- Lillis, H. A Three-Step Confidence Assessment Framework for Classified Seabed Maps; JNCC Report 591; JNCC: Peterborough, UK, 2016. [Google Scholar]
- Titschack, J.; Baum, D.; De Pol-Holz, R.; López Correa, M.; Forster, N.; Flögel, S.; Hebbeln, D.; Freiwald, A. Aggradation and carbonate accumulation of Holocene Norwegian cold-water coral reefs. Sedimentology 2015, 62, 1873–1898. [Google Scholar] [CrossRef]
Figure 1.
Map showing bathymetry in the study site Iverryggen. Inset map shows the location of the study site off the coast of Norway.
Figure 1.
Map showing bathymetry in the study site Iverryggen. Inset map shows the location of the study site off the coast of Norway.

Figure 2.
General work flow.

Figure 3.
Results of the Boruta feature selection analysis. Green colours indicate important features, red colours indicate unimportant features. Shadow features are shown in blue.
Figure 3.
Results of the Boruta feature selection analysis. Green colours indicate important features, red colours indicate unimportant features. Shadow features are shown in blue.

Figure 4.
Summary of model performance: Top left—ROC curve (bold black line) indicating AUC = 0.91. The grey diagonal indicates AUC = 0.5 (no discrimination ability). Top right—PCC versus selected threshold: The threshold selected by maximising the Youden index (0.619) gave the highest PCC. Bottom left—Sensitivity (dashed line) and specificity (solid line) versus selected threshold: Requesting Sens = 0.95 and Spec = 0.95 gave thresholds of 0.2 and 0.8, respectively. Bottom right—Histogram showing the frequency of presence (black) and absence (grey) observations against the predicted probability.
Figure 4.
Summary of model performance: Top left—ROC curve (bold black line) indicating AUC = 0.91. The grey diagonal indicates AUC = 0.5 (no discrimination ability). Top right—PCC versus selected threshold: The threshold selected by maximising the Youden index (0.619) gave the highest PCC. Bottom left—Sensitivity (dashed line) and specificity (solid line) versus selected threshold: Requesting Sens = 0.95 and Spec = 0.95 gave thresholds of 0.2 and 0.8, respectively. Bottom right—Histogram showing the frequency of presence (black) and absence (grey) observations against the predicted probability.

Figure 5.
Left—Example detail of mapping results showing predicted occurrence of carbonate mounds and associated total confidence overlaid on a hillshade image of the bathymetry. Also visible is the 1 km by 1 km raster used to aggregate data on carbonate mounds.
Figure 5.
Left—Example detail of mapping results showing predicted occurrence of carbonate mounds and associated total confidence overlaid on a hillshade image of the bathymetry. Also visible is the 1 km by 1 km raster used to aggregate data on carbonate mounds.

Figure 6.
Left—Carbonate mound area per 1 km2 block expressed as percentage of mound area per block. Right—Average total confidence per 1 km2 block. Only blocks that were occupied by at least one carbonate mound are shown.
Figure 6.
Left—Carbonate mound area per 1 km2 block expressed as percentage of mound area per block. Right—Average total confidence per 1 km2 block. Only blocks that were occupied by at least one carbonate mound are shown.

Figure 7.
Predictor feature importance expressed as the mean decrease in accuracy when a feature is randomised. Larger decreases mean that the feature is more important. The mean decrease in accuracy ranges from 0 to 1.
Figure 7.
Predictor feature importance expressed as the mean decrease in accuracy when a feature is randomised. Larger decreases mean that the feature is more important. The mean decrease in accuracy ranges from 0 to 1.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Bathymetric derivatives utilised in this study.
| Derivative | Description | Abb. | Unit | Reference |
|---|---|---|---|---|
| Slope | The maximum slope gradient | slope | ° | [22] |
| Roughness | The difference between minimum and maximum of a cell and its eight neighbours. | rgh | m | [22] |
| Vector ruggedness measure (VRM) | The variation in three-dimensional orientation of grid cells within a neighbourhood. A radius of 3 pixels was used. | vrm3 | - | [23] |
| Curvature | Rate of change of slope. Profile (PR) curvature is measured parallel to maximum slope; plan (PL) curvature is measured perpendicular to slope. | Curv curvPL curvPR | - | [22] |
| Bathymetric position index (BPI) | Vertical position of a cell relative to its neighbourhood. Radii of 3, 5, 10 and 25 pixels were used. | bpi3 bpi5 bpi10 bpi25 | m | [24] |
| Zero-mean bathymetry | A moving mean filter with a rectangular neighbourhood of 25 m by 25 m was applied to the bathymetry layer. The resulting smoothed bathymetry was subtracted from the bathymetry layer. | 0mean | m | [25] |
Table 2.
Image-object features extracted for further analysis. Abbreviations of extent and shape features given in brackets.
Table 2.
Image-object features extracted for further analysis. Abbreviations of extent and shape features given in brackets.
| Feature Type | Features |
|---|---|
| Object mean value (Mean_...) | slope, rgh, vrm3, curv, curvPL, curvPR, bpi3, bpi5, bpi10, bpi25, 0mean |
| Maximum pixel value (Max_...) | slope, rgh, vrm3, curvPL, bpi3, 0mean |
| Extent | Area (Area_Pxl), border length (Border_len), length-width ratio (LengthWidt) |
| Shape | Asymmetry, compactness (Compactnes), elliptic fit (Elliptic_f), main direction (Main_direc) |
Table 3.
Number of sample objects in training and test set.
| Training | Test | Sum | |
|---|---|---|---|
| Presence (1) | 382 | 191 | 573 |
| Absence (0) | 285 | 142 | 427 |
| Sum | 667 | 333 | 1000 |
Table 4.
Contingency table for presence-absence predictions and selected associated accuracy metrics.
Table 4.
Contingency table for presence-absence predictions and selected associated accuracy metrics.
| Observed Absence | Observed Presence | |
|---|---|---|
| Predicted absence | True negative (TN) | False negative (FN) |
| Predicted presence | False positive (FP) | True positive (TP) |
Table 5.
Variance inflation factors for the selected features.
| Feature | VIF |
|---|---|
| Mean_curPL | 2.654873 |
| Mean_rgh | 1.9249 |
| Mean_curPR | 2.250794 |
| LengthWidt | 1.133754 |
| Area_Pxl | 1.340249 |
| Mean_bpi25 | 2.28189 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Diesing, M.; Thorsnes, T. Mapping of Cold-Water Coral Carbonate Mounds Based on Geomorphometric Features: An Object-Based Approach. Geosciences 2018, 8, 34. https://doi.org/10.3390/geosciences8020034
AMA Style
Diesing M, Thorsnes T. Mapping of Cold-Water Coral Carbonate Mounds Based on Geomorphometric Features: An Object-Based Approach. Geosciences. 2018; 8(2):34. https://doi.org/10.3390/geosciences8020034
Chicago/Turabian StyleDiesing, Markus, and Terje Thorsnes. 2018. "Mapping of Cold-Water Coral Carbonate Mounds Based on Geomorphometric Features: An Object-Based Approach" Geosciences 8, no. 2: 34. https://doi.org/10.3390/geosciences8020034
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.