Abstract
Machine learning frameworks categorizing customer reviews on online products have significantly improved sales and product quality for major manufacturers. Manually scrutinizing extensive customer reviews is imprecise and time-consuming. Current product research techniques rely on text mining, neglecting audio, and image components, resulting in less productive outcomes for researchers and developers. AI-based machine learning frameworks that consider social media and online buyer reviews are essential for accurate recommendations in online e-commerce shops. This research paper proposes a novel machine-learning-based framework for categorizing customer reviews that uses a bag-of-features approach for feature extraction and a hybrid DNN framework for robust classification. We assess the performance of our machine learning framework using AliExpress and Amazon e-commerce product review data provided by customers, and we have achieved a classification accuracy of 91.5% with only 8.46% fallout. Moreover, when compared with state-of-the-art models, our proposed model shows superior performance in terms of sensitivity, specificity, precision, fallout, and accuracy.
1. Introduction
Recently, due to the COVID-19 pandemic, customers’ intention has shifted towards social media and online e-commerce platforms. They express and post their opinions about products and services, shaping brand perception [1,2]. The large-scale manufacturer relies on customer reviews, ratings, and feedback related to their product design and quality. However, the effectiveness of customer reviews is largely impeded by fake reviews [3]. Moreover, the manual analysis of these reviews is time-consuming, thus further reducing effectiveness. To address this, automated opinion extraction mechanisms use machine learning algorithms to classify customer reviews as positive, negative, or neutral. Social media platforms, including Facebook, Twitter, Instagram, YouTube, WhatsApp, and TikTok, have billions of users sharing their content, feedback, and reviews related to products, etc. Product reviews on these platforms exist in a textual, visual, and vocal form, which requires robust feature extraction techniques to improve classification performance [4]. Smart cities equipped with an intelligent navigation and positioning system can provide an intelligent recommendation system based on consumer reviews on social media platforms. The recommendation mechanisms become more sophisticated when users’ verbal, visual, and textual content is classified through machine learning and deep learning models. In the online e-commerce market, product suggestions can be made intelligently by utilizing social media reviews posted by online customers for DNN model training and optimization. The consumer textual sentimental opinions related to products require natural language processing (NLP) techniques to identify key phrases and terms that are associated with particular features [5], whereas the visual text in the shape of an image needs optical character recognition (OCR) followed by NLP [6]. The vocal feedback and reviews require voice recognition based on 1D CNN models and handcrafted models [7].
Recently developed AI frameworks have been broadly classified into two categories known as machine learning and non-machine-learning frameworks [8]. Machine learning methods require a robust and distinctive set of features extracted from the training database, whereas non-machine-learning frameworks do not require feature extraction mechanisms. The non-machine-learning techniques categorize the input files by their signature data. In the static and dynamic analysis methods, feature values are extracted in the idle and the program execution stage. Non-machine-learning methods solely depend on the developer’s expertise and do not consider prior examples of malware information. Moreover, non-machine-learning methods do not require special-purpose software and hardware resources. The machine learning models are most often employed in combination with isolated classifiers that can learn the pre-existing training data [9]. Generally, ML methods, including reinforcement learning, have become a common practice in cybersecurity and healthcare systems [10]. The machine-learning-based identification is carried out in two stages, which are the feature extraction and classification stages. Two broad categories of feature extraction are employed, consisting of handcrafted statistical methods and deep neural networks. Both extract feature values based on combinations of data values in their neighborhoods.
Depending on customer reviews, the existing feature extraction models can broadly be classified into three classes: visual-image-based representation, voice-based features, and textual features. The visual features require image descriptors to extract language characters as a pre-processing stage of the NLP methods [11]. The existing visual object segmentation and representation both are handcrafted as well as DNN-based [12]. Images with diverse set textures, shapes, and colors require a hybrid features model to include textured features, such as overlapped multi-oriented tri-scale local binary pattern (OMTLBP) [13], robustness-driven hybrid descriptor (RDHD) [14], and discriminative local features of overlapping stripes (DLFOS) [15]. Deep neural networks developed to detect textual characters of different languages include BLPnet [16], HMM-DNN [17], distance-based edge linking (DEL) [18], and KDANet [19]. The DNN model recognizes the character of specific language depending on text mining methods to bag-of-words [20,21].
The visual and vocal reviews of the customer transformed into textual shape require a pre-processing stage of voice and text character recognition. The images and voice pre-processing sub-stages are included for the precise transformation of data into textual shape [22]. Visual review can be based on either video or image data. In the case of video, vocal analysis can be used for classification, while, in the case of an image, review classification requires a distinctive feature set that remains robust and invariant to variations in view angle, scale, and illumination [23]. Text images, which consist of characters with various shapes and textures, necessitate texture and shape representation models [23]. Due to intra-class variations in color, shape, and illumination, image identification becomes challenging, and, therefore, stable features are considered. Various types of neural networks, such as AlexNet, ResNet, DagNet, Vgg-16, InceptionV3, GoogleNet, and Yolo, have been developed for the classification of the ImagNet dataset [24]. These models have achieved promising performance in image classification, but they require extensive data for fine-tuning new categories. Therefore, handcrafted statistical frameworks are associated with a pre-processing step for feature extraction. Textured images can be represented using local binary pattern (LBP) and gray-level co-occurrence matrix (GLCM) [25]. LBP and GLCM are chosen because of their noise robustness and photometric invariance. To represent the input image as a whole for object recognition, we use the concatenated shape of all three features—color, texture, and shape.
The robust features require distinctiveness and a stable classification approach for precise categorization of customer reviews. Researchers have employed various isolated classifiers, including multi-class SVM, discriminant analysis, ensemble, decision tree, and KNN, to obtain the estimated label of the test image [26]. Kernel improves the classification performance of existing classifiers by mapping non-linear data into high-dimensional space [27]. The kernel function estimates the similarity between pairs of samples in the transformed spaces. Classifier kernel functions include linear, polynomial, radial basis function (RBF), and sigmoid kernels [28]. Careful selection of kernels enhances the categorization precision of the model; the RBF kernel outperforms other kernel types in many classification problems, whereas the polynomial kernel can perform well in image recognition tasks [29]. The performance of the classification models has been validated by comparing the estimated label with the true label of the test data. The label represents the class name of the customer review. Regarding the set of true labels and estimated labels, when compared, the classification performance is evaluated and presented in the shape of a confusion matrix. The true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN) obtained from the set of true and predicted labels are used to validate the performance of the image recognition frameworks.
The industrial sectors and product manufacturers encourage constructive feedback from reviewers; however, initially, when purchasing a product, consumers can hardly provide valuable feedback related to the specific product. However, after using the product for a specific time period, reviewers can initiate effective feedback. In the case of online shops and social media platforms, customers can post comments/reviews instantly without any hurdles or visit the product manufacturing and seller’s shop. This enables online sellers to collect and provide valuable information to the manufacturer. Customer feedback, in most cases, is extensive, containing thousands of reviews and redundancies. Therefore, an AI-based algorithm is desired to automatically and precisely classify customer reviews and ratings into respective classes, helping the manufacturer to improve product quality. Existing customer reviews classification approaches have low accuracy due to the complex nature of human language. In our paper, we propose a new opinion extraction mechanism that effectively classifies customer reviews on social media using natural language processing techniques and a deep learning neural network. We evaluate our approach on a real-world dataset and show that it outperforms existing approaches, achieving high accuracy in classifying reviews. To validate our approach, we compare our results with those obtained by human evaluators.
The main contribution of this work is listed below:
- Bag-of-words hybrid approach: The proposed article employs the bag-of-words model to cluster the textual reviews and create a histogram feature. The 14-layer DNN is also employed to transform raw features into invariant BoW features.
- DNN-based optimization: The 14-layer DNN model consisting of 1D CNN, LSTM, and BiLSTM optimizes the features, and softmax along with the classification layer is introduced to classify the features into their respective categories.
The remainder of the paper is organized such that Section 2 demonstrates comprehensive details of the related work on opinion extraction and sentiment analysis. Section 3 explains the proposed approach in deep detail. Section 4 analyzes the experimental results and compares them to recently reported works. Finally, Section 5 concludes the paper and discusses future research directions.
2. Related Works
Opinion extraction based on costumers’ social media posted reviews is a crucial task with complex challenges, including language variability, syntax errors, vocal tone variations, format variability, and script variability. Opinion extraction in natural language processing (NLP) aims to identify and extract opinions from text data. Several studies have been conducted to explore the different techniques and approaches used for opinion extraction, with machine learning being a popular choice due to its ability to learn patterns and classify data. Machine learning frameworks require robust features from the input data of uniform shape and a distinctive classifier. Various features extraction methods have been adopted by researchers in their frameworks for feature extraction and classification.
2.1. Feature Extraction
Feature extraction is the process of calculating stable attributes from data that have less intra-class variation and more inter-class variation. It is the process of transforming raw data into a discrete finite set of values with a uniform and lower dimension. Feature extraction is crucial for the precise classification of data into their respective classes. Moreover, feature extraction represents the input file with a selected set of values, excluding redundant information. Researchers have developed their robust and distinctive frameworks for text feature extraction and employed them in text mining and sentiment classification applications [30,31]. Various frameworks for extracting robust and invariant features from text data have been developed by researchers, which can be broadly categorized into two classes: handcrafted and deep neural networks. The handcrafted descriptors are developed through feature engineering and mostly consist of statistical models. The researcher adopts various statistical analyses to represent the distribution of words in the textual data for precise categorization. The frameworks of shallow learning (SL) enormously comprise machine learning methods with handcrafted feature representation methods. Shallow learning requires a combination of heavy dimensional features provided in [32]. However, the SL techniques are still applicable to textual data classifications. In [33], the bag-of-n-grams and parallel convolution neural networks (CNNs) frameworks are developed to detect and categorize fake and real reviews. In [34], costumer reviews have been classified by employing the eigen-space graph generation and then classifying the graphs by KNN and SVM classification methods. In [35], the authors have developed a deep learning framework for review sentiment classification. This approach incorporates rating information to capture the overall sentiment distribution of sentences. It involves adding a classification layer over the embedding layer and fine-tuning using labeled sentences for supervised learning. The classification models of random forest, KNN, and SVM obtained an F1 score of 95%. The PDF format adopts to visualize various content, such as images, text, and sequential files. The methods showed powerful real-time classification of costumer feedback compared to previously reported work. In [36], gradient-boosted decision tree classification of the log-loss function is developed and achieves an 82% reduction in false positives.
2.2. Deep Neural Networks
Deep neural networks (DNN) are utilized to learn features from the input training data for customer review classification, which improves the accuracy and reliability of recognition and categorization techniques. Recently, deep learning methods have been heavily relied upon in a vast number of review classification frameworks developed for malware identification. The proposed MXNet approach in [36] consists of an auto-encoder and multi-layer RMBs that utilize unsupervised feature learning and supervised fine-tuning to categorize costumer reviews. In [37], a long-term memory (LSTM) network-based costumer feedback categorization mechanism is developed to resolve the multi-class imbalance issue by combining binary and multi-class classification models and converting them into values. The LSTM algorithm is optimized to improve memory and macro accuracy by 7% compared to other methods, which positively impacts malware detection. In [37], LSTMs are used for text sentiment in customer reviews classification from a different perspective in e-commerce and IoT applications. As IoT devices are becoming more widely used, they have become a prime selection of the costumer, and online shops target costumers on online social media platforms for their product sale. In [38], a recurrent neural network (RNN) is used to analyze the opcodes of ARM-based IoT devices, and three LSTM frameworks are used to analyze the trained model, with the LSTM structure having the highest accuracy of 98.18% in reviews classification. In [39], a new graph network (GCN)-based customer review classification mechanism is introduced, achieving an accuracy of 98.32%, superior to other available options. In [40], a process is used that is known as multi-label text classification, where the authors developed new data on the behavior of text functions learning models for automatic feature extraction based on convolutional neural network and hybrid bidirectional gated recurrent unit (CNN-BiGRU) that identifies the advanced features for API calls for customer rating and reviews classification.
Most deep learning models described so far are quite large and intricate, making the process of retraining them a time-consuming and resource-intensive task. Moreover, as training these models involves a great deal of repetition, achieving the desired level of accuracy can take even longer. However, as customer reviews are ubiquitous on electronic devices and platforms, it is crucial to tackle this issue by developing lightweight solutions that can handle complex control systems without requiring excessive computing power.
3. Proposed Methodology
The framework proposed in this study comprises a handcrafted bag-of-features (BoF) feature extraction model, which is followed by a deep neural network (DNN) classification model. The BoF model is cascaded to extract features, which are then further refined and classified using the proposed DNN model. To pre-process the data, we first identify repeated keywords and remove artifacts, such as articles, prepositions, adverbs, and helping verbs. The performance of the proposed model was evaluated using a dataset of 3512 reviews, collected and labeled based on customer ratings posted in the review section of an e-commerce website. The performance metrics of the proposed model are presented in the Results section. Figure 1 provides a comprehensive overview of the detailed architecture of the proposed framework, while Figure 2 presents the layered details of the DNN model.
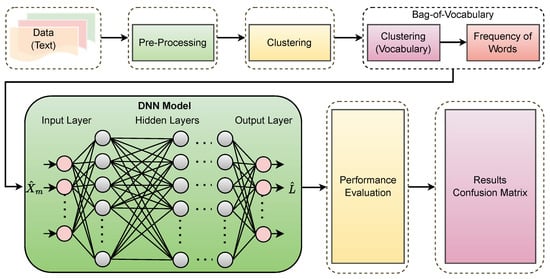
Figure 1.
Framework of the proposed model.
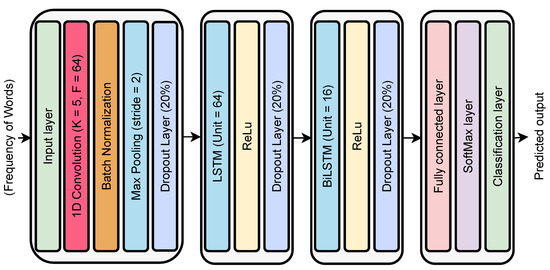
Figure 2.
Proposed DNN model.
The BoF clusters the keywords in k different sets to generate a vocabulary of features through k-means algorithm. The keywords are categorized into k classes on the basis of their similarity measures. The iterative process is adopted to optimize the clusters given in Equations (1) and (2). The total of k cluster centroids are initially selected randomly, represented with , with j ranging from 1 to k.
where denotes the ith keywords belonging to cluster j, while the denotes the centroid of cluster j. The in Equation (1) denotes the ith keyword belonging to cluster j. The symbol m in the denominator of Equation (1) denotes the cardinality of cluster j. The difference between successive centroids converges at ith and iteration iteratively. The cluster centroid collectively represents the vocabulary set. The histogram of the vocabulary centroid in the raw feature data represents the final feature vector.
where denotes vth feature value of the histogram feature vector. The denotes the nth keywords of the review data. The function calculates the distance of the mth keywords and the nth centroid. The symbol in Equation (3) denotes the minimum difference value of the vth centroid and the keywords. The final BoF feature is then fed to the proposed DNN for classification. The DNN model initial layer consists of 64 hidden neurons, which convolve with the input features vector . The in Equation (4) represents the kth hidden convoluional kernel, while the denotes the bias vector of the respective kth kernel.
where in Equation (5) denotes the batch normalization vector resulted by kth kernel output of the vth feature input. The denotes the scale operator and the represents bias variable. The batch normalization layer is followed by the max pooling layer with stride 2.
where is the max pooling result of the layer, where from each stride a maximum value is selected only. The LSTM with 64 hidden units is followed by the dropout layer in the proposed DNN architecture.
where in Equation (7) denotes the current input to the LSTM, denotes the previous cell output. The denotes weights for input and the weights for previous cell output. The is the input bias, and the indicates input weight and bias values. The LSTM is followed by ReLU layer, which removes non-linearity and vanishes the negative values in the data.
where the in Equation (8) is the output produced by ReLU layer 1. The ReLU converts all negative values to zero and preserves the positive output. The second dropout of the network is followed by ReLU layer dropping 20% of connections to reduce complexity of the model and avoid the model over-fitting. The BiLSTM is the next layer, which propagates bidirectionally to identify the temporal connection between data. The BiLSTM with 16 hidden units is employed in the proposed model. The in Equation (9) denotes the output to BiLSTM layer. The second ReLU layer removes non-linearity added by BiLSTM layer in the data. The in Equation (10) shows the output of the second ReLU function.
The in Equation (11) is the output of the fully connected layer, which has vectorized and concatenated the output of the precious layers’ ranges from 1 to M.
The in Equation (12) denotes the softmax function, while is the input and k denotes the number of output classes.
The proposed DNN model is optimized and trained for a total of 800 epoch steps, with a learning rate of 0.001. The batch size of 128 is chosen on the ADAM optimizer option selected for training. The proposed DNN model results in the estimated class label at the output of the final classification layer. The model requires performance evaluation, which has been carried out by utilizing the true positives, true negatives, false positives, and false negatives of the model. To measure classification performance, the specificity, sensitivity, precision, accuracy, discovery rate, fallout, and other parameters have been calculated with expression given here.
where, in Equations (13)–(19), the terms TP, TN, FP, and FN refer to true positives, true negatives, false positives, and false negatives, respectively. Furthermore, the terms TPR, TNR, PPV, FPR, FNR, FDR, and ACC refer to true positive rate, true negative rate, positive predictive value, false positive rate, false negative rate, false discovery rate, and accuracy, respectively.
4. Results
The proposed framework consists of two cascaded models that utilize both handcrafted techniques and the optimization and classification capabilities of deep neural networks (DNNs). When assessed on textual data from customers on an online e-commerce platform, the framework exhibited favorable performance in contrast to alternative methodologies. The performance of the proposed model was assessed on a labeled data section and subsequently tested to validate its classification performance. During the training process, bag-of-features (BoF) features are extracted and used to optimize the DNN layers’ weight and bias variables through an iterative process. The model’s hyperparameters, including the size of the bag-of-features (BoF) clusters, the configuration of the deep neural network (DNN) layers, the number of hidden units, the dropout percentages, and the epoch size, are determined through experimentation to optimize performance. To validate the efficacy of the proposed model, its performance metrics were compared against state-of-the-art benchmarks. The intel® Core i7-1255UL processor with 8 GB RAM and NVIDIA GeForce GTX 1650 is used for processing the data; moreover, the Matlab 2021a release is employed for the simulation setup.
4.1. Dataset Description
The performance of the proposed model was assessed using a dataset obtained from the AliExpress product Insta360 x3 action camera, which has an estimated value of 470 USD. The review section yielded a total of 3512 customer reviews, each consisting of a textual review and a rating. Out of the 3512 reviews, 1802 were categorized as positive reviews, while 1710 were identified as negative reviews. The second dataset utilized was collected from the Amazon ecommerce website for a similar product, with a total of 1552 reviews. Among these, 890 were positive reviews, and the remaining 662 were negative reviews. The rating system used a 5-star scale to label each textual review. Reviews with a rating above 3 stars were classified as positive, while reviews with a rating below 3 stars were labeled as negative. Reviews with a 3-star rating were excluded as they were deemed irrelevant. To evaluate the proposed framework for classifying customer reviews, reviews were selected from three different vendors who sold the same product. The dataset was divided into three sets for evaluation purposes: a training set comprising 70% of the data, a validation set comprising 15%, and a test set also consisting of 15%. The performance ROC curves in Figure 3 display the superiority of the proposed method compared to various state-of-the-art classification approaches.
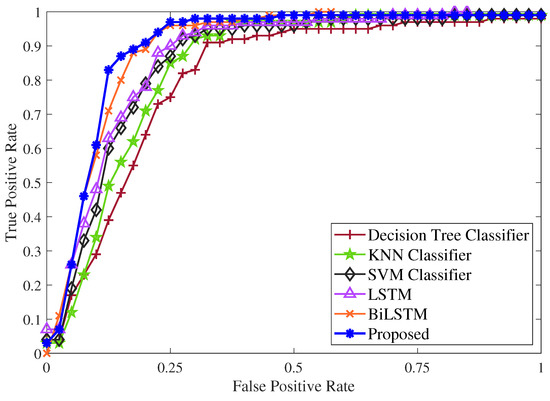
Figure 3.
Comparison of ROC curves with state-of-the-art classification methods.
4.2. Performance Evaluation
A novel method for feature extraction and classification using a bag-of-features (BoF) followed by deep neural network (DNN) framework is proposed in this study. The method is evaluated on a dataset, achieving a classification accuracy of 91.54%. When compared to standalone classifiers, the bidirectional long short-term memory (BiLSTM) achieved the second highest accuracy at 89.72%, while the simple LSTM achieved 89.55%. The support vector machine (SVM), k-nearest neighbor (KNN), and decision tree (DT) classifiers yielded classification accuracies of 85.02%, 84.85%, and 84.94%, respectively. The confusion matrix generated by each classification method is illustrated in Figure 4. The proposed DNN model, consisting of a layered architecture of LSTM and BiLSTM, achieved a classification accuracy that exceeded that of the standalone LSTM and BiLSTM classifiers by 0.94% and 0.%, respectively. The model demonstrated superior sensitivity, specificity, and precision, achieving a rate of 91.54% when compared to the other methods listed in Table 1. Additionally, the proposed method resulted in a lower fallout rate compared to other classifiers, indicating its ability to accurately detect and classify instances of interest.
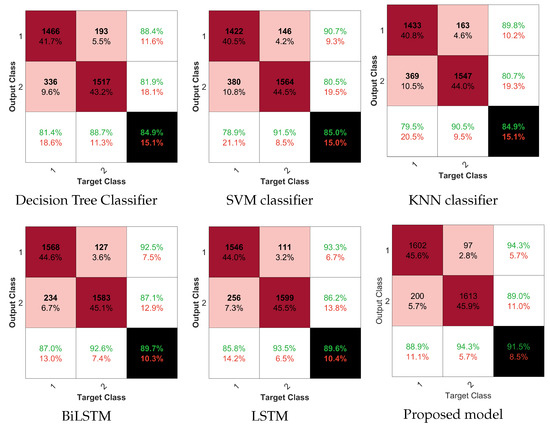
Figure 4.
Confusion matrix: where the pale rose color denote the false classification, the pinkish red color is the true classifications, white while the black denote overall accuracy of the classification models.

Table 1.
Performance comparison with related work on the AliExpress and Amazon datasets.
In Figure 5, the performance metrics of sensitivity, fallout, and accuracy were compared between decision tree, support vector machine, k-nearest neighbor, BiLSTM, LSTM, and the proposed method. The results demonstrated that the proposed method outperformed all the other models in all performance metrics. This suggests that the proposed model may be the most effective option for the task at hand.
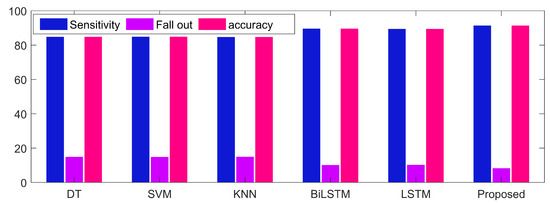
Figure 5.
Performance metric comparison for various classification frameworks.
In Table 2, different ratios of the training and testing data size have been used to investigate the performance of the proposed model. The proposed model, when evaluated on both AliExpress and Amazon data with 50% train and 50% test data, provided an accuracy of 74.65% and 70.01%. The accuracy increased to 91.54% and 90.42% when the training data size was increased to 80%, while 20% is utilized for testing.
Table 2.
Performance of the proposed framework on AliExpress and Amazon datasets with various training and testing data ratios.
5. Conclusions
In this research, we employ a hybrid framework that combines the handcrafted bag-of-features (BoF) method for feature extraction with a fourteen-layer deep neural network (DNN). This combination optimizes and effectively categorizes customer feedback related to online products. The BoF, along with the DNN, enhances the features by adding invariance and distinctiveness to the feature selection and classification models. Extensive experimentation was conducted to determine the optimal cluster dimension in BoF and the hyperparameters in the DNN. The proposed model was tested using customer feedback data collected from the AliExpress e-commerce website and Amazon product listings. Specifically, we selected the InstaX3 camera listing pages from three different sellers on both platforms. This dataset comprised a total of 3512 reviews, including 1802 positive and 1710 negative reviews from AliExpress, as well as 1552 reviews from Amazon, with 890 being positive and 662 negative. The classification model achieved a classification accuracy of 91.54% and 90.42% on the AliExpress and Amazon data, respectively. These results demonstrate the superior performance of the proposed model in categorizing customer feedback effectively.
Funding
This research work was funded by the institutional Fund Projects under grant no. (IFPRP: 461-830-1443). The author gratefully acknowledges technical and financial support provided by Ministry of Education and King Abdul Aziz University, DSR, Jeddah, Saudi Arabia.
Conflicts of Interest
The author declares no conflict of interest.
References
- Fülöp, M.T.; Topor, D.I.; Căpușneanu, S.; Ionescu, C.A.; Akram, U. Utilitarian and Hedonic Motivation in E-Commerce Online Purchasing Intentions. East. Eur. Econ. 2023, 1–23. [Google Scholar] [CrossRef]
- Akram, U.; Fülöp, M.T.; Tiron-Tudor, A.; Topor, D.I.; Căpușneanu, S. Impact of digitalization on customers’ well-being in the pandemic period: Challenges and opportunities for the retail industry. Int. J. Environ. Res. Public Health 2021, 18, 7533. [Google Scholar] [CrossRef] [PubMed]
- Salminen, J.; Kandpal, C.; Kamel, A.M.; Jung, S.G.; Jansen, B.J. Creating and detecting fake reviews of online products. J. Retail. Consum. Serv. 2022, 64, 102771. [Google Scholar] [CrossRef]
- Yan, Z.; Xing, M.; Zhang, D.; Ma, B. EXPRS: An extended pagerank method for product feature extraction from online consumer reviews. Inf. Manag. 2015, 52, 850–858. [Google Scholar] [CrossRef]
- Egger, R.; Gokce, E. Natural Language Processing (NLP): An Introduction: Making Sense of Textual Data; Springer: Berlin/Heidelberg, Germany, 2022; pp. 307–334. [Google Scholar]
- Srivastava, S.; Verma, A.; Sharma, S. Optical character recognition techniques: A review. In Proceedings of the 2022 IEEE International Students’ Conference on Electrical, Electronics and Computer Science (SCEECS), Bhopal, India, 19–20 February 2022; pp. 1–6. [Google Scholar]
- David, Y.; Harison, E. Paying Lip Service?: The Effects of Vocal Determinants on Perceived Service Quality. Int. J. Enterp. Inf. Syst. (IJEIS) 2022, 18, 1–20. [Google Scholar] [CrossRef]
- Food and Drug Administration. Proposed Regulatory Framework for Modifications to Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD). 2019. Available online: https://apo.org.au/node/228371 (accessed on 3 May 2021).
- Stanik, C.; Haering, M.; Maalej, W. Classifying multilingual user feedback using traditional machine learning and deep learning. In Proceedings of the 2019 IEEE 27th International Requirements Engineering Conference Workshops (REW), Jeju, Republic of Korea, 23–27 September 2019; pp. 220–226. [Google Scholar]
- Abdelrahman, M.M.; Zhan, S.; Miller, C.; Chong, A. Data science for building energy efficiency: A comprehensive text-mining driven review of scientific literature. Energy Build. 2021, 242, 110885. [Google Scholar] [CrossRef]
- Wu, C.; Li, X.; Guo, Y.; Wang, J.; Ren, Z.; Wang, M.; Yang, Z. Natural language processing for smart construction: Current status and future directions. Autom. Constr. 2022, 134, 104059. [Google Scholar] [CrossRef]
- Wang, J.; Yang, Z.; Hu, X.; Li, L.; Lin, K.; Gan, Z.; Liu, Z.; Liu, C.; Wang, L. Git: A generative image-to-text transformer for vision and language. arXiv 2022, arXiv:2205.14100. [Google Scholar]
- Khan, M.J.; Riaz, M.A.; Shahid, H.; Khan, M.S.; Amin, Y.; Loo, J.; Tenhunen, H. Texture representation through overlapped multi-oriented tri-scale local binary pattern. IEEE Access 2019, 7, 66668–66679. [Google Scholar]
- Saeed, A.; Khan, M.J.; Riaz, M.A.; Shahid, H.; Khan, M.S.; Amin, Y.; Loo, J.; Tenhunen, H. Robustness-driven hybrid descriptor for noise-deterrent texture classification. IEEE Access 2019, 7, 110116–110127. [Google Scholar] [CrossRef]
- Khan, M.J.; Rahman, M. Person re-identification by discriminative local features of overlapping stripes. Symmetry 2020, 12, 647. [Google Scholar]
- Onim, M.S.H.; Nyeem, H.; Roy, K.; Hasan, M.; Ishmam, A.; Akif, M.A.H.; Ovi, T.B. BLPnet: A new DNN model and Bengali OCR engine for Automatic Licence Plate Recognition. Array 2022, 15, 100244. [Google Scholar] [CrossRef]
- Smit, P.; Virpioja, S.; Kurimo, M. Advances in subword-based HMM-DNN speech recognition across languages. Comput. Speech Lang. 2021, 66, 101158. [Google Scholar] [CrossRef]
- Kamble, P.M.; Hegadi, R.S.; Hegadi, R.S. Distance based edge linking (DEL) for character recognition. In Proceedings of the Recent Trends in Image Processing and Pattern Recognition: Second International Conference, RTIP2R 2018, Solapur, India, 21–22 December 2018; Springer: Berlin/Heidelberg, Germany, 2019; pp. 261–268. [Google Scholar]
- Rabbi, K.K.; Hossain, A.; Dev, P.; Sadman, A.; Karim, D.Z.; Rasel, A.A. KDANet: Handwritten Character Recognition for Bangla Language using Deep Learning. In Proceedings of the 2022 25th International Conference on Computer and Information Technology (ICCIT), Cox’s Bazar, Bangladesh, 17–19 December 2022; pp. 651–656. [Google Scholar]
- Cardenas, D.G.J.; Han, D.Y.; Ban, H.J.; Kim, H.S.; Gurung, D.M. The text mining from online customer reviews: Implications for luxury hotel in Busan. Culin. Sci. Hosp. Res. 2022, 28, 67–80. [Google Scholar]
- Zhao, R.; Mao, K. Fuzzy bag-of-words model for document representation. IEEE Trans. Fuzzy Syst. 2017, 26, 794–804. [Google Scholar] [CrossRef]
- Paul, D.; Shifas, M.P.; Pantazis, Y.; Stylianou, Y. Enhancing speech intelligibility in text-to-speech synthesis using speaking style conversion. arXiv 2020, arXiv:2008.05809. [Google Scholar]
- Ingle, R.R.; Fujii, Y.; Deselaers, T.; Baccash, J.; Popat, A.C. A scalable handwritten text recognition system. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; pp. 17–24. [Google Scholar]
- Wang, S.; Nepal, S.; Rudolph, C.; Grobler, M.; Chen, S.; Chen, T. Backdoor attacks against transfer learning with pre-trained deep learning models. IEEE Trans. Serv. Comput. 2020, 15, 1526–1539. [Google Scholar] [CrossRef]
- Ghalati, M.K.; Nunes, A.; Ferreira, H.; Serranho, P.; Bernardes, R. Texture analysis and its applications in biomedical imaging: A survey. IEEE Rev. Biomed. Eng. 2021, 15, 222–246. [Google Scholar] [CrossRef]
- Al Dujaili, M.J.; Ebrahimi-Moghadam, A.; Fatlawi, A. Speech emotion recognition based on SVM and KNN classifications fusion. Int. J. Electr. Comput. Eng. 2021, 11, 1259. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.D.; Li, F.Z. Kernel sparse representation-based classifier ensemble for face recognition. Multimed. Tools Appl. 2015, 74, 123–137. [Google Scholar] [CrossRef]
- Lee, W.J.; Verzakov, S.; Duin, R.P. Kernel combination versus classifier combination. In Proceedings of the Multiple Classifier Systems: 7th International Workshop, MCS 2007, Prague, Czech Republic, 23–25 May 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 22–31. [Google Scholar]
- Camps-Valls, G.; Bruzzone, L. Kernel-based methods for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1351–1362. [Google Scholar] [CrossRef]
- Liang, H.; Sun, X.; Sun, Y.; Gao, Y. Text feature extraction based on deep learning: A review. EURASIP J. Wirel. Commun. Netw. 2017, 2017, 211. [Google Scholar] [CrossRef]
- Ahuja, R.; Chug, A.; Kohli, S.; Gupta, S.; Ahuja, P. The impact of features extraction on the sentiment analysis. Procedia Comput. Sci. 2019, 152, 341–348. [Google Scholar] [CrossRef]
- Gasparetto, A.; Marcuzzo, M.; Zangari, A.; Albarelli, A. A survey on text classification algorithms: From text to predictions. Information 2022, 13, 83. [Google Scholar] [CrossRef]
- Mohawesh, R.; Xu, S.; Tran, S.N.; Ollington, R.; Springer, M.; Jararweh, Y.; Maqsood, S. Fake reviews detection: A survey. IEEE Access 2021, 9, 65771–65802. [Google Scholar] [CrossRef]
- Chen, Z.; Zhou, L.J.; Da Li, X.; Zhang, J.N.; Huo, W.J. The Lao text classification method based on KNN. Procedia Comput. Sci. 2020, 166, 523–528. [Google Scholar] [CrossRef]
- Xu, F.; Pan, Z.; Xia, R. E-commerce product review sentiment classification based on a naïve Bayes continuous learning framework. Inf. Process. Manag. 2020, 57, 102221. [Google Scholar] [CrossRef]
- Neelakandan, S.; Paulraj, D. A gradient boosted decision tree-based sentiment classification of twitter data. Int. J. Wavelets Multiresolut. Inf. Process. 2020, 18, 2050027. [Google Scholar] [CrossRef]
- Haralabopoulos, G.; Anagnostopoulos, I. A Custom State LSTM Cell for Text Classification Tasks. In Proceedings of the Engineering Applications of Neural Networks: 23rd International Conference, EAAAI/EANN 2022, Chersonissos, Crete, Greece, 17–20 June 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 489–504. [Google Scholar]
- Lan, Y.; Hao, Y.; Xia, K.; Qian, B.; Li, C. Stacked residual recurrent neural networks with cross-layer attention for text classification. IEEE Access 2020, 8, 70401–70410. [Google Scholar] [CrossRef]
- Li, A.; Qin, Z.; Liu, R.; Yang, Y.; Li, D. Spam review detection with graph convolutional networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2703–2711. [Google Scholar]
- Deniz, E.; Erbay, H.; Coşar, M. Multi-label classification of e-commerce customer reviews via machine learning. Axioms 2022, 11, 436. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).