
An Optimized CNN Model for Engagement Recognition in an E-Learning Environment



Abstract
:1. Introduction
- RQ 1: Which CNN-based models are effective in recognizing student engagement in an E-learning environment?
- RQ 2: Which methods can optimize a CNN-based engagement-recognition model to adapt it to mobile devices?
- RQ 3: How does the optimized model perform compared with other selected models in recognizing student engagement in an E-learning environment?
2. Background
2.1. Activation Function
2.2. Typical and Lightweight CNN Architecture
ShuffleNet
- 1.
- When the input feature matrix of the convolutional layer and the output feature matrix channel are equal, the memory access cost is the smallest.
- 2.
- When the GConv groups increase (while keeping FLOPs unchanged), the MAC will also increase.
- 3.
- The higher the fragmentation of the network design, the slower the speed, which means more branches; hence, the speed is slower.
- 4.
- Element-wise, the impact of operations (such as ReLU, etc.) cannot be affected.
3. Related Work
4. Method
4.1. Proposed Model Architecture
4.2. Experimental Setup
4.3. Engagement Recognition Dataset
4.4. Model Training
4.5. Model Evaluation
4.5.1. Accuracy
4.5.2. F-Measure
- True Positive (TP): Both the model-derived classification results and the actual classification results of the labels are engagement.
- False Positive (FP): The classification result obtained by the model is engagement, but the actual classification result of the label is not.
- True Negative (TN): Neither the model-derived classification results nor the actual classification results of the labels are engagement.
- False Negative (FN): The classification result obtained by the model is not engagement, but the actual classification result of the label is engagement.
4.5.3. FLOPs
4.5.4. Recognition Speed
5. Results
5.1. Image Data Augmentation
5.2. Batch Examples
5.3. Activation Function
5.4. Accuracy
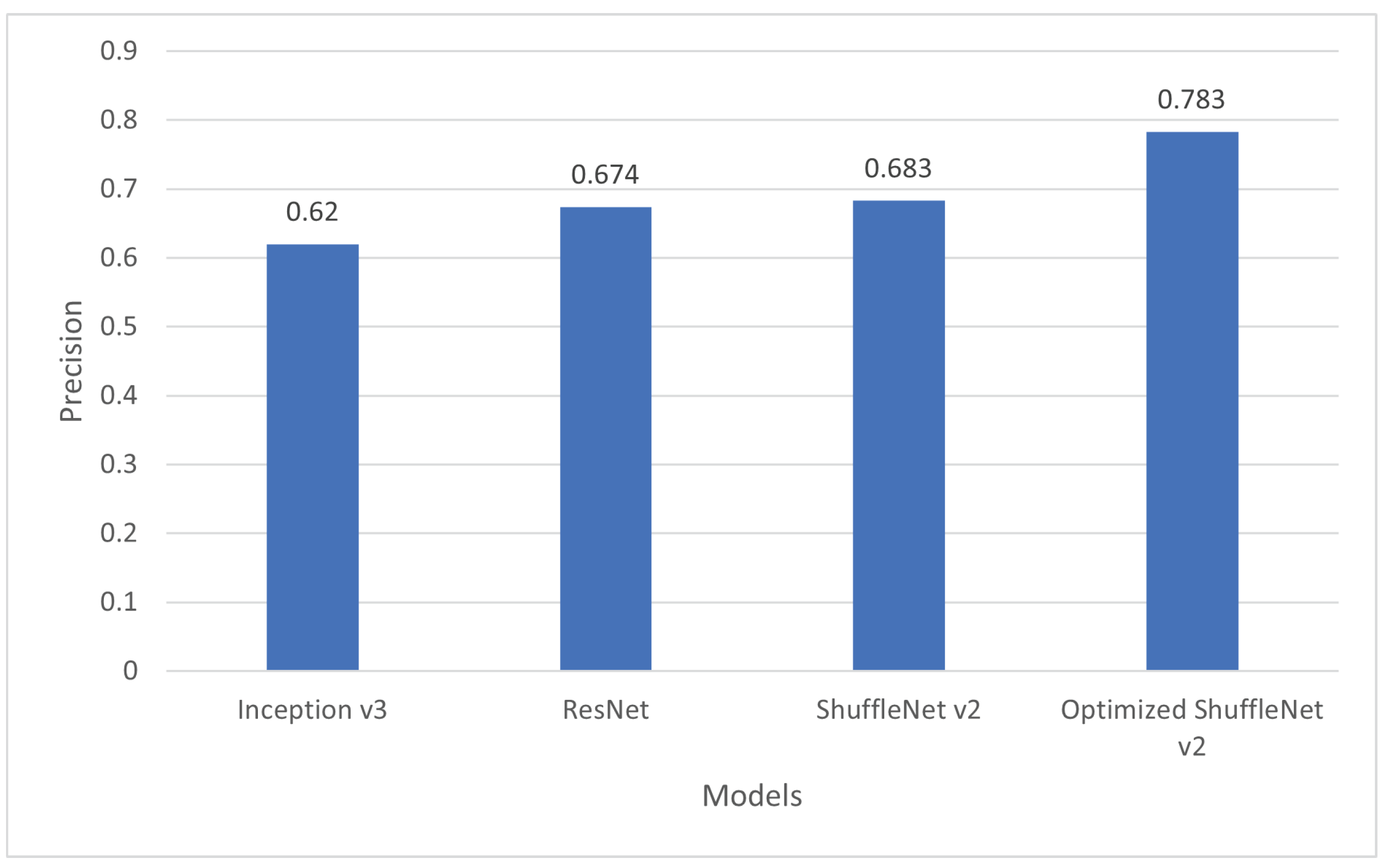
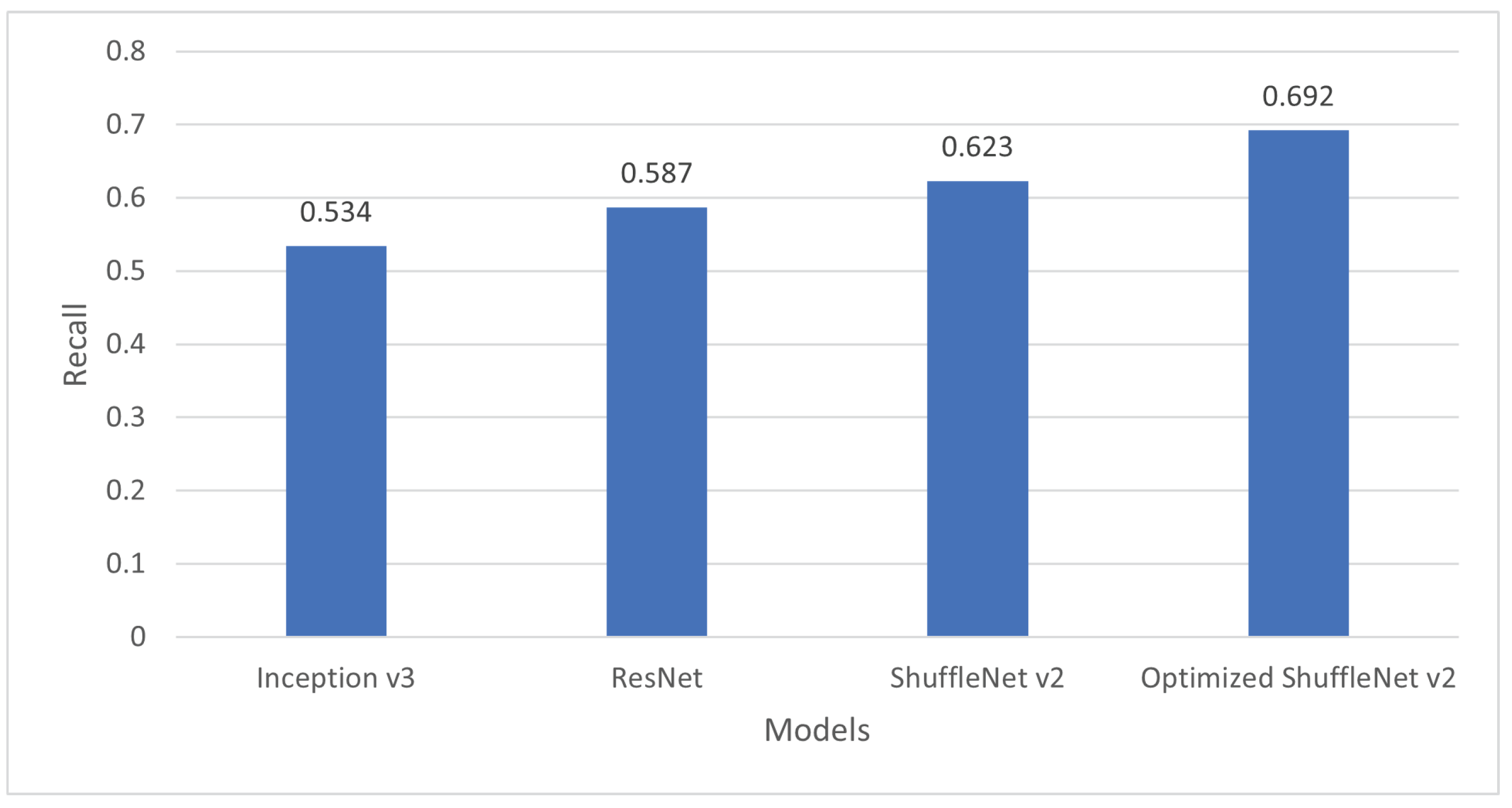
5.5. F-Measure
5.6. FLOPs
5.7. Speed
5.8. Comparison with Other Published Works
6. Discussion
6.1. Answering the Research Questions
6.2. Contributions
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dewan, M.A.A.; Murshed, M.; Lin, F. Engagement detection in online learning: A review. Smart Learn. Environ. 2019, 6, 1. [Google Scholar] [CrossRef]
- Turk, M.; Pentland, A. Eigenfaces for recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef] [PubMed]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef] [Green Version]
- Moghaddam, B.; Jebara, T.; Pentland, A. Bayesian face recognition. Pattern Recognit. 2000, 33, 1771–1782. [Google Scholar] [CrossRef]
- Guo, G.; Li, S.Z.; Chan, K. Face recognition by support vector machines. In Proceedings of the fourth IEEE International Conference on Automatic Face and Gesture Recognition (Cat. no. PR00580), Grenoble, France, 29–30 March 2000; pp. 196–201. [Google Scholar]
- Guo, G.D.; Zhang, H.J. Boosting for fast face recognition. In Proceedings of the IEEE ICCV Workshop on Recognition, Analysis, and Tracking of Faces and Gestures in Real-Time Systems, Vancouver, BC, Canada, 13 July–13 August 2001; pp. 96–100. [Google Scholar]
- Yang, M.; Zhang, L.; Yang, J.; Zhang, D. Metaface learning for sparse representation based face recognition. In Proceeding of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 12–15 September 2010; pp. 1601–1604. [Google Scholar]
- Zhao, W.; Chellappa, R.; Phillips, P.J.; Rosenfeld, A. Face recognition: A literature survey. ACM Comput. Surv. (CSUR) 2003, 35, 399–458. [Google Scholar] [CrossRef]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition; Oxford University Press: Oxford, UK, 2015. [Google Scholar]
- Fan, Y.; Lu, X.; Li, D.; Liu, Y. Video-based emotion recognition using CNN-RNN and C3D hybrid networks. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 445–450. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Eecognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar]
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN variants for computer vision: History, architecture, application, challenges and future scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Nezami, O.M.; Dras, M.; Hamey, L.; Richards, D.; Wan, S.; Paris, C. Automatic recognition of student engagement using deep learning and facial expression. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Riva del Garda, Italy, 19–23 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 273–289. [Google Scholar]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Into Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Kamencay, P.; Benčo, M.; Miždoš, T.; Radil, R. A new method for face recognition using convolutional neural network. Adv. Electr. Electron. Eng. 2017, 15, 663–672. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation functions: Comparison of trends in practice and research for deep learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Ang-bo, J.; Wei-wei, W. Research on optimization of ReLU activation function. Transducer Microsyst. Technol. 2018, 2, 50–52. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-first AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Howard, A.; Zhmoginov, A.; Chen, L.C.; Sandler, M.; Zhu, M. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation. arXiv 2018, arXiv:1801.04381. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:1807.11164. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Grafsgaard, J.; Wiggins, J.B.; Boyer, K.E.; Wiebe, E.N.; Lester, J. Automatically recognizing facial expression: Predicting engagement and frustration. Educ. Data Min. 2013, 2013, 1–8. [Google Scholar]
- Sharma, P.; Joshi, S.; Gautam, S.; Filipe, V.; Reis, M.J. Student Engagement Detection Using Emotion Analysis, Eye Tracking and Head Movement with Machine Learning. arXiv 2019, arXiv:1909.12913. [Google Scholar]
- Whitehill, J.; Serpell, Z.; Lin, Y.C.; Foster, A.; Movellan, J.R. The faces of engagement: Automatic recognition of student engagementfrom facial expressions. IEEE Trans. Affect. Comput. 2014, 5, 86–98. [Google Scholar] [CrossRef]
- Monkaresi, H.; Bosch, N.; Calvo, R.A.; D’Mello, S.K. Automated detection of engagement using video-based estimation of facial expressions and heart rate. IEEE Trans. Affect. Comput. 2016, 8, 15–28. [Google Scholar] [CrossRef]
- Gupta, A.; D’Cunha, A.; Awasthi, K.; Balasubramanian, V. Daisee: Towards user engagement recognition in the wild. arXiv 2016, arXiv:1609.01885. [Google Scholar]
- Jagadeesh, M.; Baranidharan, B. Facial expression recognition of online learners from real-time videos using a novel deep learning model. Multimed. Syst. 2022, 1–21. [Google Scholar] [CrossRef]
- Karimah, S.N.; Unoki, T.; Hasegawa, S. Implementation of Long Short-Term Memory (LSTM) Models for Engagement Estimation in Online Learning. In Proceedings of the 2021 IEEE International Conference on Engineering, Technology & Education (TALE), Wuhan, China, 5–8 December 2021; pp. 283–289. [Google Scholar]
- Ma, X.; Xu, M.; Dong, Y.; Sun, Z. Automatic student engagement in online learning environment based on neural turing machine. Int. J. Inf. Educ. Technol. 2021, 11, 107–111. [Google Scholar] [CrossRef]
- Liao, J.; Liang, Y.; Pan, J. Deep facial spatiotemporal network for engagement prediction in online learning. Appl. Intell. 2021, 51, 6609–6621. [Google Scholar] [CrossRef]
- Huang, T.; Mei, Y.; Zhang, H.; Liu, S.; Yang, H. Fine-grained engagement recognition in online learning environment. In Proceedings of the 2019 IEEE 9th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 12–14 July 2019; pp. 338–341. [Google Scholar]
- Abedi, A.; Khan, S.S. Improving state-of-the-art in detecting student engagement with resnet and TCN hybrid network. In Proceedings of the 2021 18th Conference on Robots and Vision (CRV), Burnaby, BC, Canada, 26–28 May 2021; pp. 151–157. [Google Scholar]
- Boulanger, D.; Dewan, M.A.A.; Kumar, V.S.; Lin, F. Lightweight and interpretable detection of affective rngagement for online learners. In Proceedings of the 2021 IEEE International Conference on Dependable, Autonomic and Secure Computing, Virtual, 25–28 October 2021; pp. 176–184. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. arXiv 2014, arXiv:1406.6247. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Shen, J.; Yang, H.; Li, J.; Cheng, Z. Assessing learning engagement based on facial expression recognition in MOOC’s scenario. Multimed. Syst. 2022, 28, 469–478. [Google Scholar] [CrossRef]
- Sharma, S.; Sharma, S. Activation functions in neural networks. Towards Data Sci. 2017, 6, 310–316. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Abedi, A.; Khan, S. Affect-driven engagement measurement from videos. arXiv 2021, arXiv:2106.10882. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Size | Computational Complexity(FLOPs) |
|---|---|
| ShuffleNet v2 0.5x | 41 M |
| ShuffleNet v2 1.0x | 146 M |
| ShuffleNet v2 1.5x | 299 M |
| ShuffleNet v2 2.0x | 591 M |
| Output Size | ShuffleNet v2 + Attention Module | Repeat |
|---|---|---|
| 112 × 112 | Conv 3 × 3, 24, stride 2 | 1 |
| 56 × 56 | MaxPool 3 × 3, stride 2 | 1 |
| 28 × 28 | Conv 1 × 1, 48 DWConv 3 × 3, 48 Conv 1 × 1, 48 Attention Module Shuffle | 4 |
| 14 × 14 | Conv 1 × 1, 96 DWConv 3 × 3, 96 Conv 1 × 1, 96 Attention Module Shuffle | 8 |
| 7 × 7 | Conv 1 × 1, 192 DWConv 3 × 3, 192 Conv 1 × 1, 192 Attention Module Shuffle | 1 |
| 7 × 7 | Conv 1 × 1, 1024 | 1 |
| 1 × 1 | GAP + fc + softmax | 1 |
| CPU | Intel(R) Xeon(R) Gold 6142 CPU @ 2.60 GHz |
|---|---|
| GPU | NVIDIA GeForce RTX 3080 |
| Number of CPU cores | 8 |
| RAM | 10 GB |
| Floating-point operations per second | Half-precision 29.77 TFLOPS/Single-precision 29.77 TFLOPS |
| Dataset | Sigmoid | Tanh | ReLU | Leaky ReLU |
|---|---|---|---|---|
| DAiSEE | 0.5445 | 0.5392 | 0.5773 | 0.5862 |
| Model | Inception v3 | ResNet | ShuffleNet v2 0.5 | Optimized ShuffleNet v2 |
|---|---|---|---|---|
| FLOPs | 140.26 M | 142.03 M | 43.69 M | 44.14 M |
| Model | Inception v3 | ResNet | ShuffleNet v2 0.5 | Optimized ShuffleNet v2 |
|---|---|---|---|---|
| speed | 458 ms | 514 ms | 317 ms | 362 ms |
| Models or Methods | Accuracy (%) |
|---|---|
| Convolutional 3D (C3D) [36] | 48.1 |
| Long-Term Recurrent Convolutional Network (LRCN) [36] | 57.9 |
| DFSTN [40] | 58.8 |
| C3D+TCN [42] | 59.9 |
| DERN [41] | 60.0 |
| Neural Turing Machine [39] | 61.3 |
| ResNet+LSTM [42] | 61.5 |
| ResNet+TCN [42] | 63.9 |
| (Latent Affective+Behavioral+Affect) features+TCN [49] | 63.3 |
| Our Optimized ShuffleNet v2 | 63.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Jiang, Z.; Zhu, K. An Optimized CNN Model for Engagement Recognition in an E-Learning Environment. Appl. Sci. 2022, 12, 8007. https://doi.org/10.3390/app12168007
Hu Y, Jiang Z, Zhu K. An Optimized CNN Model for Engagement Recognition in an E-Learning Environment. Applied Sciences. 2022; 12(16):8007. https://doi.org/10.3390/app12168007
Chicago/Turabian StyleHu, Yan, Zeting Jiang, and Kaicheng Zhu. 2022. "An Optimized CNN Model for Engagement Recognition in an E-Learning Environment" Applied Sciences 12, no. 16: 8007. https://doi.org/10.3390/app12168007
APA StyleHu, Y., Jiang, Z., & Zhu, K. (2022). An Optimized CNN Model for Engagement Recognition in an E-Learning Environment. Applied Sciences, 12(16), 8007. https://doi.org/10.3390/app12168007