
YOLO-SE: Improved YOLOv8 for Remote Sensing Object Detection and Recognition


Abstract
:1. Introduction
2. Related Work
2.1. Object-Detection Networks for Remote Sensing Images
2.2. Attention Mechanism
2.3. Vision Transformer
3. Materials and Method
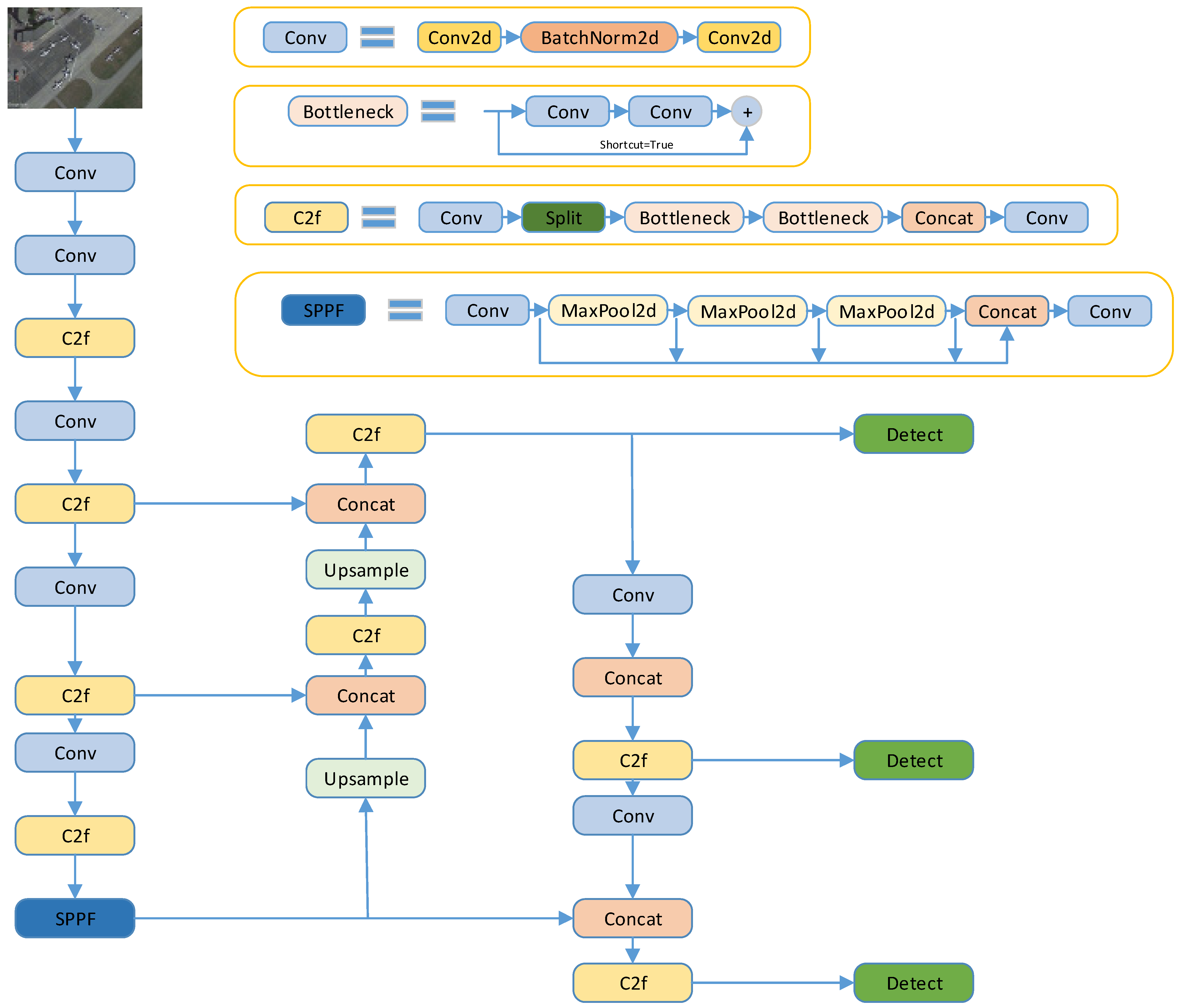
3.1. YOLOv8
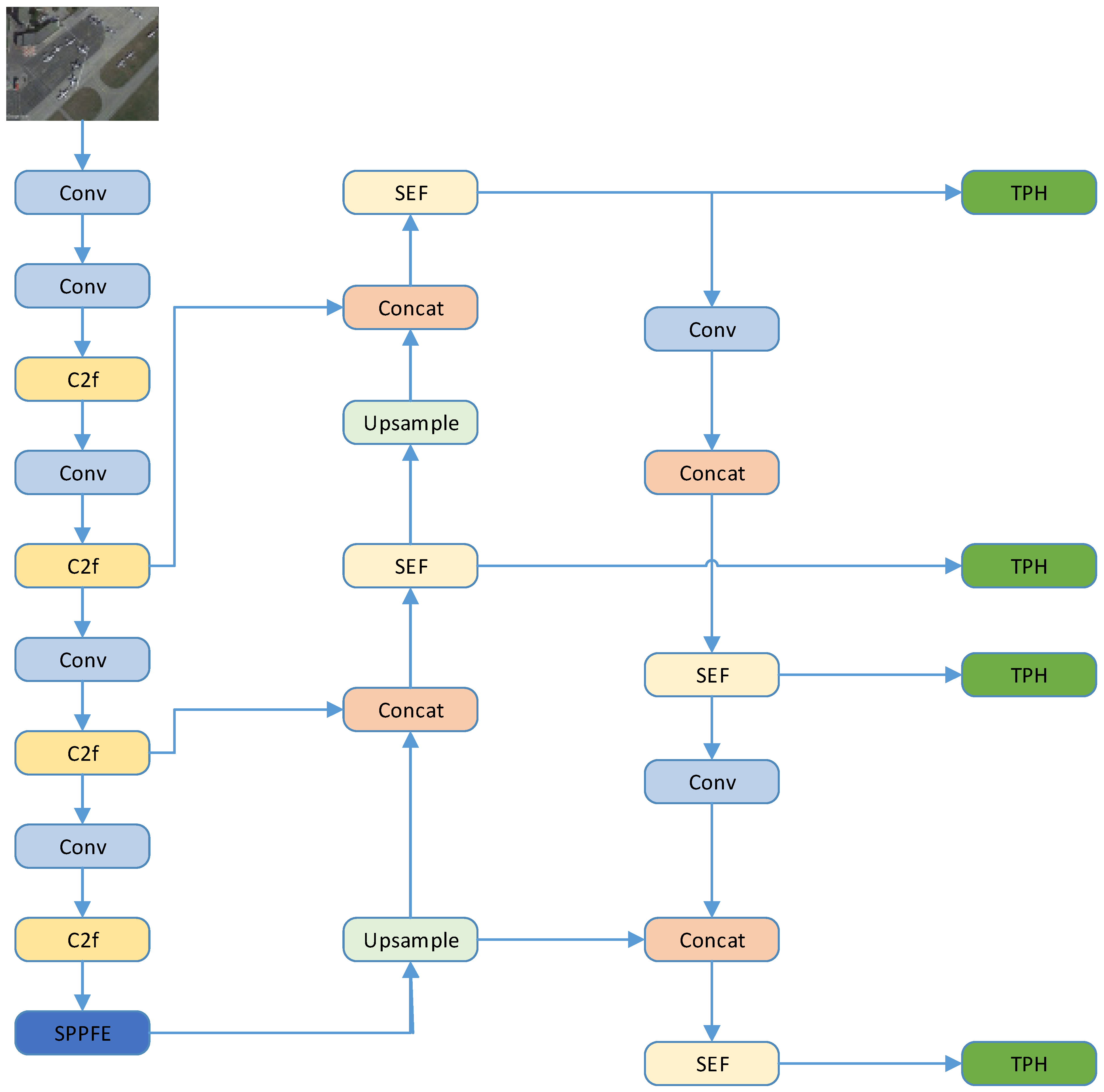
3.2. YOLO-SE
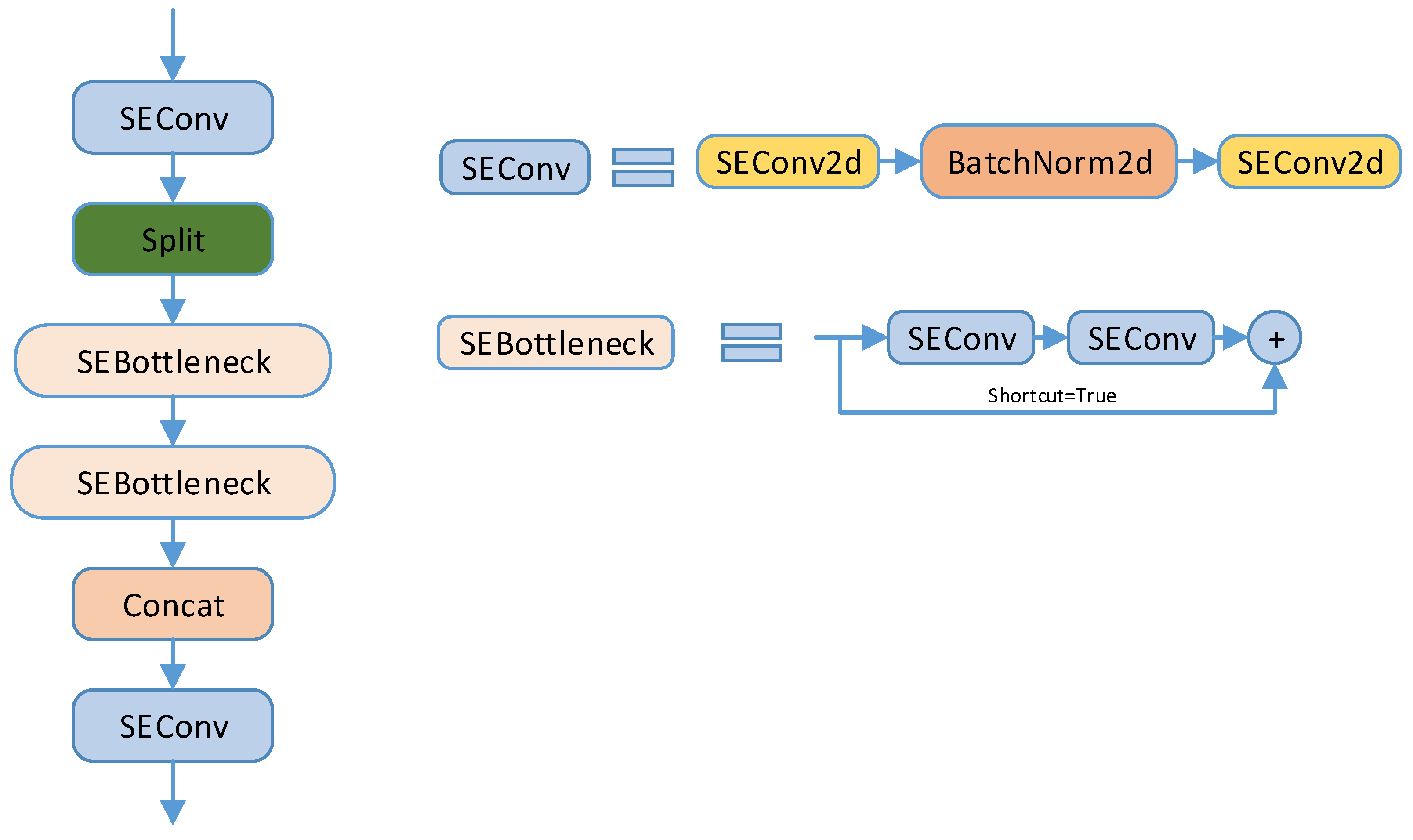
3.3. SEF
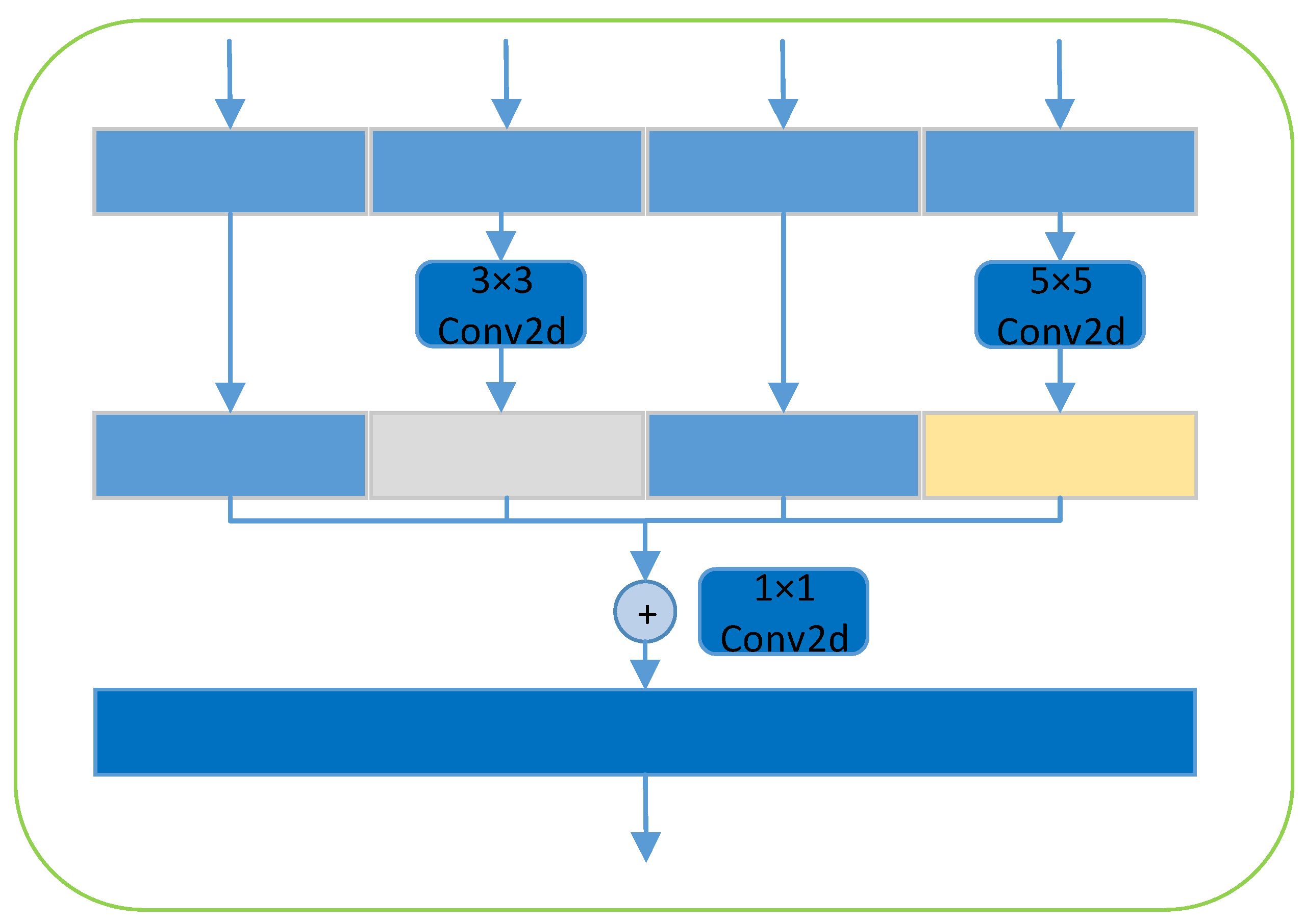
3.4. SPPFE
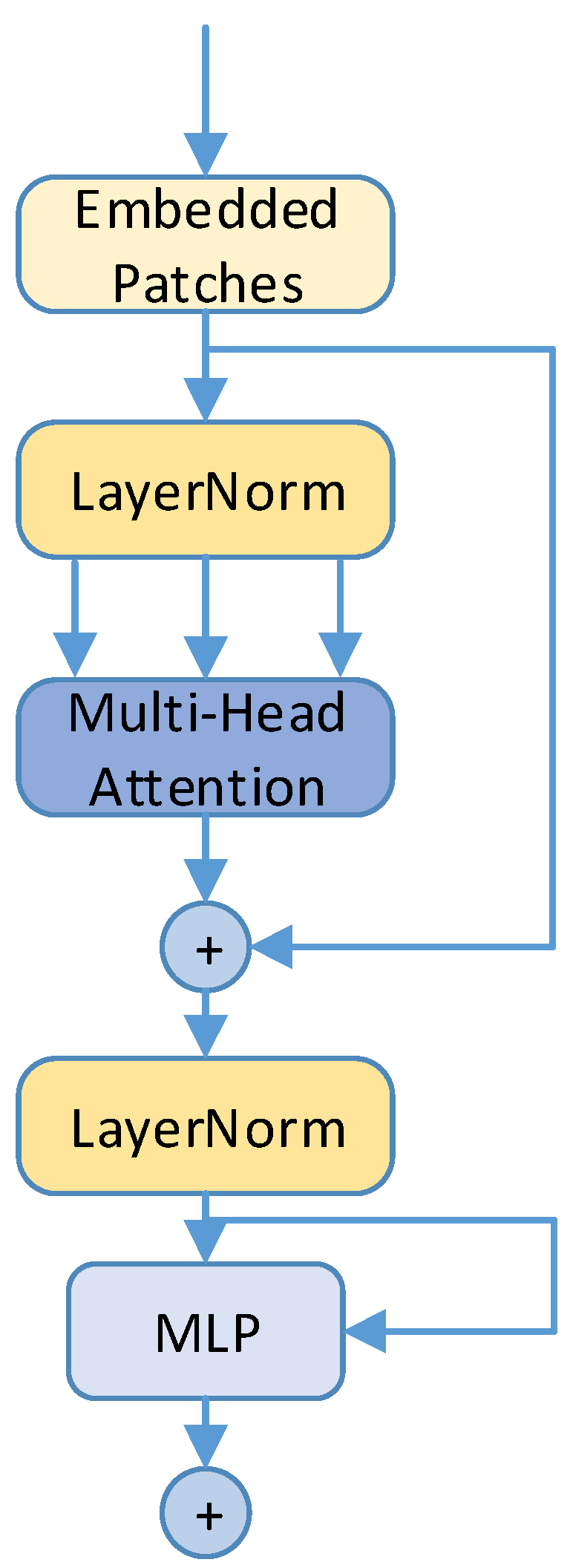
3.5. TPH
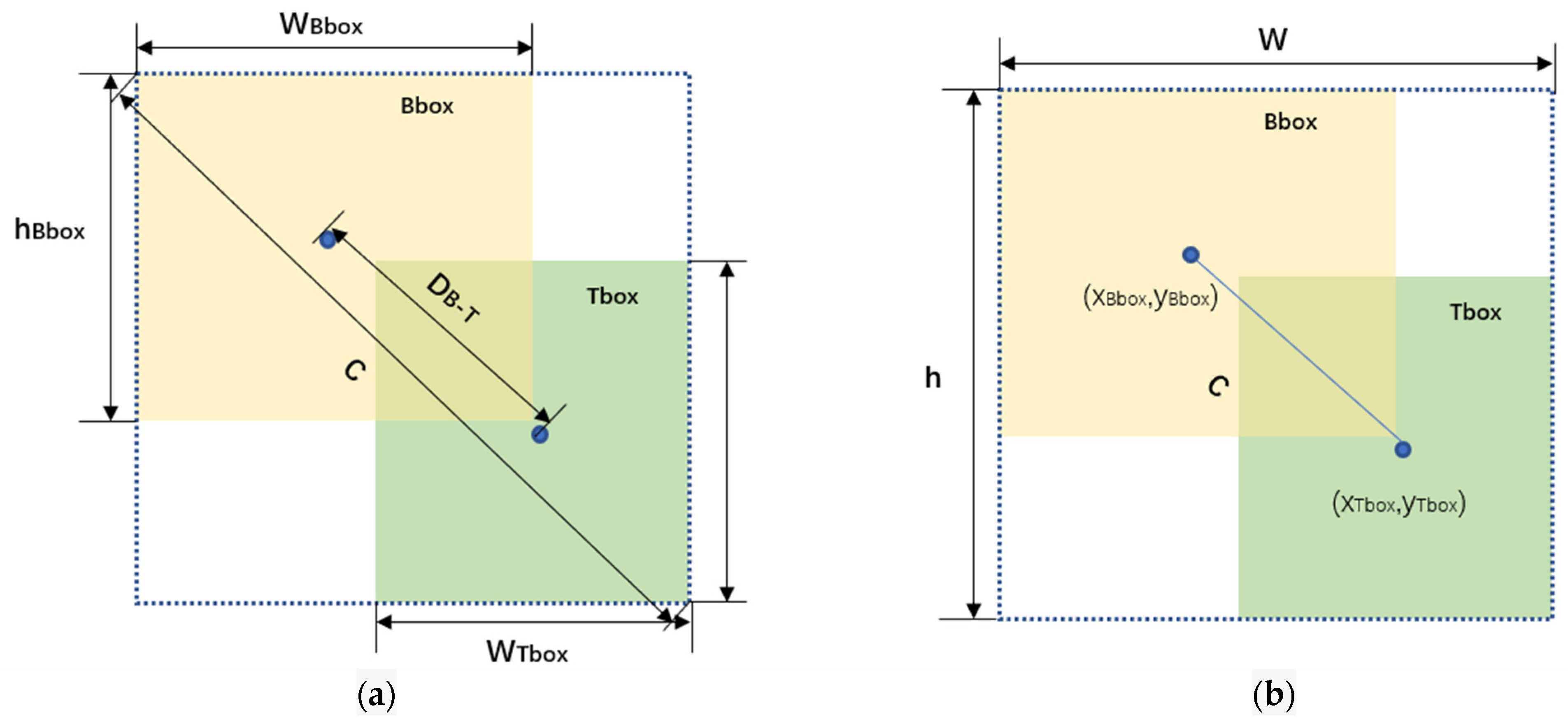
3.6. Wise-IoU Loss
4. Experimental and Results Analysis
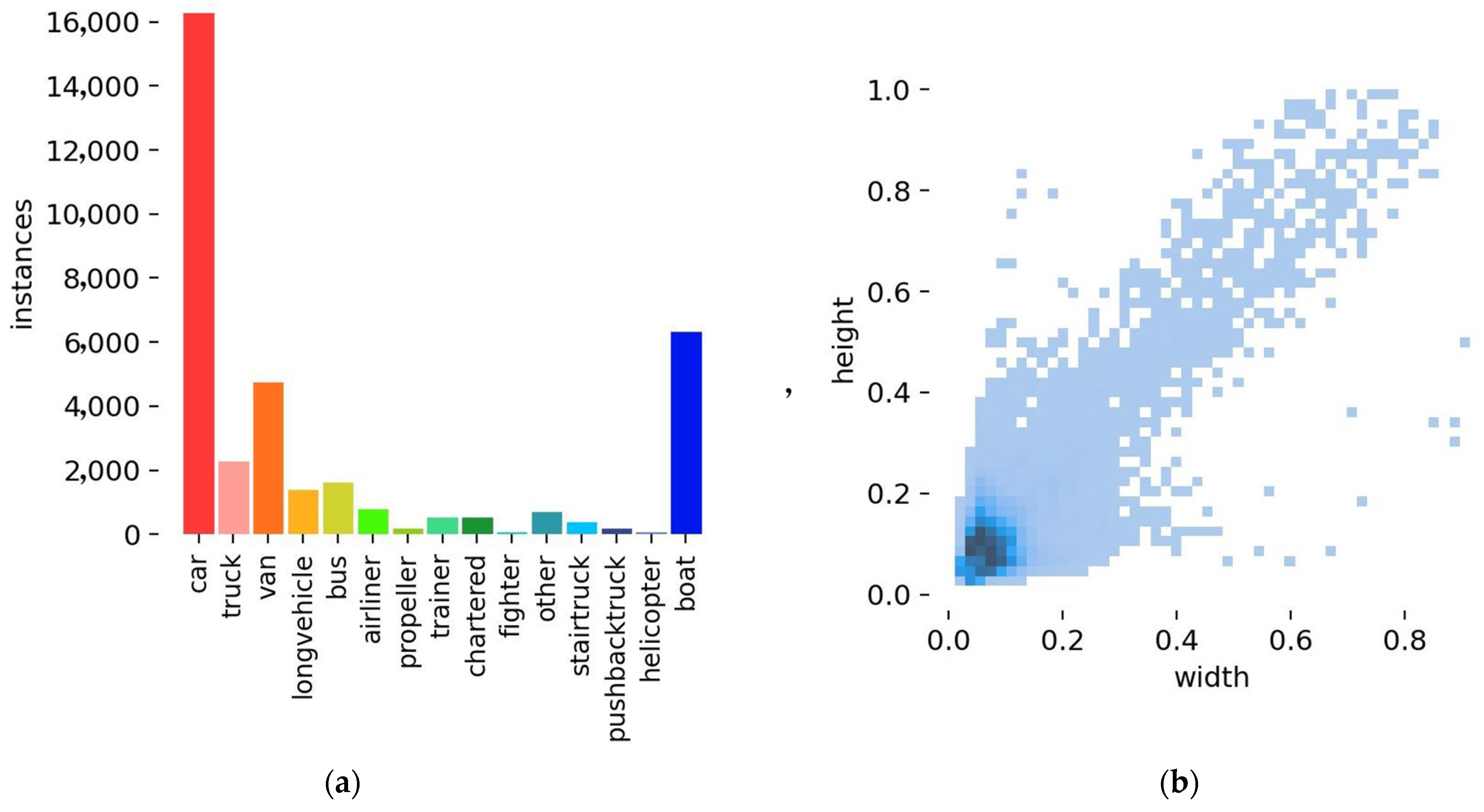
4.1. Experimental Setup and Evaluation Metrics
4.1.1. Experimental Environment
4.1.2. Evaluation Metrics
4.2. Results Analysis
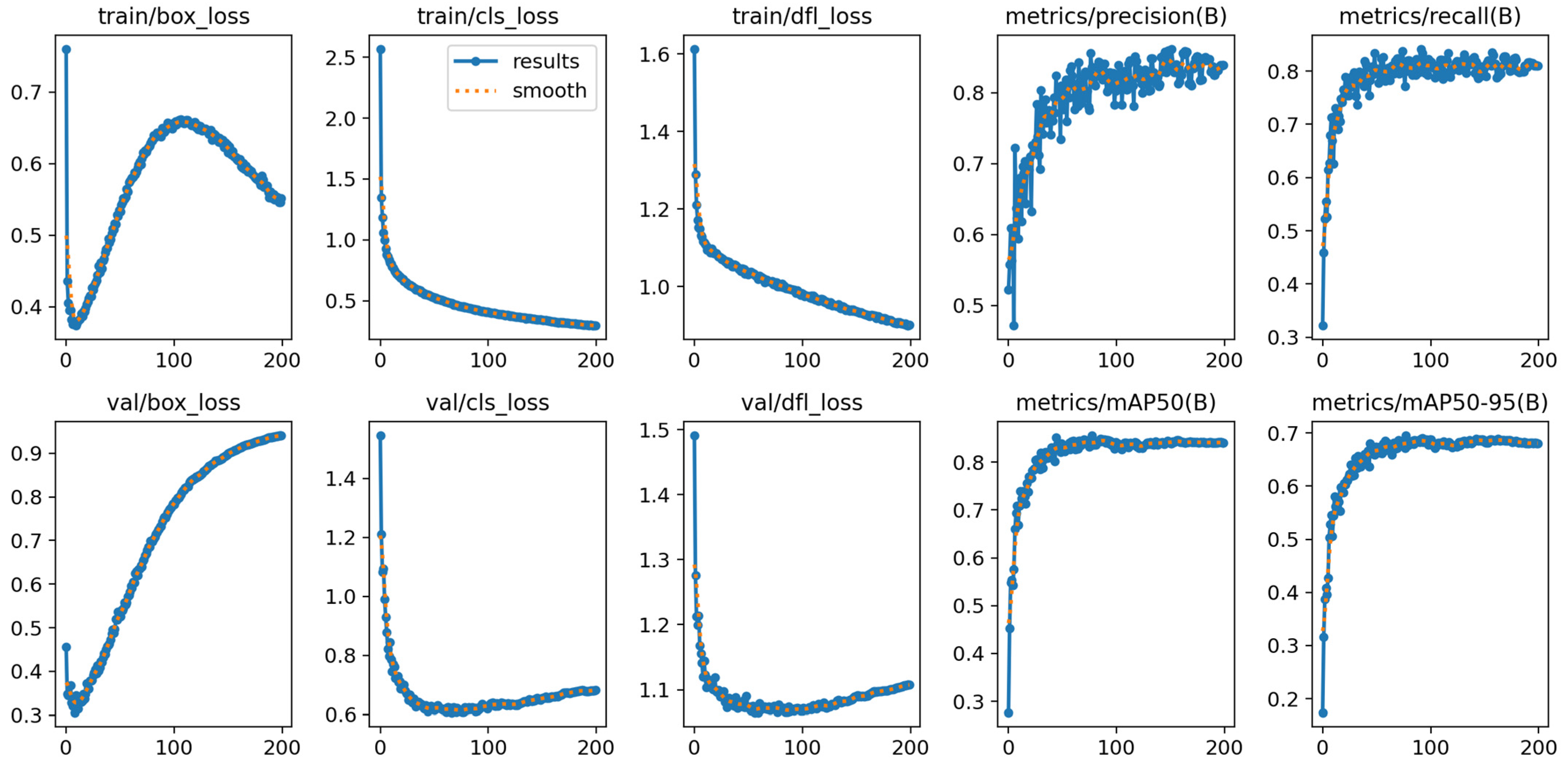
4.2.1. Experimental Results
4.2.2. Comparison Experiments
4.2.3. Ablation Test
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| YOLO-SE | You Only Look Once–Slight Edition |
| SEConv | Slight Edition Convolution |
| IoU | Intersection of Union |
| SPP | Spatial Pyramid Pooling |
| SPPF | Spatial Pyramid Pooling with less FLOPs |
| SPPFE | Spatial Pyramid Pooling with less FLOPs Edition |
| C2f | Coarse to Fine |
| SEF | Slight Editor Fine |
| CSP | Cross Stage Partial |
| CIoU | Complete Intersection of Union |
| DFL | Distribution Focal Loss |
| WIoU | Wise Intersection of Union |
| EMA | Efficient Multi-Scale Attention |
| TPH | Transformer Prediction Head |
References
- Mao, M.; Zhao, H.; Tang, G.; Ren, J. In-Season Crop Type Detection by Combing Sentinel-1A and Sentinel-2 Imagery Based on the CNN Model. Agronomy 2023, 13, 1723. [Google Scholar] [CrossRef]
- Cardama, F.J.; Heras, D.B.; Argüello, F. Consensus Techniques for Unsupervised Binary Change Detection Using Multi-Scale Segmentation Detectors for Land Cover Vegetation Images. Remote Sens. 2023, 15, 2889. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly supervised learning based on coupled convolutional neural networks for aircraft detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Z.; Lei, L.; Sun, H.; Kuang, G. A review of remote sensing image object detection algorithms based on deep learning. In Proceedings of the 2020 IEEE 5th International Conference on Image, Vision and Computing (ICIVC), Beijing, China, 10–12 July 2020; IEEE: New York, NY, USA, 2020; pp. 34–43. [Google Scholar]
- Mou, L.; Bruzzone, L.; Zhu, X.M. Learning spectral-spatial-temporal features via a recurrent convolutional neural network for change detection in multispectral imagery. IEEE Trans. Geosci. Remote Sens. 2018, 57, 924–935. [Google Scholar] [CrossRef]
- Khankeshizadeh, E.; Mohammadzadeh, A.; Moghimi, A.; Mohsenifar, A. FCD-R2U-net: Forest change detection in bi-temporal satellite images using the recurrent residual-based U-net. Earth Sci. Inform. 2022, 15, 2335–2347. [Google Scholar] [CrossRef]
- Purkait, P.; Zhao, C.; Zach, C. SPP-Net: Deep absolute pose regression with synthetic views. arXiv 2017, arXiv:1712.03452. [Google Scholar]
- Gkioxari, G.; Hariharan, B.; Girshick, R.; Malik, J. R-cnns for pose estimation and action detection. arXiv 2014, arXiv:1406.5212. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Paradise, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14. Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference On Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Ma, J.; Hu, Z.; Shao, Q.; Wang, Y.; Zhou, Y.; Liu, J.; Liu, S. Detection of large herbivores in uav images: A new method for small target recognition in large-scale images. Diversity 2022, 14, 624. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Wang, C.; Liu, Y.; Fu, K. PBNet: Part-based convolutional neural network for complex composite object detection in remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 173, 50–65. [Google Scholar] [CrossRef]
- Lai, H.; Chen, L.; Liu, W.; Yan, Z.; Ye, S. STC-YOLO: Small object detection network for traffic signs in complex environments. Sensors 2023, 23, 5307. [Google Scholar] [CrossRef] [PubMed]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Lin, W.; Wu, Z.; Chen, J.; Huang, J.; Jin, L. Scale-Aware Modulation Meet Transformer. arXiv 2023, arXiv:2307.08579. [Google Scholar]
- Wan, D.; Lu, R.; Wang, S.; Shen, S.; Xu, T.; Lang, X. YOLO-HR: Improved YOLOv5 for Object Detection in High-Resolution Optical Remote Sensing Images. Remote Sens. 2023, 15, 614. [Google Scholar] [CrossRef]
- Xu, D.; Wu, Y. Improved YOLO-V3 with DenseNet for multi-scale remote sensing target detection. Sensors 2020, 20, 4276. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; Bao, W.; Shang, H.; Yuan, M.; Cheng, Q. GCL-YOLO: A GhostConv-Based Lightweight YOLO Network for UAV Small Object Detection. Remote Sens. 2023, 15, 4932. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhou, T.; Wang, S.; Zhou, Y.; Yao, Y.; Li, J.; Shao, L. Motion-attentive transition for zero-shot video object segmentation. In Proceedings of the 2020 AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13066–13073. [Google Scholar]
- Zhou, T.; Zhang, M.; Zhao, F.; Li, J. Regional semantic contrast and aggregation for weakly supervised semantic segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4299–4309. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 10–16 December 2017. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Chen, M.; Radford, A.; Child, R.; Wu, J.; Jun, H.; Luan, D.; Sutskever, I. Generative pretraining from pixels. In Proceedings of the International Conference on Machine Learning—PMLR 2020, Virtual, 13–18 July 2020; pp. 1691–1703. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. In Proceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS 2021), Virtual, 6–14 December 2021; pp. 15908–15919. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. In Proceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS 2021), Virtual, 6–14 December 2021; pp. 9355–9366. [Google Scholar]
- Lin, H.; Cheng, X.; Wu, X.; Yang, F.; Shen, D.; Wang, Z.; Song, Q.; Yuan, W. Cat: Cross attention in vision transformer. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference On Computer Vision, Montreal, BC, Canada, 1–17 October 2021; pp. 10012–10022. [Google Scholar]
- Chen, C.F.; Panda, R.; Fan, Q. Regionvit: Regional-to-local attention for vision transformers. arXiv 2021, arXiv:2106.02689. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the 2021 IEEE/CVF International Conference ON Computer Vision, Montreal, BC, Canada, 1–17 October 2021; pp. 2778–2788. [Google Scholar]
- Zhao, Q.; Liu, B.; Lyu, S.; Wang, C.; Zhang, H. TPH-YOLOv5++: Boosting Object Detection on Drone-Captured Scenarios with Cross-Layer Asymmetric Transformer. Remote Sens. 2023, 15, 1687. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the 2020 AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual, 6–12 December 2020; pp. 21002–21012. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–5. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 20–22 June 2023; pp. 7464–7475. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Lin, J.; Zhao, Y.; Wang, S.; Tang, Y. YOLO-DA: An Efficient YOLO-based Detector for Remote Sensing Object Detection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6008705. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Version |
|---|---|
| CPU | Intel(R) Xeon(R) CPU E5-2696 v4 @ 2.20 GHz |
| GPU | NVIDIA GeForce RTX 3090, 24 GB |
| Memory | 64 GB |
| Operating system | Ubuntu 22.04 |
| Deep learning framework | Pytorch 1.13 |
| Categories | P/% | R/% | AP50/% | mAP/% |
|---|---|---|---|---|
| car | 85.7 | 91.3 | 94.1 | 75.0 |
| truck | 80.4 | 79.6 | 86.0 | 71.0 |
| van | 79.7 | 80.8 | 85.8 | 69.6 |
| long vehicle | 80.4 | 82.1 | 84.8 | 68.3 |
| bus | 87.0 | 88.3 | 93.8 | 79.6 |
| airliner | 93.3 | 96.6 | 98.9 | 91.3 |
| propeller | 92.0 | 93.9 | 95.1 | 82.9 |
| trainer | 91.3 | 99.2 | 98.2 | 85.4 |
| chartered | 87.1 | 97.2 | 95.2 | 85.7 |
| fighter | 79.3 | 100.0 | 97.1 | 87.0 |
| other | 62.4 | 42.7 | 44.7 | 34.5 |
| stair truck | 68.9 | 57.8 | 66.5 | 46.1 |
| pushback truck | 88.2 | 50.8 | 68.0 | 49.0 |
| helicopter | 82.0 | 70.4 | 90.8 | 53.3 |
| boat | 96.2 | 98.1 | 98.5 | 81.1 |
| all | 83.6 | 81.9 | 86.5 | 70.7 |
| Class | P/% | R/% | AP50/% | mAP/% |
|---|---|---|---|---|
| airplane | 87.8 | 94 | 97.2 | 88.7 |
| ship | 86.2 | 100 | 99.5 | 93.2 |
| storage tank | 99.2 | 100 | 99.5 | 84.8 |
| baseball diamond | 98.1 | 95.9 | 97.9 | 82.6 |
| tennis court | 94.5 | 93.3 | 97.6 | 81.5 |
| basketball court | 100 | 83.2 | 95.3 | 58.1 |
| ground track field | 97.2 | 76.9 | 92.5 | 60.1 |
| harbor | 88.5 | 86.7 | 93.6 | 69.5 |
| bridge | 90.3 | 100 | 98 | 86.3 |
| vehicle | 64.6 | 80 | 77.5 | 67.3 |
| all | 90.6 | 91 | 94.9 | 77.2 |
| Name | AP50 (%) | Map (%) | Params (M) |
|---|---|---|---|
| Faster RCNN | 77.7 | - | 41.2 |
| YOLOv3-Tiny | 77.2 | 54.5 | 8.68 |
| YOLOv5s | 83.85 | 66.0 | 6.72 |
| YOLOv7s | 83.80 | 66.5 | 8.92 |
| YOLOX-s | 76.6 | 56.8 | 8.94 |
| YOLO-DA | 80.6 | - | - |
| YOLO-HR | 85.59 | 65.0 | 13.2 |
| YOLOv8s | 84.4 | 68.8 | 11.2 |
| YOLO-SE | 86.5 | 70.7 | 13.9 |
| SEF | SPPFE | WIoU | TPH | AP50(%) | |
|---|---|---|---|---|---|
| Exp 1 | 84.4 | ||||
| Exp 2 | √ | 85.3 | |||
| Exp 3 | √ | √ | 85.5 | ||
| Exp 4 | √ | √ | √ | 85.9 | |
| Exp 5 | √ | √ | √ | √ | 86.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, T.; Dong, Y. YOLO-SE: Improved YOLOv8 for Remote Sensing Object Detection and Recognition. Appl. Sci. 2023, 13, 12977. https://doi.org/10.3390/app132412977
Wu T, Dong Y. YOLO-SE: Improved YOLOv8 for Remote Sensing Object Detection and Recognition. Applied Sciences. 2023; 13(24):12977. https://doi.org/10.3390/app132412977
Chicago/Turabian StyleWu, Tianyong, and Youkou Dong. 2023. "YOLO-SE: Improved YOLOv8 for Remote Sensing Object Detection and Recognition" Applied Sciences 13, no. 24: 12977. https://doi.org/10.3390/app132412977
APA StyleWu, T., & Dong, Y. (2023). YOLO-SE: Improved YOLOv8 for Remote Sensing Object Detection and Recognition. Applied Sciences, 13(24), 12977. https://doi.org/10.3390/app132412977