
A Novel K-Means Clustering Algorithm with a Noise Algorithm for Capturing Urban Hotspots



Abstract
:1. Introduction
- A novel noise K-means clustering algorithm based on a noise algorithm is developed to capture urban hotspots.
- The noise algorithm is employed to randomly enhance the attribution of data points and output results of clustering by adding noise judgment to automatically obtain the number of clusters and initialize the center cluster.
- Four unsupervised evaluation indexes of DB, PBM, SC, and SSE are directly used to evaluate and analyze the clustering result.
- A non-parametric Wilcoxon statistical analysis method is employed to verify the distribution state and difference of clustering results.
- Comprehensive experiments are designed and executed to prove the effectiveness of the proposed noise K-means clustering algorithm with five sets of taxi GPS data.
2. Noise K-Means Clustering Algorithm
2.1. The Idea of the Noise K-Means Clustering Algorithm
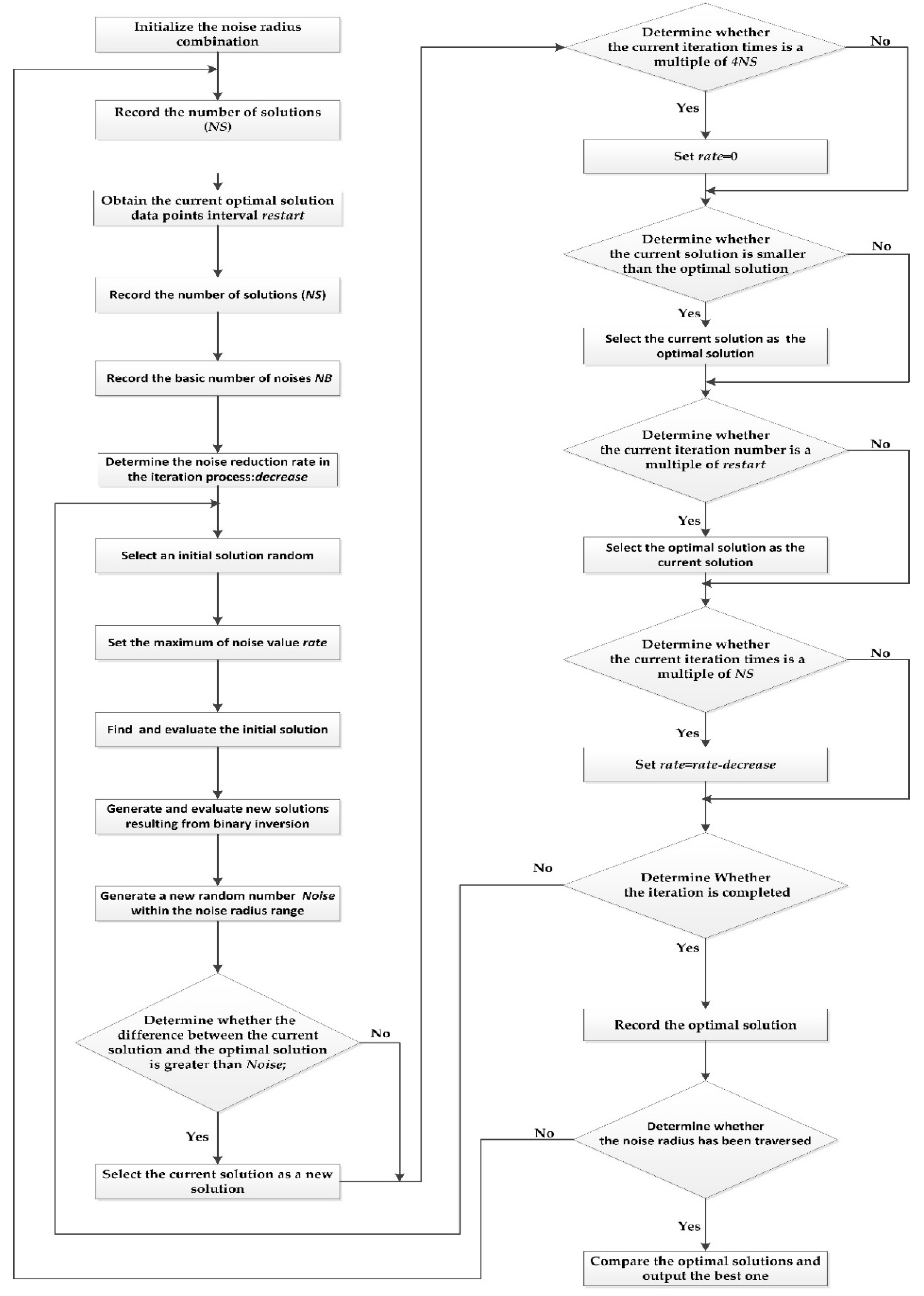
2.2. The Flow of the Noise K-Means Clustering Algorithm
2.3. The Realization of the Noise-Based K-Means Clustering Algorithm
| Algorithm 1. Noise-Based K-Means Clustering Algorithm |
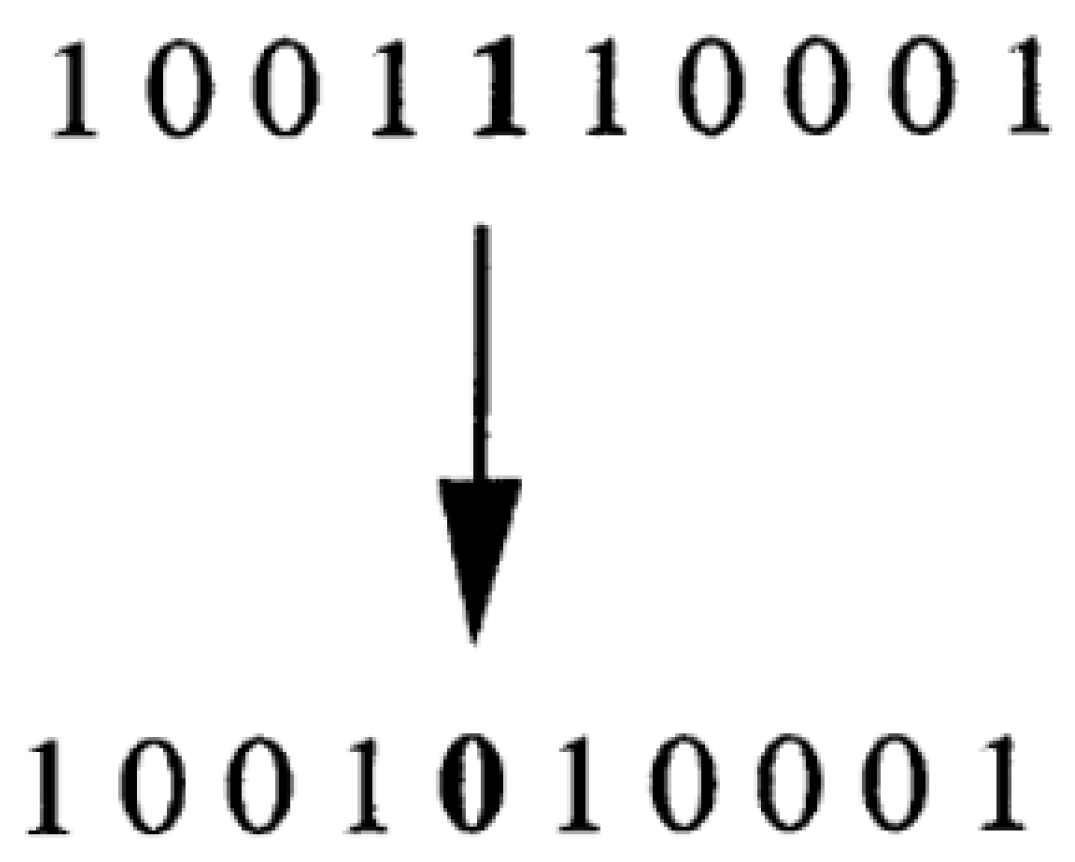
| Input: Taxi GPS dataset and the number of taxi GPS data points, noise radius rate (which can also be generated randomly), the number of clustering iterations, and the clustering termination condition. Output: Clustering results and new clustering center 1: Initialize the noise radius rate. Record the number of solutions (NS) of the current taxi GPS data. 2: Obtain the current optimal solution data points interval restart = , and takes integers. // represents the maximum number of iterations 3: Record the basic number of noises NB. Determine the noise reduction rate in the iteration process: decrease = . // represents the maximum and minimum values of the noise radius respectively. 4: Select an integer between [,] as the initial solution randomly, then evaluate it with SSE and denote it as the optimal solution. 5: Set the maximum of noise value rate. Determine whether the new solution generated by binary inversion is out of range [, ]. 6: Generate a new random number within the noise radius range to produce Noise. 7: Select the current solution as the optimal solution when the difference between the current solution and the optimal solution is greater than Noise. 8: Set rate = 0 when the current iteration times is a multiple of 4NS. Set the optimal solution as new solution when the current iteration number is a multiple of restart. Set rate = rate-decrease when the current iteration times is a multiple of NS. 9: Record the optimal solution and judge whether the iteration and the noise radius are completed. 10: Output the number of clusters and the initialization center of the given taxi GPS dataset. 11: Calculate the distance between the data point and the center point. Attribute the data points to the nearest cluster center according to the distance of the data points. Assign the data point average of each cluster as the new clustering center. 12: Calculate the SSE. Determine the termination condition of clustering. 13: Output the clustering result, which is the urban hotspots. |
3. Clustering Process of the Noise K-Means Clustering Algorithm
3.1. Obtain the Clustering Number K Value and the Initial Center
3.2. Optimize Clustering Center
3.3. Obtain Clustering Result and Capture Excellent Cluster Center
4. Experiment Results and Analysis
4.1. Urban Taxi GPS Data
4.2. Experimental Environment and Parameter Setting
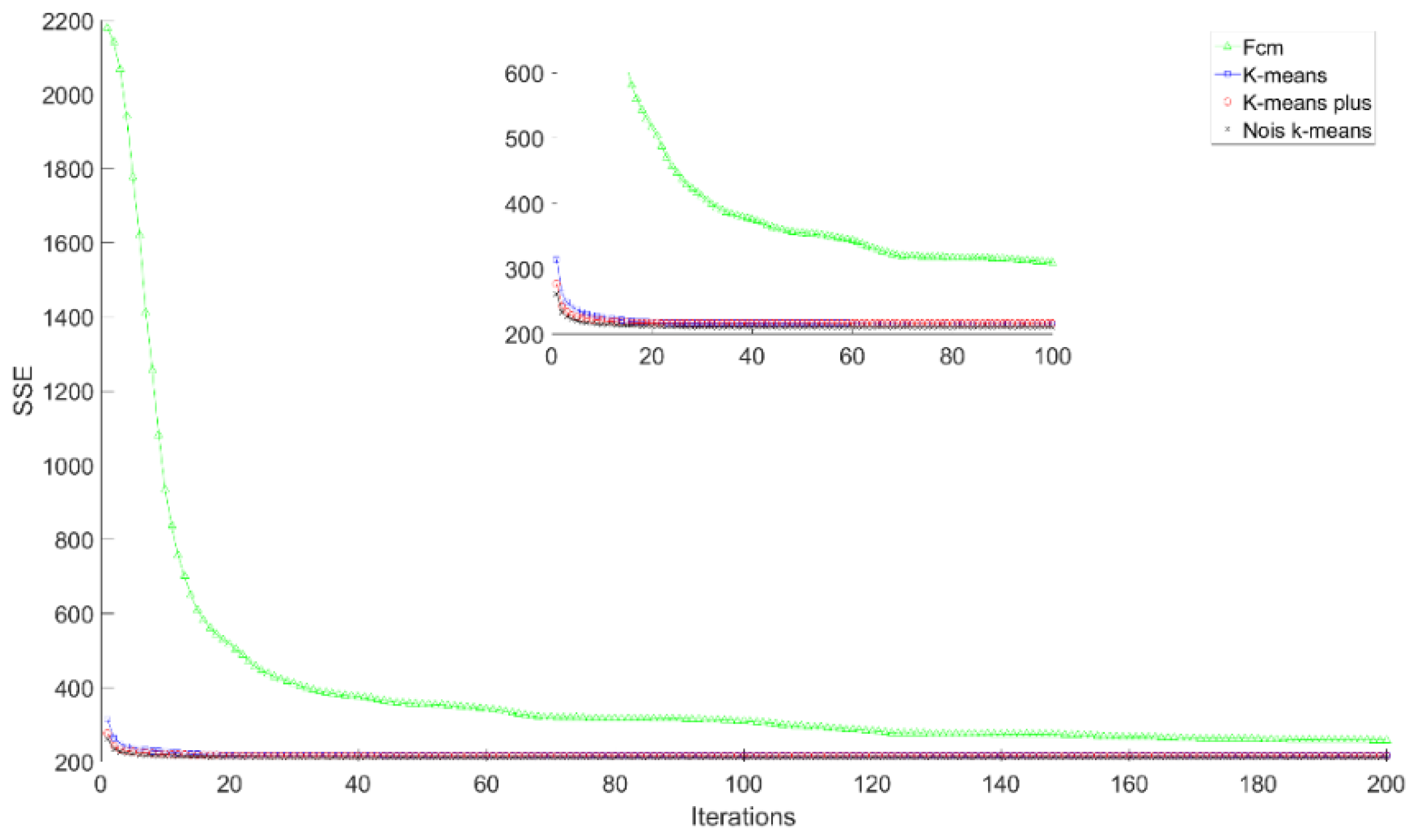
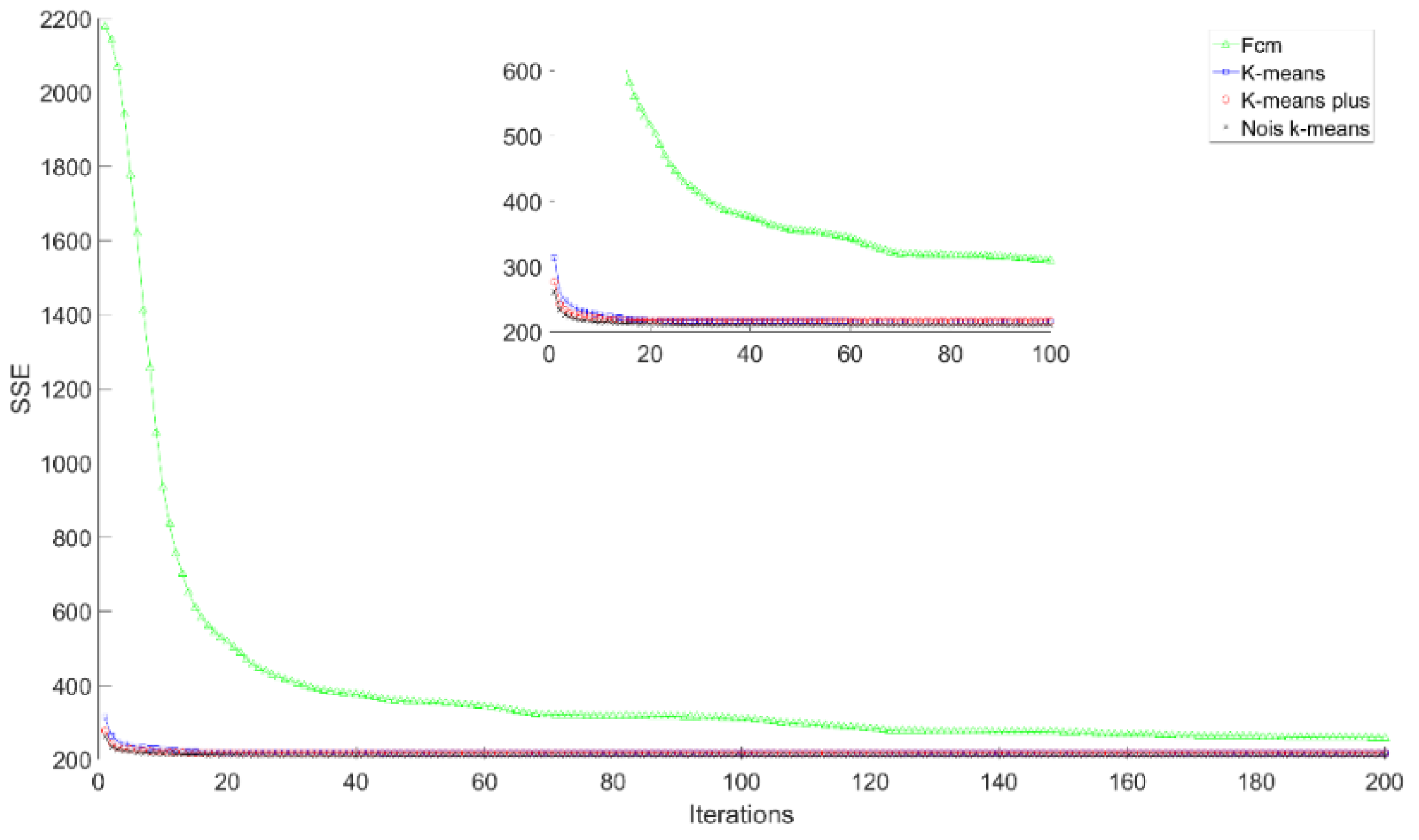
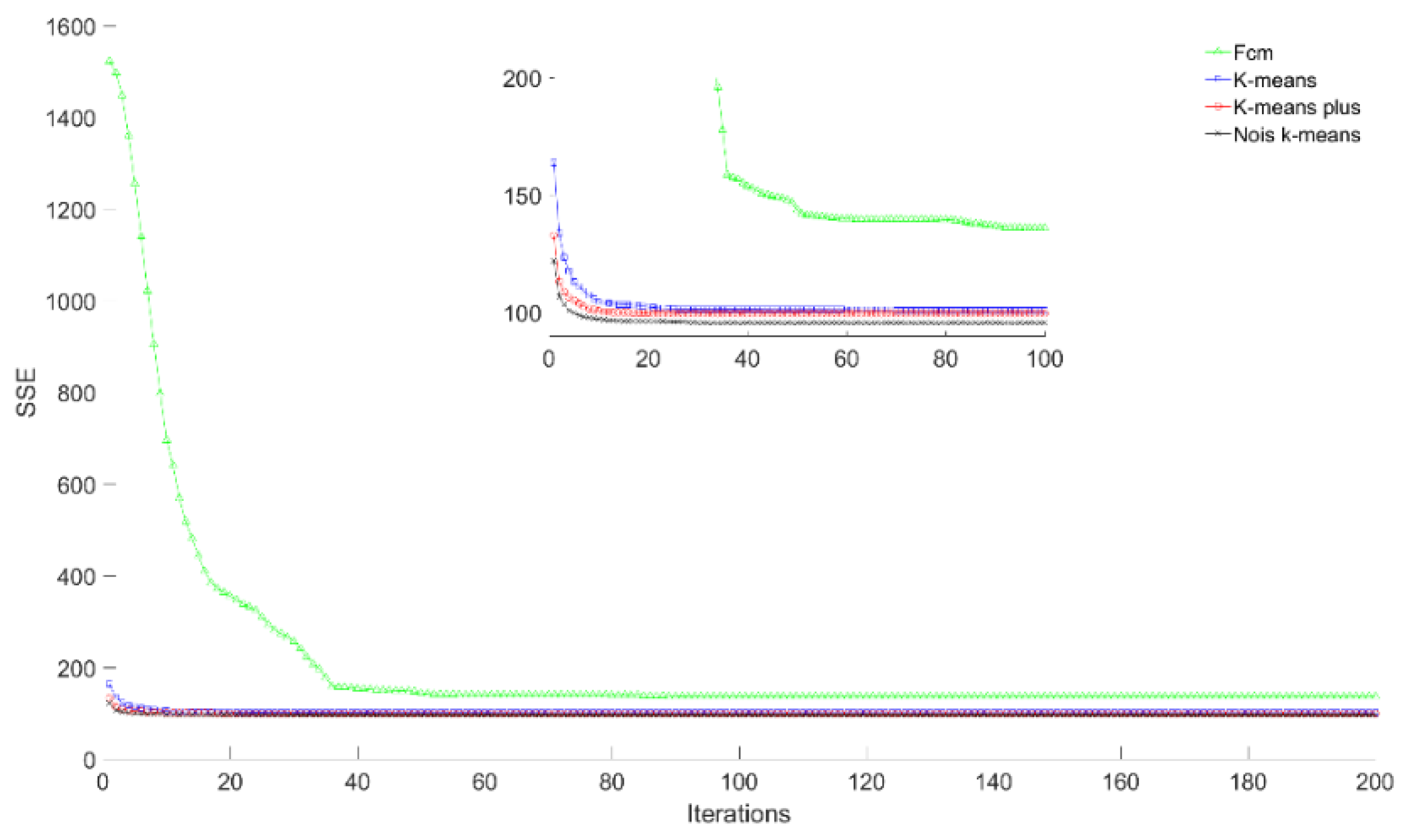
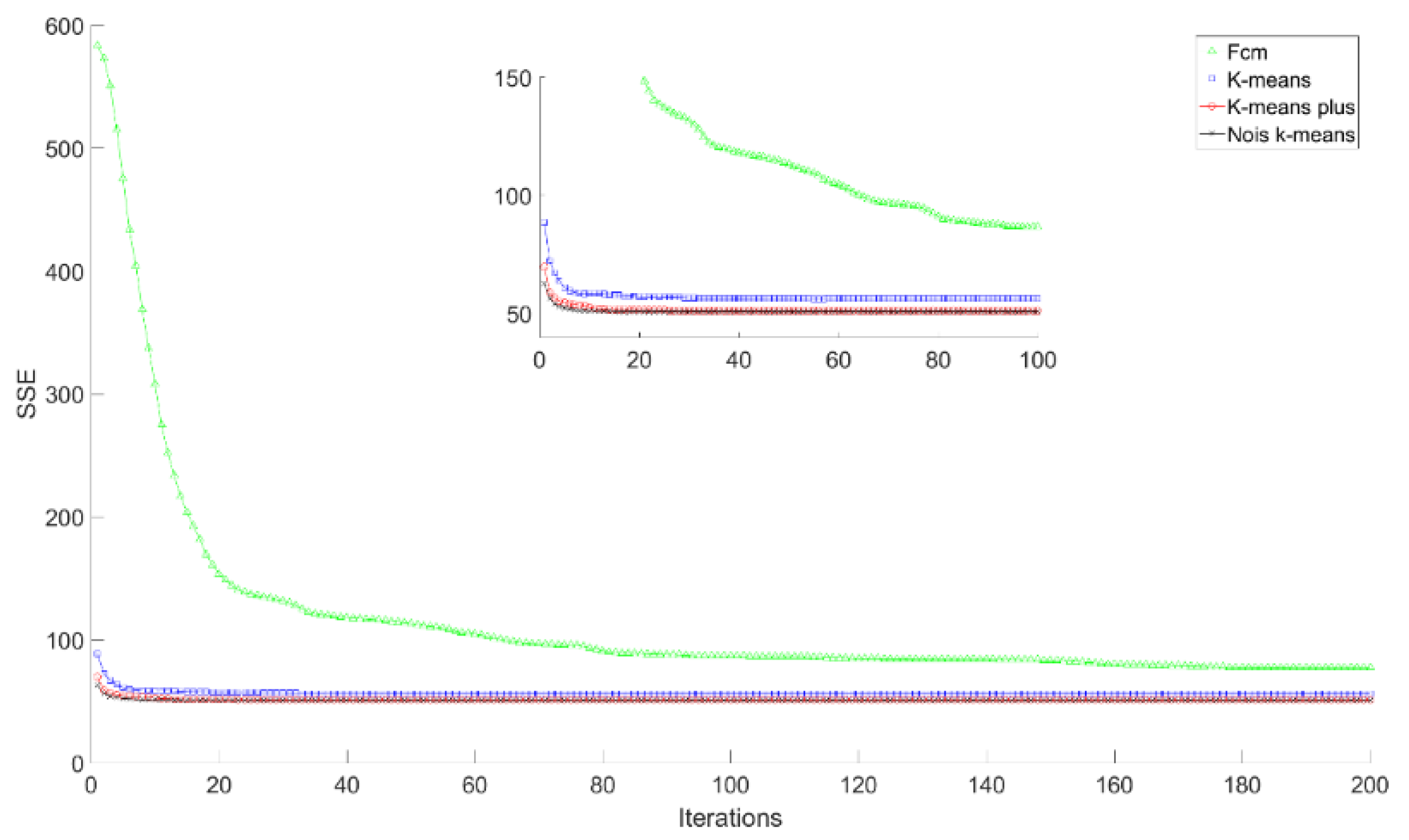
4.3. Experimental Results and Comparison Analysis
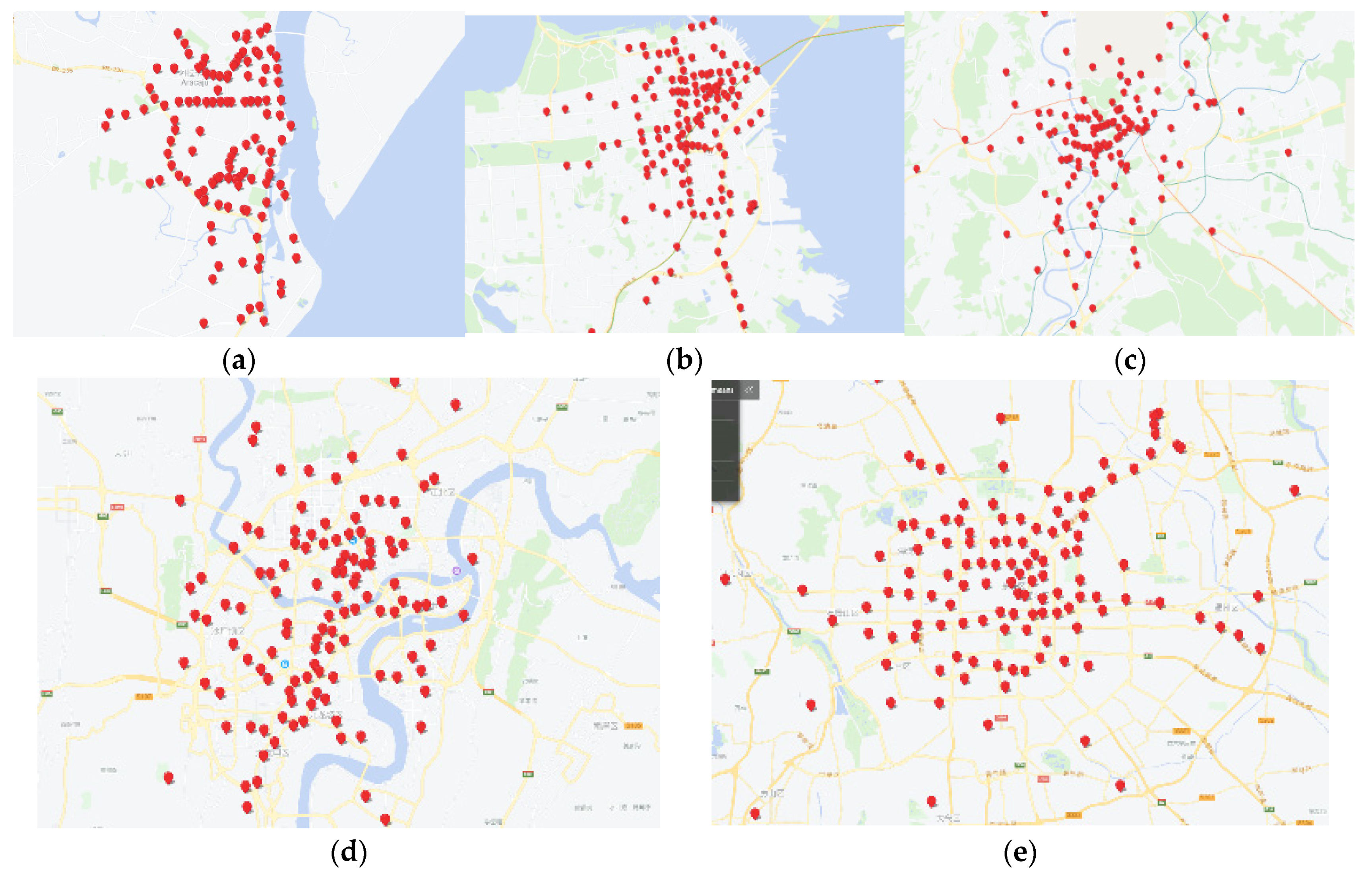
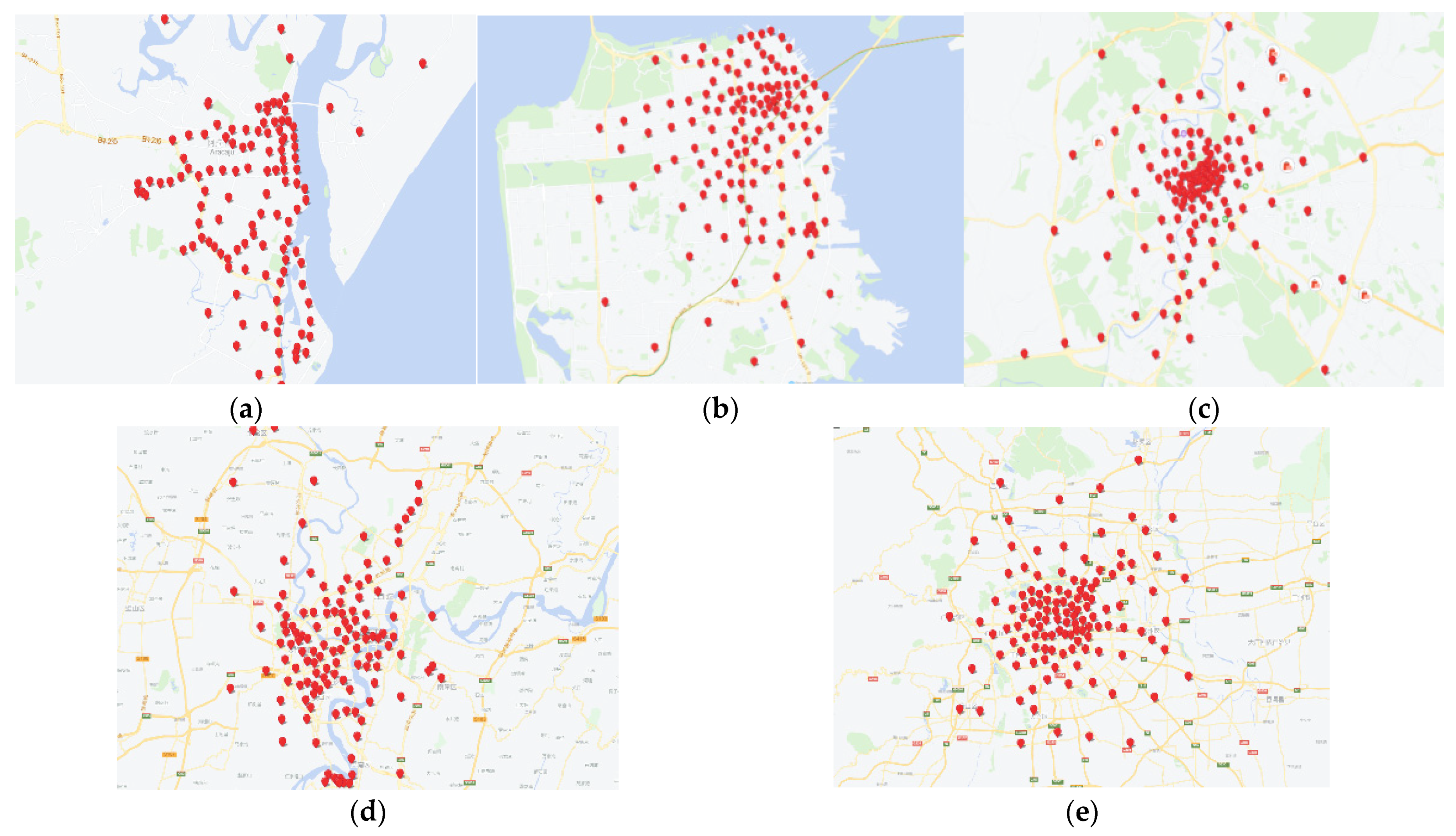
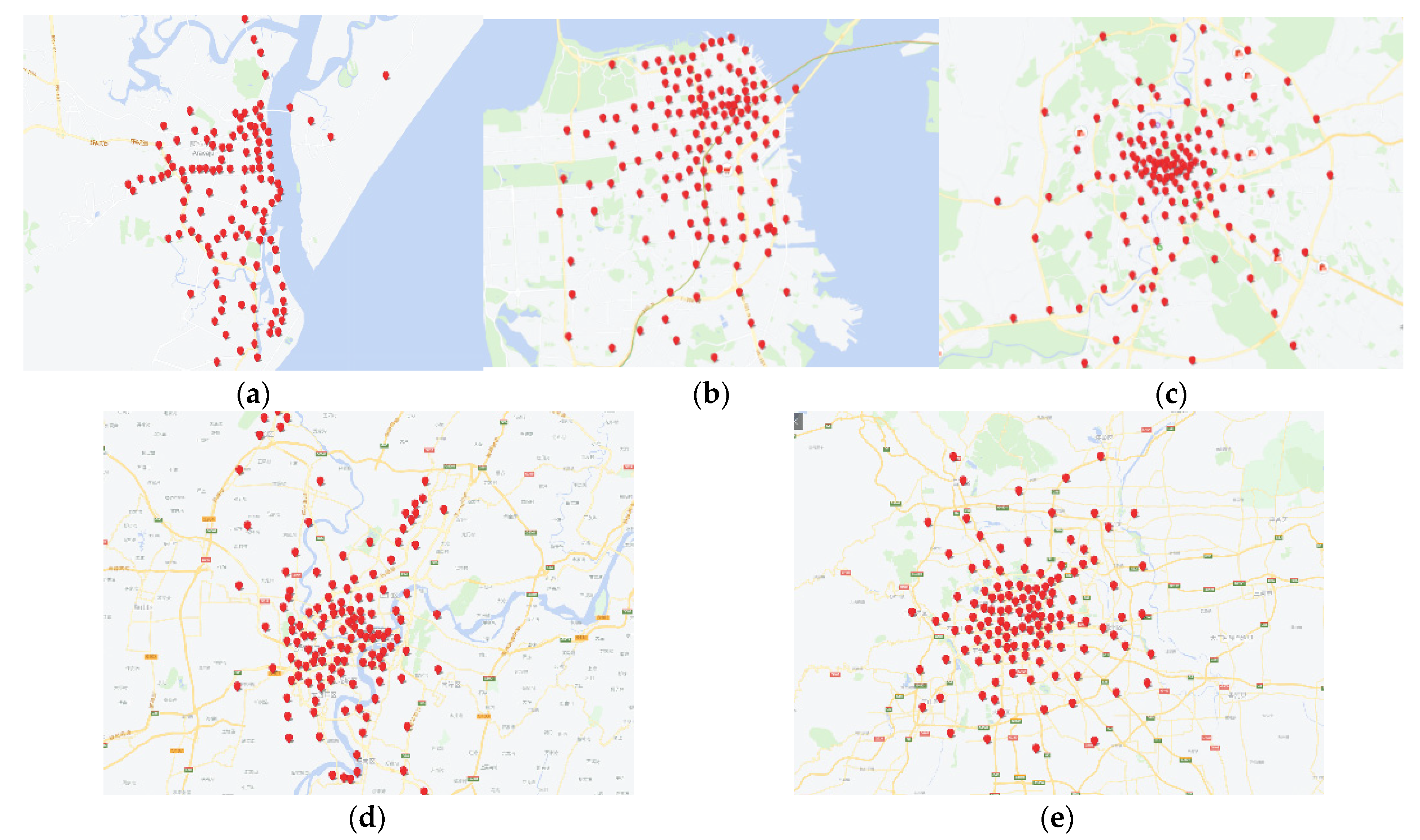
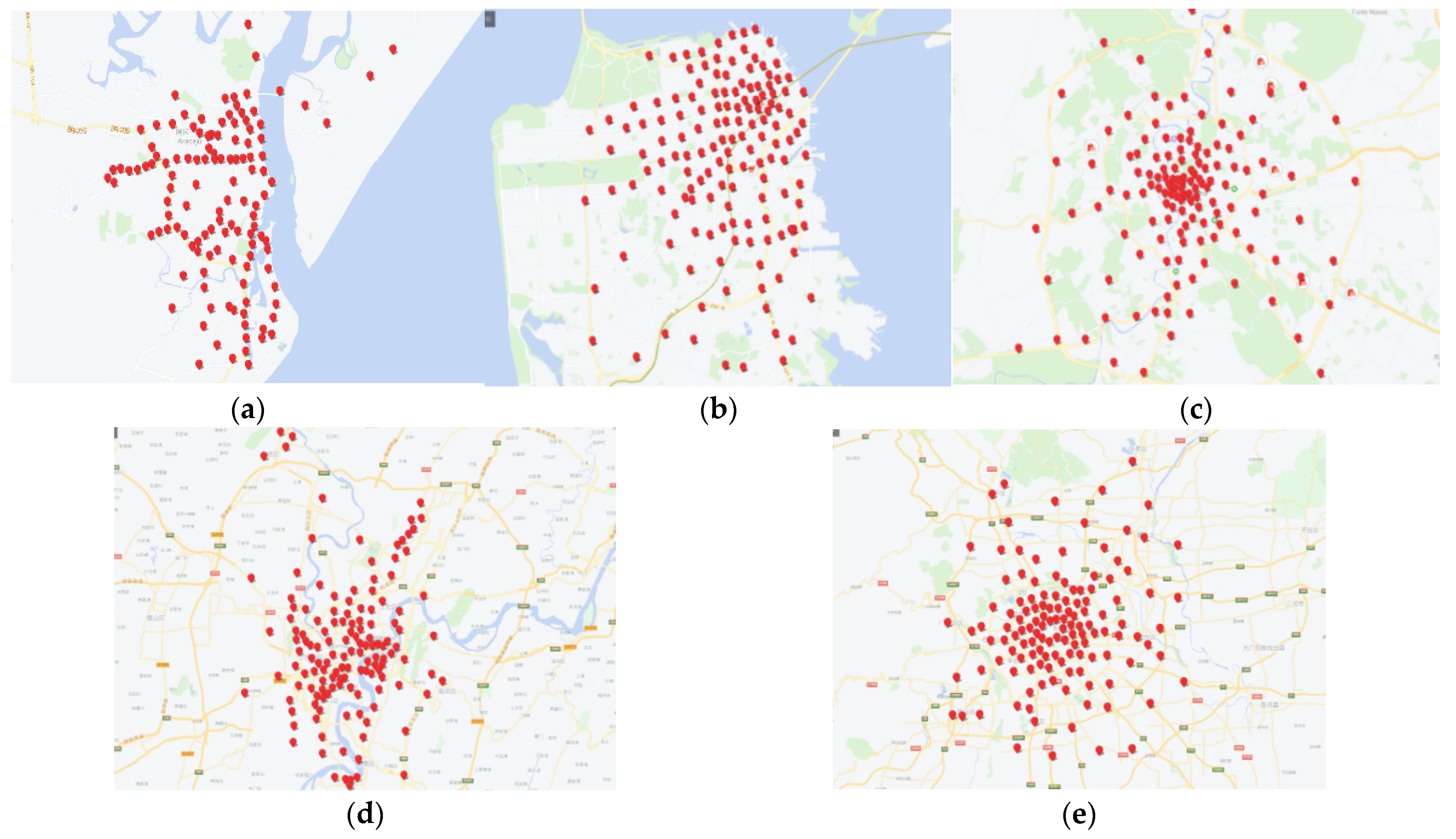
4.4. Visual Presentation of Urban Hotspots
5. Statistical Analysis of Wilcoxon
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, X.; Gu, J.; Shen, S.; Ma, H.; Miao, F.; Zhang, H.; Gong, H. An automatic k-means clustering algorithm of gps data combining a novel niche genetic algorithm with noise and density. ISPRS Int. J. Geoinf. 2017, 6, 392. [Google Scholar] [CrossRef] [Green Version]
- D’Andrea, E.; Marcelloni, F. Detection of traffic congestion and incidents from GPS trace analysis. Expert Syst. Appl. 2017, 73, 43–56. [Google Scholar] [CrossRef]
- Cui, J.; Liu, F.; Janssens, D.; An, S.; Wets, G.; Cools, M. Detecting urban road network accessibility problems using taxi GPS data. J. Transp. Geogr. 2016, 51, 147–157. [Google Scholar] [CrossRef]
- An, S.; Yang, H.; Wang, J.; Cui, N.; Cui, J. Mining urban recurrent congestion evolution patterns from GPS-equipped vehicle mobility data. Inf. Sci. 2016, 373, 515–526. [Google Scholar] [CrossRef]
- Li, T.; Qian, Z.; Deng, W.; Zhang, D.; Lu, H.; Wng, S. Forecasting crude oil prices based on variational mode decomposition and random sparse Bayesian learning. Appl. Soft Comput. 2021, 113, 108032. [Google Scholar] [CrossRef]
- Shi, Y.; Da, W.; Tang, J.; Deng, M.; Liu, H.; Liu, B. Detecting spatiotemporal extents of traffic congestion: A density-based moving object clustering approach. Int. J. Geogr. Inf. Sci. 2021, 35, 1–26. [Google Scholar] [CrossRef]
- Guo, J.; Liu, Y.; Yang, Q.; Wang, Y. GPS-based citywide traffic congestion forecasting using CNN-RNN and C3D hybrid model. Transp. A Transport. Sci. 2020, 17, 1–24. [Google Scholar] [CrossRef]
- Yongdong, W.; Dongwei, X.; Peng, P.; Guijun, Z. Analysis of road travel behaviour based on big trajectory data. IET Intell. Transp. Syst. 2020, 14, 1691–1703. [Google Scholar] [CrossRef]
- Dong, X.; Wang, L.; Hu, B. Analysis of spatio-temporal distribution characteristics of passenger travel behaviour based on online ride-sharing trajectory data. J. Phys. Conf. Ser. 2019, 1187, 052055. [Google Scholar] [CrossRef]
- Siangsuebchart, S.; Ninsawat, S.; Witayangkurn, A.; Pravinvongvuth, S. Public transport gps probe and rail gate data for assessing the pattern of human mobility in the bangkok metropolitan region, Thailand. Sustainability 2021, 13, 2178. [Google Scholar] [CrossRef]
- Cui, J.; Liu, F.; Hu, J.; Janssens, D.; Wets, G.; Cools, M. Identifying mismatch between urban travel demand and transport network services using gps data: A case study in the fast-growing Chinese city of Harbin. Neurocomputing 2016, 181, 4–18. [Google Scholar] [CrossRef]
- Tang, J.; Gao, F.; Liu, F.; Zhang, W.; Qi, Y. Understanding Spatio-temporal characteristics of urban travel demand based on the combination of GWR and GLM. Sustainability 2019, 11, 5525. [Google Scholar] [CrossRef] [Green Version]
- Luo, C.; Junlin, L.; Li, G.; Wei, W.; Li, Y.; Li, J. Efficient reverse spatial and textual k nearest neighbor queries on road networks. Knowl. Based Syst. 2016, 93, 121–134. [Google Scholar] [CrossRef]
- Han, B.; Liu, L.; Omiecinski, E. Road-network aware trajectory clustering: Integrating locality, flow, and density. IEEE Trans. Mob. Comput. 2015, 14, 416–429. [Google Scholar]
- Deng, W.; Shang, S.; Cai, X.; Zhao, H.; Zhou, Y.; Chen, H.; Deng, W. Quantum differential evolution with cooperative coevolution framework and hybrid mutation strategy for large scale optimization. Knowl.-Based Syst. 2021, 224, 107080. [Google Scholar] [CrossRef]
- Hasan, S.; Ukkusuri, S.V. Urban activity pattern classification using topic models from online geo-location data. Transp. Res. Part. C Emerg. Technol. 2014, 44, 363–381. [Google Scholar] [CrossRef]
- Iliopoulou, C.A.; Milioti, C.P.; Vlahogianni, E.I.; Kepaptsoglou, K.L. Identifying Spatio-temporal patterns of bus bunching in urban networks. J. Intell. Transp. Syst. 2020, 24, 365–382. [Google Scholar] [CrossRef]
- Deng, W.; Xu, J.; Zhao, H.; Song, Y. A novel gate resource allocation method using improved PSO-based QEA. IEEE Trans. Intell. Transp. Syst. 2020, 99, 1–9. [Google Scholar] [CrossRef]
- Lu, M.; Liang, J.; Wang, Z.; Yuan, X. Exploring od patterns of interested region based on taxi trajectories. J. Vis. 2016, 19, 811–821. [Google Scholar] [CrossRef]
- Moreira-Matias, L.; Gama, J.; Ferreira, M.; Mendes-Moreira, J.; Damas, L. Time-evolving o-d matrix estimation using high-speed GPS data streams. Expert Syst. Appl. 2016, 44, 275–288. [Google Scholar] [CrossRef] [Green Version]
- Huang, D.; Yu, J.; Shen, S.; Li, Z.; Zhao, L.; Gong, C. A method for bus od matrix estimation using multisource data. J. Adv. Transp. 2020, 2020, 5740521. [Google Scholar] [CrossRef]
- Spaccapietra, S.; Parent, C.; Damiani, M.; Macêdo, J.; Porto, F.; Vangenot, C. A conceptual view on trajectories. Data Knowl. Eng. 2008, 65, 126–146. [Google Scholar] [CrossRef] [Green Version]
- Luo, T.; Zheng, X.; Xu, G.; Fu, K.; Ren, W. An improved DBSCAN algorithm to detect stops in individual trajectories. ISPRS Int. J. Geoinf. 2017, 6, 63. [Google Scholar] [CrossRef]
- Deng, W.; Xu, J.; Gao, X.; Zhao, H. An enhanced MSIQDE algorithm with novel multiple strategies for global optimization problems. IEEE Trans. Syst. Man Cybern. Syst. 2020, 99, 1–10. [Google Scholar] [CrossRef]
- Nanni, M.; Pedreschi, D. Time-focused clustering of trajectories of moving objects. J. Intell. Inf. Syst. 2006, 27, 267–289. [Google Scholar] [CrossRef]
- Pongracic, B.; Wu, F.L.; Fathollahi, L.; Brcic, D. Midlatitude Klobuchar correction model based on the k-means clustering of ionospheric daily variations. GPS Solut. 2019, 23, 80. [Google Scholar] [CrossRef]
- Gu, Y.Y.; Wang, Y.D.; Dong, S.H. Public traffic congestion estimation using an artificial neural network. ISPRS Int. J. Geoinf. 2020, 9, 152. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Li, J.L.; Xu, Z.G.; Liu, Z.Q.; Zhao, X.M.; Chen, J.H. A novel image-based convolutional neural network approach for traffic congestion estimation. Expert Syst. Appl. 2021, 180, 115037. [Google Scholar] [CrossRef]
- Afrin, T.; Yodo, N. A probabilistic estimation of traffic congestion using Bayesian network. Measurement 2021, 174, 109051. [Google Scholar] [CrossRef]
- Zhang, G.; Zhang, C.; Zhang, H. Improved k-means algorithm based on density canopy. Knowl. Based Syst. 2018, 145, 289–297. [Google Scholar] [CrossRef]
- He, Z.; Yu, C. Clustering stability-based evolutionary k-means. Soft Comput. 2019, 23, 305–321. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2007, New Orleans, LA, USA, 77–9 January 2007; ACM, 2007; pp. 1027–1035. [Google Scholar]
- Bezdek, J. Pattern Recognition with Fuzzy Objective Function Algorithms. SIAM Rev. 1981, 25, 442. [Google Scholar]
- Borlea, I.-D.; Precup, R.-E.; Borlea, A.-B.; Iercan, D. A unified form of fuzzy c-means and k-means algorithms and its partitional implementation. Knowl. Based Syst. 2021, 214, 106731. [Google Scholar] [CrossRef]
- Heil, J.; Häring, V.; Marschner, B.; Stumpe, B. Advantages of fuzzy k-means over k-means clustering in the classification of diffuse reflectance soil spectra: A case study with west African soils. Geoderma 2019, 337, 11–21. [Google Scholar] [CrossRef]
- Bei, H.; Mao, Y.; Wang, W.; Zhang, X. Fuzzy clustering method based on improved weighted distance. Math. Probl. Eng. 2021, 2021, 6687202. [Google Scholar] [CrossRef]
- Beg, A.H.; Islam, M.Z.; Estivill-Castro, V. Genetic algorithm with healthy population and multiple streams sharing information for clustering. Knowl. Based Syst. 2016, 114, 61–78. [Google Scholar] [CrossRef]
- Ghezelbash, R.; Maghsoudi, A.; Carranza, E.J.M. Optimization of geochemical anomaly detection using a novel genetic k-means clustering (gkmc) algorithm. Comput. Geosci. 2020, 134, 104335. [Google Scholar] [CrossRef]
- Huang, S.; Kang, Z.; Xu, Z.; Liu, Q. Robust deep k-means: An effective and simple method for data clustering. Pattern Recognit. 2021, 117, 107996. [Google Scholar] [CrossRef]
- Jahangoshai Rezaee, M.; Eshkevari, M.; Saberi, M.; Hussain, O. GBK-means clustering algorithm: An improvement to the k-means algorithm based on the bargaining game. Knowl. Based Syst. 2021, 213, 106672. [Google Scholar] [CrossRef]
- Ma, H.J.; Zhou, X.B. A GPS location data clustering approach based on a niche genetic algorithm and hybrid K-means. Intell. Data Anal. 2019, 23, S175–S198. [Google Scholar] [CrossRef]
- Sun, H.D.; Chen, Y.Y.; Lai, J.H.; Wang, Y.; Liu, X.M. Identifying tourists and locals by K-means clustering method from mobile phone signaling data. J. Transp. Eng. Part. A Syst. 2021, 147, 04021070. [Google Scholar] [CrossRef]
- Rahman, M.A.; Islam, M. Seed-detective: A novel clustering technique using high quality seed for k-means on categorical and numerical attributes. In Proceedings of the 9th Australasian Data Mining Conference (AusDM’11), Ballarat, Australia, 1–2 December 2011; Volume 121. [Google Scholar]
- Liu, Y.; Wu, X.; Shen, Y. Automatic clustering using genetic algorithms. Appl. Math. Comput. 2011, 218, 1267–1279. [Google Scholar] [CrossRef]
- Piorkowski, M.; Sarafijanovic-Djukic, N.; Grossglauser, M. Crawdad Dataset epfl/Mobility (v. 24 February 2009). Available online: http://crawdad.Org/epfl/mobility/20090224 (accessed on 7 July 2021).
- Zheng, Y.; Liu, Y.; Yuan, J.; Xie, X. Urban computing with taxicabs. In Proceedings of the 13th International Conference on Ubiquitous Computing, Beijing, China, 17–21 September 2011; Association for Computing Machinery: Beijing, China, 2011; pp. 89–98. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Pakhira, M.K.; Bandyopadhyay, S.; Maulik, U. Validity index for crisp and fuzzy clusters. Pattern Recognit. 2004, 37, 487–501. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Nonparametric testing. In Principles of Managerial Statistics and Data Science; John Wiley & Sons: Hoboken, NJ, USA, 2020; pp. 533–549.
- Zhou, X. Research on Intelligent Clustering Learning Algorithm for GNSS Data; Chengdu University of Technology: Chengdu, China, 2018. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Taxi GPS Dataset | Latitude and Longitude Region | Number of GPS Data Points |
|---|---|---|
| Aracaju (Brazil) | 0.14 × 0.16 | 16,513 |
| San Francisco (USA) [39] | 0.10 × 0.10 | 21,826 |
| Rome (Italy) [39] | 0.35 × 0.50 | 20,254 |
| Chongqing (China) [1] | 0.60 × 0.36 | 19,149 |
| Beijing (China) [40] | 0.90 × 0.90 | 17,387 |
| Taxi GPS Dataset | The Clustering Number of FCM, K-Means, K-Means Plus | The Clustering Number of Noise K-Means |
|---|---|---|
| Aracaju (Brazil) | 120 | 125 |
| San Francisco (USA) | 140 | 144 |
| Rome (Italy) | 135 | 137 |
| Chongqing (China) | 130 | 134 |
| Beijing (China) | 125 | 128 |
| Taxi GPS Dataset | Algorithms | Maximum | Average | Minimum |
|---|---|---|---|---|
| Aracaju (Brazil) | Noise K-means | 0.96083 | 0.95944 | 0.95703 |
| FCM | 0.94635 | 0.94416 | 0.94285 | |
| K-means | 0.95827 | 0.95577 | 0.95355 | |
| K-means plus | 0.96004 | 0.95784 | 0.95586 | |
| San Francisco (USA) | Noise K-means | 0.9369 | 0.93522 | 0.93314 |
| FCM | 0.92914 | 0.92689 | 0.92494 | |
| K-means | 0.93389 | 0.93124 | 0.9287 | |
| K-means plus | 0.93502 | 0.93403 | 0.93219 | |
| Rome (Italy) | Noise K-means | 0.9295 | 0.9275 | 0.9231 |
| FCM | 0.91112 | 0.90662 | 0.90296 | |
| K-means | 0.9277 | 0.92535 | 0.92255 | |
| K-means plus | 0.92871 | 0.92672 | 0.92334 | |
| Chongqing (China) | Noise K-means | 0.93896 | 0.93689 | 0.93457 |
| FCM | 0.91979 | 0.91682 | 0.91311 | |
| K-means | 0.93673 | 0.93565 | 0.93424 | |
| K-means plus | 0.93708 | 0.9354 | 0.93195 | |
| Beijing (China) | Noise K-means | 0.91192 | 0.90933 | 0.90561 |
| FCM | 0.91979 | 0.91682 | 0.91311 | |
| K-means | 0.91125 | 0.91012 | 0.90853 | |
| K-means plus | 0.90963 | 0.90842 | 0.90668 |
| Taxi GPS Dataset | Algorithms | Maximum | Average | Minimum |
|---|---|---|---|---|
| Aracaju (Brazil) | Noise K-means | 0.03201 | 0.03108 | 0.02999 |
| FCM | 0.01319 | 0.01286 | 0.01259 | |
| K-means | 0.03049 | 0.02827 | 0.02681 | |
| K-means plus | 0.03229 | 0.0308 | 0.02912 | |
| San Francisco (USA) | Noise K-means | 0.01218 | 0.01172 | 0.01136 |
| FCM | 0.01034 | 0.00958 | 0.00886 | |
| K-means | 0.01132 | 0.01041 | 0.00985 | |
| K-means plus | 0.01278 | 0.01193 | 0.01114 | |
| Rome (Italy) | Noise K-means | 0.0236 | 0.022548 | 0.022006 |
| FCM | 0.011832 | 0.010484 | 0.009661 | |
| K-means | 0.020837 | 0.019411 | 0.017145 | |
| K-means plus | 0.023151 | 0.022623 | 0.021651 | |
| Chongqing (China) | Noise K-means | 0.0627 | 0.05794 | 0.05468 |
| FCM | 0.03976 | 0.03731 | 0.03568 | |
| K-means | 0.06013 | 0.0542 | 0.05118 | |
| K-means plus | 0.06133 | 0.05753 | 0.0532 | |
| Beijing (China) | Noise K-means | 0.06086 | 0.0598 | 0.05833 |
| FCM | 0.03976 | 0.03731 | 0.03568 | |
| K-means | 0.06157 | 0.05877 | 0.05694 | |
| K-means plus | 0.06011 | 0.06036 | 0.05914 |
| Taxi GPS Dataset | Algorithms | Maximum | Average | Minimum |
|---|---|---|---|---|
| Aracaju (Brazil) | Noise K-means | 0.08366 | 0.07992 | 0.07423 |
| FCM | 0.17978 | 0.15106 | 0.13756 | |
| K-means | 0.08817 | 0.07815 | 0.06961 | |
| K-means plus | 0.0858 | 0.78368 | 0.06975 | |
| San Francisco (USA) | Noise K-means | 0.09342 | 0.09039 | 0.08518 |
| FCM | 0.15793 | 0.1459 | 0.12684 | |
| K-means | 0.10198 | 0.08553 | 0.08055 | |
| K-means plus | 0.09755 | 0.09082 | 0.08518 | |
| Rome (Italy) | Noise K-means | 0.16462 | 0.10853 | 0.09498 |
| FCM | 0.17961 | 0.15236 | 0.13591 | |
| K-means | 0.09967 | 0.09159 | 0.08619 | |
| K-means plus | 0.16606 | 0.10897 | 0.09622 | |
| Chongqing (China) | Noise K-means | 0.11173 | 0.10038 | 0.09182 |
| FCM | 0.17093 | 0.14996 | 0.13769 | |
| K-means | 0.10028 | 0.09 | 0.0847 | |
| K-means plus | 0.11207 | 0.10867 | 0.0922 | |
| Beijing (China) | Noise K-means | 0.10447 | 0.09777 | 0.09215 |
| FCM | 0.17093 | 0.14996 | 0.13769 | |
| K-means | 0.0925 | 0.08668 | 0.08281 | |
| K-means plus | 0.10459 | 0.09799 | 0.09305 |
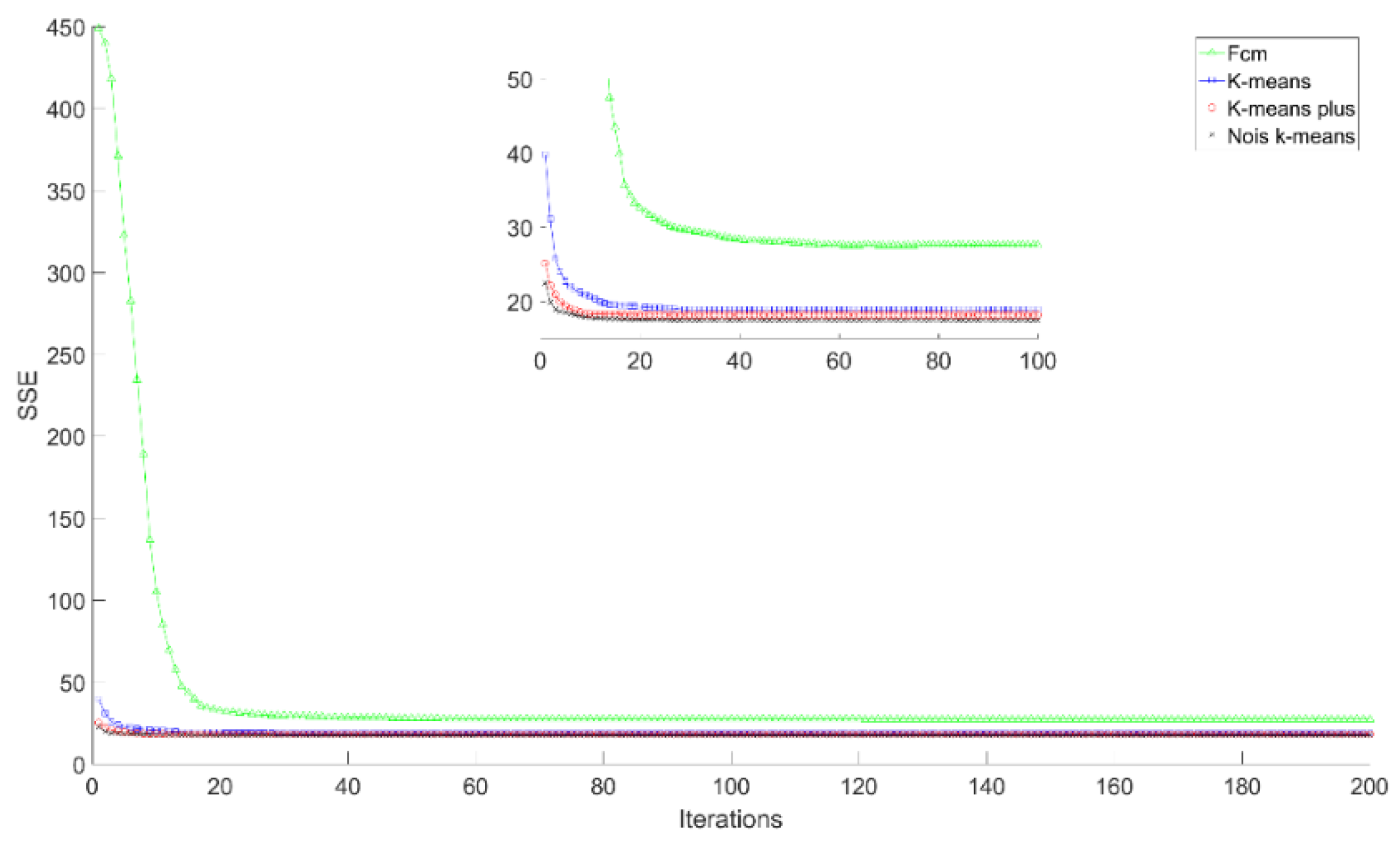
| Taxi GPS Dataset | Algorithms | Maximum | Average | Minimum |
|---|---|---|---|---|
| Aracaju (Brazil) | Noise K-means | 19.3463 | 18.1769 | 17.4351 |
| FCM | 28.7974 | 28.0926 | 27.3564 | |
| K-means | 21.4902 | 20.4493 | 18.193 | |
| K-means plus | 19.957 | 19.0552 | 17.4351 | |
| San Francisco (USA) | Noise K-means | 34.8698 | 33.8601 | 33.1321 |
| FCM | 41.1925 | 40.0136 | 38.6125 | |
| K-means | 39.1769 | 37.2797 | 35.5356 | |
| K-means plus | 35.6768 | 34.6172 | 34.0928 | |
| Rome (Italy) | Noise K-means | 54.1587 | 52.2404 | 50.6664 |
| FCM | 86.4097 | 82.9769 | 77.1727 | |
| K-means | 64.186 | 59.7377 | 56.1926 | |
| K-means plus | 54.7747 | 52.7017 | 51.1269 | |
| Chongqing (China) | Noise K-means | 102.901 | 99.4066 | 95.5405 |
| FCM | 151.343 | 144.9 | 135.923 | |
| K-means | 109.436 | 104.691 | 101.017 | |
| K-means plus | 108.112 | 101.987 | 99.5079 | |
| Beijing (China) | Noise K-means | 151.343 | 144.9 | 135.923 |
| FCM | 224.152 | 214.794 | 209.467 | |
| K-means | 223.885 | 220.258 | 216.065 | |
| K-means plus | 220.629 | 218.108 | 216.092 |
| Taxi GPS Dataset | Clustering Algorithm | Average Running Time (s) |
|---|---|---|
| Aracaju (Brazil) | Noise K-means | 8.03867 |
| FCM | 21.7398 | |
| K-means | 2.3773 | |
| K-means plus | 2.7005 | |
| San Francisco (USA) | Noise K-means | 10.86496 |
| FCM | 32.4686 | |
| K-means | 3.232 | |
| K-means plus | 3.3807 | |
| Rome (Italy) | Noise K-means | 9.87741 |
| FCM | 29.5736 | |
| K-means | 3.1264 | |
| K-means plus | 3.1248 | |
| Chongqing (China) | Noise K-means | 9.65121 |
| FCM | 26.9652 | |
| K-means | 2.9121 | |
| K-means plus | 2.9302 | |
| Beijing (China) | Noise K-means | 8.34432 |
| FCM | 26.9652 | |
| K-means | 2.6924 | |
| K-means plus | 2.5276 |
| Taxi GPS Dataset | Clustering Result Evaluation Method | Noise-Based K-Means Versus FCM | ||||
|---|---|---|---|---|---|---|
| k | p | h | Stats | |||
| Zval | Ranksum | |||||
| Aracaju (Brazil) | SC | 120 | 6.79561 × 10−8 | 1 | 5.3965 | 610 |
| SSE | 6.79561 × 10−8 | 1 | −5.3965 | 210 | ||
| DBI | 6.79561 × 10−8 | 1 | −5.3965 | 210 | ||
| PBM | 6.79561 × 10−8 | 1 | 5.3965 | 610 | ||
| San Francisco (USA) | SC | 140 | 6.79561 × 10−8 | 1 | 5.3965 | 610 |
| SSE | 6.79561 × 10−8 | 1 | −5.3965 | 210 | ||
| DBI | 6.79561 × 10−8 | 1 | −5.3965 | 210 | ||
| PBM | 6.79561 × 10−8 | 1 | 5.3965 | 610 | ||
| Roma (Italy) | SC | 135 | 6.79561 × 10−8 | 1 | 5.3965 | 610 |
| SSE | 6.79561 × 10−8 | 1 | −5.3965 | 210 | ||
| DBI | 6.79561 × 10−8 | 1 | −5.3965 | 227 | ||
| PBM | 6.79561 × 10−8 | 1 | 5.3965 | 610 | ||
| Chongqing (China) | SC | 130 | 6.79561 × 10−8 | 1 | 5.3965 | 610 |
| SSE | 6.79561 × 10−8 | 1 | −5.3965 | 210 | ||
| DBI | 6.79561 × 10−8 | 1 | −5.3965 | 210 | ||
| PBM | 6.79561 × 10−8 | 1 | 5.3965 | 610 | ||
| Beijing (China) | SC | 125 | 6.79561 × 10−8 | 1 | 5.3965 | 610 |
| SSE | 6.79561 × 10−8 | 1 | −5.3965 | 210 | ||
| DBI | 6.79561 × 10−8 | 1 | −5.3965 | 210 | ||
| PBM | 6.79561 × 10−8 | 1 | 5.3965 | 610 | ||
| Taxi GPS Dataset | Clustering Result Evaluation Method | Noise-Based K-Means Versus K-Means | ||||
|---|---|---|---|---|---|---|
| k | p | h | Stats | |||
| Zval | Ranksum | |||||
| Aracaju (Brazil) | SC | 120 | 3.41557 × 10−7 | 1 | 5.0989 | 599 |
| SSE | 9.17277 × 10−8 | 1 | −5.3424 | 212 | ||
| DBI | 9.09000 × 10−2 | 0 | 1.6906 | 473 | ||
| PBM | 1.06456 × 10−7 | 1 | 5.3153 | 607 | ||
| San Francisco (USA) | SC | 140 | 1.06456 × 10−7 | 1 | 5.3153 | 607 |
| SSE | 6.79561 × 10−8 | 1 | −5.3965 | 210 | ||
| DBI | 8.59744 × 10−6 | 1 | 4.4497 | 575 | ||
| PBM | 6.79561 × 10−8 | 1 | 5.3965 | 610 | ||
| Roma (Italy) | SC | 135 | 1.60981 × 10−4 | 1 | 3.7735 | 550 |
| SSE | 6.79561 × 10−8 | 1 | −5.3965 | 210 | ||
| DBI | 1.23463 × 10−7 | 1 | 5.2883 | 606 | ||
| PBM | 6.79561 × 10−8 | 1 | 5.3965 | 610 | ||
| Chongqing (China) | SC | 130 | 4.32000 × 10−3 | 1 | 2.8538 | 516 |
| SSE | 6.91658 × 10−7 | 1 | −4.9637 | 226 | ||
| DBI | 3.98735 × 10−6 | 1 | 4.6120 | 581 | ||
| PBM | 9.74797 × 10−6 | 1 | 4.4227 | 574 | ||
| Beijing (China) | SC | 125 | 3.36910 × 10−1 | 0 | −0.9603 | 374 |
| SSE | 6.61044 × 10−5 | 1 | −3.9899 | 262 | ||
| DBI | 7.89803 × 10−8 | 1 | 5.3694 | 609 | ||
| PBM | 2.13000 × 10−3 | 1 | 3.0702 | 524 | ||
| Taxi GPS Dataset | Clustering Result Evaluation Method | Noise-Based K-Means Versus K-Means Plus | ||||
|---|---|---|---|---|---|---|
| k | p | h | Stats | |||
| Zval | Ranksum | |||||
| Aracaju (Brazil) | SC | 120 | 3.38194 × 10−4 | 1 | 3.5841 | 543 |
| SSE | 2.04071 × 10−5 | 1 | −4.2604 | 252 | ||
| DBI | 1.80570 × 10−1 | 0 | 1.3390 | 460 | ||
| PBM | 3.79330 × 10−1 | 0 | 0.8791 | 443 | ||
| San Francisco (USA) | SC | 140 | 1.60981 × 10−4 | 1 | 3.7735 | 550 |
| SSE | 2.59598 × 10−5 | 1 | −4.2063 | 254 | ||
| DBI | 1.80570 × 10−1 | 0 | 1.3390 | 460 | ||
| PBM | 2.56300 × 10−2 | 1 | −2.2316 | 327 | ||
| Roma (Italy) | SC | 135 | 9.09100 × 10−2 | 0 | 1.6906 | 473 |
| SSE | 9.61900 × 10−2 | 0 | −1.6636 | 348 | ||
| DBI | 5.31000 × 10−2 | 0 | 1.9341 | 482 | ||
| PBM | 3.36910 × 10−1 | 0 | −0.9603 | 374 | ||
| Chongqing (China) | SC | 130 | 1.34000 × 10−3 | 1 | 3.2054 | 529 |
| SSE | 9.20913 × 10−4 | 1 | −3.3136 | 287 | ||
| DBI | 3.36910 × 10−1 | 0 | 0.9603 | 446 | ||
| PBM | 9.03110 × 10−1 | 0 | 0.1217 | 415 | ||
| Beijing (China) | SC | 125 | 7.64300 × 10−2 | 0 | 1.7718 | 476 |
| SSE | 5.62903 × 10−4 | 1 | −3.4489 | 282 | ||
| DBI | 4.73480 × 10−1 | 0 | 0.7168 | 437 | ||
| PBM | 3.79330 × 10−1 | 0 | −0.8791 | 377 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ran, X.; Zhou, X.; Lei, M.; Tepsan, W.; Deng, W. A Novel K-Means Clustering Algorithm with a Noise Algorithm for Capturing Urban Hotspots. Appl. Sci. 2021, 11, 11202. https://doi.org/10.3390/app112311202
Ran X, Zhou X, Lei M, Tepsan W, Deng W. A Novel K-Means Clustering Algorithm with a Noise Algorithm for Capturing Urban Hotspots. Applied Sciences. 2021; 11(23):11202. https://doi.org/10.3390/app112311202
Chicago/Turabian StyleRan, Xiaojuan, Xiangbing Zhou, Mu Lei, Worawit Tepsan, and Wu Deng. 2021. "A Novel K-Means Clustering Algorithm with a Noise Algorithm for Capturing Urban Hotspots" Applied Sciences 11, no. 23: 11202. https://doi.org/10.3390/app112311202