1. Introduction
Logo detection has now become a demanding task as it is applicable in many applications such as brand promotion, social media monitoring, intelligent transportation, auto-driving, illegal/fraud logo detection and market research. Logo detection is also very useful for analyzing and tracking advertisements on different platforms. However, detection of logos in real-world images is a difficult task because there are countless brands in the world and logos of each brand may have diverse context, projective transformation, resolution and illumination. Logos may have unknown fonts, different sizes and colors on diverse platforms. In real scenarios the logo appears as a small object entity compared to the resolution of the images in which it presents. Moreover, inter-class similarity and intra-class difference in the logo images make the logo detection task even more difficult [
1].
Since the evaluation of convolution neural networks, deep learning-based detectors have become the leading framework for object detection [
2,
3,
4]. Several object detection methods have been proposed in the last decade, from two-stage region proposal-based Faster R-CNN [
5] to anchor-based methods such as YOLO [
6] and SSD [
7]. Since then, object detection methods based on deep learning have been used in logo detection.
István et al. [
1] trained a Faster R-CNN model [
5] to classify logo and non-logo objects in a class-agnostic manner, they trained a separate network [
8] to retrieve logo images. Su et al. [
9,
10] proposed to use data augmentation to create synthesized logo images for model learning. Su et al. [
11] presented the model self-learning principle using logo images collected on the web. They trained a model iteratively and identified the most compatible logo images from a noisy dataset. These selected images are then used to learn the model. In [
12], the authors presented model self-co-learning method with the last method. They trained two different detectors [
5,
6] to identify compatible training logo images from the noisy dataset. These identified training images have been fed as an input in a cross-model manner. Jain et al. [
13] proposed a weakly supervised logo detection algorithm by implementing dual-attention based mechanism with the DRN network to recognition logo without using bounding box annotated training data. Although training images are synthetically or automatically generated, the results do not show satisfactory performance on real images.
Fine-tuning of these detectors usually requires tuning of various hyperparameters like size, number and aspect ratio of densely placed anchor boxes. These methods require careful design for RoIs, sizes and number of anchor-boxes. Their experimental studies show that the accuracy of two-stage detectors such as the Faster R-CNN is better than that of one-stage anchor-based detectors such as SSD, but expensive in terms of resources and detection speed. On the other hand, one-stage detectors have shown fast inference time but the accuracy is not completive in some cases. In most real applications, logo detection tasks operate at a low spec. Devices such as mobile phones or IP cameras that require algorithms to be both lightweight and have high accuracy. For a better trade-off between accuracy and computational speed, here, we present an attention-based feature extraction network with an anchor-free detector [
14], called Dual-Attention LogoNet. This paper is an extension version of our ICCE-2021 conference paper [
15]. Here, we add a channel-wise attention module together with spatial attention module to generate more balanced feature maps. Our goal is to focus on improving accuracy with attention mechanisms and to build a lightweight model which is more feasible to deploy on embedded edge computing devices. Here, we also present a novel adversarial domain adaptation-based method for practical logo detection.
Recently, various anchor-free detection methods have been designed by researchers for detection task. These anchor-free detection methods are capable of achieving better performance than the abovementioned detection methods. These methods overcome the problem of class-imbalance of RoIs proposals and the critical anchor-box design choice by locating objects in terms of keypoints. Law et al. [
16] proposed CornerNet for detecting objects as a pair of corners of a bounding box. The method was later improved by Duan et al. [
17], in which authors proposed to detect objects as center, top-left and bottom-right points. ExtremeNet is presented by Zhou et al. [
18]. ExtremeNet detects objects by identifying a single center point and four extreme points in different directions. Zhou et al. [
14] also proposed a method to detect object by its center point, they therefore named its algorithm CenterNet.
In recent years, attention architecture has become popular in deep learning tasks, which is also used by many new proposed object detection algorithms. Such methods have proved to be useful for refining and emphasizing informative features. Wang et al. [
19] proposed a method to enhance the spatial features using the mask module. This module is employed with a trunk branch consisting of bottom-up and top-down feedforward structure. Hu et al. [
8] introduced SENet module for calculating channel-wise weights of a convolutional layer to capture channel-wise responses. Wang et al. [
20] proposed ECANet block to model channel-wise features more effectively and efficiently. Chen et al. [
21] proposed an attention mechanism network to classify and localize liver lesions on CT images. Woo et al. [
22] proposed to use channel and spatial attention blocks within the convolutional block. Zhu et al. [
23] proposed a network for learning spatial information using the attention mechanism. They added the calculated attention weights to the output of the classification layer.
Normally, training of deep learning-based models follows a supervised learning scheme and relies on large annotated training datasets. A deep learning model suffers performance degradation due to domain shift (source-to-target domain) during inference time [
24,
25]. In practice, such performance degradation limits the scalability and applicability of deep learning-based models. On the other hand, fine-tuning a model on new domain might face the problem of lack of training data because object-level annotation is basically a time-consuming and labor-intensive task. Training a well-generalized model which is able to be applied to different domains is a hot research topic today. As a result, recently, several domain adaptation-based methods have been proposed to learn model from one domain and generalize well to another domain [
24,
25,
26,
27].
Inspired by the existing adversarial learning-based domain adaptation method [
25,
26] which has been developed primarily for segmentation applications, in this work, we present a domain adaptation method for logo detection using adversarial learning to mitigate errors caused by domain shift. We have used annotated logo images (source-domain) and unlabeled logo images (target-domain) for training to bring closer these source and target domains. The added discriminator-based network can be learned into an end-to-end manner like a normal detector. Since anchor-free detectors train the network to learn objects in terms of some keypoints, we propose to use mid-level output feature maps instead of class-wise heatmaps to align the distribution of target and source domains. Our adversarial learning approach is motivated by the fact that the use of mid-level outputs benefits from robust information about the domain while retaining object-level information. This method can be easily adapted to other anchor-free detectors.
2. Proposed Network
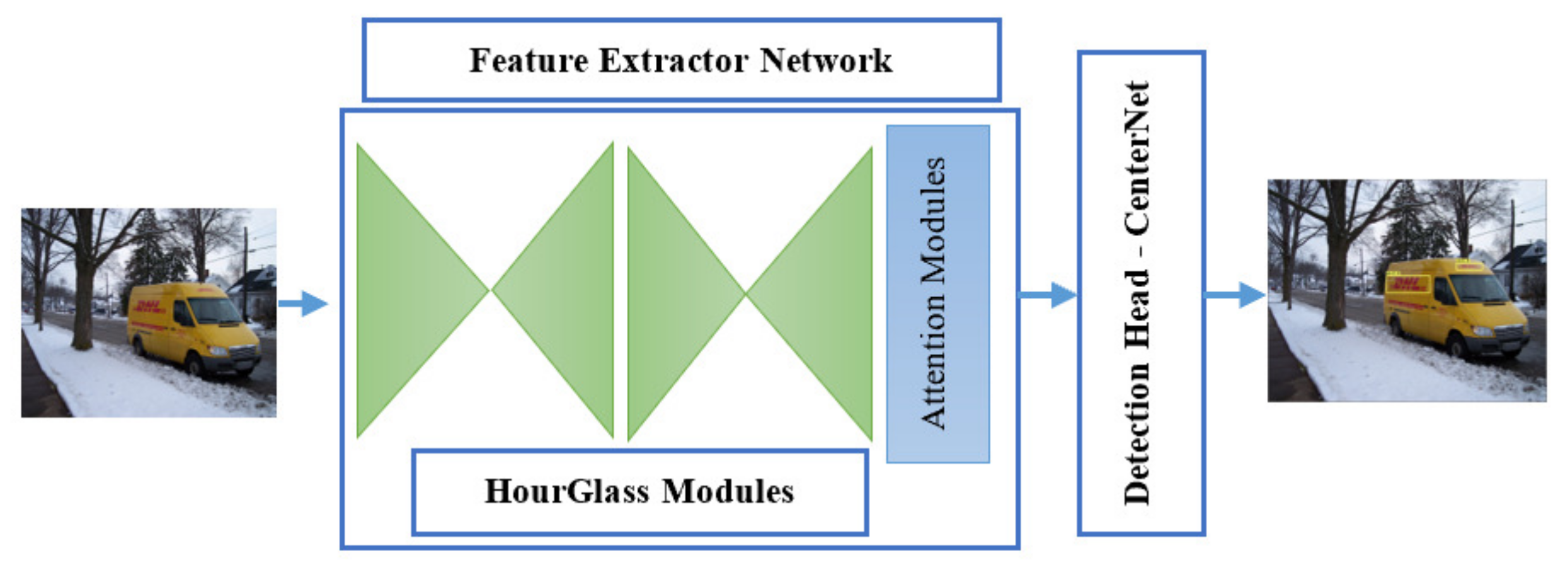
Our architecture includes a feature extractor backbone, spatial and channel attention modules and a detection head. Inspired by HourglassNet [
18] we use a top-down bottom-up network. However, different from conventional network, we aggregate both convolutional layer output feature maps within each residual block. A skip layer connection is added with this output and provided as input for the next convolution block. In our proposed method the final feature maps is generated by combining the outputs obtained by two stacked hourglass networks. To precisely emphasize the attributes of target objects in the generated feature maps, we employ a channel-wise attention module along with the spatial attention module after the feature extractor network. What makes our architecture better in detecting logos than conventional detectors is the newly added two attention modules prior to the detection head. The two branches using channel and spatial attention modules, respectively, produce category-wise keypoint heatmaps of the input images. Such feature maps are generated by their respective attention modules to emphasize the network capacity of learning longer-range dependencies and help to know what and where can be found in the image. For accurate detection of target logos in feature maps, we perform matrix element-wise addition to these two category-wise feature maps. The aggregated final feature maps is given as input to detection head. The detection head is similar to CenterNet. The overall architecture of LogoNet is shown in
Figure 1.
The detail of architecture is described as follows.
Section 2.1 provides detail about feature extractor network. The spatial attention module and channel-wise attention module are explained in
Section 2.2 and
Section 2.3, respectively. Detection head is described in
Section 2.4. Lightweight-CNNs models are reported in
Section 2.5. The Domain-Adaptation-based logo detection method is described in
Section 2.6.
2.1. Feature Extractor
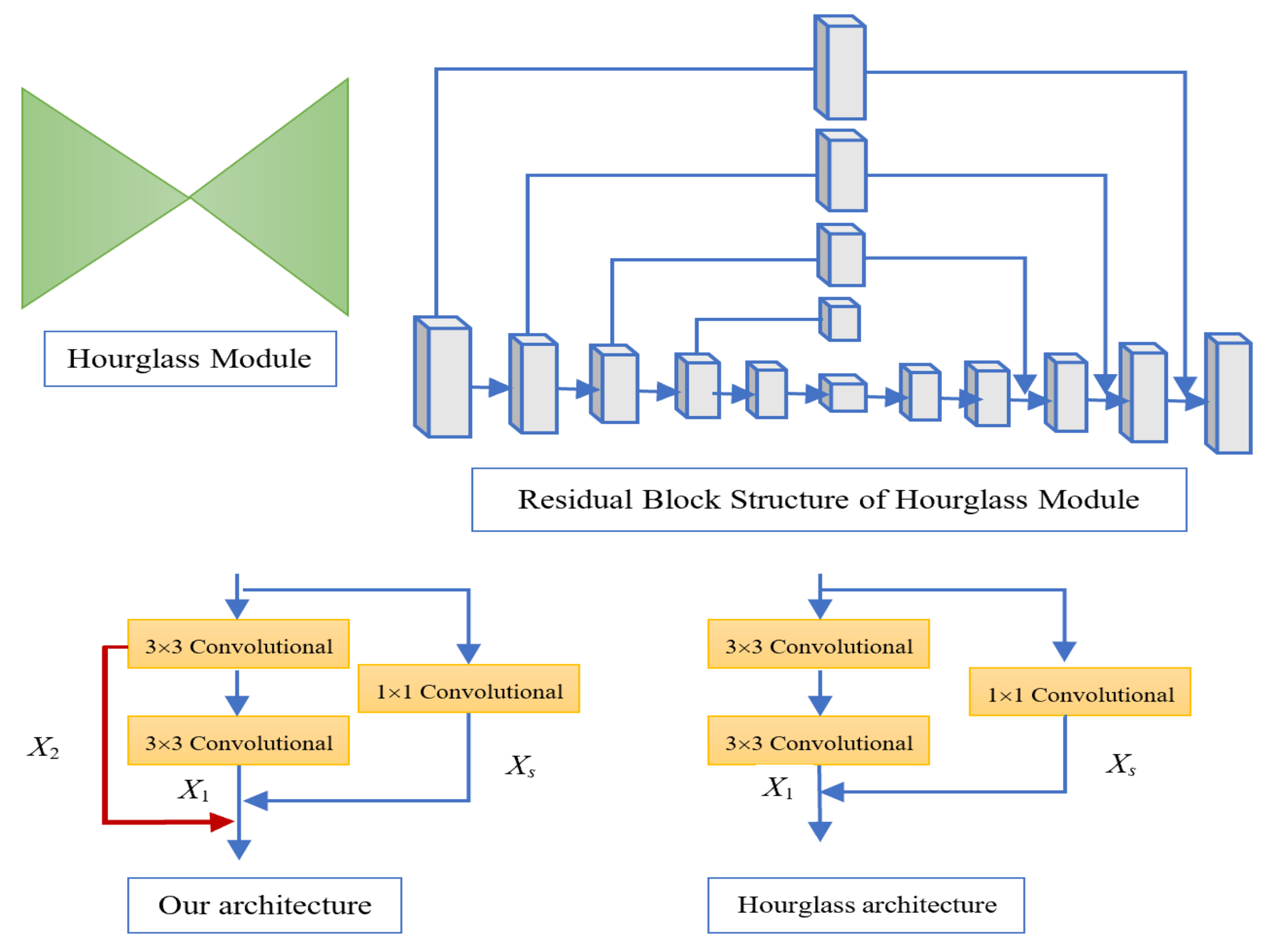
Hourglass network was introduced for the human pose estimation task by Newell et al. [
28]. The network consists of bottom-up and top-down structured modules, where input channels are expanded and dimensions of the feature maps are down-sampled by a series of convolutional, stride and max-pooling operations. Subsequently, upsampling operations are performed to produce symmetric feature map blocks in hourglass style. Skip connections are added during upsampling to prevent the loss of information. Hourglass network was used in CornerNet [
16] for object detection. After that, the same framework was used in CenterNet [
14]. Our hourglass-like feature extractor network employs the same arrangement of convolution blocks as [
16].
In the feature extractor network, first, input feature maps (3 × 128 × 128) are passed through a convolutional block which reduces the input dimension by half by using a 7 × 7 convolutional operations and a stride of size 2 with 128 channels. After that the feature maps are fed into a residual block with 3 × 3 convolutional operations and a stride of size 2. It produces a feature maps with 256 channels and spatial dimension of 128 × 128. Subsequently, feature maps are fed into stacked hourglass modules to produce feature maps with global spatial and semantic information. Hourglass module consists of bottom-up and top-down design with residual learning blocks. There are five stages in downsampling and upsampling operations. The processing modules at each stage, including the skip connection modules (there are skip connections between symmetric blocks of a hourglass module, referring to
Figure 2), consists of two residual blocks. Each residual block includes two convolutional layers and one skip connection layer. The spatial dimension of the feature map is reduced by a stride of size 2 which is employed for the first convolutional operation in the residual block. The rest of the convolution operations (including the second residual block) use a stride of size 1 and keep the spatial dimension unchanged. The kernel size of 3 × 3 is used in every convolutional operation. The skip connection layer in the residual blocks uses linear transformation (1 × 1 convolution) and matches the spatial and channel dimension of the input feature maps with the output of the convolution layer. The spatial resolution of feature maps is reduced by 5 times and the number of channels increases as [256, 384, 384, 384, 512] along the way. Upsampling of feature maps is performed using the nearest-neighbor algorithm, followed by two residual blocks at each stage. The final output feature map has 256 channels and a 128 × 128 spatial dimension. The detailed structure of the hourglass module is described in
Table 1.
Based on the original hourglass architecture, our proposed network densely aggregates convolutional layers into each residual block at different scales. Each residual block has two convolutional layers and a skip connection layer. Residual learning uses a skip connection to add with the output of the second convolutional layer. We propose to aggregate outputs of both convolutional layers with skip connection within each convolutional block inspired by [
29]. In each residual block, both convolutional operations and the skip connection layer generate feature maps of the same spatial and channel dimensions so that these output feature maps can be directly added without increasing network overhead.
where the input feature map passes through convolutional operations,
and
are the output of the two convolutional operations.
denotes output feature maps of the skip connection layer.
Figure 2 illustrates the residual block structures of the hourglass network [
28] and our proposed approach.
In order to project important information, we added the output feature maps of both stacked hourglass modules. This final output is provided to the attached attention modules. This avoids the loss of information and detail during the downsampling and upsampling operation of feature maps. Our experiments show that our approach generates a robust feature map without raising any computation cost.
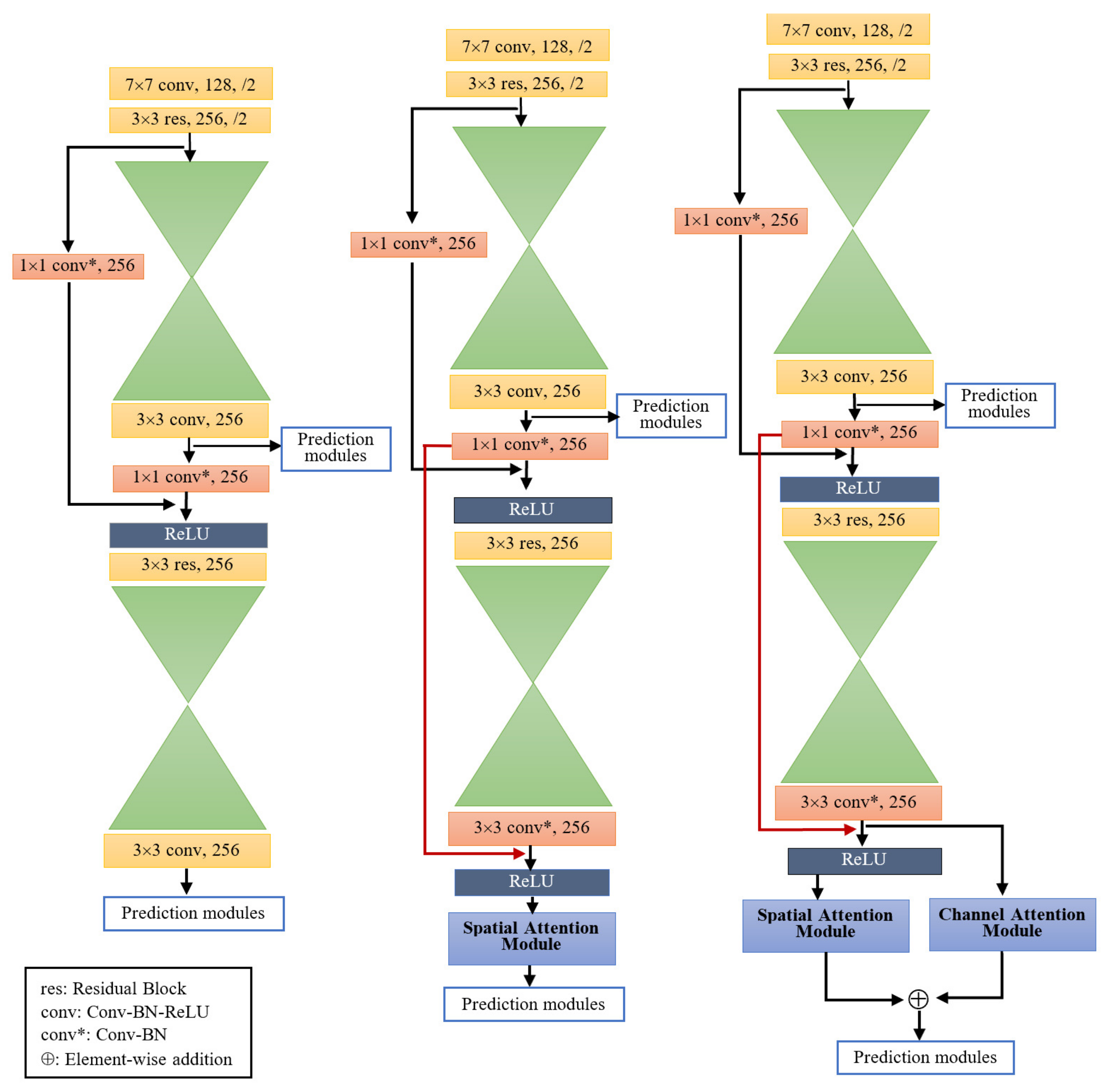
Figure 3 illustrates the overall framework of CenterNet, LogoNet and Dual-Attention LogoNet.
2.2. Spatial Attention Module
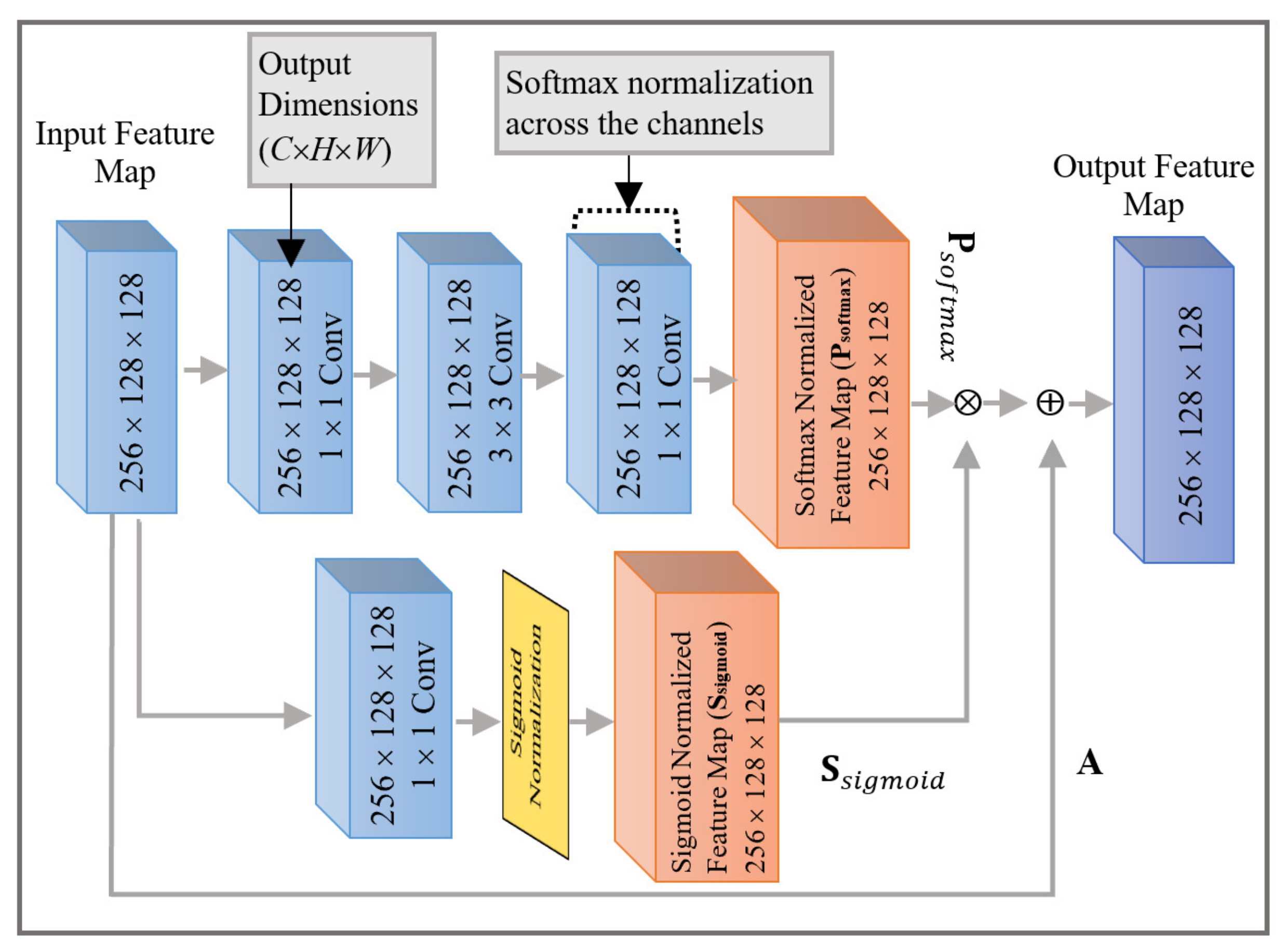
We produce spatial attention weights using the inter-spatial relationships of channels to obtain rich and global spatial information that helps to create a robust global feature map.
Figure 4 depicts the overview of our proposed spatial attention module. A feature map
is provided as an input to the spatial attention module where
denotes channel size and
are height and width of the feature map, which are
in this paper. This input
is then fed into a
linear transformation layer and a normalized feature map
is created for all channels using the sigmoid activation function.
where
is the scalar value at
ith and
jth position and
denotes corresponding activated scalar value at
ith and
jth pixel position. The output of this operation is a sigmoid activated map, i.e.,
.
Additionally, the input
is fed into a convolutional block, which generates a feature map
. This convolutional block consists of three convolutional layers with
kernel size, respectively. To keep channel-wise details, the number of channels
for each convolutional layer remains unchanged which is 256. ReLU activation is followed by the first two convolutional operations while batch normalization has been performed for all the convolutional layers. Softmax normalization strategy is applied across the channels over the output feature space of the convolutional block (
). During softmax normalization, all positional scalar values in the same pixel-position across all feature channels are considered. New scalar value is synthesized for each pixel across the channels using the value of other pixels at the same index. In Equation (
3), if
is a scalar value at
ith and
jth pixel position in
kth channel, a normalized scalar value
can be obtained as:
where
denotes the number of channels in feature map
. A softmax normalized feature maps
has been produced using these normalized scalar values (
).
We perform element-wise product of both generated normalized feature map, i.e.,
and
. The input feature map (
) is added as a skip connection to this product to obtain final attention-weighted feature map.
where ⊙ is the element-wise product.
As we mentioned in our previous conference paper [
15], our convolutional layers block follows the module structure proposed in [
23], but our method is totally different from their approach. For multi-label image classification, they employed a regularization module to generate attention weights. These attention weights were provided to the classification layer of the feature extractor network which was ResNet [
30]. Whereas, we generate a weighted feature map and perform an element-wise addition with the input to obtain a robust representation of input image. Our proposed technique uses both sigmoid and softmax functions as activation to learn important spatial weights.
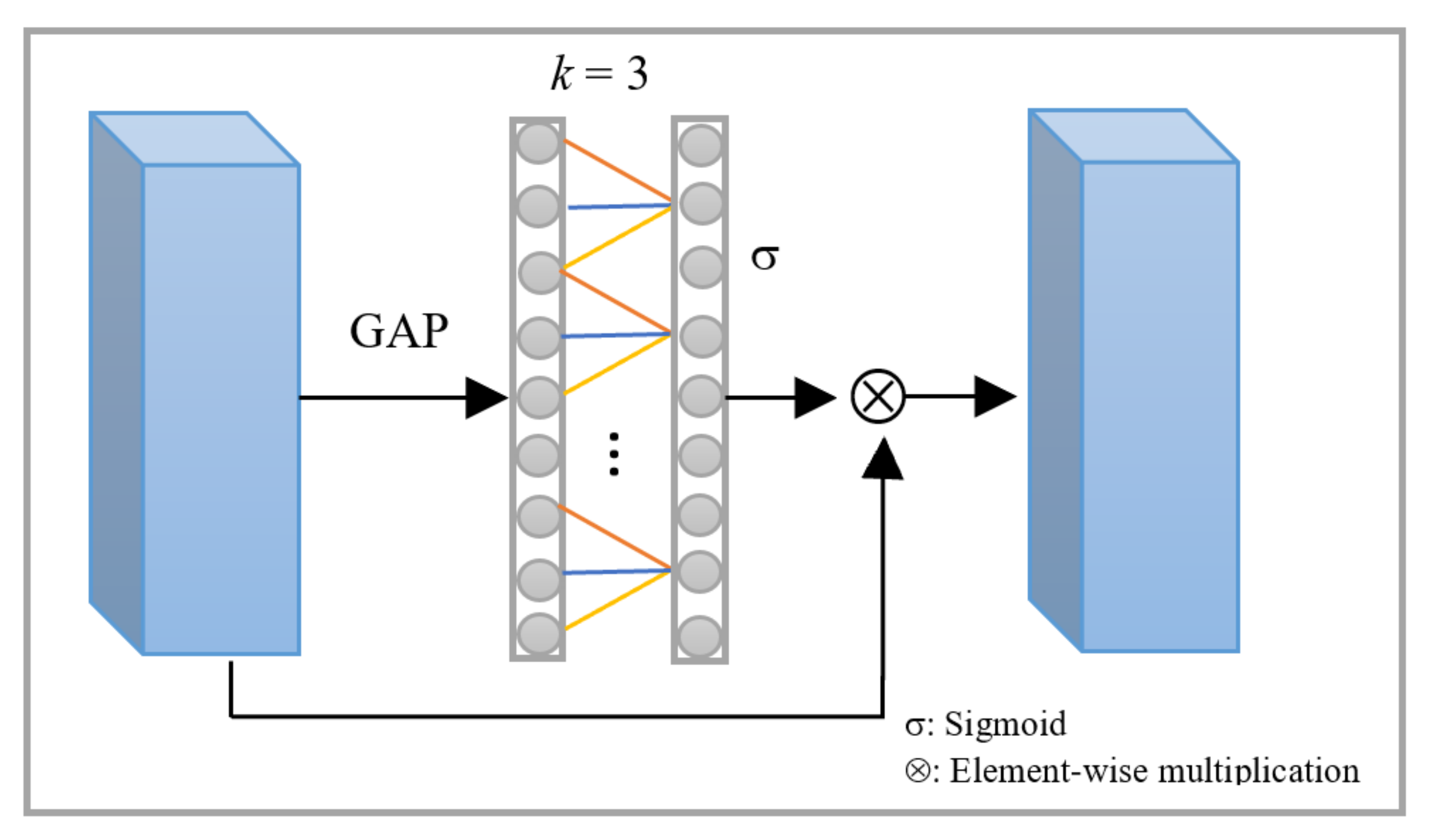
2.3. Channel-Wise Attention Module
To capture channel-wise attention weights, Wang et al. [
20] introduced ECANet block. To achieve channel-wise dependencies, global-average pooling (GAP) is performed on the input feature maps. Subsequently a 1-D convolutional operation is employed to learn cross-channel interaction. A sigmoid activation function operates at this layer to learn channel-wise attention weights. They proposed to use an adaptive kernel size to capture local cross-channel interactions by considering a channel and its
neighbors (coverage of interaction). In their method the kernel size
is proportional to the number of channels. Channel-wise response is emphasized by multiplying the attention weights with the input feature maps. This weight-enhanced feature maps is added to the input feature map as the final output.
In our proposed method, ECANet [
20] module with a kernel size of 3 is used. Unlike the proposed approach, we directly use the attention-based feature maps to produce category-wise heatmaps without adding the input feature maps as skip connection.
Figure 5 shows the channel attention module.
2.4. Detection Head—CenterNet
CenterNet is an anchor-free detector proposed in [
14]. CenterNet identifies objects as a point at their bounding box center. During training, CenterNet converts ground truth RoIs into heatmaps. For the training image a keypoint map
is generated in which if the coordinates
belong to the center of an object then it will be activated and the rest positions will be set to zero. The keypoint map is then converted into a corresponding set of heatmaps. These heatmaps are used to train the detector with a focal loss function to classify into corresponding class (
) [
31]. CenterNet also consists of an offset head for object location and a size head to regress the size of object to generate its RoIs. The final detection loss function is given as:
where
and
are
loss functions and
and
are loss weights.
loss or
regularization is used to calculate the error, where error is the difference between the ground truth bounding box and the predicted bounding box coordinates. During detection, class-wise heatmaps are generated corresponding to separate categories. Then some peak points are found out in the generated class-wise heatmaps. In the normal setting, 100 peak points are considered for detection within each category. A keypoint estimator
is used to predict all center points. A set of
n detected center point
for all
c classes is estimated as
where (
) is the integer coordinate for a keypoint location. Detection confidence score is measured using the keypoint values
. A local offset is also predicted for center point location and to regress object size. For the learned model, evaluation metric in terms of mean average precision (mAP) is determined for all classes when the Intersection over Union (IoU) with the ground truth bounding box exceeds 0.5. The precision value for any given category is the percentage of correct predictions. i.e.,
Whereas recall measures the proportion of true positive that can be determined as:
In general, the average precision (AR) for any given category is the area under the precision-recall curve (AUC—area under the curve). The mean average precision (mAP) is the average value of the AR for all categories of a dataset.
In this study, we present an architecture containing spatial and channel attention modules as an extension of the our previous method. A conventional way of implementing the channel attention module is that attention blocks are added to each convolutional block during feature extraction [
8,
20]. While some methods proposed to use both spatial and channel attention mechanisms within each convolutional block [
22]. In our proposed method we employ both attention modules only once in parallel order just before the generation of the class-wise heatmaps, which are used to make dense predictions. The spatial attention and channel attention modules generate two sets of class-wise heatmaps. This arrangement captures strong informative spatial features along with high-level semantics features. Element-wise addition of class-wise feature maps, generated by both attention modules, is performed for better fusion of class-wise information.
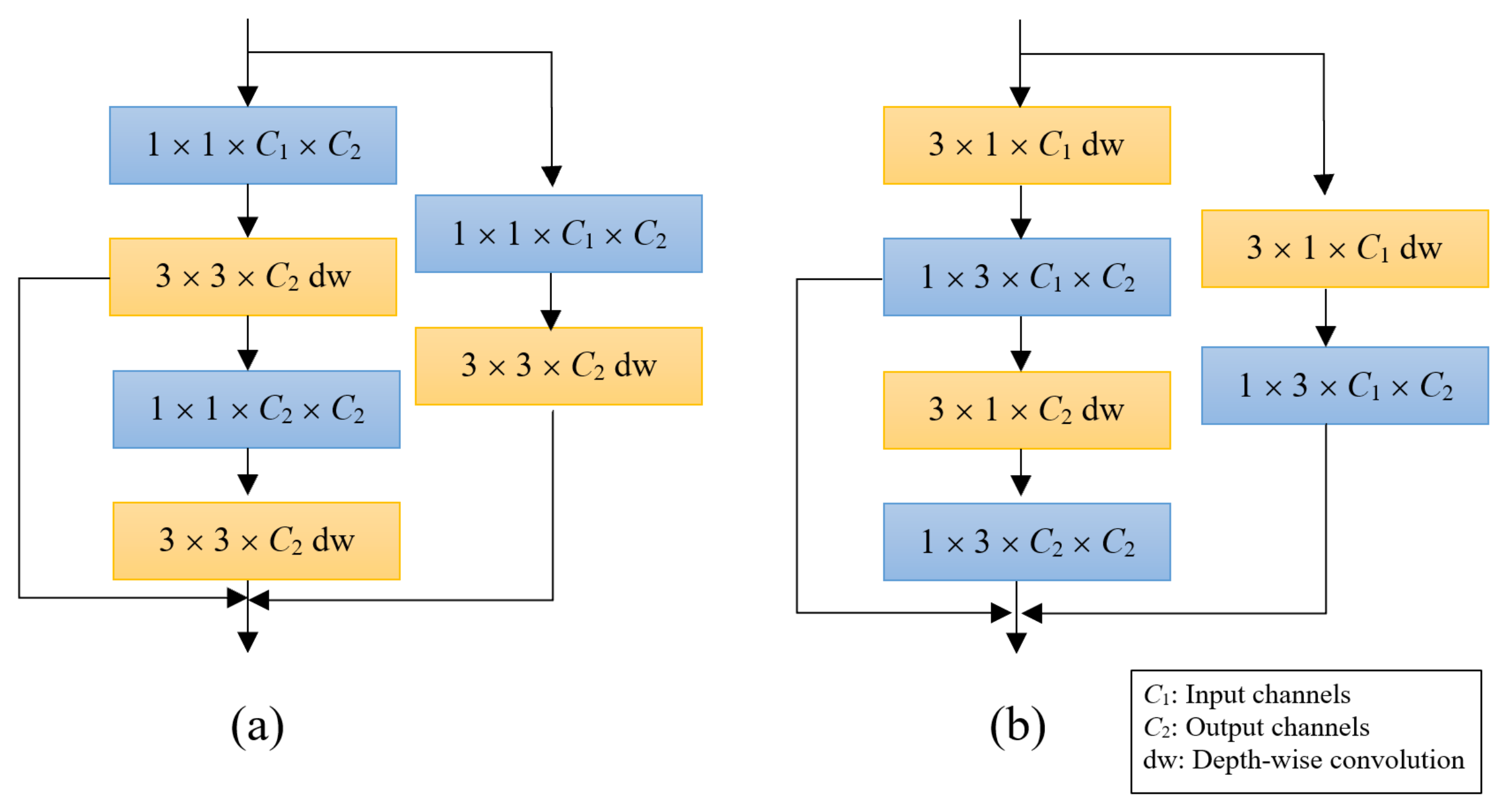
2.5. Lightweight Model
To build a compact network and improve the detection speed for practical applications, we present a Lightweight architecture. We embed factorization of standard convolutions inspired by MobileNetv2 [
32]. In our lightweight module, a convolutional operation comprises a combination of pointwise and depthwise separable convolutional layer. Pointwise is a standard 1 × 1 convolution operation that performs linear transformation of the input and changes the channel dimensionality. Depthwise convolution applies a single filter per each channel to filter the features. Our network uses Batchnorm and ReLU activation operation after the depthwise convolutional layer. The same pattern of layers is followed for skip connection layers. Spatial dimension is handled by the max-pooling operation. This design is used with the LogoNet and Dual-Attention LogoNet architecture. We convert each standard residual convolution block of our architecture into a depthwise convolution block that follows the approach of MobileNetv2 block. We employ the approach only for hourglass module layers, feature transformations of other layers including the attention modules is performed using a standard convolution operation. This approach reduces network complexity and computation compared to standard convolution. Depthwise computation can be expressed as:
where
and
are input and output feature maps with
number of channels.
is a depthwise convolution kernel of size
where
is the size of kernel, which is 3 in our case. For a feature map of
height and width, the total computation cost of depthwise and pointwise convolution operation can be computed as:
exploits where
and
are the input and output channels.
To compare the proposed architecture, we also demonstrate lightweight models, exploring the CP-Decomposition (CPD) [
33]. The CPD method is the typical method for reducing complexity, which factorizes a tensor into a sum of outer products of vectors. For a given tensor of 3-dimensional space, the CP decomposition can be explained as:
where
, and
are vectors of relevant dimension, and ‘∘’ denotes the outer product of two tensors, i.e.,
In case of rank one assumption of CPD (i.e.,
R = 1), the 4D kernel
will be separated into cross-products of four 1D filters as follows:
where
are 1D convolution vectors convolving across the dimensions and the fourth corresponds to channels.
Here, we converted a standard convolution to two 1D convolutions within each residual block of proposed feature extractor. We use 1D convolution from two axes
,
to convolve the feature maps. First, we convolve the features using single filter each channel (depthwise) by a kernel size of
. Then a kernel of size
is applied to map the number of feature channels. Same approach is applied with skip connection layer to transform the feature maps. Block structures of feature extractor with depthwise convolution and CPD methods are shown in
Figure 6.
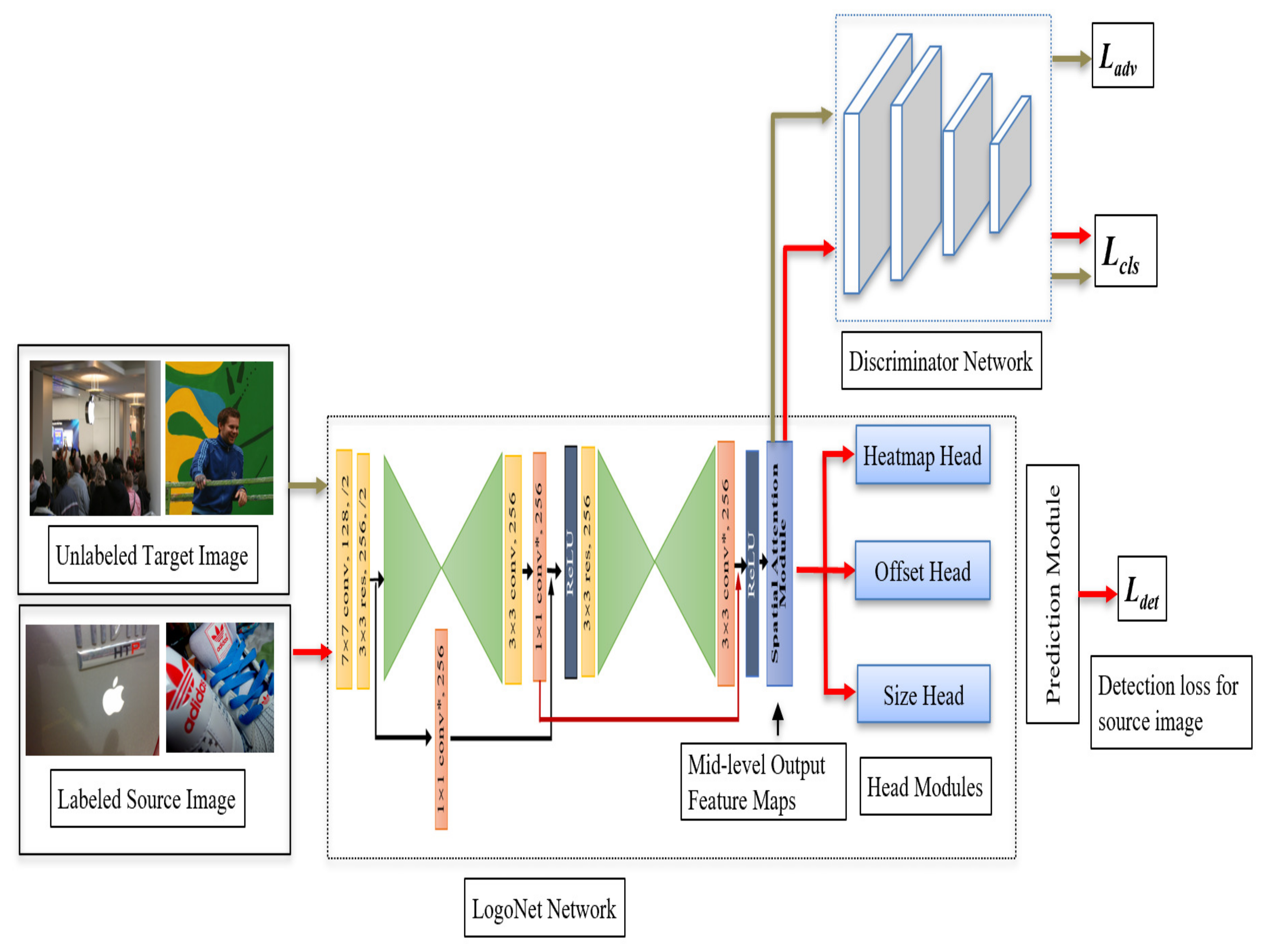
2.6. Adversarial-Based Domain Adaptation for Anchor-Free Detector
In practical applications, we need to apply the trained model (i.e., LogoNet) to a new dataset (target dataset). The model always suffers performance degradation due to domain shift because the distribution of the source dataset (training dataset) is different from that of the target dataset (test dataset). To enhance the generalization of the model, we aim to address model learning towards the distribution of target domain by aligning the output feature maps of source and target domains as close to each other as possible. In order to align the model between two different domains, we exploit the adversarial learning scheme by adding a domain discriminator network in the training phase to detection framework. The architecture of the LogoNet framework with the proposed domain adaptation training scheme is shown in
Figure 7, which consists of a feature extraction network and a detection module. The detection module has three heads, heatmaps-head (for generating class-wise heatmaps), offset-head (for identifying object locations), object-size head (for regressing the size of objects). The anchor-free detector generates class-wise heatmaps corresponding to each class using the output feature maps (mid-level output) of the feature extraction network. The offset and size output maps are also generated separately to give complete detection loss. Previously proposed adversarial learning-based schemes [
24,
25,
26,
27], which have been introduced primarily for semantic segmentation tasks, make use of the final class-wise output of the feature extraction network. Since anchor-free detectors train the network to recognize objects in terms of some keypoints, we observed that the use of class-wise heatmaps leads to the loss of some important domain-specific information. It is very important to select the most suitable output feature maps to align the domain gap. In contrast to the previous methods, here we present a domain adaption-based LogoNet network, in which we propose to use the mid-level outputs of feature extraction network. The main advantage of using mid-level output is that it contains essential domain-specific semantic and visual information and is helpful to employ adversarial learning well. Using the design advantages of anchor-free detectors, we assume LogoNet generates mid-level output feature maps for images from the source domain and the target domain. The mid-level output maps of the source images rendered to different detection heads (heatmap-head, offset-head, size-head) to train the network for the respective tasks. Whereas, the mid-level output feature maps of the target images is used to calculate the adversarial loss to match the data distribution of source and target domains. Therefore, we do not need object-level annotations for the target images.
We assume that there are
images with corresponding object-level annotations in the source domain
with corresponding object-level annotations
where
is a set of input images in the source space,
denotes the set of corresponding labels. Whereas,
is the number of images in the target domain
without object-level annotations
, where
denotes the set of images in the target domain. To employ the adversarial learning technique, we add a domain discriminator network with the LogoNet framework that introduces the adversarial loss (
) and classification loss (
). The domain discriminator network consists of 5 convolution layers with a kernel size of 4 × 4 and a stride of size 2, each layer is coupled with a leaky-ReLU activation layer with a fixed negative slope of 0.2, except for the last convolution layer. The number of channels is [64, 128, 156, 512, 1] for each layer, respectively. Finally, a classification layer gives classification outputs. The detailed structure and operations of the discriminator network is described in
Table 2.
We provide these mid-level outputs of the source image () and target image () as inputs to the discriminator network to classify the inputs form source domain (S) or target domain (T). The classification loss () is calculated to update the network weights of the discriminator network to increase the ability to distinguish the inputs into the respective domains. We assign source images (source-domain) with domain label ‘0’ and target images (target-domain) with domain label ‘1’.
The binary classification loss
(training objective of domain discriminator network) can be defined as:
where
and
are the mid-level features of the
ith source training sample and the
ith target training sample, respectively.
and
are sample numbers of source domain and target domain, respectively. Meanwhile, to bring the target domain (
) and source domain (
) distributions closer, we provide the mid-level output feature maps (
) of the target image into the discriminator network and compute the adversarial loss (
) by giving an inverted domain label, i.e., ‘0’ instead of ‘1’). The adversarial binary classification loss
can be defined as:
Adversarial loss is propagated to update the gradients of LogoNet framework, the objective loss function of the network is given in the following equation.
is loss weight. We use a value of 0.001 in our experiments. This approach encourages the network to produce similar output feature maps distributions from target () to the source domain () by mocking the discriminator network. The task-specific detection network and the domain discriminator network are jointly trained in an end-to-end manner. During inference we do not need the discriminator network and the normal detection pipeline is used to perform the detection task so we drop the discriminator network.
5. Conclusions
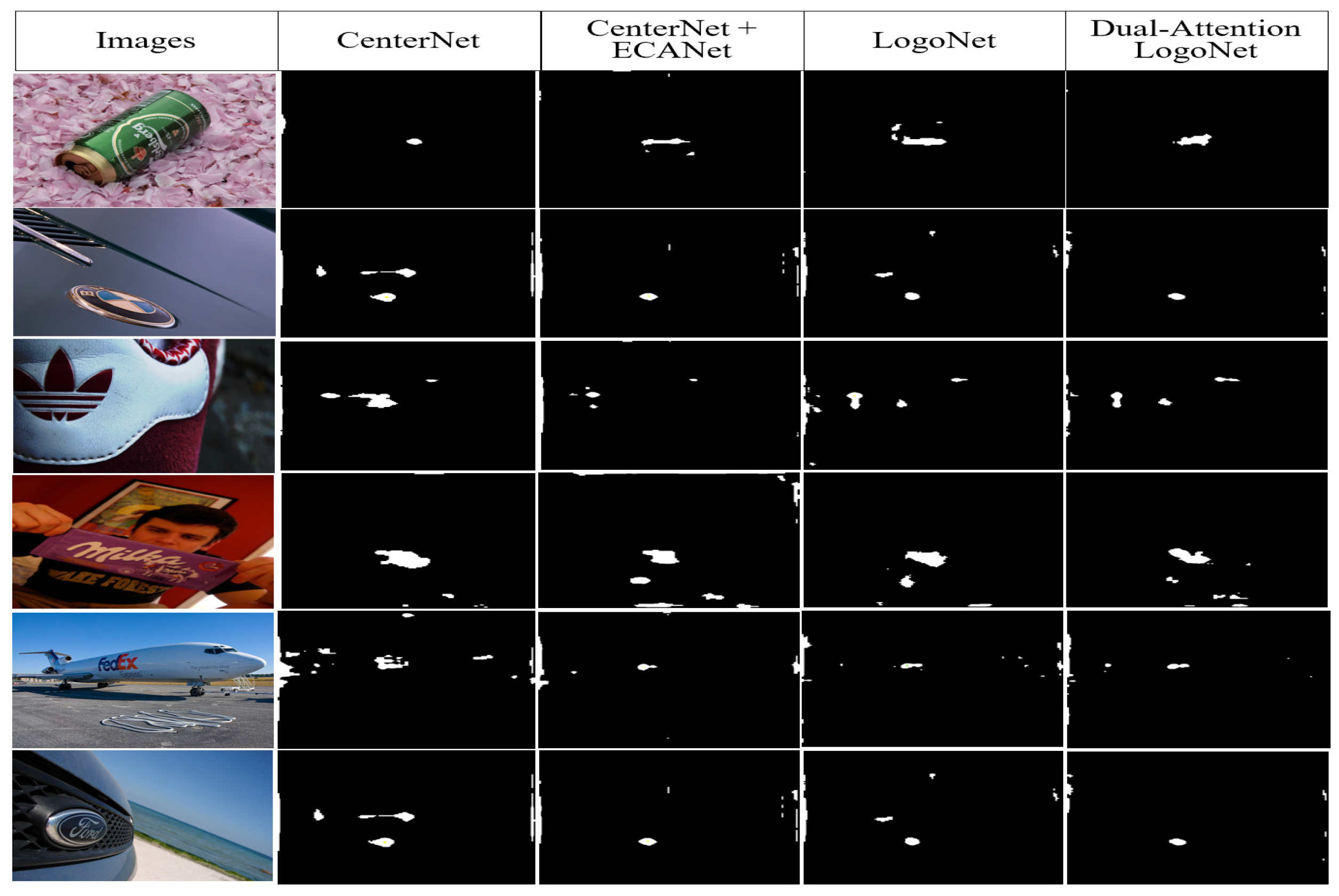
We have proposed a Dual-Attention-based LogoNet Network, using spatial and channel attention modules. Our architecture refines output feature maps and improves the performance with an accuracy gain of 1.8% in a considerable computation time. Furthermore, we propose a lightweight CNNs method with anchor-free detector. We also propose an adversarial learning-based domain adaptation approach to align the detection network between source and target domains. In future, we will discover more attention- and domain adaptation-based mechanisms including transformer [
40] and lightweight compact network for logo detection in real-time.
In this paper, we propose Dual-Attention LogoNet. The backbone architecture of the proposed method includes a densely layer-aggregated hourglass-like network. Spatial and channel attention modules are added to further refine the feature maps. The CenterNet detention head is used [
14].
Our key contributions are as follows:
(1) We propose an attention-based architecture called LogoNet, which includes a backbone feature extraction framework that aggregates feature maps at different scales. This framework efficiently extracts feature information from different scales and also prevents loss of information during spatial resolution scaling.
(2) The proposed spatial attention module enhances attention to identify target objects. This attention module refines the output feature maps. It serves as a tool to focus on the logo regions.
A preliminary version of this work was presented as a five-page conference paper at IEEE International Conference on Consumer Electronics-2021 [
15]. As an extension, here, we introduce a dual attention-based method by employing a channel attention module along with the spatial attention module, a lightweight CNN architecture, and a domain optimization-based approach. Our new contributions are as follows.
(3) The channel attention module is combined with the new proposed architecture in a different and effective manner to make it more efficient.
(4) We propose a lightweight CNNs architecture with a reduced number of network parameters and computation complexity. The architecture can boost the run-time associated with the inference of network while maintaining the performance.
(5) We propose an adversarial learning-based domain adaptation approach to generalize the network from source to target domain. We propose to use the mid-level output feature maps of the feature extraction network instead of using class-wise heatmaps, which is commonly used in most of the previously proposed domain adaptation based methods. To the best of our knowledge, this the first domain discriminator network-based adversarial learning scheme employed with an anchor-free detector.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}