


Applying Natural Language Processing and TRIZ Evolutionary Trends to Patent Recommendations for Product Design

Department of Industrial and Systems Engineering, Chung Yuan Christian University, Taoyuan City 320314, Taiwan
*
Author to whom correspondence should be addressed.
Appl. Sci. 2022, 12(19), 10105; https://doi.org/10.3390/app121910105
Submission received: 30 August 2022
/
Revised: 28 September 2022
/
Accepted: 4 October 2022
/
Published: 8 October 2022
(This article belongs to the Topic Electronic Communications, IOT and Big Data)
Abstract
:Featured Application
The research may be applied to computer-aided innovation system to assist product design process.
Abstract
Traditional TRIZ theory provides methods and processes for systematic analysis on engineering problems, which can improve the efficiency of solving problems. However, the effect of solving problems is not necessarily guaranteed, and depends on the user’s profession and experience. Therefore, this study proposes a methodology to apply evolutionary benefits in the 37 trend lines developed by TRIZ researchers to assist in intelligently screening relevant patents applicable to the content of the product design. In such a way, the efficiency of problem solving and product design quality may be improved more effectively. First, the patent database is used as the training dataset, words and sentences in the patent documents are analyzed through natural language processing to obtain keywords that may be related to evolutionary benefits. Using word vectors trained by Doc2vec, the semantic similarity can be calculated to obtain the similarity relationship between patent text and evolutionary benefit. Secondly, the goals of the product development project may make be related to the evolutionary benefits, and then applicable patent recommendations can be provided. The proposed methodology may achieve the purpose of intelligent design assistance to enhance the product development process and problem-solving.
1. Introduction
Nowadays, human beings have entered an era of massive applications of big data and artificial intelligence (AI). People use AI technology in various fields to provide better work efficiency and quality of life. Thus, data is indispensable and has become the foundation for training AI models. Through continuous training, artificial intelligence can be made smarter to meet various needs. Text Mining is based on unstructured and highly complex texts to find information that was more difficult to obtain in structured data in the past [1]. With the vigorous development of machine learning in recent years as well as the improvement of computing power, it is possible to perform computational analysis on huge amounts of text more efficiently. Natural Language Processing (NLP), combined with linguistics, information science and artificial intelligence, helps to deconstruct unstructured documents and compare with analysis, thereby interpreting the semantics and sentence structure of natural language from features. The NLP in a statistical approach gives good results in practice simply because, by learning with copious real data, they utilize the most common cases: the more abundant and representative the data, the more they improve. They also degrade more gracefully with unfamiliar/erroneous data [2].
This study is based on the 37 evolutionary trends referred from TRIZ researcher Darrell Mann. In a traditional approach, the application of the 37 evolutionary trends on a specific problem still relies on human judgment. These evolutionary trends are general principles, and some of the evolutionary stages are conceptual and consist of many subjective factors in their application. Sometimes it is not an easy task to select which evolutionary trends to apply. There are more than 100 evolutionary stages of 37 evolutionary trends, and the evolutionary benefits of each stage have the same benefits and different characteristics as well. Most of the results rely on reference materials through human judgement, and some connections are not obvious and difficult to judge during the process. Therefore, we propose a recommendation methodology that relieves subjective judgment to provide designers with more effective usage.
2. Materials and Methods
2.1. Theory of Inventive Problem Solving-TRIZ
TRIZ is the abbreviation of the Russian saying “theory of inventive problem solving”. It was developed by the former Soviet scientist G. Altshuller and his team, who studied hundreds of thousands of patents to conclude several methods including Problem Formulation, Functional Analysis, Contradiction Matrix, 40 Inventive Principles, Trends, Substance-Field, Ideal Final Result (IFR), Effects and Algorithm of Inventive Problem Solving (ARIZ), etc.
Trends of Evolution is one of the important tools in TRIZ theory. It means that a system slowly evolves from the most primitive starting point to the best ideal result. Altshuller found that the evolutionary process of different technical systems is not untraceable, but requires a pattern to evolve. Its technological system evolution can be divided into eight patterns, as described below [3]:
- Stages of evolution of a technological system
- Evolution toward increased ideality
- Non-uniform development of system elements
- Evolution toward increased dynamism and controllability
- Increased complexity followed by simplification
- Evolution with matching and mismatching elements
- Evolution toward micro-levels and increased use of fields
- Evolution toward decreased human involvement
Furthermore, Darrell Mann compiled a set of 37 evolutionary trends from these eight patterns, and the evolution is divided into three fields: Time, Space, and Interface, as shown in Table 1 [4].
The evolutionary trend is composed of several evolutionary stages, and each evolutionary stage has evolutionary reasons (reasons for jumps). These evolutionary reasons can be identified as the benefits and which are brought by the system evolution. Taking space segmentation as an example, there are five evolutionary stages as shown in Figure 1. The direction of system evolution is from left to right. The evolving benefits from “monolithic solid” to “hollow structure” are to reduce weight, reduce the use of materials, increase moment of inertia, etc. For instance, a basketball shoe, which has a single solid sole in the early design, is redesigned by adding a hollow air cushion to acquire the evolutionary benefits mentioned above, and then it can achieve certain improvements.
2.2. Natural Language Processing
Natural Language Processing (NLP) belongs to the combination of artificial intelligence and linguistics. It mainly uses mathematical models and algorithms to allow computers to recognize and understand human language. Early natural language processing technology is based on statistical concepts to train models. Converting a large amount of text into a dictionary-like format allows the computer to calculate the probability of encountering words and sentences. Recently, NLP has been widely combined with deep learning. The most famous one is BERT, which is a model developed by google based on Transformer [5].
Sentiment analysis (SA) is the use of NLP, text analysis and computational linguistics to systematically recognize personal opinions and emotional conditions. A common application of which is to collect the voice of customers for marketing purpose, such as product reviews and survey. Zhang presented a ranking product model based on sentiment analysis combined with an intuitionistic fuzzy TODIM method. Using the online review data to help customers make purchasing decisions, the proposed method considers consumers’ subjective needs and different sentiment orientations (positive, neutral, and negative) for each product feature [6]. Based on BERT fine-tuning, Sun et al. [7] converted “Aspect-Based Sentiment Analysis (ABSA)” from a single sentence classification task to a sentence-pair classification task by constructing auxiliary sentences, so that the final recommendation effect is greater than the classification effect using SA only.
Sheu and Hong used statistical methods to construct a computer-aided effect recognition system to optimize the quality of the recommendation system to match the specific topic. Combined with the accumulation of the knowledge of many experts, the system can put forward the priority of problem solving according to the principle of “similar problems have similar solutions”, and achieve higher efficiency for the solution recommendation system [8]. However, the texts used in the contents of a patent are more technology-oriented than sentiment-oriented. Regarding patent recommendation for product design, SAO structure analysis combined with dependency syntax analysis is more suitably adopted as described below.
2.2.1. Text Preprocessing
Text preprocessing is a very important step. This step is a method of sorting out the text and extracting text features. It is mainly divided into: tokenization, stemming, lemmatization, and filtering. Allahyari mentioned that a large amount of text cannot be effectively processed by a computer, and meaningful text and information must be extracted through preprocessing [9]. The steps involved in text and processing will be mentioned below.
- Tokenization: To cut the text of a paragraph into a single word, symbol and number, as shown below:Before: In Canada, all indications point to an economy growing at a much faster pace than it had in the final three months of last year and the beginning of 2019.After: /In/ /Canada/ /,/ /all/ /indications/ /point/ /to/ /an/ /economy/ /growing/ /at/ /a/ /much/ /faster/ /pace/ /than/ /it/ /had/ /in/ /the/ /final/ /three/ /months/ /of/ /last/ /year/ /and/ /the/ /beginning/ /of/ /2019/ /./
- Stemming: To reduce the number of words by extracting the root and stem of a single word, so as to achieve the effect of simplification, as shown below.Before: /indications/, /growing/, /beginning/After: /indic/, /grow/, /beginn/
- Lemmatization: Since English words have the problem of tense and form, the words in the text must be standardized as prototypes. Unlike stemming, lemmatization attempts to select the correct lemma depending on the context or basing on a dictionary that the algorithm can consult to. For example, the word “was” has “is” as its lemma. However, the previous example after lemmatization is shown below.Before: /indications/, /faster/, /had/, /beginning/After: /indicate/, /fast/, /have/, /begin/
- Filtering: To filter and delete words that appear too trivial and meaningless in the text, this step is also called stop-word removal (stop-word), because when processing a large amount of text, too many stop words may cause computer performance burden issues.Before: In Canada, all indications point to an economy growing at a much faster pace than it had in the final three months of last year and the beginning of 2019.After: /canada/ /indication / /point / /economy/ /grow / /fast / /pace / /final / /three/ /month / /year / /begin / /2019 /
2.2.2. SAO-Based Content Analysis
SAO (Subject-Action-Object) structure is composed of subject (noun phrase), action (verb phrase) and object (noun phrase), and its main function is to analyze the keywords in the sentence. For example, “sensor detects signal”, in this sentence “sensor” is the subject, “detection” is the verb, and “signal” is the object. From the SAO analysis, it can be judged that the word “detect” provides the correlation between “sensor” and “signal”. “Sensor” is the main body of “detect” and “signal”, and “signal” is the object “detected” by “sensor”. Simply put, the AO “detect signal” is a problem, and the S “sensor” is the method or tool to solve the “detect signal”. S and O can be expressed as components, and A can be expressed as the function or relationship between the two components. Cascini [10] mentioned that the SAO structure is usually used to represent technical functions, and this structure clearly indicates the related words between various functions, effects, solutions, and technical concepts that appear in the patent document.
2.2.3. Dependency Parsing
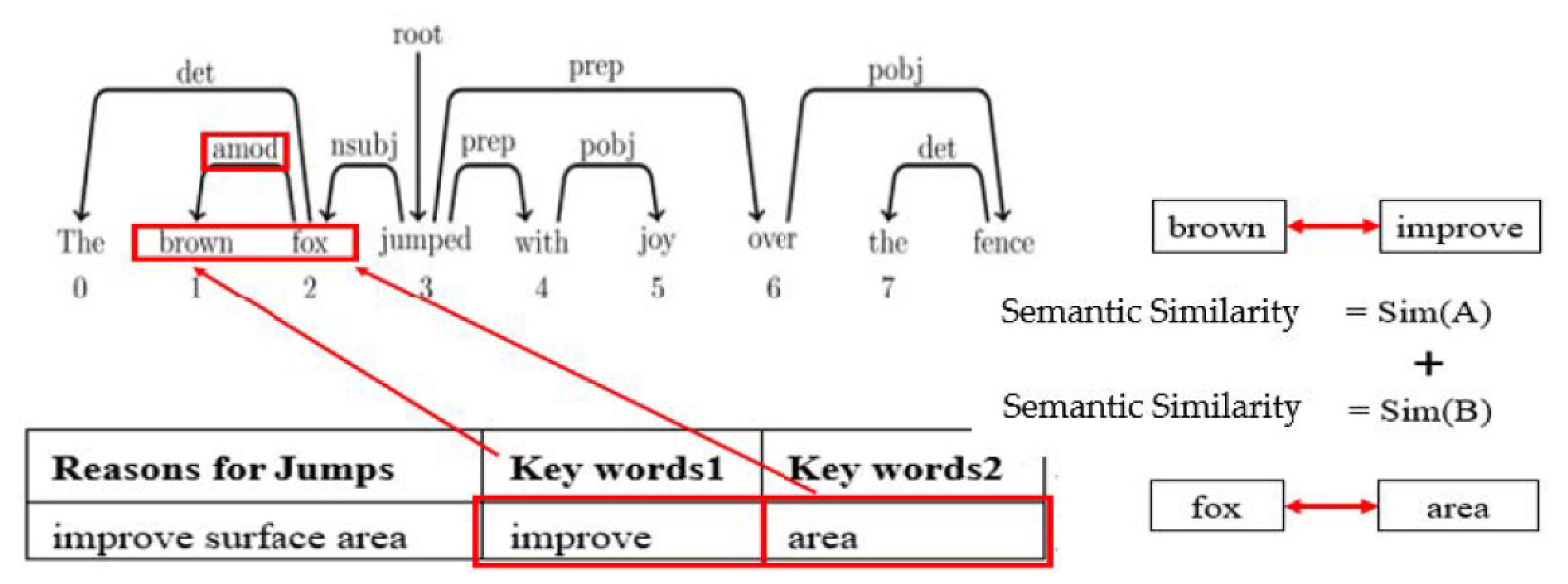
Dependency parsing is also a significant part of natural language processing technique. Its function is to identify the correlation between words in different sentences, which is called dependency. Usually, the dependency is described in a binary form with two words as a group. The advantage is that the subject, verb, and object may be presented in different orders in different sentences. It can effectively find the dependencies between words. Dependency syntactic analysis is mainly divided into clause relationship and modification relationship. The clause relationship is usually related to the predicate. The predicate also means that the main semantics in the sentence may be a verb, called ROOT, and the modification relationship is to classify modifiers to modify subject. From Figure 2, it can be clearly understood that all the arrows of the word “jumped” are called ROOT, and ROOT cannot be pointed by any arrow. From “jumped” as the starting point, the word corresponding to nsubj is found to be “fox”, and “fox” is the subject, which is a clause relationship. Another word corresponding to prep is “over” and “with”, “over” and “with” are preposition modifiers, which are modifier relationships.
2.3. Semantic Similarity
Semantic similarity is the most important part of natural language processing. However, the determination of the similarity between words is quite subjective, and it is quite difficult for computers to judge the semantic similarity. Based on the category of machine learning, we can understand that semantic similarity is the contextual interaction within the training text. If it is possible to replace each other in different contexts without changing the syntactic-semantic structure of the text, the similarity between the two will be higher, otherwise the similarity will be lower. Semantic similarity has been achieved in various fields, such as: text retrieval, information retrieval, text classification, machine translation, text recommendation, etc.
The function of cosine similarity is to use the cosine of the angle between two vectors to determine the similarity. The calculation method is described as Equation (1), which depicts the smaller the angle, the more similar, and the larger the angle, the lower the similarity. As the cosine value of the 0 degree angle is 1, it means that the A and B are completely similar. If A and B are in the opposite direction, i.e., totally dissimilar, the cosine value will be −1. So, the range of similarity is between −1 and 1.
The Doc2vec model, proposed by Mikolov and Le [11], is an improved version based on the shortcomings of Word2vec. The weakness of Word2vec is that the sequence of words in the text and the contextual relationship are lost, and the semantics are also ignored, even if the distance between words with the same semantics in the vector is far away [12], which cause the similarity is low. In other words, Word2vec can only express the relationship between words, but cannot compare the relationship between paragraphs. Therefore, Doc2vec considers the order of words and adds paragraph vectors to improve the accuracy of semantic similarity.
2.4. Methodology
The methodology of this research is based on the TRIZ evolutionary trends and Doc2vec model for similarity analysis. Through similarity comparison to find out the correlation with evolutionary benefits, we then recommend patents related to the product design for references. According to SAO structure, the research contents are mainly divided into the construction of evolutionary benefits keywords dictionary, the extraction of patent text keywords, and the calculation of semantic similarity.
2.4.1. Construction of Evolutionary Benefits Keywords Dictionary
As mentioned, each trend line is composed of several evolutionary stages, and there are evolutionary reasons (reasons for jumps) between each evolutionary stage. The evolutionary benefits of trends are usually presented in the form of binary relations, and the structures are usually “adjective” + “noun” or “verb” + “noun”. For example, in space segmentation, the evolving benefits from the second stage to the third stage are shown in Table 2. Based on the above description, we will then define an evolutionary benefits keywords dictionary, as shown in Table 3, including the expansion of synonyms to increase the vocabulary of the dictionary, which is used to evaluate the relevance of patent text keywords.
2.4.2. Extraction of SAO Structure Keywords of Patent Text by Dependency Parsing
The extraction of SAO structure keywords from patent texts is carried out through the Python package Spacy. Spacy is a natural language processing library developed by the Explosion AI team. It is mainly used for word segmentation, part-of-speech restoration, part-of-speech tagging, dependency analysis, etc. The steps are explained as follows:
- 1.
- Import patent text: The import of data is the first step of natural language processing. Through the Pandas package, the patent as shown in Figure 3 can be imported into the compiler for subsequent analysis.
- 2.
- Dependency parsing analysis: Since the evolutionary benefit is based on the word structure of the binary relation, the SAO structure keywords of the binary relation are extracted from the patent text by using Spacy to perform dependency parsing. The dependencies “amod” adjective modifiers and “dobj” direct objects are extracted through Spacy, which are related to the SAO structure. Figure 4 is partially demonstrated the output as shown below.
2.4.3. Semantic Similarity Calculation
This research applied the Doc2vec model to calculate the semantic similarity. The calculation method uses the SAO structure of the patent text and the evolutionary benefits keywords dictionary to compare the similarity. We define Pt as the patent text keyword and Eb as the evolutionary benefit keyword, and then rewrite Equation (1) to into Equation (2) as shown below.
As shown in Figure 5, the method is to compare the similarity between the text keyword 1 from the patent and the evolutionary benefits keywords dictionary keyword 1, as well as the text keyword 2 from the patent and the evolutionary benefits keywords dictionary keyword 2.
Text keywords 1 and 2 themselves are words with connected relations, and the similarity calculation with evolution benefit keywords needs to sum up the semantic similarity of the two as expressed in Equation (3). Pt(1)i is the ith word of the patent text keyword 1, and Eb(1)j is the jth word of the evolutionary benefit keyword 1. Pt(2)i is the ith word of the patent text keyword 2, and Eb(2)j is the jth word of the evolutionary benefit keyword 2. Therefore, the sum of the similarity calculation for are between −2 and 2. We illustrate the relative relationship of the similarity calculation in Figure 6.
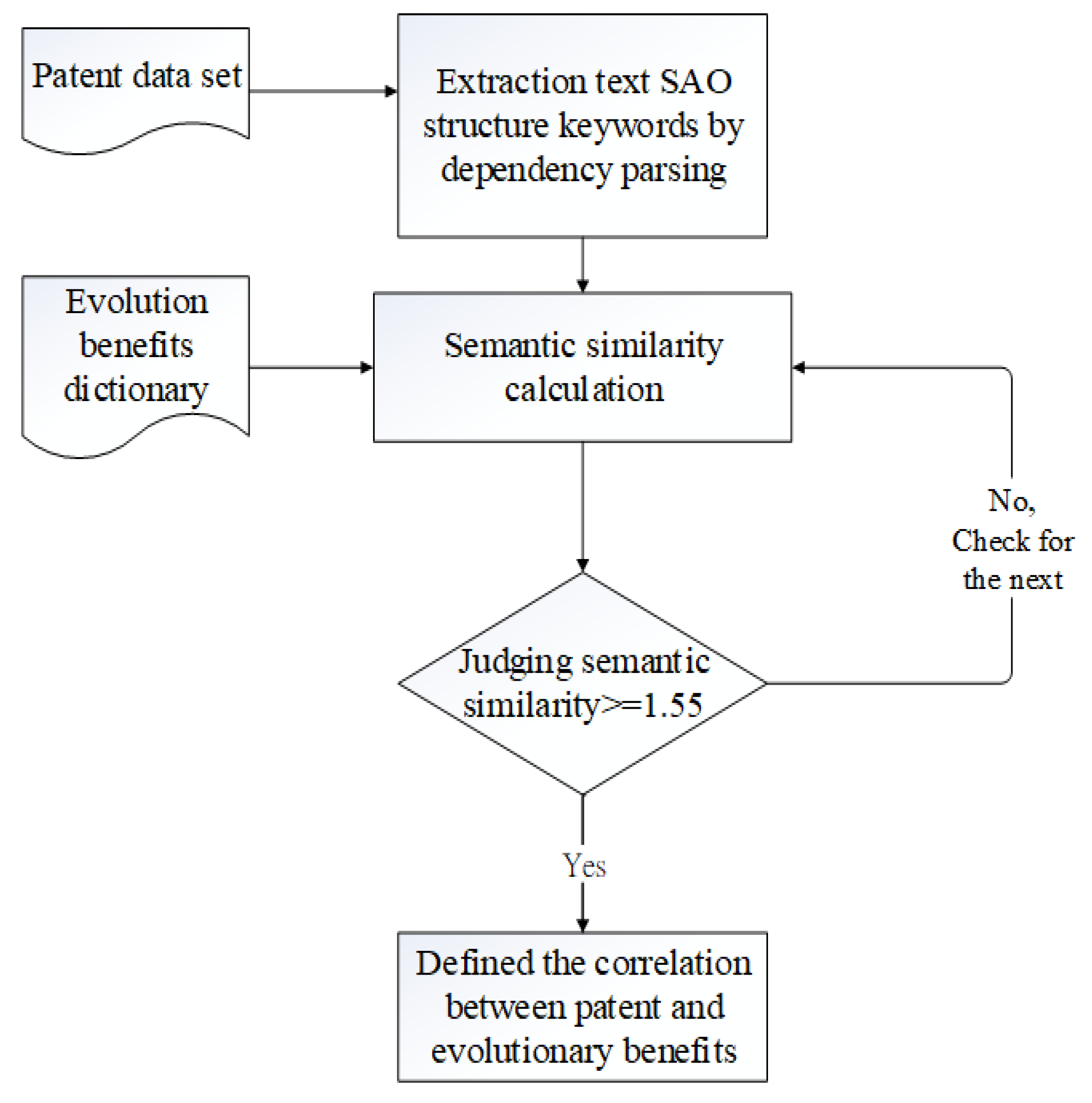
Once the similarity value reaches a certain threshold, it can be determined that the evolutionary benefit is related to the patent text, thereby recommending relevant patents. After experiments and analysis, this study defines that the threshold is 1.55, which means that the patent text is related to the evolutionary benefits. Conversely, less than 1.55 is considered irrelevant. The flowchart of the above-mentioned is shown in Figure 7.
3. Results with Case Study
Thirty patents for 3D printing and peripherals were selected for this experiment. It is assumed that the user tries to improve the problem of 3D printing, and defines the problem as “continuous printing”, “automatic calibration”, and “fault detection”. We first select several evolutionary trends that may be applicable to improve the above problems: space segmentation (S2), boundary breakdown-space (S9), geometric evolution-linear (S10), nesting structure-downward (S12), dynamization (S13), action coordination (T32), mono-bi-poly(various)-interface (I15), controllability (I28) and human involvement (I29). Through the correlation between the evolutionary benefits of the above evolutionary trends and patents, it is used as a reference for recommending patents.
Taking the patent US08970867: Secure management of 3D print media as an example, the texts based on the dependency analysis of the patent text include “structural integrity”, “further convenience”, “other device”, “based system”, “system forms”, “system access”. As shown in Figure 8, for example, “structural integrity” is related to evolutionary benefit “structural strength”, which show in the evolving stage of geometric evolution (S10). Therefore, the patent US08970867 can be used as a reference for patent recommendation for product design that geometric evolution (S10) is applied.
In addition, we use the patent US10073424: Intelligent 3D printing through optimization of 3D print parameters as another example to observe the result and explain its rationality. Through the similarity comparison with the keyword thesaurus of evolutionary benefits, the text keywords identified based on the semantic similarity above 1.55 are “lower parts”, “single object”, “fluid dynamics”, “higher quality”, “system causes”, “operation adjust”, “total failure”, “single device”, “single processor”, “optical device”, “solid device”, and the above words correspond to several evolutionary benefits, as partially shown in Table 4 below. For example, with “lower parts”, the corresponding evolutionary benefits are “reduced packaging” and “reduced number of systems”, and which are set in the evolutionary trend I15 Mono-Bi-Poly (various). Therefore, we may correlate S10073424 with I15, and the rest are inferred accordingly.
As summarized in Table 5, the correlation between the thirty patents and the selected evolutionary trends can be obtained through the similarity comparison of evolutionary benefits. Among these thirty patents, patent recommendation can be provided based on the trend lines that are applied. In such a way, users may utilize these relevant patents to help improve their product design.
4. Conclusions
This research proposes a patent recommendation method based on natural language processing technique, which is integrated with evolutionary trends in TRIZ. The results of the research are summarized as follows:
- Instead of judging merely by personal experience, a novel approach was developed to improve the application of evolutionary trends in TRIZ. This approach is not only systematic but also intelligent.
- Through evolutionary trends and their evolving benefits, the related patents could be then recommended to assist in product design for needs of improvement.
- Three-dimensional printing was used as an example to explain the methodology and demonstrate the feasibility of the methodology.
Author Contributions
Conceptualization, T.-L.L.; methodology, T.-L.L. and L.-H.H.; software, L.-H.H.; validation, T.-L.L. and K.-C.H.; formal analysis, T.-L.L. and L.-H.H.; writing—original draft preparation, T.-L.L. and L.-H.H.; writing—review and editing, T.-L.L. and K.-C.H.; project administration, T.-L.L.; funding acquisition, T.-L.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Science and Technology, Taiwan, R.O.C. under Grant No. MOST 108-2221-E-033-012-MY3.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Blake, C. Text mining. Annu. Rev. Inf. Sci. Technol. 2011, 45, 121–155. [Google Scholar] [CrossRef]
- Nadkarni, P.; Ohno-Machado, L.; Chapman, W. Natural language processing: An introduction. J. Am. Med. Inform. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Altshuller, G. The Innovation Algorithm: TRIZ, Systematic Innovation and Technical Creativity; Technical Innovation Center, Inc.: Worcester, MA, USA, 2000. [Google Scholar]
- Mann, D. Hands-On Systematic Innovation for Technical System, 2nd ed.; IFR Press: Clevedon, UK, 2007. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhang, Z.; Guo, J.; Zhang, H.; Zhou, L.; Wang, M. Product selection based on sentiment analysis of online reviews: An intuitionistic fuzzy TODIM method. Complex Intell. Syst. 2022, 8, 3349–3362. [Google Scholar] [CrossRef]
- Sun, C.; Huang, L.; Qiu, X. Utilizing BERT for aspect-based sentiment analysis via constructing auxiliary sentence. arXiv 2019, arXiv:1903.09588. [Google Scholar]
- Sheu, D.D.; Hong, J. Prioritized relevant effect identification for problem solving based on similarity measures. Expert Syst. Appl. 2018, 100, 211–223. [Google Scholar] [CrossRef]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. A brief survey of text mining: Classification, clustering and extraction techniques. arXiv 2017, arXiv:1707.02919. [Google Scholar]
- Cascini, G.; Fantechi, A.; Spinicci, E. Natural Language Processing of Patents and Technical Documentation. In International Workshop on Document Analysis Systems; Springer: Berlin/Heidelberg, Germany, 2004; pp. 89–92. [Google Scholar]
- Mikolov, T.; Le, Q. Distributed Representations of Sentences and Documents. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
Figure 1.
The Space Segmentation trend (S2) and its evolving benefits.

Figure 2.
The example of dependency relationship.

Figure 3.
Patent text.

Figure 4.
Dependency parsing of patent texts.

Figure 5.
Calculation illustration between patent text keywords and dictionary keywords.

Figure 6.
Illustration of the similarity calculation between corresponding text keywords and dictionary keywords.
Figure 6.
Illustration of the similarity calculation between corresponding text keywords and dictionary keywords.

Figure 7.
Flowchart of evolution benefits and patent text analysis.

Figure 8.
Result of similarity calculation greater than 1.55 (partial).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The 37 trend lines of evolution.
| Trend Lines | ||||
|---|---|---|---|---|
| Numbering | Trend Name | Numbering | Trend Name | |
| Space-related | S1 | Smart Materials | S8 | Increasing Asymmetry |
| S2 | Space Segmentation | S9 | Boundary Breakdown-Space | |
| S3 | Surface Segmentation | S10 | Geometric Evolution (Linear) | |
| S4 | Object Segmentation | S11 | Geometric Evolution (Volumetric) | |
| S5 | Macro to Nano Scale Space | S12 | Nesting-Down | |
| S6 | Webs and Fibers | S13 | Dynamization | |
| S7 | Decreasing Density | |||
| Interface-related | I14 | Mono-Bi-Poly(Similar)-Interface | I23 | Market Evolution |
| I15 | Mono-Bi-Poly(Various)-Interface | I24 | Design Point | |
| I16 | Mono-Bi-Poly(Inc. diff.)-Interface | I25 | Degrees of Freedom | |
| I17 | Nesting-Up | I26 | Boundary Breakdown-interface | |
| I18 | Reduced Damping | I27 | Trimming | |
| I19 | Senses Interaction | I28 | Controllability | |
| I20 | Color Interaction | I29 | Human Involvement | |
| I21 | Transparency | I30 | Design Methodology | |
| I22 | Customer Purchase Focus | I31 | Reducing Energy Conversions | |
| Time-related | T32 | Action Co-ordination | T35 | Mono-Bi-Poly(Similar-Time) |
| T33 | Rhythm Co-ordination | T36 | Mono-Bi-Poly(Various-Time) | |
| T34 | Non-linearity | T37 | Macro to Nano Scale-Time | |
Table 2.
Evolutionary benefits of the Space Segmentation trend (partially presented).
| Trend Line | Evolutionary Stage | Evolving Benefits |
|---|---|---|
| Space Segmentation (S2) | Structure with multiple hollow (S2.3) 1 | Improve surface area Improve strength/weight ratio Improve heat transfer |
| Capillary/porous (S2.4) |
1 S2.3 means the 3th evolutionary stage of trend line S2.
Table 3.
Example of synonym expansion for evolutionary benefits dictionary.
| Evolving Benefit (Reasons for Jump) | Keyword 1 | Keyword 2 |
|---|---|---|
| Improve surface area | improve, increase, better, enhance, raise | surface area, area, surface |
Table 4.
The result of similarity comparison for patent US10073424.
| Patent | Identified Keywords | Relevant Evolutionary Benefits |
|---|---|---|
| US10073424 | lower parts | reduced packaging reduced number of systems |
| fluid dynamics | improve flow distribution | |
| higher quality | improve strength properties improve surface area improve compatibility with real world effects improve structural strength increased material strength increased component flexibility increase reliability increase efficiency improve safety increased accuracy | |
| system causes | increase ability to change system characteristics | |
| operation adjust | increase operation flexibility | |
| total failure | reduced error/catastrophic failure |
Table 5.
Recommendations of the correlation between patents and evolutionary trends.
| Evolutionary Trends | Recommend Patents |
|---|---|
| S2 | US10073424, US05424801, US06900814, US04708502 |
| S9 | US10073424, US05028950, US09782934 |
| S10 | US10073424, US04232324, US05028950, US05408294, US05572633, US05625435, US05786909, US05801811, US05801812, US05825466, US05838360, US06226093, US05500712, US06602378, US09595037, US05542768 |
| S12 | US09782934 |
| S13 | US10073424, US05400096, US05408294, US05625435, US05786909, US09595037, US08970867, US06602378, US05838360, US09782934, US06037963 |
| T32 | US10073424, US04903069, US05028950, US05400096, US05412449, US05424801, US05691805, US05786909, US05838360, US06602378, US09595037 |
| I15 | US10073424, US05583971, US05657111, US05838360, US06900814, US09595037, US09782934, US04759647, US06037963, US04708502, US08970867 |
| I28 | US10073424, US05786909 |
| I29 | US10073424, US05424801, US05691805, US05786909, US05838360, US06602378, US09782934 |
| Undefined | US05717844, US05744291, US05850278 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, T.-L.; Hsieh, L.-H.; Huang, K.-C. Applying Natural Language Processing and TRIZ Evolutionary Trends to Patent Recommendations for Product Design. Appl. Sci. 2022, 12, 10105. https://doi.org/10.3390/app121910105
AMA Style
Liu T-L, Hsieh L-H, Huang K-C. Applying Natural Language Processing and TRIZ Evolutionary Trends to Patent Recommendations for Product Design. Applied Sciences. 2022; 12(19):10105. https://doi.org/10.3390/app121910105
Chicago/Turabian StyleLiu, Tien-Lun, Ling-Hsiang Hsieh, and Kuan-Chun Huang. 2022. "Applying Natural Language Processing and TRIZ Evolutionary Trends to Patent Recommendations for Product Design" Applied Sciences 12, no. 19: 10105. https://doi.org/10.3390/app121910105
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.