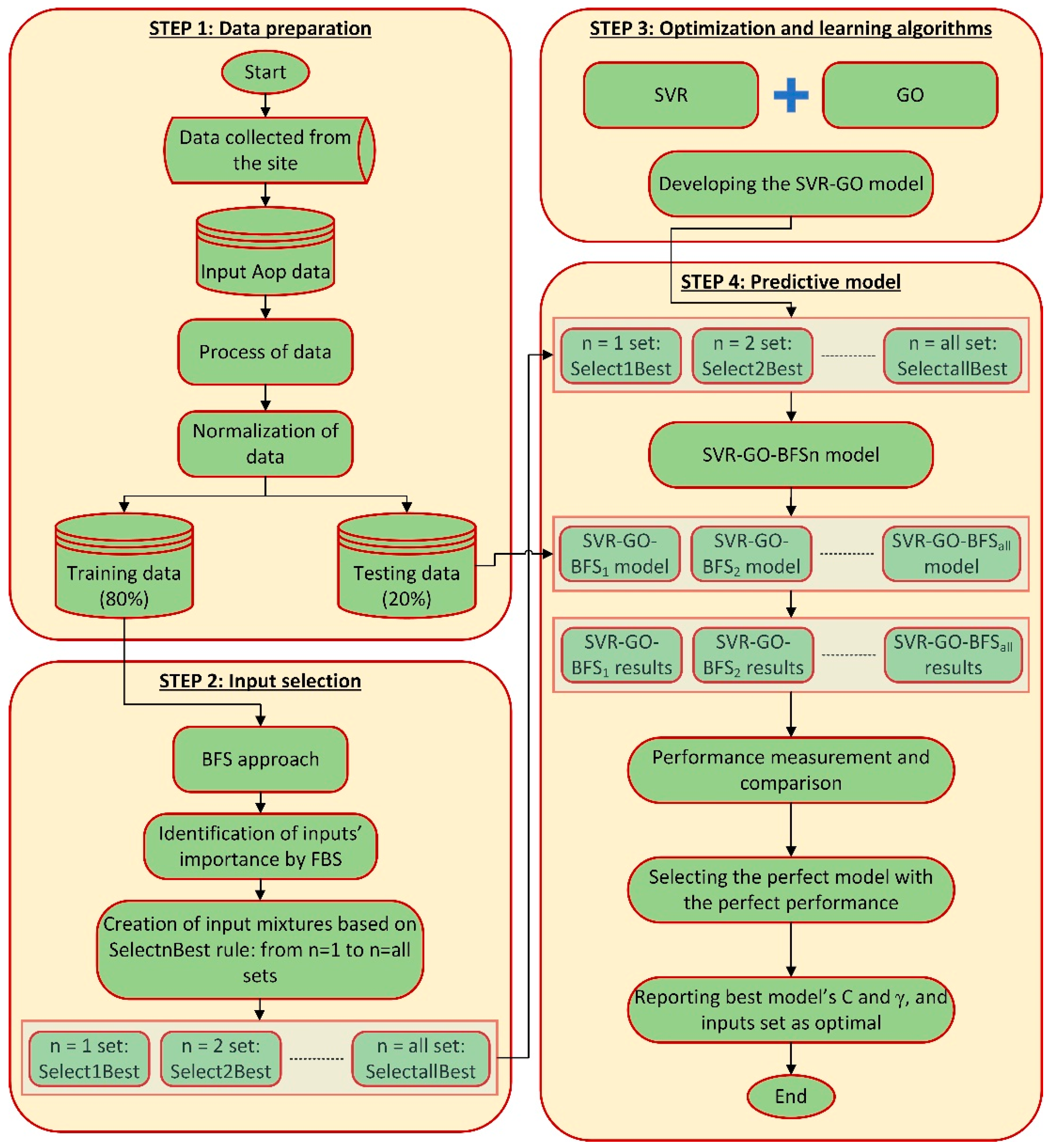
3.2. Input Selection
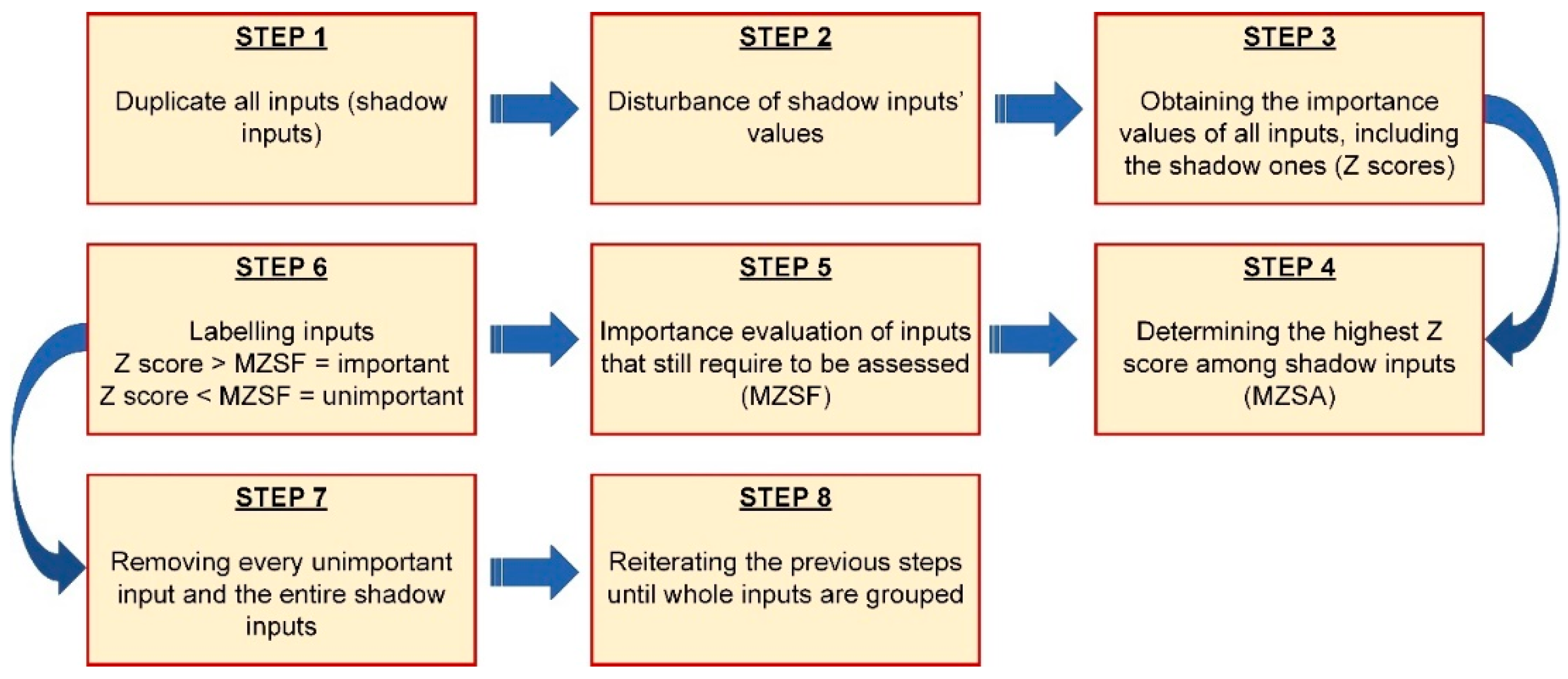
The BFS was applied to evaluate the significance of inputs for predicting the AOp. In the beginning, the suggested approach examined nine inputs for the final selection of the inputs, and 100 iterations were used to execute the BFS. The authors did not notice any variations in the research results exceeding 100 runs. The findings of the BFS-based technique are presented in
Figure 5.
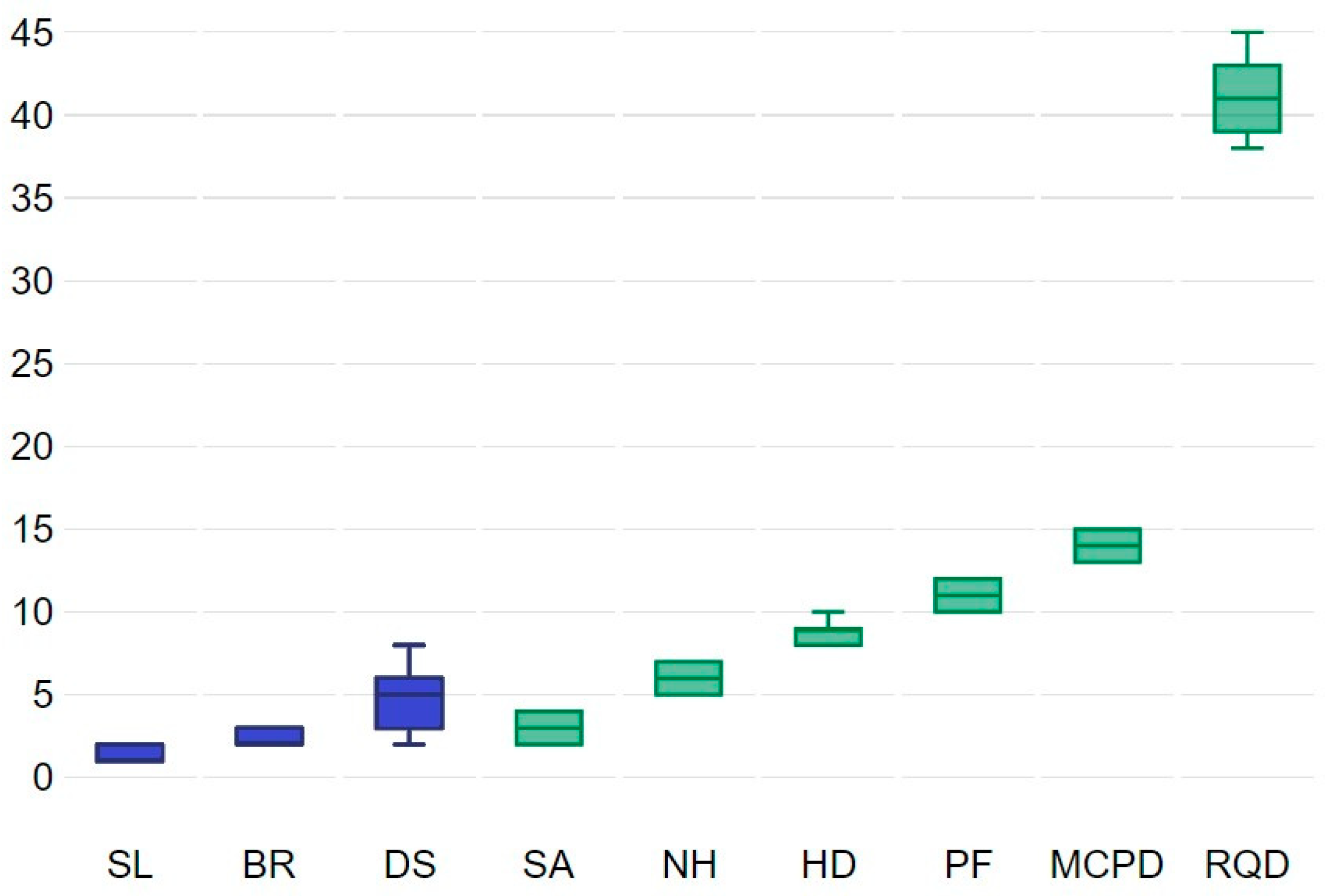
Box plots in
Figure 5 explain the significance of the inputs assessed through BFS. The green plots show those inputs that have more prominent predictability than those indicated by the blue colors. All inputs were classified as significant. Therefore, in developing various input mixtures for the AOp forecast, all nine inputs will be employed. Based on the suggested structure, nine predictive models will be proposed. This approach aims to determine the minimal optimal variable’s collection for overcoming the issues of underfitting and overfitting. Furthermore, the inputs indicated in red in the BFS results possess smaller informational potential compared with shadow traits. Hence, these inputs are eliminated from the final collection. Moreover, the yellow inputs show tentative ones. As a result, no inputs appeared tentative or unimportant.
The RQD, MCPD, and PF inputs were confirmed to be the most significant inputs, graded in the same descending form of value for the data obtained from the site. Following these inputs, the HD placed fourth in significance. These findings confirm that using the three characteristics of blasting improves the effectiveness of AOp predictability. Therefore, this study suggests that prospective scholars use these variables as inputs in their models. This algorithm is strong and can produce an unbiased and firm choice of significant and insignificant inputs from a dataset. Since combining more inputs can induce overfitting issues, the novel BFS’s capacity to prioritize inputs in decreasing sequence of values can assist scholars in deciding which inputs apply to the AOp forecast. Hence, dropping unnecessary or less correlated inputs may reduce calculation complications and time linked with enhancing the suggested hyperparameters of the scheme.
3.3. SVR-GO-BFSn Model Performance
Following recognizing the importance level of the inputs by BFS, an SVR model kernelized with RBF is employed to carry out the predictive analysis. During running the model, γ and C that are pair hyperparameters of SVR are optimized by the GO algorithm. Nine SVR-GO-BFSn models (SVR-GO-BFS1 to SVR-GO-BFS9) are developed based on nine various inputs sets (n = 1 set to n = 9). The n = 1 set comprises just the first most significant input, while the n = 9 collection encompasses all nine vital inputs estimated by BFS. To choose among the SVR-GO-BFSn model structures, this study uses MAPE as the primary criterion. In addition, the RMSE is used as GO’s objective function. Prediction of the AOp values is the target of these models.
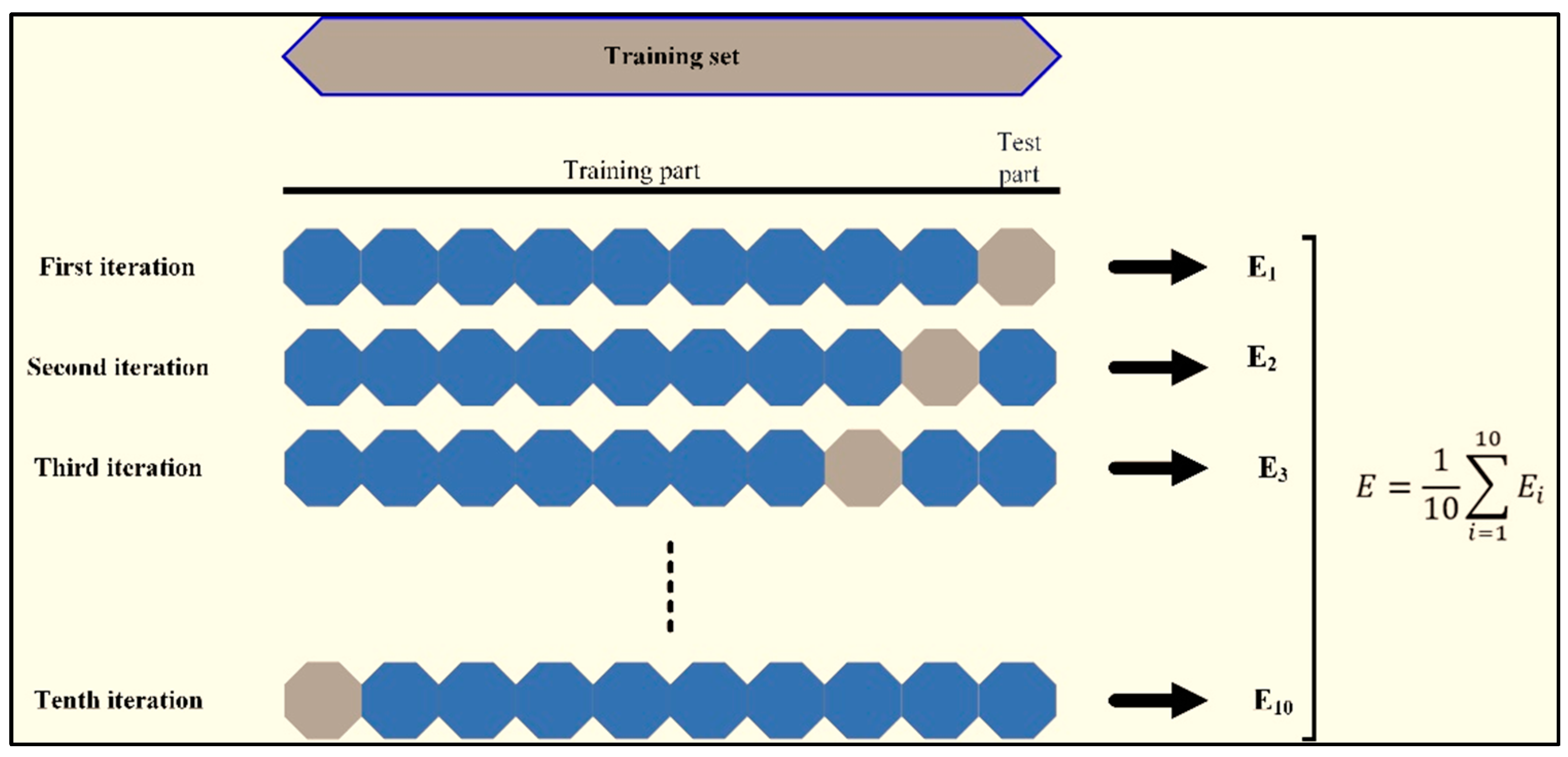
The AOp database is split into training (80%) and test (20%) sets at random throughout the experiment’s run. The training set of data is utilized to develop the forecasting model, while the testing data are utilized to evaluate the predictability. Importantly, all generated models receive the same training and test sets on a regular basis. Following building numerous models, it has been evidenced that as the number of iterations rises, the model computation time grows. Small population sizes, on the other hand, generate inconsistent fitness values. Therefore, multiple groups of 50, 100, 150, 200, and 250 population numbers in the optimization model were chosen for the purposes of the current study, and their iteration curves were made based on the right fitness values.
Concerning the GO, the number of search agents was set as 40, as well as the largest iteration number of developed models was set as 100. Regarding SVR, the lower and upper bounds of γ and C were set to (0.01–50) and (0.01, 100). All inputs were normalized between zero and one for the estimation of performance criteria, as well as to decrease the calculation complications during searching for hyperparameters of models.
Table 3 presents the best predictive fulfilment of the models developed in the current investigation. This table corresponds to SVR hyperparameter values optimized using GO and the smallest optimal collection of inputs. It can be seen that the model with seven inputs (SVR-GO-BFS
7) achieved the highest accuracy and lowest errors.
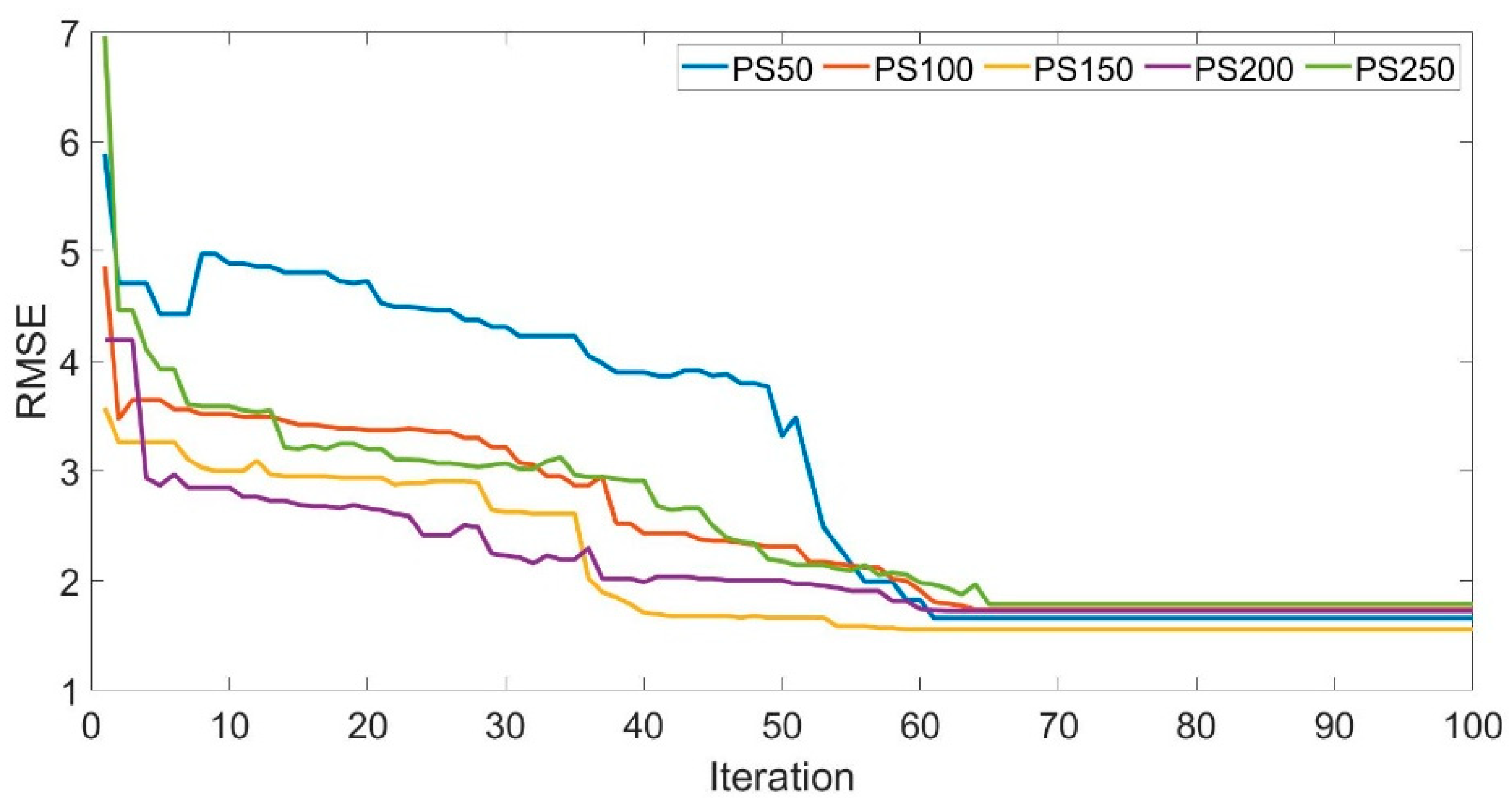
Figure 6 depicts the outcomes of fitness values for SVR-GO-BFS
7 models in forecasting AOp, along with their iteration counts. Furthermore, to minimize the GO’s cost function, the RMSE was chosen. This figure shows that the best population size for SVR-GO-BFS
7 is 200. Sizable errors in prediction are improbable to have occurred. Only average alternations were adopted up to iteration number 65; following this, no significant difference in the RMSE values was indicated. It should be noted that all models achieved the minimum RMSE in less than 70 iterations, which shows the power of GO in optimizing the SVR hyperparameters.
It was not required to have the full collection of significant inputs (n = nine) to obtain the most reliable predictive performance. Therefore, the authors can draw the conclusion that the effectiveness of SVR-GO-BFSn in forecasting the AOp is excellent.
The performance of the SVR-GO-BFS
n models based on various mixtures of significant inputs (n = 1 set to n = 9 sets) is presented in
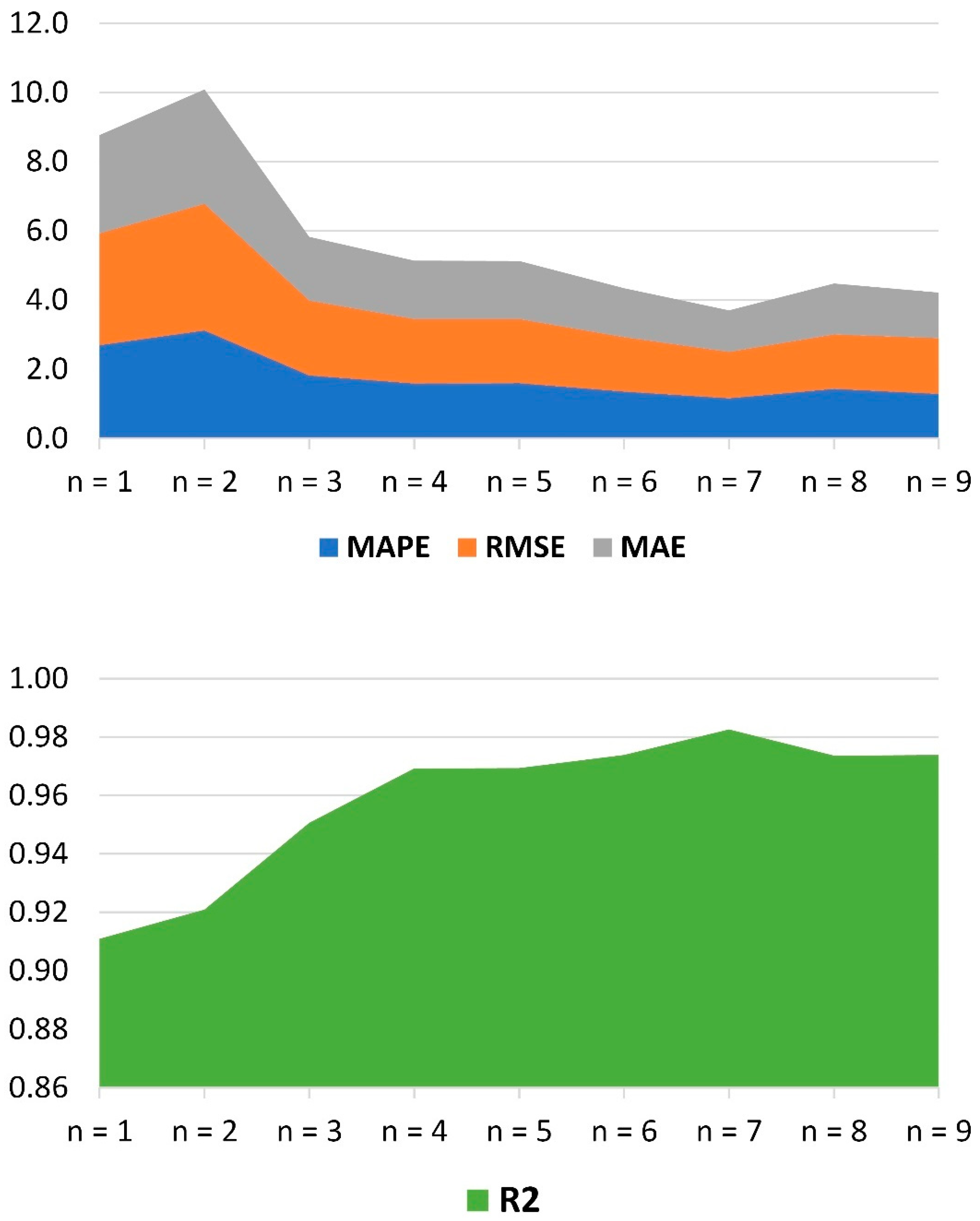
Figure 7 through the stacked area. In
Figure 7, it is obvious that the MAPE, RMSE, and MAE estimates obtained from all the SVR-GO-BFS
n models were essentially lower than 2.6953, 3.6637, and 3.3083, sequentially, even if only one input was added to the model. For instance, the achieved values of MAPE, RMSE, and MAE were 2.6953, 3.2241, and 2.8476, sequentially, if just one input is employed for the model creation. Furthermore, the SVR-GO-BFS
2 model is associated with the poorest performance. This model achieved 0.9209 for R
2, 36637 for RMSE, 3.1152 for MAPE, and 3.3083 for MAE. Instead, the developed models become more precise through employing the three most significant inputs and beyond. For instance, the acquired RMSE varied from 2.1659 to 1.6092 for the models from SVR-GO-BFS
3 to SVR-GO-BFS
9. Therefore, the authors can assume that employing just the three most significant inputs from the dataset picked and rated by BFS would produce strong prediction outcomes. Moreover, comparable issues were found with R
2, MAPE, and MAE. The scatter plots of the real and predicted AOp values made by the developed models show this trend in
Figure 8.
3.4. Performance Comparison
The authors compared the performance of the developed SVR-GO-BFS
7 model with a single SVR model. All nine variables were used to train the single SVR model. The outcomes of this comparison are presented in
Table 4. The SVR-GO-BFS
7 model achieved a notably lower MAPE value compared with the single SVR model. The value of MAPE improved by about 62% when the newly developed model was applied to the data. Furthermore, R
2 was enhanced by approximately 19%. RMSE and MAE were improved by 68.09% and 62.26%, respectively. Hence, for predictive precision, it can be assumed that SVR-GO-BFS
7 particularly beats the single SVR model for AOp forecasting in the selected granite quarry sites in Malaysia. The principal responsible for enhancing the prediction performance of the SVR-GO-BFS
7 model was SVR’s parameter optimization by GO and employing BFS for input choice.
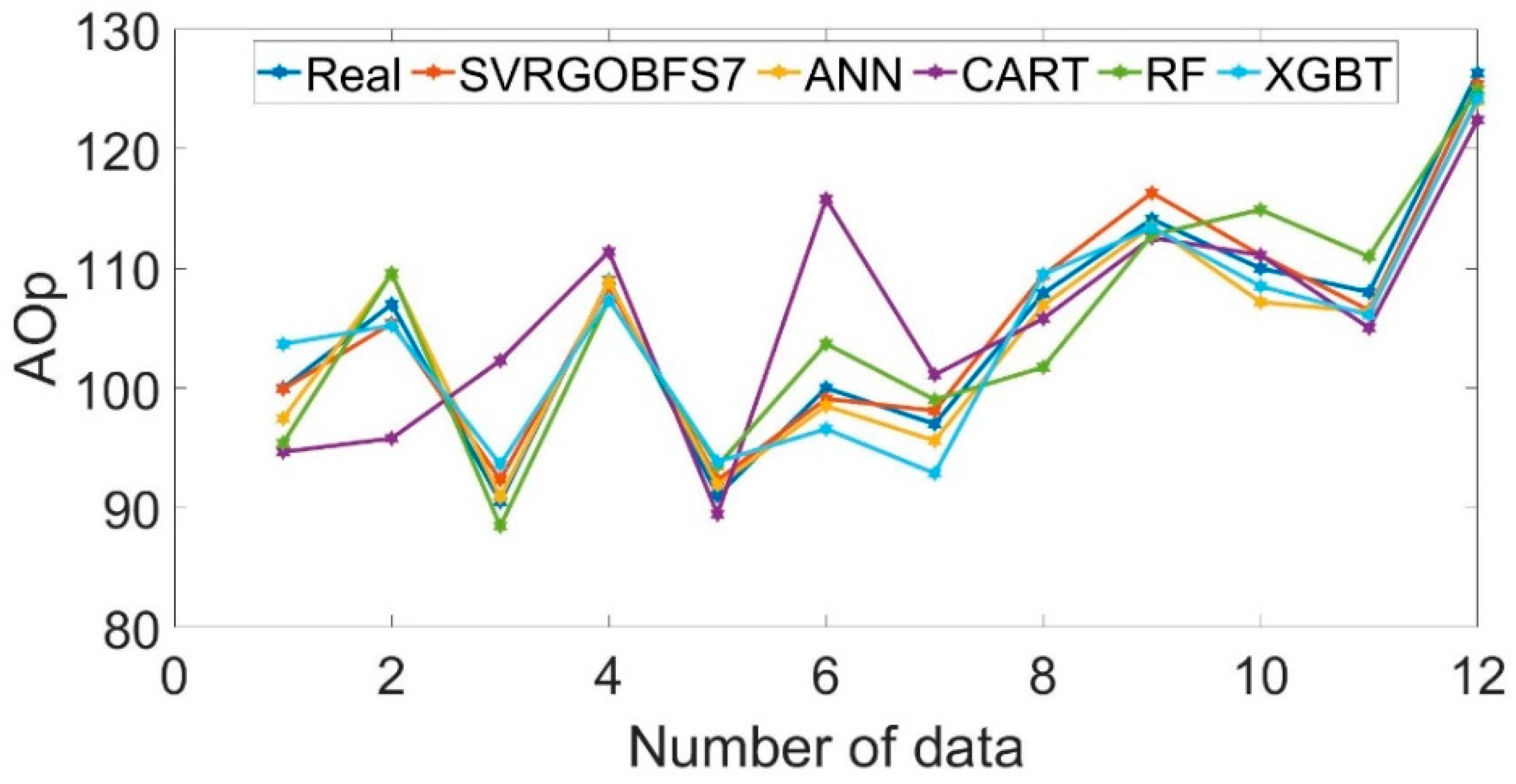
This study also compared the achievement of the developed model with some well-known ML models, including Random Forest (RF), Artificial Neural Networks (ANN), Extreme Gradient Boosting Tree (XGBT), and Classification and Regression Trees (CART). Nevertheless, BFS and GO were not hybridized with these models. All models were trained using the full set of inputs (nine inputs). For XGBT, Eta and Lambada were set as 0.3, 1.0, and its objective function was reg:linear. For CART, the maximum tree depth was 7. Concerning ANN, a backpropagation procedure by the Levenberg–Marquardt training algorithm was employed for its optimization. Additionally, the ANN structure included a single hidden layer and 11 hidden nodes. Furthermore, the authors used a sigmoid activation function while the value of the learning rate was 0.2.
Table 5 shows how these models compare to SVR-GO-BFS
7 in terms of how well they work.
The RMSE, MAPE, and MAE values of the developed SVR-GO-BFS
7 model were less than all benchmark models. Among benchmark models, ANN showed a better performance in terms of both accuracy and errors. Instead, the worst model was CART, which achieved the lowest accuracy and highest errors. While the XGBT obtained better accuracy than the RF, the RF outperformed the XGBT in terms of errors. The results of this comparison confirmed that the developed SVR-GO-BFS
7 was statistically better than the models developed for comparison. For a better explanation, the predictive effectiveness of the developed BA-GO-BFS
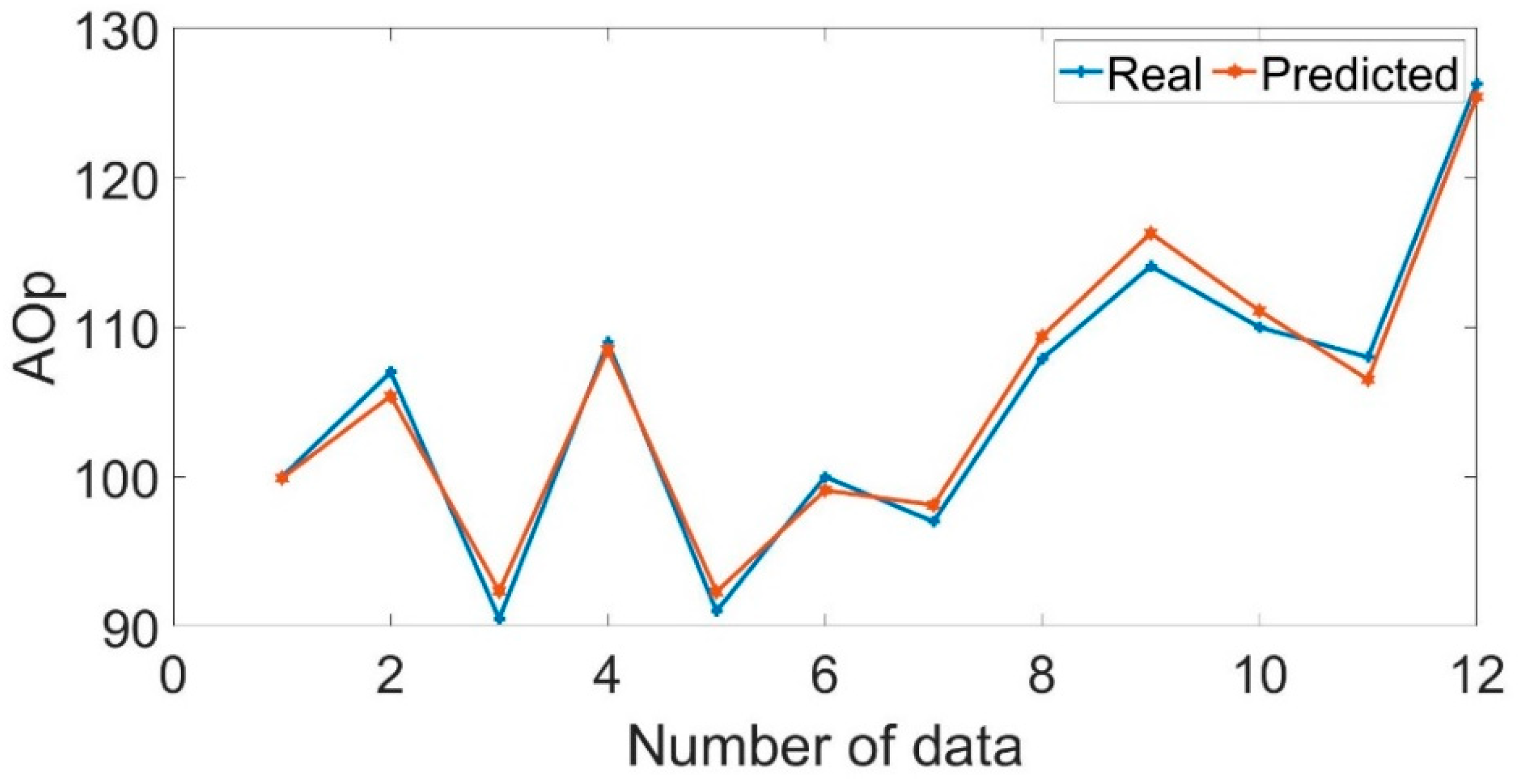
7 is demonstrated in
Figure 9. The figure showed that the predicted data effectively track the real data with insignificant differences. The results of the performance criteria in
Table 4 showed that the values of the error metrics were comparably low. The results of AOp predictions by SVR-GO-BFS
7 and other ML models are presented in
Figure 10. The advantage of the developed SVR-GO-BFS
7 model was justified through the outcomes of the comparative evaluation. So, the importance of combining methods (SVR, GO, and BFS) is confirmed in the right way.
3.5. Comparison with Other Optimization Models
In the current section, various examinations were carried out to confirm that the synthesis of BFS, SVR, and GO produces the most reliable returns. This experiment engaged three optimizers to obtain the hyperparameters of SVR. One of these techniques was PSO, which explains the regular optimization performance for adjusting the SVR’s hyperparameters. Another method was the Cuckoo Optimization Algorithm (COA), which was broadly employed for fine-tuning the parameters of ML algorithms [
38]. The last optimizer was the Neural Network Algorithm (NNA), one of the most advanced optimization techniques [
39]. The SVR model was optimized with PSO, COA, and NNA. Seven of the inputs that SVR-GO-BFS
n used were used again when the new optimized models were made.
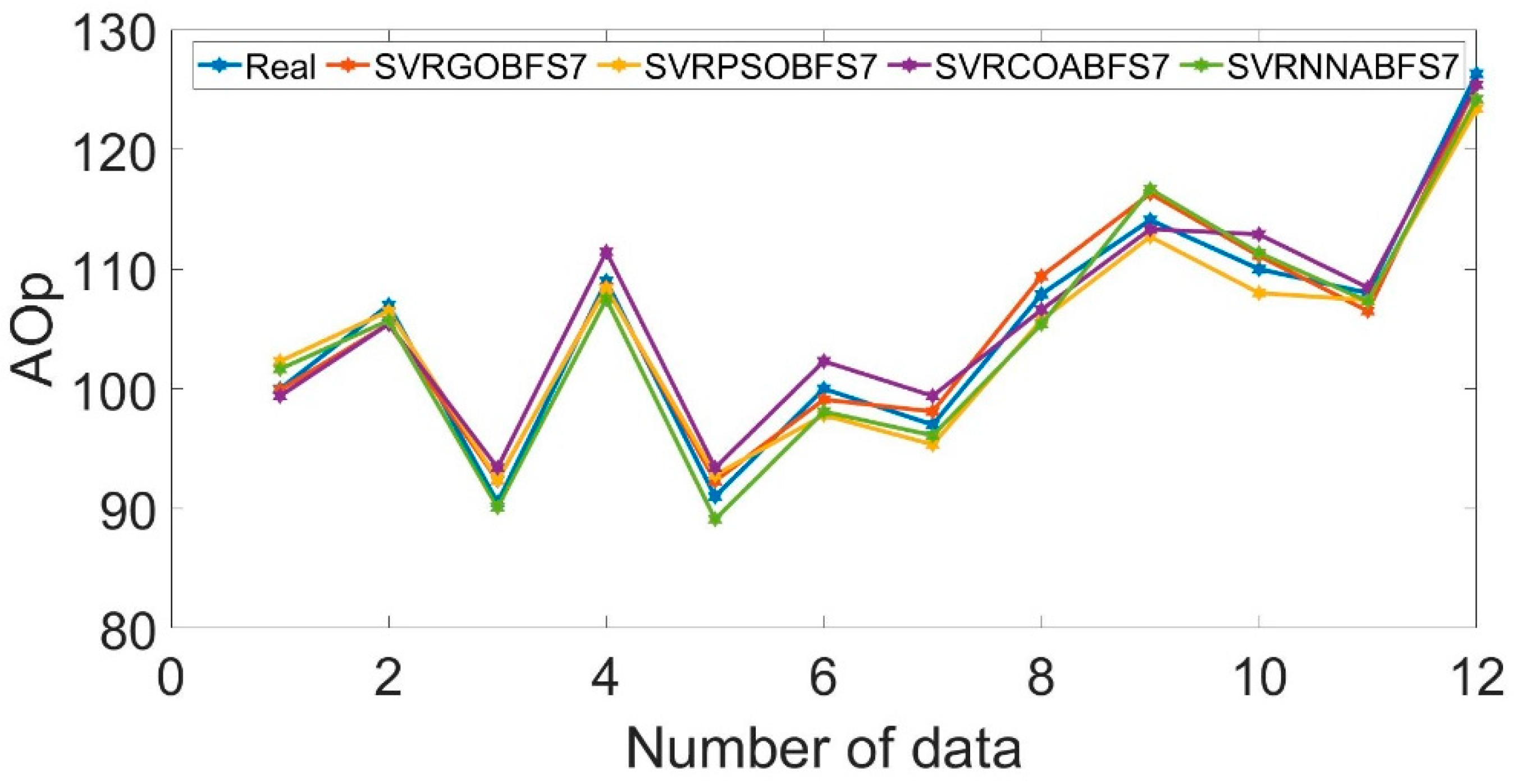
The precision of the optimized models is presented in
Figure 11. The performance results of the tuned SVR models by the optimized techniques are displayed in
Table 6. For the granite quarry dataset, the precision of the SVR-GO-BFS
7 model was higher than that of the SVR-PSO-BFS
7, SVR-COA-BFS
7, and SVR-NNA-BFS
7 models. As a result, the capacity of the GO technique to search the SVR’s hyperparameters was more effective than NNA, PSO, and COA. Simply put, the SVR-GO-BFS
7 method achieves high accuracy for AOp forecasting and has the best efficiency and consistency among all basic techniques. Overall, the SVR-GO-BFS
7 technique obtained great precision for AOp prediction and had the greatest performance and cohesion amongst all basic methods. Consequently, in this research, the SVR-GO-BFS
n model is used for prediction, and further studies are suggested to utilize this method in other investigations based on the authors’ concerns.
In comparison with the previous work, the model developed in this study showed better performance. For instance, Hajihassani et al. [
27] applied an ANN-PSO to the same inputs, and they did not utilize any input selection technique and only used their model for AOp estimation. The best R
2 that they achieved was 0.8836. The SVR-GA-BFS7 model achieved a better R
2 while using a fewer number of inputs, which decreased the model complexity. The authors of this study believe that the current study and its process and results are able to add value to the available literature.





 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}