
Discovering Intra-Urban Population Movement Pattern Using Taxis’ Origin and Destination Data and Modeling the Parameters Affecting Population Distribution


Abstract
:1. Introduction
2. Relevant Literature
3. The Study Area
4. Data and Research Method
4.1. Identify the Pattern of Intra-Urban Population Movement Using Taxis’ Origin and Destination Data
4.2. Modeling the Parameters Affecting Population Distribution
5. Results
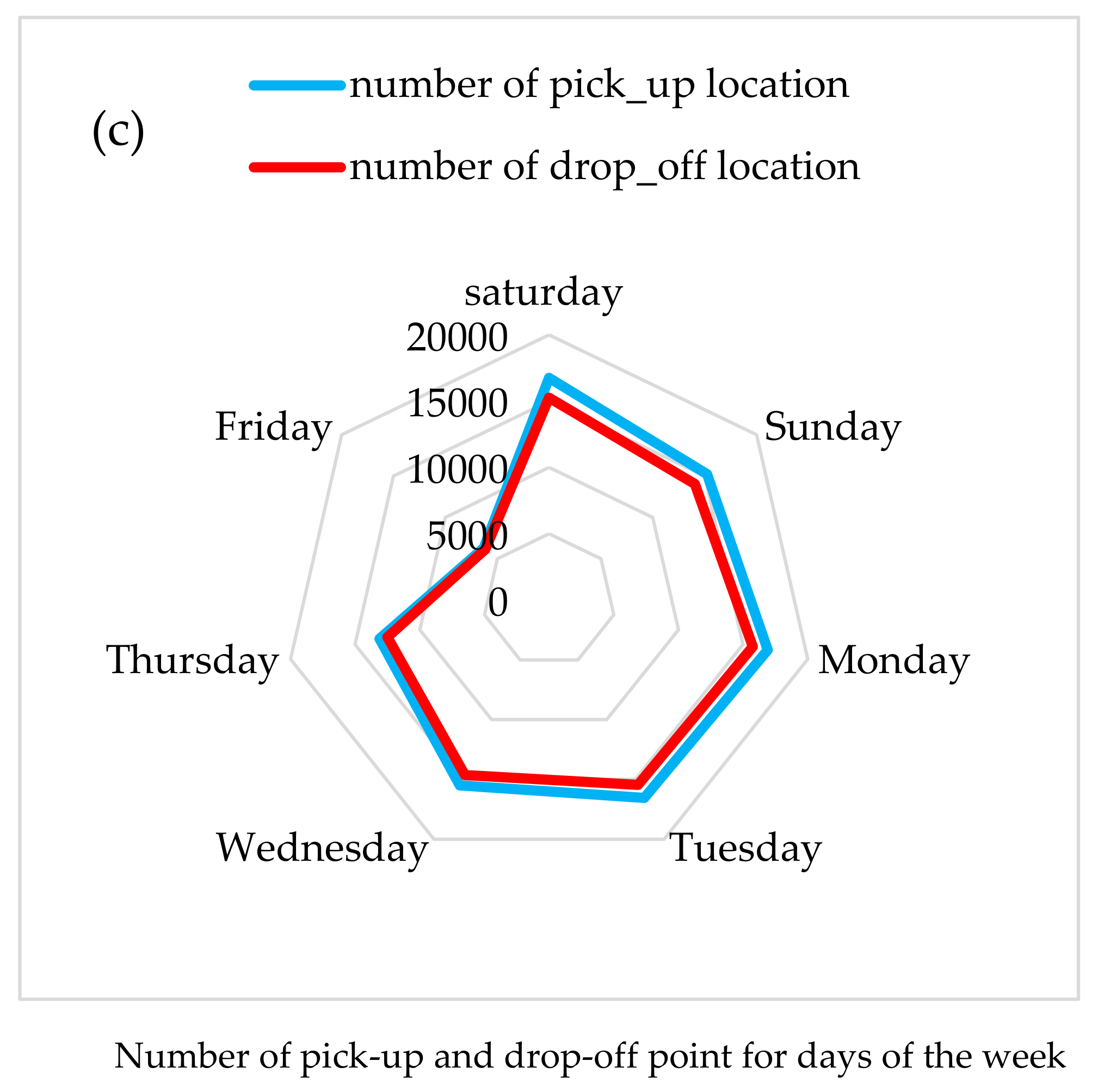
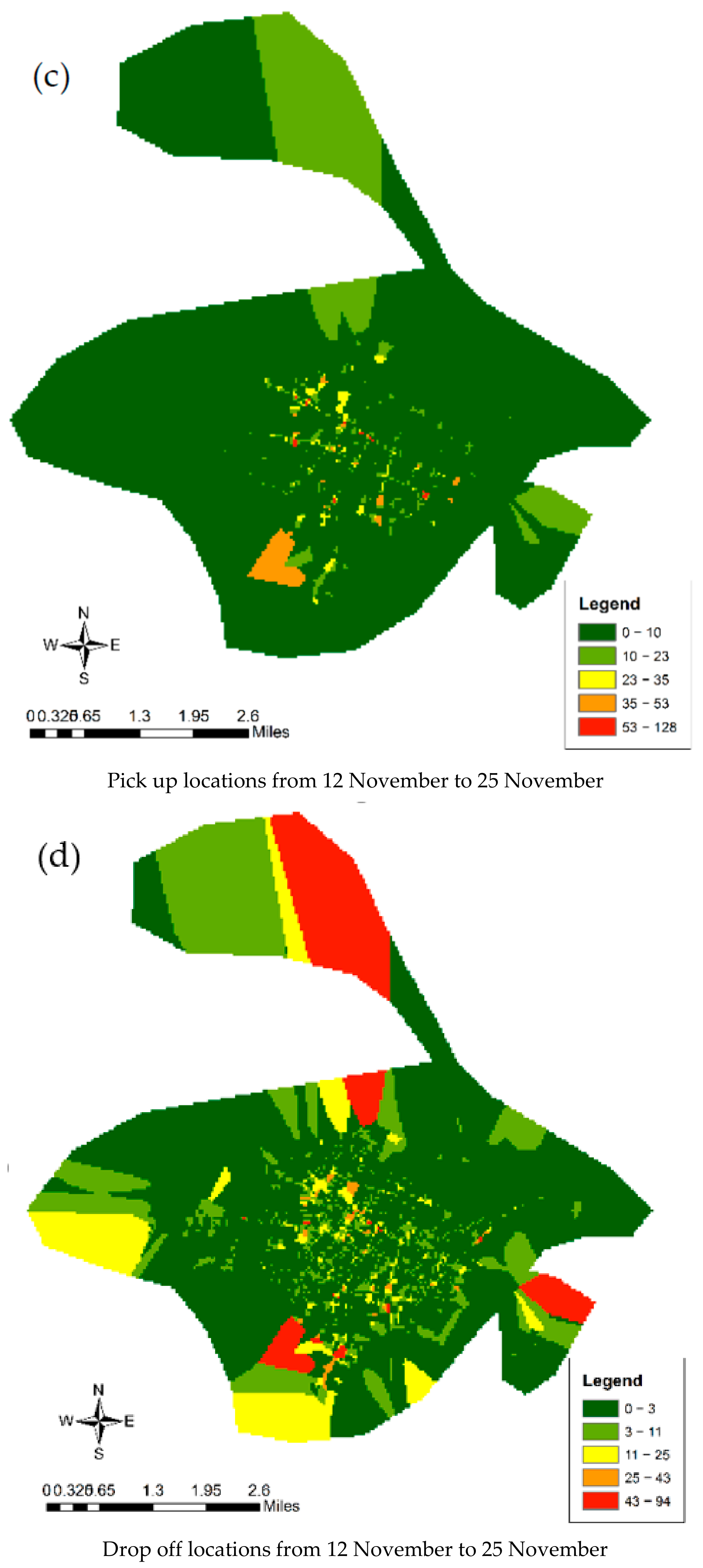
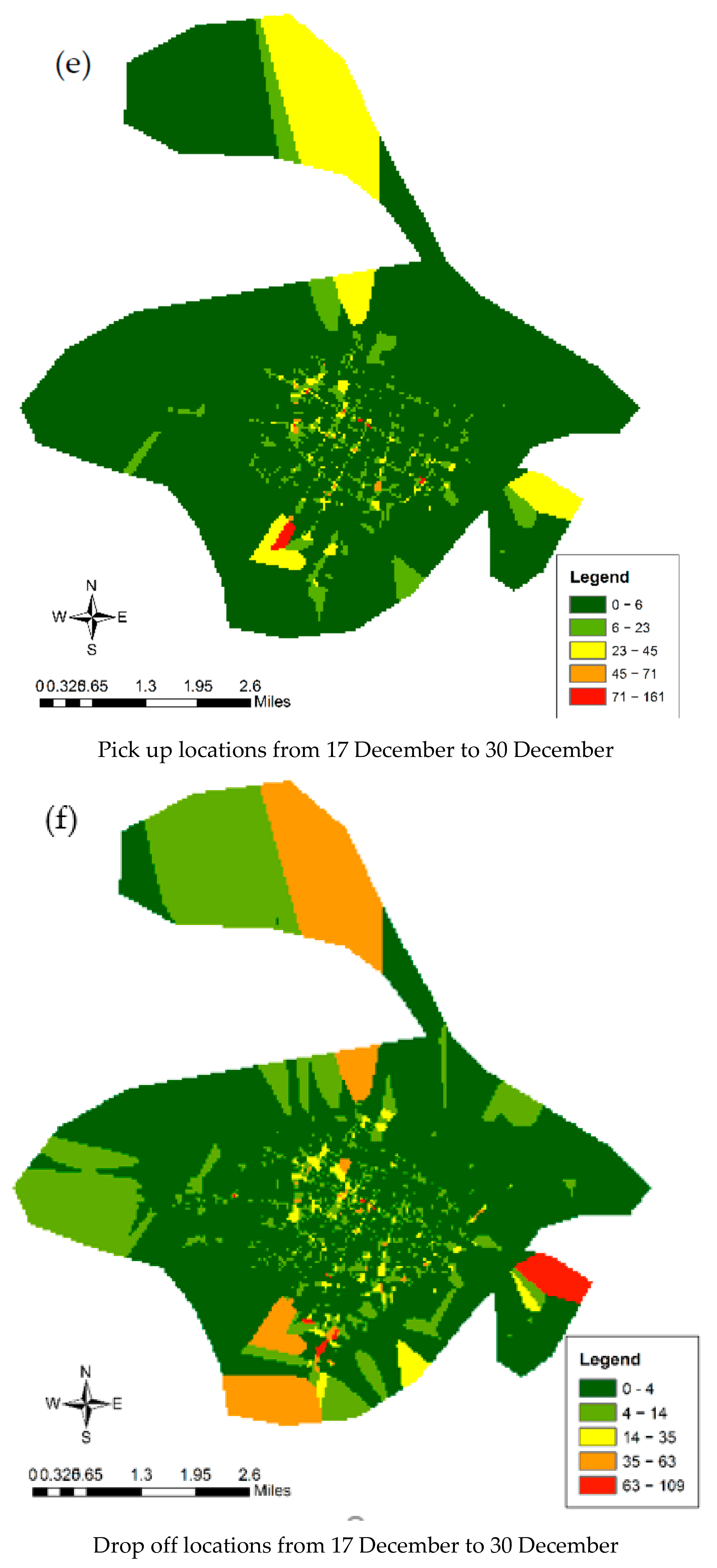
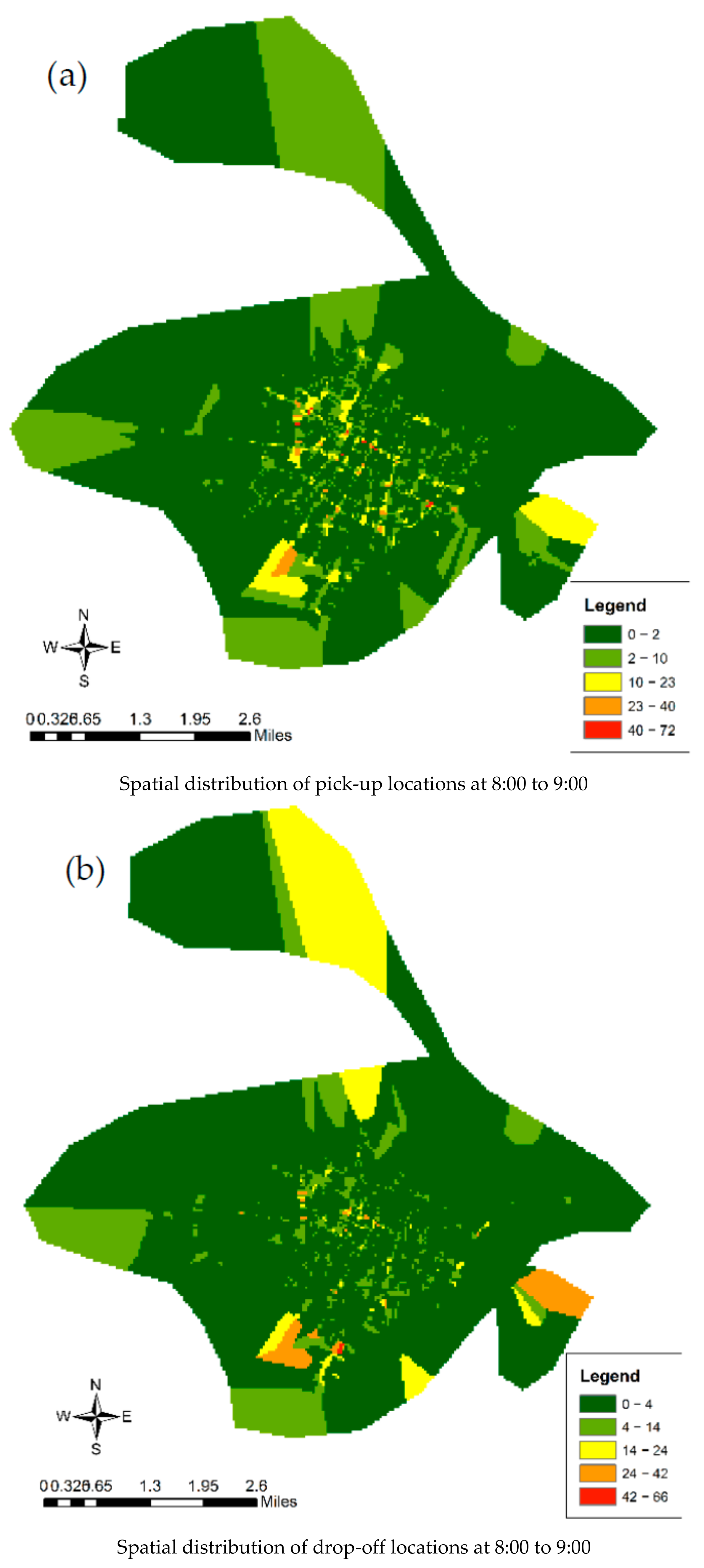
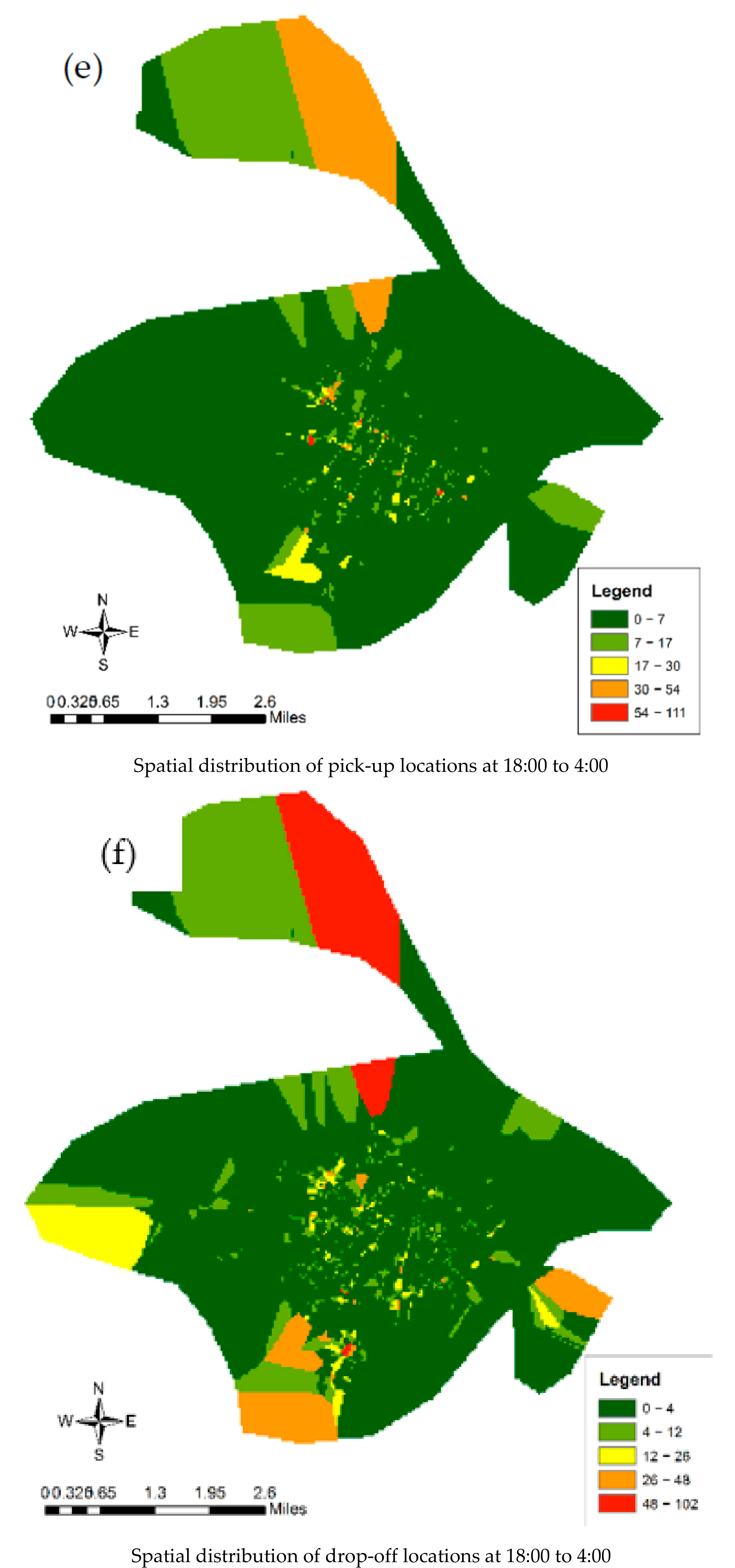
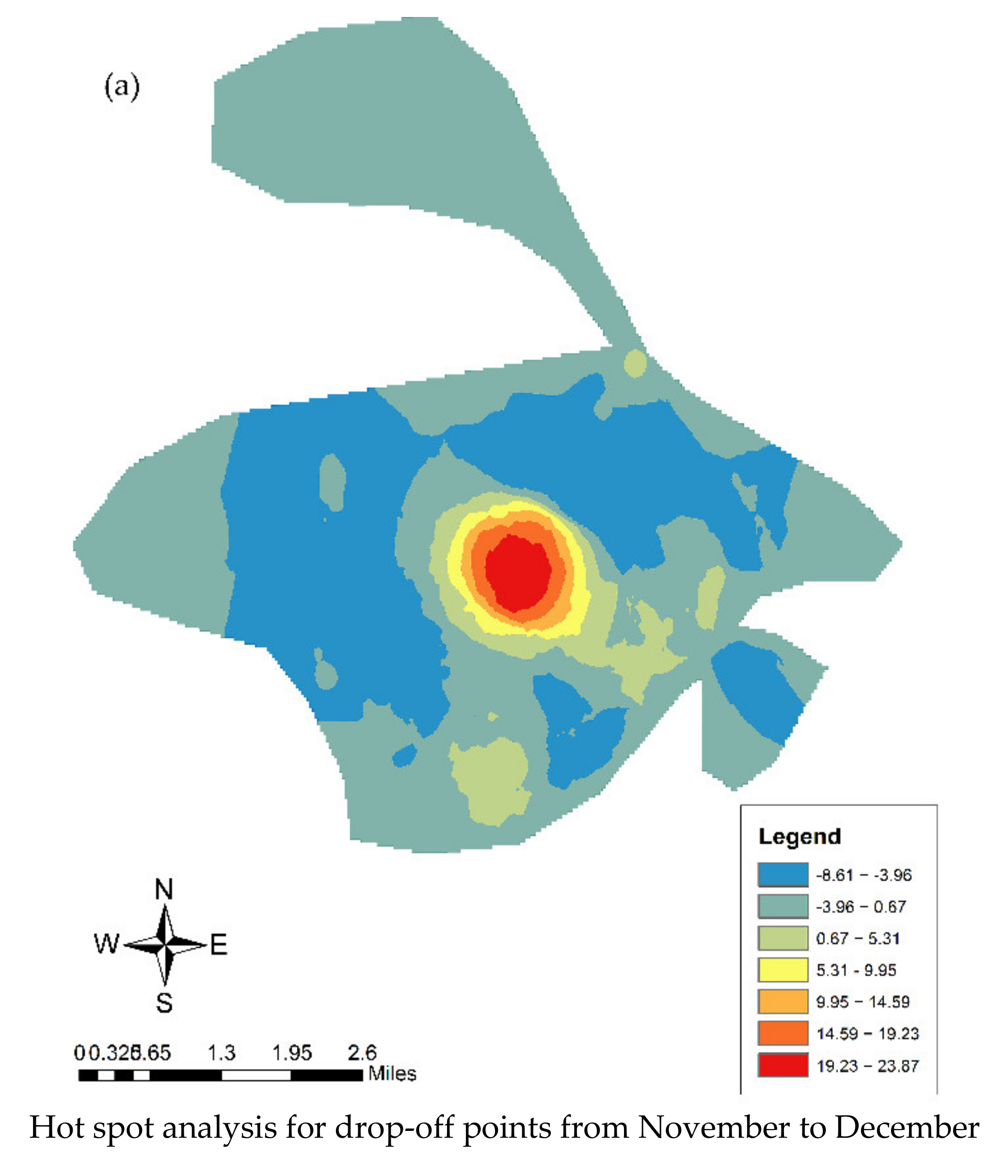
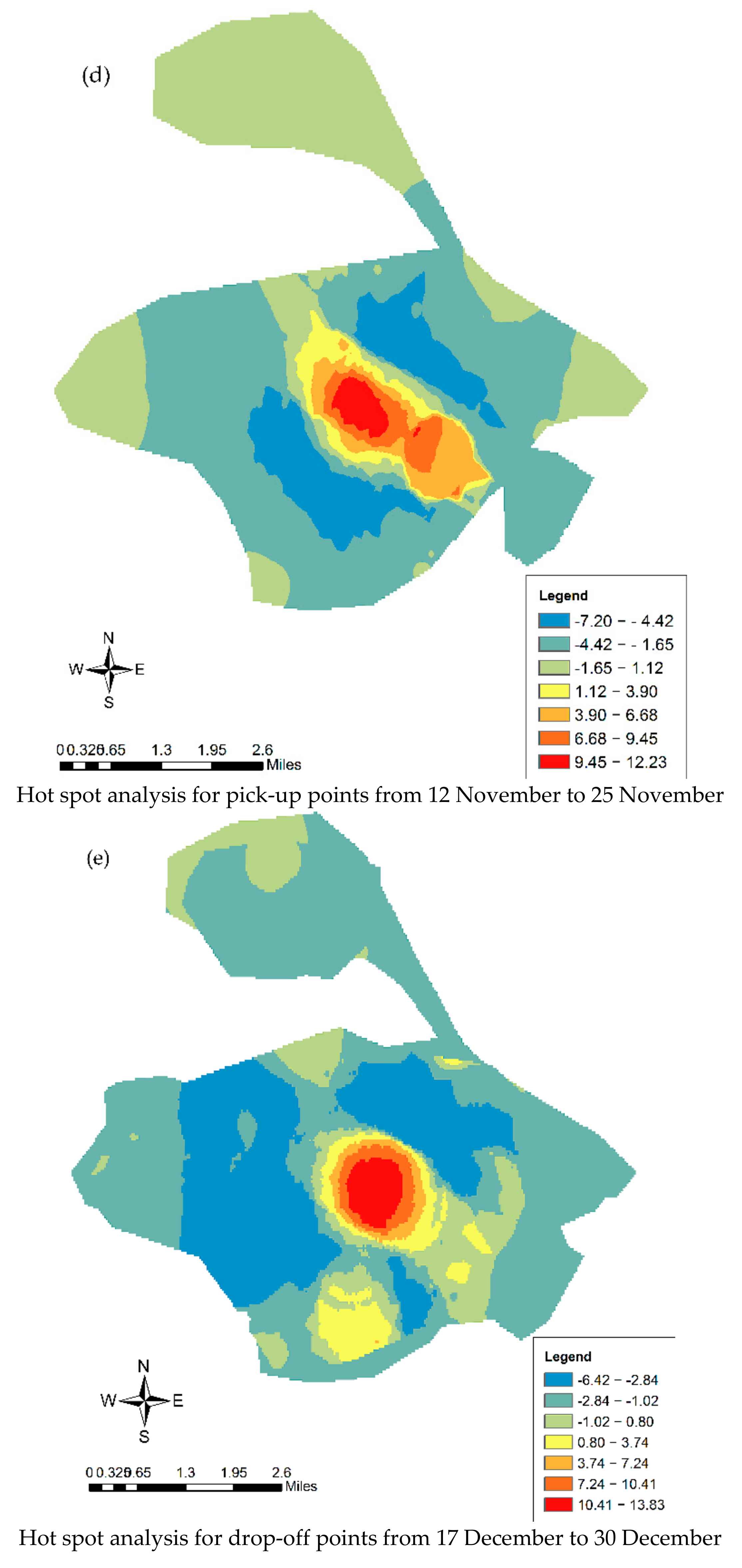
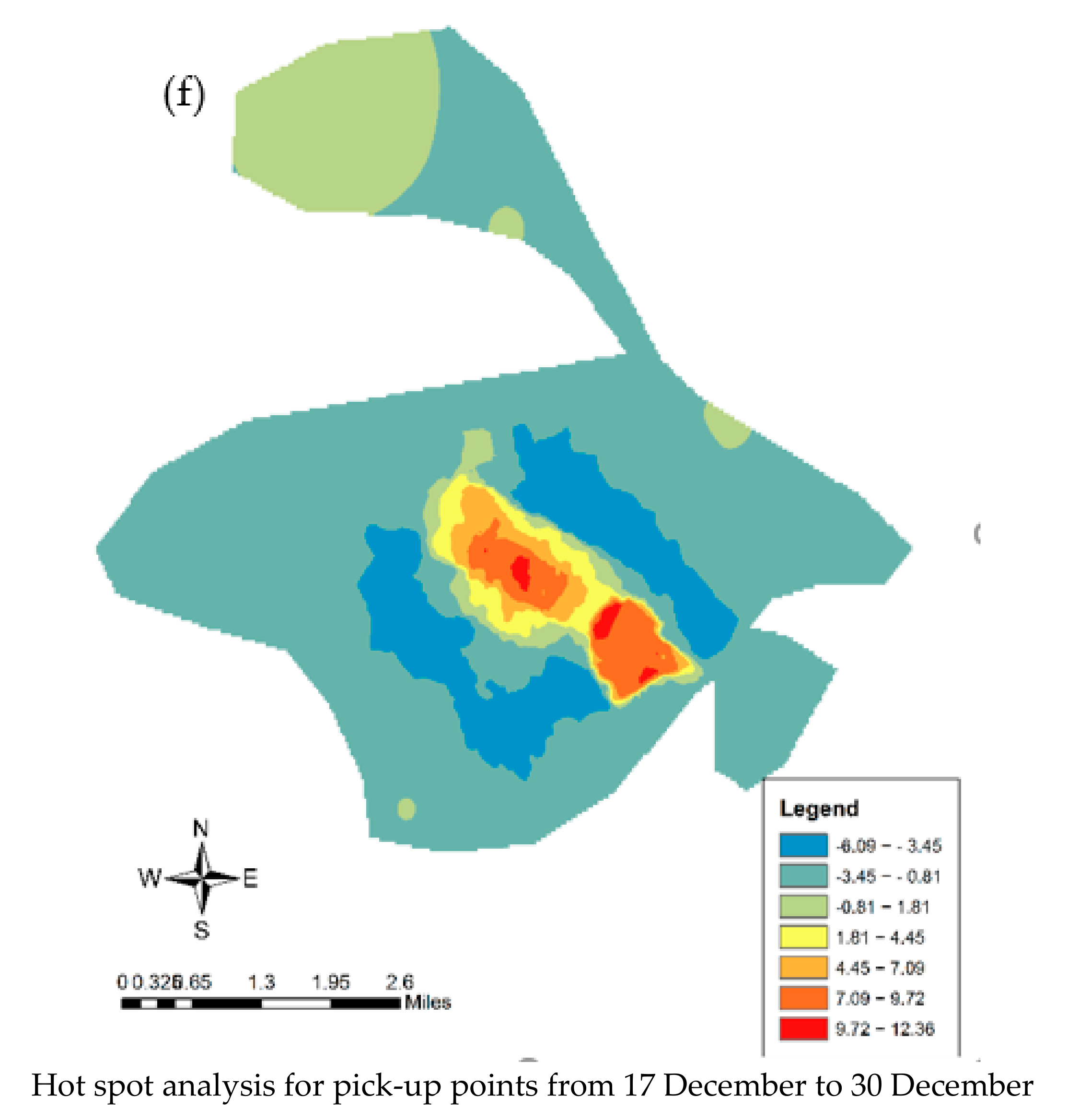
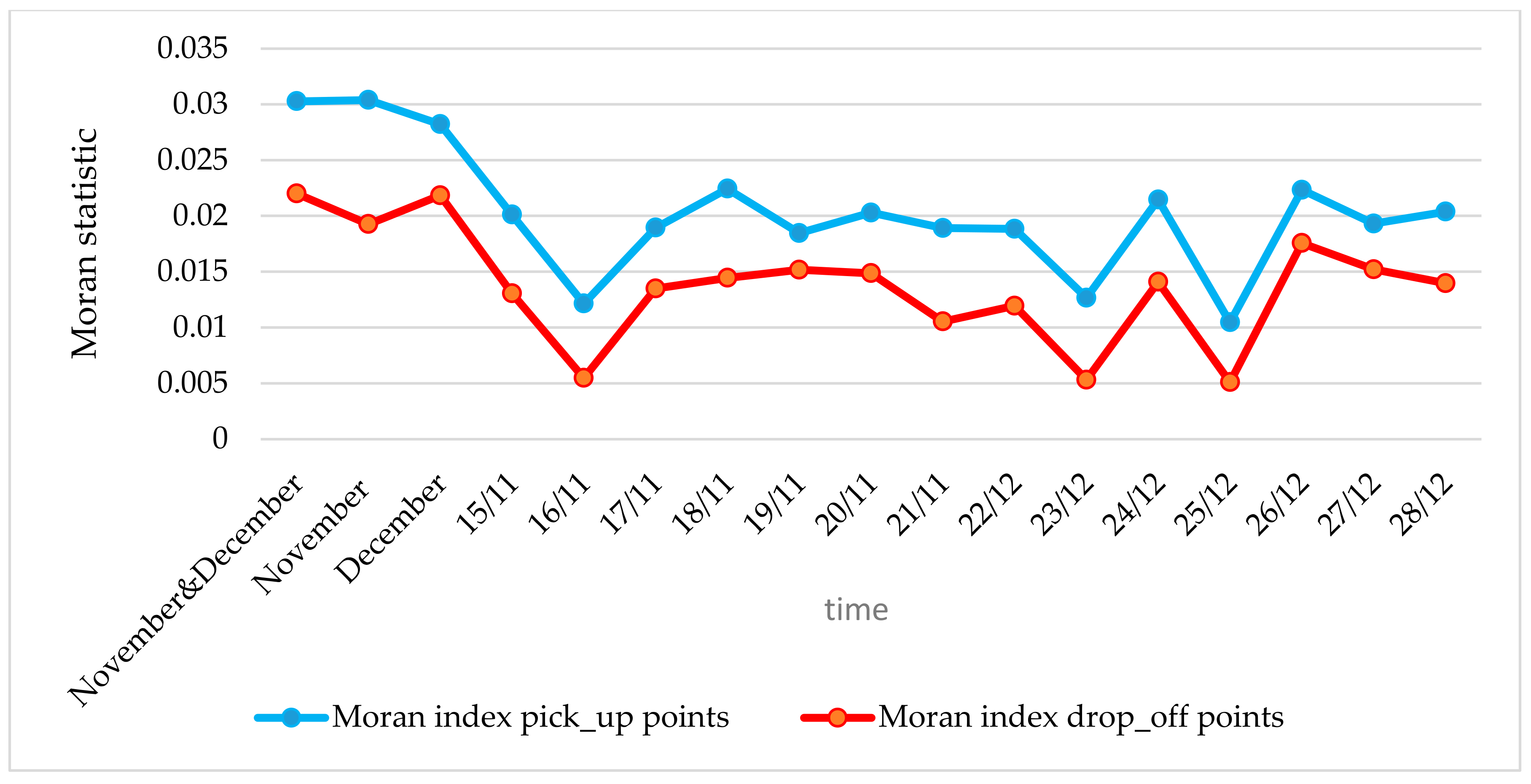
5.1. Spatiotemporal Pattern of Population Movement
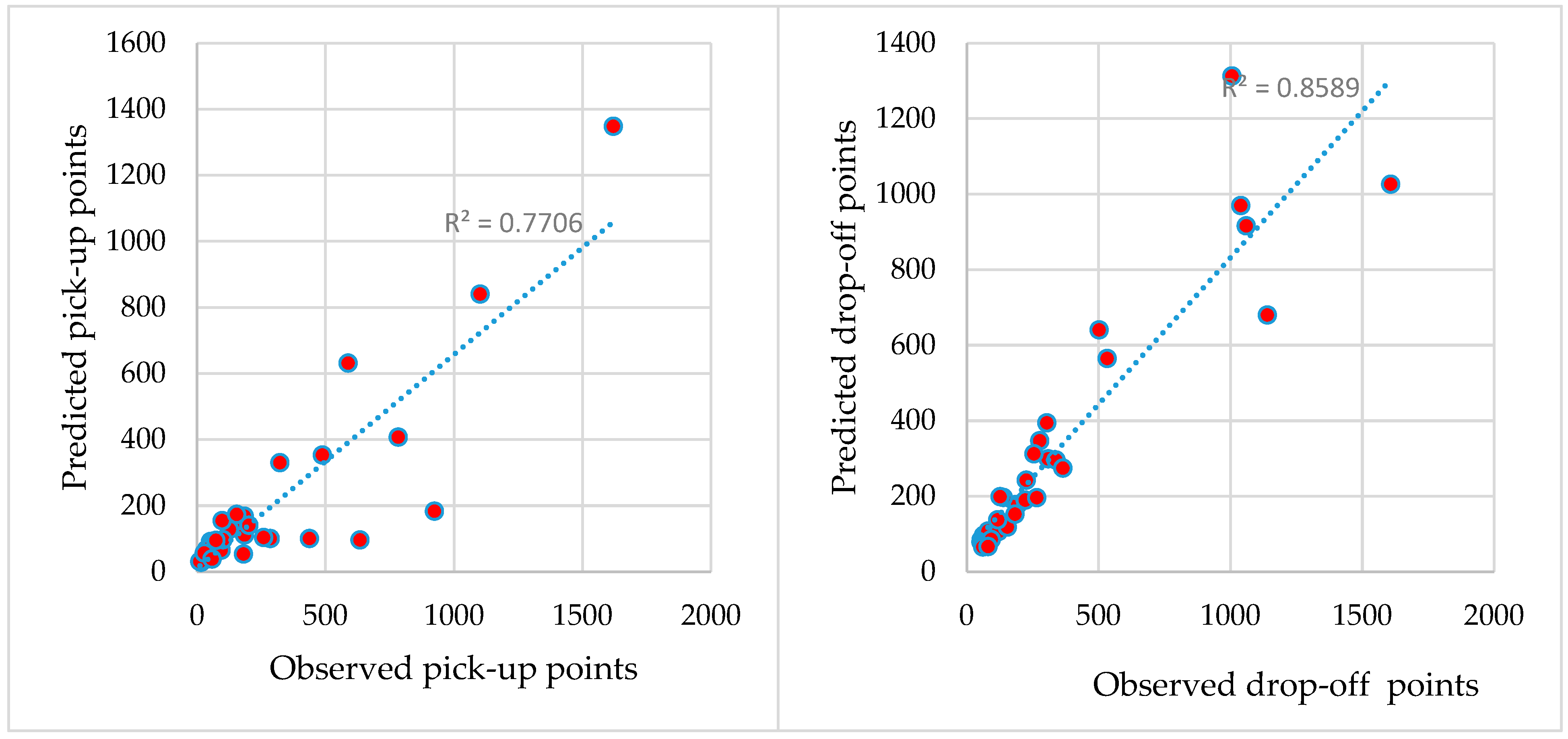
5.2. Identifying the Factors That Affect Population Movement
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aljoufie, M.; Zuidgeest, M.; Brussel, M.; Maarseveen, M. Urban growth and transport: Understanding the spatial temporal relationship. WIT Trans. Built Environ. 2011, 116, 315–328. [Google Scholar] [CrossRef] [Green Version]
- De Vos, O.; Witlox, F. Transportation policy as spatial planning tool; reducing urban sprawl by increasing travel costs and clustering infrastructure and public transportation. J. Transp. Geogr. 2013, 23, 117–125. [Google Scholar] [CrossRef]
- Lee, J. Reflecting on an Integrated Approach for Transport and Spatial Planning as a Pathway to Sustainable Urbanization. Sustainability 2020, 12, 10218. [Google Scholar] [CrossRef]
- Anagnostopoulou, E.; Urbancic, J.; Bothos, E.; Magoutas, B.; Bradeško, L.; Schrammel, J.; Mentzas, G. From mobility patterns to behavioural change: Leveraging travel behaviour and personality profiles to nudge for sustainable transportation. J. Intell. Inf. Syst. 2020, 54. [Google Scholar] [CrossRef] [Green Version]
- Wan, N.; Lin, G. Life-Space Characterization from Cellular Telephone Collected GPS Data. Comput. Environ. Urban Syst. 2013, 63–70. [Google Scholar] [CrossRef]
- Gao, S.; Yang, J.; Yan, B.; Hu, Y.; Janowicz, K.; Mckenzie, G. Detecting Origin Destination Mobility Flows from Geotagged Tweets in Greater Los Angeles Area. In Proceedings of the Eighth International Conference on Geographic Information Science (GIScience’14), Vienna, Austria, 24–26 September 2014. [Google Scholar]
- Rezende amaral, R.; Aghezzaf, E.; Raa, E.; Yadollahi, E. Adaptive Mobility: A New Policy and Research Agenda on Mobility in Horizontal Metropolises; In Planning; Department of Industrial Systems Engineering and Product Design: Groningen, The Netherlands, 2015; pp. 139–160. [Google Scholar]
- La Gatta, V.; Moscato, V.; Postiglione, M.; Sperlí, G. An Epidemiological Neural Network Exploiting Dynamic Graph Structured Data Applied to the COVID-19 Outbreak. IEEE Trans. Big Data 2021, 7, 45–55. [Google Scholar] [CrossRef]
- Mercorio, F.; Mezzanzanica, M.; Moscato, V.; Picariello, A.; Sperli, G. DICO: A Graph-DB Framework for Community Detection on Big Scholarly Data. IEEE Trans. Emerg. Top. Comput. 2019. [Google Scholar] [CrossRef]
- Wang, Y.; Qin, K.; Chen, Y.; Zhao, P. Detecting Anomalous Trajectories and Behavior Patterns Using Hierarchical Clustering from Taxi GPS Data. ISPRS Int. J. Geo-Inf. 2018, 7, 25. [Google Scholar] [CrossRef] [Green Version]
- Mazimpaka, J.D.; Timpf, S. Trajectory data mining: A review of methods and applications. J. Spat. Inf. Sci. 2016, 13, 61–99. [Google Scholar] [CrossRef]
- Sammer, G.; Saleh, W. Travel Demand Management and Road User Pricing: Success, Failure and Feasibility, 1st ed.; Routledge: London, UK, 2016. [Google Scholar]
- Jin, P.; Yang, F.; Cebelak, M.; Ran, B.; Walton, C. Urban travel demand analysis for Austin TX USAUrban Travel demand analysis for Austin TX USA using location-based social networking data. In Proceedings of the TRB 92nd Annual Meeting Compendium of Papers, Washington, DC, USA, 13–17 January 2013. [Google Scholar]
- Gemmer, M.; Becker, S.; Jiang, T. Observed monthly precipitation trends in China 1951–2002. Theor. Appl. Climatol. 2004, 77, 39–45. [Google Scholar] [CrossRef]
- Jin, P.; Cebelak, M.; Yang, F.; Zhang, J.; Walton, C.; Ran, B. Location-Based Social Networking Data: Exploration into Use of Doubly Constrained Gravity Model for Origin-Destination. Transp. Res. Rec. J. Transp. Res. Board 2014, 72–82. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Clarke, K.; Shekhar, S.; Tao, V. Big Spatiotemporal Data Analytics: A research and innovation frontier. Int. J. Geogr. Inf. 2020. [Google Scholar] [CrossRef] [Green Version]
- Ge, W.; Shao, D.; Xue, M.; Zhu, H.; Cheng, J. Urban Taxi Ridership Analysis in the Urban Taxi Ridership Analysis in the Emerging Metropolis: Case Study in Shanghai. Transp. Res. Procedia 2017, 25, 4916–4927. [Google Scholar] [CrossRef]
- Jiang, B.; Yin, J.; Zhao, S. Characterizing the human mobility pattern in a large street network. Phys. Rev. E 2009. [Google Scholar] [CrossRef] [Green Version]
- Kheiri, A.; Karimipour, F.; Forghani, M. Intra-Urban Movement Patterns Estimation Based on Location Based Social Networking Data. J. Geomat. Sci. Technol. 2016, 6, 141–158. [Google Scholar]
- Gariazzo, C.; Pelliccioni, A.; Bogliolo, M.P. Spatiotemporal Analysis of Urban Mobility Using Aggregate Mobile Phone Derived Presence and Demographic Data: A Case Study in the City of Rome, Italy. Data 2019, 4, 8. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Gao, W.; Zhao, X.; Hao, C.; Xie, X. Spatiotemporal Patterns of Population Mobility and Its Determinants in Chinese Cities Based on Travel Big Data. Sustainability 2020, 12, 4012. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, L.; Fan, L.; Yang, M.; Zhang, Y.; Feng, Y. Comparison of the spatiotemporal mobility patterns among typical subgroups of the actual population with mobile phone data: A case study of Beijing. Cities 2020, 100. [Google Scholar] [CrossRef]
- Rizwan, M.; Wan, W.; Cervantes, O.; Gwiazdzinski, L. Using Location-Based Social Media Data to Observe Check-In Behavior and Gender Difference: Bringing Weibo Data into Play. ISPRS Int. J. Geo-Inf. 2018, 7, 196. [Google Scholar] [CrossRef] [Green Version]
- Lyu, T.; Wang, P.; Gao, Y.; Wang, Y. Research on the big data of traditional taxi and online car-hailing: A systematic review. J. Traffic Transp. Eng. 2021, 8, 1–34. [Google Scholar] [CrossRef]
- Sun, Y.; Ren, Y.; Sun, X. Uber Movement Data: A Proxy for Average One-Way Commuting Times by Car. ISPRS Int. J. Geo-Inf. 2020, 9, 184. [Google Scholar] [CrossRef] [Green Version]
- Gong, S.; Cartlidge, J.; Bai, R.; Yue, Y.; Li, Q.; Qiu, G. Extracting activity patterns from taxi trajectory data: A two-layer framework using spatio-temporal clustering, Bayesian probability and Monte Carlo simulation. Int. J. Geogr. Inf. 2019. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Le Noc, M. Exploring Urban Mobility from Taxi Trajectories: A Case Study of Nanjing China. DATA 2018 2018. [Google Scholar] [CrossRef]
- Gong, L.; Liu, X.; Wu, L.; Liu, Y. Inferring trip purposes and uncovering travel patterns from taxi trajectory data. Cartogr. Geogr. Inf. Sci. 2015. [Google Scholar] [CrossRef]
- Shen, J.; Liu, X.; Chen, M. Discovering spatial and temporal patterns from taxi-based Floating Car Data: A case study from Nanjing. GIScience Remote Sens. 2017. [Google Scholar] [CrossRef]
- Rahimi, F.; Sadeghi-Niaraki, A.; Ghodousi, M.; Choi, S.-M. Modeling Population Spatial-Temporal Distribution Using Taxis Origin and Destination Data. Sustainability 2021, 13, 3727. [Google Scholar] [CrossRef]
- Hataminezhad, H.; Poorahmad, A.; Mansourian, H.; Rajaei, S.A. Spatial Analysis of Quality of Life Indicators in Tehran City. Hum. Gegraphy Res. Q. 2014, 45, 29–56. [Google Scholar]
- Saraei, M.H.; Chaharrahi, A.; Safarpour, M. Study and Analysis of Spatial Distribution of Hotels toward the Tourism Attractions Case Study: Shiraz City. Geogr. Territ. Spat. Arrange 2016, 6, 171–182. [Google Scholar]
- Saddam Hussain, M.; Jha, D.; Goswami, A.K. Using GIS to identify vehicle crash hot spots and unsafe crossroads-a case study of Kolkata, India. In Proceedings of the Asian Conference on Remote Sensing, Kuala Lumpur, Malaysia, 15–19 October 2018. [Google Scholar]
- Ahmadi, M.; AliMohammadi, A. Accidents Prediction Using Multilevel Regression Model and Time Parameters. Traffic Law Enforc. Res. Stud. 2015, 2015, 105–138. [Google Scholar]
- Dinu, R.; Veraragavan, A. Random parameter models for accident prediction on two-lane undivided highways in India. J. Saf. Res. 2011, 42, 39–42. [Google Scholar] [CrossRef]
- Zhao, P.; Xu, Y.; Liu, X.; Kwan, M. Space-time dynamics of cab drivers’ stay behaviors and their relationships with built environment characteristics. Cities 2020, 101. [Google Scholar] [CrossRef]
- Zhou, T.; Liu, X.; Qian, Z.; Chen, H.; Tao, F. Dynamic Update and Monitoring of AOI Entrance via Spatiotemporal Clustering of Drop-Off Points. Sustainability 2019, 11, 6870. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Fang, C. Spatial-temporal characteristics and determinants of PM2.5 in the Bohai Rim Urban Agglomeration. Chemosphere 2016, 148–162. [Google Scholar] [CrossRef]
- Fang, C.; Wang, Z.; Xu, G. Spatial-temporal characteristics of PM2.5 in China: A city-level perspective analysis. J. Geogr. Sci. 2016, 26, 1519–1532. [Google Scholar] [CrossRef]
- Esri. Available online: http://resources.arcgis.com/en/help/main/10.2/index.html#//005p00000006000000 (accessed on 10 April 2016).
- Shahbazi, H.; Taghvaee, S.; Hosseini, V.; Afshin, H.A. GIS based emission inventory development for Tehran. Urban Clim. 2016, 17, 216–229. [Google Scholar] [CrossRef]
- Pahlavani, P.; Sheikhian, H.; Bigdeli, B. Assessment of an air pollution monitoring network to generate urban air pollution maps using Shannon information index, fuzzy overlay, and Dempster-Shafer theory, A case study: Tehran, Iran. Atmos. Environ. 2017, 254–269. [Google Scholar] [CrossRef]
- Ord, J.K.; Getis, A. Local spatial autocorrelation statistics: Distributional issues and an application. Geogr. Anal. 1995, 27, 286–306. [Google Scholar] [CrossRef]
- Washington, S.; Karlaftis, M.; Mann, F. Statistical and Econometric Methods for Transportation Data Analysis; Chapman & Hall/CRC: Boca Raton, FL, USA, 2003. [Google Scholar]
- Oyindamola, B.Y.; Linda, O.U. On the Performance of the Poisson, Negative Binomial and Generalized Poisson Regression Models in the Prediction of Antenatal Care Visits in Nigeria. Am. J. Math. Stat. 2015. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Record ID | 204834129 |
| Taxi ID | 121 |
| Longitude | 57.3349 |
| Latitude | 37.4843 |
| Velocity (KM/h) | 41 |
| Direction | - |
| Cost (Rial) | 1350 |
| Status | 1 |
| Parameter | B | Std. Error | 95% Wald Confidence Interval | Hypothesis Test | Exp (B) | |||
|---|---|---|---|---|---|---|---|---|
| Lower | Upper | Wald Chi-Square | df | Sig. | ||||
| (Intercept) | 4.354 | 0.0206 | 4.313 | 4.394 | 44,505.011 | 1 | 0.000 | 77.773 |
| Area | 3.416 × 10−7 | 3.2644 × 10−8 | 2.776 × 10⁻⁷ | 4.056 × 10⁻⁷ | 109.501 | 1 | 0.000 | 1.000 |
| Statistical_population | 0.000 | 1.1083 × 10⁻⁵ | 0.000 | 0.000 | 193.219 | 1 | 0.000 | 1.000 |
| Migration | 0.001 | 4.2259 × 10⁻⁵ | 0.001 | 0.001 | 438.902 | 1 | 0.000 | 1.001 |
| Administrative_land use | 0.097 | 0.0021 | 0.093 | 0.101 | 2234.896 | 1 | 0.000 | 1.102 |
| Educational_land use | 0.067 | 0.0021 | 0.063 | 0.072 | 1053.625 | 1 | 0.000 | 1.070 |
| Health_land use | −0.017 | 0.0018 | −0.021 | −0.014 | 93.455 | 1 | 0.000 | 0.983 |
| Commercial_land use | 0.007 | 0.0001 | 0.006 | 0.007 | 2767.641 | 1 | 0.000 | 1.007 |
| Industrial_land use | −0.002 | 0.0007 | −0.004 | 0.000 | 10.387 | 1 | 0.001 | 0.998 |
| Cultural_land use | 0.053 | 0.0126 | 0.028 | 0.078 | 17.826 | 1 | 0.000 | 1.055 |
| Green_space_land use | 0.076 | 0.0044 | 0.068 | 0.085 | 298.922 | 1 | 0.000 | 1.079 |
| Religious_land use | 0.039 | 0.0044 | 0.031 | 0.048 | 78.762 | 1 | 0.000 | 1.040 |
| Sports_land use | 0.030 | 0.0099 | 0.011 | 0.049 | 9.284 | 1 | 0.002 | 1.030 |
| Residential_land use | −0.002 | 7.4203 × 10⁻⁵ | −0.002 | −0.001 | 414.600 | 1 | 0.000 | 0.998 |
| (Scale) | 1a | |||||||
| Parameter | B | Std. Error | 95% Wald Confidence Interval | Hypothesis Test | Exp (B) | |||
|---|---|---|---|---|---|---|---|---|
| Lower | Upper | Wald Chi-Square | df | Sig. | ||||
| (Intercept) | 4.313 | 0.0207 | 4.273 | 4.354 | 43,234.608 | 1 | 0.000 | 74.696 |
| Area | 5.547 × 10⁻⁷ | 3.0795 × 10⁻⁸ | 4.944 × 10⁻⁷ | 6.151 × 10⁻⁷ | 324.483 | 1 | 0.000 | 1.000 |
| Statistical_population | 0.000 | 1.0729 × 10⁻⁵ | 9.709 × 10⁻5 | 0.000 | 121.209 | 1 | 0.000 | 1.000 |
| Migration | 0.001 | 4.1761 × 10⁻⁵ | 0.001 | 0.001 | 932.812 | 1 | 0.000 | 1.001 |
| Administrative_land use | 0.082 | 0.0023 | 0.078 | 0.087 | 1271.767 | 1 | 0.000 | 1.086 |
| Educational_land use | 0.044 | 0.0024 | 0.039 | 0.048 | 343.451 | 1 | 0.000 | 1.045 |
| Health_land use | −0.009 | 0.0015 | −0.012 | −0.006 | 40.013 | 1 | 0.000 | 0.991 |
| Commercial_land use | 0.006 | 0.0001 | 0.005 | 0.006 | 1663.572 | 1 | 0.000 | 1.006 |
| Industrial_land use | 0.003 | 0.0007 | 0.001 | 0.004 | 15.770 | 1 | 0.000 | 1.003 |
| Cultural_land use | 0.133 | 0.0135 | 0.106 | 0.159 | 96.722 | 1 | 0.000 | 1.142 |
| Green_space_land use | 0.067 | 0.0049 | 0.058 | 0.077 | 191.870 | 1 | 0.000 | 1.070 |
| Religious_land use | 0.039 | 0.0048 | 0.029 | 0.048 | 64.291 | 1 | 0.000 | 1.039 |
| Sports_land use | 0.020 | 0.0101 | 0.000 | 0.040 | 3.975 | 1 | 0.046 | 1.020 |
| Residential_land use | −0.001 | 7.2069×10⁻⁵ | −0.002 | −0.001 | 412.918 | 1 | 0.000 | 0.999 |
| (Scale) | 1a | |||||||
| Log Likelihood | AIC 1 | BIC 2 | |
|---|---|---|---|
| Number of pick-up locations | −5794.05 | 11,616.11 | 11,648.37 |
| Number of drop-off locations | −3412.24 | 6852.49 | 6884.74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahimi, F.; Sadeghi-Niaraki, A.; Ghodousi, M.; Choi, S.-M. Discovering Intra-Urban Population Movement Pattern Using Taxis’ Origin and Destination Data and Modeling the Parameters Affecting Population Distribution. Appl. Sci. 2021, 11, 5987. https://doi.org/10.3390/app11135987
Rahimi F, Sadeghi-Niaraki A, Ghodousi M, Choi S-M. Discovering Intra-Urban Population Movement Pattern Using Taxis’ Origin and Destination Data and Modeling the Parameters Affecting Population Distribution. Applied Sciences. 2021; 11(13):5987. https://doi.org/10.3390/app11135987
Chicago/Turabian StyleRahimi, Fatema, Abolghasem Sadeghi-Niaraki, Mostafa Ghodousi, and Soo-Mi Choi. 2021. "Discovering Intra-Urban Population Movement Pattern Using Taxis’ Origin and Destination Data and Modeling the Parameters Affecting Population Distribution" Applied Sciences 11, no. 13: 5987. https://doi.org/10.3390/app11135987